
Asynchronous Federated Learning System Based on Permissioned Blockchains


{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
Abstract
:1. Introduction
- (1)
- A permissioned blockchain-based federated learning framework is proposed. The permissioned blockchains are composed of a main-blockchain and multiple sub-blockchains, each of which is responsible for partial model parameter updates and the main- blockchain is responsible for global model parameter updates.
- (2)
- A multi-chain asynchronous model aggregation algorithm is proposed, which uses deep reinforcement learning for node selection, the sub-blockchain nodes audit the gradient and proof of correctness of the encryption and partially aggregate the model parameters, and the main blockchain is responsible for the global model parameter updates.
- (3)
- A prototype permissioned blockchain-based federated learning system was implemented and extensive experiments were conducted to demonstrate its feasibility and effectiveness.
2. Background
2.1. Federated Learning
2.2. Permissioned Blockchains
- (1)
- Strong controllability. Compared with public blockchains, public blockchains generally have many nodes, and once a blockchain is formed, the block data cannot be modified. For example, Bitcoin has many nodes, and it is impossible to change the data in it if you want to modify. In contrast, in permissioned blockchains, data can be modified as long as the majority of pre-selected nodes reach consensus.
- (2)
- Better performance. The permissioned blockchain is to some extent owned only by the members within the permit as the number of nodes in the permit is limited, so it is easy to reach a consensus.
- (3)
- Fast transaction speed. Only permissioned nodes can join the blockchain network, and transactions can only be verified by consensus nodes without network-wide confirmation. In a way, the essence of permission is still a private blockchain, it has a limited number of nodes, and it is easy to reach consensus, so the transaction speed is also relatively blocky.
- (4)
- Better privacy protection. The user identity is managed and the read access is restricted, which can provide better privacy protection. The data of the public blockchain is public, but the permission is different, so only the permission internal organization and its users have the permission to access the data.
2.3. Reinforcement Learning
3. Related Works
3.1. Asynchronous Federal Learning
3.2. Blockchain-Based Federated Learning
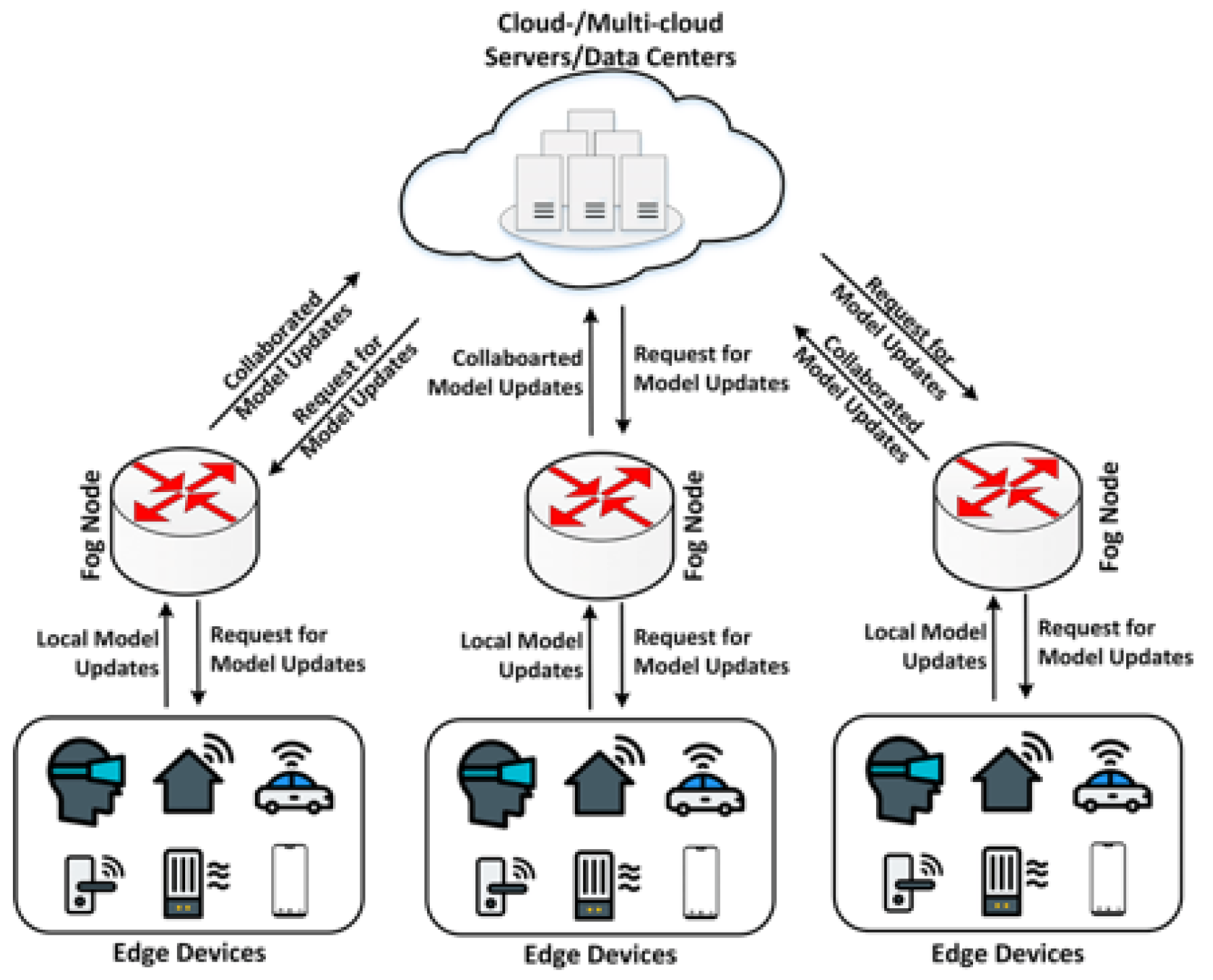
4. Asynchronous Federal Learning System Based on Permissioned Blockchains
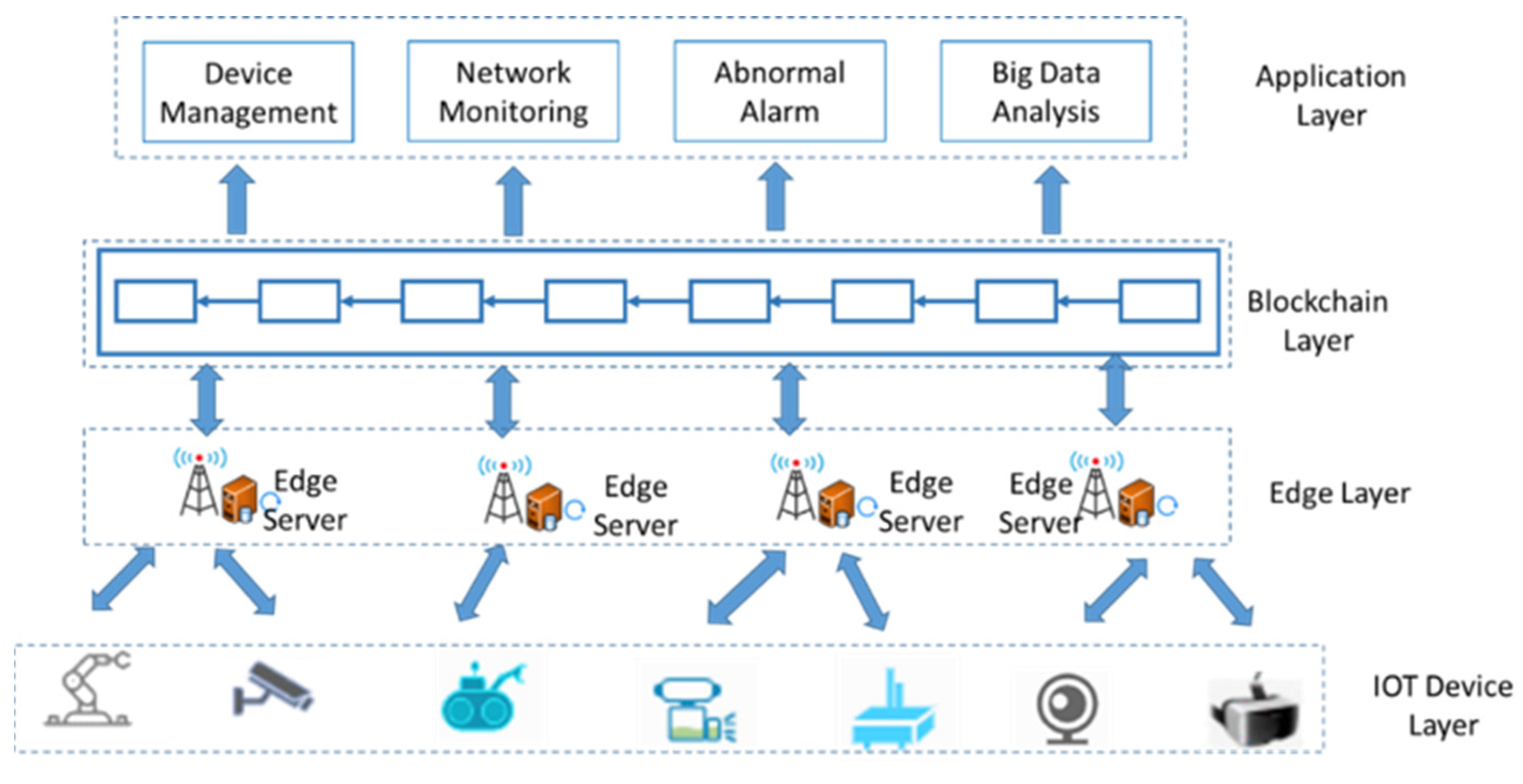
4.1. System Overview
- (1)
- IOT device layer
- (2)
- Edge computing layer
- (3)
- Blockchain layer
- (4)
- Application layer
4.2. Asynchronous Federated Learning Algorithm
| Algorithm 1: Blockchain-Based Asynchronous Federated Learning Algorithms. |
| Input: Initial network status and blockchain nodes. Initial global model θg and local models θl. The registering edge nodes as participating nodes EI = {e1, e2, …, eN}. The dataset di∈D. |
| Input: Select the participating edge nodes Ep ⊂ EI by running node selection algorithm. |
| 1: for episode∈{1,EP} do |
| 2: for s_episode∈{1,EPs} do |
| 3: sub-blockchain retrieves global model from main-blockchain |
| 4: for each edge node ei ∈EI do |
| 5: ei executes the local training on its local data di, according to Equations (1)–(3), encrypted gradient and proof of correctness, upload to sub-blockchain. |
| 6: According to Equations (3) and (4), the sub-blockchain node reviews the encrypted gradient and proof of correctness, performs local aggregation asynchronously, update local models, gives the encrypted gradient and proof of correctness, and after encryption, uploads it to the main-blockchain. |
| 7: According to Equation (5), the main-blockchain node reviews the encrypted gradient and global aggregation of model parameters. |
| 8: end for |
| 9: end for |
| 10: Repeat steps 2–6 until the model converges or reaches a predetermined number of training rounds. |
| 11: end for |
| 12: return The parameters of the final global model parameters. |
4.3. Node Selection Algorithm
| Algorithm 2: The Node Selection Algorithm Based on DDPO (BAFL-DPPO). |
| Input: Initial network status and task information. |
| Input: Initialization of network, equipment and task information and global network parameters. |
| 1: for episode∈{1,EP} do |
| 2: for s_episode∈{1,EPs} do |
| 3: . |
| 4: Calculate the reward rt according to Equation (6), select the next state st+1 according to Equation (8), and store the current state, action and reward as samples. |
| 5: Update current network and device status information. |
| 6: end for |
| 7: Each node uploads the collected data synchronously to the global network services. |
| 8: Update dominance function and actor1 network parameters θ. |
| 9: Back propagation update critic network parameters ϕ. |
| 10: if s_episode%circke == 0 do |
| 11: Update actor2 with the parameters in actor1 |
| 12: end if |
| 13: end for |
| 14: return Selected node list. |
5. Simulation Experiments
5.1. Experimental Configuration
5.2. Experimental Results
6. Conclusions
Author Contributions
Funding
Institutional Review Board Statement
Informed Consent Statement
Data Availability Statement
Conflicts of Interest
References
- Yang, Q.; Liu, Y.; Cheng, Y.; Kang, Y.; Chen, T.; Yu, H. Federated learning. Synth. Lect. Artif. Intell. Mach. Learn. 2019, 13, 1–207. [Google Scholar] [CrossRef]
- Wang, R.; Tsai, W.T.; He, J.; Liu, C.; Li, Q.; Deng, E. Logistics management system based on permissioned blockchains and RFID technology. Adv. Comput. Sci. Res. 2019, 88, 465. [Google Scholar]
- McMahan, B.; Moore, E.; Ramage, D.; Hampson, S.; y Arcas, B.A. Communication-efficient learning of deep networks from decentralized data. In Proceedings of the 20th International Conference on Artificial Intelligence and Statistics, Fort Lauderdale, FL, USA, 20–22 April 2017; pp. 1273–1282. [Google Scholar]
- Nakamoto, S. Bitcoin: A peer-to-peer electronic cash system. Decentralized Bus. Rev. 2008, 4, 21260. [Google Scholar]
- Wiering, M.A.; Van Otterlo, M. Reinforcement Learning. Adaptation, Learning, and Optimization; Springer: Berlin/Heidelberg, Germany, 2012; p. 12. [Google Scholar]
- Wang, H.; Kaplan, Z.; Niu, D.; Li, B. Optimizing federated learning on non-iid data with reinforcement learning. In Proceedings of the IEEE INFOCOM 2020-IEEE Conference on Computer Communications, Toronto, ON, Canada, 6–9 July 2020; pp. 1698–1707. [Google Scholar]
- Luping, W.A.N.G.; Wei, W.A.N.G.; Bo, L.I. CMFL: Mitigating communication overhead for federated learning. In Proceedings of the 2019 IEEE 39th International Conference on Distributed Computing Systems (ICDCS), Dallas, TX, USA, 7–10 July 2019; pp. 954–964. [Google Scholar]
- Wang, J.; Wei, Z.; Zhang, T.; Zeng, W. Deeply-fused nets. arXiv 2016, arXiv:1605.07716. [Google Scholar]
- Krizhevsky, A.; Sutskever, I.; Hinton, G.E. Imagenet classification with deep convolutional neural networks. Adv. Neural Inf. Process. Syst. 2012, 25, 1097–1105. [Google Scholar] [CrossRef]
- He, K.; Zhang, X.; Ren, S.; Sun, J. Deep residual learning for image recognition. In Proceedings of the IEEE Conference on Computer Vision and Pattern Recognition, Las Vegas, NV, USA, 26 June–1 July 2016; pp. 770–778. [Google Scholar]
- Chen, Z.; Cui, H.; Wu, E.; Yu, X. Dynamic Asynchronous Anti Poisoning Federated Deep Learning with Blockchain-Based Reputation-Aware Solutions. Sensors 2022, 22, 684. [Google Scholar] [CrossRef]
- Wang, Q.; Li, Q.; Wang, K.; Wang, H.; Zeng, P. Efficient federated learning for fault diagnosis in industrial cloud-edge computing. Computing 2021, 103, 2319–2337. [Google Scholar] [CrossRef]
- Li, M.; Chen, Y.; Wang, Y.; Pan, Y. Efficient asynchronous vertical federated learning via gradient prediction and double-end sparse compression. In Proceedings of the 2020 16th International Conference on Control, Automation, Robotics and Vision (ICARCV), Shenzhen, China, 13–15 December 2020; pp. 291–296. [Google Scholar]
- Chen, Z.; Liao, W.; Hua, K.; Lu, C.; Yu, W. Towards asynchronous federated learning for heterogeneous edge-powered internet of things. Digit. Commun. Netw. 2021, 7, 317–326. [Google Scholar] [CrossRef]
- Yang, H.; Zhao, J.; Xiong, Z.; Lam, K.Y.; Sun, S.; Xiao, L. Privacy-preserving federated learning for UAV-enabled networks: Learning-based joint scheduling and resource management. IEEE J. Sel. Areas Commun. 2021, 39, 3144–3159. [Google Scholar] [CrossRef]
- Zhang, H.; Bosch, J.; Olsson, H.H. Real-time end-to-end federated learning: An automotive case study. In Proceedings of the 2021 IEEE 45th Annual Computers, Software, and Applications Conference (COMPSAC), Madrid, Spain, 12–16 July 2021; pp. 459–468. [Google Scholar]
- Sun, W.; Lei, S.; Wang, L.; Liu, Z.; Zhang, Y. Adaptive federated learning and digital twin for industrial internet of things. IEEE Trans. Ind. Inform. 2020, 17, 5605–5614. [Google Scholar] [CrossRef]
- Xue, M.A.; Chenglin, W.E.N. An Asynchronous Quasi-Cloud/Edge/Client Collaborative Federated Learning Mechanism for Fault Diagnosis. Chin. J. Electron. 2021, 30, 969–977. [Google Scholar] [CrossRef]
- Chen, Y.; Ning, Y.; Slawski, M.; Rangwala, H. Asynchronous online federated learning for edge devices with non-iid data. In Proceedings of the 2020 IEEE International Conference on Big Data (Big Data), Atlanta, GA, USA, 10–13 December 2020; pp. 15–24. [Google Scholar]
- Lu, X.; Liao, Y.; Lio, P.; Hui, P. Privacy-preserving asynchronous federated learning mechanism for edge network computing. IEEE Access 2020, 8, 48970–48981. [Google Scholar] [CrossRef]
- Lu, Y.; Huang, X.; Dai, Y.; Maharjan, S.; Zhang, Y. Differentially private asynchronous federated learning for mobile edge computing in urban informatics. IEEE Trans. Ind. Inform. 2019, 16, 2134–2143. [Google Scholar] [CrossRef]
- Ma, Q.; Xu, Y.; Xu, H.; Jiang, Z.; Huang, L.; Huang, H. FedSA: A semi-asynchronous federated learning mechanism in heterogeneous edge computing. IEEE J. Sel. Areas Commun. 2021, 39, 3654–3672. [Google Scholar] [CrossRef]
- Liu, J.; Xu, H.; Xu, Y.; Ma, Z.; Wang, Z.; Qian, C.; Huang, H. Communication-efficient asynchronous federated learning in resource-constrained edge computing. Comput. Netw. 2021, 199, 108429. [Google Scholar] [CrossRef]
- Rizk, E.; Vlaski, S.; Sayed, A.H. Dynamic Federated Learning. In Proceedings of the 2020 IEEE 21st International Workshop on Signal Processing Advances in Wireless Communications (SPAWC), Atlanta, GA, USA, 26–29 May 2020; pp. 1–5. [Google Scholar] [CrossRef]
- Miao, Q.; Lin, H.; Wang, X.; Hassan, M.M. Federated deep reinforcement learning based secure data sharing for Internet of Things. Comput. Netw. 2021, 197, 108327. [Google Scholar] [CrossRef]
- Agrawal, S.; Chowdhuri, A.; Sarkar, S.; Selvanambi, R.; Gadekallu, T.R. Temporal Weighted Averaging for Asynchronous Federated Intrusion Detection Systems. Comput. Intell. Neurosci. 2021, 2021, 5844728. [Google Scholar] [CrossRef]
- Gao, Y.; Liu, L.; Zheng, X.; Zhang, C.; Ma, H. Federated sensing: Edge-cloud elastic collaborative learning for intelligent sensing. IEEE Internet Things J. 2021, 8, 11100–11111. [Google Scholar] [CrossRef]
- Wang, Z.; Zhang, Z.; Wang, J. Asynchronous Federated Learning over Wireless Communication Networks. In Proceedings of the ICC 2021-IEEE International Conference on Communications, Montreal, QC, Canada, 14–23 June 2021; pp. 1–7. [Google Scholar]
- Liu, K.H.; Hsu, Y.H.; Lin, W.N.; Liao, W. Fine-Grained Offloading for Multi-Access Edge Computing with Actor-Critic Federated Learning. In Proceedings of the 2021 IEEE Wireless Communications and Networking Conference (WCNC), Nanjing, China, 29 March–1 April 2021; pp. 1–6. [Google Scholar]
- Lu, Y.; Huang, X.; Dai, Y.; Maharjan, S.; Zhang, Y. Federated learning for data privacy preservation in vehicular cyber-physical systems. IEEE Netw. 2020, 34, 50–56. [Google Scholar] [CrossRef]
- Kang, J.; Xiong, Z.; Niyato, D.; Zou, Y.; Zhang, Y.; Guizani, M. Reliable federated learning for mobile networks. IEEE Wirel. Commun. 2020, 27, 72–80. [Google Scholar] [CrossRef] [Green Version]
- Qu, Y.; Gao, L.; Luan, T.H.; Xiang, Y.; Yu, S.; Li, B.; Zheng, G. Decentralized privacy using blockchain-enabled federated learning in fog computing. IEEE Internet Things J. 2020, 7, 5171–5183. [Google Scholar] [CrossRef]
- Qi, Y.; Hossain, M.S.; Nie, J.; Li, X. Privacy-preserving blockchain-based federated learning for traffic flow prediction. Future Gener. Comput. Syst. 2021, 117, 328–337. [Google Scholar] [CrossRef]
- Liu, Y.; Peng, J.; Kang, J.; Iliyasu, A.M.; Niyato, D.; Abd El-Latif, A.A. A secure federated learning framework for 5G networks. IEEE Wirel. Commun. 2020, 27, 24–31. [Google Scholar] [CrossRef]
- Kim, H.; Park, J.; Bennis, M.; Kim, S.L. Blockchained on-device federated learning. IEEE Commun. Lett. 2019, 24, 1279–1283. [Google Scholar] [CrossRef] [Green Version]
- Wang, Q.; Guo, Y.; Wang, X.; Ji, T.; Yu, L.; Li, P. AI at the edge: Blockchain-empowered secure multiparty learning with heterogeneous models. IEEE Internet Things J. 2020, 7, 9600–9610. [Google Scholar] [CrossRef]
- Lu, Y.; Huang, X.; Zhang, K.; Maharjan, S.; Zhang, Y. Blockchain empowered asynchronous federated learning for secure data sharing in internet of vehicles. IEEE Trans. Veh. Technol. 2020, 69, 4298–4311. [Google Scholar] [CrossRef]
- Kim, Y.J.; Hong, C.S. Blockchain-based node-aware dynamic weighting methods for improving federated learning performance. In Proceedings of the 2019 20th Asia-Pacific Network Operations and Management Symposium (APNOMS), Matsue, Japan, 18–20 September 2019; pp. 1–4. [Google Scholar]
- Liu, Y.; Qu, Y.; Xu, C.; Hao, Z.; Gu, B. Blockchain-enabled asynchronous federated learning in edge computing. Sensors 2021, 21, 3335. [Google Scholar] [CrossRef]
- Lu, Y.; Huang, X.; Zhang, K.; Maharjan, S.; Zhang, Y. Communication-efficient federated learning and permissioned blockchain for digital twin edge networks. IEEE Internet Things J. 2020, 8, 2276–2288. [Google Scholar] [CrossRef]
- Liang, H.; Zhang, Y.; Xiong, H. A Blockchain-based Model Sharing and Calculation Method for Urban Rail Intelligent Driving Systems. In Proceedings of the 2020 IEEE 23rd International Conference on Intelligent Transportation Systems (ITSC), Rhodes, Greece, 20–23 September 2020; pp. 1–5. [Google Scholar]
- Liu, W.; Zhang, Y.H.; Li, Y.F.; Zheng, D. A fine-grained medical data sharing scheme based on federated learning. Concurr. Comput. Pract. Exp. 2022, e6847. [Google Scholar] [CrossRef]
- Yin, M.; Malkhi, D.; Reiter, M.K.; Gueta, G.G.; Abraham, I. Hotstuff: Bft consensus with linearity and responsiveness. In Proceedings of the 2019 ACM Symposium on Principles of Distributed Computing, Toronto, ON, Canada, 29 July–2 August 2019; pp. 347–356. [Google Scholar]








Publisher’s Note: MDPI stays neutral with regard to jurisdictional claims in published maps and institutional affiliations. |
© 2022 by the authors. Licensee MDPI, Basel, Switzerland. This article is an open access article distributed under the terms and conditions of the Creative Commons Attribution (CC BY) license (https://creativecommons.org/licenses/by/4.0/).
Share and Cite
Wang, R.; Tsai, W.-T. Asynchronous Federated Learning System Based on Permissioned Blockchains. Sensors 2022, 22, 1672. https://doi.org/10.3390/s22041672
Wang R, Tsai W-T. Asynchronous Federated Learning System Based on Permissioned Blockchains. Sensors. 2022; 22(4):1672. https://doi.org/10.3390/s22041672
Chicago/Turabian StyleWang, Rong, and Wei-Tek Tsai. 2022. "Asynchronous Federated Learning System Based on Permissioned Blockchains" Sensors 22, no. 4: 1672. https://doi.org/10.3390/s22041672
APA StyleWang, R., & Tsai, W.-T. (2022). Asynchronous Federated Learning System Based on Permissioned Blockchains. Sensors, 22(4), 1672. https://doi.org/10.3390/s22041672