
RODFormer: High-Precision Design for Rotating Object Detection with Transformers


Abstract
:1. Introduction
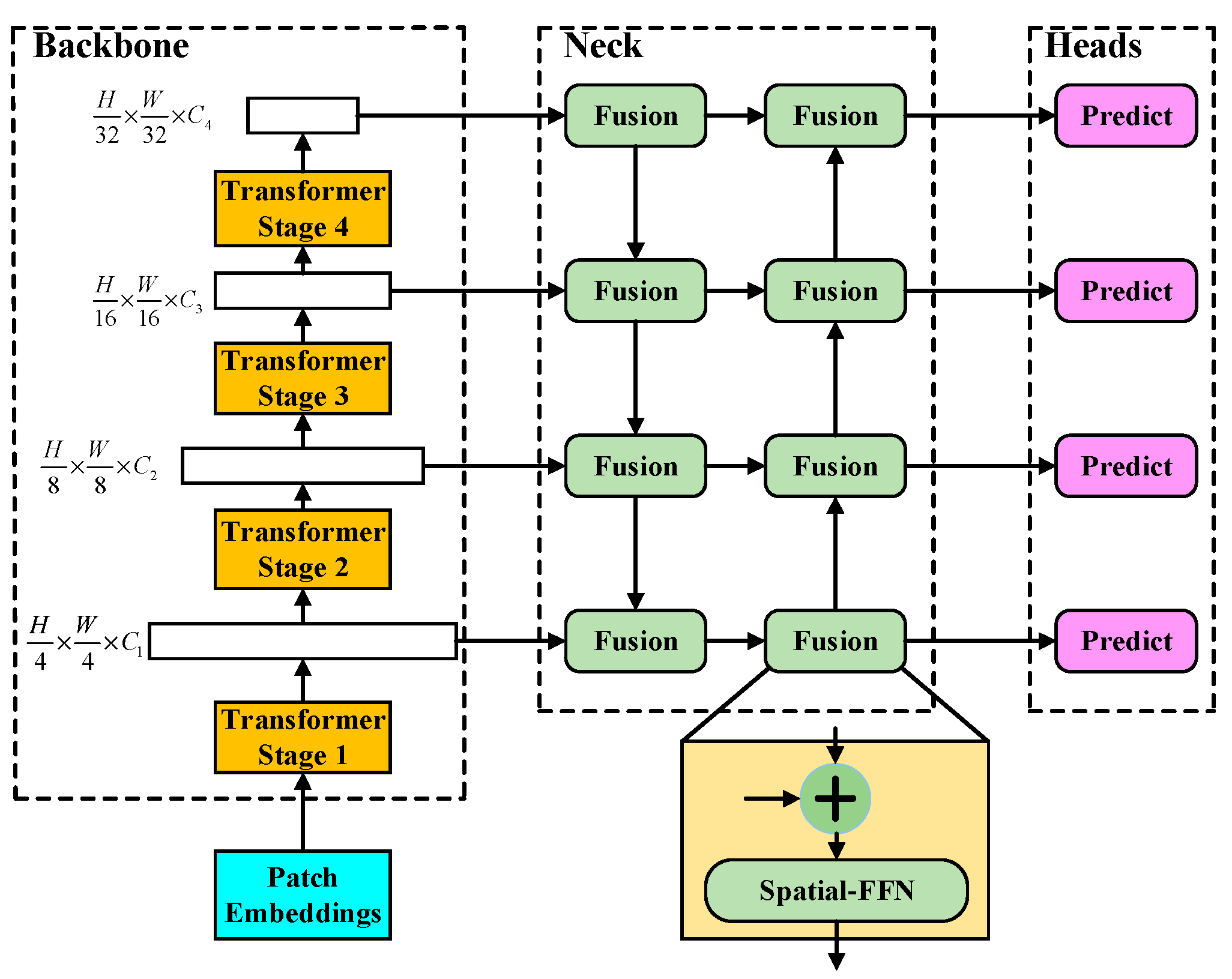
2. Methods
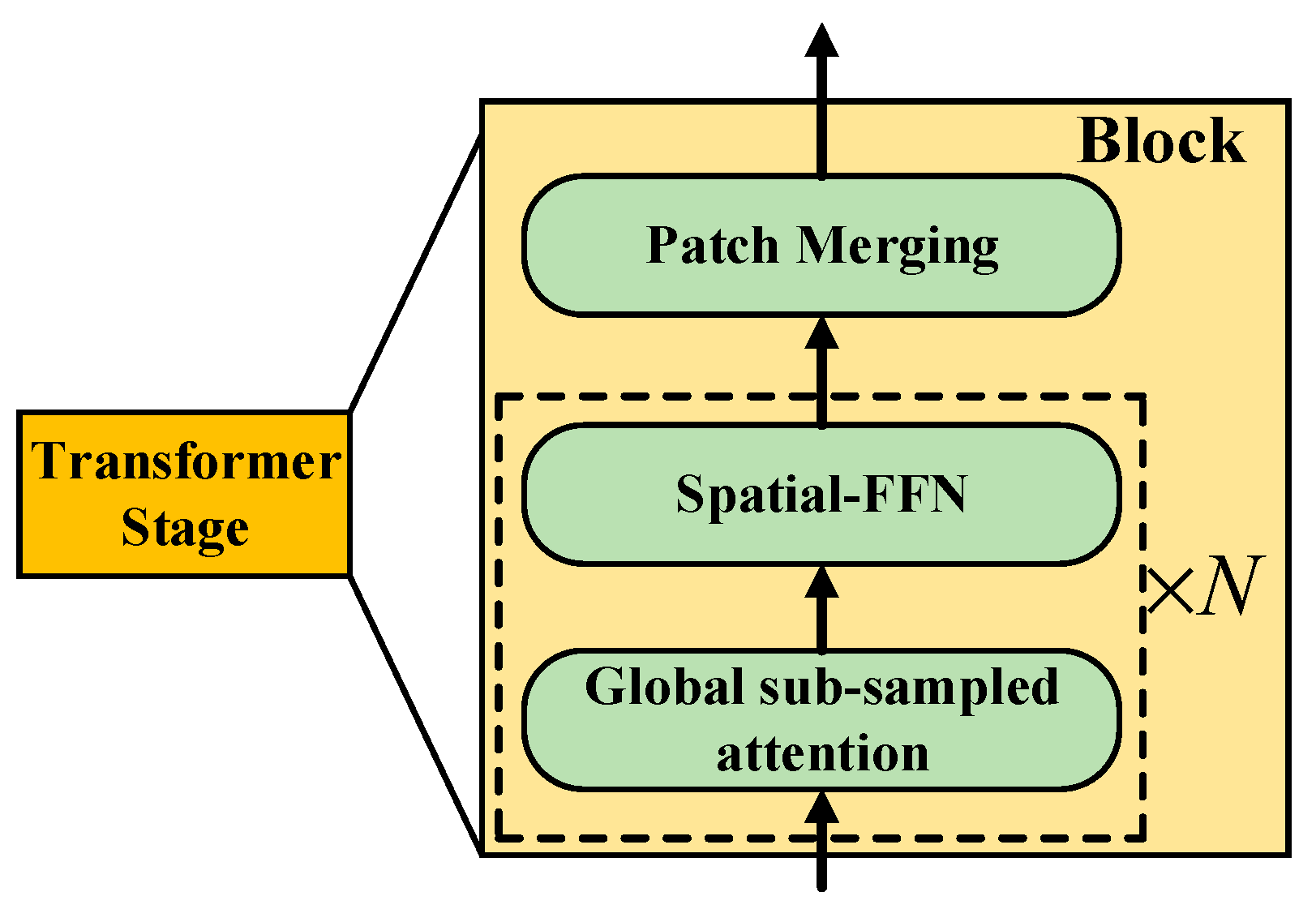
2.1. Backbone
K = Linear (C·R2, C) (K′)
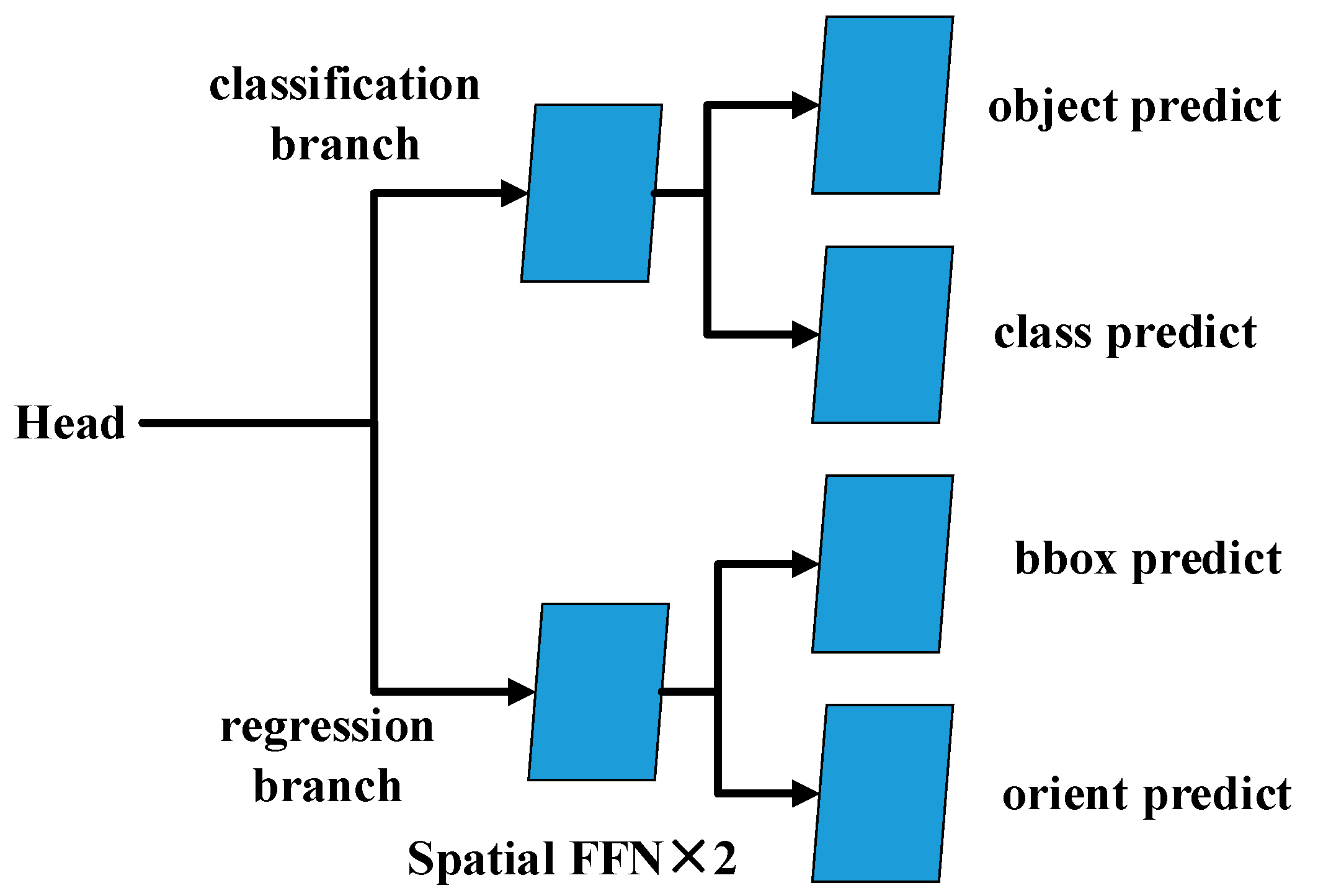
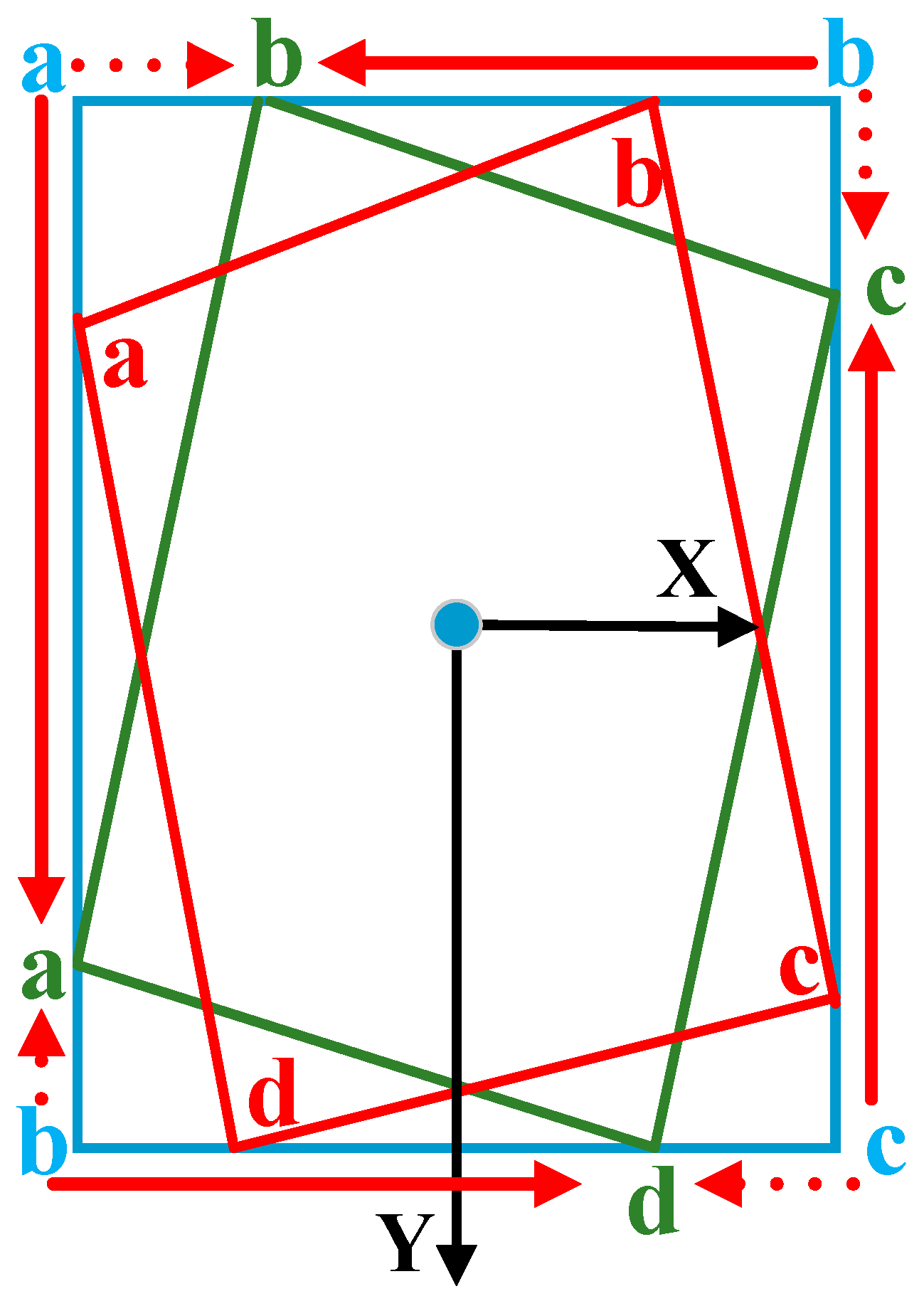
2.2. Neck and Heads
3. Experiments
3.1. Datasets
3.2. Experimental Environment and Evaluation Index
3.3. Experimental Results and Analysis
4. Conclusions
Author Contributions
Funding
Institutional Review Board Statement
Informed Consent Statement
Data Availability Statement
Conflicts of Interest
References
- Xu, M.; Fu, P.; Liu, B.; Li, J. Multi-stream attention-aware graph convolution network for video salient object detection. IEEE Trans. Image Process. 2021, 30, 4183–4197. [Google Scholar] [CrossRef] [PubMed]
- Graterol, W.; Diaz-Amado, J.; Cardinale, Y.; Dongo, I.; Santos-Libarino, C. Emotion Detection for Social Robots Based on NLP Transformerss and an Emotion Ontology. Sensors 2021, 21, 1322. [Google Scholar] [CrossRef] [PubMed]
- Ma, J.; Shao, W.; Ye, H.; Wang, L.; Wang, H.; Zheng, Y.; Xue, X. Arbitrary-Oriented Scene Text Detection via Rotation Proposals. IEEE Trans. Multimed. 2018, 20, 3111–3122. [Google Scholar] [CrossRef] [Green Version]
- Jiang, Y.; Zhu, X.; Wang, X.; Yang, S.; Li, W.; Wang, H.; Fu, P.; Luo, Z. R2CNN: Rotational region CNN for orientation robust scene text detection. arXiv 2017, arXiv:1706.09579. [Google Scholar]
- Ding, J.; Xue, N.; Long, Y.; Xia, G.-S.; Lu, Q. Learning RoI transformers for oriented object detection in aerial images. In Proceedings of the 2019 IEEE/CVF Conference on Computer Vision and Pattern Recognition (CVPR), Long Beach, CA, USA, 15–20 June 2019; pp. 2849–2858. [Google Scholar]
- Yang, X.; Yang, J.; Yan, J.; Zhang, Y.; Zhang, T.; Guo, Z.; Sun, X.; Fu, K. SCRDet:Towards More Robust Detection for Small, Cluttered and Rotated Objects. In Proceedings of the IEEE International Conference on Computer Vision (ICCV), Seoul, Korea, 27 October–2 November 2019. [Google Scholar]
- Carion, N.; Massa, F.; Synnaeve, G.; Usunier, N.; Kirillov, A.; Zagoruyko, S. End-to-end object detection with transformerss. In European Conference on Computer Vision; Springer: Cham, Switzerland, 2020. [Google Scholar]
- Vaswani, A.; Shazeer, N.; Parmar, N.; Uszkoreit, J.; Jones, L.; Gomez, A.N.; Kaiser, Ł.; Polosukhin, I. Attention Is All You Need. Adv. Neural Inf. Process. Syst. 2017, 30, 1–15. [Google Scholar]
- Zhu, X.; Su, W.; Lu, L.; Li, B.; Wang, X.; Dai, J. Deformable DETR: Deformable Transformerss for End-to-End Object Detection. arXiv 2021, arXiv:2010.04159v4. [Google Scholar]
- Dai, Z.; Cai, B.; Lin, Y.; Chen, J. UP-DETR: Unsupervised Pre-training for Object Detection with Transformerss. In Proceedings of the IEEE/CVF Conference on Computer Vision and Pattern Recognition (CVPR), Nashville, TN, USA, 20 June–25 June 2021. [Google Scholar]
- Cheng, S.; Wu, Y.; Li, Y.; Yao, F.; Min, F. TWD-SFNN: Three-way decisions with a single hidden layer feedforward neural network. Inf. Sci. 2021, 579, 15–32. [Google Scholar] [CrossRef]
- Alexander, A.; Strauss, M.T.; Sebastian, S.; Jungmann, R. NanoTRON: A Picasso module for MLP-based classification of super-resolution data. Bioinformatics 2020, 11, 3620–3622. [Google Scholar]
- Gao, P.; Zheng, M.; Wang, X.; Dai, J.; Li, H. Fast Convergence of DETR withSpatially Modulated Co-Attention. In Proceedings of the IEEE/CVF International Conference on Computer Vision (ICCV), Montreal, BC, Canada, 11–17 October 2021. [Google Scholar]
- Sun, Z.; Cao, S.; Yang, Y.; Kitani, K.M. Rethinking Transformers-based Set Prediction for Object Detection. In Proceedings of the IEEE/CVF International Conference on Computer Vision (ICCV), Montreal, BC, Canada, 11–17 October 2021. [Google Scholar]
- Ding, X.; Xia, C.; Zhang, X.; Chu, X.; Han, J.; Ding, G. RepMLP: Re-parameterizing Convolutions into Fully-connected Layers for Image Recognition. arXiv 2021, arXiv:2105.01883v2. [Google Scholar]
- Beal, J.; Kim, E.; Tzeng, E.; Park, D.H.; Zhai, A.; Kislyuk, D. Toward Transformers-Based Object Detection. arXiv 2020, arXiv:2012.09958v1. [Google Scholar]
- Wang, W.; Xie, E.; Li, X.; Fan, D.; Song, K.; Liang, D.; Lu, T.; Luo, P.; Shao, L. Pyramid Vision Transformers: A Versatile Backbone for Dense Prediction without Convolutions. arXiv 2021, arXiv:2102.12122v2. [Google Scholar]
- Law, H.; Deng, J. CornerNet: Detecting Objects as Paired Keypoints. Int. J. Comput. Vis. 2020, 128, 642–656. [Google Scholar] [CrossRef] [Green Version]
- Lyaqini, S.; Quafafou, M.; Nachaoui, M.; Chakib, A. Supervised learning as an inverseproblem based on non-smooth loss function. Knowl. Inf. Syst. 2020, 62, 10. [Google Scholar] [CrossRef]
- Zhao, P.; Qu, Z.; Bu, Y.; Tan, W.; Guna, Q. PolarDet: A fast, more precise detector for rotated target in aerial images. Int. J. Remote Sens. 2021, 42, 5831–5861. [Google Scholar] [CrossRef]
- Han, J.; Ding, J.; Li, J.; Xia, G. Align deep features for oriented object detection. IEEE Trans. Geosci. Remote Sens. 2021, 60, 5602511. [Google Scholar] [CrossRef]
- Yang, F.; Li, W.; Hu, H.; Li, W.; Wang, P. Multi-Scale Feature Integrated Attention-Based RotationNetwork for Object Detection in VHR Aerial Images. Sensors 2020, 20, 1686. [Google Scholar] [CrossRef] [Green Version]
- Wu, P.; Gong, S.; Pan, K.; Qiu, F.; Feng, W.; Pain, C. Reduced order model using convolutional auto-encoder with self-attention. Phys. Fluids 2021, 33, 077107. [Google Scholar] [CrossRef]
- Chu, X.; Tian, Z.; Wang, Y.; Zhang, B.; Ren, H.; Wei, X.; Xia, H.; Shen, C. Twins: Revisiting the Design of Spatial Attention in Vision Transformerss. Adv. Neural Inf. Process. Syst. 2021, 34, 1–12. [Google Scholar]
- Shen, Z.; Bello, I.; Vemulapalli, R.; Jia, X.; Chen, C. Global Self-attention networks for image recognition. arXiv 2020, arXiv:2010.03019v2. [Google Scholar]
- Shanga, R.; He, J.; Wang, J.; Xu, K.; Jiao, L.; Stolkin, R. Dense connection and depthwise separable convolution based CNN for polarimetric SAR image classification. Knowl.-Based Syst. 2020, 194, 105542. [Google Scholar] [CrossRef]
- Ba, J.L.; Kiros, J.R.; Hinton, G.E. Layer normalization. arXiv 2016, arXiv:1607.06450. [Google Scholar]
- He, K.; Zhang, X.; Ren, S.; Sun, J. Deep Residual Learning for Image Recognition. In Proceedings of the 2016 IEEE Conference on Computer Vision and Pattern Recognition (CVPR), Las Vegas, NV, USA, 27–30 June 2016; pp. 770–778. [Google Scholar]
- Qian, W.; Yang, X.; Peng, S.; Guo, Y.; Yan, J. Learning Modulated Loss for Rotated Object Detection. arXiv 2019, arXiv:1911.08299v3. [Google Scholar]
- Gao, J.; Chen, Y.; Wei, Y.; Li, J. Detection of Specific Building in Remote Sensing Images Using a Novel YOLO-S-CIOU Model. Case: Gas Station Identification. Sensors 2021, 21, 1375. [Google Scholar] [CrossRef] [PubMed]
- Zhang, G.; Lu, S.; Zhang, W. CAD-Net: A context-aware detection network for objects in remote sensing imagery. IEEE Trans. Geosci. Remote Sens. 2019, 57, 10015–10024. [Google Scholar] [CrossRef] [Green Version]
- Pan, X.; Ren, Y.; Sheng, K.; Dong, W.; Yuan, H.; Guo, X.; Ma, C.; Xu, C. Dynamicrefinement network for oriented and densely packed object detection. In Proceedings of the IEEE/CVF Conference on Computer Vision and Pattern Recognition (CVPR), Seattle, WA, USA, 13–19 June 2020; pp. 11207–11216. [Google Scholar]
- Azimi, S.M.; Vig, E.; Bahmanyar, R.; Körner, M.; Reinartz, P. Towards multi-classobject detection in unconstrained remote sensing imagery. In Proceedings of the 14th Asian Conference on Computer Vision, Perth, WA, Australia, 2–6 December 2018; pp. 150–165. [Google Scholar]
- Li, Y.; Huang, Q.; Pei, X.; Jiao, L.; Shang, R. RADet: Refine Feature Pyramid Network and Multi-Layer Attention Network for Arbitrary-Oriented Object Detection of Remote Sensing Images. Remote Sens. 2020, 12, 389. [Google Scholar] [CrossRef] [Green Version]
- Shi, P.; Zhao, Z.; Fan, X.; Yan, X.; Yan, W.; Xin, Y. Remote Sensing Image Object Detection Based on Angle Classification. IEEE Access 2021, 9, 118696–118707. [Google Scholar] [CrossRef]






{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
| Dataset | 10–50 Pixels | 50–300 Pixels | >300 Pixels |
|---|---|---|---|
| DOTA | 0.57 | 0.41 | 0.02 |
| NWPU VHR-10 | 0.15 | 0.83 | 0.02 |
| MSCOCO | 0.43 | 0.49 | 0.08 |
| PASCAL VOC | 0.14 | 0.61 | 0.25 |
| Configure | Setting | Parameter | Setting |
|---|---|---|---|
| Experiment system | Ubuntu 20.04 | Backbone | ViT-B4 |
| Learning framework | 1.10 | Total batch size | 16 |
| GPU | Nvidia RTX 3090 Ti | Epoch | 300 |
| Initial weight | Xavier init | Initial learning rate | 10−4 |
| Programming language | Python 3.9 | Weight decay rate | 0.0001 |
| Number stage | 1, 2, 5, 8 | ||
| IoU | 0.1 |
| Backbone | STS | SFM | C-SL1 | PL | BD | BR | GTF | SV | LV | SH | TC | BC | ST | SBF | RA | HA | SP | HC | mAP |
|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|
| AP | |||||||||||||||||||
| ResNet50 | × | × | × | 88.03 | 74.49 | 38.02 | 66.34 | 60.24 | 46.56 | 68.20 | 86.39 | 77.12 | 78.28 | 52.50 | 61.15 | 50.82 | 60.21 | 49.99 | 63.89 |
| ResNet152 | × | × | × | 88.92 | 77.82 | 41.50 | 61.86 | 67.32 | 53.97 | 72.19 | 89.88 | 78.65 | 74.92 | 53.25 | 58.41 | 52.47 | 68.85 | 62.78 | 66.85 |
| ViT-B4 | × | × | × | 88.21 | 76.63 | 45.81 | 70.25 | 66.21 | 71.59 | 80.69 | 89.64 | 80.69 | 80.25 | 57.06 | 58.61 | 62.93 | 60.96 | 48.51 | 69.20 |
| ViT-B4 | √ | × | × | 89.51 | 77.58 | 47.51 | 69.03 | 68.94 | 77.69 | 82.01 | 86.50 | 82.36 | 82.12 | 59.08 | 56.02 | 58.90 | 62.38 | 53.06 | 70.38 |
| ViT-B4 | √ | √ | × | 89.80 | 79.59 | 48.93 | 71.43 | 72.54 | 80.51 | 87.95 | 90.75 | 86.09 | 83.69 | 60.01 | 60.39 | 62.94 | 68.02 | 58.98 | 73.44 |
| ViT-B4 | √ | √ | √ | 89.76 | 79.64 | 56.61 | 71.57 | 78.60 | 85.29 | 89.93 | 90.53 | 87.73 | 83.05 | 60.19 | 60.34 | 66.03 | 69.75 | 64.95 | 75.60 |
| Category | PL | BD | BR | GTF | SV | LV | SH | TC | BC | ST | SBF | RA | HA | SP | HC | mAP | |
|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|
| Model | AP | ||||||||||||||||
| R2CNN (2017) | 80.94 | 65.67 | 35.34 | 67.44 | 59.92 | 50.91 | 55.81 | 90.67 | 66.92 | 72.39 | 55.06 | 52.23 | 55.14 | 53.35 | 48.22 | 60.67 | |
| RRPN (2018) | 88.52 | 71.20 | 31.66 | 59.30 | 51.85 | 56.19 | 57.25 | 90.81 | 72.84 | 67.38 | 56.69 | 52.84 | 53.08 | 51.94 | 53.58 | 61.01 | |
| RoI- Transformer (2019) | 88.64 | 78.52 | 43.44 | 75.92 | 68.81 | 73.68 | 83.59 | 90.74 | 77.27 | 81.46 | 58.39 | 53.54 | 62.83 | 58.93 | 47.67 | 69.56 | |
| CADNet (2019) | 87.80 | 82.40 | 49.40 | 73.50 | 71.10 | 63.50 | 76.60 | 90.90 | 79.20 | 73.30 | 48.40 | 60.90 | 62.00 | 67.00 | 62.20 | 69.90 | |
| DRN (2020) | 89.71 | 82.34 | 47.22 | 64.10 | 76.22 | 74.43 | 85.84 | 90.57 | 86.18 | 84.89 | 57.65 | 61.93 | 69.30 | 69.63 | 58.48 | 73.23 | |
| ICN (2018) | 81.40 | 74.30 | 47.70 | 70.30 | 64.90 | 67.80 | 70.00 | 90.80 | 79.10 | 78.20 | 53.60 | 62.90 | 67.00 | 64.20 | 50.20 | 68.20 | |
| RADet (2020) | 79.45 | 76.99 | 48.05 | 65.83 | 65.46 | 74.40 | 68.86 | 89.70 | 78.14 | 74.97 | 49.92 | 64.63 | 66.14 | 71.58 | 62.16 | 69.09 | |
| SCRDet (2019) | 89.98 | 80.65 | 52.09 | 68.36 | 68.36 | 60.32 | 72.41 | 90.85 | 87.94 | 86.86 | 65.02 | 66.68 | 66.25 | 68.24 | 65.21 | 72.61 | |
| MFIAR-Net (2020) | 89.62 | 84.03 | 52.41 | 70.30 | 70.13 | 67.64 | 77.81 | 90.85 | 85.40 | 86.22 | 63.21 | 64.14 | 68.31 | 70.21 | 62.11 | 73.49 | |
| IRetinaNet (2021) | 88.70 | 82.46 | 52.81 | 68.75 | 78.51 | 81.45 | 86.41 | 90.02 | 85.37 | 86.31 | 65.10 | 65.20 | 67.80 | 69.29 | 64.83 | 75.53 | |
| PolarDet (2021) | 89.73 | 87.05 | 45.30 | 63.32 | 78.44 | 76.65 | 87.13 | 90.79 | 80.58 | 85.89 | 60.97 | 67.94 | 68.20 | 74.63 | 68.67 | 75.02 | |
| S2A-Net (2021) | 89.11 | 82.84 | 48.37 | 71.11 | 78.11 | 78.39 | 87.25 | 90.83 | 84.90 | 85.64 | 60.36 | 62.60 | 65.26 | 69.13 | 57.94 | 74.12 | |
| RODFormer | 89.76 | 79.64 | 56.61 | 71.57 | 78.60 | 85.29 | 89.93 | 90.53 | 87.73 | 83.05 | 60.19 | 60.34 | 66.03 | 69.75 | 64.95 | 75.60 | |
Publisher’s Note: MDPI stays neutral with regard to jurisdictional claims in published maps and institutional affiliations. |
© 2022 by the authors. Licensee MDPI, Basel, Switzerland. This article is an open access article distributed under the terms and conditions of the Creative Commons Attribution (CC BY) license (https://creativecommons.org/licenses/by/4.0/).
Share and Cite
Dai, Y.; Yu, J.; Zhang, D.; Hu, T.; Zheng, X. RODFormer: High-Precision Design for Rotating Object Detection with Transformers. Sensors 2022, 22, 2633. https://doi.org/10.3390/s22072633
Dai Y, Yu J, Zhang D, Hu T, Zheng X. RODFormer: High-Precision Design for Rotating Object Detection with Transformers. Sensors. 2022; 22(7):2633. https://doi.org/10.3390/s22072633
Chicago/Turabian StyleDai, Yaonan, Jiuyang Yu, Dean Zhang, Tianhao Hu, and Xiaotao Zheng. 2022. "RODFormer: High-Precision Design for Rotating Object Detection with Transformers" Sensors 22, no. 7: 2633. https://doi.org/10.3390/s22072633
APA StyleDai, Y., Yu, J., Zhang, D., Hu, T., & Zheng, X. (2022). RODFormer: High-Precision Design for Rotating Object Detection with Transformers. Sensors, 22(7), 2633. https://doi.org/10.3390/s22072633