1. Introduction
The world city population has increased to 55% in the past decades, and is expected to increase to 68% in 2050, leading to an intensification of traffic congestion affecting safety [
1]. In addition, according to the investigation, 6 million traffic accidents occurred in the United States in 2018, causing more than 3.5 million deaths and 2.5 million injuries. Therefore, vehicle coordination and management are worth studying to improve the security and efficiency of future transportation systems in complex conditions, especially in urban environments. Today, there are many efforts to solve the problems, such as (a) research about the traffic structure, and (b) research about the autonomous vehicle. Difficulties in automatic driving at crossroads are mainly due to complex traffic conditions. The no-signal intersections are more complicated and challenging for the city view, involving multi-vehicle interaction [
2,
3,
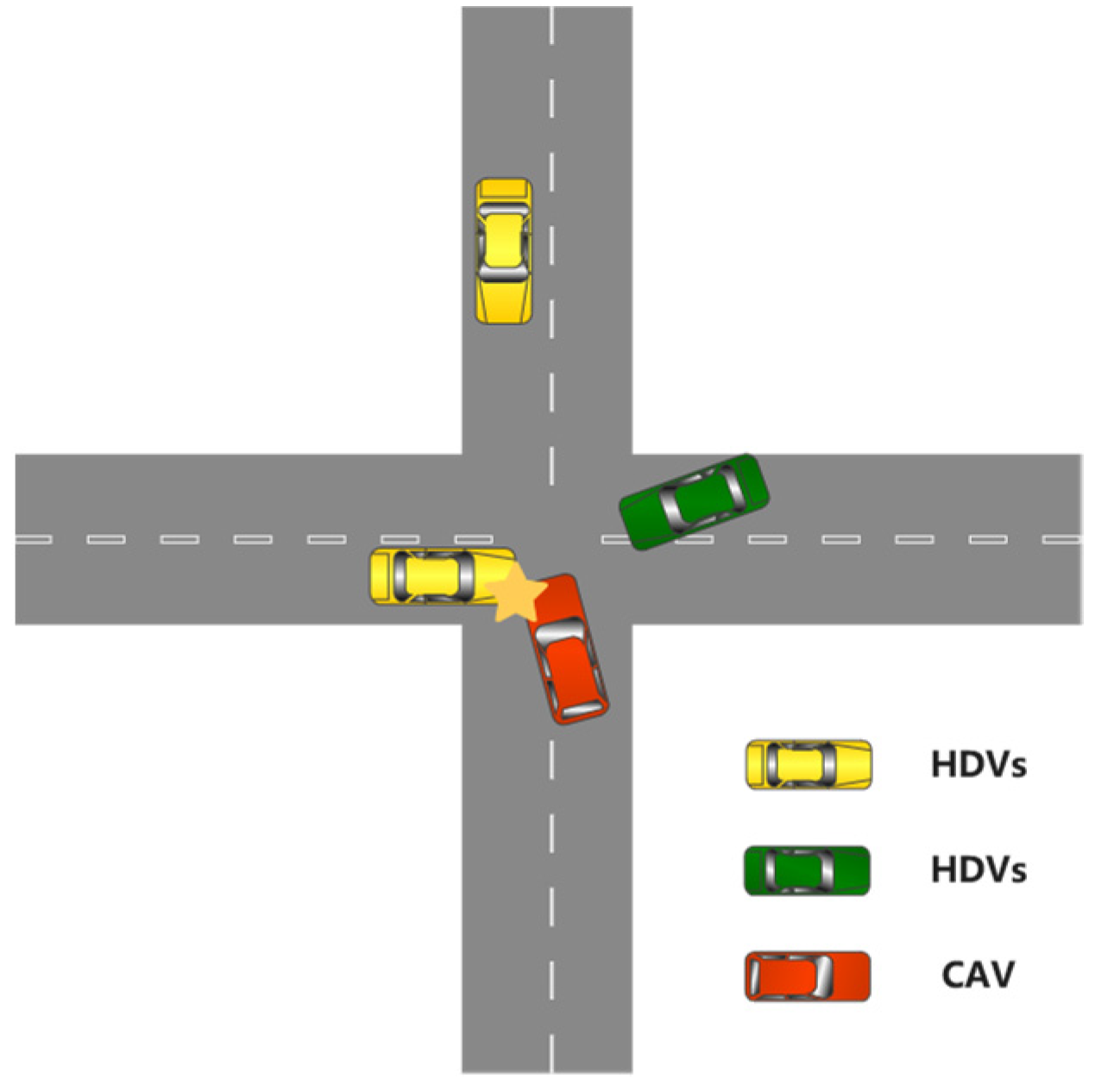
4]. Therefore, this paper specifically discusses autonomous driving in the unsignalized intersection, while considering a basic scenario where human drivers and autonomous vehicles coexist, as shown in
Figure 1.
Autonomous navigation technology has two types: sensor and communication type. In sensor systems using a camera, radar and laser radar can directly detect the surrounding obstacles. However, that has a limited smaller detection area when the obstacle hinders the sensor. The limitations of sensors can be broken by vehicles and everything (V2X) communication technology. V2X refers to a technique by which the vehicle exchanges information with other vehicles, roads, and other infrastructure by a wireless network [
1]. V2X, as a new technology, not merely provides a safer and more comfortable traffic environment, but is important for reducing accident rates, reducing pollution, and improving traffic efficiency. With the development of V2X communication technology, information sharing and vehicle coordination between connected and automated vehicles (CAVs) and connected vehicles (CVs) improves safety and efficiency [
5]. As aforementioned, this provides the possibility for the safety and efficiency of no-signal intersections. However, in an autonomous vehicles problems in urban traffic environments with unsignalized intersections, rule-based, optimization-based, learning-based and so on were proposed.
Traditional intersections (such as signal intersections) are not necessarily the best strategy in the CAVs environment. Rule-based methods have been proposed by Zhang [
6] and Zhao [
7] which have been used to solve different traffic scenarios based on the first-in-first-out (FIFO) rule. Dresner and Stone [
8] introduced a reservation-based scheme that requires CAVs to reserve a space-time slot inside the intersection. Lee and Park [
9] minimized the total length of overlapped trajectories of CAVs crossing an intersection. Gregoire et al. [
10] decomposed the coordination problem into a central priority assignment and trajectory planning. It has been proven that FCFS-based A.I.M. and its variants can reduce delay and emissions compared to traditional signal control under certain traffic conditions (Fajardo et al., 2011; Li et al., 2013) [
11].
The vehicle interaction is modelled as a dynamic system, from the action of the control vehicle as an input in the optimal control setting. An online model predictive control (MPC) method is presented by Borek et al. [
12], this model is mainly optimal for the energy of heavy trucks, which uses the best solution to track using dynamic program offline. Du et al. [
13] presented a three-layered hierarchical coordination strategy for CAVs at multiple intersections. Although experiments have proven well, the MPC-based approach relies on precise dynamic merge models (including human driving models), which typically require calculations because each step requires online optimization [
14].
However, data driving methods such as reinforcement learning (RL) are increasingly concerned, and they have been explored in automatic driving roads. The integration of Deep Learning (DL) and RL, widely referred to as Deep Reinforcement Learning (DRL), has shown its potential by successfully solving video games [
15], 3D locomotion [
16], Go games [
17] and many other problems. Vinitsky et al. [
18] proposed a merging strategy via reinforcement learning to control shockwaves from on-ramp merges, which is similar to the unsignalized intersections scenario. In the literature, there are relatively few studies using RL to solve AIM problems. Isele et al. [
19] proposed a single-agent RL approach to navigate one autonomous vehicle through the intersection.
In general, automatic driving vehicles are autonomous agents that use advanced communication technologies and sensors to perceive and interact with real-time traffic conditions (environment). Our research framework, RL, has been proposed to solve Markov decision processes (MDPs). Generally, in RL, agents learn the optimal policy by trial-and-error interaction with the dynamic environment formally described by MDPs. RL combined with deep learning has achieved outstanding success in various areas such as video games [
20] and robotics [
21]. These advances have inspired the research community to examine the performance of deep reinforcement learning in autonomous driving [
22]. So, in this paper, we explore the RL’s ability to combine radars, LiDAR, cameras, sensors, and V2X for autonomous driving at unsignalized intersections.
While the rule-based method works well in simple scenarios, it can be very unstable in complex environments [
23]. An optimal strategy is often related to computational complexity issues because online optimization is required at each time step [
14]. However, for dynamic systems such as Autonomous intersection management (AIM), the traffic environment changes over time, and predefined strategies may become unsatisfactory, especially when there is a great deal of uncertainty in a hybrid traffic environment. In this paper, our goal is to propose an optimal framework that fully considers the real-time traffic dynamics of the vehicle.
Little attention has been paid to a truly autonomous vehicle in a complex urban environment. Most of the previous studies are based on macro-control, and few are based on micro discussion. On the other hand, many studies aim at either all connected and automated or multiple vehicles. There is very little discussion of only one connected and autonomous vehicle (CAV) and many human driving vehicles (HDVs). To fill these gaps, we proposed a proximal policy optimization (PPO) advanced algorithm-based V2X. The main contributions of this paper are as follows:
We propose an intelligent transportation system for the Internet of vehicles based on 5G, edge and cloud computing technologies. Moreover, the proposed framework solves the fine-grained problem of automatic driving vehicles in hybrid traffic.
We describe an RL problem in the urban unsignalized intersection of traffic issues (a CAV and HDVs coexist on the intersection). In our paper, we consider a dynamic environment that has a time-varying connectivity topology.
This paper proposes deployment algorithms, increasing the possibility of automatic driving vehicles in a real traffic environment.
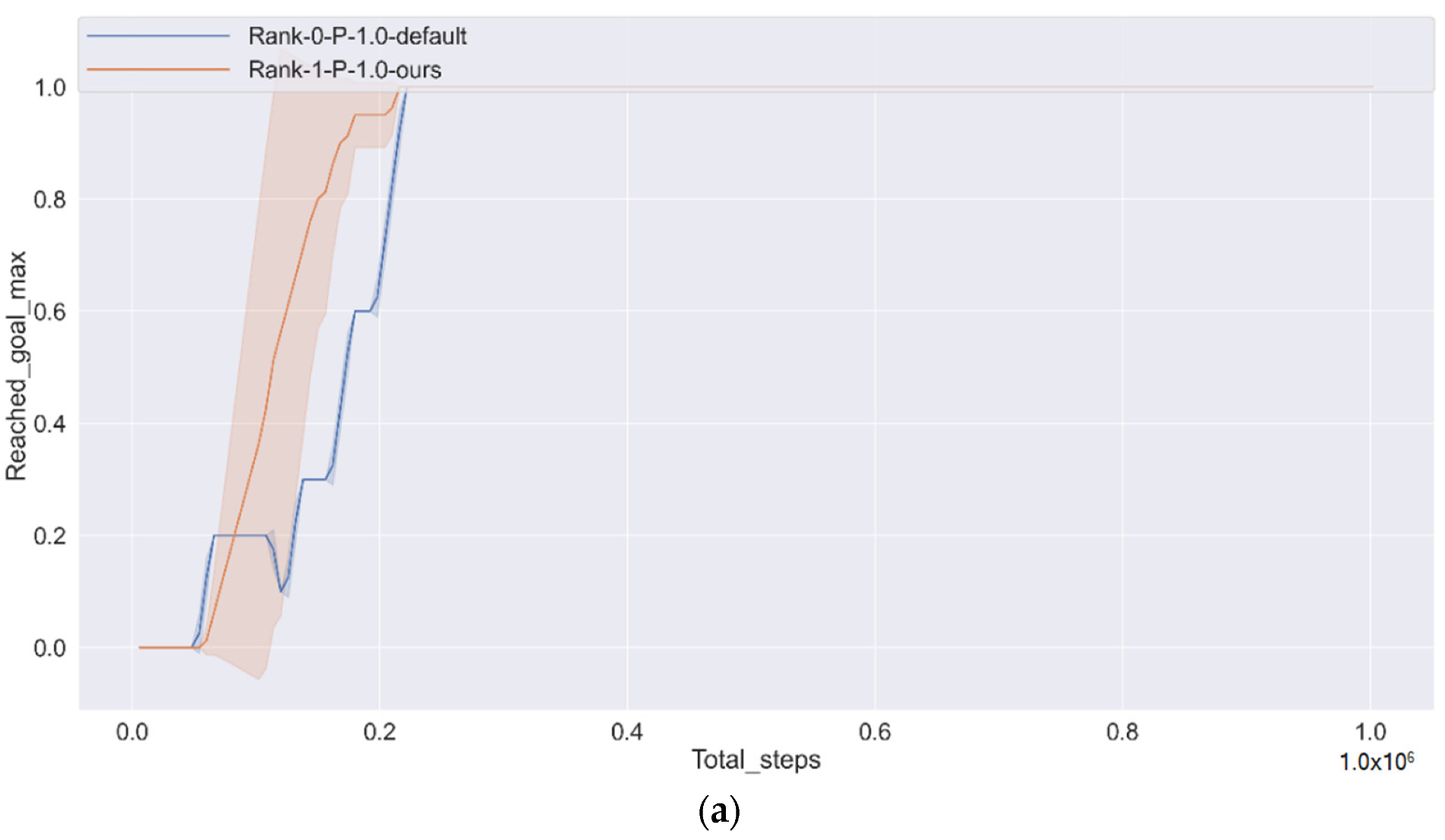
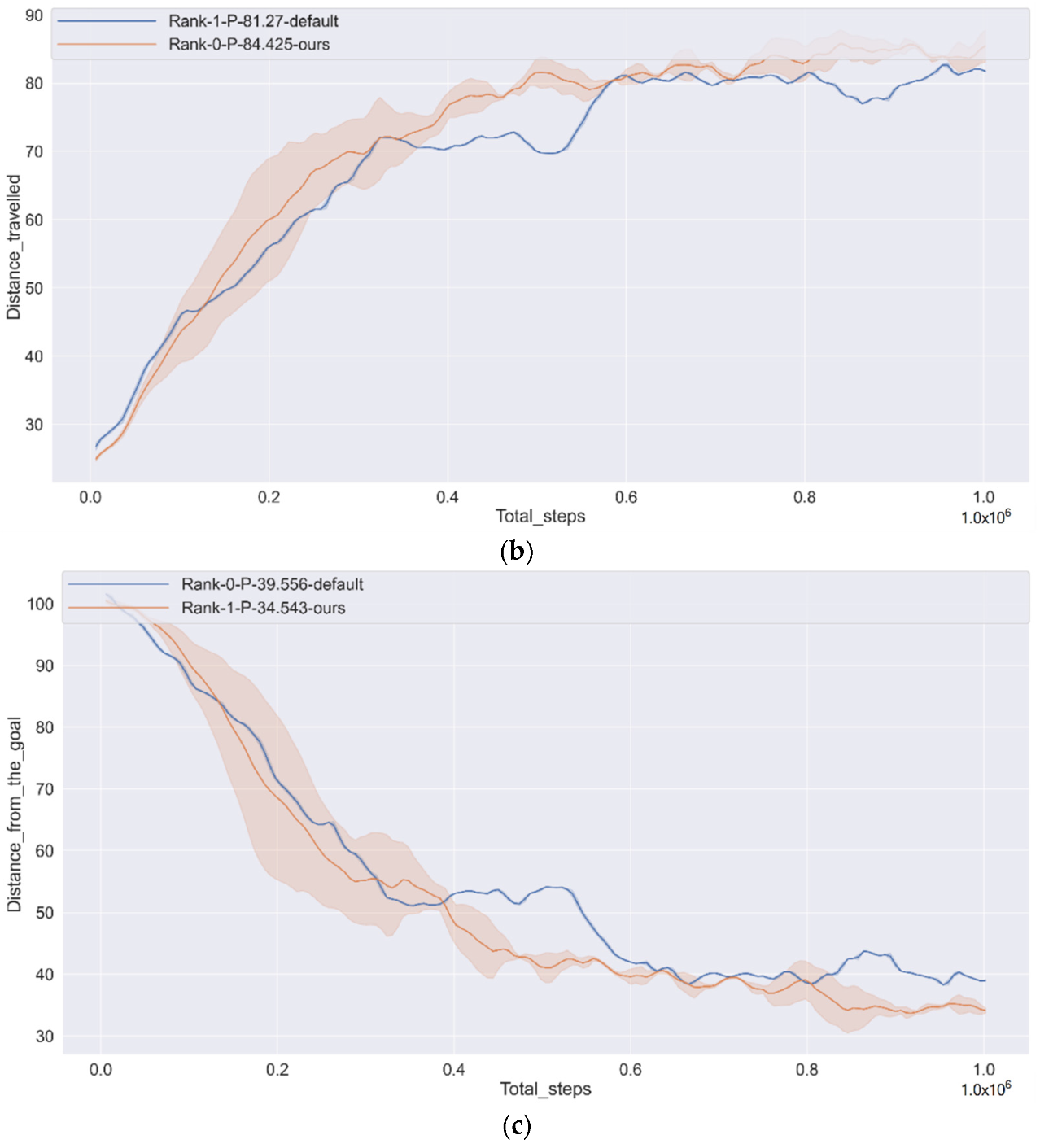
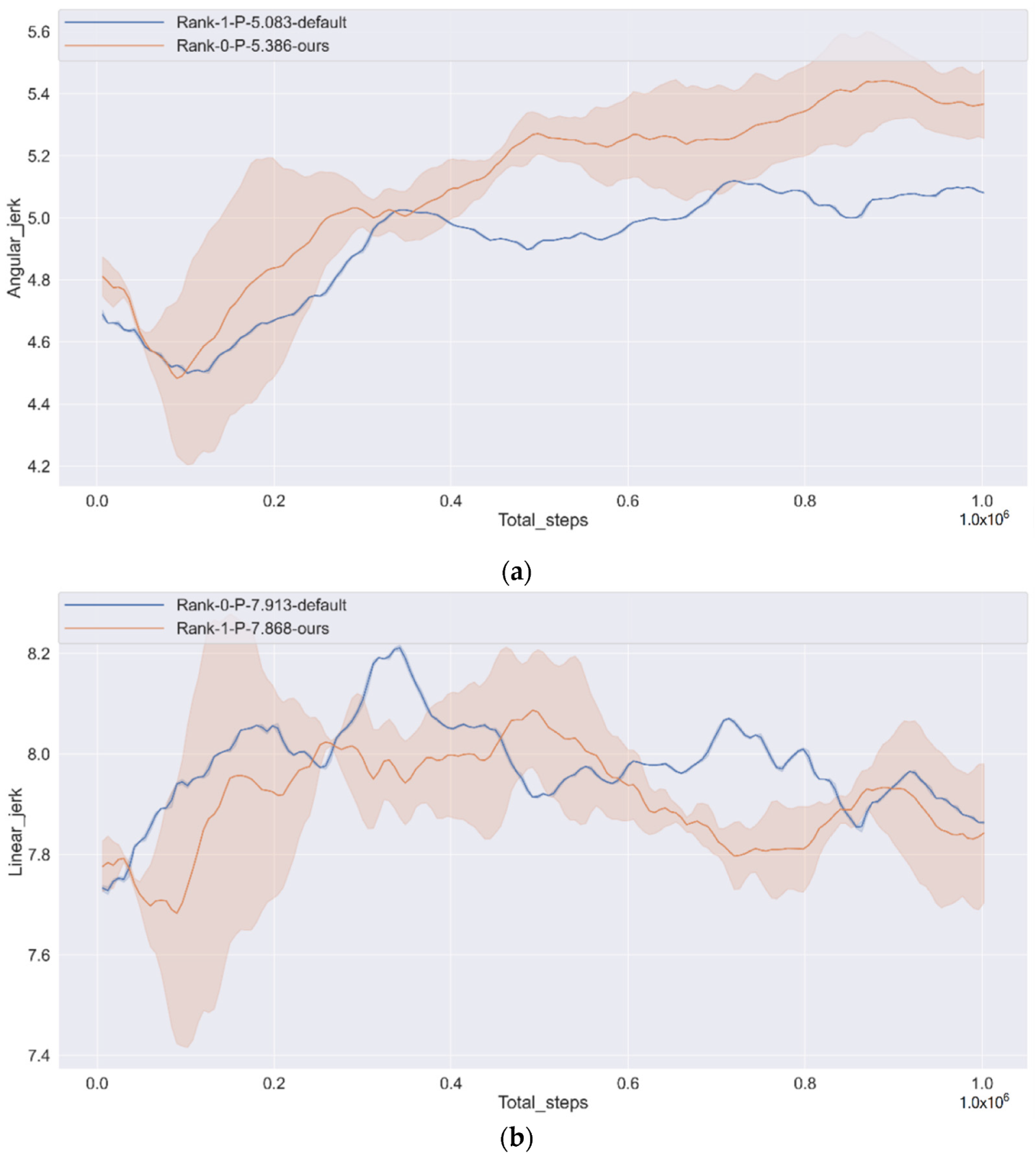
In the experimental part, we used a variety of different performance measurement methods to measure the algorithm’s performance and ablation experiments.
2. Research Methodology
2.1. VRCIS (Vehicle-Road-Cloud Integration System)
The Vehicle-Road-Cloud Integration System (VRCIS) uses a new generation of information and communication technology to connect the physical, information, and application layers of people, vehicles, roads, and clouds. As a whole, a cyber-physical system that integrates perception, decision-making, and control can realize the comprehensive improvement of vehicle driving and traffic operation safety and efficiency. It can also be called “Intelligent Networked Vehicle Cloud Control System”, or simply “Cloud Control system”.
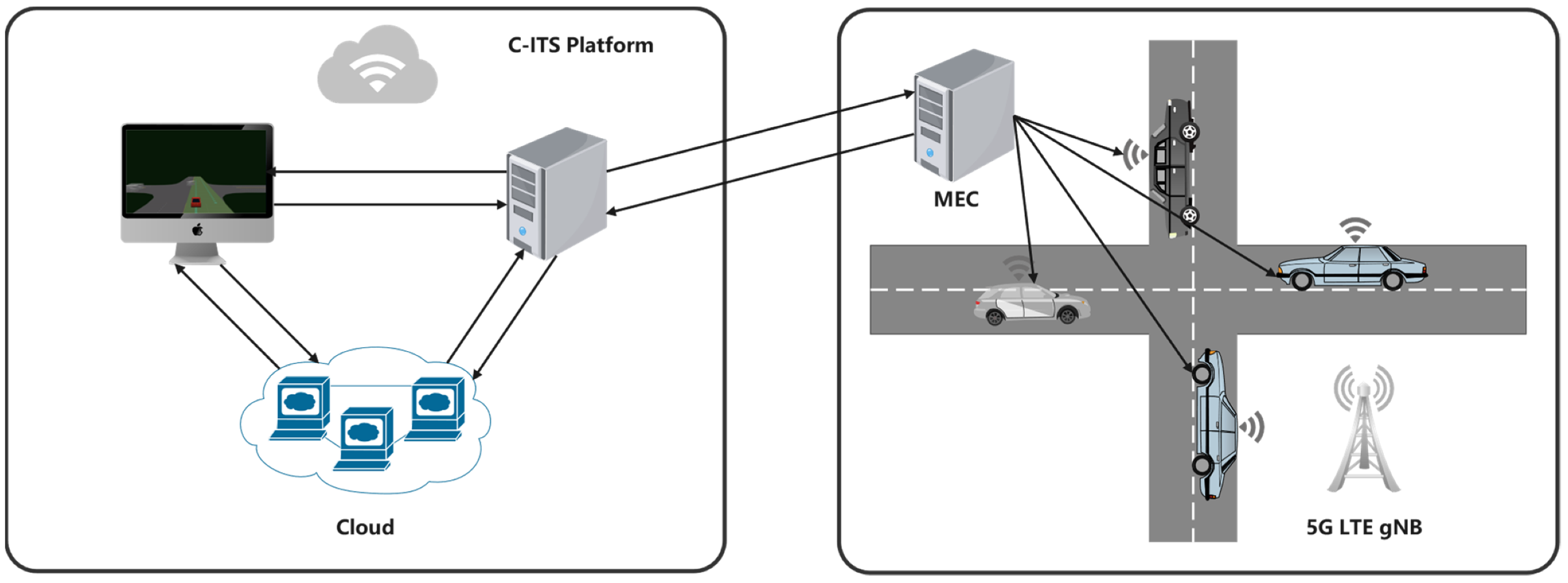
Figure 2 shows an architecture of cloud edge collaboration in the unsignalized intersection scenario, which consists of the Cloud Server, Edge devices (include RoadSide Unit (RSU) and OnBoard Unit (OBU)) and Vehicles Interactors. CAV and other vehicles information (speed, location, and so on) can be observed and shared using V2X technology, and both cloud and edge servers are equipped with powerful GPU resources for neural network training. In this proposed scheme, we use Dedicated Short Range Communications (DSRC) and Long Term Evolution (LTE-V) technology, making sure to communicate between CAV with HDVs, and vehicles and Mobile Edge Computing (MEC) communicated with Cloud.
2.2. Longitudinal Dynamic Models
The intelligent driver model (I.D.M.), as a stand car-following model, is used in our work, describing the dynamics of single vehicles’ positions and velocities. The I.D.M. is a time-continuous car-following model for highway and urban traffic simulation. Treiber, Hennecke and Helbing developed it in 2000 to improve the results of other “intelligent” drive models, such as Gipps’ model, the latter lost realistic attributes under certainty limits [
24].
These parameters are represented in
Table 1.
Table 2 shows the required parameters in the intelligent driving model.
2.3. Proximal Policy Optimization
2.3.1. Background
In this section, we reviewed basic theory about RL to understand the model proposed.
Reinforcement Learning (RL) is a subsequent field of machine learning. It is concerned about how agents interact with the environment and learn to maximize the accumulation return. In RL problems, it is often regarded as an infinite-horizon discounted MDP, defined by the quintuple
, where
is a set of states and s is a specific state; where
is a set of actions and a is a specific action;
defines a probability for a transition from
to
by an action;
defines the immediate reward for taking action.;
defines the discount factor. In order to maximize some cumulative rewards function, we try to seek to learn optimal policy
, where the policy is a stochastic policy
:
, typically the expected discounted sum over a potentially infinite horizon from each state following policy
:
where
and
. Alternatively, the definition of a state function
is expressed as follows:
However, in the proposed problem, a CAV interacts with the environment, which is just possible to model an MDP model. Our objective is to maximize a reward function to an autonomous vehicle walking as human driving in an unsignalized intersection by improving a policy.
2.3.2. Proximal Policy Optimization Advanced
Since trust region policy optimization (TRPO) [
25] is relatively complicated and we still want to implement a similar constraint, PPO simplifies it by using a clipped surrogate objective while retaining similar performance.
In this work, model-free reinforcement learning methods are used to optimize the control policy in the unsignalized intersection. For policy-based RL algorithms, we compute an estimator for the policy gradient as follows:
Here, action
a per time step
t is controlled the parameterized policy
under the state
s, and update the parameter
to maximize the cumulative reward. Where
denotes the empirical average over a finite batch of samples and
denotes the advantage function. The loss function for updating a RL policy to estimate the policy gradient has the form as:
Firstly, the probability ratio is denoted between old and new policies as:
Then, the objective function of TRPO becomes:
Without a limitation on the distance between
and
, maximizing
would lead to instability with extremely large parameter updates and big policy ratios. PPO imposes the constraint by forcing
to stay within a small interval around 1, precisely
, where
is a hyperparameter.
Network architecture applying PPO with shared parameters for policy (actor) and value (critic) functions. In addition to the clipped reward, the objective function is augmented with an error term on the value estimation
and an entropy term
to encourage sufficient exploration.
where both
and
are two hyperparameter constants, based on the above formula, the flow chart of our proposed algorithm is shown in Algorithm 1.
The advantage function
can be defined as a way of measuring how much we can improve by taking action in a particular state. We want to use the reward at each time step and calculate how much advantage can be gained by taking action, not only in the short term but also by focusing on a longer time. In order to calculate this, Generalized Advantage Estimation (GAE) [
26] is used.
where
hyperparameter content is called a discount factor to reduce the value of the future state, since we want to emphasize more on the current state than a future state; where lambda is a smoothing hyperparameter content used for reducing the variance in training which makes it more stable. The parameter
is suggested for 0.99 and the parameter lambda is suggested for 0.95.
| Algorithm 1 PPO with Clipped Objective. |
| 1: Input: initialize policy parameters , initialize |
| 2: For k = 0,1,2, … do |
| 3: Use policy , to collect trajectories by the environment |
| 4: Compute (rewards-to-go) |
| 5: Compute advantage estimates using GAE (advantage estimation algorithm) |
| 6: Update the policy: |
| 7: |
| 8: Take K steps of minibatch SGD (Adam), where: |
| 9: |
| 10: End for |
2.4. RL Formulation
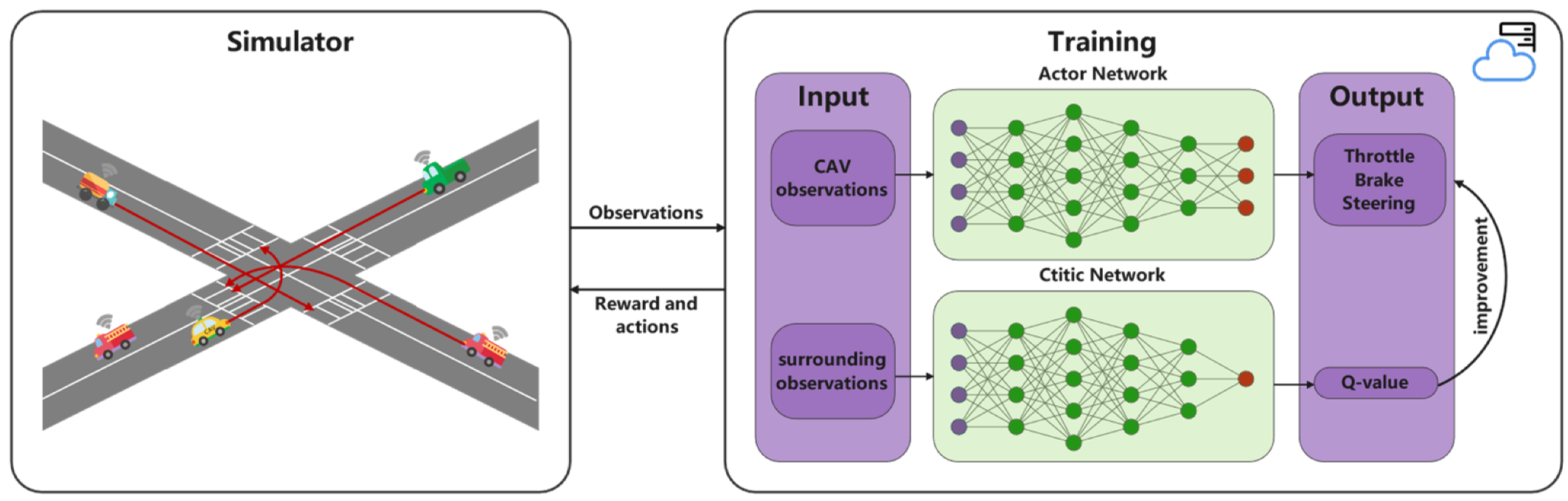
In this section, we intend to transform an unsignalized intersection problem into an RL problem. First, the simulation scene is modelled as the Markov model. Secondly, the proposed algorithm controls the CAV to complete the automatic driving. In
Figure 3, the observations returned by the simulator serve as the input of the algorithm proposed in this paper. Then, the algorithm outputs the optimal continuous actions (throttle, brake and steering) to control the behavior of CAV, and finally safely arrives at the specified location. So, defining state, action and reward is of such importance.
2.4.1. State Space
In this study, a state-space represents information about the CAV and surrounding social vehicles, such as the vehicle’s steering, heading, speed and position, obtained by V2X technology. We define the state space in
Table 3.
2.4.2. Action Space
Unlike most studies on autonomous driving, we designed the motion space to be continuous. For example, if the CAV has a vehicle in front of it, does it accelerate to pass it by throttling and steering, or does it brake? It is all guided by the algorithms that we have provided. As shown in
Table 4, the action space is defined as follows:
2.4.3. Reward Function
As the most critical factor, the reward function for optimal convergence policies in RL The purpose of the reward is to maximize discount returns. Our purpose is to avoid collisions safely, comfortably and quickly the goal. The specific part of each part of the reward function is designed as follows.
(1) Safety: To avoid collisions. In terms of safety, the penalty function of the CAV for collisions can be expressed as:
where
c is the absolute value of the penalty factor, this function tells us that we should minimize the number of collisions in the end.
(2) Comfort: Smaller jerk (angular jerk and linear jerk). In respect of comfort, the penalty function of the CAV for comfort can be represented
where
c1 and
c2 are the absolute value of the penalty factor;
and
are the lateral jerk and the longitudinal jerk. To avoid sudden acceleration or deceleration of vehicles, the vehicle occupant may not be discomfort in this reward function.
(3) Efficiency: Get to the target quickly. In terms of safety, the penalty function of the CAV for efficiency can be expressed as
where
c3 is the absolute value of the penalty factor;
and
are current speed and the max limit speed. We hope that CAV can reach the goal smoothly and quickly every time, so when it reaches the goal, give a larger reward.
Thus, the complete form of reward function is
(4) Termination
The Termination condition of an episode in reinforcement learning, when ‘Termination = True’ means that the environment needs to be reset, CAV will be randomly generated at a point again to continue the training of the loop.
When the collision is True, the agent ends an episode and then continues the next loop training.
2.5. Framework and Development
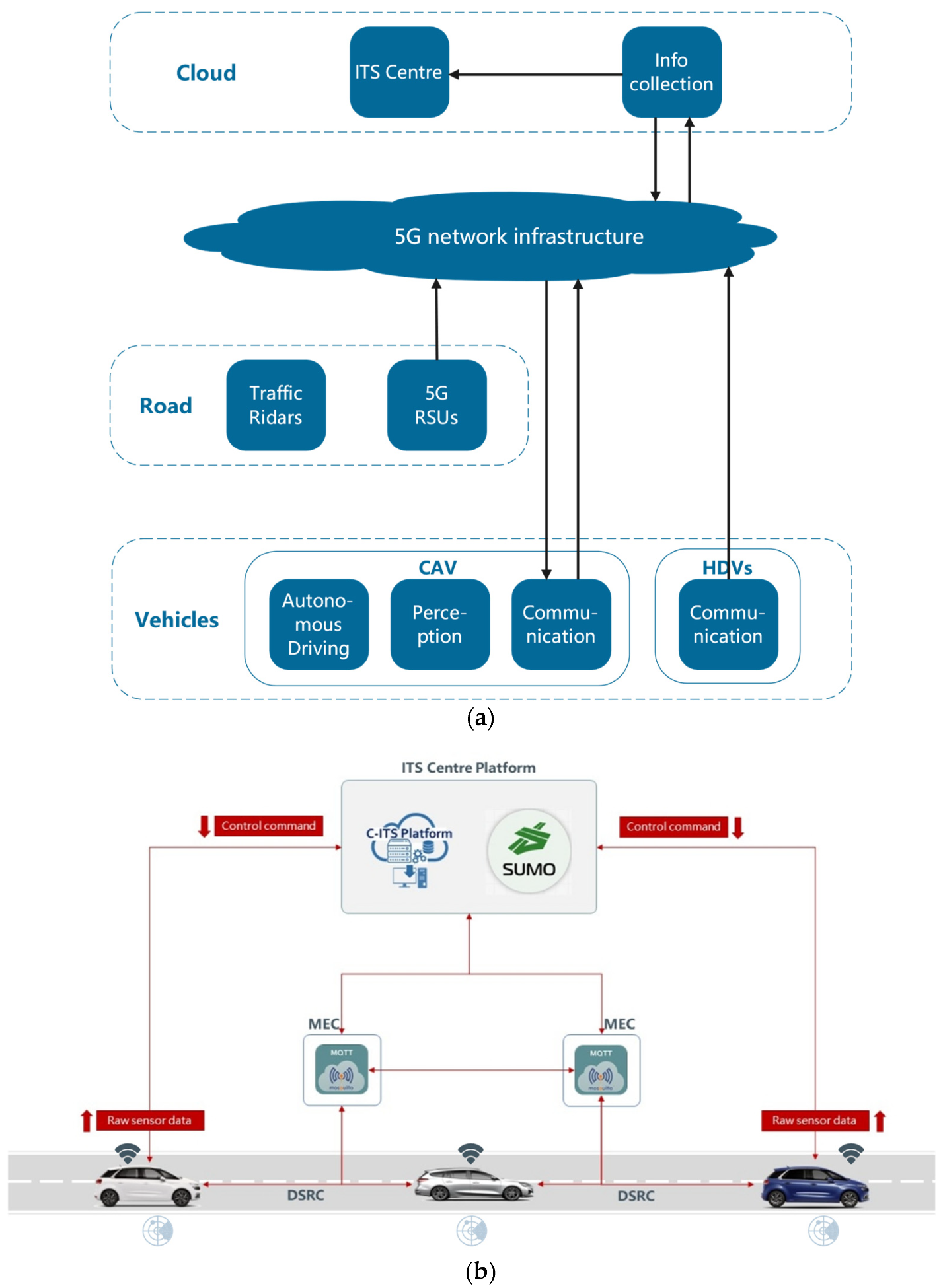
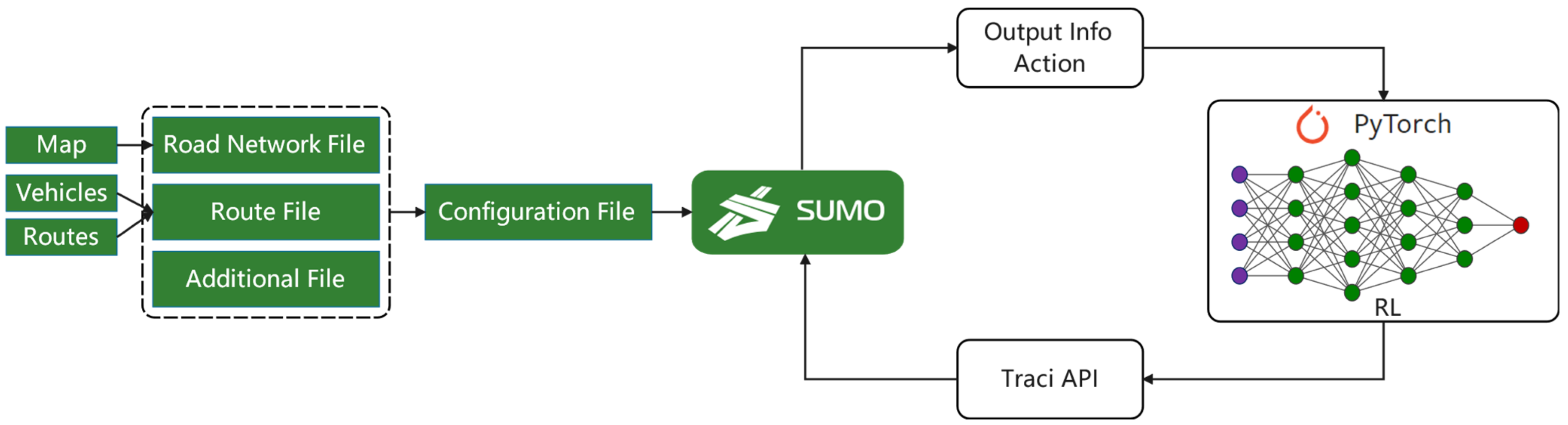
In the section, a scheme is described at the system level and it is shown in
Figure 4. The implementation of the framework includes two phases: the training phase and the deployment phase. The CAV is first trained with T intersection and Cross intersection in SMARTS, then, which is ported to the Cross intersection, connected to the real scenario with RSU, it starts to control the CAV.
(1) Training phase
The CAV is trained by interacting with the simulator. The simulator randomly generates social vehicles to arrive and specifies a CAV to drive from south to west. It obeys traffic rules and interacts with surrounding social vehicles. The simulator obtains the state, calculates the current reward rt accordingly, and provides it to the CAV. Using the Policy-Gradient update formula referenced in the previous sections, the agent updates itself based on the information from the simulator. At the same time, Ent selects an at action (throttle, steering, brake) and forwards the action to the simulator. Then the simulator will update and change the physical state of the CAV. The steps are repeated until convergence, and the agent is trained.
The agent’s performance is largely dependent on the quality of the simulator. In order to be similar to the real world, the emulator is randomly generated according to the real crossroads. To solve the difference in traffic flow at different times in a day, we granulate according to the traffic density so that the agent can adapt to different traffic flows at different times during training.
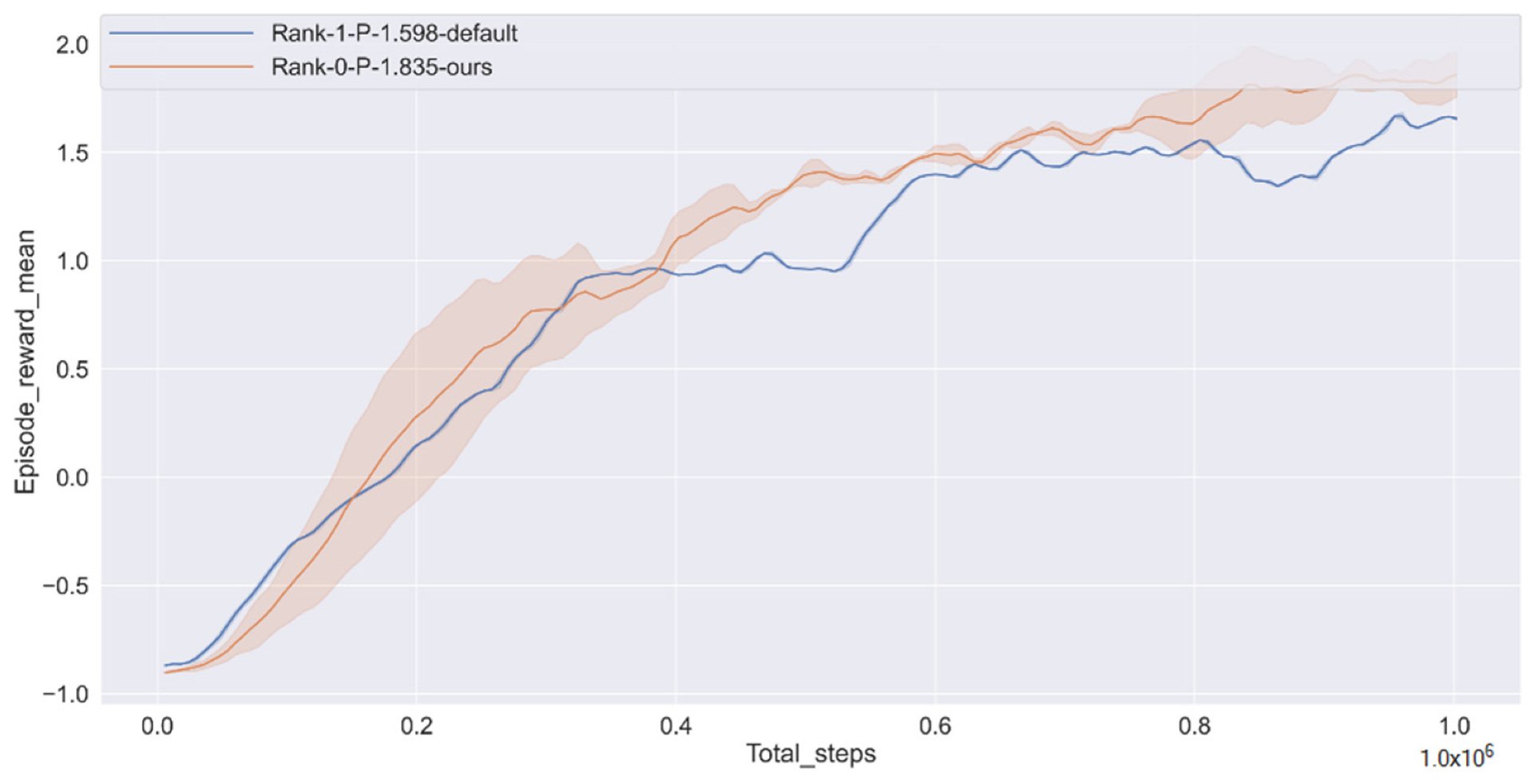
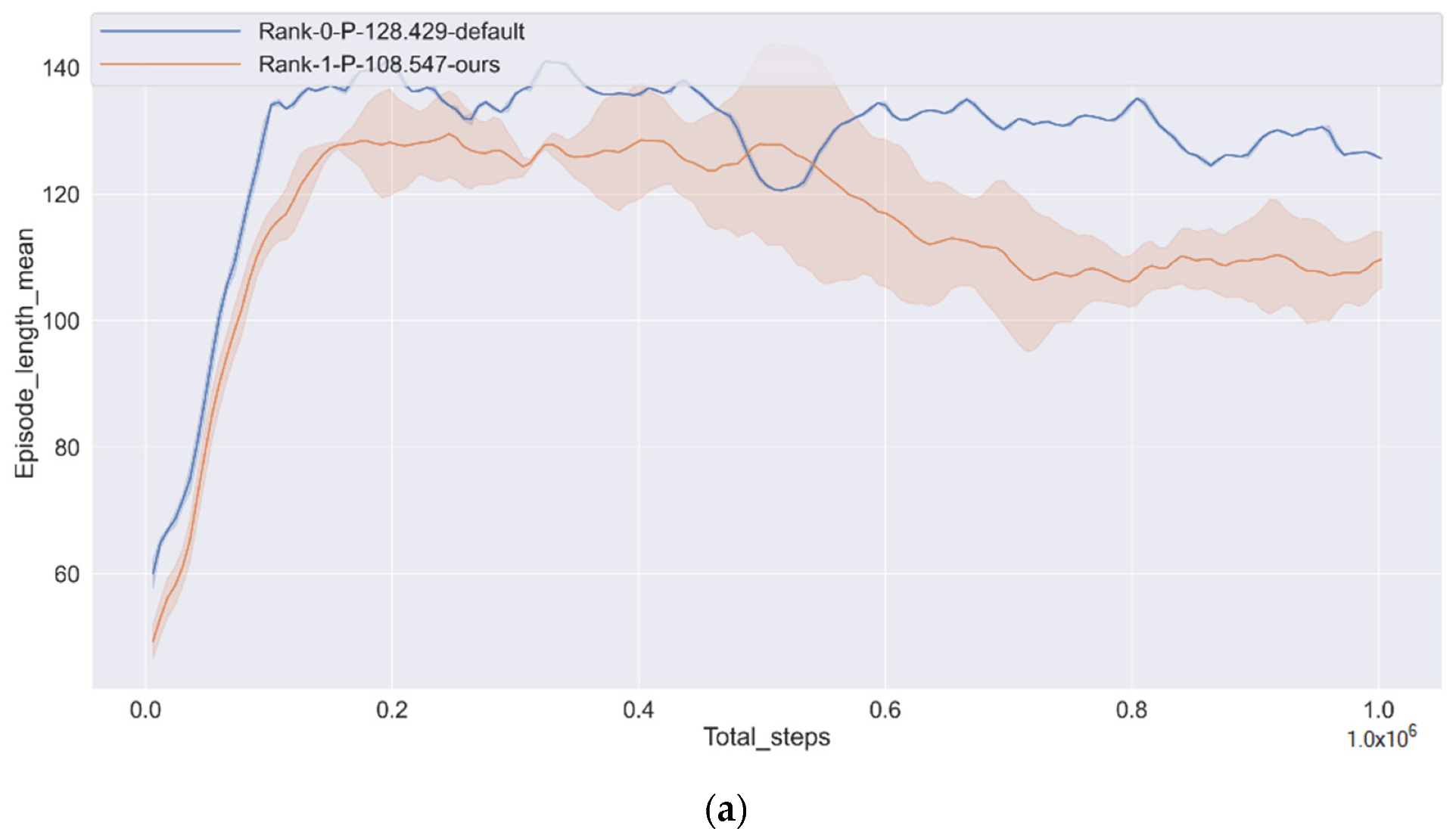
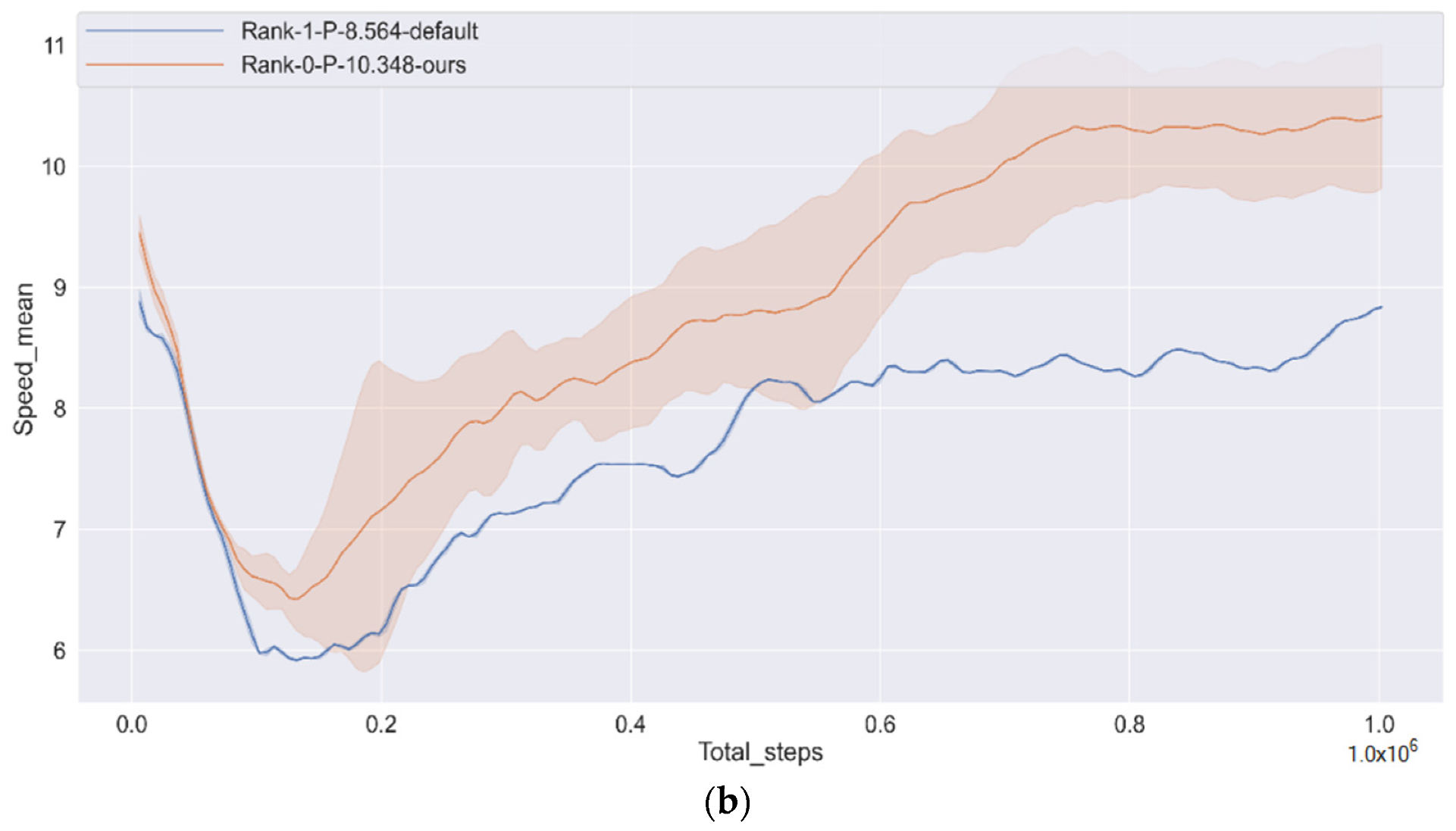
The training goal is to make the CAV smooth, safe and fast from the starting point to the finishing point, without colliding with the social vehicle or driving off the track.
As
Figure 4a, the vehicle’s information is collected and transmitted to the Cloud. In addition we were training on the Cloud through the PPO algorithm.
(2) Development
In the deployment phase, the trained agent CAV is migrated to the intersection for vehicle control and installed the software agent to the road test edge device to implement the control of the automatic driving vehicle. Here, the agent does not update the learned but controls the CAV. V2X provides the state of the current environment, and CAV selects three consecutive actions based on the trained v-network based on state. This step is executed in real-time to achieve continuous vehicle control.
















{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}