
SiamMixer: A Lightweight and Hardware-Friendly Visual Object-Tracking Network

 , ,
, ,
Abstract
:1. Introduction
- We propose a novel lightweight and hardware-friendly visual object-tracking model based on the Siamese tracking scheme, namely SiamMixer.
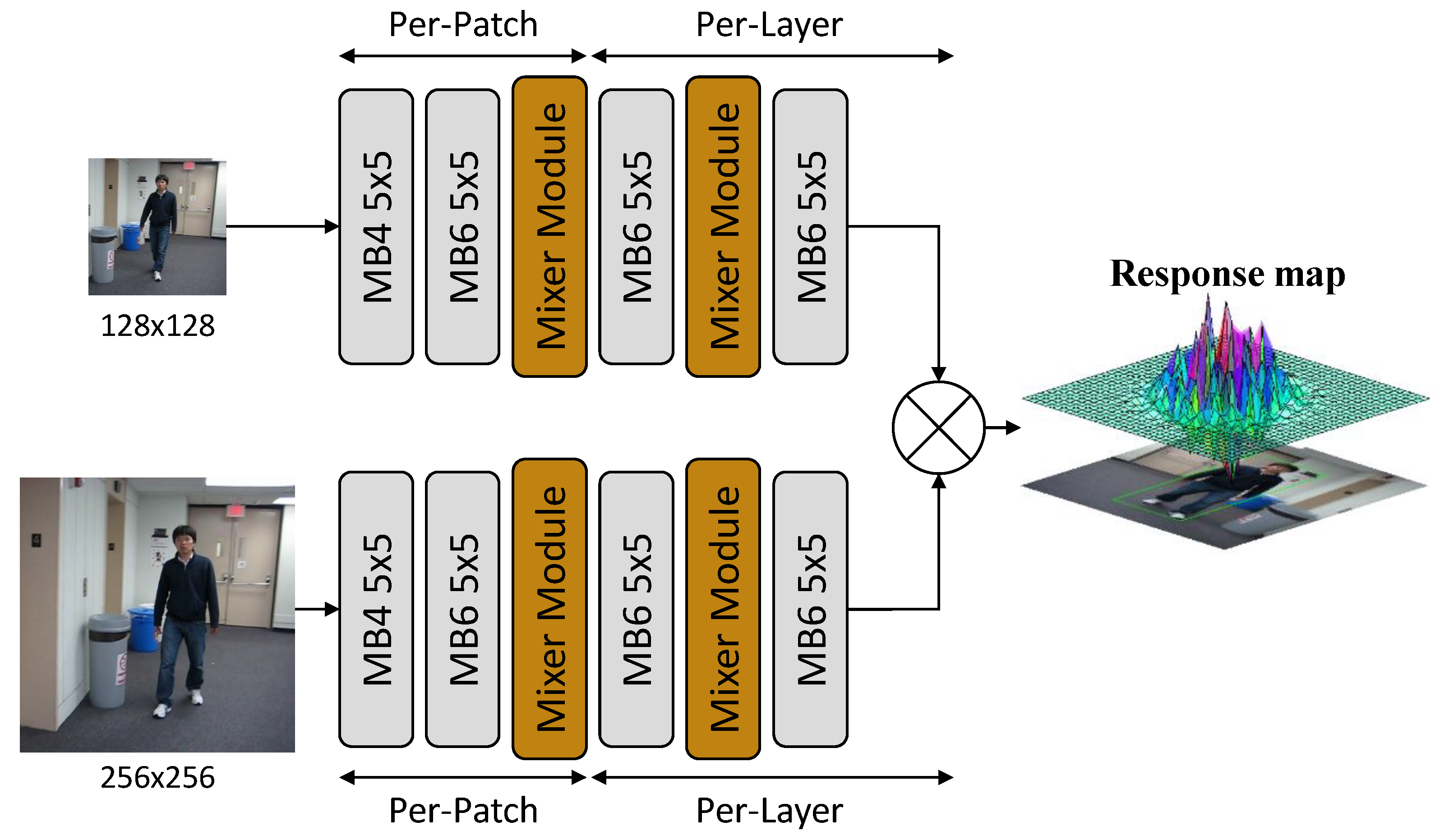
- We design a compact backbone consisting of patch-based convolutions and mixer modules. The patch-based convolution reduces feature map memory use by processing each image patch individually. The mixer module enhances the accuracy by merging and encoding global information of feature maps.
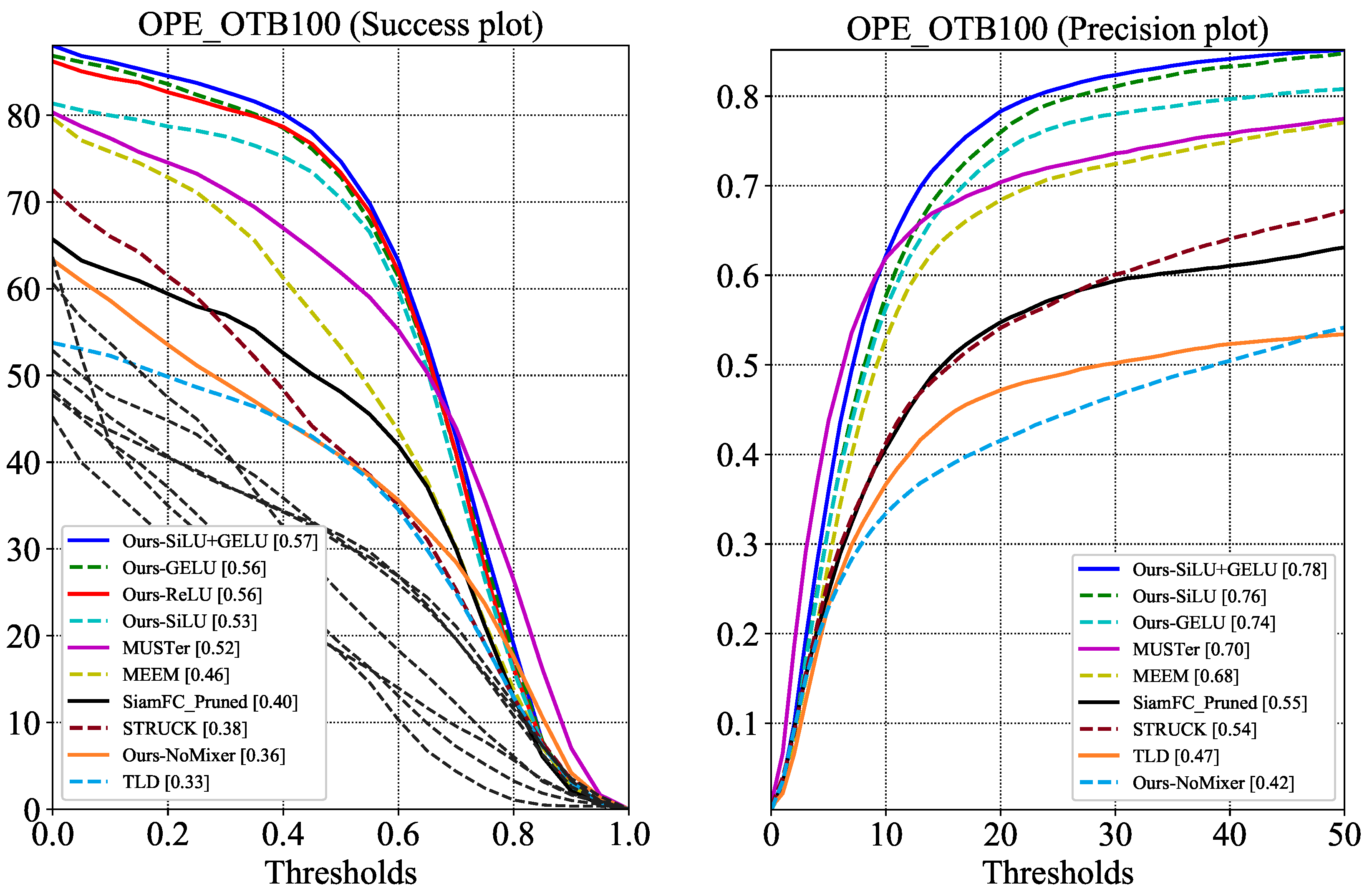
- We verify the activation function impact on tracking accuracy and use ReLU as a satisfying alternative for exponential-based functions, which is favorable for Single-Instruction Multiple-Data (SIMD) operations.
2. Related Work
2.1. Trackers Based on Siamese Network
2.2. Lightweight Network Structure Design
3. Proposed Algorithm
3.1. Convolutional Layer
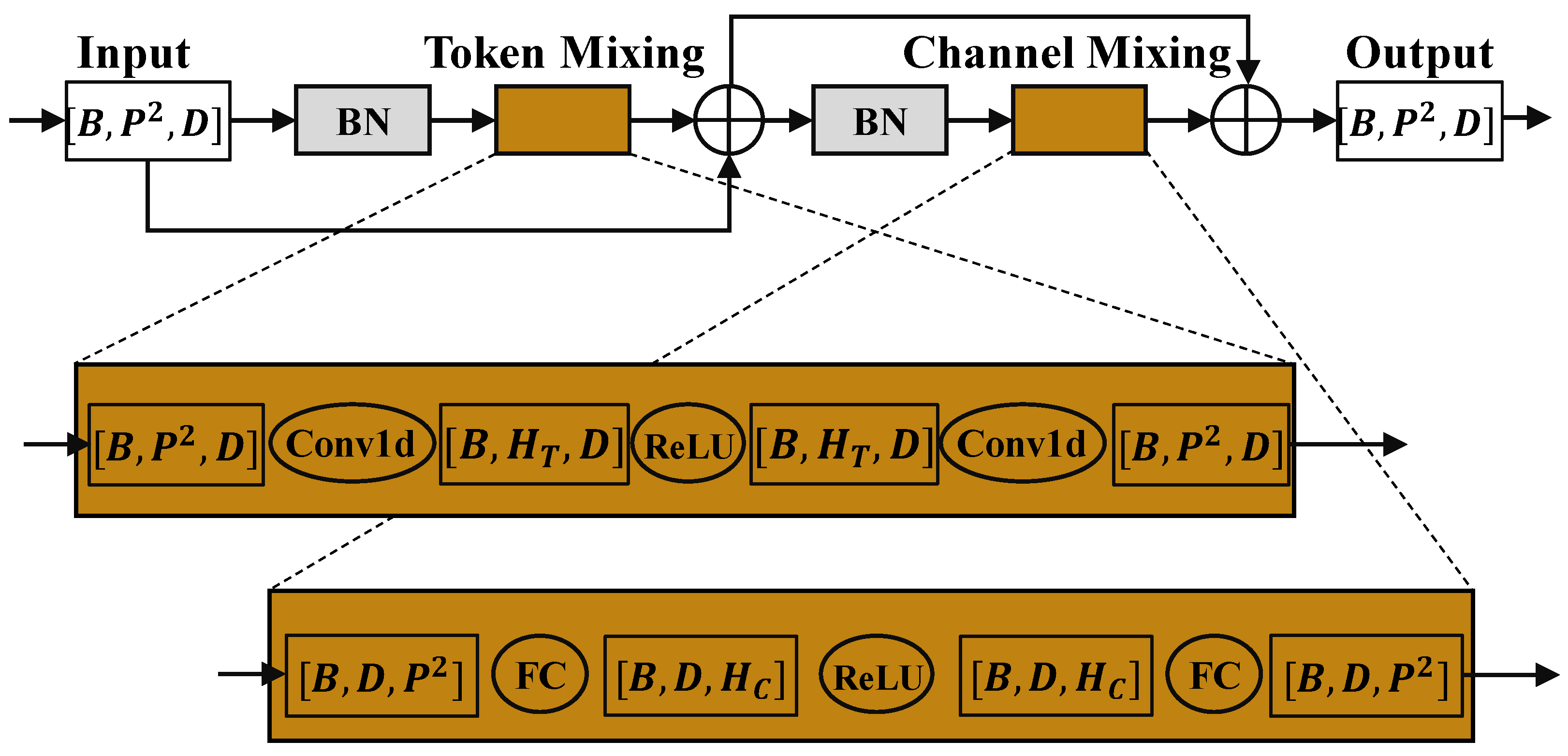
3.2. Mixing Module
- Replace GELU activation function with ReLU activation function.
- Replace LayerNorm with BatchNorm.
- Use Conv1d for channel mixing.
3.3. Target Locating
3.4. Training Setup
3.5. Datasets and Evaluation Metrics
4. Experiment Results
4.1. Ablation Analysis
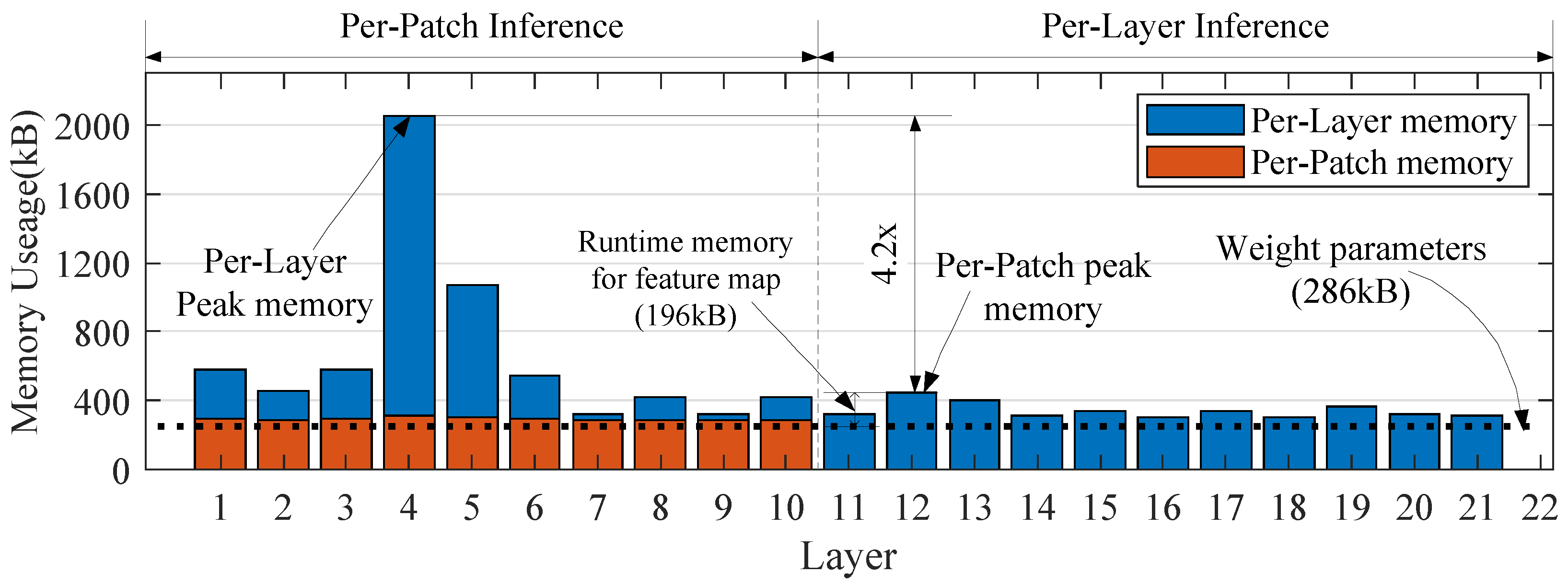
4.2. Storage and Analysis
5. Conclusions
Author Contributions
Funding
Institutional Review Board Statement
Informed Consent Statement
Data Availability Statement
Conflicts of Interest
References
- Yang, J.; Shi, C.; Liu, L.; Wu, N. Heterogeneous vision chip and LBP-based algorithm for high-speed tracking. Electron. Lett. 2014, 50, 438–439. [Google Scholar] [CrossRef] [Green Version]
- Li, B.; Wu, W.; Wang, Q.; Zhang, F.; Xing, J.; Yan, J. SiamRPN++: Evolution of Siamese Visual Tracking with Very Deep Networks. In Proceedings of the 2019 IEEE/CVF Conference on Computer Vision and Pattern Recognition (CVPR), Long Beach, CA, USA, 15–20 June 2019. [Google Scholar] [CrossRef] [Green Version]
- Zhang, Z.; Peng, H.; Fu, J.; Li, B.; Hu, W. Ocean: Object-Aware Anchor-Free Tracking. In Computer Vision—ECCV 2020; Vedaldi, A., Bischof, H., Brox, T., Frahm, J., Eds.; Springer: Berlin/Heidelberg, Germany, 2020; Volume 12366, pp. 771–787. [Google Scholar] [CrossRef]
- Xu, Y.; Wang, Z.; Li, Z.; Ye, Y.; Yu, G. SiamFC++: Towards Robust and Accurate Visual Tracking with Target Estimation Guidelines. Proc. AAAI Conf. Artif. Intell. 2020, 34, 12549–12556. [Google Scholar] [CrossRef]
- Szegedy, C.; Liu, W.; Jia, Y.; Sermanet, P.; Reed, S.E.; Anguelov, D.; Erhan, D.; Vanhoucke, V.; Rabinovich, A. Going deeper with convolutions. In Proceedings of the 2015 IEEE/CVF Conference on Computer Vision and Pattern Recognition, Boston, MA, USA, 7–12 June 2015. [Google Scholar] [CrossRef] [Green Version]
- Krizhevsky, A.; Sutskever, I.; Hinton, G.E. Imagenet classification with deep convolutional neural networks. Adv. Neural Inf. Process. Syst. 2012, 25, 1097–1105. [Google Scholar] [CrossRef]
- Danelljan, M.; Bhat, G.; Khan, F.S.; Felsberg, M. ATOM: Accurate Tracking by Overlap Maximization. In Proceedings of the 2019 IEEE/CVF Conference on Computer Vision and Pattern Recognition, Long Beach, CA, USA, 15–20 June 2019. [Google Scholar]
- Bhat, G.; Danelljan, M.; Gool, L.V.; Timofte, R. Learning Discriminative Model Prediction for Tracking. In Proceedings of the IEEE/CVF International Conference on Computer Vision (ICCV), Seoul, Korea, 27–28 October 2019. [Google Scholar]
- Iandola, F.N.; Han, S.; Moskewicz, M.W.; Ashraf, K.; Dally, W.J.; Keutzer, K. SqueezeNet: AlexNet-level accuracy with 50x fewer parameters and <0.5 MB model size. arXiv 2016, arXiv:1602.07360. [Google Scholar]
- Howard, A.G.; Zhu, M.; Chen, B.; Kalenichenko, D.; Wang, W.; Weyand, T.; Andreetto, M.; Adam, H. MobileNets: Efficient Convolutional Neural Networks for Mobile Vision Applications. arXiv 2017, arXiv:1704.04861. [Google Scholar]
- Sandler, M.; Howard, A.G.; Zhu, M.; Zhmoginov, A.; Chen, L. MobileNetV2: Inverted Residuals and Linear Bottlenecks. In Proceedings of the 2018 IEEE/CVF Conference on Computer Vision and Pattern Recognition 2018, Salt Lake City, UT, USA, 18–22 June 2018; pp. 4510–4520. [Google Scholar] [CrossRef] [Green Version]
- Bertinetto, L.; Valmadre, J.; Henriques, J.F.; Vedaldi, A.; Torr, P.H.S. Fully-Convolutional Siamese Networks for Object Tracking. In Computer Vision – ECCV 2016; Hua, G., Jégou, H., Eds.; Springer: Berlin/Heidelberg, Germany, 2016; Volume 9914, pp. 850–865. [Google Scholar] [CrossRef] [Green Version]
- Li, B.; Yan, J.; Wu, W.; Zhu, Z.; Hu, X. High Performance Visual Tracking With Siamese Region Proposal Network. In Proceedings of the 2018 IEEE/CVF Conference on Computer Vision and Pattern Recognition, Salt Lake City, UT, USA, 18–23 June 2018; pp. 8971–8980. [Google Scholar] [CrossRef]
- Zhang, Z.; Peng, H. Deeper and Wider Siamese Networks for Real-Time Visual Tracking. In Proceedings of the 2019 IEEE/CVF Conference on Computer Vision and Pattern Recognition, Long Beach, CA, USA, 15–20 June 2019; pp. 4591–4600. [Google Scholar] [CrossRef] [Green Version]
- Guo, Q.; Feng, W.; Zhou, C.; Huang, R.; Wan, L.; Wang, S. Learning Dynamic Siamese Network for Visual Object Tracking. In Proceedings of the IEEE International Conference on Computer Vision, Venice, Italy, 22–29 October 2017; pp. 1781–1789. [Google Scholar] [CrossRef]
- Yang, T.; Xu, P.; Hu, R.; Chai, H.; Chan, A.B. ROAM: Recurrently Optimizing Tracking Model. In Proceedings of the 2020 IEEE/CVF Conference on Computer Vision and Pattern Recognition, Seattle, WA, USA, 14–19 June 2020; pp. 6717–6726. [Google Scholar] [CrossRef]
- Han, S.; Mao, H.; Dally, W.J. Deep Compression: Compressing Deep Neural Network with Pruning, Trained Quantization and Huffman Coding. In Proceedings of the 4th International Conference on Learning Representations, San Juan, Puerto Rico, 2–4 May 2016. [Google Scholar]
- Hinton, G.; Vinyals, O.; Dean, J. Distilling the Knowledge in a Neural Network. arXiv 2015, arXiv:1503.02531. [Google Scholar]
- Esser, S.K.; McKinstry, J.L.; Bablani, D.; Appuswamy, R.; Modha, D.S. Learned Step Size quantization. In Proceedings of the 8th International Conference on Learning Representations, Addis Ababa, Ethiopia, 26–30 April 2020. [Google Scholar]
- Ren, P.; Xiao, Y.; Chang, X.; Huang, P.Y.; Li, Z.; Chen, X.; Wang, X. A comprehensive survey of neural architecture search: Challenges and solutions. ACM Comput. Surv. 2021, 54, 1–34. [Google Scholar] [CrossRef]
- Yan, B.; Peng, H.; Wu, K.; Wang, D.; Fu, J.; Lu, H. LightTrack: Finding Lightweight Neural Networks for Object Tracking via One-Shot Architecture Search. In Proceedings of the 2021 IEEE/CVF Conference on Computer Vision and Pattern Recognition, Nashville, TN, USA, 20–25 June 2021; pp. 15180–15189. [Google Scholar]
- Lin, J.; Chen, W.M.; Cai, H.; Gan, C.; Han, S. MCUNetV2: Memory-Efficient Patch-based Inference for Tiny Deep Learning. arXiv 2021, arXiv:2110.15352. [Google Scholar]
- Tolstikhin, I.O.; Houlsby, N.; Kolesnikov, A.; Beyer, L.; Zhai, X.; Unterthiner, T.; Yung, J.; Steiner, A.; Keysers, D.; Uszkoreit, J.; et al. MLP-mixer: An all-mlp architecture for vision. Adv. Neural Inf. Process. Syst. 2021, 34, 1–12. [Google Scholar]
- Dosovitskiy, A.; Beyer, L.; Kolesnikov, A.; Weissenborn, D.; Zhai, X.; Unterthiner, T.; Dehghani, M.; Minderer, M.; Heigold, G.; Gelly, S.; et al. An Image is Worth 16 × 16 Words: Transformers for Image Recognition at Scale. In Proceedings of the 9th International Conference on Learning Representations, Virtual Event, Austria, 3–7 May 2021. [Google Scholar]
- Dong, X.; Shen, J. Triplet Loss in Siamese Network for Object Tracking. In Computer Vision—ECCV 2018; Ferrari, V., Hebert, M., Sminchisescu, C., Weiss, Y., Eds.; Springer: Berlin/Heidelberg, Germany, 2018; Volume 11217, pp. 472–488. [Google Scholar] [CrossRef]
- Wu, Y.; Lim, J.; Yang, M. Object Tracking Benchmark. IEEE Trans. Pattern Anal. Mach. Intell. 2015, 37, 1834–1848. [Google Scholar] [CrossRef] [PubMed] [Green Version]
- Mueller, M.; Smith, N.; Ghanem, B. A Benchmark and Simulator for UAV Tracking. In Computer Vision—ECCV 2016; Leibe, B., Matas, J., Sebe, N., Welling, M., Eds.; Springer: Berlin/Heidelberg, Germany, 2016; Volume 9905, pp. 445–461. [Google Scholar] [CrossRef]
- Huang, L.; Zhao, X.; Huang, K. GOT-10k: A Large High-Diversity Benchmark for Generic Object Tracking in the Wild. IEEE Trans. Pattern Anal. Mach. Intell. 2021, 43, 1562–1577. [Google Scholar] [CrossRef] [PubMed] [Green Version]
- Held, D.; Thrun, S.; Savarese, S. Learning to Track at 100 FPS with Deep Regression Networks. In Computer Vision—ECCV 2016; Leibe, B., Matas, J., Sebe, N., Welling, M., Eds.; Springer: Berlin/Heidelberg, Germany, 2016; Volume 9905, pp. 749–765. [Google Scholar] [CrossRef] [Green Version]
- Hong, Z.; Chen, Z.; Wang, C.; Mei, X.; Prokhorov, D.V.; Tao, D. MUlti-Store Tracker (MUSTer): A cognitive psychology inspired approach to object tracking. In Proceedings of the 2015 IEEE/CVF Conference on Computer Vision and Pattern Recognition, Boston, MA, USA, 7–12 June 2015; pp. 749–758. [Google Scholar] [CrossRef]
- Zhang, J.; Ma, S.; Sclaroff, S. MEEM: Robust Tracking via Multiple Experts Using Entropy Minimization. In Computer Vision—ECCV 2014; Fleet, D.J., Pajdla, T., Schiele, B., Tuytelaars, T., Eds.; Springer: Berlin/Heidelberg, Germany, 2014; Volume 8694, pp. 188–203. [Google Scholar] [CrossRef] [Green Version]
- Hare, S.; Saffari, A.; Torr, P.H.S. Struck: Structured output tracking with kernels. In Proceedings of the IEEE International Conference on Computer Vision, Barcelona, Spain, 6–13 November 2011; pp. 263–270. [Google Scholar] [CrossRef] [Green Version]
- Kalal, Z.; Mikolajczyk, K.; Matas, J. Tracking-Learning-Detection. IEEE Trans. Pattern Anal. Mach. Intell. 2012, 34, 1409–1422. [Google Scholar] [CrossRef] [PubMed] [Green Version]
- Galoogahi, H.K.; Fagg, A.; Lucey, S. Learning Background-Aware Correlation Filters for Visual Tracking. In Proceedings of the IEEE International Conference on Computer Vision, Venice, Italy, 22–29 October 2017; pp. 1144–1152. [Google Scholar] [CrossRef] [Green Version]
- Henriques, J.F.; Caseiro, R.; Martins, P.; Batista, J. High-Speed Tracking with Kernelized Correlation Filters. IEEE Trans. Pattern Anal. Mach. Intell. 2015, 37, 583–596. [Google Scholar] [CrossRef] [PubMed] [Green Version]
- Cai, H.; Gan, C.; Wang, T.; Zhang, Z.; Han, S. Once-for-All: Train One Network and Specialize it for Efficient Deployment. In Proceedings of the 8th International Conference on Learning Representations, Addis Ababa, Ethiopia, 26–30 April 2020. [Google Scholar]
- Canziani, A.; Paszke, A.; Culurciello, E. An Analysis of Deep Neural Network Models for Practical Applications. arXiv 2016, arXiv:1605.07678. [Google Scholar]
- Wan, A.; Dai, X.; Zhang, P.; He, Z.; Tian, Y.; Xie, S.; Wu, B.; Yu, M.; Xu, T.; Chen, K.; et al. FBNetV2: Differentiable Neural Architecture Search for Spatial and Channel Dimensions. In Proceedings of the IEEE/CVF Conference on Computer Vision and Pattern Recognition, Seattle, WA, USA, 13–19 June 2020; pp. 12962–12971. [Google Scholar] [CrossRef]
- He, K.; Zhang, X.; Ren, S.; Sun, J. Deep Residual Learning for Image Recognition. In Proceedings of the 2016 IEEE/CVF Conference on Computer Vision and Pattern Recognition, Las Vegas, NV, USA, 27–30 June 2016; pp. 770–778. [Google Scholar] [CrossRef] [Green Version]





{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
| Layer | Size | Channel in | Channel out | Stride | Expansion |
|---|---|---|---|---|---|
| MB1 | 3 | 16 | 1 | 4 | |
| MB2 | 16 | 32 | 1 | 6 | |
| Mixer1 | - | 32 | 32 | - | - |
| MB3 | 32 | 64 | 1 | 6 | |
| Mixer2 | - | 64 | 128 | - | - |
| MB4 | 128 | 256 | 1 | 6 |
| Name | GTX1080 | TeslaV100 | Jetson Xavier |
|---|---|---|---|
| SiamMixer-XS | 55.89 fps | 131.35 fps | 26.64 fps |
| SiamMixer-S | 49.70 fps | 117.02 fps | 22.92 fps |
| SiamMixer-M | 45.71 fps | 115.45 fps | 22.10 fps |
| SiamMixer-L | 23.74 fps | 89.51 fps | 18.46 fps |
| Name | SiamMixer-XS | SiamMixer-S | SiamMixer-M | SiamMixer-L |
|---|---|---|---|---|
| Success Score ↑ | 0.561 | 0.576 | 0.571 | 0.556 |
| Name | Par. ↓ 1 | FLOPs. ↓ | S.S. ↑ 2 | S.P. ↑ 3 | S.G. ↑ 3 |
|---|---|---|---|---|---|
| Ours-XS | 0.286 M | 351.364 M | 0.561 | 1.962 | 1.597 |
| Ours-S | 0.389 M | 351.857 M | 0.576 | 1.481 | 1.637 |
| Ours-M | 0.593 M | 352.814 M | 0.571 | 0.963 | 1.644 |
| Ours-L | 1.003 M | 352.841 M | 0.556 | 0.554 | 1.618 |
| L.T.Mobile [21] 4 | 1.97 M | 528.88 M | — | — | — |
| SiamFC [12] | 2.336 M | 3.179 G | 0.583 | 0.250 | 0.183 |
| SiamRPN [13] | 90.436 M | 25.553 G | 0.637 | 0.007 | 0.025 |
| SiamFC(VGG) [14] | 9.220 M | 12.221 G | 0.61 | 0.066 | 0.050 |
| SiamRPN++ [2] | 23.7 M | 40.89 G | 0.696 | 0.029 | 0.017 |
| OCEAN [3] | 25.9 M | 20.3 G | 0.683 | 0.026 | 0.034 |
| SiamFC(R.33) [14] 5 | 21.3 M | 5.98 G | 0.55 | 0.026 | 0.092 |
| GOTURN [29] | 114 M | 0.977 G | 0.45 | 0.004 | 0.461 |
Publisher’s Note: MDPI stays neutral with regard to jurisdictional claims in published maps and institutional affiliations. |
© 2022 by the authors. Licensee MDPI, Basel, Switzerland. This article is an open access article distributed under the terms and conditions of the Creative Commons Attribution (CC BY) license (https://creativecommons.org/licenses/by/4.0/).
Share and Cite
Cheng, L.; Zheng, X.; Zhao, M.; Dou, R.; Yu, S.; Wu, N.; Liu, L. SiamMixer: A Lightweight and Hardware-Friendly Visual Object-Tracking Network. Sensors 2022, 22, 1585. https://doi.org/10.3390/s22041585
Cheng L, Zheng X, Zhao M, Dou R, Yu S, Wu N, Liu L. SiamMixer: A Lightweight and Hardware-Friendly Visual Object-Tracking Network. Sensors. 2022; 22(4):1585. https://doi.org/10.3390/s22041585
Chicago/Turabian StyleCheng, Li, Xuemin Zheng, Mingxin Zhao, Runjiang Dou, Shuangming Yu, Nanjian Wu, and Liyuan Liu. 2022. "SiamMixer: A Lightweight and Hardware-Friendly Visual Object-Tracking Network" Sensors 22, no. 4: 1585. https://doi.org/10.3390/s22041585
APA StyleCheng, L., Zheng, X., Zhao, M., Dou, R., Yu, S., Wu, N., & Liu, L. (2022). SiamMixer: A Lightweight and Hardware-Friendly Visual Object-Tracking Network. Sensors, 22(4), 1585. https://doi.org/10.3390/s22041585