
Network Traffic Prediction Incorporating Prior Knowledge for an Intelligent Network

Abstract
:1. Introduction
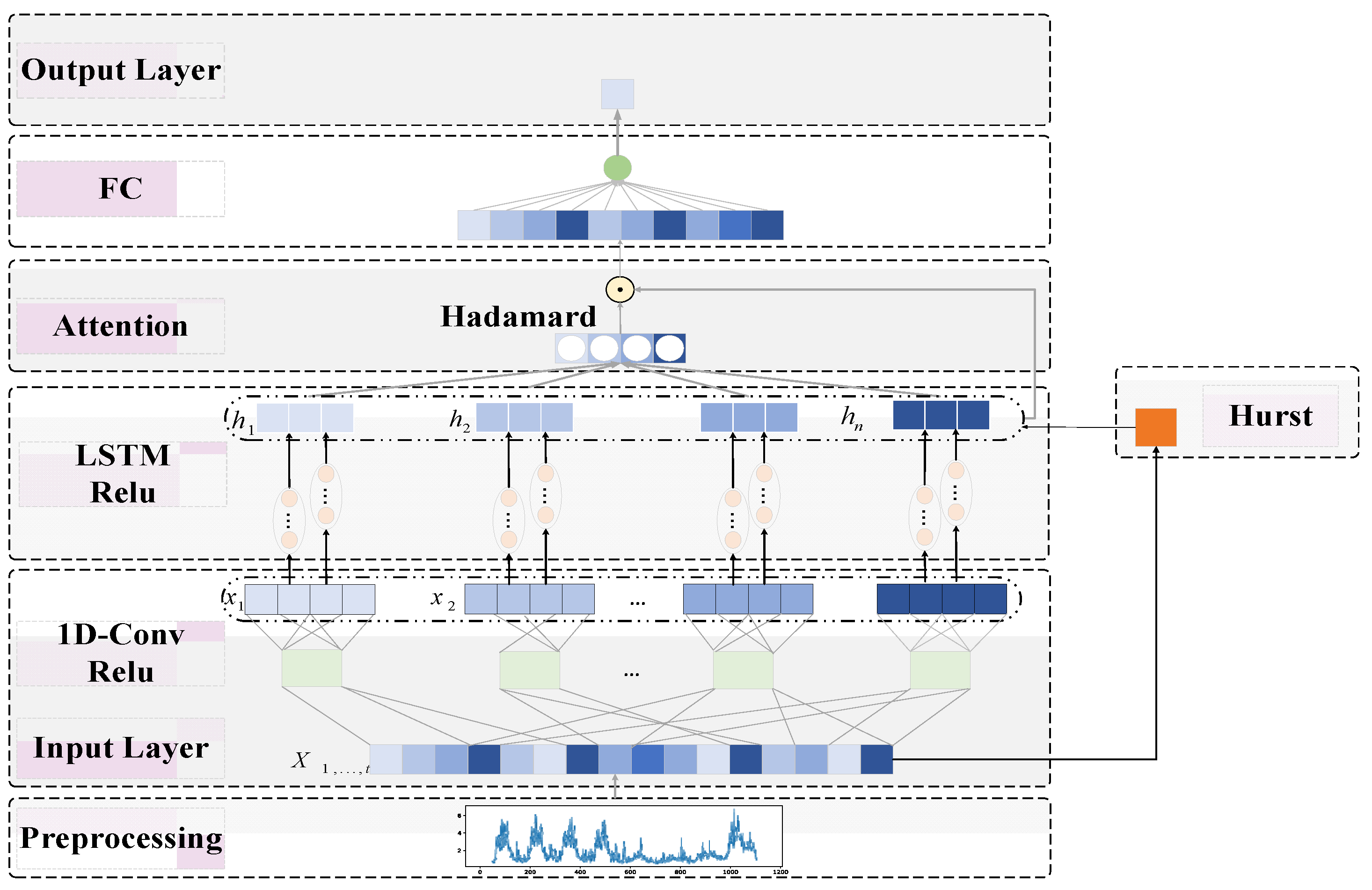
- FPK-Net consists of a CNN and an LSTM based on an attention mechanism. The self-similarity property is incorporated into the training model before model training, which results in improvements in the extraction of traffic features and in the prediction accuracy when dealing with insufficient sample data.
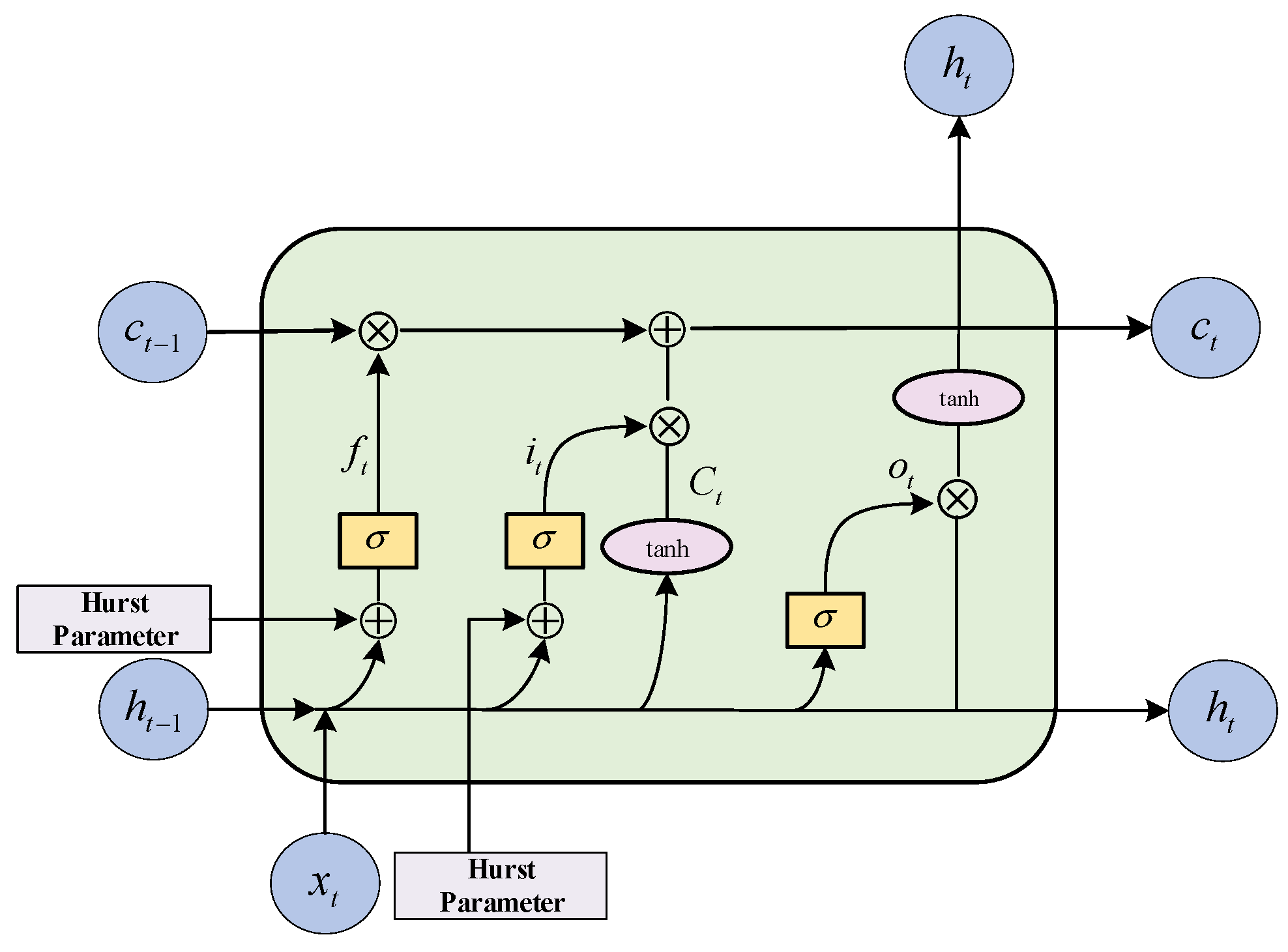
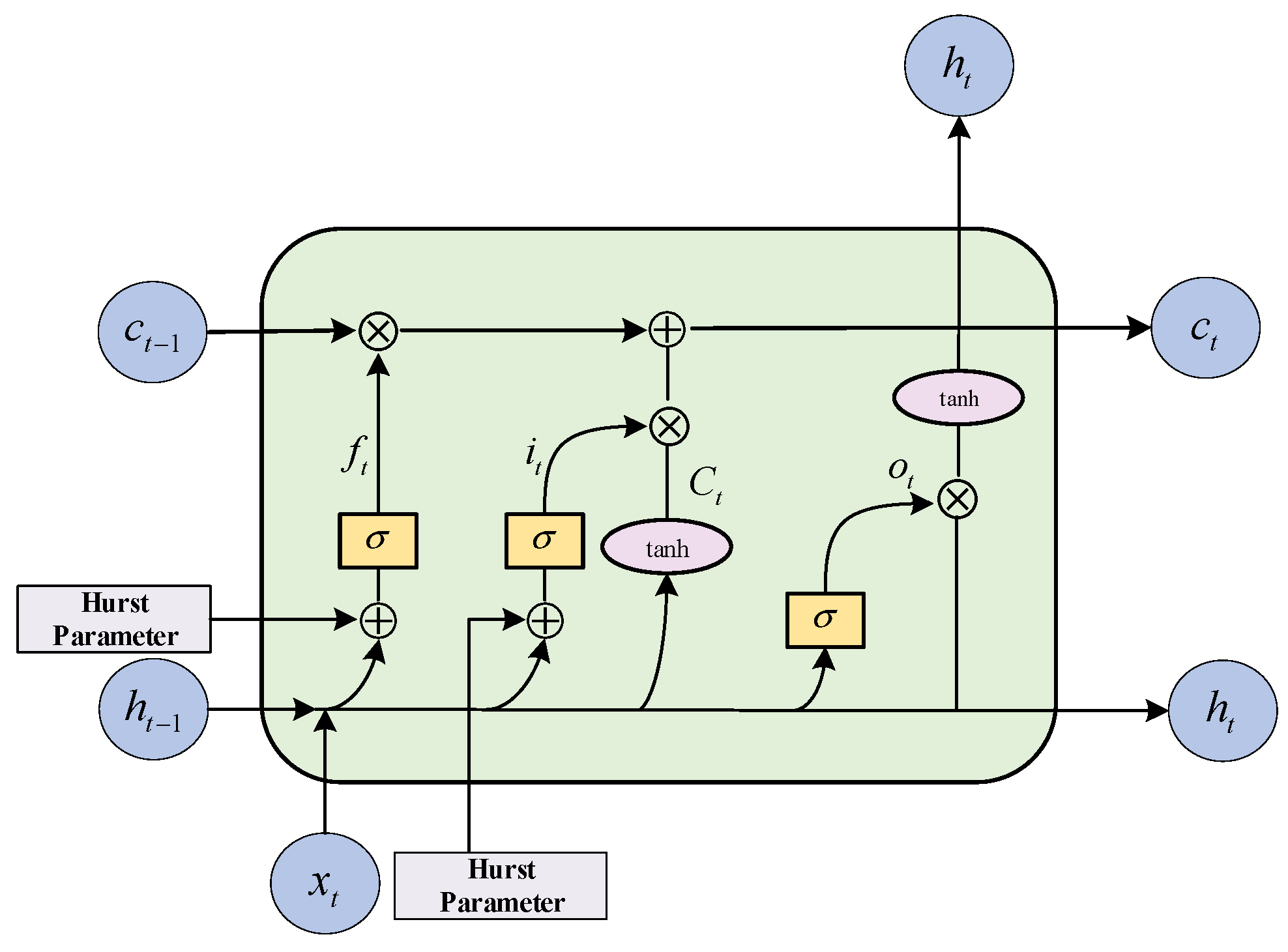
- The model incorporates the self-similarity property of network traffic as a priori knowledge into the intermediate structure of the deep network; namely, the Hurst exponent is added into the gating of the long short-term memory neural network (LSTM) as a bias term to increase the model’s interpretability.
- Experiments on publicly available datasets verified that the proposed model is consistent with the existing empirical evidence, and has better predictive power than other existing prediction methods. The accumulation of prior knowledge during training meaningfully guides the network traffic prediction, thus significantly improving the performance of the training model. In terms of the absolute coefficient of correction, the proposed model achieved values at least 10% higher than those of traditional statistical models. Thus, the reliability and superiority of the proposed model were illustrated in the article while the results demonstrated that the model is also interpretable.
2. Related Work
3. A Network Traffic Prediction Framework Incorporating Prior Knowledge
3.1. Problem Definition
- A time series is a node , which only has one feature at a given moment .
- The prediction problem refers to the information that is used to predict the next moment from historical data , where is the relevant characteristic obtained from the historical data ; that is, to find the information that satisfies:
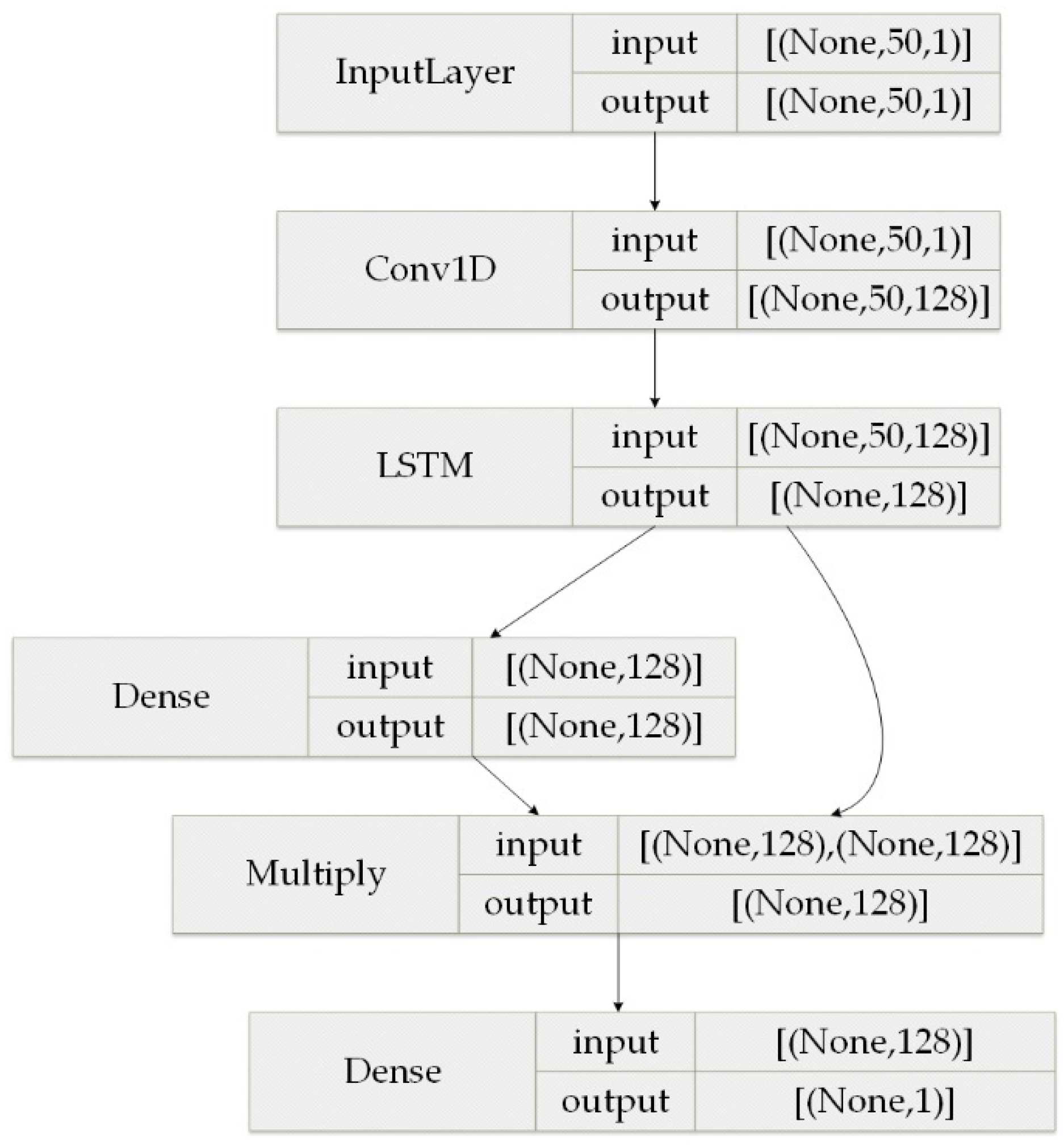
3.2. Prediction Framework
4. Predictive Models
4.1. Flow Characterization Module
- Calculate the average value of each subsequence .
- Create mean-adjusted series .
- Generate cumulative deviation series
- Calculation range
- Calculation range
- Calculating the rescaling range
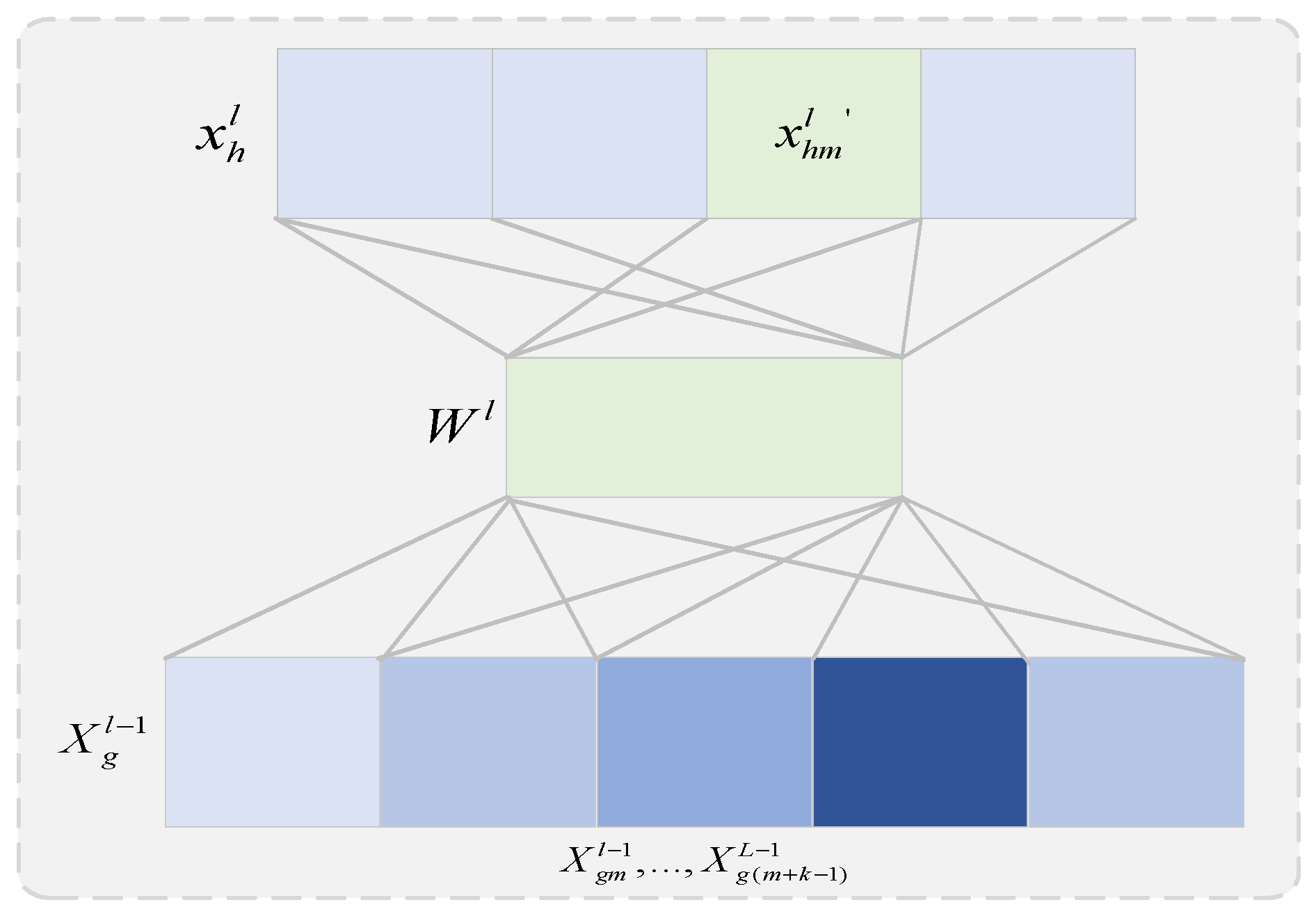
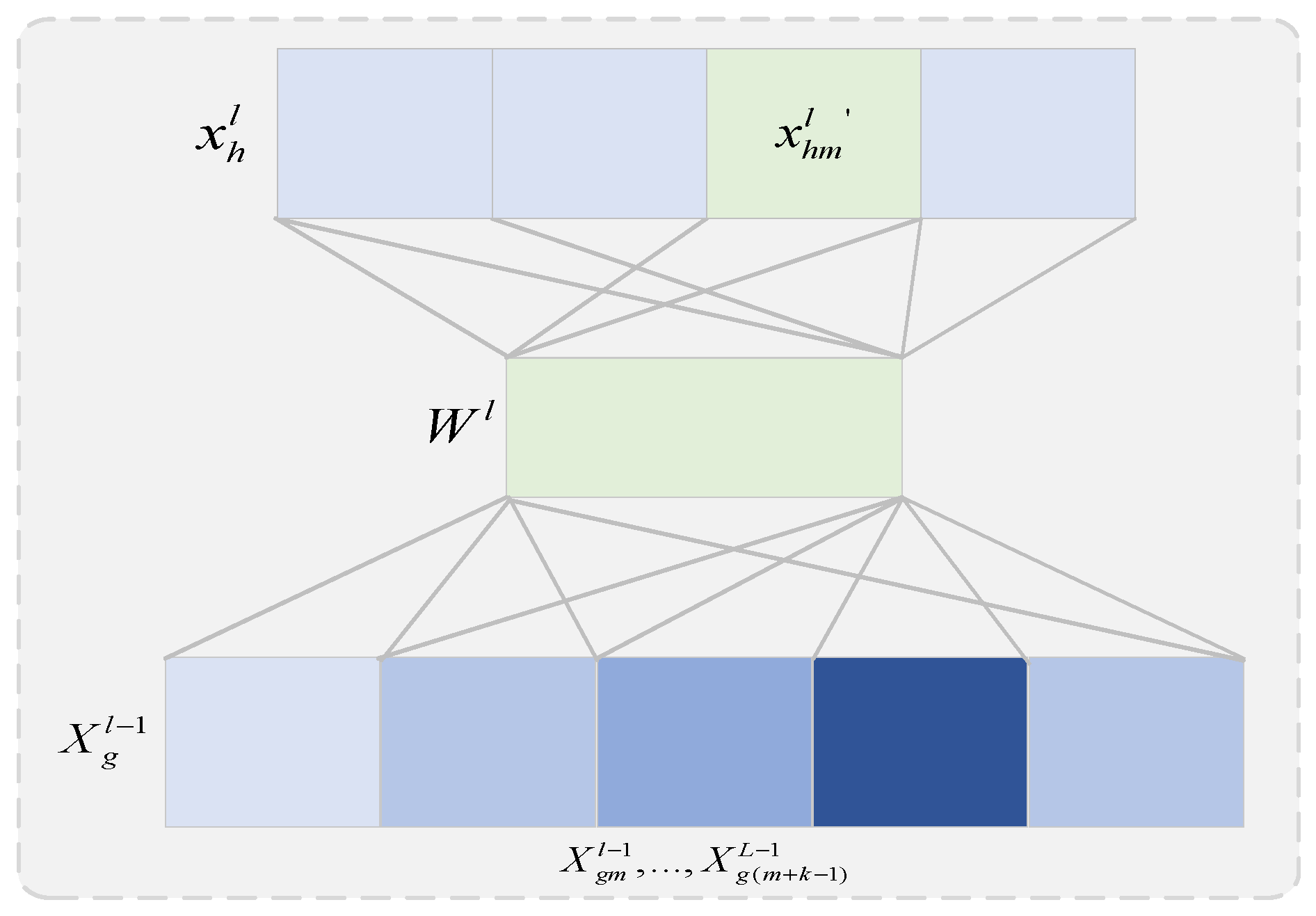
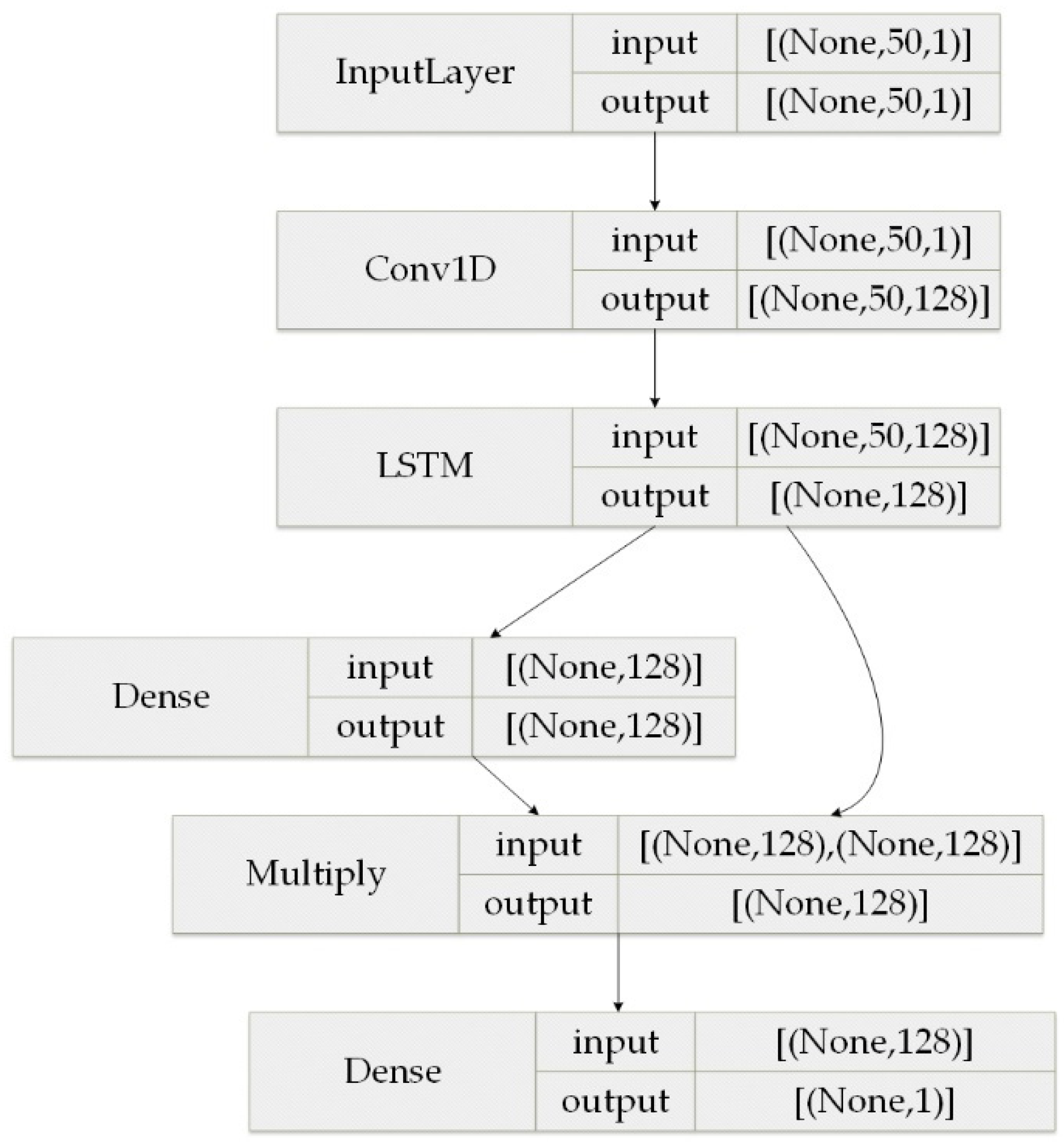
4.2. Flow Feature Extraction Module
4.3. Integration of Prior Knowledge Modules
5. Experiments and Analysis of Results
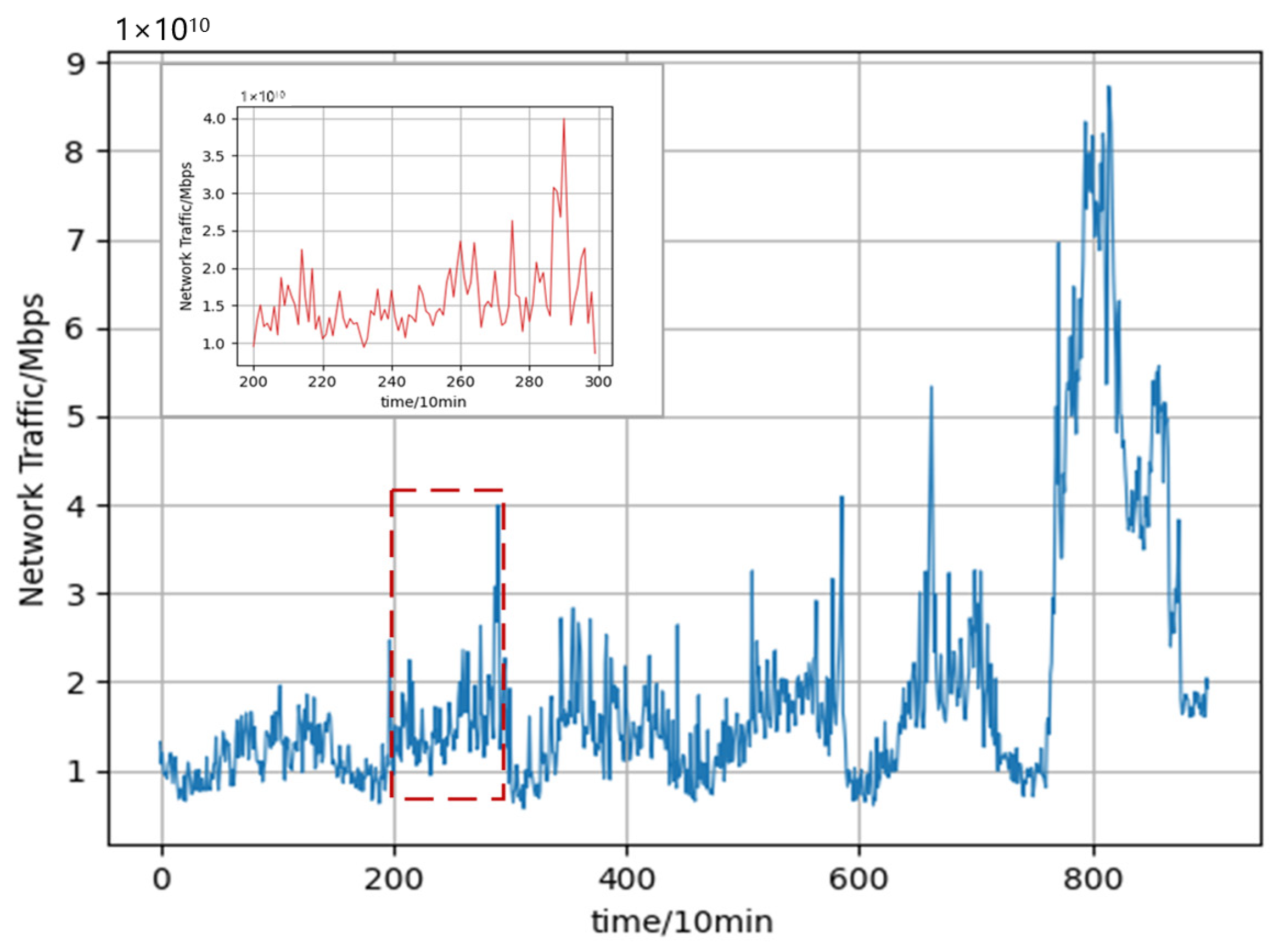
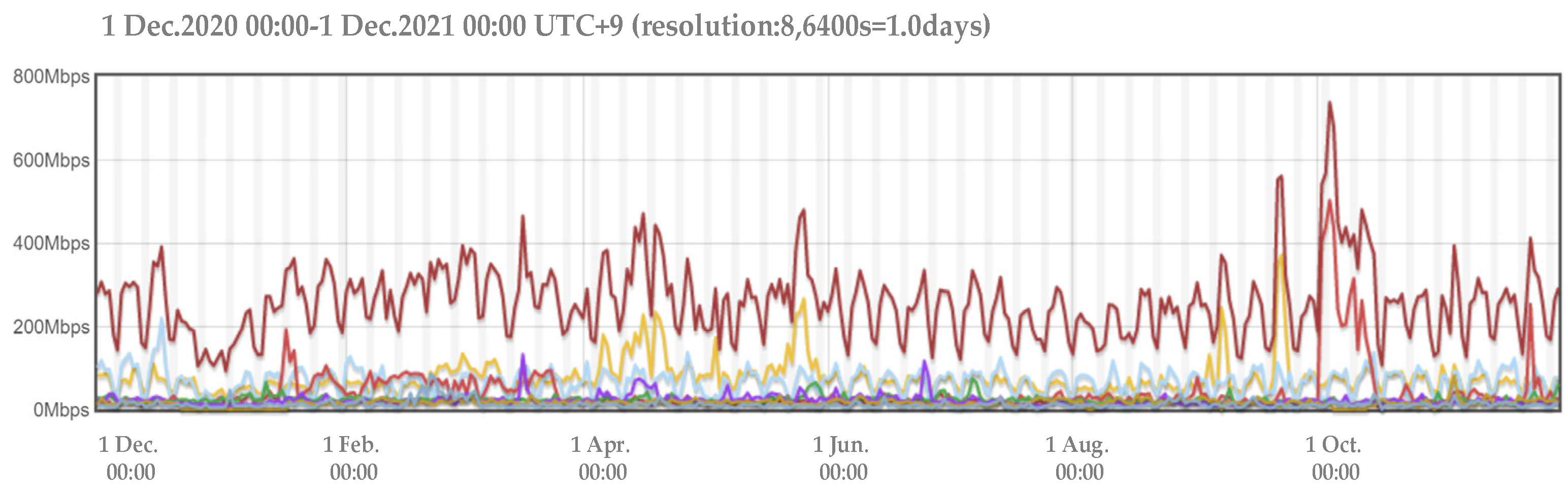
5.1. Experimental Data
5.2. Experimental Parameters and Evaluation Metrics
- (1)
- Squared absolute error (MAE): This indicator measures the mean absolute error between the error and the true value, taking values in the range of ; the closer the MAE is to 0, the better the performance of the model:
- (2)
- Mean square error (MSE): This indicator reflects the prediction error of the model, taking a value in a range of ; the smaller the error, the better the model performance:
- (3)
- The root mean square error (RMSE): This indicator reflects the prediction error of the model, taking a value in the range of ; the smaller the error, the better the model performance:
- (4)
- The absolute coefficient of correction (): This indicator reflects the quality of the model fit, taking values in the range ; the closer to 1, the better the model performance. Here, is the total number of samples and is the number of features:
5.3. Experimental Results and Analysis
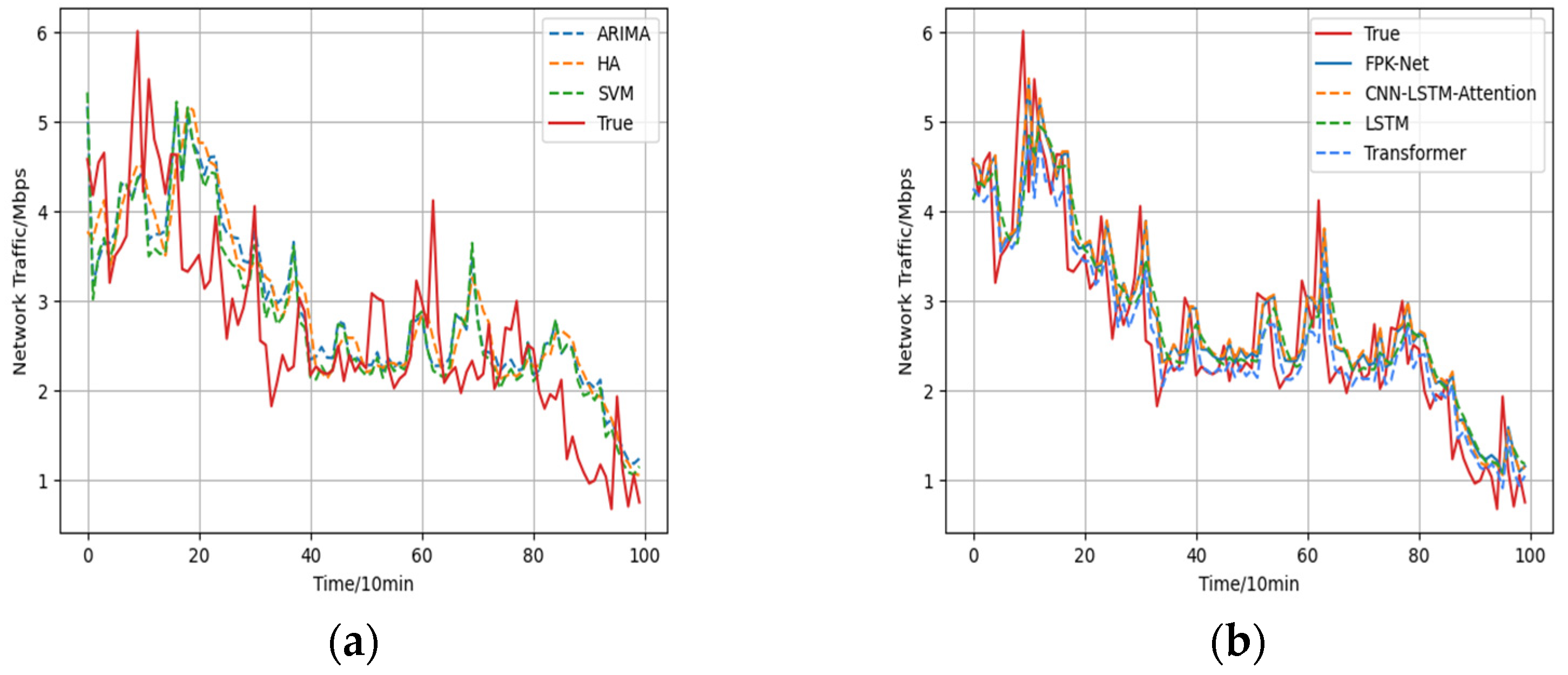
5.3.1. Results of the FPK-Net Model Compared with Other Baseline Models
- (1)
- The historical average model (HA) uses the average historical value for forecasting and, in this paper, the average value of the last eight steps was used to forecast the next step. For this method, the forecast error was large.
- (2)
- Due to the limitations of model building, traditional time-series models do not have satisfactory prediction results. Among them, the ARIMA model had the largest prediction error among the above 6 types of models, with MAE and RMSE of 0.615 and 0.757, respectively, and the smallest prediction accuracy, with an value of 0.509. As the essence of the ARIMA model is to capture the linear relationship of the flow series without considering the influence of other factors, the ARIMA model had a lesser effective prediction effect.
- (3)
- The support vector machine model (SVM) had the advantages of using fewer training parameters and producing more accurate results. The prediction results were 0.391 for MAE, 0.583 for RMSE, and 0.677 for . Its prediction results were more accurate than those of traditional statistical methods.
- (4)
- The of the LSTM model was 0.750, which indicates that it produced more accurate results than the linear prediction methods. Although the LSTM-based prediction was good and it has a certain degree of feature mining ability for long time-series, as the input series contained more information, it was difficult for the LSTM model to converge to the global optimum during training, which led to poor prediction results.
- (5)
- The transformer model uses a self-focus mechanism to model traffic sequences. The prediction results were 0.412 for MAE, 0.565 for RMSE, and 0.711 for . Its prediction results were more accurate than other linear prediction methods. Although the transformer forecasts are good, the transformer is less capable of establishing long-term dependence capturing when long time series need to be predicted.
- (6)
- Compared with the other 5 models, the proposed FPK-Net model achieved the best results, in terms of all 4 evaluation indices, and the absolute coefficient of correction of the FPK-Net model reached 76.9% while the root-mean-square error reached 0.509. Compared with the ARIMA model, the RMSE and were decreased by 0.248 and improved by 26.0% through the use of FPK-Net, respectively. Meanwhile, compared with the SVM, FPK-Net improved the value by 9.2%; the SVM was less effective in prediction as it used a linear kernel function.
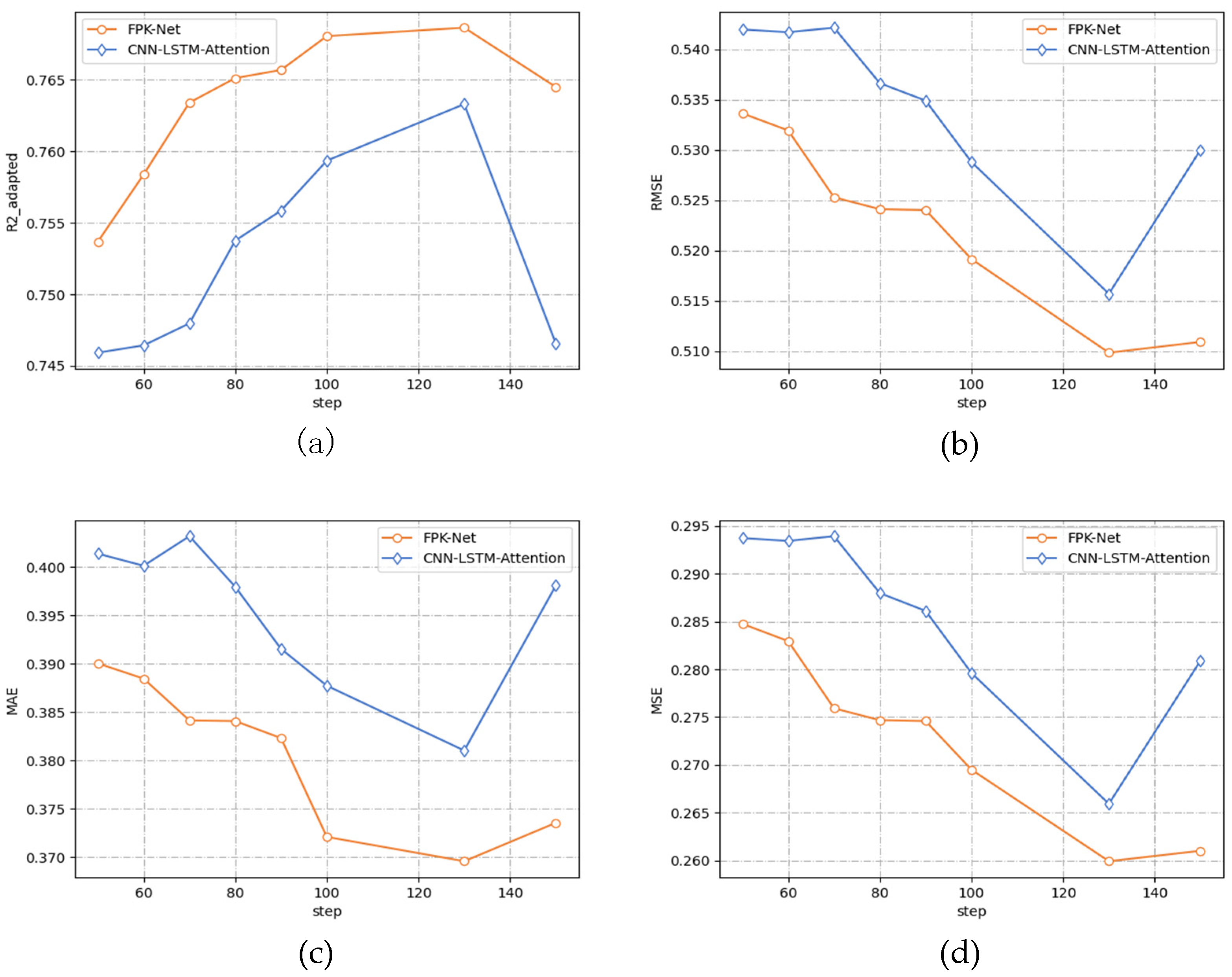
5.3.2. Ablation Experiments
- (1)
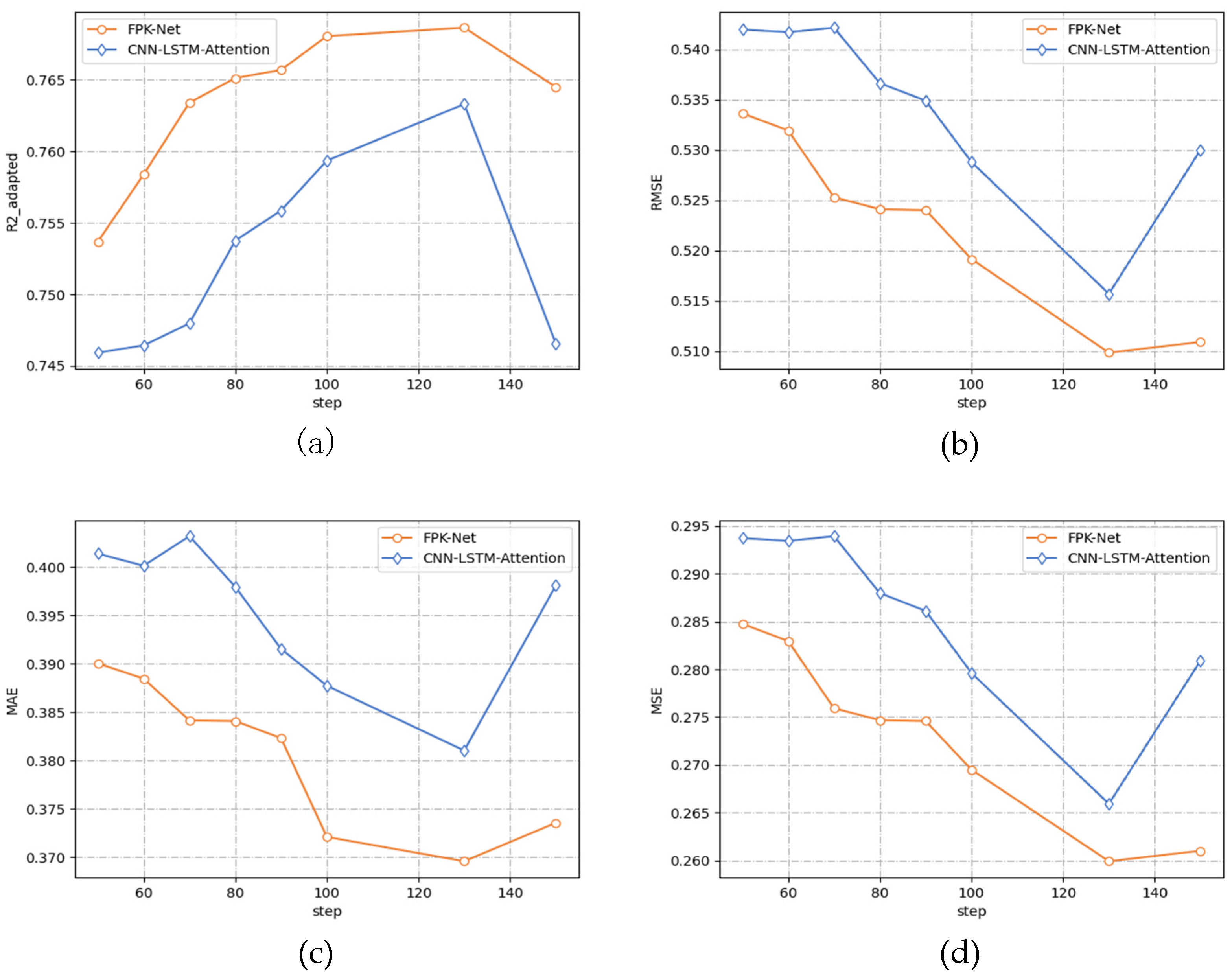
- After adding the Hurst module into the LSTM network, the change trend of the four measures on the two models was consistent. Along with a gradual increase in the size of the prediction step, all three error indicators decreased to a minimum value and then increased while the absolute coefficient of correction increased to a maximum value and then decreased, and the prediction accuracy gradually increased. The error curve presented a concave function while the absolute coefficient of correction presented a convex function.
- (2)
- When the prediction time step reached 130 min, the prediction accuracy reached its peak, and the error was the lowest. At this time, the FPK-Net model had the best prediction effect, with an MAE of 0.369 and MSE of 0.259. When the prediction time step exceeded 130 min and continued to increase, the performance of both models decreased.
- (3)
- From Figure 6 above, it can be seen that the performance of the FPK-Net model proposed in this paper was always better than that of the baseline model, regardless of the time step. In particular, the FPK-Net model, which incorporates prior knowledge, showed the most significant improvement when the step size reached 70 min, with a 1.9% reduction in the MAE measure and a 2.1% improvement in the measure.
5.3.3. Interpretability Analysis
6. Conclusions
Author Contributions
Funding
Institutional Review Board Statement
Informed Consent Statement
Data Availability Statement
Acknowledgments
Conflicts of Interest
References
- Feng, J.; Chen, X.; Gao, R.; Zeng, M.; Li, Y. DeepTP: An End-to-End Neural Network for Mobile Cellular Traffic Prediction. IEEE Netw. 2018, 32, 108–115. [Google Scholar] [CrossRef]
- Andreoletti, D.; Troia, S.; Musumeci, F.; Giordano, S.; Maier, G.; Tornatore, M. Network Traffic Prediction based on Diffusion Convolutional Recurrent Neural Networks. In Proceedings of the IEEE INFOCOM 2019—IEEE Conference on Computer Communications Workshops (INFOCOM WKSHPS), Paris, France, 29 April–2 May 2019; pp. 246–251. [Google Scholar] [CrossRef] [Green Version]
- Ahmed, M.S.; Cook, A.R. Analysis of Freeway Traffic Time-Series Data by Using Box-Jenkins Techniques; Transportation Research Board: Washington, DC, USA, 1979; pp. 1–9. [Google Scholar]
- Laner, M.; Svoboda, P.; Rupp, M. Parsimonious Fitting of Long-Range Dependent Network Traffic Using ARMA Models. IEEE Commun. Lett. 2013, 17, 2368–2371. [Google Scholar] [CrossRef]
- Yang, J.; Sheng, H.; Wan, H.; Yu, F. FARIMA Model Based on Particle Swarm-genetic Hybrid Algorithm Optimization and Application. In Proceedings of the 2021 3rd International Academic Exchange Conference on Science and Technology Innovation (IAECST), Guangzhou, China, 10–12 December 2021; pp. 188–192. [Google Scholar] [CrossRef]
- Yang, L.; Gu, X.; Shi, H. A Noval Satellite Network Traffic Prediction Method Based on GCN-GRU; WCSP: Nanjing, China, 2020; pp. 718–723. [Google Scholar]
- Zhao, L.; Song, Y.; Zhang, C.; Liu, Y.; Wang, P.; Lin, T.; Deng, M.; Li, H. T-GCN: A Temporal Graph Convolutional Network for Traffic Prediction. IEEE Trans. Intell. Transp. Syst. 2020, 21, 3848–3858. [Google Scholar] [CrossRef] [Green Version]
- He, K.; Huang, Y.; Chen, X.; Zhou, Z.; Yu, S. Graph Attention Spatial-Temporal Network for Deep Learning Based Mobile Traffic Prediction. In Proceedings of the 2019 IEEE Global Communications Conference (GLOBECOM), Waikoloa, HI, USA, 9–13 December 2019; pp. 1–6. [Google Scholar] [CrossRef]
- Tudose, A.M.; Sidea, D.O.; Picioroaga, I.I.; Boicea, V.A.; Bulac, C. A CNN Based Model for Short-Term Load Forecasting: A Real Case Study on the Romanian Power System. In Proceedings of the 2020 55th International Universities Power Engineering Conference (UPEC), Torino, Italy, 1–4 September 2020; pp. 1–6. [Google Scholar] [CrossRef]
- Du, Y.; Cui, N.; Li, H.; Nie, H.; Shi, Y.; Wang, M.; Li, T. The Vehicle’s Velocity Prediction Methods Based on RNN and LSTM Neural Network. In Proceedings of the 2020 Chinese Control and Decision Conference (CCDC), Hefei, China, 22–24 August 2020; pp. 99–102. [Google Scholar] [CrossRef]
- Ostring, S.A.M.; Sirisena, H. The influence of long-range dependence on traffic prediction. In Proceedings of the ICC 2001. IEEE International Conference on Communications. Conference Record (Cat. No.01CH37240), Helsinki, Finland, 11–14 June 2001; Volume 4, pp. 1000–1005. [Google Scholar] [CrossRef] [Green Version]
- Ramakrishnan, N.; Soni, T. Network Traffic Prediction Using Recurrent Neural Networks. In Proceedings of the 2018 17th IEEE International Conference on Machine Learning and Applications (ICMLA), Orlando, FL, USA, 17–20 December 2018; pp. 187–193. [Google Scholar] [CrossRef]
- Wu, N.; Green, B.; Ben, X.; O’Banion, S. Deep transformer models for time series forecasting: The influenza prevalence case. arXiv 2020, arXiv:2001.08317. [Google Scholar]
- Pan, C.; Zhu, J.; Kong, Z.; Shi, H.; Yang, W. DC-STGCN: Dual-Channel Based Graph Convolutional Networks for Network Traffic Forecasting. Electronics 2021, 10, 1014. [Google Scholar] [CrossRef]
- Dong, H.; Jia, L.; Sun, X.; Li, C.; Qin, Y. Road Traffic Flow Prediction with a Time-Oriented ARIMA Model. In Proceedings of the 2009 Fifth International Joint Conference on INC, IMS and IDC, Seoul, Korea, 25–27 August 2009; pp. 1649–1652. [Google Scholar] [CrossRef]
- Madan, R.; Mangipudi, P.S. Predicting Computer Network Traffic: A Time Series Forecasting Approach Using DWT, ARIMA and RNN. In Proceedings of the 2018 Eleventh International Conference on Contemporary Computing (IC3), Noida, India, 2–4 August 2018; pp. 1–5. [Google Scholar] [CrossRef]
- Zhenwei, Y. A Wavelet Neural Network Model for Forecasting Network Traffic Forecast. J. Comput. Appl. 2006, 26, 526–528. [Google Scholar] [CrossRef]
- Yang, Z.; Wang, Y.; Kong, C. Remaining Useful Life Prediction of Lithium-Ion Batteries Based on a Mixture of Ensemble Empirical Mode Decomposition and GWO-SVR Model. IEEE Trans. Instrum. Meas. 2021, 70, 1–11. [Google Scholar] [CrossRef]
- Bie, Y.; Wang, L.; Tian, Y.; Hu, Z. A Combined Forecasting Model for Satellite Network Self-Similar Traffic. IEEE Access 2019, 7, 152004–152013. [Google Scholar] [CrossRef]
- Qian, Y.; Xia, J.; Fu, K.; Zhang, R. Network traffic forecasting by support vector machines based on empirical mode decomposition denoising. In Proceedings of the 2nd International Conference on Consumer Electronics, Communications and Networks (CECNet), Yichang, China, 21–23 April 2012; pp. 3327–3330. [Google Scholar] [CrossRef]
- Xie, Y.; Zhou, F.; Soh, H. Embedding Symbolic Temporal Knowledge into Deep Sequential Models. In Proceedings of the 2021 IEEE International Conference on Robotics and Automation (ICRA), Xi’an, China, 30 May–5 June 2021; pp. 4267–4273. [Google Scholar] [CrossRef]
- Adarsh, P.; Jeyakumari, D. Multiclass SVM-based automated diagnosis of diabetic retinopathy. In Proceedings of the 2013 International Conference on Communication and Signal Processing, Melmaruvathur, India, 3–5 April 2013; pp. 206–210. [Google Scholar] [CrossRef]
- Ramachandran, R.; Bhethanabotla, V.N. Generalized autoregressive moving average modeling of the Bellcore data. In Proceedings of the 25th Annual IEEE Conference on Local Computer Networks. LCN 2000, Tampa, FL, USA, 8–10 November 2000; pp. 654–661. [Google Scholar] [CrossRef]
- Chouhan, K.; Singh, A.; Shrivastava, A.; Agrawal, S.; Shukla, B.D.; Tomar, P.S. Structural Support Vector Machine for Speech Recognition Classification with CNN Approach. In Proceedings of the 2021 9th International Conference on Cyber and IT Service Management (CITSM), Bengkulu, Indonesia, 22–23 September 2021; pp. 1–7. [Google Scholar] [CrossRef]
- Sayavong, L.; Wu, Z.; Chalita, S. Research on Stock Price Prediction Method Based on Convolutional Neural Network. In Proceedings of the 2019 International Conference on Virtual Reality and Intelligent Systems (ICVRIS), Jishou, China, 14–15 September 2019; pp. 173–176. [Google Scholar] [CrossRef]
- Cho, K. WIDE Project. Esearch 1992, 37. Available online: http://mawi.wide.ad.jp/mawi/ (accessed on 1 February 2013).
- Cho, K.; Mitsuya, K.; Kato, A. Traffic Data Repository at the WIDE Project. In Proceedings of the USENIX 2000 Annual Technical Conference: FREENIX Track, San Diego, CA, USA, 18–23 June 2000; pp. 263–270. [Google Scholar]






{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
| Models | MAE | MSE | RMSE | |
|---|---|---|---|---|
| HA | 0.447 | 0.341 | 0.584 | 0.604 |
| ARIMA | 0.615 | 0.573 | 0.757 | 0.509 |
| SVM | 0.391 | 0.339 | 0.583 | 0.677 |
| LSTM | 0.420 | 0.297 | 0.545 | 0.745 |
| CNN-LSTM-Attention | 0.387 | 0.286 | 0.535 | 0.750 |
| Transformer | 0.412 | 0.319 | 0.565 | 0.711 |
| FPK-Net | 0.369 | 0.259 | 0.509 | 0.769 |
| Step | MAE | MSE | RMSE | |
|---|---|---|---|---|
| 50 | 0.390 | 0.284 | 0.533 | 0.753 |
| 60 | 0.388 | 0.282 | 0.531 | 0.758 |
| 70 | 0.384 | 0.275 | 0.525 | 0.763 |
| 80 | 0.382 | 0.274 | 0.524 | 0.765 |
| 90 | 0.382 | 0.274 | 0.524 | 0.765 |
| 100 | 0.372 | 0.269 | 0.519 | 0.768 |
| 130 | 0.369 | 0.259 | 0.509 | 0.769 |
| 150 | 0.373 | 0.261 | 0.510 | 0.764 |
Publisher’s Note: MDPI stays neutral with regard to jurisdictional claims in published maps and institutional affiliations. |
© 2022 by the authors. Licensee MDPI, Basel, Switzerland. This article is an open access article distributed under the terms and conditions of the Creative Commons Attribution (CC BY) license (https://creativecommons.org/licenses/by/4.0/).
Share and Cite
Pan, C.; Wang, Y.; Shi, H.; Shi, J.; Cai, R. Network Traffic Prediction Incorporating Prior Knowledge for an Intelligent Network. Sensors 2022, 22, 2674. https://doi.org/10.3390/s22072674
Pan C, Wang Y, Shi H, Shi J, Cai R. Network Traffic Prediction Incorporating Prior Knowledge for an Intelligent Network. Sensors. 2022; 22(7):2674. https://doi.org/10.3390/s22072674
Chicago/Turabian StylePan, Chengsheng, Yuyue Wang, Huaifeng Shi, Jianfeng Shi, and Ren Cai. 2022. "Network Traffic Prediction Incorporating Prior Knowledge for an Intelligent Network" Sensors 22, no. 7: 2674. https://doi.org/10.3390/s22072674
APA StylePan, C., Wang, Y., Shi, H., Shi, J., & Cai, R. (2022). Network Traffic Prediction Incorporating Prior Knowledge for an Intelligent Network. Sensors, 22(7), 2674. https://doi.org/10.3390/s22072674