Abstract
As the world’s population is aging, and since access to ambient sensors has become easier over the past years, activity recognition in smart home installations has gained increased scientific interest. The majority of published papers in the literature focus on single-resident activity recognition. While this is an important area, especially when focusing on elderly people living alone, multi-resident activity recognition has potentially more applications in smart homes. Activity recognition for multiple residents acting concurrently can be treated as a multilabel classification problem (MLC). In this study, an experimental comparison between different MLC algorithms is attempted. Three different techniques were implemented: RAkEL, classifier chains, and binary relevance. These methods are evaluated using the ARAS and CASAS public datasets. Results obtained from experiments have shown that using MLC can recognize activities performed by multiple people with high accuracy. While RAkEL had the best performance, the rest of the methods had on-par results.
1. Introduction
Human activity recognition (HAR) is a research area with increased scientific interest. HAR is the task of correctly recognizing human actions and activities. Its applications vary from athlete and patient monitoring [1,2] to elderly care [3,4]. As IoT devices have become more accessible, solutions that use activity recognition are easier to deploy in smart home installations.
The main purpose of an activity recognition system is to correctly recognize human actions and inform any agent interested about those actions. Recognizing performed activities is a process that, in most cases, happens in real time, as the results are used immediately. The majority of published works focus on recognizing the actions of a single individual [5,6]. While recognizing the activity of only one person is important when monitoring elderly people living alone, it is also critical to recognize activities performed by multiple humans operating in the same space. Information about multiple actions and the way humans interact while performing those activities could provide additional insight about the actions’ context.
Machine learning approaches are a common way to recognize actions performed by humans [4,6]. In a HAR system, usually, multiple activities are recognized; thus, recognizing multiple activites is addressed as a multiclass classification problem [7]. Given a sensory input, the trained model assigns one class (i.e., activity) to that specific input. Multiclass classification algorithms have increased accuracy [8] when only a single person is present. When more than one individual is acting, the problem must be reformed as a multilabel classification problem.
Multilabel classification (MLC) is a classification task where multiple labels may be assigned to each input [9]. Instead of selecting precisely one class out of many, as multiclass classification does, MLC returns one or more classes. It is worth mentioning that there is no constraint on how many classes an input can be assigned to.
Treating HAR as a multilabel classification problem will allow activity recognition for residents acting concurrently. Sensory information, containing activity-related data for multiple people acting concurrently, is used as input.
The purpose of this paper is to perform a benchmark on multilabel classification algorithms used on HAR. Implemented classifiers were trained to recognize a broad set of activities using multiple ambient sensors (i.e., pressure, contact, etc.). Section 1 is a brief introduction to HAR and multilabel classification. Related work is briefly presented in Section 2, followed by the methodology used in our work in Section 4. Thereafter, the results obtained are presented and discussed. At the end, conclusions are drawn and future work is discussed.
2. Related Work
Human activity recognition in smart house installations with a single resident is a research area with rapid growth. Several machine learning techniques have been employed in order to address the problem [4]. Random forests have been proven an effective solution [10,11]; they provide robust and explainable results and are easy to implement and train. Hidden Markov models (HMMs) are also a common approach [12,13]; HMMs are not only used for activity recognition, but for absence and home visit detection as well [13]. Deep learning models specifically developed for HAR [14,15] have been gaining increased interest over the past years. The popularity of those models is due to their ability to handle sequential data and time series, the main form of data generated by ambient sensors used in smart home installations.
Despite the fact that machine learning algorithms can recognize performed actions with impressive accuracy, their performance is sub-par when more than one people interact in the same environment. Benchmarks on multi-resident activity recognition [16,17] provide a baseline for researchers that want to address multi-resident activity recognition. Thus, state-of-the-art algorithms, such as the hidden Markov model (HMM), recurrent neural networks (RNN), k-nearest neighbors (KNN), conditional random field (CRF), random forests (RF), and feed-forward neural networks (FFNN), were evaluated thoroughly in this study. Additionally, sensor placement was evaluated, as the sensor network is important for activity recognition [17].
In order to tackle the multiple residents concurrent activity recognition problem, ensemble techniques have been proposed in the literature. A factorial hidden Markov model (HMM) that models two different chains (one for each resident) was proposed by [18]. An ensemble method based on hidden Markov models was presented, aiming to address multi-resident activity recognition, by [19]; the proposed technique introduced a mixed-dependency model, dealing with the complexity of multiple residents acting concurrently. Combined-label HMMs were also evaluated in [20], where activity labels and observation labels of different residents were combined, generating a sequence of observations, recognized by a conventional HMM. Additionally, a model where activities are linked at each time step was proposed. Both models, combined-label and linked activities, outperformed the baseline HMM models.
As smart homes are dynamic environments not limited to their residents, the need to detect visitors, occupants, and even pets is crucial [20,21]. Calculating entropy measures and comparing them with the standard deviation, visitors can be detected and identified [22]. This method can help activity recognition systems to focus only on sensor activations that are relevant to the main residents of the house.
Incremental decision trees have also been employed [23]. While the results were promising, authors identified that further work is needed to obtain results that are on par with single-resident activity recognition. Deep learning is also often explored as a technique able to recognize activities performed by multiple residents. Recurrent neural networks (RNNs) were evaluated using not only real-world data, but also synthetic data generated with a generative adversarial network [24]. Multi-task learning, i.e., regarding the activity of each resident as a learning task, was paired with zero-shot learning to recognize previously unseen activities [25].
Multi-label classification, while extensively used on multiple domains, such as text [26], video [27], and image [28] classification, etc., have only recently drawn the attention of researchers to the activity recognition field. A comparative experimental study between two well-known MLC algorithms [29] proved that MLC can address concurrent activity recognition effectively. Interaction between actions performed by different people can be identified by transforming the multi-resident activity recognition problem into an MLC problem. Experiments have shown that random forests, when used as base classifiers on a MLC algorithm, have an impressive performance [30]. An evaluation of multilabel classification was performed by [31]. The authors use frequent item mining, a technique commonly used in data mining, in order to generate frequent itemsets as features for each activity. The generated features were used to evaluate MLC algorithms such as multilabel KNN, labelset, and decision trees.
Treating multi-resident HAR as a multi-label classification problem while transforming it to a multi-class problem was investigated by [32]. Decision trees were used as the base classifier and label combination was employed for the problem transformation. Binary relevance has been proposed in the literature for multilabel HAR [33]. The results were competitive with approaches transforming the problem into a classic classification problem. The classifier chains approach considers activity correlation, an important aspect of activity recognition [34]. This proposed approach was able to find underlying correlations between activities and reduce the classification time.
3. Our Contribution
As already discussed in the previous sections, multi-resident human activity recognition is a research area that attracts a lot of attention. Multi-class classification techniques, while they yield good results, are far from providing a robust and reliable solution. On the other hand, multilabel classification approaches seem to better recognize concurrent activities, but they have not been investigated to the same extent as multi-class classification.
In our work, we aim to provide a baseline for future research on multilabel classification in multi-resident activity recognition. This will allow future researchers to compare their results with results obtained from three well known-algorithms (considered state-of-the-art). Two datasets were used, ARAS and CASAS, which are extensively used on multi-resident activity recognition.
Furthermore, our results are compared with multilabel and multi-class algorithms used on the same problem. This is to identify whether or not the experimentally evaluated algorithms can provide similar or better results. Lastly, has never been evaluated on a multi-resident activity recognition problem before (based on our search); thus, our work reports results not available in the literature.
4. Methodology
MLC can help address the problem of multi-resident activity recognition, as the trained model is able to learn from a diverse set of sensors and assign each example to multiple classes. In our work, several state-of-the-art (, classifier chain, binary relevance) MLC algorithms are evaluated. Algorithms were chosen based on previous benchmarks [29,35]. All algorithms were implemented using Python and Scikit-Learn [36]. The features used for training were the values of each sensor, recorded every second. No sliding windows were applied on the datasets.
4.1. RAkELd
The random k-labelsets algorithm () [37] is an ensemble method for multilabel classification. Each member of the ensemble is constructed by considering a relatively small, random subset of labels. A single label classifier is trained for the prediction of each element in the powerset of the subset. The benefit of applying single label classifiers to sub-tasks with a feasible number of labels is that label correlation is taken into account.
Constructing the labelsets can be realized by using two different methods: disjoint and overlapping labelsets. In our work, disjoint labelsets were constructed. The label space was partitioned to equal partitions of size k. For each partition, a label powerset classifier was trained, and the prediction was the sum of all trained classifiers. Labelset size k was set to 3, as, according to authors, it allows the best results. An extensive evaluation was performed on the labelset size [37], and results showed that a smaller number affects the performance of the algorithm positively, with 3 being the value that leads to the best results on multiple datasets. In our work, the labelset was evaluated with different values (k = 2,3,4,5) and the value the authors proposed (k = 3) was the optimal.
Two different classifiers were used during experimentation: multilayer perceptron (MLP) and random forests. In order to fine tune the parameters of the two used classifiers, different techniques were used. The random forest classifier was tuned using randomized parameter optimization [38]. For every hyperparameter that required tuning, a set or range of values was given. A random search was then performed on these distributions M times. A model was trained for each combination and the hyperparameters for the best model were returned.
MLP’s hyperparameters were chosen using quantum genetic algorithms (QGA) [39]. Similarly to randomized parameter optimization, a range or set of values was given. The search space was then explored using QGA. Each set of parameters was represented as a chromosome consisting of qudits. A model was trained for each set of parameters. The evaluation was based on the accuracy of the trained model. Non-optimal chromosomes had a chance to re-initialize instead of converging to the best solution. This method allows for a fast convergence to the best solution while performing a random search, thereby avoiding the local optimal.
4.2. Binary Relevance
Binary relevance [40] attempts to transform a multilabel classification problem with L labels into L binary classification problems. The same classifier is used on all sub problems (random forests in our experiments). The final prediction of binary relevance is the union of all individual label classifiers. Binary relevance is a rather simple algorithm that yields promising results. The simplicity of the technique allows for low modeling complexity, linear to the number of class labels in the label space.
4.3. Classifier Chain
Another widely used MLC ensemble method is the classifier chain method [41]. A classifier chain constructs a chain of binary classifiers. The number of classifiers constructed is the same as the number of labels in the dataset. As the classifiers are linked in a chain format, a single classifier can utilize the prediction of all previously trained models. Therefore, a classifier chain reconstructs the multilabel problem into a a multi-class problem, where each label combination is a different class and the number of classifiers is equal to the total number of classes. In our experiments, the binary classifier chosen was random forests, tuned with randomized parameter optimization.
4.4. ARAS Dataset
The first dataset used in our work is the ARAS (activity recognition with ambient sensing) human activity recognition dataset [42]. The ARAS dataset contains real-life data from two houses with multiple residents. More specifically, 2 young males (25) were living in house A, and a married couple (35) was living in house B. Several ambient sensors were employed to gather data. Force and pressure sensors were placed under the bed and couches, photocells were placed in the drawers, wardrobes, and refrigerator, contact sensors were placed on the door frames, shower cabin, and cupboards, proximity sensors were placed on the chairs, closet, and taps, sonars were placed on the walls and door frames, temperature sensors were installed near the kitchen and oven, and infrared sensors were placed near the TV. The sensors and the actions associated with them are summarized in Table 1. As a result, 27 different activities were recognized (Table 2).

Table 1.
Sensors and their associated actions.
Table 2.
Activities available in the ARAS dataset.
Residents did not follow a specific activity plan during data acquisition, but continued to behave naturally. The only interaction with the system was battery replacement of the sensors and labeling the ground truth manually. Sensors were sampled at 10 Hz (the IR sensor was sampled at 100 Hz). Sensor events were logged every second, resulting in 86,400 data points for each day.
4.5. CASAS Dataset
The CASAS dataset contains data from different participants acting as residents of the same house. Each resident performed 15 unique activities (Table 3). Some activities were performed individually (ind.) while some of them required the cooperation of the participants (co-op). Motion sensors were placed on the ceiling, monitoring movement around the room, and contact switches were placed on objects, registering use events. The apartment was always occupied by two participants and 40 volunteers were recruited.
Table 3.
Activities performed by each resident on the CASAS dataset.
4.6. Data Preprocessing
Before training the classifiers mentioned, the data were preprocessed. The main purpose was to transform the dataset into a format that could be used to train the MLC models. As the encoding of the ARAS dataset labels is sequential and common for all the participants (i.e., sleeping is encoded as 11, washing dishes as 9, etc.), a transformation was applied to distinguish actions performed by different persons. Activities performed by the second individual were re-labeled with sequential numbers by adding 27 to the already existing value. As a result, a “new” set of 27 activities was introduce andd applied only to the second person, while the initial set was only referenced by the first participant.
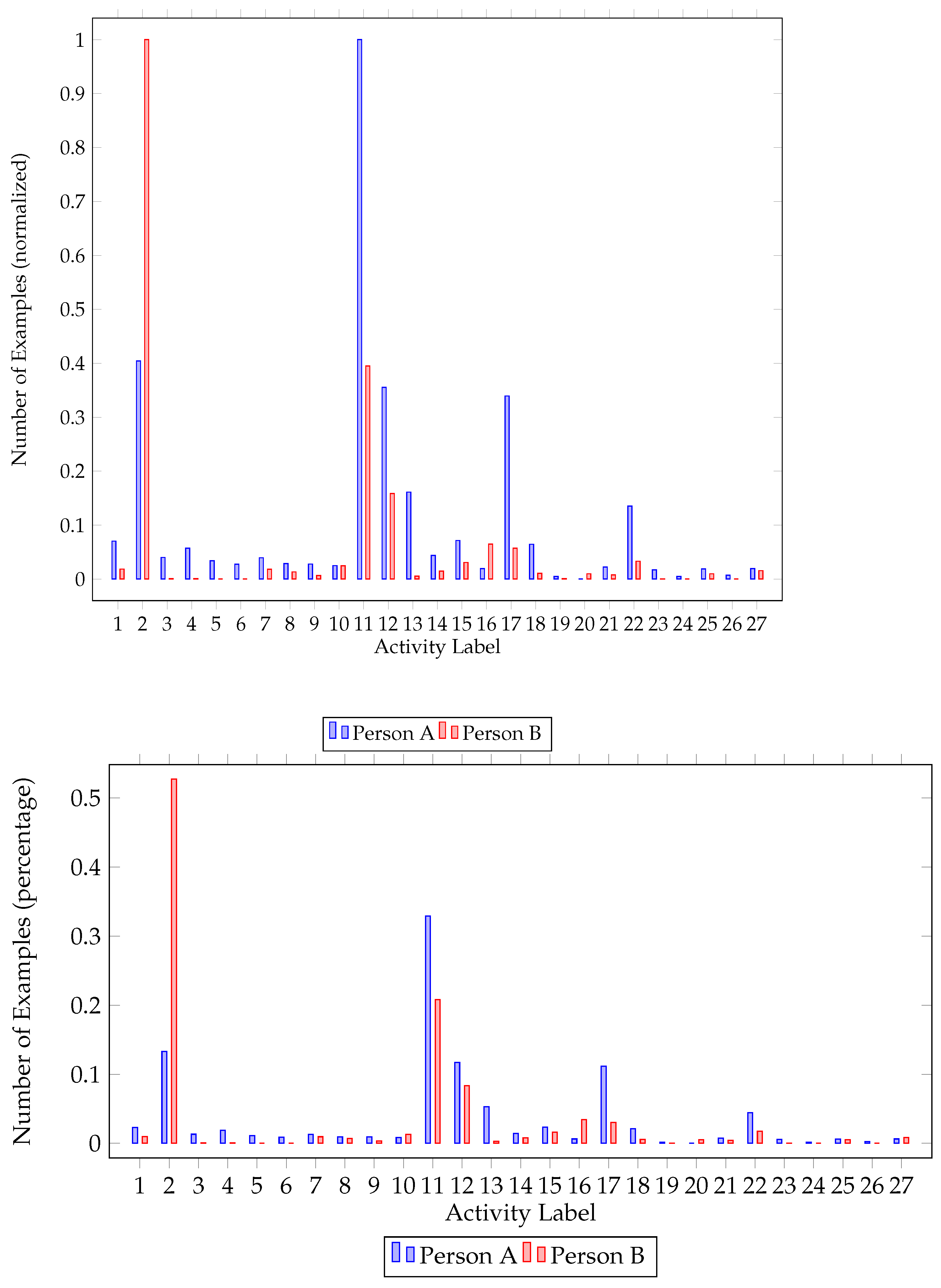
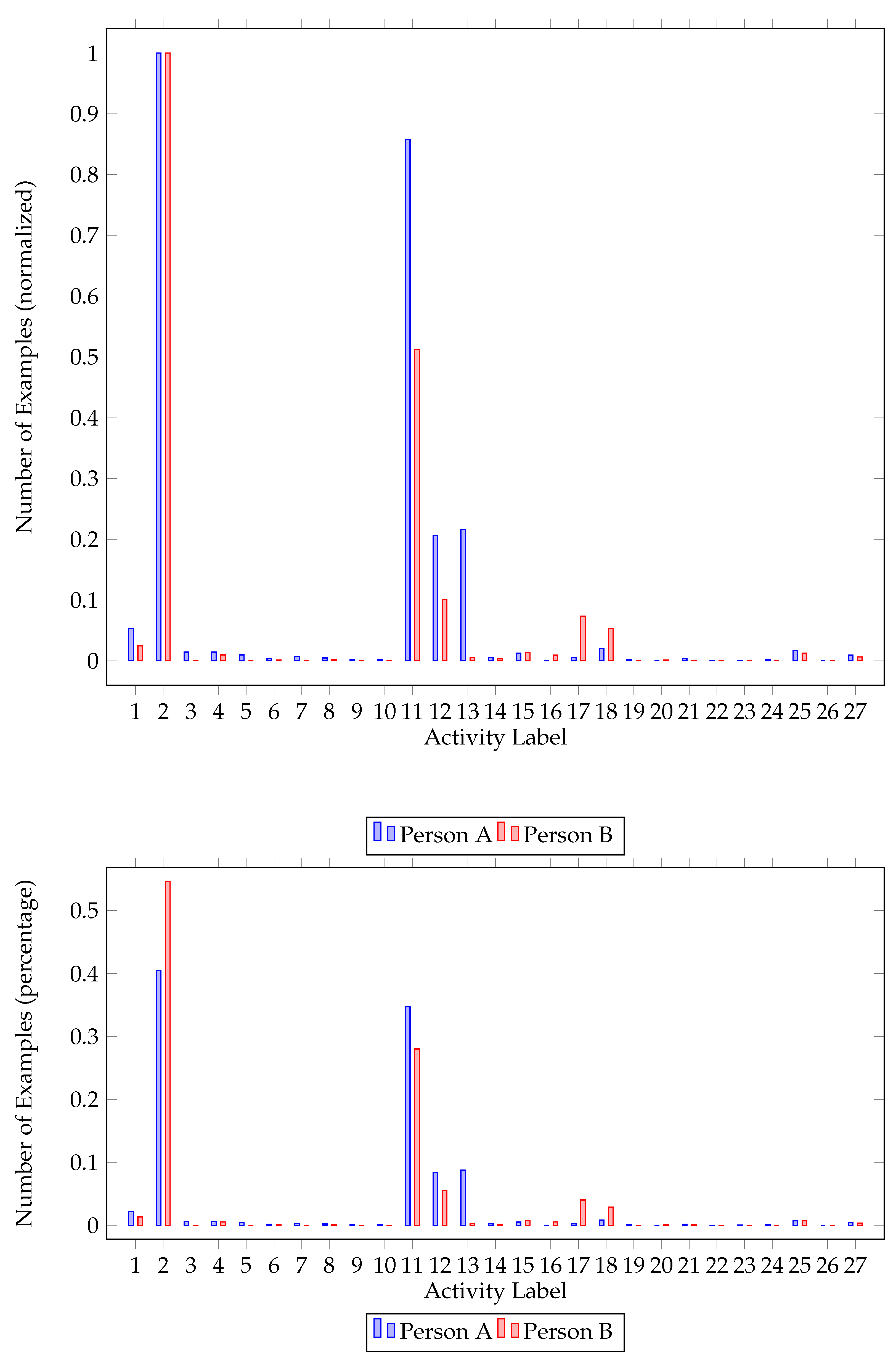
Class imbalance was also a problem we had to address while preprocessing the dataset. As activities do not occur with the same frequency, i.e., some activities are performed more times than others, the dataset was imbalanced. As seen in Figure 1 and Figure 2, there is a big difference between the major and the minor class in each house. In order to balance the dataset, we upscaled minority classes. To augment our data, the MLSMOTE [43] algorithm (multilabel synthetic minority over-sampling technique), an extension of the SMOTE [44] (synthetic minority over-sampling technique) focused on multilabel datasets, was employed.
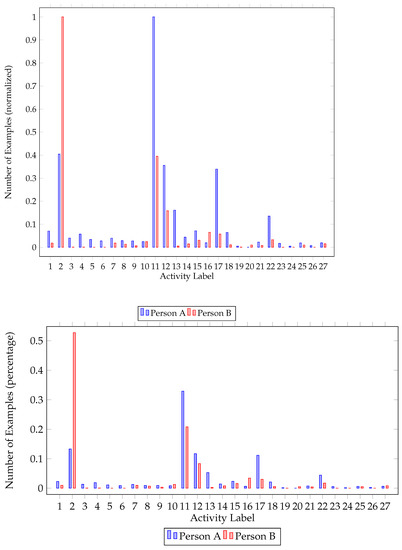
Figure 1.
House A class imbalance. Number of classes per resident (normalized) and percentage of each class for the first house.
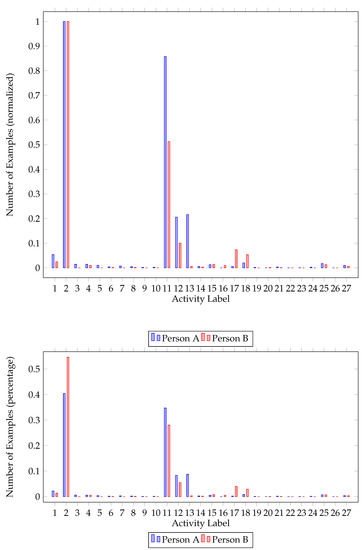
Figure 2.
House B class imbalance. Number of classes per resident (normalized) and percentage of each class for the first house.
Further inspecting class imbalance figures (Figure 1 and Figure 2), one can identify the major and minor classes. In both houses, activities 2 (Going out) and 11 (Sleeping) are the activities mostly performed, followed by watching TV (12) and studying (13). One of the residents in both houses had a major class (going out—2) that represents approximately 55% of the dataset. It is worth mentioning that not all classes are present for all participants. While upscaling the minority classes, activities never recorded were ignored.
As the CASAS dataset has sensor names and values recorded as strings, e.g., ”MD2” as the sensor ID and ”ON” as the sensor event, the data had to be transformed to a more appropriate form. Following the same approach as [45], each sensor was assigned a numerical ID, while values were converted to ”1” or ”0”, based on whether the sensor was triggered or not.
4.7. Performance Metrics
Two different metrics were used for evaluation: F1 score and Hamming loss. Before defining the metrics, the type of errors and predictions a classifier can make must be defined:
- False Positives (FP): The classifiers predicts a label that is not correct;
- False Negatives (FN): The classifier misses a label that exists in the example;
- True Positives (TP): The classifier correctly predicts the existence of a label;
- True Negatives (TN): The classifier correctly predicts the non-existence of a label.
Using the above information, we can calculate the metrics needed. F1 score is the harmonic mean of Precision (proportion of correct predictions among all predictions) and Recall (proportion of examples of a certain class predicted as members of the class). Equations for each metric can be seen in Equation (1).
Hamming loss is the fraction of labels that are incorrectly predicted [9]. While on multi-class classification, the Hamming loss is the Hamming distance between true and predicted labels, in MLC, the Hamming label penalizes only the individual classes. The Hamming loss is calculated using Equation (2), where N is the total number of data samples, L is the total number of available classes, is the target, and is the prediction. The xor operator (⊕) returns zero when the target and prediction are the same, and one otherwise. Since the metric is a loss function, the optimal value is zero and the upper bound is one.
5. Results
The experiments carried out and results are presented in this section. The evaluation was based on 10-fold cross validation. Using the 10-fold cross validation technique is a common practice when evaluating the performance of machine learning models. This technique has numerous advantages, such as reduced bias and variance, etc. The dataset was partitioned into 10 subsets. During each epoch, one subset was used for validation, while the rest (9) were used as training data. The Hamming loss and F1 score were logged after each training epoch.
5.1. ARAS Dataset
All proposed models were trained using a whole month’s data. Similar attempts to address the problem trained a different model for each day and averaged the individual results [29]. The average F1 score and Hamming loss for each classifier and house can be seen in Table 4 and Table 5, respectively. Observing the results, one can see that with MLP classifier had the best F1 score and Hamming loss for both houses. Although had a better performance and lower Hamming loss, the difference from the rest of the classifiers was not significant.
Table 4.
Average F1 score per classifier. Inside the parentheses is the confidence interval (96% confidence). The best value can be seen in bold.
Table 5.
Average Hamming loss per classifier (lower is better). Inside the parentheses is the confidence interval (96% confidence). The best value can be seen in bold.
As the activity recognition problem is, by its nature, unbalanced, experiments were also performed before applying oversampling. The results, as seen in Table 6 and Table 7, do not differ a lot compared to a balanced dataset. Therefore, multi-label classification can provide robust results on the activity recognition problem, even when the number of examples differs a lot.
Table 6.
Average F1 score per classifier trained on an unbalanced dataset. Inside the parentheses is the confidence interval (96% confidence). The best value can be seen in bold.
Table 7.
Average Hamming loss per classifier (lower is better) trained on an unbalanced dataset. Inside the parentheses is the confidence interval (96% confidence). The best value can be seen in bold.
An important observation is the significant difference between the results of the two houses. Classifiers evaluated on the second house yielded better results. This observation is justified by the difference in activities performed. Residents of the second house performed less distinct activities, compared to residents of the first house (Figure 1 and Figure 2). This is important, as classification performance is related to the number of activities performed.
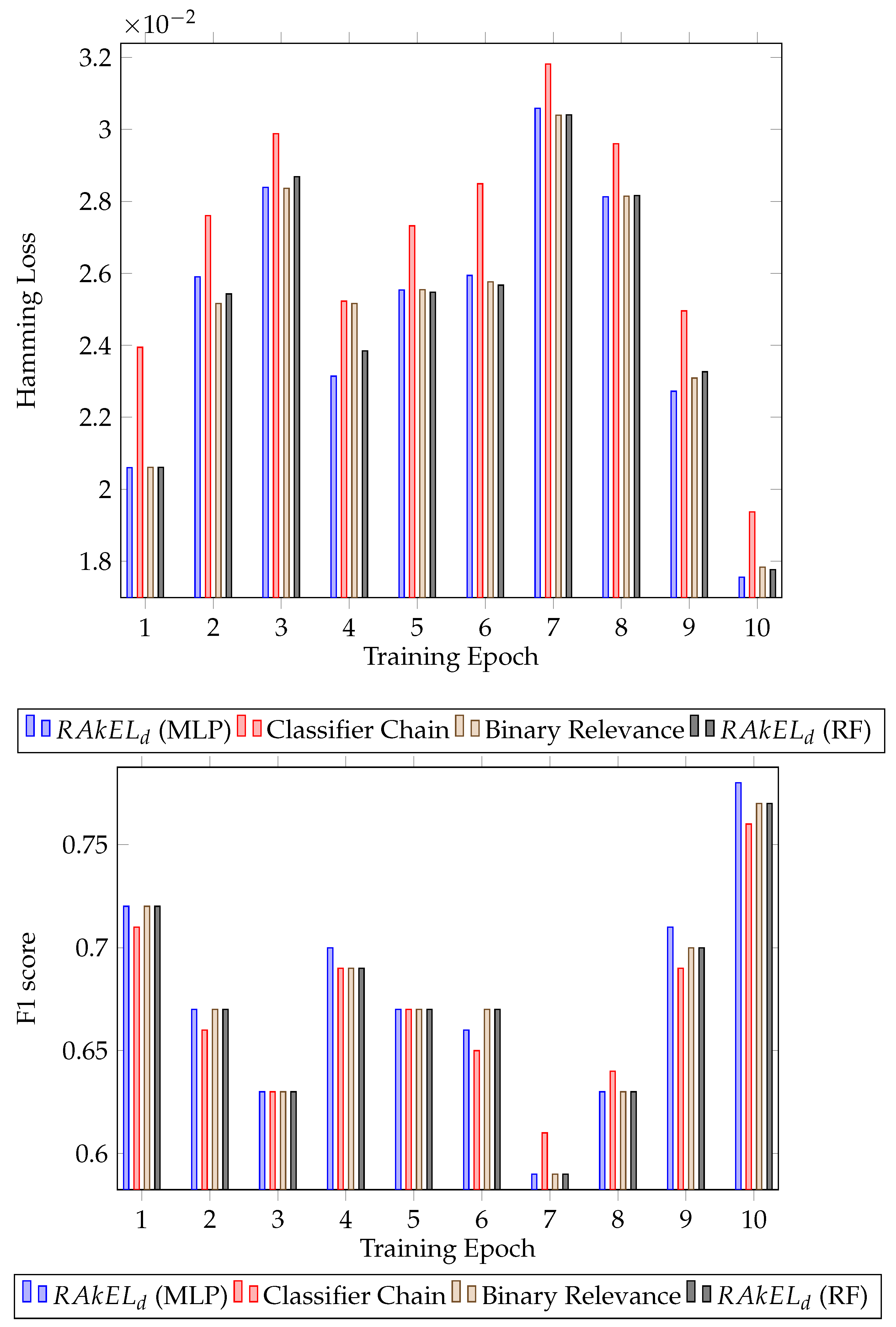
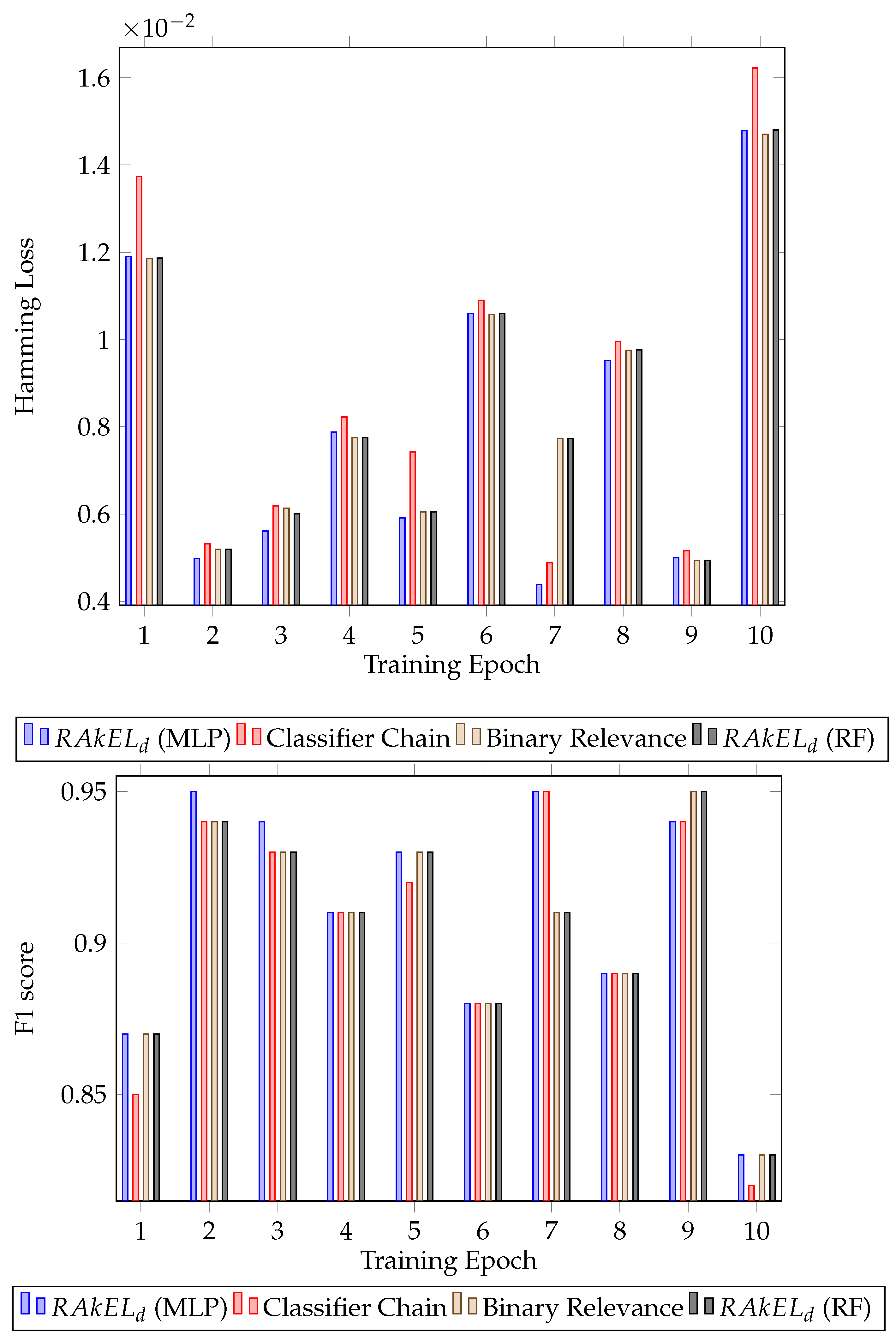
Further analysing the results, the standard deviation of the F1 score was calculated for each algorithm. For both houses, had the lower standard deviation, 0.041 for the first house ( with MLP) and 0.034 for the second house ( with random forest). The results for each epoch for all the classifiers can be seen in Figure 3 for the first house and Figure 4 for the second house.
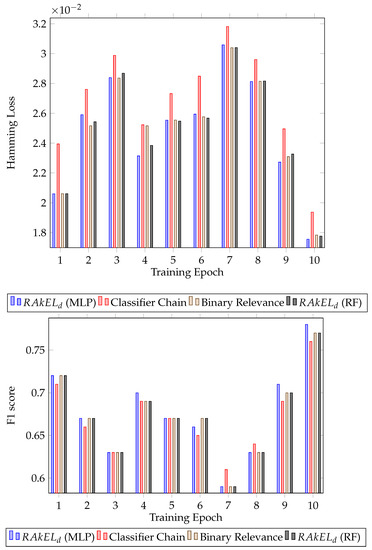
Figure 3.
Classification results for House A. Hamming loss for each classifier per validation epoch and F1 score for each classifier per validation epoch.
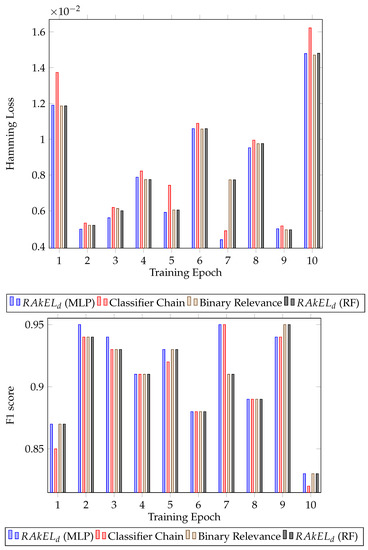
Figure 4.
Classification results for House B. Hamming loss for each classifier per validation epoch and F1 score for each classifier per validation epoch.
Performing the same experiments on a daily basis, instead of using the data from a whole month, provided the results seen in Table 8 and Table 9. , with both classifiers evaluated (MLP and RF), had the best overall performance. The results were consistent and no major deviations were observed between different days. Furthermore, the results of using MLP are compared with the results obtained on the same dataset by [29] (Table 10). The comparison is based on the only common metric, Hamming loss. By comparing the results, one can identify that performed better for both houses.
Table 8.
Average F1 score and Hamming loss per day for House A. Best value per day can be seen in bold.
Table 9.
Average F1 score and Hamming loss per day for House B. Best value per day can be seen in bold.
Table 10.
Hamming loss comparison between (MLP) and results presented in [29]. Best value per day can be seen in bold.
Analyzing the results of the experiments, one can identify activities that are more prone to misclassification. For House A, the hardest activities to recognize were having lunch and having conversation for residents 1 and 2, respectively. reparing dinner was the least recognized activity for resident 1 in House B and having conversation was least recognized for resident 2. It is worth mentioning that, except for resident 1 (House A), the rest of the least recognized classes were under-sampled. As a result, there were training epochs where the class was not represented in the training data.
5.2. CASAS Dataset
Experiments on the CASAS dataset were performed similarly to the ARAS dataset. The same classifiers, binary relevance, classifier chain, RAkEL with random forests, and RAkEL with MLP were used. The evaluation of the CASAS dataset was based on 10-fold cross validation in order to reduce bias and variance. Using the whole CASAS dataset, i.e., 26 days, provided the results seen in Table 11. RAkEL with MLP classifier had the best overall performance when the classifiers were trained and evaluated using the entire dataset. The rest of the classifiers were on par regarding performance, making them a viable solution for multi-resident activity recognition. Similarly to the ARAS dataset experiments, each classifier was evaluated using daily data (Table 12). RAkEL had the best performance with, results the being consistent with the ARAS dataset.
Table 11.
Average F1 score & Hamming loss per classifier (CASAS dataset). Inside the parentheses is the confidence interval (96% confidence). Best values can be seen in bold.
Table 12.
Average F1 score and Hamming loss per day for the CASAS Dataset. Best values per day can be seen in bold.
5.3. Multilabel and Multi-Class Comparison
Multi-resident activity recognition, as already discussed in Section 2, can be addressed both as a multilabel and multi-class classification problem. In order to further support our position that MLC can be used on multi-resident activity recognition without sacrificing accuracy, a comparison between the two approaches is needed. We did not run any experiments with multi-class models, but we compared our results with results already published in the literature [16].
As seen in Table 13, multilabel classification outperformed multi-class classification. The average F1 score was better for MLC approaches with both datasets. The multi-class classifiers with the best overall performance was recurrent neural networks for the CASAS dataset, and random forests for ARAS. It is worth mentioning that on the ARAS dataset, for House A, there was a significant difference between multilabel and multi-class classification. This is important, as the aforementioned house had increased difficulty, mainly because of the diverse set of activities performed.
Table 13.
F1 score comparison between multilabel and multi-class classification approaches. Best values are in bold.
6. Conclusions
In this work, an experimental evaluation of RAkEL, classifier chain, and binary relevance methods for multi-resident human activity recognition was performed. Experiments were performed on the ARAS and CASAS datasets, two activity recognition datasets with two residents acting concurrently. RAkEL had the best overall performance on both datasets, with the rest of the evaluated classifiers yielding on-par results. When a multi-layered perceptron was used as a base classifier on RAkEL, the performance of the algorithm was improved.
The ARAS dataset was analyzed and the findings showed that it suffers from the class imbalance problem. In order to address this, the minority classes were upscaled before training the classifiers. Balancing the dataset was an important step during data preprocessing, as the major classes represented approximately 90% of the whole data for both houses. Experiments were performed on both a balanced and unbalanced dataset, without any significant difference between the results.
Observing the activity distribution on the dataset, it was observed that residents follow a different activity pattern. Although the dataset has records for 27 different activities, not all of them are present in each house. As house B residents performed less distinct activities, the trained models had a better overall performance.
Results were also compared with multi-class classification methods used on the same set of data, as well as multilabel classification methods already published in the literature. The comparison showed that RAkELs performance is on par with, if not better than, different multilabel classification approaches, outperforming multi-class classification techniques. This can provide a baseline for future comparisons of multilabel classification solutions used on the multi-resident activity recognition problem.
Future work will be focused on identifying correlations between different activities in multi-resident environments. Some activities could potentially be mutually exclusive (i.e., both residents toileting), or inclusive (i.e., both having a conversation, lunch, etc.). That relationship could be identified and thereby further enhance the performance of classification. As the datasets used in our work do not contain mutually exclusive activities, this aspect is not investigated in this work.
Furthermore, more MLC algorithms should be evaluated. While this study extends already published works on multi-resident activity recognition, there are a lot of techniques that have not yet been evaluated, such as ML-KNN [46], CLARE decision trees [47], and deep neural networks adapted for MLC problems. While our work is tested on two different datasets, proving the robustness of the evaluated algorithms, there are more methods available in the literature. Additionally, hierarchical multilabel classification should be explored. As some activities are correlated in a hierarchical order, e.g., preparing dinner always precedes eating dinner, it is a promising idea to create efficient structures that represent that hierarchical order.
Author Contributions
Conceptualization, A.L.; Data curation, A.L. and E.D.; Formal analysis, A.L. and E.D.; Funding acquisition, D.V.; Investigation, A.L.; Methodology, A.L. and E.D.; Project administration, D.V.; Resources, A.L.; Software, A.L. and E.D.; Supervision, D.V.; Validation, A.L.; Visualization, A.L. and E.D.; Writing—original draft, A.L.; Writing—review and editing, D.V. and E.D. All authors have read and agreed to the published version of the manuscript.
Funding
This research has been co-financed by the European Regional Development Fund of the European Union, and by Greek national funds through the operational program, Competitiveness, Entrepreneurship and Innovation, under the call RESEARCH–CREATE–INNOVATE (project code: T EK 00343 - Energy Controlling Voice Enabled Intelligent Smart Home Ecosystem).
Institutional Review Board Statement
Ethical review and approval were waived for this study due to experiments conducted on already published public datasets, without the immediate participation of humans.
Informed Consent Statement
Patient consent was waived due to experiments conducted on already published public datasets, without the immediate participation of humans.
Data Availability Statement
ARAS and CASAS datasets are publicly available. ARAS dataset can be found at www.cmpe.boun.edu.tr/aras/ (accessed on 14 January 2022) and CASAS dataset at casas.wsu.edu/datasets/ (accessed on 14 January 2022). For experiment setup you can contact the corresponding author.
Acknowledgments
We would like to thank the reviewers for taking the time and effort necessary to review the manuscript. We sincerely appreciate all valuable comments and suggestions, which helped us to improve the quality of the manuscript.
Conflicts of Interest
The authors declare no conflict of interest.
Abbreviations
The following abbreviations are used in this manuscript:
| HAR | Human activity recognition |
| HMM | Hidden Markov model |
| KNN | K-nearest neighbour |
| RNN | Recurrent neural network |
| RF | Random forests |
| FNN | Feed-forward neural network |
| MLC | Multilabel classification |
| MLSMOTE | Multilabel synthetic minority over-sampling technique |
| SMOTE | Synthetic minority over-sampling technique |
| Random k-labelsets multilabel classifier | |
| MLP | Multilayer perceptron |
| QGA | Quantum genetic algorithms |
References
- Ermes, M.; Parkka, J.; Mantyjarvi, J.; Korhonen, I. Detection of Daily Activities and Sports With Wearable Sensors in Controlled and Uncontrolled Conditions. IEEE Trans. Inf. Technol. Biomed. 2008, 12, 20–26. [Google Scholar] [CrossRef] [PubMed]
- Sánchez, D.; Tentori, M.; Favela, J. Activity Recognition for the Smart Hospital. IEEE Intell. Syst. 2008, 23, 50–57. [Google Scholar] [CrossRef] [Green Version]
- Hong, Y.J.; Kim, I.J.; Ahn, S.C.; Kim, H.G. Activity Recognition Using Wearable Sensors for Elder Care. In Proceedings of the 2008 Second International Conference on Future Generation Communication and Networking, Hainan, China, 13–15 December 2008; Volume 2, pp. 302–305. [Google Scholar] [CrossRef]
- Lentzas, A.; Vrakas, D. Non-intrusive human activity recognition and abnormal behavior detection on elderly people: A review. Artif. Intell. Rev. 2020, 53, 1975–2021. [Google Scholar] [CrossRef]
- Kumari, K.; Chandankhede, P.H.; Titarmare, A.S.; Vidhale, B.R.; Tadse, S.K. A Review on Human Activity Recognition using Body Sensor Networks. In Proceedings of the 2021 5th International Conference on Computing Methodologies and Communication (ICCMC), Erode, India, 8–10 April 2021; pp. 61–66. [Google Scholar] [CrossRef]
- Labarrière, F.; Thomas, E.; Calistri, L.; Optasanu, V.; Gueugnon, M.; Ornetti, P.; Laroche, D. Machine Learning Approaches for Activity Recognition and/or Activity Prediction in Locomotion Assistive Devices—A Systematic Review. Sensors 2020, 20, 6345. [Google Scholar] [CrossRef] [PubMed]
- Aly, M. Survey on Multiclass Classification Methods. 2005. Available online: https://citeseerx.ist.psu.edu/viewdoc/download?doi=10.1.1.175.107&rep=rep1&type=pdf (accessed on 14 January 2022).
- Lentzas, A. Evaluating state-of-the-art classifiers for human activity recognition using smartphones. In Proceedings of the 3rd IET International Conference on Technologies for Active and Assisted Living (TechAAL 2019), London, UK, 25 March 2019; p. 6. [Google Scholar]
- Tsoumakas, G.; Katakis, I. Multi-Label Classification: An Overview. Int. J. Data Warehous. Min. 2007, 3, 1–13. [Google Scholar] [CrossRef] [Green Version]
- Subasi, A.; Khateeb, K.; Brahimi, T.; Sarirete, A. Chapter 5—Human activity recognition using machine learning methods in a smart healthcare environment. In Innovation in Health Informatics; Lytras, M.D., Sarirete, A., Eds.; Next Gen Tech Driven Personalized Med & Smart Healthcare; Academic Press: Cambridge, MA, USA, 2020; pp. 123–144. [Google Scholar] [CrossRef]
- Sztyler, T.; Stuckenschmidt, H. On-body localization of wearable devices: An investigation of position-aware activity recognition. In Proceedings of the 2016 IEEE International Conference on Pervasive Computing and Communications (PerCom), Sydney, NSW, Australia, 14–19 March 2016; pp. 1–9. [Google Scholar] [CrossRef]
- Sebestyen, G.; Stoica, I.; Hangan, A. Human activity recognition and monitoring for elderly people. In Proceedings of the 2016 IEEE 12th International Conference on Intelligent Computer Communication and Processing (ICCP), Cluj-Napoca, Romania, 8–10 September 2016; pp. 341–347. [Google Scholar] [CrossRef]
- Hu, R.; Pham, H.; Buluschek, P.; Gatica-Perez, D. Elderly People Living Alone: Detecting Home Visits with Ambient and Wearable Sensing. In Proceedings of the 2nd International Workshop on Multimedia for Personal Health and Health Care 2017 (MMHealth ’17), Mountain View, CA, USA, 23 October 2017; Association for Computing Machinery: New York, NY, USA, 2017; pp. 85–88. [Google Scholar] [CrossRef]
- Phyo, C.N.; Zin, T.T.; Tin, P. Deep Learning for Recognizing Human Activities Using Motions of Skeletal Joints. IEEE Trans. Consum. Electron. 2019, 65, 243–252. [Google Scholar] [CrossRef]
- Baccouche, M.; Mamalet, F.; Wolf, C.; Garcia, C.; Baskurt, A. Sequential Deep Learning for Human Action Recognition. In Human Behavior Understanding; Salah, A.A., Lepri, B., Eds.; Springer: Berlin/Heidelberg, Germany, 2011; pp. 29–39. [Google Scholar]
- Tran, S.N.; Nguyen, D.; Ngo, T.S.; Vu, X.S.; Hoang, L.; Zhang, Q.; Karunanithi, M. On multi-resident activity recognition in ambient smart-homes. Artif. Intell. Rev. 2020, 53, 3929–3945. [Google Scholar] [CrossRef] [Green Version]
- Tunca, C.; Alemdar, H.; Ertan, H.; Incel, O.D.; Ersoy, C. Multimodal Wireless Sensor Network-Based Ambient Assisted Living in Real Homes with Multiple Residents. Sensors 2014, 14, 9692–9719. [Google Scholar] [CrossRef]
- Alemdar, H.; Ersoy, C. Multi-resident activity tracking and recognition in smart environments. J. Ambient. Intell. Humaniz. Comput. 2017, 8, 513–529. [Google Scholar] [CrossRef]
- Tran, S.N.; Ngo, T.S.; Zhang, Q.; Karunanithi, M. Mixed-dependency models for multi-resident activity recognition in smart homes. Multimed. Tools Appl. 2020, 79, 23445–23460. [Google Scholar] [CrossRef]
- Benmansour, A.; Bouchachia, A.; Feham, M. Modeling interaction in multi-resident activities. Neurocomputing 2017, 230, 133–142. [Google Scholar] [CrossRef] [Green Version]
- Hao, J.; Bouzouane, A.; Gaboury, S. Recognizing multi-resident activities in non-intrusive sensor-based smart homes by formal concept analysis. Neurocomputing 2018, 318, 75–89. [Google Scholar] [CrossRef]
- Howedi, A.; Lotfi, A.; Pourabdollah, A. Exploring Entropy Measurements to Identify Multi-Occupancy in Activities of Daily Living. Entropy 2019, 21, 416. [Google Scholar] [CrossRef] [Green Version]
- Prossegger, M.; Bouchachia, A. Multi-resident Activity Recognition Using Incremental Decision Trees. In Adaptive and Intelligent Systems; Bouchachia, A., Ed.; Springer International Publishing: Cham, Switzerland, 2014; pp. 182–191. [Google Scholar]
- Natani, A.; Sharma, A.; Peruma, T.; Sukhavasi, S. Deep Learning for Multi-Resident Activity Recognition in Ambient Sensing Smart Homes. In Proceedings of the 2019 IEEE 8th Global Conference on Consumer Electronics (GCCE), Osaka, Japan, 15–18 October 2019; pp. 340–341. [Google Scholar] [CrossRef]
- Wang, W.; Miao, C. Multi-Resident Activity Recognition with Unseen Classes in Smart Homes. In Proceedings of the 2018 IEEE SmartWorld, Ubiquitous Intelligence Computing, Advanced Trusted Computing, Scalable Computing Communications, Cloud Big Data Computing, Internet of People and Smart City Innovation (SmartWorld/SCALCOM/UIC/ATC/CBDCom/IOP/SCI), Guangzhou, China, 8–12 October 2018; pp. 780–787. [Google Scholar] [CrossRef]
- Du, J.; Chen, Q.; Peng, Y.; Xiang, Y.; Tao, C.; Lu, Z. ML-Net: Multi-label classification of biomedical texts with deep neural networks. J. Am. Med. Inform. Assoc. 2019, 26, 1279–1285. [Google Scholar] [CrossRef] [PubMed] [Green Version]
- Karagoz, G.N.; Yazici, A.; Dokeroglu, T.; Cosar, A. A new framework of multi-objective evolutionary algorithms for feature selection and multi-label classification of video data. Int. J. Mach. Learn. Cybern. 2021, 12, 53–71. [Google Scholar] [CrossRef]
- Nasierding, G.; Kouzani, A.Z. Image to Text Translation by Multi-Label Classification. In Advanced Intelligent Computing Theories and Applications. With Aspects of Artificial Intelligence; Huang, D.S., Zhang, X., Reyes García, C.A., Zhang, L., Eds.; Springer: Berlin/Heidelberg, Germany, 2010; pp. 247–254. [Google Scholar]
- Jethanandani, M.; Sharma, A.; Perumal, T.; Chang, J.R. Multi-label classification based ensemble learning for human activity recognition in smart home. Internet Things 2020, 12, 100324. [Google Scholar] [CrossRef]
- Kumar, R.; Qamar, I.; Virdi, J.S.; Krishnan, N.C. Multi-label Learning for Activity Recognition. In Proceedings of the 2015 International Conference on Intelligent Environments, Prague, Czech Republic, 15–17 July 2015; pp. 152–155. [Google Scholar] [CrossRef]
- Yuan, W.; Cao, J.; Jin, Z.; Xia, F.; Wang, R. A Multi-resident Activity Recognition Approach based on Frequent Itemset Mining Features. In Proceedings of the 2019 IEEE 17th International Conference on Industrial Informatics (INDIN), Helsinki, Finland, 22–25 July 2019; Volume 1, pp. 1453–1458. [Google Scholar] [CrossRef]
- Mohamed, R.; Perumal, T.; Sulaiman, M.N.; Mustapha, N.; Zainudin, M.N.S. Modeling activity recognition of multi resident using label combination of multi label classification in smart home. AIP Conf. Proc. 2017, 1891, 020094. [Google Scholar] [CrossRef] [Green Version]
- Jethanandani, M.; Perumal, T.; Liaw, Y.C.; Chang, J.R.; Sharma, A.; Bao, Y. Binary Relevance Model for Activity Recognition in Home Environment using Ambient Sensors. In Proceedings of the 2019 IEEE International Conference on Consumer Electronics—Taiwan (ICCE-TW), Yilan, Taiwan, 20–22 May 2019; pp. 1–2. [Google Scholar] [CrossRef]
- Read, J.; Hollmén, J. A Deep Interpretation of Classifier Chains. In Advances in Intelligent Data Analysis XIII; Blockeel, H., van Leeuwen, M., Vinciotti, V., Eds.; Springer International Publishing: Cham, Switzerland, 2014; pp. 251–262. [Google Scholar]
- Yapp, E.K.; Li, X.; Lu, W.F.; Tan, P.S. Comparison of base classifiers for multi-label learning. Neurocomputing 2020, 394, 51–60. [Google Scholar] [CrossRef]
- Pedregosa, F.; Varoquaux, G.; Gramfort, A.; Michel, V.; Thirion, B.; Grisel, O.; Blondel, M.; Prettenhofer, P.; Weiss, R.; Dubourg, V.; et al. Scikit-learn: Machine Learning in Python. J. Mach. Learn. Res. 2011, 12, 2825–2830. [Google Scholar]
- Tsoumakas, G.; Katakis, I.; Vlahavas, I. Random k-Labelsets for Multilabel Classification. IEEE Trans. Knowl. Data Eng. 2011, 23, 1079–1089. [Google Scholar] [CrossRef]
- Bergstra, J.; Bengio, Y. Random Search for Hyper-Parameter Optimization. J. Mach. Learn. Res. 2012, 13, 281–305. [Google Scholar]
- Lentzas, A.; Nalmpantis, C.; Vrakas, D. Hyperparameter Tuning using Quantum Genetic Algorithms. In Proceedings of the 2019 IEEE 31st International Conference on Tools with Artificial Intelligence (ICTAI), Portland, OR, USA, 4–6 November 2019; pp. 1412–1416. [Google Scholar] [CrossRef]
- Zhang, M.L.; Li, Y.K.; Liu, X.Y.; Geng, X. Binary relevance for multi-label learning: An overview. Front. Comput. Sci. 2018, 12, 191–202. [Google Scholar] [CrossRef]
- Read, J.; Pfahringer, B.; Holmes, G.; Frank, E. Classifier Chains for Multi-label Classification. In Machine Learning and Knowledge Discovery in Databases; Buntine, W., Grobelnik, M., Mladenić, D., Shawe-Taylor, J., Eds.; Springer: Berlin/Heidelberg, Germany, 2009; pp. 254–269. [Google Scholar]
- Alemdar, H.; Ertan, H.; Incel, O.D.; Ersoy, C. ARAS human activity datasets in multiple homes with multiple residents. In Proceedings of the 2013 7th International Conference on Pervasive Computing Technologies for Healthcare and Workshops, Venice, Italy, 5–8 May 2013; pp. 232–235. [Google Scholar]
- Charte, F.; Rivera, A.J.; del Jesus, M.J.; Herrera, F. MLSMOTE: Approaching imbalanced multilabel learning through synthetic instance generation. Knowl.-Based Syst. 2015, 89, 385–397. [Google Scholar] [CrossRef]
- Chawla, N.V.; Bowyer, K.W.; Hall, L.O.; Kegelmeyer, W.P. SMOTE: Synthetic Minority over-Sampling Technique. J. Artif. Int. Res. 2002, 16, 321–357. [Google Scholar] [CrossRef]
- Singla, G.; Cook, D.J.; Schmitter-Edgecombe, M. Recognizing independent and joint activities among multiple residents in smart environments. J. Ambient. Intell. Humaniz. Comput. 2010, 1, 57–63. [Google Scholar] [CrossRef] [Green Version]
- Zhang, M.L.; Zhou, Z.H. ML-KNN: A lazy learning approach to multi-label learning. Pattern Recognit. 2007, 40, 2038–2048. [Google Scholar] [CrossRef] [Green Version]
- Chen, Y.L.; Hsu, C.L.; Chou, S.C. Constructing a multi-valued and multi-labeled decision tree. Expert Syst. Appl. 2003, 25, 199–209. [Google Scholar] [CrossRef]
Publisher’s Note: MDPI stays neutral with regard to jurisdictional claims in published maps and institutional affiliations. |
© 2022 by the authors. Licensee MDPI, Basel, Switzerland. This article is an open access article distributed under the terms and conditions of the Creative Commons Attribution (CC BY) license (https://creativecommons.org/licenses/by/4.0/).