
Bayesian-Inference Embedded Spline-Kerneled Chirplet Transform for Spectrum-Aware Motion Magnification


{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
Abstract
:1. Introduction
2. Proposed Be-Sct
2.1. Theory
2.2. Algorithm
2.3. Model Parameters and Initial Condition Estimation
| Algorithm 1 BE-SCT |
Equations Input: matrix , maximum iteration of EM steps , minor integer . while and do Generating initial states and initial variances by Equation (16); for do to evaluate Equation (11). end for for do and (12). end for Obtaining final and by Equation (15); . for do perform the Kalman filter in matrix . end for end while Output: Final matrix with s lines and i columns. |
2.4. Numerical Experiments
3. Spectrum-Aware Video Magnification
- 1.
- On the basis of the earth mover’s distance (EMOD) algorithm (readers interested in this theory, please refer to [22]), which avoids quantization and other binning problems, the moment function of original video motion information is temporally extracted;
- 2.
- By applying BE-SCT, the estimation stage seeks to understand the time-frequency characteristic of global nonstationary motions in analytical video;
- 3.
- With the appropriate prior knowledge, the dynamic ideal band-pass filter is used to remove large motions while preserving subtle ones.
3.1. Motion Metric Extraction
3.2. Dynamic Spectrum-Aware Filtering
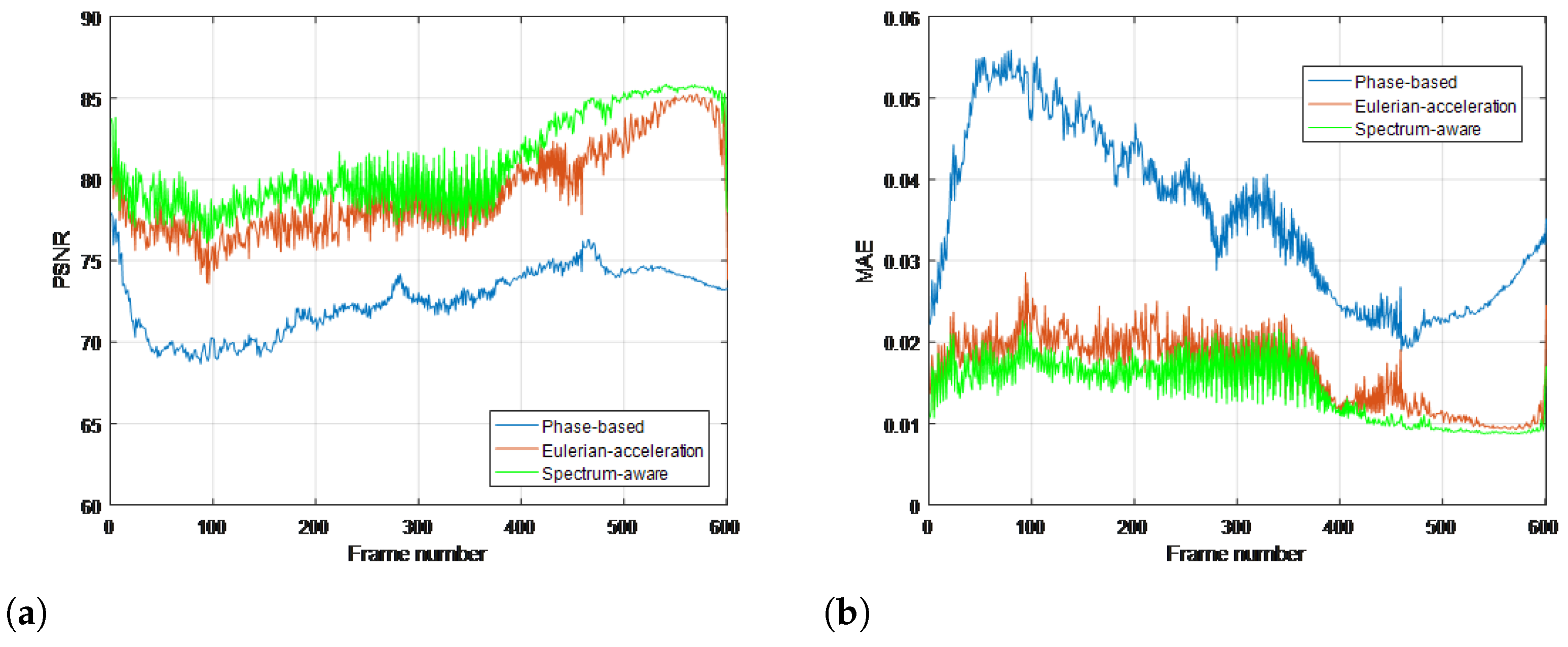
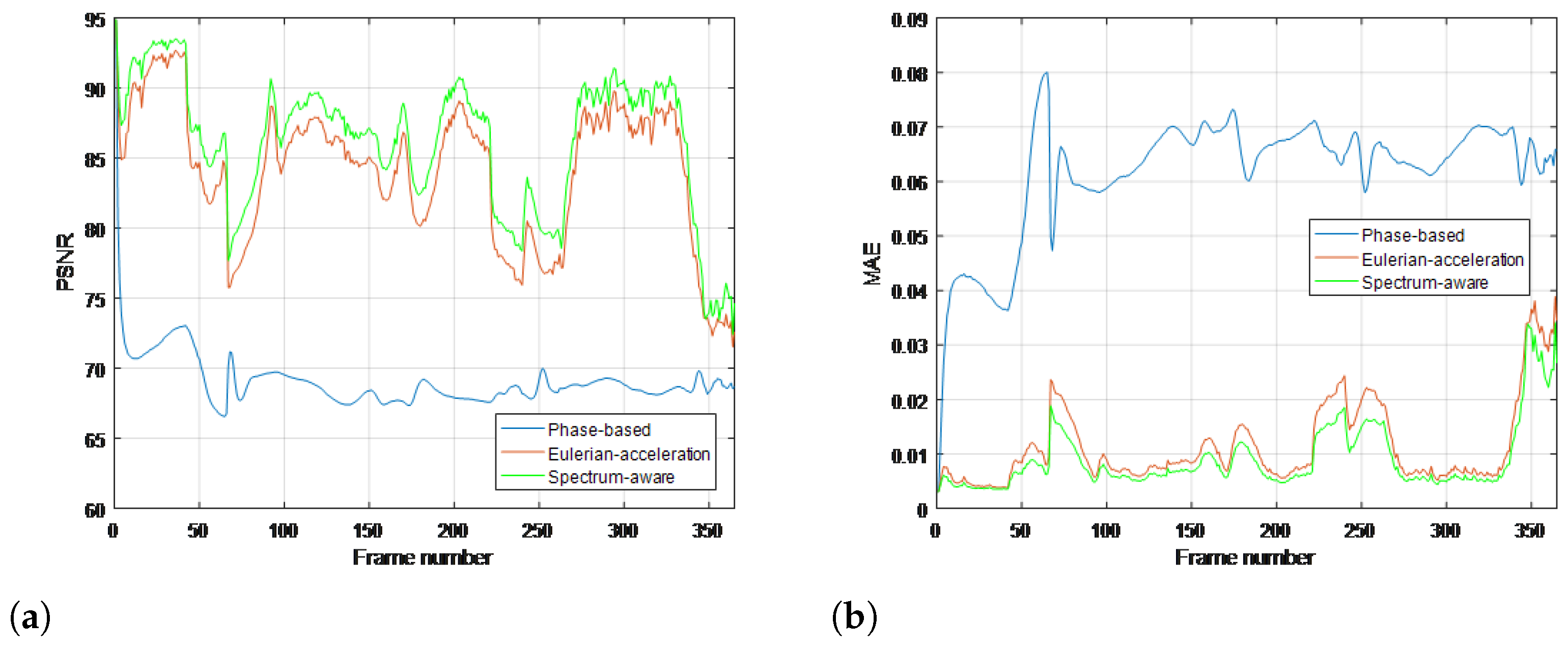
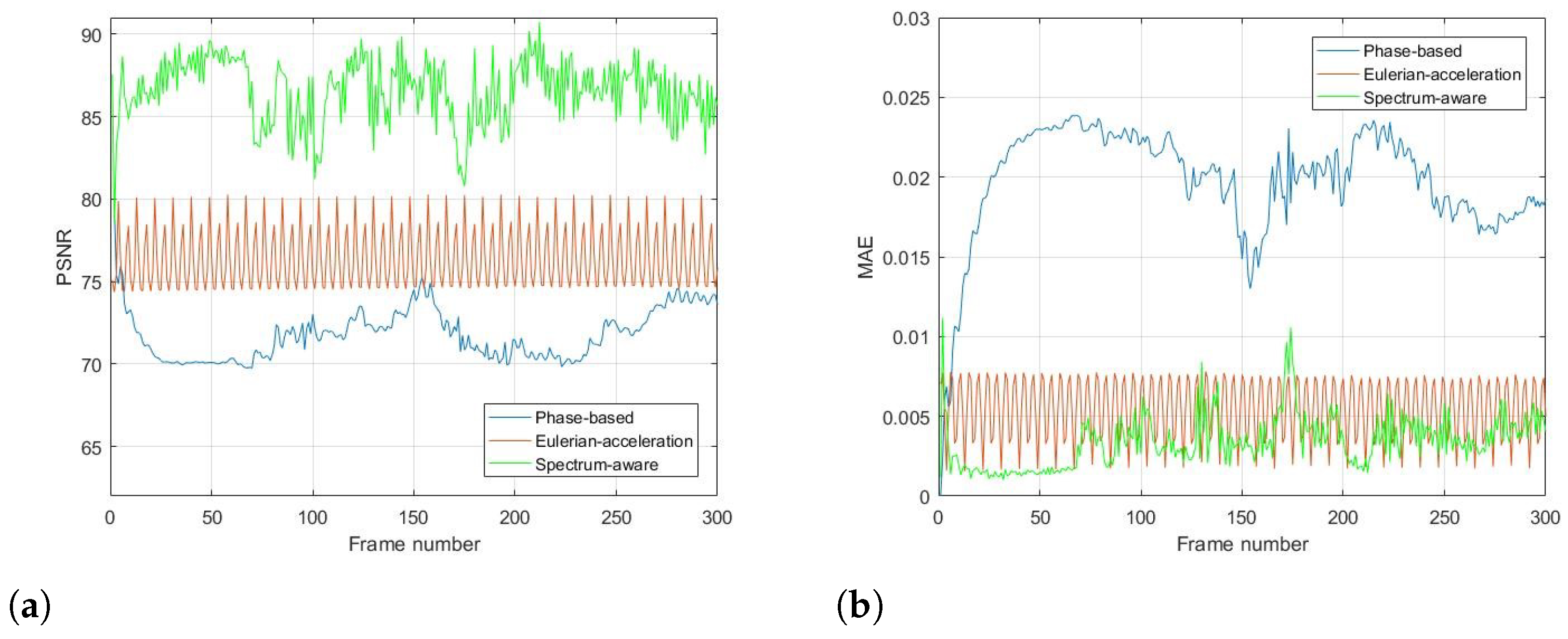
4. Experimental Results
4.1. Real-Life Sequences
4.2. Synthetic Sequence
5. Discussion
6. Conclusions
Author Contributions
Funding
Institutional Review Board Statement
Informed Consent Statement
Conflicts of Interest
References
- Balakrishnan, G.; Durand, F.; Guttag, J. Detecting Pulse from Head Motions in Video. In Proceedings of the IEEE Conference on Computer Vision and Pattern Recognition, Portland, OR, USA, 23–28 June 2013; pp. 3430–3437. [Google Scholar]
- Wu, H.Y.; Rubinstein, M.; Shih, E.; Guttag, J.; Durand, F.; Freeman, W. Eulerian Video Magnification for Revealing Subtle Changes in the World. ACM Trans. Graph. (TOG) 2012, 31, 1–8. [Google Scholar] [CrossRef]
- Aziz, N.A.; Tannemaat, M.R. A Microscope for Subtle Movements in Clinical Neurology. Neurology 2015, 85, 920. [Google Scholar] [CrossRef] [PubMed] [Green Version]
- Wang, Y.; See, J.; Oh, Y.H.; Phan, R.C.W.; Rahulamathavan, Y.; Ling, H.C.; Tan, S.W.; Li, X. Effective recognition of facial micro-expressions with video motion magnification. Multimed. Tools Appl. 2017, 76, 21665–21690. [Google Scholar] [CrossRef] [Green Version]
- Davis, A.; Rubinstein, M.; Wadhwa, N.; Mysore, G.J.; Durand, F.; Freeman, W.T. The Visual Microphone: Passive Recovery of Sound from Video. Assoc. Comput. Mach. (ACM) 2014, 33, 79. [Google Scholar] [CrossRef]
- Dorn, C.J.; Mancini, T.D.; Talken, Z.R.; Yang, Y.; Kenyon, G.; Farrar, C.; Mascareñas, D. Automated Extraction of Mode Shapes Using Motion Magnified Video and Blind Source Separation. In Topics in Modal Analysis & Testing; Springer: Berlin/ Heidelberg, Germany, 2016; Volume 10, pp. 355–360. [Google Scholar]
- Cha, Y.J.; Chen, J.G.; Büyüköztürk, O. Output-Only Computer Vision Based Damage Detection Using Phase-Based Optical Flow and Unscented Kalman Filters. Eng. Struct. 2017, 132, 300–313. [Google Scholar] [CrossRef]
- Sarrafi, A.; Mao, Z.; Niezrecki, C.; Poozesh, P. Vibration-Based Damage Detection in Wind Turbine Blades using Phase-Based Motion Estimation and Motion Magnification. J. Sound Vib. 2018, 421, 300–318. [Google Scholar] [CrossRef] [Green Version]
- Fazio, N.L.; Leo, M.; Perrotti, M.; Lollino, P. Analysis of the Displacement Field of Soft Rock Samples During UCS Tests by Means of a Computer Vision Technique. Rock Mech. Rock Eng. 2019, 52, 3609–3626. [Google Scholar] [CrossRef]
- Zhang, X.; Sheng, C.; Liu, L. Lip Motion Magnification Network for Lip Reading. In Proceedings of the 2021 7th International Conference on Big Data and Information Analytics (BigDIA), Chongqing, China, 23–31 October 2021; pp. 274–279. [Google Scholar] [CrossRef]
- Liu, C.; Torralba, A.; Freeman, W.T.; Durand, F.; Adelson, E.H. Motion Magnification. ACM Trans. Graph. (TOG) 2005, 24, 519–526. [Google Scholar] [CrossRef]
- Freeman, W.T.; Adelson, E.H. The Design and Use of Steerable Filters. IEEE Trans. Pattern Anal. Mach. Intell. 1991, 13, 891–906. [Google Scholar] [CrossRef]
- Portilla, J.; Simoncelli, E.P. A Parametric Texture Model Based on Joint Statistics of Complex Wavelet Coefficients. Int. J. Comput. Vis. 2000, 40, 49–70. [Google Scholar] [CrossRef]
- Simoncelli, E.P.; Freeman, W.T. The Steerable Pyramid: A Flexible Architecture for Multi-Scale Derivative Computation. In Proceedings of the International Conference on Image Processing, Washington, DC, USA, 23–26 October 1995; pp. 444–447. [Google Scholar]
- Wadhwa, N.; Rubinstein, M.; Durand, F.; Freeman, W.T. Phase-Based Video Motion Processing. ACM Trans. Graph. (TOG) 2013, 32, 1–10. [Google Scholar] [CrossRef] [Green Version]
- Davis, A.; Bouman, K.L.; Chen, J.G.; Rubinstein, M.; Durand, F.; Freeman, W.T. Visual Vibrometry: Estimating Material Properties from Small Motion in Video. In Proceedings of the 2015 IEEE Conference on Computer Vision and Pattern Recognition, Boston, MA, USA, 7–12 June 2015; pp. 5335–5343. [Google Scholar]
- Chen, J.G.; Wadhwa, N.; Cha, Y.J.; Durand, F.; Freeman, W.T.; Buyukozturk, O. Modal Identification of Simple Structures with High-Speed Video Using Motion Magnification. J. Sound Vib. 2015, 345, 58–71. [Google Scholar] [CrossRef]
- Wadhwa, N.; Rubinstein, M.; Durand, F.; Freeman, W.T. Riesz Pyramids for Fast Phase-Based Video Magnification. In Proceedings of the 2014 IEEE International Conference on Computational Photography (ICCP), Santa Clara, CA, USA, 2–4 May 2014; pp. 1–10. [Google Scholar]
- Elgharib, M.; Hefeeda, M.; Durand, F.; Freeman, W.T. Video Magnification in Presence of Large Motions. In Proceedings of the 2015 IEEE Conference on Computer Vision and Pattern Recognition (CVPR), Boston, MA, USA, 7–12 June 2015; pp. 4119–4127. [Google Scholar]
- Kooij, J.F.; van Gemert, J.C. Depth-Aware Motion Magnification. In European Conference on Computer Vision; Springer: Berlin/Heidelberg, Germany, 2016; pp. 467–482. [Google Scholar]
- Zhang, Y.; Pintea, S.L.; Van Gemert, J.C. Video Acceleration Magnification. In Proceedings of the 2017 IEEE Conference on Computer Vision and Pattern Recognition (CVPR), Honolulu, HI, USA, 21–26 July 2017; pp. 529–537. [Google Scholar]
- Wu, X.; Yang, X.; Jin, J.; Yang, Z. Amplitude-Based Filtering for Video Magnification in Presence of Large Motion. Sensors 2018, 18, 2312. [Google Scholar] [CrossRef] [Green Version]
- Nawab, S.H. Short-Time Fourier Transform. In Advanced Topics in Signal Processing; Prentice-Hall, Inc.: Upper Saddle River, NY, USA, 1988. [Google Scholar]
- Kwok, H.K.; Jones, D.L. Improved Instantaneous Frequency Estimation Using an Adaptive Short-Time Fourier Transform. IEEE Trans. Signal Process. 2000, 48, 2964–2972. [Google Scholar] [CrossRef]
- Kaiser, G. A Friendly Guide to Wavelets; Birkhäuser: Boston, MA, USA, 2010. [Google Scholar]
- Blodt, M.; Bonacci, D.; Regnier, J.; Chabert, M.; Faucher, J. On-Line Monitoring of Mechanical Faults in Variable-Speed Induction Motor Drives Using the Wigner Distribution. IEEE Trans. Ind. Electron. 2008, 55, 522–533. [Google Scholar] [CrossRef]
- Rosero, J.A.; Romeral, L.; Ortega, J.A.; Rosero, E. Short-Circuit Detection by Means of Empirical Mode Decomposition and Wigner–Ville Distribution for PMSM Running Under Dynamic Condition. IEEE Trans. Ind. Electron. 2009, 56, 4534–4547. [Google Scholar] [CrossRef]
- Coppola, L.; Liu, Q.; Buso, S.; Boroyevich, D.; Bell, A. Wavelet Transform as an Alternative to the Short-Time Fourier Transform for the Study of Conducted Noise in Power Electronics. IEEE Trans. Ind. Electron. 2008, 55, 880–887. [Google Scholar] [CrossRef]
- Bouzida, A.; Touhami, O.; Ibtiouen, R.; Belouchrani, A.; Fadel, M.; Rezzoug, A. Fault Diagnosis in Industrial Induction Machines through Discrete Wavelet Transform. IEEE Trans. Ind. Electron. 2010, 58, 4385–4395. [Google Scholar] [CrossRef]
- Huang, N.E.; Shen, Z.; Long, S.R.; Wu, M.C.; Shih, H.H.; Zheng, Q.; Yen, N.C.; Tung, C.C.; Liu, H.H. The Empirical Mode Decomposition and the Hilbert Spectrum for Non-linear and Non-Stationary Time Series Analysis. Proc. R. Soc. Lond. Ser. A Math. Phys. Eng. Sci. 1998, 454, 903–995. [Google Scholar] [CrossRef]
- Huang, N.E.; Wu, Z. A Review on Hilbert-Huang Transform: Method and its Applications to Geophysical Studies. Rev. Geophys. 2008, 46. [Google Scholar] [CrossRef] [Green Version]
- Yang, Y.; Peng, Z.; Meng, G.; Zhang, W. Spline-Kernelled Chirplet Transform for the Analysis of Signals with Time-Varying Frequency and its application. IEEE Trans. Ind. Electron. 2011, 59, 1612–1621. [Google Scholar] [CrossRef]
- Chatterji, S.; Blackburn, L.; Martin, G.; Katsavounidis, E. Multi-resolution Techniques for the Detection of Gravitational-Wave Bursts. Class. Quantum Gravity 2004, 21, 1809–1818. [Google Scholar] [CrossRef] [Green Version]
- Haigh, J.D.; Winning, A.R.; Toumi, R.; Harder, J.W. An Influence of Solar Spectral Variations on Radiative Forcing of Climate. Nature 2010, 467, 696–699. [Google Scholar] [CrossRef] [Green Version]
- Zheng, X.; Chen, B.M. Stock Market Modeling and Forecasting; Springer: London, UK, 2013. [Google Scholar]
- Truccolo, W.; Eden, U.T.; Fellows, M.R.; Donoghue, J.P.; Brown, E.N. A Point Process Framework for Relating Neural Spiking Activity to Spiking History, Neural Ensemble, and Extrinsic Covariate Effects. J. Neurophysiol. 2005, 93, 1074–1089. [Google Scholar] [CrossRef] [Green Version]
- Mitra, P. Observed Brain Dynamics; Oxford University Press: Oxford, UK, 2007. [Google Scholar]
- Yilmaz, T.; Foster, R.; Hao, Y. Detecting Vital Signs with Wearable Wireless Sensors. Sensors 2010, 10, 10837–10862. [Google Scholar] [CrossRef]
- Quatieri, T.F. Discrete-Time Speech Signal Processing: Principles and Practice; Pearson Education India: Delhi, India, 2006. [Google Scholar]
- Unser, M.; Aldroubi, A.; Eden, M. B-Spline Signal Processing. II. Efficiency Design and Applications. IEEE Trans. Signal Process. 1993, 41, 834–848. [Google Scholar] [CrossRef]
- Fahrmeir, L.; Tutz, G.; Hennevogl, W.; Salem, E. Multivariate Statistical Modelling Based on Generalized Linear Models; Springer: New York, NY, USA, 1994. [Google Scholar]
- Durbin, J.; Koopman, S.J. Time Series Analysis by State Space Methods; Oxford University Press: Oxford, UK, 2012. [Google Scholar]
- Qi, Y.; Minka, T.P.; Picara, R.W. Bayesian Spectrum Estimation of Unevenly Sampled Nonstationary Data. In Proceedings of the 2002 IEEE International Conference on Acoustics, Speech, and Signal Processing, Orlando, FL, USA, 13–17 May 2002. [Google Scholar]
- Kitagawa, G.; Gersch, W. Smoothness Priors Analysis of Time Series; Springer Science & Business Media: Heidelberg, Germany, 1996. [Google Scholar]
- Tarvainen, M.P.; Hiltunen, J.K.; Ranta-Aho, P.O.; Karjalainen, P.A. Estimation of Nonstationary EEG with Kalman Smoother Approach: An Application to Event-Related Synchronization (ERS). IEEE Trans. Biomed. Eng. 2004, 51, 516–524. [Google Scholar] [CrossRef]
- Ba, D.; Babadi, B.; Purdon, P.L.; Brown, E.N. Robust Spectrotemporal Decomposition by Iteratively Reweighted Least Squares. Proc. Natl. Acad. Sci. USA 2014, 111, 5336–5345. [Google Scholar] [CrossRef] [Green Version]
- Kim, S.E.; Behr, M.K.; Ba, D.; Brown, E.N. State-Space Multitaper Time-Frequency Analysis. Proc. Natl. Acad. Sci. USA 2018, 115, 5–14. [Google Scholar] [CrossRef] [Green Version]
- Shumway, R.H.; Stoffer, D.S.; Stoffer, D.S. Time Series Analysis and Its Applications; Springer: New York, NY, USA, 2000. [Google Scholar]
- Doucet, A.; De Freitas, N.; Gordon, N. An Introduction to Sequential Monte Carlo Methods. In Sequential Monte Carlo Methods in Practice; Springer: New York, NY, USA, 2001; pp. 3–14. [Google Scholar]
- Carlin, B.P.; Louis, T.A. Bayesian Methods for Data Analysis; CRC Press: Boca Raton, FL, USA, 2008. [Google Scholar]
- Beberniss, T.J.; Ehrhardt, D.A. High-Speed 3D Digital Image Correlation Vibration Measurement: Recent Advancements and Noted Limitations. Mech. Syst. Signal Process. 2017, 86, 35–48. [Google Scholar] [CrossRef]
- Poozesh, P.; Sarrafi, A.; Mao, Z.; Avitabile, P.; Niezrecki, C. Feasibility of Extracting Operating Shapes Using Phase-Based Motion Magnification Technique and Stereo-Photogrammetry. J. Sound Vib. 2017, 407, 350–366. [Google Scholar] [CrossRef]
- Tian, L.; Zhao, J.; Pan, B.; Wang, Z. Full-Field Bridge Deflection Monitoring with Off-Axis Digital Image Correlation. Sensors 2021, 21, 5058. [Google Scholar] [CrossRef] [PubMed]
- Al-Baradoni, N.; Groche, P. Sensor Integrated Load-Bearing Structures: Measuring Axis Extension with DIC-Based Transducers. Sensors 2021, 21, 4104. [Google Scholar] [CrossRef] [PubMed]
- Liu, G.; Li, M.; Zhang, W.; Gu, J. Subpixel Matching Using Double-Precision Gradient-Based Method for Digital Image Correlation. Sensors 2021, 21, 3140. [Google Scholar] [CrossRef]
- Dandois, F.; Taylan, O.; Bellemans, J.; D’hooge, J.; Vandenneucker, H.; Slane, L.; Scheys, L. Validated Ultrasound Speckle Tracking Method for Measuring Strains of Knee Collateral Ligaments In-Situ during Varus/Valgus Loading. Sensors 2021, 21, 1895. [Google Scholar] [CrossRef]
- De Domenico, D.; Quattrocchi, A.; Alizzio, D.; Montanini, R.; Urso, S.; Ricciardi, G.; Recupero, A. Experimental Characterization of the FRCM-Concrete Interface Bond Behavior Assisted by Digital Image Correlation. Sensors 2021, 21, 1154. [Google Scholar]
- Li, D.S.; Li, H.N.; Fritzen, C.P. The Connection between Effective Independence and Modal Kinetic Energy Methods for Sensor Placement. J. Sound Vib. 2007, 305, 945–955. [Google Scholar] [CrossRef]
- Li, D.S.; Li, H.N.; Fritzen, C.P. Load Dependent Sensor Placement Method: Theory and Experimental Validation. Mech. Syst. Signal Process. 2012, 31, 217–227. [Google Scholar] [CrossRef]
- Wu, Y.C.; Wu, X.C.; Lu, S.X.; Zhang, J.Q.; Cen, K.F. Novel Methods for Flame Pulsation Frequency Measurement with Image Analysis. Fire Technol. 2012, 48, 389–403. [Google Scholar] [CrossRef]
- Rubner, Y.; Tomasi, C.; Guibas, L.J. The Earth Mover’s Distance as a Metric for Image Retrieval. Int. J. Comput. Vis. 2000, 40, 99–121. [Google Scholar] [CrossRef]













Publisher’s Note: MDPI stays neutral with regard to jurisdictional claims in published maps and institutional affiliations. |
© 2022 by the authors. Licensee MDPI, Basel, Switzerland. This article is an open access article distributed under the terms and conditions of the Creative Commons Attribution (CC BY) license (https://creativecommons.org/licenses/by/4.0/).
Share and Cite
Cai, E.; Li, D.; Lin, J.; Li, H. Bayesian-Inference Embedded Spline-Kerneled Chirplet Transform for Spectrum-Aware Motion Magnification. Sensors 2022, 22, 2794. https://doi.org/10.3390/s22072794
Cai E, Li D, Lin J, Li H. Bayesian-Inference Embedded Spline-Kerneled Chirplet Transform for Spectrum-Aware Motion Magnification. Sensors. 2022; 22(7):2794. https://doi.org/10.3390/s22072794
Chicago/Turabian StyleCai, Enjian, Dongsheng Li, Jianyuan Lin, and Hongnan Li. 2022. "Bayesian-Inference Embedded Spline-Kerneled Chirplet Transform for Spectrum-Aware Motion Magnification" Sensors 22, no. 7: 2794. https://doi.org/10.3390/s22072794
APA StyleCai, E., Li, D., Lin, J., & Li, H. (2022). Bayesian-Inference Embedded Spline-Kerneled Chirplet Transform for Spectrum-Aware Motion Magnification. Sensors, 22(7), 2794. https://doi.org/10.3390/s22072794