
Few-Shot Object Detection Using Multimodal Sensor Systems of Unmanned Surface Vehicles




Abstract
:1. Introduction
- Inspired by ResNet50 [12], we introduce a regularization term for background suppression into the feature extractor, which enhances the extraction of foreground object regions and improves the accuracy of the region proposal box;
- We propose a feature fusion region proposal network (RPN) that utilizes multiple modalities to produce region proposals for small classes;
- We propose a few-shot learning module based on metric learning, with a better label classification result and a more accurate localization;
- We propose a key object detection method on the water surface that utilizes multimodal data as the data source. Our approach outperformed the state-of-the-art approach by around 2%, 10%, 5% on AP and 28%, 24%, 24% on AOS in three sampled sets of well-known datasets;
- This study can be potentially used for various applications where the number of labeled data is not enough to acquire a compromising result.
2. Related Work
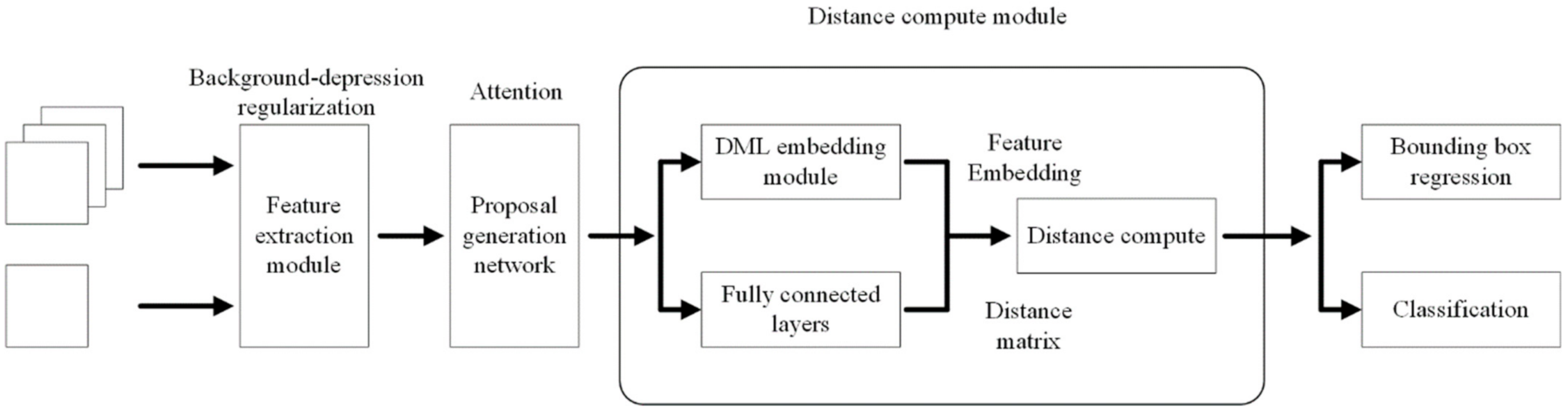
3. Few-Shot Object Detection Network Based on Metric Learning
3.1. Feature Extraction Module
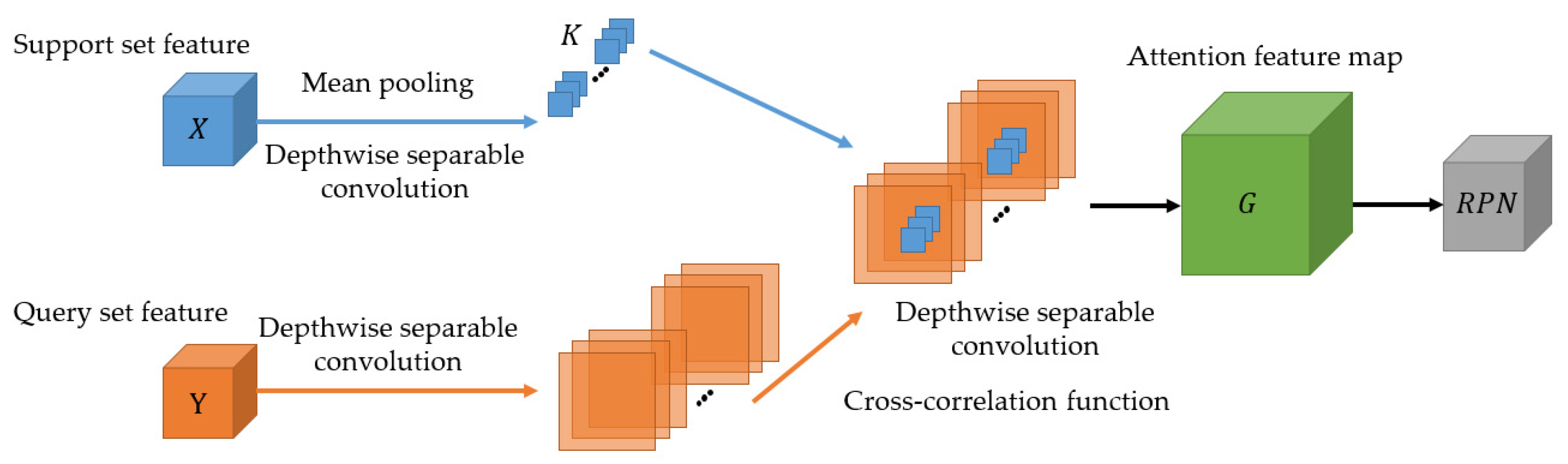
3.2. Proposal Generation Network
3.3. Few-Shot Learning Module Based on Metric Learning
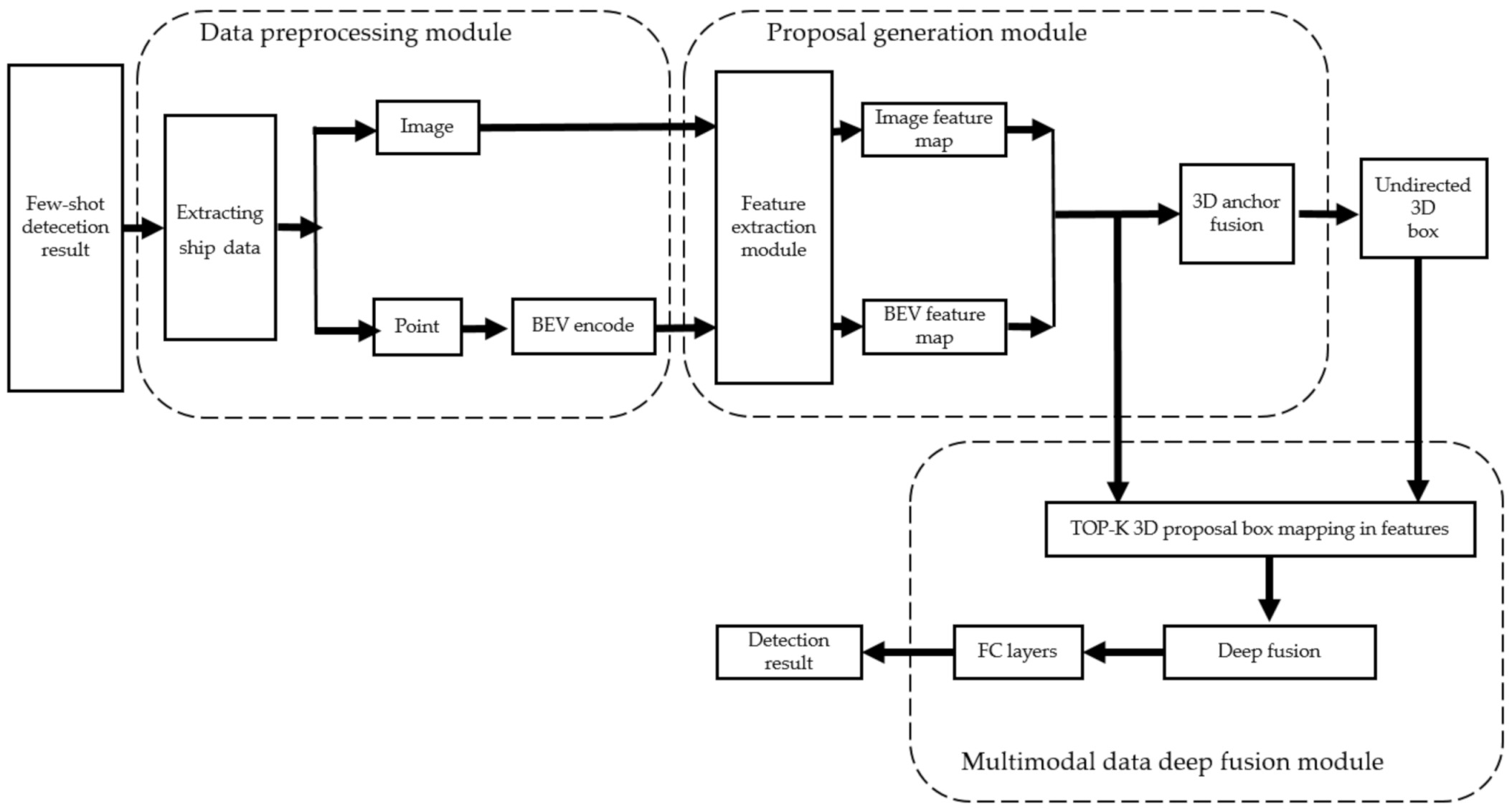
4. Detection Method of Key Objects on the Water Surface
4.1. Data Preprocessing Module
4.2. Proposal Generation Module
4.3. Multimodal Data-Deep Fusion Module
5. Experiments
5.1. Few-Shot Object Detection Experiment
5.2. Three-Dimensional Detection Experiment of Key Objects on the Water Surface
6. Conclusions
Author Contributions
Funding
Data Availability Statement
Conflicts of Interest
References
- Liu, Z.; Zhang, Y.; Yu, X.; Yuan, C. Unmanned surface vehicles: An overview of developments and challenges. Annu. Rev. Control 2016, 41, 71–93. [Google Scholar] [CrossRef]
- Sinisterra, A.J.; Dhanak, M.R.; von Ellenrieder, K. Stereo vision-based target tracking system for an USV. In Proceedings of the 2014 Oceans—St. John’s, St. John’s, NL, Canada, 14–19 September 2014; pp. 1–7. [Google Scholar] [CrossRef]
- Huntsberger, T.; Aghazarian, H.; Howard, A.; Trotz, D.C. Stereo vision–based navigation for autonomous surface vessels. J. Field Robot. 2011, 28, 3–18. [Google Scholar] [CrossRef]
- Larson, J.; Bruch, M.; Ebken, J. Autonomous navigation and obstacle avoidance for unmanned surface vehicles. Unmanned Syst. Technol. VIII 2006, 6230, 53–64. [Google Scholar] [CrossRef]
- Wang, H.; Wei, Z.; Wang, S.; Ow, C.S.; Ho, K.T.; Feng, B. A vision-based obstacle detection system for Unmanned Surface Vehicle. In Proceedings of the 2011 IEEE 5th International Conference on Robotics, Automation and Mechatronics (RAM), Qingdao, China, 17–19 September 2011; pp. 364–369. [Google Scholar] [CrossRef]
- Heo, Y.S.; Lee, K.M.; Lee, S.U. Illumination and camera invariant stereo matching. In Proceedings of the 2008 IEEE Conference on Computer Vision and Pattern Recognition, Anchorage, AK, USA, 23–28 June 2008; pp. 1–8. [Google Scholar] [CrossRef] [Green Version]
- Qi, C.R.; Su, H.; Mo, K.; Guibas, L.J. PointNet: Deep Learning on Point Sets for 3D Classification and Segmentation. In Proceedings of the 2017 IEEE Conference on Computer Vision and Pattern Recognition (CVPR), Honolulu, HI, USA, 21–26 July 2017; pp. 652–660. Available online: https://openaccess.thecvf.com/content_cvpr_2017/html/Qi_PointNet_Deep_Learning_CVPR_2017_paper.html (accessed on 29 September 2021).
- Liu, W.; Anguelov, D.; Erhan, D.; Szegedy, C.; Reed, S.; Fu, C.Y.; Berg, A.C. SSD: Single Shot MultiBox Detector. In Computer Vision—ECCV 2016; Springer: Cham, Switzerland, 2016; pp. 21–37. [Google Scholar] [CrossRef] [Green Version]
- Redmon, J.; Divvala, S.; Girshick, R.; Farhadi, A. You only look once: Unified, real-time object detection. In Proceedings of the 2016 IEEE Conference on Computer Vision and Pattern Recognition (CVPR), Las Vegas, NV, USA, 27–30 June 2016; pp. 779–788. Available online: https://www.cv-foundation.org/openaccess/content_cvpr_2016/html/Redmon_You_Only_Look_CVPR_2016_paper.html (accessed on 28 September 2021).
- Vinyals, O.; Blundell, C.; Lillicrap, T.; Kavukcuoglu, K.; Wierstra, D. Matching Networks for One Shot Learning. 2016. Available online: https://www.semanticscholar.org/paper/Siamese-Neural-Networks-for-One-Shot-Image-Koch/f216444d4f2959b4520c61d20003fa30a199670a (accessed on 29 September 2021).
- Chen, X.; Ma, H.; Wan, J.; Li, B.; Xia, T. Multi-view 3D object detection network for autonomous driving. In Proceedings of the 2017 IEEE Conference on Computer Vision and Pattern Recognition (CVPR), Honolulu, HI, USA, 21–26 July 2017; pp. 1907–1915. Available online: https://openaccess.thecvf.com/content_cvpr_2017/html/Chen_Multi-View_3D_Object_CVPR_2017_paper.html (accessed on 29 September 2021).
- He, K.; Zhang, X.; Ren, S.; Sun, J. Deep residual learning for image recognition. In Proceedings of the 2016 IEEE Conference on Computer Vision and Pattern Recognition (CVPR), Las Vegas, NV, USA, 27–30 June 2016; pp. 770–778. Available online: https://openaccess.thecvf.com/content_cvpr_2016/html/He_Deep_Residual_Learning_CVPR_2016_paper.html (accessed on 29 September 2021).
- Girshick, R.; Donahue, J.; Darrell, T.; Malik, J. Rich feature hierarchies for accurate object detection and semantic segmentation. In Proceedings of the 2014 IEEE Conference on Computer Vision and Pattern Recognition (CVPR), Columbus, OH, USA, 23–28 June 2014; pp. 580–587. Available online: https://openaccess.thecvf.com/content_cvpr_2014/html/Girshick_Rich_Feature_Hierarchies_2014_CVPR_paper.html (accessed on 29 September 2021).
- Xiao, Z.; Zhong, P.; Quan, Y.; Yin, X.; Xue, W. Few-shot object detection with feature attention highlight module in remote sensing images. In Proceedings of the 2020 International Conference on Image, Video Processing and Artificial Intelligence, Shanghai, China, 21–23 August 2020; Volume 11584, pp. 217–223. [Google Scholar] [CrossRef]
- Xiao, Z.; Qi, J.; Xue, W.; Zhong, P. Few-Shot Object Detection with Self-Adaptive Attention Network for Remote Sensing Images. IEEE J. Sel. Top. Appl. Earth Obs. Remote Sens. 2021, 14, 4854–4865. [Google Scholar] [CrossRef]
- Fan, Q.; Zhuo, W.; Tang, C.-K.; Tai, Y.-W. Few-shot object detection with attention-RPN and multi-relation detector. In Proceedings of the 2020 IEEE/CVF Conference on Computer Vision and Pattern Recognition (CVPR), Seattle, WA, USA, 13–19 June 2020; pp. 4013–4022. Available online: https://openaccess.thecvf.com/content_CVPR_2020/html/Fan_Few-Shot_Object_Detection_With_Attention-RPN_and_Multi-Relation_Detector_CVPR_2020_paper.html (accessed on 18 December 2021).
- Wang, X.; Huang, T.E.; Darrell, T.; Gonzalez, J.E.; Yu, F. Frustratingly Simple Few-Shot Object Detection. arXiv 2020, arXiv:2003.06957. Available online: http://arxiv.org/abs/2003.06957 (accessed on 18 December 2021).
- Wu, J.; Liu, S.; Huang, D.; Wang, Y. Multi-scale positive sample refinement for few-shot object detection. In Computer Vision—ECCV 2020; Springer: Cham, Switzerland, 2020; pp. 456–472. [Google Scholar] [CrossRef]
- Li, Y.; Feng, W.; Lyu, S.; Zhao, Q.; Li, X. MM-FSOD: Meta and metric integrated few-shot object detection. arXiv 2020, arXiv:2012.15159. Available online: http://arxiv.org/abs/2012.15159 (accessed on 18 December 2021).
- Yan, X.; Chen, Z.; Xu, A.; Wang, X.; Liang, X.; Lin, L. Meta R-CNN: Towards general solver for instance-level low-shot learning. In Proceedings of the 2019 IEEE/CVF International Conference on Computer Vision Workshop (ICCVW), Seoul, Korea, 27–28 October 2019; pp. 9577–9586. Available online: https://openaccess.thecvf.com/content_ICCV_2019/html/Yan_Meta_R-CNN_Towards_General_Solver_for_Instance-Level_Low-Shot_Learning_ICCV_2019_paper.html (accessed on 18 December 2021).
- Kang, B.; Liu, Z.; Wang, X.; Yu, F.; Feng, J.; Darrell, T. Few-shot object detection via feature reweighting. In Proceedings of the 2019 IEEE/CVF International Conference on Computer Vision Workshop (ICCVW), Seoul, Korea, 27–28 October 2019; pp. 8420–8429. Available online: https://openaccess.thecvf.com/content_ICCV_2019/html/Kang_Few-Shot_Object_Detection_via_Feature_Reweighting_ICCV_2019_paper.html (accessed on 18 December 2021).
- Deng, J.; Li, X.; Fang, Y. Few-shot Object Detection on Remote Sensing Images. arXiv 2020, arXiv:2006.07826. Available online: http://arxiv.org/abs/2006.07826 (accessed on 18 December 2021).
- Redmon, J.; Farhadi, A. YOLO9000: Better, faster, stronger. In Proceedings of the 2017 IEEE Conference on Computer Vision and Pattern Recognition (CVPR), Honolulu, HI, USA, 21–26 July 2017; pp. 7263–7271. Available online: https://openaccess.thecvf.com/content_cvpr_2017/html/Redmon_YOLO9000_Better_Faster_CVPR_2017_paper.html (accessed on 18 December 2021).
- Redmon, J.; Farhadi, A. YOLOv3: An Incremental Improvement. arXiv 2018, arXiv:1804.02767. Available online: http://arxiv.org/abs/1804.02767 (accessed on 18 December 2021).
- Yang, Z.; Wang, Y.; Chen, X.; Liu, J.; Qiao, Y. Context-Transformer: Tackling Object Confusion for Few-Shot Detection. Proc. AAAI Conf. Artif. Intell. 2020, 34, 12653–12660. [Google Scholar] [CrossRef]
- Koch, G. Siamese neural networks for one-shot image recognition. In Proceedings of the ICML Deep Learning Workshop, Lille, France, 6–11 July 2015; p. 30. [Google Scholar]
- Zhang, T.; Zhang, Y.; Sun, X.; Sun, H.; Yan, M.; Yang, X.; Fu, K. Comparison Network for One-Shot Conditional Object Detection. arXiv 2020, arXiv:1904.02317. Available online: http://arxiv.org/abs/1904.02317 (accessed on 29 September 2021).
- Karlinsky, L.; Karlinsky, L.; Shtok, J.; Harary, S.; Marder, M.; Pankanti, S.; Bronstein, A.M. RepMet: Representative-based metric learning for classification and one-shot object detection. arXiv 2018, arXiv:1806.04728. Available online: http://arxiv.org/abs/1806.04728 (accessed on 15 November 2021).
- Dai, J.; Qi, H.; Xiong, Y.; Li, Y.; Zhang, G.; Hu, H.; Wei, Y. Deformable convolutional networks. In Proceedings of the 2017 IEEE International Conference on Computer Vision Workshop (ICCVW), Venice, Italy, 22–29 October 2017; pp. 764–773. Available online: https://openaccess.thecvf.com/content_iccv_2017/html/Dai_Deformable_Convolutional_Networks_ICCV_2017_paper.html (accessed on 29 September 2021).
- Gupta, S.; Girshick, R.; Arbeláez, P.; Malik, J. Learning rich features from RGB-D images for object detection and segmentation. In Computer Vision—ECCV 2014; Springer: Cham, Switzerland, 2014; pp. 345–360. [Google Scholar] [CrossRef] [Green Version]
- Song, S.; Xiao, J. Deep sliding shapes for amodal 3D object detection in RGB-D images. In Proceedings of the 2016 IEEE Conference on Computer Vision and Pattern Recognition (CVPR), Las Vegas, NV, USA, 27–30 June 2016; pp. 808–816. Available online: https://openaccess.thecvf.com/content_cvpr_2016/html/Song_Deep_Sliding_Shapes_CVPR_2016_paper.html (accessed on 29 September 2021).
- Ku, J.; Mozifian, M.; Lee, J.; Harakeh, A.; Waslander, S.L. Joint 3D Proposal Generation and Object Detection from View Aggregation. In Proceedings of the 2018 IEEE/RSJ International Conference on Intelligent Robots and Systems (IROS), Madrid, Spain, 1–5 October 2018; pp. 1–8. [Google Scholar] [CrossRef] [Green Version]
- Cheng, Y.; Xu, H.; Liu, Y. Robust small object detection on the water surface through fusion of camera and millimeter wave radar. In Proceedings of the 2021 IEEE/CVF International Conference on Computer Vision, Montreal, QC, Canada, 11–17 October 2021; pp. 15263–15272. Available online: https://openaccess.thecvf.com/content/ICCV2021/html/Cheng_Robust_Small_Object_Detection_on_the_Water_Surface_Through_Fusion_ICCV_2021_paper.html (accessed on 26 January 2022).
- Wu, Y.; Qin, H.; Liu, T.; Liu, H.; Wei, Z. A 3D Object Detection Based on Multi-Modality Sensors of USV. Appl. Sci. 2019, 9, 535. [Google Scholar] [CrossRef] [Green Version]
- Lin, M.; Chen, Q.; Yan, S. Network in Network. arXiv 2014, arXiv:1312.4400. Available online: http://arxiv.org/abs/1312.4400 (accessed on 29 September 2021).
- He, K.; Gkioxari, G.; Dollar, P.; Girshick, R. Mask R-CNN. In Proceedings of the 2017 IEEE International Conference on Computer Vision (ICCV), Venice, Italy, 22–29 October 2017; pp. 2961–2969. Available online: https://openaccess.thecvf.com/content_iccv_2017/html/He_Mask_R-CNN_ICCV_2017_paper.html (accessed on 29 September 2021).
- Ioffe, S.; Szegedy, C. Batch normalization: Accelerating deep network training by reducing internal covariate shift. In Proceedings of the 32nd International Conference on Machine Learning, Lille, France, 6–11 July 2015; pp. 448–456. Available online: https://proceedings.mlr.press/v37/ioffe15.html (accessed on 29 September 2021).
- Glorot, X.; Bordes, A.; Bengio, Y. Deep Sparse Rectifier Neural Networks. In Proceedings of the Fourteenth International Conference on Artificial Intelligence and Statistics, Fort Lauderdale, FL, USA, 11–13 April 2011; pp. 315–323. Available online: https://proceedings.mlr.press/v15/glorot11a.html (accessed on 29 September 2021).
- Deng, J.; Dong, W.; Socher, R.; Li, L.-J.; Li, K.; Fei-Fei, L. ImageNet: A large-scale hierarchical image database. In Proceedings of the 2009 IEEE Conference on Computer Vision and Pattern Recognition, Miami, FL, USA, 22–25 June 2009; pp. 248–255. [Google Scholar] [CrossRef] [Green Version]
- Lin, T.-Y.; Maire, M.; Belongie, S.; Hays, J.; Perona, P.; Ramanan, D.; Zitnick, C.L. Microsoft COCO: Common objects in context. In Computer Vision—ECCV 2014; Springer: Cham, Switzerland, 2014; pp. 740–755. [Google Scholar] [CrossRef] [Green Version]
- Geiger, A.; Lenz, P.; Stiller, C.; Urtasun, R. Vision meets robotics: The KITTI dataset. Int. J. Robot. Res. 2013, 32, 1231–1237. [Google Scholar] [CrossRef] [Green Version]
- Chen, H.; Wang, Y.; Wang, G.; Qiao, Y. LSTD: A low-shot transfer detector for object detection. In Proceedings of the AAAI Conference on Artificial Intelligence, New Orleans, LA, USA, 2–7 February 2018; Volume 32. Available online: https://ojs.aaai.org/index.php/AAAI/article/view/11716 (accessed on 15 November 2021).
- Wandt, B.; Rosenhahn, B. RepNet: Weakly supervised training of an adversarial reprojection network for 3D human pose estimation. In Proceedings of the 2019 IEEE/CVF Conference on Computer Vision and Pattern Recognition (CVPR), Long Beach, CA, USA, 15–20 June 2019; pp. 7782–7791. Available online: https://openaccess.thecvf.com/content_CVPR_2019/html/Wandt_RepNet_Weakly_Supervised_Training_of_an_Adversarial_Reprojection_Network_for_CVPR_2019_paper.html (accessed on 15 November 2021).






{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
| Methods | Advantages | Limitations |
|---|---|---|
| detection based on fine tuning | High detection accuracy | Susceptible to overfitting on small-scale target domain datasets |
| detection based on the model structure | Small size, highly accurate candidates | Poor recall rate and reusability |
| detection based on metric learning | Easy to realize incremental learning | Limited positioning accuracy |
| Model | 1-shot (%) | 5-shot (%) | 10-shot (%) |
|---|---|---|---|
| LSTD [42] | 19.2 | 37.4 | 44.3 |
| RepMet [43] | 24.1 | 39.6 | 49.2 |
| The proposed model | 24.7 | 41.2 | 51.1 |
| Dataset | Method | No Episode Fine-Tuning (%) | With Episode Fine-Tuning (%) | ||||
|---|---|---|---|---|---|---|---|
| 1-shot | 5-shot | 10-shot | 1-shot | 5-shot | 10-shot | ||
| ImageNet (73 unseen) | Baseline-FT [29] | — | — | — | 35 | 21 | 59.7 |
| Baseline-DML [29] | 41.3 | 58.2 | 61.6 | 41.3 | 59.7 | 66.5 | |
| Baseline-DML-external [29] | 19 | 30.2 | 30.4 | 32.1 | 37.2 | 38.1 | |
| RepMet [43] | 56.9 | 68.8 | 71.5 | 59.2 | 73.9 | 79.2 | |
| Ours | 57.6 | 69.5 | 73.2 | 59.7 | 75.1 | 80.6 | |
| ImageNet (30 seen) | Ours-trained representatives | — | 85.3 | — | — | — | — |
| Ours-episode representatives | 65.5 | 79.6 | 82.1 | — | — | — | |
| Method | Easy | Moderate | Difficult | |||
|---|---|---|---|---|---|---|
| AP (%) | AOS (%) | AP (%) | AOS (%) | AP (%) | AOS (%) | |
| MV3D [11] | 79.57 | 51.69 | 65.87 | 44.11 | 57.83 | 39.43 |
| Ours | 81.23 | 79.89 | 75.36 | 68.17 | 62.35 | 65.83 |
Publisher’s Note: MDPI stays neutral with regard to jurisdictional claims in published maps and institutional affiliations. |
© 2022 by the authors. Licensee MDPI, Basel, Switzerland. This article is an open access article distributed under the terms and conditions of the Creative Commons Attribution (CC BY) license (https://creativecommons.org/licenses/by/4.0/).
Share and Cite
Hong, B.; Zhou, Y.; Qin, H.; Wei, Z.; Liu, H.; Yang, Y. Few-Shot Object Detection Using Multimodal Sensor Systems of Unmanned Surface Vehicles. Sensors 2022, 22, 1511. https://doi.org/10.3390/s22041511
Hong B, Zhou Y, Qin H, Wei Z, Liu H, Yang Y. Few-Shot Object Detection Using Multimodal Sensor Systems of Unmanned Surface Vehicles. Sensors. 2022; 22(4):1511. https://doi.org/10.3390/s22041511
Chicago/Turabian StyleHong, Bowei, Yuandong Zhou, Huacheng Qin, Zhiqiang Wei, Hao Liu, and Yongquan Yang. 2022. "Few-Shot Object Detection Using Multimodal Sensor Systems of Unmanned Surface Vehicles" Sensors 22, no. 4: 1511. https://doi.org/10.3390/s22041511
APA StyleHong, B., Zhou, Y., Qin, H., Wei, Z., Liu, H., & Yang, Y. (2022). Few-Shot Object Detection Using Multimodal Sensor Systems of Unmanned Surface Vehicles. Sensors, 22(4), 1511. https://doi.org/10.3390/s22041511