
Towards Synoptic Water Monitoring Systems: A Review of AI Methods for Automating Water Body Detection and Water Quality Monitoring Using Remote Sensing

 ,
,  , and
, and
Abstract
:1. Introduction and Motivation
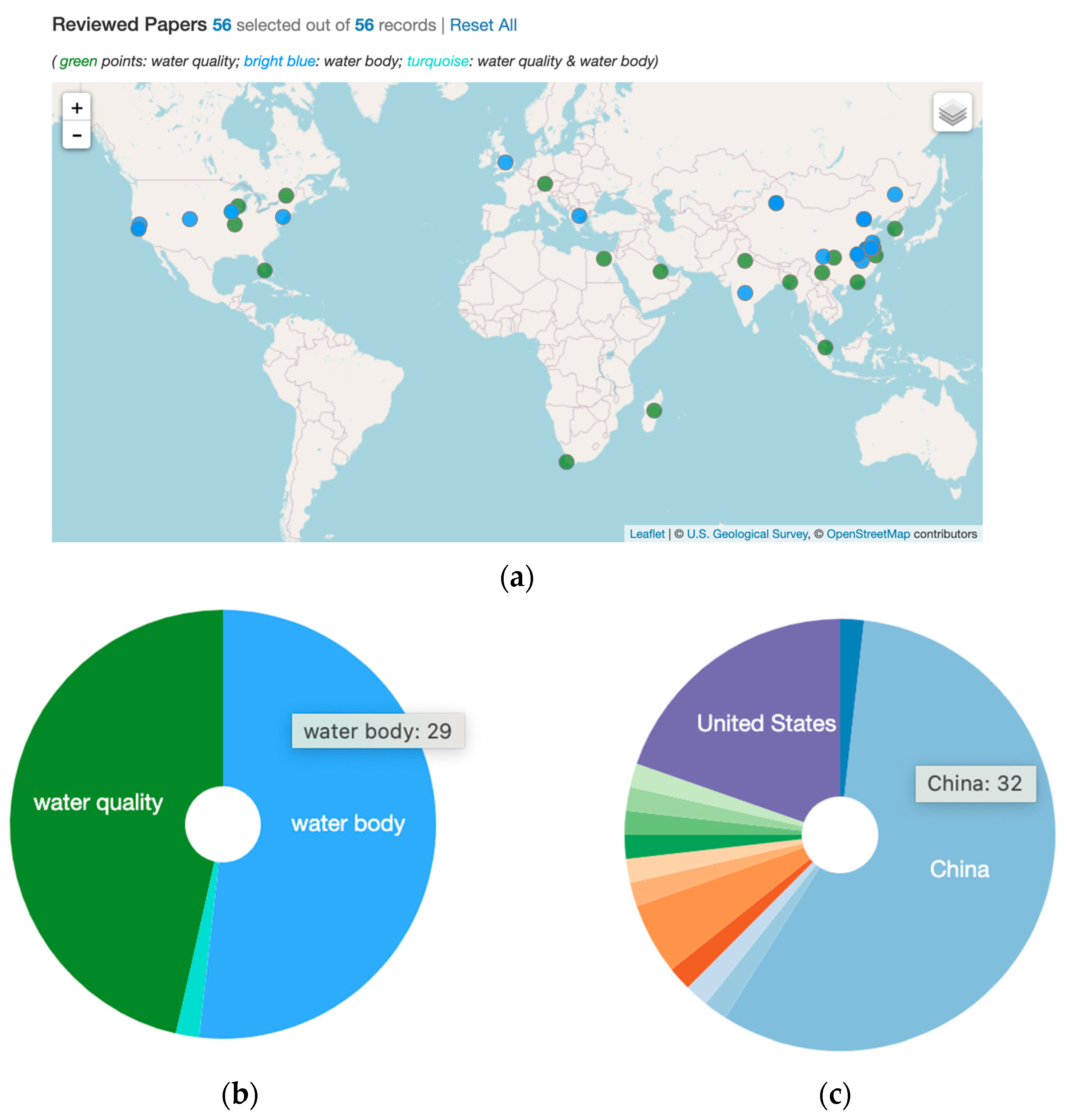
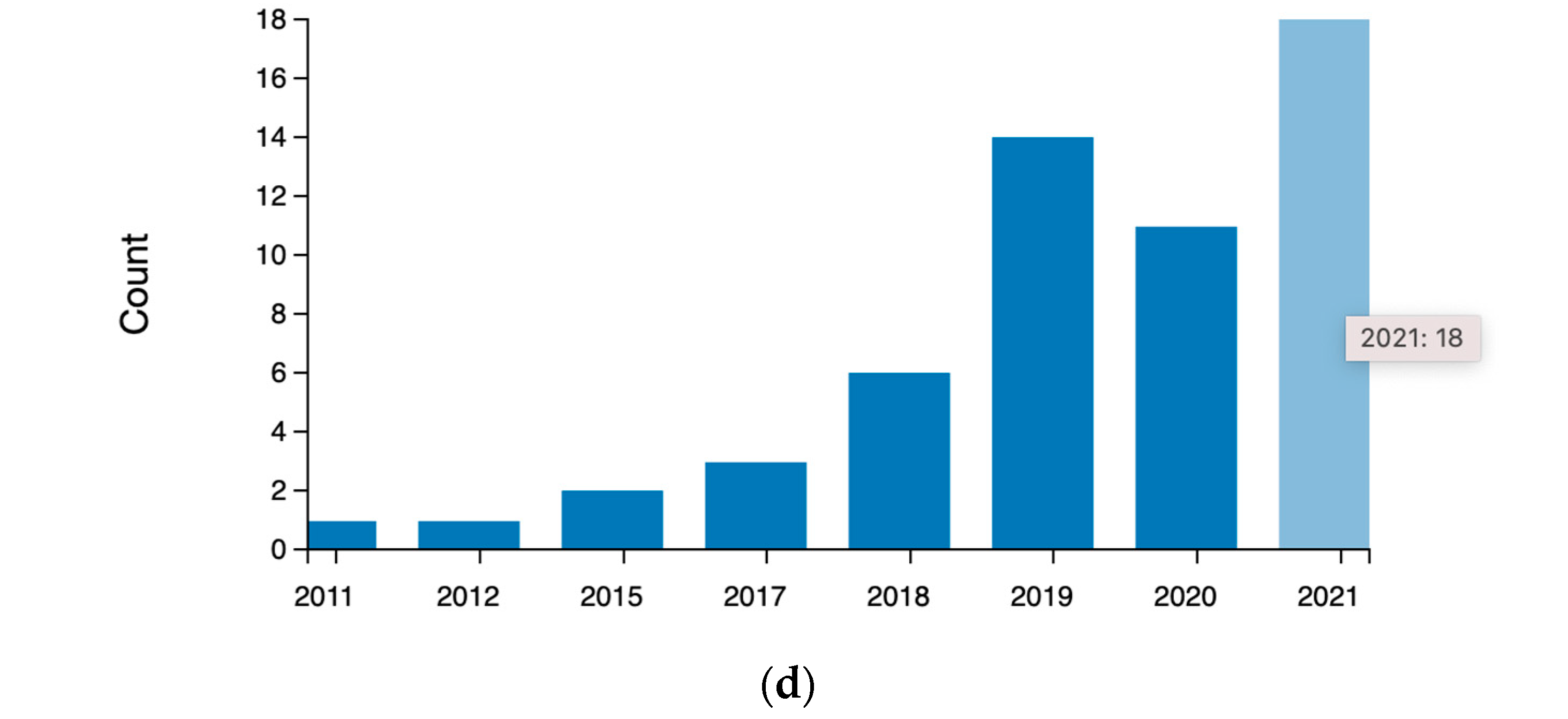
1.1. Selection Criterion for Reviewed Papers and Brief Graphic Summary
1.2. Roadmap
2. Audience and Scope
3. The State of the Art: Advances in Intelligent Waterbody Information Extraction
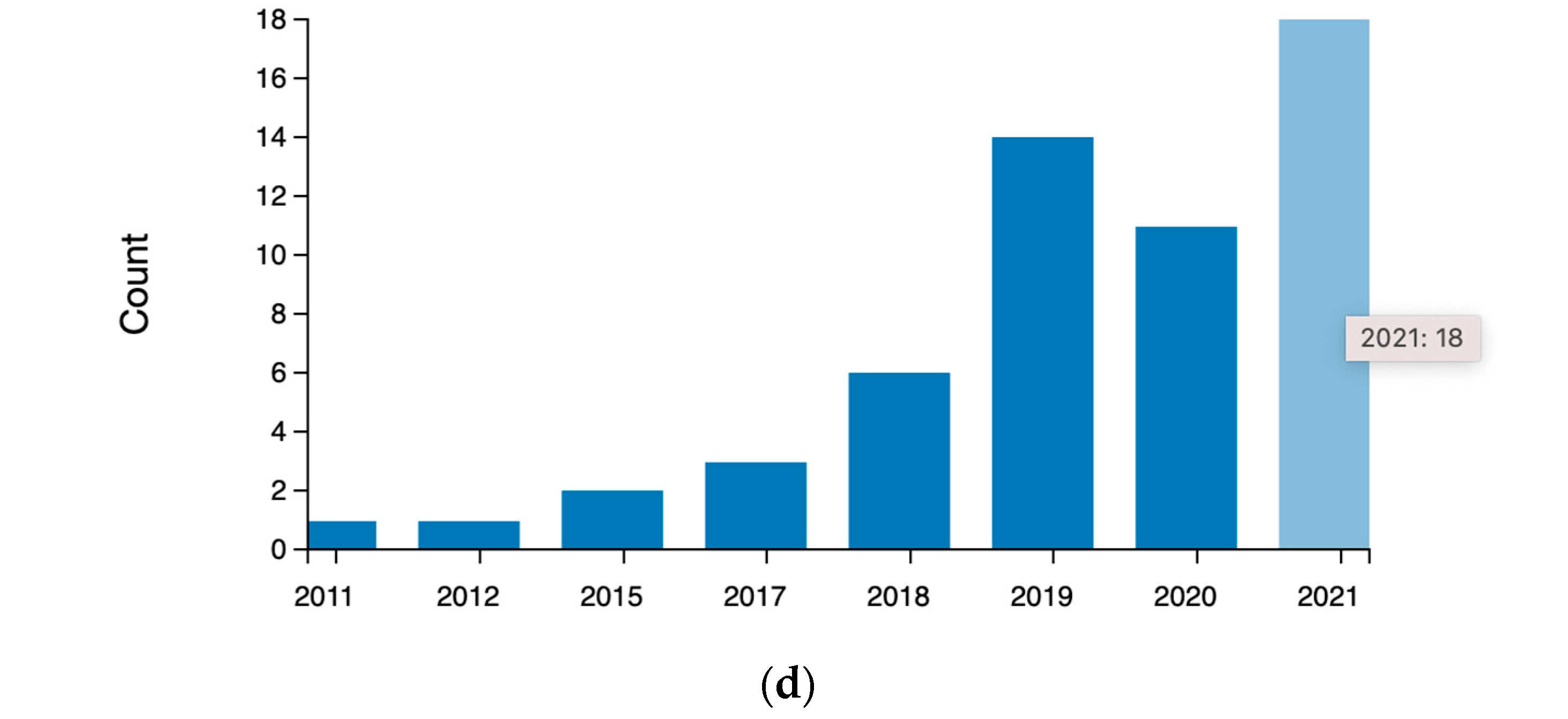
3.1. General Characteristics of the Reviewed Studies
3.2. Recent Advances in Water Body Detection Using AI
3.2.1. CNN-Based Water Body Detection
- 1.
- Addressing limitations of index-based methods:
- 2.
- Sharpening blurred boundaries caused by CNNs:
- 3.
- Addressing resolution and band related challenges
- 4.
- Robust detection of small/slender/irregular-shaped water bodies
- 5.
- Others
3.2.2. CNN Hybrid-Based Water Body Detection
3.2.3. ANN, MLP, DNN, and Other DL-Based Methods for Water Body Detection
3.2.4. “Shallow” ML-Based Water Body Detection
3.3. Recent Advances in Water Quality Monitoring Using AI
3.3.1. LSTM-Based Water Quality Detection and Monitoring
3.3.2. LSTM Hybrids Water Quality Detection and Monitoring
3.3.3. CNN-Based Water Quality Detection and Monitoring
3.3.4. “Shallow” ML-Based Water Quality Detection and Monitoring
3.3.5. ANN, MLP, DNN, and Other DL-Based Methods for Water Quality Detection and Monitoring
4. Challenges and Opportunities
4.1. Summary and Discussion
4.2. Identified Major Challenges
4.2.1. Shared Common Challenges in Both Domains
- Methods for water body detection and water quality monitoring need to be able to work quickly and reliably on large spatial and temporal scales, and yet high-resolution RS imagery is very complex. Index methods rely on subjective threshold values that can change over time and space depending on weather conditions. Shallow ML models are more accurate, but do not work at scale. DL models are complex, require very large datasets to train on, and are very computationally expensive; also, the hyperparameter tuning process is very tedious and difficult.
- It is difficult to know exactly what data to feed to ML and DL models, and it is difficult to know what to make of the output predictions. This often requires integrative expertise and/or interdisciplinary collaboration of RS, hydrology, biology, and CV/ML expertise.
- NNs generally perform the best in water quality and water body detection tasks but are often the least stable models (i.e., they do not generalize well). This is not surprising, as the datasets used in RS problem settings are often not large enough to allow NN models (too many parameters compared with shallow ML models) to overcome overfitting (see Appendix B). Table 4 summarizes the relatively few existing datasets we identified through our systematic review.
- Both domains over-rely on optical RS imagery, and thus clouds and shadows are a persistent problem and heavily skew the results towards working only in cloud-free conditions.
4.2.2. Additional Challenges in Water Body Extraction
- The majority of reviewed research focused on inland bodies of water, where only a few papers discussed applications for coastal waters (not including oceans). Moreover, many papers focus solely on only one type of water body, for example, only on lakes or rivers in a specific area. As a result, water bodies from different landscapes (e.g., inland, coastal tidal flats, urban, wetlands) are difficult to recognize with one unified method (i.e., methods do not generalize). The same applies to water bodies of different colors, especially when distinguishing them from rock, ice, snow, clouds, and shadows.
- There are very few benchmark datasets. In contrast, there are huge volumes of unlabeled data not being fully leveraged.
- CNNs blur output boundaries during the segmentation process.
4.2.3. Additional Challenges in Water Quality Monitoring
- Collecting in situ water quality data is very time- and labor-intensive and financially expensive; also, it often does not have adequate temporal or spatial resolution.
- RS imagery and existing corresponding field samples are often not stored together. Allowing water quality researchers to easily retrieve and locate two or more sources of data at the same location is critical, as computational methods require such data to verify their model performance in order to generalize to new water bodies.
- Remote water bodies are difficult to monitor.
- Urbanization, pollution, and drought are having serious effects on the economy, wildlife, and human health as they deteriorate water quality.
- Ecosystems are complex and their nutrient and pollution budgets are not well understood.
- Some studies do not use a training, validation, and testing set for DL projects (all three are necessary) or do not use nearly enough data to achieve good results with DL models.
4.3. Research Directions and Opportunities
4.3.1. Urgent Need of Large and Comprehensive Benchmark Datasets
- AI/ML/DL models need large datasets with good quality to guarantee meaningful (unbiased and generalize well) good to great performance, thus work on obtaining large but better subsets of data. Quality > quantity is critical and in urgent demand. See one piece of such evidence reported in [44], “[…] site-specific models improved as more training data was sampled from the area to be mapped, with the best models created from the maximum training datasets studied: […] However, performance did not improve consistently for sites at the intermediate training data thresholds. This outcome exemplifies that model improvement is an issue of not only increasing the quantity of training data, but also the quality”.
- Generating synthetic data as in [76] (detailed in the second paragraph in Section 3.3.5).
- Downloading RS images from Google Earth Engine (GEE) and annotating accordingly, or, even better, developing user-friendly interactive interfaces with GEE as a backend to directly allow researchers (or even citizen science volunteers) to contribute to the annotation of RS imagery available on GEE. To our knowledge, no RS datasets for water body detection and water quality monitoring are downloaded from GEE and then annotated, let alone interfaces for directly annotating RS imagery on GEE.
- Obtaining RS imagery from Google Earth (GE) manually or with the help of code scripts, then annotating accordingly (see [34,42,49] for examples). For instance, the following two datasets generated and used in [34,49] are both from GE, but are not shared publicly.
- ○
- “The first dataset was collected from the Google Earth service using the BIGEMAP software (http://www.bigemap.com, accessed on 15 December 2021). We named it as the GE-Water dataset. The GE-Water dataset contains 9000 images covering water bodies of different types, varying shapes and sizes, and diverse surface and environmental conditions all around the world. These images were mainly captured by the QuickBird and Land remote-sensing satellite (Landsat) 7 systems.” [49].
- ○
- “We constructed a new water-body data set of visible spectrum Google Earth images, which consists of RGB pan-sharpened images of a 0.5 m resolution, no infrared bands, or digital elevation models are provided. All images are taken from Suzhou and Wuhan, China, with rural areas as primary. The positive annotations include lakes, reservoirs, rivers, ponds, paddies, and ditches, while all other pixels are treated as negative. These images were then divided into patches with no overlap, which provided us with 9000 images […]” [34].
4.3.2. Generalization
- One type of body of water (e.g., ponds, lakes, rivers);
- One color (e.g., different levels of sediment, aquatic vegetation and algae, nutrients, pollutants);
- One size: Water bodies present in RS imagery come with different sizes (large and small water bodies) and various shapes. Many studies reported that it is not an easy task to correctly classify small water bodies and/or water bodies with different shapes.
- One environment setting (e.g., desert, urban, inland, coastal).
- Evaluation of CNN performance on multisensor data from multiple RS platforms [52];
- Integration of data from multiple sources (e.g., SAR, UAV, smaller sensors, water quality time series);
- Data fusion of Landsat-8 and Sentinel-2 RS imagery for water quality estimation [67]. “Virtual constellation” learning introduced in [67] could be a future direction for both water body detection and water quality estimation. A virtual constellation is constructed by using multiple RS platforms to “shorten” the revisit time and improve the spatial coverage of individual satellites. This entails fusing data sources from separate RS platforms with potentially different resolutions.
4.3.3. Addressing Interpretability
- More ablation studies are needed (see Appendix B for an introduction) to investigate the role of each DL component in terms of model performance contribution and ultimately which component(s) control the model performance.
- Exploring the output of hidden layers to obtain some information to help investigate whether the model works as expected.
- More research needs to be carried out on analyzing the importance of input data to output predictions. See examples in [62,75], each detailed below.
- ○
- The authors in [62] systematically analyzed relative variable importance to show which sets of input data contributed to the ML models’ performance. See the quoted text below: “Relative variable importance was also conducted to investigate the consistency between in situ reflectance data and satellite data, and results show that both datasets are similar. The red band (wavelength ≈ 0.665 µm) and the product of red and green band (wavelength ≈ 0.560 µm) were influential inputs in both reflectance data sets for estimating SS and turbidity, and the ratio between red and blue band (wavelength ≈ 0.490 µm) as well as the ratio between infrared (wavelength ≈ 0.865 µm) and blue band and green band proved to be more useful for the estimation of Chl-a concentration, due to their sensitivity to high turbidity in the coastal waters”.
- ○
- The authors in [75] utilized existing water quality time series data and assessed the effectiveness of multiple RS data platforms and ML models in estimating various water quality parameters. One of their interesting findings is that some sensors are poorly correlated with water quality parameters, while others are more suitable for water quality monitoring tasks. They suggested that more research needs to be carried out for assessing the suitability of paired RS imagery and in situ field data. See the quoted text below: “[…] assess the efficacy of available sensors to complement the often limited field measurements from such programs and build models that support monitoring tasks […] We observed that OLCI Level-2 Products are poorly correlated with the RNMCA data and it is not feasible to rely only on them to support monitoring operations. However, OLCI atmospherically corrected data is useful to develop accurate models using an ELM, particularly for Turbidity (R2 = 0.7).” (RNMCA is the acronym for the Mexican national water quality monitoring system).
- Water quality monitoring will benefit from more research exploring how well a certain ML/DL model contributes to which water quality parameter(s). See an example in [67], where the authors investigated how well DNNs could predict certain water quality parameters.
- The need for automatic and visually-based model evaluation metrics that are better than current visual assessment as an evaluation metric. For example, automatic assessment of how DL methods are performing in large and complex RS imagery (e.g., specifically, Bayesian DL, and Gaussian DL/ML for uncertainty measurement and visualization).
4.3.4. Ease of Use
- Simply applying (or with minor modifications) existing AI/ML/CV/DL algorithms/methods to RS big data imagery-based problems is still very far away from producing real-world applications that meet water management professionals’ and policymakers’ needs. As echoed in [13], “[…] realizing the full application potential of emerging technologies requires solutions for merging various measurement techniques and platforms into useful information for actionable management decisions, requiring effective communication between data providers and water resource managers” [116]. Much more multidisciplinary and integrative collaboration in terms of depth and breadth are in high demand. Those scholars and practitioners who have an interdisciplinary background will play a major role in this in-depth and in-breadth integration. For example, researchers who have expertise in RS but also know how to utilize AI, through collaboration with domain expertise such as water resources management officers, will significantly advance this research direction. Intuitive interactive web apps that are powered by both geovisualization and AI/ML/DL/CV will definitely make interdisciplinary collaboration much more seamless and thus easier.
- ○
- Interactive web portal empowered by geovisualization for integration of various water quality data sources. As noted in [117], it is natural and intuitive in many studies to use “space” as the organizing paradigm.
- ○
- More smart and responsive water management systems through the development of interactive web apps/libraries that integrate ML/DL backends and intuitive, user-friendly front ends are needed. Such systems would allow collaboration between technical experts and domain experts, including stakeholders, and even community volunteers, from anywhere at any time.
- ○
- This requires very close collaboration and thus very integrative research from researchers in many domains (e.g., computer science, cognitive science, informatics, RS, and water-related sub-domains). We reinforce that geovisualization will be the ideal tool to make the collaboration smooth, productive, and insightful.
- ○
- There is one recent work [118] that takes a small step in this direction, but much more work and efforts are in demand.
- Resource hubs for standardized AI/ML/DL/CV models and easy-to-follow and understandable tutorials for how to use them are needed.
4.3.5. Shifting Focus
- As noted in Section 4.3.1, the lack of large benchmark datasets is a bottleneck in water body detection and water quality monitoring research utilizing RS imagery and AI. The dominant methods in both water domains are supervised learning, which often requires very large, labeled datasets to train on, thus, there is a clear, urgent need for semi-supervised and unsupervised learning methods [15].
- ○
- ○
- Semi-supervised learning methods are able to learn from limited good-quality labeled samples. DL models do not require feature engineering, and they are also much better at discovering intricate patterns hidden in big data. However, pure supervised DL is impractical in some situations, such as those for which the labeling tasks require domain knowledge from experts. Very few domain experts have the time and are willing to label very large sets of RS images [84]. An active learning-enabled DL approach that uses a visualization interface and methods to iteratively collect modest amounts of input from domain experts and uses that input to refine the DL classifiers [84] provides a promising direction to produce well-performing DL models with limited good-quality datasets.
- From our systematic review, we can easily see that current work on water body extraction and water quality monitoring using AI and RS are, in general, carried out separately. We call for a closer integration of water body detection and water quality monitoring research and more attention focusing on handling massive datasets that may include information in a variety of formats, of varying quality, and from diverse sources. This integration is critical as it will provide the essential foundation for developing real, intelligent water monitoring systems using RS and AI capable of producing insights used for actionable decision making.
- GEE + AI: as noted in [18], GEE is a good solution to address computational costs and overcome technical challenges of processing RS big data. However, online DL functionality is still not supported on GEE. To the best of our knowledge, the only piece of research integration of the Google AI platform with GEE is performed in [119]; however, as the authors reported, “data migration and computational demands are among the main present constraints in deploying these technologies in an operational setting”. Thus, the ideal solution is to develop DL models directly on the GEE platform.
- Most current ML/DL-based RS research focuses on borrowing or slightly improving ML/DL/CV models from computer science [79,120]. Compared with natural scene images, RS data are multiresolution, multitemporal, multispectral, multiview, and multitarget [15]. Slight modifications of ML/DL/CV models simply cannot cope with the special challenges posed in RS big data. New ML/DL models specialized for RS big data are thus urgently needed [15,18]. We hope our review will draw the attention of researchers who have a multidisciplinary background to this issue. Looking deep into the mechanisms of RS and land surface processes, studying the characteristics of RS imagery would guide the design of specialized ML/DL models for RS big data and thus further improve RS applications using AI in breadth and depth [15].
5. Conclusions
Author Contributions
Funding
Institutional Review Board Statement
Informed Consent Statement
Data Availability Statement
Acknowledgments
Conflicts of Interest
Abbreviations
| AE | Autoencoder |
| AI | Artificial Intelligence |
| ANN | Artificial Neural Network |
| ARIMA | Autoregressive Integrated Moving Average |
| BOA | Boundary Overall Accuracy |
| CA | Class Accuracy |
| CART | Classification and Regression Trees |
| CB | Cubist Regression |
| CE | Commission Error |
| CNN | Convolutional Neural Network |
| COCO | Common Objects in Context |
| CPU | Central Processing Unit |
| CRF | Conditional Random Field |
| CV | Computer Vision |
| DL | Deep Learning |
| DNN | Dense Neural Network |
| DS | Dempster–Shafer Evidence Theory |
| DT | Decision Tree |
| DEM | Digital Elevation Model |
| ECE | Edge Commission Error |
| ELM | Extreme Learning Machine |
| ELR | Extreme Learning Regression |
| ESA | European Space Agency |
| EOE | Edge Omission Error |
| EOA | Edge Overall Accuracy |
| FN | False Negative |
| FP | False Positive |
| FWIoU | Frequency Weighted Intersection over Union |
| GA | Global Accuracy |
| GAN | Generative Adversarial Network |
| GBM | Gradient Boosted Machine |
| GE | Google Earth |
| GEE | Google Earth Engine |
| GPR | Gaussian Process Regression |
| GPU | Graphics Processing Unit |
| GRU | Gated Recurrent Unit |
| IoT | Internet of Things |
| IoU | Intersection over Union |
| Kappa | Kappa Coefficient |
| KNN | K-Nearest Neighbors Classifier |
| LORSAL | Logistic Regression via Variable Splitting and Augmented Lagrangian |
| LSTM | Long Short-Term Memory |
| MA | Mapping Accuracy |
| MAE | Mean Absolute Error |
| MAPE | Mean Absolute Percentage Error |
| mIoU | Mean Intersection over Union |
| MK | Mann–Kendall |
| ML | Machine Learning |
| MLC | Maximum-Likelihood Classifier |
| MLP | Multilayer Perceptron |
| MLR | Multiple Linear Regression |
| MNDWI | Modified Normalized Difference Water Index |
| MPC | Microsoft Planetary Computer |
| MRE | Mean Relative Error |
| MSE | Mean Squared Error |
| MSI | Morphological Shadow Index |
| NB | Naive Bayes Classifier |
| NDMI | Normalized Difference Moisture Index |
| NDVI | Normalized Difference Vegetation Index |
| NDWI | Normalized Difference Water Index |
| NIR | Near-Infrared |
| NN | Neural Network |
| NSEC | Nash–Sutcliffe Efficiency Coefficient |
| OA | Overall Accuracy |
| OE | Omission Error |
| PA | Producer’s Accuracy |
| PCC | Percent Classified Correctly |
| RBFNN | Radial Basis Function Neural Network |
| R-CNN | Region Based Convolutional Neural Network |
| RF | Random Forests |
| RMSE | Root Mean Squared Error |
| RMSLE | Root Mean Squared Log Error (referred to in Table 3 as RMSELE by the authors) |
| RNN | Recurrent Neural Network |
| RPART | Recursive Partitioning And Regression Trees |
| RPD | Relative Percent Difference |
| RS | Remote Sensing |
| SAR | Synthetic Aperture Radar |
| SRN | Simple Recurrent Network (same abbreviation given for Elman Neural Network) |
| SOTA | State-of-the-Art |
| SVM | Support Vector Machine |
| SVR | Support Vector Regression |
| SWIR | Short Wave Infrared |
| TB | Tree Bagger |
| TL | Transfer Learning |
| TN | True Negative |
| TP | True Positive |
| VHR | Very High Resolution |
| UA | User’s Accuracy |
| UAV | Unmanned Aerial Vehicle |
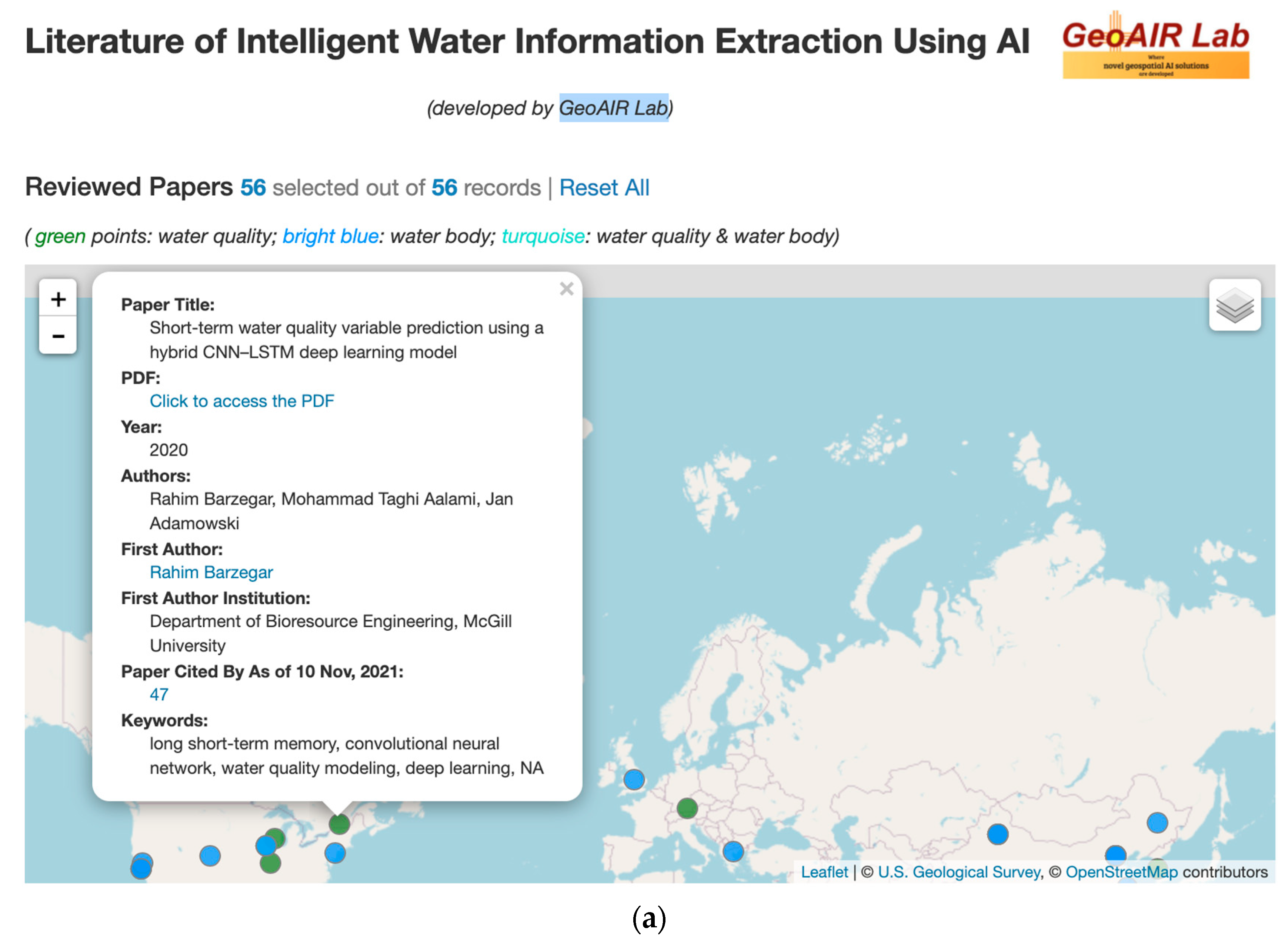
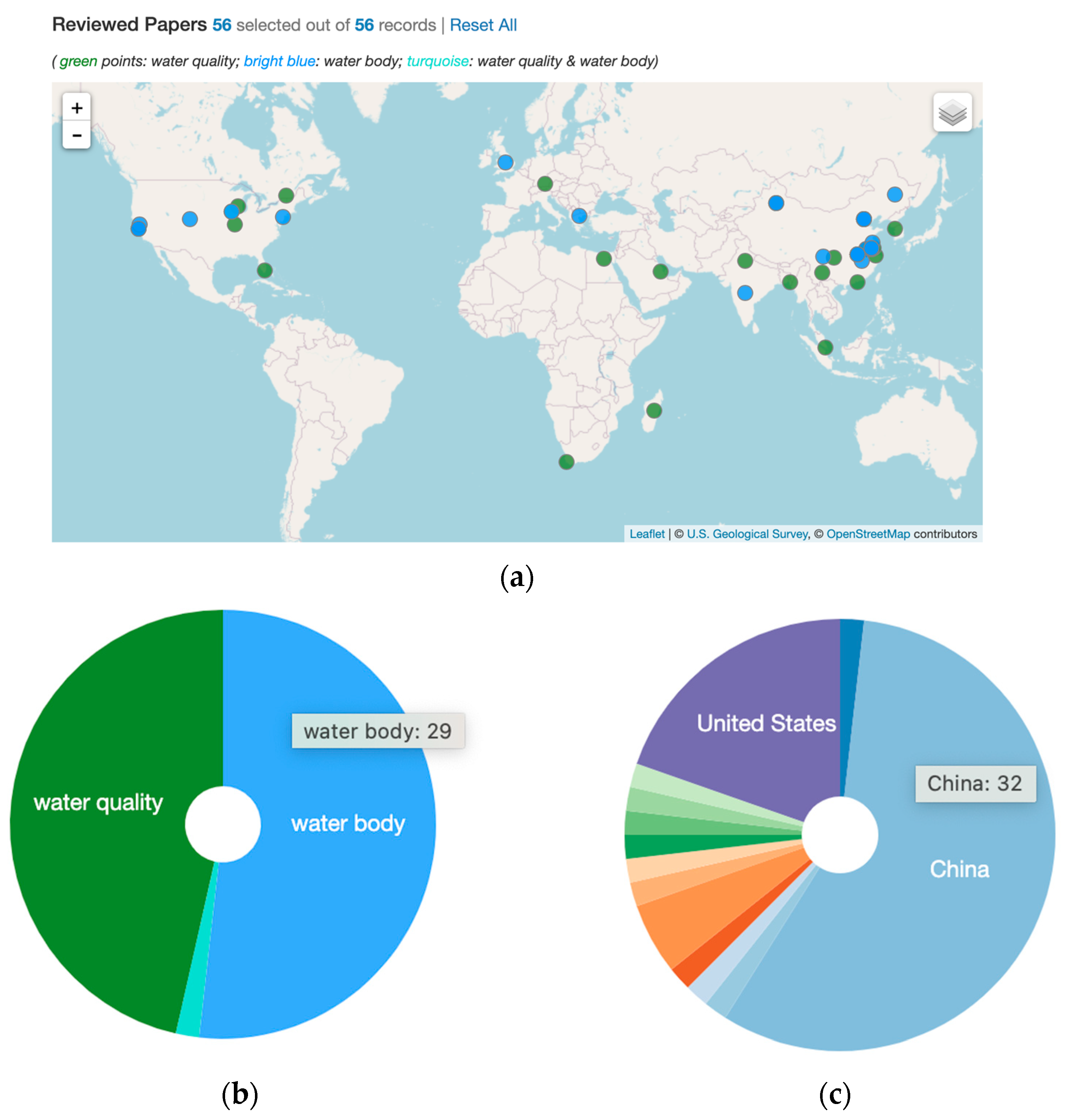
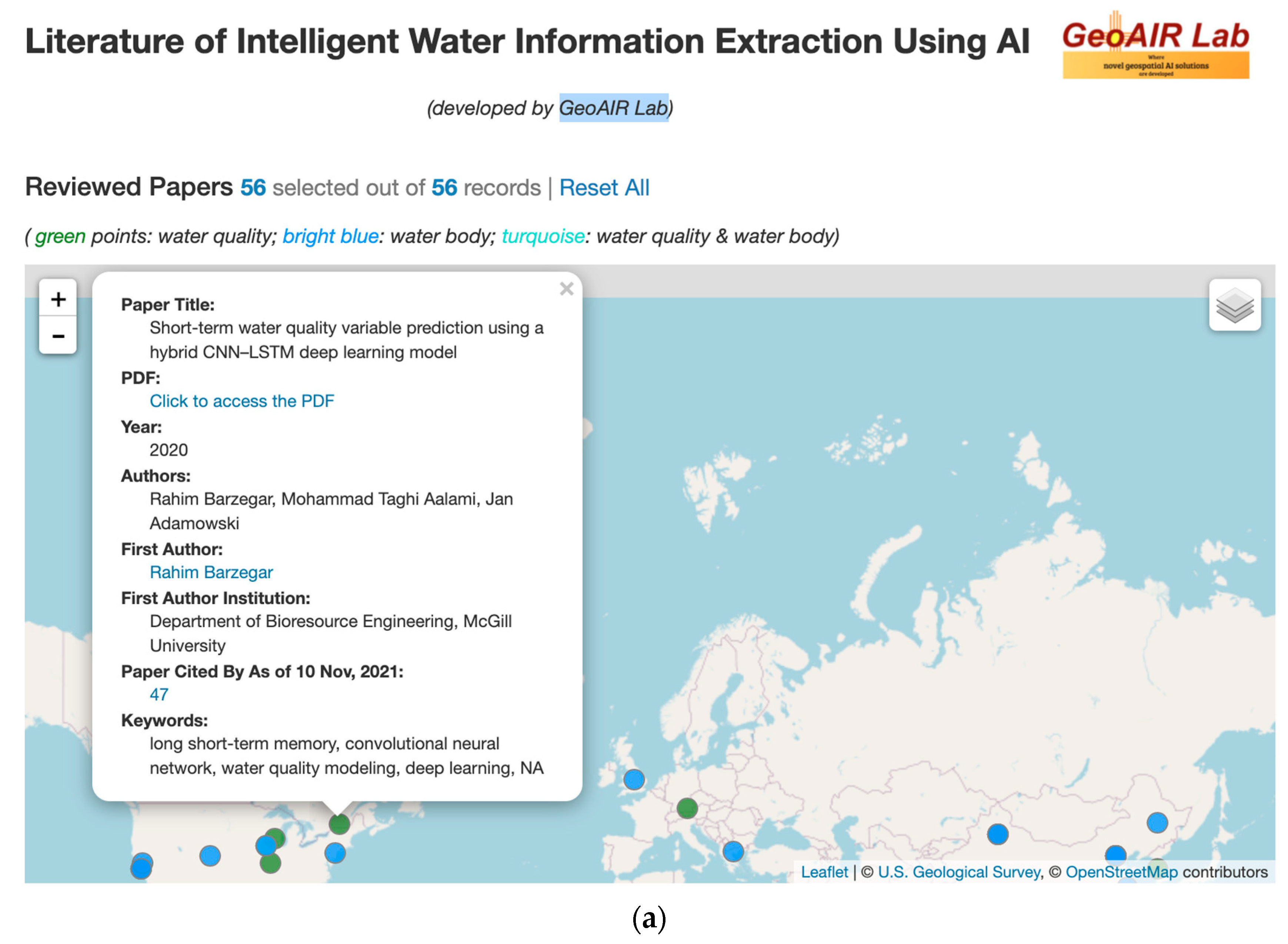
Appendix A. The Accompanying Interactive Web App Tool for the Literature of Intelligent Water Information Extraction Using AI
- Web app tool: https://geoair-lab.github.io/WaterFeatureAI-WebApp/index.html, accessed on 28 February 2022.
- Brief web app demo video (about 6 min duration): the video link is accessible at the web app page.

Appendix B. Essential AI/ML/DL/CV Terms
Appendix C. Common Evaluation Metrics in AI/ML/DL/CV Classification and Regression, and Segmentation Tasks
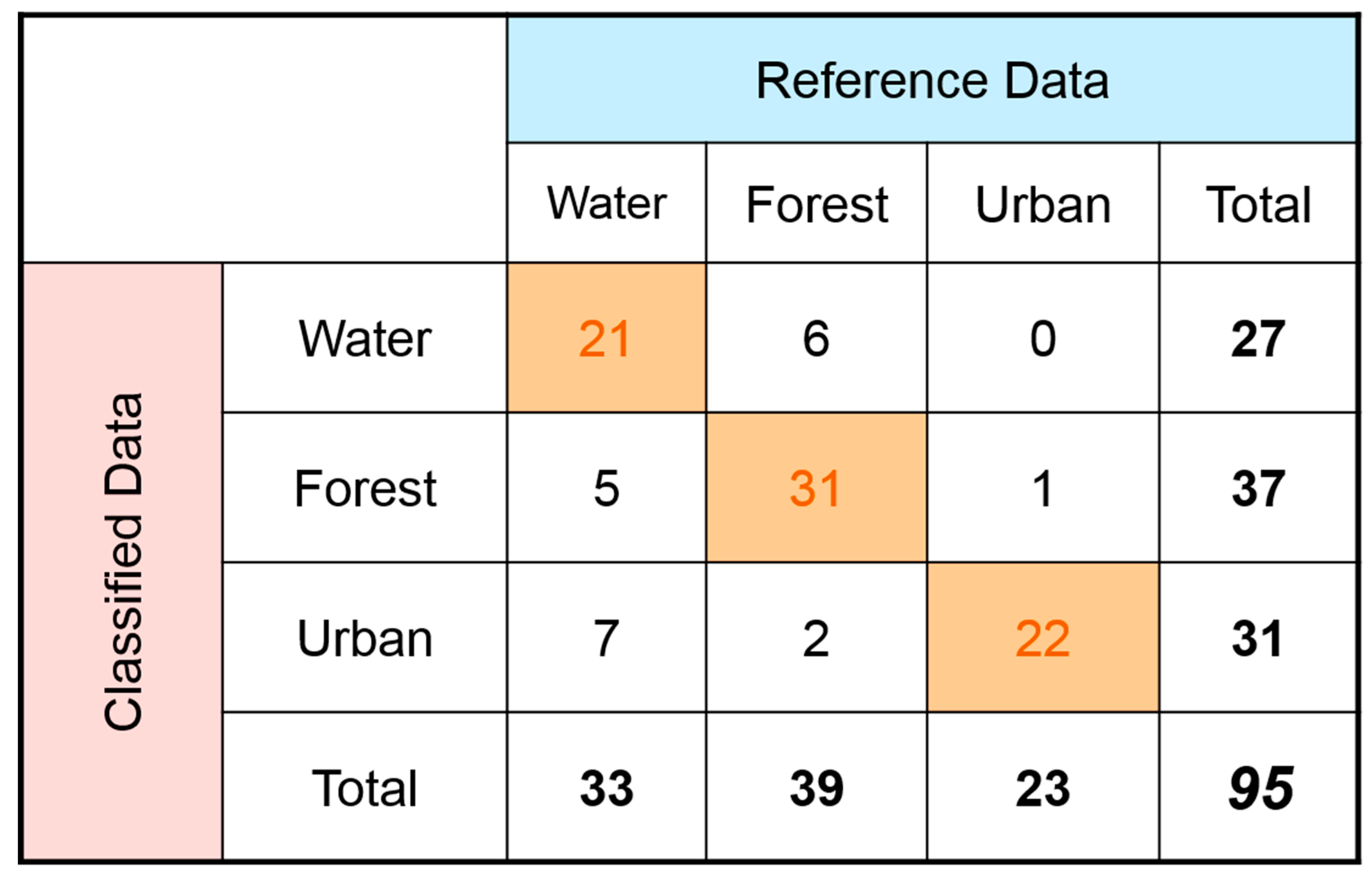
- Manually draw the boundary of water body.
- Apply morphological expansion to the water body boundary from step (1) to create a buffer zone, which is centered on the boundary line (radius = three pixels).
- Finally, the pixels in the buffer area are judged.
References
- UN Water. Climate Change Adaptation: The Pivotal Role of Water (2010). UN Water. 2010. Available online: https://www.unwater.org/publications/climate-change-adaptation-pivotal-role-water/#:~:text=Higher%20temperatures%20and%20changes%20in,likely%20to%20be%20adversely%20affected (accessed on 15 December 2021).
- U.S. Bureau of Reclamation California-Great Basin Area Office Water Facts—Worldwide Water Supply. Available online: https://www.usbr.gov/mp/arwec/water-facts-ww-water-sup.html (accessed on 3 December 2021).
- Reidmiller, D.R.; Avery, C.W.; Easterling, D.R.; Kunkel, K.E.; Lewis, K.L.M.; Maycock, T.K.; Stewart, B.C. Impacts, Risks, and Adaptation in the United States: Fourth National Climate Assessment; U.S. Global Change Research Program: Washington, DC, USA, 2018; Volume II. [CrossRef]
- IPCC (Intergovernmental Panel on Climate Change). Climate Change 2014–Impacts, Adaptation and Vulnerability: Part A: Global and Sectoral Aspects: Working Group II Contribution to the IPCC Fifth Assessment Report; Cambridge University Press: Cambridge, UK, 2014; ISBN 9781107058071. [Google Scholar]
- Steffen, W.; Richardson, K.; Rockström, J.; Cornell, S.E.; Fetzer, I.; Bennett, E.M.; Biggs, R.; Carpenter, S.R.; de Vries, W.; de Wit, C.A.; et al. Planetary Boundaries: Guiding Human Development on a Changing Planet. Science 2015, 347, 1259855. [Google Scholar] [CrossRef] [PubMed] [Green Version]
- Rockström, J.; Steffen, W.; Noone, K.; Persson, A.; Chapin, F.S., 3rd; Lambin, E.F.; Lenton, T.M.; Scheffer, M.; Folke, C.; Schellnhuber, H.J.; et al. A Safe Operating Space for Humanity. Nature 2009, 461, 472–475. [Google Scholar] [CrossRef] [PubMed]
- Walker, B.; Salt, D. Resilience Thinking: Sustaining Ecosystems and People in a Changing World; Island Press: Washington, DC, USA, 2006; ISBN 9781597266222. [Google Scholar]
- Jiménez Cisneros, B.E.; Oki, N.W.; Arnell, G.; Benito, J.G.; Cogley, P.; Döll, T.; Jiang, S.S. Mwakalila Freshwater Resources. In Climate Change 2014: Impacts, Adaptation, and Vulnerability. Part A: Global and Sectoral Aspects. Contribution of Working Group II to the Fifth Assessment Report of the Intergovernmental Panel on Climate Change; Field, C.B., Barros, V.R., Dokken, D.J., Mach, K.J., Mastrandrea, M.D., Bilir, T.E., Chatterjee, M., Ebi, K.L., Estrada, Y.O., Genova, R.C., et al., Eds.; Cambridge University Press: Cambridge, UK; New York, NY, USA, 2014; pp. 229–269. ISBN 9781107058163. [Google Scholar]
- Yamazaki, D.; Trigg, M.A.; Ikeshima, D. Development of a Global ~90m Water Body Map Using Multi-Temporal Landsat Images. Remote Sens. Environ. 2015, 171, 337–351. [Google Scholar] [CrossRef]
- Jiang, W.; He, G.; Long, T.; Ni, Y. Detecting Water Bodies In Landsat8 Oli Image Using Deep Learning. Int. Arch. Photogramm. Remote Sens. Spat. Inf. Sci. 2018, XLII-3, 669–672. [Google Scholar] [CrossRef] [Green Version]
- Shao, Z.; Fu, H.; Li, D.; Altan, O.; Cheng, T. Remote Sensing Monitoring of Multi-Scale Watersheds Impermeability for Urban Hydrological Evaluation. Remote Sens. Environ. 2019, 232, 111338. [Google Scholar] [CrossRef]
- Wang, X.; Xie, H. A Review on Applications of Remote Sensing and Geographic Information Systems (GIS) in Water Resources and Flood Risk Management. Water 2018, 10, 608. [Google Scholar] [CrossRef] [Green Version]
- El Serafy, G.Y.H.; Schaeffer, B.A.; Neely, M.-B.; Spinosa, A.; Odermatt, D.; Weathers, K.C.; Baracchini, T.; Bouffard, D.; Carvalho, L.; Conmy, R.N.; et al. Integrating Inland and Coastal Water Quality Data for Actionable Knowledge. Remote Sens. 2021, 13, 2899. [Google Scholar] [CrossRef]
- Brown, C.M.; Lund, J.R.; Cai, X.; Reed, P.M.; Zagona, E.A.; Ostfeld, A.; Hall, J.; Characklis, G.W.; Yu, W.; Brekke, L. The Future of Water Resources Systems Analysis: Toward a Scientific Framework for Sustainable Water Management. Water Resour. Res. 2015, 51, 6110–6124. [Google Scholar] [CrossRef]
- Zhang, X.; Zhou, Y.; Luo, J. Deep Learning for Processing and Analysis of Remote Sensing Big Data: A Technical Review. Big Earth Data 2021, 1–34. [Google Scholar] [CrossRef]
- Zhu, X.X.; Tuia, D.; Mou, L.; Xia, G.; Zhang, L.; Xu, F.; Fraundorfer, F. Deep Learning in Remote Sensing: A Comprehensive Review and List of Resources. IEEE Geosci. Remote Sens. Mag. 2017, 5, 8–36. [Google Scholar] [CrossRef] [Green Version]
- Hoeser, T.; Kuenzer, C. Object Detection and Image Segmentation with Deep Learning on Earth Observation Data: A Review-Part I: Evolution and Recent Trends. Remote Sens. 2020, 12, 1667. [Google Scholar] [CrossRef]
- Reichstein, M.; Camps-Valls, G.; Stevens, B.; Jung, M.; Denzler, J.; Carvalhais, N. Prabhat Deep Learning and Process Understanding for Data-Driven Earth System Science. Nature 2019, 566, 195–204. [Google Scholar] [CrossRef] [PubMed]
- Boyd, C.E. Water Quality: An Introduction; Springer Nature: Cham, Switzerland, 2019; ISBN 9783030233358. [Google Scholar]
- Ahuja, S. Monitoring Water Quality: Pollution Assessment, Analysis, and Remediation; Newnes: London, UK, 2013; ISBN 9780444594044. [Google Scholar]
- Ramadas, M.; Samantaray, A.K. Applications of Remote Sensing and GIS in Water Quality Monitoring and Remediation: A State-of-the-Art Review. In Water Remediation; Bhattacharya, S., Gupta, A.B., Gupta, A., Pandey, A., Eds.; Springer: Singapore, 2018; pp. 225–246. ISBN 9789811075513. [Google Scholar]
- Bijeesh, T.V.; Narasimhamurthy, K.N. Surface Water Detection and Delineation Using Remote Sensing Images: A Review of Methods and Algorithms. Sustain. Water Resour. Manag. 2020, 6, 68. [Google Scholar] [CrossRef]
- Gholizadeh, M.H.; Melesse, A.M.; Reddi, L. A Comprehensive Review on Water Quality Parameters Estimation Using Remote Sensing Techniques. Sensors 2016, 16, 1298. [Google Scholar] [CrossRef] [Green Version]
- Sibanda, M.; Mutanga, O.; Chimonyo, V.G.P.; Clulow, A.D.; Shoko, C.; Mazvimavi, D.; Dube, T.; Mabhaudhi, T. Application of Drone Technologies in Surface Water Resources Monitoring and Assessment: A Systematic Review of Progress, Challenges, and Opportunities in the Global South. Drones 2021, 5, 84. [Google Scholar] [CrossRef]
- Sit, M.; Demiray, B.Z.; Xiang, Z.; Ewing, G.J.; Sermet, Y.; Demir, I. A Comprehensive Review of Deep Learning Applications in Hydrology and Water Resources. Water Sci. Technol. 2020, 82, 2635–2670. [Google Scholar] [CrossRef]
- Doorn, N. Artificial Intelligence in the Water Domain: Opportunities for Responsible Use. Sci. Total Environ. 2021, 755, 142561. [Google Scholar] [CrossRef]
- Hassan, N.; Woo, C.S. Machine Learning Application in Water Quality Using Satellite Data. IOP Conf. Ser. Earth Environ. Sci. 2021, 842, 012018. [Google Scholar] [CrossRef]
- Li, M.; Xu, L.; Tang, M. An Extraction Method for Water Body of Remote Sensing Image Based on Oscillatory Network. J. Multimed. 2011, 6, 252–260. [Google Scholar] [CrossRef]
- Yang, L.; Tian, S.; Yu, L.; Ye, F.; Qian, J.; Qian, Y. Deep Learning for Extracting Water Body from Landsat Imagery. Int. J. Innov. Comput. Inf. Control 2015, 11, 1913–1929. [Google Scholar]
- Huang, X.; Xie, C.; Fang, X.; Zhang, L. Combining Pixel- and Object-Based Machine Learning for Identification of Water-Body Types From Urban High-Resolution Remote-Sensing Imagery. IEEE J. Sel. Top. Appl. Earth Obs. Remote Sens. 2015, 8, 2097–2110. [Google Scholar] [CrossRef]
- Isikdogan, F.; Bovik, A.C.; Passalacqua, P. Surface Water Mapping by Deep Learning. IEEE J. Sel. Top. Appl. Earth Obs. Remote Sens. 2017, 10, 4909–4918. [Google Scholar] [CrossRef]
- Yu, L.; Wang, Z.; Tian, S.; Ye, F.; Ding, J.; Kong, J. Convolutional Neural Networks for Water Body Extraction from Landsat Imagery. Int. J. Comput. Intell. Appl. 2017, 16, 1750001. [Google Scholar] [CrossRef]
- Chen, Y.; Fan, R.; Yang, X.; Wang, J.; Latif, A. Extraction of Urban Water Bodies from High-Resolution Remote-Sensing Imagery Using Deep Learning. Water 2018, 10, 585. [Google Scholar] [CrossRef] [Green Version]
- Miao, Z.; Fu, K.; Sun, H.; Sun, X.; Yan, M. Automatic Water-Body Segmentation From High-Resolution Satellite Images via Deep Networks. IEEE Geosci. Remote Sens. Lett. 2018, 15, 602–606. [Google Scholar] [CrossRef]
- Acharya, T.D.; Subedi, A.; Lee, D.H. Evaluation of Machine Learning Algorithms for Surface Water Extraction in a Landsat 8 Scene of Nepal. Sensors 2019, 19, 2769. [Google Scholar] [CrossRef] [PubMed] [Green Version]
- Feng, W.; Sui, H.; Huang, W.; Xu, C.; An, K. Water Body Extraction From Very High-Resolution Remote Sensing Imagery Using Deep U-Net and a Superpixel-Based Conditional Random Field Model. IEEE Geosci. Remote Sens. Lett. 2019, 16, 618–622. [Google Scholar] [CrossRef]
- Li, L.; Yan, Z.; Shen, Q.; Cheng, G.; Gao, L.; Zhang, B. Water Body Extraction from Very High Spatial Resolution Remote Sensing Data Based on Fully Convolutional Networks. Remote Sens. 2019, 11, 1162. [Google Scholar] [CrossRef] [Green Version]
- Li, Z.; Wang, R.; Zhang, W.; Hu, F.; Meng, L. Multiscale Features Supported DeepLabV3+ Optimization Scheme for Accurate Water Semantic Segmentation. IEEE Access 2019, 7, 155787–155804. [Google Scholar] [CrossRef]
- Meng, X.; Zhang, S.; Zang, S. Lake Wetland Classification Based on an SVM-CNN Composite Classifier and High-Resolution Images Using Wudalianchi as an Example. J. Coast. Res. 2019, 93, 153–162. [Google Scholar] [CrossRef]
- Isikdogan, L.F.; Bovik, A.; Passalacqua, P. Seeing Through the Clouds With DeepWaterMap. IEEE Geosci. Remote Sens. Lett. 2020, 17, 1662–1666. [Google Scholar] [CrossRef]
- Song, S.; Liu, J.; Liu, Y.; Feng, G.; Han, H.; Yao, Y.; Du, M. Intelligent Object Recognition of Urban Water Bodies Based on Deep Learning for Multi-Source and Multi-Temporal High Spatial Resolution Remote Sensing Imagery. Sensors 2020, 20, 397. [Google Scholar] [CrossRef] [Green Version]
- Yang, F.; Feng, T.; Xu, G.; Chen, Y. Applied Method for Water-Body Segmentation Based on Mask R-CNN. JARS 2020, 14, 014502. [Google Scholar] [CrossRef]
- Wang, G.; Wu, M.; Wei, X.; Song, H. Water Identification from High-Resolution Remote Sensing Images Based on Multidimensional Densely Connected Convolutional Neural Networks. Remote Sens. 2020, 12, 795. [Google Scholar] [CrossRef] [Green Version]
- O’Neil, G.L.; Goodall, J.L.; Behl, M.; Saby, L. Deep Learning Using Physically-Informed Input Data for Wetland Identification. Environ. Model. Softw. 2020, 126, 104665. [Google Scholar] [CrossRef]
- Chen, Y.; Tang, L.; Kan, Z.; Bilal, M.; Li, Q. A Novel Water Body Extraction Neural Network (WBE-NN) for Optical High-Resolution Multispectral Imagery. J. Hydrol. 2020, 588, 125092. [Google Scholar] [CrossRef]
- Dang, B.; Li, Y. MSResNet: Multiscale Residual Network via Self-Supervised Learning for Water-Body Detection in Remote Sensing Imagery. Remote Sens. 2021, 13, 3122. [Google Scholar] [CrossRef]
- Yuan, K.; Zhuang, X.; Schaefer, G.; Feng, J.; Guan, L.; Fang, H. Deep-Learning-Based Multispectral Satellite Image Segmentation for Water Body Detection. IEEE J. Sel. Top. Appl. Earth Obs. Remote Sens. 2021, 14, 7422–7434. [Google Scholar] [CrossRef]
- Tambe, R.G.; Talbar, S.N.; Chavan, S.S. Deep Multi-Feature Learning Architecture for Water Body Segmentation from Satellite Images. J. Vis. Commun. Image Represent. 2021, 77, 103141. [Google Scholar] [CrossRef]
- Yu, Y.; Yao, Y.; Guan, H.; Li, D.; Liu, Z.; Wang, L.; Yu, C.; Xiao, S.; Wang, W.; Chang, L. A Self-Attention Capsule Feature Pyramid Network for Water Body Extraction from Remote Sensing Imagery. Int. J. Remote Sens. 2021, 42, 1801–1822. [Google Scholar] [CrossRef]
- Li, W.; Li, Y.; Gong, J.; Feng, Q.; Zhou, J.; Sun, J.; Shi, C.; Hu, W. Urban Water Extraction with UAV High-Resolution Remote Sensing Data Based on an Improved U-Net Model. Remote Sens. 2021, 13, 3165. [Google Scholar] [CrossRef]
- Zhang, L.; Fan, Y.; Yan, R.; Shao, Y.; Wang, G.; Wu, J. Fine-Grained Tidal Flat Waterbody Extraction Method (FYOLOv3) for High-Resolution Remote Sensing Images. Remote Sens. 2021, 13, 2594. [Google Scholar] [CrossRef]
- Li, M.; Wu, P.; Wang, B.; Park, H.; Yang, H.; Wu, Y. A Deep Learning Method of Water Body Extraction From High Resolution Remote Sensing Images With Multisensors. IEEE J. Sel. Top. Appl. Earth Obs. Remote Sens. 2021, 14, 3120–3132. [Google Scholar] [CrossRef]
- Su, H.; Peng, Y.; Xu, C.; Feng, A.; Liu, T. Using Improved DeepLabv3+ Network Integrated with Normalized Difference Water Index to Extract Water Bodies in Sentinel-2A Urban Remote Sensing Images. JARS 2021, 15, 018504. [Google Scholar] [CrossRef]
- Ovakoglou, G.; Cherif, I.; Alexandridis, T.K.; Pantazi, X.-E.; Tamouridou, A.-A.; Moshou, D.; Tseni, X.; Raptis, I.; Kalaitzopoulou, S.; Mourelatos, S. Automatic Detection of Surface-Water Bodies from Sentinel-1 Images for Effective Mosquito Larvae Control. JARS 2021, 15, 014507. [Google Scholar] [CrossRef]
- Chebud, Y.; Naja, G.M.; Rivero, R.G.; Melesse, A.M. Water Quality Monitoring Using Remote Sensing and an Artificial Neural Network. Water Air Soil Pollut. 2012, 223, 4875–4887. [Google Scholar] [CrossRef]
- Wang, X.; Zhang, F.; Ding, J. Evaluation of Water Quality Based on a Machine Learning Algorithm and Water Quality Index for the Ebinur Lake Watershed, China. Sci. Rep. 2017, 7, 12858. [Google Scholar] [CrossRef] [Green Version]
- Lee, S.; Lee, D. Improved Prediction of Harmful Algal Blooms in Four Major South Korea’s Rivers Using Deep Learning Models. Int. J. Environ. Res. Public Health 2018, 15, 1322. [Google Scholar] [CrossRef] [Green Version]
- Wang, P.; Yao, J.; Wang, G.; Hao, F.; Shrestha, S.; Xue, B.; Xie, G.; Peng, Y. Exploring the Application of Artificial Intelligence Technology for Identification of Water Pollution Characteristics and Tracing the Source of Water Quality Pollutants. Sci. Total Environ. 2019, 693, 133440. [Google Scholar] [CrossRef]
- Pu, F.; Ding, C.; Chao, Z.; Yu, Y.; Xu, X. Water-Quality Classification of Inland Lakes Using Landsat8 Images by Convolutional Neural Networks. Remote Sens. 2019, 11, 1674. [Google Scholar] [CrossRef] [Green Version]
- Liu, P.; Wang, J.; Sangaiah, A.; Xie, Y.; Yin, X. Analysis and Prediction of Water Quality Using LSTM Deep Neural Networks in IoT Environment. Sustainability 2019, 11, 2058. [Google Scholar] [CrossRef] [Green Version]
- Chowdury, M.S.U.; Emran, T.B.; Ghosh, S.; Pathak, A.; Alam, M.M.; Absar, N.; Andersson, K.; Hossain, M.S. IoT Based Real-Time River Water Quality Monitoring System. Procedia Comput. Sci. 2019, 155, 161–168. [Google Scholar] [CrossRef]
- Hafeez, S.; Wong, M.S.; Ho, H.C.; Nazeer, M.; Nichol, J.; Abbas, S.; Tang, D.; Lee, K.H.; Pun, L. Comparison of Machine Learning Algorithms for Retrieval of Water Quality Indicators in Case-II Waters: A Case Study of Hong Kong. Remote Sens. 2019, 11, 617. [Google Scholar] [CrossRef] [Green Version]
- Li, L.; Jiang, P.; Xu, H.; Lin, G.; Guo, D.; Wu, H. Water Quality Prediction Based on Recurrent Neural Network and Improved Evidence Theory: A Case Study of Qiantang River, China. Environ. Sci. Pollut. Res. Int. 2019, 26, 19879–19896. [Google Scholar] [CrossRef]
- Randrianiaina, J.J.C.; Rakotonirina, R.I.; Ratiarimanana, J.R.; Fils, L.R. Modelling of Lake Water Quality Parameters by Deep Learning Using Remote Sensing Data. Am. J. Geogr. Inf. Syst. 2019, 8, 221–227. [Google Scholar]
- Yu, Z.; Yang, K.; Luo, Y.; Shang, C. Spatial-Temporal Process Simulation and Prediction of Chlorophyll-a Concentration in Dianchi Lake Based on Wavelet Analysis and Long-Short Term Memory Network. J. Hydrol. 2020, 582, 124488. [Google Scholar] [CrossRef]
- Zou, Q.; Xiong, Q.; Li, Q.; Yi, H.; Yu, Y.; Wu, C. A Water Quality Prediction Method Based on the Multi-Time Scale Bidirectional Long Short-Term Memory Network. Environ. Sci. Pollut. Res. Int. 2020, 27, 16853–16864. [Google Scholar] [CrossRef]
- Peterson, K.T.; Sagan, V.; Sloan, J.J. Deep Learning-Based Water Quality Estimation and Anomaly Detection Using Landsat-8/Sentinel-2 Virtual Constellation and Cloud Computing. GISci. Remote Sens. 2020, 57, 510–525. [Google Scholar] [CrossRef]
- Hanson, P.C.; Stillman, A.B.; Jia, X.; Karpatne, A.; Dugan, H.A.; Carey, C.C.; Stachelek, J.; Ward, N.K.; Zhang, Y.; Read, J.S.; et al. Predicting Lake Surface Water Phosphorus Dynamics Using Process-Guided Machine Learning. Ecol. Modell. 2020, 430, 109136. [Google Scholar] [CrossRef]
- Barzegar, R.; Aalami, M.T.; Adamowski, J. Short-Term Water Quality Variable Prediction Using a Hybrid CNN–LSTM Deep Learning Model. Stoch. Environ. Res. Risk Assess. 2020, 34, 415–433. [Google Scholar] [CrossRef]
- Aldhyani, T.H.H.; Al-Yaari, M.; Alkahtani, H.; Maashi, M. Water Quality Prediction Using Artificial Intelligence Algorithms. Appl. Bionics Biomech. 2020, 2020, 6659314. [Google Scholar] [CrossRef]
- Li, X.; Ding, J.; Ilyas, N. Machine Learning Method for Quick Identification of Water Quality Index (WQI) Based on Sentinel-2 MSI Data: Ebinur Lake Case Study. Water Sci. Technol. Water Supply 2021, 21, 1291–1312. [Google Scholar] [CrossRef]
- Sharma, C.; Isha, I.; Vashisht, V. Water Quality Estimation Using Computer Vision in UAV. In Proceedings of the 2021 11th International Conference on Cloud Computing, Data Science Engineering (Confluence), Noida, India, 28–29 January 2021; pp. 448–453. [Google Scholar]
- Cui, Y.; Yan, Z.; Wang, J.; Hao, S.; Liu, Y. Deep Learning-Based Remote Sensing Estimation of Water Transparency in Shallow Lakes by Combining Landsat 8 and Sentinel 2 Images. Environ. Sci. Pollut. Res. Int. 2022, 29, 4401–4413. [Google Scholar] [CrossRef] [PubMed]
- Zhao, X.; Xu, H.; Ding, Z.; Wang, D.; Deng, Z.; Wang, Y.; Wu, T.; Li, W.; Lu, Z.; Wang, G. Comparing Deep Learning with Several Typical Methods in Prediction of Assessing Chlorophyll-a by Remote Sensing: A Case Study in Taihu Lake, China. Water Supply 2021, 21, 3710–3724. [Google Scholar] [CrossRef]
- Arias-Rodriguez, L.F.; Duan, Z.; de Díaz-Torres, J.; Basilio Hazas, M.; Huang, J.; Kumar, B.U.; Tuo, Y.; Disse, M. Integration of Remote Sensing and Mexican Water Quality Monitoring System Using an Extreme Learning Machine. Sensors 2021, 21, 4118. [Google Scholar] [CrossRef]
- Kravitz, J.; Matthews, M.; Lain, L.; Fawcett, S.; Bernard, S. Potential for High Fidelity Global Mapping of Common Inland Water Quality Products at High Spatial and Temporal Resolutions Based on a Synthetic Data and Machine Learning Approach. Front. Environ. Sci. 2021, 19. [Google Scholar] [CrossRef]
- Sun, X.; Zhang, Y.; Shi, K.; Zhang, Y.; Li, N.; Wang, W.; Huang, X.; Qin, B. Monitoring Water Quality Using Proximal Remote Sensing Technology. Sci. Total Environ. 2021, 803, 149805. [Google Scholar] [CrossRef] [PubMed]
- Chen, Y.; Fan, R.; Bilal, M.; Yang, X.; Wang, J.; Li, W. Multilevel Cloud Detection for High-Resolution Remote Sensing Imagery Using Multiple Convolutional Neural Networks. ISPRS Int. J. Geo-Inf. 2018, 7, 181. [Google Scholar] [CrossRef] [Green Version]
- Tong, X.-Y.; Xia, G.-S.; Lu, Q.; Shen, H.; Li, S.; You, S.; Zhang, L. Land-Cover Classification with High-Resolution Remote Sensing Images Using Transferable Deep Models. Remote Sens. Environ. 2020, 237, 111322. [Google Scholar] [CrossRef] [Green Version]
- Boguszewski, A.; Batorski, D.; Ziemba-Jankowska, N.; Dziedzic, T.; Zambrzycka, A. LandCover. Ai: Dataset for Automatic Mapping of Buildings, Woodlands, Water and Roads From Aerial Imagery. In Proceedings of the IEEE/CVF Conference on Computer Vision and Pattern Recognition, Virtual, 19–25 June 2021; pp. 1102–1110. [Google Scholar]
- Schmitt, M.; Hughes, L.H.; Qiu, C.; Zhu, X.X. SEN12MS—A Curated Dataset of Georeferenced Multi-Spectral Sentinel-1/2 Imagery for Deep Learning and Data Fusion. arXiv 2019, arXiv:1906.07789. [Google Scholar] [CrossRef] [Green Version]
- Ross, M.R.V.; Topp, S.N.; Appling, A.P.; Yang, X.; Kuhn, C.; Butman, D.; Simard, M.; Pavelsky, T.M. AquaSat: A Data Set to Enable Remote Sensing of Water Quality for Inland Waters. Water Resour. Res. 2019, 55, 10012–10025. [Google Scholar] [CrossRef]
- Wang, S.; Li, J.; Zhang, W.; Cao, C.; Zhang, F.; Shen, Q.; Zhang, X.; Zhang, B. A Dataset of Remote-Sensed Forel-Ule Index for Global Inland Waters during 2000–2018. Sci. Data 2021, 8, 26. [Google Scholar] [CrossRef]
- Yang, L.; MacEachren, A.M.; Mitra, P.; Onorati, T. Visually-Enabled Active Deep Learning for (Geo) Text and Image Classification: A Review. ISPRS Int. J. Geo-Inf. 2018, 7, 65. [Google Scholar] [CrossRef] [Green Version]
- Yang, L.; Gong, M.; Asari, V.K. Diagram Image Retrieval and Analysis: Challenges and Opportunities. In Proceedings of the IEEE/CVF Conference on Computer Vision and Pattern Recognition Workshops, Virtual, 14–19 June 2020; pp. 180–181. [Google Scholar]
- Yang, L.; MacEachren, A.M.; Mitra, P. Geographical Feature Classification from Text Using (active) Convolutional Neural Networks. In Proceedings of the 2020 19th IEEE International Conference on Machine Learning and Applications (ICMLA), Virtual, 14–17 December 2020; pp. 1182–1198. [Google Scholar]
- Deng, J.; Dong, W.; Socher, R.; Li, L.; Li, K.; Fei-Fei, L. ImageNet: A Large-Scale Hierarchical Image Database. In Proceedings of the IEEE Conference on Computer Vision and Pattern Recognition, Miami, FL, USA, 20–25 June 2009; pp. 248–255. [Google Scholar]
- Lin, T.-Y.; Maire, M.; Belongie, S.; Hays, J.; Perona, P.; Ramanan, D.; Dollár, P.; Zitnick, C.L. Microsoft COCO: Common Objects in Context. In Proceedings of the European Conference on Computer Vision (ECCV), Zurich, Switzerland, 6–12 September 2014; pp. 740–755. [Google Scholar]
- Maaten, L.; Chen, M.; Tyree, S.; Weinberger, K. Learning with Marginalized Corrupted Features. In Proceedings of the International Conference on Machine Learning (ICML), Atlanta, GA, USA, 16–21 June 2013; pp. 410–418. [Google Scholar]
- Nakkiran, P.; Neyshabur, B.; Sedghi, H. The Deep Bootstrap Framework: Good Online Learners Are Good Offline Generalizers. arXiv 2020, arXiv:2010.08127. [Google Scholar]
- Montavon, G.; Samek, W.; Müller, K.-R. Methods for Interpreting and Understanding Deep Neural Networks. Digit. Signal Process. 2018, 73, 1–15. [Google Scholar] [CrossRef]
- Li, X.; Xiong, H.; Li, X.; Wu, X.; Zhang, X.; Liu, J.; Bian, J.; Dou, D. Interpretable Deep Learning: Interpretations, Interpretability, Trustworthiness, and beyond. arXiv 2021, arXiv:2103.10689. [Google Scholar]
- Doshi-Velez, F.; Kim, B. Towards A Rigorous Science of Interpretable Machine Learning. arXiv 2017, arXiv:1702.08608. [Google Scholar]
- Carvalho, D.V.; Pereira, E.M.; Cardoso, J.S. Machine Learning Interpretability: A Survey on Methods and Metrics. Electronics 2019, 8, 832. [Google Scholar] [CrossRef] [Green Version]
- Fong, R.C.; Vedaldi, A. Interpretable Explanations of Black Boxes by Meaningful Perturbation. In Proceedings of the IEEE International Conference on Computer Vision, Venice, Italy, 22–29 October 2017; pp. 3429–3437. [Google Scholar]
- Zeiler, M.D.; Fergus, R. Visualizing and Understanding Convolutional Networks. In Proceedings of the European Conference on Computer Vision, Zurich, Switzerland, 6–12 September 2014; pp. 818–833. [Google Scholar]
- Zhou, B.; Khosla, A.; Lapedriza, A.; Oliva, A.; Torralba, A. Learning Deep Features for Discriminative Localization. In Proceedings of the IEEE Conference on Computer Vision and Pattern Recognition, Las Vegas, NV, USA, 27–30 June 2016; pp. 2921–2929. [Google Scholar]
- Xu, K.; Ba, J.; Kiros, R.; Cho, K.; Courville, A.; Salakhudinov, R.; Zemel, R.; Bengio, Y. Show, Attend and Tell: Neural Image Caption Generation with Visual Attention. In Proceedings of the International Conference on Machine Learning, Lille, France, 6–11 July 2015; Bach, F., Blei, D., Eds.; pp. 2048–2057. [Google Scholar]
- Woo, S.; Park, J.; Lee, J.-Y.; Kweon, I.S. Cbam: Convolutional Block Attention Module. In Proceedings of the European Conference on Computer Vision (ECCV), Munich, Germany, 8–14 September 2018; pp. 3–19. [Google Scholar]
- Mahendran, A.; Vedaldi, A. Understanding Deep Image Representations by Inverting Them. In Proceedings of the IEEE Conference on Computer Vision and Pattern Recognition, Boston, MA, USA, 7–12 June 2015; pp. 5188–5196. [Google Scholar]
- Ribeiro, M.T.; Singh, S.; Guestrin, C. “Why Should I Trust You?”: Explaining the Predictions of Any Classifier. arXiv 2016, arXiv:1602.04938. [Google Scholar]
- Laurini, R. Geographic Knowledge Infrastructure: Applications to Territorial Intelligence and Smart Cities; Elsevier: Oxford, UK, 2017. [Google Scholar]
- MacEachren, A.M.; Gahegan, M.; Pike, W.; Brewer, I.; Cai, G.; Lengerich, E.; Hardisty, F. Geovisualization for Knowledge Construction and Decision Support. IEEE Comput. Graph. Appl. 2004, 24, 13–17. [Google Scholar] [CrossRef] [Green Version]
- Lan, Y.; Desjardins, M.R.; Hohl, A.; Delmelle, E. Geovisualization of COVID-19: State of the Art and Opportunities. Cartographica 2021, 56, 2–13. [Google Scholar] [CrossRef]
- MacEachren, A.M.; Cai, G. Supporting Group Work in Crisis Management: Visually Mediated Human—GIS—Human Dialogue. Environ. Plann. B Plann. Des. 2006, 33, 435–456. [Google Scholar] [CrossRef] [Green Version]
- Tomaszewski, B.; MacEachren, A.M. Geovisual Analytics to Support Crisis Management: Information Foraging for Geo-Historical Context. Inf. Vis. 2012, 11, 339–359. [Google Scholar] [CrossRef]
- Harrower, M.; MacEachren, A.; Griffin, A.L. Developing a Geographic Visualization Tool to Support Earth Science Learning. Cartogr. Geogr. Inf. Sci. 2000, 27, 279–293. [Google Scholar] [CrossRef]
- Cova, T.J.; Dennison, P.E.; Kim, T.H.; Moritz, M.A. Setting Wildfire Evacuation Trigger Points Using Fire Spread Modeling and GIS. Trans. GIS 2005, 9, 603–617. [Google Scholar] [CrossRef]
- Cliburn, D.C.; Feddema, J.J.; Miller, J.R.; Slocum, T.A. Design and Evaluation of a Decision Support System in a Water Balance Application. Comput. Graph. 2002, 26, 931–949. [Google Scholar] [CrossRef]
- Kiss, E.; Zichar, M.; Fazekas, I.; Karancsi, G.; Balla, D. Categorization and Geovisualization of Climate Change Strategies Using an Open-Access WebGIS Tool. Infocommun. J. 2020, 12, 32–37. [Google Scholar] [CrossRef]
- Pekel, J.-F.; Cottam, A.; Gorelick, N.; Belward, A.S. High-Resolution Mapping of Global Surface Water and Its Long-Term Changes. Nature 2016, 540, 418–422. [Google Scholar] [CrossRef]
- Brodlie, K.; Fairbairn, D.; Kemp, Z.; Schroeder, M. Connecting People, Data and Resources—distributed Geovisualization. In Exploring Geovisualization; Elsevier: Amsterdam, The Netherlands, 2005; pp. 423–443. [Google Scholar]
- Robinson, A.C. Design for Synthesis in Geovisualization; The Pennsylvania State University: Ann Arbor, MI, USA, 2008. [Google Scholar]
- Robinson, A.C. Supporting Synthesis in Geovisualization. Int. J. Geogr. Inf. Sci. 2011, 25, 211–227. [Google Scholar] [CrossRef]
- Andrienko, G.; Andrienko, N.; Jankowski, P.; Keim, D.; Kraak, M.-J.; MacEachren, A.; Wrobel, S. Geovisual Analytics for Spatial Decision Support: Setting the Research Agenda. Int. J. Geogr. Inf. Sci. 2007, 21, 839–857. [Google Scholar] [CrossRef]
- Schaeffer, B.A.; Schaeffer, K.G.; Keith, D.; Lunetta, R.S.; Conmy, R.; Gould, R.W. Barriers to Adopting Satellite Remote Sensing for Water Quality Management. Int. J. Remote Sens. 2013, 34, 7534–7544. [Google Scholar] [CrossRef]
- Smith, M.J.; Hillier, J.K.; Otto, J.-C.; Geilhausen, M. Geovisualization. In Treatise on Geomorphology; Shroder, J.F., Ed.; Academic Press: Cambridge, MA, USA, 2013; Volume 3, pp. 299–325. [Google Scholar]
- Sit, M.; Sermet, Y.; Demir, I. Optimized Watershed Delineation Library for Server-Side and Client-Side Web Applications. Open Geospat. Data Softw. Stand. 2019, 4, 8. [Google Scholar] [CrossRef] [Green Version]
- Mayer, T.; Poortinga, A.; Bhandari, B.; Nicolau, A.P.; Markert, K.; Thwal, N.S.; Markert, A.; Haag, A.; Kilbride, J.; Chishtie, F.; et al. Deep Learning Approach for Sentinel-1 Surface Water Mapping Leveraging Google Earth Engine. ISPRS Open J. Photogramm. Remote Sens. 2021, 2, 100005. [Google Scholar] [CrossRef]
- Cheng, G.; Zhou, P.; Han, J. Learning Rotation-Invariant Convolutional Neural Networks for Object Detection in VHR Optical Remote Sensing Images. IEEE Trans. Geosci. Remote Sens. 2016, 54, 7405–7415. [Google Scholar] [CrossRef]
- CS231n: Convolutional Neural Networks for Visual Recognition. Available online: http://cs231n.stanford.edu/ (accessed on 8 December 2021).
- Mather, P.M.; Koch, M. Computer Processing of Remotely-Sensed Images: An Introduction; John Wiley & Sons: Hoboken, NJ, USA, 2011; ISBN 9781119956402. [Google Scholar]
- Goodfellow, I.; Bengio, Y.; Courville, A. Deep Learning; MIT Press: Cambridge, MA, USA, 2016. [Google Scholar]
- Chollet, F. Deep Learning with Python, 2nd ed.; Manning Publications Co.: Shelter Island, NY, USA, 2021; ISBN 9781617296864. [Google Scholar]
- Chen, L.-C.; Papandreou, G.; Schroff, F.; Adam, H. Rethinking Atrous Convolution for Semantic Image Segmentation. arXiv 2017, arXiv:1706.05587. [Google Scholar]
- Chen, L.-C.; Zhu, Y.; Papandreou, G.; Schroff, F.; Adam, H. Encoder-Decoder with Atrous Separable Convolution for Semantic Image Segmentation. In Proceedings of the European Conference on Computer Vision (ECCV), Munich, Germany, 8–14 September 2018; pp. 801–818. [Google Scholar]
- Goodfellow, I.; Pouget-Abadie, J.; Mirza, M.; Xu, B.; Warde-Farley, D.; Ozair, S.; Courville, A.; Bengio, Y. Generative Adversarial Nets. In Proceedings of the Advances in Neural Information Processing Systems, Montreal, QC, Canada, 8–13 December 2014; pp. 2672–2680. [Google Scholar]
- Zhu, J.-Y.; Park, T.; Isola, P.; Efros, A.A. Unpaired Image-to-Image Translation Using Cycle-Consistent Adversarial Networks. In Proceedings of the IEEE International Conference on Computer Vision, Venice, Italy, 22–29 October 2017; pp. 2223–2232. [Google Scholar]
- Bishop, C.M. Pattern Recognition and Machine Learning; Springer: New York, NY, USA, 2006. [Google Scholar]
- Hastie, T.; Friedman, J.; Tibshirani, R. The Elements of Statistical Learning: Data Mining, Inference, and Prediction; Springer: New York, NY, USA, 2001. [Google Scholar]
- Gorelick, N.; Hancher, M.; Dixon, M.; Ilyushchenko, S.; Thau, D.; Moore, R. Google Earth Engine: Planetary-Scale Geospatial Analysis for Everyone. Remote Sens. Environ. 2017, 202, 18–27. [Google Scholar] [CrossRef]
- Google Earth Engine. Available online: https://earthengine.google.com/ (accessed on 15 December 2021).
- Toadvine, H. Microsoft Launches a “Planetary Computer” To Support Global Sustainability. Available online: https://earth.org/planetary-computer/ (accessed on 22 December 2021).
- Microsoft Planetary Computer. Available online: https://planetarycomputer.microsoft.com/ (accessed on 15 December 2021).
- Yang, L.; Cervone, G. Analysis of Remote Sensing Imagery for Disaster Assessment Using Deep Learning: A Case Study of Flooding Event. Soft Comput. 2019, 23, 13393–13408. [Google Scholar] [CrossRef]
- Wilson, E.H.; Sader, S.A. Detection of Forest Harvest Type Using Multiple Dates of Landsat TM Imagery. Remote Sens. Environ. 2002, 80, 385–396. [Google Scholar] [CrossRef]
- Skakun, R.S.; Wulder, M.A.; Franklin, S.E. Sensitivity of the Thematic Mapper Enhanced Wetness Difference Index to Detect Mountain Pine Beetle Red-Attack Damage. Remote Sens. Environ. 2003, 86, 433–443. [Google Scholar] [CrossRef]
- Measuring Vegetation (NDVI & EVI). Available online: https://earthobservatory.nasa.gov/features/MeasuringVegetation (accessed on 20 December 2021).
- Gao, B.-C. NDWI—A Normalized Difference Water Index for Remote Sensing of Vegetation Liquid Water from Space. Remote Sens. Environ. 1996, 58, 257–266. [Google Scholar] [CrossRef]
- McFEETERS, S.K. The Use of the Normalized Difference Water Index (NDWI) in the Delineation of Open Water Features. Int. J. Remote Sens. 1996, 17, 1425–1432. [Google Scholar] [CrossRef]
- Xu, H. Modification of Normalised Difference Water Index (NDWI) to Enhance Open Water Features in Remotely Sensed Imagery. Int. J. Remote Sens. 2006, 27, 3025–3033. [Google Scholar] [CrossRef]
- Paszke, A.; Gross, S.; Massa, F.; Lerer, A.; Bradbury, J.; Chanan, G.; Killeen, T.; Lin, Z.; Gimelshein, N.; Antiga, L.; et al. PyTorch: An Imperative Style, High-Performance Deep Learning Library. In Proceedings of the Advances in Neural Information Processing Systems, Vancouver, BC, Canada, 8–14 December 2019; pp. 8026–8037. [Google Scholar]
- Breiman, L. Random Forests. Mach. Learn. 2001, 45, 5–32. [Google Scholar] [CrossRef] [Green Version]
- Pal, M. Random Forest Classifier for Remote Sensing Classification. Int. J. Remote Sens. 2005, 26, 217–222. [Google Scholar] [CrossRef]
- Wu, X.; Sahoo, D.; Hoi, S.C.H. Recent Advances in Deep Learning for Object Detection. Neurocomputing 2020, 396, 39–64. [Google Scholar] [CrossRef] [Green Version]
- Ben-Hur, A.; Horn, D.; Siegelmann, H.T.; Vapnik, V. Support Vector Clustering. J. Mach. Learn. Res. 2001, 2, 125–137. [Google Scholar] [CrossRef]
- Pratt, L.Y. Discriminability-Based Transfer between Neural Networks. In Proceedings of the Advances in Neural Information Processing Systems, Denver, CO, USA, 29 November–2 December 1993; pp. 204–211. [Google Scholar]
- Pan, S.J.; Yang, Q. A Survey on Transfer Learning. IEEE Trans. Knowl. Data Eng. 2010, 22, 1345–1359. [Google Scholar] [CrossRef]
- Weiss, K.; Khoshgoftaar, T.M.; Wang, D. A Survey of Transfer Learning. J. Big Data 2016, 3, 9. [Google Scholar] [CrossRef] [Green Version]
- Tan, C.; Sun, F.; Kong, T.; Zhang, W.; Yang, C.; Liu, C. A Survey on Deep Transfer Learning. In Proceedings of the International Conference on Artificial Neural Networks, Rhodes, Greece, 4–7 October 2018; pp. 270–279. [Google Scholar]
- Zhuang, F.; Qi, Z.; Duan, K.; Xi, D.; Zhu, Y.; Zhu, H.; Xiong, H.; He, Q. A Comprehensive Survey on Transfer Learning. Proc. IEEE 2019, 109, 43–76. [Google Scholar] [CrossRef]
- Li, C.; Zhang, S.; Qin, Y.; Estupinan, E. A Systematic Review of Deep Transfer Learning for Machinery Fault Diagnosis. Neurocomputing 2020, 407, 121–135. [Google Scholar] [CrossRef]
- Bar, Y.; Diamant, I.; Wolf, L.; Lieberman, S.; Konen, E.; Greenspan, H. Chest Pathology Detection Using Deep Learning with Non-Medical Training. In Proceedings of the 2015 IEEE 12th International Symposium on Biomedical Imaging (ISBI), Brooklyn, NY, USA, 16–19 April 2015; pp. 294–297. [Google Scholar]
- Ronneberger, O.; Fischer, P.; Brox, T. U-Net: Convolutional Networks for Biomedical Image Segmentation. In Proceedings of the Medical Image Computing and Computer-Assisted Intervention (MICCAI), Munich, Germany, 5–9 October 2015; pp. 234–241. [Google Scholar]
- Long, J.; Shelhamer, E.; Darrell, T. Fully Convolutional Networks for Semantic Segmentation. In Proceedings of the IEEE Conference on Computer Vision and Pattern Recognition, Boston, MA, USA, 7–12 June 2015; pp. 3431–3440. [Google Scholar]
- Maxwell, A.E.; Warner, T.A. Thematic Classification Accuracy Assessment with Inherently Uncertain Boundaries: An Argument for Center-Weighted Accuracy Assessment Metrics. Remote Sens. 2020, 12, 1905. [Google Scholar] [CrossRef]
- Sokolova, M.; Lapalme, G. A Systematic Analysis of Performance Measures for Classification Tasks. Inf. Process. Manag. 2009, 45, 427–437. [Google Scholar] [CrossRef]
- Garcia-Garcia, A.; Orts-Escolano, S.; Oprea, S.; Villena-Martinez, V.; Martinez-Gonzalez, P.; Garcia-Rodriguez, J. A Survey on Deep Learning Techniques for Image and Video Semantic Segmentation. Appl. Soft Comput. 2018, 70, 41–65. [Google Scholar] [CrossRef]
- Pontius, R.G.; Millones, M. Death to Kappa: Birth of Quantity Disagreement and Allocation Disagreement for Accuracy Assessment. Int. J. Remote Sens. 2011, 32, 4407–4429. [Google Scholar] [CrossRef]
- Yang, X.; Zhao, S.; Qin, X.; Zhao, N.; Liang, L. Mapping of Urban Surface Water Bodies from Sentinel-2 MSI Imagery at 10 M Resolution via NDWI-Based Image Sharpening. Remote Sens. 2017, 9, 596. [Google Scholar] [CrossRef] [Green Version]
- GSP216Online Accuracy Metrics. Available online: http://gsp.humboldt.edu/olm_2019/courses/GSP_216_Online/lesson6-2/metrics.html (accessed on 23 December 2021).
- Stehman, S.V. Selecting and Interpreting Measures of Thematic Classification Accuracy. Remote Sens. Environ. 1997, 62, 77–89. [Google Scholar] [CrossRef]
- Rezatofighi, H.; Tsoi, N.; Gwak, J.; Sadeghian, A.; Reid, I.; Savarese, S. Generalized Intersection over Union: A Metric and a Loss for Bounding Box Regression. In Proceedings of the IEEE/CVF Conference on Computer Vision and Pattern Recognition, Long Beach, CA, USA, 16–20 June 2019; pp. 658–666. [Google Scholar]
- Padilla, R.; Netto, S.L.; da Silva, E.A.B. A Survey on Performance Metrics for Object-Detection Algorithms. In Proceedings of the 2020 International Conference on Systems, Signals and Image Processing (IWSSIP), Niteroi, Brazil, 1–3 July 2020; pp. 237–242. [Google Scholar]
- Landis, J.R.; Koch, G.G. The Measurement of Observer Agreement for Categorical Data. Biometrics 1977, 33, 159–174. [Google Scholar] [CrossRef] [Green Version]
- McHugh, M.L. Interrater Reliability: The Kappa Statistic. Biochem. Med. 2012, 22, 276–282. [Google Scholar] [CrossRef]
- Congalton, R.G. A Review of Assessing the Accuracy of Classifications of Remotely Sensed Data. Remote Sens. Environ. 1991, 37, 35–46. [Google Scholar] [CrossRef]
- Stehman, S.V.; Foody, G.M. Key Issues in Rigorous Accuracy Assessment of Land Cover Products. Remote Sens. Environ. 2019, 231, 111199. [Google Scholar] [CrossRef]
- Stehman, S.V.; Wickham, J.D. Pixels, Blocks of Pixels, and Polygons: Choosing a Spatial Unit for Thematic Accuracy Assessment. Remote Sens. Environ. 2011, 115, 3044–3055. [Google Scholar] [CrossRef]
- Foody, G.M. Status of Land Cover Classification Accuracy Assessment. Remote Sens. Environ. 2002, 80, 185–201. [Google Scholar] [CrossRef]
- Congalton, R.G. Accuracy Assessment and Validation of Remotely Sensed and Other Spatial Information. Int. J. Wildland Fire 2001, 10, 321–328. [Google Scholar] [CrossRef] [Green Version]
- Stehman, S.V. Sampling Designs for Accuracy Assessment of Land Cover. Int. J. Remote Sens. 2009, 30, 5243–5272. [Google Scholar] [CrossRef]
- Strutz, T. Data Fitting and Uncertainty. Available online: https://link.springer.com/book/9783658114558 (accessed on 31 December 2021).
- Willmott, C.J.; Matsuura, K. Advantages of the Mean Absolute Error (MAE) over the Root Mean Square Error (RMSE) in Assessing Average Model Performance. Clim. Res. 2005, 30, 79–82. [Google Scholar] [CrossRef]
- Rosenblad, A. The Concise Encyclopedia of Statistics. J. Appl. Stat. 2011, 38, 867–868. [Google Scholar] [CrossRef]
- Schütze, H.; Manning, C.D.; Raghavan, P. Introduction to Information Retrieval; Cambridge University Press: Cambridge, UK, 2008; Volume 39. [Google Scholar]
- Goutte, C.; Gaussier, E. A Probabilistic Interpretation of Precision, Recall and F-Score, with Implication for Evaluation. In Proceedings of the Advances in Information Retrieval, Santiago de Compostela, Spain, 21–23 March 2005; pp. 345–359. [Google Scholar]


{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
| Keyword Category | Search Strategy |
|---|---|
| General keywords 1 | “remote sensing” OR “satellite data” OR “UAV” AND “computer vision” OR “machine learning” OR “deep learning” OR “neural networks” OR “AI” |
| Water body | “water body” AND “detection” OR “extraction” |
| Water quality | “water quality” AND “sensing” OR “monitoring” |
| Reference | Method | Model Comparison | RS Data Type | Evaluation Metrics |
|---|---|---|---|---|
| Li et al. (2011) [28] | DNN | NDWI | Landsat TM | coherence |
| Yang et al. (2015) [29] | AE | DNN, SVM | Landsat ETM+ | accuracy |
| Huang et al. (2015) [30] | ELM | DT, LORSAL, RF, SVM, TB | GeoEye-1, WorldView-2 | Kappa, F-score |
| Isikdogan et al. (2017) [31] | CNN | MDWI, MLP | Landsat | F1-score, CE, OE, precision, recall |
| Yu et al. (2017) [32] | CNN–LR hybrid | ANN, CNN, SVM | Landsat ETM+ | accuracy |
| Jiang et al. (2018) [10] | MLP | MLC, NDWI | Landsat-8 OLI | Kappa, OA |
| Chen et al. (2018) [33] | CNN | CNN, NDWI, SVM | GaoFen-2, Zi Yuan-3 | ECE, EOA, EOE, OA, PA, UA |
| Miao et al. (2018) [34] | CNN | DNN | Google Earth imagery | OA |
| Acharya et al. (2019) [35] | SVM | ANN, DT, GMB, NB, NDWI, RF, RPART | Landsat-8 OLI | Kappa, OA |
| Feng et al. (2019) [36] | CNN–CRF hybrid | CNN, CV-method | GaoFen-2, WorldView-2 | Kappa, PCC, precision |
| Li et al. (2019) [37] | CNN | CNN, NDWI, SVM | GaoFen-2 | F1-score |
| Li et al. (2019) [38] | CNN–CRF hybrid | CNN, NDWI | GaoFen-1 | IoU, pixel accuracy, recall |
| Meng et al. (2019) [39] | CNN–SVM hybrid | CNN, SVM | GaoFen-2 | accuracy, MA, UA |
| Isikdogan et al. (2020) [40] | CNN | CNN, MLP, MNDWI | Landsat-8 | F1-score, precision, recall |
| Song et al. (2020) [41] | CNN | CART, KNN, RF, SVM | GaoFen-2, WorldView-3 | IoU, precision, recall |
| Yang et al. (2020) [42] | CNN | CNN | GaoFen-2 | IoU |
| Wang et al. (2020) [43] | CNN | CNN, NDWI | GaoFen-1 | F1-score, mIoU, precision, recall |
| O’Neil et al. (2020) [44] | CNN | DEM, NDVI, RF | LiDAR DEMs, NAIP | precision, recall |
| Chen et al. (2020) [45] | CNN | NDWI, SVM | GaoFen-1, GaoFen-2, Zi Yuan-3 | BOA, Kappa, OA |
| Dang and Li (2021) [46] | CNN | CNN | GaoFen-2, GID | mIoU, FWIoU, OA |
| Yuan et al. (2021) [47] | CNN | CNN, MNDWI, NDMI, NDWI | Sentinel-2 | accuracy, mIoU |
| Tambe et al. (2021) [48] | CNN | CNN | Landsat-8 OLI | CA, F1-score, GA, IoU, precision, recall |
| Yu et al. (2021) [49] | CNN | CNN | GaoFen-2, Landsat-7 | F1-score, OA, precision, recall |
| Li et al. (2021) [50] | CNN | CNN, CV-method, SVM | UAV | Kappa, F-score, OA, precision |
| Zhang et al. (2021) [51] | CNN | CNN, MLC, NDWI, SVM | GaoFen-2 | IoU, Kappa, pixel accuracy |
| Li et al. (2021) [52] | CNN | CNN, NDWI, SVM | GaoFen-2, GaoFen-6, Sentinel-2, Zi Yuan-3 | F1-score, IoU, OA |
| Su et al. (2021) [53] | CNN | CNN | Landsat-8, Sentinel-2A | IoU, pixel accuracy, recall |
| Ovakoglou et al. (2021) [54] | KMeans | fuzzy-rules classification, Haralick’s textural features of dissimilarity, Otsu valley-emphasis | Sentinel-1 | Kappa, OA, precision, recall |
| Reference | Method | Model Comparison | RS Data Type | Evaluation Metrics |
|---|---|---|---|---|
| Chebud et al. (2012) [55] | DNN | / | Landsat TM | RMSE, R2 |
| Wang et al. (2017) [56] | SVR | index methods | spectroradiometer, water samples | RMSE, RPD, R2 |
| Lee and Lee (2018) [57] | LSTM | DNN, RNN | water quality time series | RMSE |
| Wang et al. (2019) [58] | LSTM | / | water quality time series | accuracy, cross-correlation |
| Pu et al. (2019) [59] | CNN | RF, SVM | Landsat-8 | accuracy |
| Liu et al. (2019) [60] | LSTM | ARIMA, SVM | IoT data | MSE |
| Chowdury et al. (2019) [61] | MLP | / | IoT data | threshold value |
| Hafeez et al. (2019) [62] | DNN | CB, RF, SVR | Landsat | accuracy, relative variable importance |
| Li et al. (2019) [63] | RNN–DS hybrid | GRU, LSTM, SRN, SVR | water quality time series | MAE, MAPE, RMSE |
| Randrianiaina et al. (2019) [64] | DNN | / | Landsat-8 | RMSE, R2 |
| Yu et al. (2020) [65] | LSTM | / | water quality time series | MAE, RMSE |
| Zou et al. (2020) [66] | LSTM | DNN, GRU, LSTM | meteorological time series, water quality time series | MAE |
| Peterson et al. (2020) [67] | ELR | MLR, SVR | Landsat-8, Sentinel-2 | MAPE, RMSE, R2 |
| Hanson et al. (2020) [68] | LSTM | / | water quality time series | auto-correlation, MK statistics, RMSE |
| Barzegar et al. (2020) [69] | CNN–LSTM hybrid | CNN, LSTM | water quality data from multiprobe sensor | MAE, NSEC, Percentage of Bias, RMSE, Wilmott’s index |
| Aldhyani et al. (2020) [70] | LSTM | ANN, DNN, KNN, NB, SVM | water quality time series | accuracy, F-score, MSE, precision, R, sensitivity, specificity |
| Li et al. (2021) [71] | RF | SVM | Sentinel-2 MSI | RMSE, RPD, R2, Z-score |
| Sharma et al. (2021) [72] | CNN | CNN | UAV camera | precision, recall |
| Cui et al. (2021) [73] | CNN | KNN, index method, RF, SVM | Landsat-8, Sentinel-2 | RPD, RMSE, R2 |
| Zhao et al. (2021) [74] | DNN | RBFNN | Landsat-8, water quality time series | MAE, MSE, R2 |
| Arias-Rodriguez et al. (2021) [75] | ELM | LR, SVR | Landsat-8, Sentinel-2 MSI, Sentinel-3 OLI | MAE, MSE, RMSE, R2 |
| Kravitz et al. (2021) [76] | DNN | KNN, RF, XGBoost | Landsat 8 OLI, Sentinel-2 MSI | MAPE, RMSE, RMSLE 1 |
| Sun et al. (2021) [77] | DNN | GPR, RF | proximal hyperspectral imager, water samples | accuracy, MRE, RMSE, R2 |
| Datasets | Source | Category | Link to the Dataset | Notes |
|---|---|---|---|---|
| DeepWaterMap v2 | [40] | Water body | https://github.com/isikdogan/deepwatermap, accessed on 15 December 2021 | >1 TB of Landsat-7 imagery paired with Global Inland Water dataset labels. |
| 2020 GaoFen Challenge | / | Water body | https://github.com/AICyberTeam/2020Gaofen, accessed on 15 December 2021 | Dataset containing both 2500 optical and 1200 SAR satellite images with pixel level labels for water body segmentation. |
| GID-15 | [79] | Water body | https://captain-whu.github.io/GID15/, accessed on 15 December 2021 | 150 pixel-level annotated GaoFen-2 images for semantic segmentation tasks. |
| LandCover.ai | [80] | Water body | https://landcover.ai/, accessed on 15 December 2021 | A dataset from 2015–2018 of 10,674 annotated tiles of RGB imagery with labeled water bodies. |
| SEN12MS | [81] | Water body | https://mediatum.ub.tum.de/1474000, accessed on 15 December 2021 | A curated dataset of 180, 662 georeferenced multispectral Sentinel-1 and -2 imagery with MODIS land cover labels. |
| AquaSat | [82] | Water quality | https://github.com/GlobalHydrologyLab/AquaSat, accessed on 15 December 2021 | 600,000 data matchups between satellite imagery and water quality measurements from 1984–2019. |
| Forel–Ule Index | [83] | Water quality | https://doi.org/10.6084/m9.figshare.13014299, accessed on 15 December 2021 | 151 data matchups between satellite imagery and water quality measurements from 2000–2018. |
Publisher’s Note: MDPI stays neutral with regard to jurisdictional claims in published maps and institutional affiliations. |
© 2022 by the authors. Licensee MDPI, Basel, Switzerland. This article is an open access article distributed under the terms and conditions of the Creative Commons Attribution (CC BY) license (https://creativecommons.org/licenses/by/4.0/).
Share and Cite
Yang, L.; Driscol, J.; Sarigai, S.; Wu, Q.; Lippitt, C.D.; Morgan, M. Towards Synoptic Water Monitoring Systems: A Review of AI Methods for Automating Water Body Detection and Water Quality Monitoring Using Remote Sensing. Sensors 2022, 22, 2416. https://doi.org/10.3390/s22062416
Yang L, Driscol J, Sarigai S, Wu Q, Lippitt CD, Morgan M. Towards Synoptic Water Monitoring Systems: A Review of AI Methods for Automating Water Body Detection and Water Quality Monitoring Using Remote Sensing. Sensors. 2022; 22(6):2416. https://doi.org/10.3390/s22062416
Chicago/Turabian StyleYang, Liping, Joshua Driscol, Sarigai Sarigai, Qiusheng Wu, Christopher D. Lippitt, and Melinda Morgan. 2022. "Towards Synoptic Water Monitoring Systems: A Review of AI Methods for Automating Water Body Detection and Water Quality Monitoring Using Remote Sensing" Sensors 22, no. 6: 2416. https://doi.org/10.3390/s22062416
APA StyleYang, L., Driscol, J., Sarigai, S., Wu, Q., Lippitt, C. D., & Morgan, M. (2022). Towards Synoptic Water Monitoring Systems: A Review of AI Methods for Automating Water Body Detection and Water Quality Monitoring Using Remote Sensing. Sensors, 22(6), 2416. https://doi.org/10.3390/s22062416