1. Introduction
In the last two decades, we have seen tremendous innovation in vision-based systems [
1]. The massive installations of cameras in almost all essential sites, from banks to supermarkets and in prominent streets, have further helped in developing and testing these systems. Visual surveillance is one of the most important and relevant domains for intelligent vision systems [
2]. Visually surveying a site can include various tasks, such as object detection, object tracking and anomalous behaviour detection [
3]. One such task is perimeter intrusion detection (PID), which aims to detect the presence of an unauthorized object in a protected outdoor site during a certain time [
4,
5,
6]. The cameras record videos continuously in the outdoor site to be protected. The fact that it is an outdoor environment is very important here as it comes with challenges such as changing weather and light conditions, insects, animals, etc., contrary to an indoor environment [
7,
8]. The user defines protection area on the scene, potential intruder objects and the time during which the system needs to protect (e.g., protection during night only). Given user needs, the perimeter intrusion detection system (PIDS) detects intrusion and sends an alarm signal to the surveillance personnel for verification.
One of the key goals of video surveillance is to detect behaviours that can be considered anomalous. Anomalies are patterns in data that do not follow a well-defined notion of normal behaviour [
9]. Depending on the nature of input data and context, anomalies can refer to different patterns, such as abnormal sections in a time-series data, abnormal patches in an image, abnormal spatio-temporal volumes in a video, etc., as illustrated in
Figure 1. Concerning video data, video anomaly detection [
10,
11] refers to the detection of unusual appearance or motion attributes in the video. In [
12], a dataset is proposed containing 13 anomalous activities, such as abuse, arrest, accident, explosion, etc., and they used multiple instance learning to detect anomalies. Depending on the context, video anomaly detection can be specified in different tasks, such as abandoned object detection [
13], loitering detection [
14], illegally parked vehicle detection [
15], etc. Perimeter intrusion detection also falls into this category [
16,
17,
18]. In fact, intrusions are a particular type of anomalies, classified as point and contextual anomalies by (Chandola et al. [
9],
Section 3.5). Moreover, the notions of perimeter, intruder movement and site protection time are crucial for the PID task, i.e., anomalous/unauthorized objects present in the video are intruders only if they are in movement inside the designated perimeter when the site is being surveyed. In other words, all intrusions are anomalies but not all anomalies are intrusions.
In the visual surveillance literature, we find several comprehensive reviews on various tasks, such as object detection [
19,
20], object tracking [
21], anomaly detection [
9], etc. However, the PID task lacks such a review work. Few works define the PID task, but their definition requires clarity [
4,
22,
23]. It is essential to mathematically define the task as its definition has a direct impact on the evaluation. In practice, when the PIDS detects an intrusion, it sends a short video to the security post, where a human operator validates the alarm as a true intrusion or otherwise. This short video, composed of several frames before and after the suspected intrusion, must contain the intruder so that the operator can decide to send the security team to the perimeter. The end of the intrusion event is not relevant for this application. Consequently, the task of PID by video can be seen as the detection of the beginning of an abnormal event in a perimeter. In the PID task, we want to detect intrusion caused by human-based activities such as walking, driving a car, etc. To be sure to not miss such an intrusion, the video must be acquired at between 5 and 25 frames per second (FPS) [
24]. This is the real-time constraint of this task. In practice, we would like to detect intrusion as soon as it occurs; thus, we have time constraints. This requires a suitable evaluation protocol that takes these particularities into account.
The intrusion detection task is closely related to other surveillance tasks and many of these tasks, such as motion detection and tracking, can be an essential part of a PIDS pipeline. Many existing methods address one of these auxiliary tasks in the surveillance system. Only few methods tackle the problem of PIDS completely [
22,
24,
25]. Since missing intrusions in a site is considered as a major failure for a PIDS, existing methods are optimized to detect as much as possible even at the cost of some false alarms [
24]. Similarly, unlike for auxiliary tasks, there is no standard protocol for evaluating a PIDS. The dataset i-LIDS defines an evaluation protocol [
26] but it is not widely adopted and has several drawbacks, which we detail in
Section 5.2.
Our main contributions are summarized as follows: (i) We propose a formal definition of the PID task; (ii) We review the existing methods, datasets and evaluation protocols; (iii) We provide a novel PID evaluation protocol; (iv) We compare all evaluation protocols on a common dataset using existing methods.
This article is organized as follows. In
Section 2, we review the PID data with different data acquisition strategies, their challenges and available datasets. Existing PID methods are presented in
Section 3.
Section 4 formalizes the PID task using mathematical definitions. In
Section 5, we explain various evaluation protocols/metrics and present a new evaluation protocol. In
Section 6, we compare the evaluation protocols using existing methods. We next provide a discussion in
Section 7. Finally, we conclude in
Section 8.
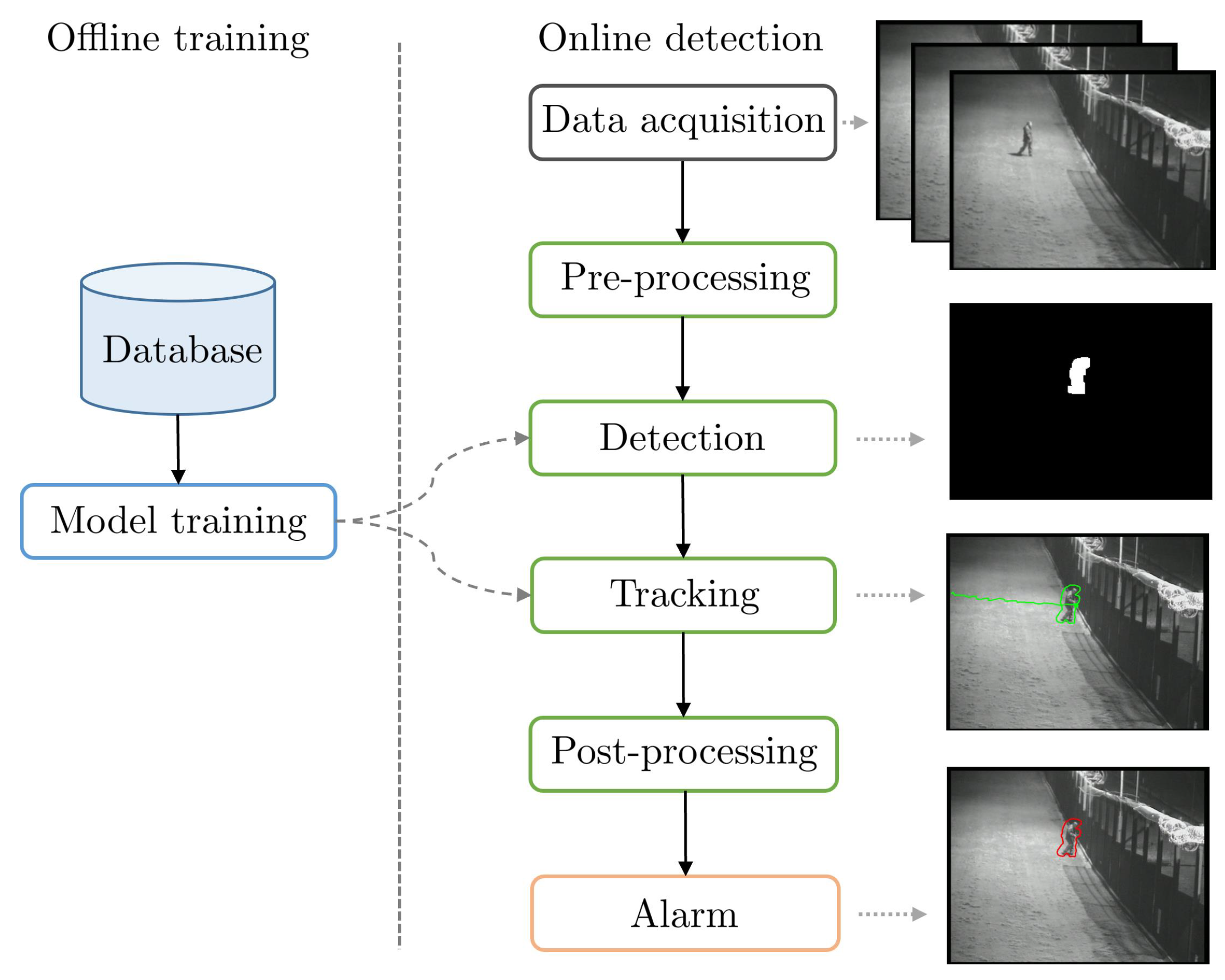
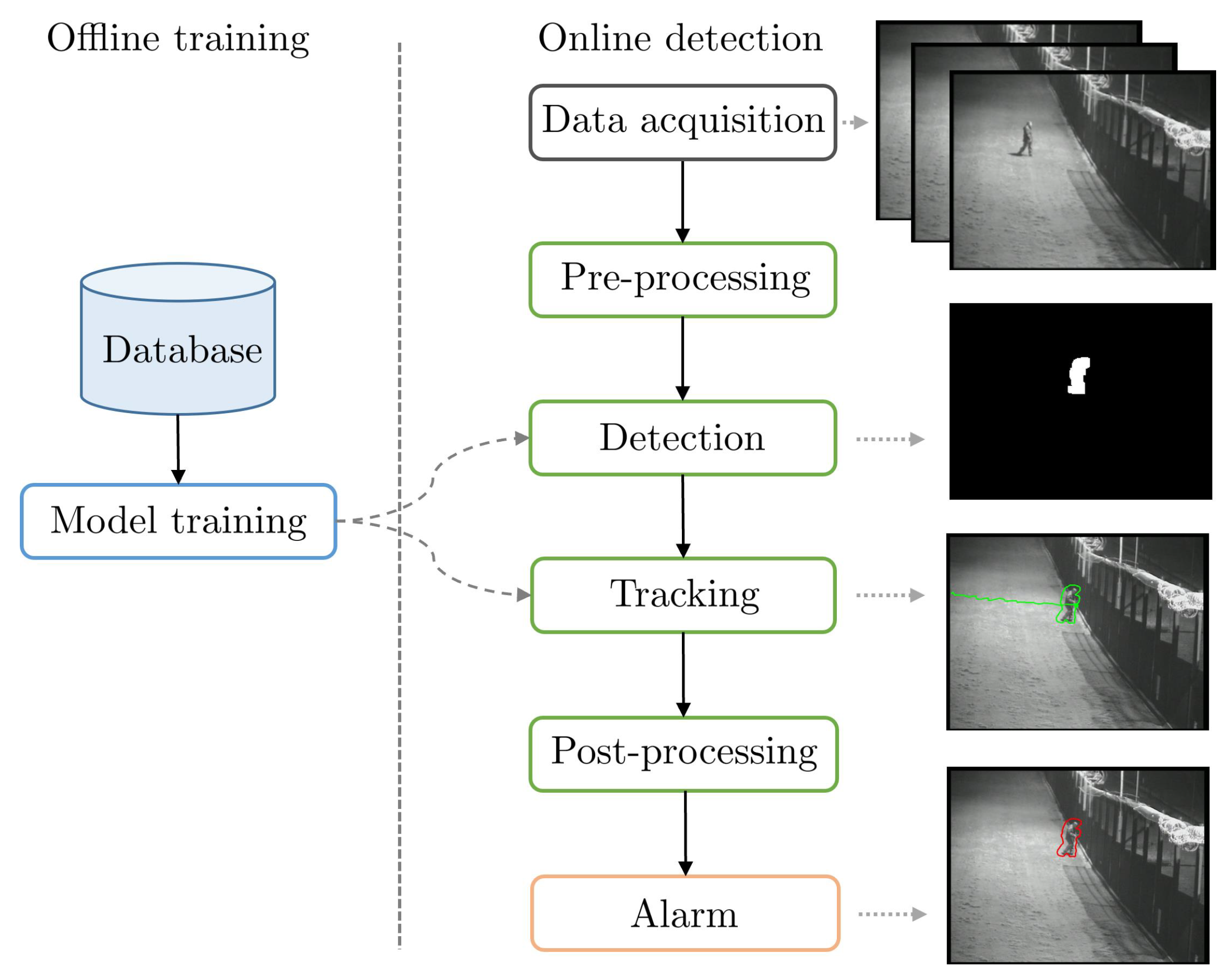
3. PID Methods
Figure 3 shows the typical PIDS pipeline with various associated tasks. In order to review PID methods, we must review methods that tackled one or several of these tasks with the aim to improve the PIDS pipeline, as only a few methods tackle the complete PID task.
3.1. Pre-Processing
Low quality sensors and adverse environmental conditions such as snow, fog, rain, extreme sunshine, etc., may produce highly noisy video streams. We cannot directly feed this noisy data into the detection algorithm. Therefore, video enhancement is needed to remove noise and improve the visual appearance of the video.
The existing video enhancement methods can be classified into two broad categories [
50,
51]: spatial domain enhancement and transform domain enhancement. Spatial domain video enhancement deals directly with pixels, i.e., it makes a direct manipulation of pixels in video frames. It is conceptually simple and has a low time complexity, which favors real-time implementation but lacks robustness. Some surveys on this method can be found in [
52,
53,
54]. In most PIDS, some standard spatial enhancement is carried out on raw frames [
6,
25,
41], such as image resizing, image normalization, mean centering, colorspace conversion (RGB to grayscale or vice versa), histogram equalization, etc.
Transform domain video enhancement operates on the transform coefficients of the video frame, such as Fourier transform, discrete wavelet transform and discrete cosine transform [
54,
55]. The video quality is enhanced by manipulating the transform coefficients. This category of methods has a low computational complexity with ease of manipulating the frequency composition of the video frame. Some major examples of PIDS using these techniques are [
25,
41], using fast Fourier transform (FFT) on video frame patches and decreasing noise by removing very low or high frequencies from FFT.
Apart from video enhancement, some other pre-processing can be conducted depending on the PIDS. In [
25], patches of 16-pixel squares in each video frame are defined and two regions (grass and fence area) are further designated for segregating the scene into an authorized/unauthorized zone. Another common pre-processing is to have a fixed spatial perimeter in each frame of the video [
6,
22,
24,
47]. This helps the PIDS to focus only on this region of the scene and to ignore activities outside this perimeter.
3.2. Detection
This is an important step of the pipeline as the goal of PIDS is to detect certain categories of objects that might cause an intrusion. There are two main families of detection in video: (i) detection of blobs, analyzing the pixel motion, and (ii) detection of objects, analyzing the image appearance with the localization and classification of objects.
3.2.1. Motion Detection
The act of intrusion is caused by a moving object in a protected perimeter during an unauthorized time. Therefore, motion detection is essential in a PIDS. The main approaches can be classified into three categories.
Optical Flow
The notion of optical flow literally refers to the displacements of intensity patterns. It is an approximation of image motion defined as the projection of velocities of 3D surface points onto the imaging plane of a visual sensor [
56]. Optical-flow-based methods use partial derivatives with respect to the spatial and temporal coordinates to calculate the motion between video frames. However, most optical flow methods are computationally complex, very sensitive to noise and tough to implement in real-time settings. Some surveys on optical flow approaches are [
56,
57].
Temporal Differencing
Temporal differencing uses pixel-wise differences among consecutive video frames to extract moving regions. It is adaptive to dynamic environments and has a low computational complexity. However, it can fail to extract all of the relevant pixels and can leave holes in regions. Some important studies can be found in [
2,
24,
58,
59]. The studies in [
25,
41] use simple inter-frame differencing followed by some morphological operations for motion detection in their PIDS.
Background Subtraction
Background subtraction is one of the key techniques for detecting moving objects in video. It detects moving regions by taking the difference between the current frame and the reference frame, often referred to as the ‘background model’. The detection ability depends on the adaptiveness of the background model. Some popular background subtraction methods are: running Gaussian average (RGA) [
60], Gaussian mixture model (GMM) [
61], kernel density estimator (KDE) [
62] and visual background extractor (ViBe) [
63]. Background subtraction mainly suffers from illumination changes, a dynamic background, shadows, camouflage, video noise, etc. [
40]. These effects can present a background object as a false foreground moving object or vice-versa. Most comprehensive surveys on background subtraction-based methods are [
19,
33,
40].
Concerning PIDS, Refs. [
25,
41] use Gaussian background modeling to discriminate people (intruder) from background. The study in [
4] uses background subtraction to extract object blobs from the video frame, which are later used for tracking. The study in [
22] detects moving objects by comparing a background model with an input video frame in real-time. The study in [
24] detects objects using the RGA method.
3.2.2. Object Detection
Object detection, i.e., object localization and classification, has been a field of intensive research, and intrusion detection is closely related to it. In fact, intruders belong to certain categories of objects, such as people, car, bike, etc., to be detected in a protected area. Even though intrusion can be caused by vehicles, animals, etc., the state of art mostly focuses on detecting people. Object detection methods can be categorized into traditional and deep-learning-based detectors [
20]. Some traditional object detectors are the Viola–Jones detector [
64], histograms of oriented gradients (HOG) detector [
65] and deformable part-based model (DPM) [
66]. With the advent of deep learning, we have achieved an excellent performance in object detection with methods such as Faster R-CNN [
67] and YOLO [
68]. Still human detection can be challenging, especially in scenes with an atypical human pose, such as crawling/creeping, occluded scenes [
69] and scenes with low luminosity, such as during night. The study in [
70] addresses the problem of detecting humans at night using a consistency–constancy bi-knowledge learning network that exploits the cross-time (day and night) scene consistency and cross-frame background constancy. In [
22], a 2D CNN-based supervised classifier for human intruder detection is used. Similarly, Ref. [
47] uses a pre-trained YOLO v2 network for intruder object detection.
3.3. Tracking
Tracking objects can be useful for a PIDS. Perimeter protection solutions may use this information to impose detection constraints. For example, leaving an area can be allowed, but not entering it. We can also think of raising an intrusion alarm only if an object is inside the area for a specified amount of time. Furthermore, an efficient tracking module can help a PIDS to not lose an object and re-initialize its timer.
A Kalman filter is applied on the texture of objects with a motion mask to build object tracks [
41]. Particle filters can be used too to track intruders [
22,
24]. In [
25], an intruder is tracked by logging positions of foreground objects over time. The study in [
48] proposes a tracking algorithm based on tracklet clustering. Finally, [
47] uses the simple on-line and real-time tracking (SORT) algorithm [
71] for intruder tracking.
3.4. Joint Detection and Tracking
Since a video has two components, spatial and temporal, it is usually analyzed in two steps. The first step captures spatial patterns by using detection on each frame (see
Section 3.2), whereas the second step uses tracking to apprehend temporal coherence (see
Section 3.3). This approach creates the hypothesis that spatial and temporal dimensions are independent and can be processed sequentially.
Recent approaches jointly model spatial and temporal dimensions using 3D convolutions and improve results in video analysis [
72,
73]. Applied to PIDS, an implicit joint detection and tracking is performed by a 3D convolutional autoencoder in [
6], trained in an unsupervised way.
3.5. Post-Processing
Missing intrusions in the site are considered a major failure for a PIDS; therefore, methods try to detect as much as possible, even at the cost of some false alarms [
24]. These false alarms need to be filtered, which is why we might need some sort of post-processing. Even though this step is crucial in a PIDS, there are few publications on this topic because manufacturers prefer to keep their post-processing confidential. However, despite this, we can list several post-processing techniques.
Filtering objects of interest outside the chosen perimeter is the most common post-processing and is used in major PIDSs [
22,
24,
47]. Sometimes, blobs are inconsistent across time, such as rain drops, and a filter can check the coherence of the blob trajectory. Detected objects can also be filtered with a minimum threshold on the blob size. For example, Ref. [
24] filters all of the objects with a size less than four pixels. Since foreground objects are bigger than background ones, perspective calibration learns the dimension of object of interest as a function of its position in the scene. This allows us to filter objects with a size smaller than the expected size of the object of interest at the same position in the scene [
74,
75].
3.6. Alarm
To transform detected and tracked objects into alarms, PIDSs apply some sensibility thresholds to set the omissions–false alarms trade-off [
4,
22,
41,
47]. These thresholds are usually manually tuned during the actual deployment of the PIDS.
Moreover, some high-level rules can be applied to trigger the alarm. In [
25], the alarm is triggered if the intruder shows movement towards the target for a minimum time of 2 s. In [
22,
47], alarms are generated as long as the intruder is inside the protection boundary, while [
24] adds an extra constraint, where it must be tracked for at least three frames.
Interestingly, some publications evaluate PIDS in a pure machine learning approach, using metrics that integrate performances for all possible threshold values [
6,
7]. However, they do not describe a strategy to choose the thresholds, making it difficult to use them in practical cases.
3.7. System Deployment
The actual deployment of the system is realized in three stages: an optional offline model training, then an online initialization of the system, and, finally, online execution.
3.7.1. Model Training
Some PIDSs require offline training on part of the dataset for their detection or tracking steps [
6,
22,
47]. This training can be supervised, requiring labeled videos (tagging intrusion frames or events); or, it can be unsupervised, under the assumption that there are no annotated data in the dataset. In [
4], a classifier model is trained as a multiple instance learning problem by employing image-based features to distinguish intruder objects from moving vegetation and other distractions. The studies in [
22,
47] use supervised object detectors for intruder detection. The study in [
6] learns an unsupervised deep autoencoder on training videos having no intrusions in order to detect intrusions in testing videos.
3.7.2. System Initialization
During real-life deployment, most of the PIDS must be initialized for several seconds in order to set the system’s internal state of the system aligned with the new scene in order to protect [
24,
25]; for example, the mean and standard deviation of a GMM. This online initialization must not be confused with the offline model training. Moreover, a PIDS can have sensibility thresholds, which are manually tuned by the installer during the deployment.
3.7.3. System Execution
The last stage is the online execution of the PIDS. It includes all of the steps of the pipeline as illustrated in the right part of
Figure 3. To provide a reliable protection, most of the PIDSs work between 5 and 25 FPS [
6,
24,
25].
Table 2 summarizes major PIDSs with various methods used in different steps of the pipeline and the availability of the source code. We can observe that most systems use the visual camera for data acquisition. Only one system uses the thermal camera and just one system is multi-camera-based. Background modeling is used in most traditional systems for detection, whereas deep-learning-based models use 2DCNN, a YOLO detector and autoencoders. Regarding tracking, the Kalman filter, particle filter, tracklet-based tracking and SORT are used. For alarms, most systems have their own rules depending on the method. Three systems use supervised training, one system uses unsupervised training and the rest do not include a training step.
4. Definition of PID Task for Video Surveillance
The task of perimeter intrusion detection (PID) has been defined in various ways in the state-of-the-art. In [
4], it is defined as a monitoring system that identifies the presence of humans or devices in a pre-defined field-of-view. In [
22], the PIDS is defined as a system that detects physical intrusions on a site having a protective barrier to isolate it from outside. In [
23], it is described as a system that detects the movements of intruders attempting to breach a security wall or region and alert security. However, all of these definitions lack clarity and formalization; for example, the following questions need to be addressed: “what are intruders?”, “does moving intruder cause intrusion?” and “is a protective area necessary?”. To answer all of these questions, we mathematically define a PIDS. Before defining a PIDS, we must define what an intrusion is.
4.1. Intrusion in the Video
To properly define an intrusion, we need to define an object in the video.
4.1.1. Object in the Video
We define a video
acquired for
T frames during the interval
as:
where
denotes the frame at the time instant
t, with height
H, width
W and number of channels
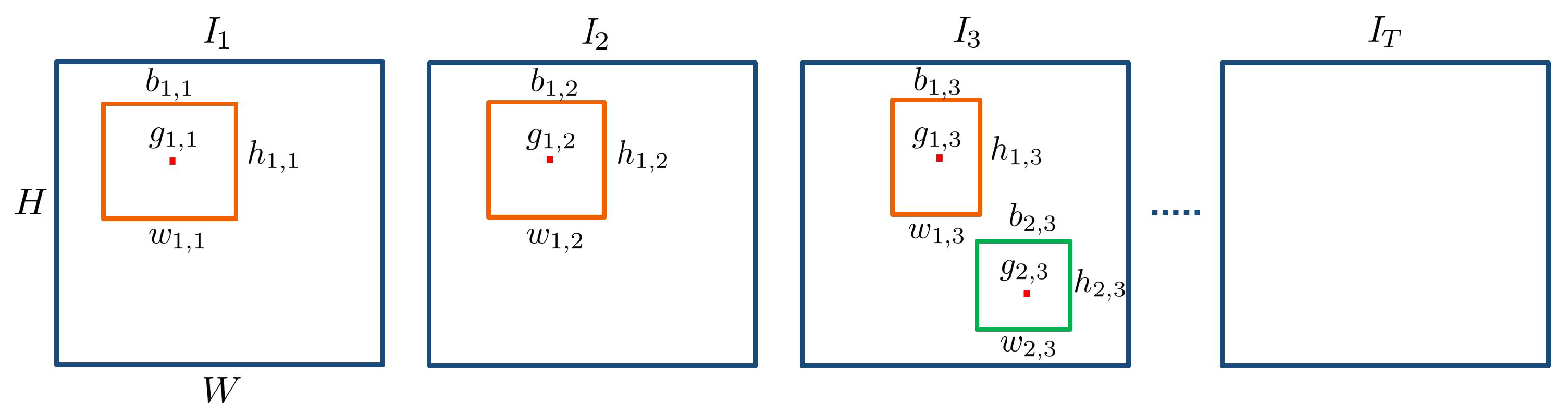
D. To define an object in the video, we must first specify the object definition at frame-level. An object in a frame or image is defined with a spatial specification and a class that distinguishes one family of objects from another (such as humans, animals or cars). The spatial specification can be either on pixel-level by allocating each pixel to an object or background, or on area-level by encapsulating the object in a bounding box. We choose the bounding box as it has been used in the literature extensively [
20]. It should be noted that the choice of spatial specification cannot have an impact on the intrusion definition. Thus, we define an object at frame-level with a class and a bounding box. To define an object in the video, we take into account all of the frames where it is present. Therefore, an object
in the video is defined as:
where
is the class of the object from the set of object classes
, and
is its bounding box at time instant
t, which is defined as:
where
,
and
are the center, width and height of the bounding box, respectively. The center is defined by its coordinates as
. Note that, instead of the bounding box center, it is possible to choose other points, such as the bounding box bottom, as reference. We illustrate these definitions in
Figure 4.
4.1.2. Intrusion Event and Intrusion Interval
For the protection of a site, the user must define parameters that qualify objects as non-authorized (na), i.e., intruders.
: the subset of the frame/image, defining the surface to protect.
: the time interval during which the surface must be protected (e.g., protection during night).
: the set of non-authorized classes, such as person, car, truck, etc. These classes of objects are considered as possible intruders and can be different according to site and client demands.
Since is a non-finite set (it is impossible to make the exhaustive list of non-authorized objects, exposing the system to omissions), it is easier to ask the user to explicitly define the short list of authorized objects (such as small animals), which leads to .
An object causes an intrusion event if it belongs to a non-authorized class and is moving in a protected area during a prohibited time interval. We define the intrusion event caused by an object
as:
where
is the gradient of object
at instant
t and it being non-zero signifies that the object is in motion. Thus, the intrusion event caused by object
is a collection of all of the frames
such that
, object class
, the gradient is non-zero and the bounding box center lies in the protected area.
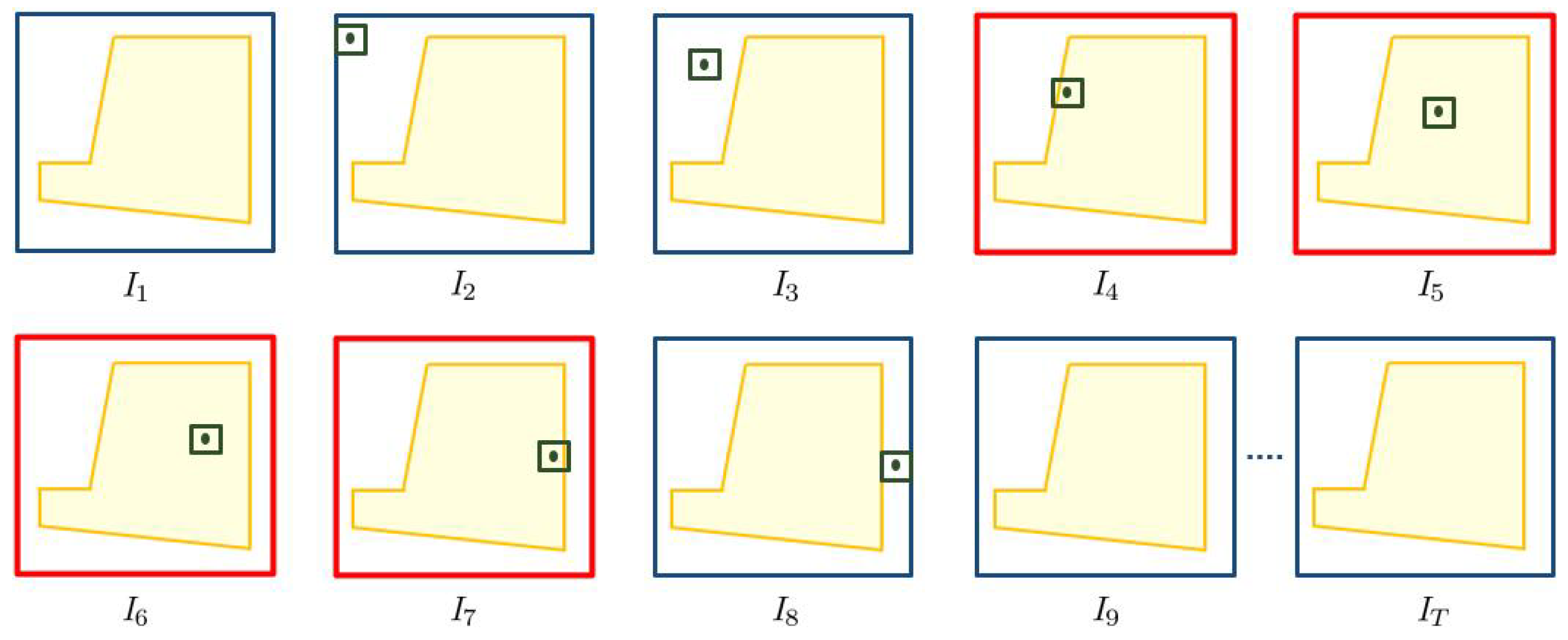
Figure 5 illustrates the intrusion event caused by an object. The surface to protect
is depicted with a pink trapezoid in each frame, and we assume that we want to protect during the entire video. One object is present in the video and it is shown with a rectangular bounding box plus a center. The object is in motion from the second frame to the eighth frame. While in motion, the object’s center lies in
from the fourth frame until the seventh frame, causing an intrusion event. Thus, this object triggers an intrusion event for four frames.
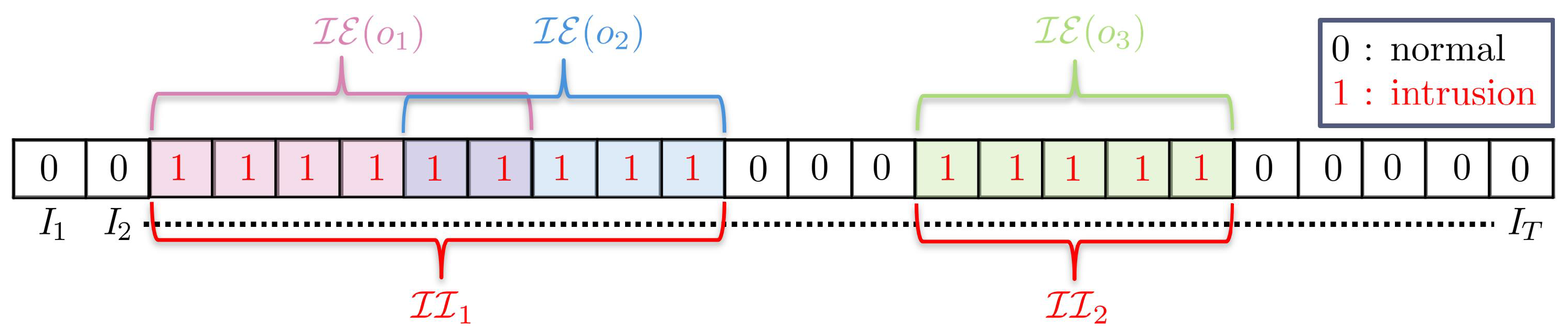
Since a video can have more than one object causing intrusion events, we define the intrusion event of the whole video containing
j objects as:
Figure 6 shows three intrusion events caused by three objects in the video. We can observe that intrusion events of object 1 and 2 overlap for two frames, meaning that, for those two frames, there were two objects causing intrusion events simultaneously. The intrusion event of this video is a collection of all of the intrusion frames, marked by 1 in the figure. In the context of video surveillance, we are concerned with whether there is an intrusion event or not, regardless of whether one object or many objects are causing it. Therefore, we are interested in an interval of a contiguous sequence of intrusion frames. We term this as an intrusion interval, and the task of intrusion detection is focused on detecting them. Formally, an intrusion interval
is defined on a closed interval as:
where
and
denote the first and last frames of an intrusion interval. In other words, an intrusion interval is a contiguous sequence of frames of maximal size derived from
.
Figure 6 depicts two intrusion intervals of the video.
4.2. PIDS
Given a precise definition of intrusion, we can now define a perimeter intrusion detection system (PIDS). Given a video
and intrusion parameters
, the prediction of a PIDS can be defined as:
where
is a binary prediction for each frame
t of video
for time
, with 1 denoting a frame predicted as an intrusion, and 0 otherwise. Therefore, a PIDS classifies each frame into an intrusion frame or otherwise. This type of output is useful when we want to evaluate a PIDS at frame-level [
6]. In a real-life surveillance system, the system sends an alarm signal to surveillance personnel as soon as there is a transition from a normal to intrusion state [
26]. The output of the PIDS can be derived from
as follows:
This is a set of intrusion alarms created by the system, marked by the rising edge, i.e., the transition of the system state from non-alarm to alarm. These alarms alert the surveillance personnel about a suspicious activity. For each alarm, a mini-clip is sent containing some frames before the alarm and some frames after the alarm. The surveillance personnel visually analyze this mini-clip and decide whether it is an actual intrusion activity or a false alarm. Therefore, we need an evaluation scheme that takes into account this real-life scenario.
5. Evaluation Protocols
Given a video or set of videos, the PIDS detects intrusions. To evaluate the performance, we need to compare the PIDS output with ground truth annotations. The manner in which this evaluation is carried out impacts the final score metric. The following subsections present different evaluation protocols.
5.1. Frame-Level Evaluation
As the name suggests, in this type of evaluation, we are interested in checking whether each frame of the video is correctly classified as intrusion/normal or not. For a video
and given intrusion parameters (
), the frame-level ground truth is defined as:
where
is the ground truth label for each frame
t of the video
at time
; value 1 denotes an intrusion class, and 0 otherwise.
Given ground truth
and prediction
(see Equation (
5)), the frame-level intrusion evaluation is simply the binary classification evaluation of each frame of the video [
76]. We can calculate elements of the confusion matrix, i.e., the true positive (TP), false negative (FN), false positive (FP) and true negative (TN), with intrusion as the objective class [
6]. We can then evaluate the performance of the PIDS depending on the choice of metric, such as the precision, recall,
score, etc., as defined in
Section 5.4.
In this type of evaluation, each frame contributes equally to the overall score. Thus, it can provide the same overall score for an algorithm that gives us multiple omissions of intrusion events versus an algorithm that gives us an omission of some intrusion frames in multiple intrusion events. This is an undesirable evaluation in the case of intrusion detection because we cannot afford to have omissions of intrusion events. In reality, we are more interested in knowing if the system is able to classify the intrusion events correctly as a whole. This demands an event-level evaluation. In other words, we want to detect all intrusion intervals (s) from the video. More specifically, we are interested in evaluating whether the beginning of these intrusion intervals are detected correctly. This is because, if an intrusion event is detected too late, then that detection is not very useful. The idea is to detect each intrusion interval as soon as it occurs and, thus, we need an evaluation scheme that takes this into account.
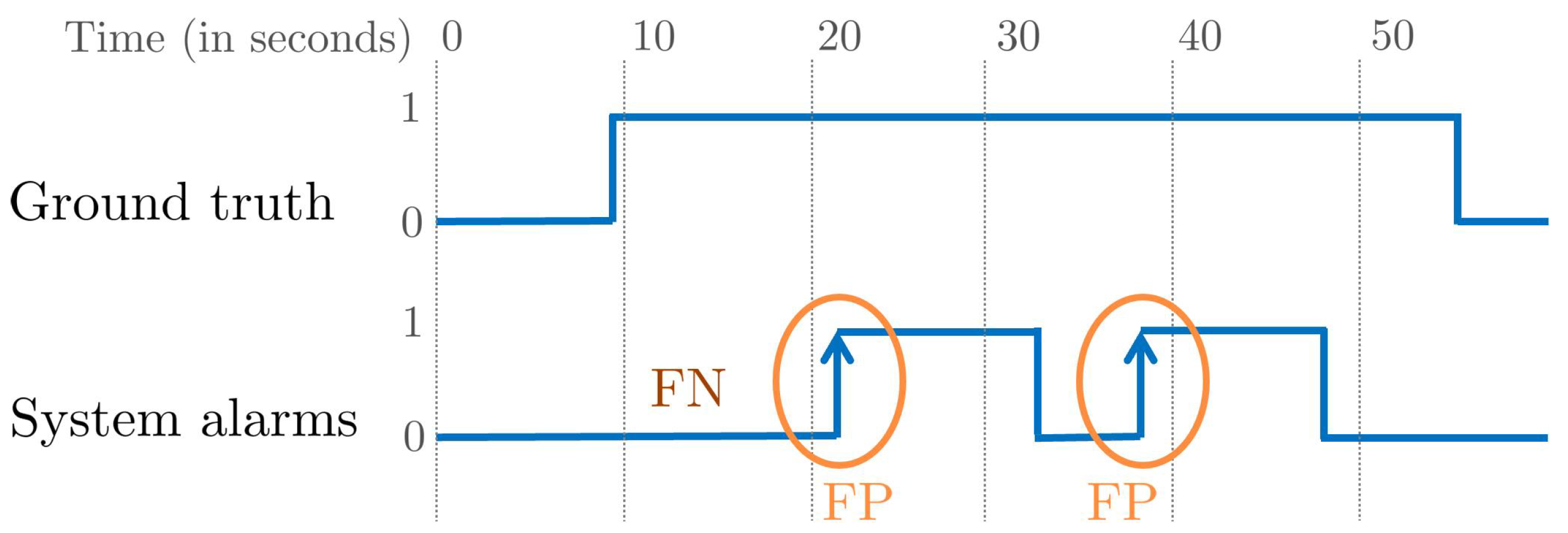
5.2. i-LIDS Evaluation
For evaluating on the i-LIDS dataset, their user guide provides an evaluation procedure [
26]. It focus on evaluating intrusion at event-level rather than frame-level. To be precise, an intrusion is considered correctly detected if there is at least one system alarm within 10 s from the start of the intrusion event. For an
of the video and alarms
, the rules of the i-LIDS evaluation protocol are as follows:
- 1.
TP: if there is at least one alarm within 10 s from the beginning of the . If there are multiple alarms candidates, the first one is taken and the rest are ignored.
- 2.
FN: if there is no alarm within 10 s from the beginning of the .
- 3.
FP: if there is an alarm but not within 10 s from the beginning of the . If there are consecutive FPs within a 5-s gap among them, only the first one is considered and the rest are ignored.
Apart from these, one rule is i-LIDS-dataset-specific: all
s and alarms that start within 5 min from the beginning of the video are ignored. This means that they wanted to give a preparation time to the system. This evaluation scheme is not generic and has several drawbacks, as illustrated in
Figure 7. It penalizes an alarm as an FP after 10 s from the beginning of an
without taking into account the duration of intrusion. If the
has a long duration (such as an hour) and we have an alarm at the 11th second, it is not ideal to mark it as an FP. From a practical point of view, the surveillance personnel will receive a mini-clip as soon as the alarm is triggered and, if the intrusion is present, then it is not sensible to mark this as an FP. Instead, this alarm should be ignored as it is not detected within 10 s. Similarly, each alarm after 10 s but within
is considered as an FP, and this strongly penalizes the system precision. Instead, these extra alarms should be counted without assigning them as an FP.
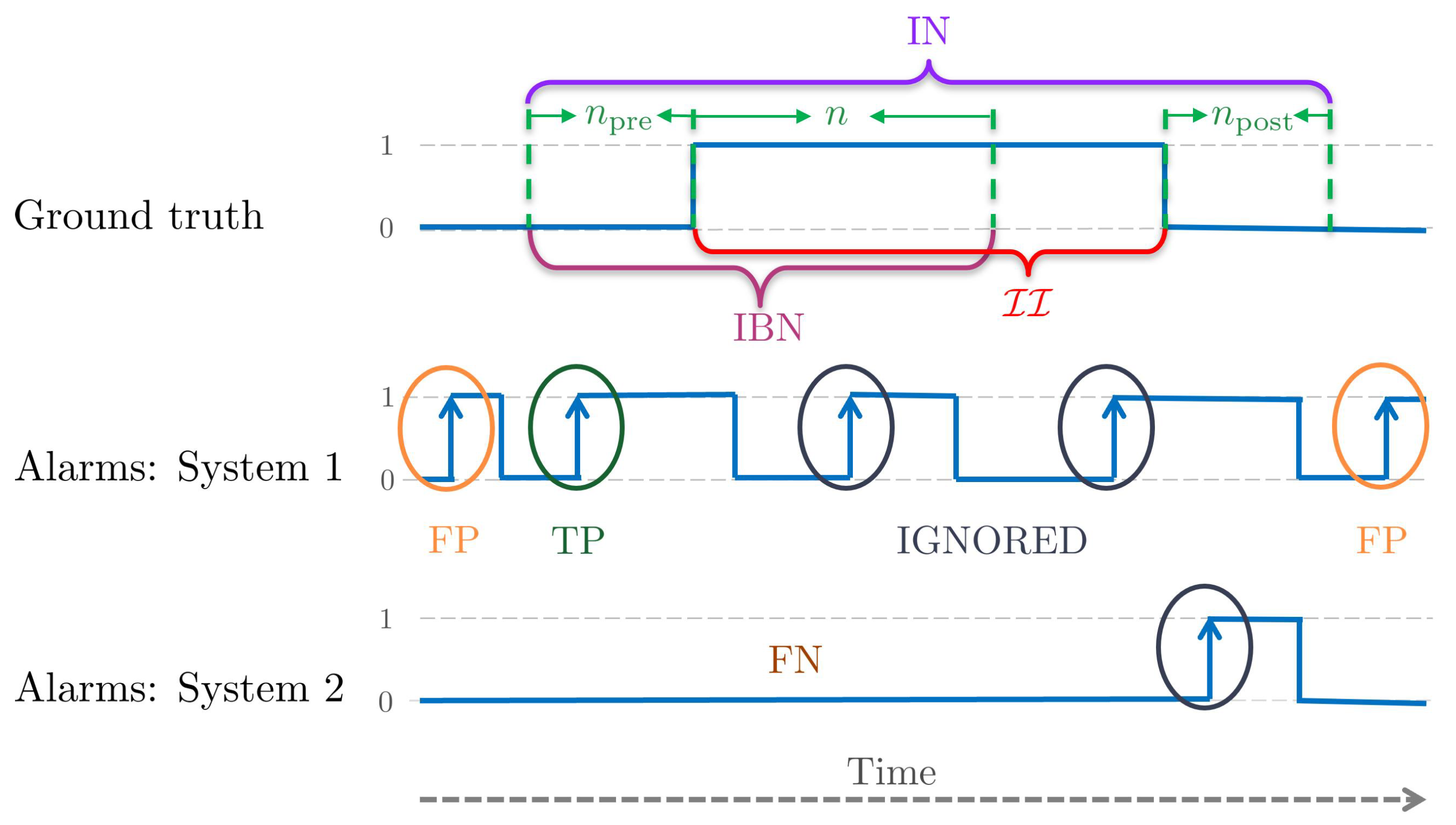
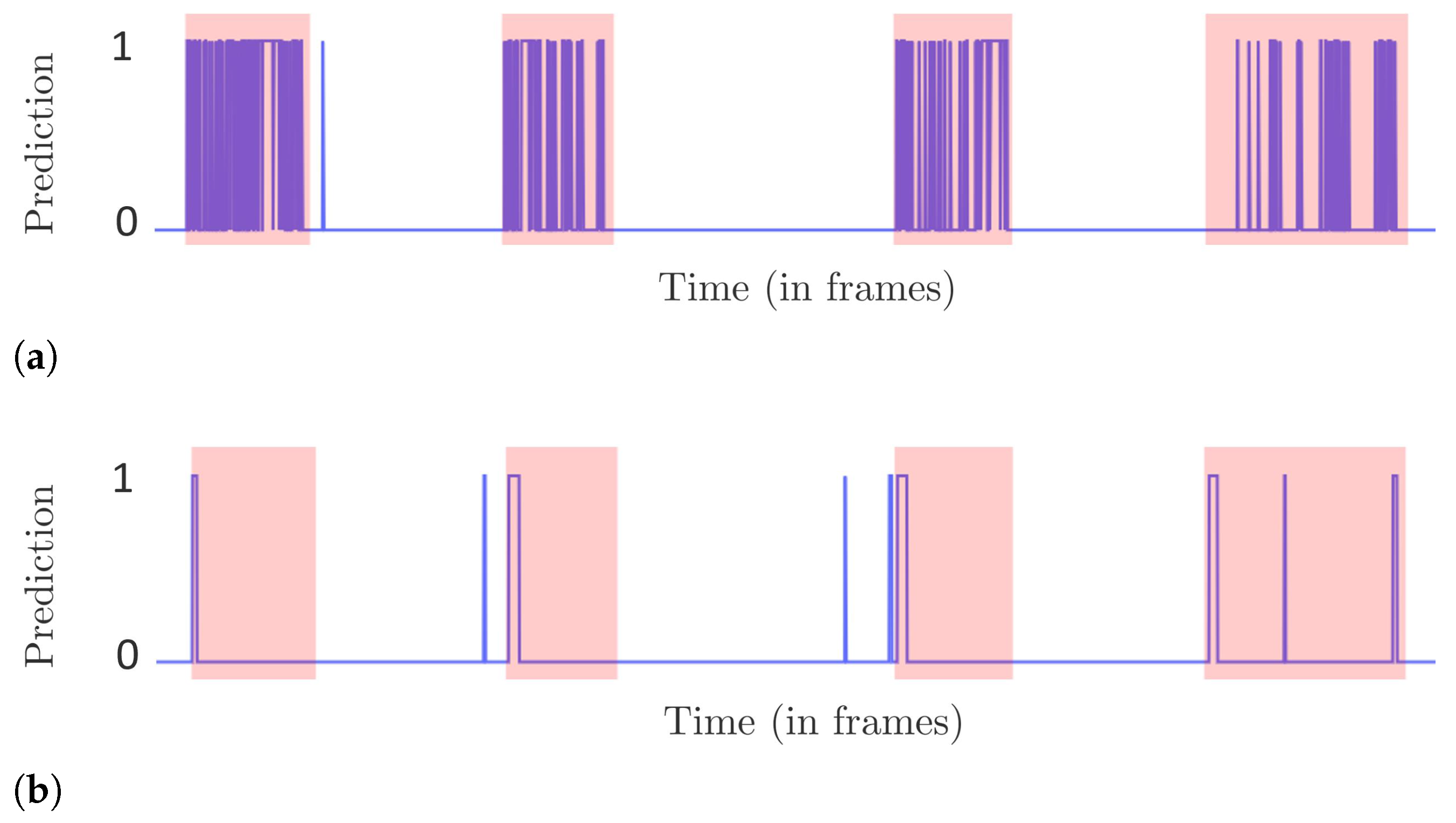
5.3. Edge-Level Evaluation
To appropriately evaluate a PIDS while considering the real-world aspects, we propose a new evaluation protocol. An intrusion event begins with a transition from a non-intrusion to intrusion state, i.e., we have a rising edge as shown in
Figure 8. Similarly, an intrusion event stops by a reverse transition, i.e., a falling edge. We are interested in detecting intrusion within a few frames from the rising edge. Since we focus on this rising edge, we call this the edge-level evaluation. In other words, we emphasize detecting the beginning of intrusion intervals. We first define the following terms from an intrusion interval of the video (see
Figure 8).
The intrusion interval neighborhood IN is an expanded interval defined by
frames before and
frames after the
:
These and frames are in the range of one to five (less than 1/5 s for a video at 25 FPS) and are added in order to take into account the error of annotation. This error is due to the fact that it is difficult to mark the exact frame at which the intrusion starts or ends. This tolerance further permits not strictly penalizing the system when an intrusion event is detected a few frames before the actual event or when the system detects a few more intrusion frames after the actual event is finished. These cases arise often when the intrusion object is in the scene but not inside the surface to protect. Therefore, IN is an interval where the actual intrusion activity takes place, and an alarm given by a PIDS in this interval can be counted as either TP or ignored. An alarm given outside IN must be a false alarm and should be counted as an FP.
The intrusion beginning neighborhood IBN is an interval comprising
frames before and
n frames from the beginning of
:
This interval signifies the importance of the initial frames of an , where an intruder has just entered the protected area, and it is in this interval where we ideally want the PIDS to raise an alarm. An alarm raised in IBN must be a TP.
For an
and alarms
, the possible outcomes at edge-level are defined as (see
Figure 8):
- 1.
TP: if there is at least one alarm in IBN. For multiple alarms in IBN, only the first one is considered, and the rest are ignored.
- 2.
FN: if there is no alarm in IBN.
- 3.
FP: if an alarm is outside IN. Each alarm outside of IN is counted as an FP.
In this evaluation scheme, alarms lying outside IBN but inside IN are ignored. This means that we neither adversely penalize these alarms as an FP nor count them as a TP. In event-level evaluation, whether i-LIDS or this scheme, we do not define a true negative (TN). A TN is when a normal (non-intrusion) event is detected as such; in other words, how well we are classifying a normal event as normal. However, this is not the aim of intrusion detection; indeed, it is the opposite. Furthermore, the calculation of TN is ambiguous. We cannot generalize what length of the non-intrusion video should be considered as a TN. For example, a non-intrusion video clip of 5 min cannot be considered as similar to a non-intrusion video clip of 5 days.
These rules are for individual
s, but how we deal with scenarios where the intrusion neighborhoods are so close that they intersect one another is another matter. If INs of two or more
intersect one another, then we merge them into a single IN. The new IN consists of
frames of the first
and
frames of the last
, and all of the frames in between are merged as an
. Algorithm 1 summarizes the protocol to evaluate a video at edge-level.
| Algorithm 1: Edge-Level Evaluation of a PIDS |
|
1 Initialize variables n, and .
|
| 2 Calculate IN for all s of the video.
|
| 3 If two or more INs intersect, merge them into a single expanded IN.
|
| 4 Calculate intrusion beginning neighbourhood IBN for each .
|
| 5 Obtain alarms from the PIDS.
|
| 6 Calculate TP, FN and FP.
|
| 7 Calculate precision, recall and other metrics.
|
5.4. Metrics
Since a PIDS has a binary classification task to classify a frame or event as an intrusion (positive) or not (negative), we can naturally apply common metrics. The following metrics are primarily suitable for a PIDS and have been widely used in the literature.
5.4.1. Precision and Recall
The precision is the percentage of correctly predicted intrusions out of the total predicted alarms, as defined in the left part of Equation (
6). It is particularly useful when we want to measure how false alarms are affecting the system. A high value of precision denotes that we have very low false alarms. Clients usually demand a certain minimum precision from the system.
The recall is the percentage of correctly predicted intrusions out of the total intrusions, as defined in the right part of Equation (
6). It is useful when the cost of the false negative is high, i.e., when we cannot afford to have an omission of intrusion. Usually, the clients prefer to have the minimum omissions possible. This means that we need to ideally maximize recall.
5.4.2. Score
To take into account both omissions (FN) and false alarms (FP), we need a way to combine precision and recall. The
score combines them with the
parameter as the bias to give more or less importance to recall or precision.
The most common values used for
are 0.5, 1 and 2. With
= 1, we obtain the
score. The
score is the harmonic mean of precision and recall and it is widely used [
4,
48]. The choice of the value of
depends on the client needs. For the i-LIDS dataset, they propose two system roles with different bias values [
26]. The roles are called ‘Operational Alert’ and ‘Event Recording’, with
as 0.81 and 0.87, respectively (In [
26], they use
instead of
. For equivalency,
). The former role is designed for real-time intrusion detection and, therefore, has a lower
value to give more importance to precision, as false alarms are essential here. The latter role is for non-real-time systems, where videos are recorded and analyzed on an offline basis. It has a higher
value, as we cannot afford omissions in this case. Most PID systems [
24,
25,
41] use this
metric for evaluating on the i-LIDS dataset.
5.4.3. Other Metrics
The metrics listed above are threshold-based, i.e., they depend on a single chosen threshold of the classifier. Therefore, systems tend to choose a threshold to maximize the final score, e.g., the study in [
25] chooses a high detection threshold to eliminate false alarms, as the metric used is
with
= 0.81, which favors precision. Thus, the results from these metrics tend to overfit the dataset, the choice of metric hyperparameters such as
, etc.
Alternatively, PIDS can be compared over a range of all possible thresholds, avoiding bias evaluation by the choice of a given threshold. For this, we can either build the receiver operating characteristic (ROC) curve or the precision–recall (PR) curve [
76,
77]. The area under the curve (AUC) of ROC or PR curves gives an overall score between 0 and 1, where 1 is the best possible score. Since intrusions are rare events in videos, it is frequent to have PID datasets with a very low number of abnormal (intrusion) frames compared to the normal (non-intrusion) frames. When classes are highly imbalanced, such as in PID, AUC-PR (AUPR) must be used to compare methods [
6,
77], rather than AUC-ROC (AUROC), which gives inconclusive results. Then, when deploying the PIDS in a real site, the value of the threshold must be defined and the results can be finally reported with precision, recall and
scores.
7. Discussion
It is clear that detecting intrusions should be evaluated at a higher level than frame-level. That is why almost all methods in the state of the art use i-LIDS evaluation [
24,
25,
41]. However, the major problem with this evaluation is that it penalizes all alarms after 10 s, even if they are well within the intrusion interval. It is indeed too strict in counting FPs, and this hits the overall score negatively, regardless of the fact that the system has detected intrusion well within 10 s. To address the issue, we have proposed the edge-level evaluation. Here, we can parameterize the time after intrusion beginning for the evaluation. This helps in testing the system for different practical time settings and testing its robustness. More importantly, the alarms after a specified time are not counted as an FP if they are within the intrusion space. Thanks to this, we can evaluate a PIDS to check whether it has detected intrusions in the first few seconds without penalizing it for extra alarms.
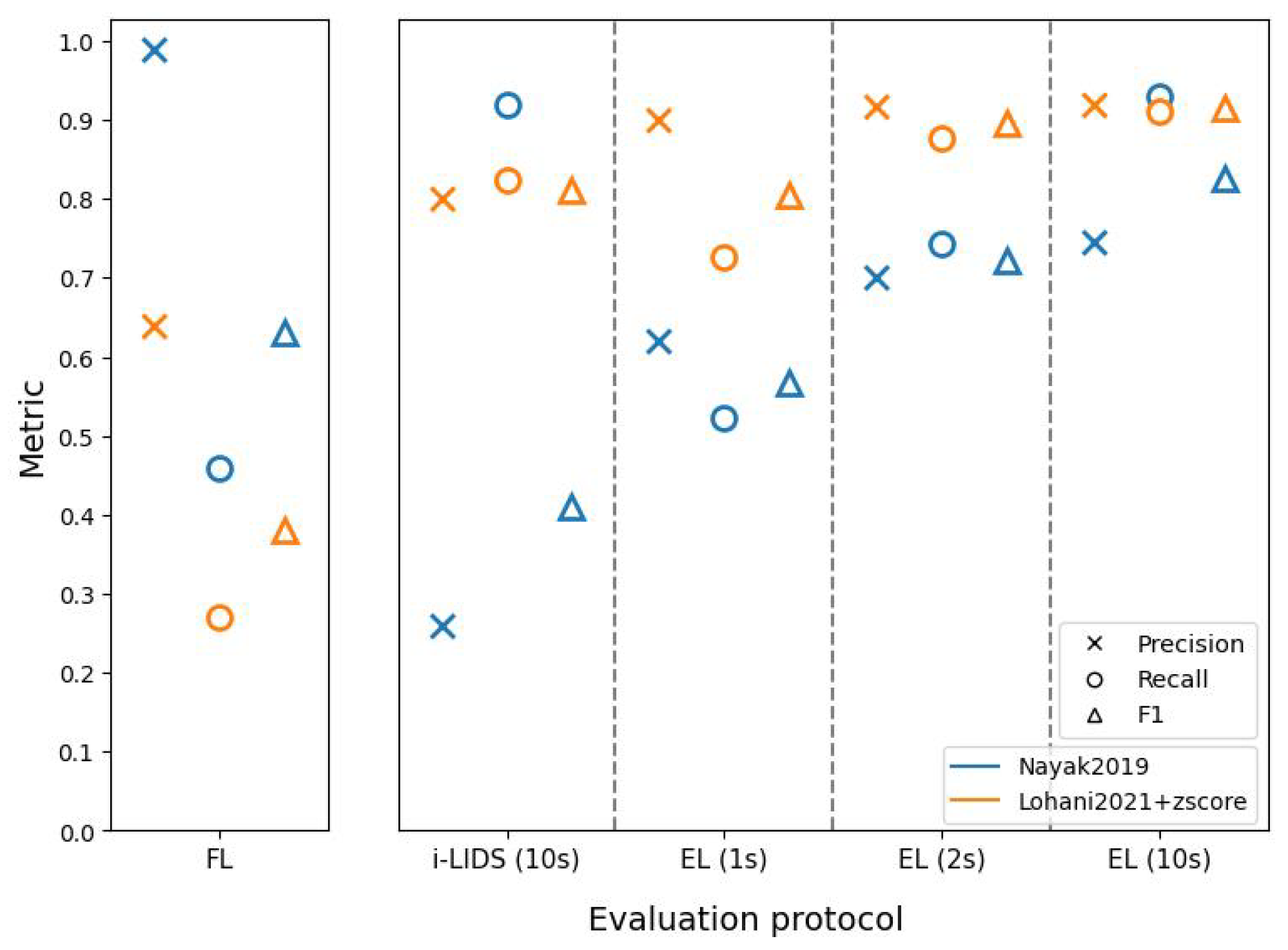
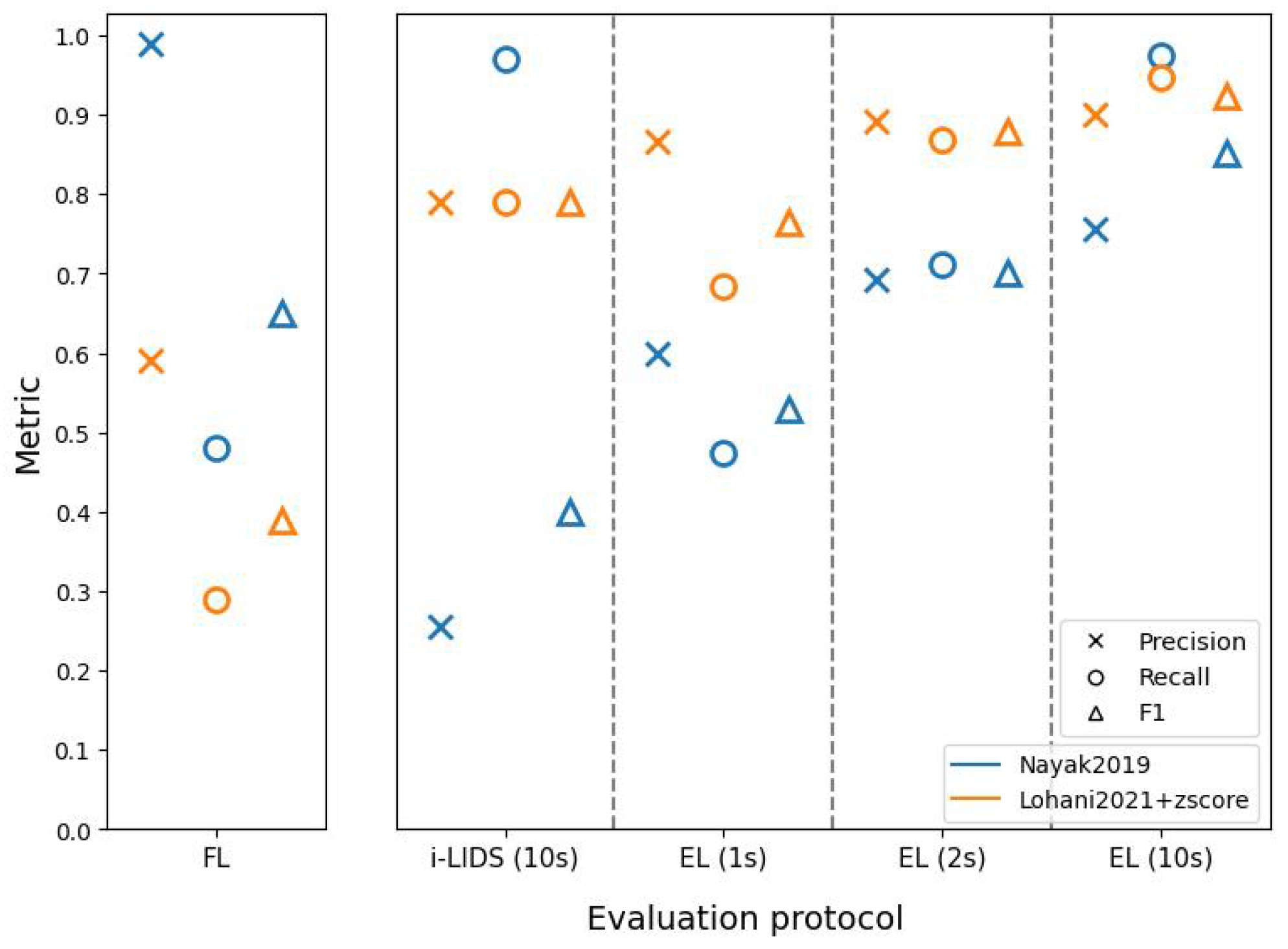
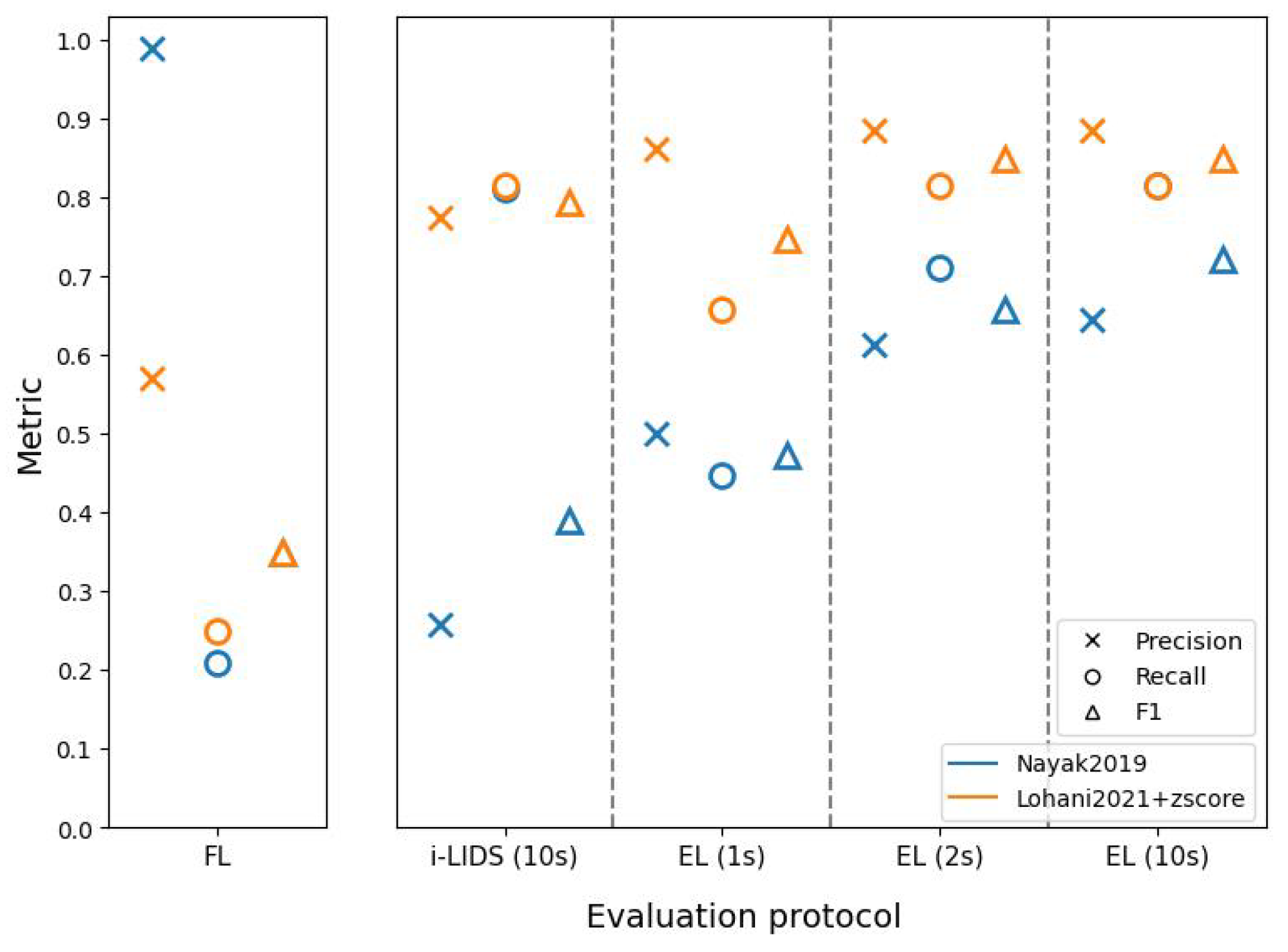
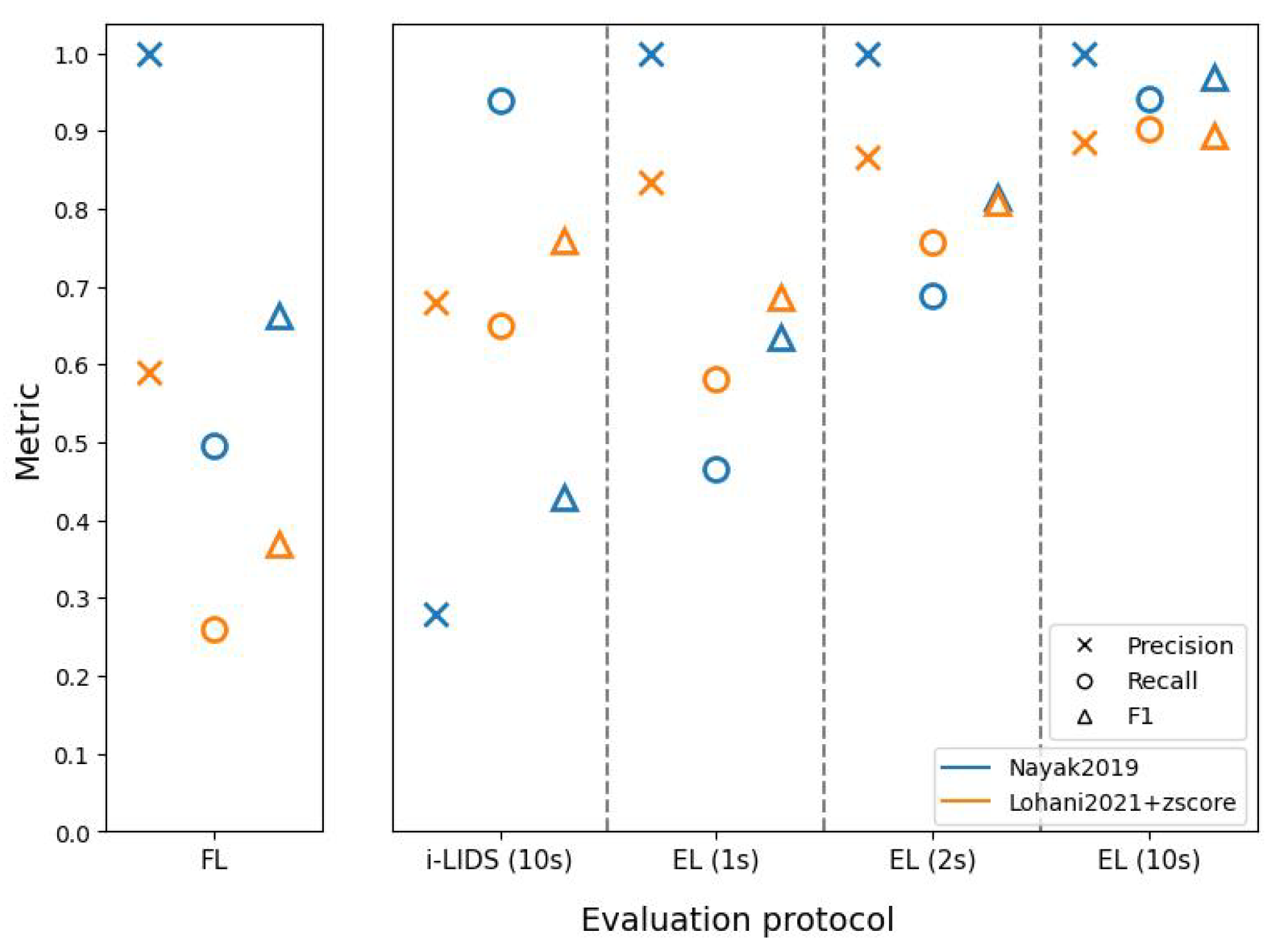
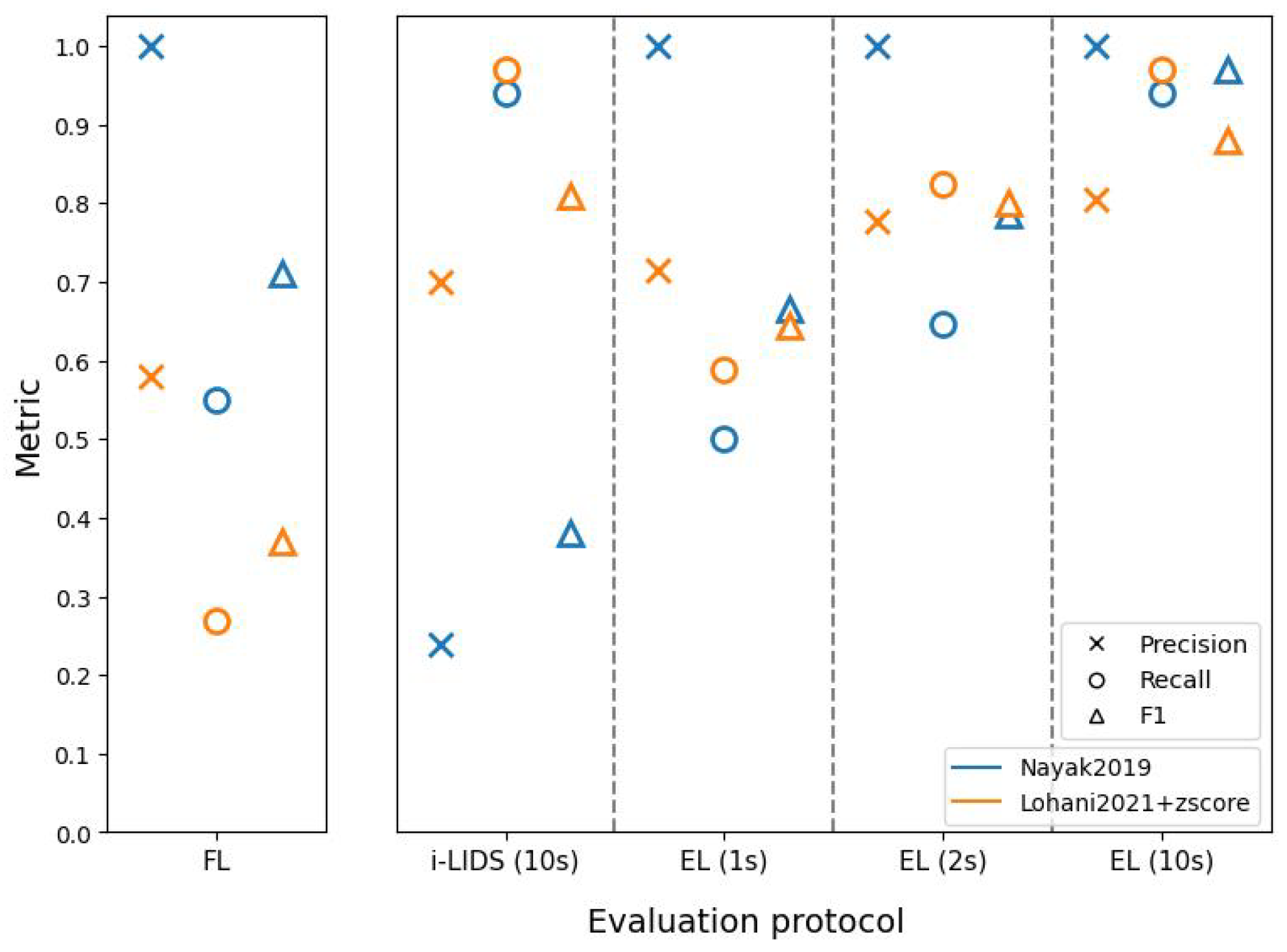
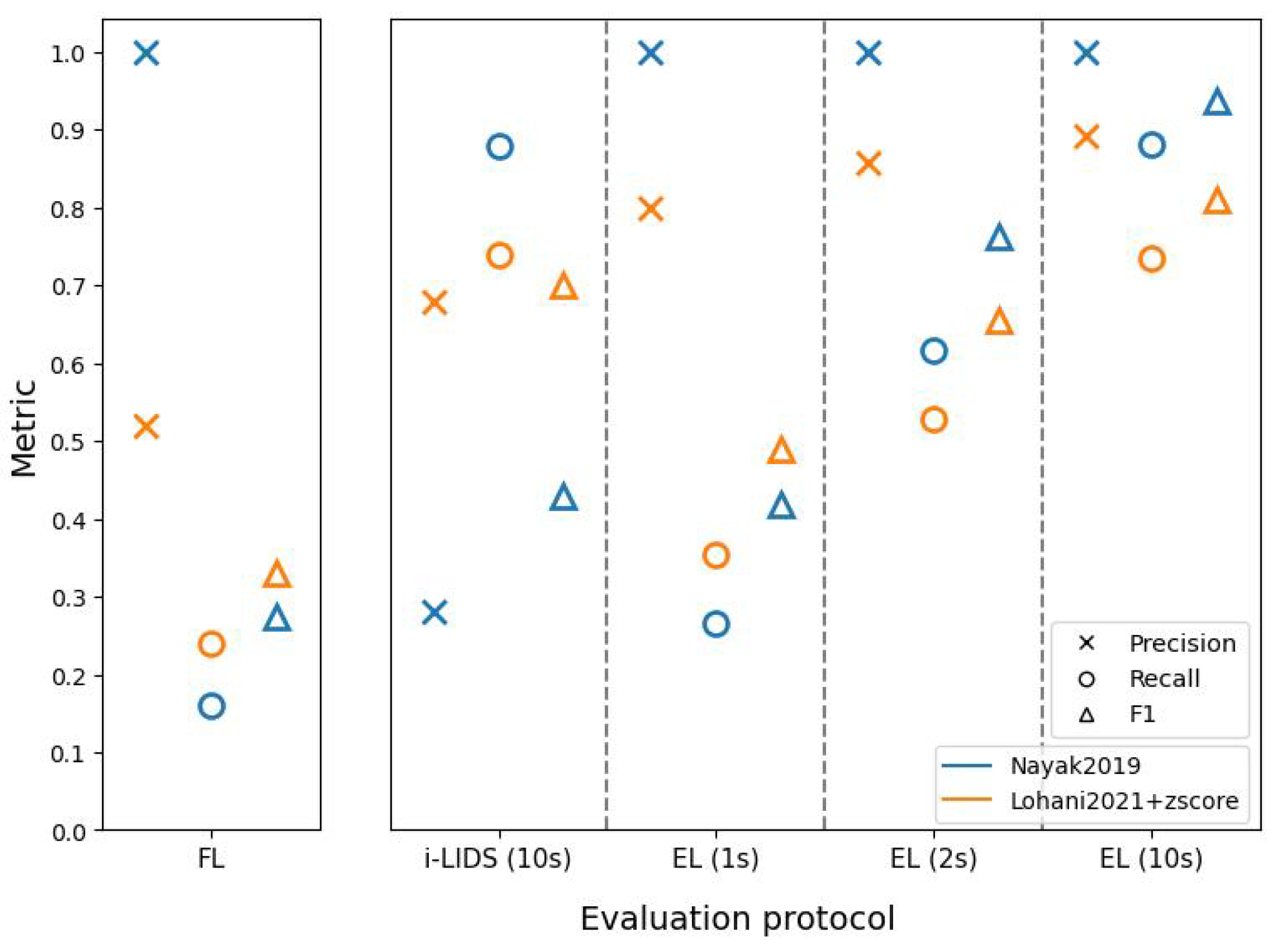
These evaluation protocols further helped in understanding the two PIDSs. The method of Nayak et al. [
47] had better frame-level scores than the method based on Lohani et al. [
6], but this does not necessarily indicate that the former is a better PIDS. As we saw in edge-level scores, the latter method was better at detecting intrusion events and sending alarms quickly. In fact, EL(1 s) and EL(2 s) show that the latter method detected intrusions within 1 and 2 s, with a better performance than the former method. When we compare edge-level evaluation at 10 s with i-LIDS evaluation, we see that the former method has a very poor performance, while it performs similar to latter method at edge-level. This shows that i-LIDS evaluation is not able to capture this gain in performance. This ambiguity in scores shows that it is important to choose the right metric when evaluating a PIDS. The task here focuses on intrusion event and alarms; therefore, we must evaluate systems with a metric suitable for it. The edge-level evaluation should be used for this purpose with 1 or 2 s as time constraints in order to evaluate a PIDS in real-life conditions.
Although we have extensive real-life elements in the i-LIDS dataset, it has some major drawbacks. Firstly, it contains only humans as intruders, and not other objects, such as cars, bikes, trucks, etc. This is crucial because intrusions can also be caused by some other objects that the user has not thought of, as explained in
Section 4.1.2, because
is non-finite. Using a YOLO detector with supervised training on the VOC2012 dataset [
79], the PIDS of Nayak et al. [
47] explicitly defines
as the single class human. Consequently, it gives very few false positives on the i-LIDS dataset, but there is a risk of omissions when this PIDS will protect sites with unexpected intruders, because it has a bias on the target class. On the contrary, the unsupervised PIDS of Lohani et al. [
6] implicitly defines
as all objects contained in the training set without intrusions. This approach seems to be more coherent with the definition of the PID task. The second crucial limitation is that we have only two views with very similar settings. This makes it easy for the algorithms (particularly supervised-learning-based) to learn the scene. A multi-view dataset would have added an additional difficulty in the PID task, allowing us to assess cross-view transfer learning. Therefore, we have a strong requirement of a new challenging dataset in this community, with multiple classes for intruders and several views.
In video surveillance, PID can be performed at different levels depending on the client requirements: on the edge device, on a server situated at the surveyed site or on the cloud. A PID running on the edge requires a computing device powered by a CPU or a GPU [
47,
59]. Most clients prefer the classical server-based analysis [
4,
6,
22,
24,
25,
41,
48]. While these two solutions keep videos locally, the cloud analysis is not a widespread solution for the PID task because it requires a stable and secure network connection to stream videos in real-time, and it is not easy to ensure data privacy [
2]. In our experiments, the methods have been tested on a single-camera dataset at the server. They can be deployed on the edge given appropriate devices, and they can also be scaled with more cameras given necessary computing resources and multi-camera datasets.
8. Conclusions
In this paper, we explored the task of perimeter intrusion detection in video surveillance. We first explained the typical PIDS pipeline and provided a review of major PIDS methods. We found that there are very few PIDSs that perform a full intrusion detection. We then provided a clear mathematical definition of an intrusion in an outdoor perimeter. In relation to the definition of intrusion, we revisited various existing evaluation protocols. We found that no existing evaluation protocol is suitable for the task and, therefore, we proposed a novel edge-level evaluation protocol. This protocol takes into account the real-life PIDS constraints, such as detecting intrusion in the first few seconds of its occurrence.
We also reviewed the existing PIDS datasets. We found that only the i-LIDS dataset is currently available for this task. This dataset was found to be challenging as it has different weather conditions, animals and intruder-approaching scenarios. It does have some major drawbacks, such as only person as the intrusion and just two camera views. Indeed, this community requires new datasets to develop and test intrusion detection systems.
Finally, we used two recent PIDSs to assess proposed definitions and evaluation protocols. We found that the frame-level evaluation does not give many details about the intrusion detection. The frames were poorly classified by both methods, giving us no finer details on which intrusion events were correctly detected. The i-LIDS evaluation protocol focused on evaluating intrusions at an event-level and thus helped in the better understanding of detections. However, it had a major drawback of penalizing system alarms as false detections, which made it difficult to compare the PIDSs. Finally, the edge-level evaluation overcame this drawback. It focused on evaluating the start of the intrusion event, which is completely coherent with the proposed intrusion definition and real-life constraints. As a result, the edge-level evaluation helped in the better understanding and comparison of the two PIDSs.
In the future work, we would like to further strengthen the unsupervised learning work for the PIDS. We hope that this work will result in motivating the community to propose methods with open-source codes and open-access challenging intrusion datasets in order to move reproducible research forward.


 ,
, 



{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}