In this section, the obtained experimental results are described. A new dataset for classification of non-standard human behavior was created. This new dataset was created because there is no other appropriate dataset for recognition and classification of non-standard human behavior. The obtained experimental results using the proposed architecture of ConvLSTM were compared with results from four well-known neural networks (ConvLSTM, 3D Resnet50, 3D Resnet101 and 3D Resnet152).
3.1. Abnormal Activities Dataset
As part of our abnormal behavior classification research, we created a dataset called the Abnormal Activities Dataset. The dataset consists of videos with ten non-professional actors. The dataset contains 1069 videos. This dataset was divided into eleven classes (Begging, Drunkenness, Fight, Harassment, Hijack, Knife Hazard, Normal Videos, Pollution, Property Damage, Robbery, Terrorism), as shown in the
Figure 6. These scenes were performed in different lighting conditions. During the creation of the dataset, our goal was to simulate the layout of the security camera system in public places such as in buildings, in parking lots, and in nature. The Abnormal Activities Dataset provides diversity mainly in terms of actions in real environments with the presence of different variations in camera motion, appearance and position of the examined object, different illumination conditions, etc. The complexity of the dataset is influenced by the choice of categories, some of which are very similar, such as the Knife Hazard and Fight categories. In the mentioned categories, the classification can be influenced by similar reactions of people to fighting, but also to being threatened with a knife, as well as similar movements during attacking and fighting. The categories of Drunkenness and Begging can also be very similar, as the drunkard also appears to annoy the people around him. These similarities between categories make the dataset we created more difficult to classify. Furthermore, all the categories created contain entries from different angles and backgrounds. Each category contains about 100 videos. In each video in all categories, the event takes place for the entire video, so the length of the videos ranges from about 1 s to 30 s. Videos in the same category may have some features in common, such as the same person, similar or the same background, and similar or the same camera angle. Uploaded videos are in .avi format. All videos were recorded by two different cameras. The first camera was the GoPro Hero 4 and the second was the Lamax X7. The GoPro Hero4 camera can record in 4 K resolution (UltraHD). It also supports lower video resolutions such as 1080 p, 720 p, and 480 p. It can record up to 120 frames per second, which is excellent for recording fast movements. The Lamax 7 camera can record in native 2.7 K resolution. It also supports lower video resolutions such as 1080 p, 720 p, and 480 p. It can record 60 frames per second.
The Abnormal Activities Dataset consists of the following categories: Begging, Drunkenness, Fight, Harassment, Hijack, Knife Hazard, Normal Videos, Pollution, Property Damage, Robbery, Terrorism. The aforementioned categories can be seen in
Figure 6.
Specification and description of individual categories:
Knife Hazard: The video contains scenes where a person threatens his surroundings with a knife;
Robbery: We can see different types of robbery in the videos;
Pollution: The videos contain people throwing trash, polluting their surroundings;
Fight: The category contains videos where a fight takes place between two or more people;
Harassment: The videos contain scenes with inappropriate gestures, as well as direct unwanted contact with people and exposure to the public;
Property damage: The videos contain people who are damaging someone else’s property;
Hijack: The videos show various abductions of one person from a crowd, as well as a lone person;
Terrorism: The videos show actions where a person places a bag with a bomb among people or shows a bomb on himself, or where the person starts shooting at people around him;
Begging: The videos feature people who annoy or harass surrounding people by begging or asking for money;
Normal videos: These are videos where no abnormal activity occurs;
Drunkenness: There are people in the videos who obviously have problems with balance, stability, and drunkenness.
The already designed architectures were subsequently tested on the designed Abnormal Activities Dataset.
3.3. Results
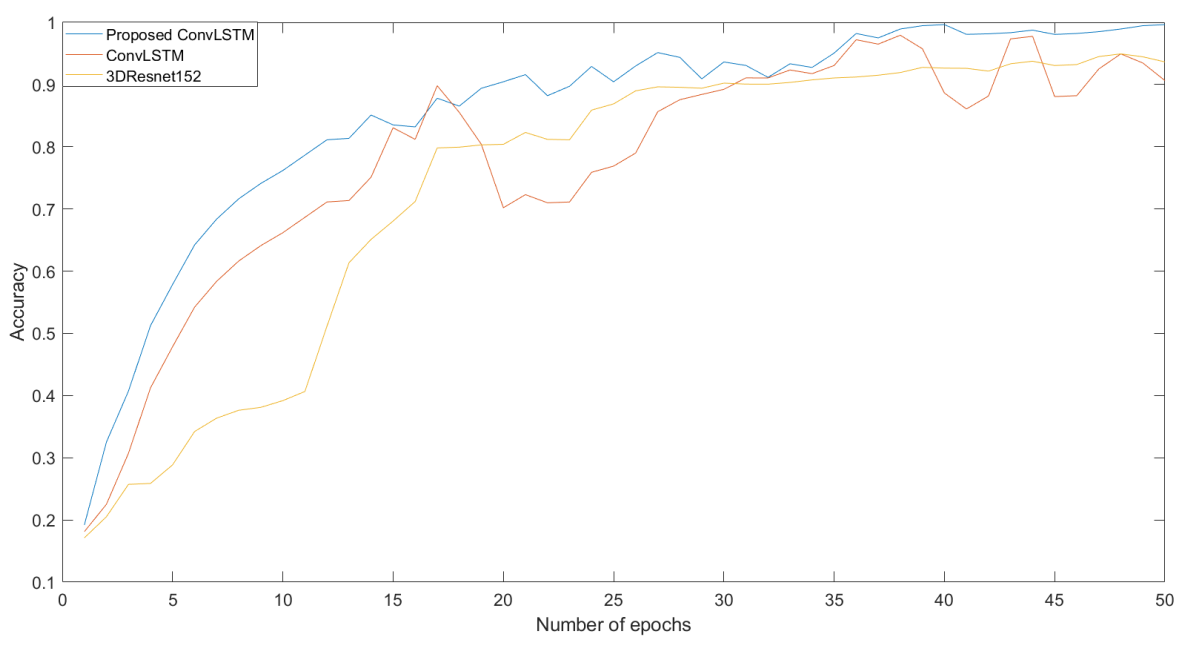
A dataset (Abnormal Activities Dataset) was used to test the neural network architectures mentioned in the previous chapter. The dataset was divided into three sets—training, testing, and validation—at a ratio of 70:20:10. The training set contained 748 videos, which represent 70% of the data. The testing set contained 214 videos, which represent 20% of the dataset. The validation set contained 107 videos, which represent 10% of the data. The neural network model learned to classify videos into 11 classes. We used the already mentioned architectures for classification. We compared the result with our dataset and the neural network architecture we created with other already proposed architectures such as 3D Resnet50, 3D Resnet101, and 3D Resnet152, as well as ConvLSTM. We only used 3D Resnet architectures, with no pre-trained model. The length of the sequence was 50 frames and the size of the image was 50 × 50 × 3 (the final number indicates that the image has three channels) at the input of the networks. Videos were pre-processed to these dimensions. The comparison of the training process between the proposed neural networks, ConvLSTM, and 3D Resnet152 can be seen in
Figure 8.
As we can see, each neural network’s training started at a different loss value. However, we are interested in which loss function had the largest decrease. We can see that the decline was rapidly large. Accuracy grew from 0 to 1 in all cases. However, in some cases, it was smoother and more even, while elsewhere, there were decreases and sudden increases in the given epoch. After the testing process, we processed the resulting metrics for each neural network architecture into a confusion matrix. The confusion matrix tells us how a video was classified into a given category. Subsequently, we analyzed each confusion matrix separately for each neural network architecture.
Continuing, we generated a confusion matrix of the first neural network architecture taken by ConvLSTM [
18,
21,
22,
23]. This confusion matrix can be seen in
Table 3. The videos are classified into the following categories: 1—Begging, 2—Drunkenness, 3—Fight, 4—Harassment, 5—Hijack, 6—Knife Hazard, 7—Normal Videos, 8—Pollution, 9—Property Damage, 10—Robbery, 11—Terrorism. We can observe that the architecture of the neural network had the greatest problem with category number 4, Harassment. Here, it correctly classified only two videos and categorized the others as 8, Pollution, and 10, Robbery. The Harassment class has many similar features with Robbery. A person most often looks for one person, most often they are alone, and the reaction is quick and unpleasant. While Pollution can be very similar, it also contains people who are trying to be inconspicuous.
We also applied a 3D Resnet network. We tested 3D Resnet50, 100, and 152. For each of these networks, we generated a confusion matrix so that we could observe how the classification accuracy increased with increasing number of layers. The first 3D Resnet50 network had a classification problem; the overall accuracy was only 36.19%. Thus, we generated a confusion matrix, which can be seen in
Table 4.
As we can see the confusion matrix is scattered. The neural network most often classified videos into categories 3. Fight and 9. Property damage. Clear and distinctive features are in these categories. The neural network could classify obscure features into these categories because it could not predict what the other might be. We also tested 3D Resnet101, where we can already see a significant increase in accuracy but also straightness as the number of layers increases with increasing accuracy. In this case we have achieved accuracy 61.91%. The generated confusion matrix can be seen in the
Table 5.
We see fewer classification errors in this confusion matrix. Again, the largest problem with classification was with class 4, Harassment. The harassment class may contain features that resemble multiple features in other classes. For example, harassment may resemble robbery, and hijacking, but also begging. The rising trend of accuracy led us to test the 3D Resnet152. As we expected, the accuracy in this case increased to 90.47%. Again, we can observe a directly proportional increase in accuracy with increasing layers. At the same time, we can evaluate that with every 50 layers, our accuracy increased by 30%. The confusion matrix after testing 3D Resnet 152 can be seen in the
Table 6.
The confusion matrix after testing 3D Resnet152 showed promising results. We see that the classification errors occurred in class 4, Harassment, with, however, a smaller number of errors than in the previous case. An error also occurred during classification into category 7, Normal Videos. There were minimal classification errors in the other categories. Subsequently, we tested our designed architecture on the dataset we created. We also generated the resulting confusion matrix. The overall results were the best compared to other architectures. In this case, we achieved a classification accuracy of 96.19%. The results of the confusion matrix can be seen in
Table 7.
As we can see, the classification error was minimal. During the classification, this time the neural network did not fail once in the classification of the Harassment class. The neural network was mistaken only once in class 7, Normal Videos, and once in class 8, Pollution. It made a mistake twice in class 11, Terrorism.
For all results of the experiments, we also evaluated the resulting evaluations such as F1 score, precision, and recall. We then compared the evaluation criterion in
Table 8. We compared the adopted architectures with the architecture we designed. All experiments were performed under the same conditions, with the same batch size and number of epochs. We inserted the same size pictures and the same number of frames for the input.
The proposed architecture of ConvLSTM achieved the best results (evaluation metrics) on the created dataset. To better represent our results, we created
Table 9, where we can see the resulting accuracy and precision values for all the architectures used on our dataset.
We achieved the best value for all evaluation metrics, which proves that the dataset we created is usable within the range of abnormal behaviors of people and. at the same time, that we have designed an architecture that can accurately classify these categories in the dataset to an accuracy of 96.19%. In the results of 3D Resnet networks, we can observe a linear increase in accuracy. Each increase in the number of layers increases the average accuracy by 30%. In this case, we can evaluate that 3D networks are usable for video classification, but with such a demanding dataset, they achieve worse results than networks containing ConvLSTM layers.
We also tested the proposed architecture and the three networks with the best results—ConvLSTM, 3D Resnet152, and our proposed architecture, ConvLSTM—on the freely available AIRTLab dataset. This dataset is mainly used to test architectures to see if violent or a nonviolent incident in a video is correctly classified. We compared the obtained results in terms of the evaluation metrics of accuracy and F1 score. We also generated confusion matrices to compare the results, which can be seen in
Table 10,
Table 11 and
Table 12.
In the case of the first confusion matrix, we observe that during the classification, an error occurred in which three nonviolent videos were classified into the violent class. In the second case, three videos in the violent class were incorrectly classified as nonviolent.
The best results were obtained with the ConvLSTM architecture, which correctly ranked all videos in the nonviolent class. In the violent class, only two videos were classified as nonviolent.
The proposed architecture in this case classified two violent videos into the nonviolent class and two nonviolent videos into the violent class. The resulting values of the evaluation metrics accuracy and F1 score can be seen in
Table 13.
The best results on the AIRTLab dataset were achieved by the proposed ConvLSTM architecture. The proposed ConvLSTM achieved an accuracy of 98.29% and a F1 score of 97.66%. When comparing the results with the previous dataset, we can observe a significant change in evaluation metrics for the ConvLSTM network and the proposed ConvLSTM architecture. The difference in results for the ConvLSTM architecture could be due to large differences in the datasets. On the AIRTLab dataset, the tested architectures obtained significantly better results because the dataset contained only two classes with 350 videos. The dataset we created was therefore more demanding for the ConvLSTM architecture. The complexity of the Abnormal Activities Dataset was also confirmed by the 3D Resnet152 architecture, which achieved an accuracy of 90.47% on our dataset and an accuracy of 91.42% on the AIRTLab dataset.














{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}