1. Introduction
The expansion of renewable energy sources is vital for ensuring the energy supply of a fast-paced market growing in the coming decades, with expectations for it to double by 2060 [
1]. Clean energy already accounts for three quarters of newly installed capacity annually [
1], and those related to water resources are the most-used ones. The building of small hydroelectric plants (SHPs), which accounts for a significant share of this group, has increased worldwide due to the lower initial investment, lower operating costs, and expanding regulation of energy markets. The potential total energy generation capacity of these SHPs is twice the total capacity of the currently installed energy plants [
2].
The maintenance of a hydropower plant is a complex task. It demands a specific level of skill to ensure an adequate level of dependability of the asset through its useful life. There are three kinds of maintenance. The first and most basic is corrective maintenance, in which a component is replaced after a failure occurs. The second is preventive maintenance, which estimates the service life of a component and realizes a replacement once the operating lifetime is reached. Finally, there is predictive maintenance, in which the system condition is assessed from data periodically or continually acquired from various sensors [
3,
4]. A predictive or condition-based maintenance system consists of two stages. The first stage is the diagnosis, which incorporates fault detection or anomalous operating conditions, fault isolation by subcomponents, and identification of the character and degree of the failure [
4]. The second stage is the prognosis, which involves using statistical and machine learning models in order to calculate the use life of the assets and the confidence interval of the estimation [
5], foresee maintenance, and increase the dependability and availability of the generation units.
Many data-driven models have been proposed for fault detection and diagnosis in hydroelectric plants. These models include principal component analysis (PCA) [
6], independent component analysis (ICA) [
7], and a least square support vector machine [
8,
9,
10,
11]. PCA decomposition is used to assist specialists in determining and selecting the principal features which contribute to cavitation in hydro-turbines [
12]. Current studies have presented a new monitoring method based on ICA-PCA that can extract both non-Gaussian and Gaussian information from operating data for fault detection and diagnosis [
13]. This ICA-PCA method has been expanded with the adoption of a nonlinear kernel transformation prior to the application of the decomposition method, which has become known as kernel ICA-PCA [
14]. Zhu et al. applied this method in the hydropower generation context with increased success rates and lower fault detection delays than either the PCA or ICA-PCA applications. While most models rely on signal processing, De Souza Gomes et al. proposed functional analysis and computational intelligence models for fault classification in power transmission lines [
15]. Santis and Costa proposed the application of isolation iForest for small hydroelectric monitoring, where iForest isolates anomalous sensor readings by creating a health index based on the average distance of the points to the tree root [
16]. Hara et al. extended iForest’s performance by implementing a preliminary step of feature selection using the Hilbert–Schmidt independence criterion [
17]. It is worth emphasizing that in addition to data-driven models, there is the application of analytic model-based methods, which have been presenting significant design results in the context of fault diagnosis in power systems, such as in [
18].
For prognoses, the techniques generally applied for estimating the use life are classified into statistical techniques, comprising regression techniques [
19], Wiener-, Gamma-, and Markovian-based processes such as machine learning techniques, comprising neural networks, vector support machines, and electrical signature analysis [
20], and principal component analysis [
21], as well as deep learning techniques more recently, comprising auto-encoder, recurrent, and convolutional neural networks [
22].
Reports on the prognoses of hydroelectric generating units are scarcer than publications related to their diagnosis [
23]. A great challenge in the area is proposing procedures that contemplate faults between different generating units and auxiliary interconnected systems [
23]. An et al. presented a prognosis model based on the application of Shepard’s interpolation of three variables: bearing vibration, apparent power, and working head [
24]. The signal is decomposed by applying intrinsic time-scale decomposition to a limited number of rotating components, and the artificial neural network is trained for each of the temporal components of the signal. Thereafter, the models present a similar framework, with varied individual methods for signal decomposition and regression models. Fu et al. applied variational mode decomposition for signal decomposition and a least square support vector machine regression model fine-tuned using an adaptive sine cosine algorithm [
8,
25]. Zhou et al. combined a feature strategy using empirical wavelet decomposition for decomposing and Gram–Schmidt orthogonal process feature selection combined with kernel extreme learning machine regression [
26].
Since feature extraction is a key factor in the success of data-driven diagnosis and prognosis systems, the Time Series Feature Extraction Based on Scalable Hypothesis Tests (TSFRESH, or TSF for short) algorithm has gained prominent attention in the literature, leading to better results than physical and statistical features alone [
27]. The algorithm is capable of generating hundreds of new features while reducing collinearity through its hypothesis test-integrated selection procedure. Tan et al. adopted TSF along with a probability-based forest for bearing diagnosis [
28]. A two-stage feature learning approach combining TSF and a multi-layer perceptron classifier was adopted for anomaly detection in machinery processes by Tnani et al. [
44] and for earthquake detection by Khan et al. [
29].
Finally, the random survival forest (RSF) is a survival analysis model that has recently been adapted for data-driven maintenance prognosis systems. Voronov et al. proposed the application of RSF for heavy vehicle battery prognosis [
30], an important part of the electrical system and mostly affected by lead-acid during the engine starting. Gurung adopted the RSF along with histogram data for interpretive modeling and prediction of the remaining survival time of components of heavy-duty trucks, aiming to improve operation and maintenance processes [
31]. Snider and McBean proposed an RSF-based model for the water main pipe replacement model, expecting savings of USD 26 million, or 14% [
32] of the total cost of the ductile iron pipe, over the next 50 years.
In this context, the present paper innovates by proposing a framework for the prognosis of hydroelectric plants, based on the TSF feature extraction and selection algorithm and survival analysis models. The authors did not find any evidence or study that has adopted a similar approach in the literature thus far. We compare the different strategies of feature engineering associated with three survival model analyses, evaluating the models using the concordance index metric. The main findings and contributions of the current paper are the following:
The proposal of a data-oriented framework including feature engineering strategies and machine learning survival models for intelligent fault diagnosis of the SHP generating unit;
Evaluation of the importance of attributes using the permutation importance method associated with the RSF survival model;
Affirmation that the RSF survival analysis model associated with the TSF feature engineering hybrid model obtained the highest concordance index score (77.44%).
The remainder of the present article is organized as follows.
Section 2 defines the study methodology, describing the methods, algorithms, and dataset applied.
Section 3 presents the results and discussions of the simulations of the models, in addition to the outputs of the feature engineering strategies and survival analysis models, with illustrative examples of those models’ inference. Finally,
Section 4 presents the conclusions and recommendations for future work.
2. Problem Formulation
The prognosis problem was formulated as an inference problem based on historical data, specialist knowledge, external factors, and future usage profiles. Prognosis is a condition-based maintenance (CBM) practice widely applied to reduce costs incurred during inefficient schedule-based maintenance. In mechanical systems, the repetitive stresses from rotating machinery vibration temperature cycles leads to structural failures. Since mechanical parts commonly move slowly to a critical level, monitoring the growth of these failures permits evaluating the degradation and estimating the remaining component life over a period of time [
33].
The current study was developed in Ado Popinhak, an SHP situated in the southern region of Brazil. With an installed capacity of 22.6 MW, the plant supplies energy to 50,000 residences. Monitoring data from the main single hydro generator unit were registered every 5 min, and the study period was from 13 August 2018 to 9 August 2019.
Table 1 describes the number of runs by the generators contained in the dataset, the number of runs that ended due to failure, the average cycle time per run, and the longest cycle time.
The objective was to predict the remaining useful life (RUL) of a power system based on multiple component-level sensor and event data. The RUL information allows decision makers to better plan maintenance and interventions, improving availability and reducing costs.
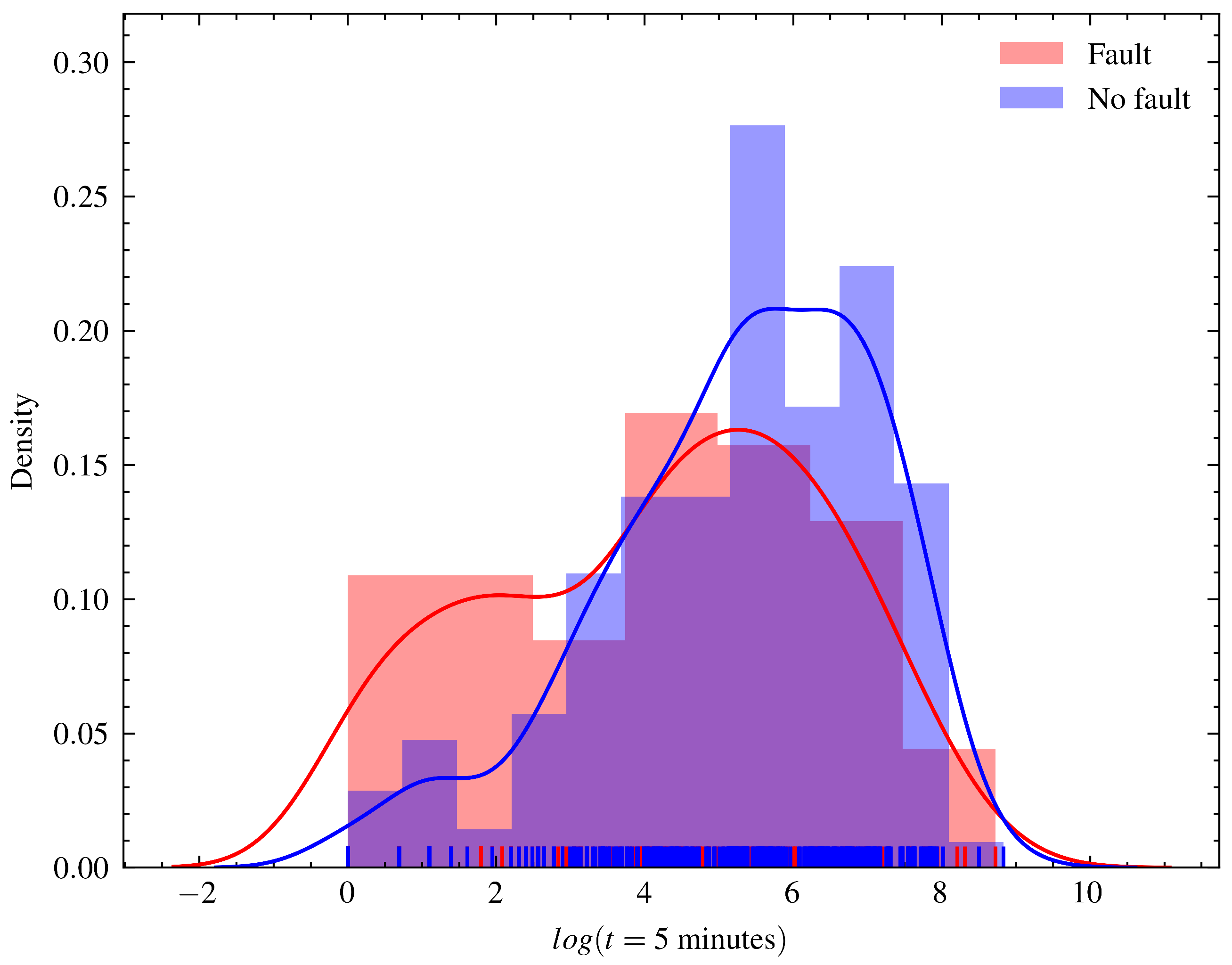
Raw sensor reading data and event data, such as interventions, shutdowns, and planned and corrective maintenance, were curated and merged. The data registered were classified and split into runs, which are periods from the moment the generating unit is turned on until it is shut down, whether due to failure or not. Runs that ended because of failure were labeled with a true or false failure label. The time distribution plot until the end of the runs that ended in failure and those that were interrupted for another reason is shown in
Figure 1.
The nature of the problem is interpreted as a problem of survival analysis, given that the system does not run to failure and can be shut down due to a lack of water resources for generation, failures in the transmission system, or the execution of scheduled maintenance. A summary of the characteristics of the problem and dataset is as follows:
Data were collected for four generator units of the same manufacturer, model, and age;
Fifty-four variables were monitored, and readings were registered in the transactional database every 5 min;
Data were heterogeneous, including either control settings or monitored variables, both numerical and categorical;
Missing data represented around 5% of total registrations, mostly caused by loss of a network connection between the remote plants and the operations center;
The runs in which the subsequent state was a forced stop were labeled, and the last reading was registered as the logged time of failure;
There were many runs where no failure was registered during the time (i.e., data were right-censored).
The runs were considered independent, given that the systems could be turned off for a long time and undergo modifications, such as routine maintenance, during this period, and because machine start-up is the biggest cause of system deterioration. For this reason, the Kaplan–Meier model was adjusted and presented in order to describe the survival function of each run of the four generators in
Figure 2.
The data transformation workflow is described in
Figure 3. Sensor and event data were collected from the transactional database of telemetric systems and stored in text files. In the data-wrangling phase, the record tables were parsed and joined with the event tables, and the records were resampled into 5 min periods. While still in this stage, the imputation of the missing data and the classification of the runs were made if they ended due to failure or programmed shutdowns (censoring).
In the feature extraction and selection step, the features were extracted from each of the time series of the sensors during the first 30 5 min time units (150 min of operation) using the feature engineering strategies described in
Section 3.1. The fixed period of the first 30 cycle times was selected from each run to extract features and adjust the survival models. Runs with a cycle time of fewer than 30 s were excluded from the training base. This approach was adopted to avoid data leakage in model training, where size-related features can contribute to models readily predicting the estimated total time to failure. These features were recorded in a text file and zipped due to the size of the generated tables.
In the next step, the runs were randomly divided into training and test sets, using proportions of 90% of the runs for training and 10% for testing. In each of the simulations, the partitioning was performed using a different random seed. The models were fitted to the training set, and metrics were calculated on the training set. The computational time was calculated for each fit of the models and saved for later analysis.
Finally, the model metrics were compared using a set of statistical tests in order to identify if there was a difference in the average scores for different groups of models or feature strategies.
4. Results and Discussion
4.1. Simulation Results
Figure 5 shows the C-index scores calculated for each of the 100 randomized simulations with different training and testing sets. This visualization format provides better understanding of the metric distribution of each of the CN, RSF, and GBS survival analysis models when combined with HOS and TSF feature engineering.
From the box plot analysis, we observed that the HOS-CN group obtained the lowest accuracy, while the TSF-RSF and TSF-GBS groups obtained the highest accuracies. The variance of CN was higher than those for the other survival models, especially when adopted with TSF feature engineering.
There were a few outliers in all models which were mostly in the lower bound, indicating possible convergence problems. A suggestion for both improving the variances and reducing outliers is to adopt a model selection schema for tuning and adjusting the models. The TSF-RSF and TSF-GBA groups presented close distribution in terms of both median and variance. In general, most of the RSF and GBS groups presented close variance.
Table 2 presents the average and standard deviation of the C-index score and fitting time, highlighting in bold the model with the highest score and the one with the lowest fitting time. The nonlinear models RSF and GSA, which require more computational time for training, achieved better accuracy scores than the linear model with regularization (CN). This trade-off between accuracy and computational time is expected in machine learning applications. When comparing RSF and GBS, RSF required up to 10 times more fitting time than GBS. However, it is worth mentioning that RSF, a bagging ensemble, can be more easily parallelized than GBS, a boosting ensemble. The fitting time difference between the TSF-CN and the nonlinear models was significant, requiring more than 1000 times less time than TSF-RSF for training.
Table 3 presents the total time necessary to execute both feature engineering strategies. As this is a step preceding model adjustment, it is worth considering its time when evaluating the models.
The computational time required to extract and select attributes using the TSF method was about 20 times greater than the time required using HOS. This is a significant difference that must be taken into account, especially for real-time applications of the prognosis model. However, it is interesting to point out that the TSF library offers the possibility of implementing cluster parallel computing. Furthermore, the time required for inference was lower, given that only the features previously selected by the feature hypothesis tests and applied in the model training needed to be calculated.
One-way ANOVA [
57] was applied to test the null hypothesis that the groups had the same mean C-index score.
Table 4 displays the
statistics, which represent the ratio of the variance among score means divided by the average variance within groups, and the
p value calculated for the statistics. By adopting a confidence level of
, we rejected the hypothesis that the score was equal between all groups since the
p-value was lower than
. Normality was checked using a Q-Q plot. The homogeneity of the variance when checking the ratio of the largest to the smallest sample standard deviations was less than 2 (1.44).
Sequentially, a pairwise Tukey test [
58] was applied, and the results are presented in
Table 5. The pair of groups in which the mean difference of the scores was not significant at the 0.95 level is highlighted in bold. The results show that the mean score metrics of the HOS-GBS, TSF-GBS, and TSF-RSF groups were statistically different. These results indicate that, from our experimentation, it is not possible to verify significant differences among the scores in these models. A reasonable model for the dataset we simulated was the HOS-GBS group, since it presented the least computational time for both preprocessing and fitting and was among the top three models.
4.2. Feature Importance Analysis
Feature importance was evaluated using the permutation importance method, which measures how the score decreases when a feature is not available [
59]. The score adopted for evaluation was the C-index, the base estimator was the RSF model, and the number of permutation iterations was equal to 15.
Table 6 presents the 20 most important features of the HOS-RSF combination, detailed by the sensor and the statistic used for aggregation into the feature used to train the RSF model.
The features associated with the speed registered in the speed regulator and the temperature of the oil were the most important features, contributing to an average increase of 2.8% in the C-index score. The features related to the coupled side bearing temperature of the generator were the most frequent ones (4/20), the oil temperature of the hydraulic unit was the second-most-frequent feature (3/20), and the uncoupled side bearing temperature was the third-most-frequent feature (2/20). When analyzing the type of aggregation, kurtosis and variance were the most frequent types (6/20), and skewness and average were the least frequent types (4/20), although there was a balance among all four types.
Table 7 presents the top 20 most important features of the TSF-RSF combination, detailed by the sensor and the type of feature extraction technique applied.
The most important features were the CWT coefficient of the radial bushing temperature in the turbine and the absolute energy of the voltage in the bar, which contributed to an increase of 1.1% in the C-index score. Since more features were extracted using the TSF strategy than the HOS, it was expected that the weight of each individual feature would be lower. The features related to the radial bushing temperature in the turbine were most frequent (4/20), followed by those related to the coupled bearing temperature in the generator (2/20) and the bar voltage (2/20). The features originating from CWT were most frequent (9/20), followed by the FFT (3/20). The dominance of the CWT and FFT indicates the importance and efficiency of the time–frequency decomposition methods in this type of application.
It is important to note that the TSF algorithm includes the statistical aggregations of kurtosis, skewness, mean, and variance from the HOS feature engineering strategy. Additionally, none of these aggregations were present in the 20 most important attributes after the inclusion of more complex features, such as the FFT and CWT.
4.3. Model Application Analysis
In this section, we present a deeper look at the model which presented the highest mean score in the simulation: TSF-RSF. The C-index of the model was 0.8139. It is worth noting that the maximum value for the C-index is 1, which indicates the order of observed events followed the same order as all predicted events, and a C-index value of 0.5 indicates the prediction was no better than a random guess [
32]. For comparative purposes, the application of the RSF method on the remaining service life of water mains obtained a C-index of 0.88 [
32], while for modeling the disruption durations of a subway service, the metric was 0.672 [
60].
Figure 6 presents the reliability, and
Figure 7 presents the cumulative hazard function plots predicted by the model for 20 instances randomly selected from the test set. When analyzing the representations, we can identify three operation cycles with a reliability pitfall in the earliest minutes of operation. These indicate some cases in which there was an intrinsic problem in the generator-turbine system prior to or during start-up, and those systems must be stopped as soon as possible for maintenance. There was a second group of four instances in which the reliability dropped by half in the first 1000 5 min time units. This behavior might be related to some operating conditions that were observed in the operation of the machine. Finally, there was a third group containing the other instances with a steadier rhythm of reliability decay, in which more than half of the systems were expected to fail after 2000 5 min time units.
In practical applications, the survival model can be used to evaluate both the current and previous runs of a generator unit, returning both the risks and the expected remaining useful life. Maintenance teams may want to keep all their systems with a reliability function closer to the third group described before, especially right before the rainy periods. During these periods, the generation is higher, and the stopped periods are rarer, making it more difficult and less desirable to execute maintenance procedures on the machines, which may lead to a loss in power generation.
The model can also be extended for a prescriptive perspective combined with the parameters of the start-up process, aiming to optimize the start-up process in order to achieve the highest reliability level possible. With this, a longer lifetime of the assets and greater time between failures can be expected.
5. Conclusions
In the present paper, we presented a structured modeling pipeline for survival analysis and remaining useful life estimation in a small hydroelectric plant in CBM. The available period of operations was approximately 1 year, and the 54 variables were monitored in 4 generating units of the same model and manufacturer. The HOS-GBS, TSF-RSF, and TSF-GBS models presented the highest C-index scores in our simulation. All three are suitable for production deployment.
Identifying failures before they happen is crucial for allowing better management of asset maintenance, lowering operating costs, and in the case of SHPs, promoting the expansion of renewable energy sources in the energy matrix [
61]. Applying time series feature engineering and machine learning survival models, such as a framework, aims to enhance the health of the equipment and decrease power generation downtime.
Looking at variable importance, variance and kurtosis represented the most frequent transformation functions in HOS feature engineering, while the FFT and CWT were the most frequent transformations in TSF feature engineering. The sensors that contributed the most to the model accuracy were the generator bearing temperature, hydraulic unit oil temperature, and turbine radial bushing temperature. The data-driven framework presents generalities, and thus it can be reused to model generator units with different types of sensors.
Future studies should examine feature and model selection through exhaustive searching and Bayesian or evolutionary optimization, as the parameters were manually adjusted. Fine-tuning the models can contribute even more to improving the model accuracy. From the point of the modeling assumptions, runs are set to be independent, but features can be crafted to include times from other runs and from the last imperfect or perfect repairs. Additionally, the predictive model opens a path for prescriptive optimization of the machine operation parameters, aiming to minimize wear, operational wear, and risk over time. Reinforcement learning approaches are a prominent course of action, since they have been adopted for dynamically developing maintenance policies for multi-component systems such as the power system of our object of study [
62].
Finally, the present study contributes to the advancement of SHP maintenance, a crucial renewable power resource with enormous potential for supplying energy worldwide. By determining the faults before failure, management can carry out actions to avoid additional damage caused to combined systems and additional aggravation of the components, thus reducing the operating costs of power plants.











{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}