
CNN Deep Learning with Wavelet Image Fusion of CCD RGB-IR and Depth-Grayscale Sensor Data for Hand Gesture Intention Recognition

Abstract
:1. Introduction
- (1)
- An effective deep learning recognition framework, CNN, incorporated with wavelet image fusion of the dual modalities of sensor data, CCD RGB-IR and depth-grayscale, is proposed for hand gesture intention recognition.
- (2)
- Compared with traditional CNN deep learning and recognition using only a single modality of sensor data (either CCD RGB-IR or depth-grayscale), the presented CNN with wavelet image fusion of both CCD RGB-IR and depth-grayscale has obvious and significant performance impacts on gesture recognition accuracy.
- (3)
- Compared with those studies using fusion of VIS and IR images in CCD camera-based surveillance applications with human activity recognition, gesture recognition using a fusion of CCD RGB-IR and depth-grayscale, as per the presented approach, will be much competitive, especially in adverse conditions such as darkness or low illumination.
- (4)
- Compared with those works by IR thermal image-based approaches for overcoming the problem of gesture recognition in the condition of low lights, the presented approach will be much more advantageous and acceptable given the costs of sensor deployments.
2. Typical VGG-16 CNN Deep Learning on Recognition
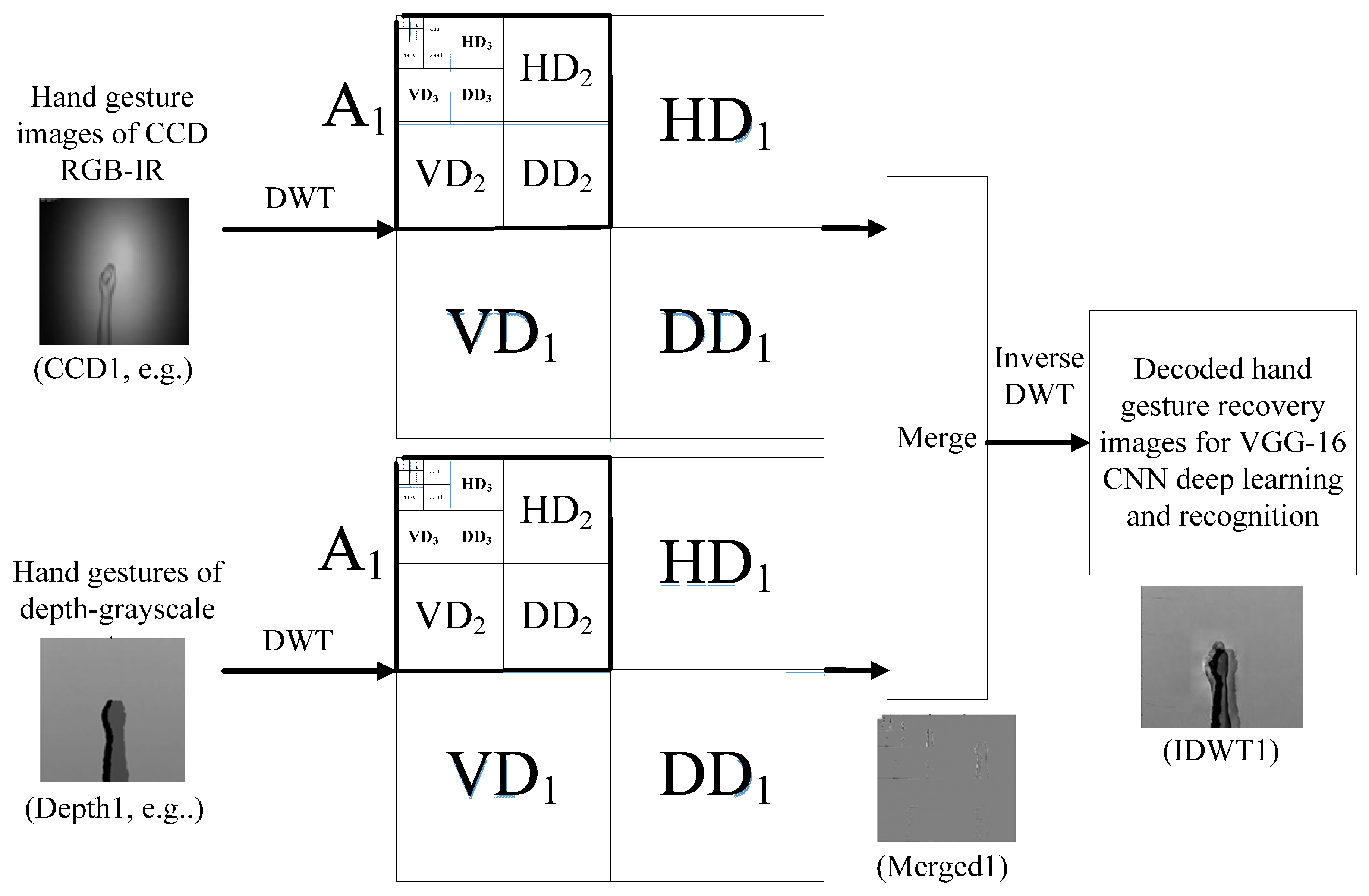
3. Hand Gesture Intention Recognition by Presented VGG-16 CNN Deep Learning Incorporated with Wavelet Fusion of CCD RGB-IR and Depth-Grayscale Sensing Images
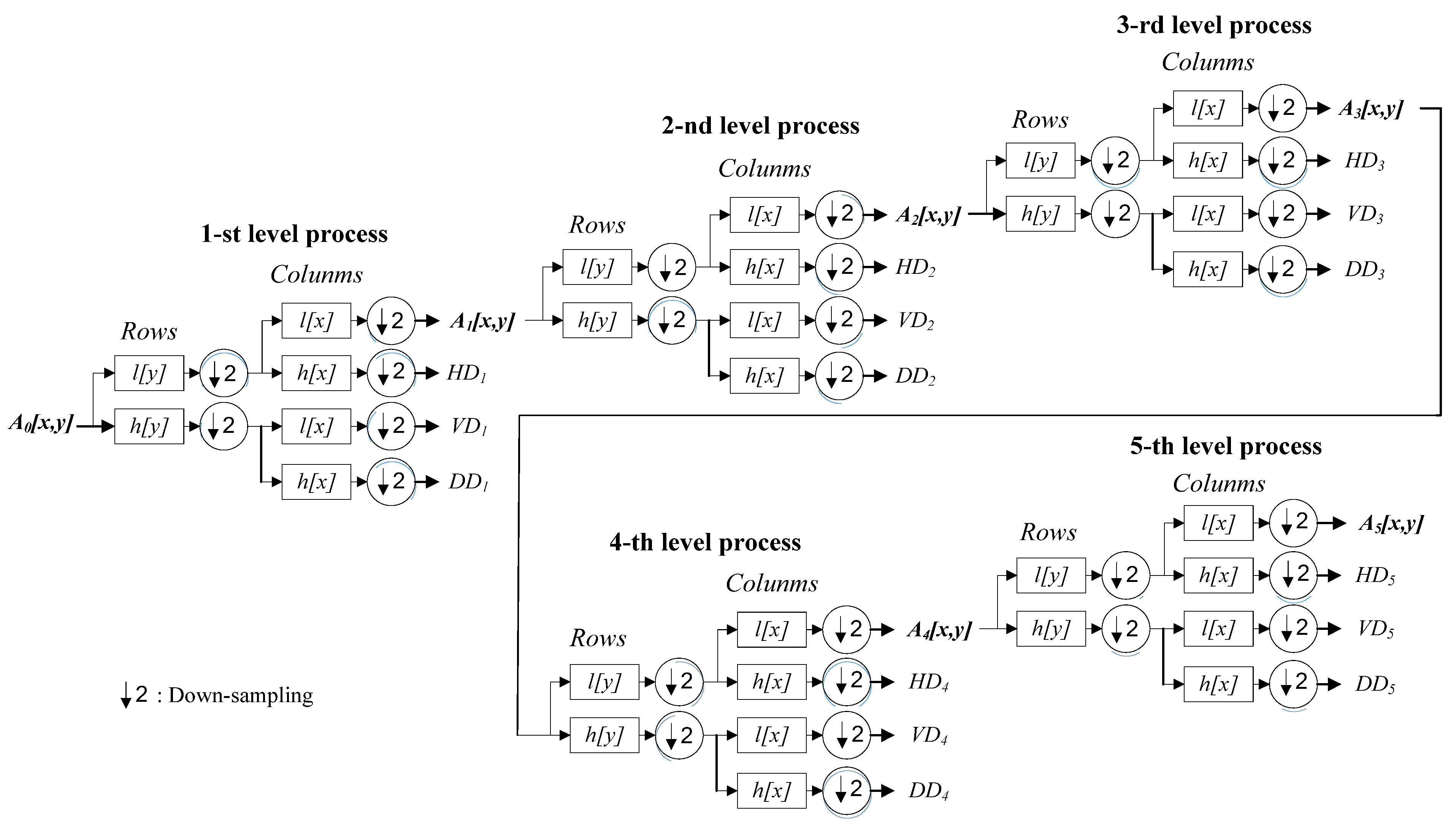
3.1. Discrete Wavelet Transform of Five Levels for Decompositions of CCD RGB-IR and Depth-Grayscale Hand Gesture Action Data
3.2. Decomposition Data Merge and IDWT-Decode to Derive Hybridized Data Streams for VGG-16 CNN Deep Learning on Hand Gesture Intention Action Recognition
- (1)
- The data fusion strategy of max-min
- (2)
- The data fusion strategy of min-max
- (3)
- The data fusion strategy of mean-mean
4. Experiments
| (The normal): Where are you going? | (The disabled): To the restroom! |
| (The normal): Do you remember? | (The disabled): What? |
| (The normal): I’m going back first. | (The disabled): Good bye! |
| (The normal): Ok, finished! | (The disabled): Is it ok? |
| (The normal): Hi, good morning! | (The disabled): Good morning! |
| (The normal): Who is him? | (The disabled): The teacher! |
| (The normal): Is it an exam or quiz? | (The disabled): The exam! |
| (The normal): Hello! | (The disabled): Hello! |
| (The normal): I’m so excited now. | (The disabled): Calm down! |
| (The normal): Is academic exchange required? | (The disabled): Exchange! |
5. Discussions
6. Conclusions
Author Contributions
Funding
Informed Consent Statement
Data Availability Statement
Acknowledgments
Conflicts of Interest
References
- Tina; Sharma, A.K.; Tomar, S.; Gupta, K. Various Approaches of Human Activity Recognition: A Review. In Proceedings of the 5th International Conference on Computing Methodologies and Communication, Erode, India, 8–10 April 2021; pp. 1668–1676. [Google Scholar] [CrossRef]
- Ding, I.J.; Chang, Y.J. On the use of Kinect sensors to design a sport instructor robot for rehabilitation and exercise training of the aged person. Sens. Mater. 2016, 28, 463–476. [Google Scholar] [CrossRef]
- Ding, I.J.; Chang, Y.J. HMM with improved feature extraction-based feature parameters for identity recognition of gesture command operators by using a sensed Kinect-data stream. Neurocomputing 2017, 262, 108–119. [Google Scholar] [CrossRef]
- Ding, I.J.; Lin, R.Z.; Lin, Z.Y. Service robot system with integration of wearable Myo armband for specialized hand gesture human–computer interfaces for people with disabilities with mobility problems. Comput. Electr. Eng. 2018, 69, 815–827. [Google Scholar] [CrossRef]
- Ding, I.J.; Wu, Z.G. Two user adaptation-derived features for biometrical classifications of user identity in 3D-sensor-based body gesture recognition applications. IEEE Sens. J. 2019, 19, 8432–8440. [Google Scholar] [CrossRef]
- Ding, I.J.; Wu, Z.G. Combinations of eigenspace and GMM with Kinect sensor-extracted action gesture features for person identity recognition. Eng. Comput. 2016, 33, 2489–2503. [Google Scholar] [CrossRef]
- Gama, A.E.D.; Chaves, T.M.; Figueiredo, L.S.; Baltar, A.; Meng, M.; Navab, N.; Teichrieb, V.; Fallavollita, P. MirrARbilitation: A clinically-related gesture recognition interactive tool for an AR rehabilitation system. Comput. Methods Programs Biomed. 2016, 135, 105–114. [Google Scholar] [CrossRef]
- Zhao, L.; Lu, X.; Tao, X.; Chen, X. A Kinect-Based Virtual Rehabilitation System through Gesture Recognition. In Proceedings of the International Conference on Virtual Reality and Visualization, Hangzhou, China, 24–26 September 2016; pp. 380–384. [Google Scholar] [CrossRef]
- Fayyaz, S.; Bukhsh, R.; Khan, M.A.; Hamza Gondal, H.A.; Tahir, S. Adjustment of Bed for a Patient through Gesture Recognition: An Image Processing Approach. In Proceedings of the IEEE International Multi-Topic Conference, Karachi, Pakistan, 1–2 November 2018; pp. 1–8. [Google Scholar] [CrossRef]
- Kamruzzaman, M.M. Arabic sign language recognition and generating Arabic speech using convolutional neural network. Wirel. Commun. Mob. Comput. 2020, 2020, 1–9. [Google Scholar] [CrossRef]
- Wen, F.; Zhang, Z.; He, T.; Lee, C. AI enabled sign language recognition and VR space bidirectional communication using triboelectric smart glove. Nat. Commun. 2021, 12, 5378. [Google Scholar] [CrossRef]
- Ding, I.J.; Zheng, N.W.; Hsieh, M.C. Hand gesture intention-based identity recognition using various recognition strategies incorporated with VGG convolution neural network-extracted deep learning features. J. Intell. Fuzzy Syst. 2021, 40, 7775–7788. [Google Scholar] [CrossRef]
- Wang, B.; Bai, G.; Lin, S.; Wang, Y.; Zeng, J. A novel synchronized fusion model for multi-band Images. IEEE Access 2019, 7, 139196–139211. [Google Scholar] [CrossRef]
- Hu, H.; Wu, J.; Li, B.; Guo, Q.; Zheng, J. An adaptive fusion algorithm for visible and infrared videos based on entropy and the cumulative distribution of gray levels. IEEE Trans. Multimed. 2017, 19, 2706–2719. [Google Scholar] [CrossRef]
- Li, Q.; Lu, L.; Li, Z.; Wu, W.; Liu, Z.; Jeon, G.; Yang, X. Coupled GAN with relativistic discriminators for infrared and visible images fusion. IEEE Sens. J. 2021, 21, 7458–7467. [Google Scholar] [CrossRef]
- Ma, J.; Xu, H.; Jiang, J.; Mei, X.; Zhang, X.-P. DDcGAN: A dual-discriminator conditional generative adversarial network for multi-resolution image Fusion. IEEE Trans. Image Process 2020, 29, 4980–4995. [Google Scholar] [CrossRef] [PubMed]
- Liao, B.; Du, Y.; Yin, X. Fusion of infrared-visible images in UE-IoT for fault point detection based on GAN. IEEE Access 2020, 8, 79754–79763. [Google Scholar] [CrossRef]
- Zhang, X.; Ye, P.; Peng, S.; Liu, J.; Gong, K.; Xiao, G. SiamFT: An RGB-infrared fusion tracking method via fully convolutional Siamese networks. IEEE Access 2019, 7, 122122–122133. [Google Scholar] [CrossRef]
- Hou, R.; Zhou, D.; Nie, R.; Liu, D.; Xiong, L.; Guo, Y.; Yu, C. VIF-Net: An unsupervised framework for infrared and visible image fusion. IEEE Trans. Comput. Imag. 2020, 6, 640–651. [Google Scholar] [CrossRef]
- Hossen, J.; Jacobs, E.; Chowdhury, F.K. Human Suspicious Activity Recognition in Thermal Infrared Video. In Proceedings of the SPIE 9220, Infrared Sensors, Devices, and Applications IV, San Diego, CA, USA, 7 October 2014; p. 92200E. [Google Scholar] [CrossRef]
- Kawashima, T.; Kawanishi, Y.; Ide, I.; Murase, H.; Deguchi, D.; Aizawa, T.; Kawade, M. Action Recognition from Extremely Low-Resolution Thermal Image Sequence. In Proceedings of the 14th IEEE International Conference on Advanced Video and Signal Based Surveillance, Lecce, Italy, 29 August–1 September 2017; pp. 1–6. [Google Scholar] [CrossRef]
- Morawski, I.; Lie, W.-N. Two-Stream Deep Learning Architecture for Action Recognition by Using Extremely Low-Resolution Infrared Thermopile Arrays. In Proceedings of the SPIE 11515, International Workshop on Advanced Imaging Technology, Yogyakarta, Indonesia, 1 June 2020. [Google Scholar] [CrossRef]
- Naik, K.; Pandit, T.; Naik, N.; Shah, P. Activity recognition in residential spaces with internet of things devices and thermal imaging. Sensors 2021, 21, 988. [Google Scholar] [CrossRef] [PubMed]
- Simonyan, K.; Zisserman, A. Very Deep Convolutional Networks for Large-Scale Image Recognition. In Proceedings of the International Conference on Learning Representations, San Diego, CA, USA, 7–9 May 2015. [Google Scholar]
- Amolins, K.; Zhang, Y.; Dare, P. Wavelet based image fusion techniques—An introduction, review and comparison. ISPRS J. Photogramm. Remote Sens. 2007, 62, 249–263. [Google Scholar] [CrossRef]
- Mehra, I.; Nishchal, N.K. Wavelet-based image fusion for securing multiple images through asymmetric keys. Opt. Commun. 2015, 335, 153–160. [Google Scholar] [CrossRef]
- Jepsen, J.B.; De Clerck, G.; Lutalo-Kiingi, S.; McGregor, W.B. Sign Languages of the World: A Comparative Handbook; De Gruyter Mouton: Berlin, Germany, 2015. [Google Scholar] [CrossRef]
- Abbasi, M. Color image steganography using dual wavelet transforms. Int. J. Comput. Appl. 2019, 181, 32–38. [Google Scholar] [CrossRef]
- Papastratis, I.; Chatzikonstantinou, C.; Konstantinidis, D.; Dimitropoulos, K.; Daras, P. Artificial intelligence technologies for sign language. Sensors 2021, 21, 5843. [Google Scholar] [CrossRef] [PubMed]





















{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
| Action Classes | Data Streams of Continuous-Time CCD RGB-IR Hand Gesture Actions |
|---|---|
| Action 1 (To the restroom!) |  |
| Action 2 (What?) |  |
| Action 3 (Good bye!) |  |
| Action 4 (Is it ok?) |  |
| Action 5 (Good morning!) |  |
| Action 6 (The teacher!) |  |
| Action 7 (The exam!) |  |
| Action 8 (Hello!) |  |
| Action 9 (Calm down!) |  |
| Action 10 (Exchange!) |  |
| Data Modality | CCD RGB-IR | Depth-Grayscale | Wavelet Fusion Using Max-Min | Wavelet Fusion Using Min-Max | Wavelet Fusion Using Mean-Mean |
|---|---|---|---|---|---|
| Average | 100% | 100% | 100% | 100% | 100% |
| Single Sensor Modality | CCD RGB-IR | Depth-Grayscale |
|---|---|---|
| Action-1 | 67.67% | 93.33% |
| Action-2 | 100.00% | 99.93% |
| Action-3 | 40.33% | 17.93% |
| Action-4 | 59.67% | 69.60% |
| Action-5 | 2.67% | 25.20% |
| Action-6 | 86.33% | 95.26% |
| Action-7 | 100.00% | 77.66% |
| Action-8 | 100.00% | 91.46% |
| Action-9 | 100.00% | 98.00% |
| Action-10 | 96.67% | 61.06% |
| Average | 75.33% | 72.94% |
| Action Categorization | Wavelet Fusion of the Max-Min Type | Wavelet Fusion of the Min-Max Type | Wavelet Fusion of the Mean-Mean Type |
|---|---|---|---|
| Action-1 | 98.20% | 99.53% | 99.20% |
| Action-2 | 94.27% | 99.07% | 97.87% |
| Action-3 | 6.00% | 24.20% | 44.87% |
| Action-4 | 43.93% | 84.80% | 71.13% |
| Action-5 | 44.33% | 37.53% | 18.13% |
| Action-6 | 72.33% | 98.33% | 99.27% |
| Action-7 | 82.13% | 99.00% | 81.67% |
| Action-8 | 98.40% | 98.33% | 99.13% |
| Action-9 | 99.47% | 100.00% | 100.00% |
| Action-10 | 100.00% | 98.00% | 98.20% |
| Average | 73.91% | 83.88% | 80.95% |
| Max-Min | 1 | 2 | 3 | 4 | 5 | 6 | 7 | 8 | 9 | 10 |
|---|---|---|---|---|---|---|---|---|---|---|
| 1 | 1473 | 0 | 0 | 11 | 16 | 0 | 0 | 0 | 0 | 0 |
| 2 | 0 | 1414 | 1 | 0 | 0 | 0 | 0 | 84 | 1 | 0 |
| 3 | 132 | 0 | 90 | 7 | 1003 | 29 | 239 | 0 | 0 | 0 |
| 4 | 41 | 0 | 25 | 659 | 47 | 456 | 10 | 0 | 0 | 262 |
| 5 | 107 | 0 | 13 | 0 | 665 | 0 | 665 | 0 | 0 | 50 |
| 6 | 4 | 302 | 18 | 0 | 6 | 1085 | 24 | 44 | 5 | 12 |
| 7 | 0 | 0 | 0 | 0 | 0 | 241 | 1232 | 2 | 10 | 15 |
| 8 | 0 | 24 | 0 | 0 | 0 | 0 | 0 | 1476 | 0 | 0 |
| 9 | 0 | 0 | 0 | 8 | 0 | 0 | 0 | 0 | 1492 | 0 |
| 10 | 0 | 0 | 0 | 0 | 0 | 0 | 0 | 0 | 0 | 1500 |
| Min-Max | 1 | 2 | 3 | 4 | 5 | 6 | 7 | 8 | 9 | 10 |
|---|---|---|---|---|---|---|---|---|---|---|
| 1 | 1493 | 0 | 0 | 7 | 0 | 0 | 0 | 0 | 0 | 0 |
| 2 | 0 | 1486 | 0 | 0 | 0 | 0 | 0 | 13 | 1 | 0 |
| 3 | 161 | 0 | 363 | 637 | 322 | 17 | 0 | 0 | 0 | 0 |
| 4 | 26 | 2 | 35 | 1272 | 7 | 75 | 1 | 0 | 2 | 80 |
| 5 | 0 | 0 | 192 | 0 | 563 | 0 | 292 | 0 | 0 | 453 |
| 6 | 0 | 0 | 4 | 0 | 8 | 1475 | 13 | 0 | 0 | 0 |
| 7 | 0 | 0 | 0 | 6 | 0 | 0 | 1485 | 0 | 0 | 9 |
| 8 | 0 | 25 | 0 | 0 | 0 | 0 | 0 | 1475 | 0 | 0 |
| 9 | 0 | 0 | 0 | 0 | 0 | 0 | 0 | 0 | 1500 | 0 |
| 10 | 12 | 0 | 0 | 18 | 0 | 0 | 0 | 0 | 0 | 1470 |
| Mean-Mean | 1 | 2 | 3 | 4 | 5 | 6 | 7 | 8 | 9 | 10 |
|---|---|---|---|---|---|---|---|---|---|---|
| 1 | 1488 | 0 | 0 | 12 | 0 | 0 | 0 | 0 | 0 | 0 |
| 2 | 0 | 1468 | 0 | 0 | 0 | 0 | 0 | 32 | 0 | 0 |
| 3 | 506 | 0 | 673 | 131 | 74 | 50 | 66 | 0 | 0 | 0 |
| 4 | 25 | 1 | 107 | 1067 | 0 | 252 | 14 | 0 | 34 | 0 |
| 5 | 5 | 0 | 712 | 0 | 272 | 0 | 192 | 0 | 0 | 319 |
| 6 | 3 | 0 | 7 | 0 | 0 | 1489 | 1 | 0 | 0 | 0 |
| 7 | 0 | 0 | 0 | 27 | 0 | 58 | 1225 | 96 | 0 | 94 |
| 8 | 0 | 13 | 0 | 0 | 0 | 0 | 0 | 1487 | 0 | 0 |
| 9 | 0 | 0 | 0 | 0 | 0 | 0 | 0 | 0 | 1500 | 0 |
| 10 | 16 | 0 | 0 | 11 | 0 | 0 | 0 | 0 | 0 | 1473 |
| Merge Types of Wavelet Image Fusion for VGG-16 CNN | Wavelet Fusion Using Max-Min | Wavelet Fusion Using Min-Max | Wavelet Fusion Using Mean-Mean |
|---|---|---|---|
| Training time in total | 9067.80 s | 9070.75 s | 9096.67 s |
| Test time in total | 133.96 s | 128.17 s | 128.57 s |
| Test time (averaged, one-action) | 0.54 s | 0.51 s | 0.51 s |
Publisher’s Note: MDPI stays neutral with regard to jurisdictional claims in published maps and institutional affiliations. |
© 2022 by the authors. Licensee MDPI, Basel, Switzerland. This article is an open access article distributed under the terms and conditions of the Creative Commons Attribution (CC BY) license (https://creativecommons.org/licenses/by/4.0/).
Share and Cite
Ding, I.-J.; Zheng, N.-W. CNN Deep Learning with Wavelet Image Fusion of CCD RGB-IR and Depth-Grayscale Sensor Data for Hand Gesture Intention Recognition. Sensors 2022, 22, 803. https://doi.org/10.3390/s22030803
Ding I-J, Zheng N-W. CNN Deep Learning with Wavelet Image Fusion of CCD RGB-IR and Depth-Grayscale Sensor Data for Hand Gesture Intention Recognition. Sensors. 2022; 22(3):803. https://doi.org/10.3390/s22030803
Chicago/Turabian StyleDing, Ing-Jr, and Nai-Wei Zheng. 2022. "CNN Deep Learning with Wavelet Image Fusion of CCD RGB-IR and Depth-Grayscale Sensor Data for Hand Gesture Intention Recognition" Sensors 22, no. 3: 803. https://doi.org/10.3390/s22030803
APA StyleDing, I.-J., & Zheng, N.-W. (2022). CNN Deep Learning with Wavelet Image Fusion of CCD RGB-IR and Depth-Grayscale Sensor Data for Hand Gesture Intention Recognition. Sensors, 22(3), 803. https://doi.org/10.3390/s22030803