
AFD-StackGAN: Automatic Mask Generation Network for Face De-Occlusion Using StackGAN

Abstract
:1. Introduction
- The result heavily depends on the accuracy of detection of the occluded region (i.e., failing to detect an occluded region properly may cause generation of poor binary mask that severely affects de-occlusion task);
- It is not easy to recover complex semantics of the face under the occluded region detected due to significant variations in the occluded region (i.e., occluded objects/non-face items have vast structures, sizes, colors, shapes, types, and positions variations in the facial images);
- Training data, i.e., facial image pairs with and without mask object datasets, are sparse or non-existent.
- This work proposes a novel GAN-based inpainting method by employing an automatic mask generation network for face de-occlusion without human interaction. This work automatically eliminates challenging mask objects from the face and synthesizes the damaged area with fine details while holding the restored face’s appearance and structural consistency;
- This work attempts to alleviate the manual mask selection burden by creating a straightforward method that can intelligently and automatically generate the occluded region’s binary mask in facial images;
- One potential application of an automatic mask generation network could be a video where mask objects continuously conceal the face’s structural semantics;
- We experimentally show that the proposed model with an automatically generated mask is more effective than those with manually generated masks for removing mask objects and generating realistic semantics of face images.
2. Related Works
2.1. Object Detection Methods
2.2. Object Removal Methods
3. Our Approach
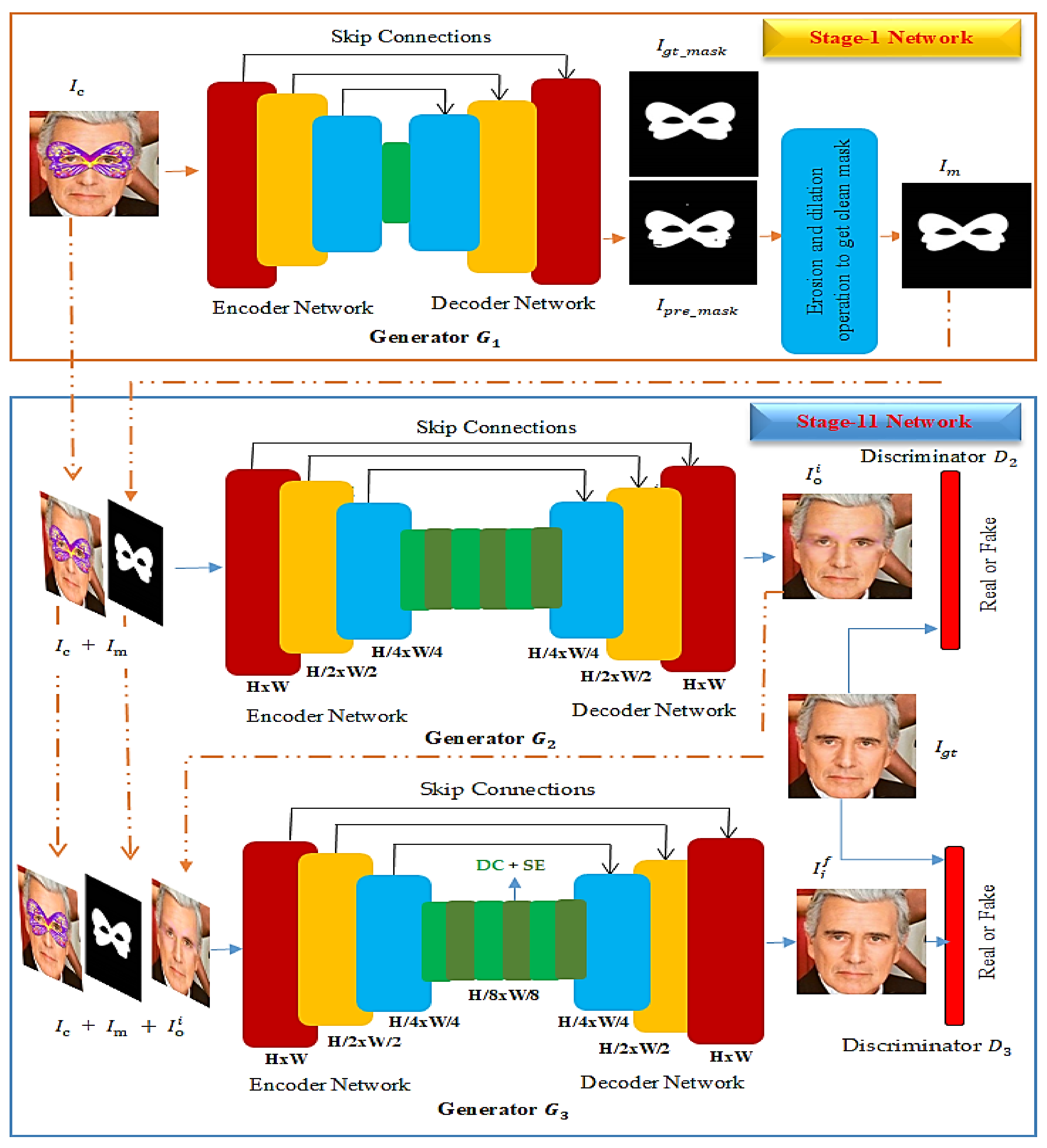
3.1. Stage-I Network: Binary Mask Generation Network
3.2. Stage-II Network: Face De-Occlusion Network
3.3. Total Loss Function
4. Experiments
4.1. Training and Implementation Details
4.2. Competing Methods
4.3. Datasets
4.3.1. Synthetic Generated Dataset
4.3.2. Real-World Generated Dataset
4.4. Performance Evaluation Metrics
5. Results and Comparisons
5.1. Results of Stage-I Network
5.2. Results of Stage-II Network
5.3. Qualitative Comparisons
- Hard Examples. Although the proposed AFD-StackGAN can handle the removal of occlusion masks of various shapes, sizes, colors, and structures, even on images not used to train the network, there are some examples, as shown in Figure 7, AFD-StackGAN fails to remove the occlusion masks altogether. Common failure cases occur when the Stage-I Network (Binary Mask Generation Network) cannot produce a good binary mask of the mask object, as shown in the first row of Figure 7, failing to detect them correctly. This happened when occlusion masks were different from those in our synthetic dataset in shape, position, and structure, as they mainly cover the regions around both eyes. As seen in the first row of Figure 7, the mask objects’ shapes, colors, positions, and structures are different from the mask types we used in our synthetic dataset. Moreover, the proposed model was trained using images from the CelebA dataset, and the CelebA data set images are roughly cropped and aligned, while the other dataset image (e.g., real-world images) are not processed in this manner, as shown in the first row of Figure 7. Our model cannot handle unaligned faces well and fails to generate missing regions of the images with unaligned faces. As expected, AFD-StackGAN produces worse results overall, as seen in the third row.
5.4. Quantitative Comparisons
5.5. Ablation Studies
5.5.1. Performance Comparison between Using User-Defined Mask and Auto-Defined Mask
5.5.2. Role of Refiner Networks
6. Conclusions
Author Contributions
Funding
Institutional Review Board Statement
Informed Consent Statement
Data Availability Statement
Conflicts of Interest
Abbreviations
| GAN | Generative Adversarial Network | |
| CNN | Convolutional Neural Network | |
| FCN | Fully Convolutional Network | |
| SE | Squeeze and Excitation block | |
| DC | Dilated Convolution | |
| TTUR | Two Time-scale Update Rules | |
| Notations | ||
| Occluded image | ||
| Ground truth image | ||
| Generated binary mask | ||
| Noise-free binary mask | ||
| Initially generated de-occluded facial image | ||
| Finally generated de-occluded facial image | ||
References
- Goodfellow, I.; Abadie, J.; Mirza, M.; Xu, B.; Warde-Farley, D.; Ozair, S.; Courville, A. Generative Adversarial Nets. Neural Inf. Process. Syst. 2014, 27, 2672–2680. [Google Scholar]
- Girshick, R.; Donahue, J.; Darrell, T.; Malik, J. Rich feature hierarchies for accurate object detection and semantic segmentation. In Proceedings of the IEEE Conference on Computer Vision and Pattern Recognition, Columbus, OH, USA, 28 June 2014; pp. 580–587. [Google Scholar]
- Girshick, R. Fast R-CNN. In Proceedings of the IEEE International Conference on Computer Vision (ICCV), Santiago, Chile, 7–13 December 2015; pp. 1440–1448. [Google Scholar]
- Ren, S.; He, K.; Girshick, R.; Sun, J. Faster R-CNN: Towards real-time object detection with region proposal networks. Adv. Neural Inf. Process. Syst. 2015, 28, 91–99. [Google Scholar] [CrossRef] [PubMed] [Green Version]
- He, K.; Gkioxari, G.; Dollár, P.; Girshick, R. Mask R-CNN. In Proceedings of the IEEE International Conference on Computer Vision, Venice, Italy, 22–29 October 2017; pp. 2961–2969. [Google Scholar]
- Krizhevsky, I.; Sutskever, G.; Hinton, E. AlexNet. Adv. Neural Inf. Process. Syst. 2012, 1, 1–9. [Google Scholar]
- Long, J.; Shelhamer, E.; Darrell, T. Fully convolutional networks for semantic segmentation. In Proceedings of the IEEE Conference on Computer Vision and Pattern Recognition, Boston, MA, USA, 7–12 June 2015; pp. 3431–3440. [Google Scholar]
- He, D.; Yang, X.; Liang, C.; Zhou, Z.; Ororbi, A.G.; Kifer, D.; Giles, C.L. Multi-scale with cascaded instance aware segmentation for arbitrary oriented word spotting in the wild. In Proceedings of the IEEE Conference on Computer Vision and Pattern Recognition, Honolulu, HI, USA, 21–26 July 2017; pp. 3519–3528. [Google Scholar]
- Badrinarayanan, V.; Kendall, A.; Cipolla, R. Segnet: A deep convolutional encoder-decoder architecture for image segmentation. IEEE Trans. Pattern Anal. Mach. Intell. 2017, 39, 2481–2495. [Google Scholar] [CrossRef] [PubMed]
- Chen, L.C.; Papandreou, G.; Kokkinos, l.; Murphy, K.; Yuille, A.L. Deeplab: Semantic image segmentation with deep convolutional nets, atrous convolution, and fully connected crfs. IEEE Trans. Pattern Anal. Mach. Intell. 2017, 40, 834–848. [Google Scholar] [CrossRef] [PubMed] [Green Version]
- Ronneberger, O.; Fischer, P.; Brox, T. U-net: Convolutional networks for biomedical image segmentation. In Lecture Notes in Computer Science; Springer: Cham, Germany, 2015; pp. 234–241. [Google Scholar]
- Ehsani, K.; Mottaghi, R.; Farhadi, A. Segan: Segmenting and generating the invisible. In Proceedings of the IEEE Conference on Computer Vision and Pattern Recognition, Salt Lake City, UT, USA, 18–23 June 2018; pp. 6144–6153. [Google Scholar]
- Li, J.; Liang, X.; Wei, Y.; Xu, T.; Feng, J.; Yan, S. Perceptual generative adversarial networks for small object detection. In Proceedings of the IEEE Conference on Computer Vision and Pattern Recognition, Honolulu, HI, USA, 21–26 July 2017; pp. 1222–1230. [Google Scholar]
- Bai, Y.; Zhang, Y.; Ding, M.; Ghanem, B. Sod-mtgan: Small object detection via a multi-task generative adversarial network. In Proceedings of the European Conference on Computer Vision, Munich, Germany, 8–14 September 2018; pp. 206–221. [Google Scholar]
- Prakash, C.D.; Karam, L.J. It gan do better: Gan based detection of objects on images with varying quality. arXiv 2019, arXiv:1912.01707. [Google Scholar] [CrossRef] [PubMed]
- Criminisi, A.; Perez, P.; Toyama, K. Region filling and object removal by exemplar-based image inpainting. IEEE Trans. Image Process. 2004, 13, 1200–1212. [Google Scholar] [CrossRef] [PubMed]
- Wang, J.; Lu, K.; Pan, D.; He, N.; Bao, B.-K. Robust object removal with an exemplar-based image inpainting approach. Neurocomputing 2014, 123, 150–155. [Google Scholar] [CrossRef]
- Hays, J.; Efros, A.A. Scene completion using millions of photographs. ACM Trans. Graph. 2007, 26, 4. [Google Scholar] [CrossRef]
- Park, J.-S.; Oh, Y.H.; Ahn, S.C.; Lee, S.-W. Glasses removal from facial image using recursive error compensation. IEEE Trans. Pattern Anal. Mach. Intell. 2005, 27, 805–811. [Google Scholar] [CrossRef] [PubMed]
- Li, Y.; Liu, S.; Yang, J.; Yang, M.H. Generative face completion. In Proceedings of the IEEE Conference on Computer Vision and Pattern Recognition, Honolulu, HI, USA, 21–26 July 2017; pp. 5892–5900. [Google Scholar]
- Iizuka, S.; Simo-serra, E.; Ishikawa, H. Globally and Locally Consistent Image Completion. ACM Trans. Graph. 2017, 36, 1–14. [Google Scholar] [CrossRef]
- Yeh, R.A.; Chen, C.; Lim, T.Y.; Schwing, A.G.; Hasegawa-Johnson, M.; Do, M.N. Semantic image inpainting with deep generative models. In Proceedings of the 30th IEEE Conference on Computer Vision and Pattern Recognition, Honolulu, HI, USA, 21–26 July 2017; pp. 6882–6890. [Google Scholar]
- Mirza, M.; Osindero, S. Conditional generative adversarial nets. arXiv 2014, arXiv:1411.1784. [Google Scholar]
- Liao, H.; Funka-Lea, G.; Zheng, Y.; Luo, J.; Zhou, S.K. Face Completion with Semantic Knowledge and Collaborative Adversarial Learning. In Lecture Notes in Computer Science; Springer: Cham, Germany, 2019; pp. 382–397. [Google Scholar]
- Yu, J.; Lin, Z.; Yang, J.; Shen, X.; Lu, X.; Huang, T.S. Generative image inpainting with contextual attention. In Proceedings of the IEEE Conference on Computer Vision and Pattern Recognition, Salt Lake City, UT, USA, 18–22 June 2018. [Google Scholar]
- Song, L.; Cao, J.; Song, L.; Hu, Y.; He, R. Geometry-aware face completion and editing. In Proceedings of the 33rd AAAI Conference on Artificial Intelligence, Honolulu, HI, USA, 27 January–1 February 2019; pp. 2506–2513. [Google Scholar]
- Nazeri, K.; Ng, E.; Joseph, T.; Qureshi, F.; Ebrahimi, M. EdgeConnect: Generative Image Inpainting with Adversarial Edge Learning. arXiv 2019, arXiv:1901.00212. [Google Scholar]
- Din, N.U.; Javed, K.; Bae, S.; Yi, J. A novel GAN-based network for the unmasking of masked face. IEEE Access 2020, 8, 44276–44287. [Google Scholar] [CrossRef]
- Khan, K.; Din, N.U.; Bae, S.; Yi, J. Interactive removal of microphone object in facial images. Electronics 2019, 8, 1115. [Google Scholar] [CrossRef] [Green Version]
- Chen, L.-C.; Papandreou, G.; Schroff, F.; Adam, H. Rethinking Atrous Convolution for Semantic Image Segmentation. arXiv 2017, arXiv:1706.05587. [Google Scholar]
- Hu, J.; Shen, L.; Sun, G. Squeeze-and-Excitation Networks. In Proceedings of the IEEE Conference on Computer Vision and Pattern Recognition, Salt Lake City, UT, USA, 18–23 June 2018; pp. 7132–7141. [Google Scholar]
- Isola, P.; Efros, A.A.; Ai, B.; Berkeley, U.C. Image-to-Image Translation with Conditional Adversarial Networks. In Proceedings of the IEEE Conference on Computer Vision and Pattern Recognition, Honolulu, HI, USA, 21–26 June 2017; pp. 5967–5976. [Google Scholar]
- Wang, Z.; Bovik, A.C.; Sheikh, H.R.; Simoncelli, E.P. Image quality assessment: From error visibility to structural similarity. IEEE Trans. Image Process. 2004, 13, 600–612. [Google Scholar] [CrossRef] [PubMed] [Green Version]
- Simonyan, K.; Zisserman, A. Very deep convolutional networks for large-scale image recognition. In Proceedings of the International Conference on Learning Representations, San Diego, CA, USA, 7–9 May 2015; pp. 1–14. [Google Scholar]
- Russakovsky, O.; Deng, J.; Su, H.; Krause, J.; Satheesh, S.; Ma, S.; Huang, Z.; Karpathy, A.; Khosla, A.; Bernstein, M.; et al. Imagenet large scale visual recognition challenge. Int. J. Comput. Vis. 2015, 115, 211–252. [Google Scholar] [CrossRef] [Green Version]
- Abadi, M.; Barham, P.; Chen, J.; Chen, Z.; Davis, A.; Dean, J.; Devin, M.; Ghemawat, S.; Irving, G.; Isard, M.; et al. TensorFlow: A system for large-scale machine learning. In Proceedings of the OSDI: Operating System Design and Implementation, Savannah, GA, USA, 2–4 November 2016; pp. 265–283. [Google Scholar]
- Kingma, D.; Ba, J. Adam: A method for stochastic optimization. arXiv 2014, arXiv:1412.6980. [Google Scholar]
- Heusel, M.; Ramsauer, H.; Unterthiner, T.; Nessler, B.; Hochreiter, S. GAN Trained by a Two Time Scale Update Rule Converge to Local Nash Equilibrium. Adv. Neural Inf. Process. Syst. 2017, 6629–6640. [Google Scholar]
- Liu, Z.; Luo, P.; Wang, X.; Tang, X. Deep learning face attributes in the wild. In Proceedings of the IEEE International Conference on Computer Vision, Santiago, Chile, 7–13 December 2015; pp. 3730–3738. [Google Scholar]
- Mittal, A.; Moorthy, A.K.; Bovik, A.C. No-Reference Image Quality Assessment in the Spatial Domain. In Proceedings of the IEEE Transactions on Image Processing, Austin, TX, USA, 21 December 2012; pp. 4695–4708. [Google Scholar]
- Mittal, A.; Moorthy, A.K.; Bovik, A.C. Blind/Referenceless Image Spatial Quality Evaluator. In Proceedings of the 45th Asilomar Conference on Signals, Systems and Computers (ASILOMAR), Pacific Grove, CA, USA, 6–9 November 2011; pp. 723–727. [Google Scholar]









{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
| Synthetic Generated Dataset | Feature Description |
|---|---|
| Total Number of Samples | 20,000 |
| Number of Training Samples | 18,000 |
| Number of Testing Samples | 2000 |
| No. of Classes | 50 |
| Samples Per Class | 400 |
| Number of Training Samples | 18,000 |
| Methods | SSIM ↑ | PSNR ↑ | MSE ↓ | NIQE ↓ | BRISQUE ↓ |
|---|---|---|---|---|---|
| Iizuka et al. [21] | 0.763 | 21.953 | 2329.062 | 4.754 | 34.106 |
| Yu et al. [25] | 0.797 | 15.469 | 2316.839 | 4.951 | 32.761 |
| Nazeri et. [27] | 0.561 | 15.848 | 2450.889 | 16.991 | 36.426 |
| Din et al. [28] | 0.850 | 16.209 | 2223. 938 | 5.721 | 31.016 |
| AFD-StackGAN | 0.978 | 33.201 | 32.435 | 4.902 | 39.872 |
| Methods | SSIM ↑ | PSNR ↑ | MSE ↓ | NIQE ↓ | BRISQUE ↓ |
|---|---|---|---|---|---|
| User-Defined Mask | 0.981 | 32.803 | 34.145 | 4.499 | 42.504 |
| Auto-Defined Mask | 0.978 | 33.201 | 32.435 | 4.902 | 39.872 |
Publisher’s Note: MDPI stays neutral with regard to jurisdictional claims in published maps and institutional affiliations. |
© 2022 by the authors. Licensee MDPI, Basel, Switzerland. This article is an open access article distributed under the terms and conditions of the Creative Commons Attribution (CC BY) license (https://creativecommons.org/licenses/by/4.0/).
Share and Cite
Jabbar, A.; Li, X.; Assam, M.; Khan, J.A.; Obayya, M.; Alkhonaini, M.A.; Al-Wesabi, F.N.; Assad, M. AFD-StackGAN: Automatic Mask Generation Network for Face De-Occlusion Using StackGAN. Sensors 2022, 22, 1747. https://doi.org/10.3390/s22051747
Jabbar A, Li X, Assam M, Khan JA, Obayya M, Alkhonaini MA, Al-Wesabi FN, Assad M. AFD-StackGAN: Automatic Mask Generation Network for Face De-Occlusion Using StackGAN. Sensors. 2022; 22(5):1747. https://doi.org/10.3390/s22051747
Chicago/Turabian StyleJabbar, Abdul, Xi Li, Muhammad Assam, Javed Ali Khan, Marwa Obayya, Mimouna Abdullah Alkhonaini, Fahd N. Al-Wesabi, and Muhammad Assad. 2022. "AFD-StackGAN: Automatic Mask Generation Network for Face De-Occlusion Using StackGAN" Sensors 22, no. 5: 1747. https://doi.org/10.3390/s22051747
APA StyleJabbar, A., Li, X., Assam, M., Khan, J. A., Obayya, M., Alkhonaini, M. A., Al-Wesabi, F. N., & Assad, M. (2022). AFD-StackGAN: Automatic Mask Generation Network for Face De-Occlusion Using StackGAN. Sensors, 22(5), 1747. https://doi.org/10.3390/s22051747