
Making the Most of Single Sensor Information: A Novel Fusion Approach for 3D Face Recognition Using Region Covariance Descriptors and Gaussian Mixture Models †




Abstract
:1. Introduction
2. Related Work
2.1. Single Sensor Techniques
2.2. Multi-Sensor Modality
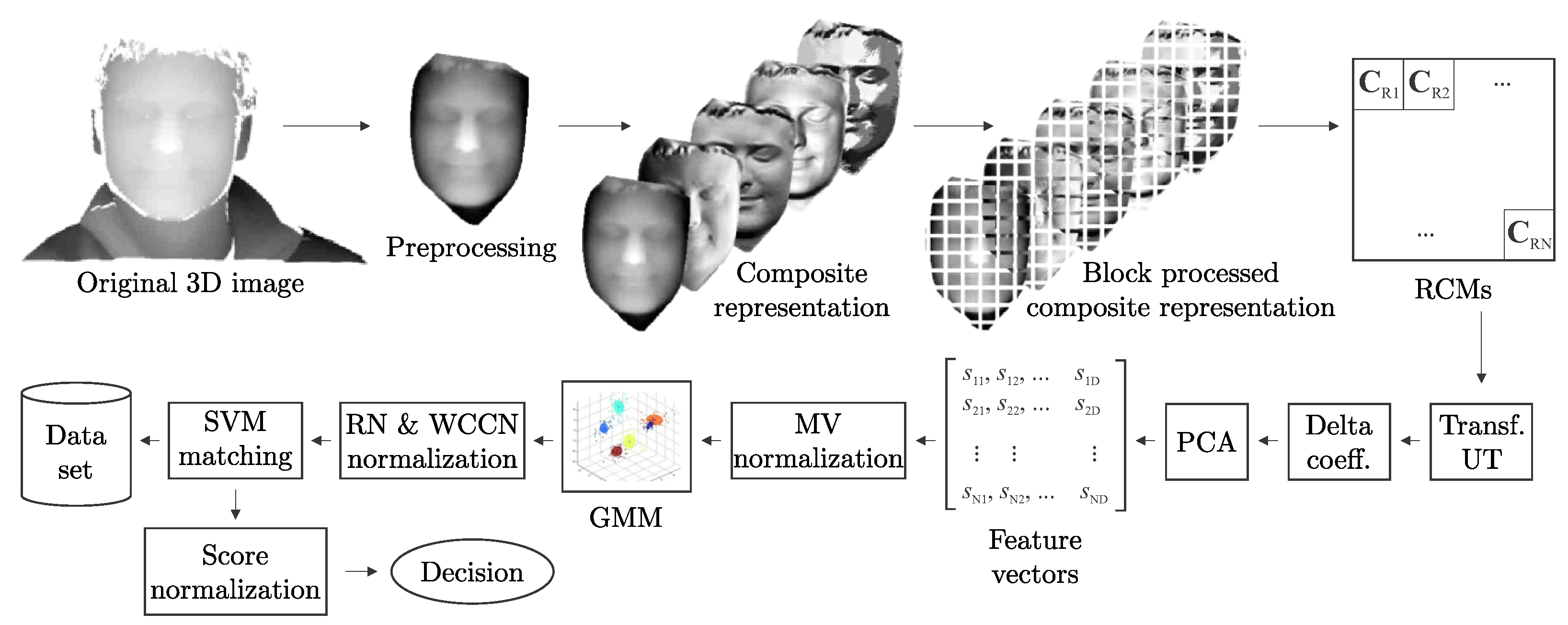
3. The Proposed System
3.1. Overview
3.2. Data Preprocessing and Localization
3.3. Data Representation
3.4. Region Covariance Matrix
3.5. Unscented Transform
3.6. Delta Coefficients
3.7. PCA Projection
3.8. Modeling
3.9. Classification
3.10. Data Normalization
3.11. Characteristics of the Proposed Approach
- (i)
- RCM descriptors are able to elegantly combine various face representations into a single coherent descriptor and can be considered as an efficient data fusion/integration scheme.
- (ii)
- RCM descriptors do not encode information about the arrangement or number of feature vectors in the region from which they are computed, and thus can be made scale and rotation invariant to some extent, but only if appropriate feature representations are selected for the construction of the composite representation (see, e.g., [47,48]).
- (iii)
- Since RCM descriptors are computable regardless of the number of feature vectors used for their computation, they can handle missing data in the feature extraction step (i.e., even in the presence of holes in the face scans or in regions near the borders of the face scans, the RCM descriptor is still computable). Please note that this is not the case for other local features commonly used with GMMs, such as 2D DCT features, which require that all elements of a rectangular image-block are present.
- (iv)
- The size of the RCM-derived feature vectors does not depend on the size of the region from which they were extracted. Feature vectors of the same size can therefore be computed from image blocks of variable size. Thus, RCM-based feature vectors enable a multi-scale analysis By the term multi-scale analysis, we refer to the fact that the face can be examined at different levels of locality up to the holistic level.) of the 3D face scans.
- (v)
- GMM-based systems treat data (i.e., feature vectors) as independent and identically distributed (i.i.d.) observations and therefore represent 3D facial images as a series of orderless blocks. This characteristic is reflected in good robustness to imperfect face alignment, moderate pose changes (The term moderate pose changes refers to the pose variability typically encountered with cooperating subjects in a 3D acquisition setup. Examples of such variability are, for example, illustrated in Figure 3), and expression variations, as shown by several researchers, e.g., [60,61].
- (vi)
- The probabilistic nature of GMMs makes it easy to include domain-specific prior knowledge into the modeling procedure, e.g., by relying on the universal background model (UBM).
- (vii)
- Image reconstructions from GMMs confirm that the representations are invariant to partial occlusions and moderate rotations.
4. Experiments
4.1. Used Databases
4.2. Experimental Parameter Setting
4.3. Robustness to Imprecise Localization
- Nose tip alignment (NT). The technique automatically detects the nose tip of the 3D faces and then crops the data using a sphere with radius , similar to what is described in [69];
- Metadata localization (MD). The technique uses the metadata provided by the FRGC protocol for face localization, i.e., manually annotated eye, nose tip and mouth coordinates;
- ICP alignment (ICP). The technique localizes the face scans by first coarsely normalizing the position of the 3D faces using the available metadata, and then applying the iterative closest point algorithm for fine alignment with the mean face model.
4.4. Composite Representation Selection
4.5. Contribution of UT Transform and Delta Features
4.6. Evaluation of Normalization Techniques
4.7. Comparative Assessment on the FRGC v2 Database
4.8. Comparative Assessment on the UMB-DB Database
4.9. Comparative Assessment on the CASIA Database
4.10. Reconstruction of 3D Face Images from GMMs
4.11. Time Complexity
5. Conclusions
Author Contributions
Funding
Institutional Review Board Statement
Informed Consent Statement
Conflicts of Interest
References
- Križaj, J.; Peer, P.; Štruc, V.; Dobrišek, S. Simultaneous multi-descent regression and feature learning for facial landmarking in depth images. Neural Comput. Appl. 2020, 32, 17909–17926. [Google Scholar] [CrossRef] [Green Version]
- Meden, B.; Rot, P.; Terhörst, P.; Damer, N.; Kuijper, A.; Scheirer, W.J.; Ross, A.; Peer, P.; Štruc, V. Privacy–Enhancing Face Biometrics: A Comprehensive Survey. IEEE Transact. Inform. For. Sec. 2021, 16, 4147–4183. [Google Scholar] [CrossRef]
- Grm, K.; Štruc, V.; Artiges, A.; Caron, M.; Ekenel, H.K. Strengths and weaknesses of deep learning models for face recognition against image degradations. IET Biom. 2018, 7, 81–89. [Google Scholar] [CrossRef] [Green Version]
- Grm, K.; Struc, V. Deep face recognition for surveillance applications. IEEE Intell. Syst. 2018, 33, 46–50. [Google Scholar]
- Liu, F.; Zhao, Q.; Liu, X.; Zeng, D. Joint Face Alignment and 3D Face Reconstruction with Application to Face Recognition. IEEE Trans. Pattern Anal. Mach. Intell. 2020, 42, 664–678. [Google Scholar] [CrossRef] [Green Version]
- Zheng, W.; Yue, M.; Zhao, S.; Liu, S. Attention-Based Spatial-Temporal Multi-Scale Network for Face Anti-Spoofing. IEEE Trans. Biom. Behav. Identity Sci. 2021, 3, 296–307. [Google Scholar] [CrossRef]
- Kim, J.; Yu, S.; Kim, I.J.; Lee, S. 3D Multi-Spectrum Sensor System with Face Recognition. Sensors 2013, 13, 12804–12829. [Google Scholar] [CrossRef] [Green Version]
- Zhou, S.; Xiao, S. 3D face recognition: A survey. Hum.-Centric Comput. Inf. Sci. 2018, 8, 35. [Google Scholar] [CrossRef] [Green Version]
- Bud, A. Facing the future: The impact of Apple FaceID. Biom. Technol. Today 2018, 2018, 5–7. [Google Scholar] [CrossRef]
- Neto, L.B.; Grijalva, F.; Maike, V.R.M.L.; Martini, L.C.; Florencio, D.; Baranauskas, M.C.C.; Rocha, A.; Goldenstein, S. A Kinect-Based Wearable Face Recognition System to Aid Visually Impaired Users. IEEE Trans. Hum.-Mach. Syst. 2017, 47, 52–64. [Google Scholar] [CrossRef]
- Facial Recognition for High Security Access Control Verification. Available online: http://auroracs.co.uk/wp-content/uploads/2015/06/Aurora-FaceSentinel-Datasheet-1506.pdf (accessed on 25 April 2019).
- Sensor for Facial Recognition from Behind Device OLED Screens. Available online: https://ams.com/TCS3701#tab/description (accessed on 25 April 2019).
- Krišto, M.; Ivasic-Kos, M. An overview of thermal face recognition methods. In Proceedings of the 2018 41st International Convention on Information and Communication Technology, Electronics and Microelectronics (MIPRO), Opatija, Croatia, 21–25 May 2018; pp. 1098–1103. [Google Scholar] [CrossRef]
- Xu, W.; Shen, Y.; Bergmann, N.; Hu, W. Sensor-Assisted Multi-View Face Recognition System on Smart Glass. IEEE Trans. Mob. Comput. 2018, 17, 197–210. [Google Scholar] [CrossRef]
- Chiesa, V. On Multi-View Face Recognition Using Lytro Images. In Proceedings of the 2018 26th European Signal Processing Conference (EUSIPCO), Rome, Italy, 3–7 September 2018; pp. 2250–2254. [Google Scholar]
- Gokberk, B.; Dutagaci, H.; Ulas, A.; Akarun, L.; Sankur, B. Representation Plurality and Fusion for 3-D Face Recognition. IEEE Trans. Syst. Man Cybern. Part B 2008, 38, 155–173. [Google Scholar] [CrossRef] [PubMed] [Green Version]
- Masi, I.; Tran, A.T.; Hassner, T.; Sahin, G.; Medioni, G. Face-Specific Data Augmentation for Unconstrained Face Recognition. Int. J. Comput. Vis. 2019, 127, 642–667. [Google Scholar] [CrossRef]
- Abudarham, N.; Shkiller, L.; Yovel, G. Critical features for face recognition. Cognition 2019, 182, 73–83. [Google Scholar] [CrossRef] [PubMed]
- Su, Y.; Shan, S.; Chen, X.; Gao, W. Hierarchical Ensemble of Global and Local Classifiers for Face Recognition. IEEE Trans. Image Process. 2009, 18, 1885–1896. [Google Scholar] [CrossRef]
- Li, J.; Qiu, T.; Wen, C.; Xie, K.; Wen, F. Robust Face Recognition Using the Deep C2D-CNN Model Based on Decision-Level Fusion. Sensors 2018, 17, 2080. [Google Scholar] [CrossRef] [Green Version]
- Ratyal, N.; Taj, I.A.; Sajid, M.; Mahmood, A.; Razzaq, S.; Dar, S.H.; Ali, N.; Usman, M.; Baig, M.J.A.; Mussadiq, U. Deeply Learned Pose Invariant Image Analysis with Applications in 3D Face Recognition. Math. Probl. Eng. 2019, 2019, 1–21. [Google Scholar] [CrossRef] [Green Version]
- Du, H.; Shi, H.; Zeng, D.; Zhang, X.P.; Mei, T. The Elements of End-to-End Deep Face Recognition: A Survey of Recent Advances. ACM Comput. Surv. 2021. [Google Scholar] [CrossRef]
- Horng, S.J.; Supardi, J.; Zhou, W.; Lin, C.T.; Jiang, B. Recognizing Very Small Face Images Using Convolution Neural Networks. IEEE Trans. Intell. Transp. Syst. 2022, 23, 2103–2115. [Google Scholar] [CrossRef]
- Križaj, J.; Štruc, V.; Dobrišek, S. Combining 3D Face Representations using Region Covariance Descriptors and Statistical Models. Automatic Face and Gesture Recognition Workshops (FG Workshops). In Proceedings of the IEEE International Conference and Workshops on Automatic Face and Gesture Recognition (FG), Shanghai, China, 22–26 April 2013. [Google Scholar]
- Beltran, D.; Basañez, L. A Comparison between Active and Passive 3D Vision Sensors: BumblebeeXB3 and Microsoft Kinect. In ROBOT2013: First Iberian Robotics Conference: Advances in Robotics, Madrid, Spain, 28–28 November 2013; Springer International Publishing: Cham, Switzerland, 2014; Volume 1, pp. 725–734. [Google Scholar] [CrossRef]
- Phillips, P.J.; Flynn, P.J.; Scruggs, T.; Bowyer, K.W.; Chang, J.; Hoffman, K.; Marques, J.; Min, J.; Worek, W. Overview of the Face Recognition Grand Challenge; CVPR: San Diego, CA, USA, 2005; pp. 947–954. [Google Scholar] [CrossRef]
- Savran, A.; Alyüz, N.; Dibeklioğlu, H.; Çeliktutan, O.; Gökberk, B.; Sankur, B.; Akarun, L. Bosphorus Database for 3D Face Analysis. In Biometrics and Identity Management; Schouten, B., Juul, N.C., Drygajlo, A., Tistarelli, M., Eds.; Springer: Berlin/Heidelberg, Germany, 2008; pp. 47–56. [Google Scholar]
- CASIA-3D Face V1. Available online: http://biometrics.idealtest.org (accessed on 25 April 2019).
- Colombo, A.; Cusano, C.; Schettini, R. UMB-DB: A database of partially occluded 3D faces. In Proceedings of the IEEE International Conference on Computer Vision Workshops (ICCV Workshops), Barcelona, Spain, 6–13 November 2011; pp. 2113–2119. [Google Scholar] [CrossRef]
- Erdogmus, N.; Dugelay, J.L. 3D Assisted Face Recognition: Dealing With Expression Variations. Inf. Forensics Secur. IEEE Trans. 2014, 9, 826–838. [Google Scholar] [CrossRef]
- Yu, C.; Zhang, Z.; Li, H. Reconstructing A Large Scale 3D Face Dataset for Deep 3D Face Identification. arXiv 2020, arXiv:cs.CV/2010.08391. [Google Scholar]
- Xu, K.; Wang, X.; Hu, Z.; Zhang, Z. 3D Face Recognition Based on Twin Neural Network Combining Deep Map and Texture. In Proceedings of the 2019 IEEE 19th International Conference on Communication Technology (ICCT), Xi’an, China, 16–19 November 2019; pp. 1665–1668. [Google Scholar] [CrossRef]
- Sharma, S.; Kumar, V. 3D Face Reconstruction in Deep Learning Era: A Survey. Arch. Comput. Methods Eng. 2022. [Google Scholar] [CrossRef] [PubMed]
- Guo, Y.; Zhang, J.; Lu, M.; Wan, J.; Ma, Y. Benchmark datasets for 3D computer vision. In Proceedings of the 9th IEEE Conference on Industrial Electronics and Applications, Hangzhou, China, 9–14 June 2014; pp. 1846–1851. [Google Scholar] [CrossRef]
- Mráček, Š.; Drahanský, M.; Dvořák, R.; Provazník, I.; Váňa, J. 3D face recognition on low-cost depth sensors. In Proceedings of the International Conference of the Biometrics Special Interest Group (BIOSIG), Darmstadt, Germany, 10–12 September 2014; pp. 1–4. [Google Scholar]
- De Melo Nunes, L.F.; Zaghetto, C.; de Barros Vidal, F. 3D Face Recognition on Point Cloud Data—An Approaching based on Curvature Map Projection using Low Resolution Devices. In Proceedings of the 15th International Conference on Informatics in Control, Automation and Robotics, Porto, Portugal, 29–31 July 2018; Volume 2, pp. 266–273. [Google Scholar] [CrossRef]
- Hayasaka, A.; Ito, K.; Aoki, T.; Nakajima, H.; Kobayashi, K. A Robust 3D Face Recognition Algorithm Using Passive Stereo Vision. IEICE Transact. 2009, 92-A, 1047–1055. [Google Scholar] [CrossRef] [Green Version]
- Roth, J.; Tong, Y.; Liu, X. Adaptive 3D Face Reconstruction from Unconstrained Photo Collections. In Proceedings of the 2016 IEEE Conference on Computer Vision and Pattern Recognition (CVPR), Vegas, NV, USA, 27–30 June 2016; pp. 4197–4206. [Google Scholar] [CrossRef]
- Aissaoui, A.; Martinet, J.; Djeraba, C. 3D face reconstruction in a binocular passive stereoscopic system using face properties. In Proceedings of the 19th IEEE International Conference on Image Processing, Orlando, FL, USA, 30 September–3 October 2012; pp. 1789–1792. [Google Scholar] [CrossRef]
- Gecer, B.; Ploumpis, S.; Kotsia, I.; Zafeiriou, S.P. Fast-GANFIT: Generative Adversarial Network for High Fidelity 3D Face Reconstruction. IEEE Transact. Pattern Anal. Mach. Intell. 2021, 1. [Google Scholar] [CrossRef] [PubMed]
- Fan, Z.; Hu, X.; Chen, C.; Peng, S. Dense Semantic and Topological Correspondence of 3D Faces without Landmarks. In Proceedings of the European Conference on Computer Vision (ECCV), Munich, Germany, 8–14 September 2018. [Google Scholar]
- Xue, Y.; Jianming, L.; Takashi, Y. A method of 3D face recognition based on principal component analysis algorithm. In Proceedings of the 2005 IEEE International Symposium on Circuits and Systems, Kobe, Japan, 23–26 May 2005; Volume 4, pp. 3211–3214. [Google Scholar] [CrossRef]
- Chang, K.I.; Bowyer, K.W.; Flynn, P.J. Multimodal 2D and 3D biometrics for face recognition. In Proceedings of the IEEE International SOI Conference, Nice, France, 7 October 2003; pp. 187–194. [Google Scholar] [CrossRef] [Green Version]
- Tian, L.; Liu, J.; Guo, W. Three-Dimensional Face Reconstruction Using Multi-View-Based Bilinear Model. Sensors 2019, 19, 459. [Google Scholar] [CrossRef] [Green Version]
- Kluckner, S.; Mauthner, T.; Bischof, H. A Covariance Approximation on Euclidean Space for Visual Tracking. In Proceedings of the OAGM, Stainz, Austria, 14–15 May 2009. [Google Scholar]
- Jain, A.K.; Dubes, R.C. Algorithms for Clustering Data; Prentice-Hall, Inc.: Upper Saddle River, NJ, USA, 1988. [Google Scholar]
- Tuzel, O.; Porikli, F.; Meer, P. Region Covariance: A Fast Descriptor for Detection and Classification. In Proceedings of the ECCV, Graz, Austria, 7–13 May 2006; Volume 3952, pp. 589–600. [Google Scholar]
- Pang, Y.; Yuan, Y.; Li, X. Gabor-Based Region Covariance Matrices for Face Recognition. TCSVT 2008, 18, 989–993. [Google Scholar]
- Tuzel, O.; Porikli, F.; Meer, P. Human Detection via Classification on Riemannian Manifolds. In Proceedings of the CVPR, Minneapolis, MN, USA, 18–23 June 2007; pp. 1–8. [Google Scholar]
- Porikli, F.; Tuzel, O.; Meer, P. Covariance Tracking using Model Update Based on Lie Algebra. In Proceedings of the CVPR, New York, NY, USA, 17–22 June 2006; Volume 1, pp. 728–735. [Google Scholar]
- Julier, S.; Uhlmann, J.K. A General Method for Approximating Nonlinear Transformations of Probability Distributions; Technical Report; Department of Engineering Science, University of Oxford: Oxford, UK, 1996. [Google Scholar]
- Moon, T. The Expectation-Maximization Algorithm. Sig. Proc. Mag. IEEE 1996, 13, 47–60. [Google Scholar] [CrossRef]
- Reynolds, D.A.; Quatieri, T.F.; Dunn, R.B. Speaker verification using Adapted GMMs. Dig. Sig. Proc. 2000, 10, 19–41. [Google Scholar] [CrossRef] [Green Version]
- Bredin, H.; Dehak, N.; Chollet, G. GMM-based SVM for face recognition. In Proceedings of the 18th International Conference on Pattern Recognition, ICPR, Hong Kong, China, 20–24 August 2006; Volume 3, pp. 1111–1114. [Google Scholar]
- Bishop, C.M. Pattern Recognition and Machine Learning (Information Science and Statistics); Springer: New York, NY, USA, 2006. [Google Scholar]
- Hatch, A.O.; Kajarekar, S.; Stolcke, A. Within-class Covariance Normalization for SVM-based Speaker Recognition. Proc. ICSLP 2006, 1471–1474. Available online: https://www.sri.com/wp-content/uploads/pdf/within-class_covariance_normalization_for_svm-based_speaker_recogniti.pdf (accessed on 17 February 2021).
- Vesnicer, B.; Žganec Gros, J.; Vitomir Štruc, N.P. Face Recognition using Simplified Probabilistic Linear Discriminant Analysis. Int. J. Adv. Robot. Syst. 2012, 9, 180. [Google Scholar] [CrossRef] [Green Version]
- Hatch, A.; Stolcke, A. Generalized Linear Kernels for One-Versus-All Classification: Application to Speaker Recognition. In Proceedings of the IEEE International Conference on Acoustics, Speech and Signal Processing, ICASSP 2006, Toulouse, France, 14–16 May 2006; Volume 5. [Google Scholar] [CrossRef] [Green Version]
- Bromiley, P. Products and Convolutions of Gaussian Distributions; Internal Report 2003-003; TINA Vision. 2003. Available online: http://www.tina-vision.net/ (accessed on 17 February 2021).
- Križaj, J.; Štruc, V.; Dobrišek, S. Towards Robust 3D Face Verification using Gaussian Mixture Models. Int. J. Adv. Robot. Syst. 2012, 9, 1–11. [Google Scholar] [CrossRef] [Green Version]
- Wallace, R.; McLaren, M.; McCool, C.; Marcel, S. Cross-pollination of normalization techniques from speaker to face authentication using GMMs. IEEE TIFS 2012, 7, 553–562. [Google Scholar]
- Tsalakanidou, F.; Tzovaras, D.; Strintzis, M. Use of depth and colour eigenfaces for face recognition. Pattern Recognit. Lett. 2003, 24, 1427–1435. [Google Scholar] [CrossRef]
- Križaj, J.; Štruc, V.; Pavešić, N. Adaptation of SIFT features for face recognition under varying illumination. In Proceedings of the 33rd International Convention on Information and Communication Technology, Electronics and Microelectronics (MIPRO), Opatija, Croatia, 24–28 May 2010; pp. 691–694. [Google Scholar]
- Lumini, A.; Nanni, L.; Brahnam, S. Ensemble of texture descriptors and classifiers for face recognition. Appl. Comput. Inform. 2017, 13, 79–91. [Google Scholar] [CrossRef]
- Križaj, J.; Štruc, V.; Mihelič, F. A Feasibility Study on the Use of Binary Keypoint Descriptors for 3D Face Recognition. In Pattern Recognition; Springer International Publishing: Cham, Switzerland, 2014; Volume 8495. [Google Scholar]
- Geng, C.; Jiang, X. SIFT features for face recognition. In Proceedings of the 2009 2nd IEEE International Conference on Computer Science and Information Technology, Beijing, China, 8–11 August 2009; pp. 598–602. [Google Scholar] [CrossRef]
- Tome, P.; Fierrez, J.; Alonso-Fernandez, F.; Ortega-Garcia, J. Scenario-based score fusion for face recognition at a distance. In Proceedings of the Recognition—Workshops, San Francisco, CA, USA, 13–18 June 2010; pp. 67–73. [Google Scholar] [CrossRef] [Green Version]
- Soni, N.; Sharma, E.K.; Kapoor, A. Novel BSSSO-Based Deep Convolutional Neural Network for Face Recognition with Multiple Disturbing Environments. Electronics 2021, 10, 626. [Google Scholar] [CrossRef]
- Segundo, M.; Queirolo, C.; Bellon, O.R.P.; Silva, L. Automatic 3D facial segmentation and landmark detection. In Proceedings of the 14th International Conference on Image Analysis and Processing, Modena, Italy, 10–14 September 2007; pp. 431–436. [Google Scholar]
- Wang, Y.; Liu, J.; Tang, X. Robust 3D Face Recognition by Local Shape Difference Boosting. Pattern Anal. Mach. Intell. IEEE Trans. 2010, 32, 1858–1870. [Google Scholar] [CrossRef] [Green Version]
- Inan, T.; Halici, U. 3-D Face Recognition With Local Shape Descriptors. Inf. Forensics Secur. IEEE Trans. 2012, 7, 577–587. [Google Scholar] [CrossRef]
- Mohammadzade, H.; Hatzinakos, D. Iterative Closest Normal Point for 3D Face Recognition. Pattern Anal. Mach. Intell. IEEE Trans. 2013, 35, 381–397. [Google Scholar] [CrossRef]
- Drira, H.; Ben Amor, B.; Srivastava, A.; Daoudi, M.; Slama, R. 3D Face Recognition Under Expressions, Occlusions and Pose Variations. IEEE Transact. Pattern Anal. Mach. Intell. 2013, 35, 2270–2283. [Google Scholar] [CrossRef] [Green Version]
- Huang, D.; Ardabilian, M.; Wang, Y.; Chen, L. 3-D Face Recognition Using eLBP-Based Facial Description and Local Feature Hybrid Matching. Inf. Forensics Secur. IEEE Trans. 2012, 7, 1551–1565. [Google Scholar] [CrossRef] [Green Version]
- Cai, L.; Da, F. Nonrigid-Deformation Recovery for 3D Face Recognition Using Multiscale Registration. Comput. Graph. Appl. IEEE 2012, 32, 37–45. [Google Scholar] [CrossRef]
- Al-Osaimi, F.; Bennamoun, M.; Mian, A. Spatially Optimized Data-Level Fusion of Texture and Shape for Face Recognition. Image Process. IEEE Trans. 2012, 21, 859–872. [Google Scholar] [CrossRef] [PubMed]
- Queirolo, C.; Silva, L.; Bellon, O.; Segundo, M. 3D Face Recognition Using Simulated Annealing and the Surface Interpenetration Measure. Pattern Anal. Mach. Intell. IEEE Trans. 2010, 32, 206–219. [Google Scholar] [CrossRef] [PubMed]
- Kakadiaris, I.; Passalis, G.; Toderici, G.; Murtuza, M.; Lu, Y.; Karampatziakis, N.; Theoharis, T. Three-Dimensional Face Recognition in the Presence of Facial Expressions: An Annotated Deformable Model Approach. Pattern Anal. Mach. Intell. IEEE Trans. 2007, 29, 640–649. [Google Scholar] [CrossRef] [PubMed] [Green Version]
- Emambakhsh, M.; Evans, A. Nasal Patches and Curves for an Expression-robust 3D Face Recognition. IEEE Transact. Pattern Anal. Mach. Intell. 2016, 39, 995–1007. [Google Scholar] [CrossRef] [Green Version]
- Soltanpour, S.; Wu, Q.J. Multimodal 2D-3D face recognition using local descriptors: Pyramidal shape map and structural context. IET Biom. 2016, 6, 27–35. [Google Scholar] [CrossRef]
- Cai, Y.; Lei, Y.; Yang, M.; You, Z.; Shan, S. A fast and robust 3D face recognition approach based on deeply learned face representation. Neurocomputing 2019, 363, 375–397. [Google Scholar] [CrossRef]
- Zhang, Z.; Da, F.; Yu, Y. Learning directly from synthetic point clouds for “in-the-wild” 3D face recognition. Pattern Recognit. 2022, 123, 108394. [Google Scholar] [CrossRef]
- Alyuz, N.; Gokberk, B.; Akarun, L. 3-D Face Recognition Under Occlusion Using Masked Projection. Inf. Forensics Secur. IEEE Trans. 2013, 8, 789–802. [Google Scholar] [CrossRef]
- Xiao, X.; Chen, Y.; Gong, Y.J.; Zhou, Y. 2D Quaternion Sparse Discriminant Analysis. IEEE Trans. Image Process. 2020, 29, 2271–2286. [Google Scholar] [CrossRef]
- Xu, C.; Li, S.; Tan, T.; Quan, L. Automatic 3D face recognition from depth and intensity Gabor features. Pattern Recogn. 2009, 42, 1895–1905. [Google Scholar] [CrossRef]
- Dutta, K.; Bhattacharjee, D.; Nasipuri, M. SpPCANet: A simple deep learning-based feature extraction approach for 3D face recognition. Multimedia Tools Appl. 2020, 79, 31329–31352. [Google Scholar] [CrossRef]









{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
| Module | |||
|---|---|---|---|
| Method | Feature Extraction | Feature Modeling | Classification |
| PCA_EUC [62] | PCA based holistic feature extraction | / | Euclidean distance-based similarity measure with nearest neighbor classifier |
| GSIFT_EUC [63] | SIFT descriptors extracted from uniformly distributed locations on facial area | / | Euclidean distance-based similarity measure with nearest neighbor classifier |
| GSIFT_SVM [64] | SIFT descriptors extracted from uniformly distributed locations on facial area | / | SVM |
| GSIFT_GMM_SVM [65] | SIFT descriptors extracted from uniformly distributed locations on facial area | GMM | SVM |
| SIFT_GMM_SVM [65] | Classic SIFT descriptors | GMM | SVM |
| SIFT_SIFTmatch [66] | Classic SIFT descriptors | / | SIFT matching |
| DCT_GMM_SVM [67] | DCT-based descriptors | GMM | SVM |
| RCM_GMM_SVM | RCM-based descriptors | GMM | SVM |
| Parameter | Parameter Value/Verification Rate | |||||
|---|---|---|---|---|---|---|
| Block size (pixels) | 15/95.6 | 20/95.7 | 25/96.1 | 30/95.1 | 35/92.1 | 40/91.9 |
| Step size (pixels) | 3/96.2 | 4/96.1 | 5/95.0 | 6/92.4 | 7/88.9 | 8/83.2 |
| Feature vector length (no. of PCA comp.) | 15/95.0 | 20/95.7 | 25/96.1 | 30/96.1 | 35/96.2 | 40/95.8 |
| No. of training images to build the UMB | 10/79.0 | 50/92.2 | 100/94.4 | 200/95.5 | 400/95.9 | 943/96.1 |
| No. of Gaussian mixtures | 32/86.9 | 64/92.7 | 128/94.1 | 256/95.7 | 512/96.1 | 1024/96.1 |
| Localization Technique | ||||
|---|---|---|---|---|
| Method | ICP | MD | NT | CB |
| PCA_EUC | 41.1 | 38.4 | 38.1 | 18.6 |
| GSIFT_SVM | 72.3 | 71.1 | 70.3 | 61.4 |
| SIFT_SIFTmatch | 90.2 | 90.0 | 89.9 | 89.1 |
| RCM_GMM_SVM | 97.9 | 97.9 | 97.8 | 97.7 |
| Experiment | |||
|---|---|---|---|
| FRGC v2 all vs. all | UMB-DB neut., n.-occl. vs. occl. | CASIA neut., front. vs. n-neut., front. | |
| 94.8 | 81.2 | 94.2 | |
| 95.8 | 83.5 | 93.6 | |
| 95.7 | 84.7 | 94.8 | |
| 94.7 | 83.9 | 93.2 | |
| 93.6 | 82.0 | 92.1 | |
| 92.3 | 82.3 | 81.4 | |
| 78.3 | 65.6 | 77.2 | |
| UT Modality | |||
|---|---|---|---|
| Method | Without UT | Without UT, Added | With UT |
| RCM_GMM_SVM | 93.9 | 94.7 | 96.1 |
| Delta Features | ||||
|---|---|---|---|---|
| Method | Without | Horizontal | Vertical | Horizontal + Vertical |
| RCM_GMM_SVM | 94.9 | 95.8 | 95.9 | 96.1 |
| Normalization Technique | |||||
|---|---|---|---|---|---|
| Method | ∅ | MVN | MVN + RN | MVN + RN + WCCN | MVN + RN + WCCN + SN |
| GSIFT_SVM | 47.1 | 50.5 | 57.9 | 61.3 | 61.4 |
| RCM_GMM_SVM | 81.0 | 84.0 | 96.1 | 97.5 | 97.7 |
| Experiment | |||||||
|---|---|---|---|---|---|---|---|
| Method | all vs. all | neut. vs. all | neut. vs. neut. | neut. vs.
n.-neut. | ROC I | ROC II | ROC III |
| Drira et al., 2013 [73] | 94.0 | n/a | n/a | n/a | n/a | n/a | 97.1 |
| Huang et al., 2012 [74] | 94.2 | 98.4 | 99.6 | 97.2 | 95.1 | 95.1 | 95.0 |
| Cai et al., 2012 [75] | 97.4 | n/a | 98.7 | 96.2 | n/a | n/a | n/a |
| Al-Osaimi et al., 2012 [76] | n/a | n/a | 99.8 | 97.9 | n/a | n/a | n/a |
| Queirolo et al., 2010 [77] | 96.5 | 98.5 | 100.0 | n/a | n/a | n/a | 96.6 |
| Kakadiaris et al., 2007 [78] | n/a | n/a | n/a | n/a | 97.3 | 97.2 | 97.0 |
| Wang et al., 2010 [70] | 98.1 | 98.6 | n/a | n/a | 98.0 | 98.0 | 98.0 |
| Inan et al., 2012 [71] | 98.4 | n/a | n/a | n/a | n/a | n/a | 98.3 |
| Mohammadzade et al., 2013 [72] | 99.2 | n/a | 99.9 | 98.5 | n/a | n/a | 99.6 |
| Emambakhsh et al., 2016 [79] | n/a | n/a | n/a | n/a | n/a | n/a | 93.5 |
| Soltanpour et al., 2016 [80] | 99.0 | 99.3 | 99.9 | 98.4 | n/a | n/a | 98.7 |
| Ratyal et al., 2019 [21] | 99.8 | n/a | n/a | n/a | n/a | n/a | n/a |
| Cai et al., 2019 [81] | n/a | 100 | 100 | 100 | n/a | n/a | 100 |
| Zhang et al., 2022 [82] | n/a | 99.6 | 100 | 99.1 | n/a | n/a | n/a |
| GSIFT_EUC | 49.6 | 52.3 | 55.2 | 46.7 | 52.8 | 50.7 | 48.4 |
| GSIFT_SVM | 61.4 | 64.1 | 66.2 | 59.8 | 64.9 | 62.6 | 60.2 |
| GSIFT_GMM_SVM | 65.6 | 67.7 | 70.0 | 63.1 | 67.6 | 66.0 | 64.1 |
| SIFT_GMM_SVM | 77.3 | 83.7 | 94.4 | 69.9 | 78.1 | 77.0 | 75.9 |
| RCM_GMM_EUC | 82.7 | 91.2 | 97.9 | 83.7 | 84.3 | 83.1 | 81.8 |
| RCM_SIFTmatch | 87.5 | 91.9 | 97.1 | 82.4 | 88.0 | 87.6 | 87.2 |
| SIFT_SIFTmatch | 89.1 | 92.5 | 98.7 | 85.3 | 89.6 | 89.2 | 88.1 |
| DCT_GMM_SVM | 93.3 | 96.1 | 98.9 | 93.2 | 94.6 | 93.8 | 93.1 |
| RCM_GMM_SVM | 97.7 | 99.2 | 99.8 | 98.5 | 98.6 | 98.1 | 97.7 |
| Max. Number of Images per Gallery Subject | ||||||
|---|---|---|---|---|---|---|
| Method | 1 | 2 | 3 | 4 | 5 | 6 |
| Mohamadzae et al. [72] | n/a | 90.6 | 98.4 | 99.2 | 99.5 | 99.6 |
| RCM_GMM_SVM | 97.7 | 99.6 | 99.8 | 99.9 | 99.9 | 99.9 |
| Experiment | ||||
|---|---|---|---|---|
| Method | A-A | N-A | N-N | N- |
| Drira et al., 2013 [73] | 97.0 | n/a | n/a | n/a |
| Huang et al., 2012 [74] | n/a | 97.6 | 99.2 | 95.1 |
| Cai et al., 2012 [75] | 98.2 | n/a | n/a | n/a |
| Al-Osaimi et al., 2012 [76] | 97.4 | n/a | 99.2 | 95.7 |
| Inan et al., 2012 [71] | 97.5 | n/a | n/a | n/a |
| Wang et al., 2010 [70] | 98.2 | 98.4 | n/a | n/a |
| Queirolo et al., 2010 [77] | 98.4 | n/a | n/a | n/a |
| Kakadiaris et al., 2007 [78] | 97.0 | n/a | n/a | n/a |
| Emambakhsh et al., 2016 [79] | n/a | 97.9 | 98.5 | 98.5 |
| Soltanpour et al., 2016 [80] | n/a | 96.9 | 99.6 | 96.0 |
| Ratyal et al., 2019 [21] | 99.6 | n/a | n/a | n/a |
| Cai et al., 2019 [81] | n/a | 100 | 99.9 | 99.9 |
| Yu et al., 2020 [31] | 98.2 | n/a | n/a | n/a |
| Zhang et al., 2022 [82] | 99.5 | n/a | n/a | n/a |
| SIFT_SIFTmatch | 89.4 | 91.2 | 96.1 | 85.3 |
| DCT_GMM_SVM | 94.8 | 96.8 | 98.6 | 94.6 |
| RCM_GMM_SVM | 98.1 | 98.9 | 99.6 | 98.2 |
| Subset | Method | |||||
|---|---|---|---|---|---|---|
| Gallery | Probe | Training | Colombo et al. [29] | GSIFT_ GMM_SVM | SIFT_ SIFTmatch | RCM_ GMM_SVM |
| neut., n.-occl. | neut., n.-occl. | n.-neut., n.-occl. | 1.9 | 4.8 (90.4) | 0.8 (99.2) | 0.6 (99.2) |
| neut., n.-occl. | n.-neut., n.-occl. | occl. | 18.4 | 9.7 (63.6) | 5.0 (90.2) | 3.0 (93.8) |
| neut., n.-occl. | neut., occl. | n.-neut., n.-occl. | n/a | 31.4 (11.5) | 7.2 (79.1) | 3.6 (85.8) |
| neut., n.-occl. | occl. | n.-neut., n.-occl. | 23.8 | 34.9 (10.7) | 7.9 (77.8) | 4.1 (84.7) |
| Experiment | |||
|---|---|---|---|
| Method | N¯O- | N¯O-¯N¯O | N¯O-O |
| Alyuz et al., 2013 [83] | 97.3 | n/a | 73.6 |
| Ratyal et al., 2019 [21] | 99.3 | n/a | n/a |
| Xiao et al., 2020 [84] | n/a | n/a | 61.6 |
| GSIFT_GMM_SVM | 92.3 | 76.0 | 21.2 |
| SIFT_SIFTmatch | 99.0 | 93.0 | 90.8 |
| RCM_GMM_SVM | 99.7 | 97.9 | 91.8 |
| Subset | Method | ||
|---|---|---|---|
| Gallery | Probe | SIFT_ SIFTmatch | RCM_ GMM_SVM |
| neut., front. | neut., front. | 98.8 | 98.8 |
| neut., front. | n.-neut., front. | 95.8 | 96.9 |
| neut., front. | neut., n.-front. | 59.5 | 66.0 |
| neut., front. | n.-neut., n.-front. | 53.0 | 59.3 |
| neut., front. | all | 77.6 | 74.3 |
| Method | |||||
|---|---|---|---|---|---|
| Probe | Xu et al., 2009 [85] | Xu et al., 2019 [32] | Dutta et al., 2020 [86] | SIFT_ SIFTmatch | RCM_ GMM_SVM |
| IV(400) | 98.3 | n/a | 98.2 | 99.3 | 99.5 |
| EV(500) | 74.4 | n/a | n/a | 97.6 | 98.8 |
| EVI(500) | 75.5 | 99.1 | n/a | 98.2 | 99.2 |
| PVS(700) | 91.4 | n/a | 88.8 | 83.3 | 85.3 |
| PVL(200) | 51.5 | n/a | n/a | 55.5 | 59.5 |
| PVSS(700) | 82.4 | n/a | n/a | 76.7 | 80.3 |
| PVSL(200) | 49.0 | n/a | n/a | 48.0 | 51.5 |
Publisher’s Note: MDPI stays neutral with regard to jurisdictional claims in published maps and institutional affiliations. |
© 2022 by the authors. Licensee MDPI, Basel, Switzerland. This article is an open access article distributed under the terms and conditions of the Creative Commons Attribution (CC BY) license (https://creativecommons.org/licenses/by/4.0/).
Share and Cite
Križaj, J.; Dobrišek, S.; Štruc, V. Making the Most of Single Sensor Information: A Novel Fusion Approach for 3D Face Recognition Using Region Covariance Descriptors and Gaussian Mixture Models. Sensors 2022, 22, 2388. https://doi.org/10.3390/s22062388
Križaj J, Dobrišek S, Štruc V. Making the Most of Single Sensor Information: A Novel Fusion Approach for 3D Face Recognition Using Region Covariance Descriptors and Gaussian Mixture Models. Sensors. 2022; 22(6):2388. https://doi.org/10.3390/s22062388
Chicago/Turabian StyleKrižaj, Janez, Simon Dobrišek, and Vitomir Štruc. 2022. "Making the Most of Single Sensor Information: A Novel Fusion Approach for 3D Face Recognition Using Region Covariance Descriptors and Gaussian Mixture Models" Sensors 22, no. 6: 2388. https://doi.org/10.3390/s22062388
APA StyleKrižaj, J., Dobrišek, S., & Štruc, V. (2022). Making the Most of Single Sensor Information: A Novel Fusion Approach for 3D Face Recognition Using Region Covariance Descriptors and Gaussian Mixture Models. Sensors, 22(6), 2388. https://doi.org/10.3390/s22062388