Spatial Alignment for Unsupervised Domain Adaptive Single-Stage Object Detection

Abstract
:1. Introduction
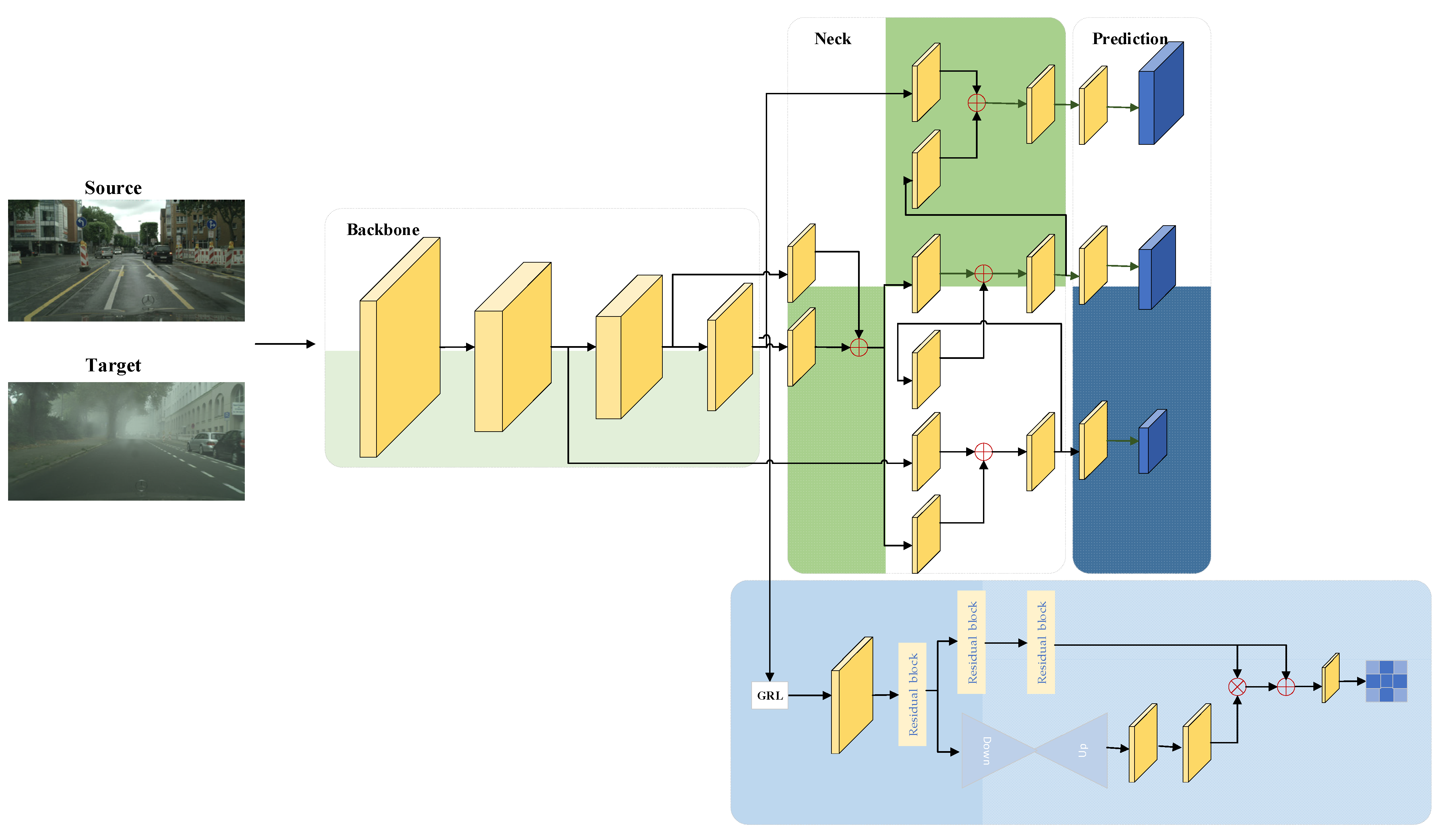
- We propose a domain adaptation framework suitable for single-stage detectors, which combines image-level alignment and instance-level alignment. Balances the domain offset by applying different attention to the background and target through spatial domain alignment (SDA) and spatial consistency regularization (SCR);
- We improve a new target loss in the target domain loss calculation, reducing the negative impact of false-negative samples by suppressing the loss of false-negative samples.
- We validate the effectiveness of our method from four different perspectives (weather difference, camera angle, synthetic to real-world, and real images to artistic images). Experimental results show that this method can effectively improve the cross-domain detection performance of single-stage object detectors. Additionally, almost no increase in inference time and real-time detection can be achieved on GPU.
2. Related Work
3. Proposed Methods
3.1. Framework Overview
3.2. Spatial Domain Alignment Module
3.3. Spatial Consistency Regularization
3.4. False-Negative Suppression Loss
4. Experiments
4.1. Datasets and Evaluation
4.2. Implementation Details
4.3. Experimental Results
4.3.1. Weather Discrepancy
4.3.2. Camera Angle
4.3.3. Synthetic to Real
4.3.4. Real to Artistic
4.4. Ablation Experiment
4.5. Visualization
5. Conclusions
Author Contributions
Funding
Institutional Review Board Statement
Informed Consent Statement
Data Availability Statement
Conflicts of Interest
References
- Sermanet, P.; Eigen, D.; Zhang, X.; Mathieu, M.; Fergus, R.; LeCun, Y. Overfeat: Integrated recognition, localization, and detection using convolutional networks. arXiv 2013, arXiv:1312.6229. [Google Scholar]
- Girshick, R.; Donahue, J.; Darrell, T.; Malik, J. Rich feature hierarchies for accurate object detection and semantic segmentation. In Proceedings of the IEEE Conference on Computer Vision and Pattern Recognition, Columbus, OH, USA, 23–28 June 2014; pp. 580–587. [Google Scholar]
- Gidaris, S.; Komodakis, N. Object detection via a multi-region and semantic segmentation-aware cnn model. In Proceedings of the IEEE International Conference on Computer Vision, Santiago, Chile, 7–13 December 2015; pp. 1134–1142. [Google Scholar]
- Dai, J.; Li, Y.; He, K.; Sun, J. R-fcn: Object detection via region-based fully convolutional networks. Adv. Neural Inf. Process. Syst. 2016, 29, 379–387. [Google Scholar]
- Li, Y.; Yang, X.; Shang, X.; Chua, T.S. Interventional video relation detection. In Proceedings of the 29th ACM International Conference on Multimedia, Virtual Event, China, 20–24 October 2021; pp. 4091–4099. [Google Scholar]
- Yang, X.; Wang, S.; Dong, J.; Dong, J.; Wang, M.; Chua, T.S. Video Moment Retrieval with Cross-Modal Neural Architecture Search. IEEE Trans. Image Process. 2022, 31, 1204–1216. [Google Scholar] [CrossRef] [PubMed]
- Torralba, A. EAA: Unbiased look at dataset bias. In Proceedings of the IEEE Conference on Computer Vision and Pattern Recognition (CVPR), Colorado Springs, CO, USA, 20–25 June 2011; pp. 1521–1528. [Google Scholar]
- Zhao, S.; Yue, X.; Zhang, S.; Li, B.; Zhao, H.; Wu, B.; Keutzer, K. A review of single-source deep unsupervised visual domain adaptation. IEEE Trans. Neural Netw. Learn. Syst. 2020, 33, 473–493. [Google Scholar] [CrossRef] [PubMed]
- Chen, Y.; Li, W.; Sakaridis, C.; Dai, D.; Van Gool, L. Domain adaptive faster r-cnn for object detection in the wild. In Proceedings of the IEEE Conference on Computer Vision and Pattern Recognition, Salt Lake City, UT, USA, 18–23 June 2018; pp. 3339–3348. [Google Scholar]
- Saito, K.; Ushiku, Y.; Harada, T.; Saenko, K. Strong-weak distribution alignment for adaptive object detection. In Proceedings of the IEEE/CVF Conference on Computer Vision and Pattern Recognition, Long Beach, CA, USA, 15–20 June 2019; pp. 6956–6965. [Google Scholar]
- He, Z.; Zhang, L. Multi-adversarial faster-rcnn for unrestricted object detection. In Proceedings of the IEEE/CVF International Conference on Computer Vision, Seoul, Korea, 27–28 October 2019; pp. 6668–6677. [Google Scholar]
- Girshick, R. Fast r-cnn. In Proceedings of the IEEE International Conference on Computer Vision, Washington, DC, USA, 7–3 December 2015; pp. 1440–1448. [Google Scholar]
- Ren, S.; He, K.; Girshick, R.; Sun, J. Faster r-cnn: Towards real-time object detection with region proposal networks. IEEE Trans. Pattern Anal. Mach. Intell. 2017, 39, 1137–1149. [Google Scholar] [CrossRef] [PubMed] [Green Version]
- Chen, C.; Zheng, Z.; Ding, X.; Huang, Y.; Dou, Q. Harmonizing transferability and discriminability for adapting object detectors. In Proceedings of the IEEE/CVF Conference on Computer Vision and Pattern Recognition, Seattle, WA, USA, 13–19 June 2020; pp. 8869–8878. [Google Scholar]
- Zhu, X.; Pang, J.; Yang, C.; Shi, J.; Lin, D. Adapting object detectors via selective cross-domain alignment. In Proceedings of the IEEE/CVF Conference on Computer Vision and Pattern Recognition, Long Beach, CA, USA, 15–20 June 2019; pp. 687–696. [Google Scholar]
- Hsu, H.K.; Yao, C.H.; Tsai, Y.H.; Hung, W.C.; Tseng, H.Y.; Singh, M.; Yang, M.H. Progressive domain adaptation for object detection. In Proceedings of the IEEE/CVF Winter Conference on Applications of Computer Vision, Waikoloa, HI, USA, 4–8 January 2020; pp. 749–757. [Google Scholar]
- Raj, A.; Namboodiri, V.P.; Tuytelaars, T. Subspace alignment based domain adaptation for rcnn detector. arXiv 2015, arXiv:1507.05578. [Google Scholar]
- Kim, S.; Choi, J.; Kim, T.; Kim, C. Self-training and adversarial background regularization for unsupervised domain adaptive one-stage object detection. In Proceedings of the IEEE/CVF International Conference on Computer Vision, Seoul, Korea, 27–28 October 2019; pp. 6092–6101. [Google Scholar]
- RoyChowdhury, A.; Chakrabarty, P.; Singh, A.; Jin, S.; Jiang, H.; Cao, L.; Learned-Miller, E. Automatic adaptation of object detectors to new domains using self-training. In Proceedings of the IEEE/CVF Conference on Computer Vision and Pattern Recognition, Long Beach, CA, USA, 15–20 June 2019; pp. 780–790. [Google Scholar]
- Redmon, J.; Divvala, S.; Girshick, R.; Farhadi, A. You only look once: Unified, real-time object detection. In Proceedings of the IEEE Conference on Computer Vision and Pattern Recognition, Las Vegas, NV, USA, 27–30 June 2016; pp. 779–788. [Google Scholar]
- Redmon, J.; Farhadi, A. Yolov3: An incremental improvement. arXiv 2018, arXiv:1804.02767. [Google Scholar]
- Bochkovskiy, A.; Wang, C.Y.; Liao, H.Y.M. Yolov4: Optimal speed and accuracy of object detection. arXiv 2020, arXiv:2004.10934. [Google Scholar]
- Liu, W.; Anguelov, D.; Erhan, D.; Szegedy, C.; Reed, S.; Fu, C.Y.; Berg, A.C. Ssd: Single shot multibox detector. In European Conference on Computer Vision; Springer: Cham, Switzerland, 2016; pp. 21–37. [Google Scholar]
- Lin, T.Y.; Goyal, P.; Girshick, R.; He, K.; Dollar, P. Focal loss for dense object detection. IEEE Trans. Pattern Anal. Mach. Intell. 2020, 2, 318–327. [Google Scholar] [CrossRef] [PubMed] [Green Version]
- Na, J.; Jung, H.; Chang, H.J.; Hwang, W. Fixbi: Bridging domain spaces for unsupervised domain adaptation. In Proceedings of the IEEE/CVF Conference on Computer Vision and Pattern Recognition, Nashville, TN, USA, 20–25 June 2021; pp. 1094–1103. [Google Scholar]
- Mansour, Y.; Mohri, M.; Rostamizadeh, A. Domain adaptation: Learning bounds and algorithms. arXiv 2009, arXiv:0902.3430. [Google Scholar]
- Ben-David, S.; Blitzer, J.; Crammer, K.; Kulesza, A.; Pereira, F.; Vaughan, J.W. A theory of learning from different domains. Mach. Learn. 2010, 79, 151–175. [Google Scholar] [CrossRef] [Green Version]
- Lu, H.; Zhang, L.; Cao, Z.; Wei, W.; Xian, K.; Shen, C.; van den Hengel, A. When unsupervised domain adaptation meets tensor representations. In Proceedings of the IEEE International Conference on Computer Vision, Venice, Italy, 22–29 October 2017; pp. 599–608. [Google Scholar]
- Tzeng, E.; Hoffman, J.; Darrell, T.; Saenko, K. Simultaneous deep transfer across domains and tasks. In Proceedings of the IEEE International Conference on Computer Vision, Washington, DC, USA, 7–13 December 2015; pp. 4068–4076. [Google Scholar]
- Borgwardt, K.M.; Gretton, A.; Rasch, M.J.; Kriegel, H.P.; Schölkopf, B.; Smola, A.J. Integrating structured biological data by kernel maximum mean discrepancy. Bioinformatics 2006, 22, e49–e57. [Google Scholar] [CrossRef] [PubMed] [Green Version]
- Shen, J.; Qu, Y.; Zhang, W.; Yu, Y. Wasserstein distance guided representation learning for domain adaptation. In Proceedings of the Thirty-Second AAAI Conference on Artificial Intelligence, New Orleans, LA, USA, 2–7 February 2018. [Google Scholar]
- Zhuang, F.; Cheng, X.; Luo, P.; Pan, S.J.; He, Q. Supervised representation learning: Transfer learning with deep autoencoders. In Proceedings of the Twenty-Fourth International Joint Conference on Artificial Intelligence, Buenos Aires, Argentina, 25–31 July 2015. [Google Scholar]
- Xu, C.D.; Zhao, X.R.; Jin, X.; Wei, X.S. Exploring categorical regularization for domain adaptive object detection. In Proceedings of the IEEE/CVF Conference on Computer Vision and Pattern Recognition, Seattle, WA, USA, 14–19 June 2020; pp. 11724–11733. [Google Scholar]
- Wang, Y.; Zhang, R.; Zhang, S.; Li, M.; Xia, Y.; Zhang, X.; Liu, S. Domain-specific suppression for adaptive object detection. In Proceedings of the IEEE/CVF Conference on Computer Vision and Pattern Recognition, Nashville, TN, USA, 20–25 June 2021; pp. 9603–9612. [Google Scholar]
- Zhao, Z.; Guo, Y.; Shen, H.; Ye, J. Adaptive object detection with dual multi-label prediction. In Proceedings of the European Conference on Computer Vision, Glasgow, UK, 23–28 August 2020; Springer: Cham, Switzerland, 2020; pp. 54–69. [Google Scholar]
- Cordts, M.; Omran, M.; Ramos, S.; Rehfeld, T.; Enzweiler, M.; Benenson, R.; Schiele, B. The cityscapes dataset for semantic urban scene understanding. In Proceedings of the IEEE Conference on Computer Vision and Pattern Recognition, Las Vegas, NV, USA, 27–30 June 2016; pp. 3213–3223. [Google Scholar]
- Sakaridis, C.; Dai, D.; Van Gool, L. Semantic foggy scene understanding with synthetic data. Int. J. Comput. Vis. 2018, 126, 973–992. [Google Scholar] [CrossRef] [Green Version]
- Geiger, A.; Lenz, P.; Urtasun, R. Are we ready for autonomous driving? The kitti vision benchmark suite. In Proceedings of the 2012 IEEE Conference on Computer Vision and Pattern Recognition, Providence, RI, USA, 16–21 June 2012; pp. 3354–3361. [Google Scholar]
- Johnson-Roberson, M.; Barto, C.; Mehta, R.; Sridhar, S.N.; Rosaen, K.; Vasudevan, R. Driving in the matrix: Can virtual worlds replace human-generated annotations for real world tasks? arXiv 2016, arXiv:1610.01983. [Google Scholar]
- Everingham, M.; Van Gool, L.; Williams, C.K.; Winn, J.; Zisserman, A. The pascal visual object classes (voc) challenge. Int. J. Comput. Vis. 2010, 88, 303–338. [Google Scholar] [CrossRef] [Green Version]
- Inoue, N.; Furuta, R.; Yamasaki, T.; Aizawa, K. Cross-domain weakly-supervised object detection through progressive domain adaptation. In Proceedings of the IEEE Conference on Computer Vision and Pattern Recognition, Salt Lake City, UT, USA, 18–22 June 2018; pp. 5001–5009. [Google Scholar]
- Zheng, Y.; Huang, D.; Liu, S.; Wang, Y. Cross-domain object detection through coarse-to-fine feature adaptation. In Proceedings of the IEEE/CVF Conference on Computer Vision and Pattern Recognition, Seattle, WA, USA, 14–19 June 2020; pp. 13766–13775. [Google Scholar]
- Nguyen, D.K.; Tseng, W.L.; Shuai, H.H. Domain-adaptive object detection via uncertainty-aware distribution alignment. In Proceedings of the 28th ACM International Conference on Multimedia, Seattle, WA, USA, 12–16 October 2020; pp. 2499–2507. [Google Scholar]
- Deng, J.; Li, W.; Chen, Y.; Duan, L. Unbiased mean teacher for cross-domain object detection. In Proceedings of the IEEE/CVF Conference on Computer Vision and Pattern Recognition, Nashville, TN, USA, 19–25 June 2021; pp. 4091–4101. [Google Scholar]
- Wan, Z.; Li, L.; Li, H.; He, H.; Ni, Z. One-shot unsupervised domain adaptation for object detection. In Proceedings of the 2020 International Joint Conference on Neural Networks (IJCNN), Glasgow, UK, 19–24 July 2020; pp. 1–8. [Google Scholar]
- Rodriguez, A.L.; Mikolajczyk, K. Domain adaptation for object detection via style consistency. arXiv 2019, arXiv:1911.10033. [Google Scholar]



{kind=link}
{kind=link}
{kind=link}
| Cityscapes → Foggy Cityscapes | |||||||||
|---|---|---|---|---|---|---|---|---|---|
| Methods | Car | Person | Bicycle | Rider | Motorcycle | Bus | Truck | Train | mAP |
| Source Only | 38.8 | 24.7 | 30.1 | 28.6 | 21.2 | 30.1 | 18.1 | 19.3 | 26.4 |
| Two-stage methods | |||||||||
| DA-Faster-RCNN [9] | 40.5 | 25.0 | 27.1 | 31.0 | 20.1 | 23.8 | 22.1 | 20.2 | 27.6 |
| SWDA [10] | 43.5 | 29.9 | 35.3 | 42.3 | 30.0 | 36.2 | 24.5 | 32.6 | 34.3 |
| HTCN [14] | 47.9 | 33.2 | 37.1 | 47.5 | 32.3 | 47.4 | 31.6 | 40.9 | 39.8 |
| SCDA [15] | 48.5 | 33.5 | 33.6 | 38.0 | 28.0 | 39.0 | 26.5 | 23.3 | 33.8 |
| Faster-RCNN + ART + PSA [42] | 52.1 | 34.0 | 37.4 | 46.9 | 34.7 | 43.2 | 30.8 | 29.9 | 38.6 |
| MCAR [35] | 43.9 | 32.0 | 36.6 | 42.1 | 37.4 | 44.1 | 31.3 | 43.4 | 38.8 |
| MEAA [43] | 52.4 | 34.2 | 36.2 | 48.9 | 33.2 | 42.7 | 30.3 | 46.0 | 40.5 |
| UMT [44] | 48.6 | 33.0 | 37.3 | 46.7 | 30.4 | 56.5 | 34.1 | 46.8 | 41.7 |
| One-stage methods | |||||||||
| OSFA [45] | 43.8 | 23.6 | 33.2 | 32.6 | 23.1 | 35.4 | 22.9 | 14.7 | 28.7 |
| ST + C + RPL [46] | 41.5 | 24.2 | 30.3 | 29.2 | 26.9 | 35.4 | 23.1 | 26.7 | 29.7 |
| Ours | 50.2 | 36.2 | 35.2 | 41.8 | 30.4 | 45.6 | 29.9 | 29.5 | 37.4 |
| Cityscapes → KITTI | |
|---|---|
| Methods | Car mAP |
| Source Only | 37.7 |
| DA-Faster-RCNN [9] | 41.9 |
| SCDA [15] | 43.0 |
| HTCN [14] | 42.5 |
| Faster-RCNN + ART + PSA [42] | 41.0 |
| Ours | 46.2 |
| SIM10K → Cityscapes | |
|---|---|
| Methods | Car mAP |
| Source Only | 36.8 |
| DA-Faster-RCNN [9] | 38.9 |
| SCDA [15] | 42.5 |
| HTCN [14] | 42.5 |
| Faster-RCNN + ART + PSA [42] | 43.8 |
| MEAA [43] | 42.0 |
| Ours | 42.6 |
| PASCAL VOC → Clipart | |||||||||||||||||||||
|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|
| Methods | Areo | Bike | Bird | Boat | Butt | Bus | Car | Cat | Chair | Cow | Tab | Dog | Horse | Mbike | Prsn | Plnt | Sheep | Sofa | Train | TV | mAP |
| Source Only | 15.1 | 46.2 | 19.8 | 26.3 | 43.9 | 48.8 | 33.2 | 8.1 | 53.2 | 30.2 | 29.6 | 8.6 | 23.6 | 48.9 | 43.4 | 48.5 | 14.2 | 29.8 | 33.2 | 45.2 | 32.5 |
| Two-stage methods | |||||||||||||||||||||
| DA-Faster [9] | 15.0 | 34.6 | 12.4 | 11.9 | 19.8 | 21.1 | 23.2 | 3.1 | 22.1 | 26.3 | 10.6 | 10.0 | 19.6 | 39.4 | 34.6 | 29.3 | 1.0 | 17.1 | 19.7 | 24.8 | 19.8 |
| SWDA [10] | 26.2 | 48.5 | 32.6 | 33.7 | 38.5 | 54.3 | 37.1 | 18.6 | 34.8 | 58.3 | 17.0 | 12.5 | 33.8 | 65.55 | 61.6 | 52.0 | 9.3 | 24.9 | 54.1 | 49.1 | 38.1 |
| HTCN [14] | 33.6 | 58.9 | 34.0 | 23.4 | 45.6 | 57.0 | 39.8 | 12.0 | 39.7 | 51.3 | 21.1 | 20.1 | 39.1 | 72.8 | 63.0 | 43.1 | 19.3 | 30.1 | 50.2 | 51.8 | 40.3 |
| MEAA [43] | 31.3 | 53.5 | 38.0 | 17.8 | 38.5 | 69.9 | 38.2 | 23.8 | 38.3 | 58.1 | 14.6 | 18.1 | 33.8 | 88.1 | 60.3 | 42.1 | 7.8 | 30.8 | 61.1 | 58.7 | 41.1 |
| UMT [44] | 39.6 | 59.1 | 32.4 | 35.0 | 45.1 | 61.9 | 48.4 | 7.5 | 46.0 | 67.6 | 21.4 | 29.5 | 48.2 | 75.9 | 70.5 | 56.7 | 25.9 | 28.9 | 39.4 | 43.6 | 44.1 |
| One-stage methods | |||||||||||||||||||||
| SSD + BSR + WST [17] | 28.0 | 64.5 | 23.9 | 19.0 | 21.9 | 64.3 | 43.5 | 16.4 | 42.2 | 25.9 | 30.5 | 7.9 | 25.5 | 67.6 | 54.5 | 36.4 | 10.3 | 31.2 | 57.4 | 43.5 | 35.7 |
| ST + C + RPL [46] | 36.9 | 55.1 | 26.4 | 42.7 | 23.6 | 64.4 | 52.1 | 10.1 | 50.9 | 57.2 | 48.2 | 16.2 | 45.9 | 83.7 | 69.5 | 41.5 | 21.6 | 46.1 | 48.3 | 55.7 | 44.8 |
| Ours | 32.6 | 58.2 | 30.7 | 40.2 | 54.4 | 65.3 | 47.6 | 12.7 | 64.5 | 42.2 | 39.2 | 13.6 | 35.4 | 70.7 | 72.4 | 57.6 | 21.4 | 39.9 | 48.3 | 59.1 | 45.3 |
| PASCAL VOC → Watercolor | |||||||
|---|---|---|---|---|---|---|---|
| Methods | Bike | Bird | Car | Cat | Dog | Person | mAP |
| Source Only | 82.3 | 49.2 | 44.6 | 34.7 | 20.3 | 60.7 | 48.6 |
| Two-stage methods | |||||||
| DA-Faster [9] | 75.2 | 40.6 | 48.0 | 31.5 | 20.6 | 60.0 | 46.0 |
| SWDA [10] | 82.3 | 55.9 | 46.5 | 32.7 | 35.5 | 66.7 | 53.3 |
| HTCN [14] | 87.9 | 52.1 | 51.8 | 41.6 | 33.8 | 68.8 | 56.0 |
| MCAR [35] | 87.9 | 52.1 | 51.8 | 41.6 | 33.8 | 68.8 | 56.0 |
| MEAA [43] | 81.0 | 53.2 | 54.0 | 40.1 | 39.2 | 65.3 | 55.5 |
| UMT [44] | 88.2 | 55.3 | 51.7 | 39.8 | 43.6 | 69.9 | 58.1 |
| One-stage methods | |||||||
| SSD + BSR + WST [17] | 75.6 | 45.8 | 49.3 | 34.1 | 30.3 | 64.1 | 49.9 |
| ST + C + RPL [46] | 79.9 | 56.5 | 48.6 | 42.1 | 42.9 | 73.7 | 57.3 |
| Ours | 88.0 | 53.3 | 54.2 | 38.2 | 33.9 | 77.6 | 57.5 |
| Methods | SCR | FNS | mAP |
|---|---|---|---|
| Source Only | 26.4 | ||
| Ours-Type1 (K = 1) | √ | √ | 34.4 |
| Ours-Type2 (K = 5) | √ | √ | 36.7 |
| Ours-Type3 (K = 7) | 29.8 | ||
| Ours-Type4 (K = 7) | √ | 31.2 | |
| Ours-Type5 (K = 7) | √ | 35.3 | |
| Ours-Type6 (K = 7) | √ | √ | 37.4 |
Publisher’s Note: MDPI stays neutral with regard to jurisdictional claims in published maps and institutional affiliations. |
© 2022 by the authors. Licensee MDPI, Basel, Switzerland. This article is an open access article distributed under the terms and conditions of the Creative Commons Attribution (CC BY) license (https://creativecommons.org/licenses/by/4.0/).
Share and Cite
Liang, H.; Tong, Y.; Zhang, Q. Spatial Alignment for Unsupervised Domain Adaptive Single-Stage Object Detection. Sensors 2022, 22, 3253. https://doi.org/10.3390/s22093253
Liang H, Tong Y, Zhang Q. Spatial Alignment for Unsupervised Domain Adaptive Single-Stage Object Detection. Sensors. 2022; 22(9):3253. https://doi.org/10.3390/s22093253
Chicago/Turabian StyleLiang, Hong, Yanqi Tong, and Qian Zhang. 2022. "Spatial Alignment for Unsupervised Domain Adaptive Single-Stage Object Detection" Sensors 22, no. 9: 3253. https://doi.org/10.3390/s22093253