1. Introduction
In the medical imaging field, a computer-aided diagnosis (CAD) (e.g., [
1,
2,
3]) system which gives a second opinion is strongly needed. Ultrasound imaging is non-invasive and widely used for the diagnosis of liver cirrhosis [
4]. Cirrhosis of the liver is expected to progress to liver cancer in the worst case. Therefore, we are investigating a CAD system to diagnose liver cirrhosis sooner [
5,
6]. Many believe that using machine learning and artificial intelligence is effective for designing CAD systems. In general, there are two types of ultrasound images: B-mode and M-mode. The B-mode shows the whole of the breast imaging, including the liver. On the other hand, the M-mode provides motion images of the liver aortic vessels [
7].
In this study, B-mode liver ultrasound imaging is focused on. B-mode ultrasound image data was provided by the collaborator. These data include 12 cirrhosis patients and 8 normal subjects. There were five ultrasound images per person.
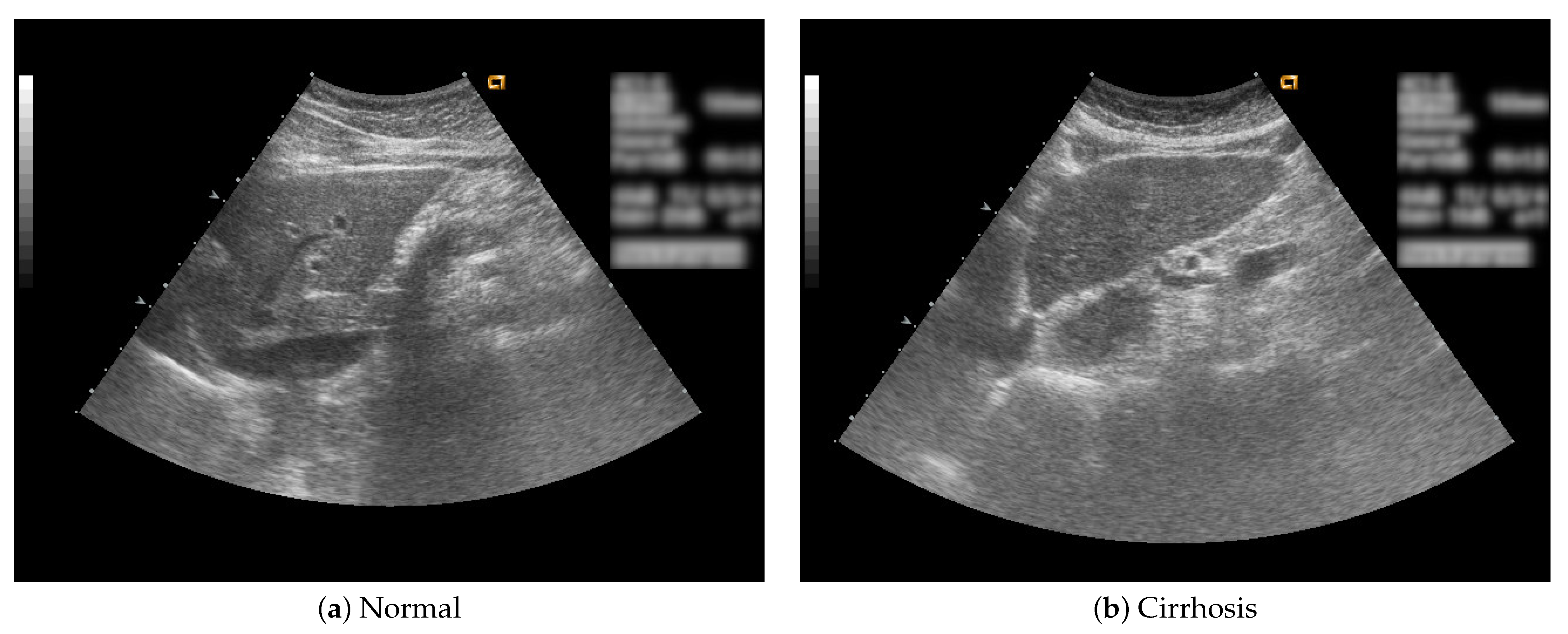
Figure 1 shows B-mode liver ultrasound images.
Figure 1a,b show a normal and a cirrhosis liver, respectively. In this study, we focus on classifying regions of interest (ROIs) from the B-mode ultrasound images.
Figure 2 shows examples of ROI images. The ROI images were manually cut out from the liver areas by a physician. A total of 200 normal and 300 cirrhosis ROI images were collected.
Figure 2a,b show normal and cirrhosis livers. The size of each ROI image was 32 by 32 pixels. The grey level was 8 bits. Thus, the values ranged from 0 to 255. This is a typical two-class problem, normal or cirrhosis. From this figure, it seems difficult to visually classify a liver as normal or cirrhosis if one is not a physician because of noisy ultrasound images.
In a previous study [
5], we explored liver cirrhosis classification using an approach based on higher-order local auto-correlation (HLAC) features, which are known as hand-crafted features in the pattern recognition field. The HLAC feature approach produced the best performance among our experimental results. However, this experimental result showed that the average error rate was over 40%. Even the best performance from the conventional approach was not very good.
Convolution neural networks (CNNs) are widely used in the medical imaging field (e.g., [
8]). In recent studies, as shown in (e.g., [
9,
10,
11]), issues of liver diseases as captured in ultrasound images have been addressed. Deep learning approaches were adopted in [
9,
11], and a combination of hand-crafted features and the classical classifier was used in [
10]. Each of these approaches was reported to result in better accuracy. Note, however, that the datasets themselves were all different. Each of the datasets used in [
9,
11] was for liver fibrosis staging classification. The dataset in [
11] was for normal and fatty liver, not cirrhosis. On the other hand, the dataset we used was for normal and cirrhosis. Cirrhosis is the most dangerous liver disease, as mentioned above. Therefore, it is difficult to collect a sufficient amount of data on it. The limitation on the available cirrhosis data increases the difficultly of the pattern recognition problem. The average error rate on the limited dataset may thus be high compared to another type of dataset.
We expect that the deep neural nets will be able to yield a good performance in this liver cirrhosis classification problem. One defect of CNNs is the need for many training samples. This leads to an over-training problem. In a previous study [
6], we showed the effectiveness of the ROI image augmentation method by a perspective transformation.
Apart from the ROI image data augmentation, we would also like to improve the average error rate of liver cirrhosis classification using CNNs. By contrast with the conventional pattern recognition system, the CNN could work well by learning a combination of input images and output labels or class names. Thus, we may overlook the importance of obtaining better image quality. In the pattern recognition field in general, the richer the features that are obtained, the better the classification performance of the pattern recognition system. Most classifiers work well only if the features are good. Therefore, there has always been much effort devoted to obtaining better features, with both the classical and the deep learning approaches. However, deep learning can reduce the efforts because the CNN learns automatically by feeding up a combination of input images and output labels. Therefore, our focus is on improving the image quality of ROI images with the goal of improving the classification of liver cirrhosis. The method called CEUS (contrast-enhanced ultrasound) (e.g., [
12]) has been expected to obtain more contrast-enhanced images than conventional ultrasound imaging. In this study, on the other hand, the aim is to apply image processing to the already available images to obtain higher-quality images.
Livers with cirrhosis are known to be physically harder. This would make the image regions slightly lighter. On the other hand, a normal liver is not so hard. In this case, the image regions are slightly darker. Therefore, we expect that the image contrast of ROI images is one of the important factors in classifying liver cirrhosis. In order to highlight the image contrast of ROI images, we adopted the approach of enhancing the image contrast of the ROI images. The image quality was expected to be better when using the image correction methods of tone curves (e.g., [
13]). We hoped that the improvement in the image quality would lead to a decrease in the average error rate in liver cirrhosis classification.
In the experiments, we used grey-level transformation functions, i.e., tone curves, for image quality improvement. In this study, in order to enhance the image contrast of ROI images, we used two line-type tone curves and one curved line-type tone curve. Furthermore, we also expected that the darker regions of the ROI images would have better features as well as lighter regions. In order to implement this, we used the inverses of the tone curves. In the experiments, we also used three types of inverses of tone curves. In this paper, we examined the effect of the changes in image quality with image correction methods classifying cirrhosis of the liver on B-mode ultrasound images. The experimental results show the effectiveness of the image correction methods in improving the image quality of ROI images. By enhancing the image contrast of the ROI images, the image quality improved, and thus the generalization ability of the CNN also improved.
In the Discussion section, classical classifiers,
k-NN (
), SVM, LDA, and RF, as well as the transfer learning method, VGG16, are compared to investigate the effects of the proposed method. The
k-NN (nearest neighbour) classifier [
14,
15] classifies a test sample based on
k nearest neighbour samples. The decision is basically made by
k majority votes. In particular, the nearest neighbour classifier (
) is very well known and used in the pattern recognition field and in ultrasound liver classification. The SVM (support vector machine) [
16] is known as an effective classifier and it is frequently used for medical imaging. The basic idea of SVM is to find a hyperplane with a margin that maximizes the distance to each sample. The LDA (linear discriminant analysis) classifier [
14,
15] classifies a test sample based on the statistics, mean vectors, and the same covariance matrix for each class. The RF (random forest) [
17] is one of the ensemble learning approaches which are based on decision trees. The RF classifies a test sample based on the multiple outputs performed by each decision tree. The RF with multiple decision trees was expected avoid over-training. The VGG16 [
18] is one of the transfer learning approaches. A VGG16 such as CNN (convolution neural network) only requires combinations of inputs or the image itself and its class label. Transfer learning was expected for a small training sample size problem such as one with the current dataset.
2. Materials and Methods
The generalization ability of CNNs has been improved by adding more layers to deeply train the networks [
19,
20]. We hoped that the deep nets would improve the generalization ability for this difficult cirrhosis pattern recognition problem. From our preliminary experimental results, the deeper nets could memorize all the training samples. However, they seemed not to address the unknown test samples. This is known as over-training. In particular, the number of available samples, such as in this set of medical data, is limited. This is known as the small sample size problem in the pattern recognition field [
21,
22]. With small training sample sizes, deeper nets do not work well. Therefore, we conducted our investigation using shallow nets. The generalization ability of CNNs depends on their network structure and the parameters to be determined. First, we showed the CNN architecture, which is the same as in [
6].
Figure 3 shows the structure of the CNN. The input of the CNN is the ROI image of a 32 by 32 size. Firstly, we convolved the ROI image using 32 filters with a 3 by 3 filter size. Furthermore, through 2 by 2 max-pooling, we reduced the ROI image size to a half-sized image, 16 by 16 in size. Secondly, we repeatedly convolved and performed max-pooling in the same manner. Then, we obtained 32 images 8 by 8 in size. Thirdly, we flattened this image into a 2048 (=32 by 8 by 8) dimensional vector. To implement the classification stage, we used a fully connected artificial neural network, with one hidden layer and 2 output neurons for {cirrhosis, healthy}. We explored how performance varied with the number of neurons, with 100 neurons in the final configuration, which was 2048-100-2. The intermediate activation functions were ReLU, and the output layer used softmax. The dropout rate was 0.5, with a batch size of 400. The network was optimized using ADAM over 100 time periods.
Secondly, we showed the image correction methods used. We expected that the image contrast of the ROI images would be important in classifying liver cirrhosis. Thus, we adopted the approach of emphasizing the image contrast of the ROI images. In this study, we used 2 line-type tone curves and 1 curved line-type tone curve as image correction methods [
13]. We also used their inverted types.
Figure 4 and
Figure 5 show the tone curves and the inverse tone curves. In the figures, each of the image correction processing techniques from type 0 to III corresponds to that from type IV to VII. We can see the relationships among the tone curves and the inverse tone curves. The aim of type I to III and type V to VII is to obtain enhanced-contrast images using the parameter values
t and
. By controlling the parameter values of
t and
, we expected to obtain enhanced-contrast images. The image correction techniques we used are as follows. The notation
means the maximum value of the grey level. The grey level was 8. The values ranged from 0 to 255. Then, we could read
as 255. In each of
Figure 4 and
Figure 5, the figure is drawn according to
. For 12 grey levels, the values ranged from 0 to 4095. Then, we could read
. The notations
f and
g are the intensities of input and output images, respectively.
2.1. Type 0 Original Line
The type 0 original line is the same for both input and output values. The value of output
g flows is the same as the input value
f.
This means that the intensities of the input and the output images are the same.
2.2. Type I Linear Line
The type I linear line behaves in the same manner as a linear line except for having a lower threshold point. When pixel values are less than threshold
t, the intensity values are zero. This means they turn black and will be ignored.
We could vary the threshold value t from 0 to . If the value of t is 0, this means that the intensities of the input and the output images are the same. The higher the value of t is, the larger the dark regions are.
Figure 5.
Inverse of tone curves.
Figure 5.
Inverse of tone curves.
2.3. Type II Linear Line
The type II line is similar to the type I line. When it becomes equal to or greater than a threshold, the values of the intensity linearly increase. Otherwise, the intensities are zero.
We could vary the threshold value t from 0 to . If the value of t is 0, the intensities of the input and the output images are the same. These are the same as those for type I. The higher the value of t is, the larger the dark regions are. At the same time, the contrast of the image is enhanced.
2.4. Type III Gamma Curve
The gamma curve is one of the curved line-type tone curves. It is not a linear line but a non-linear curve.
We could control the degree of non-linearity with the value of . When the value of is equal to 1, the intensities of the input and the output images are the same. If the value of is less than 1, the image is darker. Otherwise, the image is brighter.
2.5. Type IV Inverse of Linear Line
The type IV inverse of linear line behaves in the same manner as a linear type 0 line. The value of output
g flows is the same as the inverse of the input value
f.
This means that the intensities of the input and the output images are inverse. The darker regions become lighter. By contrast, the lighter regions become darker.
2.6. Type V Inverse of Linear Line
The type V inverse of linear line behaves in the same manner as the inverse of a linear line except for values larger than a threshold, where the values are set to zero. That means that they turn black and will be ignored.
We could vary the threshold t from 0 to . If the value of t is , this means that the intensities of the input and the output images are inverse. The lower the value of t is, the larger the dark regions are.
2.7. Type VI Inverse of Linear Line
The type VI linear line behaves in the same manner as the inverse of a linear line except for a greater threshold. When the pixel values are greater than the threshold, the intensity values are zero. This means that they turn black and will be ignored.
We could vary the threshold t from 0 to . If the value of t is , this means that the intensities of the input and the output images are inverse. The lower the value of t is, the larger the dark regions are. Simultaneously, the contrast of the image is emphasized.
2.8. Type VII Inverse of Gamma Curve
The type VII inverse of gamma curve behaves as a type III gamma curve.
We could control the degree of non-linearity with the value of . When the value of is equal to 1, the intensities of the input and the output images are inverse. If the value of is less than 1, the image is darker. Otherwise, the image is lighter.
In the experiments, we used ROI images modified by these image correction methods, from type I to VII and including type 0. We tried to investigate the effectiveness with and without the image correction methods on CNNs in terms of the average error rate.
4. Discussion
Enhancing the image contrast of ROI images is considered to lead to improved image quality, at least when considering human viewing. Here, we investigated whether the contrast enhancement would also help reduce classification error rates. Type VI (
) showed the best average error rate in our limited experiments. Thus, we tried to observe the modified ROI image with the image correction method of type VI.
Figure 7 shows the difference between the original and the modified ROI images for normal and cirrhosis livers. From the appearance of the modified images and the experimental results, we draw the following conclusions:
For the type VI method (), the modified ROI images were much lighter because the modified ROI images were inverted and their intensities of greater than 200 were ignored. The image contrast was slightly enhanced because the gradient of the line was steeper. Through this method of image processing, we could obtain richer features for classifying liver cirrhosis. As a result, the features may be richer and the generalization ability of the CNN may improve.
On the other hand, the generalization ability of the images corrected through the type II () method yielded the second best average error rate in our limited experiments. For the type II method (), the modified ROI images were much darker because the intensities of less than 100 were ignored. By cutting the darker regions and inclining the gradient of the linear line, we could obtain richer features for classifying liver cirrhosis. Thus, the features may richer and the generalization ability of the CNN may improve.
Furthermore, the effect of the classifiers which are well known and widely used as machine learning was also investigated on original images and modified images (type VI (
)). The classifiers were
k-nearest neighbour, support vector machine (SVM), linear discriminant analysis (LDA), random forest (RF), and transfer learning [
23,
24]. The same experiments as shown in the Results section were conducted. The feature we used was the image itself. In the experiments,
k-NN (
) [
14,
15], the linear-type SVM [
16], the RF [
17] with 100 decision trees, and VGG16 [
18] as the transfer learning approach were used. In the VGG16, a fully artificially connected network of the same kind as previously mentioned in the CNN was added. The VGG16 was retrained by 5 out of 20 layers by fine-tuning. That is, the 15 remaining layers were frozen.
Table 5 shows the average error rates of the classifiers on original images and modified images. The average error rates of the classifiers except for VGG16 were very poor. They were over 40%. There was almost no difference between the original images and the modified images. These results are in line with our previous findings [
5]. In principle, these classifiers cannot avoid using one-dimensional data flattening from two-dimensional image data. They could not use the data as a 2D image. On the other hand, the VGG16 was better. A VGG16 such as the CNN could use the data as a 2D image for image pattern recognition. Slight improvement when using modified images also seems to have occurred with VGG16.
Finally, the limitations of the experiments are discussed. From the experimental results, the image correction method with type VI () for ROIs of liver cirrhosis classification on the CNN was found to work better on our dataset. When it comes to using the transfer learning VGG16, the effectiveness also seemed clear. There is a possibility for attaining an appropriate image quality through a modified method for each classifier and for each dataset. The actual selection of parameters t and for each image quality correction method should be conducted as follows, for example:
- Step 1
Prepare several candidates for t or .
- Step 2
Using these candidates, calculate the average error rate with available data, e.g., through the three- or five-fold cross-validation method.
- Step 3
Select the value of t or that gives the smallest value among these average error rates.


 ,
, 






{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}