
Skeleton-Based Spatio-Temporal U-Network for 3D Human Pose Estimation in Video


Abstract
:1. Introduction
- the previous methods have difficulty in handling complex long-time sequence action features;
- the existing approach neglects to consider the compression and fusion of features in both temporal and spatial dimensions for human pose estimation.
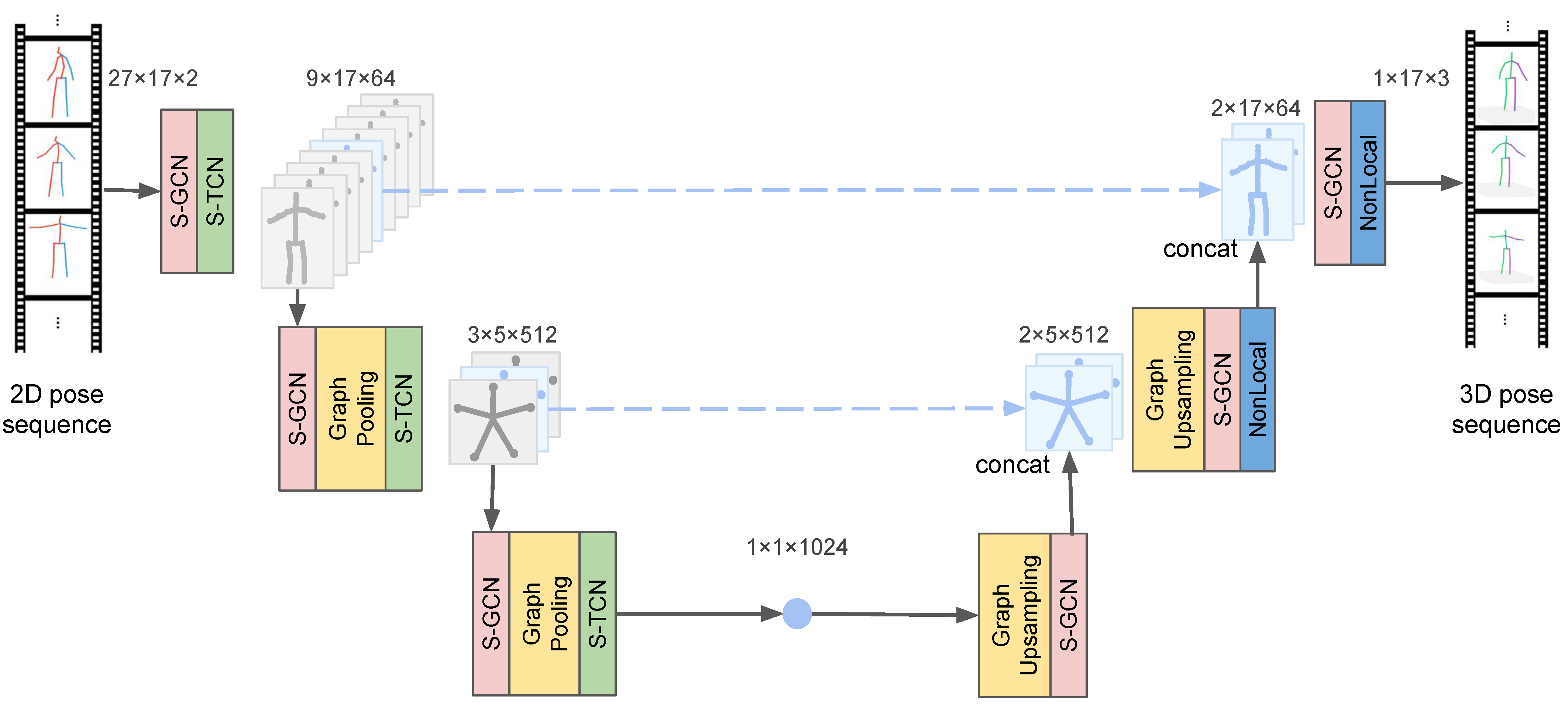
- this work presents a novel spatio-temporal U-Net architecture with a cascade structure of temporal convolution layers and semantic graph convolution layers to gradually integrate the semantic features of local time and space;
- the proposed structural temporal dilated convolution layer fuses long-time key point sequences in the temporal dimension to eliminate jitter and blur in 3D pose estimation in the single frame case;
- the proposed semantic graph convolution layer fuses the semantic features of the human body in the spatial dimension with novel graph convolution, pooling, and unpooling layers.
2. Related Work
2.1. 3D Human Pose Estimation
2.2. Video Pose Estimation
3. Skeleton-Based Spatio-Temporal U-Net
3.1. Structural Temporal Dilated Convolutional Layer
3.2. Semantic Graph Convolutional Network
3.2.1. Structure-Based Graph Layer
3.2.2. Graph Pooling and Upsampling
3.2.3. Data-Dependent Non-Local Layer
4. Experiments and Results
4.1. Datasets and Metrics
4.2. Implementation Details
4.3. Experimental Results
4.4. Computational Complexity
4.5. Ablation Study and Analysis
5. Conclusions
Author Contributions
Funding
Institutional Review Board Statement
Informed Consent Statement
Data Availability Statement
Conflicts of Interest
Abbreviations
| GCN | Graph Convolutional Network |
| TCN | Temporal Convolutional Network |
| CNN | Convolutional Neural Network |
| ST-GCN | Spatial Temporal Graph Convolutional Network |
References
- Pavlakos, G.; Zhou, X.; Derpanis, K.G.; Daniilidis, K. Coarse-to-Fine Volumetric Prediction for Single-Image 3D Human Pose. In Proceedings of the 2017 IEEE Conference on Computer Vision and Pattern Recognition (CVPR), Las Vegas, NV, USA, 27–30 June 2016; pp. 1263–1272. [Google Scholar]
- Tekin, B.; Márquez-Neila, P.; Salzmann, M.; Fua, P. Learning to Fuse 2D and 3D Image Cues for Monocular Body Pose Estimation. In Proceedings of the 2017 IEEE International Conference on Computer Vision (ICCV), Venice, Italy, 22–29 October 2017; pp. 3961–3970. [Google Scholar]
- Martinez, J.; Hossain, R.; Romero, J.; Little, J. A Simple Yet Effective Baseline for 3d Human Pose Estimation. In Proceedings of the 2017 IEEE International Conference on Computer Vision (ICCV), Venice, Italy, 22–29 October 2017; pp. 2659–2668. [Google Scholar]
- Sun, X.; Shang, J.; Liang, S.; Wei, Y. Compositional Human Pose Regression. Comput. Vis. Image Underst. 2018, 176–177, 1–8. [Google Scholar]
- Fang, H.; Xu, Y.; Wang, W.; Liu, X.; Zhu, S.C. Learning Pose Grammar to Encode Human Body Configuration for 3D Pose Estimation. In Proceedings of the AAAI 2018, Arlington, VA, USA, 18–20 October 2018. [Google Scholar]
- Pavlakos, G.; Zhou, X.; Daniilidis, K. Ordinal Depth Supervision for 3D Human Pose Estimation. In Proceedings of the 2018 IEEE/CVF Conference on Computer Vision and Pattern Recognition, Salt Lake City, UT, USA, 18–22 June 2018; pp. 7307–7316. [Google Scholar]
- Yang, W.; Ouyang, W.; Wang, X.; Ren, J.S.J.; Li, H.; Wang, X. 3D Human Pose Estimation in the Wild by Adversarial Learning. In Proceedings of the 2018 IEEE/CVF Conference on Computer Vision and Pattern Recognition, Salt Lake City, UT, USA, 18–22 June 2018; pp. 5255–5264. [Google Scholar]
- Luvizon, D.C.; Picard, D.; Tabia, H. 2D/3D Pose Estimation and Action Recognition Using Multitask Deep Learning. In Proceedings of the 2018 IEEE/CVF Conference on Computer Vision and Pattern Recognition, Salt Lake City, UT, USA, 18–22 June 2018; pp. 5137–5146. [Google Scholar]
- Hossain, M.R.I.; Little, J. Exploiting temporal information for 3D pose estimation. arXiv 2017, arXiv:1711.08585. [Google Scholar]
- Lee, K.; Lee, I.; Lee, S. Propagating LSTM: 3D Pose Estimation Based on Joint Interdependency. In Proceedings of the European Conference on Computer Vision (ECCV), Munich, Germany, 8–14 September 2018. [Google Scholar]
- Zhao, L.; Peng, X.; Tian, Y.; Kapadia, M.; Metaxas, D.N. Semantic Graph Convolutional Networks for 3D Human Pose Regression. In Proceedings of the 2019 IEEE/CVF Conference on Computer Vision and Pattern Recognition (CVPR), Long Beach, CA, USA, 15–20 June 2019; pp. 3420–3430. [Google Scholar]
- Cai, Y.; Ge, L.; Liu, J.; Cai, J.; Cham, T.; Yuan, J.; Magnenat-Thalmann, N. Exploiting Spatial-Temporal Relationships for 3D Pose Estimation via Graph Convolutional Networks. In Proceedings of the 2019 IEEE/CVF Conference on Computer Vision and Pattern Recognition (CVPR), Long Beach, CA, USA, 15–20 June 2019; pp. 2272–2281. [Google Scholar]
- Yan, S.; Xiong, Y.; Lin, D. Spatial Temporal Graph Convolutional Networks for Skeleton-Based Action Recognition. arXiv 2018, arXiv:1801.07455. [Google Scholar]
- Gehring, J.; Auli, M.; Grangier, D.; Yarats, D.; Dauphin, Y. Convolutional Sequence to Sequence Learning. In Proceedings of the 34th International Conference on Machine Learning, Sydney, Australia, 6–11 August 2017. [Google Scholar]
- Dauphin, Y.; Fan, A.; Auli, M.; Grangier, D. Language Modeling with Gated Convolutional NetwoOrdinal depth supervision for 3d humanrks. In Proceedings of the 34th International Conference on Machine Learning, Sydney, Australia, 6–11 August 2017. [Google Scholar]
- van den Oord, A.; Dieleman, S.; Zen, H.; Simonyan, K.; Vinyals, O.; Graves, A.; Kalchbrenner, N.; Senior, A.W.; Kavukcuoglu, K. WaveNet: A Generative Model for Raw Audio. arXiv 2016, arXiv:1609.03499. [Google Scholar]
- Collobert, R.; Puhrsch, C.; Synnaeve, G. Wav2Letter: An End-to-End ConvNet-based Speech Recognition System. arXiv 2016, arXiv:1609.03193. [Google Scholar]
- Ronneberger, O.; Fischer, P.; Brox, T. U-Net: Convolutional Networks for Biomedical Image Segmentation. In Proceedings of the MICCAI, Munich, Germany, 5–9 October 2015. [Google Scholar]
- Sminchisescu, C. 3D Human Motion Analysis in Monocular Video Techniques and Challenges. In Proceedings of the AVSS, Sydney, Australia, 22–24 November 2006. [Google Scholar]
- Ramakrishna, V.; Kanade, T.; Sheikh, Y. Reconstructing 3D Human Pose from 2D Image Landmarks. In Proceedings of the 12th European Conference on Computer Vision, Florence, Italy, 7–13 October 2012. [Google Scholar]
- Ionescu, C.; Papava, D.; Olaru, V.; Sminchisescu, C. Human3.6M: Large Scale Datasets and Predictive Methods for 3D Human Sensing in Natural Environments. IEEE Trans. Pattern Anal. Mach. Intell. 2014, 36, 1325–1339. [Google Scholar] [CrossRef] [PubMed]
- Ionescu, C.; Carreira, J.; Sminchisescu, C. Iterated Second-Order Label Sensitive Pooling for 3D Human Pose Estimation. In Proceedings of the 2014 IEEE Conference on Computer Vision and Pattern Recognition, Columbus, OH, USA, 23–28 June 2014; pp. 1661–1668. [Google Scholar]
- Li, S.; Chan, A.B. 3D Human Pose Estimation from Monocular Images with Deep Convolutional Neural Network. In Proceedings of the ACCV 2014, Singapore, 1–5 November 2014. [Google Scholar]
- Tekin, B.; Rozantsev, A.; Lepetit, V.; Fua, P.V. Direct Prediction of 3D Body Poses from Motion Compensated Sequences. In Proceedings of the 2017 IEEE Conference on Computer Vision and Pattern Recognition (CVPR), Las Vegas, NV, USA, 27–30 June 2016; pp. 991–1000. [Google Scholar]
- Tekin, B.; Katircioglu, I.; Salzmann, M.; Lepetit, V.; Fua, P.V. Structured Prediction of 3D Human Pose with Deep Neural Networks. arXiv 2016, arXiv:1605.05180. [Google Scholar]
- Jiang, H. 3D Human Pose Reconstruction Using Millions of Exemplars. In Proceedings of the 2010 20th International Conference on Pattern Recognition, Istanbul, Turkey, 23–26 August 2010; pp. 1674–1677. [Google Scholar]
- Chen, C.H.; Ramanan, D. 3D Human Pose Estimation = 2D Pose Estimation + Matching. In Proceedings of the 2017 IEEE Conference on Computer Vision and Pattern Recognition (CVPR), Honolulu, HI, USA, 21–26 July 2017; pp. 5759–5767. [Google Scholar]
- Park, S.; Hwang, J.; Kwak, N. 3D Human Pose Estimation Using Convolutional Neural Networks with 2D Pose Information. In Proceedings of the ECCV Workshops, Amsterdam, The Netherlands, 11–14 October 2016. [Google Scholar]
- Zhou, X.; Huang, Q.; Sun, X.; Xue, X.; Wei, Y. Towards 3D Human Pose Estimation in the Wild: A Weakly-Supervised Approach. In Proceedings of the 2017 IEEE International Conference on Computer Vision (ICCV), Venice, Italy, 22–29 October 2017; pp. 398–407. [Google Scholar]
- Brau, E.; Jiang, H. 3D Human Pose Estimation via Deep Learning from 2D Annotations. In Proceedings of the 2016 Fourth International Conference on 3D Vision (3DV), Stanford, CA, USA, 25–28 October 2016; pp. 582–591. [Google Scholar]
- He, Y.; Yan, R.; Fragkiadaki, K.; Yu, S.I. Epipolar Transformers. In Proceedings of the 2020 IEEE/CVF Conference on Computer Vision and Pattern Recognition (CVPR), Seattle, WA, USA, 13–19 June 2020; pp. 7776–7785. [Google Scholar]
- Plizzari, C.; Cannici, M.; Matteucci, M. Spatial Temporal Transformer Network for Skeleton-based Action Recognition. In Proceedings of the ICPR Workshops, Virtual Event, 10–15 January2021. [Google Scholar]
- Hu, W.; Zhang, C.; Zhan, F.; Zhang, L.; Wong, T.T. Conditional Directed Graph Convolution for 3D Human Pose Estimation. In Proceedings of the 29th ACM International Conference on Multimedia, Virtual Event, 20–24 October 2021. [Google Scholar]
- Nan, M.; Trascau, M.; Florea, A.M.; Iacob, C.C. Comparison between Recurrent Networks and Temporal Convolutional Networks Approaches for Skeleton-Based Action Recognition. Sensors 2021, 21, 2051. [Google Scholar] [CrossRef]
- Lin, M.; Lin, L.; Liang, X.; Wang, K.; Cheng, H. Recurrent 3D Pose Sequence Machines. In Proceedings of the 2017 IEEE Conference on Computer Vision and Pattern Recognition (CVPR), Honolulu, HI, USA, 21–26 July 2017; pp. 5543–5552. [Google Scholar]
- Katircioglu, I.; Tekin, B.; Salzmann, M.; Lepetit, V.; Fua, P.V. Learning Latent Representations of 3D Human Pose with Deep Neural Networks. Int. J. Comput. Vis. 2018, 126, 1326–1341. [Google Scholar] [CrossRef] [Green Version]
- Hossain, M.R.I.; Little, J. Exploiting Temporal Information for 3D Human Pose Estimation. In Proceedings of the European Conference on Computer Vision (ECCV), Munich, Germany, 8–14 September 2018. [Google Scholar]
- Li, M.; Chen, S.; Chen, X.; Zhang, Y.; Wang, Y.; Tian, Q. Actional-Structural Graph Convolutional Networks for Skeleton-Based Action Recognition. In Proceedings of the 2019 IEEE/CVF Conference on Computer Vision and Pattern Recognition (CVPR), Long Beach, CA, USA, 15–20 June 2019; pp. 3590–3598. [Google Scholar]
- Shi, L.; Zhang, Y.; Cheng, J.; Lu, H. Skeleton-Based Action Recognition with Directed Graph Neural Networks. In Proceedings of the 2019 IEEE/CVF Conference on Computer Vision and Pattern Recognition (CVPR), Long Beach, CA, USA, 15–20 June 2019; pp. 7904–7913. [Google Scholar]
- Shi, L.; Zhang, Y.; Cheng, J.; Lu, H. Two-Stream Adaptive Graph Convolutional Networks for Skeleton-Based Action Recognition. In Proceedings of the 2019 IEEE/CVF Conference on Computer Vision and Pattern Recognition (CVPR), Long Beach, CA, USA, 15–20 June 2019; pp. 12018–12027. [Google Scholar]
- Pavllo, D.; Feichtenhofer, C.; Grangier, D.; Auli, M. 3D human pose estimation in video with temporal convolutions and semi-supervised training. In Proceedings of the 2019 IEEE/CVF Conference on Computer Vision and Pattern Recognition (CVPR), Long Beach, CA, USA, 15–20 June 2019. [Google Scholar]
- Wang, X.; Girshick, R.B.; Gupta, A.K.; He, K. Non-local Neural Networks. In Proceedings of the 2018 IEEE/CVF Conference on Computer Vision and Pattern Recognition, Salt Lake City, UT, USA, 18–22 June 2018; pp. 7794–7803. [Google Scholar]
- Sigal, L.; Balan, A.O.; Black, M.J. HumanEva: Synchronized Video and Motion Capture Dataset and Baseline Algorithm for Evaluation of Articulated Human Motion. Int. J. Comput. Vis. 2009, 87, 4–27. [Google Scholar] [CrossRef]
- Yeh, R.A.; Hu, Y.T.; Schwing, A.G. Chirality Nets for Human Pose Regression. In Proceedings of the NeurIPS 2019, Vancouver, BC, Canada, 8–14 December 2019. [Google Scholar]
- Xu, J.; Yu, Z.; Ni, B.; Yang, J.; Yang, X.; Zhang, W. Deep Kinematics Analysis for Monocular 3D Human Pose Estimation. In Proceedings of the 2020 IEEE/CVF Conference on Computer Vision and Pattern Recognition (CVPR), Seattle, WA, USA, 13–19 June 2020; pp. 896–905. [Google Scholar]
- Ci, H.; Wang, C.; Ma, X.; Wang, Y. Optimizing Network Structure for 3D Human Pose Estimation. In Proceedings of the 2019 IEEE/CVF Conference on Computer Vision and Pattern Recognition (CVPR), Long Beach, CA, USA, 15–20 June 2019; pp. 2262–2271. [Google Scholar]
- Ioffe, S.; Szegedy, C. Batch Normalization: Accelerating Deep Network Training by Reducing Internal Covariate Shift. arXiv 2015, arXiv:1502.03167. [Google Scholar]
- Reddi, S.J.; Kale, S.; Kumar, S. On the Convergence of Adam and Beyond. arXiv 2018, arXiv:1904.09237. [Google Scholar]
- Liu, R.; Shen, J.; Wang, H.; Chen, C.; Cheung, S.C.S.; Asari, V.K. Attention Mechanism Exploits Temporal Contexts: Real-Time 3D Human Pose Reconstruction. In Proceedings of the 2020 IEEE/CVF Conference on Computer Vision and Pattern Recognition (CVPR), Seattle, WA, USA, 13–19 June 2020; pp. 5063–5072. [Google Scholar]
- Ying, R.; You, J.; Morris, C.; Ren, X.; Hamilton, W.L.; Leskovec, J. Hierarchical Graph Representation Learning with Differentiable Pooling. arXiv 2018, arXiv:1806.08804. [Google Scholar]
- Lee, J.; Lee, I.; Kang, J. Self-Attention Graph Pooling. arXiv 2019, arXiv:1904.08082. [Google Scholar]






{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
| Dir. | Disc. | Eat | Greet | Phone | Photo | Pose | Purch. | Sit | SitD. | Smoke | Wait | WalkD. | Walk | WalkT. | Avg | |
|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|
| Pavlakos et al. [1] | 67.4 | 71.9 | 66.7 | 69.1 | 72.0 | 77.0 | 65.0 | 68.3 | 83.7 | 96.5 | 71.7 | 65.8 | 74.9 | 59.1 | 63.2 | 71.9 |
| Fang et al. [5] | 50.1 | 54.3 | 57.0 | 57.1 | 66.6 | 73.3 | 53.4 | 55.7 | 72.8 | 88.6 | 60.3 | 57.7 | 62.7 | 47.5 | 50.6 | 60.4 |
| Pavlakos et al. [6] | 48.5 | 54.4 | 54.4 | 52.0 | 59.4 | 65.3 | 49.9 | 52.9 | 65.8 | 71.1 | 56.6 | 52.9 | 60.9 | 44.7 | 47.8 | 56.2 |
| Yang et al. [7] | 51.5 | 58.9 | 50.4 | 57.0 | 62.1 | 65.4 | 49.8 | 52.7 | 69.2 | 85.2 | 57.4 | 58.4 | 43.6 | 60.1 | 47.7 | 58.6 |
| Luvizon et al. [8] | 49.2 | 51.6 | 47.6 | 50.5 | 51.8 | 60.3 | 48.5 | 51.7 | 61.5 | 70.9 | 53.7 | 48.9 | 57.9 | 44.4 | 48.9 | 53.2 |
| Hossain et al. [9] | 48.4 | 50.7 | 57.2 | 55.2 | 63.1 | 72.6 | 53.0 | 51.7 | 66.1 | 80.9 | 59.0 | 57.3 | 62.4 | 46.6 | 49.6 | 58.3 |
| Lee et al. [10] | 40.2 | 49.2 | 47.8 | 52.6 | 50.1 | 75.0 | 50.2 | 43.0 | 55.8 | 73.9 | 54.1 | 55.6 | 58.2 | 43.3 | 43.3 | 52.8 |
| Pavllo et al. [41] | 45.9 | 48.5 | 44.3 | 47.8 | 51.9 | 57.8 | 46.2 | 45.6 | 59.9 | 68.5 | 50.6 | 46.4 | 51.0 | 34.5 | 35.4 | 49.0 |
| Cai et al. [12] | 44.6 | 47.4 | 45.6 | 48.8 | 50.8 | 59.0 | 47.2 | 43.9 | 57.9 | 61.9 | 49.7 | 46.6 | 51.3 | 37.1 | 39.4 | 48.8 |
| Yeh et al. [44] | 44.8 | 46.1 | 43.3 | 46.4 | 49.0 | 55.2 | 44.6 | 44.0 | 58.3 | 62.7 | 47.1 | 43.9 | 48.6 | 32.7 | 33.3 | 46.7 |
| Xu et al. [45] | 37.4 | 43.5 | 42.7 | 42.7 | 46.6 | 59.7 | 41.3 | 45.1 | 52.7 | 60.2 | 45.8 | 43.1 | 47.7 | 33.7 | 37.1 | 45.6 |
| Liu et al. [49] | 41.8 | 44.8 | 41.1 | 44.9 | 47.4 | 54.1 | 43.4 | 42.2 | 56.2 | 63.6 | 45.3 | 43.5 | 45.3 | 31.3 | 32.2 | 45.1 |
| Ours (27 frames) | 43.5 | 44.8 | 43.9 | 44.1 | 47.7 | 56.5 | 44.0 | 44.2 | 55.8 | 67.9 | 47.3 | 46.5 | 45.7 | 33.4 | 33.6 | 46.6 |
| Ours (81 frames) | 42.6 | 43.6 | 42.8 | 43.1 | 46.1 | 54.6 | 43.3 | 42.4 | 53.5 | 63.2 | 45.8 | 44.2 | 44.9 | 31.9 | 32.0 | 45.0 |
| Ours (243 frames) | 41.9 | 43.1 | 42.3 | 42.9 | 46.3 | 54.2 | 42.9 | 41.8 | 53.1 | 62.8 | 45.3 | 43.9 | 43.4 | 31.2 | 31.8 | 44.5 |
| Dir. | Disc. | Eat | Greet | Phone | Photo | Pose | Purch. | Sit | SitD. | Smoke | Wait | WalkD. | Walk | WalkT. | Avg | |
|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|
| Martinez et al. [3] | 39.5 | 43.2 | 46.4 | 47.0 | 51.0 | 56.0 | 41.4 | 40.6 | 56.5 | 69.4 | 49.2 | 45.0 | 49.5 | 38.0 | 43.1 | 47.7 |
| Sun et al. [4] | 42.1 | 44.3 | 45.0 | 45.4 | 51.5 | 53.0 | 43.2 | 41.3 | 59.3 | 73.3 | 51.0 | 44.0 | 48.0 | 38.3 | 44.8 | 48.3 |
| Fang et al. [5] | 38.2 | 41.7 | 43.7 | 44.9 | 48.5 | 55.3 | 40.2 | 38.2 | 54.5 | 64.4 | 47.2 | 44.3 | 47.3 | 36.7 | 41.7 | 45.7 |
| Pavlakos et al. [6] | 34.7 | 39.8 | 41.8 | 38.6 | 42.5 | 47.5 | 38.0 | 36.6 | 50.7 | 56.8 | 42.6 | 39.6 | 43.9 | 32.1 | 36.5 | 41.8 |
| Yang et al. [7] | 26.9 | 30.9 | 36.3 | 39.9 | 43.9 | 47.4 | 28.8 | 29.4 | 36.9 | 58.4 | 41.5 | 30.5 | 29.5 | 42.5 | 32.2 | 37.7 |
| Hossain et al. [9] | 35.7 | 39.3 | 44.6 | 43.0 | 47.2 | 54.0 | 38.3 | 37.5 | 51.6 | 61.3 | 46.5 | 41.4 | 47.3 | 34.2 | 39.4 | 44.1 |
| Pavllo et al. [41] | 34.2 | 36.8 | 33.9 | 37.5 | 37.1 | 43.2 | 34.4 | 33.5 | 45.3 | 52.7 | 37.7 | 34.1 | 38.0 | 25.8 | 27.7 | 36.8 |
| Cai et al. [12] | 35.7 | 37.8 | 36.9 | 40.7 | 39.6 | 45.2 | 37.4 | 34.5 | 46.9 | 50.1 | 40.5 | 36.1 | 41.0 | 29.6 | 33.2 | 39.0 |
| Xu et al. [45] | 31.0 | 34.8 | 34.7 | 34.4 | 36.2 | 43.9 | 31.6 | 33.5 | 42.3 | 49.0 | 37.1 | 33.0 | 39.1 | 26.9 | 31.9 | 36.2 |
| Liu et al. [49] | 32.3 | 35.2 | 33.3 | 35.8 | 35.9 | 41.5 | 33.2 | 32.7 | 44.6 | 50.9 | 37.0 | 32.4 | 37.0 | 25.2 | 27.2 | 35.6 |
| Ours (27 frames) | 34.3 | 35.7 | 34.9 | 36.6 | 37.5 | 42.7 | 33.1 | 36.0 | 44.4 | 53.7 | 38.5 | 33.5 | 38.4 | 26.0 | 28.4 | 36.9 |
| Ours (81 frames) | 33.5 | 35.1 | 33.9 | 36.0 | 36.9 | 42.1 | 32.3 | 34.5 | 42.9 | 50.1 | 37.7 | 33.0 | 37.8 | 25.6 | 27.6 | 36.0 |
| Ours (243 frames) | 33.3 | 34.8 | 33.6 | 35.2 | 36.3 | 42.2 | 32.1 | 33.7 | 42.6 | 49.4 | 36.9 | 32.8 | 37.4 | 25.1 | 27.2 | 35.4 |
| Walk | Jog | Box | |||||||
|---|---|---|---|---|---|---|---|---|---|
| S1 | S2 | S3 | S1 | S2 | S3 | S1 | S2 | S3 | |
| Pavlakos et al. [6] | 22.3 | 19.5 | 29.7 | 28.9 | 21.9 | 23.8 | - | - | - |
| Lee et al. [10] | 18.6 | 19.9 | 30.5 | 25.7 | 16.8 | 17.7 | 42.8 | 48.1 | 53.4 |
| Pavllo et al. [41] | 13.9 | 10.2 | 46.6 | 20.9 | 13.1 | 13.8 | 23.8 | 33.7 | 32.0 |
| Yeh et al. [44] | 15.2 | 10.3 | 47.0 | 21.8 | 13.1 | 13.7 | 22.8 | 31.8 | 31.0 |
| Xu et al. [45] | 13.2 | 10.2 | 29.9 | 12.6 | 12.3 | 13.0 | 13.2 | 18.1 | 20.4 |
| Liu et al. [49] | 13.1 | 9.8 | 26.8 | 16.9 | 12.8 | 13.3 | - | - | - |
| Ours (243 frames) | 12.8 | 9.7 | 26.5 | 16.0 | 12.2 | 12.7 | 14.6 | 16.9 | 19.3 |
| Model | Parameters | FLOPs | MPJPE (mm) |
|---|---|---|---|
| Hossain et al. [9] | 16.96M | 33.88M | 58.3 |
| Pavllo (81 frames) et al. [41] | 12.75M | 25.48M | 47.7 |
| Pavllo (243 frames) et al. [41] | 16.95M | 33.87M | 46.8 |
| Ours (27 frames) | 14.80 M | 29.03 M | 45.8 |
| Ours (81 frames) | 19.67 M | 38.45 M | 45.0 |
| Ours (243 frames) | 29.58 M | 64.84 M | 44.5 |
| Frames | MPJPE (mm) | ||
|---|---|---|---|
| 81 | 1 | 2 | 45.8 |
| 81 | 1 | 3 | 45.0 |
| 81 | 2 | 3 | 45.3 |
| 243 | 1 | 3 | 45.5 |
| 243 | 1 | 4 | 45.3 |
| 243 | 2 | 3 | 44.9 |
| 243 | 2 | 4 | 44.5 |
| 243 | 3 | 4 | 44.7 |
Publisher’s Note: MDPI stays neutral with regard to jurisdictional claims in published maps and institutional affiliations. |
© 2022 by the authors. Licensee MDPI, Basel, Switzerland. This article is an open access article distributed under the terms and conditions of the Creative Commons Attribution (CC BY) license (https://creativecommons.org/licenses/by/4.0/).
Share and Cite
Li, W.; Du, R.; Chen, S. Skeleton-Based Spatio-Temporal U-Network for 3D Human Pose Estimation in Video. Sensors 2022, 22, 2573. https://doi.org/10.3390/s22072573
Li W, Du R, Chen S. Skeleton-Based Spatio-Temporal U-Network for 3D Human Pose Estimation in Video. Sensors. 2022; 22(7):2573. https://doi.org/10.3390/s22072573
Chicago/Turabian StyleLi, Weiwei, Rong Du, and Shudong Chen. 2022. "Skeleton-Based Spatio-Temporal U-Network for 3D Human Pose Estimation in Video" Sensors 22, no. 7: 2573. https://doi.org/10.3390/s22072573
APA StyleLi, W., Du, R., & Chen, S. (2022). Skeleton-Based Spatio-Temporal U-Network for 3D Human Pose Estimation in Video. Sensors, 22(7), 2573. https://doi.org/10.3390/s22072573