
SHEL5K: An Extended Dataset and Benchmarking for Safety Helmet Detection

 , , ,
, , , 
Abstract
:1. Introduction
2. Related Work
2.1. Datasets for Safety Helmet Detection
2.1.1. Safety Helmet Detection Dataset
2.1.2. Hardhat Dataset
2.1.3. Hard Hat Workers Object Detection Dataset
2.1.4. Safety Helmet Wearing Dataset
3. SHEL5K Dataset
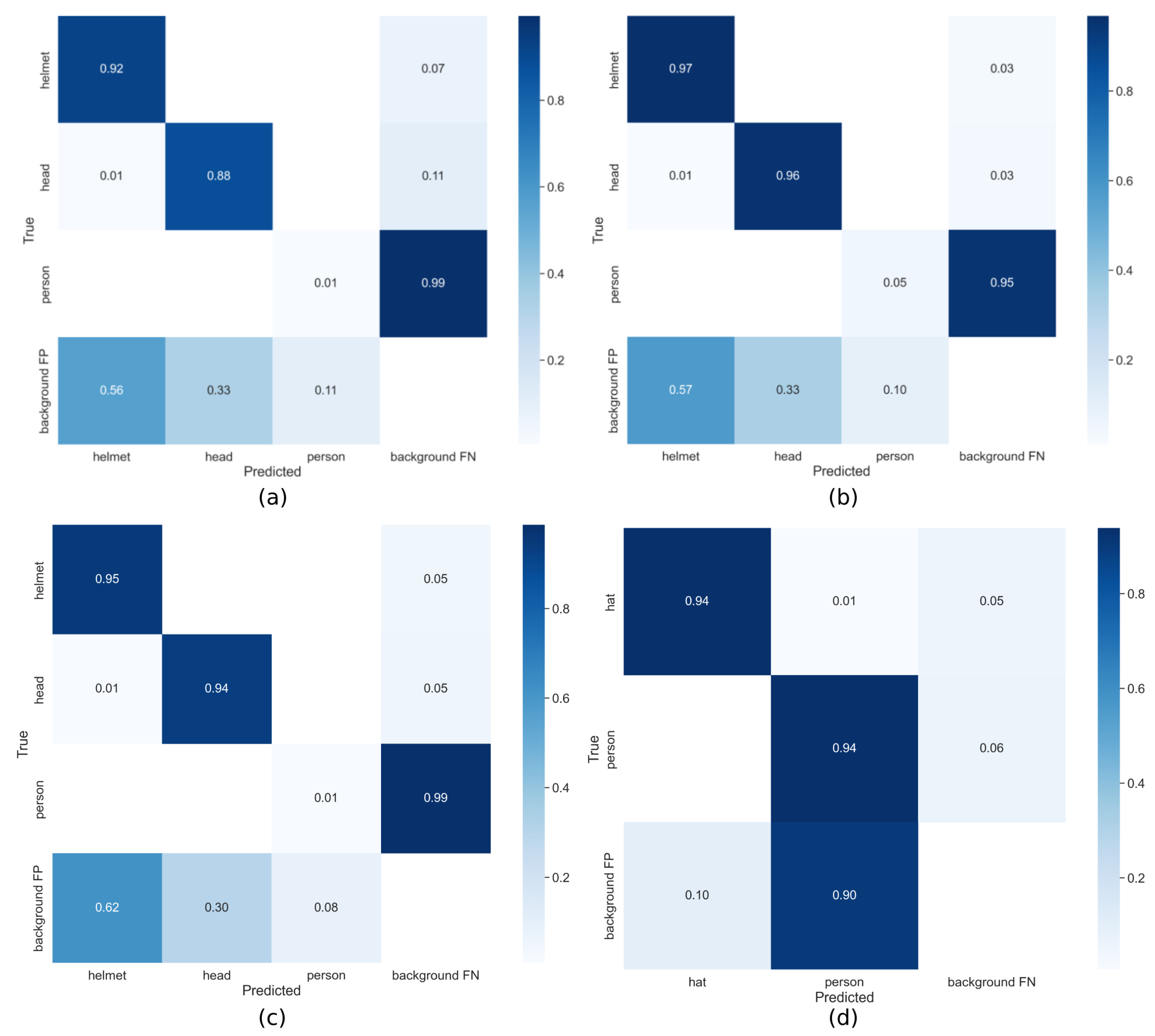
4. Results and Discussion
4.1. Evaluation Metrics
4.2. Experimental Setup
4.3. Three-Class Results
4.4. Six-Class Results
5. Conclusions
Author Contributions
Funding
Institutional Review Board Statement
Informed Consent Statement
Data Availability Statement
Acknowledgments
Conflicts of Interest
Appendix A





References
- Keller, J.R. Construction Accident Statistics. Available online: https://www.2keller.com/library/construction-accident-statistics.cfm (accessed on 5 January 2022).
- U.S. Bureau of Labor Statistics (BLS). National Census of Fatal Occupational Injuries in 2014. September 2015. Available online: https://www.bls.gov/news.release/archives/cfoi_09172015.pdf (accessed on 5 January 2022).
- U.S. Bureau of Labor Statistics (BLS). Census of Fatal Occupational Injuries Summary, 2019. December 2020. Available online: https://www.bls.gov/news.release/cfoi.nr0.html (accessed on 5 January 2022).
- Jeon, J.-h. 971 S. Korean Workers Died on the Job in 2018, 7 More than Previous Year. May 2019. Available online: https://www.hani.co.kr/arti/english_edition/e_national/892709.html (accessed on 5 January 2022).
- HexArmor. The Hard Truth about Safety Helmet Injuries and Statistics. June 2019. Available online: https://www.hexarmor.com/posts/the-hard-truth-about-safety-helmet-injuries-and-statistics (accessed on 5 January 2022).
- Konda, S.; Tiesman, H.M.; Reichard, A.A. Fatal traumatic brain injuries in the construction industry, 2003–2010. Am. J. Ind. Med. 2016, 59, 212–220. [Google Scholar] [CrossRef]
- Headway the Brain Injury Association. Workplace hArd Hat Safety Survey Results. Available online: https://www.headway.org.uk/media/8785/workplace-hard-hat-safety-survey-results.pdf (accessed on 5 January 2022).
- Larxel. Safety Helmet Detection. Available online: https://www.kaggle.com/andrewmvd/hard-hat-detection (accessed on 5 January 2022).
- Redmon, J.; Farhadi, A. YOLOv3: An Incremental Improvement. arXiv 2018, arXiv:1804.02767. [Google Scholar]
- Adarsh, P.; Rathi, P.; Kumar, M. YOLO v3-Tiny: Object Detection and Recognition using one stage improved model. In Proceedings of the 2020 6th International Conference on Advanced Computing and Communication Systems (ICACCS), Tamil Nadu, India, 6–7 March 2020. [Google Scholar] [CrossRef]
- Zhang, X.; Gao, Y.; Wang, H.; Wang, Q. Improve YOLOv3 using dilated spatial pyramid module for multi-scale object detection. Int. J. Adv. Robot. Syst. 2020, 17. [Google Scholar] [CrossRef]
- Bochkovskiy, A.; Wang, C.-Y.; Liao, H.-Y.M. YOLOv4: Optimal Speed and Accuracy of Object Detection. arXiv 2020, arXiv:2004.10934. [Google Scholar]
- Jocher, G.; Stoken, A.; Borovec, J.; Liu, C.; Hogan, A. Ultralytics/yolov5: v4.0-nn.SiLU() activations, Weights & Biases logging, PyTorch Hub integration (v4.0). Zenodo 2021. [Google Scholar] [CrossRef]
- Ren, S.; He, K.; Girshick, R.; Sun, J. Faster R -CNN: Towards real-time object detection with region proposal networks. In Proceedings of the Advances in Neural Information Processing Systems, Montreal, QC, Canada, 7–12 December 2015; pp. 91–99. [Google Scholar]
- Szegedy, C.; Vanhoucke, V.; Ioffe, S.; Shlens, J.; Wojna, Z. Rethinking the Inception architecture for computer vision. arXiv 2015, arXiv:1512.00567. [Google Scholar]
- Wang, C.-Y.; Yeh, I.-H.; Liao, H.-Y.M. You Only Learn One Representation: Unified Network for Multiple Tasks. arXiv 2021, arXiv:2105.04206. [Google Scholar]
- Li, Y.; Wei, H.; Han, Z.; Huang, J.; Wang, W. Deep Learning-Based Safety Helmet Detection in Engineering Management Based on Convolutional Neural Networks. Adv. Civ. Eng. 2020, 2020, 9703560. [Google Scholar] [CrossRef]
- Wang, H.; Hu, Z.; Guo, Y.; Yang, Z.; Zhou, F.; Xu, P. A Real-Time Safety Helmet Wearing Detection Approach Based on CSYOLOv3. Appl. Sci. 2020, 10, 6732. [Google Scholar] [CrossRef]
- Wang, L.; Xie, L.; Yang, P.; Deng, Q.; Du, S.; Xu, L. Hardhat-Wearing Detection Based on a Lightweight Convolutional Neural Network with Multi-Scale Features and a Top-Down Module. Sensors 2020, 20, 1868. [Google Scholar] [CrossRef] [PubMed] [Green Version]
- Xie, L. Hardhat. Harvard Dataverse. 2019. Available online: https://dataverse.harvard.edu/dataset.xhtml?persistentId=doi:10.7910/DVN/7CBGOS (accessed on 5 January 2022).
- Li, K.; Zhao, X.; Bian, J.; Tan, M. Automatic Safety Helmet Wearing Detection. In Proceedings of the 2017 IEEE 7th Annual International Conference on CYBER Technology in Automation, Control, and Intelligent Systems (CYBER), Honolulu, HI, USA, 31 July–4 August 2017. [Google Scholar] [CrossRef] [Green Version]
- Dalal, N. INRIA Person Dataset. Available online: http://pascal.inrialpes.fr/data/human/ (accessed on 5 January 2022).
- Rubaiyat, A.H.M.; Toma, T.T.; Kalantari-Khandani, M.; Rahman, S.A.; Chen, L.; Ye, Y.; Pan, C.S. Automatic Detection of Helmet Uses for Construction Safety. In Proceedings of the 2016 IEEE/WIC/ACM International Conference on Web Intelligence Workshops (WIW), Omaha, NE, USA, 13–16 October 2016. [Google Scholar] [CrossRef]
- Kamboj, A.; Powar, N. Safety Helmet Detection in Industrial Environment using Deep Learning. In Proceedings of the 9th International Conference on Information Technology Convergence and Services (ITCSE 2020), Zurich, Switzerland, 30–31 May 2020. [Google Scholar] [CrossRef]
- Geng, R.; Ma, Y.; Huang, W. An improved helmet detection method for YOLOv3 on an unbalanced dataset. arXiv 2020, arXiv:2011.04214. [Google Scholar]
- Long, X.; Cui, W.; Zheng, Z. Safety Helmet Wearing Detection Based On Deep Learning. In Proceedings of the 2019 IEEE 3rd Information Technology, Networking, Electronic and Automation Control Conference (ITNEC), Chengdu, China, 15–17 March 2019. [Google Scholar] [CrossRef]
- Northeastern University—China. Hard Hat Workers Object Detection Dataset. Available online: https://public.roboflow.com/object-detection/hard-hat-workers (accessed on 5 January 2022).
- Safety-Helmet-Wearing-Dataset. Available online: https://github.com/njvisionpower/Safety-Helmet-Wearing-Dataset (accessed on 5 January 2022).
- Peng, D.; Sun, Z.; Chen, Z.; Cai, Z.; Xie, L.; Jin, L. Detecting Heads using Feature Refine Net and Cascaded Multi-scale Architecture. In Proceedings of the 2018 24th International Conference on Pattern Recognition (ICPR), Beijing, China, 20–22 August 2018. [Google Scholar] [CrossRef] [Green Version]
- Tzutalin. LabelImg. Git Code. 2015. Available online: https://github.com/tzutalin/labelImg (accessed on 5 January 2022).
- Lin, T.-Y.; Maire, M.; Belongie, S.; Hays, J.; Perona, P.; Ramanan, D.; Dollár, P.; Zitnick, C.L. Microsoft COCO: Common Objects in Context. arXiv 2014, arXiv:1405.0312. [Google Scholar]
- Russakovsky, O.; Deng, J.; Su, H.; Krause, J.; Satheesh, S.; Ma, S.; Huang, Z.; Karpathy, A.; Khosla, A.; Bernstein, M.; et al. ImageNet largescale visual recognition challenge. Int. J. Comput. Vis. 2015, 115, 211–252. [Google Scholar] [CrossRef] [Green Version]
- Padilla, R.; Passos, W.L.; Dias, T.L.B.; Netto, S.L.; da Silva, E.A.B. A Comparative Analysis of Object Detection Metrics with a Companion Open-Source Toolkit. Electronics 2021, 10, 279. [Google Scholar] [CrossRef]









{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
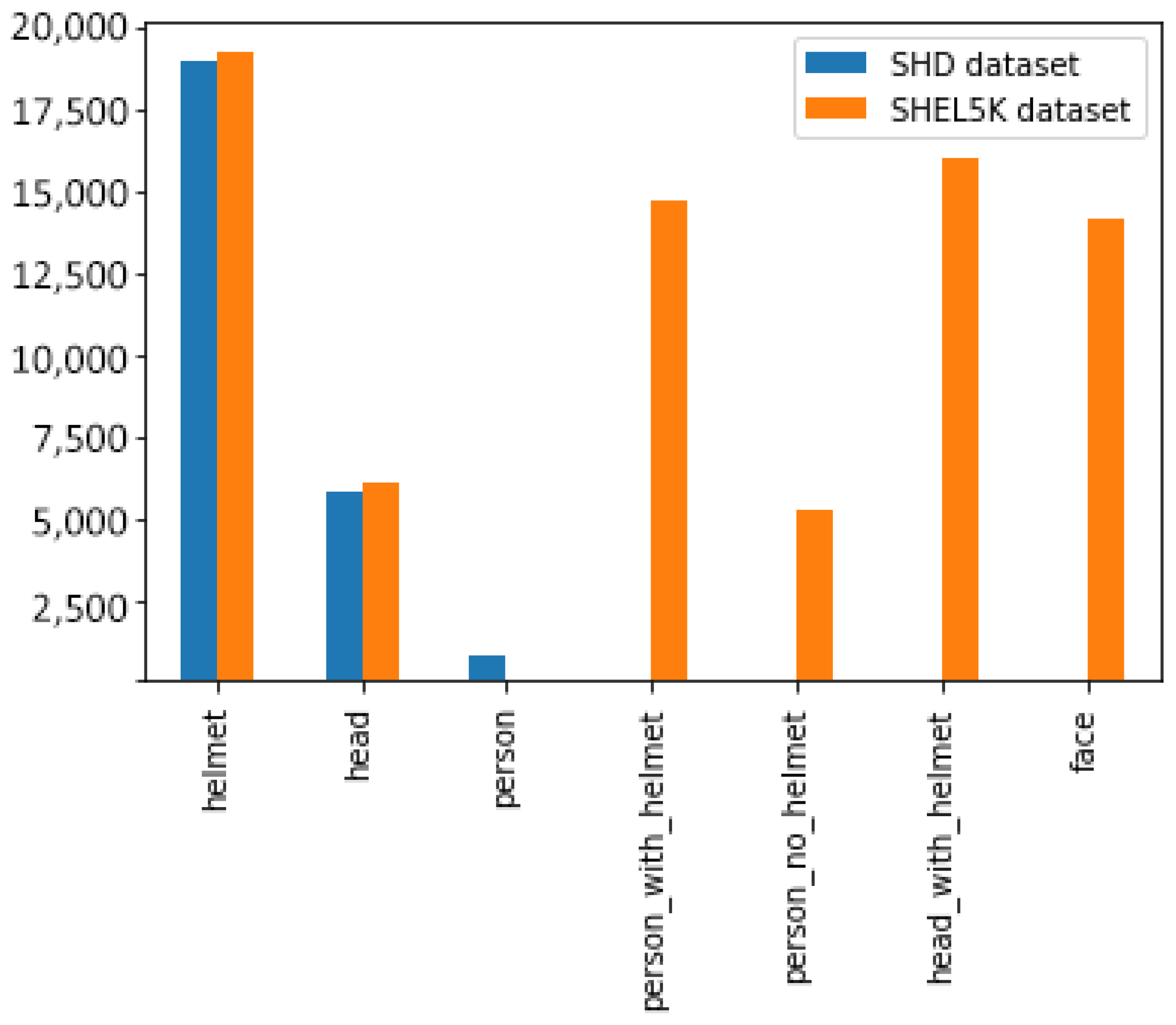
| Datasets | Hardhat [20] | HHW [27] | SHD [8] | SHW [28] | SHEL5K |
|---|---|---|---|---|---|
| Total sample | 7063 | 7041 | 5000 | 7581 | 5000 |
| Class | 3 | 3 | 3 | 2 | 6 |
| Number of labels in each class | |||||
| Helmet | 19,852 | 26,506 | 18,966 | - | 19,252 |
| Head | 6781 | 8263 | 5785 | - | 6120 |
| Person * | 616 | 998 | 751 | 9044 | - |
| Head and helmet | - | - | - | - | 16,048 |
| Person not helmet | - | - | - | - | 5248 |
| Person and helmet | - | - | - | - | 14,767 |
| Face | - | - | - | - | 14,135 |
| Hat ** | - | - | - | 111,514 | - |
| Total | 27,249 | 35,767 | 25,502 | 120,558 | 75,570 |
| YOLOv3-SPP [11] | ||||||||
|---|---|---|---|---|---|---|---|---|
| SHD Dataset [8] | SHEL5K Dataset with 3 Classes | |||||||
| Class | Precision | Recall | mAP0.5 | F1 | Precision | Recall | mAP0.5 | F1 |
| Helmet | 0.9578 | 0.4976 | 0.4869 | 0.6549 | 0.9222 | 0.7197 | 0.7028 | 0.8084 |
| Head | 0.9154 | 0.302 | 0.2923 | 0.4542 | 0.9114 | 0.6642 | 0.6484 | 0.7684 |
| Person | 0 | 0 | 0 | 0 | 0.9092 | 0.6354 | 0.6148 | 0.748 |
| Average | 0.6244 | 0.2665 | 0.2597 | 0.3697 | 0.9143 | 0.6731 | 0.6553 | 0.775 |
| YOLOv5x [13] | ||||||||
| SHD Dataset [8] | SHEL5K Dataset with 3 Classes | |||||||
| Class | Precision | Recall | mAP0.5 | F1 | Precision | Recall | mAP0.5 | F1 |
| Helmet | 0.9559 | 0.9162 | 0.9162 | 0.9356 | 0.9402 | 0.8858 | 0.8774 | 0.9122 |
| Head | 0.909 | 0.879 | 0.8686 | 0.8938 | 0.9216 | 0.8562 | 0.8499 | 0.8877 |
| Person | 0.0345 | 0.0052 | 0.0003 | 0.009 | 0.9203 | 0.8409 | 0.8311 | 0.8788 |
| Average | 0.6331 | 0.6001 | 0.595 | 0.6128 | 0.9274 | 0.861 | 0.8528 | 0.8929 |
| YOLOv3-SPP [11] | ||||||||||||
|---|---|---|---|---|---|---|---|---|---|---|---|---|
| Scratch | Pretrained on ImagesNet Dataset [32] | Pretrained on MS COCO Dataset [31] | ||||||||||
| Class | Precision | Recall | mAP0.5 | F1 | Precision | Recall | mAP0.5 | F1 | Precision | Recall | mAP0.5 | F1 |
| Helmet | 0.9253 | 0.3144 | 0.3053 | 0.4693 | 0.9373 | 0.6275 | 0.6105 | 0.7518 | 0.8277 | 0.2971 | 0.2602 | 0.4372 |
| Head with helmet | 0.9244 | 0.4035 | 0.3871 | 0.5618 | 0.9349 | 0.6668 | 0.6459 | 0.7784 | 0.7806 | 0.463 | 0.4043 | 0.5813 |
| person with helmet | 0.7778 | 0.1442 | 0.12 | 0.2433 | 0.8746 | 0.6288 | 0.5924 | 0.7316 | 0.8622 | 0.4491 | 0.4076 | 0.5906 |
| Head | 0.8868 | 0.2295 | 0.2173 | 0.3646 | 0.9268 | 0.6184 | 0.5978 | 0.7418 | 0.8378 | 0.2775 | 0.2422 | 0.4169 |
| Person without helmet | 0.8241 | 0.1563 | 0.1339 | 0.2628 | 0.8784 | 0.4957 | 0.4729 | 0.6338 | 0.8389 | 0.3823 | 0.3528 | 0.5252 |
| Face | 0.4191 | 0.0556 | 0.0295 | 0.0982 | 0.7588 | 0.4715 | 0.4238 | 0.5816 | 0.3978 | 0.013 | 0.007 | 0.0252 |
| Average | 0.7929 | 0.2173 | 0.1988 | 0.3333 | 0.8851 | 0.5848 | 0.5572 | 0.7032 | 0.7575 | 0.3137 | 0.279 | 0.4294 |
| YOLOv5s [13] | YOLOv5m [13] | YOLOv5x [13] | ||||||||||
|---|---|---|---|---|---|---|---|---|---|---|---|---|
| Class | Precision | Recall | mAP0.5 | F1 | Precision | Recall | mAP0.5 | F1 | Precision | Recall | mAP0.5 | F1 |
| Helmet | 0.961 | 0.7825 | 0.872 | 0.8626 | 0.9632 | 0.7981 | 0.8795 | 0.8729 | 0.96 | 0.8205 | 0.8896 | 0.8848 |
| Head with helmet | 0.9437 | 0.7973 | 0.8761 | 0.8608 | 0.9476 | 0.7946 | 0.8783 | 0.8641 | 0.9357 | 0.8247 | 0.8912 | 0.8767 |
| Person with helmet | 0.9061 | 0.8385 | 0.8935 | 0.871 | 0.9131 | 0.8346 | 0.8922 | 0.8721 | 0.8953 | 0.8723 | 0.9089 | 0.8836 |
| Head | 0.9341 | 0.8219 | 0.889 | 0.8744 | 0.9335 | 0.8252 | 0.8897 | 0.876 | 0.9344 | 0.8497 | 0.9025 | 0.89 |
| Person without helmet | 0.8791 | 0.7583 | 0.8493 | 0.8142 | 0.8872 | 0.7602 | 0.8527 | 0.8188 | 0.8921 | 0.7924 | 0.8732 | 0.8393 |
| Face | 0.8991 | 0.6514 | 0.7863 | 0.7558 | 0.9061 | 0.6982 | 0.8122 | 0.7886 | 0.895 | 0.7427 | 0.8301 | 0.8117 |
| Average | 0.9207 | 0.774 | 0.861 | 0.8397 | 0.9251 | 0.7851 | 0.8687 | 0.84887 | 0.9188 | 0.817 | 0.8826 | 0.8644 |
| YOLOv5x [13] | YOLOR [16] | ||||||||
|---|---|---|---|---|---|---|---|---|---|
| Datasets | Class | Precision | Recall | mAP0.5 | F1 | Precision | Recall | mAP0.5 | F1 |
| SHW [28] | 2 | 0.9334 | 0.9297 | 0.9219 | 0.9294 | 0.9486 | 0.8063 | 0.889 | 0.8697 |
| Hardhat [20] | 3 | 0.6715 | 0.6545 | 0.6389 | 0.6546 | 0.6367 | 0.6263 | 0.6407 | 0.6315 |
| HHW [27] | 3 | 0.6355 | 0.6295 | 0.6214 | 0.6288 | 0.6289 | 0.6177 | 0.6344 | 0.6233 |
| SHD [8] | 3 | 0.6331 | 0.6001 | 0.595 | 0.6128 | 0.6211 | 0.6341 | 0.6431 | 0.6276 |
| SHEL5K | 6 | 0.9187 | 0.817 | 0.8826 | 0.8644 | 0.9322 | 0.8066 | 0.8828 | 0.8637 |
| YOLOR [16] | ||||
|---|---|---|---|---|
| Class | Precision | Recall | mAP0.5 | F1 |
| Helmet | 0.9658 | 0.7981 | 0.8846 | 0.874 |
| Head with helmet | 0.9464 | 0.8172 | 0.8898 | 0.877 |
| Person with helmet | 0.9225 | 0.8771 | 0.9204 | 0.8992 |
| Head | 0.9461 | 0.8464 | 0.9068 | 0.8935 |
| Person without helmet | 0.8859 | 0.8019 | 0.8767 | 0.8418 |
| Face | 0.9264 | 0.6992 | 0.8182 | 0.797 |
| Average | 0.9322 | 0.8066 | 0.8828 | 0.8637 |
| K1 | K2 | K3 | K4 | K5 | ||||||
|---|---|---|---|---|---|---|---|---|---|---|
| mAP0.5 | F1 | mAP0.5 | F1 | mAP0.5 | F1 | mAP0.5 | F1 | mAP0.5 | F1 | |
| Helmet | 0.8846 | 0.874 | 0.8813 | 0.8704 | 0.8878 | 0.8787 | 0.881 | 0.8702 | 0.8896 | 0.878 |
| Head with helmet | 0.8898 | 0.877 | 0.8848 | 0.8741 | 0.8932 | 0.8815 | 0.8859 | 0.8713 | 0.8953 | 0.88 |
| person with helmet | 0.9204 | 0.8992 | 0.9146 | 0.8976 | 0.9213 | 0.9048 | 0.9319 | 0.9117 | 0.9226 | 0.9037 |
| Head | 0.9068 | 0.8935 | 0.893 | 0.8805 | 0.8979 | 0.885 | 0.9068 | 0.8921 | 0.9134 | 0.9003 |
| person without helmet | 0.8767 | 0.8418 | 0.8731 | 0.8433 | 0.8867 | 0.8547 | 0.8749 | 0.8412 | 0.8832 | 0.8584 |
| face | 0.8182 | 0.797 | 0.8213 | 0.7943 | 0.814 | 0.79 | 0.8094 | 0.7795 | 0.8244 | 0.8008 |
| Average | 0.8828 | 0.8637 | 0.878 | 0.8614 | 0.8835 | 0.8658 | 0.8817 | 0.861 | 0.8881 | 0.8714 |
| Models | Precision | Recall | mAP0.5 | F1 | Training Time (hours) | Testing Time (s) | Parameters (Million) | Layers |
|---|---|---|---|---|---|---|---|---|
| Faster-RCNN [14] | 0.7808 | 0.3862 | 0.3689 | 0.5167 | 55.6 | 0.084 | 13.3 | 48 |
| YOLOv3-tiny [10] | 0.7695 | 0.4225 | 0.3779 | 0.5408 | 5.2 | 0.006 | 8.7 | 37 |
| YOLOv3 [9] | 0.8509 | 0.4482 | 0.417 | 0.5848 | 24.6 | 0.011 | 61.6 | 222 |
| YOLOv3-SPP [11] | 0.8851 | 0.5848 | 0.5572 | 0.7032 | 24.6 | 0.012 | 62.6 | 225 |
| YOLOv4 [12] | 0.925 | 0.7798 | 0.7693 | 0.8449 | 11.2 | 0.014 | 63.9 | 488 |
| YOLOv4pacsp-x-mish [12] | 0.9195 | 0.8036 | 0.7915 | 0.8567 | 14.5 | 0.014 | 63.9 | 488 |
| YOLOv5s [13] | 0.9205 | 0.774 | 0.861 | 0.8397 | 0.3 | 0.018 | 7.1 | 224 |
| YOLOv5m [13] | 0.9251 | 0.7851 | 0.8687 | 0.8488 | 2.7 | 0.022 | 21.1 | 308 |
| YOLOv5x [13] | 0.9188 | 0.817 | 0.8826 | 0.8644 | 6.3 | 0.032 | 87.2 | 476 |
| YOLOR [16] | 0.9322 | 0.8066 | 0.8828 | 0.8637 | 9.8 | 0.012 | 36.9 | 665 |
Publisher’s Note: MDPI stays neutral with regard to jurisdictional claims in published maps and institutional affiliations. |
© 2022 by the authors. Licensee MDPI, Basel, Switzerland. This article is an open access article distributed under the terms and conditions of the Creative Commons Attribution (CC BY) license (https://creativecommons.org/licenses/by/4.0/).
Share and Cite
Otgonbold, M.-E.; Gochoo, M.; Alnajjar, F.; Ali, L.; Tan, T.-H.; Hsieh, J.-W.; Chen, P.-Y. SHEL5K: An Extended Dataset and Benchmarking for Safety Helmet Detection. Sensors 2022, 22, 2315. https://doi.org/10.3390/s22062315
Otgonbold M-E, Gochoo M, Alnajjar F, Ali L, Tan T-H, Hsieh J-W, Chen P-Y. SHEL5K: An Extended Dataset and Benchmarking for Safety Helmet Detection. Sensors. 2022; 22(6):2315. https://doi.org/10.3390/s22062315
Chicago/Turabian StyleOtgonbold, Munkh-Erdene, Munkhjargal Gochoo, Fady Alnajjar, Luqman Ali, Tan-Hsu Tan, Jun-Wei Hsieh, and Ping-Yang Chen. 2022. "SHEL5K: An Extended Dataset and Benchmarking for Safety Helmet Detection" Sensors 22, no. 6: 2315. https://doi.org/10.3390/s22062315
APA StyleOtgonbold, M.-E., Gochoo, M., Alnajjar, F., Ali, L., Tan, T.-H., Hsieh, J.-W., & Chen, P.-Y. (2022). SHEL5K: An Extended Dataset and Benchmarking for Safety Helmet Detection. Sensors, 22(6), 2315. https://doi.org/10.3390/s22062315