
Popularity-Aware Closeness Based Caching in NDN Edge Networks





Abstract
:1. Introduction
2. Background and Motivations
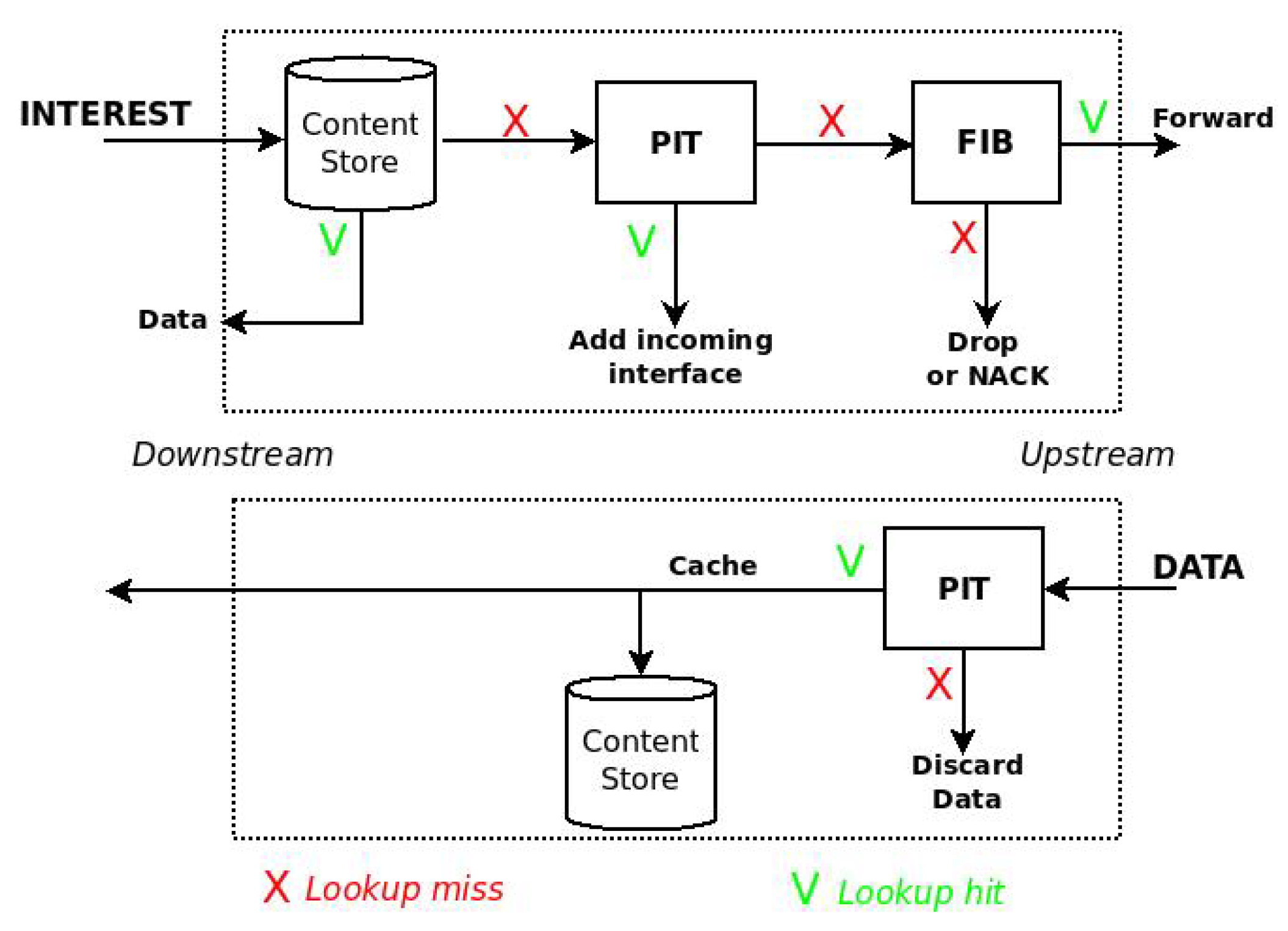
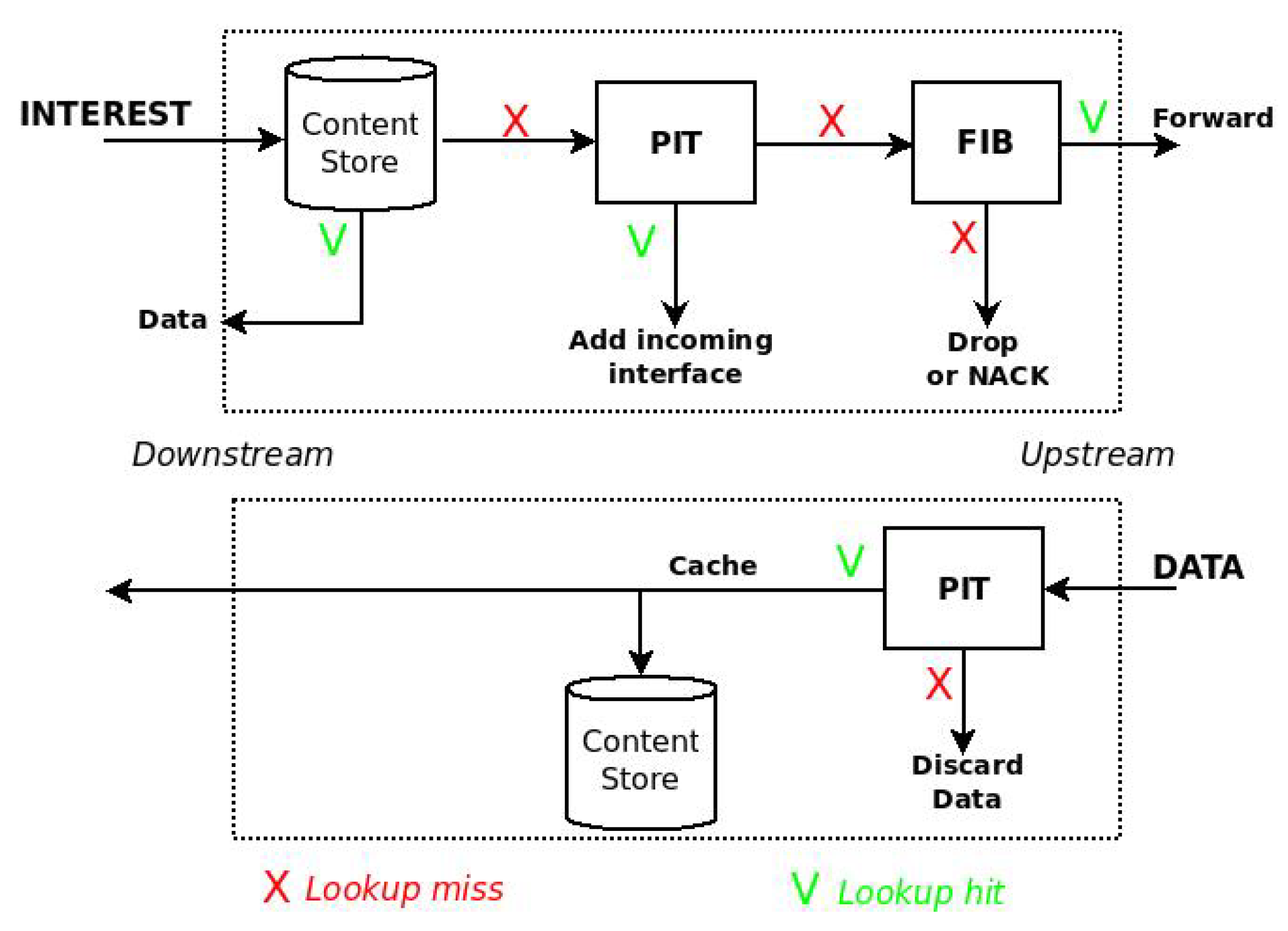
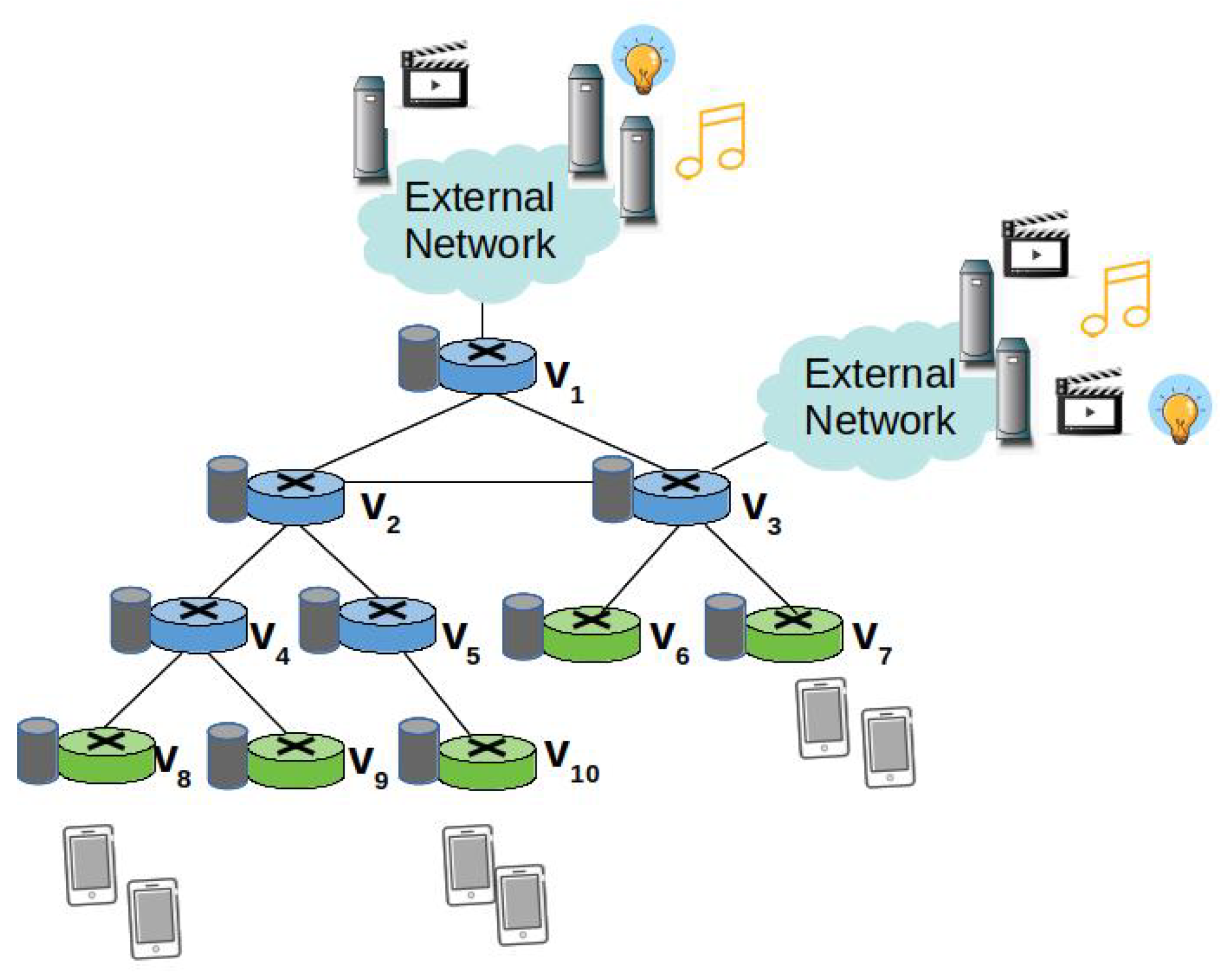
2.1. NDN in a Nutshell
2.2. Caching Strategies in the Literature
3. PaC-Based Caching
3.1. Main Pillars and Assumptions
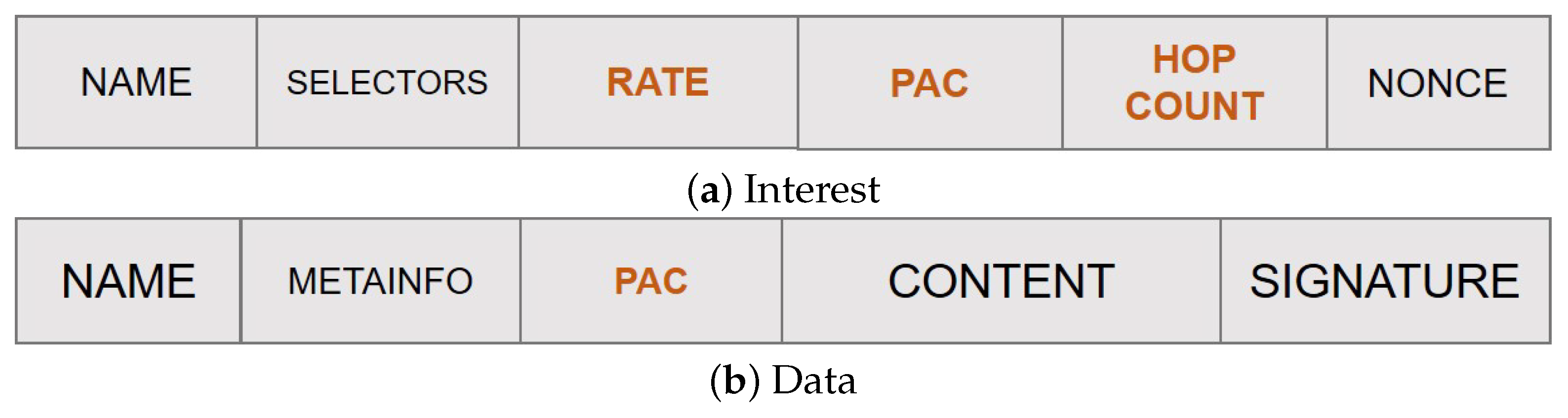
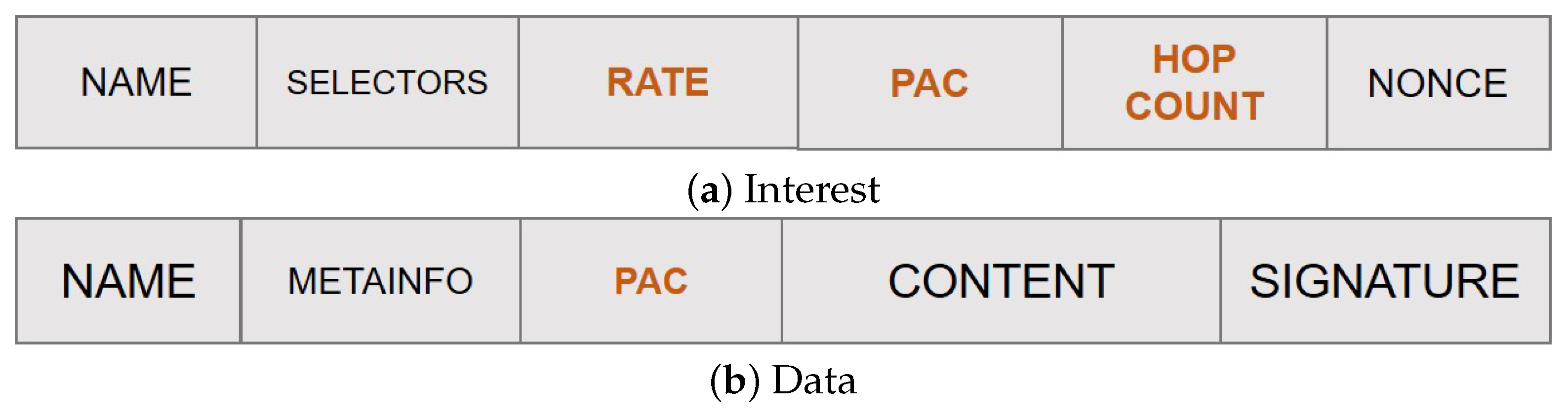
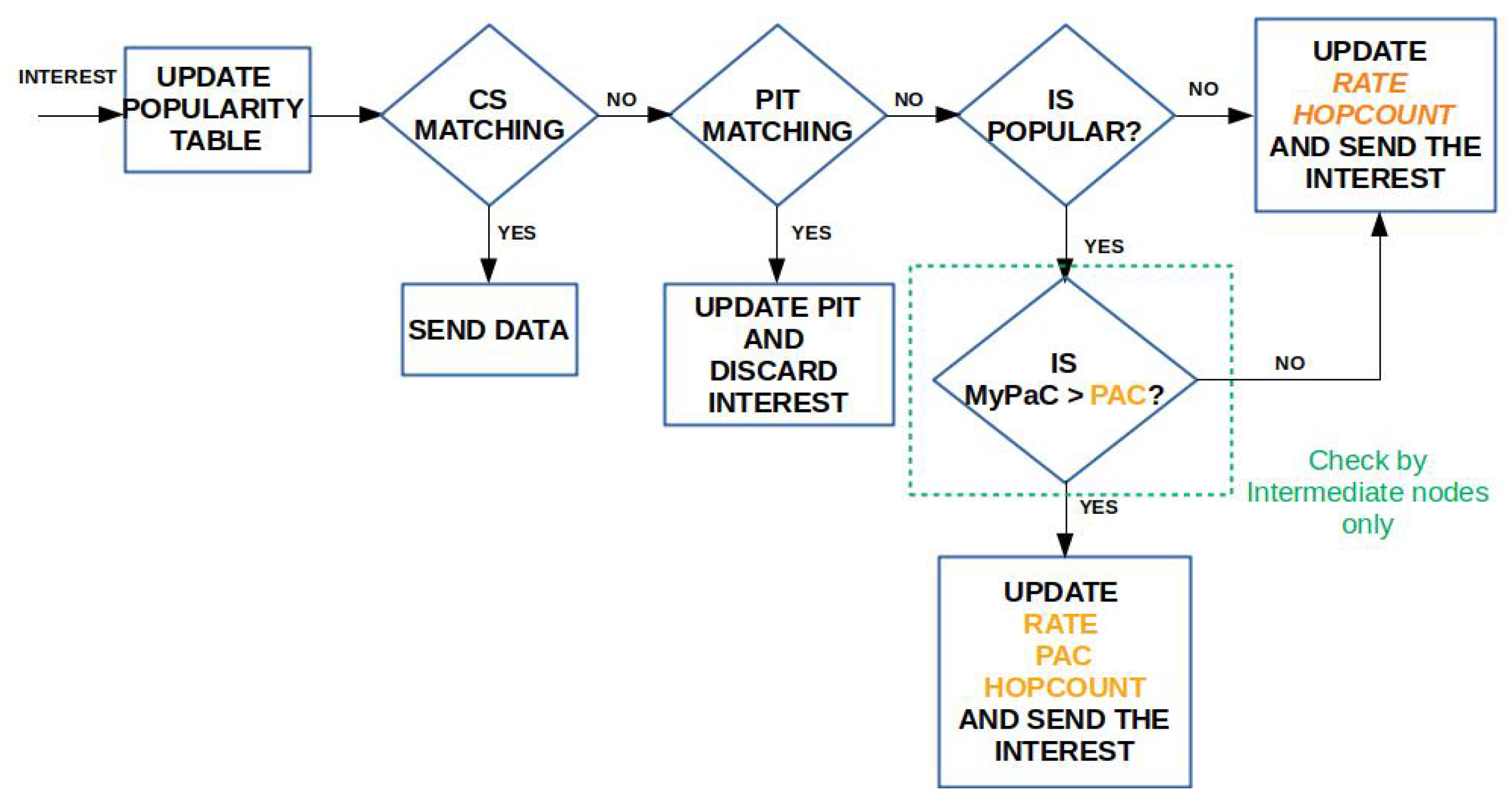
- Content popularity is tracked at the edge nodes in terms of locally perceived content request rate. Values are maintained in a Popularity Table and properly advertised in the new rate field of the Interest packet to account for the actual content request number over each edge link.
- Each node tracks the distance, in terms of hop count, from the on-path ingress nodes through a newly added field hopCount. This information, combined with the content request rate, is used to compute the PaC metric that is then advertised in the new pac field of the Interest packet by the forwarding nodes.
- The highest PaC metric, discovered during the Interest forwarding, is carried by the returning Data packet in a new pac field, and it is used to select the cacher.
3.2. Tracking Content Popularity
3.3. Popularity-Aware Closeness Metric
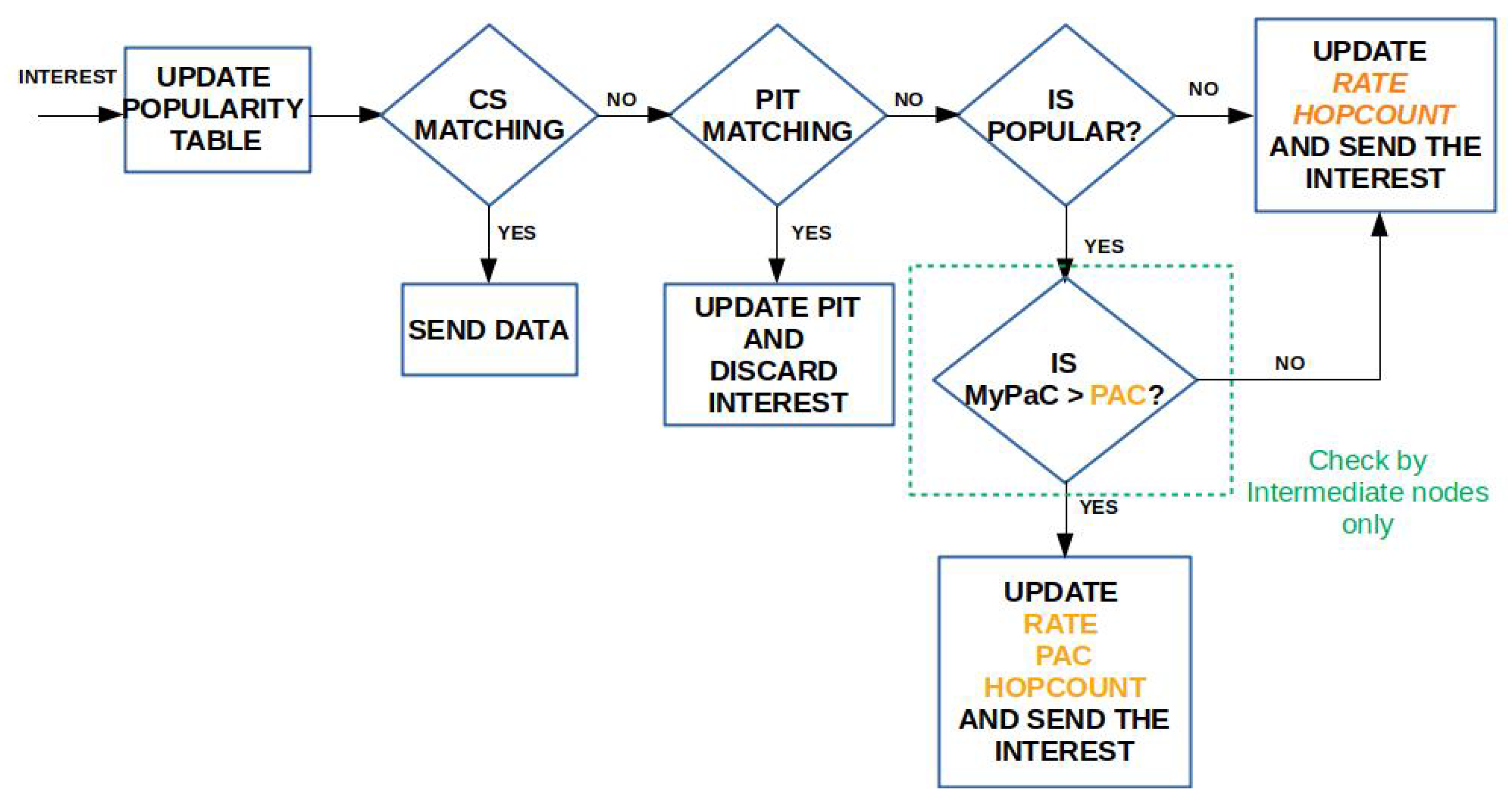
3.4. Caching Algorithm
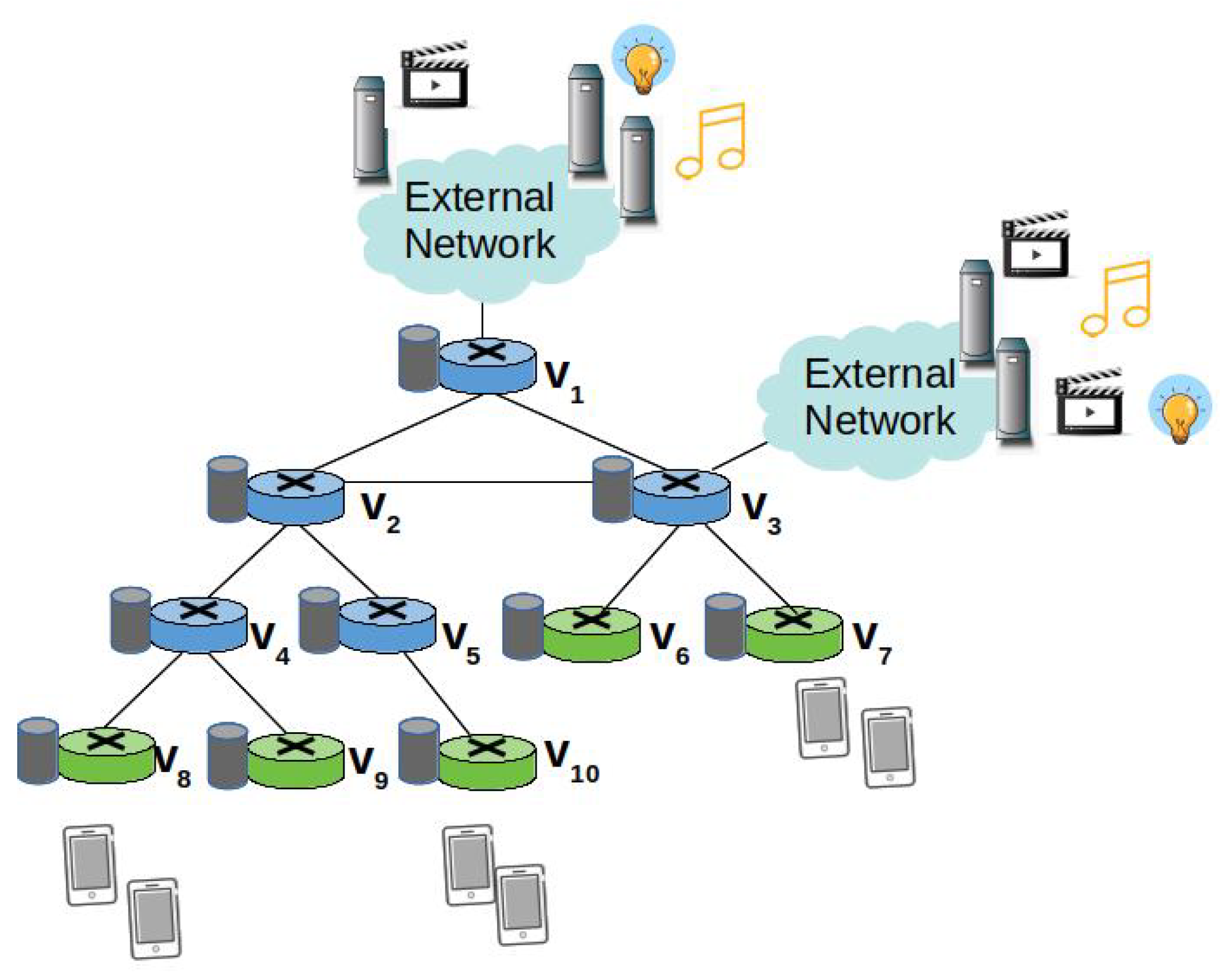
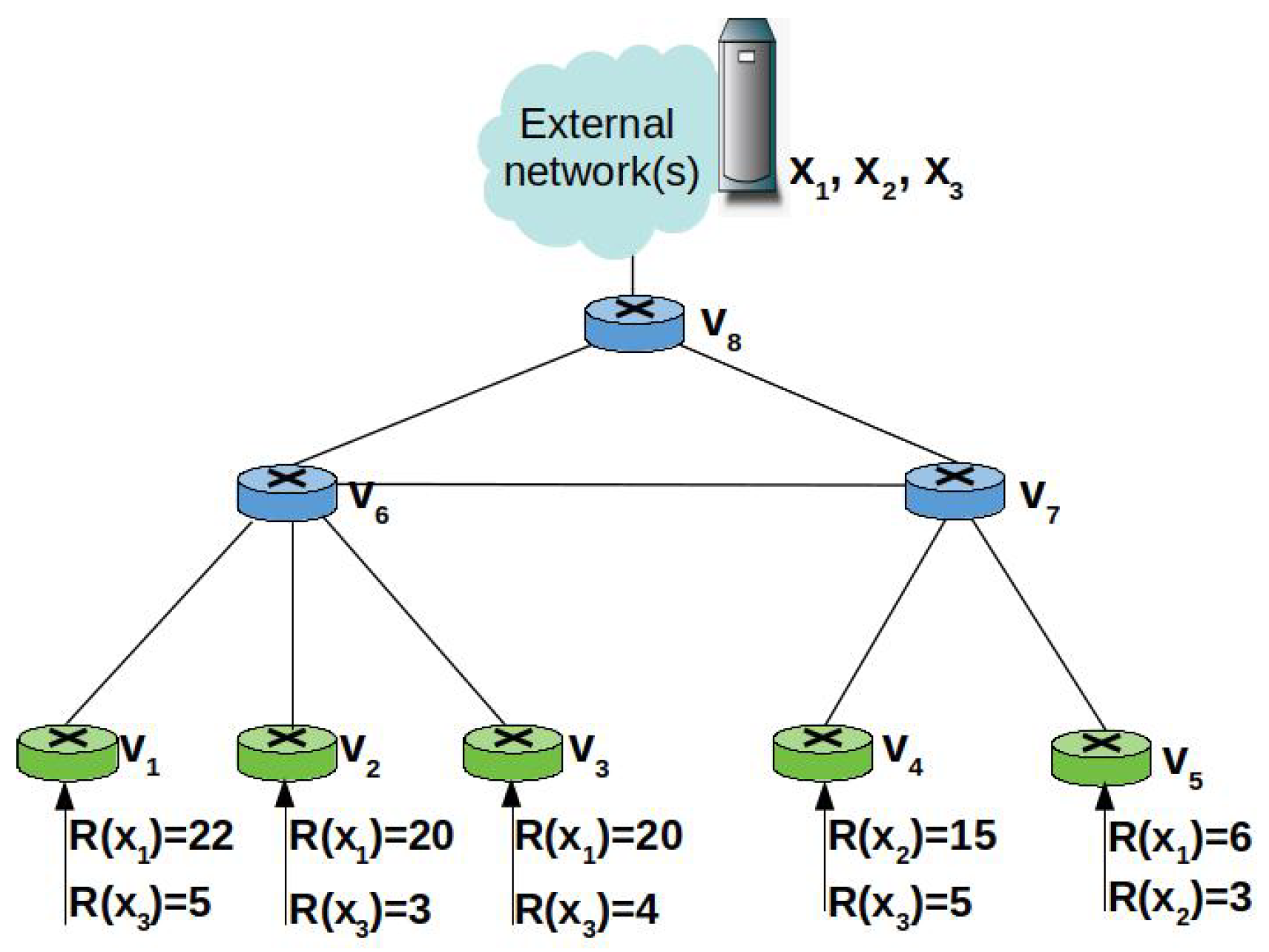
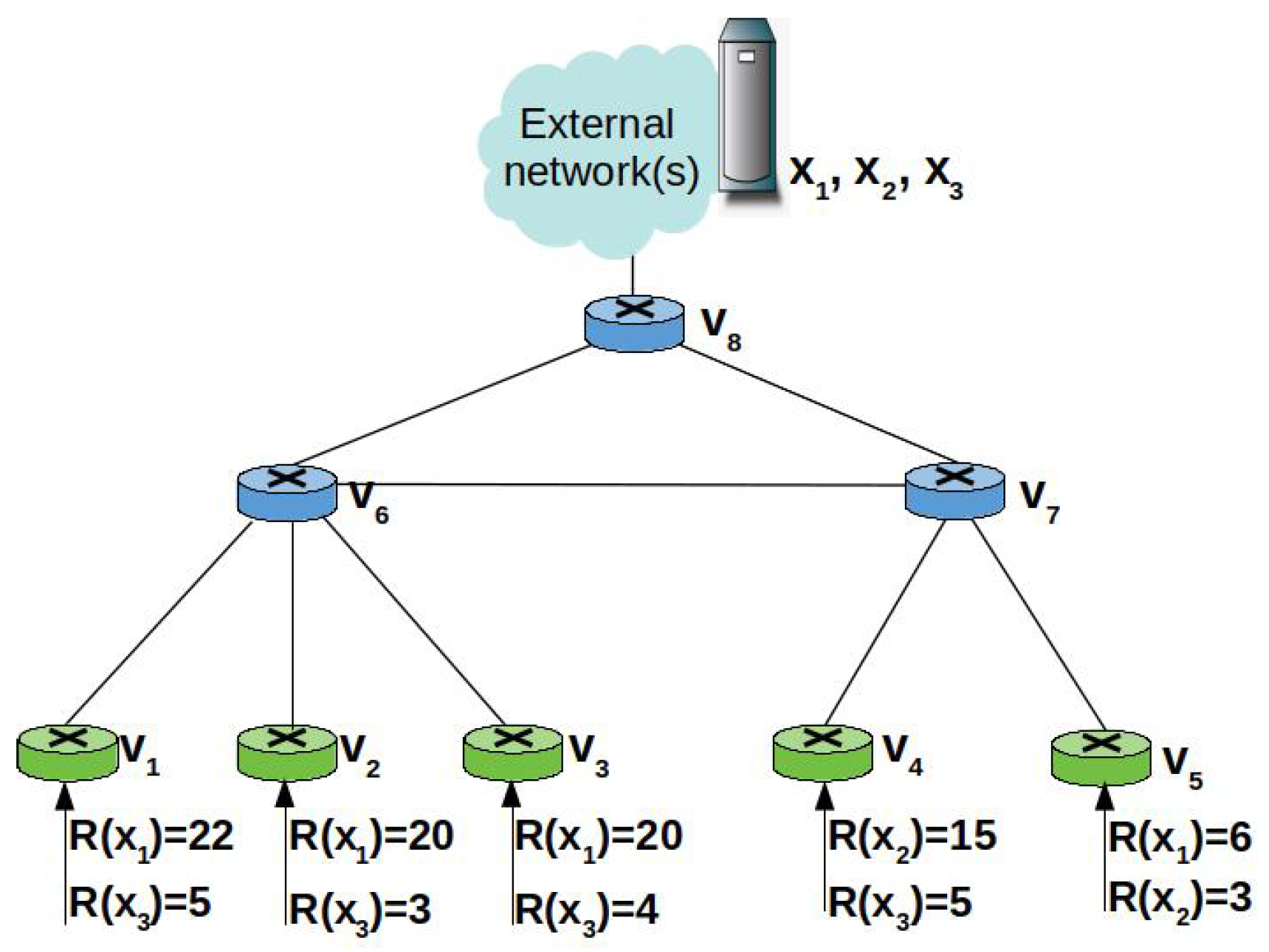
3.5. A Toy Example
4. Performance Evaluation
4.1. Simulation Settings
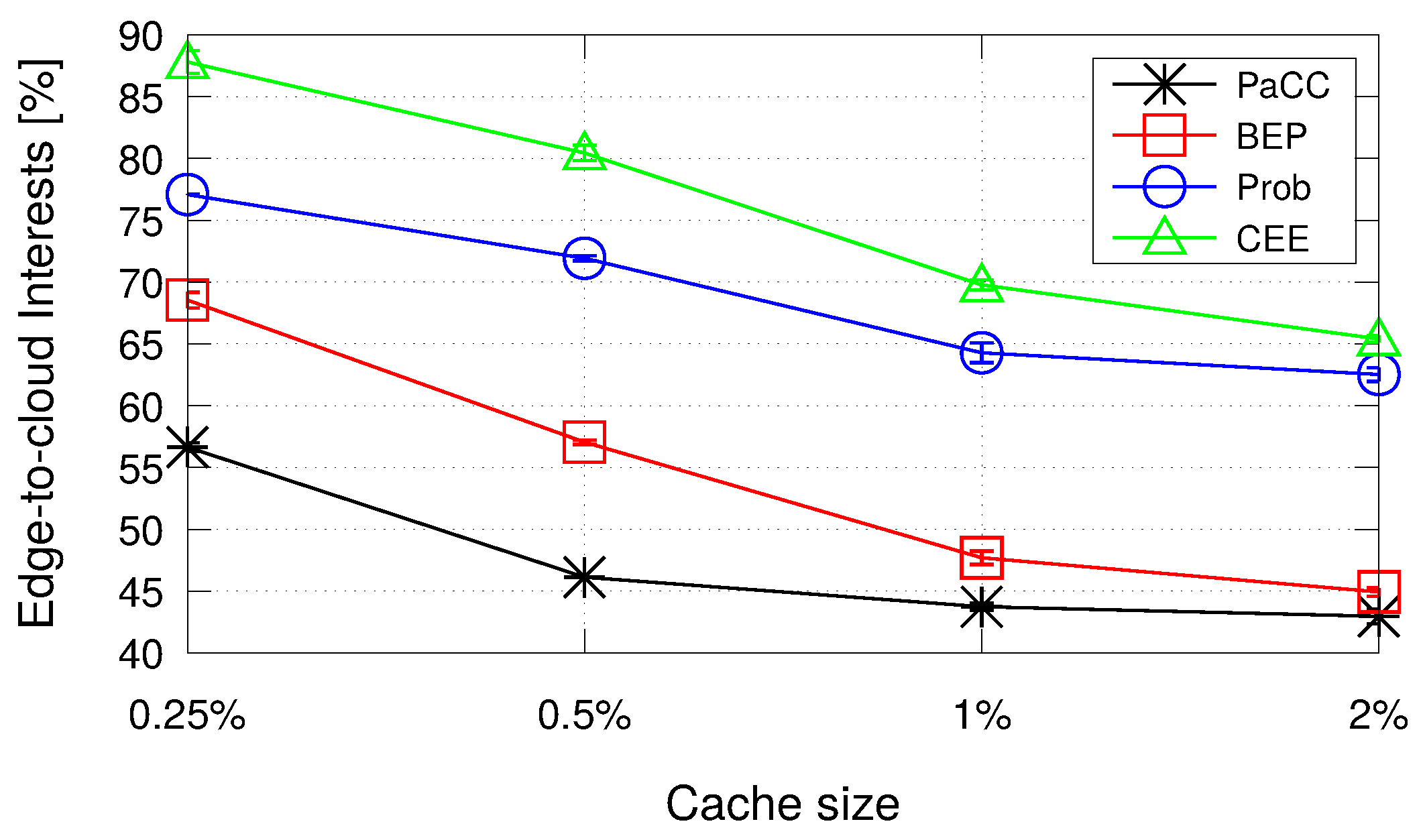
- In the first scenario, we assume that the total caching capacity of the edge domain, uniformly distributed among the nodes, is varying from 0.25% to 2% of the overall catalog size, similarly to the values reported in [19]. The number of consumers is set to 60.
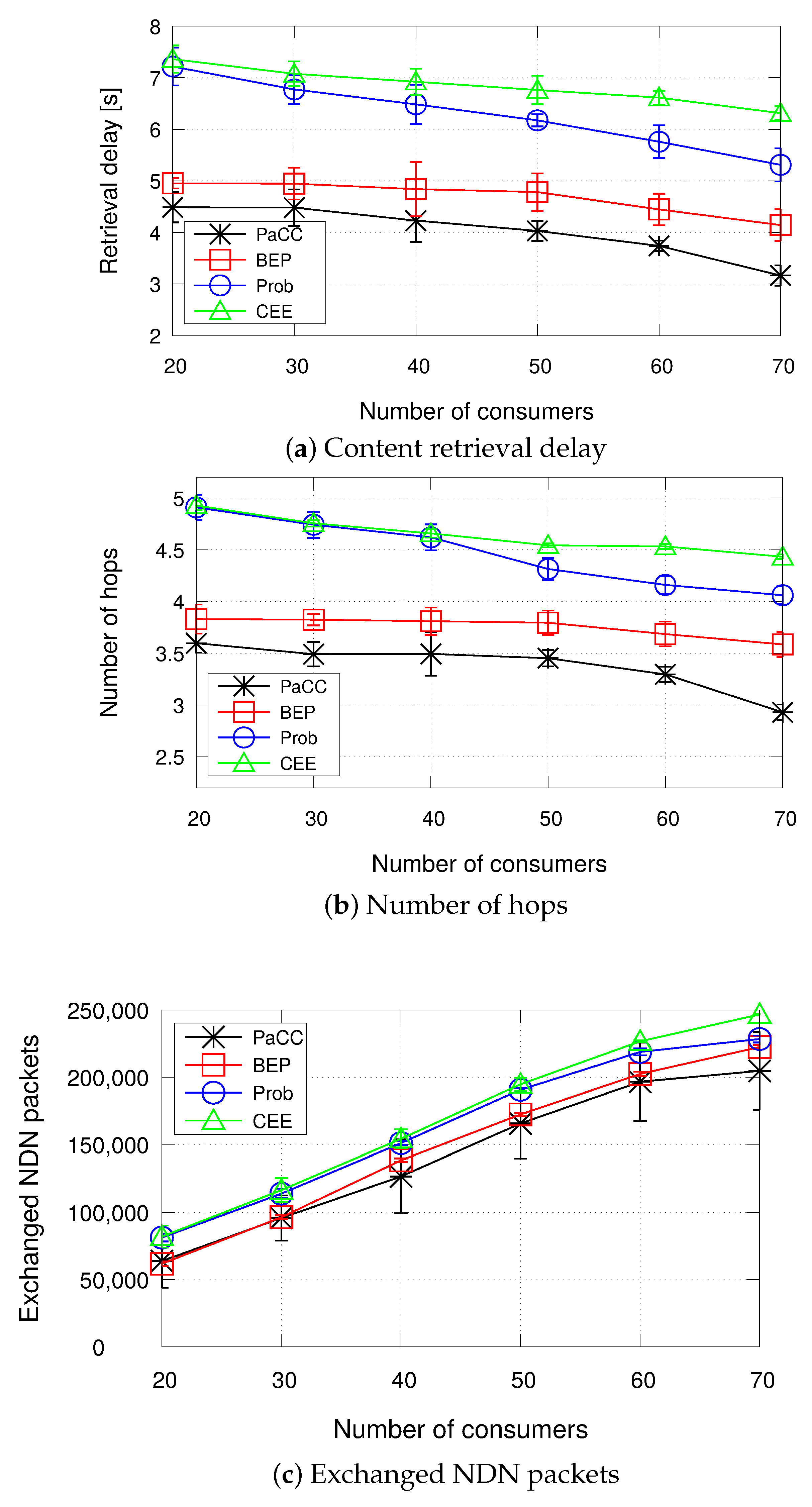
- In the second scenario, we assume that the cache capacity is fixed to 0.5% of the overall catalog size, whereas the number of consumers range from 20 to 70.
- Cache everything everywhere (labeled as in the plots). It is the vanilla NDN caching strategy where all the incoming Data packets are cached.
- Fixed probability-based caching (labeled as Prob in the plots). It caches incoming Data according to a fixed probability set to 0.5 [9].
- Betweenness and edge popularity caching (labeled as in the plots). It implements a caching scheme based on the popularity-aware betweenness centrality metric, as in [6].
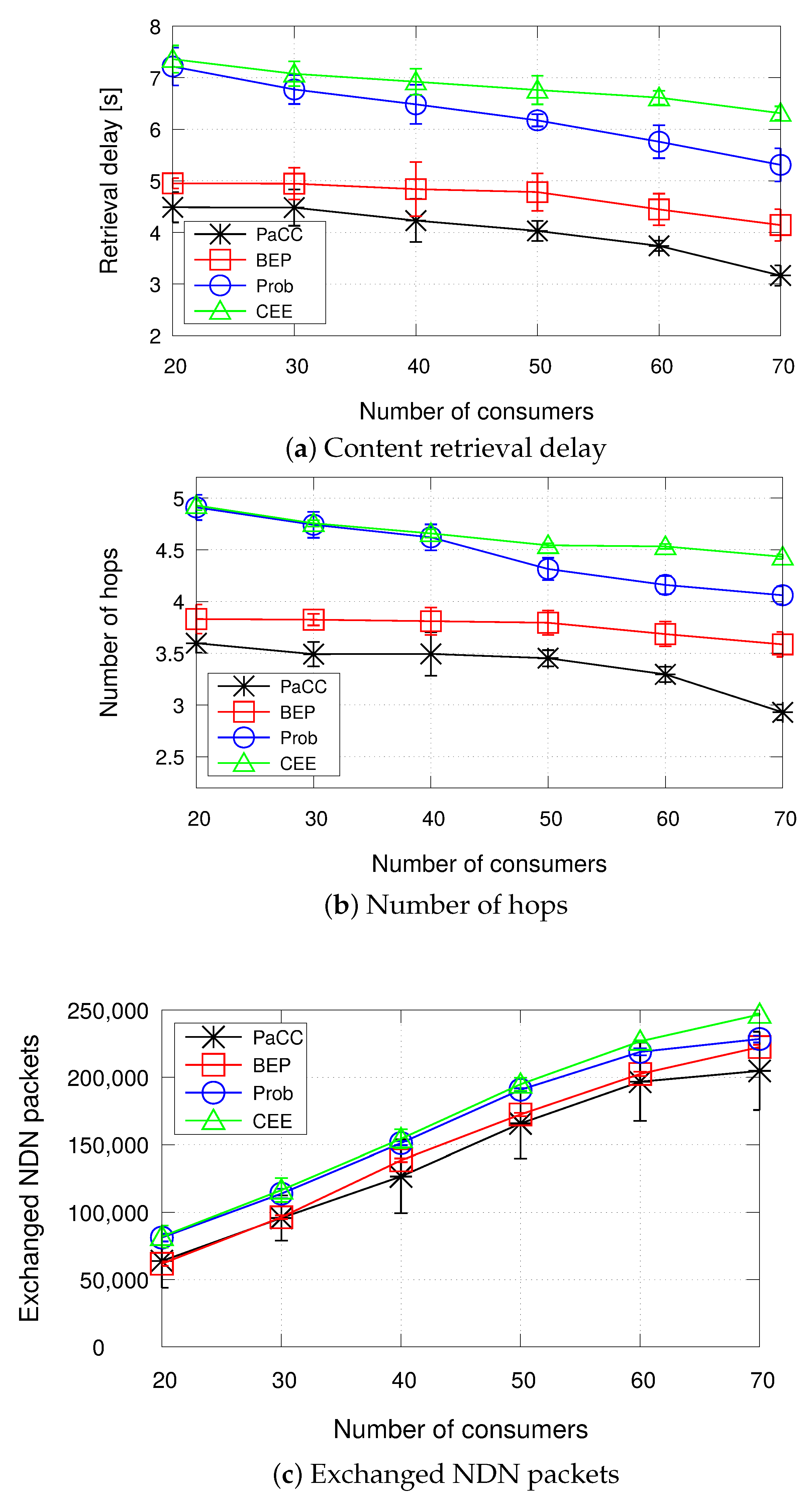
- Retrieval delay: it is computed as the average time taken by a consumer to retrieve a content.
- Number of hops: it is computed as the average number of hops traveled by the Interest packets for retrieving the corresponding Data packets.
- Exchanged NDN packets: it is the total number of Interest and Data packets transmitted by all the nodes, i.e., consumers, providers, and edge nodes, during the simulation, to retrieve the contents.
4.2. Results
4.2.1. Impact of the Cache Size
4.2.2. Impact of the Number of Consumers
4.2.3. Overhead Analysis
5. Conclusions
Author Contributions
Funding
Institutional Review Board Statement
Informed Consent Statement
Data Availability Statement
Conflicts of Interest
References
- Zhang, L.; Afanasyev, A.; Burke, J.; Jacobson, V.; Claffy, K.; Crowley, P.; Papadopoulos, C.; Wang, L.; Zhang, B. Named data networking. ACM SIGCOMM Comput. Commun. Rev. 2014, 44, 66–73. [Google Scholar] [CrossRef]
- Zhang, M.; Luo, H.; Zhang, H. A Survey of Caching Mechanisms in Information-Centric Networking. IEEE Commun. Surv. Tutorials 2015, 17, 1473–1499. [Google Scholar] [CrossRef]
- Breslau, L.; Cao, P.; Fan, L.; Philips, G.; Shenker, S. Web caching and Zipf-like distributions: Evidence and implications. In Proceedings of the IEEE INFOCOM ’99. Conference on Computer Communications, Eighteenth Annual Joint Conference of the IEEE Computer and Communications Societies, The Future is Now (Cat. No.99CH36320), New York, NY, USA, 21–25 March 1999; pp. 126–134. [Google Scholar]
- Chai, W.K.; He, D.; Psaras, I.; Pavlou, G. Cache “less for more” in Information-Centric Networks. In Proceedings of the International Conference on Research in Networking, Prague, Czech Republic, 21–25 May 2012; Springer: Berlin/Heidelberg, Germany, 2012; pp. 27–40. [Google Scholar]
- Khan, J.A.; Westphal, C.; Ghamri-Doudane, Y. A popularity-aware centrality metric for content placement in information centric networks. In Proceedings of the 2018 International Conference on Computing, Networking and Communications (ICNC), Maui, HI, USA, 5–8 March 2018; pp. 554–560. [Google Scholar]
- Zheng, Q.; Kan, Y.; Chen, J.; Wang, S.; Tian, H. A Cache Replication Strategy Based on Betweenness and Edge Popularity in Named Data Networking. In Proceedings of the ICC 2019—2019 IEEE International Conference on Communications (ICC), Shanghai, China, 20–24 May 2019; pp. 1–7. [Google Scholar]
- Khan, J.A.; Westphal, C.; Garcia-Luna-Aceves, J.; Ghamri-Doudane, Y. Nice: Network-oriented information-centric centrality for efficiency in cache management. In Proceedings of the 5th ACM Conference on Information-Centric Networking, Boston, MA, USA, 21–23 September 2018; pp. 31–42. [Google Scholar]
- Perino, D.; Gallo, M.; Boislaigue, R.; Linguaglossa, L.; Varvello, M.; Carofiglio, G.; Muscariello, L.; Ben Houidi, Z. A high speed information-centric network in a mobile backhaul setting. In Proceedings of the 1st ACM Conference on Information-Centric Networking, Paris, France, 24–26 September 2014; pp. 199–200. [Google Scholar]
- Tarnoi, S.; Suksomboon, K.; Kumwilaisak, W.; Ji, Y. Performance of probabilistic caching and cache replacement policies for content-centric networks. In Proceedings of the 39th Annual IEEE Conference on Local Computer Networks, Edmonton, AB, Canada, 8–11 September 2014; pp. 99–106. [Google Scholar]
- Bernardini, C.; Silverston, T.; Olivier, F. MPC: Popularity-based Caching Strategy for Content Centric Networks. In Proceedings of the 2013 IEEE International Conference on Communications (ICC), Budapest, Hungary, 9–13 June 2013; pp. 3619–3623. [Google Scholar]
- Amadeo, M.; Ruggeri, G.; Campolo, C.; Molinaro, A.; Mangiullo, G. Caching Popular and Fresh IoT Contents at the Edge via Named Data Networking. In Proceedings of the IEEE INFOCOM 2020—IEEE Conference on Computer Communications Workshops (INFOCOM WKSHPS), Toronto, ON, Canada, 6–9 July 2020; pp. 610–615. [Google Scholar]
- Amadeo, M.; Campolo, C.; Ruggeri, G.; Molinaro, A. Beyond Edge Caching: Freshness and Popularity Aware IoT Data Caching via NDN at Internet-Scale. IEEE Trans. Green Commun. Netw. 2021, 6, 352–364. [Google Scholar] [CrossRef]
- Ong, M.D.; Chen, M.; Taleb, T.; Wang, X.; Leung, V. FGPC: Fine-Grained Popularity-based Caching Design for Content Centric Networking. In Proceedings of the 17th ACM International Conference on Modeling, Analysis and Simulation of Wireless and Mobile Systems, Montreal, QC, Canada, 21–26 September 2014; pp. 295–302. [Google Scholar]
- Li, J.; Wu, H.; Liu, B.; Lu, J.; Wang, Y.; Wang, X.; Zhang, Y.; Dong, L. Popularity-driven coordinated caching in named data networking. In Proceedings of the 2012 ACM/IEEE Symposium on Architectures for Networking and Communications Systems (ANCS), Austin, TX, USA, 29–30 October 2012; pp. 15–26. [Google Scholar]
- Wang, L.; Lehman, V.; Hoque, A.M.; Zhang, B.; Yu, Y.; Zhang, L. A secure link state routing protocol for NDN. IEEE Access 2018, 6, 10470–10482. [Google Scholar] [CrossRef]
- Mastorakis, S.; Afanasyev, A.; Moiseenko, I.; Zhang, L. ndnSIM 2: An Updated NDN Simulator for NS-3. NDN, Technical Report NDN-0028. Revision 2. Available online: https://named-data.net/publications/techreports/ndn-0028-1-ndnsim-v2/ (accessed on 20 March 2022).
- GT-ITM: Georgia Tech Internetwork Topology Models. Available online: https://www.cc.gatech.edu/projects/gtitm/ (accessed on 20 March 2022).
- Al Azad, M.W.; Shannigrahi, S.; Stergiou, N.; Ortega, F.R.; Mastorakis, S. CLEDGE: A Hybrid Cloud-Edge Computing Framework over Information Centric Networking. In Proceedings of the 2021 IEEE 46th Conference on Local Computer Networks (LCN), Edmonton, AB, Canada, 4–7 October 2021; pp. 589–596. [Google Scholar]
- Rossi, D.; Rossini, G. Caching performance of content centric networks under multi-path routing (and more). Relatório Técnico Telecom ParisTech 2011, 2011, 1–6. [Google Scholar]
- Skaperas, S.; Mamatas, L.; Chorti, A. Real-time algorithms for the detection of changes in the variance of video content popularity. IEEE Access 2020, 8, 30445–30457. [Google Scholar] [CrossRef]



{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
| Work | Popularity | Topology | Domain | Decision Strategy |
|---|---|---|---|---|
| [10] | ✓ | - | Edge/Core | Caching popular contents based on a fixed popularity threshold |
| [11] | ✓ | - | Edge | Caching popular and fresh contents based on a flexible popularity threshold |
| [12] | ✓ | - | Edge/Core | Caching only popular long-lasting contents (in the core network); caching popular short-lasting contents only once per each delivery path (in the edge network) |
| [13] | ✓ | - | Edge/Core | Caching popular contents based on a flexible popularity threshold |
| [14] | ✓ | - | Edge | Caching popular contents based on a strict hierarchical coordination between the nodes |
| [4] | - | ✓ | Edge/Core | Caching contents in the most central nodes based on the betweenness centrality metric |
| [5] | ✓ | ✓ | Edge | Caching based on a popularity-weighted content-based centrality |
| [6] | ✓ | ✓ | Edge/Core | Caching based on popularity and betweenness centrality metric |
| Our work | ✓ | ✓ | Edge | Caching based on a popularity aware consumer proximity metric |
| Symbol | Description |
|---|---|
| V | set of NDN edge nodes |
| I | set of NDN ingress nodes, with |
| X | catalogue of contents |
| generic ingress node | |
| generic edge node | |
| generic content | |
| average request rate for content at node | |
| popularity threshold | |
| average content request rate at ingress node | |
| T | time interval for updating caching decision parameters |
| number of distinct contents received at the ingress node | |
| set of ingress nodes forwarding Interests for content to node | |
| popularity-aware closeness metric for content at node | |
| hop distance between nodes and |
| Parameter | Value |
|---|---|
| Content catalog size | 15,000 contents |
| Content size | 1000 Data packets |
| Data packet size | 1000 bytes |
| Content Popularity | Zipf-distributed with = 1 |
| Scenario | GT-ITM [17] |
| Edge link latency | Uniformly distributed in [2, 5] ms |
| Number of consumers | 20–70 |
| Number of edge nodes | 28 |
| Caching capacity | From 0.25% to 2% of the catalogue size |
| Strategy | Interest (Size in Bytes) | Data (Size in Bytes) |
|---|---|---|
| CEE | - | - |
| Prob | - | - |
| BEP | PopularityRanking (4) | Betweenness (4) |
| BetweennessArray (4×) | ||
| PaCC | Rate (4) | Pac (4) |
| Pac (4) | ||
| HopCount (2) |
Publisher’s Note: MDPI stays neutral with regard to jurisdictional claims in published maps and institutional affiliations. |
© 2022 by the authors. Licensee MDPI, Basel, Switzerland. This article is an open access article distributed under the terms and conditions of the Creative Commons Attribution (CC BY) license (https://creativecommons.org/licenses/by/4.0/).
Share and Cite
Amadeo, M.; Campolo, C.; Ruggeri, G.; Molinaro, A. Popularity-Aware Closeness Based Caching in NDN Edge Networks. Sensors 2022, 22, 3460. https://doi.org/10.3390/s22093460
Amadeo M, Campolo C, Ruggeri G, Molinaro A. Popularity-Aware Closeness Based Caching in NDN Edge Networks. Sensors. 2022; 22(9):3460. https://doi.org/10.3390/s22093460
Chicago/Turabian StyleAmadeo, Marica, Claudia Campolo, Giuseppe Ruggeri, and Antonella Molinaro. 2022. "Popularity-Aware Closeness Based Caching in NDN Edge Networks" Sensors 22, no. 9: 3460. https://doi.org/10.3390/s22093460
APA StyleAmadeo, M., Campolo, C., Ruggeri, G., & Molinaro, A. (2022). Popularity-Aware Closeness Based Caching in NDN Edge Networks. Sensors, 22(9), 3460. https://doi.org/10.3390/s22093460