
Deep Learning Post-Filtering Using Multi-Head Attention and Multiresolution Feature Fusion for Image and Intra-Video Quality Enhancement



Abstract
:1. Introduction
2. Related Work
3. Proposed Method
3.1. Network Design
3.2. Loss Function
4. Experimental Validation
4.1. Experimental Setup
4.2. Quality Enhancement of RGB images
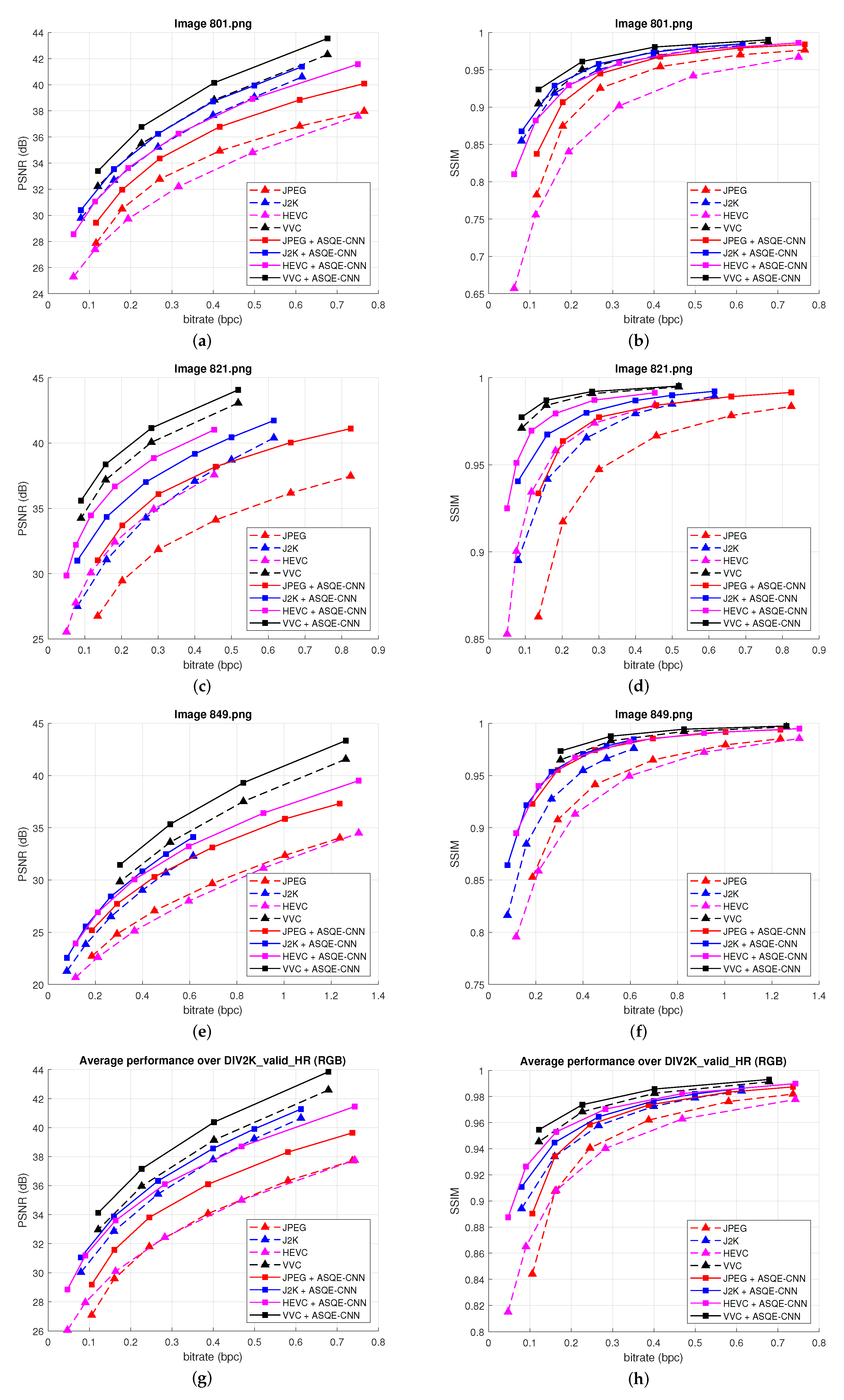
4.2.1. Rate-Distortion Results
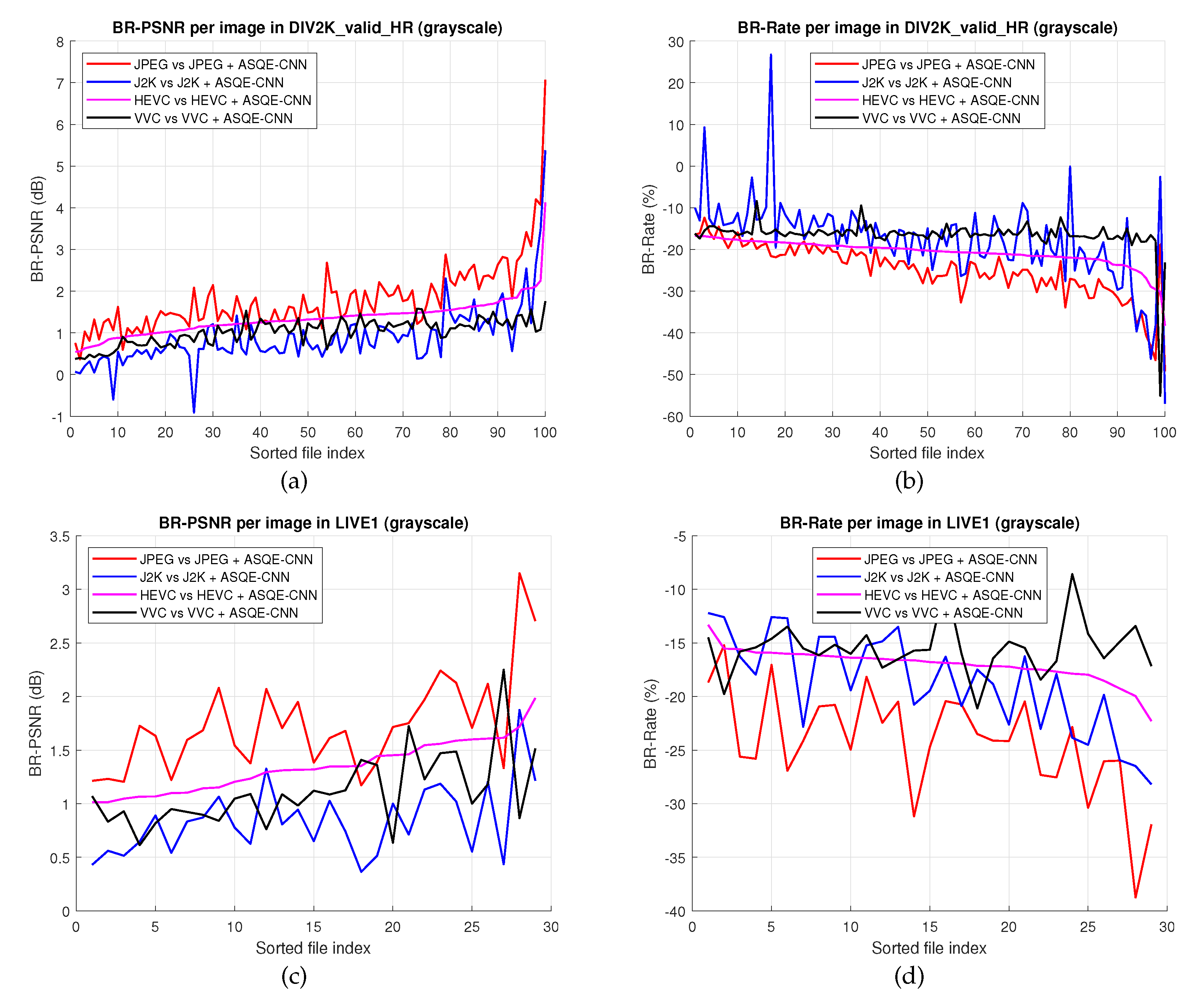
4.2.2. Bjøntegaard Metrics
4.2.3. Visual Results
4.3. Quality Enhancement of Grayscale Images
4.3.1. Rate-Distortion Results
4.3.2. Bjøntegaard Metrics
4.3.3. Visual Results
4.4. Quality Enhancement of Video Sequences
4.4.1. Bjøntegaard Metrics
4.4.2. Visual Results
4.5. Complexity
4.6. Ablation Study
5. Conclusions
Author Contributions
Funding
Conflicts of Interest
Abbreviations
| JPEG | Joint Photographic Experts Group |
| HEVC | High-efficiency video coding |
| VVC | Versatile video coding |
| CNN | Convolutional neural network |
| MPEG | Moving Picture Experts Group |
| ASQE-CNN | Attention-based shared weights quality enhancement CNN |
| CB | Convolutional block |
| DB | Deconvolutional block |
| CBAM | Covolutional block attention module |
| ASB | Attention-based shared weights block |
| ASRB | Attention-based shared weights residual block |
| MHA | Multi-head attention block |
| LFF | Low-resolution feature fusion |
| HFF | High-resolution feature fusion |
References
- Wallace, G.K. The JPEG Still Picture Compression Standard. Commun. ACM 1991, 34, 30–44. [Google Scholar] [CrossRef]
- Taubman, D.S.; Marcellin, M.W. JPEG2000: Standard for interactive imaging. Proc. IEEE 2002, 90, 1336–1357. [Google Scholar] [CrossRef]
- Sullivan, G.J.; Ohm, J.; Han, W.; Wiegand, T. Overview of the High Efficiency Video Coding (HEVC) Standard. IEEE Trans. Circuits Syst. Video Technol. 2012, 22, 1649–1668. [Google Scholar] [CrossRef]
- Huang, H.; Schiopu, I.; Munteanu, A. Frame-wise CNN-based Filtering for Intra-Frame Quality Enhancement of HEVC Videos. IEEE Trans. Circuits Syst. Video Technol. 2020, 31, 2100–2113. [Google Scholar] [CrossRef]
- Schiopu, I.; Munteanu, A. Deep-Learning-Based Lossless Image Coding. IEEE Trans. Circuits Syst. Video Technol. 2020, 30, 1829–1842. [Google Scholar] [CrossRef]
- Huang, H.; Schiopu, I.; Munteanu, A. Macro-pixel-wise CNN-based filtering for quality enhancement of light field images. Electron. Lett. 2020, 56, 1413–1416. [Google Scholar] [CrossRef]
- Lan, C.; Xu, J.; Zeng, W.; Shi, G.; Wu, F. Variable Block-Sized Signal-Dependent Transform for Video Coding. IEEE Trans. Circuits Syst. Video Technol. 2018, 28, 1920–1933. [Google Scholar] [CrossRef]
- Li, J.; Li, B.; Xu, J.; Xiong, R.; Gao, W. Fully Connected Network-Based Intra Prediction for Image Coding. IEEE Trans. Image Process 2018, 27, 3236–3247. [Google Scholar] [CrossRef]
- Pfaff, J.; Helle, P.; Maniry, D.; Kaltenstadler, S.; Samek, W.; Schwarz, H.; Marpe, D.; Wieg, T. Neural network based intra prediction for video coding. In Applications of Digital Image Processing XLI; Tescher, A.G., Ed.; International Society Optics and Photonics, SPIE: Bellingham, WA, USA; pp. 359–365.
- Schiopu, I.; Huang, H.; Munteanu, A. CNN-Based Intra-Prediction for Lossless HEVC. IEEE Trans. Circuits Syst. Video Technol. 2020, 30, 1816–1828. [Google Scholar] [CrossRef]
- Li, Y.; Li, B.; Liu, D.; Chen, Z. A convolutional neural network-based approach to rate control in HEVC intra coding. In Proceedings of the IEEE Visual Communications and Image Process, St. Petersburg, FL, USA, 10–13 December 2017; pp. 1–4. [Google Scholar]
- Wu, C.; Singhal, N.; Krähenbühl, P. Video Compression through Image Interpolation. In Proceedings of the European Conference on Computer Vision (ECCV), Munich, Germany, 8–14 September 2018. [Google Scholar]
- Dong, C.; Deng, Y.; Loy, C.C.; Tang, X. Compression Artifacts Reduction by a Deep Convolutional Network. In Proceedings of the IEEE International Conference on Computer Vision (ICCV), Santiago, Chile, 7–13 December 2015; pp. 576–584. [Google Scholar] [CrossRef] [Green Version]
- Dong, C.; Loy, C.C.; He, K.; Tang, X. Learning a Deep Convolutional Network for Image Super-Resolution. In Proceedings of the European Conference on Computer Vision (ECCV), Zurich, Switzerland, 6–12 September 2014; pp. 184–199. [Google Scholar]
- Dai, Y.; Liu, D.; Wu, F. A Convolutional Neural Network Approach for Post-Processing in HEVC Intra Coding. In Proceedings of the International Conference on Multimedia Model, Reykjavik, Iceland, 4–6 January 2017; pp. 28–39. [Google Scholar]
- Norkin, A.; Bjontegaard, G.; Fuldseth, A.; Narroschke, M.; Ikeda, M.; Andersson, K.; Zhou, M.; Van der Auwera, G. HEVC Deblocking Filter. IEEE Trans. Circuits Syst. Video Technol. 2012, 22, 1746–1754. [Google Scholar] [CrossRef]
- Fu, C.M.; Alshina, E.; Alshin, A.; Huang, Y.W.; Chen, C.Y.; Tsai, C.Y.; Hsu, C.W.; Lei, S.M.; Park, J.H.; Han, W.J. Sample Adaptive Offset in the HEVC Standard. IEEE Trans. Circuits Syst. Video Technol. 2012, 22, 1755–1764. [Google Scholar] [CrossRef]
- Zhao, H.; He, M.; Teng, G.; Shang, X.; Wang, G.; Feng, Y. A CNN-Based Post-Processing Algorithm for Video Coding Efficiency Improvement. IEEE Access 2020, 8, 920–929. [Google Scholar] [CrossRef]
- Ororbia, A.G.; Mali, A.; Wu, J.; O’Connell, S.; Dreese, W.; Miller, D.; Giles, C.L. Learned Neural Iterative Decoding for Lossy Image Compression Systems. In Proceedings of the Data Compression Conference, Snowbird, UT, USA, 26–29 March 2019; pp. 3–12. [Google Scholar] [CrossRef] [Green Version]
- Hurakadli, V.; Kulkarni, S.; Patil, U.; Tabib, R.; Mudengudi, U. Deep Learning based Radial Blur Estimation and Image Enhancement. In Proceedings of the IEEE International Conference on Electronics, Computing and Communication Technologies (CONECCT), Bangalore, India, 26–27 July 2019; pp. 1–5. [Google Scholar] [CrossRef]
- Zhuang, L.; Guan, Y. Image Enhancement by Deep Learning Network Based on derived image and Retinex. In Proceedings of the IEEE Advanced Information Management, Communicates, Electronic and Automation Control Conference (IMCEC), Chongqing, China, 11–13 October 2019; pp. 1670–1673. [Google Scholar] [CrossRef]
- Kinoshita, Y.; Kiya, H. Hue-Correction Scheme Based on Constant-Hue Plane for Deep-Learning-Based Color-Image Enhancement. IEEE Access 2020, 8, 9540–9550. [Google Scholar] [CrossRef]
- Gao, S.; Xiong, Z. Deep Enhancement for 3D HDR Brain Image Compression. In Proceedings of the IEEE International Conference on Image Processing, Taipei, Taiwan, 22–25 September 2019; pp. 714–718. [Google Scholar] [CrossRef]
- Jin, Z.; Iqbal, M.Z.; Zou, W.; Li, X.; Steinbach, E. Dual-Stream Multi-Path Recursive Residual Network for JPEG Image Compression Artifacts Reduction. IEEE Trans. Circuits Syst. Video Technol. 2021, 31, 467–479. [Google Scholar] [CrossRef]
- Jin, Z.; An, P.; Yang, C.; Shen, L. Quality Enhancement for Intra Frame Coding Via CNNs: An Adversarial Approach. In Proceedings of the IEEE International Conference on Acoustics, Speech and Signal Processing, Calgary, AB, Canada, 15–20 April 2018; pp. 1368–1372. [Google Scholar]
- Li, F.; Tan, W.; Yan, B. Deep Residual Network for Enhancing Quality of the Decoded Intra Frames of HEVC. In Proceedings of the IEEE International Conference on Image Processing, Athens, Greece, 7–10 October 2018; pp. 3918–3922. [Google Scholar]
- Ma, L.; Tian, Y.; Huang, T. Residual-Based Video Restoration for HEVC Intra Coding. In Proceedings of the IEEE International Conference on Multimedia Big Data (BigMM), Xi’an, China, 13–16 September 2018; pp. 1–7. [Google Scholar]
- Zhang, S.; Fan, Z.; Ling, N.; Jiang, M. Recursive Residual Convolutional Neural Network-Based In-Loop Filtering for Intra Frames. IEEE Trans. Circuits Syst. Video Technol. 2019, 30, 1888–1900. [Google Scholar] [CrossRef]
- Park, W.; Kim, M. CNN-based in-loop filtering for coding efficiency improvement. In Proceedings of the IEEE Image, Video, and Multidimensional Signal Processing Workshop (IVMSP), Bordeaux, France, 11–12 July 2016; pp. 1–5. [Google Scholar]
- Wang, T.; Chen, M.; Chao, H. A Novel Deep Learning-Based Method of Improving Coding Efficiency from the Decoder-End for HEVC. In Proceedings of the Data Compression Conference, Snowbird, UT, USA, 4–7 April 2017; pp. 410–419. [Google Scholar]
- Zhang, Y.; Shen, T.; Ji, X.; Zhang, Y.; Xiong, R.; Dai, Q. Residual Highway Convolutional Neural Networks for in-loop Filtering in HEVC. IEEE Trans. Image Process. 2018, 27, 3827–3841. [Google Scholar] [CrossRef]
- Jia, C.; Wang, S.; Zhang, X.; Wang, S.; Liu, J.; Pu, S.; Ma, S. Content-Aware Convolutional Neural Network for In-Loop Filtering in High Efficiency Video Coding. IEEE Trans. Image Process. 2019, 28, 3343–3356. [Google Scholar] [CrossRef]
- Lin, W.; He, X.; Han, X.; Liu, D.; See, J.; Zou, J.; Xiong, H.; Wu, F. Partition-Aware Adaptive Switching Neural Networks for Post-Processing in HEVC. IEEE Trans. Multimed. 2020, 22, 2749–2763. [Google Scholar] [CrossRef] [Green Version]
- Zhang, F.; Ma, D.; Feng, C.; Bull, D.R. Video Compression with CNN-based Post Processing. IEEE Multimed. 2021, 28, 74–83. [Google Scholar] [CrossRef]
- Ma, D.; Zhang, F.; Bull, D.R. MFRNet: A New CNN Architecture for Post-Processing and In-loop Filtering. IEEE J. Sel. Top. Signal Process. 2021, 15, 378–387. [Google Scholar] [CrossRef]
- Li, T.; Xu, M.; Zhu, C.; Yang, R.; Wang, Z.; Guan, Z. A Deep Learning Approach for Multi-Frame In-Loop Filter of HEVC. IEEE Trans. Image Process. 2019, 28, 5663–5678. [Google Scholar] [CrossRef] [Green Version]
- Meng, X.; Chen, C.; Zhu, S.; Zeng, B. A New HEVC In-Loop Filter Based on Multi-channel Long-Short-Term Dependency Residual Networks. In Proceedings of the Data Compression Conference, Snowbird, UT, USA, 27–30 March 2018; pp. 187–196. [Google Scholar] [CrossRef]
- Yang, R.; Xu, M.; Wang, Z. Decoder-side HEVC quality enhancement with scalable convolutional neural network. In Proceedings of the IEEE International Conference on Multimedia and Expo (ICME), Hong Kong, China, 10–14 July 2017; pp. 817–822. [Google Scholar]
- Lu, M.; Cheng, M.; Xu, Y.; Pu, S.; Shen, Q.; Ma, Z. Learned Quality Enhancement via Multi-Frame Priors for HEVC Compliant Low-Delay Applications. In Proceedings of the IEEE International Conference on Image Processing, Taipei, Taiwan, 22–25 September 2019; pp. 934–938. [Google Scholar]
- Yin, H.; Yang, R.; Fang, X.; Ma, S. CE10-1.7: Adaptive convolutional neural network loop filter. In Proceedings of the Joint Video Experts Team (JVET) Meeting, Gothenburg, Sweden, 3–12 July 2019; No. JVET-O0063, ITU-T, ISO/IEC: Gothenburg, Sweden, 2019. [Google Scholar]
- Wan, S.; Wang, M.; Ma, Y.; Huo, J.; Gong, H.; Zou, C. CE10: Integrated in-loop filter based on CNN. In Proceedings of the Joint Video Experts Team (JVET) Meeting, Gothenburg, Sweden, 3–12 July 2019; No. JVET-O0079, ITU-T, ISO/IEC: Gothenburg, Sweden, 2019. [Google Scholar]
- Kidani, Y.; Kawamura, K.; Unno, K.; Naito, S. CE10- 1.10/CE10-1.11: Evaluation results of CNN-based filtering with on-line learning model. In Proceedings of the Joint Video Experts Team (JVET) Meeting, Gothenburg, Sweden, 3–12 July 2019; No. JVET-O0131, ITU-T, ISO/IEC: Gothenburg, Sweden, 2019. [Google Scholar]
- Kidani, Y.; Kawamura, K.; Unno, K.; Naito, S. CE10- 2.10/CE10-2.11: Evaluation results of CNN-based filtering with off-line learning model. In Proceedings of the Joint Video Experts Team (JVET) Meeting, Gothenburg, Sweden, 3–12 July 2019; No. JVET-O0132, ITU-T, ISO/IEC: Gothenburg, Sweden, 2019. [Google Scholar]
- Woo, S.; Park, J.; Lee, J.Y.; Kweon, I.S. CBAM: Convolutional Block Attention Module. In Proceedings of the European Conference on Computer Vision (ECCV), Munich, Germany, 8–14 September 2018. [Google Scholar]
- Huang, W.; Zhu, Y.; Huang, R. Low Light Image Enhancement Network With Attention Mechanism and Retinex Model. IEEE Access 2020, 8, 74306–74314. [Google Scholar] [CrossRef]
- Chen, Q.; Fan, J.; Chen, W. An improved image enhancement framework based on multiple attention mechanism. Displays 2021, 70, 102091. [Google Scholar] [CrossRef]
- Bross, B.; Chen, J.; Ohm, J.R.; Sullivan, G.J.; Wang, Y.K. Developments in International Video Coding Standardization After AVC, With an Overview of Versatile Video Coding (VVC). Proc. IEEE 2021, 109, 1463–1493. [Google Scholar] [CrossRef]
- Ioffe, S.; Szegedy, C. Batch Normalization: Accelerating Deep Network Training by Reducing Internal Covariate Shift. In Proceedings of the International Conference on Machine Learning (ICML), Lille, France, 6–11 July 2015; pp. 448–456. [Google Scholar]
- Nair, V.; Hinton, G. Rectified Linear Units Improve Restricted Boltzmann Machines. In Proceedings of the International Conference on Machine Learning (ICML), Haifa, Israel, 21–24 June 2010; pp. 807–814. [Google Scholar]
- He, K.; Zhang, X.; Ren, S.; Sun, J. Deep Residual Learning for Image Recognition. In Proceedings of the IEEE Conference on Computer Vision and Pattern Recognition (CVPR), Las Vegas, NV, USA, 27–30 June 2016; pp. 770–778. [Google Scholar] [CrossRef] [Green Version]
- Kingma, D.; Ba, J. Adam: A Method for Stochastic Optimization. arXiv 2014, arXiv:1412.6980. [Google Scholar]
- Agustsson, E.; Timofte, R. NTIRE 2017 Challenge on Single Image Super-Resolution: Dataset and Study. In Proceedings of the IEEE Conference on Computer Vision and Pattern Recognition (CVPR) Workshops, Honolulu, HI, USA, 21–26 July 2017. [Google Scholar]
- Ignatov, A.; Timofte, R.; Van Vu, T.; Minh Luu, T.; XPham, T.; Van Nguyen, C.; Kim, Y.; Choi, J.S.; Kim, M.; Huang, J.; et al. PIRM challenge on perceptual image enhancement on smartphones: Report. In Proceedings of the European Conference on Computer Vision (ECCV) Workshops, Munich, Germany, 8–14 September 2019; 2019. [Google Scholar]
- Sheikh, H.R.; Sabir, M.F.; Bovik, A.C. A statistical evaluation of recent full reference image quality assessment algorithms. IEEE Trans. Image Process 2006, 15, 3440–3451. [Google Scholar] [CrossRef]
- Sheikh, H.; Wang, Z.; Cormack, L.; Bovik, A. LIVE Image Quality Assessment Database. Available online: https://live.ece.utexas.edu/research/quality/subjective.htm (accessed on 1 July 2021).
- Bossen, F. Common HM test conditions and software reference Configurations. In Proceedings of the Joint Collaborative Team on Video Coding (JCT-VC) Meeting, Report No. JCTVC-G1100, San Jose, CA, USA, 11–20 July 2012. [Google Scholar]
- FFmpeg. Available online: http://ffmpeg.org/documentation.html (accessed on 1 February 2021).
- Fraunhofer Institute, HHI. VVC Test Model (VTM) Source Code. Available online: https://vcgit.hhi.fraunhofer.de/jvet/VVCSoftware_VTM (accessed on 1 July 2021).
- Wang, Z.; Bovik, A.C.; Sheikh, H.R.; Simoncelli, E.P. Image quality assessment: From error visibility to structural similarity. IEEE Trans. Image Process 2004, 13, 600–612. [Google Scholar] [CrossRef] [Green Version]
- Bjøntegaard, G. Calculation of average PSNR differences between RD-Curves. In Proceedings of the joint International Telecommunication Union Telecommunication Standardization Sector (ITU-T) and Video Coding Experts Group (VCEG) Meeting, Pattaya, Thailand, 4–7 December 2001. [Google Scholar]
- Bjontegaard Metrics Computation. Available online: https://github.com/Anserw/Bjontegaard_metric (accessed on 1 February 2021).
- Mao, X.J.; Shen, C.; Yang, Y.B. Image restoration using very deep convolutional encoder-decoder networks with symmetric skip connections. In Proceedings of the Advances in Neural Information Processing Systems, Barcelona, Spain, 5–10 December 2016; pp. 2802–2810. [Google Scholar]
- Tai, Y.; Yang, J.; Liu, X. Image Super-Resolution via Deep Recursive Residual Network. In Proceedings of the IEEE Conference on Computer Vision and Pattern Recognition (CVPR), Honolulu, HI, USA, 21–26 July 2017; pp. 2790–2798. [Google Scholar] [CrossRef]
- Zhang, Y.; Sun, L.; Yan, C.; Ji, X.; Dai, Q. Adaptive Residual Networks for High-Quality Image Restoration. IEEE Trans. Image Process 2018, 27, 3150–3163. [Google Scholar] [CrossRef]
- Chollet, F. Keras. Available online: https://keras.io (accessed on 1 July 2017).














{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
| Usage | Dataset Name | Number of Images | Megapixels |
|---|---|---|---|
| Training | DIV2K_train_HR [52] | 800 | 1.3–4 MP |
| Testing | DIV2K_valid_HR [52] | 100 | 1.6–4 MP |
| Testing | LIVE1 [54] | 29 | 0.28–0.39 MP |
| ID | Video Sequence Name | Number of Frames | Class | Frame Resolution |
|---|---|---|---|---|
| A1 | Traffic | 150 | A | |
| A2 | PeopleOnStreet | 150 | ||
| B1 | Kimono | 240 | B | |
| B2 | ParkScene | 240 | ||
| B3 | Cactus | 500 | ||
| B4 | BQTerrace | 600 | ||
| B5 | BasketballDrive | 500 | ||
| C1 | RaceHorses | 300 | C | |
| C2 | BQMall | 600 | ||
| C3 | PartyScene | 500 | ||
| C4 | BasketballDrill | 500 | ||
| D1 | RaceHorses | 300 | D | |
| D2 | BQSquare | 600 | ||
| D3 | BlowingBubbles | 500 | ||
| D4 | BasketballPass | 500 |
| Method | BD-Rate (%) | BD-PSNR (dB) | ||
|---|---|---|---|---|
| DIV2K [52] | LIVE1 [54] | DIV2K [52] | LIVE1 [54] | |
| JPEG+ASQE-CNN | ||||
| J2K+ASQE-CNN | ||||
| HEVC+ASQE-CNN | ||||
| VVC+ASQE-CNN | ||||
| JPEG [1] | ARCNN [13] | RED30 [62] | DRRN [63] | ARN [64] | STRNN [24] | JPEG+ ASQE-CNN | |
|---|---|---|---|---|---|---|---|
| 10 | 27.77 | 28.73 | 29.32 | 29.21 | 29.27 | 29.38 | 29.42 |
| 20 | 30.07 | 30.89 | 31.69 | 31.19 | 31.34 | 31.72 | 31.79 |
| 40 | 32.35 | 33.63 | − | − | 33.13 | 34.06 | 34.16 |
| Method | Y-BD-Rate (%) | Y-BD-PSNR (dB) | ||
|---|---|---|---|---|
| DIV2K [52] | LIVE1 [54] | DIV2K [52] | LIVE1 [54] | |
| JPEG+ASQE-CNN | ||||
| J2K+ASQE-CNN | ||||
| HEVC+ASQE-CNN | ||||
| VVC+ASQE-CNN | ||||
| ID | HEVC [3] Codec | VVC [47] | ||||||
|---|---|---|---|---|---|---|---|---|
| (All Frames) | (30 Frames) | |||||||
| VR-CNN | FE-CNN | MLSDRN | RRCNN | VRCNN-BN | FQE-CNN | Proposed | ||
| [15] | [26] | [37] | [28] | [18] | [4] | ASQE-CNN | ||
| A1 | −5.6 | −6.6 | − | −9.8 | −8.7 | −11.0 | −18.46 | −14.04 |
| A2 | −5.4 | −5.8 | − | −8.7 | −9.3 | −9.6 | −17.09 | −11.85 |
| B1 | −2.5 | −5.7 | −6.2 | −6.6 | −11.8 | −8.4 | −19.02 | −16.32 |
| B2 | −4.4 | −5.1 | −6.5 | −7.6 | −8.7 | −8.0 | −18.12 | −20.43 |
| B3 | −4.6 | −4.9 | −5.8 | −7.0 | −10.5 | −7.7 | −14.10 | −15.46 |
| B4 | −2.6 | −2.5 | −3.7 | −3.3 | −7.7 | −4.3 | −12.87 | −12.39 |
| B5 | −2.5 | −5.2 | −4.4 | −6.7 | −14.5 | −8.5 | −13.37 | −14.35 |
| C1 | −4.2 | −4.2 | −4.7 | −6.3 | −6.7 | −8.4 | −14.65 | −14.59 |
| C2 | −5.1 | −5.4 | −6.0 | −9.9 | −7.5 | −11.8 | −15.94 | −15.87 |
| C3 | −3.6 | −3.6 | −4.3 | −5.9 | −4.0 | −6.5 | −13.43 | −14.45 |
| C4 | −6.9 | −8.6 | −8.3 | −15.1 | −8.5 | −14.7 | −19.54 | −16.34 |
| D1 | −7.6 | −7.7 | −8.9 | −10.0 | −6.6 | −9.6 | −14.20 | −14.93 |
| D2 | −3.8 | −4.2 | −4.3 | −7.4 | −3.4 | −6.8 | −11.61 | −12.82 |
| D3 | −4.9 | −5.0 | −5.7 | −6.8 | −4.3 | −7.0 | −12.32 | −15.05 |
| D4 | −5.3 | −5.9 | −6.6 | −10.0 | −7.4 | −10.6 | −12.74 | −15.55 |
| A | −5.5 | −6.2 | − | −9.3 | −9.0 | −10.3 | −17.77 | −12.95 |
| B | −3.3 | −4.7 | −5.3 | −6.2 | −10.6 | −7.4 | −15.51 | −15.79 |
| C | −5.0 | −5.5 | −5.8 | −9.3 | −6.7 | −10.4 | −15.89 | −15.31 |
| D | −5.4 | −5.7 | −6.4 | −8.6 | −5.4 | −8.5 | −12.72 | −14.59 |
| All | −4.8 | −5.5 | − | −8.4 | −8.3 | −9.2 | −15.47 | −14.66 |
| Class | HEVC [3] | VVC [47] |
|---|---|---|
| (Average) | (All Frames) | (30 Frames) |
| A | 1.2007 dB | 0.7551 dB |
| B | 0.7827 dB | 0.6743 dB |
| C | 1.2006 dB | 1.0315 dB |
| D | 1.3279 dB | 1.0689 dB |
| ALL | 1.1280 dB | 0.8824 dB |
| Method | BD-Rate | BD-PSNR | #param | Time (bs = 100) |
|---|---|---|---|---|
| noAttention | dB | M | 144 ms | |
| noWeightSharing | dB | M | 169 ms | |
| noMFF (U-Net) | dB | M | ms | |
| Proposed | dB | M | 165 ms |
Publisher’s Note: MDPI stays neutral with regard to jurisdictional claims in published maps and institutional affiliations. |
© 2022 by the authors. Licensee MDPI, Basel, Switzerland. This article is an open access article distributed under the terms and conditions of the Creative Commons Attribution (CC BY) license (https://creativecommons.org/licenses/by/4.0/).
Share and Cite
Schiopu, I.; Munteanu, A. Deep Learning Post-Filtering Using Multi-Head Attention and Multiresolution Feature Fusion for Image and Intra-Video Quality Enhancement. Sensors 2022, 22, 1353. https://doi.org/10.3390/s22041353
Schiopu I, Munteanu A. Deep Learning Post-Filtering Using Multi-Head Attention and Multiresolution Feature Fusion for Image and Intra-Video Quality Enhancement. Sensors. 2022; 22(4):1353. https://doi.org/10.3390/s22041353
Chicago/Turabian StyleSchiopu, Ionut, and Adrian Munteanu. 2022. "Deep Learning Post-Filtering Using Multi-Head Attention and Multiresolution Feature Fusion for Image and Intra-Video Quality Enhancement" Sensors 22, no. 4: 1353. https://doi.org/10.3390/s22041353
APA StyleSchiopu, I., & Munteanu, A. (2022). Deep Learning Post-Filtering Using Multi-Head Attention and Multiresolution Feature Fusion for Image and Intra-Video Quality Enhancement. Sensors, 22(4), 1353. https://doi.org/10.3390/s22041353