
Efficient Hardware Design and Implementation of the Voting Scheme-Based Convolution




Abstract
:1. Introduction
2. Related Works
3. Design and Implementation
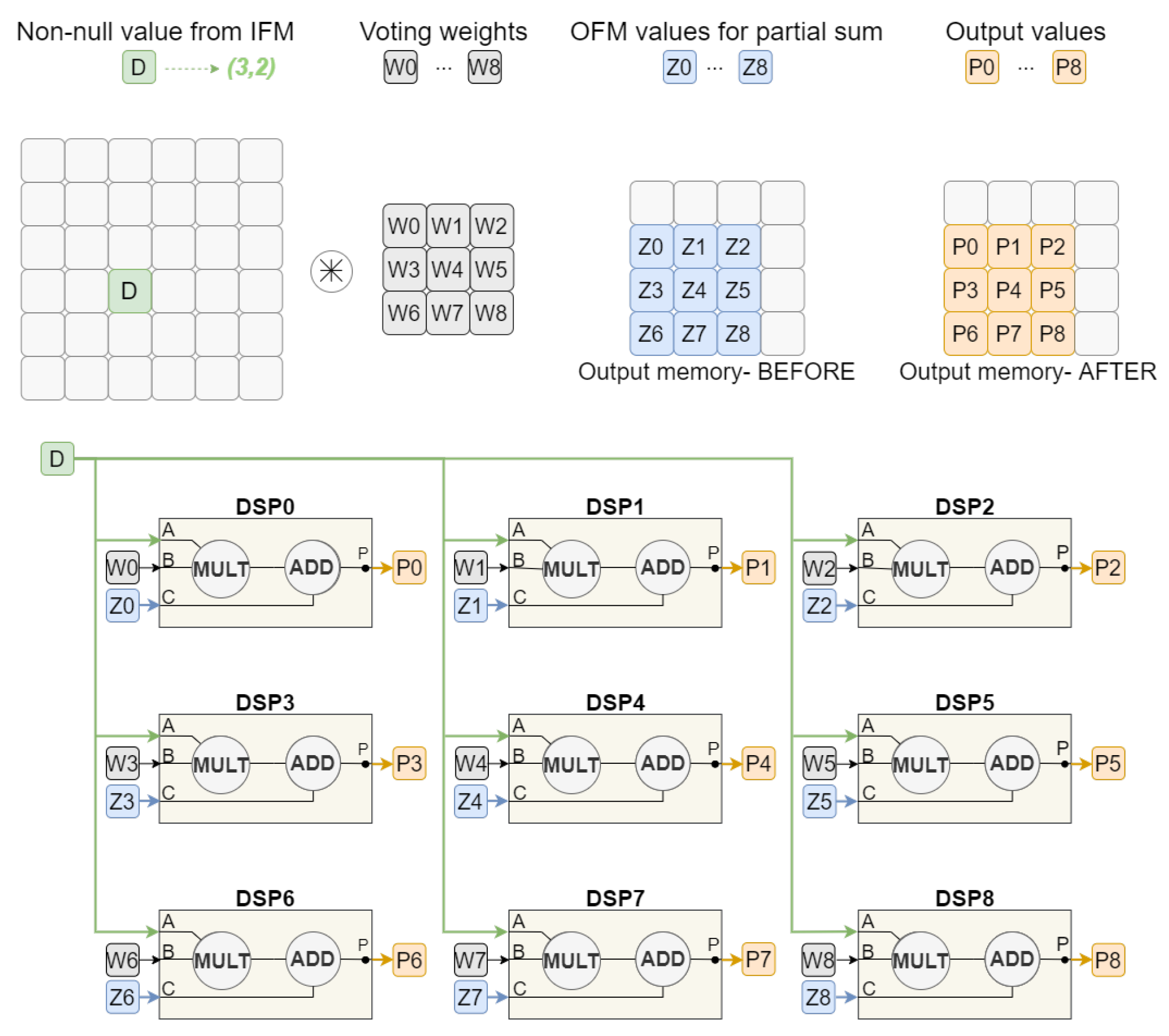
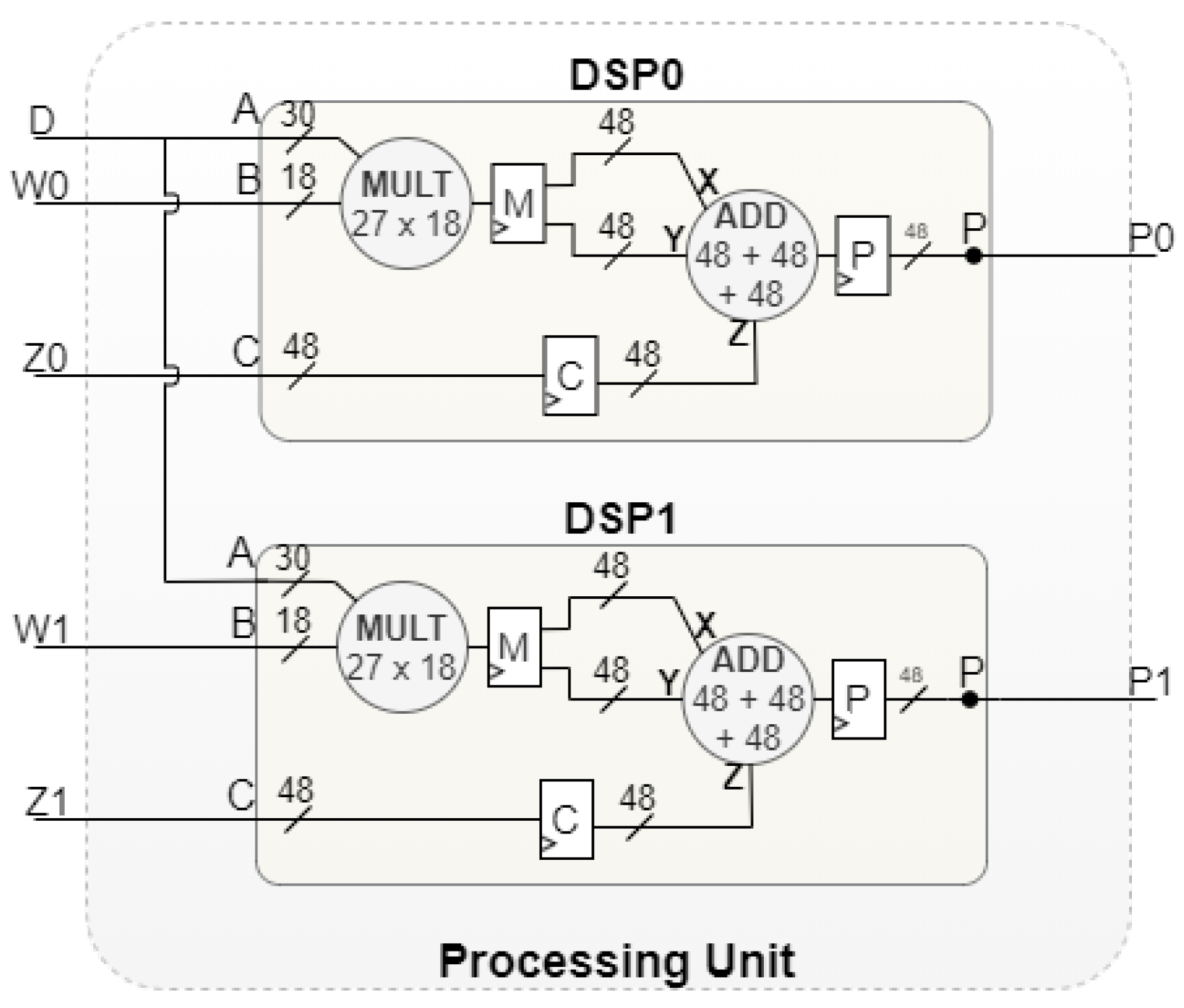
3.1. Processing Unit
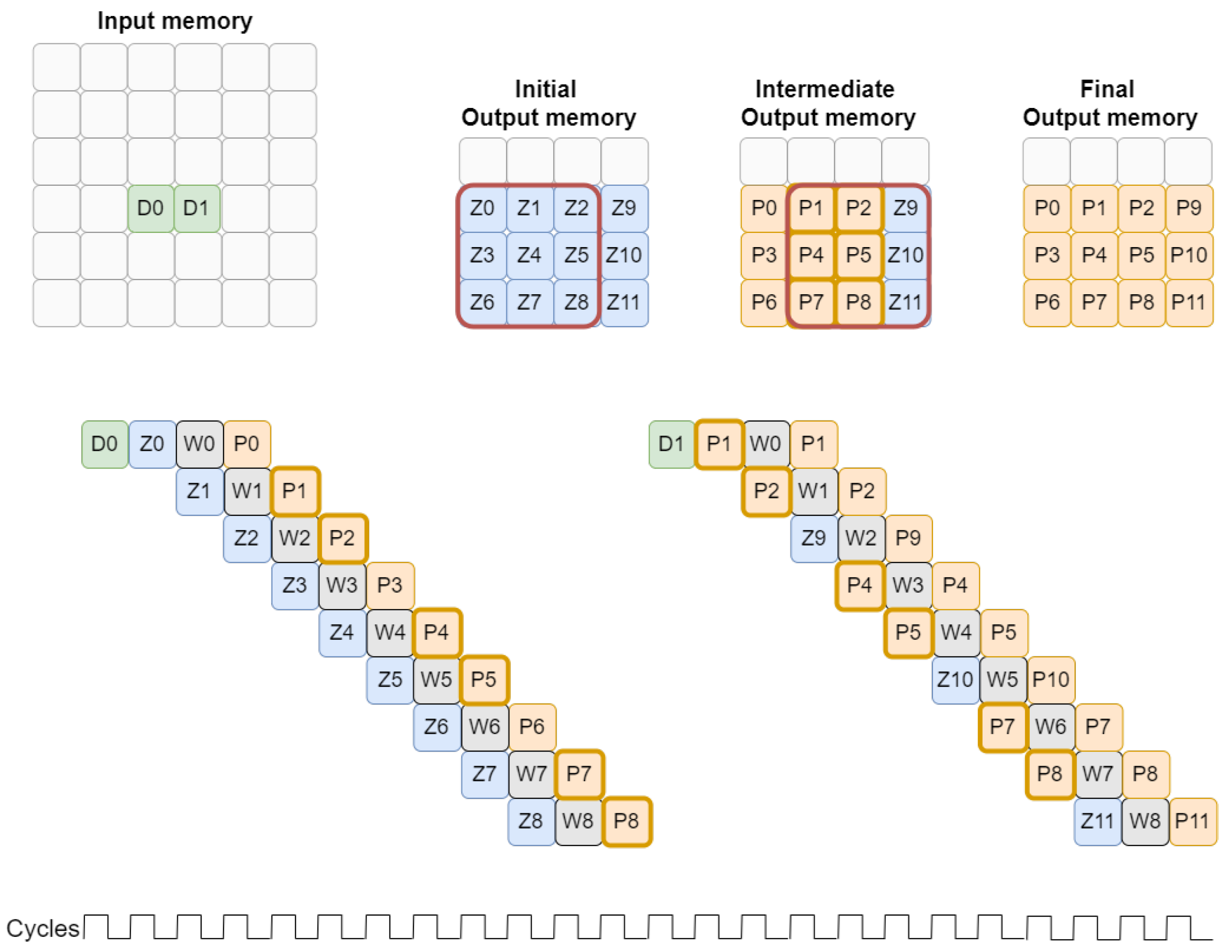
3.1.1. Four-Stage Sequential Convolution
3.1.2. Pipeline-Based Double Computing
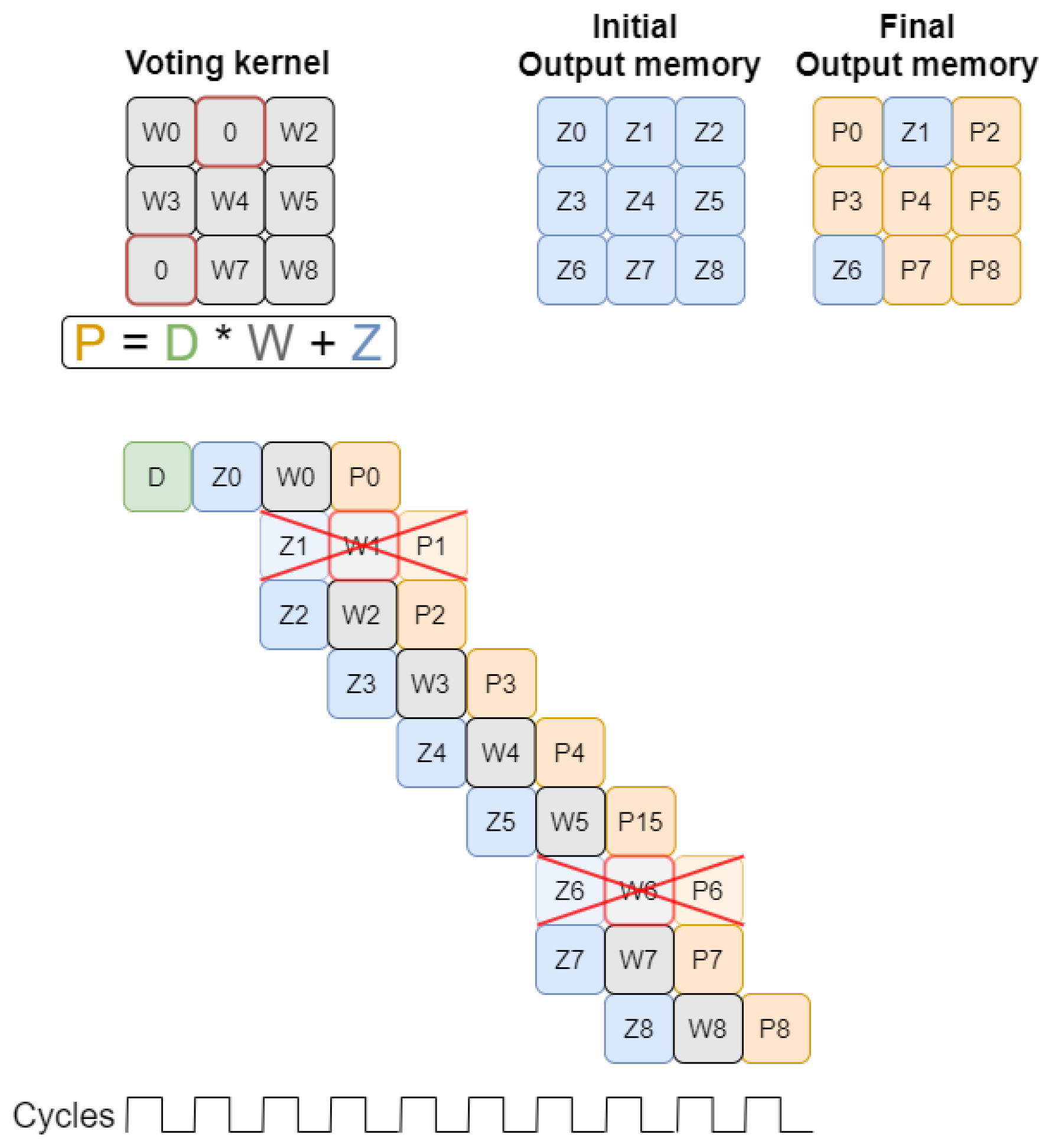
3.1.3. Weight-Based Optimization
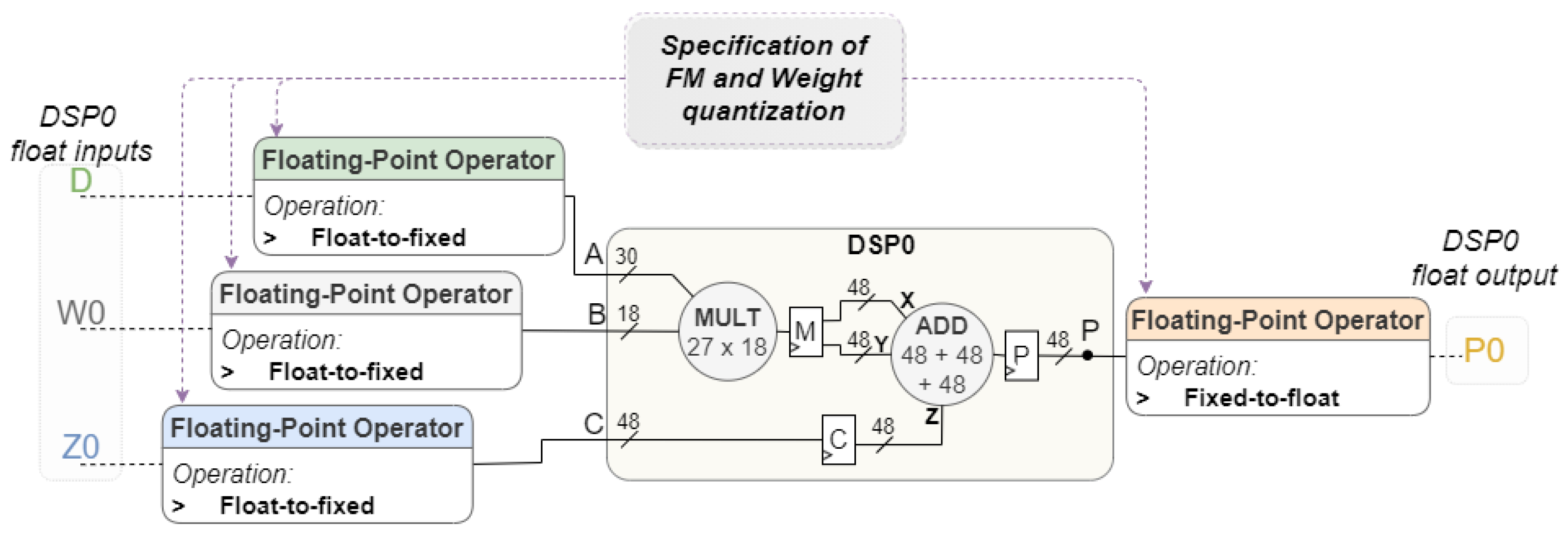
3.1.4. Data Quantization
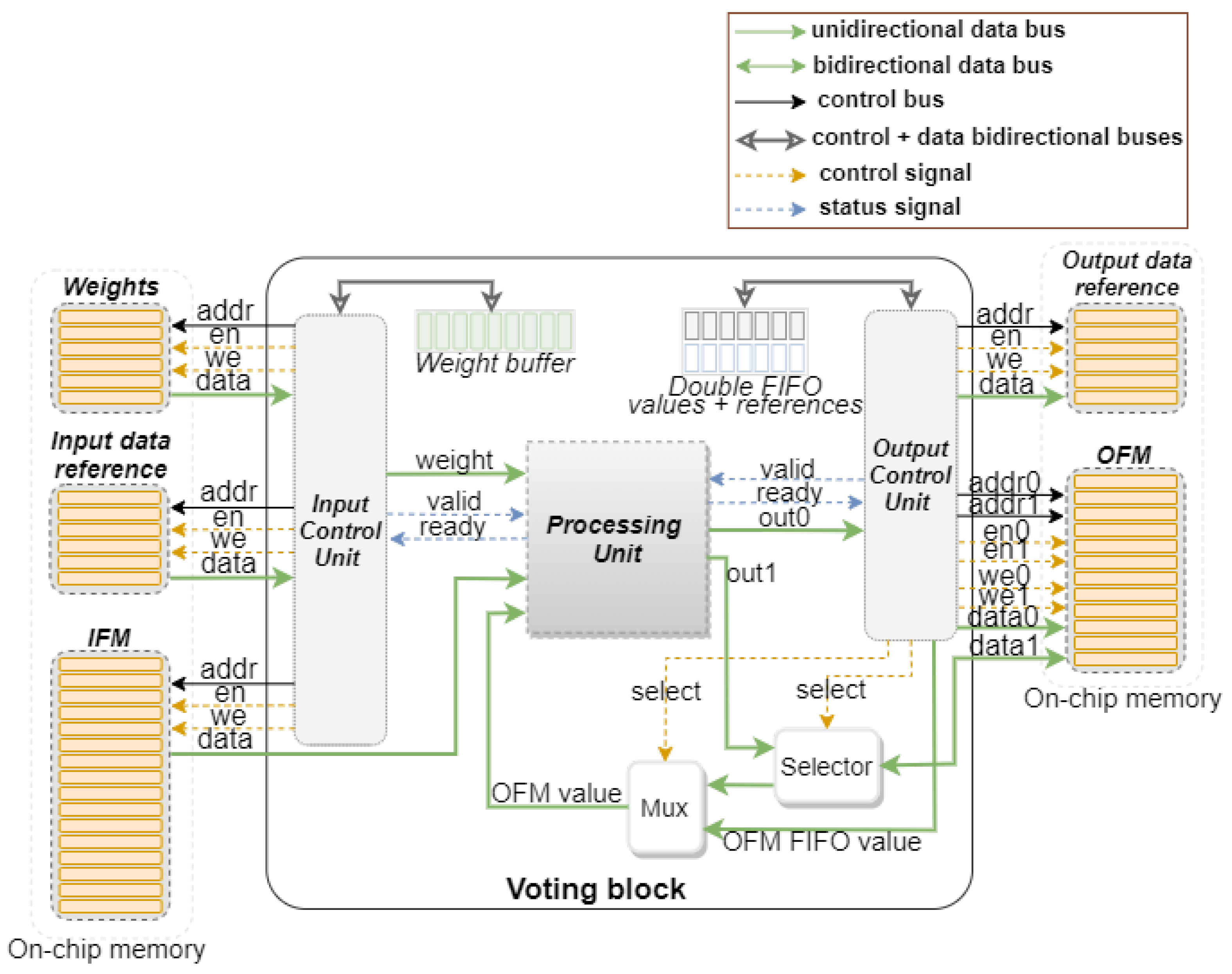
3.2. Control Unit
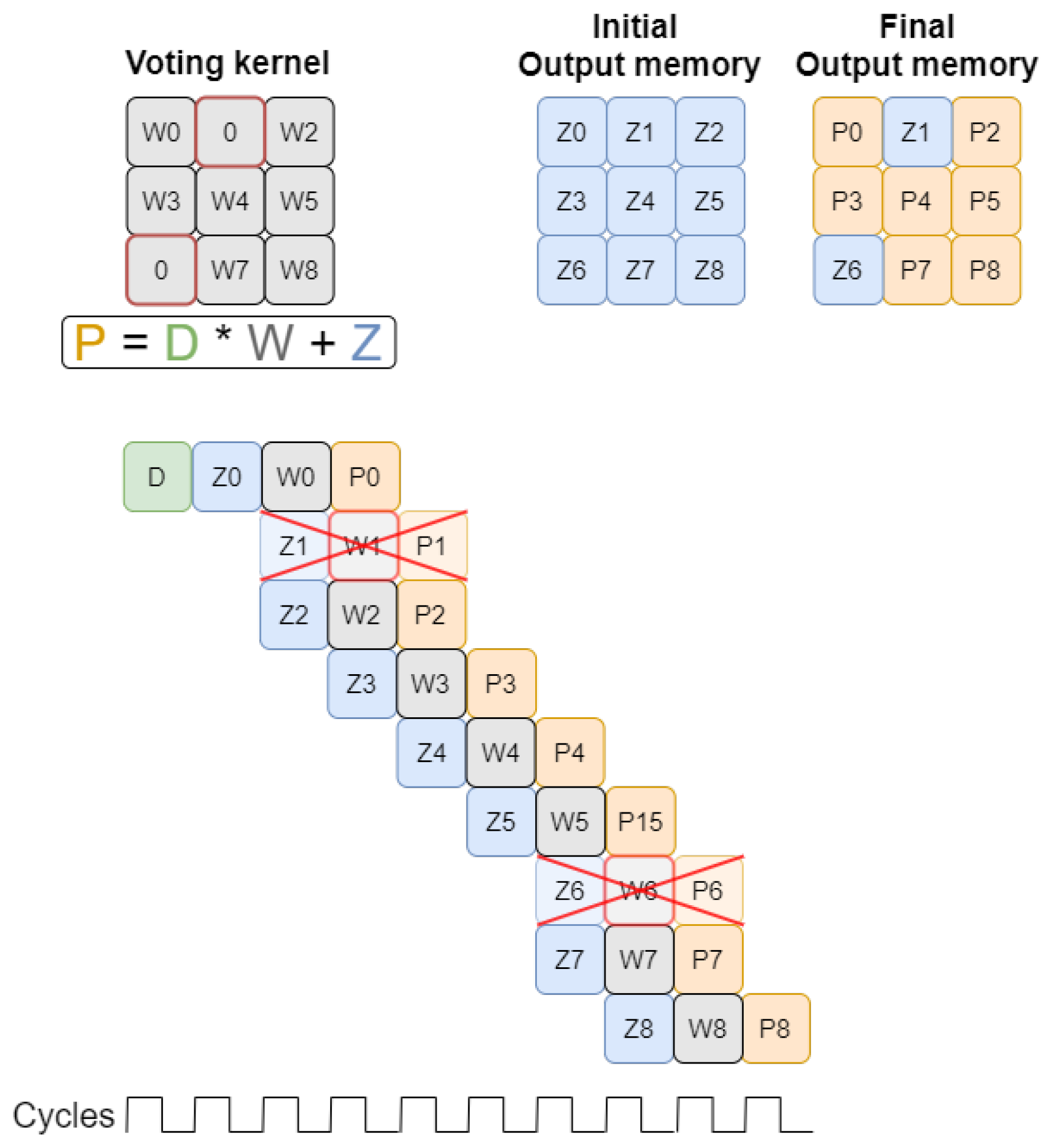
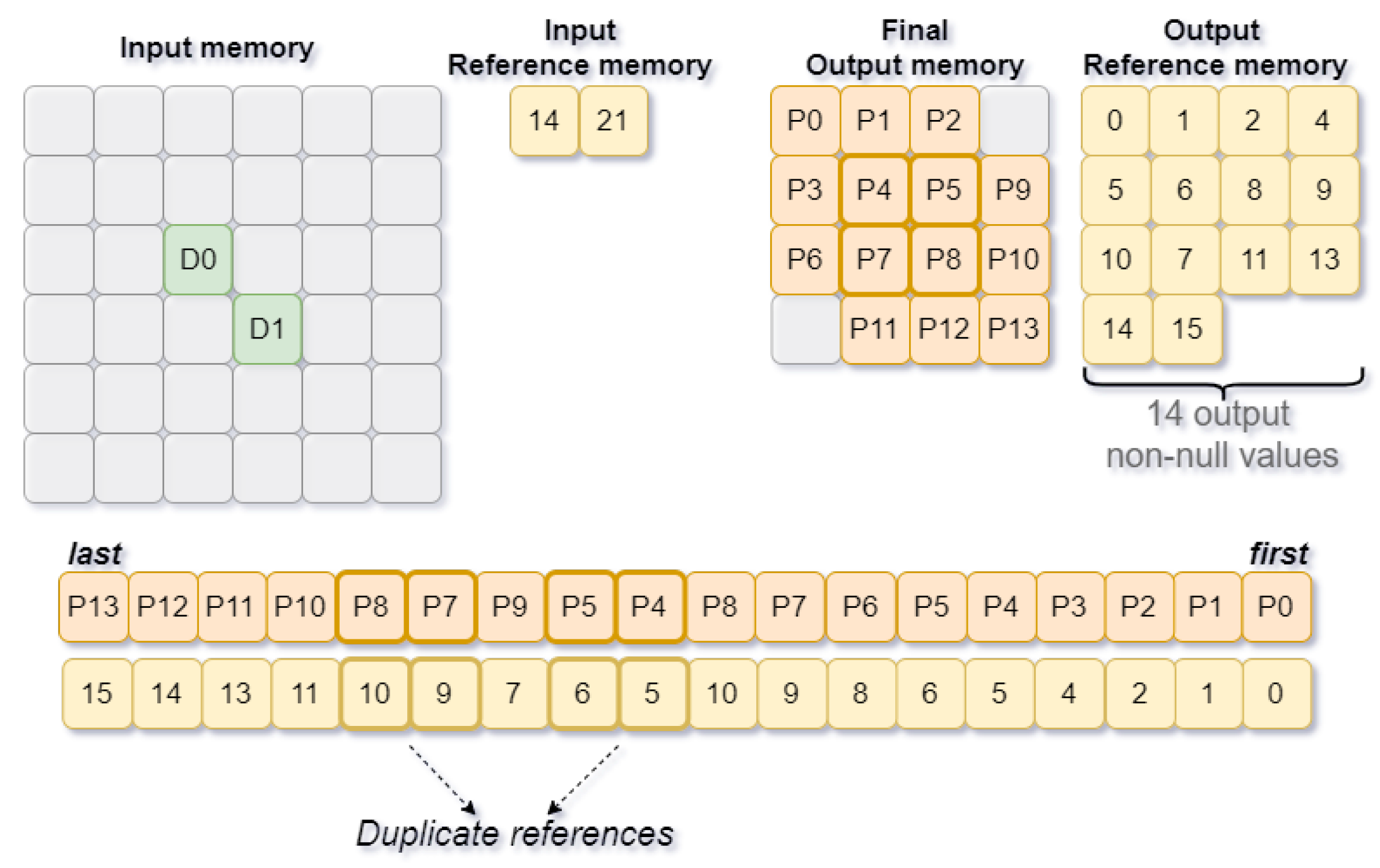
3.2.1. Output Reference Generation
3.2.2. User Configuration
4. Results
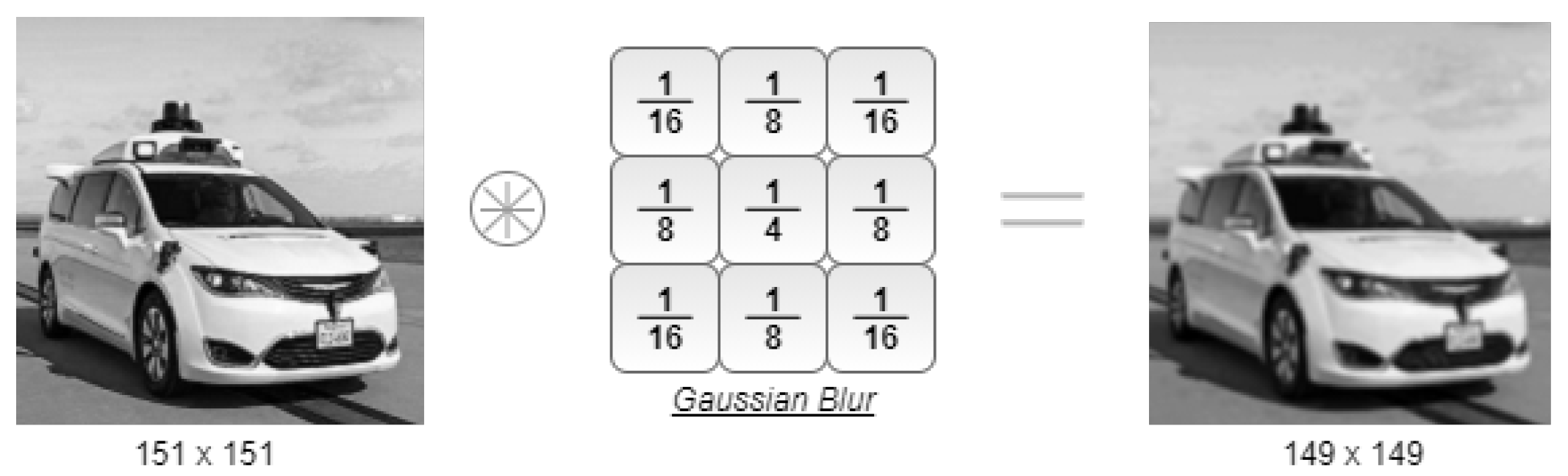
4.1. Functional Validation
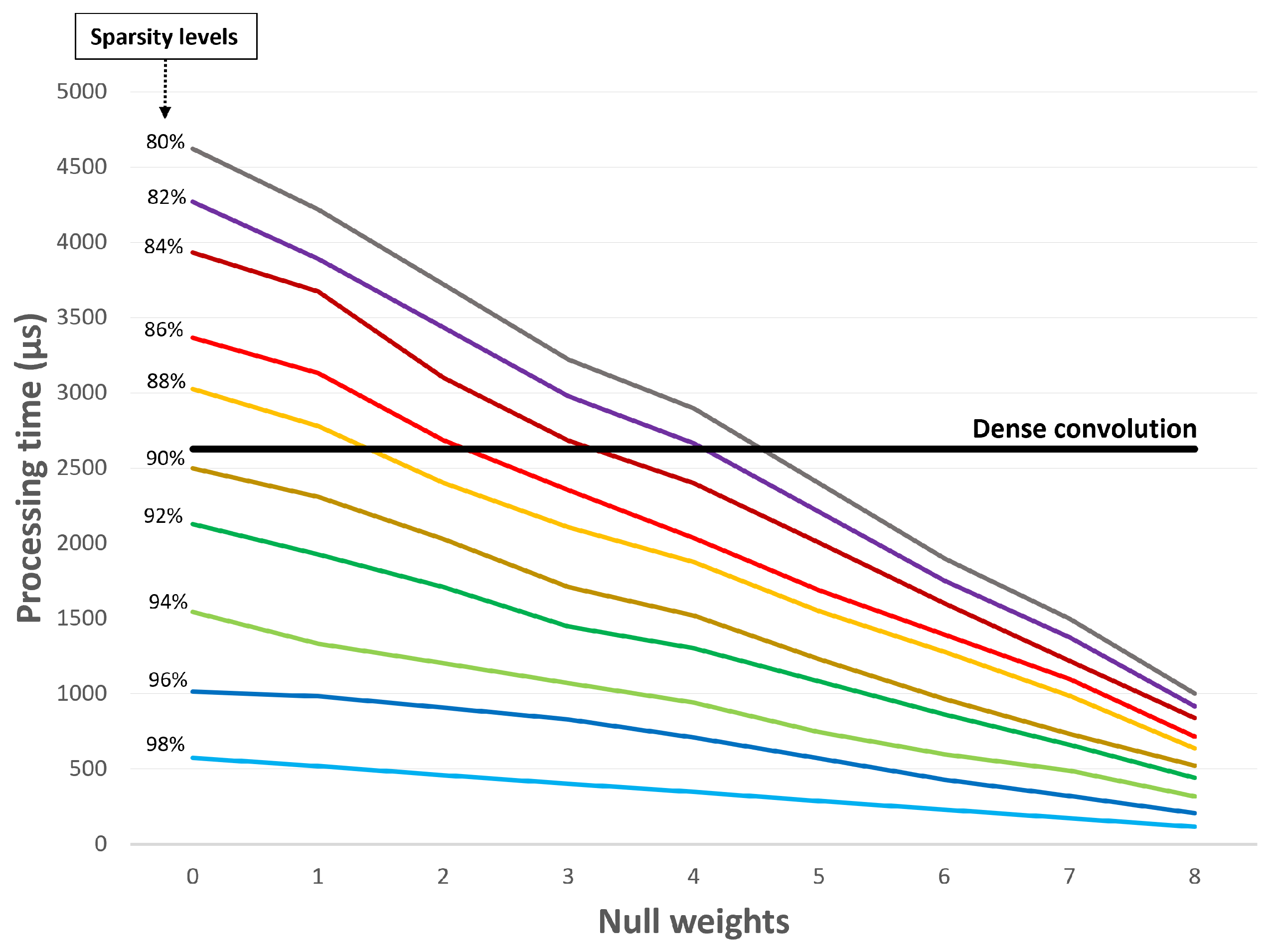
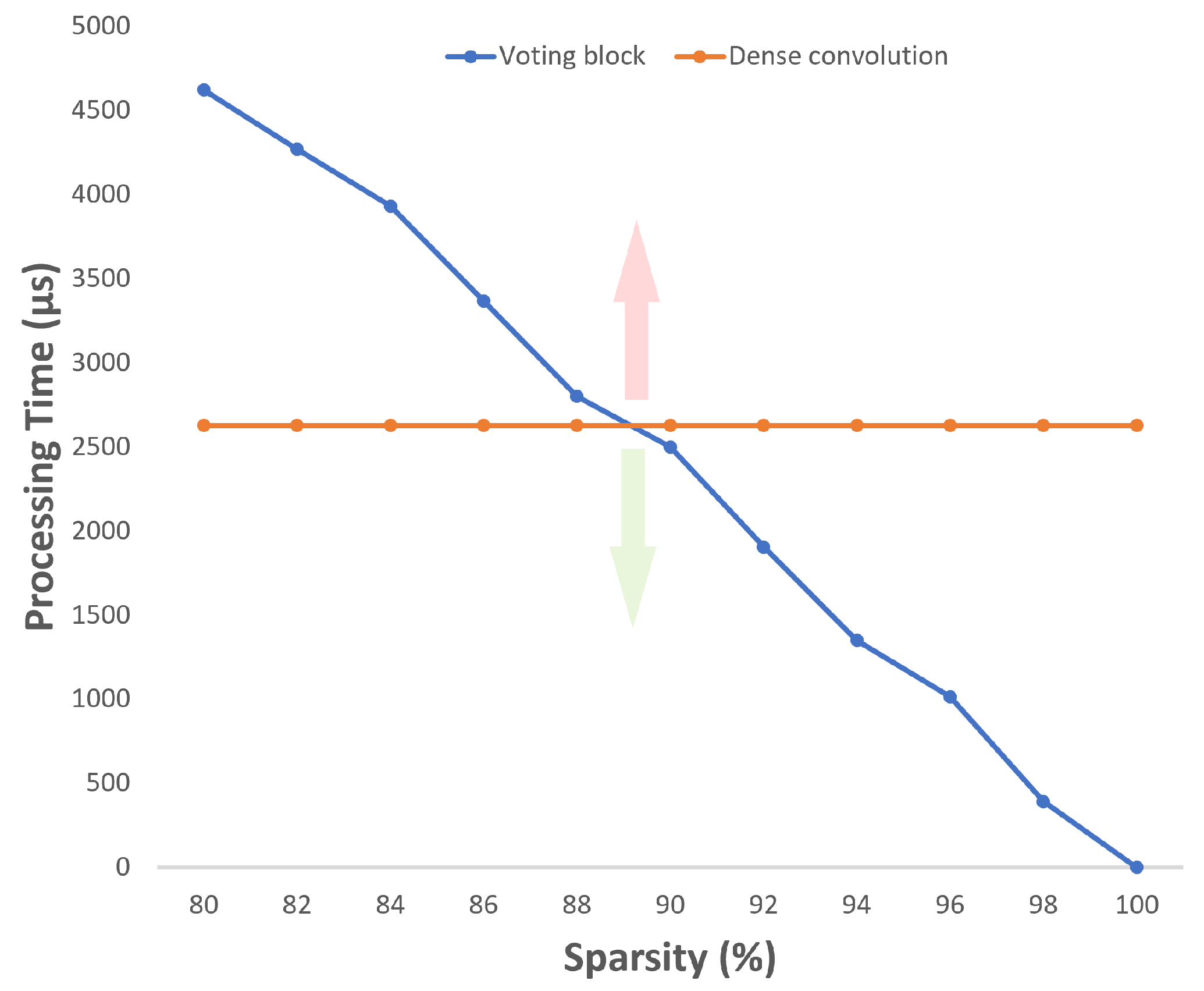
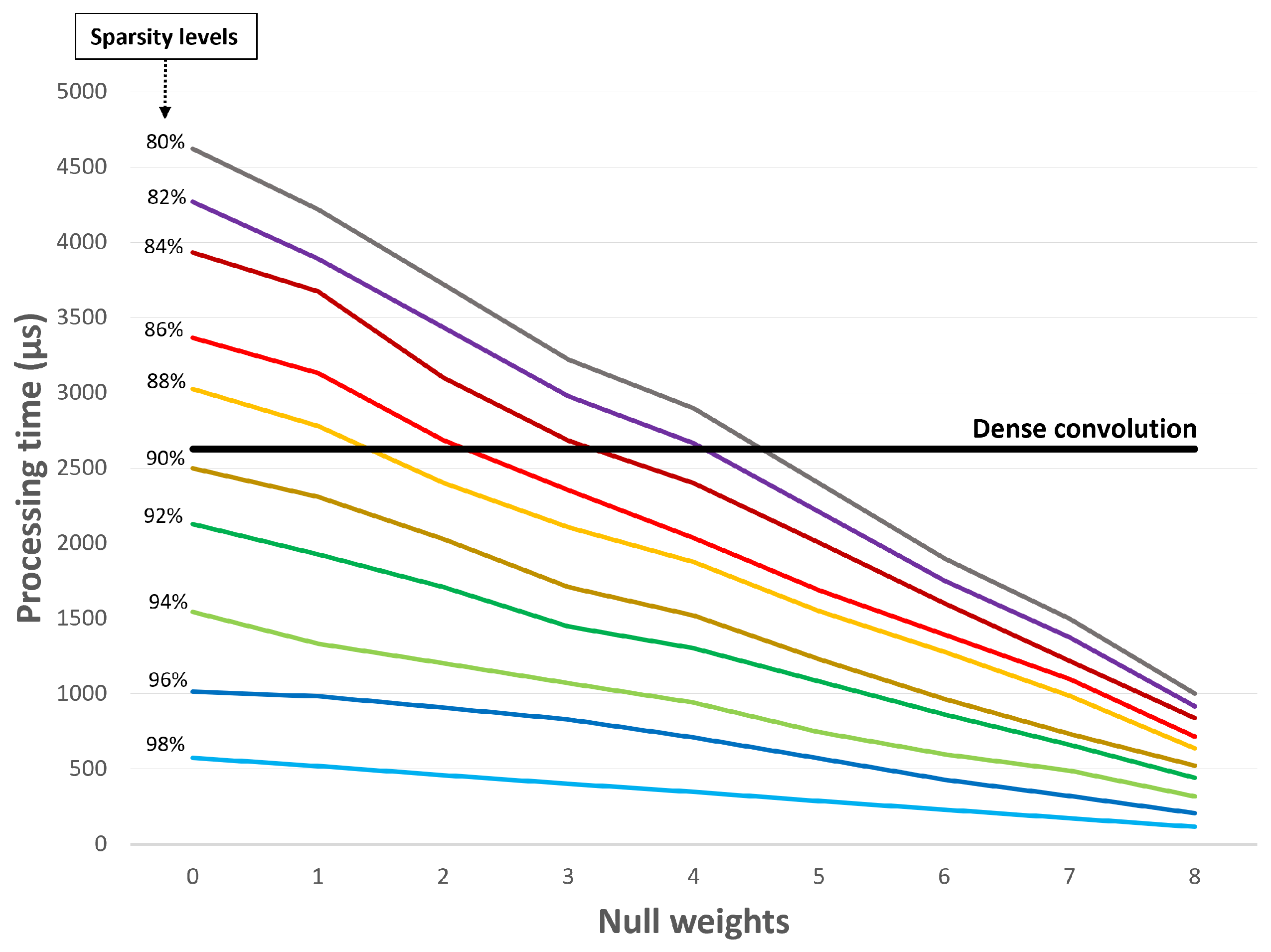
4.2. Sparsity Effect
4.3. Concentration Metric
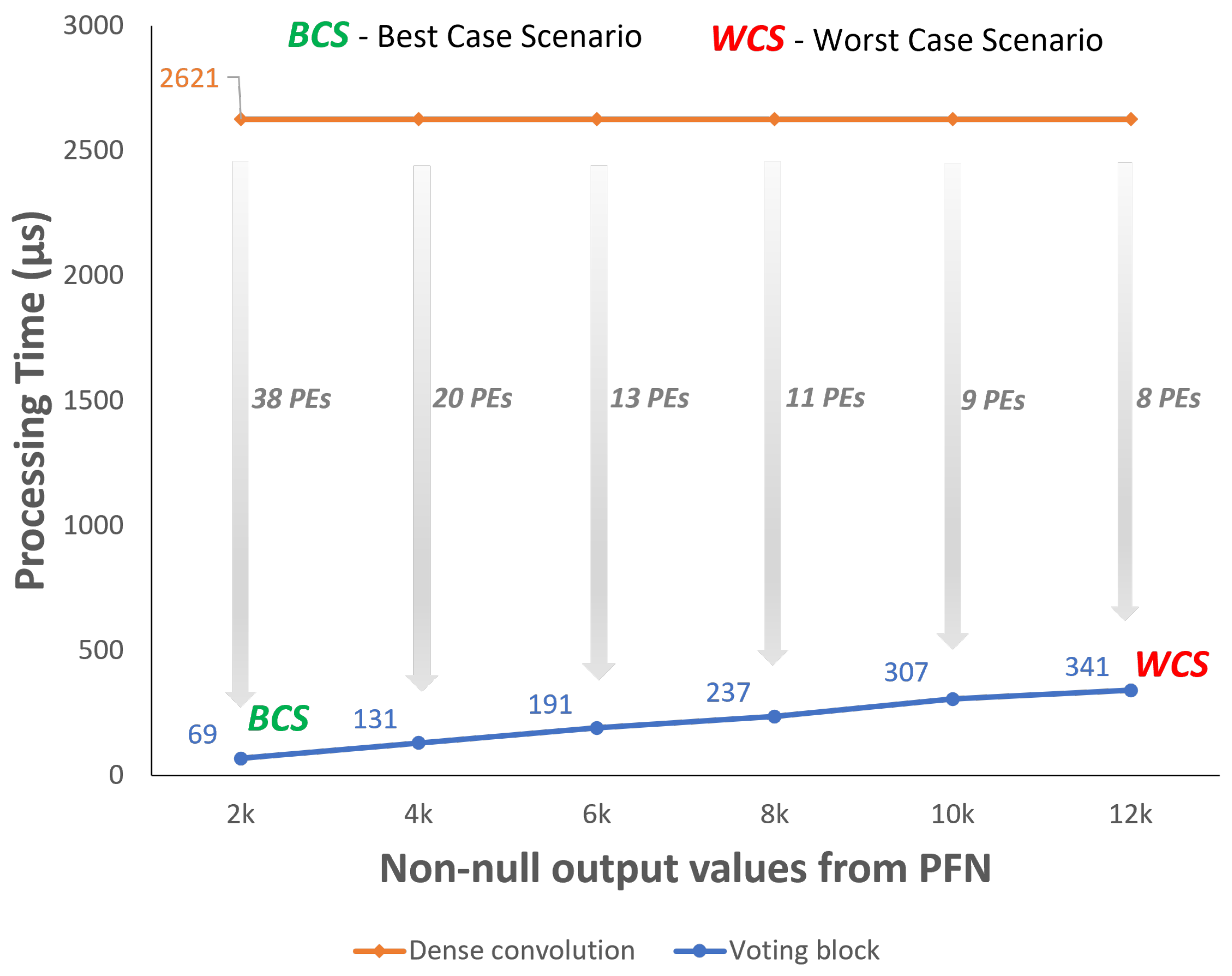
4.4. Null-Weight Processing Optimization
4.5. Strided Operation Boost
4.6. PointPillars
5. Conclusions
Author Contributions
Funding
Conflicts of Interest
References
- Guo, Y.; Wang, H.; Hu, Q.; Liu, H.; Liu, L.; Bennamoun, M. Deep learning for 3d point clouds: A survey. IEEE Trans. Pattern Anal. Mach. Intell. 2020, 43, 4338–4364. [Google Scholar] [CrossRef] [PubMed]
- LeCun, Y.; Bengio, Y.; Hinton, G. Deep learning. Nature 2015, 521, 436–444. [Google Scholar] [CrossRef] [PubMed]
- Libano, F.; Wilson, B.; Wirthlin, M.; Rech, P.; Brunhaver, J. Understanding the Impact of Quantization, Accuracy, and Radiation on the Reliability of Convolutional Neural Networks on FPGAs. IEEE Trans. Nucl. Sci. 2020, 67, 1478–1484. [Google Scholar] [CrossRef]
- Fernandes, D.; Silva, A.; Névoa, R.; Simões, C.; Gonzalez, D.; Guevara, M.; Novais, P.; Monteiro, J.; Melo-Pinto, P. Point-cloud based 3D object detection and classification methods for self-driving applications: A survey and taxonomy. Inf. Fusion 2021, 68, 161–191. Available online: https://www.sciencedirect.com/science/article/pii/S1566253520304097 (accessed on 15 January 2021). [CrossRef]
- Wang, D.; Posner, I. Voting for voting in online point cloud object detection. Robot. Sci. Syst. 2015, 1, 10–15. [Google Scholar]
- Engelcke, M.; Rao, D.; Wang, D.; Tong, C.; Posner, I. Vote3deep: Fast object detection in 3d point clouds using efficient convolutional neural networks. In Proceedings of the 2017 IEEE International Conference On Robotics And Automation (ICRA), Singapore, 29 May–3 June 2017; pp. 1355–1361. [Google Scholar]
- Graham, B.; Maaten, L. Submanifold sparse convolutional networks. arXiv 2017, arXiv:1706.01307. [Google Scholar]
- Abdelouahab, K.; Pelcat, M.; Serot, J.; Berry, F. Accelerating CNN inference on FPGAs: A survey. arXiv 2018, arXiv:1806.01683. [Google Scholar]
- Mittal, S. A survey of FPGA-based accelerators for convolutional neural networks. Neural Comput. Appl. 2020, 32, 1109–1139. [Google Scholar] [CrossRef]
- Rahman, A.; Oh, S.; Lee, J.; Choi, K. Design space exploration of FPGA accelerators for convolutional neural networks. In Proceedings of the Design, Automation & Test In Europe Conference & Exhibition (DATE), Lausanne, Switzerland, 27–31 March 2017; pp. 1147–1152. [Google Scholar]
- Chen, Y.; Yang, T.; Emer, J.; Sze, V. Eyeriss v2: A flexible accelerator for emerging deep neural networks on mobile devices. IEEE J. Emerg. Sel. Top. Circuits Syst. 2019, 9, 292–308. [Google Scholar] [CrossRef] [Green Version]
- Qiu, J.; Wang, J.; Yao, S.; Guo, K.; Li, B.; Zhou, E.; Yu, J.; Tang, T.; Xu, N.; Song, S.; et al. Going Deeper with Embedded FPGA Platform for Convolutional Neural Network. In Proceedings of the 2016 ACM/SIGDA International Symposium On Field-Programmable Gate Arrays, Monterey, CA, USA, 21–23 February 2016. [Google Scholar]
- Xilinx Adaptable and Real-Time AI Inference Acceleration. 2020. Available online: https://www.xilinx.com/products/design-tools/vitis/vitis-ai.html (accessed on 20 January 2021).
- CDL A Deep Learning Platform Optimized for Implementation of FPGAs. 2020. Available online: https://coredeeplearning.ai/, (accessed on 1 July 2021).
- He, K.; Zhang, X.; Ren, S.; Sun, J. Deep residual learning for image recognition. In Proceedings of the IEEE Conference On Computer Vision And Pattern Recognition, Las Vegas, NV, USA, 27–30 June 2016; pp. 770–778. [Google Scholar]
- Redmon, J.; Divvala, S.; Girshick, R.; Farhadi, A. You only look once: Unified, real-time object detection. In Proceedings of the IEEE Conference on Computer Vision and Pattern Recognition, Las Vegas, NV, USA, 27–30 June 2016; pp. 779–788. [Google Scholar]
- Abdelouahab, K.; Pelcat, M.; Serot, J.; Bourrasset, C.; Quinton, J.; Berry, F. Hardware Automated Dataflow Deployment of CNNs. arXiv 2017, arXiv:1705.04543. [Google Scholar]
- Chen, Y.; Emer, J.; Sze, V. Eyeriss: A spatial architecture for energy-efficient dataflow for convolutional neural networks. ACM SIGARCH Comput. Archit. News 2016, 44, 367–379. [Google Scholar] [CrossRef]
- Albericio, J.; Judd, P.; Hetherington, T.; Aamodt, T.; Jerger, N.; Moshovos, A. Cnvlutin: Ineffectual-neuron-free deep neural network computing. ACM SIGARCH Comput. Archit. News 2016, 44, 1–13. [Google Scholar] [CrossRef]
- Zhang, S.; Du, Z.; Zhang, L.; Lan, H.; Liu, S.; Li, L.; Guo, Q.; Chen, T.; Chen, Y. Cambricon-X: An accelerator for sparse neural networks. In Proceedings of the 2016 49th Annual IEEE/ACM International Symposium On Microarchitecture (MICRO), Taipei, Taiwan, 15–19 October 2016; pp. 1–12. [Google Scholar]
- Han, S.; Kang, J.; Mao, H.; Hu, Y.; Li, X.; Li, Y.; Xie, D.; Luo, H.; Yao, S.; Wang, Y.; et al. Ese: Efficient speech recognition engine with sparse lstm on fpga. In Proceedings of the 2017 ACM/SIGDA International Symposium On Field-Programmable Gate Arrays, Monterey, CA, USA, 22–24 February 2017; pp. 75–84. [Google Scholar]
- Lu, L.; Xie, J.; Huang, R.; Zhang, J.; Lin, W.; Liang, Y. An efficient hardware accelerator for sparse convolutional neural networks on FPGAs. In Proceedings of the 2019 IEEE 27th Annual International Symposium On Field-Programmable Custom Computing Machines (FCCM), San Diego, CA, USA, 28 April–1 May 2019; pp. 17–25. [Google Scholar]
- Lang, A.; Vora, S.; Caesar, H.; Zhou, L.; Yang, J.; Beijbom, O. Pointpillars: Fast encoders for object detection from point clouds. In Proceedings of the IEEE/CVF Conference On Computer Vision And Pattern Recognition, Long Beach, CA, USA, 15–20 June 2019; pp. 12697–12705. [Google Scholar]
- Yan, Y.; Mao, Y.; Li, B. Second: Sparsely embedded convolutional detection. Sensors 2018, 18, 3337. [Google Scholar] [CrossRef] [PubMed] [Green Version]
- Silva, J.; Pereira, P.; Machado, R.; Névoa, R.; Melo-Pinto, P.; Fernandes, D. Customizable FPGA-based Hardware Accelerator For Standard Convolution Processes Empowered with Quantization Applied to LiDAR Data. Sensors 2022, 22, 2184. [Google Scholar] [CrossRef] [PubMed]
- Jo, J.; Kim, S.; Park, I. Energy-Efficient Convolution Architecture Based on Rescheduled Dataflow. IEEE Trans. Circuits Syst. I Regul. Pap. 2018, 65, 4196–4207. [Google Scholar] [CrossRef]
- Chen, Y.-H.; Krishna, T.; Emer, J.S.; Sze, V. Eyeriss: An Energy-Efficient Reconfigurable Accelerator for Deep Convolutional Neural Networks. IEEE J. Solid-State Circuits 2017, 52, 127–138. [Google Scholar] [CrossRef] [Green Version]
- Versatran01 Kittiarchives. GitHub Repository. 2021. Available online: https://gist.github.com/versatran01/19bbb78c42e0cafb1807625bbb99bd85 (accessed on 15 January 2021).












{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
| Resource | Utilization | Available | Utilization |
|---|---|---|---|
| LUT | 2364 | 17,600 | 13.43 |
| FF | 4416 | 35,200 | 12.55 |
| BRAM | 1 | 60 | 1.67 |
| DSP | 2 | 80 | 2.50 |
| Sparsity (%) | Processing Time (s) | Improvement (%) | |
|---|---|---|---|
| Concentration (0%) | Concentration (100%) | ||
| 80 | 4622 | 3507 | 24.1 |
| 82 | 4270 | 3227 | 24.4 |
| 84 | 3932 | 2946 | 25.1 |
| 86 | 3367 | 2506 | 25.6 |
| 88 | 2800 | 2079 | 25.8 |
| 90 | 2500 | 1845 | 26.2 |
| 92 | 1905 | 1393 | 26.9 |
| 94 | 1412 | 1026 | 27.3 |
| 96 | 1085 | 773 | 28.8 |
| 98 | 392 | 272 | 30.6 |
| 100 | 0 | 0 | 0.0 |
| Input Sparsity (%) | Stride = 1 | Stride = 2 | ||||
|---|---|---|---|---|---|---|
| Time (s) | Output Values | Output Sparsity (%) | Time (s) | Output Values | Output Sparsity (%) | |
| 80 | 3507 | 53,372 | 79.6 | 1378 | 12,845 | 80.4 |
| 82 | 3227 | 48,082 | 81.6 | 1266 | 11,665 | 82.2 |
| 84 | 2946 | 42,782 | 83.7 | 1156 | 10,420 | 84.1 |
| 86 | 2506 | 37,472 | 85.7 | 989 | 9043 | 86.2 |
| 88 | 2079 | 32,181 | 87.7 | 881 | 7667 | 88.3 |
| 90 | 1845 | 26,870 | 89.8 | 714 | 6488 | 90.1 |
| 92 | 1393 | 21,580 | 91.8 | 585 | 5046 | 92.3 |
| 94 | 1026 | 16,232 | 93.8 | 441 | 3932 | 94.0 |
| 96 | 773 | 10,905 | 95.8 | 285 | 2490 | 96.2 |
| 98 | 272 | 5515 | 97.9 | 121 | 1245 | 98.1 |
| 100 | 0 | 0 | 100 | 0 | 0 | 100 |
| Non-Null Values | Null Values | Sparsity | ||
|---|---|---|---|---|
| PFN | 768,000 | 16,009,216 | 0.95 | |
| Block1 | Conv0 | 293,601 | 1,803,551 | 0.86 |
| Conv1 | 440,402 | 1,656,750 | 0.79 | |
| Conv2 | 734,003 | 1,363,149 | 0.65 | |
| Conv3 | 775,946 | 1,321,206 | 0.63 | |
| Block2 | 256,901 | 267,387 | 0.51 | |
| Block3 | 138,936 | 123,208 | 0.47 | |
| Software | Dense Convolution | Voting Block | |||
|---|---|---|---|---|---|
| Time (s) | Time (s) | Improvement (%) | Time (s) | Improvement (%) | |
| B1-Conv0 | 874 | 654 | 25.18 | 171 | 80.44 |
| B1-Conv1 | 321 | 262 | 18.32 | 247 | 23.05 |
| B1-Conv2 | 321 | 262 | 18.32 | 356 | −10.90 |
Publisher’s Note: MDPI stays neutral with regard to jurisdictional claims in published maps and institutional affiliations. |
© 2022 by the authors. Licensee MDPI, Basel, Switzerland. This article is an open access article distributed under the terms and conditions of the Creative Commons Attribution (CC BY) license (https://creativecommons.org/licenses/by/4.0/).
Share and Cite
Pereira, P.; Silva, J.; Silva, A.; Fernandes, D.; Machado, R. Efficient Hardware Design and Implementation of the Voting Scheme-Based Convolution. Sensors 2022, 22, 2943. https://doi.org/10.3390/s22082943
Pereira P, Silva J, Silva A, Fernandes D, Machado R. Efficient Hardware Design and Implementation of the Voting Scheme-Based Convolution. Sensors. 2022; 22(8):2943. https://doi.org/10.3390/s22082943
Chicago/Turabian StylePereira, Pedro, João Silva, António Silva, Duarte Fernandes, and Rui Machado. 2022. "Efficient Hardware Design and Implementation of the Voting Scheme-Based Convolution" Sensors 22, no. 8: 2943. https://doi.org/10.3390/s22082943
APA StylePereira, P., Silva, J., Silva, A., Fernandes, D., & Machado, R. (2022). Efficient Hardware Design and Implementation of the Voting Scheme-Based Convolution. Sensors, 22(8), 2943. https://doi.org/10.3390/s22082943