
Improving Depth Estimation by Embedding Semantic Segmentation: A Hybrid CNN Model




Abstract
:1. Introduction
2. Related Works
3. Proposed Methodology
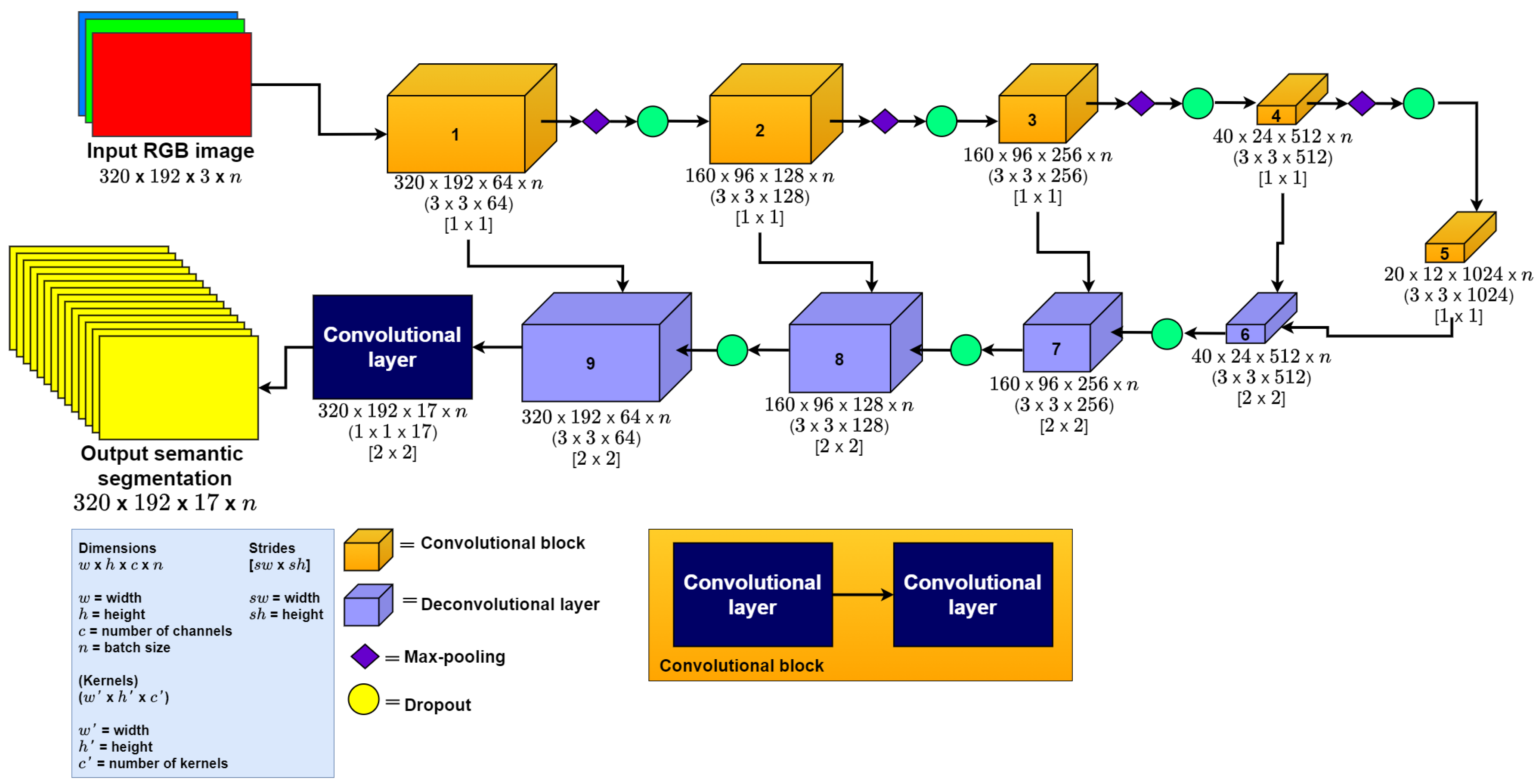
3.1. Semantic Segmentation
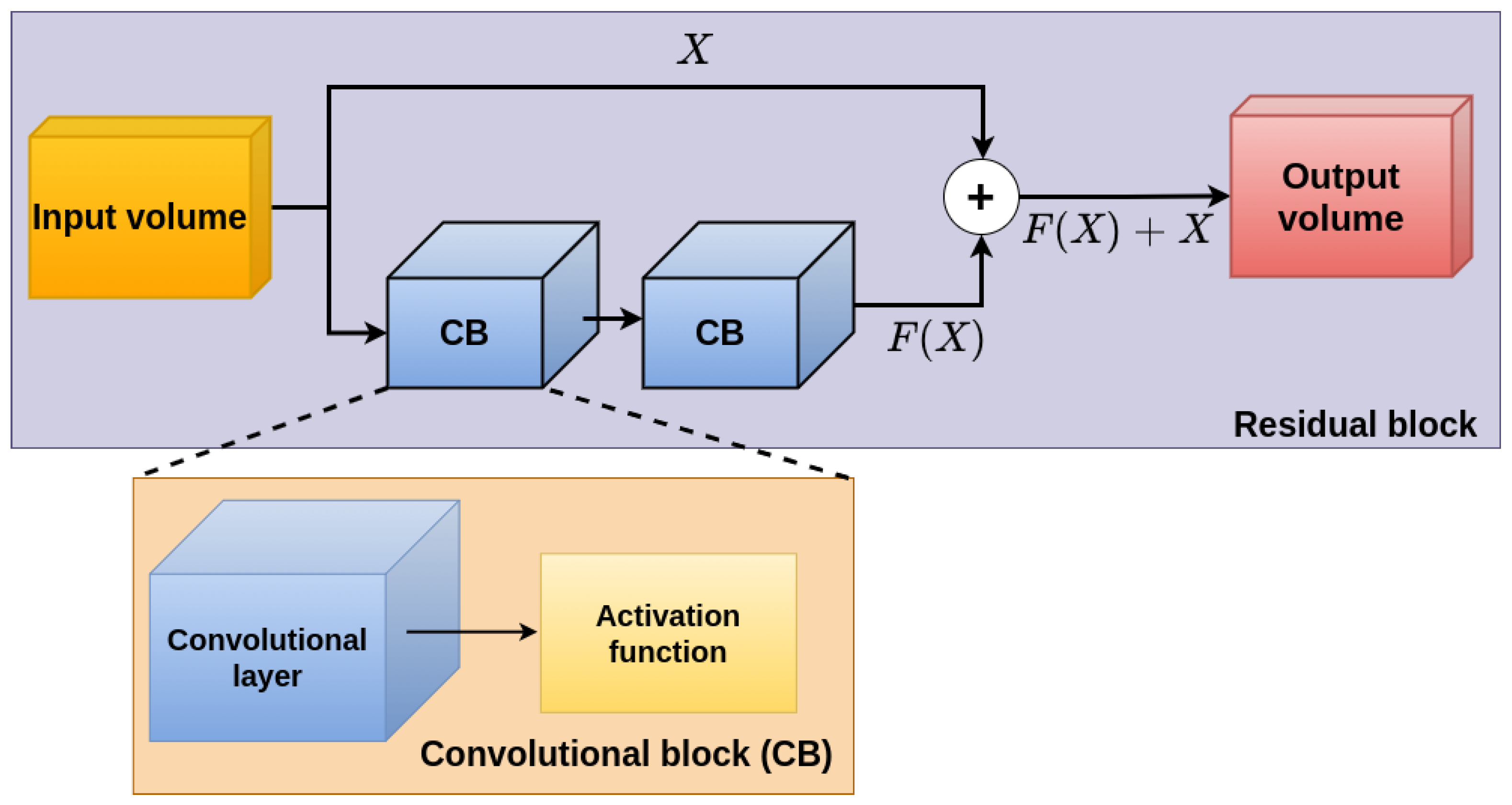
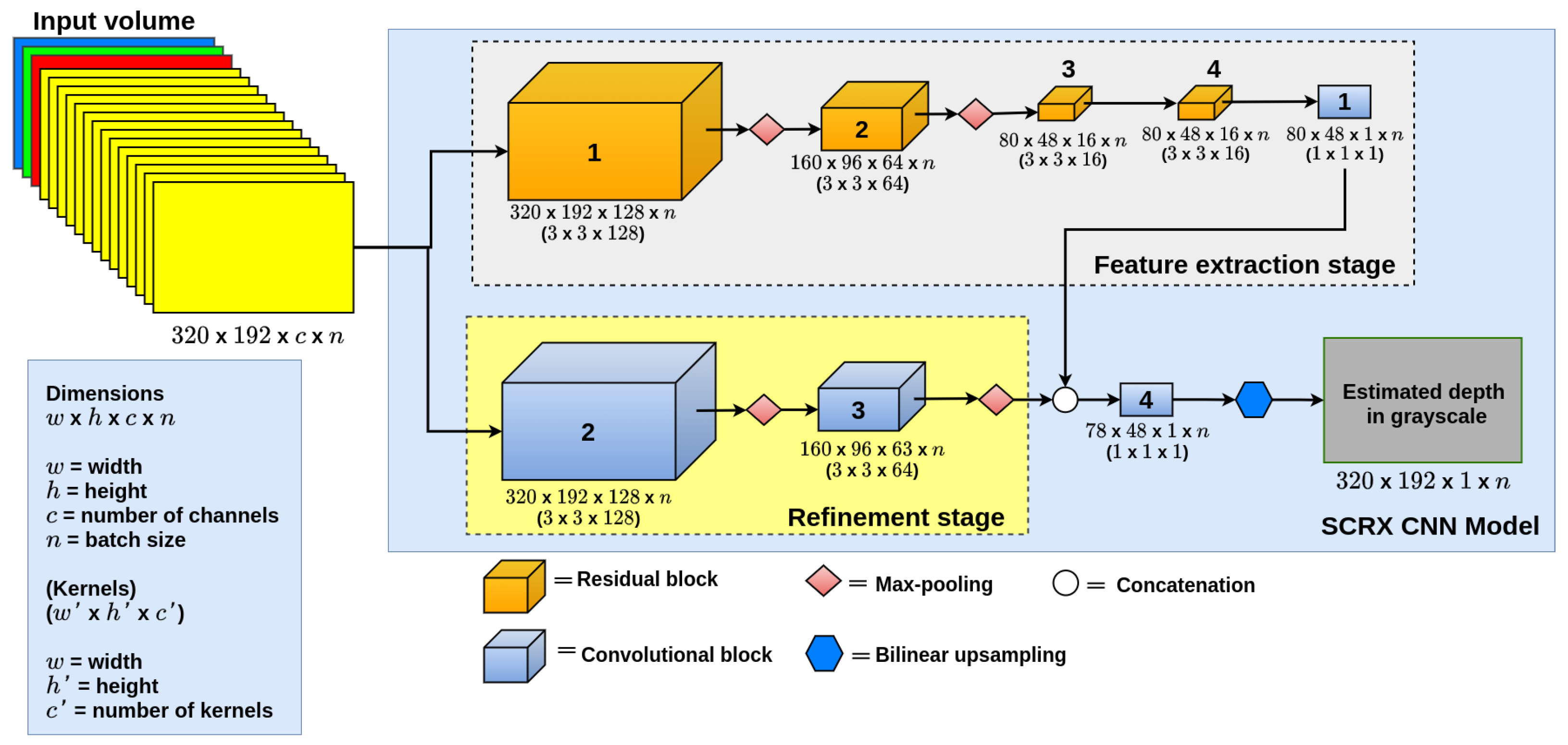
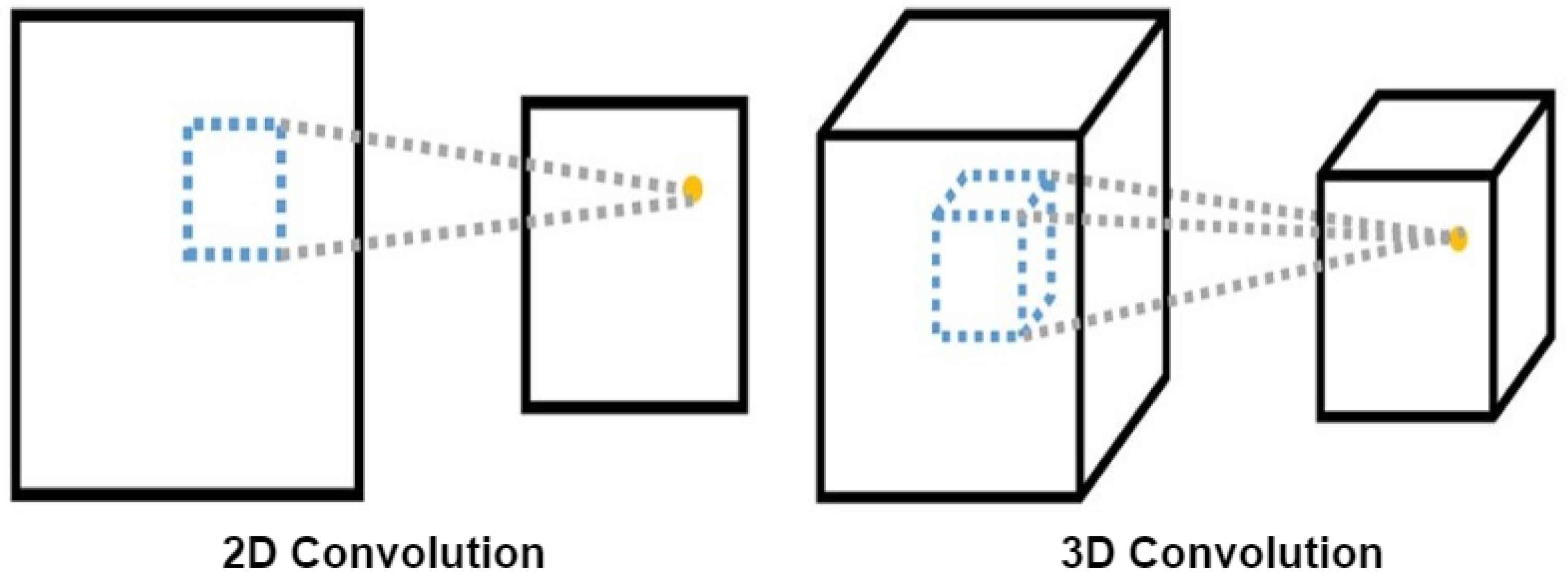
3.2. Depth Estimation Architectures
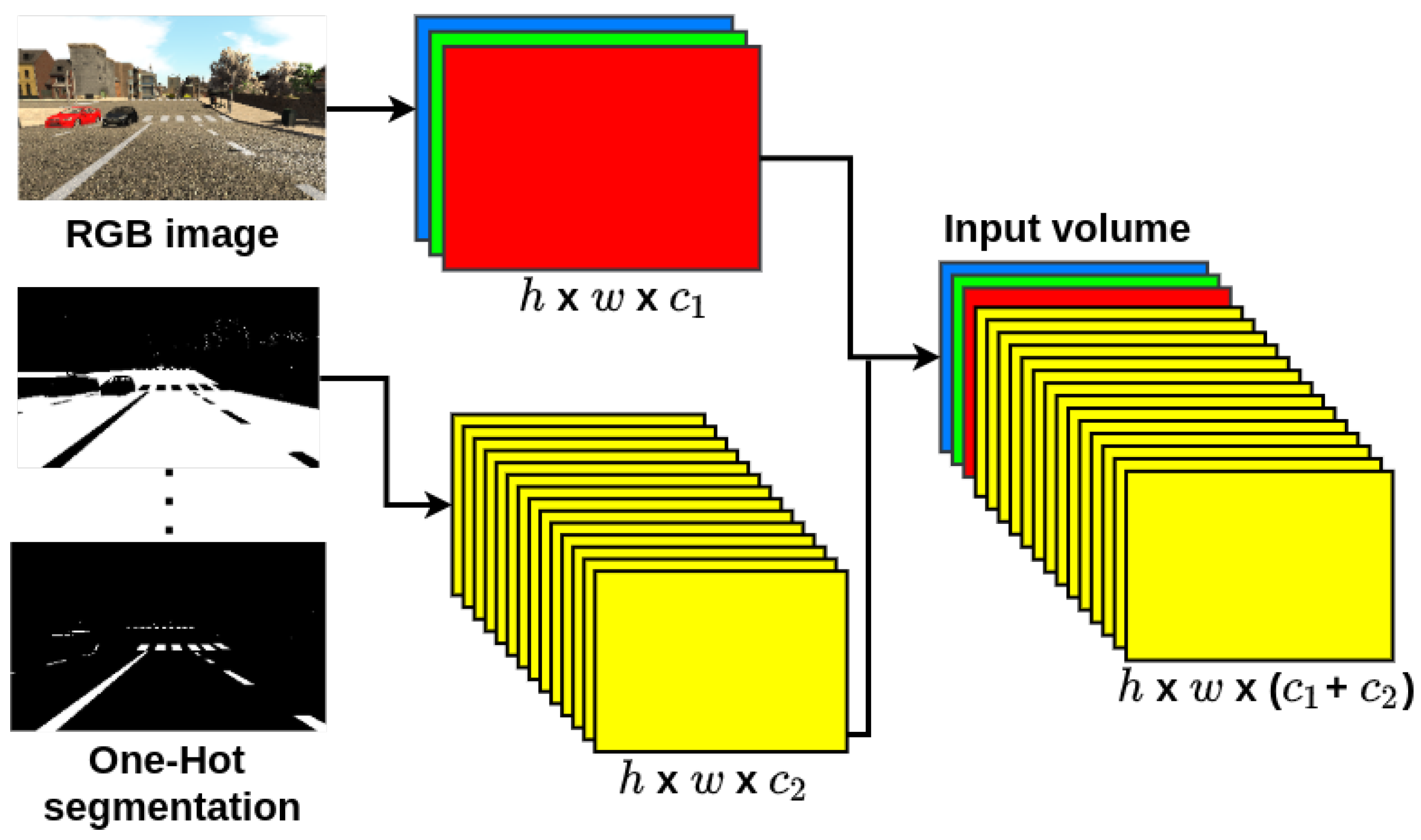
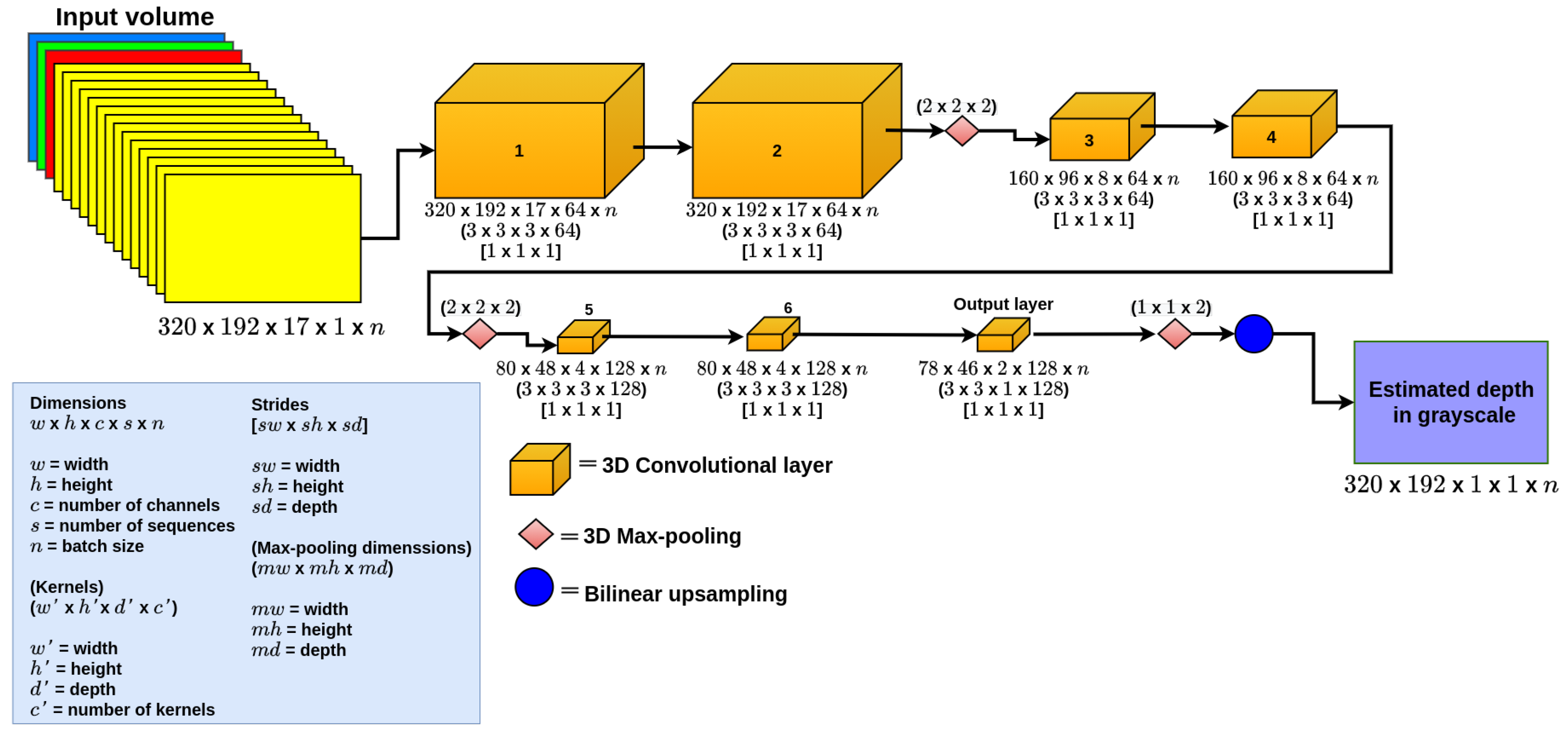
3.3. SSegDep-Net: Hybrid 2D–3D CNN Architecture
4. Experiments and Results
4.1. Dataset
4.2. U-Net Semantic Segmentation Results
4.3. Depth Estimation Qualitative Results
4.3.1. SCRX Model Qualitative Results
4.3.2. 3D CNNs Qualitative Results
4.4. Hybrid Semantic Segmentation and Depth Estimation: SSegDep-Net
4.5. Implementation and Evaluation
5. Conclusions and Future Work
Author Contributions
Funding
Institutional Review Board Statement
Informed Consent Statement
Data Availability Statement
Conflicts of Interest
Appendix A. Evaluation Metrics
| Root Mean Square Error: | |
| Mean Quadratic Error: | |
| Logarithmic Root Mean Square Error: | |
| Logarithmic Root Mean Square Error Scale Invariant: | |
| Absolute Relative Difference: | |
| Squared Relative Difference: | |
| Threshold (, , ): | |
| Reconstructed depth map | |
| Target depth map | y |
| Number of pixels in the images | T |
References
- Blake, R.; Sekuler, R. Perception; McGraw-Hill Higher Education; McGraw-Hill Companies Incorporated: New York, NY, USA, 2006. [Google Scholar]
- Howard, I.P. Perceiving in Depth, Volume 1: Basic Mechanisms; Oxford University Press: Oxford, UK, 2012. [Google Scholar]
- Valdez-Rodríguez, J.E.; Calvo, H.; Felipe-Riverón, E.M. Road perspective depth reconstruction from single images using reduce-refine-upsample CNNs. In Proceedings of the Mexican International Conference on Artificial Intelligence, Enseneda, Mexico, 23–28 October 2017; Springer: Cham, Switzerland, 2017; pp. 30–40. [Google Scholar]
- Eigen, D.; Puhrsch, C.; Fergus, R. Depth map prediction from a single image using a multi-scale deep network. In Proceedings of the 27th International Conference on Neural Information Processing Systems, Montreal, QC, Canada, 8–13 December 2014; pp. 2366–2374. [Google Scholar]
- Eigen, D.; Fergus, R. Predicting depth, surface normals and semantic labels with a common multi-scale convolutional architecture. In Proceedings of the IEEE International Conference on Computer Vision, Santiago, Chile, 7–13 December 2015; pp. 2650–2658. [Google Scholar]
- Liu, F.; Shen, C.; Lin, G.; Reid, I. Learning depth from single monocular images using deep convolutional neural fields. IEEE Trans. Pattern Anal. Mach. Intell. 2016, 38, 2024–2039. [Google Scholar] [CrossRef] [PubMed] [Green Version]
- Mousavian, A.; Pirsiavash, H.; Košecká, J. Joint semantic segmentation and depth estimation with deep convolutional networks. In Proceedings of the 2016 Fourth International Conference on 3D Vision (3DV), Stanford, CA, USA, 25–28 October 2016; pp. 611–619. [Google Scholar]
- Afifi, A.J.; Hellwich, O. Object depth estimation from a single image using fully convolutional neural network. In Proceedings of the International Conference on Digital Image Computing: Techniques and Applications (DICTA), Gold Coast, Australia, 30 November–2 December 2016; pp. 1–7. [Google Scholar]
- Laina, I.; Rupprecht, C.; Belagiannis, V.; Tombari, F.; Navab, N. Deeper depth prediction with fully convolutional residual networks. In Proceedings of the 2016 Fourth International Conference 3D Vision (3DV), Stanford, CA, USA, 25–28 October 2016; pp. 239–248. [Google Scholar]
- Li, B.; Dai, Y.; Chen, H.; He, M. Single image depth estimation by dilated deep residual convolutional neural network and soft-weight-sum inference. arXiv 2017, arXiv:1705.00534. [Google Scholar]
- Xu, D.; Ricci, E.; Ouyang, W.; Wang, X.; Sebe, N. Multi-scale continuous crfs as sequential deep networks for monocular depth estimation. In Proceedings of the IEEE Conference on Computer Vision and Pattern Recognition (CVPR), Honolulu, HI, USA, 21–26 July 2017; Volume 1. [Google Scholar]
- Koch, T.; Liebel, L.; Fraundorfer, F.; Körner, M. Evaluation of CNN-based single-image depth estimation methods. arXiv 2018, arXiv:1805.01328. [Google Scholar]
- Atapour-Abarghouei, A.; Breckon, T.P. To complete or to estimate, that is the question: A multi-task approach to depth completion and monocular depth estimation. In Proceedings of the 2019 International Conference on 3D Vision (3DV), Quebec, QC, Canada, 16–19 September 2019; pp. 183–193. [Google Scholar]
- Ronneberger, O.; Fischer, P.; Brox, T. U-net: Convolutional networks for biomedical image segmentation. In Proceedings of the International Conference on Medical Image Computing and Computer-Assisted Intervention, Munich, Germany, 5–9 October 2015; Springer: Cham, Switzerland, 2015; pp. 234–241. [Google Scholar]
- Lin, X.; Sánchez-Escobedo, D.; Casas, J.R.; Pardàs, M. Depth estimation and semantic segmentation from a single RGB image using a hybrid convolutional neural network. Sensors 2019, 19, 1795. [Google Scholar] [CrossRef] [PubMed] [Green Version]
- Yue, M.; Fu, G.; Wu, M.; Wang, H. Semi-Supervised Monocular Depth Estimation Based on Semantic Supervision. J. Intell. Robot. Syst. 2020, 100, 455–463. [Google Scholar] [CrossRef]
- Sun, W.; Gao, Z.; Cui, J.; Ramesh, B.; Zhang, B.; Li, Z. Semantic Segmentation Leveraging Simultaneous Depth Estimation. Sensors 2021, 21, 690. [Google Scholar] [CrossRef] [PubMed]
- Wang, H.M.; Lin, H.Y.; Chang, C.C. Object Detection and Depth Estimation Approach Based on Deep Convolutional Neural Networks. Sensors 2021, 21, 4755. [Google Scholar] [CrossRef] [PubMed]
- Genovese, A.; Piuri, V.; Rundo, F.; Scotti, F.; Spampinato, C. Driver attention assistance by pedestrian/cyclist distance estimation from a single RGB image: A CNN-based semantic segmentation approach. In Proceedings of the 2021 22nd IEEE International Conference on Industrial Technology (ICIT), Valencia, Spain, 10–12 March 2021; Volume 1, pp. 875–880. [Google Scholar]
- He, K.; Zhang, X.; Ren, S.; Sun, J. Deep residual learning for image recognition. In Proceedings of the IEEE Conference on Computer Vision and Pattern Recognition, Las Vegas, NV, USA, 27–30 June 2016; pp. 770–778. [Google Scholar]
- Zhao, H.; Shi, J.; Qi, X.; Wang, X.; Jia, J. Pyramid scene parsing network. In Proceedings of the IEEE Conference on Computer Vision and Pattern Recognition, Honolulu, HI, USA, 21–26 July 2017; pp. 2881–2890. [Google Scholar]
- Ozturk, O.; Saritürk, B.; Seker, D.Z. Comparison of Fully Convolutional Networks (FCN) and U-Net for Road Segmentation from High Resolution Imageries. Int. J. Environ. Geoinform. 2020, 7, 272–279. [Google Scholar] [CrossRef]
- Tran, L.A.; Le, M.H. Robust U-Net-based road lane markings detection for autonomous driving. In Proceedings of the 2019 International Conference on System Science and Engineering (ICSSE), Dong Hoi, Vietnam, 20–21 July 2019; pp. 62–66. [Google Scholar]
- Valdez Rodríguez, J.E.; Calvo, H.; Felipe Riverón, E.M. Single-Stage Refinement CNN for Depth Estimation in Monocular Images. Comput. Sist. 2020, 24, 439–451. [Google Scholar] [CrossRef]
- Arora, R.; Basu, A.; Mianjy, P.; Mukherjee, A. Understanding Deep Neural Networks with Rectified Linear Units. arXiv 2016, arXiv:1611.01491. [Google Scholar]
- LeCun, Y.; Boser, B.E.; Denker, J.S.; Henderson, D.; Howard, R.E.; Hubbard, W.E.; Jackel, L.D. Handwritten digit recognition with a back-propagation network. In Proceedings of the Advances in Neural Information Processing Systems, Denver, CO, USA, 27–30 November 1989; pp. 396–404. [Google Scholar]
- Zeiler, M.D.; Fergus, R. Visualizing and understanding convolutional networks. In Proceedings of the European Conference on Computer Vision, Zurich, Switzerland, 6–12 September 2014; Springer: Cham, Switzerland, 2014; pp. 818–833. [Google Scholar]
- Xu, N.; Price, B.; Cohen, S.; Huang, T. Deep Image Matting. arXiv 2017, arXiv:1703.03872. [Google Scholar]
- LeCun, Y.; Bottou, L.; Bengio, Y.; Haffner, P. Gradient-based learning applied to document recognition. Proc. IEEE 1998, 86, 2278–2324. [Google Scholar] [CrossRef] [Green Version]
- Zolfaghari Bengar, J.; Gonzalez-Garcia, A.; Villalonga, G.; Raducanu, B.; Aghdam, H.H.; Mozerov, M.; Lopez, A.M.; van de Weijer, J. Temporal Coherence for Active Learning in Videos. arXiv 2019, arXiv:1908.11757. [Google Scholar]
- Geiger, A.; Lenz, P.; Urtasun, R. Are we ready for autonomous driving? The kitti vision benchmark suite. In Proceedings of the 2012 IEEE Conference on Computer Vision and Pattern Recognition, Providence, RI, USA, 16–21 June 2012; pp. 3354–3361. [Google Scholar]
- Cordts, M.; Omran, M.; Ramos, S.; Rehfeld, T.; Enzweiler, M.; Benenson, R.; Franke, U.; Roth, S.; Schiele, B. The cityscapes dataset for semantic urban scene understanding. In Proceedings of the IEEE Conference on Computer Vision and Pattern Recognition (CVPR), Las Vegas, NV, USA, 27–30 June 2016. [Google Scholar]
- Ros, G.; Sellart, L.; Materzynska, J.; Vazquez, D.; Lopez, A.M. The SYNTHIA dataset: A large collection of synthetic images for semantic segmentation of urban scenes. In Proceedings of the IEEE Conference on Computer Vision and Pattern Recognition (CVPR), Las Vegas, NV, USA, 27–30 June 2016. [Google Scholar]
- Chen, T.; Li, M.; Li, Y.; Lin, M.; Wang, N.; Wang, M.; Xiao, T.; Xu, B.; Zhang, C.; Zhang, Z. Mxnet: A flexible and efficient machine learning library for heterogeneous distributed systems. arXiv 2015, arXiv:1512.01274. [Google Scholar]
- Chollet, F.; Duryea, E.; Hu, W. Keras. 2015. Available online: https://keras.io (accessed on 20 February 2022).
- LeCun, Y.A.; Bottou, L.; Orr, G.B.; Müller, K.R. Efficient backprop. In Neural Networks: Tricks of the Trade; Springer: Cham, Switzerland, 2012; pp. 9–48. [Google Scholar]
- Honauer, K. Performance Metrics and Test Data Generation for Depth Estimation Algorithms. Ph.D. Thesis, Faculty of Mathematics and Computer Science, Heidelberg, Germany, 2019. [Google Scholar]
- Wang, Y.; Tsai, Y.H.; Hung, W.C.; Ding, W.; Liu, S.; Yang, M.H. Semi-supervised multi-task learning for semantics and depth. In Proceedings of the IEEE/CVF Winter Conference on Applications of Computer Vision, Waikoloa, HI, USA, 3–8 January 2022; pp. 2505–2514. [Google Scholar]

















{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
| SYNTHIA-AL Dataset | |
|---|---|
| Class | IoU |
| Miscellaneous | 0.9089 |
| Sky | 0.8954 |
| Building | 0.7780 |
| Road | 0.8193 |
| Sidewalk | 0.9251 |
| Fence | 0.8098 |
| Vegetation | 0.7521 |
| Pole | 0.6287 |
| Vehicle | 0.8415 |
| Sign | 0.6528 |
| Pedestrian | 0.8839 |
| Cyclist | 0.7570 |
| Lanemark | 0.9165 |
| Traffic light | 0.6878 |
| Average | 0.8041 |
| Lower Is Better | ||||
|---|---|---|---|---|
| RMS | MQE | RMSL | ||
| SCRX Model | RGB | 0.1258 | 0.0245 | 0.6252 |
| RGB+OHESS | 0.0752 | 0.0068 | 0.8457 | |
| 3D CNN Models | 3D CNN-S | 0.0887 | 0.0101 | 1.2255 |
| 3D CNN-S | 0.0885 | 0.0097 | 1.2176 | |
| 3D CNN-UP | 0.0676 | 0.0062 | 0.1042 | |
| 3D CNN-UP | 0.1025 | 0.0135 | 0.5613 | |
| SSegDep-Net | 0.0944 | 0.0126 | 0.1402 | |
| Lower Is Better | ||||
|---|---|---|---|---|
| RMSLSI | ABSR | ABSQ | ||
| SCRX Model | RGB | 0.3055 | 0.2470 | 0.0463 |
| RGB+OHESS | 0.4170 | 0.2435 | 0.0282 | |
| 3D CNN Models | 3D CNN-S | 0.5799 | 0.2841 | 0.0612 |
| 3D CNN-S | 0.5580 | 0.0054 | 0.0500 | |
| 3D CNN-UP | 0.0282 | 0.0054 | 0.0050 | |
| 3D CNN-UP | 0.2730 | 0.2930 | 0.0790 | |
| SSegDep-Net | 0.0467 | 0.0125 | 0.0087 | |
| Higher Is Better | ||||
|---|---|---|---|---|
| SCRX Model | RGB | 0.7573 | 0.7900 | 0.8021 |
| RGB+OHESS | 0.8021 | 0.8065 | 0.8102 | |
| 3D CNN Models | 3D CNN-S | 0.7662 | 0.7974 | 0.8072 |
| 3D CNN-S | 0.7768 | 0.7825 | 0.8025 | |
| 3D CNN-UP | 0.8919 | 0.9105 | 0.9500 | |
| 3D CNN-UP | 0.8454 | 0.8347 | 0.8433 | |
| SSegDep-Net | 0.8610 | 0.8861 | 0.8929 | |
| Number of Iterations | Batch Size | Training Time (h) | Time to Test a Single Image (s) | ||
|---|---|---|---|---|---|
| SCRX Model | RGB | 50 | 27 | 12 | 0.95 |
| RGB+OHESS | 50 | 17 | 36 | 1.25 | |
| 3D CNN Models | 3D CNN-S | 50 | 10 | 72 | 1.25 |
| 3D CNN-S | 50 | 10 | 72 | 1.55 | |
| 3D CNN-UP | 50 | 10 | 72 | 0.87 | |
| 3D CNN-UP | 50 | 10 | 72 | 0.98 | |
| 2D CNN Model | U-Net | 3 | 27 | 24 | 0.68 |
| Hybrid CNN Model | SSegDep-Net | - | - | - | 0.83 |
| RMS | MQE | RMSL | RMSLI | ABSR | ABSQ | |
|---|---|---|---|---|---|---|
| SSegDep-Net | 0.1196 | 0.0225 | 0.01732 | 0.2356 | 0.1638 | 0.0129 |
| SemiMTL [38] | 0.0755 | - | - | - | 0.334 | - |
| SSegDep-Net | 0.8323 | 0.8422 | 0.8587 |
| SemiMTL [38] | 0.6148 | 0.8300 | 0.9190 |
Publisher’s Note: MDPI stays neutral with regard to jurisdictional claims in published maps and institutional affiliations. |
© 2022 by the authors. Licensee MDPI, Basel, Switzerland. This article is an open access article distributed under the terms and conditions of the Creative Commons Attribution (CC BY) license (https://creativecommons.org/licenses/by/4.0/).
Share and Cite
Valdez-Rodríguez, J.E.; Calvo, H.; Felipe-Riverón, E.; Moreno-Armendáriz, M.A. Improving Depth Estimation by Embedding Semantic Segmentation: A Hybrid CNN Model. Sensors 2022, 22, 1669. https://doi.org/10.3390/s22041669
Valdez-Rodríguez JE, Calvo H, Felipe-Riverón E, Moreno-Armendáriz MA. Improving Depth Estimation by Embedding Semantic Segmentation: A Hybrid CNN Model. Sensors. 2022; 22(4):1669. https://doi.org/10.3390/s22041669
Chicago/Turabian StyleValdez-Rodríguez, José E., Hiram Calvo, Edgardo Felipe-Riverón, and Marco A. Moreno-Armendáriz. 2022. "Improving Depth Estimation by Embedding Semantic Segmentation: A Hybrid CNN Model" Sensors 22, no. 4: 1669. https://doi.org/10.3390/s22041669
APA StyleValdez-Rodríguez, J. E., Calvo, H., Felipe-Riverón, E., & Moreno-Armendáriz, M. A. (2022). Improving Depth Estimation by Embedding Semantic Segmentation: A Hybrid CNN Model. Sensors, 22(4), 1669. https://doi.org/10.3390/s22041669