
Semantic Segmentation Using Pixel-Wise Adaptive Label Smoothing via Self-Knowledge Distillation for Limited Labeling Data


Abstract
:1. Introduction
- We propose a new probability regularization method for limited training data using a self-knowledge distillation scheme;
- We propose a pixel-wise adaptive label smoothing (PALS) by fully utilizing the internal statistics of pixels within an input image;
2. Related Work
2.1. Semantic Segmentation
2.2. Regularization
3. Revisit of CE, LS, CP, KD
3.1. Cross Entropy
3.2. Label Smoothing
3.3. Confidence Penalty
3.4. Knowledge Distillation
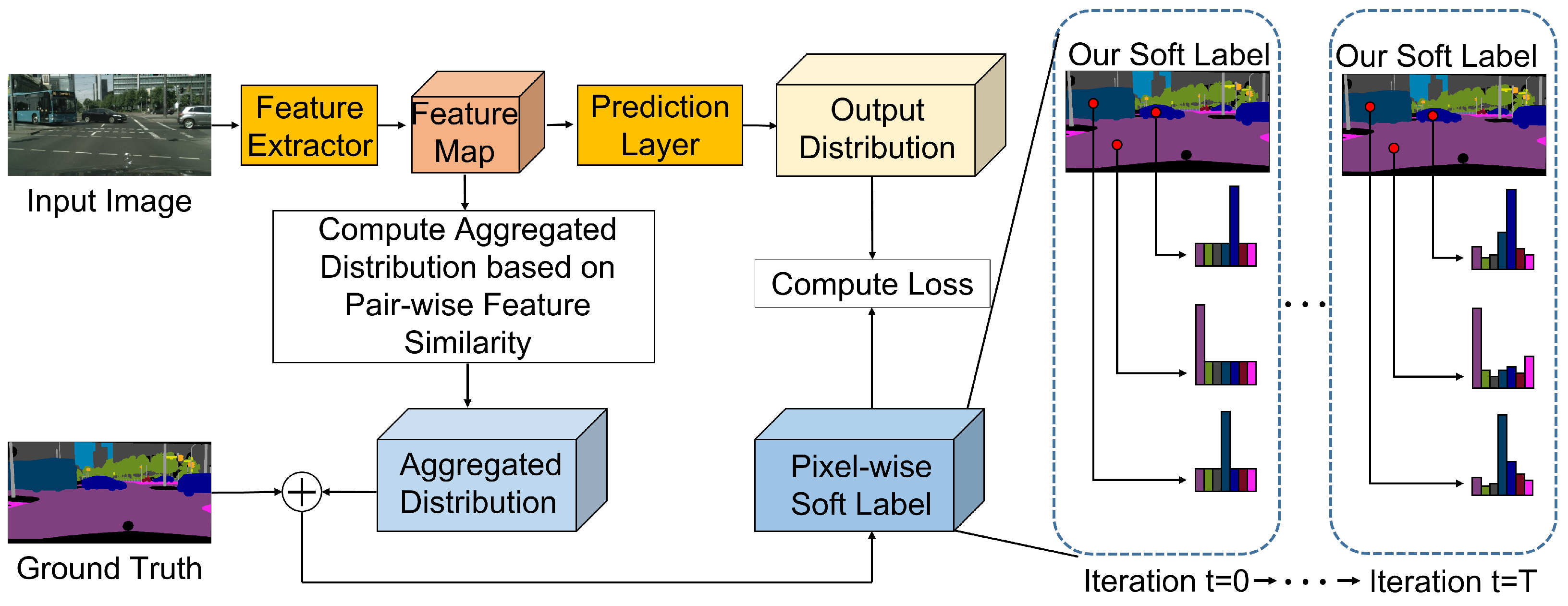
4. Proposed Method
4.1. PALS Module
4.2. Loss Function
5. Experiments
5.1. Dataset
5.2. Implementation Details
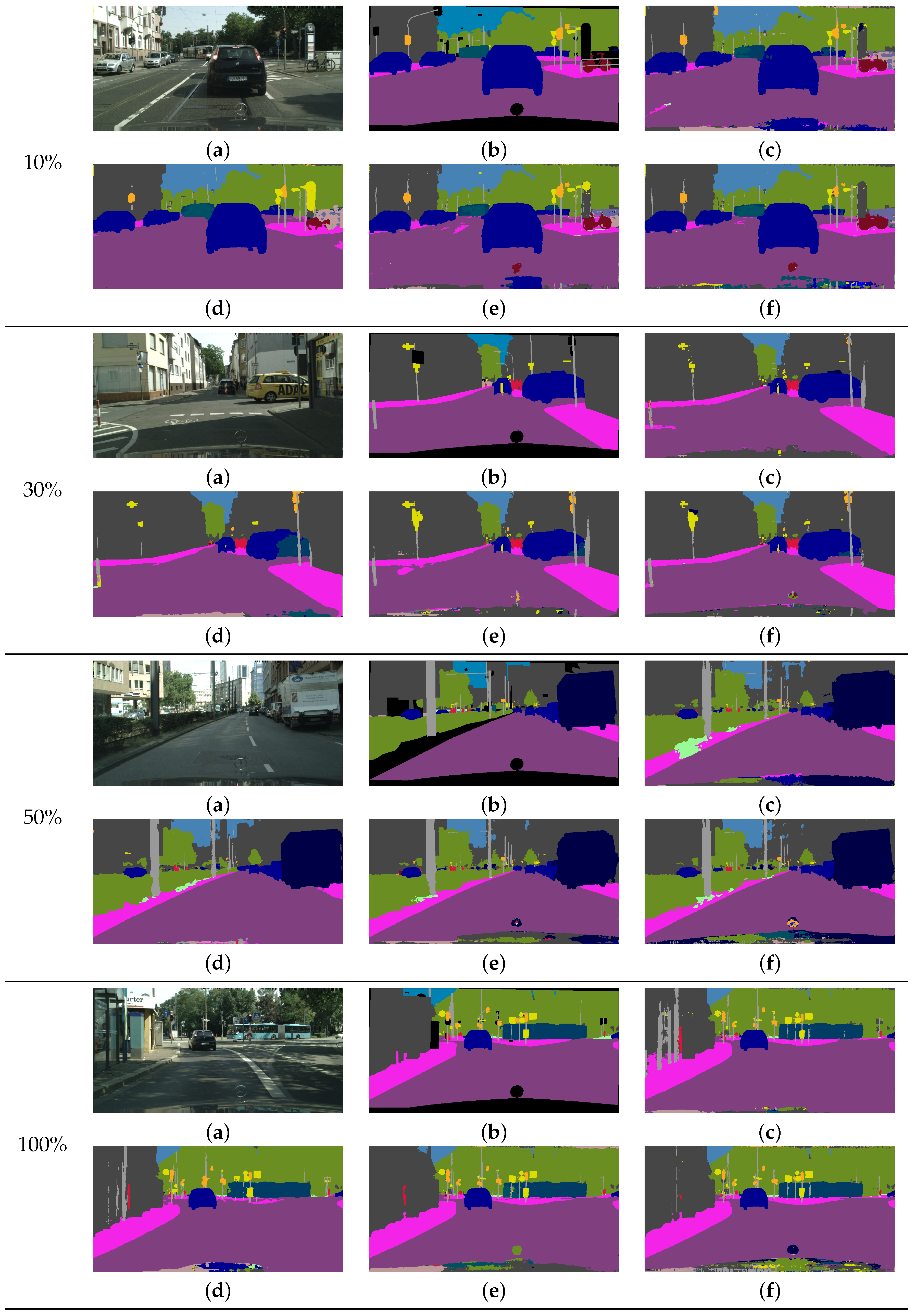
5.3. Comparison with Previous Methods
5.3.1. The Cityscapes Dataset
5.3.2. Pascal VOC2012 Dataset
6. Ablation Study
7. Conclusions
Author Contributions
Funding
Institutional Review Board Statement
Informed Consent Statement
Data Availability Statement
Acknowledgments
Conflicts of Interest
References
- Zeng, W.; Luo, W.; Suo, S.; Sadat, A.; Yang, B.; Casas, S.; Urtasun, R. End-To-End Interpretable Neural Motion Planner. In Proceedings of the IEEE Conference on Computer Vision and Pattern Recognition (CVPR), Long Beach, CA, USA, 15–20 June 2019; pp. 8652–8661. [Google Scholar]
- Philion, J.; Fidler, S. Lift, Splat, Shoot: Encoding Images From Arbitrary Camera Rigs by Implicitly Unprojecting to 3D. In Proceedings of the European Conference on Computer Vision (ECCV), Glasgow, UK, 23–28 August 2020. [Google Scholar]
- Cherabier, I.F.; Schönberger, J.L.; Oswald, M.R.; Pollefeys, M.; Geiger, A. Learning Priors for Semantic 3D Reconstruction. In Proceedings of the European Conference on Computer Vision (ECCV), Munich, Germany, 8–14 September 2018; pp. 314–330. [Google Scholar]
- Ronneberger, O.; Fischer, P.; Brox, T. U-Net: Convolutional Networks for Biomedical Image Segmentation. In Proceedings of the Medical Image Computing and Computer-Assisted Intervention (MICCAI), Munich, Germany, 5–9 October 2015; Volume 9351, pp. 234–241. [Google Scholar]
- Srivastava, A.; Jha, D.; Chanda, S.; Pal, U.; Johansen, H.D.; Johansen, D.; Riegler, M.A.; Ali, S.; Halvorsen, P. MSRF-Net: A Multi-Scale Residual Fusion Network for Biomedical Image Segmentation. arXiv 2021, arXiv:2105.07451. [Google Scholar] [CrossRef] [PubMed]
- Long, J.; Shelhamer, E.; Darrell, T. Fully convolutional networks for semantic segmentation. In Proceedings of the IEEE Conference on Computer Vision and Pattern Recognition (CVPR), Boston, MA, USA, 7–12 June 2015; pp. 3431–3440. [Google Scholar] [CrossRef] [Green Version]
- Chen, L.C.; Papandreou, G.; Kokkinos, I.; Murphy, K.; Yuille, A.L. Semantic Image Segmentation with Deep Convolutional Nets and Fully Connected CRFs. In Proceedings of the International Conference on Learning Representations (ICLR), San Diego, CA, USA, 7–9 May 2015. [Google Scholar]
- Chen, L.; Papandreou, G.; Kokkinos, I.; Murphy, K.; Yuille, A.L. DeepLab: Semantic Image Segmentation with Deep Convolutional Nets, Atrous Convolution, and Fully Connected CRFs. IEEE Trans. Pattern Anal. Mach. Intell. 2018, 40, 834–848. [Google Scholar] [CrossRef] [PubMed] [Green Version]
- Chen, L.; Papandreou, G.; Schroff, F.; Adam, H. Rethinking Atrous Convolution for Semantic Image Segmentation. arXiv 2017, arXiv:abs/1706.05587. [Google Scholar]
- Chen, L.C.; Zhu, Y.; Papandreou, G.; Schroff, F.; Adam, H. Encoder-Decoder with Atrous Separable Convolution for Semantic Image Segmentation. In Proceedings of the European Conference on Computer Vision, Munich, Germany, 8–14 September 2018; pp. 833–851. [Google Scholar]
- Zhao, H.; Shi, J.; Qi, X.; Wang, X.; Jia, J. Pyramid Scene Parsing Network. In Proceedings of the IEEE Conference on Computer Vision and Pattern Recognition (CVPR), Honolulu, HI, USA, 21–26 July 2017. [Google Scholar]
- Dubey, A.; Gupta, O.; Raskar, R. Regularizing Prediction Entropy Enhances Deep Learning with Limited Data. In Proceedings of the Neural Information Processing Systems (NIPS), Long Beach, CA, USA, 4–9 December 2017. [Google Scholar]
- Bishop, C. Regularization and complexity control in feed-forward networks. In Proceedings of the International Conference on Artificial Neural Networks ICANN’95, Paris, France, 9–13 October 1995; pp. 141–148. [Google Scholar]
- Nowlan, S.J.; Hinton, G.E. Simplifying Neural Networks by Soft Weight-Sharing. Neural Comput. 1992, 4, 473–493. [Google Scholar] [CrossRef]
- Ioffe, S.; Szegedy, C. Batch Normalization: Accelerating Deep Network Training by Reducing Internal Covariate Shift. In Proceedings of the 32nd International Conference on Machine Learning, Lille, France, 7–9 July 2015; Volume 37, pp. 448–456. [Google Scholar]
- Srivastava, N.; Hinton, G.; Krizhevsky, A.; Sutskever, I.; Salakhutdinov, R. Dropout: A Simple Way to Prevent Neural Networks from Overfitting. J. Mach. Learn. Res. 2014, 15, 1929–1958. [Google Scholar]
- Zhang, H.; Cisse, M.; Dauphin, Y.N.; Lopez-Paz, D. mixup: Beyond Empirical Risk Minimization. In Proceedings of the International Conference on Learning Representations (ICLR), Vancouver, BC, Canada, 27 November 2017–5 January 2018. [Google Scholar]
- Yun, S.; Han, D.; Oh, S.J.; Chun, S.; Choe, J.; Yoo, Y. CutMix: Regularization Strategy to Train Strong Classifiers with Localizable Features. In Proceedings of the IEEE International Conference on Computer Vision (ICCV), Seoul, Korea, 27 October–2 November 2019. [Google Scholar]
- DeVries, T.; Taylor, G.W. Improved Regularization of Convolutional Neural Networks with Cutout. arXiv 2017, arXiv:1708.04552. [Google Scholar]
- Müller, R.; Kornblith, S.; Hinton, G.E. When does label smoothing help? In Proceedings of the Advances in Neural Information Processing Systems, Vancouver, BC, Canada, 8–14 December 2019; Volume 32.
- Szegedy, C.; Vanhoucke, V.; Ioffe, S.; Shlens, J.; Wojna, Z. Rethinking the Inception Architecture for Computer Vision. In Proceedings of the IEEE Conference on Computer Vision and Pattern Recognition (CVPR), Honolulu, HI, USA, 21–26 July 2016; pp. 2818–2826. [Google Scholar] [CrossRef] [Green Version]
- Pereyra, G.; Tucker, G.; Chorowski, J.; Kaiser, L.; Hinton, G.E. Regularizing Neural Networks by Penalizing Confident Output Distributions. In Proceedings of the International Conference on Learning Representations (ICLR), OpenReview.net, Toulon, France, 24–26 April 2017. [Google Scholar]
- Dubey, A.; Gupta, O.; Raskar, R.; Naik, N. Maximum-Entropy Fine Grained Classification. In Proceedings of the Advances in Neural Information Processing Systems, Montreal, QC, Canada, 3–8 December 2018; Volume 31. [Google Scholar]
- Yun, S.; Park, J.; Lee, K.; Shin, J. Regularizing Class-Wise Predictions via Self-Knowledge Distillation. In Proceedings of the IEEE Conference on Computer Vision and Pattern Recognition (CVPR), Seattle, WA, USA, 13–19 June 2020. [Google Scholar]
- Hinton, G.; Vinyals, O.; Dean, J. Distilling the Knowledge in a Neural Network. arXiv 2015, arXiv:1503.02531. [Google Scholar]
- Gou, J.; Yu, B.; Maybank, S.J.; Tao, D. Knowledge Distillation: A Survey. Int. J. Comput. Vis. 2021, 129, 1789–1819. [Google Scholar] [CrossRef]
- Hoffman, J.; Tzeng, E.; Darrell, T.; Saenko, K. Simultaneous Deep Transfer Across Domains and Tasks. In Proceedings of the IEEE International Conference on Computer Vision (ICCV), Santiago, Chile, 7–13 December 2015; pp. 4068–4076. [Google Scholar]
- Zhou, H.; Song, L.; Chen, J.; Zhou, Y.; Wang, G.; Yuan, J.; Zhang, Q. Rethinking Soft Labels for Knowledge Distillation: A Bias–Variance Tradeoff Perspective. In Proceedings of the International Conference on Learning Representations (ICLR), Virtual Event, Austria, 3–7 May 2021. [Google Scholar]
- Cordts, M.; Omran, M.; Ramos, S.; Rehfeld, T.; Enzweiler, M.; Benenson, R.; Franke, U.; Roth, S.; Schiele, B. The Cityscapes Dataset for Semantic Urban Scene Understanding. In Proceedings of the IEEE Conference on Computer Vision and Pattern Recognition (CVPR), Las Vegas, NV, USA, 27–30 June 2016. [Google Scholar]
- Everingham, M.; Van Gool, L.; Williams, C.K.I.; Winn, J.; Zisserman, A. The PASCAL Visual Object Classes Challenge 2012 (VOC2012) Results. Available online: http://www.pascal-network.org/challenges/VOC/voc2012/workshop/index.html (accessed on 17 March 2022).
- Noh, H.; Hong, S.; Han, B. Learning Deconvolution Network for Semantic Segmentation. In Proceedings of the IEEE International Conference on Computer Vision (ICCV), Santiago, Chile, 7–13 December 2015; pp. 1520–1528. [Google Scholar]
- Badrinarayanan, V.; Kendall, A.; Cipolla, R. SegNet: A Deep Convolutional Encoder-Decoder Architecture for Image Segmentation. IEEE Trans. Pattern Anal. Mach. Intell. 2017, 39, 2481–2495. [Google Scholar] [CrossRef]
- Liu, W.; Rabinovich, A.; Berg, A.C. Parsenet: Looking wider to see better. arXiv 2015, arXiv:1506.04579. [Google Scholar]
- Peng, C.; Zhang, X.; Yu, G.; Luo, G.; Sun, J. Large Kernel Matters—Improve Semantic Segmentation by Global Convolutional Network. In Proceedings of the IEEE Conference on Computer Vision and Pattern Recognition (CVPR), Honolulu, HI, USA, 21–26 July 2017. [Google Scholar]
- Zhao, H.; Qi, X.; Shen, X.; Shi, J.; Jia, J. ICNet for Real-Time Semantic Segmentation on High-Resolution Images. In Proceedings of the European Conference on Computer Vision (ECCV), Munich, Germany, 8–14 September 2018. [Google Scholar]
- Lin, G.; Milan, A.; Shen, C.; Reid, I. RefineNet: Multi-Path Refinement Networks for High-Resolution Semantic Segmentation. In Proceedings of the IEEE Conference on Computer Vision and Pattern Recognition (CVPR), Honolulu, HI, USA, 21–26 July 2017. [Google Scholar]
- Wang, J.; Sun, K.; Cheng, T.; Jiang, B.; Deng, C.; Zhao, Y.; Liu, D.; Mu, Y.; Tan, M.; Wang, X.; et al. Deep High-Resolution Representation Learning for Visual Recognition. IEEE Trans. Pattern Anal. Mach. Intell. 2021, 43, 3349–3364. [Google Scholar] [CrossRef] [Green Version]
- Xiao, T.; Liu, Y.; Zhou, B.; Jiang, Y.; Sun, J. Unified Perceptual Parsing for Scene Understanding. In Proceedings of the European Conference on Computer Vision (ECCV), Munich, Germany, 8–14 September 2018. [Google Scholar]
- Li, X.; Zhao, H.; Han, L.; Tong, Y.; Tan, S.; Yang, K. Gated Fully Fusion for Semantic Segmentation. AAAI Conf. Artif. Intell. 2020, 34, 11418–11425. [Google Scholar] [CrossRef]
- Li, X.; You, A.; Zhu, Z.; Zhao, H.; Yang, M.; Yang, K.; Tong, Y. Semantic Flow for Fast and Accurate Scene Parsing. In Proceedings of the European Conference on Computer Vision (ECCV), Glasgow, UK, 23–28 August 2020. [Google Scholar]
- Vaswani, A.; Shazeer, N.; Parmar, N.; Uszkoreit, J.; Jones, L.; Gomez, A.N.; Kaiser, L.U.; Polosukhin, I. Attention is All you Need. In Proceedings of the Advances in Neural Information Processing Systems, Long Beach, CA, USA, 4–9 December 2017; Volume 30. [Google Scholar]
- Wang, X.; Girshick, R.; Gupta, A.; He, K. Non-local Neural Networks. In Proceedings of the IEEE Conference on Computer Vision and Pattern Recognition (CVPR), Salt Lake City, UT, USA, 18–23 June 2018; pp. 7794–7803. [Google Scholar] [CrossRef] [Green Version]
- Fu, J.; Liu, J.; Tian, H.; Li, Y.; Bao, Y.; Fang, Z.; Lu, H. Dual Attention Network for Scene Segmentation. In Proceedings of the IEEE Conference on Computer Vision and Pattern Recognition (CVPR), Long Beach, CA, USA, 15–20 June 2019; pp. 3141–3149. [Google Scholar] [CrossRef] [Green Version]
- Zhang, H.; Zhang, H.; Wang, C.; Xie, J. Co-Occurrent Features in Semantic Segmentation. In Proceedings of the IEEE Conference on Computer Vision and Pattern Recognition (CVPR), Long Beach, CA, USA, 15–20 June 2019; pp. 548–557. [Google Scholar] [CrossRef]
- Yuan, Y.; Wang, J. OCNet: Object Context Network for Scene Parsing. arXiv 2018, arXiv:1809.00916. [Google Scholar]
- Yuan, Y.; Chen, X.; Wang, J. Object-Contextual Representations for Semantic Segmentation. In Proceedings of the European Conference on Computer Vision (ECCV), Glasgow, UK, 23–28 August 2020; pp. 173–190. [Google Scholar]
- Araslanov, N.; Roth, S. Single-Stage Semantic Segmentation From Image Labels. In Proceedings of the IEEE Conference on Computer Vision and Pattern Recognition (CVPR), Los Alamitos, CA, USA, 13–19 June 2020; pp. 4252–4261. [Google Scholar] [CrossRef]
- Huang, Z.; Wang, X.; Wang, J.; Liu, W.; Wang, J. Weakly-Supervised Semantic Segmentation Network with Deep Seeded Region Growing. In Proceedings of the IEEE Conference on Computer Vision and Pattern Recognition (CVPR), Salt Lake City, UT, USA, 18–23 June 2018; pp. 7014–7023. [Google Scholar] [CrossRef]
- Lee, J.; Kim, E.; Lee, S.; Lee, J.; Yoon, S. FickleNet: Weakly and Semi-Supervised Semantic Image Segmentation Using Stochastic Inference. In Proceedings of the IEEE Conference on Computer Vision and Pattern Recognition (CVPR), Long Beach, CA, USA, 15–20 June 2019; pp. 5262–5271. [Google Scholar] [CrossRef] [Green Version]
- Papandreou, G.; Chen, L.C.; Murphy, K.P.; Yuille, A.L. Weakly-and Semi-Supervised Learning of a Deep Convolutional Network for Semantic Image Segmentation. In Proceedings of the IEEE International Conference on Computer Vision (ICCV), Santiago, Chile, 7–13 December 2015; pp. 1742–1750. [Google Scholar] [CrossRef]
- Dai, J.; He, K.; Sun, J. BoxSup: Exploiting Bounding Boxes to Supervise Convolutional Networks for Semantic Segmentation. In Proceedings of the IEEE International Conference on Computer Vision (ICCV), Santiago, Chile, 7–13 December 2015; pp. 1635–1643. [Google Scholar] [CrossRef] [Green Version]
- Khoreva, A.; Benenson, R.; Hosang, J.; Hein, M.; Schiele, B. Simple Does It: Weakly Supervised Instance and Semantic Segmentation. In Proceedings of the IEEE Conference on Computer Vision and Pattern Recognition (CVPR), Honolulu, HI, USA, 21–26 July 2017; pp. 1665–1674. [Google Scholar] [CrossRef] [Green Version]
- Song, C.; Huang, Y.; Ouyang, W.; Wang, L. Box-Driven Class-Wise Region Masking and Filling Rate Guided Loss for Weakly Supervised Semantic Segmentation. In Proceedings of the IEEE Conference on Computer Vision and Pattern Recognition (CVPR), Long Beach, CA, USA, 15–20 June 2019; pp. 3131–3140. [Google Scholar] [CrossRef] [Green Version]
- Chen, L.; Lopes, R.G.; Cheng, B.; Collins, M.D.; Cubuk, E.D.; Zoph, B.; Adam, H.; Shlens, J. Leveraging Semi-Supervised Learning in Video Sequences for Urban Scene Segmentation. In Proceedings of the European Conference on Computer Vision (ECCV), Glasgow, UK, 23–28 August 2020. [Google Scholar]
- Feng, Z.; Zhou, Q.; Gu, Q.; Tan, X.; Cheng, G.; Lu, X.; Shi, J.; Ma, L. DMT: Dynamic Mutual Training for Semi-Supervised Learning. arXiv 2020, arXiv:2004.08514. [Google Scholar]
- Olsson, V.; Tranheden, W.; Pinto, J.; Svensson, L. ClassMix: Segmentation-Based Data Augmentation for Semi-Supervised Learning. In Proceedings of the IEEE Winter Conference on Applications of Computer Vision (WACV), Waikoloa, HI, USA, 3–8 January 2021; pp. 1368–1377. [Google Scholar] [CrossRef]
- Mittal, S.; Tatarchenko, M.; Brox, T. Semi-Supervised Semantic Segmentation With High- and Low-Level Consistency. IEEE Trans. Pattern Anal. Mach. Intell. 2021, 43, 1369–1379. [Google Scholar] [CrossRef] [Green Version]
- Souly, N.; Spampinato, C.; Shah, M. Semi Supervised Semantic Segmentation Using Generative Adversarial Network. In Proceedings of the IEEE International Conference on Computer Vision (ICCV), Venice, Italy, 22–29 October 2017; pp. 5689–5697. [Google Scholar] [CrossRef]
- Zou, Y.; Zhang, Z.; Zhang, H.; Li, C.L.; Bian, X.; Huang, J.B.; Pfister, T. PseudoSeg: Designing Pseudo Labels for Semantic Segmentation. In Proceedings of the International Conference on Learning Representations (ICLR), Virtual Event, Austria, 3–7 May 2021. [Google Scholar]
- Chen, X.; Yuan, Y.; Zeng, G.; Wang, J. Semi-Supervised Semantic Segmentation with Cross Pseudo Supervision. In Proceedings of the IEEE Conference on Computer Vision and Pattern Recognition (CVPR), Nashville, TN, USA, 20–25 June 2021; pp. 2613–2622. [Google Scholar] [CrossRef]
- Zhao, X.; Vemulapalli, R.; Mansfield, P.A.; Gong, B.; Green, B.; Shapira, L.; Wu, Y. Contrastive Learning for Label Efficient Semantic Segmentation. In Proceedings of the IEEE International Conference on Computer O Vision (ICCV), Montreal, BC, Canada, 11–17 October 2021; pp. 10623–10633. [Google Scholar]
- Khosla, P.; Teterwak, P.; Wang, C.; Sarna, A.; Tian, Y.; Isola, P.; Maschinot, A.; Liu, C.; Krishnan, D. Supervised Contrastive Learning. In Proceedings of the Advances in Neural Information Processing Systems, Online, 6–12 December 2020; Volume 33, pp. 18661–18673. [Google Scholar]
- Hernández-García, A.; König, P. Data augmentation instead of explicit regularization. arXiv 2018, arXiv:1806.03852. [Google Scholar]
- Zou, Y.; Yu, Z.; Liu, X.; Kumar, B.V.K.V.; Wang, J. Confidence Regularized Self-Training. In Proceedings of the IEEE International Conference on Computer Vision (ICCV), Seoul, Korea, 27 October–2 November 2019; pp. 5981–5990. [Google Scholar] [CrossRef] [Green Version]
- Saito, K.; Kim, D.; Sclaroff, S.; Darrell, T.; Saenko, K. Semi-Supervised Domain Adaptation via Minimax Entropy. In Proceedings of the IEEE International Conference on Computer Vision (ICCV), Seoul, Korea, 27 October–2 November 2019; pp. 8049–8057. [Google Scholar] [CrossRef] [Green Version]
- Yu, L.; Liu, X.; van de Weijer, J. Self-Training for Class-Incremental Semantic Segmentation. arXiv 2020, arXiv:2012.03362. [Google Scholar] [CrossRef] [PubMed]
- Xu, T.B.; Liu, C.L. Data-Distortion Guided Self-Distillation for Deep Neural Networks. AAAI Conf. Artif. Intell. 2019, 33, 5565–5572. [Google Scholar] [CrossRef] [Green Version]
- Wang, X.; Hua, Y.; Kodirov, E.; Clifton, D.A.; Robertson, N.M. ProSelfLC: Progressive Self Label Correction for Training Robust Deep Neural Networks. In Proceedings of the IEEE Conference on Computer Vision and Pattern Recognition (CVPR), Nashville, TN, USA, 20–25 June 2021; pp. 752–761. [Google Scholar] [CrossRef]
- Li, J.; Wong, Y.; Zhao, Q.; Kankanhalli, M.S. Learning to Learn From Noisy Labeled Data. In Proceedings of the IEEE Conference on Computer Vision and Pattern Recognition (CVPR), Long Beach, CA, USA, 15–20 June 2019; pp. 5046–5054. [Google Scholar] [CrossRef] [Green Version]
- Liu, Y.; Shu, C.; Wang, J.; Shen, C. Structured Knowledge Distillation for Dense Prediction. IEEE Trans. Pattern Anal. Mach. Intell. 2020. [Google Scholar] [CrossRef]
- Wang, Y.; Zhou, W.; Jiang, T.; Bai, X.; Xu, Y. Intra-class Feature Variation Distillation for Semantic Segmentation. In Proceedings of the European Conference on Computer Vision (ECCV), Glasgow, UK, 23–28 August 2020. [Google Scholar]
- Park, S.; Heo, Y.S. Knowledge Distillation for Semantic Segmentation Using Channel and Spatial Correlations and Adaptive Cross Entropy. Sensors 2020, 20, 4616. [Google Scholar] [CrossRef]
- Yuan, L.; Tay, F.E.; Li, G.; Wang, T.; Feng, J. Revisiting Knowledge Distillation via Label Smoothing Regularization. In Proceedings of the IEEE Conference on Computer Vision and Pattern Recognition (CVPR), Seattle, WA, USA, 13–19 June 2020; pp. 3902–3910. [Google Scholar] [CrossRef]
- Zhang, L.; Song, J.; Gao, A.; Chen, J.; Bao, C.; Ma, K. Be Your Own Teacher: Improve the Performance of Convolutional Neural Networks via Self Distillation. In Proceedings of the IEEE International Conference on Computer Vision (ICCV), Seoul, Korea, 27 October–2 November 2019; pp. 3712–3721. [Google Scholar] [CrossRef] [Green Version]
- Kim, K.; Ji, B.; Yoon, D.; Hwang, S. Self-Knowledge Distillation With Progressive Refinement of Targets. In Proceedings of the IEEE International Conference on Computer Vision (ICCV), Montreal, BC, Canada, 11–17 October 2021; pp. 6567–6576. [Google Scholar]
- Chollet, F. Xception: Deep learning with depthwise separable convolutions. In Proceedings of the IEEE conference on computer vision and pattern recognition (CVPR), Honolulu, HI, USA, 21–26 July 2017; pp. 1251–1258. [Google Scholar]
- He, K.; Zhang, X.; Ren, S.; Sun, J. Deep Residual Learning for Image Recognition. arXiv 2015, arXiv:1512.03385. [Google Scholar]
- Deng, J.; Dong, W.; Socher, R.; Li, L.J.; Li, K.; Fei-Fei, L. Imagenet: A large-scale hierarchical image database. In Proceedings of the IEEE Conference on Computer Vision and Pattern Recognition (CVPR), Miami, FL, USA, 20–25 June 2009; pp. 248–255. [Google Scholar]
- Guo, C.; Pleiss, G.; Sun, Y.; Weinberger, K.Q. On Calibration of Modern Neural Networks. In Proceedings of the 34th International Conference on Machine Learning (ICML), Sydney, Australia, 6–11 August 2017; Volume 70, pp. 1321–1330. [Google Scholar]







{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
| Method | Strength | Weakness |
|---|---|---|
| LS [20] |
|
|
| CP [22] |
|
|
| KD [25] |
|
|
| Ours |
|
|
| Method | Data | 10% | 30% | 50% | 100% |
|---|---|---|---|---|---|
| CE (baseline) [10] | train | 79.054 ± 0.307 | 81.650 ± 0.511 | 82.291 ± 0.024 | 82.586 ± 0.157 |
| val | 59.886 ± 0.430 | 67.756 ± 0.312 | 69.895 ± 0.212 | 73.167 ± 0.155 | |
| test | 59.348 ± 0.046 | 66.224 ± 1.270 | 69.522 ± 0.003 | 72.272 ± 0.237 | |
| LS [20] | train | 78.117 ± 0.040 | 82.032 ± 0.001 | 83.505 ± 0.008 | 83.219 ± 0.117 |
| val | 59.459 ± 0.051 | 68.822 ± 0.141 | 70.190 ± 0.499 | 73.748 ± 0.137 | |
| test | 59.331 ± 0.015 | 67.717 ± 0.111 | 69.606 ± 0.081 | 72.542 ± 0.082 | |
| CP [22] | train | 76.269 ± 13.697 | 79.411 ± 6.892 | 80.755 ± 4.305 | 82.303 ± 2.204 |
| val | 58.137 ± 3.820 | 67.715 ± 4.373 | 70.517 ± 0.393 | 73.830 ± 0.151 | |
| test | 57.339 ± 3.997 | 65.397 ± 1.011 | 68.650 ± 0.483 | 72.814 ± 0.643 | |
| Ours | train | 78.641 ± 0.187 | 81.784 ± 0.799 | 82.711 ± 0.002 | 83.342 ± 0.023 |
| val | 59.767 ± 0.209 | 69.285 ± 0.618 | 70.974 ± 0.240 | 73.889 ± 0.288 | |
| test | 59.424 ± 0.122 | 68.072 ± 0.077 | 70.659 ± 0.467 | 73.335 ± 0.102 |
| Method | Data | 10% | 30% | 50% | 100% |
|---|---|---|---|---|---|
| CE (baseline) [10] | train | 68.878 ± 1.464 | 74.616 ± 2.380 | 76.337 ± 5.025 | 78.619 ± 0.061 |
| val | 51.215 ± 2.327 | 61.104 ± 2.133 | 63.656 ± 2.274 | 67.754 ± 3.187 | |
| test | 51.091 ± 0.873 | 59.862 ± 1.684 | 63.506 ± 3.966 | 68.795 ± 0.213 | |
| LS [20] | train | 70.774 ± 1.395 | 78.384 ± 0.195 | 78.766 ± 0.020 | 79.837 ± 0.025 |
| val | 53.650 ± 0.736 | 64.088 ± 0.038 | 65.463 ± 0.050 | 70.424 ± 0.087 | |
| test | 54.182 ± 0.508 | 62.089 ± 0.048 | 65.507 ± 0.059 | 69.752 ± 0.139 | |
| CP [22] | train | 66.839 ± 34.734 | 74.860 ± 1.199 | 75.303 ± 1.723 | 78.585 ± 0.263 |
| val | 49.267 ± 12.073 | 61.485 ± 1.302 | 63.292 ± 1.325 | 69.134 ± 0.120 | |
| test | 49.943 ± 10.104 | 60.262 ± 1.324 | 62.889 ± 2.235 | 69.752 ± 0.139 | |
| Ours | train | 71.452 ± 1.704 | 78.227 ± 0.113 | 78.838 ± 0.131 | 79.849 ± 0.003 |
| val | 54.219 ± 0.065 | 64.172 ± 0.157 | 65.672 ± 0.005 | 70.374 ± 0.008 | |
| test | 54.683 ± 0.048 | 62.649 ± 0.022 | 65.441 ± 0.175 | 69.837 ± 0.118 |
| Method | Data | 10% | 30% | 50% | 100% |
|---|---|---|---|---|---|
| CE (baseline) [10] | val | 57.338 | 67.049 | 70.079 | 74.708 |
| test | 56.538 | 68.240 | 69.745 | 73.615 | |
| LS [20] | val | 56.981 | 69.772 | 73.733 | 76.320 |
| test | 57.111 | 68.666 | 72.535 | 74.650 | |
| CP [22] | val | 52.951 | 68.424 | 69.603 | 74.373 |
| test | 53.982 | 67.368 | 69.452 | 73.817 | |
| Ours | val | 58.989 | 70.939 | 73.814 | 76.407 |
| test | 57.985 | 68.953 | 72.930 | 74.768 |
| Method | 10% | 30% | 50% | 100% |
|---|---|---|---|---|
| Our original method | 60.279 | 69.912 | 71.535 | 73.849 |
| w/o class mask A | 59.181 | 68.756 | 71.317 | 73.490 |
| w/o correct mask B | 59.211 | 69.620 | 70.706 | 73.369 |
| w/o uniform distribution U | 59.785 | 69.107 | 71.279 | 72.563 |
| w/o adaptive weight | 59.902 | 68.681 | 71.481 | 72.996 |
| 10% | 30% | 50% | 100% | |
|---|---|---|---|---|
| 0.05 | 59.552 | 68.080 | 69.352 | 73.153 |
| 0.10 | 60.074 | 68.399 | 70.269 | 72.686 |
| 0.15 | 60.201 | 66.600 | 68.719 | 73.093 |
| 0.20 | 60.279 | 69.912 | 71.535 | 73.849 |
| 0.25 | 59.758 | 69.683 | 71.830 | 73.540 |
| 0.30 | 59.807 | 69.481 | 69.780 | 73.450 |
| 0.40 | 58.150 | 68.095 | 71.040 | 72.629 |
| 0.50 | 58.062 | 69.460 | 70.531 | 73.746 |
Publisher’s Note: MDPI stays neutral with regard to jurisdictional claims in published maps and institutional affiliations. |
© 2022 by the authors. Licensee MDPI, Basel, Switzerland. This article is an open access article distributed under the terms and conditions of the Creative Commons Attribution (CC BY) license (https://creativecommons.org/licenses/by/4.0/).
Share and Cite
Park, S.; Kim, J.; Heo, Y.S. Semantic Segmentation Using Pixel-Wise Adaptive Label Smoothing via Self-Knowledge Distillation for Limited Labeling Data. Sensors 2022, 22, 2623. https://doi.org/10.3390/s22072623
Park S, Kim J, Heo YS. Semantic Segmentation Using Pixel-Wise Adaptive Label Smoothing via Self-Knowledge Distillation for Limited Labeling Data. Sensors. 2022; 22(7):2623. https://doi.org/10.3390/s22072623
Chicago/Turabian StylePark, Sangyong, Jaeseon Kim, and Yong Seok Heo. 2022. "Semantic Segmentation Using Pixel-Wise Adaptive Label Smoothing via Self-Knowledge Distillation for Limited Labeling Data" Sensors 22, no. 7: 2623. https://doi.org/10.3390/s22072623