
Attention Module Magnetic Flux Leakage Linked Deep Residual Network for Pipeline In-Line Inspection


Abstract
:1. Introduction
- (1)
- An MFL in-line inspection method based on attention module and convolution residual modules is proposed for oil and gas pipeline, which effectively improve the pipeline features inspection accuracy and efficiency.
- (2)
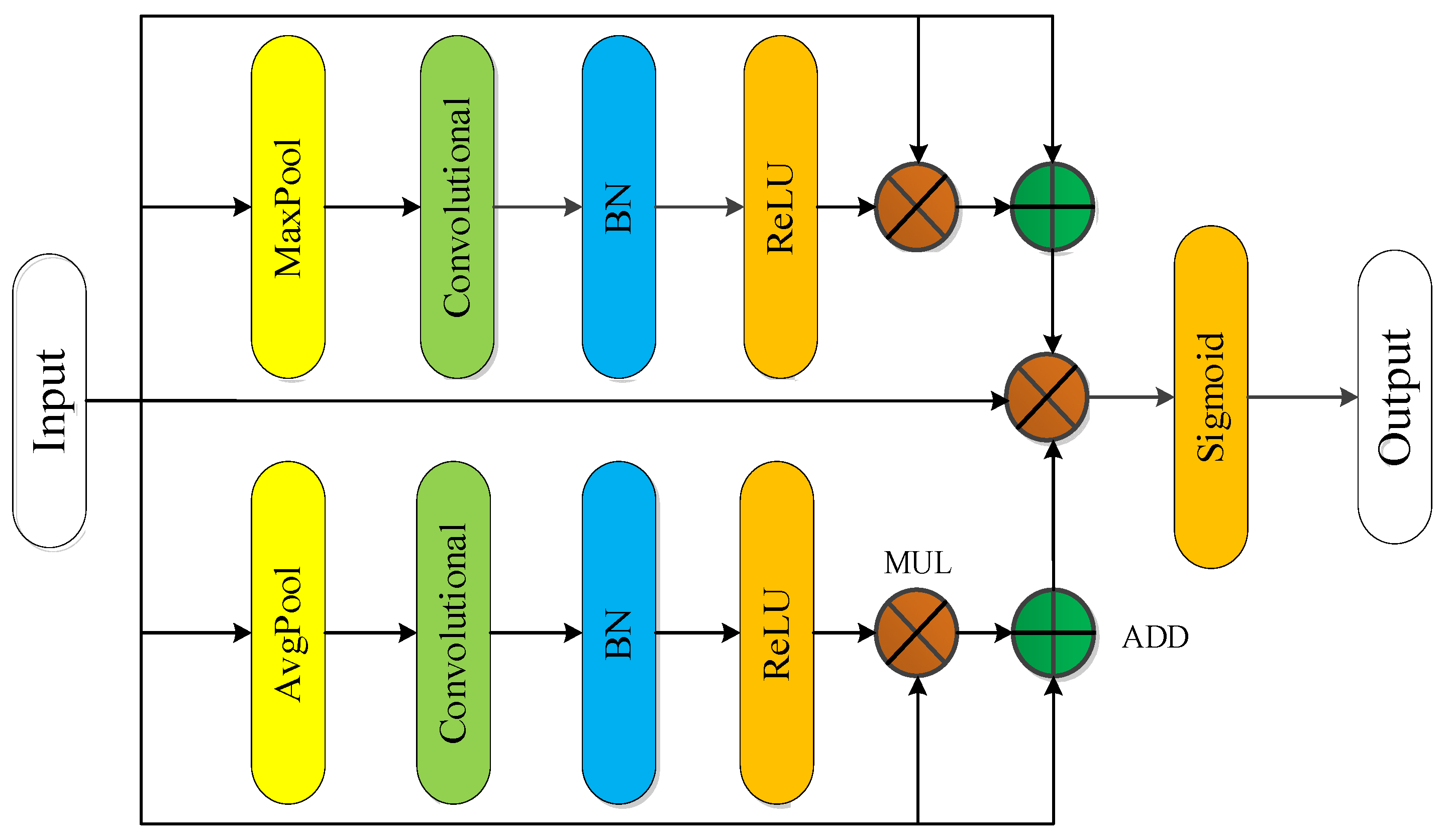
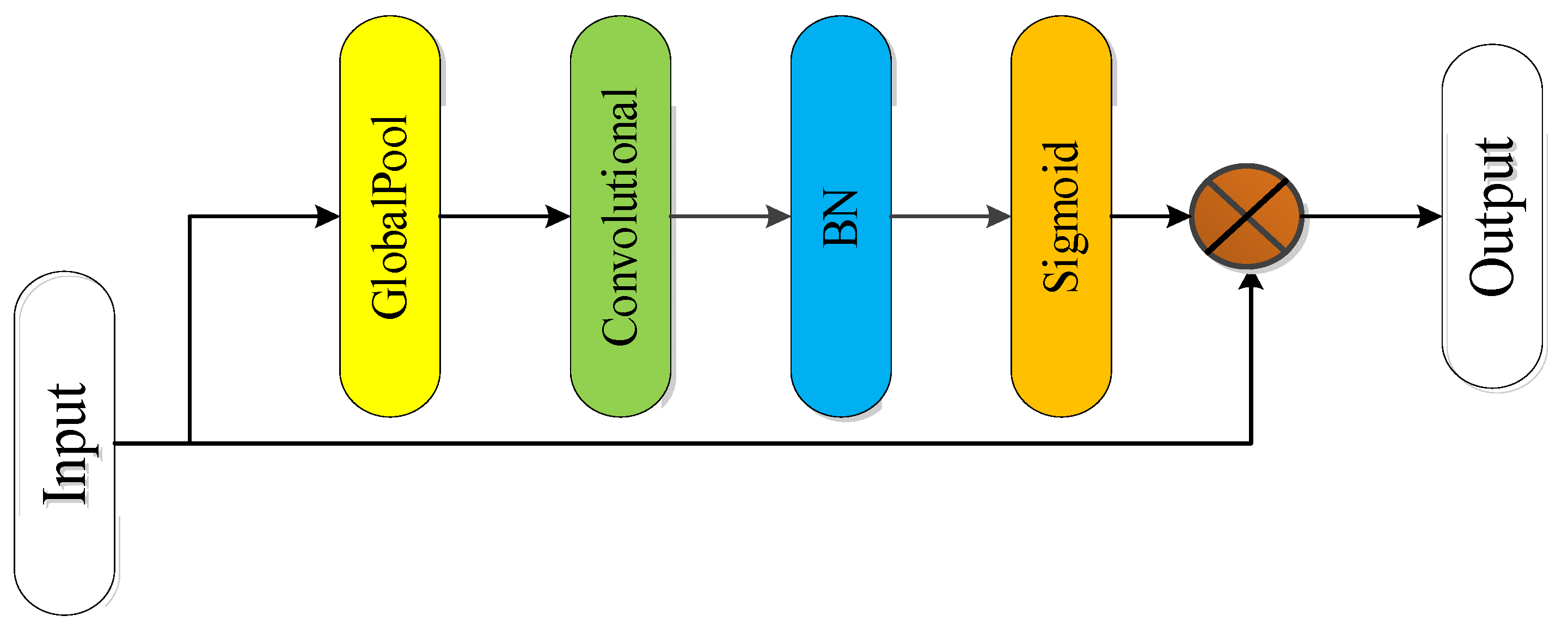
- Aiming at the influence of the complex operating environment, high noises, composite defects to MFL in-line inspection of oil and gas pipelines, attention module composed of channel attention and spatial attention are designed to fully extract MFL image feature information.
- (3)
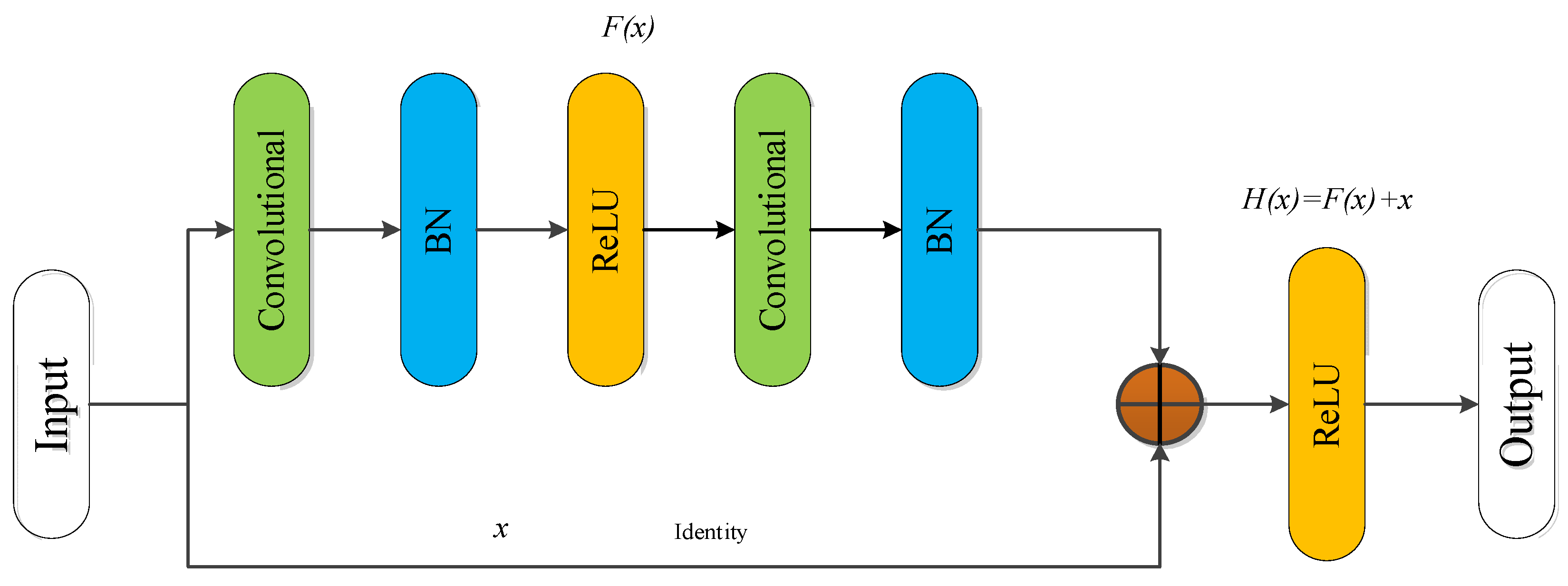
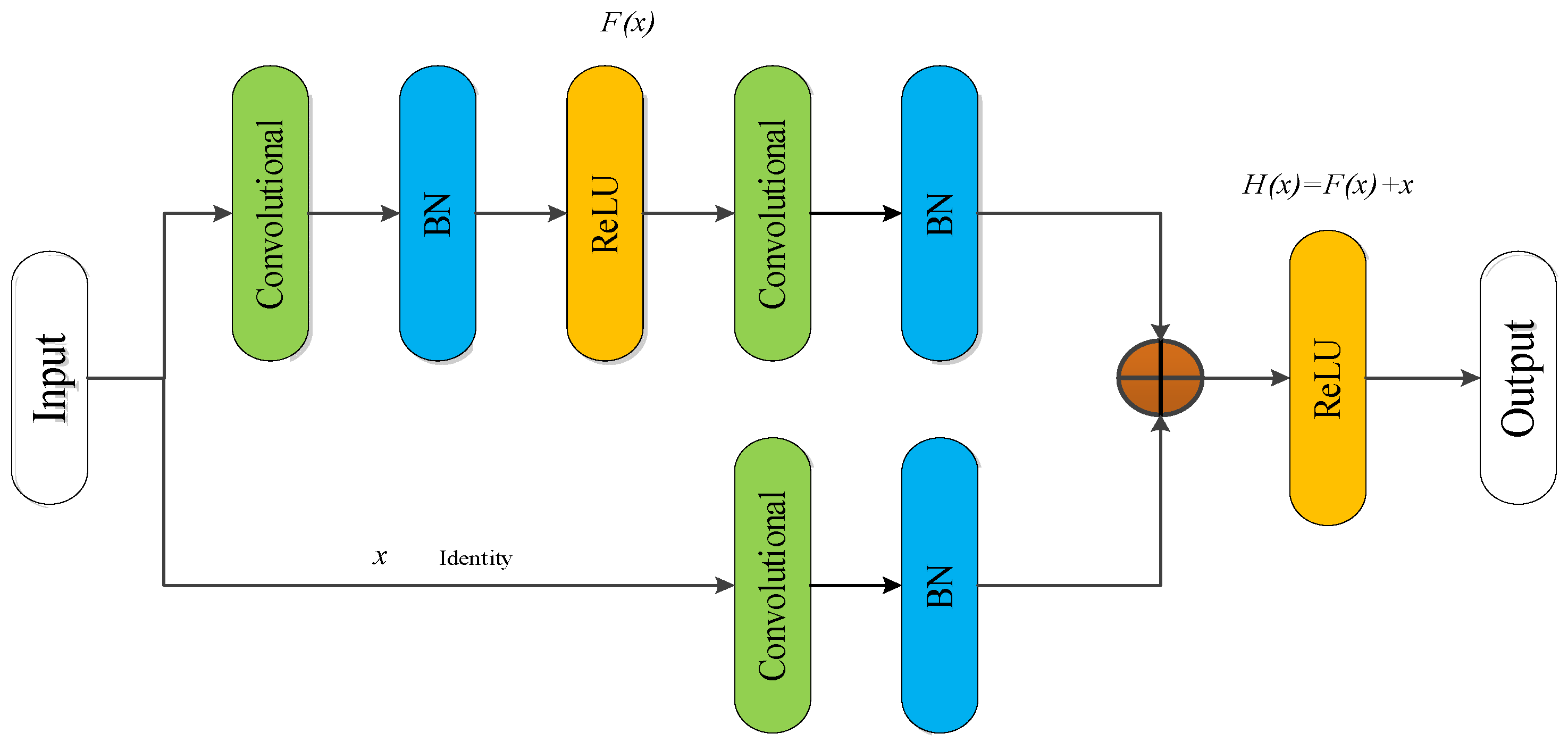
- To solve the problem of gradient dispersion caused by the increase of the number of network layers, an improved residual convolutional neural network is constructed to reduce the error of the deep network as well as the amount of calculation parameters, and effectively improve the training efficiency.
2. Methods
2.1. Related Work
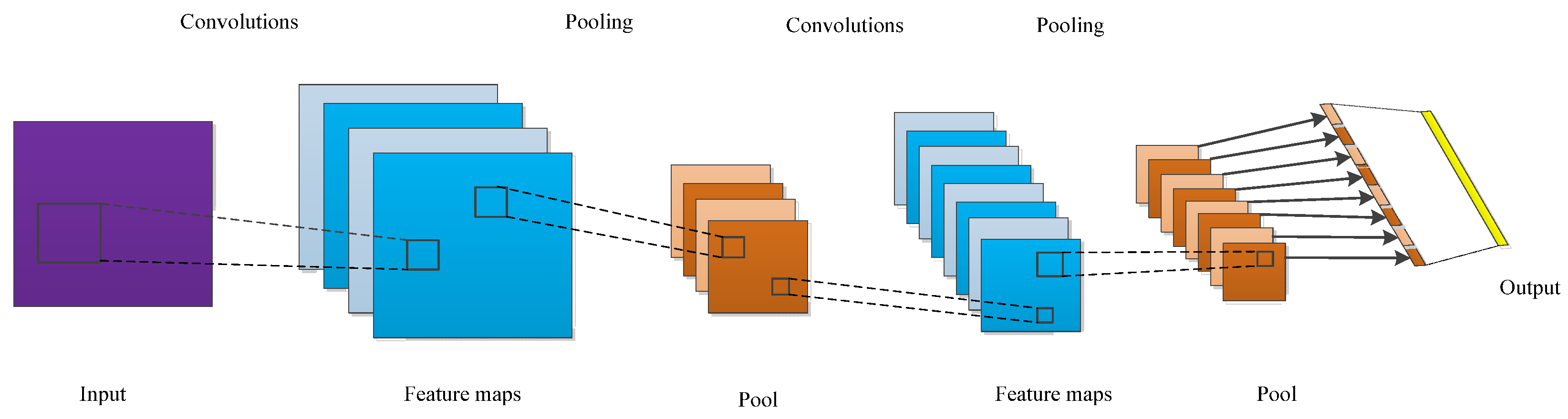
2.1.1. Convolutional Neural Network (CNN)
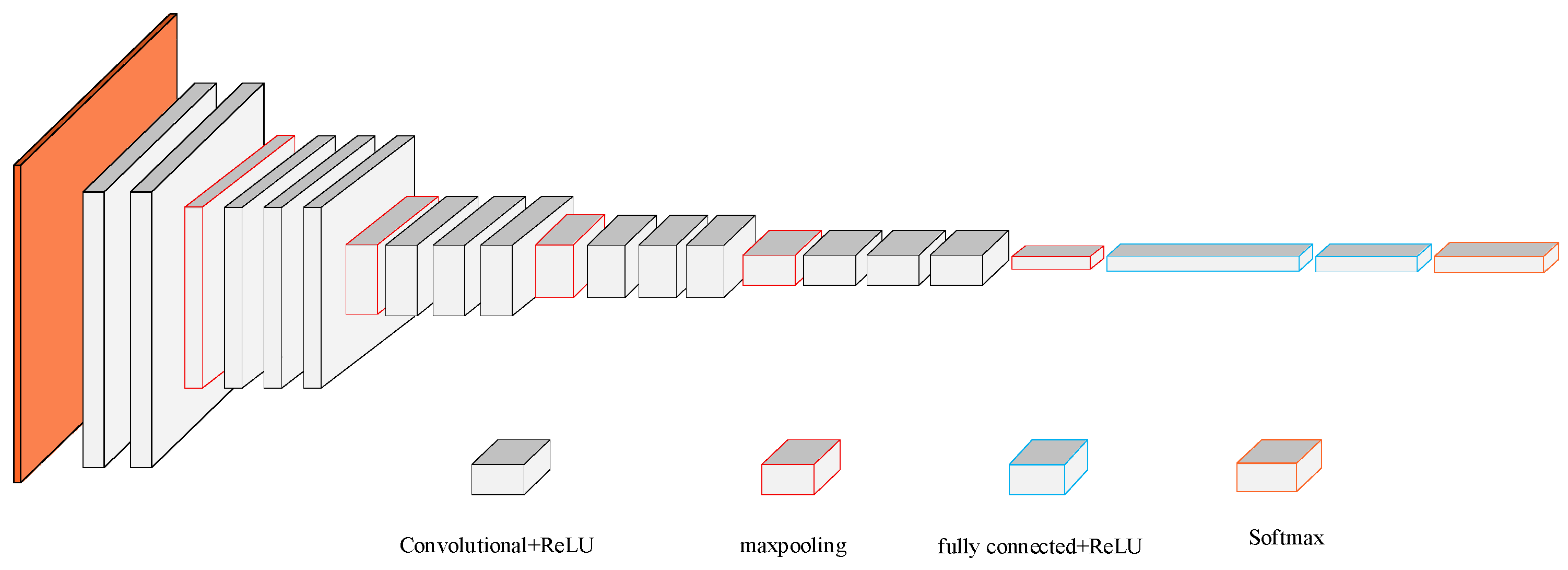
2.1.2. VGG16 Deep Convolutional Neural Network
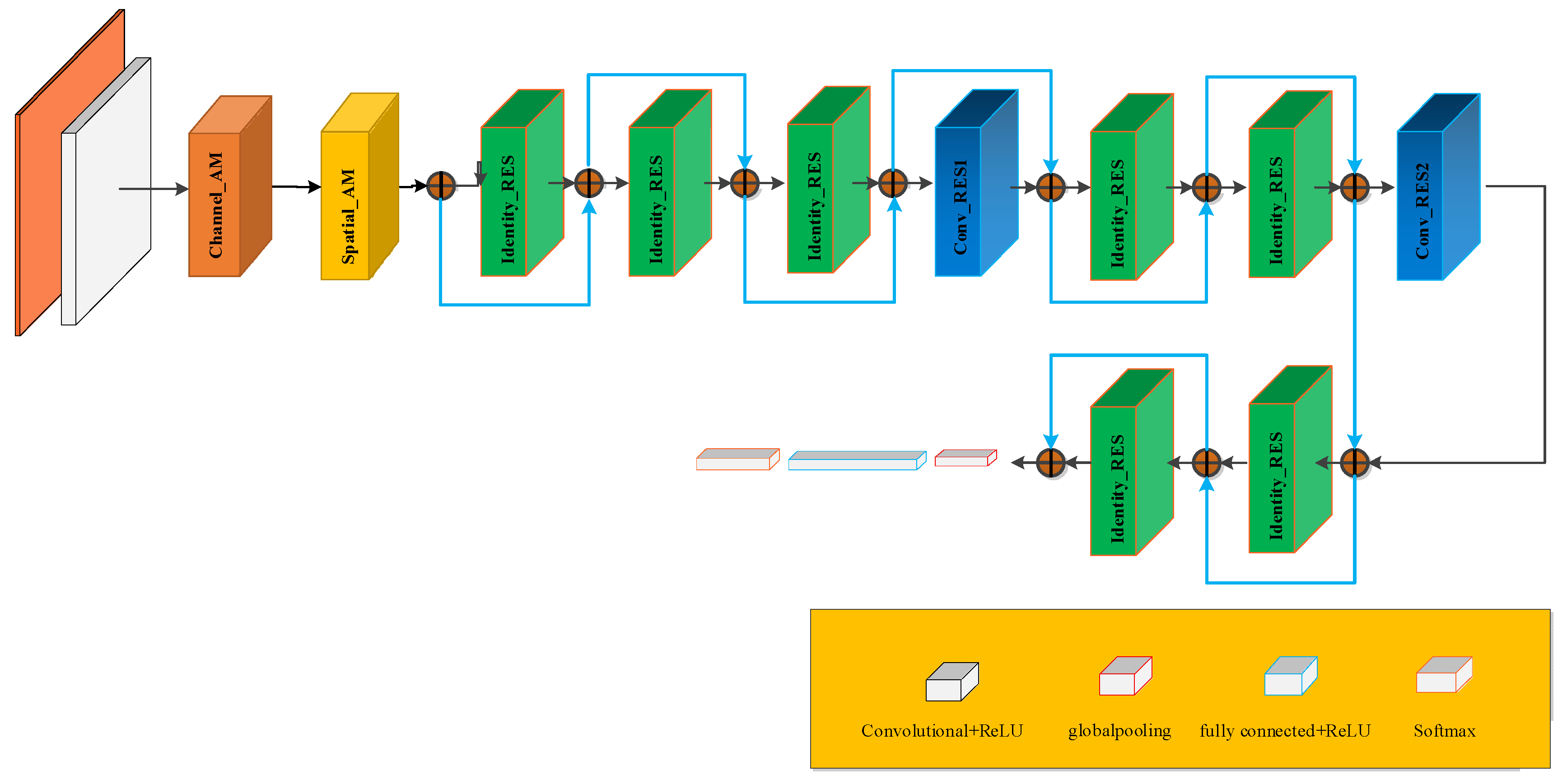
2.2. Proposed Attention Module MFL In-Line Inspection Technology for Pipeline
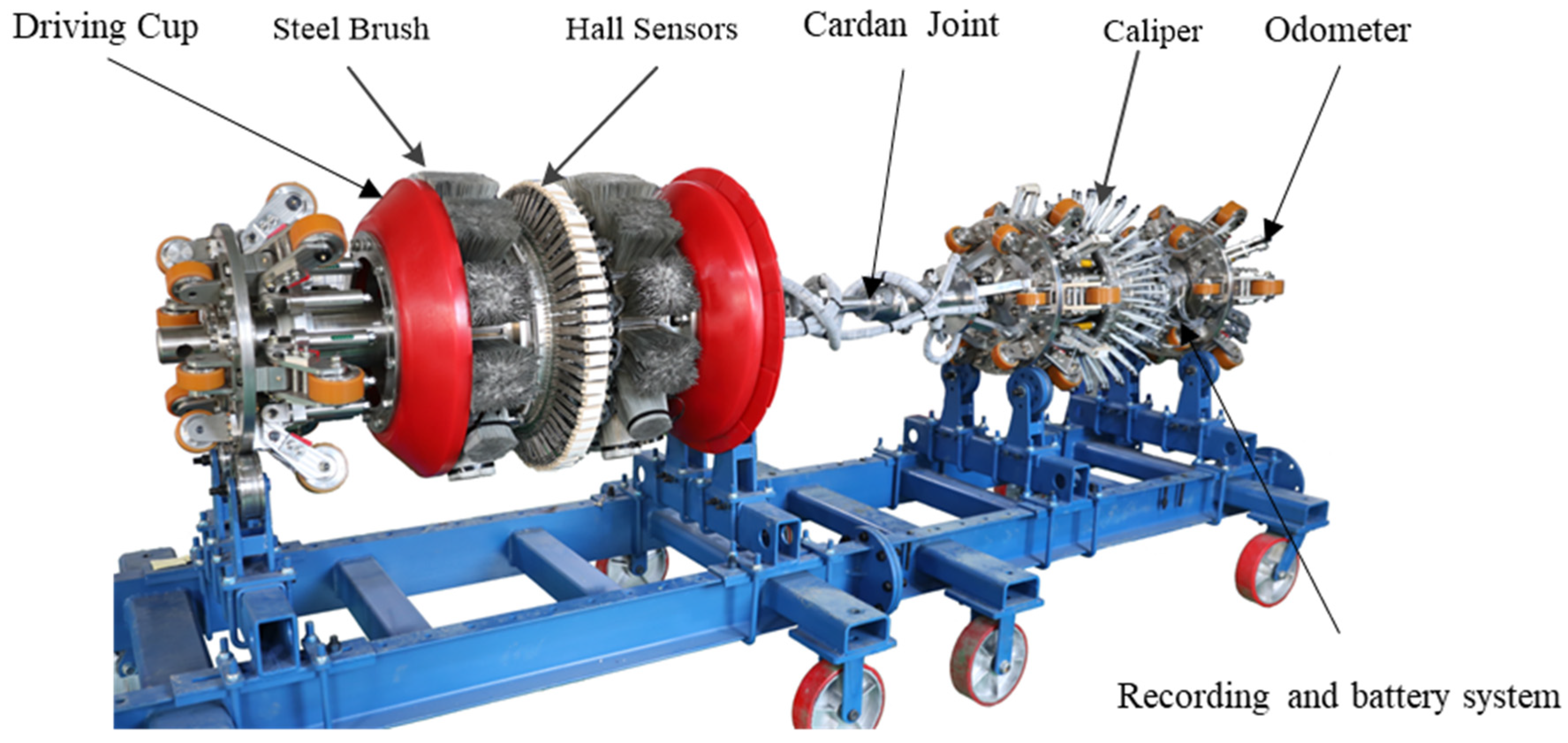
2.2.1. MFL In-Line Inspection Tool
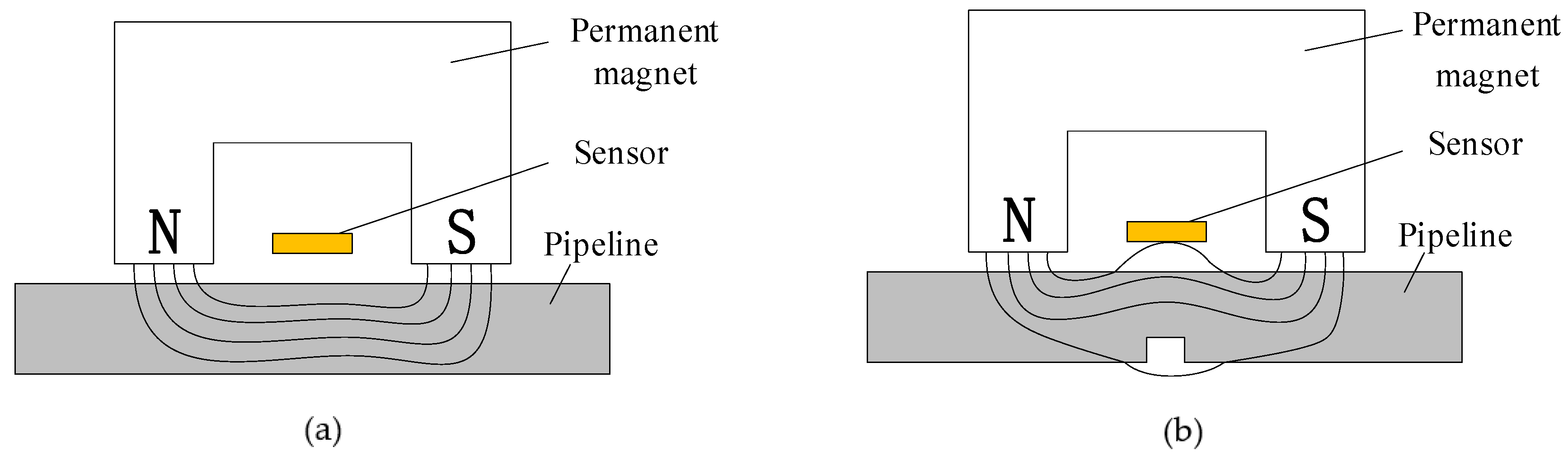
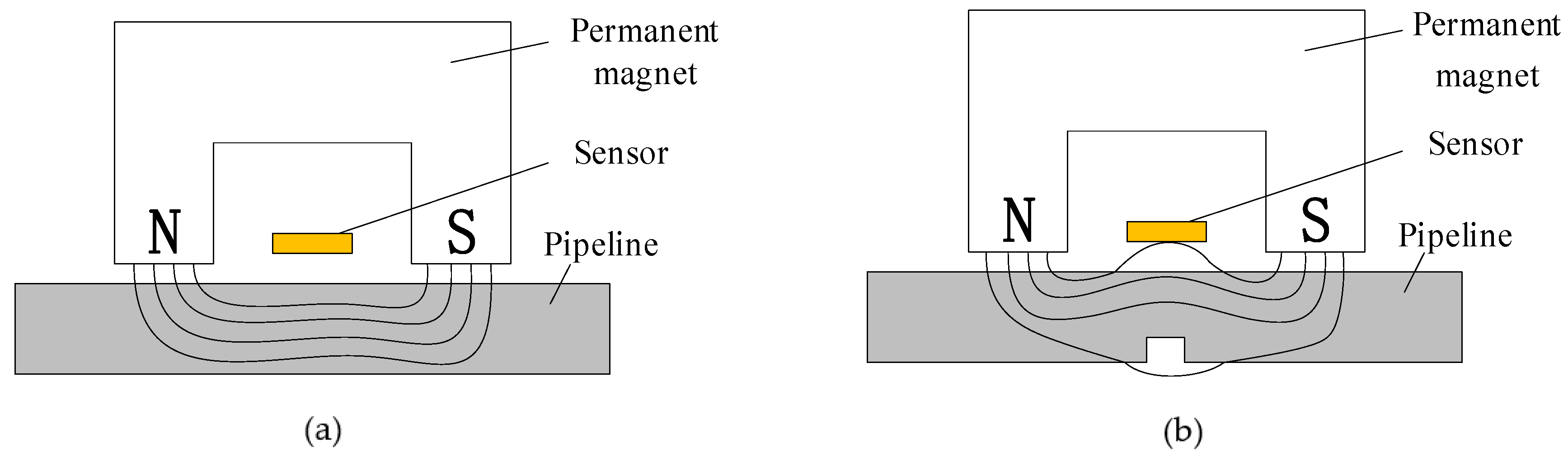
2.2.2. Principle and Disturbance for Pipeline MFL In-Line Inspection
2.2.3. Convolutional Attention Module for MFL In-Line Inspection
2.3. Intelligent Identification of MFL In-Line Detection Signal of Oil and Gas Pipeline Based on Deep Residual Convolutional Neural Network
2.3.1. Residual Network Design
2.3.2. MFL In-Line Inspection Signal Identification Based on Improved Deep Residual Network
3. Experiment and Results Analysis
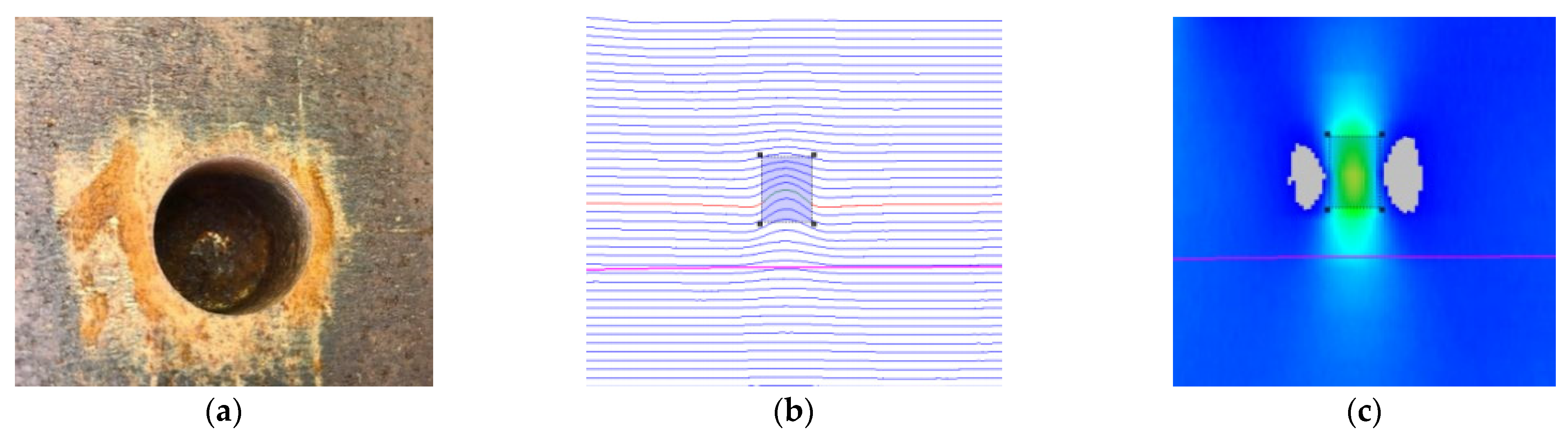
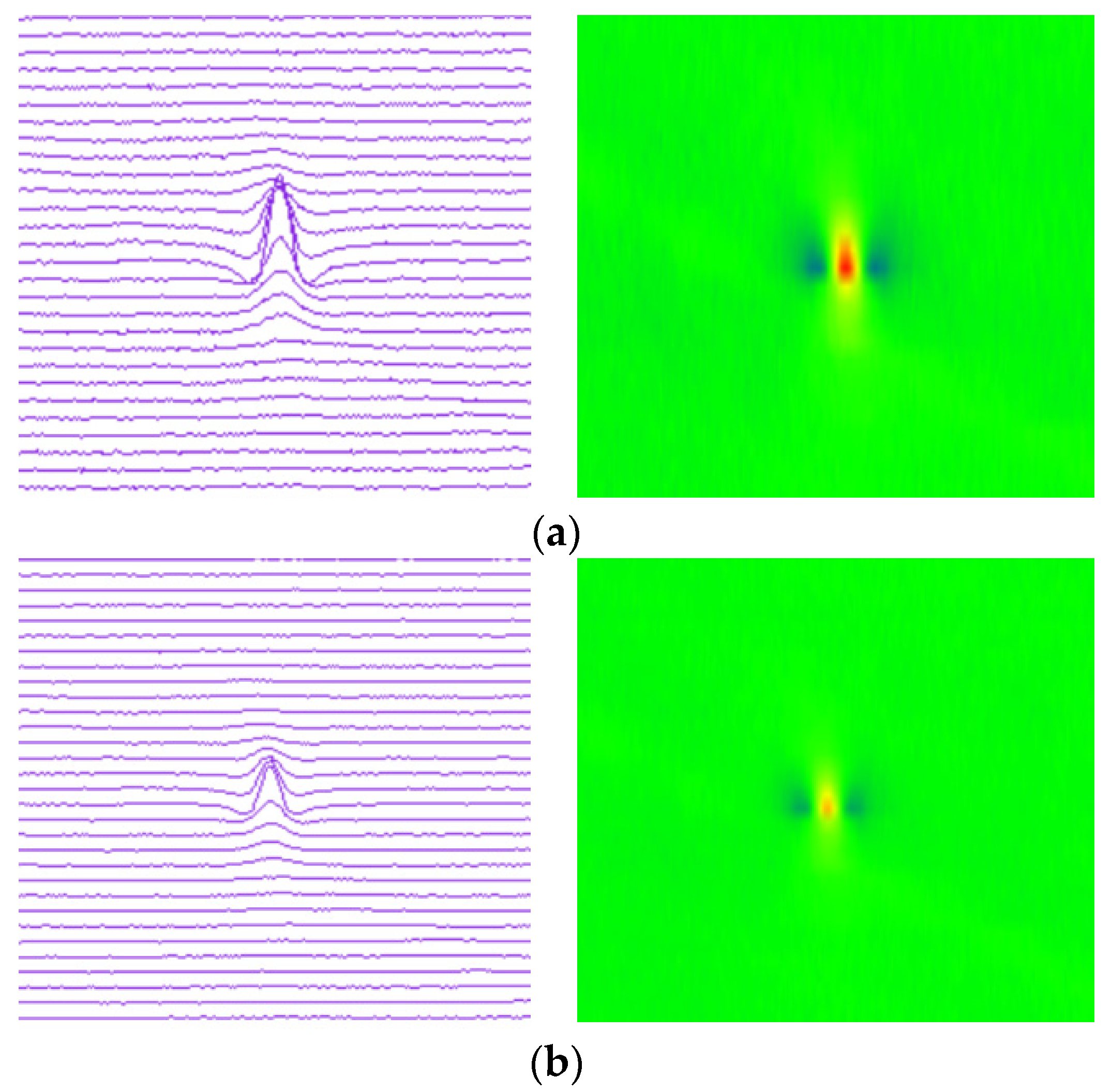
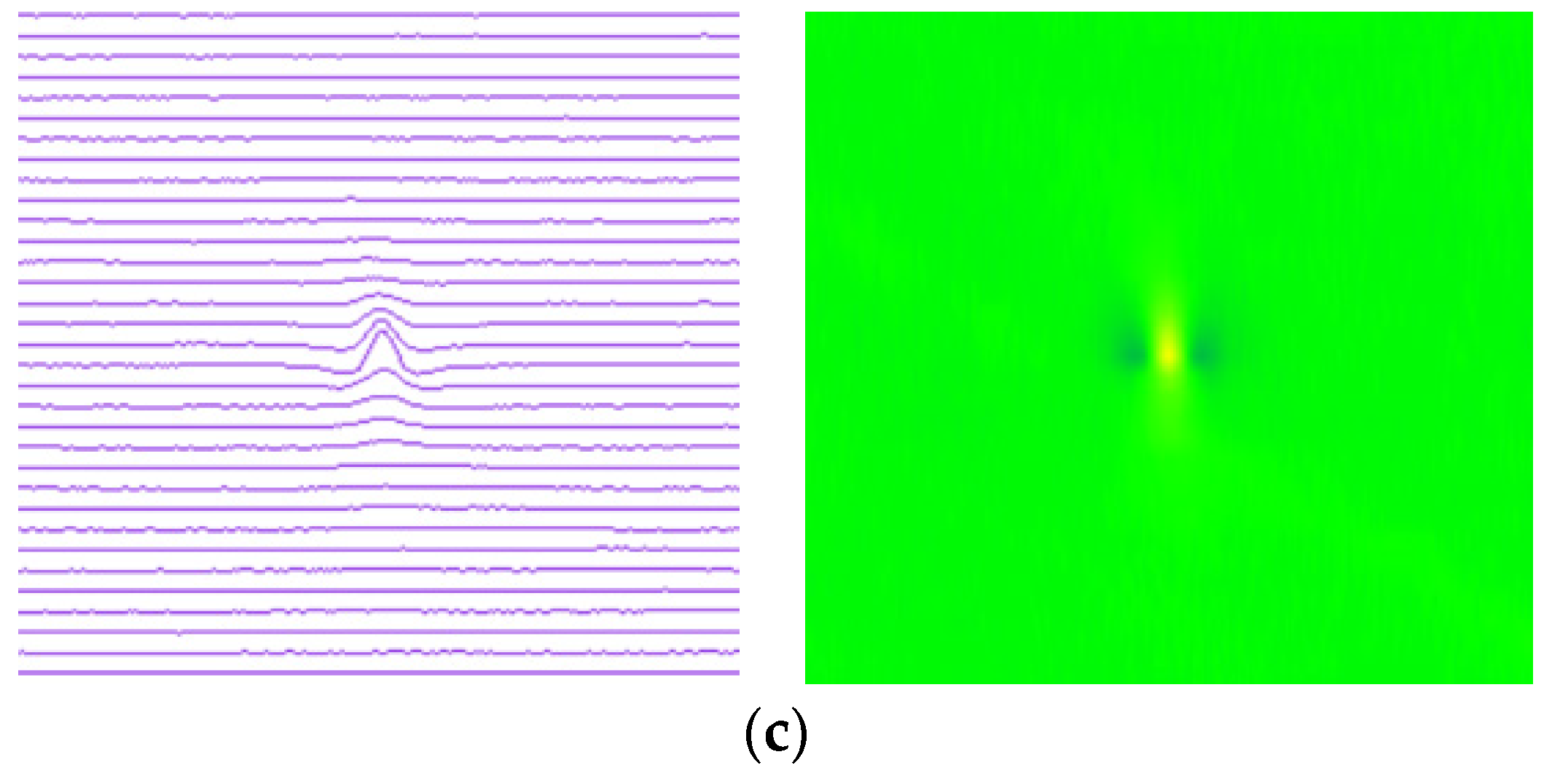
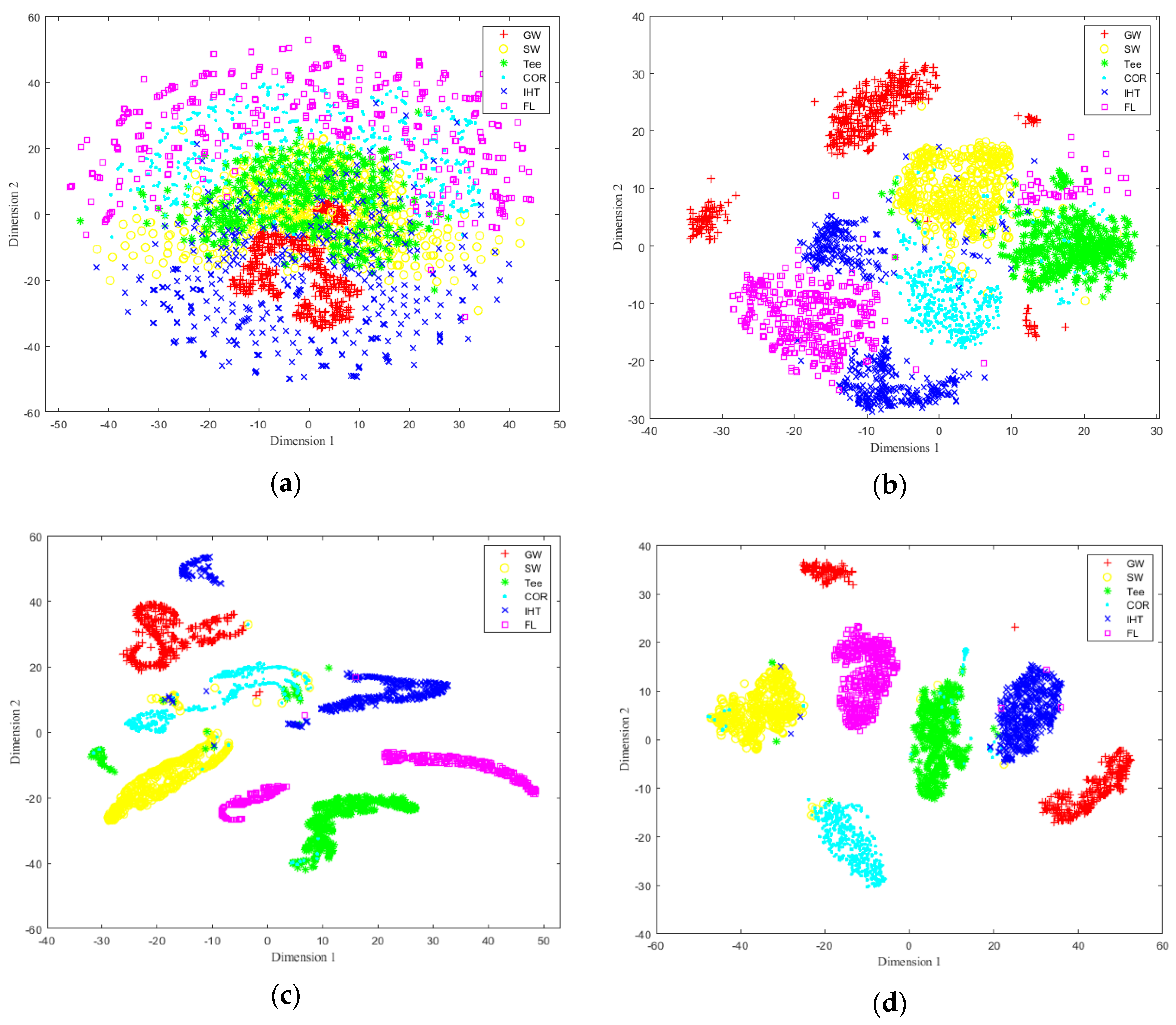
3.1. Establishment of Pipeline MFL Feature Image and Sample Set
3.2. Selection of Hyperparameters
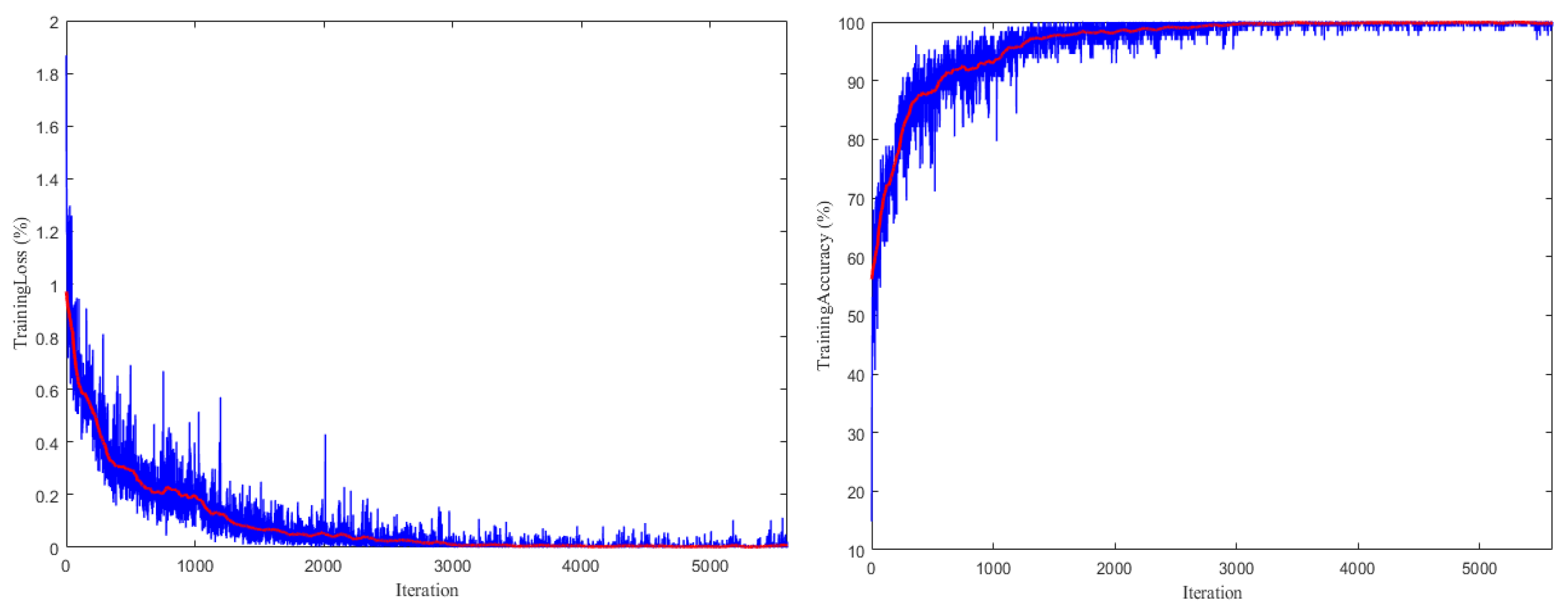
3.3. Neural Network Model Training
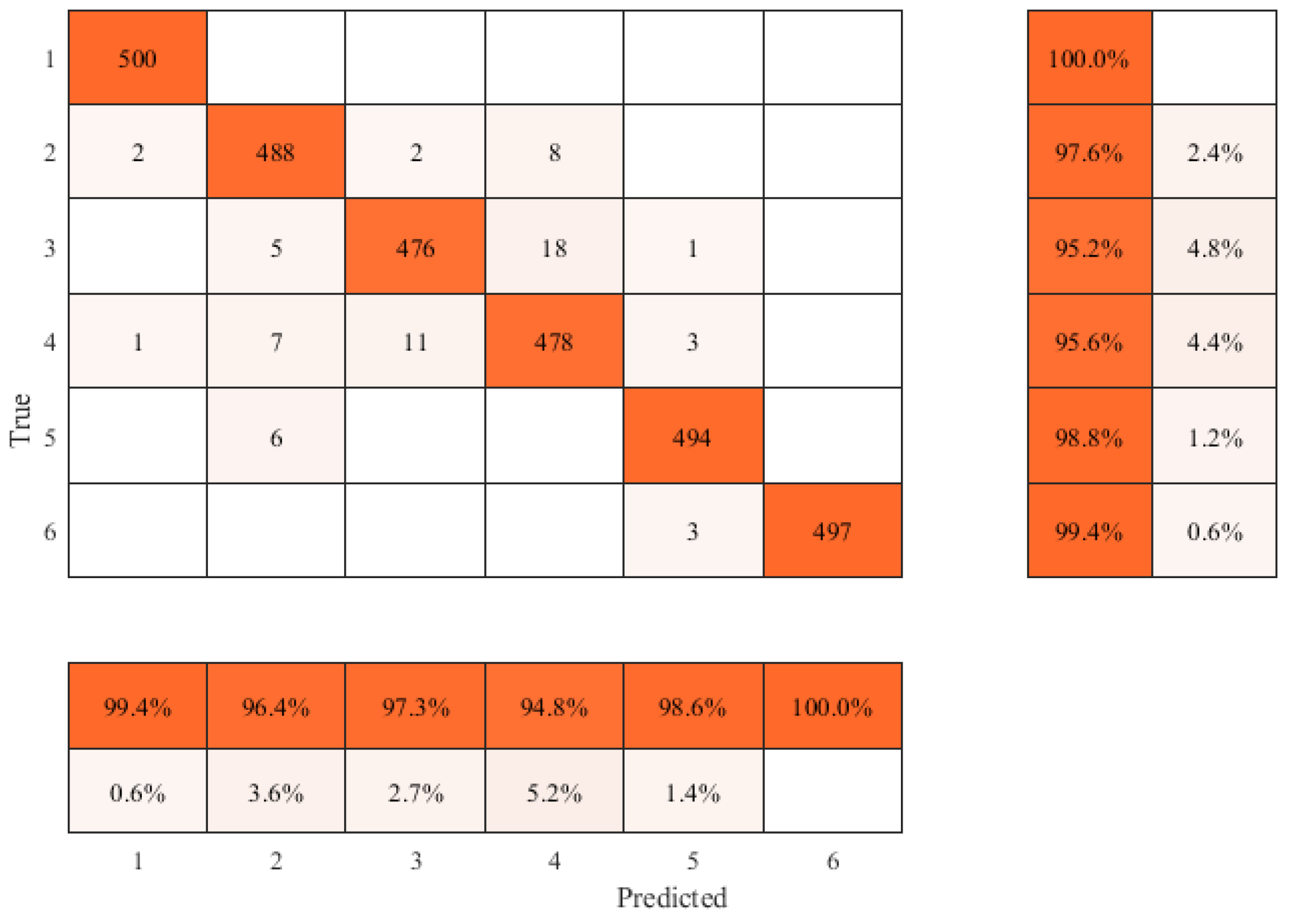
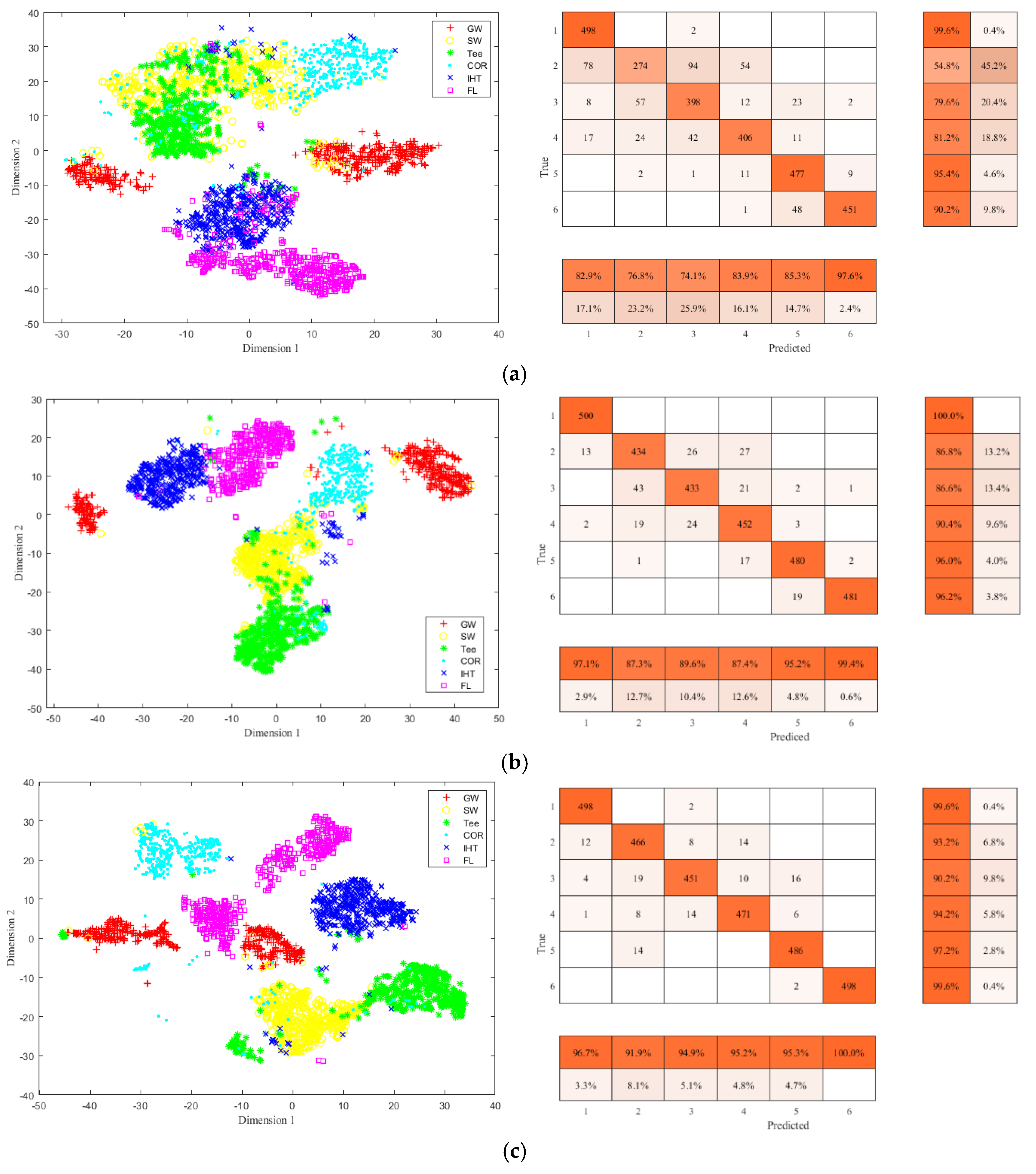
3.4. Model Performance Evaluation
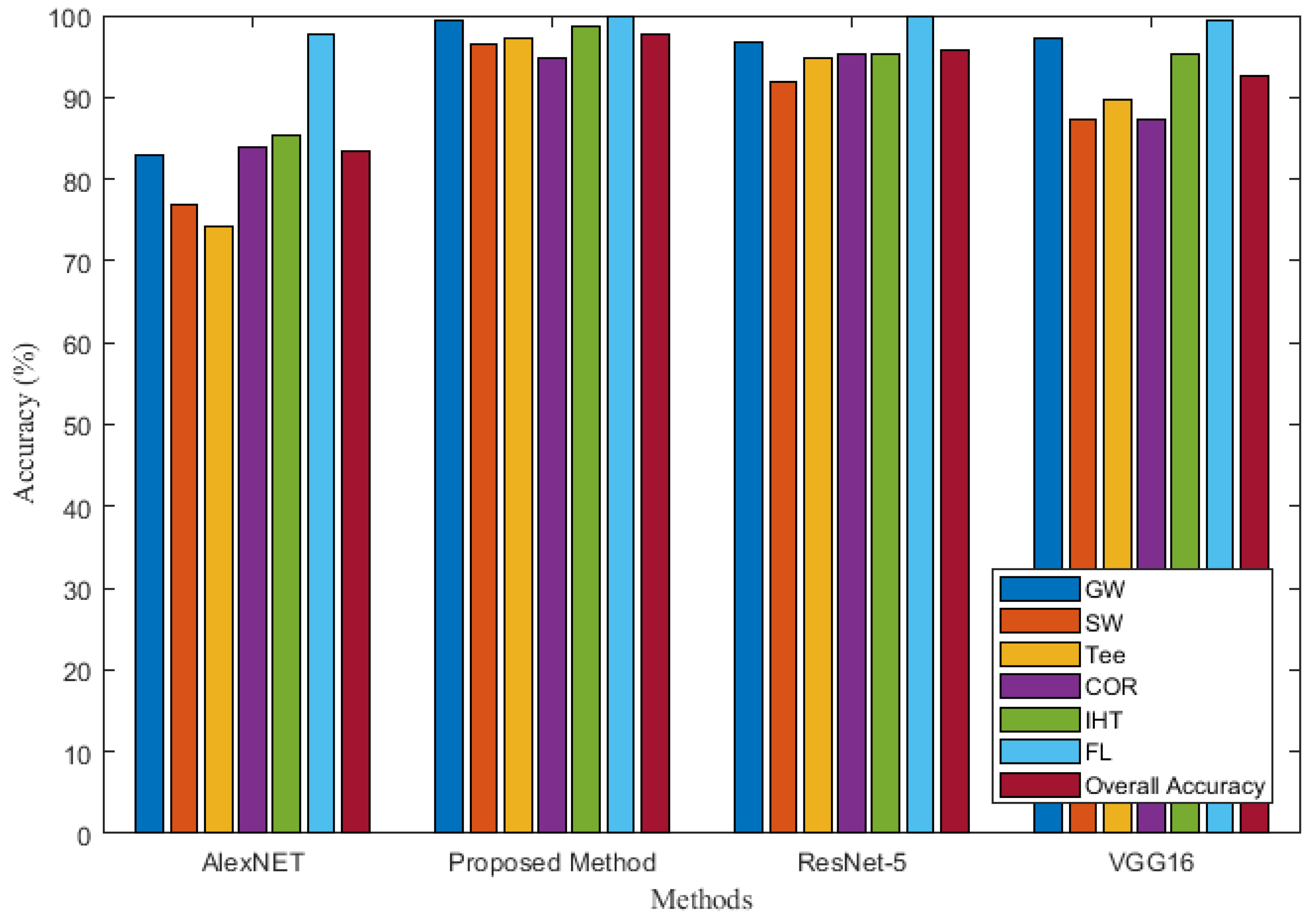
3.5. Comparisons with Other Methods
4. Conclusions
- (1)
- In view of the influence of complex operating environments, high noises, compound defects, and features on the feature identification results in the pipeline, the attention module method is constructed. The channel attention and spatial attention structures are adopted to fully extract the image feature information to improve the classification accuracy.
- (2)
- Aiming at the problem that the gradient dispersion caused by the increase in network layers makes it difficult for the model to converge and network degradation, an improved residual convolutional neural network based on VGG16 is constructed. The identity and convolution residual modules are introduced to reduce the errors of the deep network and the number of computing parameters, and improves the training efficiency.
- (3)
- By field test, the pipeline feature types were analyzed and sample sets of the MFL pseudo-color images were established. Experiment results indicate that the identification accuracy of six types of pipeline features and defects reached 97.7%.
Author Contributions
Funding
Institutional Review Board Statement
Informed Consent Statement
Data Availability Statement
Acknowledgments
Conflicts of Interest
References
- Biezma, M.V.; Andrés, M.A.; Agudo, D.; Briz, E. Most fatal oil & gas pipeline accidents through history: A lessons learned approach. Eng. Fail. Anal. 2020, 110, 104446. [Google Scholar]
- Li, R.; Cai, M.; Shi, Y.; Feng, Q.; Liu, S.; Zhao, X. Pipeline Bending Strain Measurement and Compensation Technology Based on Wavelet Neural Network. J. Sens. 2016, 2016, 8363242. [Google Scholar] [CrossRef] [Green Version]
- Li, R.; Cai, M.; Shi, Y.; Feng, Q.; Chen, P. Technologies and application of pipeline centerline and bending strain of In-line inspection based on inertial navigation. Trans. Inst. Meas. Control 2018, 40, 1554–1567. [Google Scholar] [CrossRef]
- Vanaei, H.R.; Eslami, A.; Egbewande, A. A review on pipeline corrosion, in-line inspection (ILI), and corrosion growth rate models. Int. J. Press. Vessel. Pip. 2017, 149, 43–54. [Google Scholar] [CrossRef]
- Dann, M.R.; Dann, C. Automated matching of pipeline corrosion features from in-line inspection data. Reliab. Eng. Syst. Saf. 2017, 162, 40–50. [Google Scholar] [CrossRef]
- Feng, Q.; Li, R.; Nie, B.; Liu, S.; Zhao, L.; Zhang, H. Literature Review: Theory and Application of In-Line Inspection Technologies for Oil and Gas Pipeline Girth Weld Defection. Sensors 2017, 17, 50. [Google Scholar] [CrossRef]
- Aron, J.; Jia, J.; Vance, B.; Chang, W.; Pohler, R.; Gore, J.; Eaton, S.; Bowles, A.; Jarman, T. Development of an EMAT In-Line Inspection System for Detection, Discrimination, and Grading of Stress Corrosion Cracking in Pipelines Doe Project Officer; Tuboscope Pipeline Services: Houston, TX, USA, 2018. [Google Scholar]
- Wang, Y.; Zhang, P.; Hou, X.Q.; Qin, G. Failure probability assessment and prediction of corroded pipeline under earthquake by introducing in-line inspection data. Eng. Fail. Anal. 2020, 115, 104607. [Google Scholar] [CrossRef]
- Liu, S.; Zheng, D.; Li, R. Compensation Method for Pipeline Centerline Measurement of in-Line Inspection during Odometer Slips Based on Multi-Sensor Fusion and LSTM Network. Sensors 2019, 19, 3740. [Google Scholar] [CrossRef] [PubMed] [Green Version]
- Shi, Y.; Zhang, C.; Li, R.; Cai, M.; Jia, G. Theory and Application of Magnetic Flux Leakage Pipeline Detection. Sensors 2015, 15, 31036–31055. [Google Scholar] [CrossRef] [PubMed]
- Liu, J.; Fu, M.; Tang, J. MFL inner detection based defect recognition method. Chin. J. Sci. Instrum. 2016, 37, 2572–2579. [Google Scholar]
- Chen, J.; Huang, S.; Zhao, W. Three-dimensional defect inversion from magnetic flux leakage signals using iterative neural network. IET Sci. Meas. Technol. 2015, 9, 418–426. [Google Scholar] [CrossRef]
- Kandroodi, M.R.; Araabi, B.N.; Ahmadabadi, M.N.; Shirani, F.; Bassiri, M.M. Detection of natural gas pipeline defects using magnetic flux leakage measurements. In Proceedings of the 2013 21st Iranian Conference on Electrical Engineering (ICEE), Mashhad, Iran, 14–16 May 2013; pp. 1–6. [Google Scholar] [CrossRef]
- Sorabh; Gupta, A.; Chandrasekaran, K. Finite Element Modeling of Magnetic Flux Leakage from Metal Loss Defects in Steel Pipeline. J. Fail. Anal. Prev. 2016, 16, 316–323. [Google Scholar] [CrossRef]
- Wang, Z.; Yang, L.; Gao, S. Pipeline Magnetic Flux Leakage Image Detection Algorithm Based on Multiscale SSD Network. IEEE Trans. Ind. Inform. 2019, 16, 501–509. [Google Scholar]
- Yang, L.; Wang, Z.; Gao, S.; Shi, M.; Liu, B. Magnetic flux leakage image classification method for pipeline weld based on optimized convolution kernel. Neurocomputing 2019, 365, 229–238. [Google Scholar] [CrossRef]
- Lu, S.; Feng, J.; Zhang, H.; Liu, J.; Wu, Z. An Estimation Method of Defect Size from MFL Image Using Visual Transformation Convolutional Neural Network. IEEE Trans. Ind. Inform. 2019, 15, 213–224. [Google Scholar] [CrossRef]
- Chen, L.; Li, J.; Zeng, Y.; Chen, Y.; Liang, W. Magnetic Flux Leakage Image Enhancement using Bidimensional Empirical Mode Decomposition with Wavelet Transform Method in Oil Pipeline Nondestructive Evaluation. J. Magn. 2019, 24, 423–428. [Google Scholar] [CrossRef]
- Feng, J.; Li, F.; Lu, S.; Liu, J.; Ma, D. Injurious or Noninjurious Defect Identification From MFL Images in Pipeline Inspection Using Convolutional Neural Network. IEEE Trans. Instrum. Meas. 2017, 66, 1883–1892. [Google Scholar] [CrossRef]
- Shi, M.; Zhao, H.; Huang, Z.; Liu, Q. Signal extraction using complementary ensemble empirical mode in pipeline magnetic flux leakage nondestructive evaluation. Rev. Sci. Instrum. 2019, 90, 075101. [Google Scholar] [CrossRef] [PubMed]
- Tajbakhsh, N.; Shin, J.Y.; Gurudu, S.R.; Hurst, R.T.; Kendall, C.B.; Gotway, M.B.; Liang, J. Convolutional Neural Networks for Medical Image Analysis: Full Training or Fine Tuning. IEEE Trans. Med. Imaging 2016, 35, 1299–1312. [Google Scholar] [CrossRef] [Green Version]
- Chen, Y.H.; Emer, J.; Sze, V. Eyeriss: A Spatial Architecture for Energy-Efficient Dataflow for Convolutional Neural Networks. IEEE Micro 2017, 37, 12–21. [Google Scholar] [CrossRef]
- Yuan, J.; Han, T.; Tang, J.; An, L. An Approach to Intelligent Fault Diagnosis of Rolling Bearing Using Wavelet Time-Frequency Representations and CNN. Mach. Des. Res. 2017, 33, 93–97. [Google Scholar]
- Neupane, D.; Kim, Y.; Seok, J. Bearing Fault Detection Using Scalogram and Switchable Normalization-Based CNN (SN-CNN). IEEE Access 2021, 9, 88151–88166. [Google Scholar] [CrossRef]
- He, J.; Li, X.; Chen, Y.; Chen, D.; Guo, J.; Zhou, Y. Deep Transfer Learning Method Based on 1D-CNN for Bearing Fault Diagnosis. Shock. Vib. 2021, 2021, 6687331. [Google Scholar] [CrossRef]
- Wang, Z.; Liu, Q.; Chen, H.; Chu, X. A deformable CNN-DLSTM based transfer learning method for fault diagnosis of rolling bearing under multiple working conditions. Int. J. Prod. Res. 2020, 59, 4811–4825. [Google Scholar] [CrossRef]
- Kiranyaz, S.; Ince, T.; Gabbouj, M. Real-Time Patient-Specific ECG Classification by 1-D Convolutional Neural Networks. IEEE Trans. Biomed. Eng. 2016, 63, 664–675. [Google Scholar] [CrossRef]
- Desai, P.; Pujari, J.; Sujatha, C.; Kamble, A.; Kambli, A. Hybrid Approach for Content-Based Image Retrieval using VGG16 Layered Architecture and SVM: An Application of Deep Learning. SN Comput. Sci. 2021, 2, 170. [Google Scholar] [CrossRef]
- Qu, Z.; Mei, J.; Liu, L.; Zhou, D.-Y. Crack Detection of Concrete Pavement With Cross-Entropy Loss Function and Improved VGG16 Network Model. IEEE Access 2020, 8, 54564–54573. [Google Scholar] [CrossRef]
- Qian, R.; Kong, J.J.; Zhu, J. Research on Intelligent Identification of Rice Pests Based on VGG-16 Convolutional Neural Network. J. Anhui Agric. Sci. 2020, 48, 235–238. [Google Scholar] [CrossRef]
- Duan, J.; Liu, X. Online Monitoring of Green Pellet Size Distribution in Haze-Degraded Images Based on VGG16-LU-Net and Haze Judgment. IEEE Trans. Instrum. Meas. 2021, 70, 5006316. [Google Scholar]
- Omiotek, Z.; Kotyra, A. Flame Image Processing and Classification Using a Pre-Trained VGG16 Model in Combustion Diagnosis. Sensors 2021, 21, 500. [Google Scholar] [CrossRef]
- Ma, J.; Zhang, R.; Guo, T.; Zhang, Z.; Li, Q.; Wang, R.; Li, Z. Image classification of migration learning chip based on VGG-16 network. Opt. Instrum. 2020, 42, 21–27. [Google Scholar] [CrossRef]
- Chen, P.; Li, R.; Fu, K.; Zhao, X. Research and Method for In-line Inspection Technology of Girth Weld in Long-Distance Oil and Gas Pipeline. J. Phys. Conf. Ser. 2021, 1986, 012052. [Google Scholar] [CrossRef]
- Wang, Z.J.; Yang, L.J.; Gao, S.W. Pipeline magnetic flux leakage image detection algorithm based on improved SSD network. J. Shenyang Aerosp. Univ. 2019, 36, 74–82. [Google Scholar]
- He, M.; Shi, P.; Xie, S.; Chen, Z.; Uchimoto, T.; Takagi, T. A numerical simulation method of nonlinear magnetic flux leakage testing signals for nondestructive evaluation of plastic deformation in a ferromagnetic material. Mech. Syst. Signal Process. 2021, 155, 107670. [Google Scholar] [CrossRef]
- Zhou, Z.; Liu, Z. Fault Diagnosis of Steel Wire Ropes Based on Magnetic Flux Leakage Imaging Under Strong Shaking and Strand Noises. IEEE Trans. Ind. Electron. 2020, 68, 2543–2553. [Google Scholar] [CrossRef]
- Woo, S.; Park, J.; Lee, J.Y.; Kweon, I.S. CBAM: Convolutional Block Attention Module. In Proceedings of the European Conference on Computer Vision, Munich, Germany, 8–14 September 2018; Springer: Cham, Switzerland, 2018. [Google Scholar]
- Wang, J.; Qiao, X.; Liu, C.; Wang, X.; Liu, Y.; Yao, L.; Zhang, H. Automated ECG classification using a non-local convolutional block attention module. Comput. Methods Programs Biomed. 2021, 203, 106006. [Google Scholar] [CrossRef] [PubMed]
- Hu, Y.; Xia, B.; Mao, M.; Jin, Z.; Du, J.; Guo, L.; Frangi, A.F.; Lei, B.; Wang, T. AIDAN: An Attention-Guided Dual-Path Network for Pediatric Echocardiography Segmentation. IEEE Access 2020, 8, 29176–29187. [Google Scholar] [CrossRef]
- Du, J.; Cheng, K.; Yu, Y.; Wang, D.; Zhou, H. Panchromatic Image Super-Resolution Via Self Attention-Augmented Wasserstein Generative Adversarial Network. Sensors 2021, 21, 2158. [Google Scholar] [CrossRef]
- Szegedy, C.; Ioffe, S.; Vanhoucke, V.; Alemi, A.A. Inception-v4, Inception-ResNet and the Impact of Residual Connections on Learning. In Proceedings of the Thirty-First AAAI Conference on Artificial Intelligence, San Francisco, CA, USA, 4–9 February 2017. [Google Scholar]
- He, K.; Zhang, X.; Ren, S.; Sun, J. Deep Residual Learning for Image Recognition. In Proceedings of the IEEE Conference on Computer Vision and Pattern Recognition, Las Vegas, NV, USA, 27–30 June 2016. [Google Scholar]
- Yu, L.; Hao, C.; Dou, Q.; Qin, J.; Heng, P.A. Automated Melanoma Recognition in Dermoscopy Images via Very Deep Residual Networks. IEEE Trans. Med. Imaging 2016, 36, 994–1004. [Google Scholar] [CrossRef]
- Mo, J.; Zhang, L.; Feng, Y. Exudate-based Diabetic Macular Edema Recognition in Retinal Images using Cascaded Deep Residual Networks. Neurocomputing 2018, 290, 161–171. [Google Scholar] [CrossRef]
- Zhao, Q.; Gan, Z.; Liu, F. Facial structure based compressed face image restoration algorithm with deep residual networks. J. Nanjing Univ. Posts Telecommun. (Nat. Sci. Ed.) 2019, 39, 39–46. [Google Scholar]
- Xu, Y.; Mao, Z.; Chen, Z.; Wen, X.; Li, Y. Context propagation embedding network for weakly supervised semantic segmentation. Multimed. Tools Appl. 2020, 79, 33925–33942. [Google Scholar] [CrossRef]
- Wang, S.; Liu, S.; Yuan, Y.; Zhang, J.; Wang, Z.; Che, X. A novel CC-tSNE-SVR model for rapid determination of diesel fuel quality by near infrared spectroscopy. Infrared Phys. Technol. 2020, 106, 103276. [Google Scholar] [CrossRef]
- Jiao, J.; Fan, Z.; Liang, Z. Remote Sensing Estimation of Rape Planting Area Based on Improved AlexNET Model. Comput. Meas. Control 2018, 2, 186–189. [Google Scholar]
- Chen, Q.; Zhang, H. Hybrid Model for Compressive Image Recovery: Integrating ResNet-Based Denoiser into GAMP. Signal Process. 2020, 173, 107583. [Google Scholar] [CrossRef]



















{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
| Layer Number | Network | Kernel Size | Stride | Kernel Number | Output | Other |
|---|---|---|---|---|---|---|
| 1 | Input | 112 × 112 × 3 | ||||
| 2–4 | Conv + BN + ReLU | 3 × 3 | 1 × 1 | 16 | 112 × 112 × 16 | Same |
| 5–15 | Channel_AM | 112 × 112 × 16 | ||||
| 16–22 | Spatial_AM | 112 × 112 × 16 | ||||
| 23–43 | (Identity_RES + ReLU) × 3 | 112 × 112 × 16 | ||||
| 44–52 | Conv_RES1 + ReLU | 56 × 56 × 32 | ||||
| 53–66 | (Identity_RES + ReLU) × 2 | 56 × 56 × 32 | ||||
| 67–75 | Conv_RES2 + ReLU | 56 × 56 × 32 | ||||
| 76–89 | (Identity_RES + ReLU) × 2 | 28 × 28 × 64 | ||||
| 90 | POOL | 8 × 8 | 21 × 21 × 64 | Global | ||
| 91 | FC | 1 × 1 × 6 | ||||
| 92 | Softmax | 1 × 1 × 6 | ||||
| 93 | Classification | 1 × 1 × 6 |
| GW | SW | Tee | COR | IHT | FL | |
|---|---|---|---|---|---|---|
| Recall | 100% | 97.6 | 95.2% | 95.6% | 98.8% | 99.4% |
| PRE | 99.4% | 96.4% | 97.3% | 94.8% | 98.6% | 100% |
| ACC | 97.7% | |||||
| Identification Model | Index | GW | SW | Tee | COR | IHT | FL | Number of Network Layers |
|---|---|---|---|---|---|---|---|---|
| AlexNET | Recall | 99.6% | 54.8% | 79.6% | 81.2% | 95.4% | 90.2% | 8 |
| PRE | 82.9% | 76.8% | 74.1% | 83.9% | 85.3% | 97.6% | ||
| ACC | 83.5% | |||||||
| VGG16 | Recall | 100% | 86.8% | 86.6% | 90.4% | 96% | 96.2% | 41 |
| PRE | 97.1% | 87.3% | 89.6% | 87.4% | 95.2% | 99.4% | ||
| ACC | 92.67% | |||||||
| ResNet-50 | Recall | 99.6% | 93.2% | 90.2% | 94.2% | 97.2% | 99.6% | 50 |
| PRE | 96.7% | 91.9% | 94.9% | 95.2% | 95.3% | 100% | ||
| ACC | 95.7% | |||||||
| The proposed method | Recall | 100% | 97.6% | 95.2% | 95.6% | 98.8% | 99.4% | 93 |
| PRE | 99.4% | 96.4% | 97.3% | 94.8% | 98.6% | 100% | ||
| ACC | 97.7% | |||||||
Publisher’s Note: MDPI stays neutral with regard to jurisdictional claims in published maps and institutional affiliations. |
© 2022 by the authors. Licensee MDPI, Basel, Switzerland. This article is an open access article distributed under the terms and conditions of the Creative Commons Attribution (CC BY) license (https://creativecommons.org/licenses/by/4.0/).
Share and Cite
Liu, S.; Wang, H.; Li, R. Attention Module Magnetic Flux Leakage Linked Deep Residual Network for Pipeline In-Line Inspection. Sensors 2022, 22, 2230. https://doi.org/10.3390/s22062230
Liu S, Wang H, Li R. Attention Module Magnetic Flux Leakage Linked Deep Residual Network for Pipeline In-Line Inspection. Sensors. 2022; 22(6):2230. https://doi.org/10.3390/s22062230
Chicago/Turabian StyleLiu, Shucong, Hongjun Wang, and Rui Li. 2022. "Attention Module Magnetic Flux Leakage Linked Deep Residual Network for Pipeline In-Line Inspection" Sensors 22, no. 6: 2230. https://doi.org/10.3390/s22062230
APA StyleLiu, S., Wang, H., & Li, R. (2022). Attention Module Magnetic Flux Leakage Linked Deep Residual Network for Pipeline In-Line Inspection. Sensors, 22(6), 2230. https://doi.org/10.3390/s22062230