
Equivalent MIMO Channel Matrix Sparsification for Enhancement of Sensor Capabilities

{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
Abstract
:1. Introduction
- capital letter, e.g., used for matrices;
- : determinant of a matrix;
- : trace of a matrix;
- : Cholesky decomposition of a matrix;
- : transpose of matrix ;
- : inverse of a matrix ;
- : modulo of ;
- : block-component matrix of matrix V;
- : the prior distribution;
- : the equivalent likelihood function.
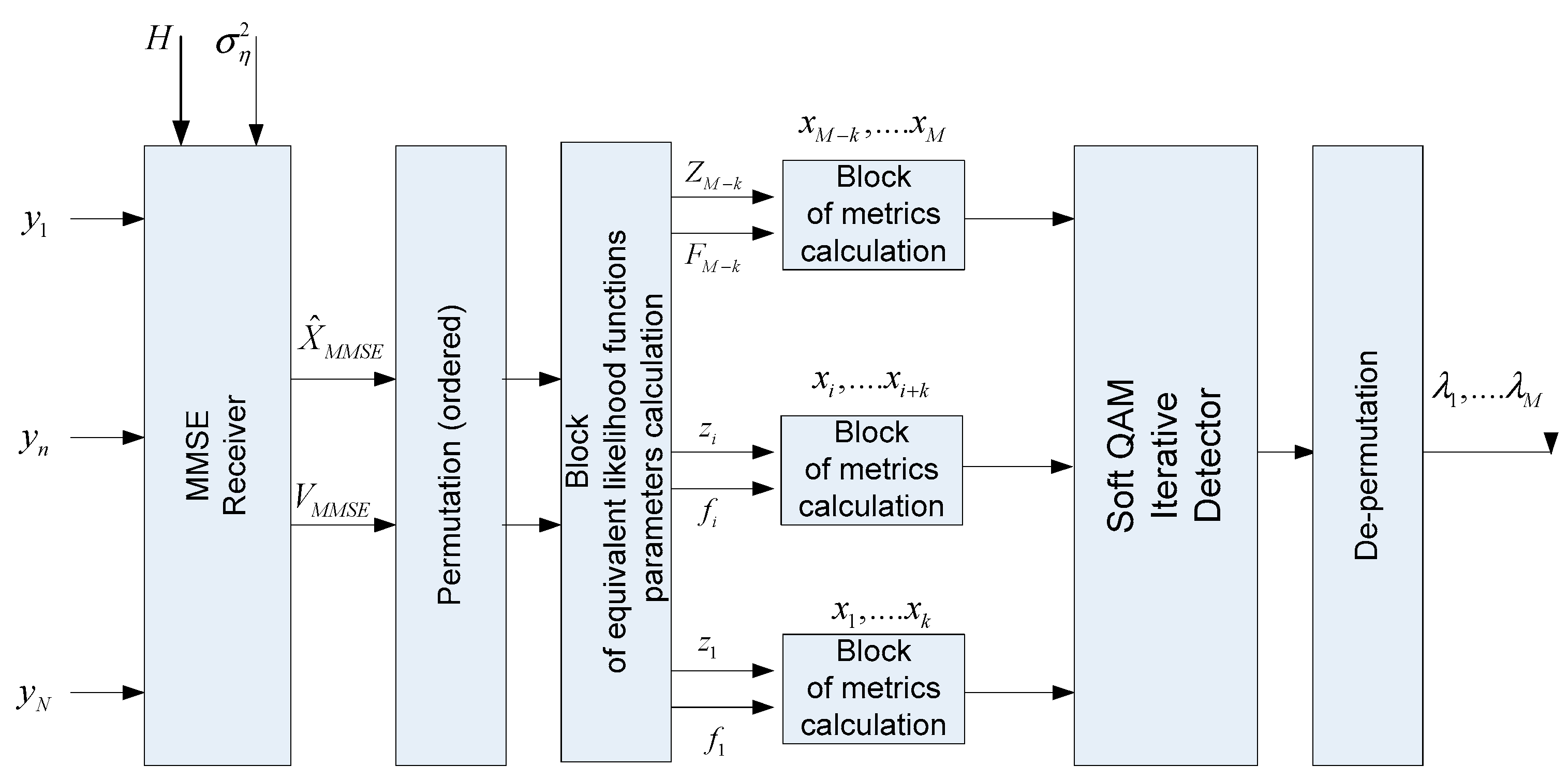
2. Representation of the MIMO Channel Matrix in the Sparse Format
3. Methods for the Approximation of the Channel Matrix by a Sparse Matrix
3.1. Kullback Distance for the Approximated Channel Model
3.2. Diagonal Matrix Approximation
3.3. Block Diagonal Matrix Approximation
3.4. Strip Matrix Approximation
3.5. Approximation by a Markov Process
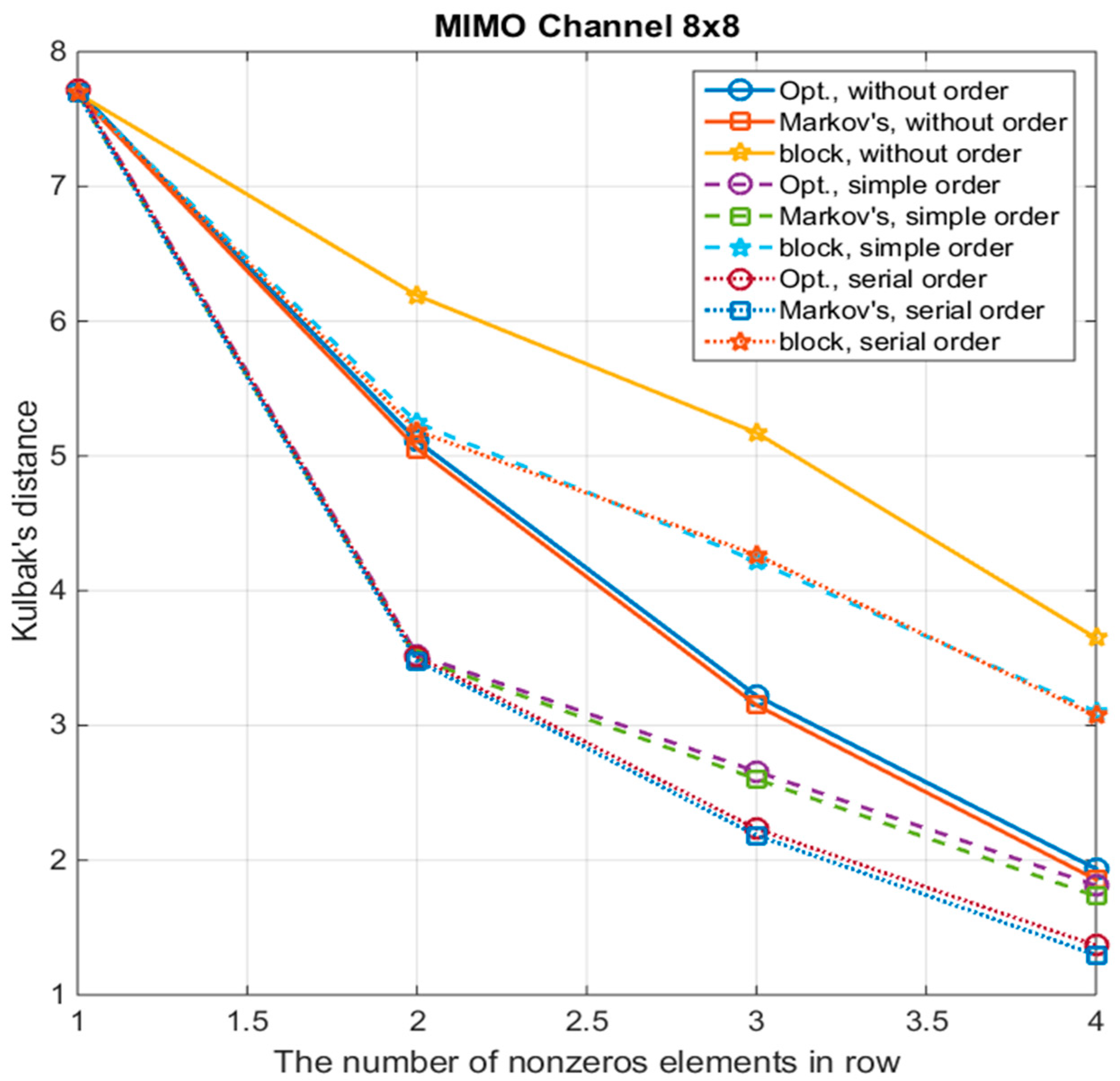
- Algorithm with a block-diagonal matrix—“block”;
- Algorithm with a strip matrix and the calculation of the coefficients of the sparse matrix by the method of stochastic optimization—“Opt.”;
- Algorithm with approximation by a Markov process—“Markov’s”.
- These curves are shown for three options of symbols ordering:
- Without ordering—“without order”;
- Simple ordering—“simple order”. In this option, the symbol with the highest total power of all mutual correlation coefficients is put in the first place, and the rest are arranged in descending order of the magnitudes of their mutual correlation coefficients with the first symbols;
- Serial ordering—“serial order”. In this option, the symbol with the highest total power of (m − 1) cross-correlation coefficients is selected, and a set of (m − 1) symbols having the maximum correlation with the first symbol is set. Next, from this set, the second symbol is selected, with the largest total power of (m − 1) cross-correlation coefficients, where (m − 2) symbols are already specified and are taken from the set (except for the first and second selected symbols) and one symbol is selected from the rest, not included in this set. Then, the third symbol is determined according to the same principle, etc.
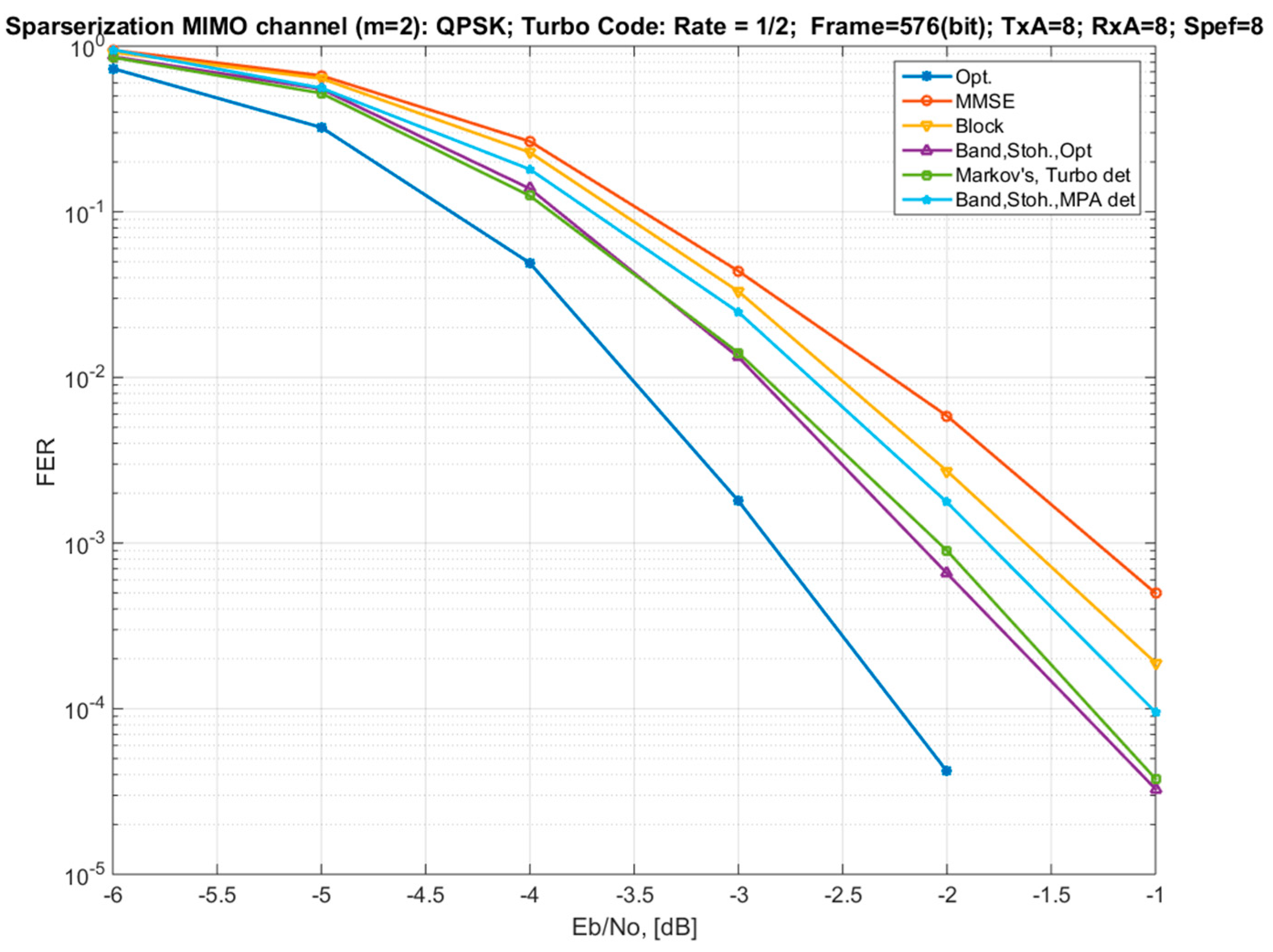
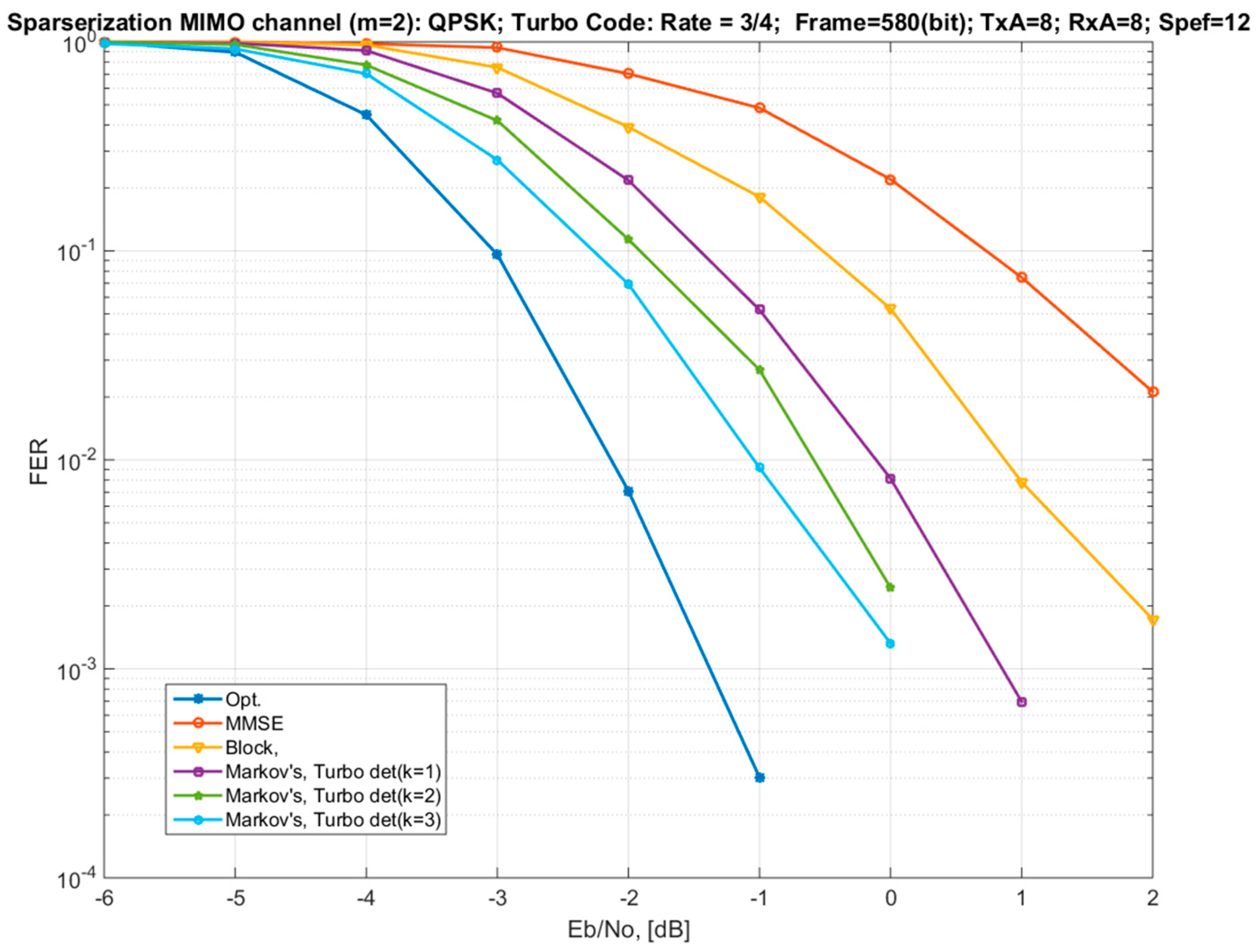
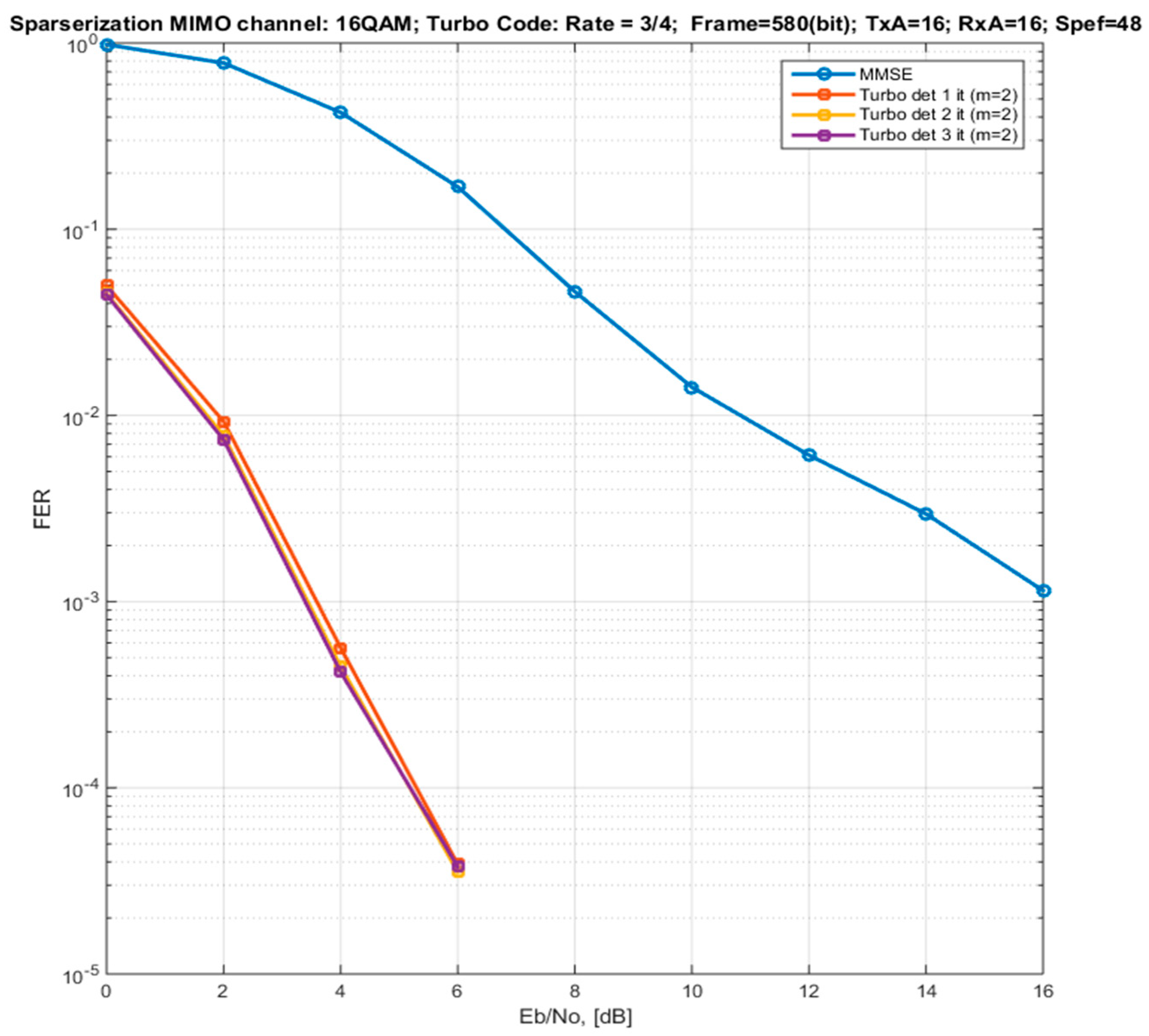
4. Modeling and Verification
- “Opt.”—optimal soft MIMO demodulator for the exact model (1);
- “MMSE”—MMSE demodulator for the exact model. It also corresponds to the variant of the channel model approximation by a diagonal matrix (Section 3.1);
- “Block”—a demodulator using an approximated block-diagonal MIMO channel model (Section 3.2; Equations (21) and (25)) with a block size of 2 × 2, with an optimal demodulator for each block;
- “Band, Stoh., Opt”—a demodulator using a striped two-diagonal MIMO channel model (Section 3.3; Equation (28)), in which the parameters of the striped channel matrix are calculated by the stochastic optimization method and the optimal demodulator for this model is used;
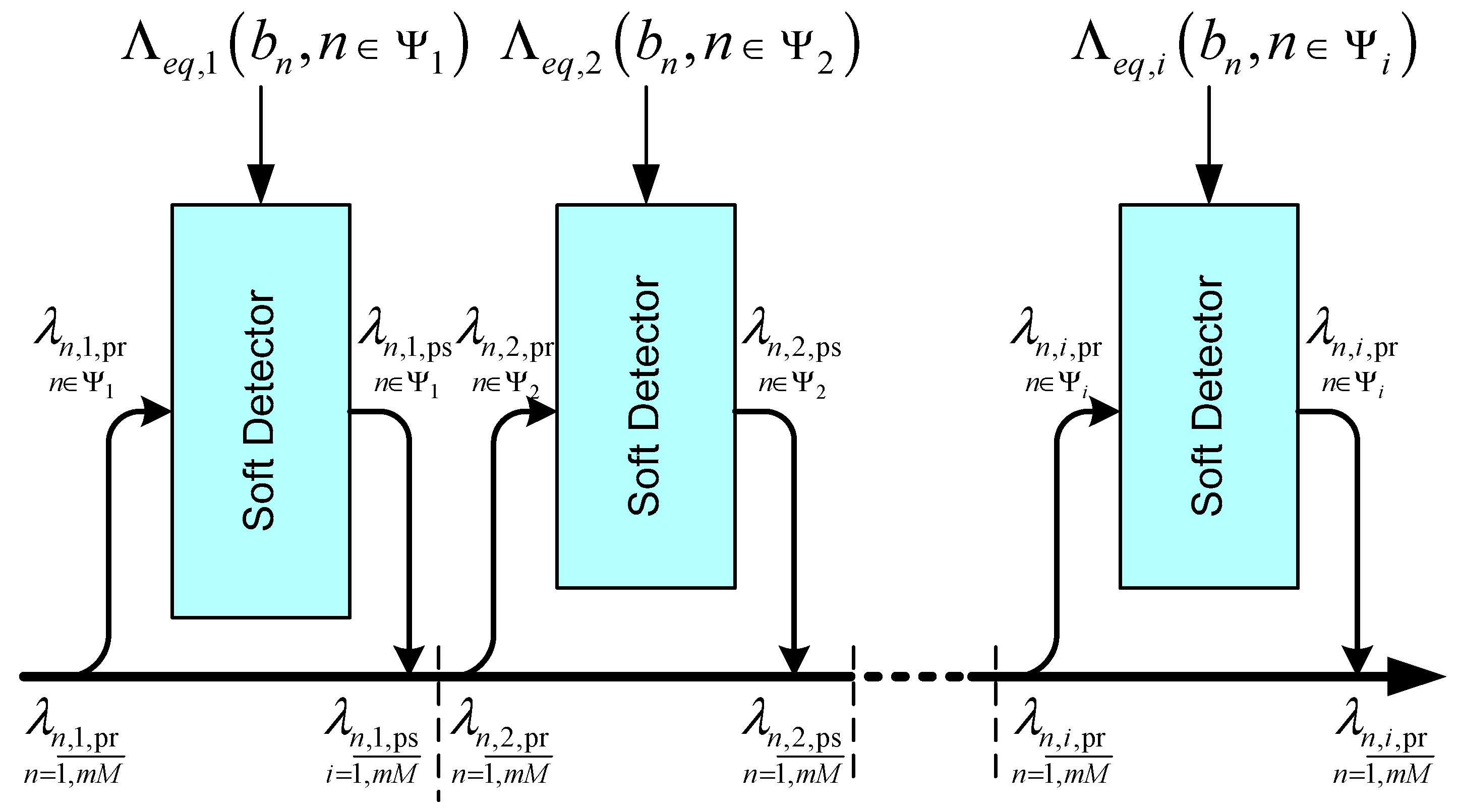
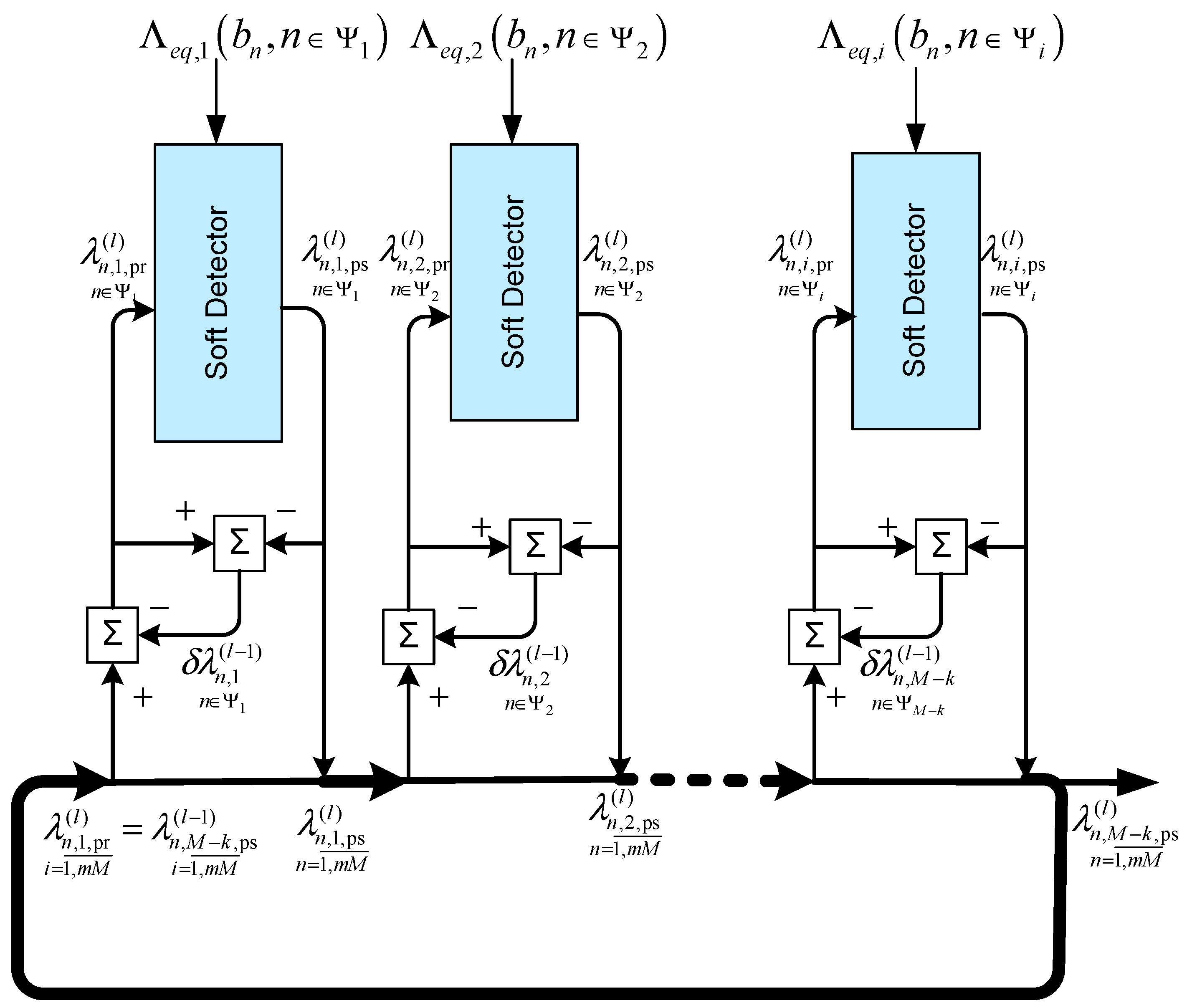
- “Markov’s, Turbo det”—a Markov approximation of the channel model (Section 3.4) with connectivity parameters and iterative detection using the method of equivalent likelihood functions (Equations (47) and (50)) and the principle of Turbo processing (two iterations);
- “Band, Stoh., MPA det”—iterative MPA detector (three iterations) using a two-diagonal striped MIMO channel model (Section 3.3), in which the channel strip matrix parameters are calculated by the stochastic optimization method.
5. Conclusions
Author Contributions
Funding
Informed Consent Statement
Conflicts of Interest
References
- Bakulin, M.G.; Kreyndelin, V.B.; Melnik, S.V.; Sudovtsev, V.A.; Petrov, D.A. Equivalent MIMO Channel Matrix Sparcification for Enhancement of Sensor Capabilities. In Proceedings of the 2021 International Conference on Engineering Management of Communication and Technology (EMCTECH), Vienna, Austria, 20–22 October 2021; pp. 1–6. [Google Scholar]
- Maruta, K.; Falcone, F. Massive MIMO Systems: Present and Future. Electronics 2020, 9, 385. [Google Scholar] [CrossRef] [Green Version]
- Vasuki, A.; Ponnusam, V. Latest Wireless Technologies towards 6G. In Proceedings of the 2021 International Conference on Computer Communication and Informatics (ICCCI), Coimbatore, India, 27–29 January 2021; pp. 1–4. [Google Scholar]
- Xu, G.; Yang, W.; Xu, B. Ultra-Massive multiple input multiple output technology in 6G. In Proceedings of the 2020 5th International Conference on Information Science, Computer Technology and Transportation (ISCTT), Shenyang, China, 13–15 November 2020; pp. 56–59. [Google Scholar]
- Yang, S.; Hanzo, L. Fifty Years of MIMO Detection: The Road to Large-Scale MIMOs. IEEE Commun. Surv. Tutor. 2015, 17, 1941–1988. [Google Scholar] [CrossRef] [Green Version]
- Xu, C.; Sugiura, S.; Ng, S.X.; Zhang, P.; Wang, L.; Hanzo, L. Two Decades of MIMO Design Tradeoffs and Reduced-Complexity MIMO Detection in Near-Capacity Systems. IEEE Access 2017, 5, 18564–18632. [Google Scholar] [CrossRef]
- Bakulin, M.G.; Kreyndelin, V.B.; Grigoriev, V.A.; Aksenov, V.O.; Schesnyak, A.S. Bayesian Estimation with Successive Rejection and Utilization of A Priori Knowledge. J. Commun. Technol. Electron. 2020, 65, 255–264. [Google Scholar] [CrossRef]
- Bakulin, M.; Kreyndelin, V.; Rog, A.; Petrov, D.; Melnik, S. MMSE based K-best algorithm for efficient MIMO detection. In Proceedings of the 2017 9th International Congress on Ultra Modern Telecommunications and Control Systems and Workshops (ICUMT), Munich, Germany, 6–8 November 2017; pp. 258–263. [Google Scholar]
- Challa, N.R.; Bagadi, K. Design of near-optimal local likelihood search-based detection algorithm for coded large-scale MU-MIMO system. Int. J. Commun. Syst. 2020, 33, e4436. [Google Scholar] [CrossRef]
- Liu, L.; Peng, G.; Wei, S. Massive MIMO Detection Algorithm and VLSI Architecture; Science Press: Beijing, China, 2020. [Google Scholar]
- Fukuda, R.M.; Abrão, T. Linear, Quadratic, and Semidefinite Programming Massive MIMO Detectors: Reliability and Complexity. IEEE Access 2019, 7, 29506–29519. [Google Scholar] [CrossRef]
- Azizipour, M.J.; Mohamed-Pour, K. Compressed channel estimation for FDD massive MIMO systems without prior knowledge of sparse channel model. IET Commun. 2019, 13, 657–663. [Google Scholar] [CrossRef]
- Albreem, M.A.; Alsharif, M.H.; Kim, S. Impact of Stair and Diagonal Matrices in Iterative Linear Massive MIMO Uplink Detectors for 5G Wireless Networks. Symmetry 2020, 12, 71. [Google Scholar] [CrossRef] [Green Version]
- Sun, M.; Wang, J.; Wang, D.; Zhai, L. A Novel Iterative Detection in Downlink of Massive MIMO System. J. Comput. Commun. 2021, 7, 116–126. [Google Scholar] [CrossRef] [Green Version]
- Zhang, G.; Gu, Z.; Zhao, Q.; Ren, J.; Han, S.; Lu, W. A Multi-Node Detection Algorithm Based on Serial and Threshold in Intelligent Sensor Networks. Sensors 2020, 20, 1960. [Google Scholar] [CrossRef] [Green Version]
- Albreem, M.A. A Low Complexity Detector for Massive MIMO Uplink Systems. Natl. Acad. Sci. Lett. 2021, 44, 545–549. [Google Scholar] [CrossRef]
- Liu, L.; Chi, Y.; Yuen, C.; Guan, Y.L.; Li, Y. Capacity-Achieving MIMO-NOMA: Iterative LMMSE Detection. IEEE Trans. Signal Process. 2019, 67, 1758–1773. [Google Scholar] [CrossRef]
- Caliskan, C.; Maatouk, A.; Koca, M.; Assaad, M.; Gui, G.; Sari, H. A Simple NOMA Scheme with Optimum Detection. In Proceedings of the 2018 IEEE Global Communications Conference (GLOBECOM), Abu Dhabi, United Arab Emirates, 9–13 December 2018; pp. 1–6. [Google Scholar]
- Wang, J.; Jiang, C.; Kuang, L. Iterative NOMA Detection for Multiple Access in Satellite High-Mobility Communications. IEEE J. Sel. Areas Commun. 2022. [Google Scholar] [CrossRef]
- Hoshyar, R.; Wathan, F.P.; Tafazolli, R. Novel Low-Density Signature for Synchronous CDMA Systems over AWGN Channel. IEEE Trans. Signal Process. 2008, 56, 1616–1626. [Google Scholar] [CrossRef] [Green Version]
- Nikopour, H.; Baligh, H. Sparse code multiple access. In Proceedings of the 2013 IEEE 24th Annual International Symposium on Personal, Idoor, and Mobile Radio Communications (PIMRC), London, UK, 8–11 September 2013; pp. 332–336. [Google Scholar]
- Taherzadeh, M.; Nikopour, H.; Bayesteh, A.; Baligh, H. SCMA Codebook Design. In Proceedings of the 2014 IEEE 80th Vehicular Technology Conference (VTC2014-Fall), Vancouver, BC, Canada, 14–17 September 2014; pp. 1–5. [Google Scholar]
- Aquino, G.P.; Mendes, L.L. Sparse code multiple access on the generalized frequency division multiplexing. J. Wirel. Commun. Netw. 2020, 2020, 212. [Google Scholar] [CrossRef]
- Hai, H.; Li, C.; Li, J.; Peng, Y.; Hou, J.; Jiang, X.-Q. Space-Time Block Coded Cooperative MIMO Systems. Sensors 2021, 21, 109. [Google Scholar] [CrossRef]
- Wang, Y.; Zhou, S.; Xiao, L.; Zhang, X.; Lian, J. Sparse Bayesian learning based user detection and channel estimation for SCMA uplink systems. In Proceedings of the 2015 International Conference on Wireless Communications & Signal Processing (WCSP), Nanjing, China, 15–17 October 2015; pp. 1–5. [Google Scholar]
- Hou, Z.; Xiang, Z.; Ren, P.; Cao, B. SCMA Codebook Design Based on Decomposition of the Superposed Constellation for AWGN Channel. Electronics 2021, 10, 2112. [Google Scholar] [CrossRef]
- Mheich, Z.; Wen, L.; Xiao, P.; Maaref, A. Design of SCMA Codebooks Based on Golden Angle Modulation. IEEE Trans. Veh. Technol. 2019, 68, 1501–1509. [Google Scholar] [CrossRef]
- Bakulin, M.; Kreyndelin, V.; Rog, A.; Petrov, D.; Melnik, S. A new algorithm of iterative MIMO detection and decoding using linear detector and enhanced turbo procedure in iterative loop. In Proceedings of the 2019 Conference of Open Innovation Association, FRUCT, Moscow, Russia, 8–12 April 2019; pp. 40–46. [Google Scholar]
- Bakulin, M.; Kreyndelin, V.; Rog, A.; Petrov, D.; Melnik, S. Low-complexity iterative MIMO detection based on turbo-MMSE algorithm. In Lecture Notes in Computer Science (Including Subseries Lecture Notes in Artificial Intelligence and Lecture Notes in Bioinformatics); Springer: Cham, Switzerland, 2017; pp. 550–560. [Google Scholar]
- Kong, W.; Li, H.; Zhang, W. Compressed Sensing-Based Sparsity Adaptive Doubly Selective Channel Estimation for Massive MIMO Systems. Wirel. Commun. Mob. Comput. 2019, 2019, 6071672. [Google Scholar] [CrossRef]
- Amin, B.; Mansoor, B.; Nawaz, S.J.; Sharma, S.K.; Patwary, M.N. Compressed Sensing of Sparse Multipath MIMO Channels with Superimposed Training Sequence. Wirel. Pers. Commun. 2017, 94, 3303–3325. [Google Scholar] [CrossRef] [Green Version]
- Albreem, M.A.; Juntti, M.; Shahabuddin, S. Massive MIMO Detection Techniques: A Survey. IEEE Commun. Surv. Tutor. 2019, 21, 3109–3132. [Google Scholar] [CrossRef] [Green Version]
- Minka, T. Divergence Measures and Message Passing; Technical Report; Microsoft Research: Cambridge, MA, USA, 2005. [Google Scholar]
- Ghodhbani, E.; Kaaniche, M.; Benazza-Benyahia, A. Close Approximation of Kullback–Leibler Divergence for Sparse Source Retrieval. IEEE Signal Processing Lett. 2019, 26, 745–749. [Google Scholar] [CrossRef]
- Mansoor, B.; Nawaz, S.; Gulfam, S. Massive-MIMO Sparse Uplink Channel Estimation Using Implicit Training and Compressed Sensing. Appl. Sci. 2017, 7, 63. [Google Scholar] [CrossRef]
- Shahabuddin, S.; Islam, M.H.; Shahabuddin, M.S.; Albreem, M.A.; Juntti, M. Matrix Decomposition for Massive MIMO Detection. In Proceedings of the 2020 IEEE Nordic Circuits and Systems Conference (NorCAS), Oslo, Norway, 27–28 October 2020; pp. 1–6. [Google Scholar]
- Terao, T.; Ozaki, K.; Ogita, T. LU-Cholesky QR algorithms for thin QR decomposition in an oblique inner product. J. Phys. Conf. Ser. 2020, 1490, 012067. [Google Scholar] [CrossRef]
- Chinnadurai, S.; Selvaprabhu, P.; Jeong, Y.; Jiang, X.; Lee, M.H. Worst-Case Energy Efficiency Maximization in a 5G Massive MIMO-NOMA System. Sensors 2017, 17, 2139. [Google Scholar] [CrossRef] [Green Version]
- Chinnadurai, S.; Selvaprabhu, P.; Sarker, A.L. Correlation Matrices Design in the Spatial Multiplexing Systems. Int. J. Discret. Math. 2017, 2, 20–30. [Google Scholar]
- Liu, H.; Zhang, L.; Su, Z.; Zhang, Y.; Zhang, L. Bayesian Variational Inference Algorithm Based on Expectation-Maximization and Simulated Annealing. J. Electron. Inf. Technol. 2021, 43, 2046–2054. [Google Scholar]







Publisher’s Note: MDPI stays neutral with regard to jurisdictional claims in published maps and institutional affiliations. |
© 2022 by the authors. Licensee MDPI, Basel, Switzerland. This article is an open access article distributed under the terms and conditions of the Creative Commons Attribution (CC BY) license (https://creativecommons.org/licenses/by/4.0/).
Share and Cite
Bakulin, M.; Kreyndelin, V.; Melnik, S.; Sudovtsev, V.; Petrov, D. Equivalent MIMO Channel Matrix Sparsification for Enhancement of Sensor Capabilities. Sensors 2022, 22, 2041. https://doi.org/10.3390/s22052041
Bakulin M, Kreyndelin V, Melnik S, Sudovtsev V, Petrov D. Equivalent MIMO Channel Matrix Sparsification for Enhancement of Sensor Capabilities. Sensors. 2022; 22(5):2041. https://doi.org/10.3390/s22052041
Chicago/Turabian StyleBakulin, Mikhail, Vitaly Kreyndelin, Sergei Melnik, Vladimir Sudovtsev, and Dmitry Petrov. 2022. "Equivalent MIMO Channel Matrix Sparsification for Enhancement of Sensor Capabilities" Sensors 22, no. 5: 2041. https://doi.org/10.3390/s22052041
APA StyleBakulin, M., Kreyndelin, V., Melnik, S., Sudovtsev, V., & Petrov, D. (2022). Equivalent MIMO Channel Matrix Sparsification for Enhancement of Sensor Capabilities. Sensors, 22(5), 2041. https://doi.org/10.3390/s22052041