
Enhancing Detection Quality Rate with a Combined HOG and CNN for Real-Time Multiple Object Tracking across Non-Overlapping Multiple Cameras


Abstract
:1. Introduction
2. Related Works
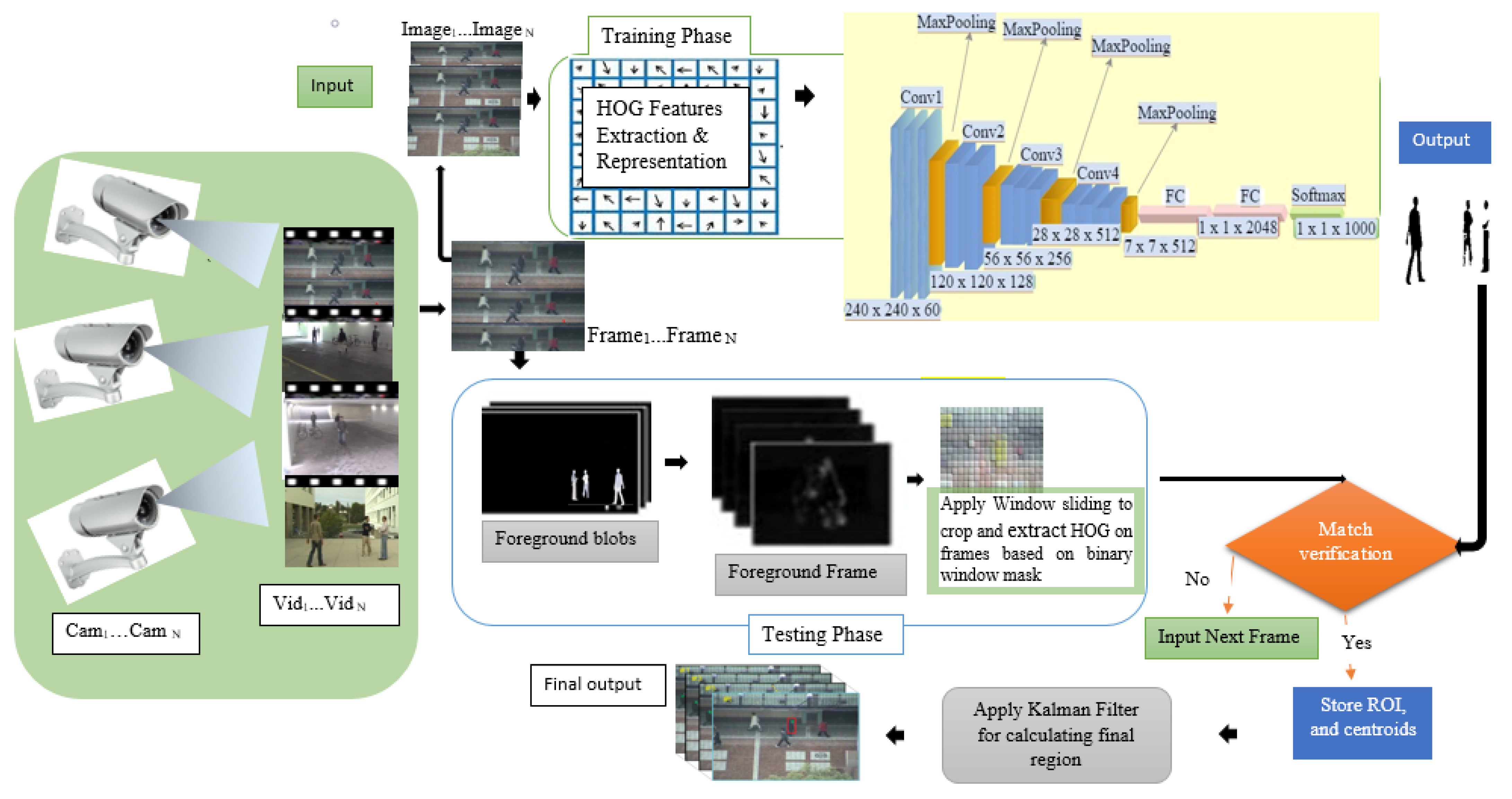
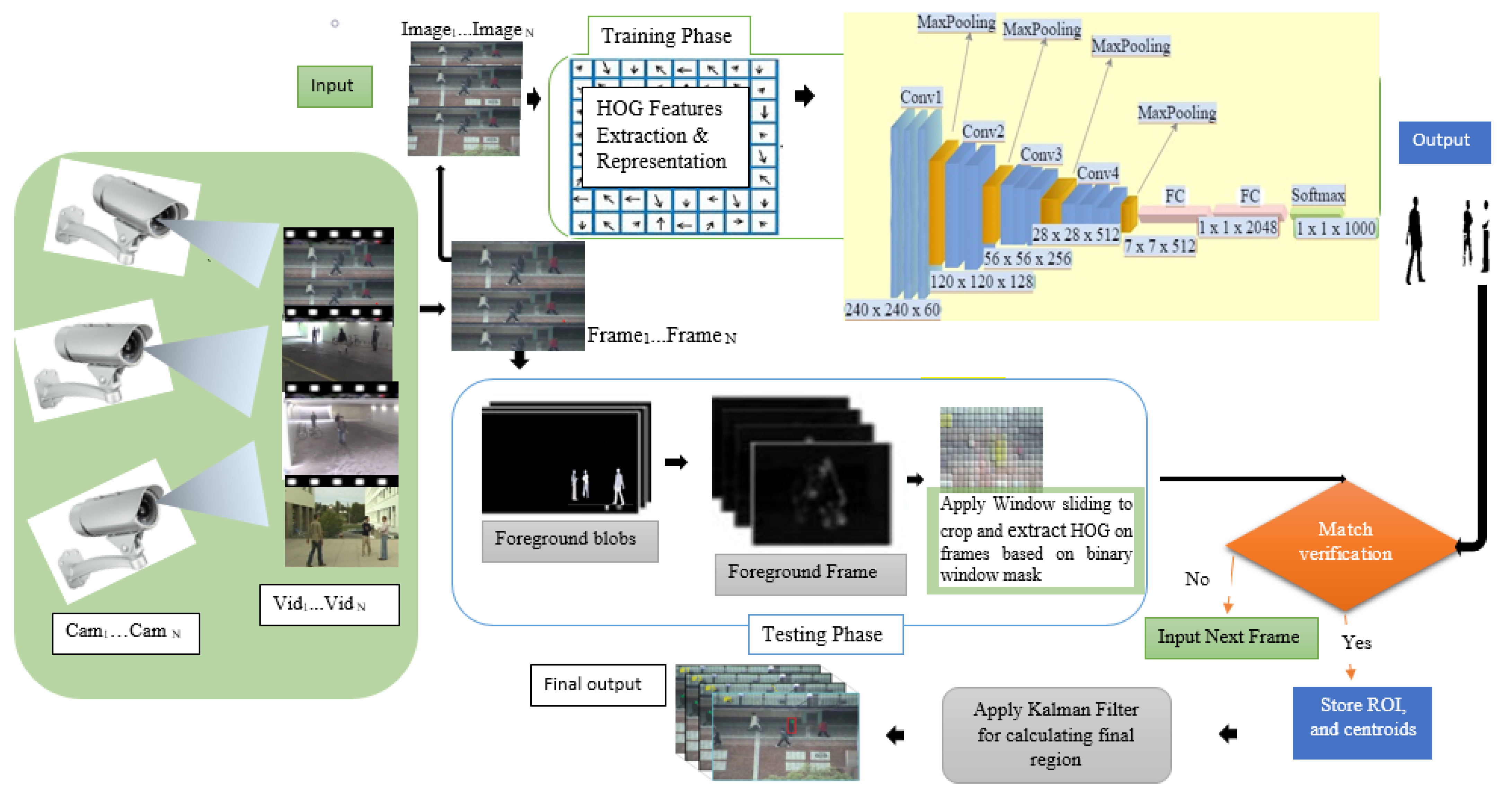
3. Proposed HCNN for Real-Time MOT
3.1. Background Segmenting Modeling
3.2. Foreground Blobs Windowing Modeling
3.3. HOG Descriptor’s Features Extraction
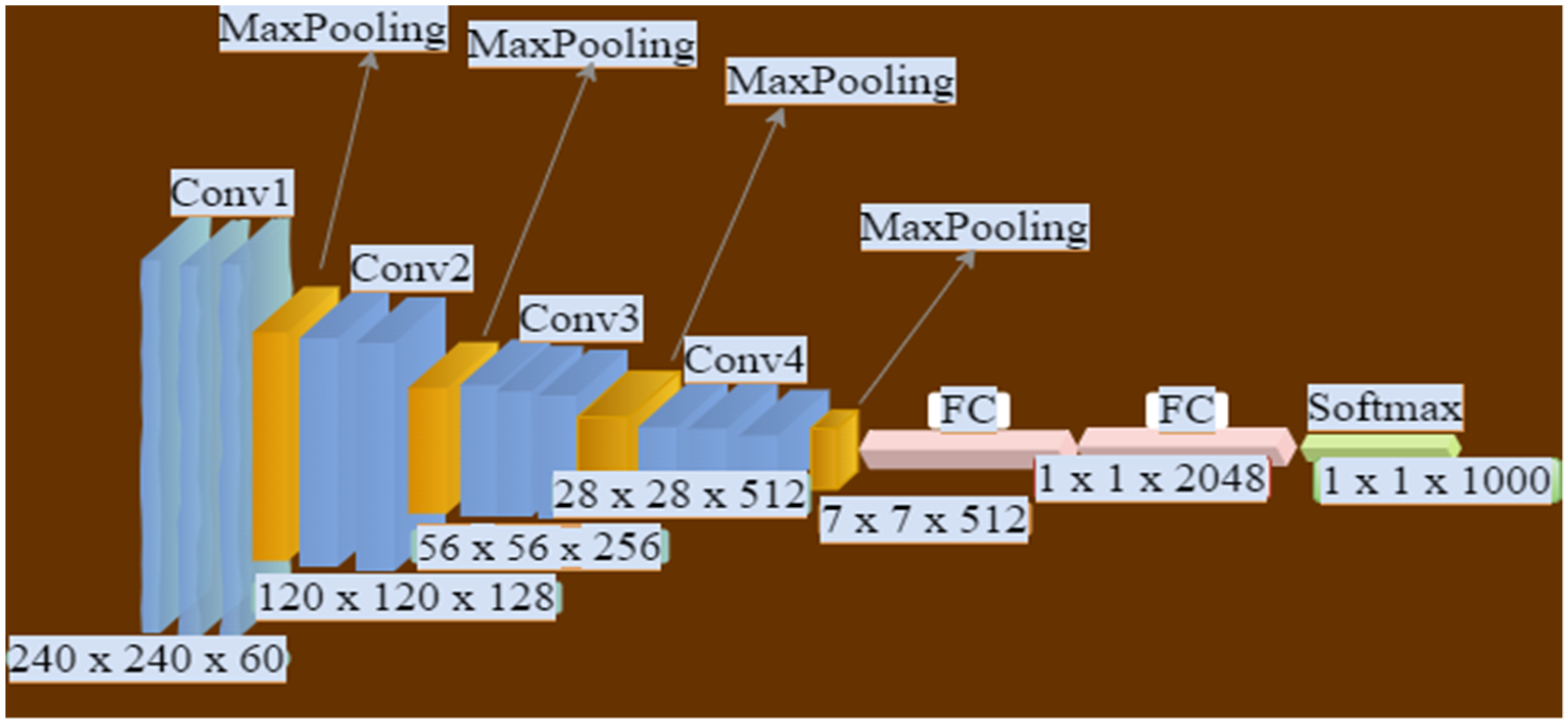
3.4. Structure of the Convolutional Neural Network
3.5. Designing Kalman Filter for Our HCNN Algorithm
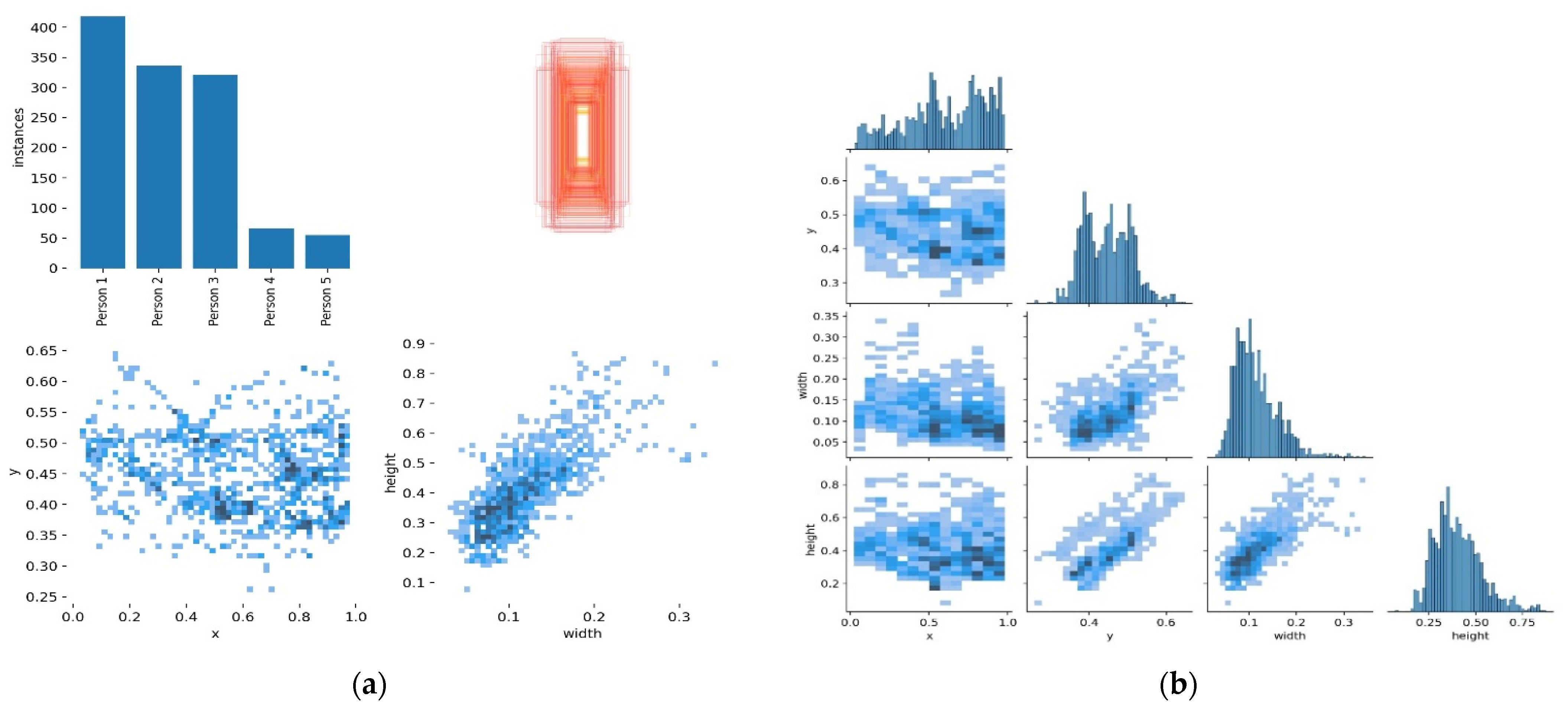
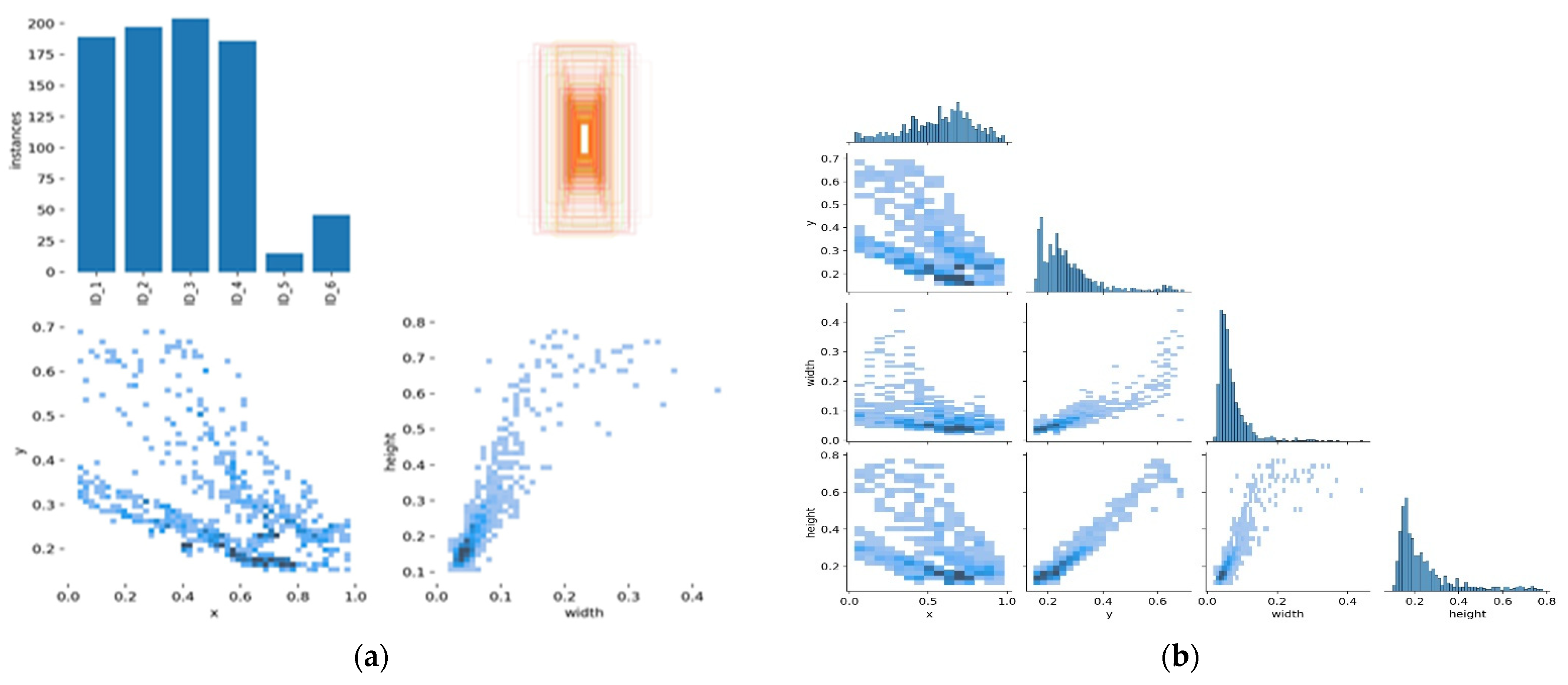
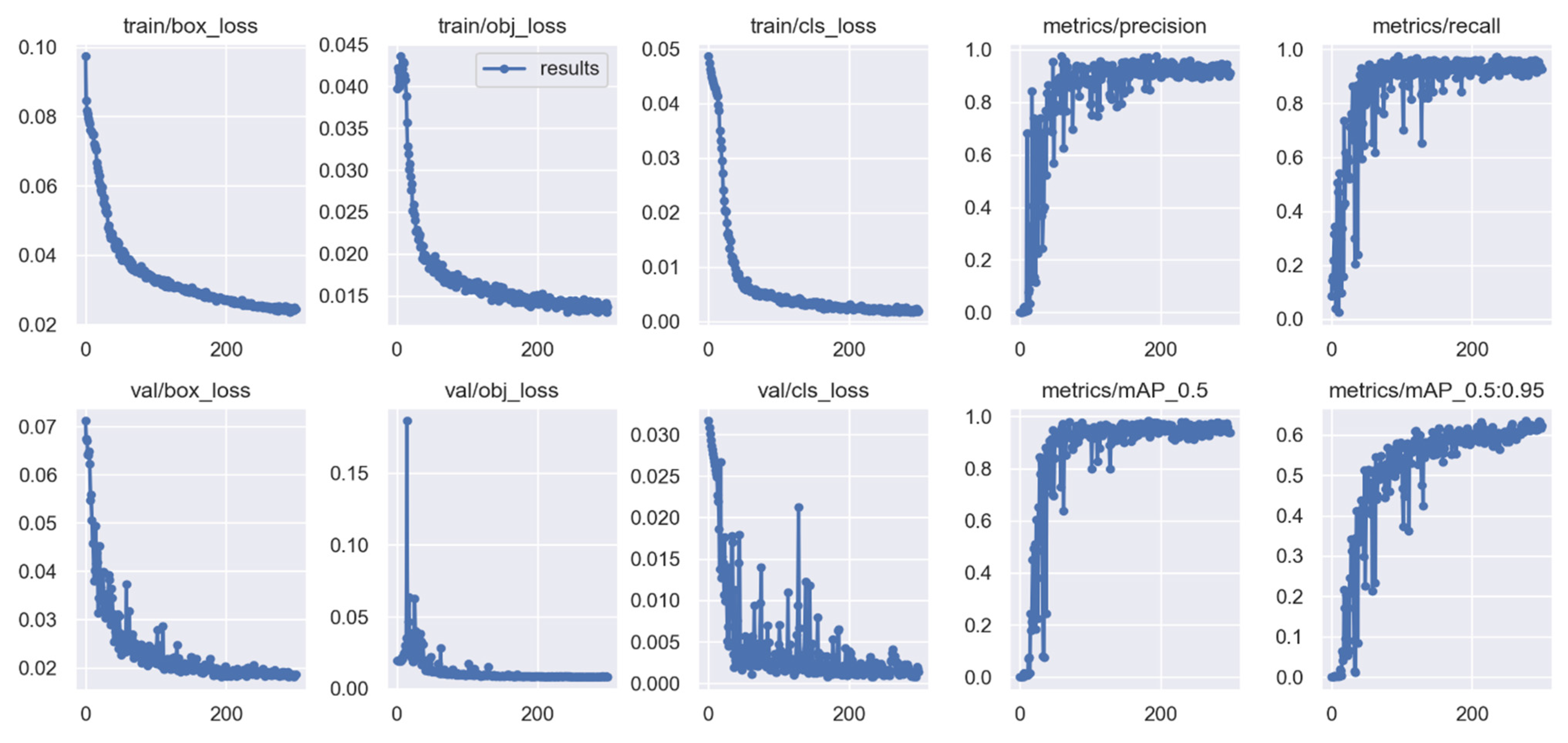
4. Experiments
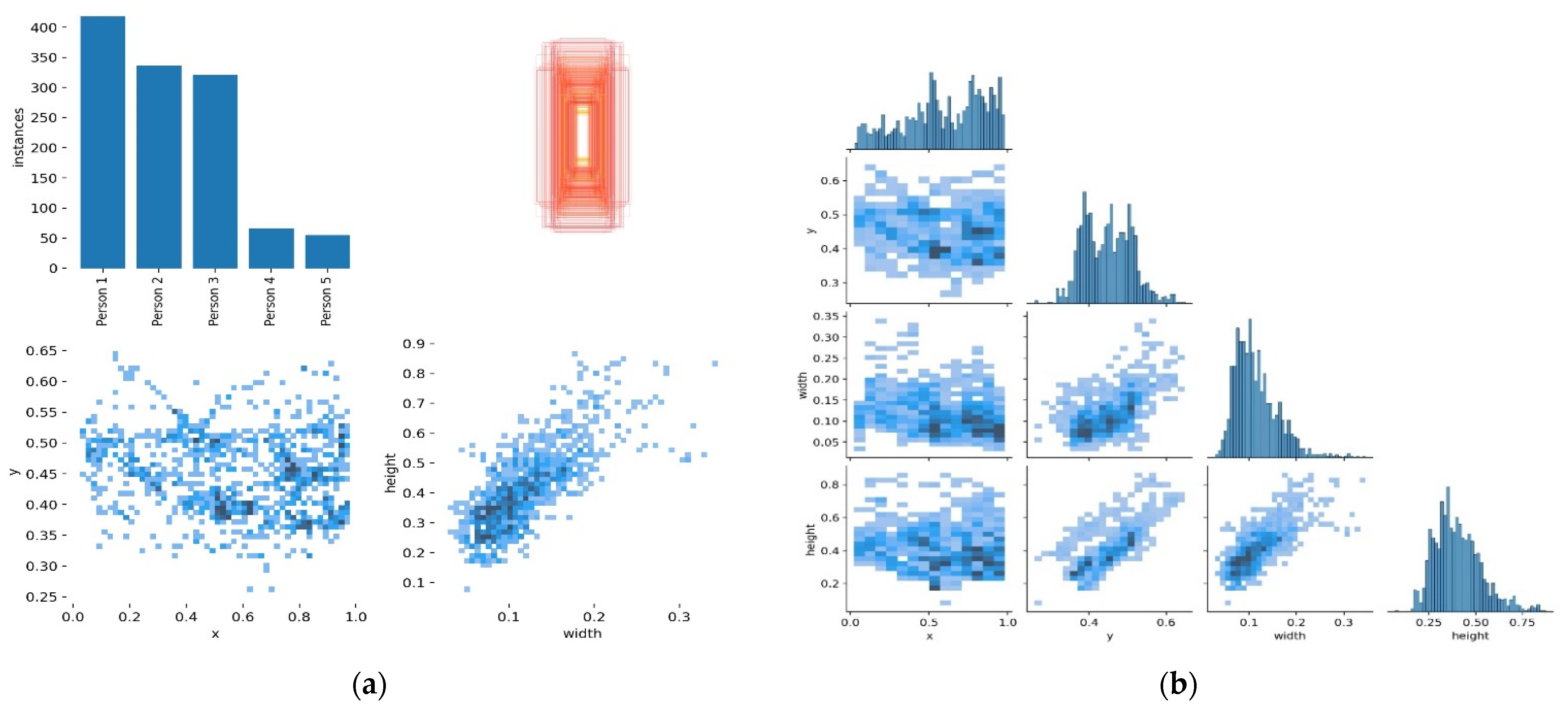
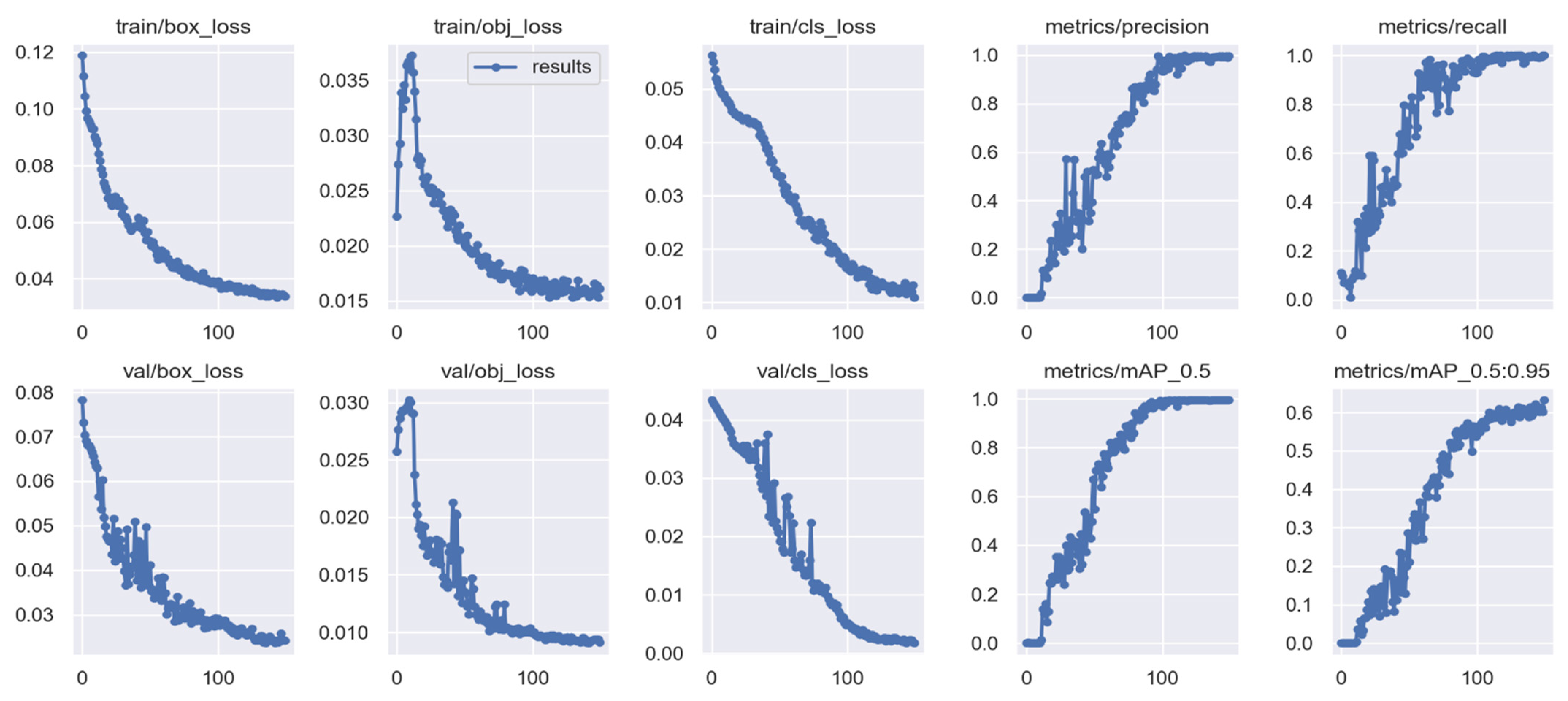
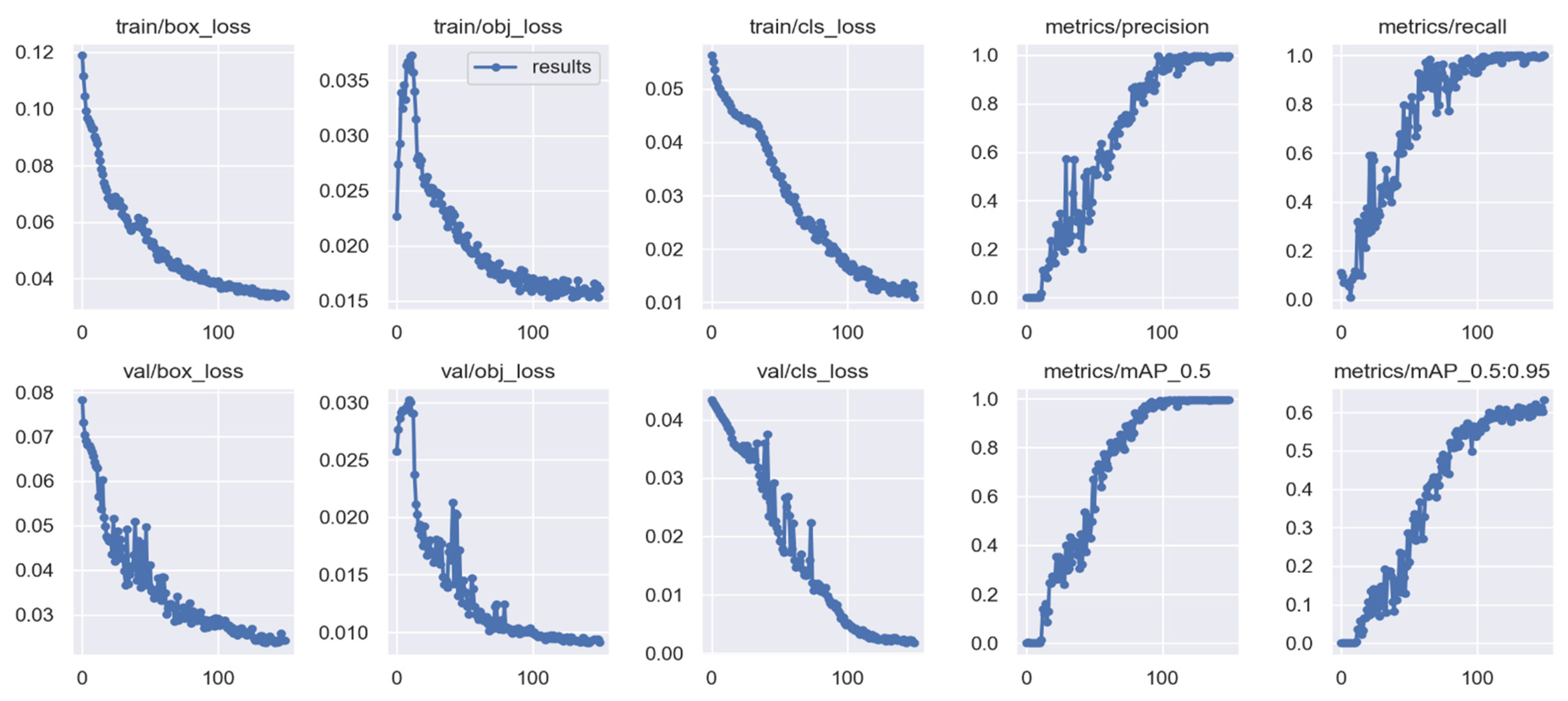
Experimental Setup
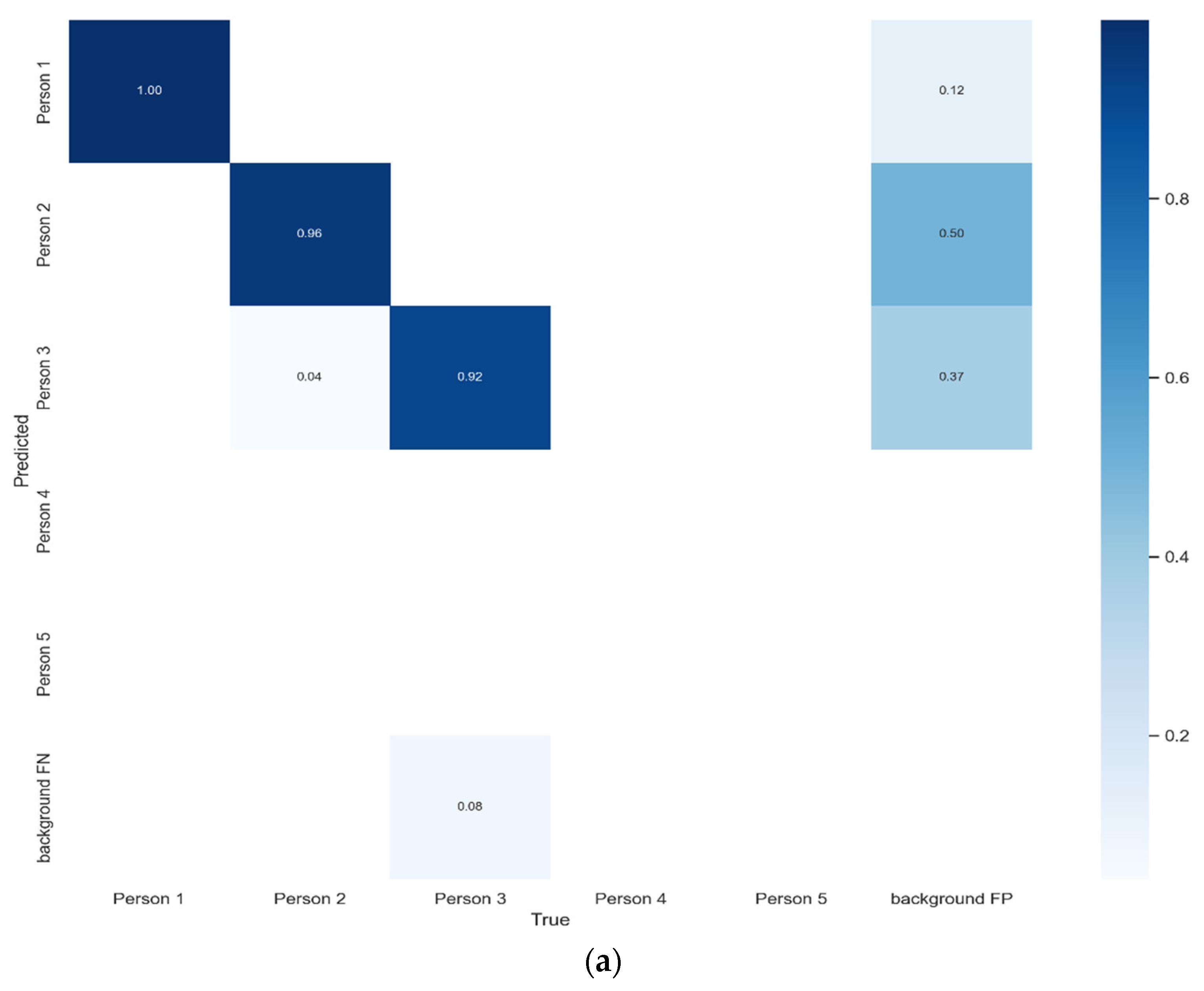
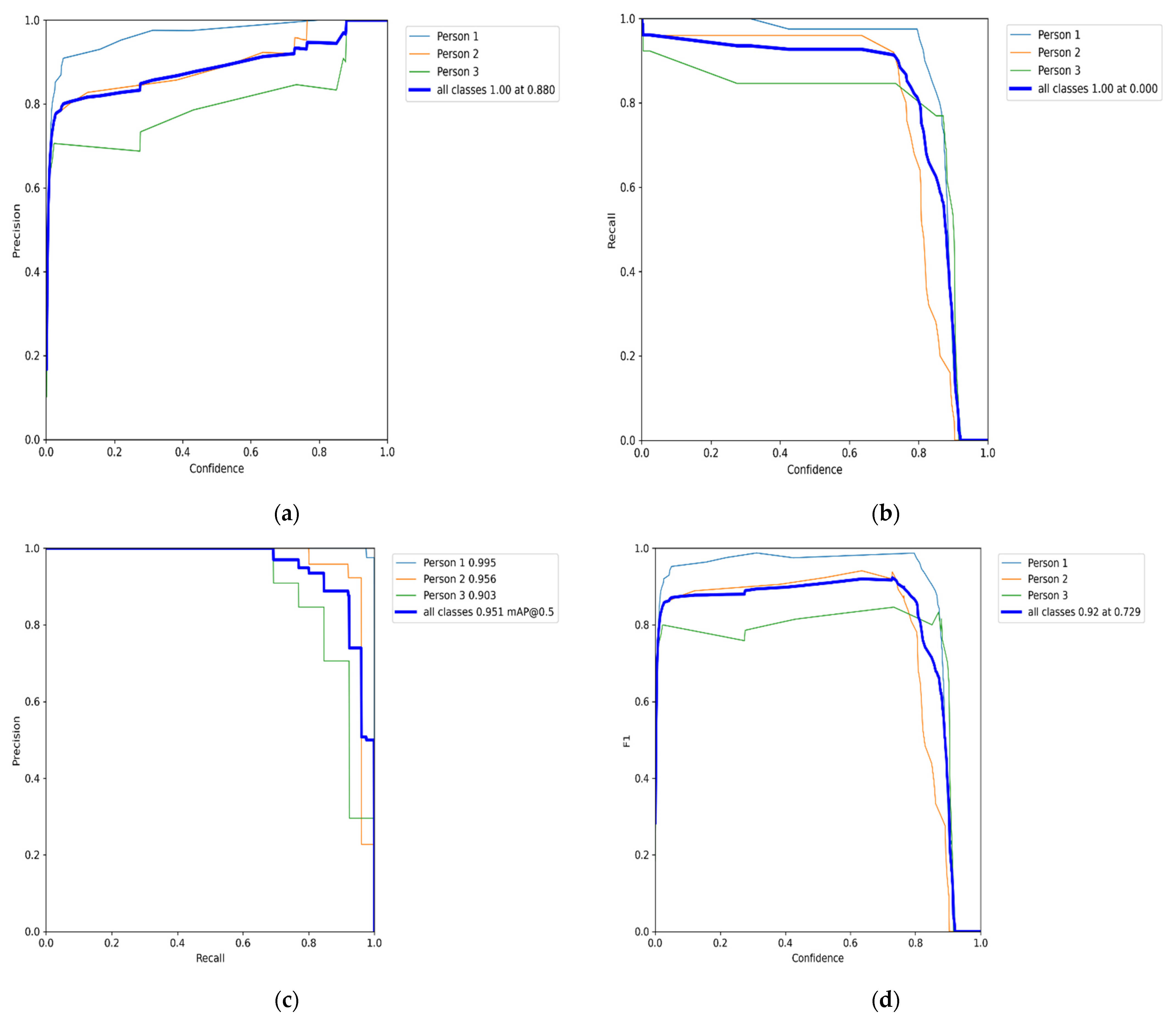
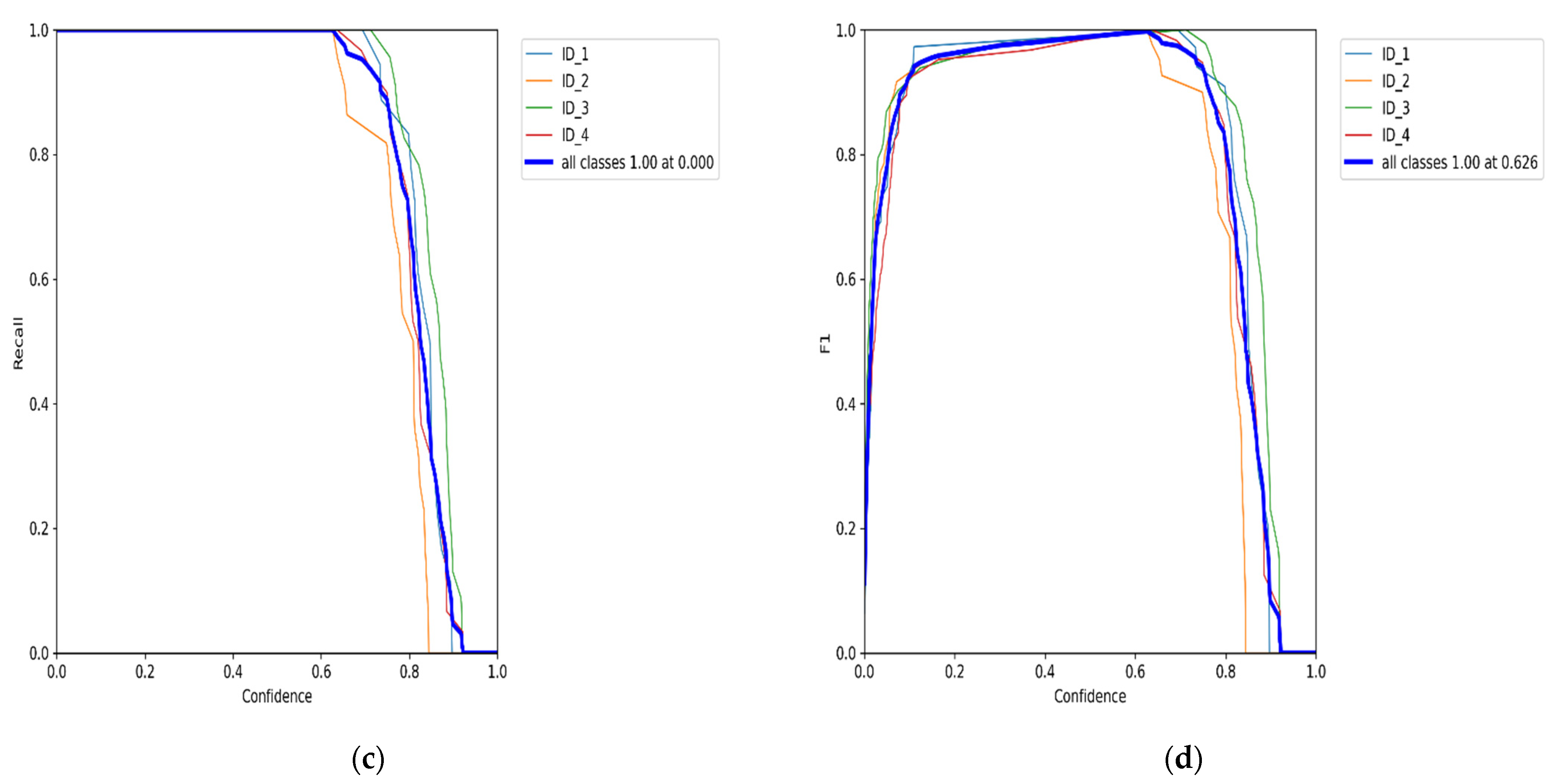
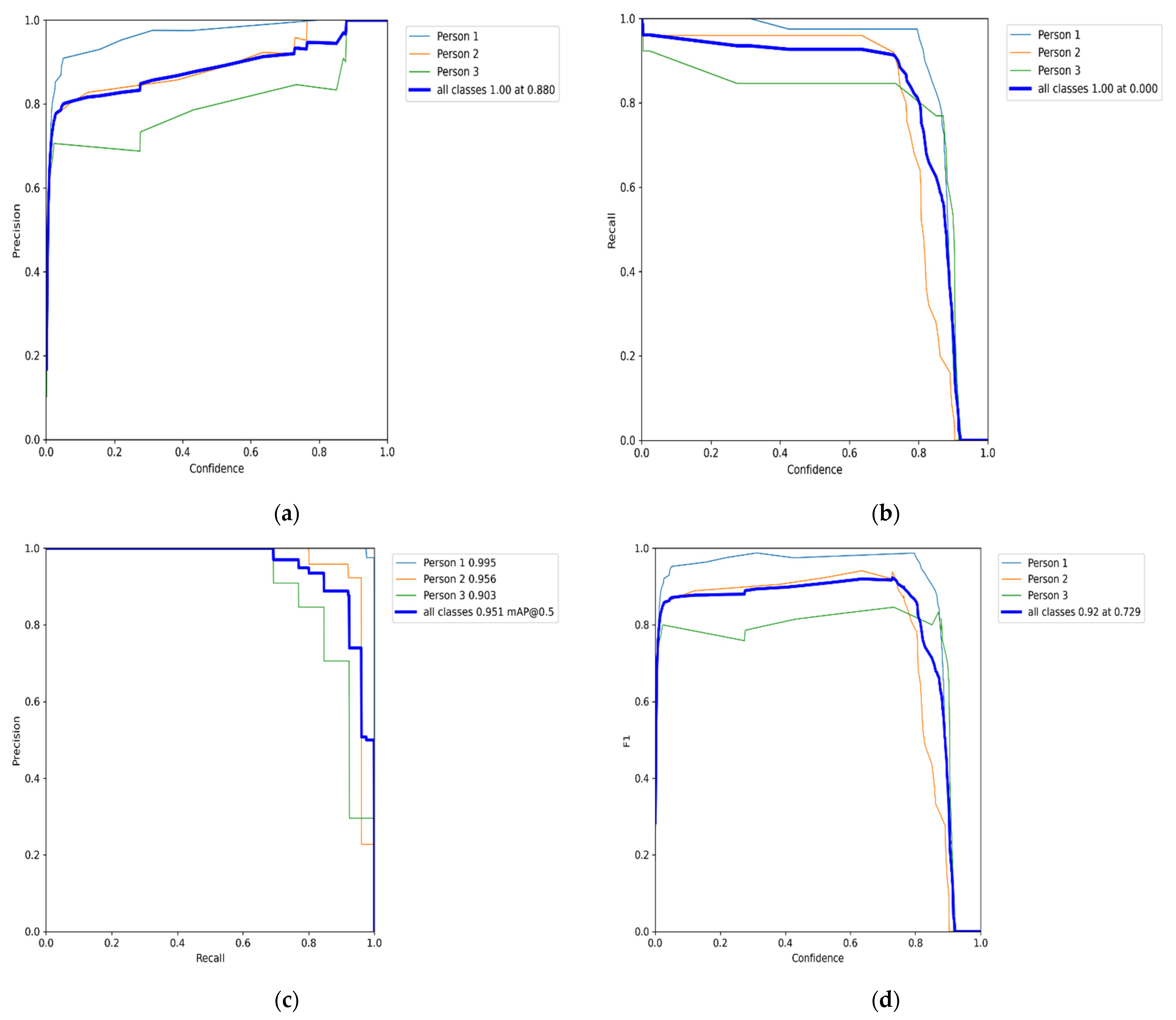
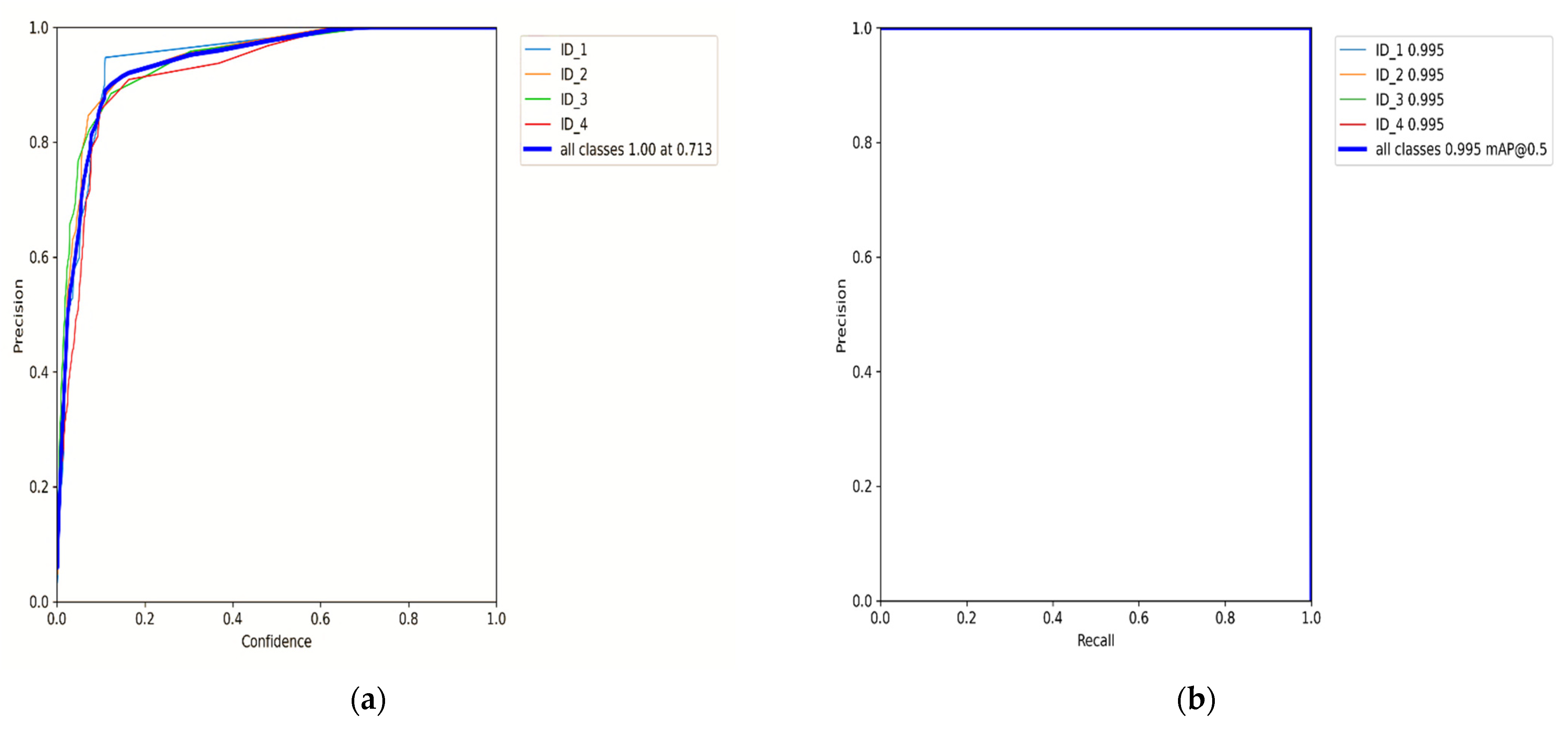
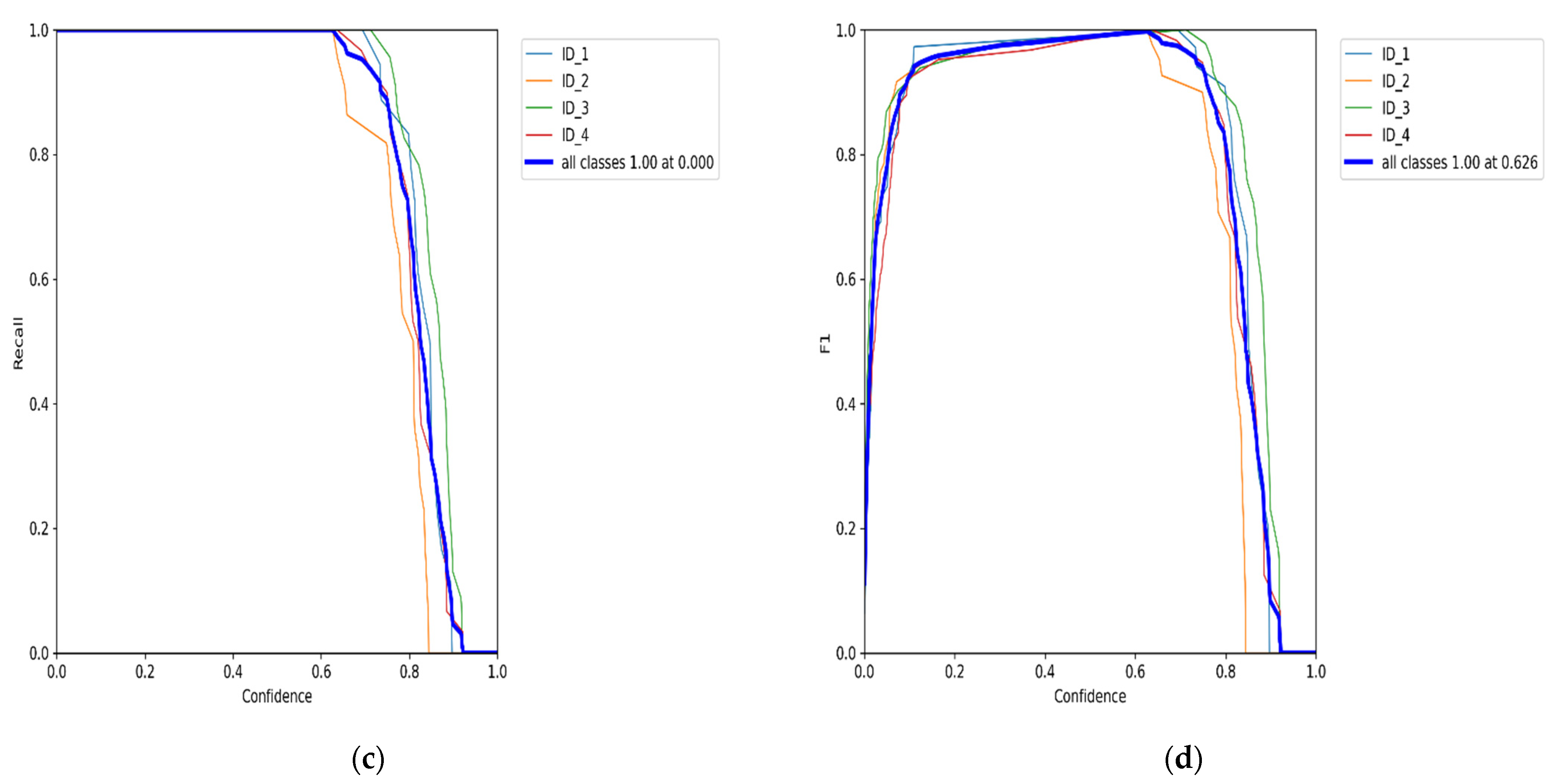
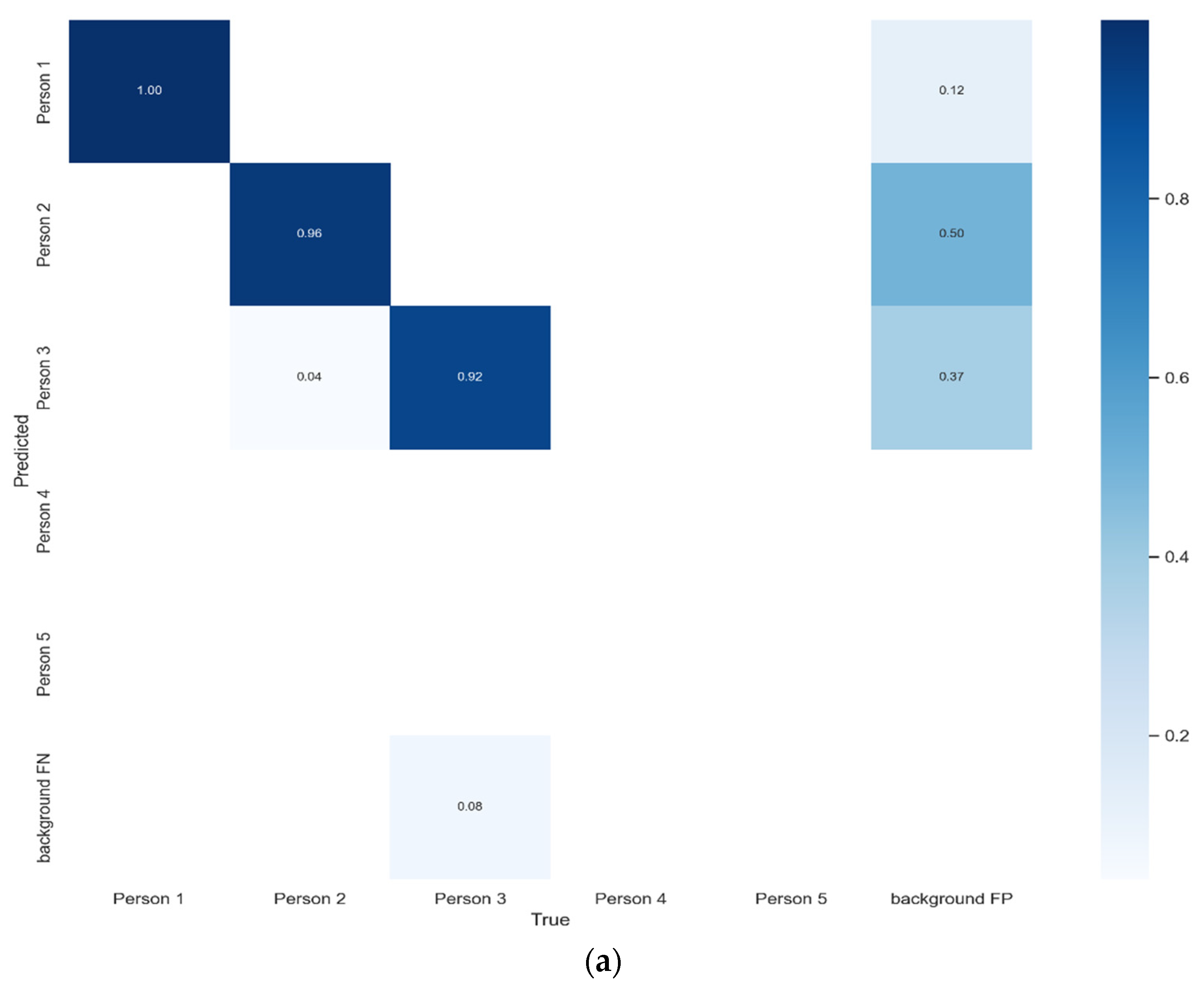
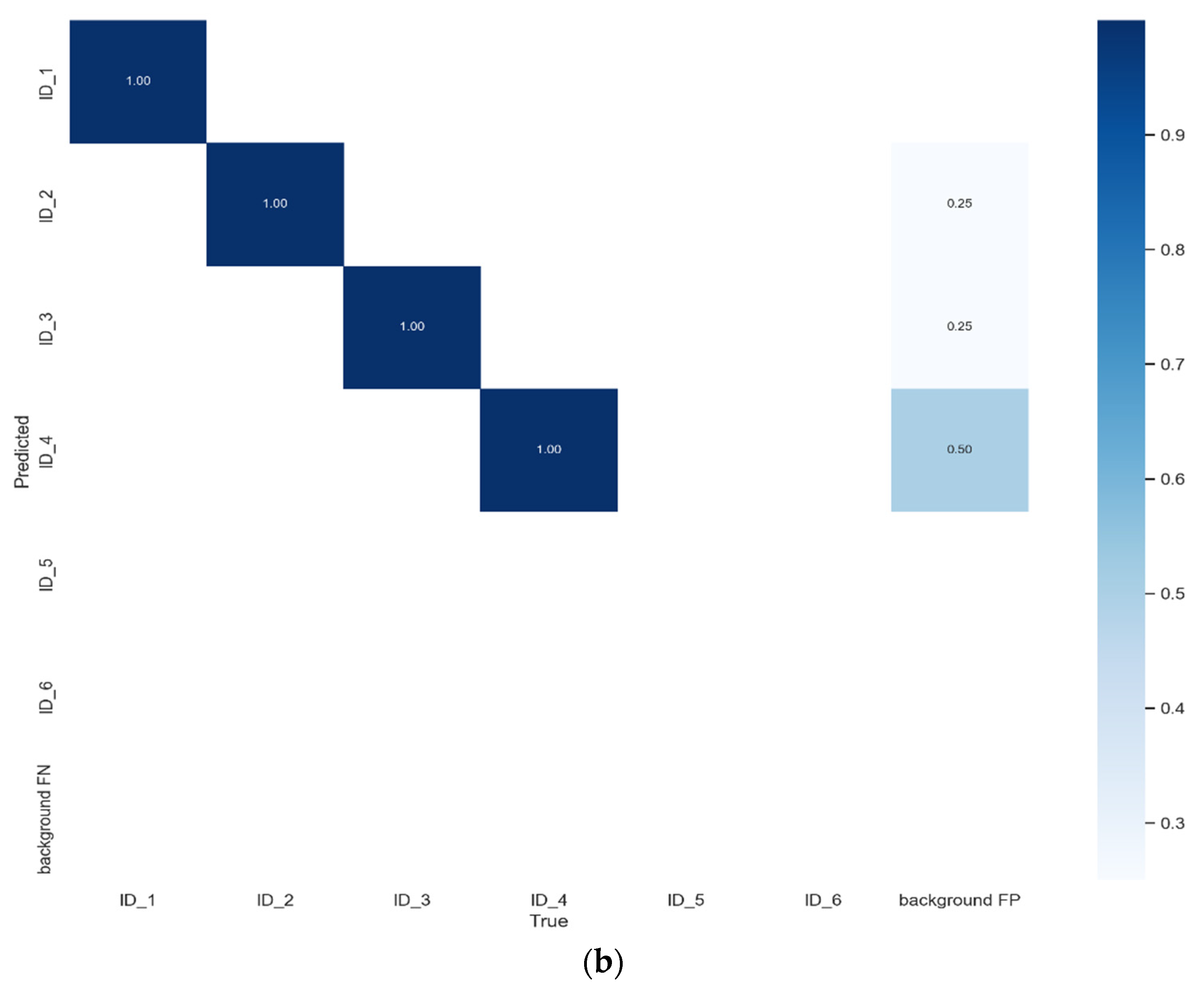
5. Results Analysis
Benchmark Evaluation Results
6. Conclusions
Author Contributions
Funding
Informed Consent Statement
Data Availability Statement
Acknowledgments
Conflicts of Interest
Appendix A

References
- Angeline, R.; Kavithvajen, K.; Balaji, T.; Saji, M.; Sushmitha, S.R. CNN integrated with HOG for efficient face recognition. Int. J. Recent Technol. Eng. 2019, 7, 1657–1661. [Google Scholar]
- Zhang, C.; Patras, P.; Haddadi, H. Deep Learning in Mobile and Wireless Networking: A Survey. IEEE Commun. Surv. Tutor. 2019, 21, 2224–2287. [Google Scholar] [CrossRef] [Green Version]
- Sanchez-Matilla, R.; Poiesi, F.; Cavallaro, A. Online multi-target tracking with strong and weak detections. In Lecture Notes in Computer Science (Including Subseries Lecture Notes in Artificial Intelligence and Lecture Notes in Bioinformatics); Springer: Cham, Switzerland, 2016; Volume 9914, pp. 84–99. [Google Scholar] [CrossRef]
- Bai, Y.X.; Zhang, S.-H.; Fan, Z.; Liu, X.-Y.; Zhao, X.; Feng, X.-Z.; Sun, M.-Z. Automatic multiple zebrafish tracking based on improved HOG features. Sci. Rep. 2018, 8, 10884. [Google Scholar] [CrossRef] [PubMed]
- Lipetski, Y.; Sidla, O. A combined HOG and deep convolution network cascade for pedestrian detection. IS T Int. Symp. Electron. Imaging Sci. Technol. 2017, 2017, 11–17. [Google Scholar] [CrossRef]
- Madan, R.; Agrawal, D.; Kowshik, S.; Maheshwari, H.; Agarwal, S.; Chakravarty, D. Traffic sign classification using hybrid HOG-SURF features and convolutional neural networks. In Proceedings of the 8th International Conference on Pattern Recognition Applications and Methods (ICPRAM 2019), Prague, Czech Republic, 19–21 February 2019; pp. 613–620. [Google Scholar] [CrossRef]
- Bao, T.Q.; Kiet, N.T.T.; Dinh, T.Q.; Hiep, H.X. Plant species identification from leaf patterns using histogram of oriented gradients feature space and convolution neural networks. J. Inf. Telecommun. 2020, 4, 140–150. [Google Scholar] [CrossRef] [Green Version]
- Bahri, H.; Chouchene, M.; Sayadi, F.E.; Atri, M. Real-time moving human detection using HOG and Fourier descriptor based on CUDA implementation. J. Real-Time Image Process. 2020, 17, 1841–1856. [Google Scholar] [CrossRef]
- Kalake, L.; Wan, W.; Hou, L. Analysis Based on Recent Deep Learning Approaches Applied in Real-Time Multi-Object Tracking: A Review. IEEE Access 2021, 9, 32650–32671. [Google Scholar] [CrossRef]
- Kumar, K.C.A.; Jacques, L.; De Vleeschouwer, C. Discriminative and Efficient Label Propagation on Complementary Graphs for Multi-Object Tracking. IEEE Trans. Pattern Anal. Mach. Intell. 2017, 39, 61–64. [Google Scholar] [CrossRef] [Green Version]
- Zhang, T.; Zeng, Y.; Xu, B. HCNN: A neural network model for combining local and global features towards human-like classification. Int. J. Pattern Recognit. Artif. Intell. 2016, 30, 1655004. [Google Scholar] [CrossRef] [Green Version]
- Aslan, M.F.; Durdu, A.; Sabanci, K.; Mutluer, M.A. CNN and HOG based comparison study for complete occlusion handling in human tracking. Meas. J. Int. Meas. Confed. 2020, 158, 107704. [Google Scholar] [CrossRef]
- Zhang, J.; Cao, J.; Mao, B. Moving Object Detection Based on Non-parametric Methods and Frame Difference for Traceability Video Analysis. Procedia Comput. Sci. 2016, 91, 995–1000. [Google Scholar] [CrossRef] [Green Version]
- Najva, N.; Bijoy, K.E. SIFT and Tensor Based Object Detection and Classification in Videos Using Deep Neural Networks. Procedia Comput. Sci. 2016, 93, 351–358. [Google Scholar] [CrossRef] [Green Version]
- Rui, T.; Zou, J.; Zhou, Y.; Fang, H.; Gao, Q. Pedestrian detection based on multi-convolutional features by feature maps pruning. Multimed. Tools Appl. 2017, 76, 25079–25089. [Google Scholar] [CrossRef]
- Sujanaa, J.; Palanivel, S. HOG-based emotion recognition using one-dimensional convolutional neural network. ICTACT J. Image Video Process. 2020, 11, 2310–2315. [Google Scholar] [CrossRef]
- Qi, X.; Liu, C.; Schuckers, S. IoT edge device based key frame extraction for face in video recognition. In Proceedings of the 18th IEEE/ACM International Symposium on Cluster, Cloud and Grid Computing, CCGRID 2018, Washington, DC, USA, 1–4 May 2018; pp. 641–644. [Google Scholar] [CrossRef]
- Yudin, D.; Ivanov, A.; Shchendrygin, M. Detection of a human head on a low-quality image and its software implementation. Int. Arch. Photogramm. Remote Sens. Spat. Inf. Sci.-ISPRS Arch. 2019, 42, 237–241. [Google Scholar] [CrossRef] [Green Version]
- Girdhar, R.; Gkioxari, G.; Torresani, L.; Paluri, M.; Tran, D. Detect-and-Track: Efficient Pose Estimation in Videos. Proc. IEEE Comput. Soc. Conf. Comput. Vis. Pattern Recognit. 2018, 1, 350–359. [Google Scholar] [CrossRef] [Green Version]
- Perwaiz, N.; Fraz, M.M.; Shahzad, M. Stochastic attentions and context learning for person re-identification. PeerJ Comput. Sci. 2021, 7, e447. [Google Scholar] [CrossRef]
- Mewada, H.; Al-Asad, J.F.; Patel, A.; Chaudhari, J.; Mahant, K.; Vala, A. A Fast Region-based Active Contour for Non-rigid Object Tracking and its Shape Retrieval. PeerJ Comput. Sci. 2021, 7, e373. [Google Scholar] [CrossRef]
- Fiaz, M.; Mahmood, A.; Jung, S.K. Tracking Noisy Targets: A Review of Recent Object Tracking Approaches. arXiv 2018, arXiv:1802.03098. Available online: http://arxiv.org/abs/1802.03098 (accessed on 10 October 2021).
- Patel, D.M.; Jaliya, U.K.; Vasava, H.D. Multiple Object Detection and Tracking: A Survey. Int. J. Res. Appl. Sci. Eng. Technol. 2018, 6, 809–813. [Google Scholar]
- Abdelhafiz, D.; Yang, C.; Ammar, R.; Nabavi, S. Deep convolutional neural networks for mammography: Advances, challenges and applications. BMC Bioinform. 2019, 20 (Suppl. 11), 281. [Google Scholar] [CrossRef] [PubMed] [Green Version]
- Liu, P.; Li, X.; Liu, H.; Fu, Z. Online learned siamese network with auto-encoding constraints for robust multi-object tracking. Electronics 2019, 8, 595. [Google Scholar] [CrossRef] [Green Version]
- Stojnić, V.; Risojević, V.; Muštra, M.; Jovanović, V.; Filipi, J.; Kezić, N.; Babić, Z. A method for detection of small moving objects in UAV videos. Remote Sens. 2021, 13, 653. [Google Scholar] [CrossRef]
- Ahmad, M.; Ahmed, I.; Khan, F.A.; Qayum, F.; Aljuaid, H. Convolutional neural network–based person tracking using overhead views. Int. J. Distrib. Sens. Netw. 2020, 16, 1–12. [Google Scholar] [CrossRef]
- Zhao, D.; Fu, H.; Xiao, L.; Wu, T.; Dai, B. Multi-object tracking with correlation filter for autonomous vehicle. Sensors 2018, 18, 2004. [Google Scholar] [CrossRef] [PubMed] [Green Version]
- Bhuvana, V.P.; Schranz, M.; Regazzoni, C.S.; Rinner, B.; Tonello, A.M.; Huemer, M. Multi-camera object tracking using surprisal observations in visual sensor networks. Eurasip J. Adv. Signal Process. 2018, 2016, 50. [Google Scholar] [CrossRef]
- Hu, C.; Huang, H.; Chen, M.; Yang, S.; Chen, H. Video object detection from one single image through opto-electronic neural network. APL Photonics 2021, 6, 046104. [Google Scholar] [CrossRef]
- Milan, A.; Leal-Taixe, L.; Reid, I.; Roth, S.; Schindler, K. MOT16: A Benchmark for Multi-Object Tracking. arXiv 2016, arXiv:1603.00831. Available online: http://arxiv.org/abs/1603.00831 (accessed on 18 September 2021).
- Rahman, M.M.; Nooruddin, S.; Hasan, K.M.A.; Dey, N.K. HOG + CNN Net: Diagnosing COVID-19 and Pneumonia by Deep Neural Network from Chest X-Ray Images. SN Comput. Sci. 2021, 2, 371–386. [Google Scholar] [CrossRef]
- Ghosh, S.K.; Islam, M.R. Bird Species Detection and Classification Based on HOG Feature Using Convolutional Neural Network. Commun. Comput. Inf. Sci. 2019, 1035, 363–373. [Google Scholar] [CrossRef]
- Lee, B.; Erdenee, E.; Jin, S.; Nam, M.Y.; Jung, Y.G.; Rhee, P.K. Multi-class multi-object tracking using changing point detection. In Lecture Notes in Computer Science (Including Subseries Lecture Notes in Artificial Intelligence and Lecture Notes in Bioinformatics); Springer: Cham, Switzerland, 2016; Volume 9914, pp. 68–83. [Google Scholar] [CrossRef] [Green Version]







{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
| Methods | Precision ↑ | Causality |
|---|---|---|
| Improved HOG [4] | 86.70% | Online |
| HOG + 1DCNN [16] | 90.23% | Offline |
| HOG + DCNN Net [32] | 96.74 | Offline |
| HOG + CNN [33] | 94.14% | Offline |
| Ours | 91.00% | Online |
| Sequences | Precision ↑ | Recall ↑ | IDF Score ↑ | MOTA ↑ | MOTP ↑ | IDS ↓ | ML ↓ | MT ↑ | FM ↓ |
|---|---|---|---|---|---|---|---|---|---|
| CAM#4_scene0 | 99.4% | 96.0% | 95.9% | 94.0% | 91.9% | 1 | 1% | 96.0% | 2 |
| CAM#4_scene1 | 98.0% | 97.0% | 98.0% | 93.0% | 92.0% | 1 | 1% | 94.0% | 1 |
| CAM#4_scene2 | 98.0% | 94.0% | 96.0% | 93.0% | 89.0% | 2 | 2% | 92.0% | 3 |
| CAM#7_scene0 | 68.0% | 80.2% | 76.4% | 63.3% | 75.0% | 4 | 3% | 82.0% | 5 |
| CAM#7_scene1 | 88.9% | 87.6% | 88.2% | 83.9% | 82.5% | 3 | 2% | 88% | 2 |
| CAM#7_scene2 | 95.0% | 96.8% | 96.3% | 90.0% | 91.8% | 1 | 1% | 92% | 1 |
| Overall performance | 91.22% | 91.93% | 91.80% | 86.20% | 87.03% | 2 | 1.67% | 90.67% | 3 |
| Sequences | Precision ↑ | Recall ↑ | IDF Score ↑ | MOTA ↑ | MOTP ↑ | IDS ↓ | ML ↓ | MT ↑ | FM ↓ |
|---|---|---|---|---|---|---|---|---|---|
| CAM#1_scene0 | 94.0% | 92.0% | 93.0% | 89.4% | 87.0% | 2 | 2.0% | 88.0% | 3 |
| CAM#2_scene1 | 83.0% | 82.0% | 82.0% | 78.0% | 76.8% | 4 | 3.0% | 86.0% | 5 |
| CAM#3_scene2 | 97.0% | 90.8% | 93.8% | 92.3% | 85.8% | 2 | 1.0% | 93.0% | 2 |
| CAM#4_scene3 | 76.0% | 71.2% | 73.5% | 71.0% | 66.3% | 4 | 4.0% | 81.0% | 8 |
| Overall performance | 87.50% | 84.00% | 85.58% | 82.68% | 78.98% | 3 | 2.50% | 87.00% | 5 |
| Sequences | Precision ↑ | Recall ↑ | IDF Score ↑ | MOTA ↑ | MOTP ↑ | IDS ↓ | ML ↓ | MT ↑ | FM ↓ |
|---|---|---|---|---|---|---|---|---|---|
| Campus scenes | 96.0% | 90.6% | 91.5% | 92.0% | 85.0% | 2 | 1.0% | 93.0% | 2 |
| Passageway scenes | 94.0% | 92.0% | 93.0% | 89.4% | 87.0% | 2 | 2.0% | 88.0% | 3 |
| Sequences | Precision ↑ | Recall ↑ | IDF Score ↑ | MOTA ↑ | MOTP ↑ | IDS ↓ | ML ↓ | MT ↑ | FM ↓ |
|---|---|---|---|---|---|---|---|---|---|
| Overall performance | 65.0% | 56.2% | 58.5% | 52.0% | 46.3% | 24 | 34.0% | 54.0% | 14 |
| Method | MOTA ↑ | MOTP ↑ | Causality |
|---|---|---|---|
| NCA-Net [32] | 64.5% | 78.2% | Offline |
| CNN + HOG Template Matching [11] | 94.0% | 80.9% | Offline |
| Yolo + Deepsort [33] | 86.1% | 88.6% | Online |
| MCMOT HDM [34] | 62.4% | 78.2% | Offline |
| Ours | 68.2% | 65.0% | Online |
Publisher’s Note: MDPI stays neutral with regard to jurisdictional claims in published maps and institutional affiliations. |
© 2022 by the authors. Licensee MDPI, Basel, Switzerland. This article is an open access article distributed under the terms and conditions of the Creative Commons Attribution (CC BY) license (https://creativecommons.org/licenses/by/4.0/).
Share and Cite
Kalake, L.; Dong, Y.; Wan, W.; Hou, L. Enhancing Detection Quality Rate with a Combined HOG and CNN for Real-Time Multiple Object Tracking across Non-Overlapping Multiple Cameras. Sensors 2022, 22, 2123. https://doi.org/10.3390/s22062123
Kalake L, Dong Y, Wan W, Hou L. Enhancing Detection Quality Rate with a Combined HOG and CNN for Real-Time Multiple Object Tracking across Non-Overlapping Multiple Cameras. Sensors. 2022; 22(6):2123. https://doi.org/10.3390/s22062123
Chicago/Turabian StyleKalake, Lesole, Yanqiu Dong, Wanggen Wan, and Li Hou. 2022. "Enhancing Detection Quality Rate with a Combined HOG and CNN for Real-Time Multiple Object Tracking across Non-Overlapping Multiple Cameras" Sensors 22, no. 6: 2123. https://doi.org/10.3390/s22062123
APA StyleKalake, L., Dong, Y., Wan, W., & Hou, L. (2022). Enhancing Detection Quality Rate with a Combined HOG and CNN for Real-Time Multiple Object Tracking across Non-Overlapping Multiple Cameras. Sensors, 22(6), 2123. https://doi.org/10.3390/s22062123