The action intention of the upper limb includes what action the upper limb performs and how the upper limb performs the action. The purpose of this paper is to render the manipulator able of completing foot movements as flexibly and accurately as the human hand. Therefore, the research content of this paper is divided into two parts: (1) apply the DTW algorithm based on motor unit to predict the action type of the upper limb; (2) use the GRNN algorithm to identify the grasping action intention of the upper limb to control the manipulator grabbing objects.
3.1. DTW Algorithm Based on Motion Units
The foot movements studied in this paper include putting on socks, putting on shoes, and tying shoelaces. Different action types are comprised of different action steps. Therefore, distinguishing the types of foot movements is the key to identifying upper limb movement intentions. There are two difficulties in this research:
(1) It is necessary to predict the type of action during the movement of the upper limb. In the process of controlling the manipulator, the action of the manipulator has high real-time requirements. Therefore, the upper limb action intention studied in this paper is different from the previous action recognition. Action recognition is a “posteriori judgment”, that is, after the action is completed, the action type is identified. However, the intention recognition studied in this paper belongs to a “priori judgment”, that is, in the process of action, the type of action is identified to predict the intention of the upper limb. Solving the problem of action type prediction represents one of the research difficulties.
(2) It is necessary to predict the action intention of the upper limb based on less data sets. As mentioned above, in the movement process of the upper limb, the earlier the action intention of the upper limb is predicted, the better the effect of the recognition method is. The capacity of the dataset greatly affects the performance of the learning algorithm. Therefore, in the case of a small dataset, improving the accuracy of recognizing action intent presents another difficulty in research.
There have been many machine learning algorithms successfully applied in the field of action recognition. The performance of machine learning algorithms largely depends on a large number of datasets, and the computational cost is high. Moreover, most machine learning algorithms identify the type of upper limb movement after the movement is completed. After comparing many action recognition methods, this paper selects the DTW algorithm to predict the action types of the upper limb.
The DTW algorithm is a method employed to calculate the difference between two time series. When the lengths of the two time series are different, the DTW algorithm can also obtain the optimal value by adjusting the relationship between the corresponding elements at different time points of the time series. As a result, it bears a wide range of applications in the field of action recognition. Guoquan Li et al. [
26] used the DTW algorithm to identify the motion patterns of smart terminals, which improved the positioning accuracy of the pedestrian dead reckoning system. Xu Leiyang et al. [
27] implemented a dynamic time warping algorithm to calculate the minimum distance between two node trajectories, and realized the classification of Taijiquan actions.
The essential function of the DTW algorithm is to calculate a set of actions with the smallest error by comparing the current motion data with the motion data of all standard actions in the template library. The Euclidean distance is usually calculated to measure the similarity between motion data and template data. The basic idea of DTW algorithm is as follows:
Given a reference template represented as
where
M represents the total number of eigenvalues contained in the reference template, and
is the mth eigenvalue.
The test template is represented as
where
N represents the total number of eigenvalues contained in the test template, and
is the
n-th eigenvalue.
The calculation formula of the distortion degree between the motion data and the template data is:
Finally, the overall distortion D[T,R] is used to judge the similarity between the motion data and the template data. Since the total number of eigenvalues in the reference template is not necessarily equal to the total number of eigenvalues in the test template, there are two cases when calculating the overall distortion degree D[T,R]:
(1)
N =
M, the total number of eigenvalues in the reference template is equal to the total number of eigenvalues in the test template. Calculate the distortion of
n =
m = 1,⋯,
n =
m =
N in turn and take the sum, that is
(2) N ≠ M, that is, the total number of eigenvalues of the two is not equal. The smaller patterns are mapped onto the larger pattern sequence by some expansion method. Then, the distortion between the new corresponding eigenvalues is calculated separately, so as to obtain the total distortion D[T, R].
However, by analyzing the experimental data, at least 15 s was required to finish a complete action. Since the sampling frequency of the device is 50 Hz, at least 800 sampling points will be obtained during the process of collecting data. In the course of using the DTW algorithm, problems arise if the complete sample points are compared to all reference templates. With the accumulation of time, the number of sampling points will gradually increase, and the algorithm will consume more time. However, the control of the manipulator bears the requirement of low latency, and the processing process of large amount of data clearly cannot meet the control requirements of the manipulator. Based on the above analysis, this paper proposes a DTW algorithm based on motion unit.
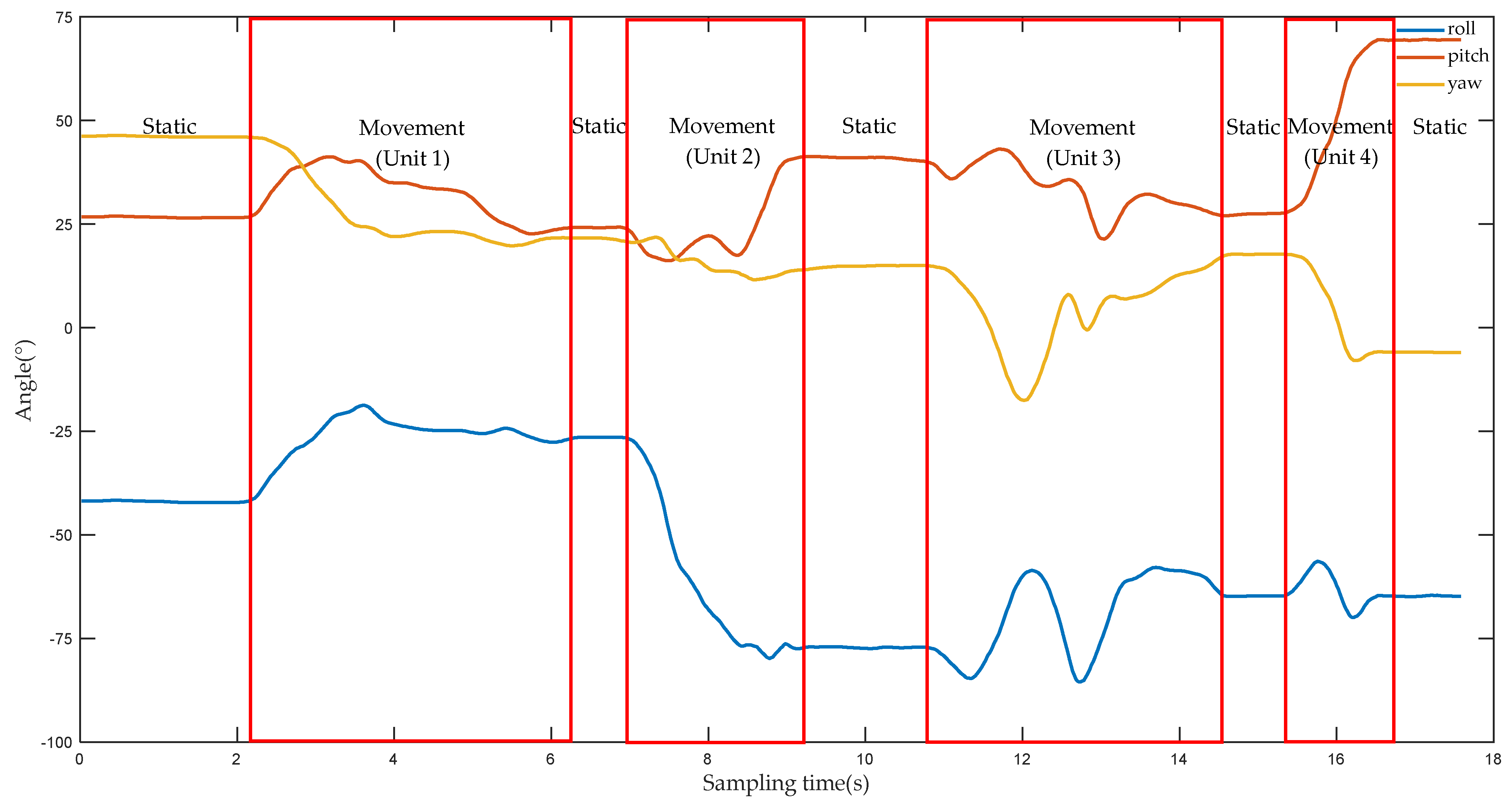
Figure 5 shows the angle change values of the three axes of the hand as the upper limb performs the action of putting on socks. When the amplitude of the angle values of several consecutive sampling points no longer changes, it means that the upper limb is in a static state, such as in the range of the sampling time (0–2 s). When the fluctuation range of the angle values of several consecutive sampling points varies greatly, it indicates that the upper limb are in an movement state, such as within the range of the sampling time (4–6 s). Therefore, the static state of the upper limb is defined as the “static segment”, and the movement state of the upper limb is defined as the “movement segment”. The two states are determined as follows:
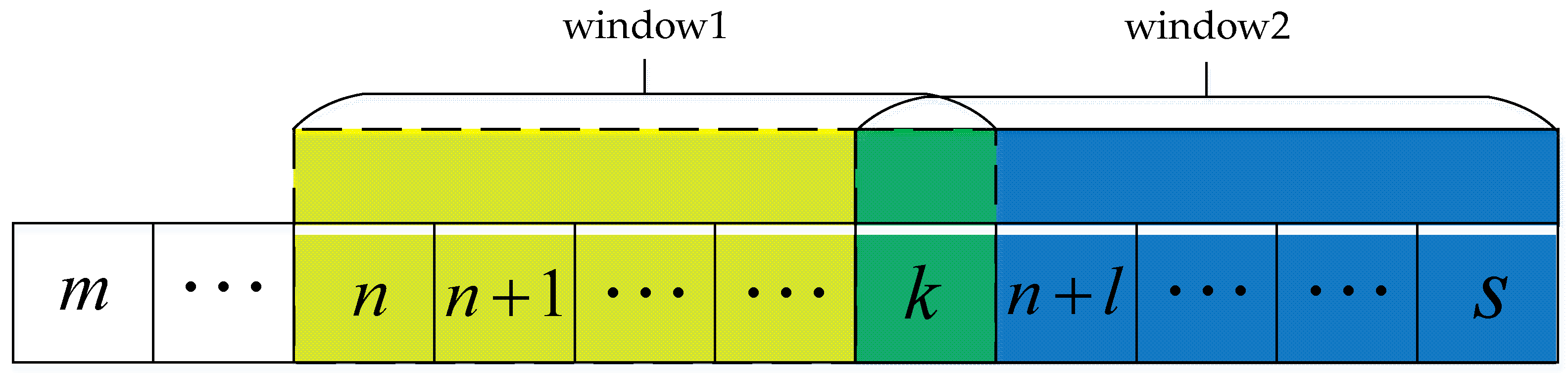
(1) In the sliding window, first calculate the difference between all two adjacent sampling points, and calculate the absolute value. Then, compare all the absolute values to identify the one with the largest value;
(2) If for the three parts of the upper limb, the maximum values of the three axial directions are all less than 0.3°, then the motion state of the upper limb is static at this time, and the window is the static segment;
(3) For the three parts of the upper limb, if the maximum value of the three axial directions exceeds 1°, then the motion state of the upper limb at this time is motion, and the window is the movement segment.
A complete action can be composed of several static segments and movement segments. For example, the action of putting on socks in
Figure 6 includes five static segments and four movement segments. The movement segment of the upper limb is called a motion unit, and then a complete action can be divided into several motion units. The length of a motion unit depends on the duration of the action. In
Figure 5, a movement segment includes at least 50 sampling points, which is equivalent to 1 s. The duration of the movement segment is relatively small relative to the duration of the full action. If only movement segments are identified, the time consumed by the algorithm will be greatly reduced. Therefore, when using the DTW to identify the type of action of the upper limb, the object of analysis is the motion unit, not the time series.
Considering the real-time requirement of controlling the manipulator, this study only selects the first motion unit and the second motion unit of a complete action for analysis.
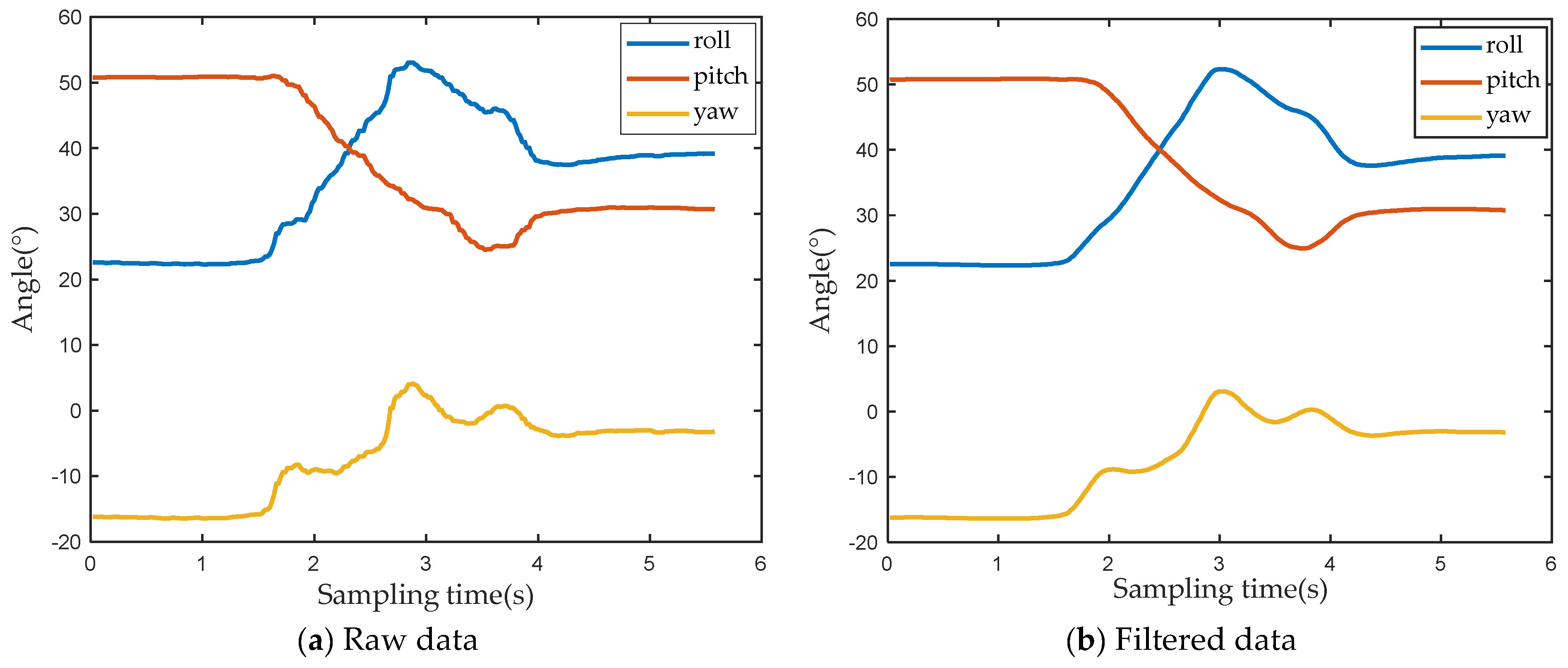
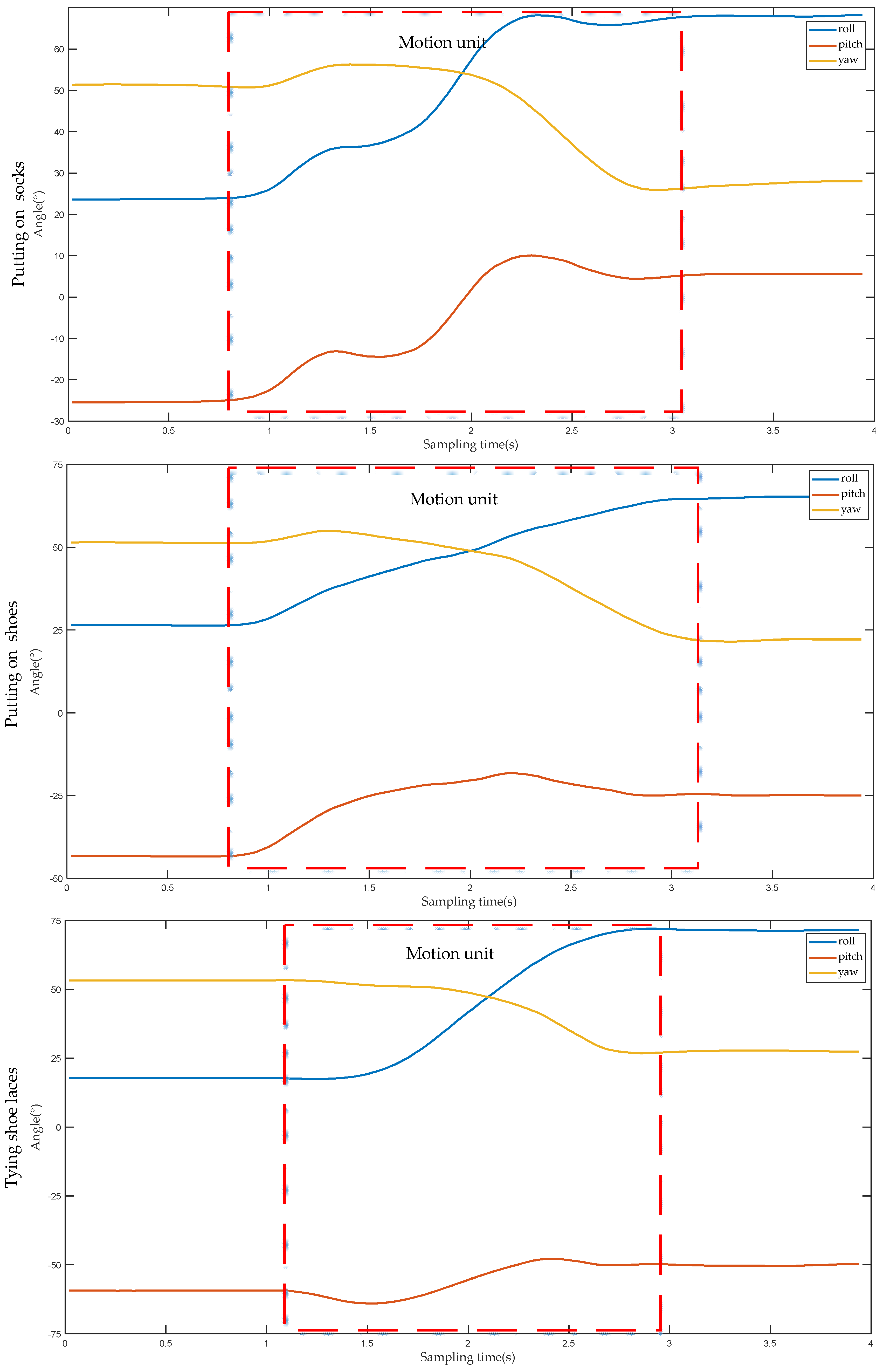
Figure 6 illustrates the angle change curve of the first motion unit when the lower performs three different actions. Whether putting on socks, putting on shoes, or tying shoelaces, the action represented by the first motion unit refers to the movement of the upper limb from the initial position to the vicinity of socks, shoes or shoelaces. Among them, the initial positions of the upper limbs are all at the waist; and the socks, shoes and shoelaces are all located at the same position, indicating that the initial and destination positions of the upper limb are the same. During the process from the initial position to the target position, the direction of the angle change of the lower is also the same for the three different actions. Therefore, the angle values of each part of the upper limb before and after the first motion unit are recorded, respectively, and then the difference between the two can be used to obtain the angle change value of each part of the upper limb when this motion unit is performed, as shown in
Table 1. It can be observed from
Table 1, that for the same part, although the action type is different, the positive and negative angle values in three directions are the same, that is, the angle values in all directions change in the same direction, and the difference in angle values is caused solely by the amplitude of upper limb movement. Combined with the data in
Table 1, it is shown that for different action types, all parts of the upper limb move in the same direction when carrying out the first motion unit. Therefore, the type of action of the upper limb cannot be distinguished effectively by the first motion unit alone.
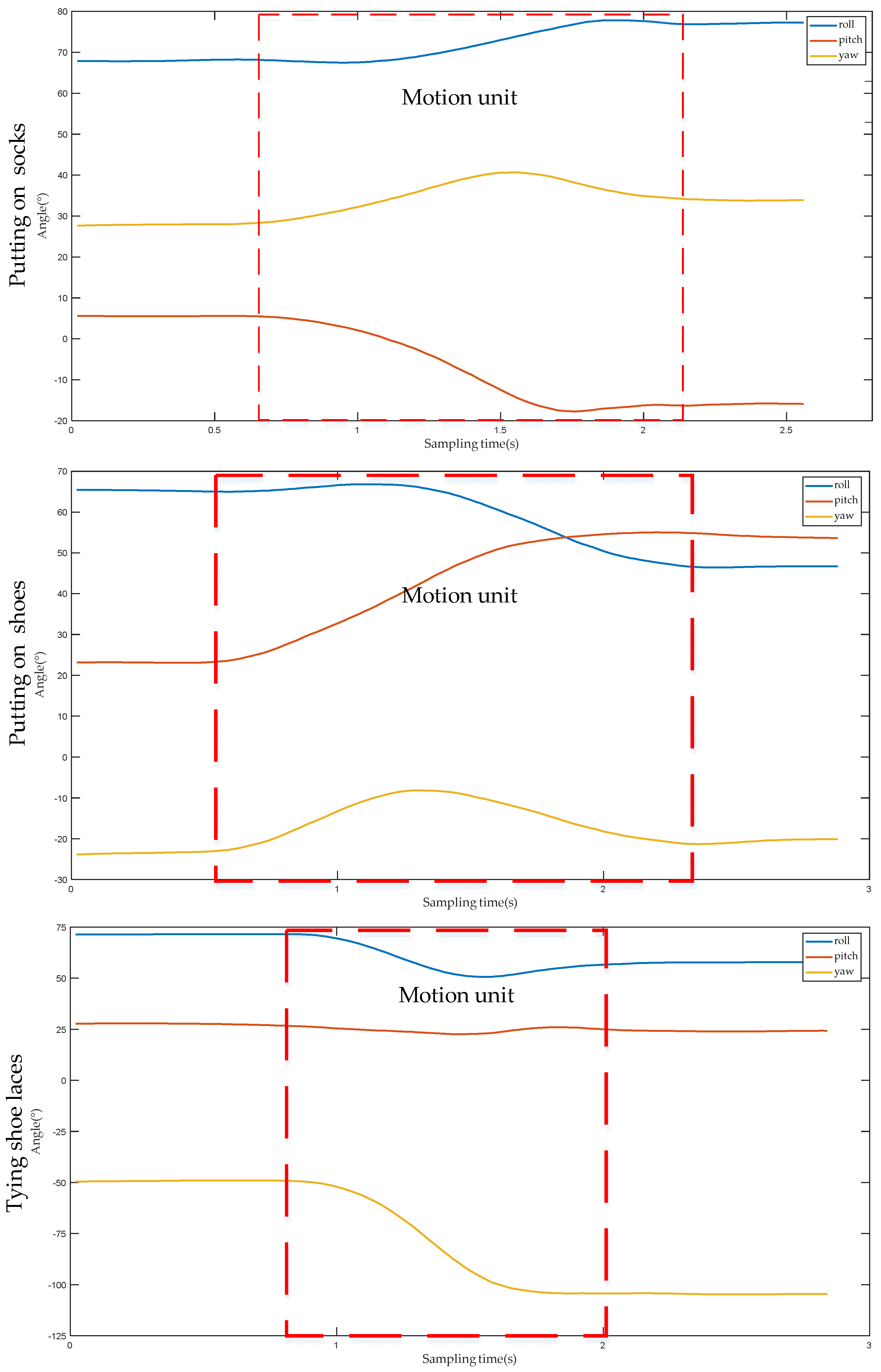
Figure 7 shows the angle change curve of the second motion unit when the lower arm performs three different actions. Although the initial positions of putting on socks, putting on shoes and tying shoelaces are the same, due to the different target positions of each action, the angle changes of each part of the upper limb are also different. For example, for the hand, the angle value of the yaw angle changes greatly when putting on socks, the angle value of the pitch angle changes greatly when putting on shoes, and the angle value of the roll angle changes greatly when tying shoelaces.
Table 2 displays the angle change values of each part of the upper limb after performing the second motion unit under three different action types. It can be seen from
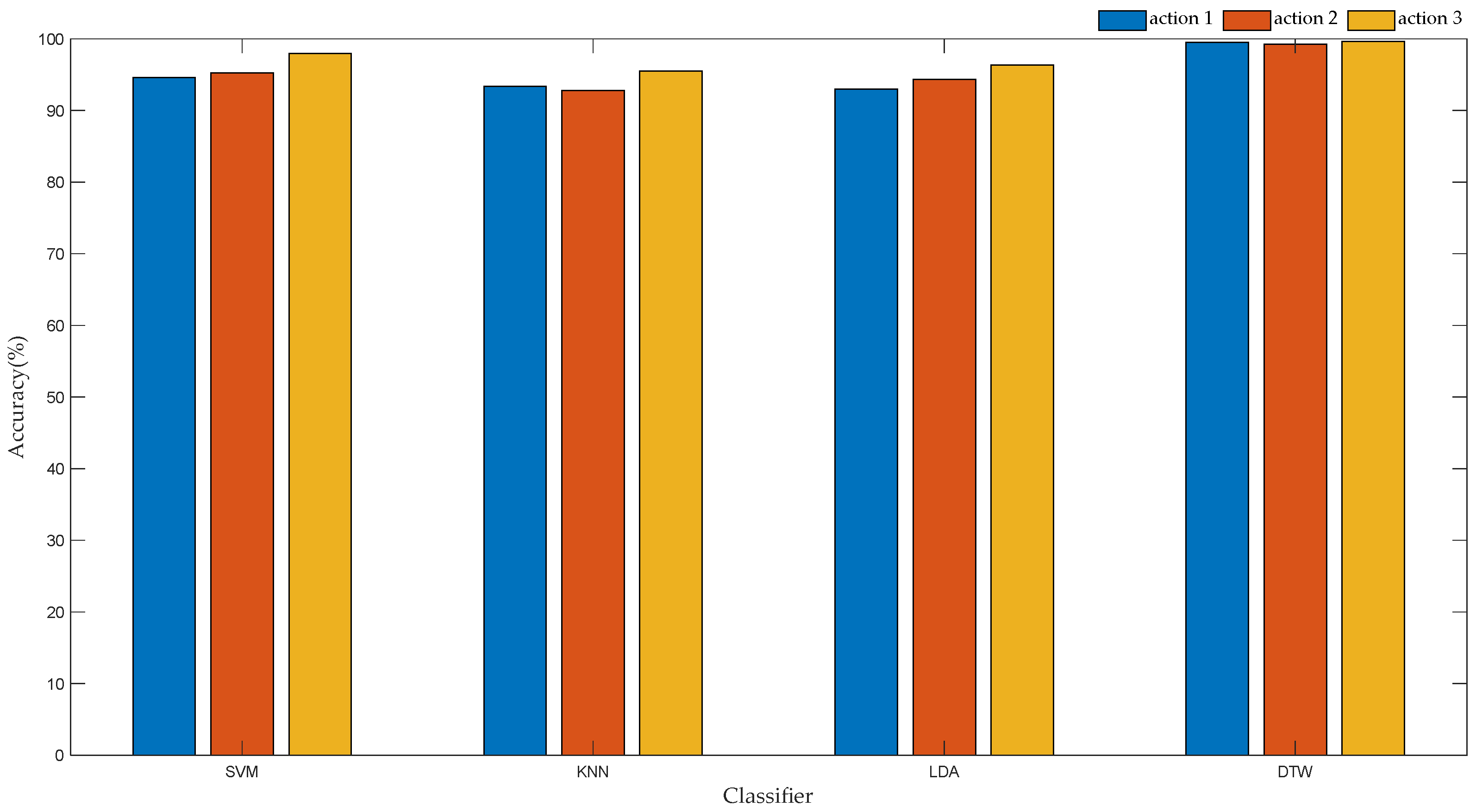
Table 2 that for different actions, the change range and direction of the angle value of each part of the upper limb are different. Therefore, according to the first motion unit and the second motion unit, the DTW algorithm can be used to distinguish the action types of the upper limb.
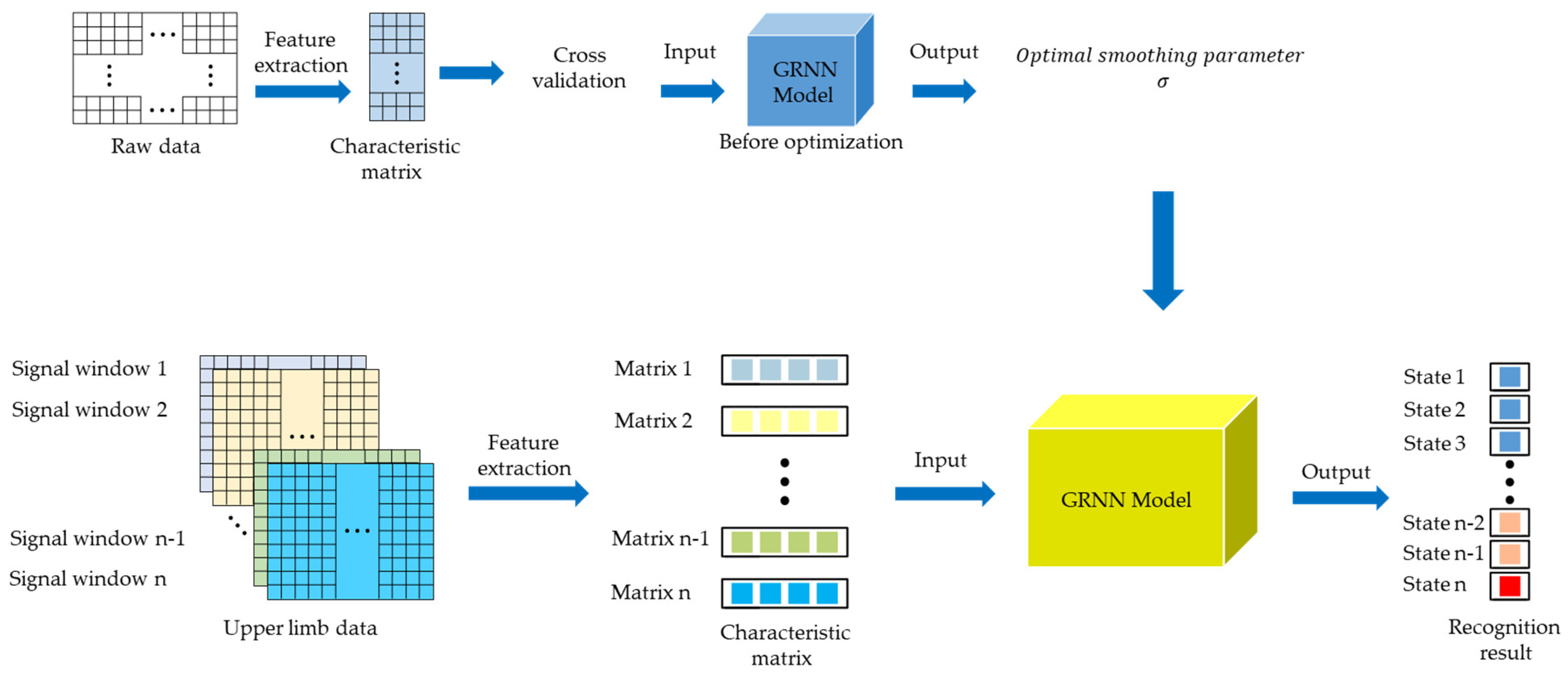
The recognition model of the DTW algorithm based on the motion unit is shown in
Figure 8. First, the movement data of each part of the upper limb is collected, and the angle data is processed by moving average filtering and data segmentation. Then, the angle change values before and after the first motion unit and the angle change values before and after the second motion unit are recorded to construct a feature vector. Secondly, the DTW algorithm is used to calculate the similarity between the feature vector and the standard vector of the template library, and the smallest similarity value represents the action type of the current upper limb. For three different action types, 350 datasets under each action type are taken, and the angle change values from the first motion unit to the second motion unit are calculated separately. For the angle change value of the same motion unit, 350 data are summed first, and then the average value is calculated. The obtained data is the standard data of each action type, and the standard vector of the template library is shown in
Table 3.
3.2. GRNN Algorithm Based on 10-Fold Cross Validation
Predicting the action types of the upper limb is mainly used for manipulator control. The key to controlling the manipulator is to accurately judge the user’s grasping intention, and to control the manipulator’s fingers to open or close in time. Generally speaking, the grasping action of the human hand generally occurs after the upper limb is static. Grasping and releasing objects are essentially controlling finger movements, and the control methods are the same. Thus, the action rules of grasping objects are also applicable to the actions of releasing objects. Based on these understandings, we analyze the movement rules of human grasping objects based on the changes in the movement state of the upper limb. Whether putting on socks, putting on shoes, or tying shoelaces, the essence of these actions is grabbing or releasing objects. A complete action can be divided into several grasping actions. Analyzing the action law of a single grasping action is helpful to design the control method of the manipulator.
Figure 9 shows the change curve of the comprehensive value of the angular velocity of the hand during the grasping process of the human hand. In
Figure 9, the first segment is defined as a “static segment”. This segment is the stage in which the upper limb is in a static state before the grasping action. At this time, the comprehensive value of the angular velocity of the hand bears only a small fluctuation around a 0 value. The second and third sections are defined as the “acceleration section” and “deceleration section”. Both the acceleration segment and the deceleration segment represent the stage when the upper limb moves toward the object. The comprehensive value of the angular velocity of the hand first increases and then decreases, with a clear process of first accelerating and then decelerating. The fourth segment is defined as the “grab segment”. This segment represents the phase in which the fingers are closed to grasp the object when the upper limb is static. Due to the movement of the fingers, the integrated value of the angular velocity of the hand fluctuates, but when the fingers are closed, the integrated value of the angular velocity of the hand remains only around 0.
In the above analysis of the comprehensive value of the hand angular velocity during finger grasping, it can be observed that the motion state of the upper limb includes static, acceleration and deceleration, and the grasping action generally occurs in the static state following the deceleration state. According to the fundamental principles of kinematics, it can be concluded that the acceleration state of an object appears only after the static state, and the deceleration state only appears following the acceleration state. Therefore, the control method of the manipulator is designed as follows: the motion process of the upper limb is divided into static, acceleration, and deceleration. In a set of motion data, when the upper limb is detected as reaching a static state following the deceleration state, the manipulator is programmed to open or close. It needs to be clarified that at this time, the upper limb has already experienced the acceleration state by default.
This study employs a GRNN to identify the motion states of the upper limb. GRNN is a general non-parametric regression model that approximates the objective function by activating neurons, and bears stronger advantages than RBF in local approximation, global optimization and classification performance [
28]. The GRNN converges on the optimized regression surface with a large number of data samples. When the number of samples is small or the sample data is unstable, the regression prediction results are extremely clear. In a GRNN model, the smoothing parameter is the only parameter that can be implemented to optimize the network model. The selection of smoothing parameters includes two methods, one is to use manual adjustment, which is simple and easy to operate, but exhibits low efficiency and poor accuracy; the other is to use an algorithm to obtain the optimal value [
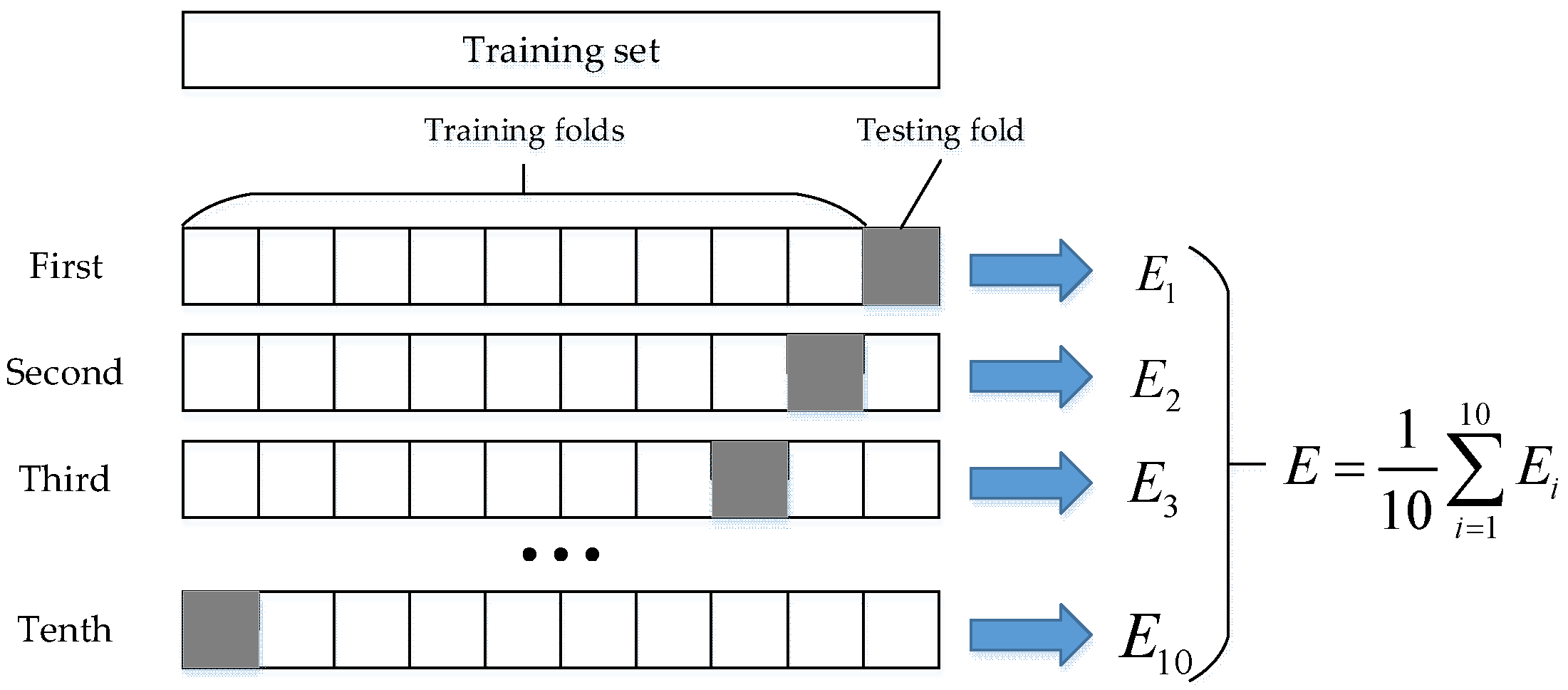
29]. In this study, the 10-fold cross-validation method was used to select the optimal smoothing parameters of the GRNN according to the minimum mean square error.
In summary, this paper proposes a GRNN algorithm model based on a 10-fold cross-validation to identify the motion states of the upper limb, as shown in
Figure 10. The algorithm is divided into the following two processes: (1) The experimental data is divided into training set and test set, and the optimal smoothing parameters of GRNN are selected by 10-fold cross-validation method. (2) According to the collected angular velocity data of each part of the upper limb, the optimized GRNN is used to identify the motion state of the upper limb.
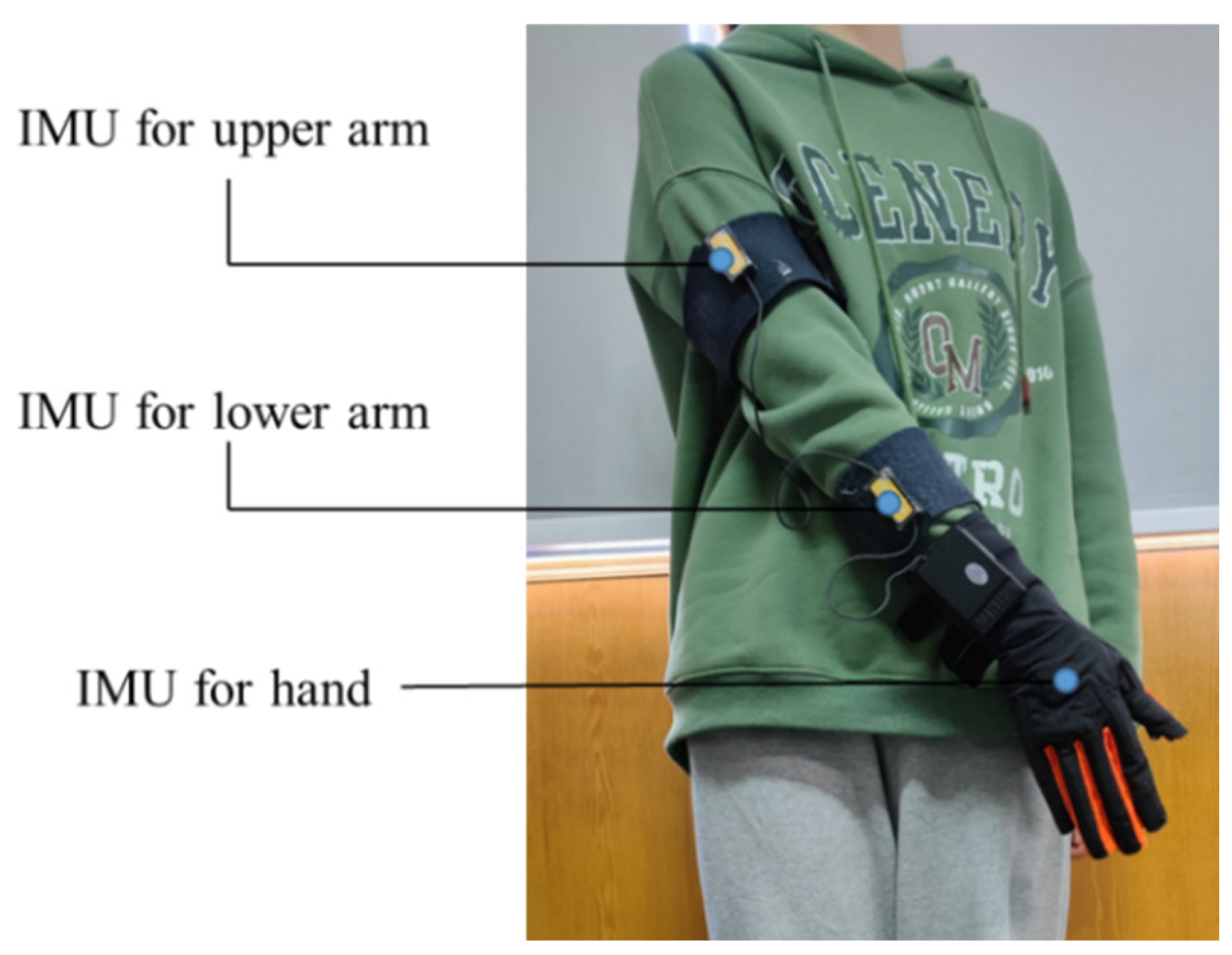
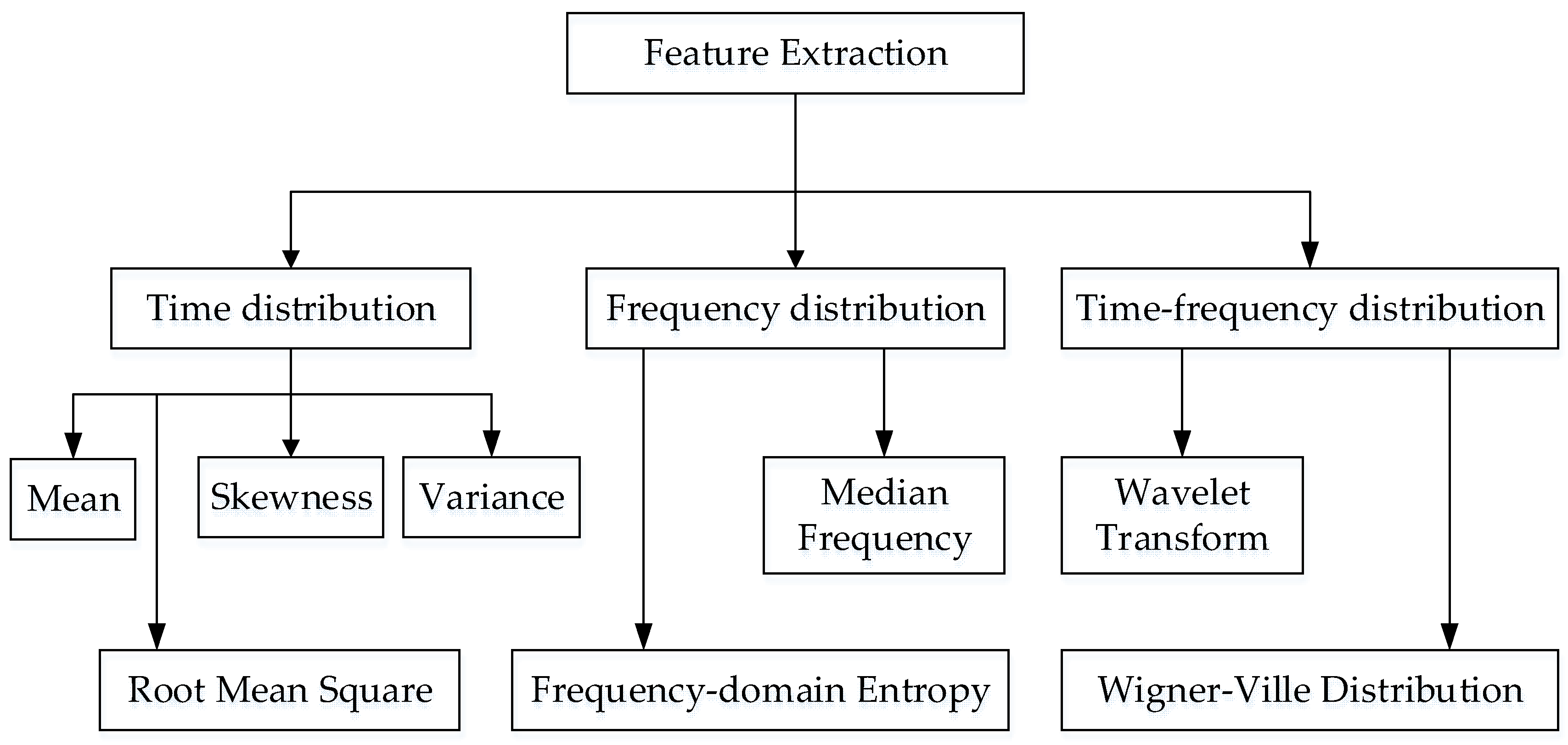
Consider the action of putting on socks as an example. First, use the inertial sensor to obtain the raw data, including the angular velocity data of the x-axis, y-axis, and z-axis of the upper arm, lower arm and hand, and record the motion state of the upper limb. Among them, “1” represents the acceleration state of the upper limb, “−1” represents the deceleration state of the upper limb, and “0” represents the static state of the upper limb. After filtering, the method of time domain feature extraction is employed to extract characteristic parameters such as variance, difference, maximum value, and minimum value, to construct a feature vector. The matrix vector contains 4 columns. The motion state of the upper limb was used as the state vector, and the state vector and feature vector were randomly divided into 10 parts, 9 of which were used as training data, and the other part was used as test data. The average accuracy of the results of 10 iterations of training and verification was used as the estimation of the algorithm accuracy. The process of 10-fold cross-validation is shown in
Figure 11. Then, the neural network is trained by the 10-fold cross-validation method, and the mean square error is selected to measure the performance of the neural network, so that the optimal smoothing parameter σ can be obtained. According to the training results, the smoothing parameter of the GRNN was set to 0.7. In the process of the manipulator reproducing the action of the human hand, since the length of the signal window is 10, it is necessary to identify the motion state every instance 10 sampling points are obtained. By filtering the data in the sliding window and extracting the feature parameters, the feature matrix vector matrix can be obtained. Input the feature matrix vector into the trained GRNN model, and the output of the model represents the motion state of the current sampling point.






















{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
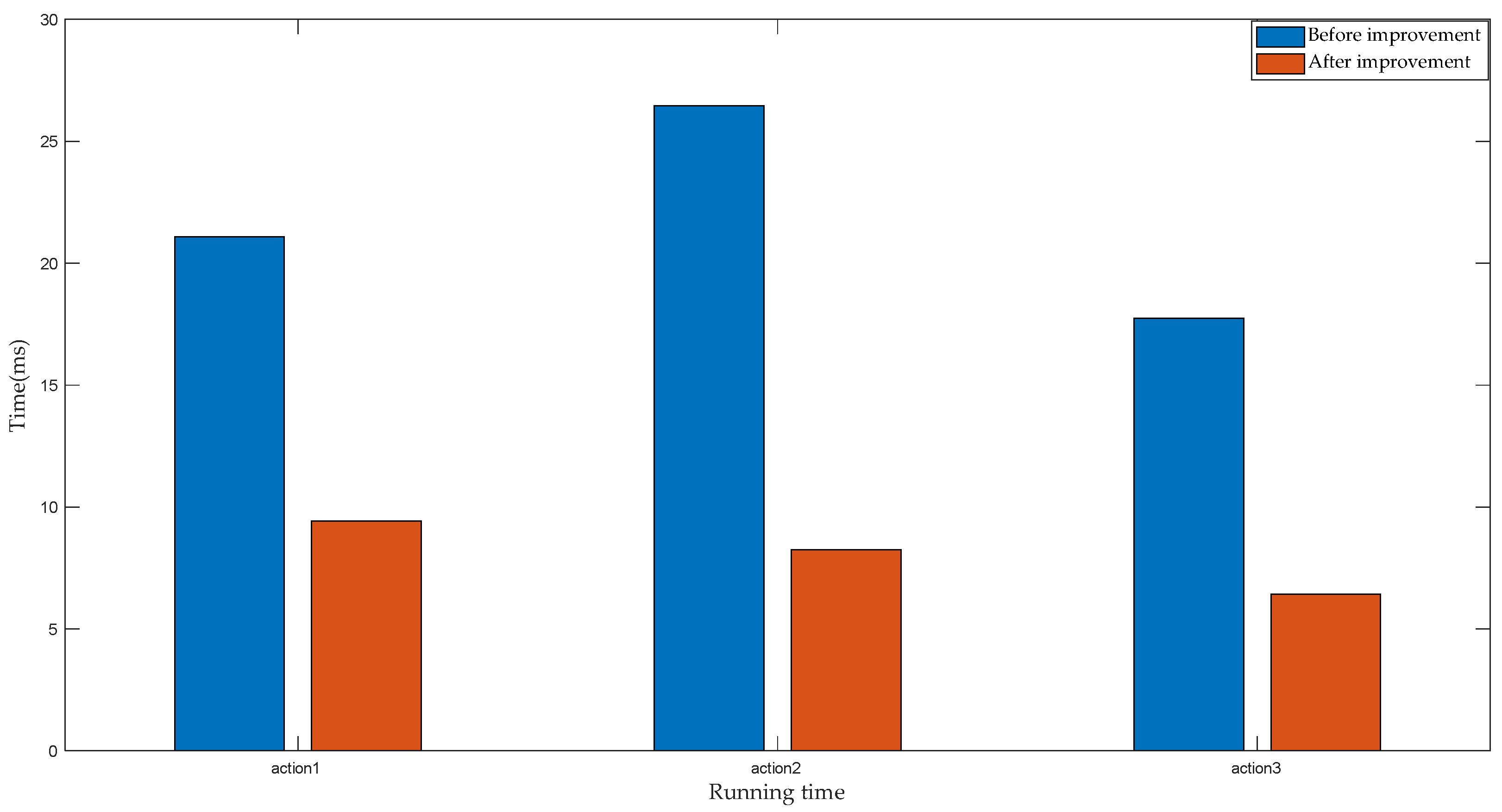{kind=link}
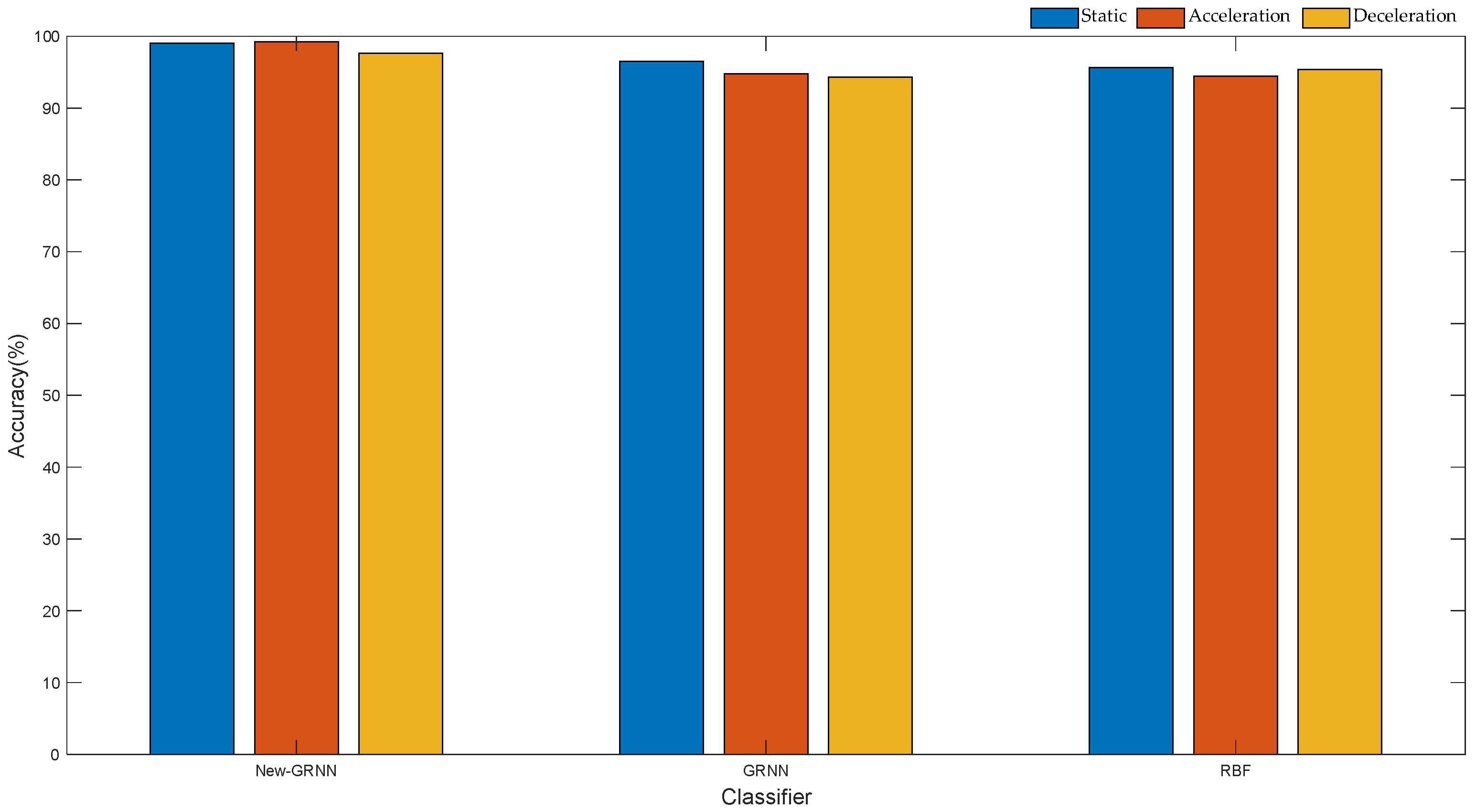{kind=link}