Abstract
The rapid evolution of Internet of Things (IoT) applications, such as e-health and the smart ecosystem, has resulted in the emergence of numerous security flaws. Therefore, security protocols must be implemented among IoT network nodes to resist the majority of the emerging threats. As a result, IoT devices must adopt cryptographic algorithms such as public-key encryption and decryption. The cryptographic algorithms are computationally more complicated to be efficiently implemented on IoT devices due to their limited computing resources. The core operation of most cryptographic algorithms is the finite field multiplication operation, and concise implementation of this operation will have a significant impact on the cryptographic algorithm’s entire implementation. As a result, this paper mainly concentrates on developing a compact and efficient word-based serial-in/serial-out finite field multiplier suitable for usage in IoT devices with limited resources. The proposed multiplier structure is simple to implement in VLSI technology due to its modularity and regularity. The suggested structure is derived from a formal and systematic technique for mapping regular iterative algorithms onto processor arrays. The proposed methodology allows for control of the processor array workload and the workload of each processing element. Managing processor word size allows for control of system latency, area, and consumed energy. The ASIC experimental results indicate that the proposed processor structure reduces area and energy consumption by factors reaching up to 97.7% and 99.2%, respectively.
1. Introduction
The Internet of Things (IoT) is a contemporary technology that links a large number of items to the internet, including wearable devices, sensors, smartphones, smart meters, and auto-mobiles [1,2] It offers services and cost-effective solutions in a variety of fields, including healthcare, smart grid, industrial manufacturing, smart cities, business, and smart railway infrastructure [3,4,5].
For most IoT-based systems, privacy and security are the top priorities. They restrict it from being used in the majority of applications. As a result, to defend IoT-based systems, we should use effective and realistic security solutions. To address all of the security flaws, cryptographic protocols should be used at various levels of the IoT paradigm, particularly, at edge devices. Conventional cryptographic algorithms such as Rivest, Shamir, and Adleman (RSA) and Digital Signature Algorithm (DSA) [6] are expensive to execute on most IoT edge devices due to of their restricted processing capability. The Elliptic Curve Cryptographic (EEC) algorithm [6,7] is the preferred cryptography for resource-constrained integrated devices due to its small key sizes and increased computing effectiveness. The critical part in implementing ECC is the efficient implementation of the finite field multiplication operation. This operation is the core operation in all field arithmetic operations used in ECC such as finite-field inversion and division [8,9,10,11].
1.1. Related Work
Depending on the application, finite field multipliers can be built in serial or parallel. When the multiplier is constructed in parallel, it generates all output bits in a single clock cycle, resulting in a significant throughput at the cost of a lot of hardware resources [12,13]. Serial architectures, on the other hand, are optimized for low-space applications at the cost of increasing processing latency to n clock cycles, where n is the field size [14,15]. We will focus on serial development of the finite field multiplier algorithm because we are targeting resource-constrained IoT applications [15]. The multiplier can be implemented in either a bit-serial or a word-serial fashion. The word-serial version is more economical for resource-constrained IoT devices, because it achieves better area and time complexity than the bit-serial version [16].
The basic four constructions of word-serial finite field multipliers are: serial-in/serial-out (SISO), serial-in/parallel-out (SIPO), parallel-in/serial-out (PISO), and scalable constructions. References [17,18,19,20,21] discussed the polynomial SISO multipliers. The multipliers presented in [17,18,19] have systolic structures that have area complexity of order and latecny of order , where n represents the field size and l is the bus word size. The multiplier design proposed in [20] is also a systolic design, but has area complexity of approximately and a lower latency of order . The multiplier design explained in [21] is a three operand non-systolic multiplier with area complexity of order and latency of order .
References [22,23] provide the details of the polynomial SIPO multipliers. The multiplier offered in [22] has a systolic structure with area complexity of order and latency of order . The multiplier discussed in [23] has a systolic structure with area complexity of order and latency of order ). In [24], the PISO multiplier was explained using a Type-T Gaussian normal basis. The proposed architecure consumes area of order and has latency of order , but have a very long critical pass delay that it is a function of word size l, , making the total computation time very high specially for long word sizes.
Later, in [25,26,27,28], the scalable multiplier constructions were discussed in detail. The scalable multipliers of [25,26] are based on a fixed bit-parallel Hankel matrix-vector multiplier whose latency is clock cycles. The multiplier architecture of [25] has area complexity of order , while the multiplier architecture of [26] has lower area complexity of order . The multiplier of [27] is based on the dual basis multiplication and targets lightweight cryptographic architectures. It has estimated area complexity of order and latency of order . The design proposed in [28] is a unified structure that performs both multiplication and inversion operations. It has estimated area complexity of order and latency of the same order.
From the previous discussion, we notice that most SISO multiplier constructions provide improved area and time complexity than other forms of word-serial multiplier constructions. As a result, we will concentrate on obtaining the SISO construction of the adopted algorithm.
1.2. Paper Contribution
In this paper, we present a SISO finite field multiplier processor that is two-dimensional (2-D) and word-based. Regularity, modularity, concurrency, and local interconnectivity of the explored processor’s systolic structure are all special aspects, which makes it more convenient for VLSI implementation. The system developer can manage the area and power consumption of the investigated multiplier construction to suit IoT devices by using the formal mapping technique provided in [29,30,31]. The system developer can adjust the workload of the processor array as well as the workload of each processing element by using a non-linear scheduling function. Furthermore, non-linear task scheduling is used to manage the algorithm’s latency. The actual results reveal that the improved multiplier construction saves a large amount of space and energy, making it more suitable for IoT devices with restricted resources.
1.3. Paper Organization
The following describes the layout of the manuscript: Section 2 modifies the adopted finite field multiplication algorithm, offered by [32], to be represented in the bit level form. The algorithm performs the multiplication operation over GF() and is based on the irreducible All-One Polynomial (AOP). The dependency graph (DG) of the explained algorithm is investigated in Section 3. The systematic technique utilized to extract the 2-D word-based SISO processor is explained in Section 4. The experimental findings and analysis of the produced word-based multiplier construction and the competitor ones are displayed in Section 5. Finally, under Section 6, you can find the conclusion of this work.
2. Formulation of the Multiplication Algorithm
Suppose that a degree n irreducible polynomial characterizes the finite field over . It can be described in the polynomial form as:
with . Consider also that the above polynomial has a root denoted as . As a result, the field elements can be defined by the set of polynomial basis .
Assume that polynomials E and H denote any two field elements in space. They can be described in degree polynomial form as follows:
where .
To multiply E and H over , we can use the following formula.
Equation (4) could be extended to include a multiplication recurrence formula as follows:
where is a polynomial of degree n that can be written as:
with and for .
We can derive the following expression by extending the polynomial of (6) and multiplying by .
As we mentioned before, is a root of and this leads to . As a result, we can find the following expression by substituting with in Equation (1).
As is an AOP polynomial, Equation (8) can be expressed as:
By multiplying both sides of Equation (9) by , we obtain the following result:
As indicated in Equation (11), the cyclic-shift-left of polynomial K creates the partially-reduced polynomial of polynomial . Additionally, the cyclic-shift-left of polynomial produces the partially-reduced polynomial of polynomial . In general, cyclic-shift-left of polynomial forms the partially-reduced polynomial of polynomial . The following is a mathematical representation of the cyclic-shift-left procedure:
where . L denotes the cyclic-shift-left operation. Equation (12) could be used to construct Equation (13) as:
with .
Alternatively, Equation (13) might be written as:
where V is the sum of polynomials of degree n that can be expressed as:
with .
Equation (15) can be described in the subsequent form:
By substituting in Equation (16) with the expansion given in Equation (9), we could derive the reduced form of polynomial (polynomial of degree ) as:
We can describe Equations (12) and (15) in bit-level format as shown in Equations (18) and (19), respectively. The subscript j in these equations denotes the bit position in their binary coding.
with , , , and 0 .
Equation (17) provides the reduced form of the product polynomial D, which can be interpreted in the bit-level formate as:
with 0 .
Algorithms 1 and 2 are the algorithm structure of the previously stated formulas. Algorithm 2 represents the bit-level version of Algorithm 1.
| Algorithm 1 Finite Field Multiplication Algorithm based on AOP polynomial. |
Input: E, H, and U Output: D Initialization: , Algorithm:
|
| Algorithm 2 Finite Field Multiplication Algorithm in the bit-level formate. |
Input: , Output: Initialization: Algorithm:
|
3. Construction of Algorithm Dependence Graph
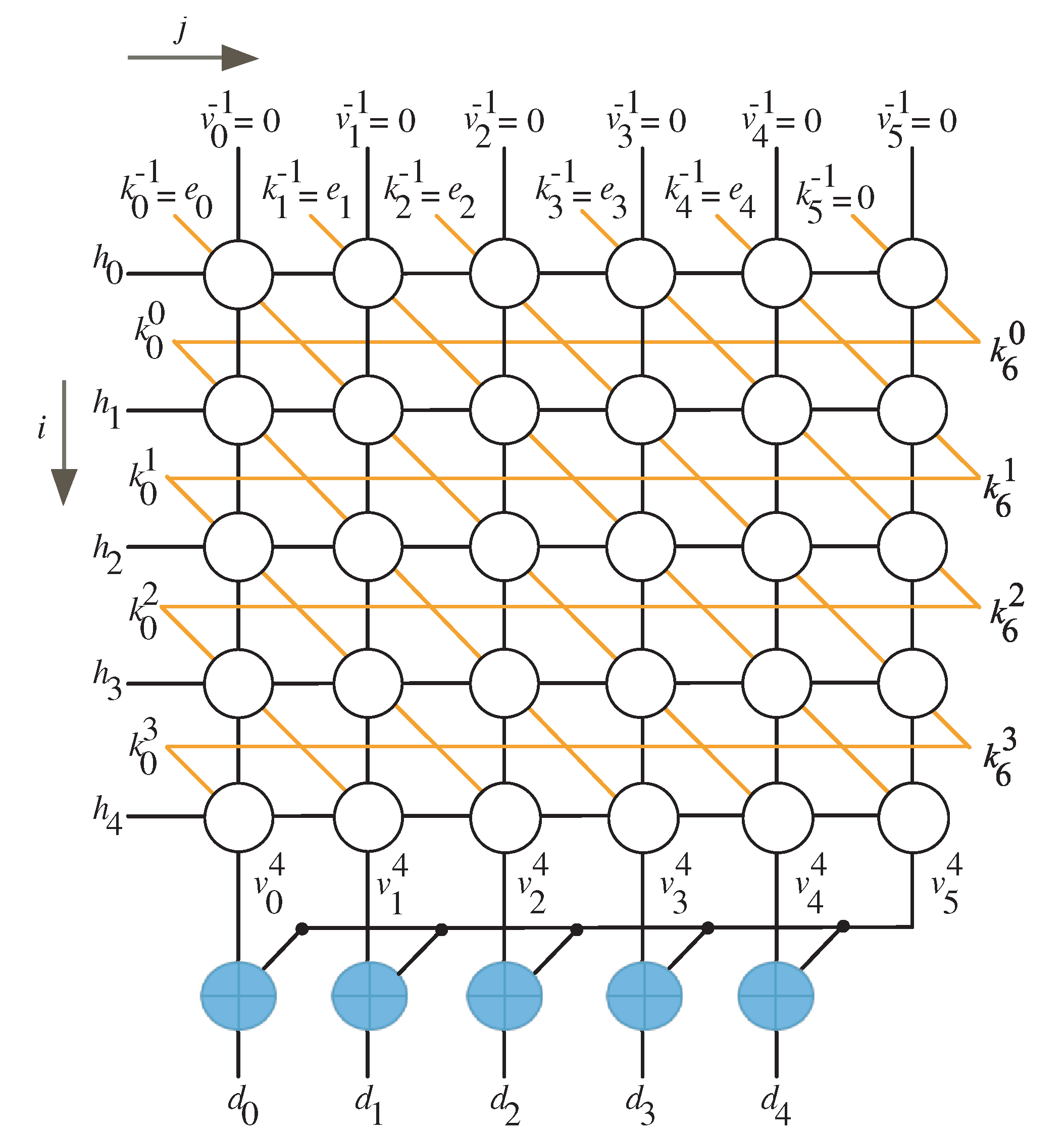
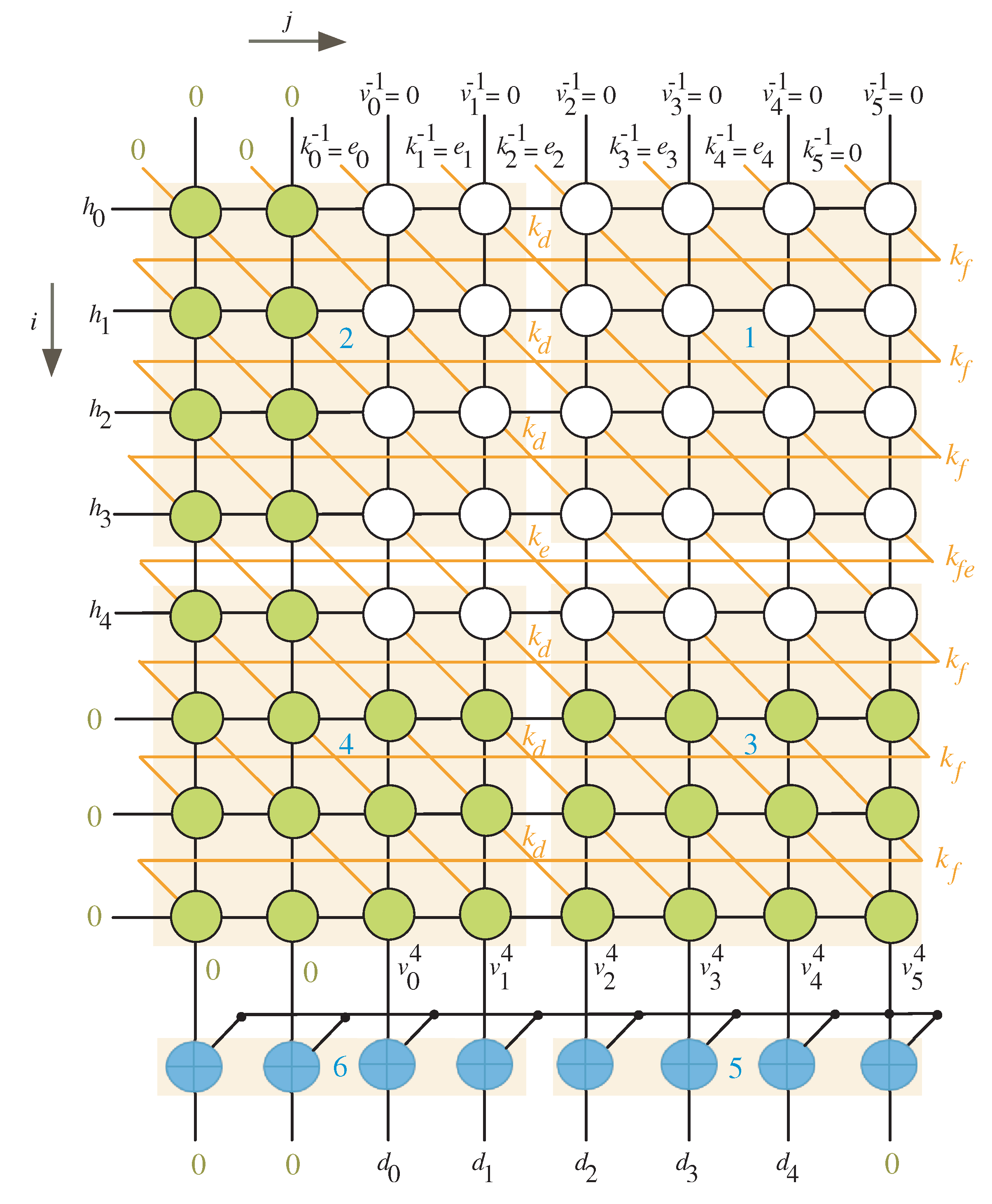
Algorithm 2 has two indices, i and j, that define the iterative phase of the multiplication algorithm. The approach described in reference [29] can be used to generate a dependence graph (DG) in the two-dimensional integer domain . Figure 1 shows the DG for the situation when . The nodes of the DG indicates the operations specified by the algorithm steps 3 to 5. According to the design criteria of reference [29], signals are indicated by vertical lines. The signals are denoted by horizontal lines. The signals are depicted by the diagonal lines.
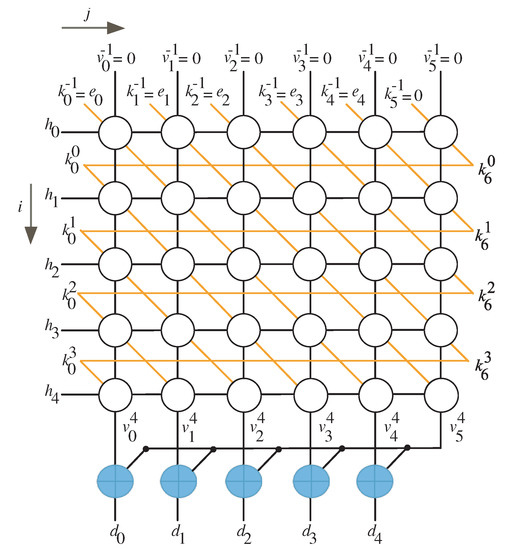
Figure 1.
DG of the recommended multiplication algorithm for .
The signals of are generated by the nodes in the last column and transmitted to the nodes in the first column. As indicated in the reduction step of the Algorithm 2, step 9, the resultant signals , , are combined with the most significant signal , using the XOR gates, to generate the final product output signals , . The algorithm inputs and are displayed in the DG as vertical and diagonal inputs to the top row nodes, respectively. On the other hand, the reduced product output , is created by merging the vertical outputs of the bottom nodes with the output of the most right bottom node as depicted in Figure 1.
Using the technique outlined in [29], the DG of Figure 1 can be used for design space exploration by selecting proper node scheduling and projection functions.
We will not employ the linear scheduling and projection functions presented in [29], as they give us few alternatives for determining the resulting processor array area, latency, processing element workload, and total system workload. We will apply the non-linear node scheduling and projection techniques described in [29] to the DG. This option provides a wide range of design alternatives for optimizing the resulting processor array area, latency, workload of processing elements, and overall system workload.
4. Two-Dimensional SISO Multiplier
Our objective is to create a SISO multiplier that accepts inputs K and H in a word-serial format. In addition, the resultant output D is generated from the SISO multiplier in the word-serial format. Assume the system designer’s aim is to process l bits of each input at the same time in order to find l bits of the output. The following subsections describe the steps that the system developer should follow to construct the SISO multiplier.
4.1. Non-Linear Task Scheduling
As explained in [29], the nonlinear scheduling technique is employed to divide the domain into equitemporal zones or clusters. The l value allows the system designer to set the number of bits of inputs and outputs that are processed at the same time. This has an indirect impact on the system’s size, speed, and latency.
To assign timing to each node of the DG, we use the following non-linear scheduling function:
where is the time allocated to the DG’s node ; , , and is defined as:
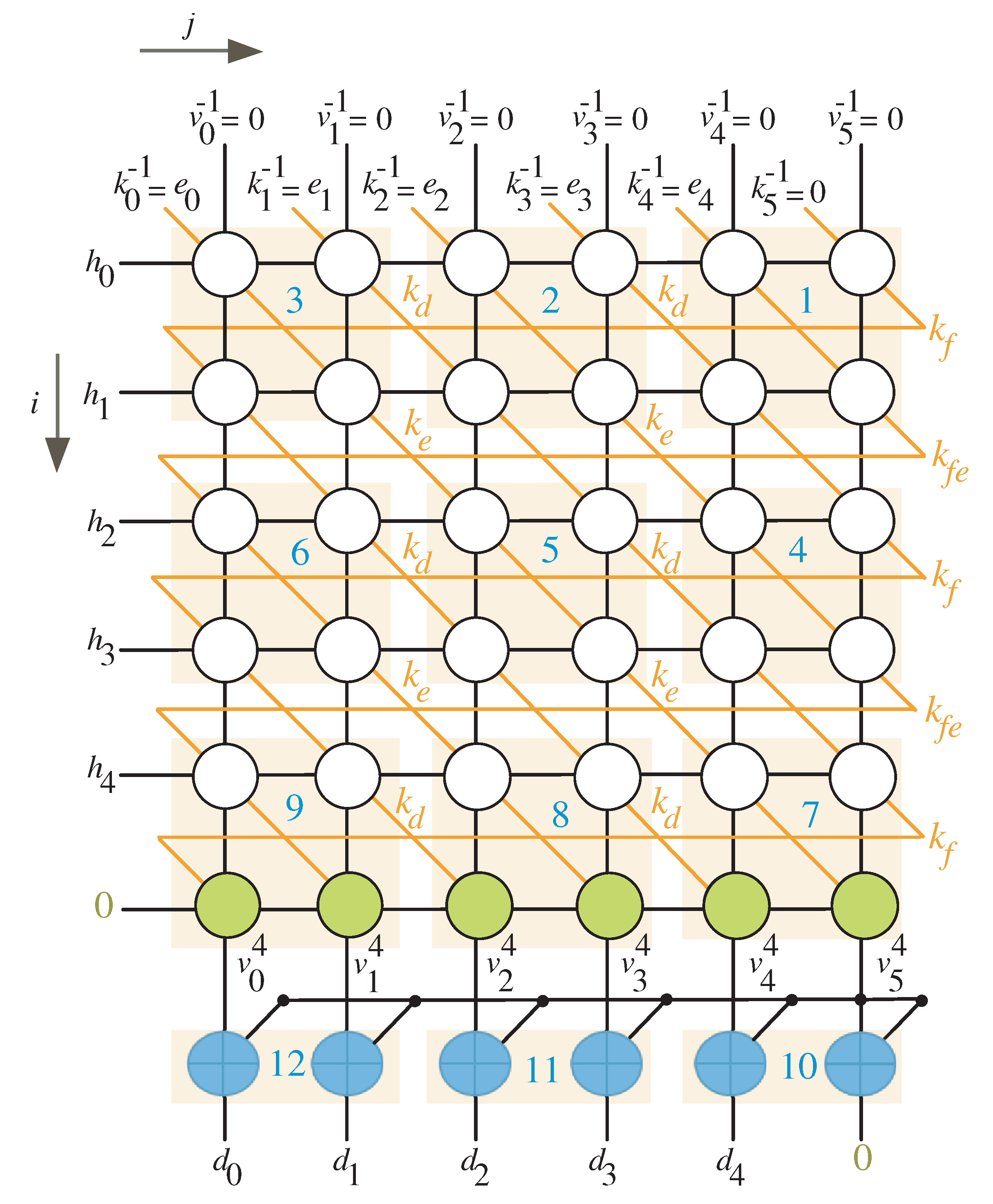
To make the DG’s rows an integer multiple of l, we should add rows to it. In addition, columns must be added to the DG in order for the number of columns to be an integer multiple of l. We have equal to 1 in the scenario depicted in Figure 2 where and , implying that one row should be placed at the bottom (row with green nodes) and no columns at the left. The equitemporal zones (the cluster of nodes having the same time values) are determined by the light red boxes and marked with the blue numbers as displayed in Figure 2.
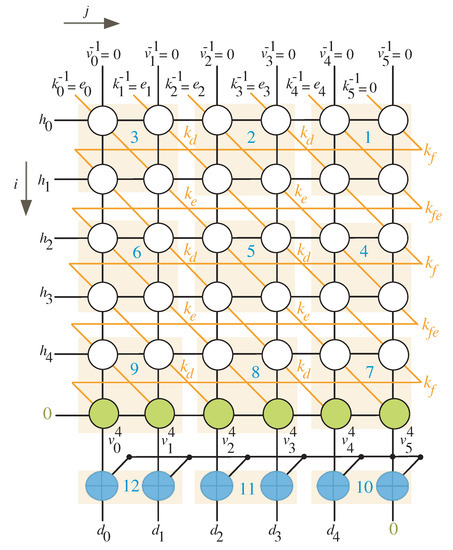
Figure 2.
Scheduling time for and .
The scheduling time for the DG nodes when and is shown in Figure 3. We have equal to 3 in this scenario, which means we need to employ two columns on the left and three rows on the bottom (rows and columns with green nodes).
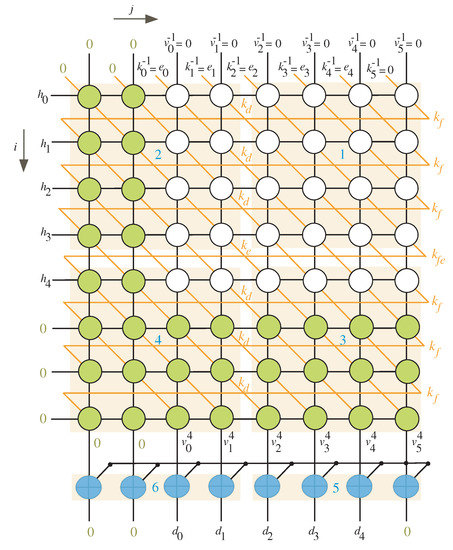
Figure 3.
Scheduling time for and .
By inspecting Figure 2 and Figure 3, we notice that any equitemporal zone (give it name block k) takes inputs from the north and west sides and generates outputs from the south and east sides. Table 1 summarizes the timings associated with these inputs and outputs (I/Os).

Table 1.
I/Os timing for block k.
It is worth noting that the top row’s inputs result in the right column’s outputs. Similarly, the left column’s inputs result in the bottom row’s outputs. As a result, the total number of iterations (I) for finite field multiplication should be calculated using the following expression.
4.2. Non-Linear Task Projection
As we observe from Figure 2 and Figure 3, the equitemporal zones execute at the same time. This remark, together with the projection technique described in [29], yields the nonlinear task projection function shown below:
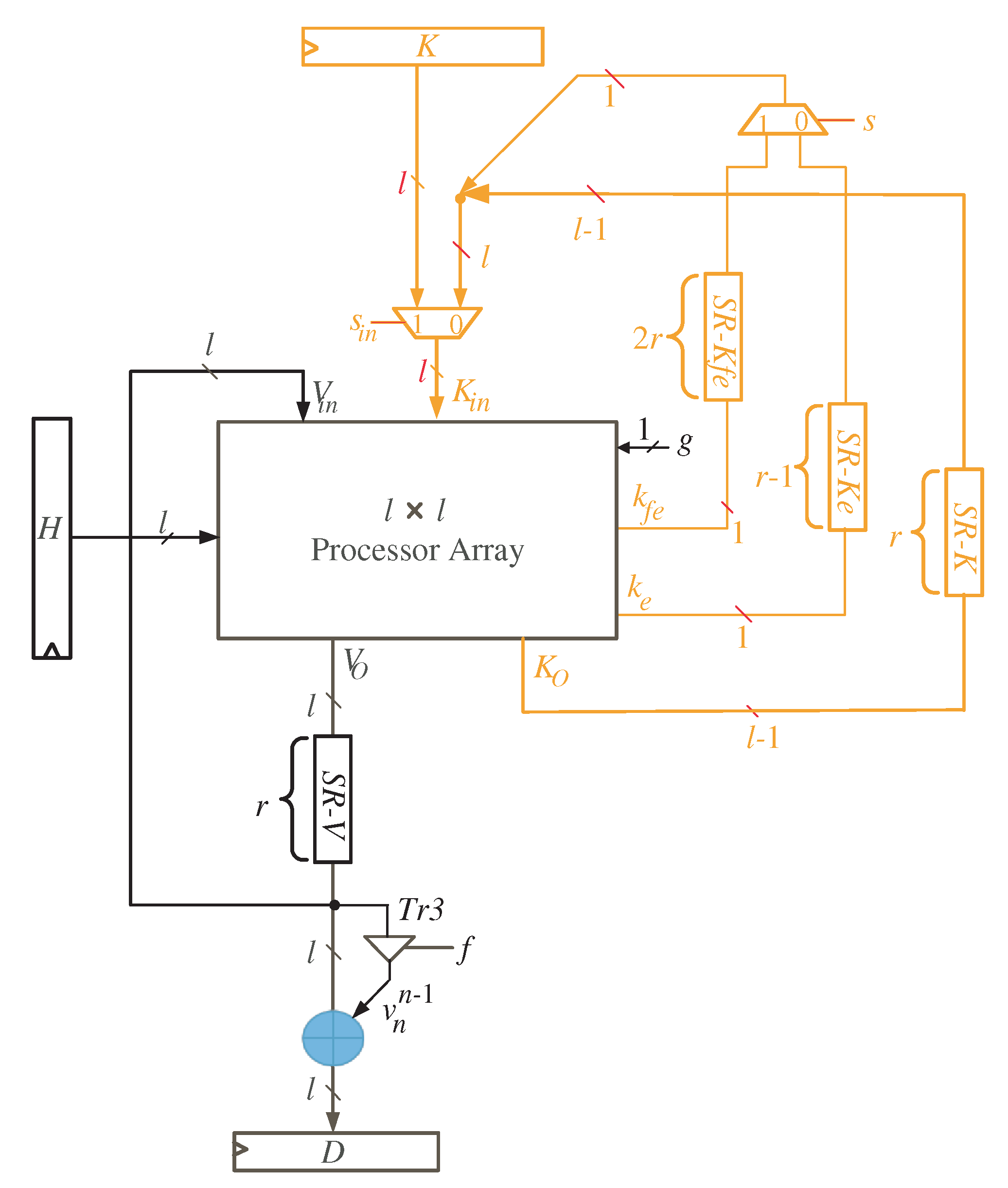
The node clusters are mapped to a single processor array using the extracted projection function. The processor array is made up of processing elements (PEs) that are arranged in a two-dimensional array. The processor structure of Figure 4 depicts the entire system.
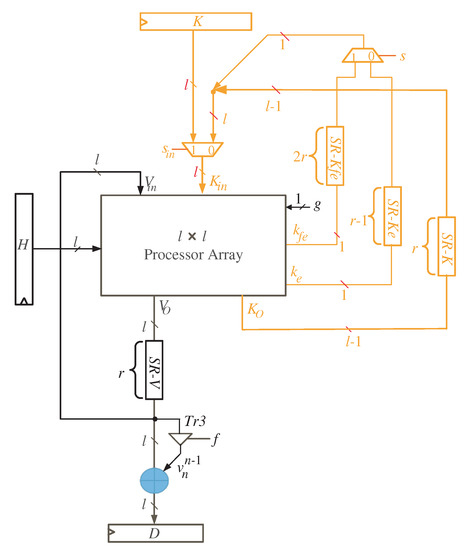
Figure 4.
Multiplier SISO processor Structure.
By reading Figure 4, we notice that registers K and H are of size l and used to feed the word inputs of K and H, in sequence, to the processor array block. Furthermore, register D is used to synchronize the output product D before delivering it to the processor data bus. As input words of variable V have zero initial values, there is no need to feed them to the processor array through an input register. They will be initialized by clearing the shift register SR-V shown in the figure. This shift register has a width of l bits and depth of r registers, where . The depth of SR-V is sufficient to the guarantee that all the initial input words of variable V are fed to the processor array block.
With a closer look at Figure 4, we can notice that the words of K variable () resulted from the processor array block have three different types of signals due to the delay differences between signals , , and the remaining signals of word K, as shown in Figure 2 and Figure 3. signal should be delayed by time steps, , before feeding it back to the input of the processor array block. Additionally, before returning the signal to the input of the processor array block, it should be delayed by time steps. The remaining signals of the word K () should be delayed by r time steps before being fed back to the processor array’s input. These delays are implemented using the shift registers (SR) related to variable K as shown in Figure 4. The width and depth of each SR are indicated in the figure. As we also notice from Figure 4, the intermediate words of V are looped back through the shift register SR-V to be delayed by r time steps before reaching out to the inputs of the processor array block.
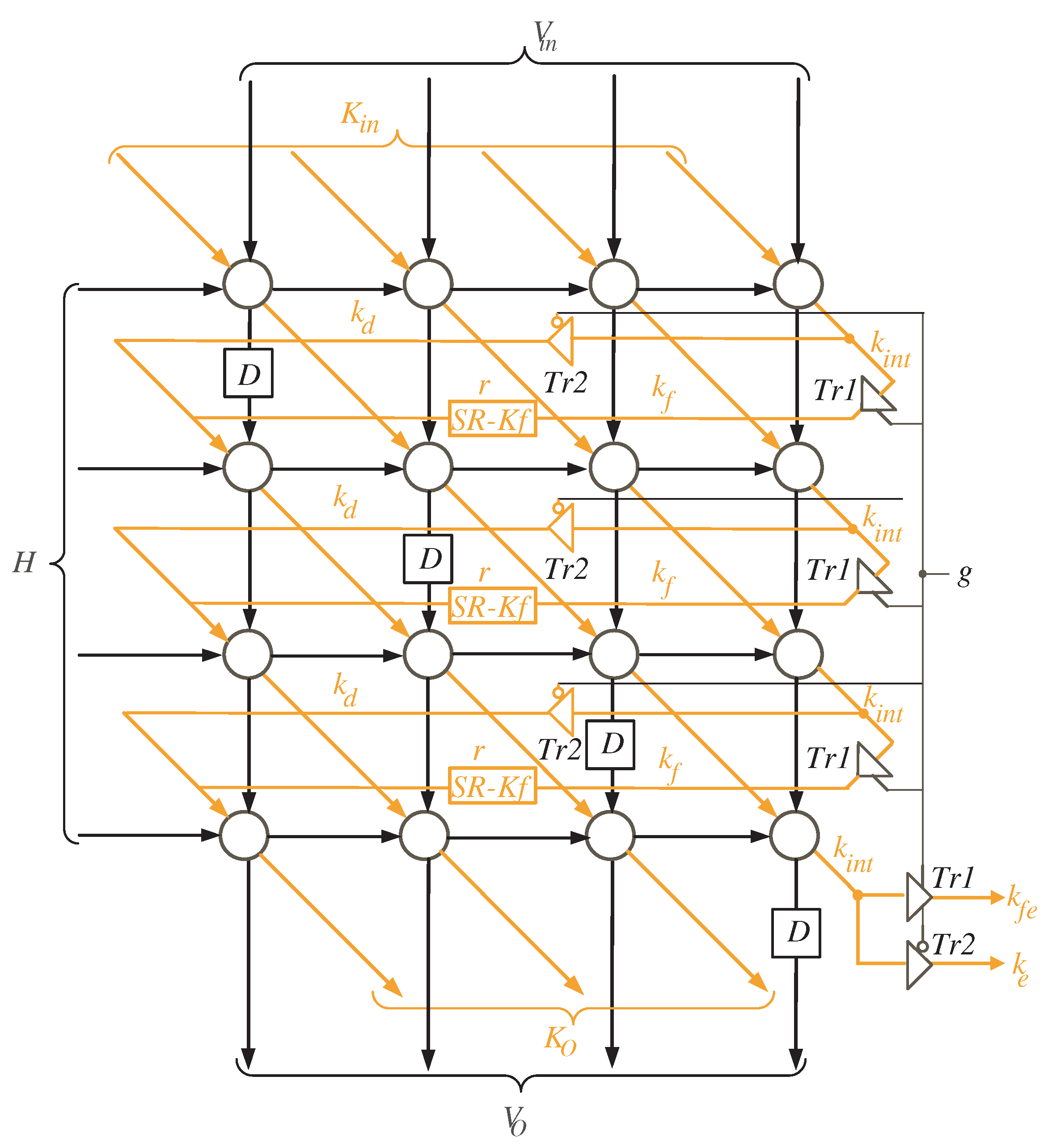
The processor array description is shown in Figure 5 for the case when and . Two types of tri-state buffers are used to select between signals and . Another two types of tri-state buffers are used to select between signals and . All of these buffers are controlled with the control signal g. At time instances , , the control signal g is enabled (), allowing the tri-state buffers to pass and signals shown in Figure 5. The control signal g is deactivated () for the remaining time instances, allowing the and signals to pass through tri-state buffers .
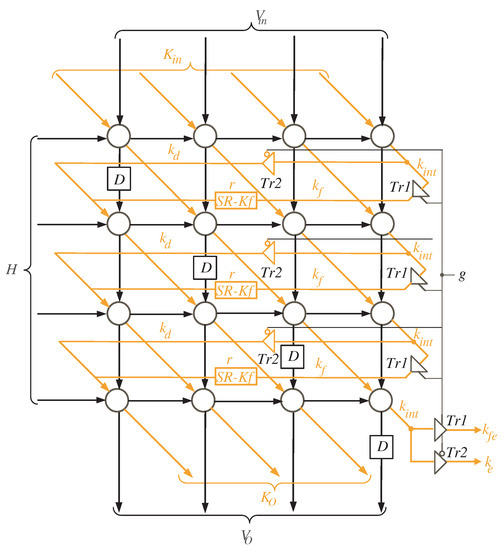
Figure 5.
The structure of Multiplier SISO processor array.
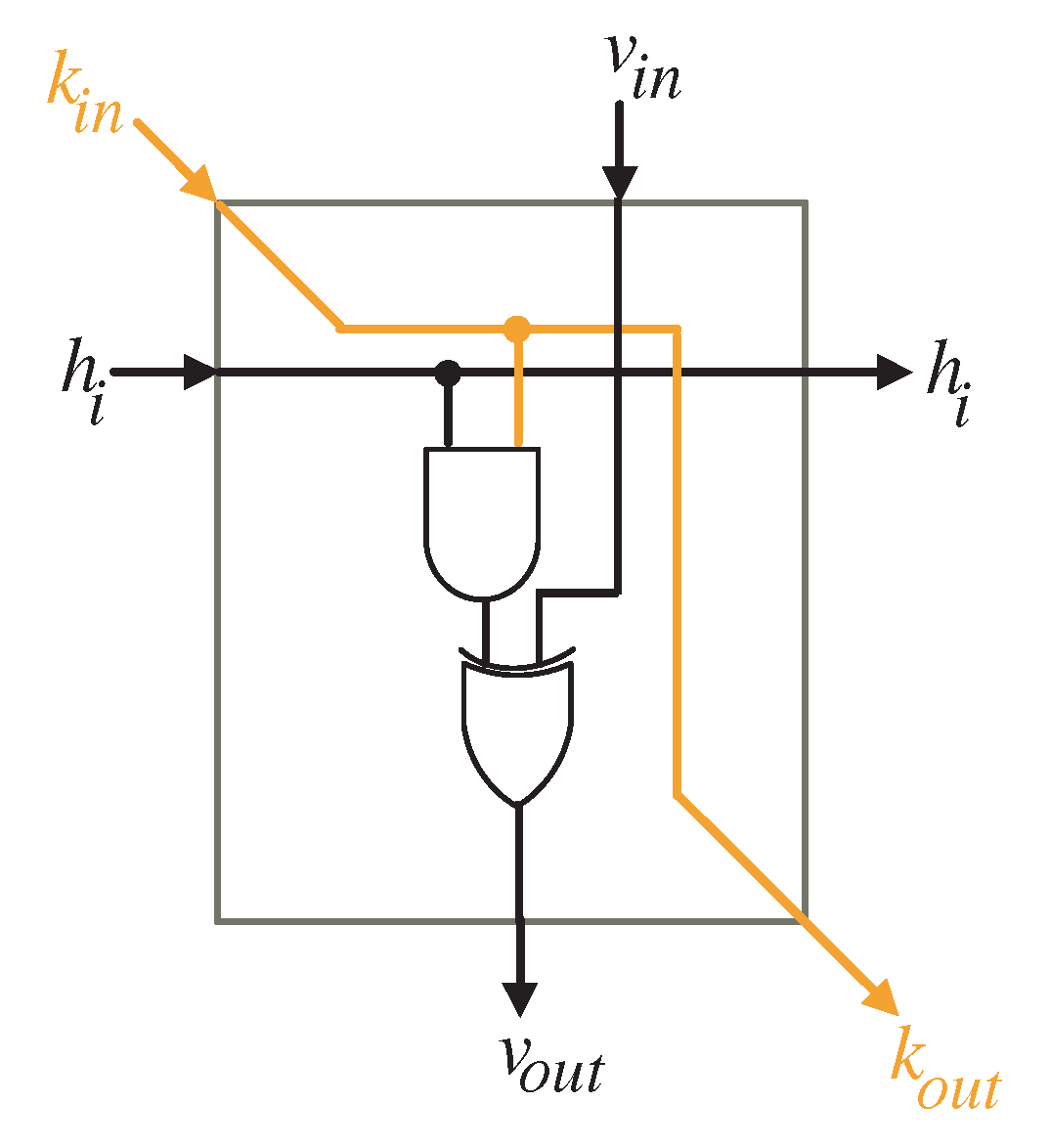
To compute the intermediate bits of word V, the input bits of word H () should be transferred to the processing elements of the processor array as displayed in Figure 5. The logic diagram of the PE is depicted in Figure 6. It includes one AND gate and one XOR gates.
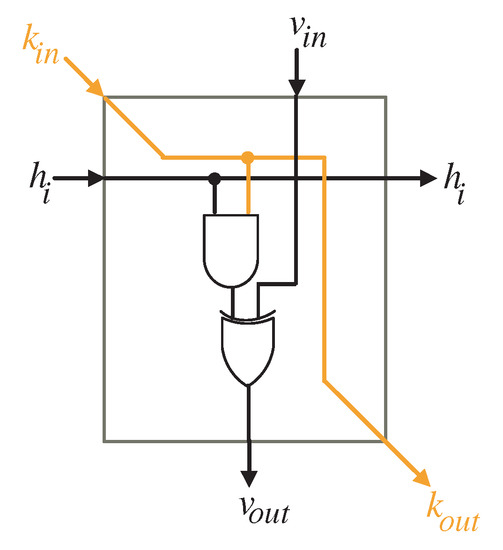
Figure 6.
PE logic details.
The operation details of the 2-D SISO multiplier for general values of n and l are as follows:
- At the first time instance , the controller activates the MUX with select signal () to allow the l most significant bits (MSB) of variable K to reach out to the input of the processor array block as shown in Figure 4. To ensure V variable has zero initial value as described in Algorithm 1, the controller resets the shift register SR-V at the first time instance. At the same time instance, the least significant l bits of variable H are transmitted horizontally to the PEs nodes of the processor array block. Notice that the H word transferred at this time instance should be hold for the following time instances.
- At time instances , the controller still activates the MUX with select signal () to enable the remaining words of input K to reach out to the processor array input. These words, together with the previously held H words at the first time instance, are used to calculate in sequence the partial words of V and K. The V words resulted from the output of the processor array block () are looped back to its input through the shift register SR-V. The K words resulted from the output of the processor array block are looped back to its input through the shift registers SR-K, SR-Ke, SR-Kfe, and the MUX controlled by the select signal S as displayed in Figure 4. It is worth noticing that the depth of the shift register SR-V keeps the initial values of V having zero values during these time instances.
- During times , and , the controller deactivates the MUX controlled by the select signal S (), see Figure 4, to pass the signal to be concatenated with the word. At the same time instances, the controller deactivates the MUX controlled by the select signal () to transfer the whole partial word of K to the input of the processor array block as displayed in Figure 4.
- During times , , the controller activates the MUX controlled by the select signal S (), see Figure 4, to pass the signal to be concatenated with the word. At the same time instances, the controller deactivates the MUX controlled by the select signal () to transfer the whole partial word of K to the input of the processor array block as displayed in Figure 4.
- At times , , the remaining H words are transferred to the input of the processor array block to be used alongside the word inputs , in updating the partial words of variable V ().
- Starting at time , the output words of product D will be available in sequence at the output bus.
To ensure that there is always one time instance difference between the words of V, we inserted delay elements (D Flip-Flop blocks) to the processor array, as illustrated in Figure 5. These elements synchronize the processor array’s work by delaying V words by one time instance to arrive at the same time as the resultant bits of . The bits are created starting at the second time instance, as seen in Figure 3, and this results in increasing the total number of clock cycles by one as indicated in Equation (23). Furthermore, shift registers SR-Kf of depth r are added to the processor array (see Figure 5) to ensure that the signals arrive at the left processing elements at the appropriate time.
5. Experimental Results and Discussion
We compared the suggested 2-D word-based multiplier structure to the optimal word-based ones in the literature [20,23,33,34]. The area estimation is determined by the number of basic logic gates and components in the examined multiplier architectures (AND gates, Tri-state buffers, XOR gates, Flip-Flops (FFs), and MUXs). The number of clock cycles needed to accomplish the multiplication operation is defined as latency. The delay of the basic gates/components of the multiplier logic circuit’s longest path is referred to as critical path delay (CPD). The estimated area and time results of the multiplier structures are shown in Table 2. The following symbols are used in Table 2. They can be translated as follows:
Table 2.
The word-based multipliers’ area and time complexities.
- ∎
- l denotes the word size of the multiplier constructions.
- ∎
- denotes the delay of the fundamental 2-input AND gate.
- ∎
- denotes the delay of the fundamental 2-input XOR gate.
- ∎
- denotes the delay of the 2-input MUX.
- ∎
- expresses the overall number of FFs employed in the multiplier construction of Pan [20].
- ∎
- expresses the overall number of FFs employed in the multiplier construction of Hua [33].
- ∎
- expresses the overall number of FFs employed in the multiplier construction of Chen [34].
- ∎
- designates the latency of the multiplier construction of Chen [34].
- ∎
- is the approximated CPD of Pan’s multiplier construction [20].
- ∎
- is the approximated CPD of Hua’s multiplier construction [33].
- ∎
- is the approximated CPD of Chen’s multiplier construction [34].
- ∎
- is the approximated CPD of the suggested multiplier construction.
It is worth mentioning that the input/output registers are included in the approximated number of FFs. This guarantees that the multiplier architectures are fairly compared.
We can find the following conclusions from examining the area expressions in Table 2:
- The area complexities of Pan [20] and Xie [23] multipliers are roughly of order and , respectively.
- Except for the MUXes and FFs of the recommended multiplier structure, which have area complexity of order and , all other components have area complexity of order .
- Pan’s [20] and Xie’s [23] multiplier constructions have a larger area complexity than the other multiplier constructions. This is due to the fact that the field size n is significantly bigger than the embedded word size l.
- In comparison to the other multipliers, the suggested multiplier has the smallest number of FFs. This is due to the suggested multiplier having an area complexity of order , as opposed to and for the other multiplier structures.
- The number of FFs in the proposed multiplier structure does not rise significantly as the word size l is increased. This is due to the fact that the proposed multiplier structure’s FFs have an area complexity of order .
According to the data books of most typical CMOS libraries, the FFs require more chip space than the other logic components. As a result, lowering the number of FFs reduces the overall size of the multiplier structures dramatically. Increasing the word size does not considerably increase the overall number of FFs in the proposed multiplier structures, as we previously stated. As a result, the overall area of the suggested multiplier structure will not rise considerably as l grows.
We can notice the following by examining the latency expressions in Table 2:
- When compared to the other multiplier constructions, the multiplier of Hua [33] has the lowest latency.
- The latency findings in Table 3, for the field size and word sizes , indicate that the suggested multiplier structure’s latency expression will result in a larger latency than the multiplier constructions in [20,23], and inexpensive latency compared to the Hua [33] and Chen [34] multiplier constructions.
Table 3. Performance results of word-based modular multipliers for and various embedded word sizes l.
- When the word size l increases, the latency reduces. This is due to the fact that latency expressions are inversely related to l.
We could remark the following facts when we examine CPD expressions:
- The word sizes l have no effect on the CPD expressions of the Xie [23], Hua [33], and Chen [34] multiplier constructions. As a result, for all l values, they will always have constant CPD values.
- CPD expressions of Pan [20] and the proposed multiplier structure are both directly dependent on l. As a result, the CPD values of these multipliers will rise as l rises.
We cannot accurately predict which multiplier architecture has the perfect computation time because it is challenging to qualitatively evaluate the latency reduction and CPD increment as l rises. Nevertheless, the quantitative results provided in Table 3 will demonstrate which multiplier layout outperforms the others in computation time.
The VHDL programming language has been used to describe all of the multiplier constructions. For the field size and embedded word sizes , the multipliers are synthesized. Synopsys tools version 2005.09-SP2 and the NanGate (15 nm, 0.8 V) Open Cell Library have been used to synthesize the modeled multipliers.
The design performance indicators—Latency, Area (A), CPD, Total Computation Time (T), Consumed Power (P), and Consumed Energy (E)—are used to compare the chosen word-based multiplier constructions. The obtained results are listed in Table 3. The area and CPD are provided by the synthesis tools. The area of a 2-input NAND gate is used to normalize the area. The needed time to accomplish one product operation can be defined as the total computation time. It is calculated by multiplying latency and CPD together. At a frequency of 1 kHz, the consumed power is measured. The product of P and T yields the consumed energy results.
The performance results achieved in Table 3 can be interpreted as follows:
- In terms of area (A), the proposed multiplier structure is superior to all existing multiplier structures. It greatly decreases area for all embedded word sizes l, with reduction rates ranging from 67.3% to 97.7%. The reduction in area is primarily due to the proposed multiplier structure’s area, which is mainly determined by the field size l, drastically reducing the number of counted logic gates when compared to most other existing multiplier structures. Furthermore, due to the systolic nature of the suggested multiplier, the majority of its connections are local, leading to a reduction in the area to a large extent.
- In terms of the area-time product (AT), Pan’s multiplier structure [20] surpasses all other multiplier structures, including the suggested one, at . This is mainly attributed to the significant reduction in its latency compared to the other multiplier constructions at this word size. At this embedded size, it outperforms the offered design by 37.9%. The proposed architecture, on the other hand, surpasses Pan’s multiplier structure for and . At , it reduces AT by 26.3%, while at , it reduces AT by 49.2%. Furthermore, the suggested multiplier structure outperforms all alternative multiplier structures by percentages ranging from 21.1% to 99.4% based on the embedded word size.The reduction in AT over the other multiplier structures is mainly due to the significant savings in area complexity of the suggested multiplier structure.
- In terms of consumed power (P), the proposed multiplier outperforms the other multiplier structures at all embedded word sizes. It reduces power consumption at all l values by percentages ranging from 64.4% to 99.5%. The power reduction is attributed to the substantial reduction in the consumed area of the proposed design when compared to the consumed area of the other multiplier designs. The reduced area minimises parasitic capacitance and, as a result, the circuit’s dynamic power significantly reduces. The systolic nature of the proposed design reduces the switching activities of the proposed design compared to the other conventional designs. The switching activities is one of the major parameters that significantly affects the dynamic power consumption.
- In terms of consumed energy (E), the offered multiplier construction surpasses the other multiplier constructions at all embedded sizes. It saves energy at rates ranging from 70.6% to 99.2%. The energy savings are due to the massive reduction in consumed power and the reasonable computation time of the offered multiplier construction compared to the other multiplier structures.
From the obtained results, we can conclude that the offered multiplier outperforms its competitors in terms of area, consumed power, and consumed energy for all popular embedded word sizes. As a result, the proposed design can be used to efficiently implement crypto-processors in resource-constrained IoT devices such as wearable and implantable devices. It can also be used in other resource-constrained applications that set restrictions on the area and energy consumed.
6. Summary and Conclusions
In this paper, we offered a compact and practical 2-D word-based serial-in/serial-out processor for the finite field multiplier in GF(). A rigorous and systematic technique for mapping regular iterative algorithms onto processor arrays is used to create the proposed processor structure. The methodology enables the system developer to manage the overall workload of the processor array system as well as the workload of each processing element. Controlling processor word size allows us to adjust system speed, latency, and area. The recommended processor size can be adjusted to meet the intended chip area, allowing for better implementation of the suggested multiplier processor in resource-constrained IoT devices. The obtained experimental results confirm that the suggested multiplier processor has the benefit of reducing size, power consumption, and utilized energy when compared to the conventional multiplier processor.
7. Future Work
As a future work, we will incorporate the proposed multiplier into the ECC cryptography to evaluate the amount of savings in its area and consumed energy. The process will start by replacing the inversion operation by several multiplication operations by representing the elliptic curve points as projective coordinate points.
Author Contributions
Conceptualization, A.I. and F.G.; methodology, A.I. and F.G.; software, A.I.; validation, A.I. and F.G.; formal analysis, A.I.; investigation, A.I.; resources, A.I.; data curation, A.I.; writing—original draft preparation, A.I.; writing—review and editing, A.I. and F.G.; visualization, A.I. and F.G.; supervision, A.I.; project administration, A.I. and F.G.; and funding acquisition, F.G. All authors have read and agreed to the published version of the manuscript.
Funding
Deputyship for Research & Innovation, Ministry of Education in Saudi Arabia, project number (IF-PSAU-2021/01/17867).
Institutional Review Board Statement
Not Applicable.
Informed Consent Statement
Not Applicable.
Data Availability Statement
Not Applicable.
Acknowledgments
The authors extend their appreciation to the Deputyship for Research & Innovation, Ministry of Education in Saudi Arabia for funding this research work through the project number (IF-PSAU-2021/01/17867).
Conflicts of Interest
The authors declare no conflict of interest.
Abbreviations
The following abbreviations are used in this manuscript:
| IoT | Internet of Things |
| ASIC | Application Specific Integrated Circuit |
| ECC | Elliptic Curve Cryptography |
| DG | Dependency Graph |
| AOP | All-One Polynomial |
| VLSI | Very Large Scale Integrated Circuit |
| L | Cyclic-Shift-Left |
| DSA | Digital Signature Algorithm |
| FFs | Flip-Flops |
| RSA | Rivest, Shamir, and Adleman |
| SISO | Serial-In/Serial-Out |
| SIPO | Serial-In/Parallel-Out |
| PISO | Parallel-In/Serial-Out |
| CPD | Critical Path Delay |
References
- Rondon, L.P.; Babun, L.; Aris, A.; Akkaya, K.; Uluagac, A.S. Survey on enterprise Internet-of-Things systems (E-IoT): A security perspective. Ad Hoc Netw. 2022, 125, 102728. [Google Scholar] [CrossRef]
- Sowjanya, K.; Dasgupta, M.; Ray, S. An elliptic curve cryptography based enhanced anonymous authentication protocol for wearable health monitoring systems. Int. J. Inf. Secur. 2020, 19, 129–146. [Google Scholar] [CrossRef]
- Rana, M.; Mamun, Q.; Islam, R. Lightweight cryptography in IoT networks: A survey. Future Gener. Comput. Syst. 2022, 129, 77–89. [Google Scholar] [CrossRef]
- Omolara, A.E.; Alabdulatif, A.; Abiodun, O.I.; Alawida, M.; Alabdulatif, A.; Alshours, W.H.; Arshad, H. The internet of things security: A survey encompassing unexplored areas and new insights. Comput. Secur. 2022, 112, 102494. [Google Scholar] [CrossRef]
- Liu, J.; Liu, H.; Chakraborty, C.; Yu, K.; Shao, X.; Ma, Z. Cascade Learning Embedded Vision Inspection of Rail Fastener by Using a Fault Detection IoT Vehicle. IEEE Internet Things J. 2021. [Google Scholar] [CrossRef]
- Heninger, N. RSA, DH, and DSA in the Wild. Cryptology ePrint Archive. 2022. Available online: https://eprint.iacr.org/2022/048.pdf (accessed on 5 February 2022).
- Dong, J.; Zheng, F.; Lin, J.; Liu, Z.; Xiao, F.; Fan, G. EC-ECC: Accelerating Elliptic Curve Cryptography for Edge Computing on Embedded GPU TX2. IACM Trans. Embed. Comput. Syst. (TECS) 2022, 21, 1–25. [Google Scholar] [CrossRef]
- Chiou, C.W.; Lee, C.Y.; Deng, A.W.; Lin, J.M. Concurrent error detection in Montgomery multiplication over GF(2m). IEICE Trans. Fundam. Electron. Commun. Comput. Sci. 2006, E89-A, 566–574. [Google Scholar] [CrossRef]
- Kim, K.W.; Jeon, J.C. Polynomial Basis Multiplier Using Cellular Systolic Architecture. IETE J. Res. 2014, 60, 194–199. [Google Scholar] [CrossRef]
- Choi, S.; Lee, K. Efficient systolic modular multiplier/squarer for fast exponentiation over GF(2m). IEICE Electron. Express 2015, 12, 1–6. [Google Scholar] [CrossRef] [Green Version]
- Kim, K.W.; Kim, S.H. Efficient bit-parallel systolic architecture for multiplication and squaring over GF(2m). IEICE Electron. Express 2018, 15, 1–6. [Google Scholar] [CrossRef] [Green Version]
- Mathe, S.E.; Boppana, L. Bit-parallel systolic multiplier over GF(2m) for irreducible trinomials with ASIC and FPGA implementations. IET Circuits Desvices Syst. 2018, 12, 315–325. [Google Scholar] [CrossRef]
- Devi, S.; Mahajan, R.; Bagai, D. Low complexity design of bit parallel polynomial basis systolic multiplier using irreducible polynomials. Egypt. Inform. J. 2022, 23, 105–112. [Google Scholar] [CrossRef]
- Pillutla, S.R.; Boppana, L. An area-efficient bit-serial sequential polynomial basis finite field GF(2m) multiplier. AEU- Int. J. Electron. Commun. 2020, 114, 153017. [Google Scholar] [CrossRef]
- Imana, J.L. LFSR-Based Bit-Serial GF(2m) Multipliers Using Irreducible Trinomials. IEEE Trans. Comput. 2020, 70, 156–162. [Google Scholar]
- Pillutla, S.R.; Boppana, L. Low-Hardware Digit-Serial Sequential Polynomial Basis Finite Field GF(2m) Multiplier for Trinomials. Adv. Commun. Signal Process. VLSI Trans. Comput. 2021, 722, 401–410. [Google Scholar]
- Kim, C.H.; Hong, C.P.; Kwon, S. A digit-serial multiplier for finite Field GF(2m). IEEE Trans. Very Large Scale Integr. (VLSI) Syst. 2005, 13, 476–483. [Google Scholar]
- Talapatra, S.; Rahaman, H.; Mathew, J. Low complexity digit serial systolic montgomery multipliers for special class of GF(2m). IEEE Trans. Very Large Scale Integr. (VLSI) Syst. 2010, 18, 847–852. [Google Scholar] [CrossRef]
- Guo, J.H.; Wang, C.L. Hardware-efficient Systolic Architecture for Inversion and Division in GF(2m). IEE Proc. Comput. Digit. Tech. 1998, 145, 272–278. [Google Scholar] [CrossRef]
- Pan, J.S.; Lee, C.Y.; Meher, P.K. Low-Latency Digit-Serial and Digit-Parallel Systolic Multipliers for Large Binary Extension Fields. IEEE Trans. Circuits Syst. 2013, 60, 3195–3204. [Google Scholar] [CrossRef]
- Lee, C.Y.; Fan, C.C.; Yuan, S.M. New Digit-Serial Three-Operand Multiplier over Binary Extension Fields for High-Performance Applications. In Proceedings of the 2017 2nd IEEE International Conference on Computational Intelligence and Applications, Beijing, China, 8–11 September 2017; pp. 498–502. [Google Scholar]
- Lee, C.Y. Super digit-serial systolic multiplier over GF(2m). In Proceedings of the 2012 Sixth International Conference on Genetic and Evolutionary Computing, Kitakyushu, Japan, 25–28 August 2012; pp. 509–513. [Google Scholar]
- Xie, J.; Meher, P.K.; Mao, Z. Low-latency high-throughput systolic multipliers over GF(2m) for NIST recommended pentanomials. IEEE Trans. Circuits Syst. 2015, 62, 881–890. [Google Scholar] [CrossRef]
- Namin, A.H.; Wu, H.; Ahmadi, M. A word-level finite field multiplier using normal basis. IEEE Trans. Comput. 2011, 60, 890–895. [Google Scholar] [CrossRef]
- Lee, C.Y.; Chiou, C.W.; Lin, J.M.; Chang, C.C. Scalable and systolic Montgomery multiplier over generated by trinomials. IET Circuits Devices Syst. 2007, 1, 477–484. [Google Scholar] [CrossRef]
- Chen, L.H.; Chang, P.L.; Lee, C.Y.; Yang, Y.K. Scalable and systolic dual basis multiplier Over GF(2m). Int. J. Innov. Comput. Inf. Control 2011, 7, 1193–1208. [Google Scholar]
- Bayat-Sarmadi, S.; Kermani, M.M.; Azarderakhsh, R.; Lee, C.Y. Dual-Basis Superserial Multipliers for Secure Applications and Lightweight Cryptographic Architectures. IEEE Trans. Circ. Syst.-II 2014, 61, 125–129. [Google Scholar] [CrossRef]
- Ibrahim, A.; Gebali, F. Scalable and Unified Digit-Serial Processor Array Architecture for Multiplication and Inversion over GF(2m). IEEE Trans. Circuits Syst. I Regul. Pap. 2017, 22, 2894–2906. [Google Scholar] [CrossRef]
- Gebali, F. Algorithms and Parallel Computers; John Wiley: New York, NY, USA, 2011. [Google Scholar]
- Ibrahim, A.; Elsimary, H.; Gebali, F. New systolic array architecture for finite field division. IEICE Electron. Express 2018, 15, 1–11. [Google Scholar] [CrossRef] [Green Version]
- Ibrahim, A. Scalable digit-serial processor array architecture for finite field division. Microelectron. J. 2019, 85, 83–91. [Google Scholar] [CrossRef]
- Meher, P.K.; Lou, X. Low-Latency, Low-Area, and Scalable Systolic-Like Modular Multipliers for GF(2m) Based on Irreducible All-One Polynomials. IEEE Trans. Circuits Syst. I Regul. Pap. 2016, 64, 399–408. [Google Scholar] [CrossRef]
- Hua, Y.Y.; Lin, J.M.; Chiou, C.W.; Lee, C.Y.; Liu, Y.H. Low Space-Complexity Digit-Serial Dual Basis Systolic Multiplier over GF(2m) Using Hankel Matrix and Karatsuba Algorithm. IET Inf. Secur. 2013, 7, 75–86. [Google Scholar]
- Chen, C.C.; Lee, C.Y.; Lu, E.H. Scalable and Systolic Montgomery Multipliers Over GF(2m). IEICE Trans. Fundam. Electron. Commun. Comput. Sci. 2008, E91-A, 1763–1771. [Google Scholar] [CrossRef]
Publisher’s Note: MDPI stays neutral with regard to jurisdictional claims in published maps and institutional affiliations. |
© 2022 by the authors. Licensee MDPI, Basel, Switzerland. This article is an open access article distributed under the terms and conditions of the Creative Commons Attribution (CC BY) license (https://creativecommons.org/licenses/by/4.0/).