2.1. Improved Network Framework of Vehicle Target Detection
In the field of deep learning, there are many ways to obtain the bounding box of the vehicle target. One method is to directly predict the bounding box value of the vehicle. Szegedy et al. [
18] proved that neural networks can be directly used for coordinate regression purposes. Yolo V1 [
19] directly predicted the four values of the bounding box, but the corresponding loss function did not truly reflect the accuracy of the predicted box. The disadvantage of this method is that it is more inclined to use a large-size bounding box. Although the approximate position of the vehicle can be identified, it has a large defect in the warning system that requires accurate vehicle positioning. In addition, the training process of this method is unstable, because the predicted frame value may change significantly as the posture of the vehicle changes or the distance relationship changes. Other methods, such as Mask R-CNN, Faster R-CNN, and Single Shot Detector (SSD) [
20], use anchors. Based on the preset anchors, after obtaining the proposed frame, going back, and fine-tuning the frame size and position, the problems of former method can be solved.
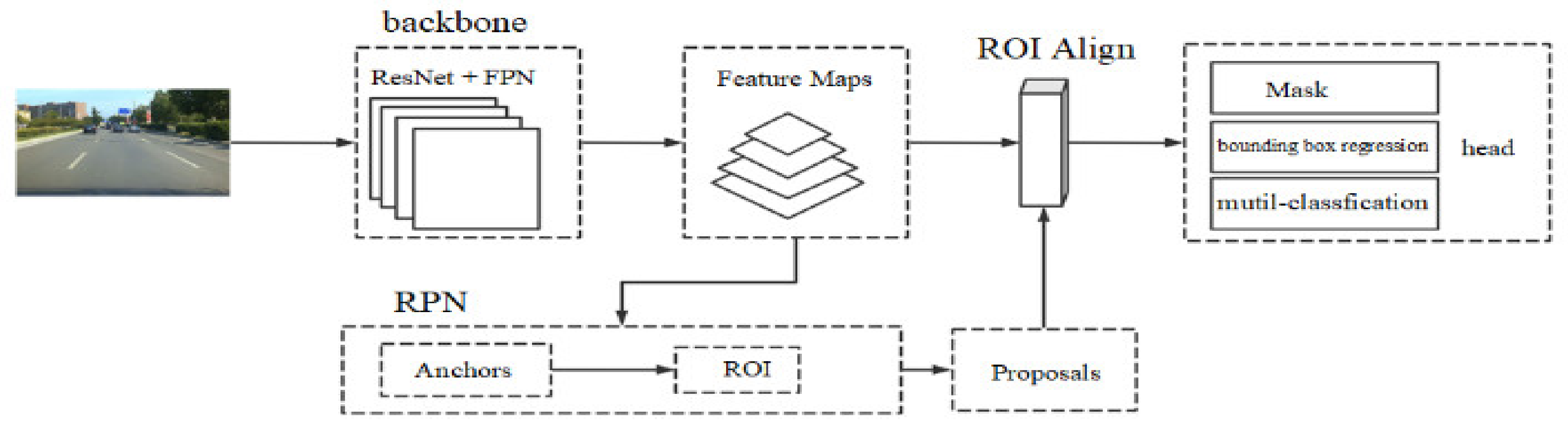
Mask R-CNN is a multi-task deep learning model. This network can realize the classification and positioning tasks of the instances in the picture by the end-to-end learning, and can realize the pixel-level mask to complete the instance segmentation. Mask R-CNN includes three main sub-networks, namely the backbone network, which is a combination of ResNet and Feature Pyramid Network (FPN) [
21], RPN, and the head network, as shown in
Figure 1.
The head network has three branches. In the classification and regression branches, the input of the head network first passes through a two-layer convolutional network, enters two fully connected layers, and then enters a Softmax classification layer and the linear regression layer. The same activation function as in the RPN network is used. The Mask branch goes through the steps of multi-layer convolution, Batch Normalization (BatchNorm), Rectified Linear Unit (ReLU) layer, etc., and the 28 × 28 Mask feature map of each class is obtained. The activation function Sigmoid is used to distinguish the value of each pixel as 0 or 1. A binary cross-entropy loss function is used for training.
Anchor boxes are a series of candidate boxes obtained by combining different aspect ratios and different aspect proportions. According to (P2, P3, P4, P5, P6), five pyramid feature layers, three anchor frames, and 15 anchor frame sizes are set in Mask R-CNN to detect the preset of the frames (see
Figure 2). There are 5 scales of anchor frames (16, 32, 64, 128, 256). The ratios of anchor frames have three kinds of aspect ratios (0.5, 1.0, 2.0). Three anchor boxes with different aspect ratios, as shown in
Figure 3, are generated on each feature map as the pre-selection boxes.
The proportions of the anchor frames need to be modified appropriately to adapt to different target detection tasks, speed up the convergence of the model, and improve the positioning accuracy of the targets. In order to obtain the appropriate anchor frame ratios setting for the vehicle targets, the K-means++ clustering algorithm [
22] was performed for the vehicle bounding box label of the dataset to obtain the appropriate width/height ratios of anchor frames.
The K-means algorithm is a distance-based clustering algorithm that uses the distances between points as an indicator of similarity. If the distance between two pixels is closer, the similarity is higher. This algorithm gathers points that are close to each other into a cluster, and finally obtains compact, bounded, and independent cluster objects. The inherent defect of the K-means algorithm is that it needs to manually specify the number of cluster points. The K-means algorithm is more sensitive to the location of the starting point. The K-means++ algorithm compensates for these defects to a certain extent. It can speed up the convergence of the model and improve the positioning accuracy of the target by using K-means++ clustering to obtain more suitable anchor frame ratios of vehicle targets. A higher positioning accuracy is used to meet the need of accurate vehicle lane-changing detection.
We used the road target dataset labeled by CrowdAI Company in the United States to perform the clustering task. The data contained traffic information in Mountain View, California, USA, and nearby cities, including 9423 frames of pictures (sampled at 2 Hz) and a road traffic information dataset for a total of 72,064 targets. The resolution was 1920 × 1200.
We cleaned the dataset before clustering. The dataset contained three different targets: cars, trucks, and pedestrians. The lane-changing warning system we designed was to conduct research on vehicles. Pedestrians were not the subject of research, so the pedestrian tag data were eliminated, leaving 66,389 vehicle targets.
If the anchor was appropriately increased in an appropriate proportion, more appropriate anchor frames could be generated, which could theoretically increase the value of the average Intersection over Union (IoU). This was because choosing more priori anchor frames would cause the anchor frames to have greater overlap with the real frames. However, as the number of anchor frames increases, the corresponding convolution filter would also increase, increasing the size of the network and leading to a longer training time. Therefore, we set the ratios of anchor frames to 4, which is one more set of anchor frames than the original setting to ensure that the generation accuracy of candidate boxes can be improved without sacrificing more network performance.
The results of clustering four cluster points according to the vehicle’s aspect ratio are shown in
Figure 4, and the colors distinguish the clusters of the four cluster points. According to the coordinates of the center of the cluster points, the corresponding four anchor frames were set with a ratio of (1.26249845, 1.20118061, 1.40220561, 1.15757855). As the vehicle proportions were relatively consistent, taking the average of the above four types of anchor frames could obtain the new anchor frame ratio of 1.256. Adding a new ratio to the original anchor frame ratios could obtain four anchor frame width/height ratios (0.5, 1.0, 1.256, 2.0). The anchor frames of the feature map would generate four proportions of frames on the original field of view, as shown in
Figure 5.
2.2. Dataset Preparation for Vehicle Detection Network
The datasets in the field of target detection usually include the Pascal Visual Object Classification (VOC) dataset, MS Common Objects in COntext dataset, and ImageNet dataset. We annotated the original data according to the standard format of the Pascal VOC dataset, and created the vehicle detection dataset of CQ_Vehicle_Dataset for the training of the improved Mask R-CNN network.
The original data were 4-channel videos collected by the staff of the China Automotive Engineering Research Institute. The video contained a total of 4 perspectives, namely the left, the right, the front, and the back perspective. The road information in front of the vehicle and vehicle dynamic information were analyzed and processed, so the data source needed to be tailored. An example of the original video screenshot was shown in
Figure 6a. The video screenshot was obtained after cropping by FFmpeg software, as shown in
Figure 6b.
The size of the video was 1280 × 720. The 64 videos obtained were subjected to frame extraction processing to obtain a sufficient amount of data. A batch conversion file was written based on Python. The 64 videos in the folder were batch-converted and sampled every 50 frames to prepare pictures as a prerequisite for annotation. After data cleaning, 2537 images were retained, which covered the urban, suburban, and highway driving conditions, and the weather covered sunny and rainy. The size of the image was 1280 × 720 pixels. On this basis, a total of 317 images had been marked with mask information for a total of 1364 vehicle targets.
Labelme software (
https://github.com/wkentaro/labelme, accessed on 1 March 2020) uses polygon boxes to label target objects. We used Labelme software to label the entire shape of the vehicles, as shown in
Figure 7. The effect diagrams of instance segmentation of vehicles on the road are shown in
Figure 8 and
Figure 9.
The vehicle dataset contained two folders, which were image and groundtruth. The image folder was a set of pictures with 1280 × 720 pixels, and the groundtruth folder was a set of segmentation mask pictures for vehicle instances.
2.3. Vehicle Lane-Changing Detecting Algorithm
Combining the improved vehicle detection network and the end-to-end lane detection network in series [
23], the integrated outputs were obtained, as shown in
Figure 10. We proposed a lane-changing detection method based on the first-person perspective, which can discriminate the target vehicle’s lane-changing behavior and obtain a higher detection accuracy.
The proportion of straight driving sections in the highway driving conditions is very large, and driving under good road conditions for a long time will make the driver tired and easily cause accidents. Therefore, it is necessary to inform the driver of the lane-changing behavior of the preceding vehicles under highway conditions to reduce the accident rate. The lane-changing detection algorithm made the following assumptions: (1) the driver’s ego-vehicle was stable without obvious lateral displacement; (2) the driving section was a straight section.
According to the perspective principle, two parallel lane lines will intersect at a point in the distance. If two other parallel lines are added between the two parallel lines, because the fan-shaped area in the two lane lines eventually converge to a point, the other two parallel lines eventually converge to the same intersection. Thus, the four parallel lanes will eventually converge to a point
P0 (
P1) in the distance. As shown in
Figure 11.
The middle lane in
Figure 12 was the driving lane of the ego-vehicle, and the other two lanes were adjacent lanes on the left and right. All lane lines intersected at a point
P0. The lower corner points on the outside of the target vehicle detection frames were selected as the mark points connected with the point
P0. The reason for choosing the lower corner points on the outside of the detection frames as the marking points was as follows.
Figure 12a,b show the detection characteristics of the white van on the adjacent left lane. It could be seen that the lower left corner of the white van detection frame was close to the body, and there was basically no offset. As the distance between the target vehicle and the ego-vehicle increased, the information on the right side of the target vehicle was gradually reduced and compressed, resulting in a shift in the lower right corner point to the left.
Figure 12c,d show the detection results of the blue target vehicle on the adjacent right lane line. Therefore, the lower right corner of the detection frame should be selected as the target vehicle marking point to avoid the relative deviation in the marking point caused by the change in relative displacement of the target vehicle and ego-vehicle.
The lower right corner of the target vehicle in the right adjacent lane at time t
0 was marked as
A0, and the pixel coordinates of
A0 in
Figure 11 were (
xA0,
yA0). The target vehicle changed lane to the left, the lower right corner of the target vehicle at time t
1 was marked as
A1 (
xA1,
yA1), and the yellow box on the right side indicated the position where the target vehicle did not change lane. In
Figure 11, a point on the right lane line of the ego-vehicle was marked as
B0, and ∠
A0P0B0 was set to the angle
α. The angle
α between frames would change, and the rate of change of the angle
α between frames was defined as
βt. For time t (frame):
where
αt is the angle
α at time t,
α−1 is the angle
α of the previous frame at time t, and
βt is the inter-frame change rate.
As the two premise assumptions of the lane-changing detection algorithm were met, the road intersection P0 of adjacent frames and P1 (the next frame intersection) approximately coincided. If the target vehicle with the yellow detection frame on the right was driving along the parallel direction of the lane, at time t1 (the next frame), the lower right corner of the target vehicle detection frame should be near the straight line P1A0.
If the target vehicle on the right made a lane-changing to the ego-vehicle lane, the lower right corner point at this moment was A1 (xA1, yA1), which should be on the left side of the line P1A0, and the corresponding angle α also reduced.
When the target vehicle changed lanes, the inter-frame angle α would decrease. As the target vehicle lane-changing was a continuous behavior, the inter-frame change rate should remain at a certain negative value. According to this, the lane-changing behavior could be determined according to the change law of the inter-frame change rate. The actual measurement found that the rate of change between frames was negative in most cases, but positive in a few cases. In order to suppress the influence of the detection fluctuation of some frames, a measure was taken to accumulate the inter-frame change rate. If the detection misalignment of the previous frame caused the inter-frame change rate to fluctuate greatly, the accurate detection of the next frame of the picture would cause the inter-frame change rate to fluctuate in the opposite direction, which would largely suppress the detection fluctuation. We designed a data pool (array) with 5 elements. The detection result of each frame of the picture was the inter-frame change rate, which is rolled and stored in sequence, summing the elements of the array and taking the opposite number, and comparing it with the adjustable parameter threshold
ρ. If it was greater than
ρ, it was regarded as a lane-changing; otherwise, no lane change had occurred. For a specific calculation example, see the introduction in
Section 4.























{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}