
Prediction of Pedestrian Crossing Behavior Based on Surveillance Video



Abstract
:1. Introduction
2. Related Works
3. Research Methodology
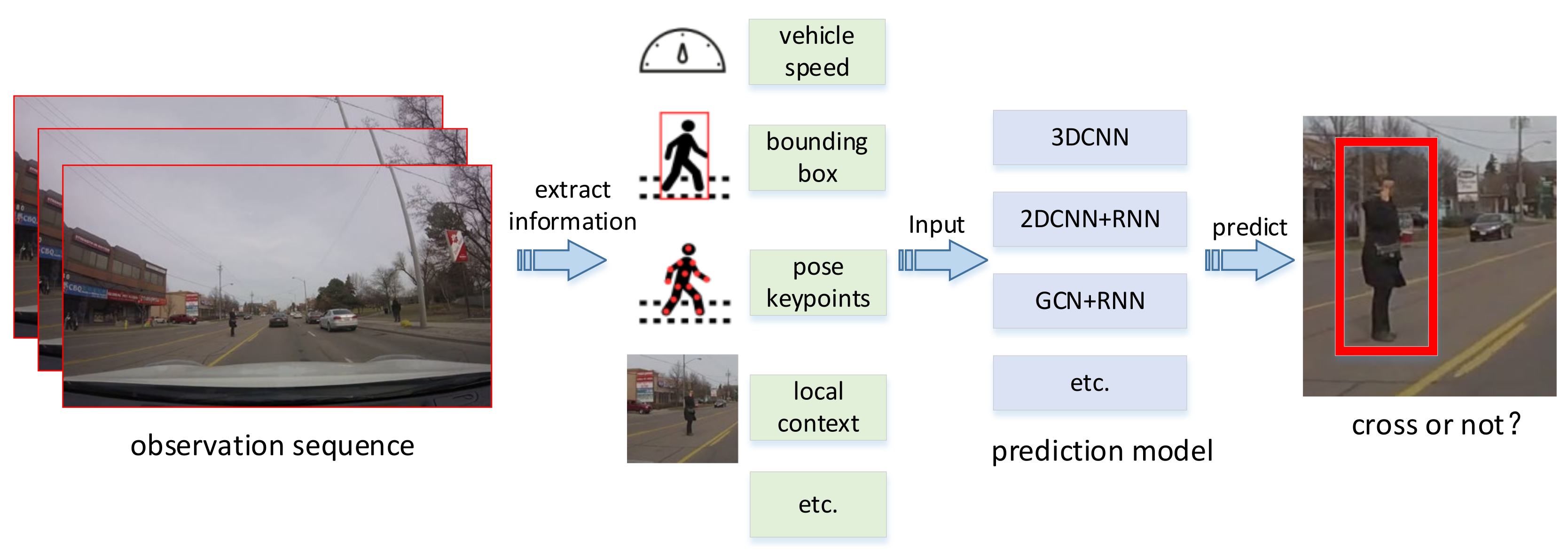
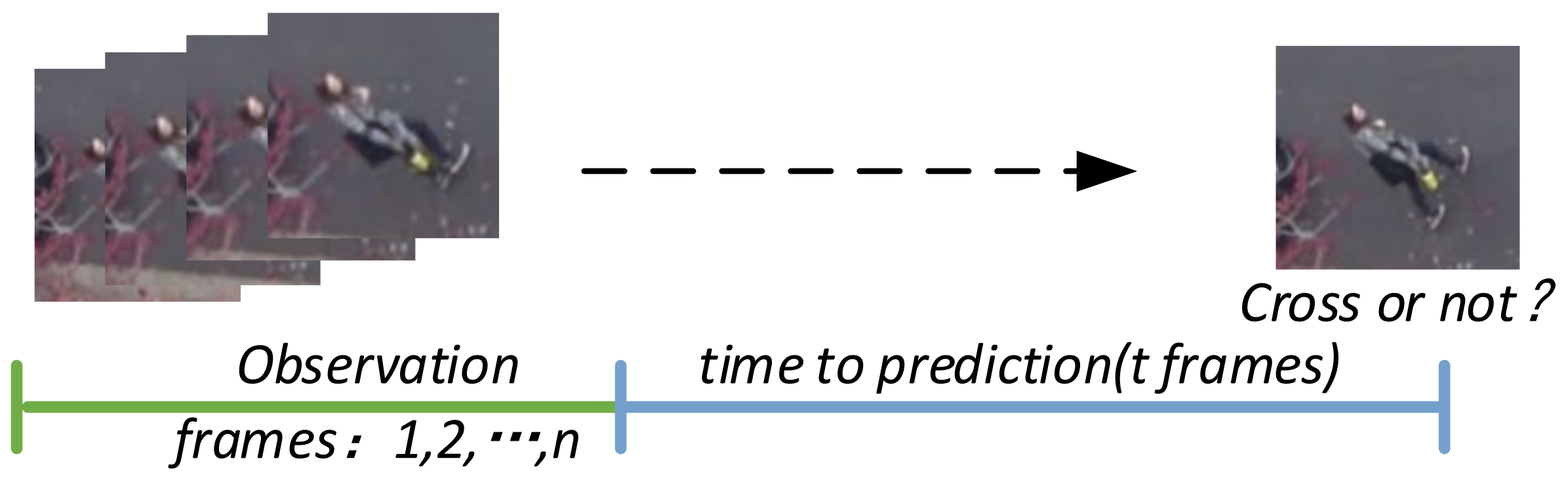
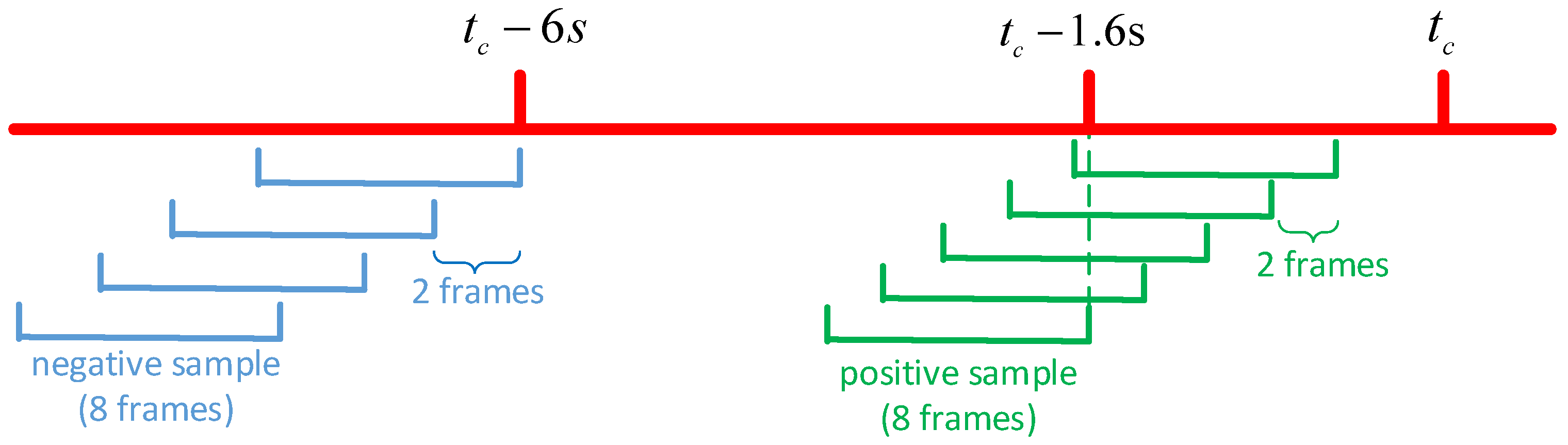
3.1. Problem Formulation
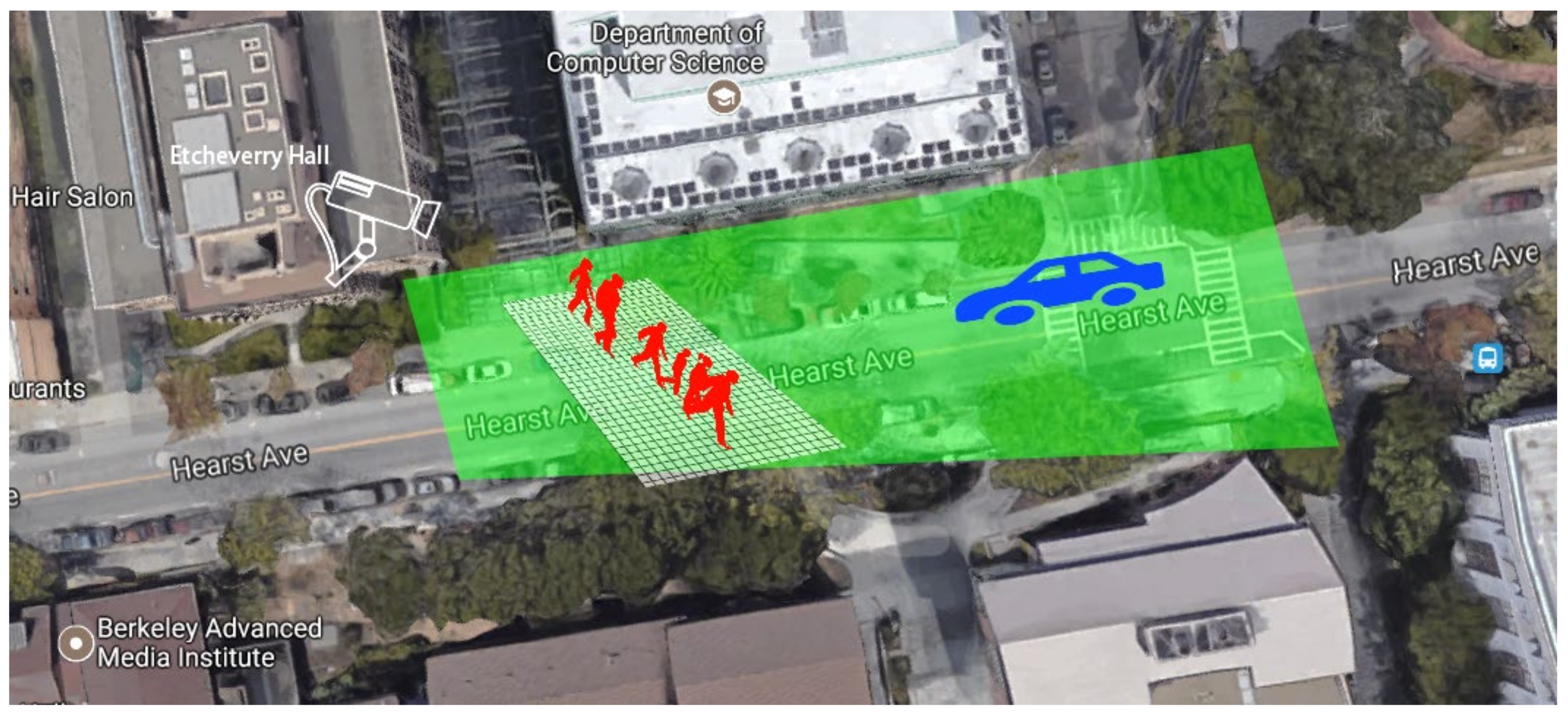
3.2. Dataset
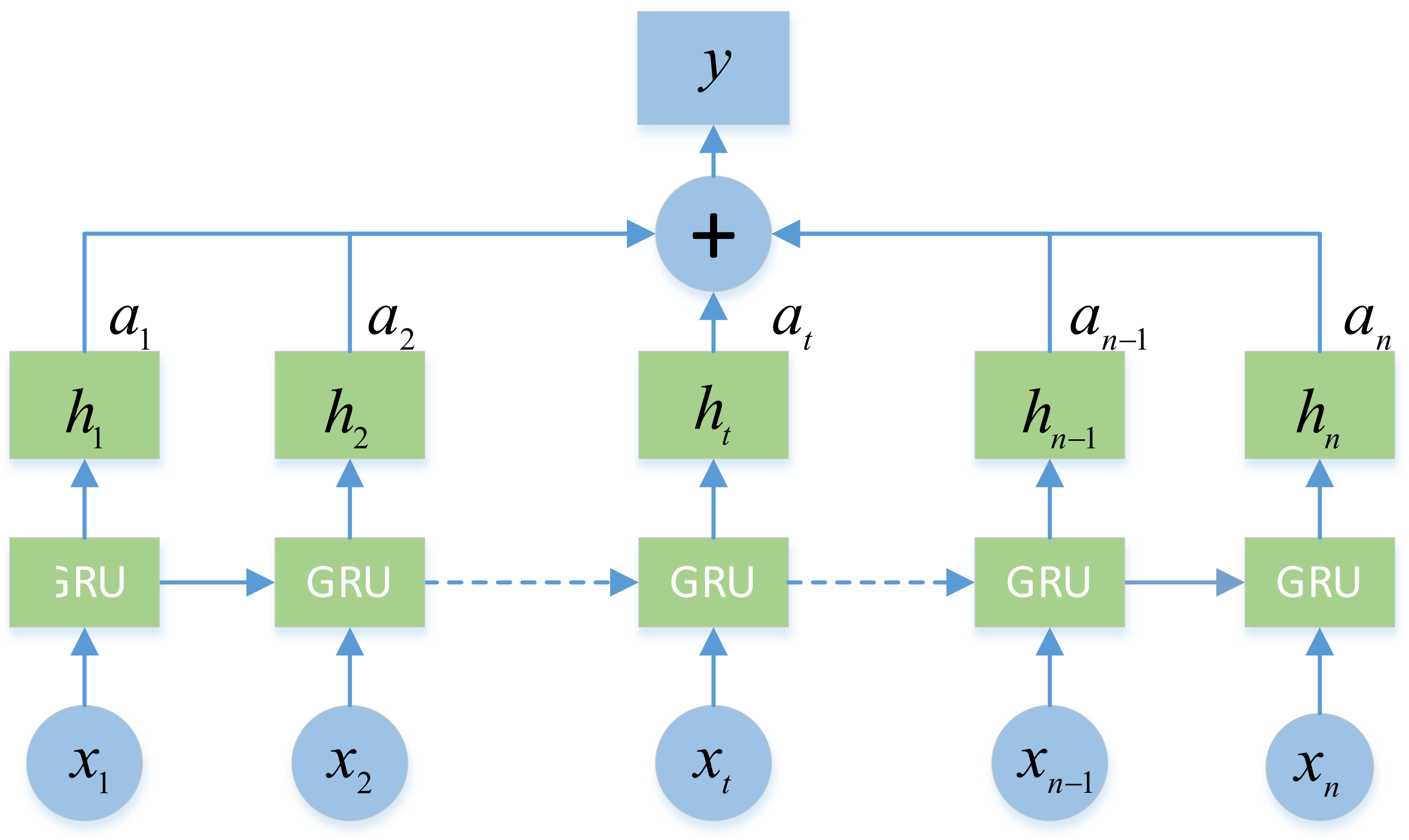
3.3. Model Construction
3.4. Model Input Acquisition
3.4.1. Pedestrian Pose Key Points
3.4.2. Local Context
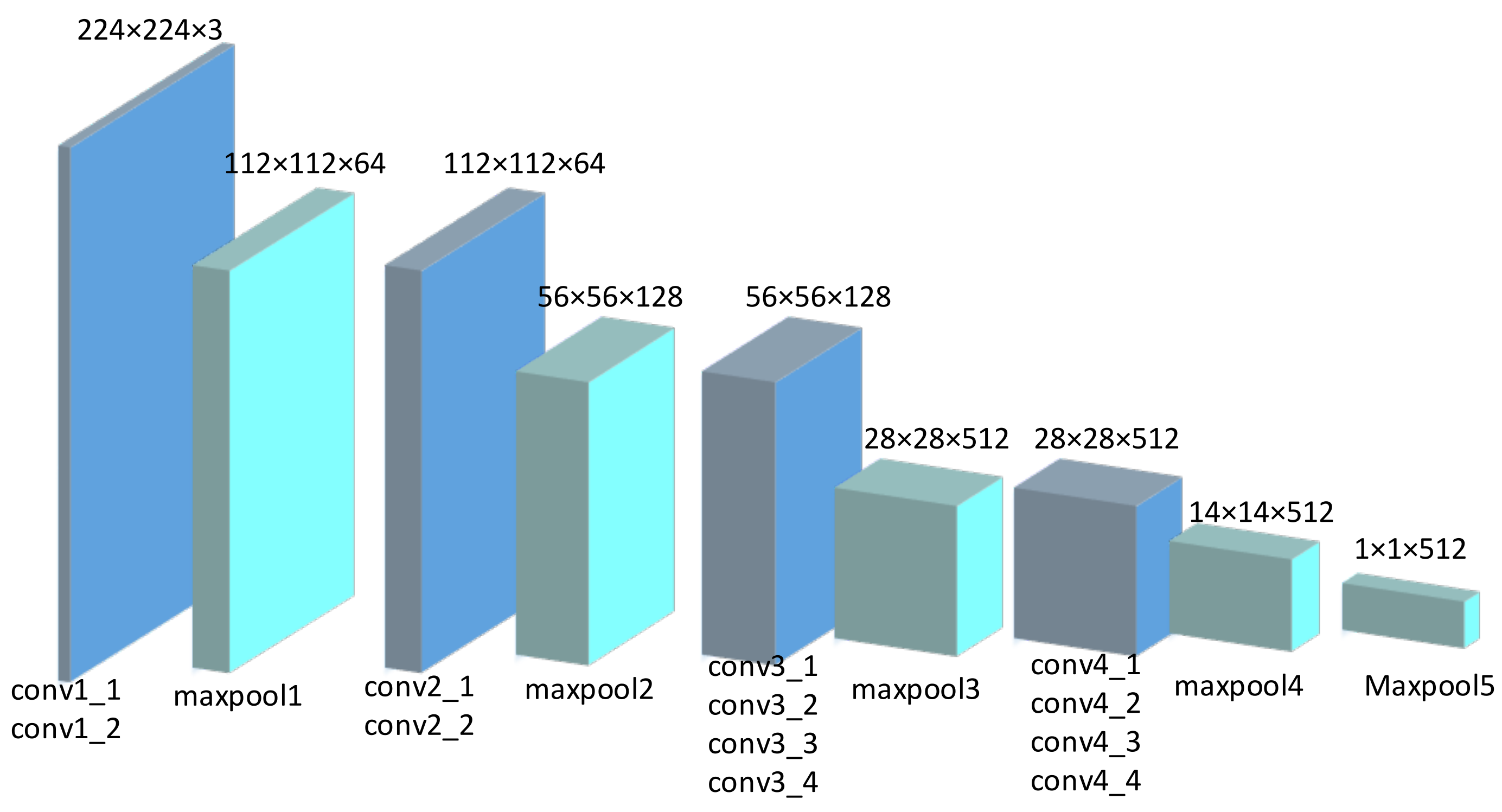
3.4.3. Global Context
4. Experiment and Results
4.1. Benchmark and Metrics
4.2. Quantitative Experiment
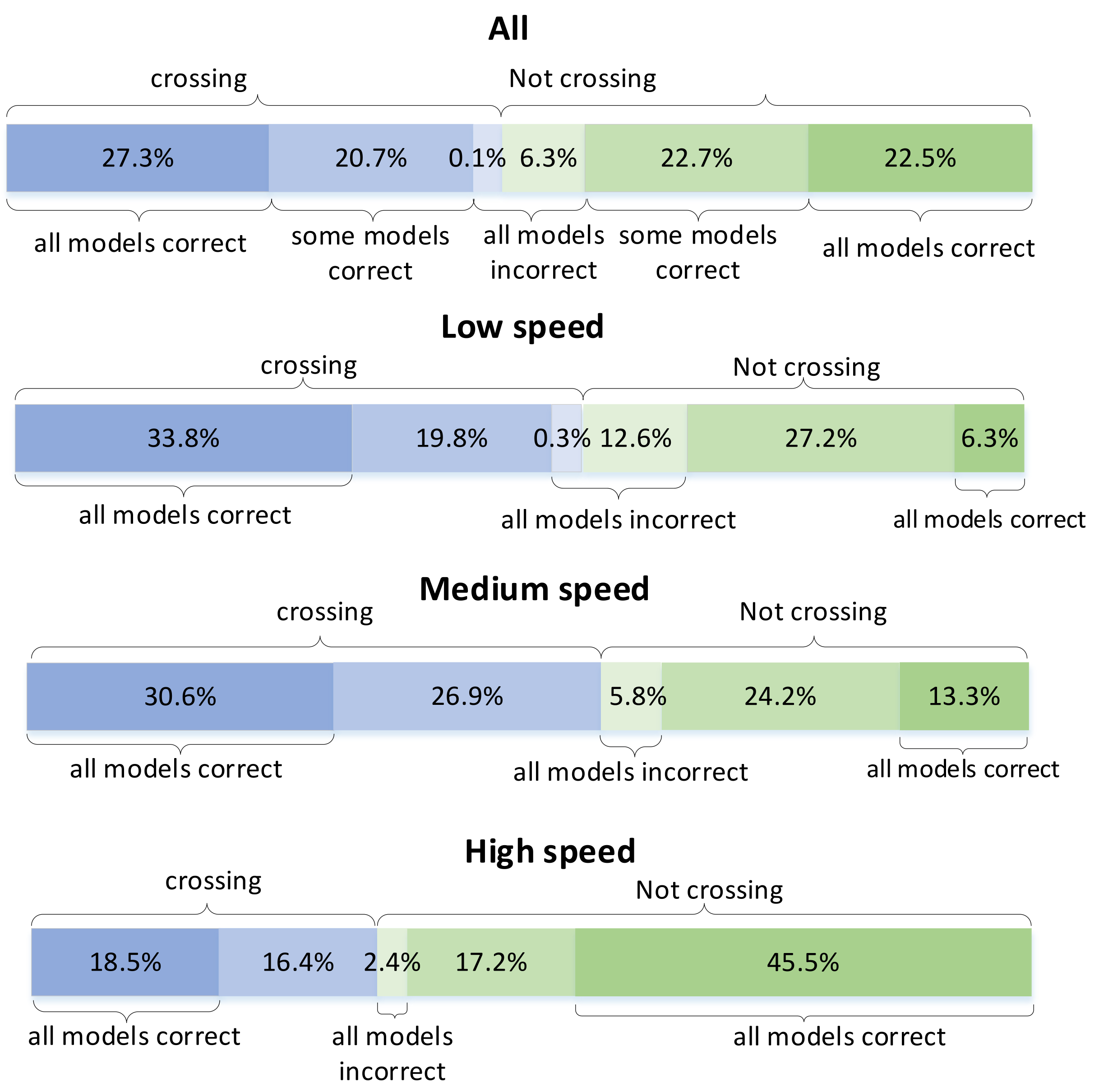
4.3. Effect of Pedestrian Speed
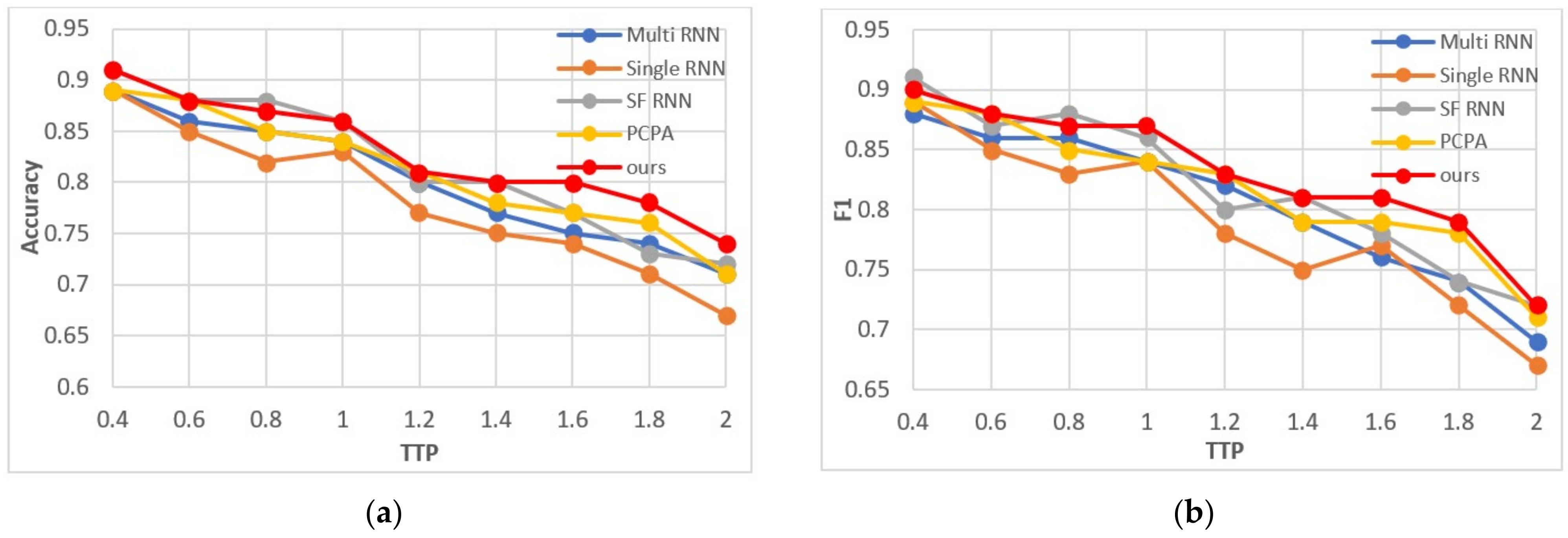
4.4. Effect of Time to Prediction
4.5. Qualitative Experiment
5. Discussion
- (1)
- The surveillance video does not capture all the information on the road, especially the information on the right side of the camera. Pedestrians can observe farther road information than cameras. Therefore, many vehicles that affect pedestrian crossing behavior do not appear in the video.
- (2)
- The rules of pedestrian-vehicle interaction when pedestrians cross the street are complex and changeable. The amount of data in the current dataset is difficult to make the model fully learn these rules. Our positive and negative samples are from different stages of pedestrians who will cross. There is a lack of samples of pedestrians who won’t cross. This makes the model less robust and reduces a certain accuracy. These reasons lead to the rapid reduction of model accuracy with the increase of TTP.
- (3)
- The proposed method relies on the labeling of key points to encode human posture, which restricts the practical use of the proposed method.
6. Conclusions
Author Contributions
Funding
Institutional Review Board Statement
Informed Consent Statement
Data Availability Statement
Conflicts of Interest
References
- Fang, Z.; Vázquez, D.; López, A.M. On-board detection of pedestrian intentions. Sensors 2017, 17, 2193. [Google Scholar] [CrossRef] [PubMed]
- He, Y.; Sun, C.; Huang, H.; Jiang, L.; Ma, M.; Wang, P.; Wu, C. Safety of micro-mobility: Riders’ psychological factors and risky behaviors of cargo TTWs in China. Transp. Res. Part F Traffic Psychol. Behav. 2021, 80, 189–202. [Google Scholar] [CrossRef]
- Yang, D.; Zhang, H.; Yurtsever, E.; Redmill, K.; Özgüner, Ü. Predicting pedestrian crossing intention with feature fusion and spatio-temporal attention. arXiv 2021, arXiv:2104.05485. [Google Scholar]
- Rasouli, A.; Kotseruba, I.; Tsotsos, J.K. Are they going to cross? A benchmark dataset and baseline for pedestrian crosswalk behavior. In Proceedings of the IEEE International Conference on Computer Vision Workshops (ICCV), Venice, Italy, 22–29 October 2017; pp. 206–213. [Google Scholar]
- Liu, B.; Adeli, E.; Cao, Z.; Lee, K.H.; Shenoi, A.; Gaidon, A.; Niebles, J.C. Spatio-temporal relationship reasoning for pedestrian intent prediction. IEEE Robot. Autom. Lett. 2020, 5, 3485–3492. [Google Scholar] [CrossRef] [Green Version]
- Tran, D.; Bourdev, L.; Fergus, R.; Torresani, L.; Paluri, M. Learning spatio-temporal features with 3D convolutional networks. In Proceedings of the IEEE International Conference on Computer Vision (ICCV), Santiago, Chile, 7–13 December 2015; pp. 4489–4497. [Google Scholar]
- Saleh, K.; Hossny, M.; Nahavandi, S. Real-time intent prediction of pedestrians for autonomous ground vehicles via spatio-temporal densenet. In Proceedings of the 2019 International Conference on Robotics and Automation (ICRA), Montreal, QC, Canada, 20–24 May 2019; pp. 9704–9710. [Google Scholar]
- Saleh, K.; Hossny, M.; Nahavandi, S. Spatio-temporal DenseNet for real-time intent prediction of pedestrians in urban traffic environments. Neurocomputing 2020, 386, 317–324. [Google Scholar] [CrossRef]
- Lorenzo, J.; Parra, I.; Wirth, F.; Stiller, C.; Llorca, D.F.; Sotelo, M.A. Rnn-based pedestrian crossing prediction using activity and pose-related features. In Proceedings of the 2020 IEEE Intelligent Vehicles Symposium (IV), Las Vegas, NV, USA, 19 October–13 November 2020; pp. 1801–1806. [Google Scholar]
- Rasouli, A.; Yau, T.; Rohani, M.; Luo, J. Multi-modal hybrid architecture for pedestrian action prediction. arXiv 2020, arXiv:2012.00514. [Google Scholar]
- Rasouli, A.; Kotseruba, I.; Tsotsos, J.K. Pedestrian action anticipation using contextual feature fusion in stacked rnns. arXiv 2020, arXiv:2005.06582. [Google Scholar]
- Rasouli, A.; Rohani, M.; Luo, J. Pedestrian behavior prediction via multitask learning and categorical interaction modeling. arXiv 2020, arXiv:2012.03298. [Google Scholar]
- Kotseruba, I.; Rasouli, A.; Tsotsos, J.K. Benchmark for evaluating pedestrian action prediction. In Proceedings of the IEEE/CVF Winter Conference on Applications of Computer Vision, Waikoloa, HI, USA, 3–8 January 2021; pp. 1258–1268. [Google Scholar]
- Piccoli, F.; Balakrishnan, R.; Perez, M.J.; Sachdeo, M.; Nunez, C.; Tang, M. Fussi-net: Fusion of spatio-temporal skeletons for intention prediction network. In Proceedings of the 2020 54th Asilomar Conference on Signals Systems, and Computers, Pacific Grove, CA, USA, 1–4 November 2020; pp. 68–72. [Google Scholar]
- Abboud, K.; Omar, H.A.; Zhuang, W. Interworking of DSRC and cellular network technologies for V2X communications: A survey. IEEE Trans. Veh. Technol. 2016, 65, 9457–9470. [Google Scholar] [CrossRef]
- He, Y.; Yang, S.; Chan, C.Y.; Chen, L.; Wu, C. Visualization analysis of intelligent vehicles research field based on mapping knowledge domain. IEEE Trans. Intell. Transp. Syst. 2020, 22, 5721–5736. [Google Scholar] [CrossRef]
- Simonyan, K.; Zisserman, A. Very deep convolutional networks for large-scale image recognition. arXiv 2014, arXiv:1409.1556. [Google Scholar]
- Chung, J.; Gulcehre, C.; Cho, K.; Bengio, Y. Empirical evaluation of gated recurrent neural networks on sequence modeling. arXiv 2014, arXiv:1412.3555. [Google Scholar]
- Shen, M.; Habibi, G.; How, J.P. Transferable pedestrian motion prediction models at intersections. In Proceedings of the 2018 IEEE/RSJ International Conference on Intelligent Robots and Systems (IROS), Madrid, Spain, 1–5 October 2018; pp. 4547–4553. [Google Scholar]
- Kipf, T.N.; Welling, M. Semi-supervised classification with graph convolutional networks. arXiv 2016, arXiv:1609.02907. [Google Scholar]
- Lee, N.; Choi, W.; Vernaza, P.; Choy, C.B.; Torr, P.H.; Chandraker, M. Desire: Distant future prediction in dynamic scenes with interacting agents. In Proceedings of the IEEE Conference on Computer Vision and Pattern Recognition(CVPR), Honolulu, HI, USA, 21–26 July 2017; pp. 336–345. [Google Scholar]
- Ullah, A.; Ahmad, J.; Muhammad, K.; Sajjad, M.; Baik, S.W. Action recognition in video sequences using deep bi-directional LSTM with CNN features. IEEE Access 2017, 6, 1155–1166. [Google Scholar] [CrossRef]
- Hochreiter, S.; Schmidhuber, J. Long short-term memory. Neural Comput. 1997, 9, 1735–1780. [Google Scholar] [CrossRef] [PubMed]
- Luong, M.T.; Pham, H.; Manning, C.D. Effective approaches to attention-based neural machine translation. arXiv 2015, arXiv:1508.04025. [Google Scholar]
- Doellinger, J.; Spies, M.; Burgard, W. Predicting occupancy distributions of walking humans with convolutional neural networks. IEEE Robot. Autom. Lett. 2018, 3, 1522–1528. [Google Scholar] [CrossRef]
- Sighencea, B.I.; Stanciu, R.I.; Căleanu, C.D. A review of deep learning-based methods for pedestrian trajectory prediction. Sensors 2021, 21, 7543. [Google Scholar] [CrossRef] [PubMed]
- Fang, Z.; López, A.M. Is the pedestrian going to cross? Answering by 2d pose estimation. In Proceedings of the 2018 IEEE Intelligent Vehicles Symposium (IV), Changshu, China, 26–30 June 2018; pp. 1271–1276. [Google Scholar]
- Cadena PR, G.; Yang, M.; Qian, Y.; Wang, C. Pedestrian graph: Pedestrian crossing prediction based on 2d pose estimation and graph convolutional networks. In Proceedings of the 2019 IEEE Intelligent Transportation Systems Conference (ITSC), Auckland, New Zealand, 27–30 October 2019; pp. 2000–2005. [Google Scholar]
- Wang, Z.; Papanikolopoulos, N. Estimating pedestrian crossing states based on single 2D body pose. In Proceedings of the 2020 IEEE/RSJ International Conference on Intelligent Robots and Systems (IROS), Las Vegas, NV, USA, 25–29 October 2020; pp. 2205–2210. [Google Scholar]
- Gesnouin, J.; Pechberti, S.; Bresson, G.; Stanciulescu, B.; Moutarde, F. Predicting intentions of pedestrians from 2d skeletal pose sequences with a representation-focused multi-branch deep learning network. Algorithms 2020, 13, 331. [Google Scholar] [CrossRef]
- Cai, Y.; Li, D.; Zhou, X.; Mou, X. Robust drivable road region detection for fixed-route autonomous vehicles using map-fusion images. Sensors 2018, 18, 4158. [Google Scholar] [CrossRef] [PubMed] [Green Version]
- Cai, Y.; Zhou, X.; Li, D.; Ming, Y.; Mou, X. Head pose estimation with neural networks from surveillant images. In Proceedings of the Eleventh International Conference on Machine Vision (ICMV 2018), Munich, Germany, 1–3 November 2018; Volume 11041, pp. 267–274. [Google Scholar]
- Deng, J.; Dong, W.; Socher, R.; Li, L.J.; Li, K.; Fei-Fei, L. Imagenet: A large-scale hierarchical image database. In Proceedings of the 2009 IEEE Conference on Computer Vision and Pattern Recognition (CVPR), Miami, FL, USA, 20–25 June 2009; pp. 248–255. [Google Scholar]
- Kotseruba, I.; Rasouli, A.; Tsotsos, J.K. Do they want to cross? Understanding pedestrian intention for behavior prediction. In Proceedings of the 2020 IEEE Intelligent Vehicles Symposium (IV), Las Vegas, NV, USA, 23 June 2020; pp. 1688–1693. [Google Scholar]
- Bhattacharyya, A.; Fritz, M.; Schiele, B. Long-term on-board prediction of people in traffic scenes under uncertainty. In Proceedings of the IEEE Conference on Computer Vision and Pattern Recognition (CVPR), Salt Lake City, UT, USA, 18–23 June 2018; pp. 4194–4202. [Google Scholar]














{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
| Time | Numbers of Videos |
|---|---|
| 9:00–11:00 | 17 |
| 11:00–13:00 | 40 |
| 13:00–15:00 | 108 |
| 15:00–17:00 | 104 |
| 17:00–19:00 | 31 |
| Total | 300 |
| Models | Acc | AUC | F1 | Prec | Recall | Average |
|---|---|---|---|---|---|---|
| Single RNN | 0.74 | 0.74 | 0.77 | 0.67 | 0.88 | 0.760 |
| Multi RNN | 0.75 | 0.75 | 0.76 | 0.70 | 0.84 | 0.760 |
| SF RNN | 0.77 | 0.77 | 0.78 | 0.73 | 0.82 | 0.774 |
| PCPA | 0.77 | 0..78 | 0.79 | 0.70 | 0.90 | 0.788 |
| ours | 0.80 | 0.80 | 0.81 | 0.75 | 0.88 | 0.808 |
| Approach | Time |
|---|---|
| Single RNN | 0.4 ms |
| Multi RNN | 0.6 ms |
| SF RNN | 0.8 ms |
| PCPA | 0.7 ms |
| ours | 0.7 ms |
| Extraction of local context | 7.6 ms |
| Extraction of global context | 17.4 ms |
Publisher’s Note: MDPI stays neutral with regard to jurisdictional claims in published maps and institutional affiliations. |
© 2022 by the authors. Licensee MDPI, Basel, Switzerland. This article is an open access article distributed under the terms and conditions of the Creative Commons Attribution (CC BY) license (https://creativecommons.org/licenses/by/4.0/).
Share and Cite
Zhou, X.; Ren, H.; Zhang, T.; Mou, X.; He, Y.; Chan, C.-Y. Prediction of Pedestrian Crossing Behavior Based on Surveillance Video. Sensors 2022, 22, 1467. https://doi.org/10.3390/s22041467
Zhou X, Ren H, Zhang T, Mou X, He Y, Chan C-Y. Prediction of Pedestrian Crossing Behavior Based on Surveillance Video. Sensors. 2022; 22(4):1467. https://doi.org/10.3390/s22041467
Chicago/Turabian StyleZhou, Xiao, Hongyu Ren, Tingting Zhang, Xingang Mou, Yi He, and Ching-Yao Chan. 2022. "Prediction of Pedestrian Crossing Behavior Based on Surveillance Video" Sensors 22, no. 4: 1467. https://doi.org/10.3390/s22041467
APA StyleZhou, X., Ren, H., Zhang, T., Mou, X., He, Y., & Chan, C.-Y. (2022). Prediction of Pedestrian Crossing Behavior Based on Surveillance Video. Sensors, 22(4), 1467. https://doi.org/10.3390/s22041467