
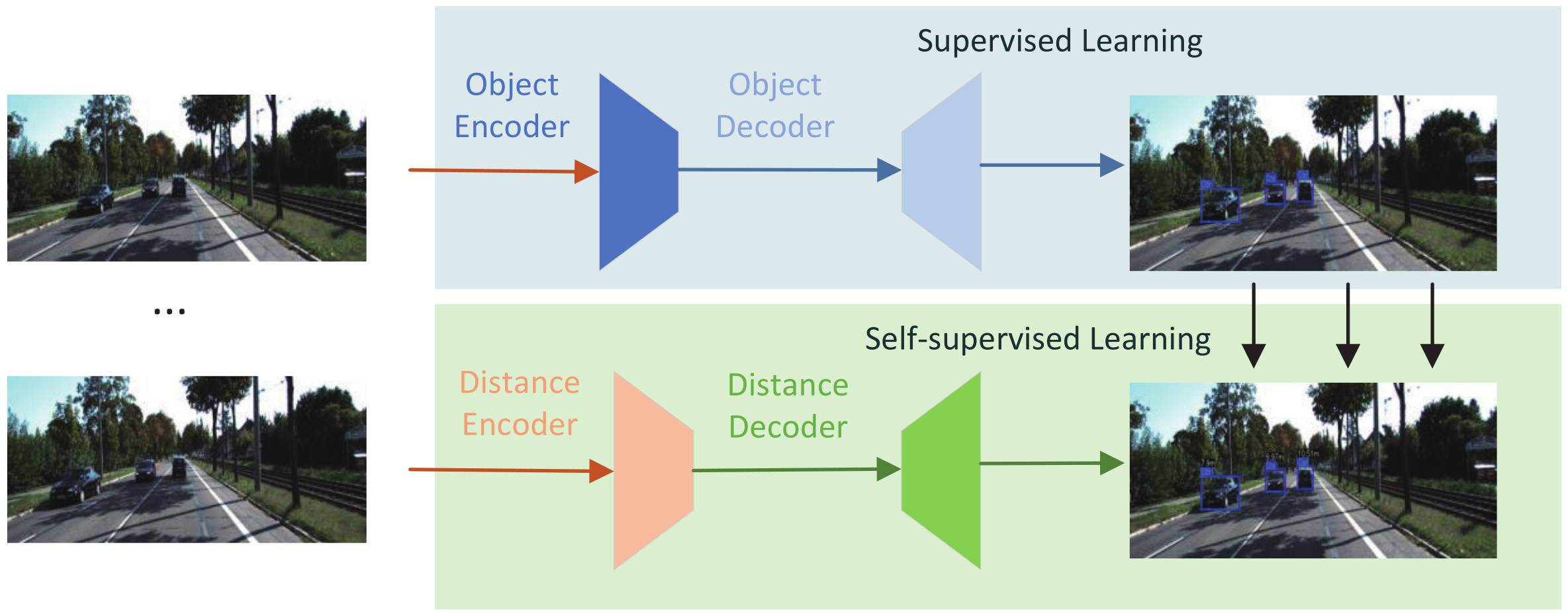
Self-Supervised Object Distance Estimation Using a Monocular Camera

Abstract
:1. Introduction
- We propose the Light-Fast YOLO network, combined with the multi-scale prediction of YOLOv5 and the light network Shufflenetv2, which reduces the number of parameters of the network and improves the speed without loss of much accuracy; we use the loss function combined with class, confidence and bounding box.
- We propose a self-supervised method and new reconstruction loss function to resolve the unknown scale factor through sequence input images and use multi-scale-resolution depth maps with self-attention module to output detected objects’ distance.
- We calibrate and analyze the camera and perform experiments on KITTI and CCP datasets to evaluate our method.
2. Related Work
2.1. Traditional Geometric Methods of Measuring Distance
2.2. Deep Learning Methods of Measuring Distance
2.3. Acquire Object
3. Materials and Methods
3.1. Light-Fast YOLO
YOLO Loss Function
3.2. Self-Supervised Scale-Aware Networks
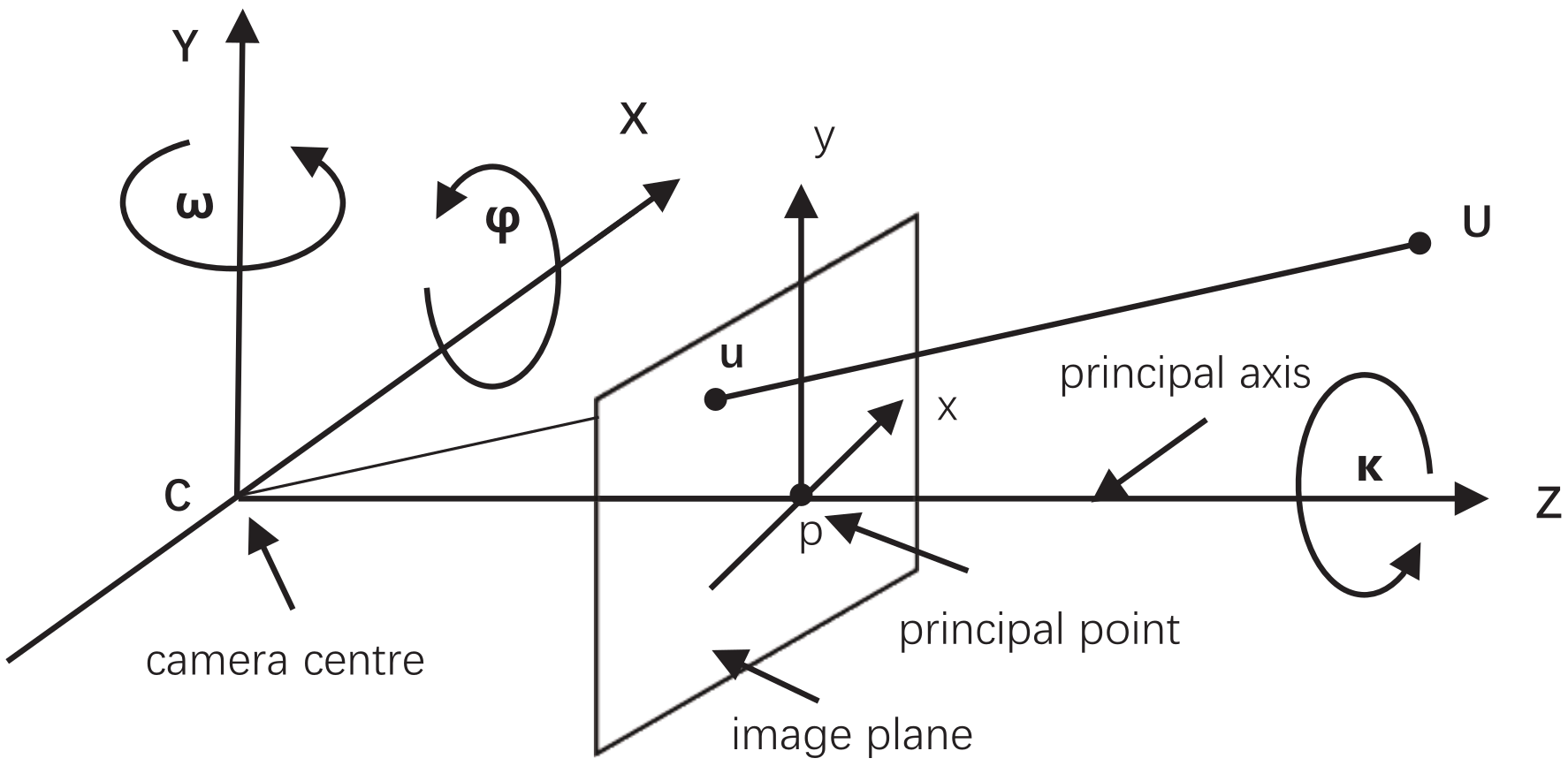
3.2.1. Pinhole Model
3.2.2. Camera Calibration
3.2.3. Transformation between Camera Coordinates and Image Coordinates
3.2.4. Edge Smooth Loss and Ego Mask
3.2.5. Resolving Scale Factor at Training Time
3.2.6. Photometric Loss
3.2.7. Attention Module in Distance Decoder
3.2.8. Multi-Scale Resolution Estimation Map
3.2.9. Final Loss
4. Experiments
4.1. Evaluation Metrics
4.2. Implementation
4.3. Camera Calibration Result
4.4. KITTI Dataset
4.5. CCP Dataset
4.6. Ablation Studies
5. Conclusions
Author Contributions
Funding
Institutional Review Board Statement
Informed Consent Statement
Data Availability Statement
Conflicts of Interest
References
- Redmon, J.; Divvala, S.; Girshick, R.; Farhadi, A. You Only Look Once: Unified, Real-Time Object Detection. In Proceedings of the IEEE Conference on Computer Vision and Pattern Recognition (CVPR), Las Vegas, NV, USA, 27–30 June 2016. [Google Scholar]
- He, K.; Gkioxari, G.; Dollár, P.; Girshick, R. Mask R-CNN. In Proceedings of the IEEE International Conference on Computer Vision, Venice, Italy, 22–29 October 2017; pp. 2961–2969. [Google Scholar]
- Krizhevsky, A.; Sutskever, I.; Hinton, G. ImageNet Classification with Deep Convolutional Neural Networks. In Proceedings of the 25th International Conference on Neural Information Processing Systems, Lake Tahoe, NV, USA, 3–6 December 2012; Volume 1. [Google Scholar]
- Redmon, J.; Farhadi, A. YOLO9000: Better, Faster, Stronger. In Proceedings of the IEEE Conference on Computer Vision and Pattern Recognition, Honolulu, HI, USA, 21–26 July 2017; pp. 6517–6525. [Google Scholar]
- Tripathi, N.; Yogamani, S. Trained Trajectory based Automated Parking System using Visual SLAM on Surround View Cameras. arXiv 2020, arXiv:2001.02161. [Google Scholar]
- Liu, D.; Long, C.; Zhang, H.; Yu, H.; Xiao, C. ARShadowGAN: Shadow Generative Adversarial Network for Augmented Reality in Single Light Scenes. In Proceedings of the 2020 IEEE/CVF Conference on Computer Vision and Pattern Recognition (CVPR), Seattle, WA, USA, 16–18 June 2020. [Google Scholar]
- Ca Ruso, D.; Engel, J.; Cremers, D. Large-scale direct SLAM for omnidirectional cameras. In Proceedings of the IEEE/RSJ International Conference on Intelligent Robots and Systems, Hamburg, Germany, 28 September–2 October 2015. [Google Scholar]
- Zhang, K.; Xie, J.; Snavely, N.; Chen, Q. Depth Sensing Beyond LiDAR Range. In Proceedings of the IEEE/CVF Conference on Computer Vision and Pattern Recognition, Seattle, WA, USA, 16–18 June 2020. [Google Scholar]
- Mayer, N.; Ilg, E.; Hausser, P.; Fischer, P.; Brox, T. A Large Dataset to Train Convolutional Networks for Disparity, Optical Flow, and Scene Flow Estimation. In Proceedings of the 2016 IEEE Conference on Computer Vision and Pattern Recognition (CVPR), Las Vegas, NV, USA, 27–30 June 2016. [Google Scholar]
- Xu, H.; Zhang, J. AANet: Adaptive Aggregation Network for Efficient Stereo Matching. In Proceedings of the IEEE/CVF Conference on Computer Vision and Pattern Recognition, Seattle, WA, USA, 16–18 June 2020. [Google Scholar]
- Davison, A.J.; Reid, I.D.; Molton, N.D.; Stasse, O. MonoSLAM: Real-time single camera SLAM. IEEE Trans. Pattern Anal. Mach. Intell. 2007, 29, 1052–1067. [Google Scholar] [CrossRef] [PubMed] [Green Version]
- Shi, J.; Tomasi, C. Good Features to Track. In Proceedings of the CVPR, IEEE Computer Society Conference on Computer Vision and Pattern Recognition, Seattle, WA, USA, 21–23 June 1994; Volume 600. [Google Scholar]
- Tuohy, S.; O’Cualain, D.; Jones, E.; Glavin, M. Distance determination for an automobile environment using Inverse Perspective Mapping in OpenCV. In Proceedings of the IET Irish Signals and Systems Conference, Cork, Ireland, 23–24 June 2010; pp. 100–105. [Google Scholar]
- Yin, X.; Wang, X.; Du, X.; Chen, Q. Scale Recovery for Monocular Visual Odometry Using Depth Estimated with Deep Convolutional Neural Fields. In Proceedings of the IEEE International Conference on Computer Vision, Honolulu, HI, USA, 22–25 July 2017. [Google Scholar]
- Wang, X.; Hui, Z.; Yin, X.; Du, M.; Chen, Q. Monocular Visual Odometry Scale Recovery Using Geometrical Constraint. In Proceedings of the 2018 IEEE International Conference on Robotics and Automation (ICRA), Brisbane, Australia, 21–25 May 2018. [Google Scholar]
- Song, Z.; Lu, J.; Zhang, T.; Li, H. End-to-end Learning for Inter-Vehicle Distance and Relative Velocity Estimation in ADAS with a Monocular Camera. In Proceedings of the 2020 IEEE International Conference on Robotics and Automation (ICRA), Paris, France, 1–17 June 2020. [Google Scholar]
- Yin, Z.; Shi, J. GeoNet: Unsupervised Learning of Dense Depth, Optical Flow and Camera Pose. In Proceedings of the 2018 IEEE/CVF Conference on Computer Vision and Pattern Recognition (CVPR), Salt Lake City, UT, USA, 19–21 June 2018. [Google Scholar]
- Shu, C.; Yu, K.; Duan, Z.; Yang, K. Feature-metric Loss for Self-supervised Learning of Depth and Egomotion. In Proceedings of the 16th European Conference on Computer Vision, Glasgow, UK, 23–28 August 2020. [Google Scholar]
- Guizilini, V.; Ambrus, R.; Pillai, S.; Raventos, A.; Gaidon, A. 3D Packing for Self-Supervised Monocular Depth Estimation. In Proceedings of the 2020 IEEE/CVF Conference on Computer Vision and Pattern Recognition (CVPR), Seattle, WA, USA, 16–18 June 2020. [Google Scholar]
- Liu, J.; Zhang, R. Vehicle Detection and Ranging Using Two Different Focal Length Cameras. J. Sens. 2020, 2020, 4372847. [Google Scholar]
- Tsai, Y.M.; Chang, Y.L.; Chen, L.G. Block-based Vanishing Line and Vanishing Point Detection for 3D Scene Reconstruction. In Proceedings of the International Symposium on Intelligent Signal Processing and Communications, Yonago, Japan, 12–15 December 2006. [Google Scholar]
- Zhuo, S.; Sim, T. Defocus map estimation from a single image. Pattern Recognit. 2011, 44, 1852–1858. [Google Scholar] [CrossRef]
- Ming, A.; Wu, T.; Ma, J.; Sun, F.; Zhou, Y. Monocular Depth-Ordering Reasoning with Occlusion Edge Detection and Couple Layers Inference. IEEE Intell. Syst. 2016, 31, 54–65. [Google Scholar] [CrossRef]
- Luo, Y.; Ren, J.; Lin, M.; Pang, J.; Sun, W.; Li, H.; Lin, L. Single View Stereo Matching. In Proceedings of the IEEE Conference on Computer Vision and Pattern Recognition (CVPR), Salt Lake City, UT, USA, 19–21 June 2018. [Google Scholar]
- Zhu, J.; Fang, Y. Learning Object-Specific Distance From a Monocular Image. In Proceedings of the 2019 IEEE/CVF International Conference on Computer Vision (ICCV), Seoul, Korea, 27 October–2 November 2019. [Google Scholar]
- Zhang, Y.; Ding, L.; Li, Y.; Lin, W.; Zhan, Y. A regional distance regression network for monocular object distance estimation. J. Vis. Commun. Image Represent. 2021, 79, 103224. [Google Scholar] [CrossRef]
- Xu, D.; Ricci, E.; Ouyang, W.; Wang, X.; Sebe, N. Multi-Scale Continuous CRFs as Sequential Deep Networks for Monocular Depth Estimation. In Proceedings of the IEEE Conference on Computer Vision and Pattern Recognition (CVPR), Honolulu, HI, USA, 22–25 July 2017. [Google Scholar]
- Fu, H.; Gong, M.; Wang, C.; Ba Tmanghelich, K.; Tao, D. Deep Ordinal Regression Network for Monocular Depth Estimation. In Proceedings of the 2018 IEEE/CVF Conference on Computer Vision and Pattern Recognition, Salt Lake City, UT, USA, 19–21 June 2018. [Google Scholar]
- Kreuzig, R.; Ochs, M.; Mester, R. DistanceNet: Estimating Traveled Distance from Monocular Images using a Recurrent Convolutional Neural Network. In Proceedings of the 2019 IEEE/CVF Conference on Computer Vision and Pattern Recognition Workshops (CVPRW), Long Beach, CA, USA, 16–20 June 2019. [Google Scholar]
- Zhou, T.; Brown, M.; Snavely, N.; Lowe, D.G. Unsupervised Learning of Depth and Ego-Motion from Video. In Proceedings of the IEEE Conference on Computer Vision and Pattern Recognition (CVPR), Honolulu, HI, USA, 22–25 July 2017. [Google Scholar]
- Viola, P.A.; Jones, M.J. Rapid Object Detection using a Boosted Cascade of Simple Features. In Proceedings of the 2001 IEEE Computer Society Conference on Computer Vision and Pattern Recognition, Kauai, HI, USA, 8–14 December 2001. [Google Scholar]
- Dalal, N.; Triggs, B. Histograms of Oriented Gradients for Human Detection. In Proceedings of the IEEE Computer Society Conference on Computer Vision and Pattern Recognition, San Diego, CA, USA, 20–25 June 2005. [Google Scholar]
- Felzenszwalb, P.F.; Mcallester, D.A.; Ramanan, D. A discriminatively trained, multiscale, deformable part model. In Proceedings of the 2008 IEEE Conference on Computer Vision and Pattern Recognition, Anchorage, AK, USA, 23–28 June 2008. [Google Scholar]
- Ren, S.; He, K.; Girshick, R.; Sun, J. Faster R-CNN: Towards Real-Time Object Detection with Region Proposal Networks. IEEE Trans. Pattern Anal. Mach. Intell. 2017, 39, 1137–1149. [Google Scholar] [CrossRef] [PubMed] [Green Version]
- Cai, Z.; Vasconcelos, N. Cascade R-CNN: Delving into High Quality Object Detection. In Proceedings of the IEEE Conference on Computer Vision and Pattern Recognition (CVPR), Honolulu, HI, USA, 22–25 July 2017. [Google Scholar]
- Redmon, J.; Farhadi, A. YOLOv3: An Incremental Improvement. arXiv 2018, arXiv:1804.02767. [Google Scholar]
- Bochkovskiy, A.; Wang, C.Y.; Liao, H. YOLOv4: Optimal Speed and Accuracy of Object Detection. arXiv 2020, arXiv:2004.10934. [Google Scholar]
- Law, H.; Deng, J. CornerNet: Detecting Objects as Paired Keypoints. Int. J. Comput. Vis. 2020, 128, 642–656. [Google Scholar] [CrossRef] [Green Version]
- Duan, K.; Bai, S.; Xie, L.; Qi, H.; Huang, Q.; Tian, Q. CenterNet: Keypoint Triplets for Object Detection. In Proceedings of the 2019 IEEE/CVF International Conference on Computer Vision (ICCV), Seoul, Korea, 27 October–2 November 2019. [Google Scholar]
- Zhu, C.; He, Y.; Savvides, M. Feature Selective Anchor-Free Module for Single-Shot Object Detection. In Proceedings of the 2019 IEEE/CVF Conference on Computer Vision and Pattern Recognition (CVPR), Long Beach, CA, USA, 16–20 June 2019. [Google Scholar]
- Carion, N.; Massa, F.; Synnaeve, G.; Usunier, N.; Kirillov, A.; Zagoruyko, S. End-to-End Object Detection with Transformers. In European Conference on Computer Vision; Springer: Cham, Switzerland, 2020. [Google Scholar]
- Zhang, G.; Luo, Z.; Cui, K.; Lu, S. Meta-DETR: Few-Shot Object Detection via Unified Image-Level Meta-Learning. arXiv 2021, arXiv:2103.11731. [Google Scholar]
- Vaswani, A.; Shazeer, N.; Parmar, N.; Uszkoreit, J.; Jones, L.; Gomez, A.N.; Kaiser, L.; Polosukhin, I. Attention Is All You Need. arXiv 2017, arXiv:1706.03762. [Google Scholar]
- He, K.; Fan, H.; Wu, Y.; Xie, S.; Girshick, R. Momentum Contrast for Unsupervised Visual Representation Learning. In Proceedings of the 2020 IEEE/CVF Conference on Computer Vision and Pattern Recognition (CVPR), Seattle, WA, USA, 16–18 June 2020. [Google Scholar]
- Chen, T.; Kornblith, S.; Norouzi, M.; Hinton, G. A Simple Framework for Contrastive Learning of Visual Representations. In Proceedings of the 37th International Conference on Machine Learning, Online, 12–18 July 2020. [Google Scholar]
- Ma, N.; Zhang, X.; Zheng, H.T.; Sun, J. ShuffleNet V2: Practical Guidelines for Efficient CNN Architecture Design. In Proceedings of the European Conference on Computer Vision, Salt Lake City, UT, USA, 19–21 June 2018. [Google Scholar]
- Chollet, F. Xception: Deep Learning with Depthwise Separable Convolutions. In Proceedings of the 2017 IEEE Conference on Computer Vision and Pattern Recognition (CVPR), Honolulu, HI, USA, 22–25 July 2017. [Google Scholar]
- Jie, H.; Li, S.; Gang, S.; Albanie, S. Squeeze-and-Excitation Networks. arXiv 2017, arXiv:1709.01507. [Google Scholar]
- Zhang, Y.F.; Ren, W.; Zhang, Z.; Jia, Z.; Wang, L.; Tan, T. Focal and Efficient IOU Loss for Accurate Bounding Box Regression. arXiv 2021, arXiv:2101.08158. [Google Scholar]
- Kumar, V.R.; Hiremath, S.A.; Milz, S.; Witt, C.; Pi Nn Ard, C.; Yogamani, S.; Mader, P. FisheyeDistanceNet: Self-Supervised Scale-Aware Distance Estimation using Monocular Fisheye Camera for Autonomous Driving. In Proceedings of the 2020 IEEE International Conference on Robotics and Automation (ICRA), Montreal, QC, Canada, 20–22 May 2019. [Google Scholar]
- Godard, C.; Aodha, O.M.; Brostow, G.J. Unsupervised Monocular Depth Estimation with Left-Right Consistency. In Proceedings of the 2017 IEEE Conference on Computer Vision and Pattern Recognition (CVPR), Honolulu, HI, USA, 22–25 July 2017. [Google Scholar]
- Mahjourian, R.; Wicke, M.; Angelova, A. Unsupervised Learning of Depth and Ego-Motion from Monocular Video Using 3D Geometric Constraints. In Proceedings of the 2018 IEEE/CVF Conference on Computer Vision and Pattern Recognition, Salt Lake City, UT, USA, 19–21 June 2018. [Google Scholar]
- Jaderberg, M.; Simonyan, K.; Zisserman, A.; Kavukcuoglu, K. Spatial Transformer Networks; MIT Press: Cambridge, MA, USA, 2015. [Google Scholar]
- Zhao, H.; Gallo, O.; Frosio, I.; Kautz, J. Loss Functions for Image Restoration With Neural Networks. IEEE Trans. Comput. Imaging 2017, 3, 47–57. [Google Scholar] [CrossRef]
- Zhou, W.; Bovik, A.C.; Sheikh, H.R.; Simoncelli, E.P. Image quality assessment: From error visibility to structural similarity. IEEE Trans. Image Process. 2004, 13, 600–612. [Google Scholar]
- Barron, J.T. A General and Adaptive Robust Loss Function. In Proceedings of the 2019 IEEE/CVF Conference on Computer Vision and Pattern Recognition (CVPR), Long Beach, CA, USA, 16–20 June 2019. [Google Scholar]
- Kumar, V.R.; Klingner, M.; Yogamani, S.; Milz, S.; Maeder, P. SynDistNet: Self-Supervised Monocular Fisheye Camera Distance Estimation Synergized with Semantic Segmentation for Autonomous Driving. In Proceedings of the 2021 IEEE Winter Conference on Applications of Computer Vision (WACV), Online, 5–9 January 2021. [Google Scholar]
- Godard, C.; Aodha, O.M.; Firman, M.; Brostow, G. Digging Into Self-Supervised Monocular Depth Estimation. In Proceedings of the 2019 IEEE/CVF International Conference on Computer Vision (ICCV), Seoul, Korea, 27 October–2 November 2019. [Google Scholar]
- Ramachandran, P.; Parmar, N.; Vaswani, A.; Bello, I.; Levskaya, A.; Shlens, J.B. Stand-alone self-attention in vision models. In Proceedings of the 2019 IEEE/CVF Conference on Computer Vision and Pattern Recognition (CVPR), Long Beach, CA, USA, 16–20 June 2019. [Google Scholar]
- Woo, S.; Park, J.; Lee, J.Y.; Kweon, I.S. CBAM: Convolutional Block Attention Module. In Proceedings of the 15th European Conference on Computer Vision, Munich, Germany, 8–14 September 2018. [Google Scholar]
- Miangoleh, S.; Dille, S.; Long, M.; Paris, S.; Aksoy, Y. Boosting Monocular Depth Estimation Models to High-Resolution via Content-Adaptive Multi-Resolution Merging. In Proceedings of the 2021 IEEE/CVF Conference on Computer Vision and Pattern Recognition (CVPR), Online, 19–25 June 2021. [Google Scholar]
- Kingma, D.; Ba, J. Adam: A Method for Stochastic Optimization. arXiv 2014, arXiv:1412.6980. [Google Scholar]
- Geiger, A.; Lenz, P.; Urtasun, R. Are we ready for autonomous driving? The KITTI vision benchmark suite. In Proceedings of the IEEE Conference on Computer Vision and Pattern Recognition, Providence, RI, USA, 16–21 June 2012. [Google Scholar]
- Casser, V.; Pirk, S.; Mahjourian, R.; Angelova, A. Depth Prediction without the Sensors: Leveraging Structure for Unsupervised Learning from Monocular Videos. In Proceedings of the Thirty-Third AAAI Conference on Artificial Intelligence (AAAI’19), Hawaii, HI, USA, 27 January–1 February 2019. [Google Scholar]
- Eigen, D.; Fergus, R. Predicting Depth, Surface Normals and Semantic Labels with a Common Multi-Scale Convolutional Architecture. In Proceedings of the 2015 IEEE International Conference on Computer Vision (ICCV), Santiago, Chile, 13–16 December 2015. [Google Scholar]
- Zhang, Z. A Flexible New Technique for Camera Calibration. IEEE Trans. Pattern Anal. Mach. Intell. 2000, 22, 1330–1334. [Google Scholar] [CrossRef] [Green Version]







{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
| Class | Method | EIoU | SE Layer | Precision (%) | Recall (%) |
|---|---|---|---|---|---|
| Car | YOLOv5s | × ✓ | - | 94.4 95.3 | 90.2 91.3 |
| LF-YOLO | × ✓ × ✓ | × × ✓ ✓ | 88.0 89.5 90.3 92.4 | 84.1 84.9 87.4 88.7 | |
| Pedestrian | YOLOv5s | × ✓ | - | 95.0 95.6 | 93.5 94.0 |
| LF-YOLO | × ✓ × ✓ | × × ✓ ✓ | 90.1 90.9 92.5 93.2 | 85.6 86.6 89.3 89.9 | |
| Cyclist | YOLOv5s | × ✓ | - | 90.3 91.0 | 81.5 83.1 |
| LF-YOLO | × ✓ × ✓ | × × ✓ ✓ | 80.2 82.9 83.0 86.1 | 75.8 77.2 78.7 79.6 |
| Method | SE Layer | Infer Time per Frame (ms) | Parameters |
|---|---|---|---|
| YOLOv5s | - | 94.5 | 7.3 M |
| LF-YOLO | × | 47.5 | 2.1 M |
| ✓ | 56 | 3.9 M |
| Approach | Lower Is Better | Higher Is Better | ||||
|---|---|---|---|---|---|---|
| < 1.25 | < | < | ||||
| Zhou [30] | 0.183 | 1.595 | 0.270 | 0.734 | 0.902 | 0.959 |
| GeoNet [17] | 0.149 | 1.060 | 0.226 | 0.796 | 0.935 | 0.975 |
| Struct2depth [64] | 0.141 | 1.026 | 0.215 | 0.816 | 0.945 | 0.979 |
| PackNet-SfM [19] | 0.120 | 0.892 | 0.196 | 0.864 | 0.954 | 0.980 |
| Monodepth2 [58] | 0.115 | 0.903 | 0.193 | 0.877 | 0.959 | 0.981 |
| FisheyeNet [50] | 0.117 | 0.867 | 0.190 | 0.869 | 0.960 | 0.982 |
| SynDistNet [57] | 0.109 | 0.718 | 0.180 | 0.896 | 0.973 | 0.986 |
| Shu [18] | 0.104 | 0.729 | 0.179 | 0.893 | 0.965 | 0.984 |
| Ours | 0.101 | 0.715 | 0.178 | 0.899 | 0.981 | 0.990 |
| Method | Lower Is Better | Higher Is Better | ||||
|---|---|---|---|---|---|---|
| < 1.25 | < | < | ||||
| Baseline | 0.198 | 1.034 | 0.241 | 0.841 | 0.886 | 0.910 |
| Baseline + Att | 0.163 | 0.894 | 0.192 | 0.851 | 0.897 | 0.924 |
| Baseline + | 0.154 | 0.887 | 0.190 | 0.849 | 0.891 | 0.923 |
| Baseline + Att + | 0.121 | 0.723 | 0.181 | 0.872 | 0.915 | 0.941 |
| Method | SA | CBAM | MRE | < 1.25 | ||||
|---|---|---|---|---|---|---|---|---|
| Ours | × | × | × | × | 0.205 | 1.617 | 0.282 | 0.812 |
| Ours | ✓ | × | × | × | 0.154 | 1.129 | 0.216 | 0.848 |
| Ours | ✓ | ✓ | × | × | 0.121 | 0.812 | 0.191 | 0.874 |
| Ours | ✓ | × | ✓ | × | 0.130 | 0.856 | 0.208 | 0.859 |
| Ours | ✓ | ✓ | × | ✓ | 0.101 | 0.715 | 0.178 | 0.899 |
Publisher’s Note: MDPI stays neutral with regard to jurisdictional claims in published maps and institutional affiliations. |
© 2022 by the authors. Licensee MDPI, Basel, Switzerland. This article is an open access article distributed under the terms and conditions of the Creative Commons Attribution (CC BY) license (https://creativecommons.org/licenses/by/4.0/).
Share and Cite
Liang, H.; Ma, Z.; Zhang, Q. Self-Supervised Object Distance Estimation Using a Monocular Camera. Sensors 2022, 22, 2936. https://doi.org/10.3390/s22082936
Liang H, Ma Z, Zhang Q. Self-Supervised Object Distance Estimation Using a Monocular Camera. Sensors. 2022; 22(8):2936. https://doi.org/10.3390/s22082936
Chicago/Turabian StyleLiang, Hong, Zizhen Ma, and Qian Zhang. 2022. "Self-Supervised Object Distance Estimation Using a Monocular Camera" Sensors 22, no. 8: 2936. https://doi.org/10.3390/s22082936