
Two-Way Feature Extraction for Speech Emotion Recognition Using Deep Learning

 ,
,  ,
,  , , and
, , and 
Abstract
:1. Introduction
- 1.
- Two-way feature extraction is proposed by utilizing super convergence to extract two sets of potential features from the speech data.
- 2.
- Principal component analysis (PCA) and deep neural network (DNN) with dense and dropout layers are applied to the features obtained from the proposed two-way feature extraction model.
- 3.
- The pre-trained VGG-16 model is also trained on the features from the proposed two-way feature extraction model.
- 4.
- Multimodal speech data is utilized for training.
2. Materials and Methods
2.1. Dataset Description
2.2. Approach I
2.2.1. Feature Extraction
2.2.2. Dimensionality Reduction and Preprocessing
2.2.3. Model Architecture
2.3. Approach II
2.3.1. Feature Extraction
2.3.2. Model Architecture
2.4. Experiments
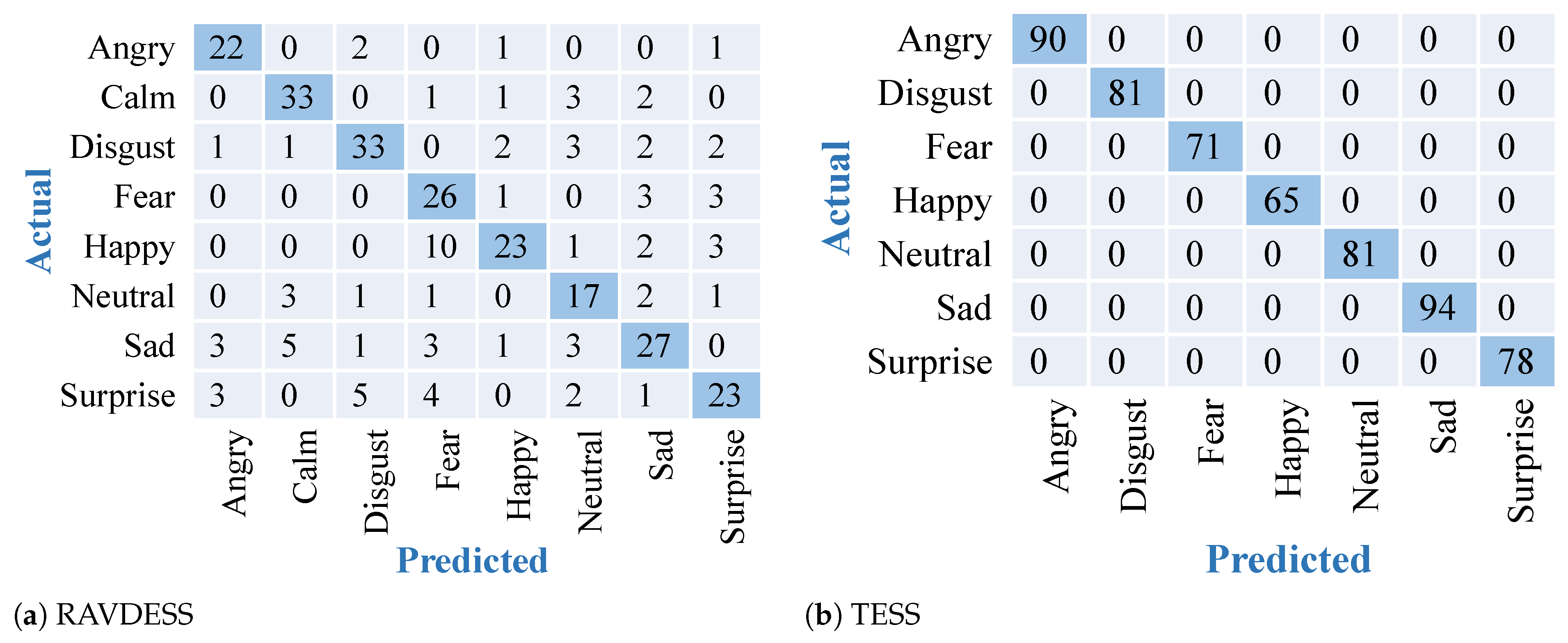
3. Results
3.1. Results on Approach I
3.2. Results on Approach II
3.3. Comparison with State-of-Art Approaches
3.4. Comparative Analysis
3.5. Comparison with Benchmark Algorithms
4. Conclusions
Author Contributions
Funding
Institutional Review Board Statement
Informed Consent Statement
Data Availability Statement
Acknowledgments
Conflicts of Interest
References
- Lech, M.; Stolar, M.; Best, C.; Bolia, R. Real-time speech emotion recognition using a pre-trained image classification network: Effects of bandwidth reduction and companding. Front. Comput. Sci. 2020, 2, 14. [Google Scholar] [CrossRef]
- Khalil, R.A.; Jones, E.; Babar, M.I.; Jan, T.; Zafar, M.H.; Alhussain, T. Speech emotion recognition using deep learning techniques: A review. IEEE Access 2019, 7, 117327–117345. [Google Scholar] [CrossRef]
- Joy, J.; Kannan, A.; Ram, S.; Rama, S. Speech Emotion Recognition using Neural Network and MLP Classifier. IJESC 2020, 2020, 25170–25172. [Google Scholar]
- Damodar, N.; Vani, H.; Anusuya, M. Voice emotion recognition using CNN and decision tree. Int. J. Innov. Technol. Exp. Eng. 2019, 8, 4245–4249. [Google Scholar]
- Noroozi, F.; Sapiński, T.; Kamińska, D.; Anbarjafari, G. Vocal-based emotion recognition using random forests and decision tree. Int. J. Speech Technol. 2017, 20, 239–246. [Google Scholar] [CrossRef]
- Eom, Y.; Bang, J. Speech Emotion Recognition Using 2D-CNN with Mel-Frequency Cepstrum Coefficients. J. Inf. Commun. Converg. Eng. 2021, 19, 148–154. [Google Scholar]
- Rezaeipanah, A.; Mojarad, M. Modeling the Scheduling Problem in Cellular Manufacturing Systems Using Genetic Algorithm as an Efficient Meta-Heuristic Approach. J. Artif. Intell. Technol. 2021, 1, 228–234. [Google Scholar] [CrossRef]
- Krishnamoorthi, R.; Joshi, S.; Almarzouki, H.Z.; Shukla, P.K.; Rizwan, A.; Kalpana, C.; Tiwari, B. A Novel Diabetes Healthcare Disease Prediction Framework Using Machine Learning Techniques. J. Healthc. Eng. 2022, 2022, 1684017. [Google Scholar] [CrossRef]
- Dubey, M.; Kumar, V.; Kaur, M.; Dao, T.P. A systematic review on harmony search algorithm: Theory, literature, and applications. Math. Probl. Eng. 2021, 2021, 5594267. [Google Scholar] [CrossRef]
- Shukla, P.K.; Zakariah, M.; Hatamleh, W.A.; Tarazi, H.; Tiwari, B. AI-DRIVEN Novel Approach for Liver Cancer Screening and Prediction Using Cascaded Fully Convolutional Neural Network. J. Healthc. Eng. 2022, 2022, 4277436. [Google Scholar] [CrossRef] [PubMed]
- Weiqiao, Z.; Yu, J.; Zou, Y. An experimental study of speech emotion recognition based on deep convolutional neural networks. In Proceedings of the 2015 International Conference on Affective Computing and Intelligent Interaction (ACII), Xi’an, China, 21–24 September 2015; pp. 827–831. [Google Scholar] [CrossRef]
- Kurpukdee, N.; Kasuriya, S.; Chunwijitra, V.; Wutiwiwatchai, C.; Lamsrichan, P. A study of support vector machines for emotional speech recognition. In Proceedings of the 2017 8th International Conference of Information and Communication Technology for Embedded Systems (IC-ICTES), Chonburi, Thailand, 7–9 May 2017; pp. 1–6. [Google Scholar]
- Shukla, P.K.; Shukla, P.K.; Sharma, P.; Rawat, P.; Samar, J.; Moriwal, R.; Kaur, M. Efficient prediction of drug–drug interaction using deep learning models. IET Syst. Biol. 2020, 14, 211–216. [Google Scholar] [CrossRef]
- Liu, J.; Liu, Z.; Sun, C.; Zhuang, J. A Data Transmission Approach Based on Ant Colony Optimization and Threshold Proxy Re-encryption in WSNs. J. Artif. Intell. Technol. 2022, 2, 23–31. [Google Scholar] [CrossRef]
- De Luca, G. A survey of NISQ era hybrid quantum-classical machine learning research. J. Artif. Intell. Technol. 2022, 2, 9–15. [Google Scholar] [CrossRef]
- Sultana, S.; Iqbal, M.Z.; Selim, M.R.; Rashid, M.M.; Rahman, M.S. Bangla Speech Emotion Recognition and Cross-Lingual Study Using Deep CNN and BLSTM Networks. IEEE Access 2021, 10, 564–578. [Google Scholar] [CrossRef]
- Lee, K.H.; Choi, H.K.; Jang, B.T. A study on speech emotion recognition using a deep neural network. In Proceedings of the 2019 International Conference on Information and Communication Technology Convergence (ICTC), Jeju, Korea, 16–18 October 2019; pp. 1162–1165. [Google Scholar]
- Kaur, M.; Kumar, V. Parallel non-dominated sorting genetic algorithm-II-based image encryption technique. Imaging Sci. J. 2018, 66, 453–462. [Google Scholar] [CrossRef]
- Pandey, S.; Shekhawat, H.; Prasanna, S. Deep Learning Techniques for Speech Emotion Recognition: A Review. In Proceedings of the 2019 29th International Conference Radioelektronika (RADIOELEKTRONIKA), Pardubice, Czech Republic, 16–18 April 2019. [Google Scholar] [CrossRef]
- Sarma, M.; Ghahremani, P.; Povey, D.; Goel, N.K.; Sarma, K.K.; Dehak, N. Emotion Identification from Raw Speech Signals Using DNNs. Interspeech 2018, 2018, 3097–3101. [Google Scholar]
- Li, P.; Song, Y.; McLoughlin, I.V.; Guo, W.; Dai, L.R. An attention pooling based representation learning method for speech emotion recognition. In Proceedings of the ISCA Conference, Los Angeles, CA, USA, 2–6 June 2018. [Google Scholar]
- Palo, H.; Mohanty, M.N.; Chandra, M. Use of different features for emotion recognition using MLP network. In Computational Vision and Robotics; Springer: Berlin/Heidelberg, Germany, 2015; pp. 7–15. [Google Scholar]
- Neumann, M.; Vu, N.T. Attentive convolutional neural network based speech emotion recognition: A study on the impact of input features, signal length, and acted speech. arXiv 2017, arXiv:1706.00612. [Google Scholar]
- Fayek, H.M.; Lech, M.; Cavedon, L. Evaluating deep learning architectures for Speech Emotion Recognition. Neural Netw. 2017, 92, 60–68. [Google Scholar] [CrossRef] [PubMed]
- Luo, D.; Zou, Y.; Huang, D. Investigation on Joint Representation Learning for Robust Feature Extraction in Speech Emotion Recognition. Interspeech 2018, 2018, 152–156. [Google Scholar]
- Tzinis, E.; Potamianos, A. Segment-based speech emotion recognition using recurrent neural networks. In Proceedings of the 2017 Seventh International Conference on Affective Computing and Intelligent Interaction (ACII), San Antonio, TX, USA, 23–26 October 2017; pp. 190–195. [Google Scholar]
- Mirsamadi, S.; Barsoum, E.; Zhang, C. Automatic speech emotion recognition using recurrent neural networks with local attention. In Proceedings of the 2017 IEEE International Conference on Acoustics, Speech and Signal Processing (ICASSP), New Orleans, LA, USA, 5–9 March 2017; pp. 2227–2231. [Google Scholar]
- Tao, F.; Liu, G. Advanced LSTM: A study about better time dependency modeling in emotion recognition. In Proceedings of the 2018 IEEE International Conference on Acoustics, Speech and Signal Processing (ICASSP), Calgary, AB, Canada, 15–20 April 2018; pp. 2906–2910. [Google Scholar]
- Lee, J.; Tashev, I. High-level Feature Representation using Recurrent Neural Network for Speech Emotion Recognition. Interspeech 2015, 2015, 336. [Google Scholar] [CrossRef]
- Rokach, L.; Maimon, O. Decision Trees. In Data Mining and Knowledge Discovery Handbook; Maimon, O., Rokach, L., Eds.; Springer: Boston, MA, USA, 2005; pp. 165–192. [Google Scholar]
- Ali, J.; Khan, R.; Ahmad, N.; Maqsood, I. Random forests and decision trees. Int. J. Comput. Sci. Issues (IJCSI) 2012, 9, 272. [Google Scholar]
- Ramchoun, H.; Idrissi, M.A.J.; Ghanou, Y.; Ettaouil, M. Multilayer Perceptron: Architecture Optimization and Training. Int. J. Interact. Multim. Artif. Intell. 2016, 4, 26–30. [Google Scholar] [CrossRef]
- He, K.; Zhang, X.; Ren, S.; Sun, J. Deep residual learning for image recognition. In Proceedings of the IEEE Conference on Computer Vision and Pattern Recognition, Las Vegas, NV, USA, 27–30 June 2016; pp. 770–778. [Google Scholar]
- Lok, E.J. Toronto Emotional Speech Set (TESS). 2019. Available online: https://www.kaggle.com/ejlok1/toronto-emotional-speech-set-tess (accessed on 16 December 2021).
- Livingstone, S.R. RAVDESS Emotional Speech Audio Emotional Speech Dataset. 2018. Available online: https://www.kaggle.com/uwrfkaggler/ravdess-emotional-speech-audio (accessed on 6 December 2021).
- Satapathy, S.; Loganathan, D.; Kondaveeti, H.K.; Rath, R. Performance analysis of machine learning algorithms on automated sleep staging feature sets. CAAI Trans. Intell. Technol. 2021, 6, 155–174. [Google Scholar] [CrossRef]
- Zou, Q.; Xiong, K.; Fang, Q.; Jiang, B. Deep imitation reinforcement learning for self-driving by vision. CAAI Trans. Intell. Technol. 2021, 6, 493–503. [Google Scholar] [CrossRef]
- Chen, R.; Pu, D.; Tong, Y.; Wu, M. Image-denoising algorithm based on improved K-singular value decomposition and atom optimization. CAAI Trans. Intell. Technol. 2022, 7, 117–127. [Google Scholar]
- Dissanayake, V.; Zhang, H.; Billinghurst, M.; Nanayakkara, S. Speech Emotion Recognition’in the Wild’Using an Autoencoder. Interspeech 2020, 2020, 526–530. [Google Scholar]
- Li, H.; Ding, W.; Wu, Z.; Liu, Z. Learning Fine-Grained Cross Modality Excitement for Speech Emotion Recognition. arXiv 2020, arXiv:2010.12733. [Google Scholar]
- Xu, M.; Zhang, F.; Zhang, W. Head fusion: Improving the accuracy and robustness of speech emotion recognition on the IEMOCAP and RAVDESS dataset. IEEE Access 2021, 9, 74539–74549. [Google Scholar] [CrossRef]







{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
| SERIAL NO. | APPROACH | MODEL USED | DATASET USED | ACCURACY |
|---|---|---|---|---|
| 01 | Dissanayake [39] | CNN-LSTM (encoder) | RAVDESS | 56.71% |
| 02 | Li et al. [40] | Multimodal Fine-Grained Learning | RAVDESS | 74.7 |
| 03 | Xu et al. [41] | Attention Networks | RAVDESS | 77.4% |
| 04 | Proposed II Approach | 2-D Feature Extration + VGG-16 | RAVDESS | 81.94 |
| SERIAL NO. | MODEL | RAVDESS | TESS |
|---|---|---|---|
| 01 | ResNet18 | 79.16% | 96.26% |
| 02 | Proposed-I | 73.95% | 99.99% |
| 03 | Proposed-II | 81.94% | 97.15% |
| SERIAL NO. | MODEL | RAVDESS | TESS |
|---|---|---|---|
| 01 | Decision Tree | 37.85% | 3.21% |
| 02 | Random Forest | 46.88% | 7.68% |
| 03 | MLPClassifier | 33.68% | 15.54% |
| 04 | ResNet18 | 79.16% | 96.26% |
| 05 | Proposed-I | 73.95% | 99.99% |
| 06 | Proposed-II | 81.94% | 97.15% |
Publisher’s Note: MDPI stays neutral with regard to jurisdictional claims in published maps and institutional affiliations. |
© 2022 by the authors. Licensee MDPI, Basel, Switzerland. This article is an open access article distributed under the terms and conditions of the Creative Commons Attribution (CC BY) license (https://creativecommons.org/licenses/by/4.0/).
Share and Cite
Aggarwal, A.; Srivastava, A.; Agarwal, A.; Chahal, N.; Singh, D.; Alnuaim, A.A.; Alhadlaq, A.; Lee, H.-N. Two-Way Feature Extraction for Speech Emotion Recognition Using Deep Learning. Sensors 2022, 22, 2378. https://doi.org/10.3390/s22062378
Aggarwal A, Srivastava A, Agarwal A, Chahal N, Singh D, Alnuaim AA, Alhadlaq A, Lee H-N. Two-Way Feature Extraction for Speech Emotion Recognition Using Deep Learning. Sensors. 2022; 22(6):2378. https://doi.org/10.3390/s22062378
Chicago/Turabian StyleAggarwal, Apeksha, Akshat Srivastava, Ajay Agarwal, Nidhi Chahal, Dilbag Singh, Abeer Ali Alnuaim, Aseel Alhadlaq, and Heung-No Lee. 2022. "Two-Way Feature Extraction for Speech Emotion Recognition Using Deep Learning" Sensors 22, no. 6: 2378. https://doi.org/10.3390/s22062378
APA StyleAggarwal, A., Srivastava, A., Agarwal, A., Chahal, N., Singh, D., Alnuaim, A. A., Alhadlaq, A., & Lee, H.-N. (2022). Two-Way Feature Extraction for Speech Emotion Recognition Using Deep Learning. Sensors, 22(6), 2378. https://doi.org/10.3390/s22062378