
User-Independent Hand Gesture Recognition Classification Models Using Sensor Fusion



Abstract
:1. Introduction
2. Materials and Methods
2.1. Participant Recruitment
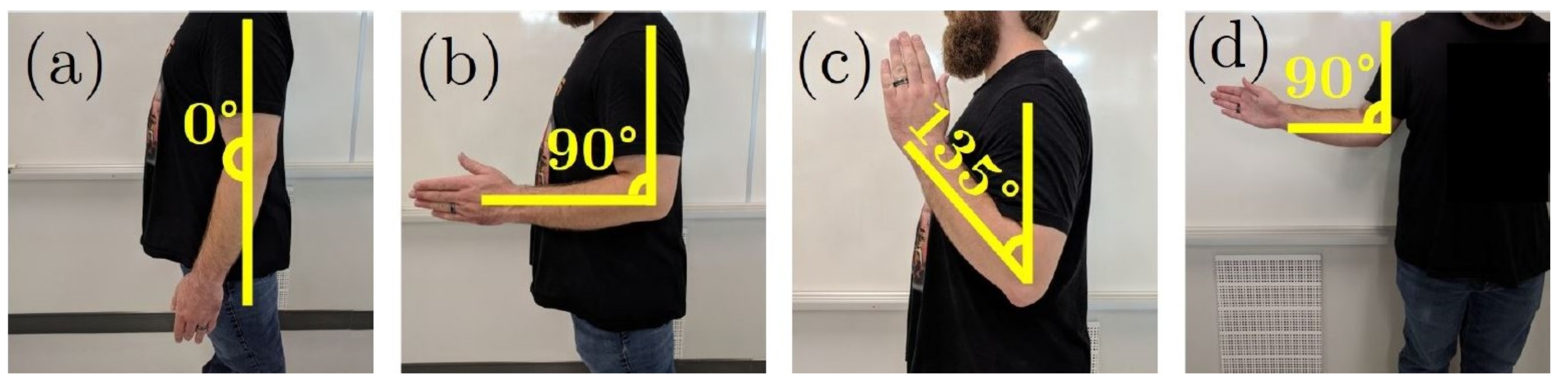
2.2. Experimental Protocol
2.3. Gestures
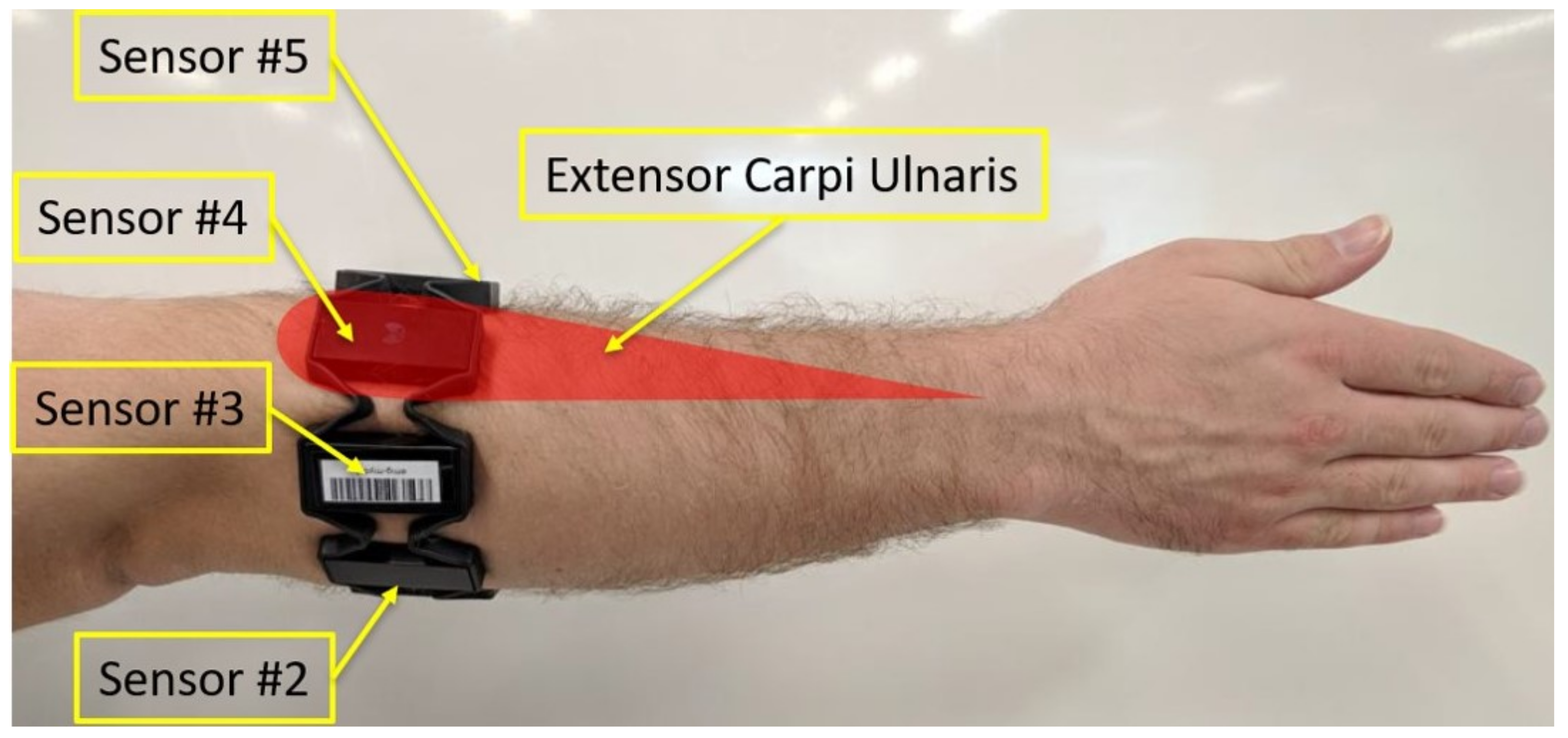
2.4. Data Acquisition and Processing
2.5. Feature Extraction
2.6. Cross-Validation Sets
3. User-Independent Classification Methods
3.1. The Adaptive LS-SVM
3.2. Bilinear Model-Based Classifier
3.3. Classic MLP Network
3.4. Statistical Analysis
4. Results
4.1. Adaptive LS-SVM Classification Results
4.2. Bilinear Models-Based Classification Results
4.3. Classic MLP Network Classification Results
4.4. Comparison of Classification Methods
5. Discussion
5.1. Adaptive LS-SVM Classification
5.2. Bilinear Models-Based Classification
5.3. Classic MLP Network Classification
6. Conclusions and Future Work
Author Contributions
Funding
Institutional Review Board Statement
Informed Consent Statement
Data Availability Statement
Acknowledgments
Conflicts of Interest
References
- Duret, C.; Courtial, O.; Grosmaire, A.G.; Hutin, E. Use of a robotic device for the rehabilitation of severe upper limb paresis in subacute stroke: Exploration of patient/robot interactions and the motor recovery process. BioMed Res. Int. 2015, 2015, 482389. [Google Scholar] [CrossRef] [PubMed]
- Asokan, A.; Pothen, A.J.; Vijayaraj, R.K. ARMatron—A wearable gesture recognition glove: For control of robotic devices in disaster management and human rehabilitation. In Proceedings of the 2016 International Conference on Robotics and Automation for Humanitarian Applications (RAHA), Amritapuri, India, 18–20 December 2016; pp. 1–5. [Google Scholar]
- Wolf, M.T.; Assad, C.; Vernacchia, M.T.; Fromm, J.; Jethani, H.L. Gesture-based robot control with variable autonomy from the JPL BioSleeve. In Proceedings of the IEEE International Conference on Robotics and Automation, Karlsruhe, Germany, 6–10 May 2013; pp. 1160–1165. [Google Scholar]
- Meng, Q.; Meng, Q.; Yu, H.; Wei, X. A survey on sEMG control strategies of wearable hand exoskeleton for rehabilitation. In Proceedings of the IEEE 2nd Asia-Pacific Conference on Intelligent Robot Systems (ACIRS), Wuhan, China, 16–18 June 2017; pp. 165–169. [Google Scholar]
- Georgi, M.; Amma, C.; Schultz, T. Fusion and Comparison of IMU and EMG signals for wearable gesture recognition. In Proceedings of the International Joint Conference on Biomedical Engineering Systems and Technologies, Lisbon, Portugal, 12–15 January 2015; pp. 308–323. [Google Scholar]
- Wahid, M.F.; Tafreshi, R.; Al-Sowaidi, M.; Langari, R. Subject-independent hand gesture recognition using normalization and machine learning algorithms. J. Comput. Sci. 2018, 27, 69–76. [Google Scholar] [CrossRef]
- Huang, Q.; Yang, D.; Jiang, L.; Zhang, H.; Liu, H.; Kotani, K. A novel unsupervised adaptive learning method for long-term electromyography (EMG) pattern recognition. Sensors 2017, 17, 1370. [Google Scholar] [CrossRef] [PubMed] [Green Version]
- Tommasi, T.; Orabona, F.; Castellini, C.; Caputo, B. Improving control of dexterous hand prostheses using adaptive learning. IEEE Trans. Robot. 2013, 29, 207–219. [Google Scholar] [CrossRef]
- Matsubara, T.; Morimoto, J. Bilinear modeling of EMG signals to extract user-independent features for multiuser myoelectric interface. IEEE Trans. Biomed. Eng. 2013, 60, 2205–2213. [Google Scholar] [CrossRef]
- Novak, D.; Riener, R. A survey of sensor fusion methods in wearable robotics. Robot. Auton. Syst. 2015, 73, 155–170. [Google Scholar] [CrossRef]
- Kundu, A.S.; Mazumder, O.; Lenka, P.K.; Bhaumik, S. Hand gesture recognition based omnidirectional wheelchair control using IMU and EMG sensors. J. Intell. Robot. Syst. 2018, 91, 529–541. [Google Scholar] [CrossRef]
- Repnik, E.; Puh, U.; Goljar, N.; Munih, M.; Mihelj, M. Using inertial measurement units and electromyography to quantify movement during action research arm test execution. Sensors 2018, 18, 2767. [Google Scholar] [CrossRef] [Green Version]
- Krasoulis, A.; Kyranou, I.; Erden, M.S.; Nazarpour, K.; Vijayakumar, S. Improved prosthetic hand control with concurrent use of myoelectric and inertial measurements. J. Neuroeng. Rehabil. 2017, 14, 71. [Google Scholar] [CrossRef]
- Shi, C.; Qi, L.; Yang, D.; Zhao, J.; Liu, H. A novel method of combining computer vision, eye-tracking, EMG, and IMU to control dexterous prosthetic hand. In Proceedings of the IEEE International Conference on Robotics and Biomimetics (ROBIO), Dali, China, 6–8 December 2019; pp. 2614–2618. [Google Scholar]
- Colli Alfaro, J.G.; Ibrahim, A.; Trejos, A.L. Design of user-independent hand gesture recognition using multilayer perceptron networks and sensor fusion techniques. In Proceedings of the IEEE 16th International Conference on Rehabilitation Robotics, Toronto, ON, Canada, 24–28 June 2019; pp. 1103–1108. [Google Scholar]
- Campbell, E.; Phinyomark, A.; Scheme, E. Differences in Perspective on Inertial Measurement Unit Sensor Integration in Myoelectric Control. arXiv 2020, arXiv:2003.03424. [Google Scholar]
- Myo Gesture Control Armband—Wearable Technology by Thalmic Labs. Available online: https://www.myo.com/ (accessed on 3 November 2017).
- Höglund, G.; Grip, H.; Öhberg, F. The importance of inertial measurement unit placement in assessing upper limb motion. Med. Eng. Phys. 2021, 92, 1–9. [Google Scholar] [CrossRef] [PubMed]
- Fougner, A.; Scheme, E.; Chan, A.D.; Englehart, K.; Stavdahl, Ø. Resolving the limb position effect in myoelectric pattern recognition. IEEE Trans. Neural Syst. Rehabil. Eng. 2011, 19, 644–651. [Google Scholar] [CrossRef] [PubMed] [Green Version]
- Tomaszewski, M. Myo SDK Matlab MEX Wrapper. 2016. Available online: https://github.com/mark-toma/MyoMex (accessed on 12 February 2018).
- Solnik, S.; Rider, P.; Steinweg, K.; DeVita, P.; Hortobágyi, T. Teager–Kaiser energy operator signal conditioning improves EMG onset detection. Eur. J. Appl. Physiol. 2010, 110, 489–498. [Google Scholar] [CrossRef] [PubMed] [Green Version]
- Drapała, J.; Brzostowski, K.; Szpala, A.; Rutkowska-Kucharska, A. Two stage EMG onset detection method. Arch. Control Sci. 2012, 22, 427–440. [Google Scholar] [CrossRef]
- Englehart, K.; Hudgins, B. A robust, real-time control scheme for multifunction myoelectric control. IEEE Trans. Biomed. Eng. 2003, 50, 848–854. [Google Scholar] [CrossRef] [PubMed]
- Phinyomark, A.; Phukpattaranont, P.; Limsakul, C. Feature reduction and selection for EMG signal classification. Expert Syst. Appl. 2012, 39, 7420–7431. [Google Scholar] [CrossRef]
- Gravina, R.; Alinia, P.; Ghasemzadeh, H.; Fortino, G. Multi-sensor fusion in body sensor networks: State-of-the-art and research challenges. Inf. Fusion 2017, 35, 68–80. [Google Scholar] [CrossRef]
- Lima, A.A.M.; Araujo, R.M.; dos Santos, F.A.G.; Yoshizumi, V.H.; de Barros, F.K.; Spatti, D.H.; Liboni, L.H.; Dajer, M.E. Classification of hand movements from EMG signals using optimized MLP. In Proceedings of the IEEE International Joint Conference on Neural Networks (IJCNN), Rio de Janeiro, Brazil, 8–13 July 2018; pp. 1–7. [Google Scholar]
- Abadi, M.; Agarwal, A.; Barham, P.; Brevdo, E.; Chen, Z.; Citro, C.; Corrado, G.S.; Davis, A.; Dean, J.; Devin, M.; et al. TensorFlow: Large-scale machine learning on heterogeneous systems. arXiv 2016, arXiv:1603.04467. [Google Scholar]
- Python Software Foundation. Python Language Reference. Version 3.6. Available online: http://www.python.org (accessed on 9 September 2018).
- Srivastava, N.; Hinton, G.; Krizhevsky, A.; Sutskever, I.; Salakhutdinov, R. Dropout: A simple way to prevent neural networks from overfitting. J. Mach. Learn. Res. 2014, 15, 1929–1958. [Google Scholar]
- Santurkar, S.; Tsipras, D.; Ilyas, A.; Madry, A. How does batch normalization help optimization? In Proceedings of the 32nd Conference on Neural Information Processing Systems (NeurIPS), Montréal, QC, Canada, 3–8 December 2018; pp. 2483–2493. [Google Scholar]
- Kingma, D.P.; Ba, J. Adam: A method for stochastic optimization. In Proceedings of the 3rd International Conference on Learning Representations (ICLR), San Diego, CA, USA, 7–9 May 2015. [Google Scholar]
- RStudio Team. RStudio: Integrated Development Environment for R; Version 1.1.463; RStudio, Inc.: Boston, MA, USA, 2015. [Google Scholar]
- Bergmeir, C.; Benítez, J.M. Neural Networks in R Using the Stuttgart Neural Network Simulator: RSNNS. 2018. Available online: https://github.com/cbergmeir/RSNNS (accessed on 9 September 2018).
- Ishii, A.; Kondo, T.; Yano, S. Improvement of EMG pattern recognition by eliminating posture-dependent components. In Proceedings of the International Conference on Intelligent Autonomous Systems, Shanghai, China, 3–7 July 2016; pp. 19–30. [Google Scholar]
- Zhang, Y.; Chen, Y.; Yu, H.; Yang, X.; Lu, W.; Liu, H. Wearing-independent hand gesture recognition method based on EMG armband. Pers. Ubiquitous Comput. 2018, 22, 511–524. [Google Scholar] [CrossRef]
- Allard, U.C.; Nougarou, F.; Fall, C.L.; Giguère, P.; Gosselin, C.; Laviolette, F.; Gosselin, B. A convolutional neural network for robotic arm guidance using sEMG based frequency-features. In Proceedings of the IEEE/RSJ International Conference on Intelligent Robots and Systems (IROS), Daejeon, Korea, 9–14 October 2016; pp. 2464–2470. [Google Scholar]
- Hudgins, B.; Parker, P.; Scott, R.N. A new strategy for multifunction myoelectric control. IEEE Trans. Biomed. Eng. 1993, 40, 82–94. [Google Scholar] [CrossRef] [PubMed]
- Zhai, X.; Jelfs, B.; Chan, R.H.; Tin, C. Self-recalibrating surface EMG pattern recognition for neuroprosthesis control based on convolutional neural network. Front. Neurosci. 2017, 11, 379. [Google Scholar] [CrossRef] [PubMed] [Green Version]
- Khushaba, R.N. Correlation analysis of electromyogram signals for multiuser myoelectric interfaces. IEEE Trans. Neural Syst. Rehabil. Eng. 2014, 22, 745–755. [Google Scholar] [CrossRef] [PubMed] [Green Version]
- Crotty, E.D.; Furlong, L.A.M.; Hayes, K.; Harrison, A.J. Onset detection in surface electromyographic signals across isometric explosive and ramped contractions: A comparison of computer-based methods. Physiol. Meas. 2021, 42, 035010. [Google Scholar] [CrossRef]












{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
| Sex | Dominant Hand | Age (yrs) | Weight (kg) | Height (cm) | Wrist Circumference (cm) | Forearm Circumference (cm) |
|---|---|---|---|---|---|---|
| 18 Male | 22 Right | 23.70 ± 3.92 | 71.30 ± 12.13 | 173.67 ± 10.51 | 16.42 ± 1.20 | 26.41 ± 2.81 |
| 6 Female | 2 Left |
| EMG | EMG + IMU | ||||
|---|---|---|---|---|---|
| Classification Method | Accuracy Range (%) | Mean Accuracy (%) | Accuracy Range (%) | Mean Accuracy (%) | p Value |
| Adaptive LS-SVM | 61.7–92.5 | 83.5 () | 62.5–92.9 | 84.6 () | <0.01 |
| Bilinear Model-based | 21.2–67.3 | 42.8 () | 43–84.9 | 67.5 () | <0.01 |
| MLP Network | 36.5–78.9 | 64.8 () | 36.1–88.3 | 73.7 () | <0.01 |
| Classification Method | Mean Difference (%) | Std. Error (%) | Significance | |
|---|---|---|---|---|
| Adaptive LS-SVM | Bilinear Models | 28.827 | 2.508 | <0.001 |
| MLP Networks | 14.751 | 3.230 | 0.001 | |
| Bilinear Models | MLP Networks | −14.076 | 2.077 | <0.001 |
Publisher’s Note: MDPI stays neutral with regard to jurisdictional claims in published maps and institutional affiliations. |
© 2022 by the authors. Licensee MDPI, Basel, Switzerland. This article is an open access article distributed under the terms and conditions of the Creative Commons Attribution (CC BY) license (https://creativecommons.org/licenses/by/4.0/).
Share and Cite
Colli Alfaro, J.G.; Trejos, A.L. User-Independent Hand Gesture Recognition Classification Models Using Sensor Fusion. Sensors 2022, 22, 1321. https://doi.org/10.3390/s22041321
Colli Alfaro JG, Trejos AL. User-Independent Hand Gesture Recognition Classification Models Using Sensor Fusion. Sensors. 2022; 22(4):1321. https://doi.org/10.3390/s22041321
Chicago/Turabian StyleColli Alfaro, Jose Guillermo, and Ana Luisa Trejos. 2022. "User-Independent Hand Gesture Recognition Classification Models Using Sensor Fusion" Sensors 22, no. 4: 1321. https://doi.org/10.3390/s22041321