
Federated Learning Attacks Revisited: A Critical Discussion of Gaps, Assumptions, and Evaluation Setups

 ,
,
Abstract
1. Introduction
- (1)
- the properties of the attacks, and
- (2)
- the choice of experimental setups used to evaluate the attacks.
- We recognize three research gaps that raise questions about the effectiveness of attacks against specific ML functions (e.g., clustering and ranking) and models (e.g., Recurrent Reural Networks and Autoencoders).
- We highlight three recurring assumptions that limit the applicability of the proposed attacks to real-world deployments. These assumptions are related to the hyper-parameters of the ML model, the fraction of malicious clients, and data distribution.
- We identify six fallacies in the evaluation practices that can cause overestimation of the attacks’ effectiveness. The main fallacies stem from the choice of: datasets, models, and the size of the client population. In addition, we also propose a set of recommendations to mitigate these fallacies.
2. Background
2.1. Neural Networks
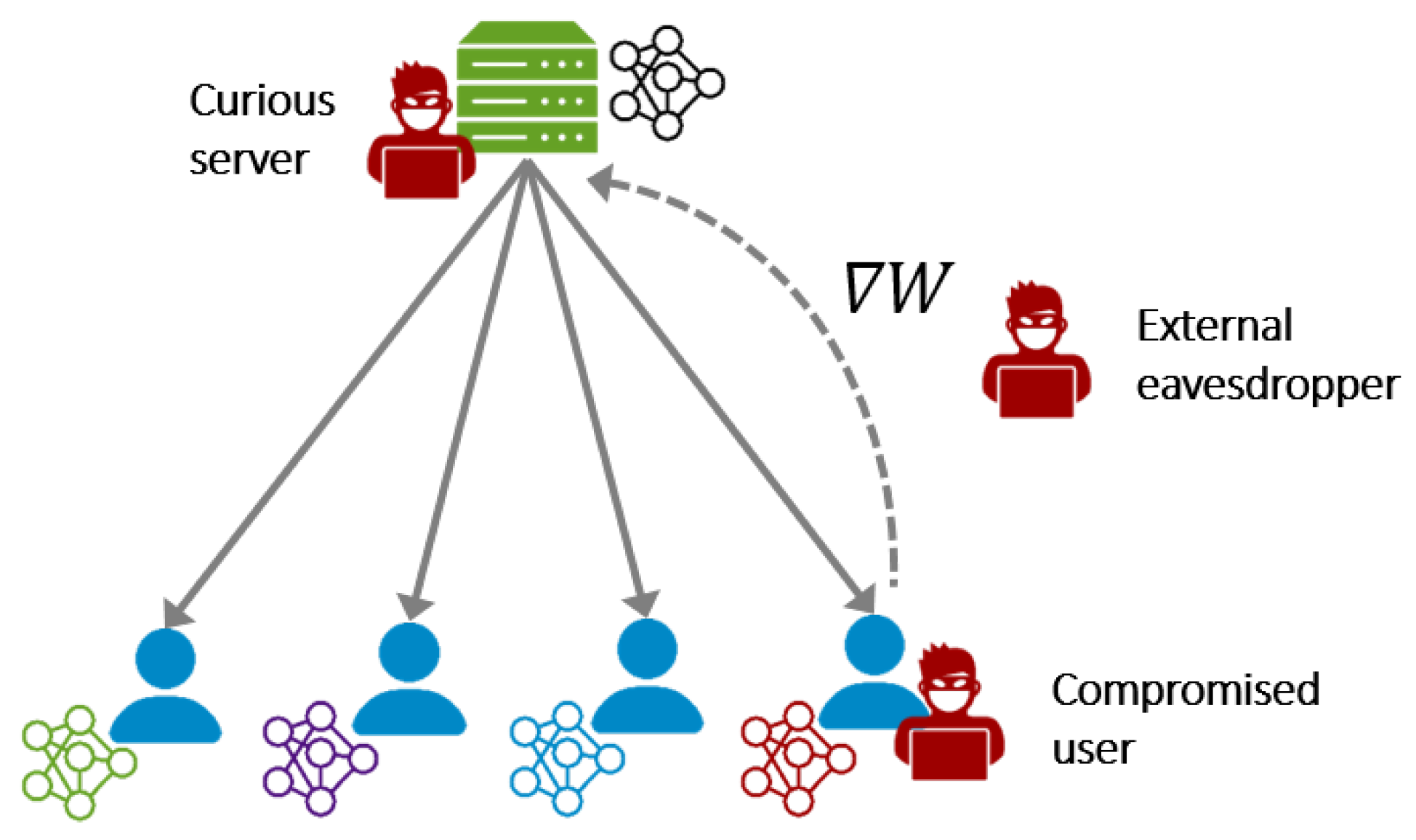
2.2. Federated Learning
- The server samples a subset of users clients to participate in the training round;
- The server disseminates the model and training algorithm to the selected clients;
- Clients train the model locally on their own data;
- Clients share (only) the resulting gradients (or model updates) with the server;
- The server aggregates the gradients to derive a new updated global model as followswhere is the number of data samples of user k, and n is total number of data samples.
2.3. Review Studies
- (1)
- structure the publications dealing with privacy and security FL attacks according to classification schemes, thereby providing a structured overview of the research field,
- (2)
- conduct a quantitative analysis of the publications, highlighting areas of focus and gaps in the literature, and
- (3)
- provide a critical discussion of the applicability of the proposed attacks by taking a closer look at their assumptions and evaluation setups.
2.4. Introduction to Systematic Mapping Studies
- (1)
- providing classification(s) and a taxonomy,
- (2)
- identifying research gaps in the existing literature and possible future research, and
- (3)
- identifying trends and future research directions.
- Define a set of research questions to be answered by the analysis of the study.
- Conduct a search to find the relevant papers.
- Refine the selection of papers by employing inclusion and exclusion criteria.
- Define classification schemes to structure the papers into categories.
- Map the papers to the defined categories.
- Answer the research questions by analyzing the frequency of papers appearing in the defined categories.

3. Method
3.1. Objectives and Research Questions
- What are the research trends in the domain? For this question, we look at the development of the number of papers over years, the communities that conduct the research, and the type of research.
- What are the different types of attacks carried out against FL? We identify the attacks that have been proposed in FL and their properties.
- Which are the evaluation setups commonly used in the literature? We determine common evaluation practices in the field and discuss their implications.
- (1)
- identifying and capturing the research trends, attack types, and evaluation setups in terms of categories and characteristics, and
- (2)
- analyzing the literature and mapping it according to the established categories and characteristics of the respective research trends, attack types, and evaluation setups.
3.2. Search Strategy
- Automatic Search (src2.1 in Figure 3): We conducted the automatic search by relying on several popular search engines, namely, ACM Digital Library, IEEEXplore, Google Scholar, and arXiv. ACM Digital Library and IEEEXplore were considered. as they cover the key research communities (i.e., ML and security communities) and most cited publications from ACM and IEEE computer society. In addition, Google Scholar was used to ensure comprehensive results and avoid any bias towards specific publishers. Furthermore, using arXiv helps to cover the most recent advancements, which are not yet accepted for publication. The keywords to include FL-related terms are: “federated learning” and “collaborative learning”. Additionally, precise keywords related to attacks, namely, “inference attack”, “privacy attack”, and “poisoning attack” were also added to the search. Thereafter, a search string was composed using the updated keywords. This search retrieved all the papers that contain the search string in any part of them, i.e., title, abstract, or body. This in turn might have led to many papers that mention the relevant terms but do not fall within the scope of our study. Such papers werer filtered out in a subsequent step (selection process). The results of the automatic search are shown in Table 1.
- Manual Search (src2.2 in Figure 3): The titles of the papers published in a set of selected journals and conferences were manually reviewed. The journals and conferences were chosen based on the results of the pilot search to cover all the venues where papers on attacks in FL are published. The complete list of sources is shown in Table 2. As a complementary procedure, a number of well-known researchers in the field (e.g., H. Brendan McMahan) were identified, and their publications (on Google Scholar, private webpages, and university webpages) were tracked. The manual search resulted in identifying 20 potentially relevant articles.

{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
| Database & Papers Found | Search String |
|---|---|
| Google Scholar: 1.070 | (“federated learning” OR “collaborative learning”) AND (“inference attack” OR “privacy attack” OR “poisoning attack”) |
| ACM Digital Library: 49 | |
| IEEEXplore: 171 | |
| arXiv: 91 |
3.3. Selection Process
- (1)
- applying inclusion and exclusion criteria, and
- (2)
- performing a complementary forward and backward snowballing search.
- (1)
- Papers discuss attacks in FL. These papers include those that introduce novel attacks and papers that review existing attacks.
- (2)
- Papers published between 2016 (the year of coining the term Federated Learning by McMahan et al. [9]) and 2021.
- (1)
- Posters.
- (2)
- Papers about FL that do not cover any attack.
- (3)
- Papers not written in English.
- (4)
- Papers not accessible in full-text.
- (5)
- Duplicate papers.
3.4. Information Extraction and Classification
- (1)
- propose an initial set of classification schemes, and
- (2)
- sort the papers accordingly.
4. Results of the Mapping
4.1. Research Trends
- Solution: Proposes an approach to solve a problem. The approach can be novel or improves on existing ones. The proposed approach should be supported by good arguments or by other means.
- Validation: Investigates the validity of a novel approach that has not yet been “realized”. The validation can be performed through experiments, simulations, mathematical proofs, etc.
- Evaluation: Studies the properties of an existing approach (analyze, assess, and evaluate) to achieve a better understanding of its potential and limitations.
- Philosophical: Provides new insights, a new way of thinking, or a new conceptual view of research.
- Opinion: States the authors’ position towards a specific topic without introducing any research results.
- Experience: Describes the personal experience of the authors in conducting “a practice”.
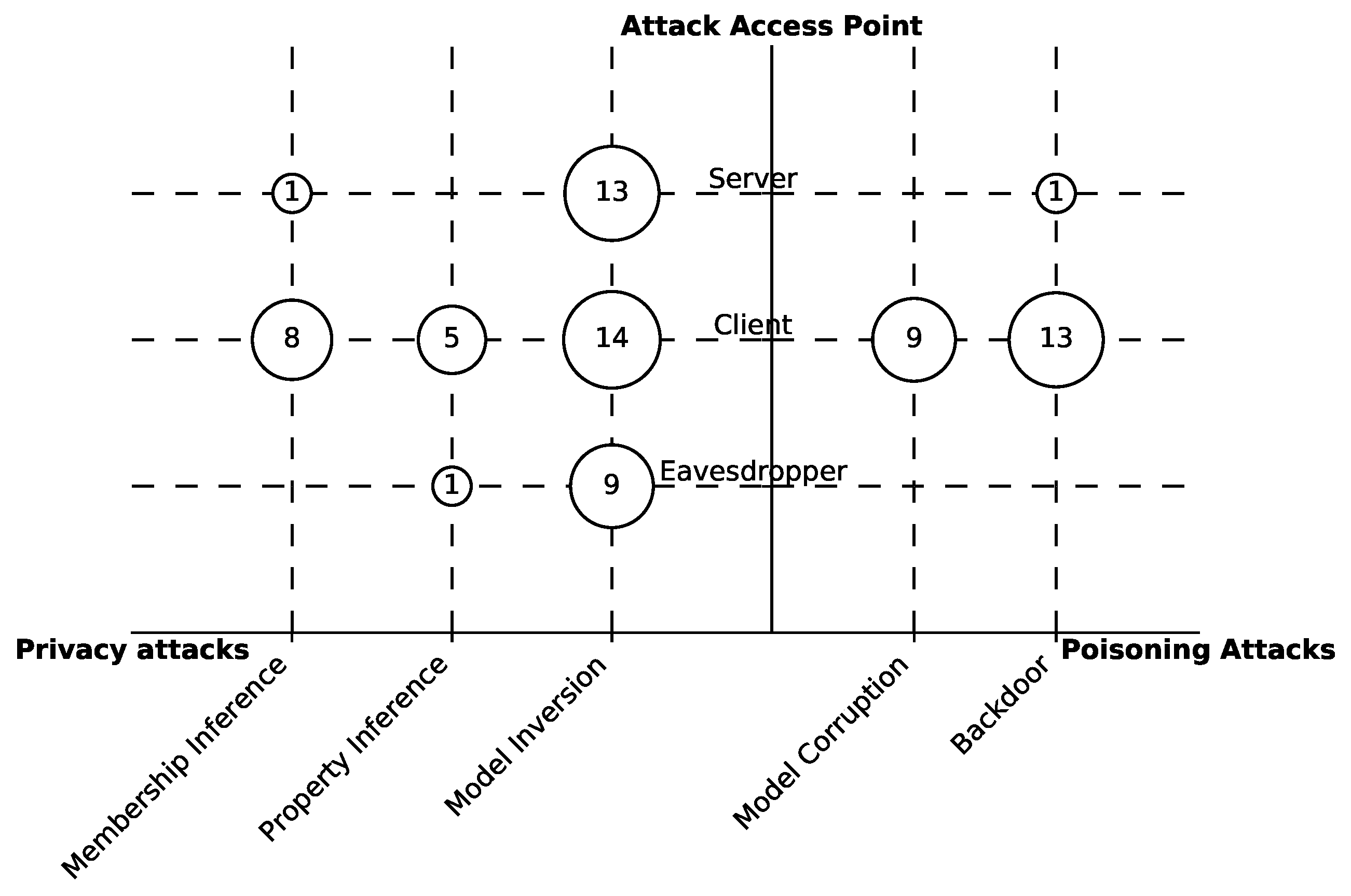
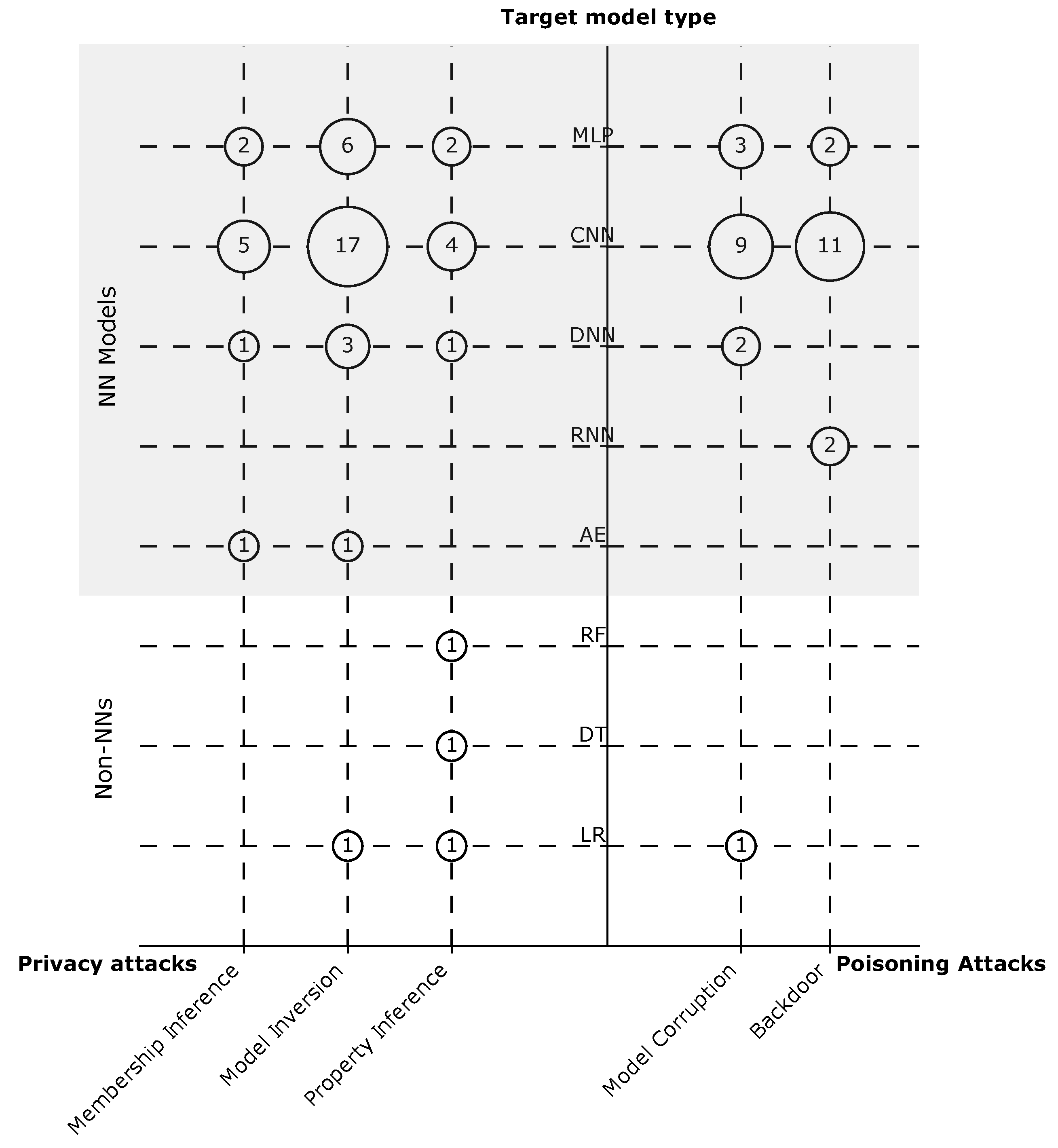
4.2. Attack Types
- Privacy attacks (inference attacks): These attacks extract information about the training dataset, i.e., user data [30], and fall into three groups based on the obtained information:
- Membership inference: The adversary aims to determine whether a particular individual (or a data record) belongs to the training dataset [48].
- Property inference: The adversary aims to infer features of the training dataset; these features are not intended to be used for the main task of the model [49].
- Model inversion (attribute inference): The adversary aims to infer sensitive features used as input to the model [18].
- Poisoning attacks: These attacks target the model and data integrity. The adversary maliciously alters the model through manipulating the raw data, or the model updates on the user side or as an external eavesdropper. These attacks aim to achieve one of the following goals.
- Model corruption (label-flipping): The adversary corrupts the model to reduce its overall accuracy in its main task. This attack can target specific classes or be untargeted [50].
- Backdoor: The adversary implants a backdoor sub-task in the model while maintaining good accuracy of the main task. This backdoor is used later in the production phase to exploit the model, e.g., by forcing misclassification of a specific input [16].
- Black-box: The adversary can query the model and thus knows the inference result of a particular input. However, it does not observe the model’s parameters [51].
- White-box: The adversary can observe the model’s parameters [25]. This capability typically enables adversaries to carry out more sophisticated attacks.
4.3. Common Evaluation Setups
- Text: CLiPS Stylometry Investigation, Yelp-author, Reddit, Amazon Review, Yahoo Answers.
- Image: MNIST, Fashion-MNIST, LFW, CelebA, AT&T, CIFAR, CH-MNIS, ChestX-ray8, EndAD, EMNIST, Fer-2013, HAM10000, ImageNet, PIPA, SVHN, PubFig, Omniglot, mini-ImageNet, VGG2Face, fMRI, CASIA, Face, CINIC, Breast Histopathology Images.
- Key–value: Purchase, BC Wisconsin, Adult, FourSquare, Human Activity Recognition, Landmine, Texas-100, UNSW-Benign, Parkinson Data, Yelp-health, Bank Marketing, Credit Card, Drive Diagnosis, News Popularity, KDDCup99, DIoT, Criteo.
- Perturbation: This mechanism reduces the information leakage about the clients in FL by applying one of the following perturbation techniques.
- Regularization: While training the model locally on the client’s device, the client can apply regularization techniques such as dropout and batch normalization [59].
- Cryptographic approaches: Exposing the updates of an individual client can lead to severe information leakage about their training data [19]. Several techniques based on cryptography are proposed to mitigate this risk.
- Homomorphic encryption: Users can encrypt their updates with homomorphic encryption before sharing them with the server. Due to the homomorphic property, the server can compute the aggregation of the encrypted updates from all users to obtain an updated and encrypted global model. This model then is shared with the users, who can decrypt it [60].
- Secret sharing: Users can encrypt their updates with keys derived from shared secrets. That is, the server needs to aggregate the encrypted updates and thus the shared secrets from a sufficient number of users in order to be able to decrypt the aggregate [45].
- Trusted execution environment (TEE): The aggregation process on the server can be moved into a TEE, such that the executed code can be attested and verified to not leak individual clients’ updates [24].
- Sanitization: This mechanism is proposed to mitigate poisoning attacks. In this respect, two defense mechanisms have been developed in the literature
- Robust aggregation: To limit the impact of malicious updates on the global model, aggregation methods such as trimming the mean and calculating the median [61] are proposed.
- Technology description: We checked whether the authors state clearly which technologies they use to implement their experiments, such as programming languages and libraries.
- Source code availability: We checked whether the source code has been made publicly available.
| ID | Paper | Year | Venue | Affiliation | Type of Research | Attack Purpose | Attack Mode | Observation | Access Point |
|---|---|---|---|---|---|---|---|---|---|
| 1 | Hitaj et al. [18] | 2017 | C,R | A | S | MV | A | W | C |
| 2 | Bagdasaryan et al. [16] | 2018 | C,R | A | S | BD | A | W | C |
| 3 | Bhagoji et al. [17] | 2018 | W | A,I | S | BD | A | W | C |
| 4 | Bhagoji et al. [67] | 2019 | C,R | A,I | S | BD | A | W | C |
| 5 | Wang et al. [25] | 2019 | C,R | A | S | MV | A,P | W | S |
| 6 | Nasr et al. [27] | 2019 | C,R | A | S | MI | A,P | W,B | C,S |
| 7 | Zhu et al. [19] | 2019 | C,R | A | S | MV | P | W | C,S,E |
| 8 | Wang et al. [68] | 2019 | R | A | S | PI | P | W | C |
| 9 | Melis et al. [69] | 2019 | C,R | A | S | MI,PI | A,P | W | C |
| 10 | Mao et al. [70] | 2019 | C | A | S | MI,MV | A | W | C |
| 11 | Liu et al. [71] | 2019 | C,R | A | S | MI | P | W | C |
| 12 | Sun et al. [72] | 2019 | R | I | E | BD | A | W | C |
| 13 | Fang et al. [51] | 2019 | R | A | S | MC | A | W,B | C |
| 14 | Zhang et al. [73] | 2019 | C | A | S | BD | A | W | C |
| 15 | Mahloujifar et al. [54] | 2019 | C | A | S | BD | A | W | C,S |
| 16 | Tomsett et al. [74] | 2019 | C | I | S | BD | A | W | C |
| 17 | Cao et al. [75] | 2019 | C | A | E | BD | A | W | C |
| 18 | Baruch et al. [76] | 2019 | C,R | A | S | MC,BD | A | W | C |
| 19 | Fung et al. [77] | 2019 | R | A | S,E | MC,BD | A | B | C |
| 20 | Zhao et al. [20] | 2020 | R | A | S | MV | P | W | C,S,E |
| 21 | Wei et al. [78] | 2020 | R | A | E | MV | A | W | C,S,E |
| 22 | Pustozerova and Mayer [56] | 2020 | W | A | E | MI | P | W | C |
| 23 | Geiping et al. [79] | 2020 | R | A | S | MV | A,P | W | S,E |
| 24 | Sun et al. [80] | 2020 | R | A | S | MC | A | W | C |
| 25 | Nguyen et al. [81] | 2020 | W | A | S | BD | A | B | C |
| 26 | Chen et al. [63] | 2020 | C,R | A | S | BD | A | W | C |
| 27 | Song et al. [82] | 2020 | J | A | S | MV | A,P | W | S |
| 28 | Zhang et al. [21] | 2020 | C | A | S | MI | P | W | C |
| 29 | Zhang et al. [83] | 2020 | J | A | S | MC,BD | A | W | C |
| 30 | Tolpegin et al. [50] | 2020 | C,R | A | S | MC | A | W | C |
| 31 | Luo et al. [52] | 2020 | R | A | S | PI | P | W | C |
| 32 | Zhu et al. [84] | 2020 | R | A | S | PI | P | W | C,E |
| 33 | Mo et al. [85] | 2020 | R | A | S | MV | P | W | C |
| 34 | Wu et al. [86] | 2020 | C | A | S | MV | P | W | C,S,E |
| 35 | Wang et al. [87] | 2020 | R | A,I | S | MV | P | W | C,S,E |
| 36 | Xu et al. [88] | 2020 | C | A | E | PI | A,P | W | C |
| 37 | Chen et al. [89] | 2020 | C | A | E | MI | P | W | C |
| 38 | Lu et al. [90] | 2020 | R | A,I | E | MI | P | W | E |
| 39 | Xu et al. [91] | 2020 | C | A | E | MV | A | W | C |
| 40 | Qian et al. [92] | 2020 | R | A | E | MV | P | W | C,S,E |
| 41 | Xie et al. [93] | 2020 | C,R | A | E | MC | A,P | B | C |
| 42 | Wainakh et al. [94] | 2021 | C | A | S | MV | P | B,W | C,S,E |
| 43 | Shen et al. [95] | 2021 | J | A | E | MV | P | W | C,S |
| 44 | Enthoven et al. [22] | 2021 | R | A | S | MV | P | W | S |
| 45 | Fu et al. [96] | 2021 | R | A | S | MV | A,P | W | C |
| 46 | Shejwalkar et al. [23] | 2021 | R | A,I | S | MC | A | B,W | C |
| 47 | Wainakh et al. [97] | 2021 | R | A | S | MV | P | B,W | C,S,E |
| 48 | Shejwalkar et al. [98] | 2021 | R | A | S | MC | A | W | C |
| Reported | Unreported | |
|---|---|---|
| Python | 23 (48%) | - |
| PyTorch | 18 (38%) | |
| Public source code | 8 (16%) | |
| Total | 25 (52%) | 23 (48%) |
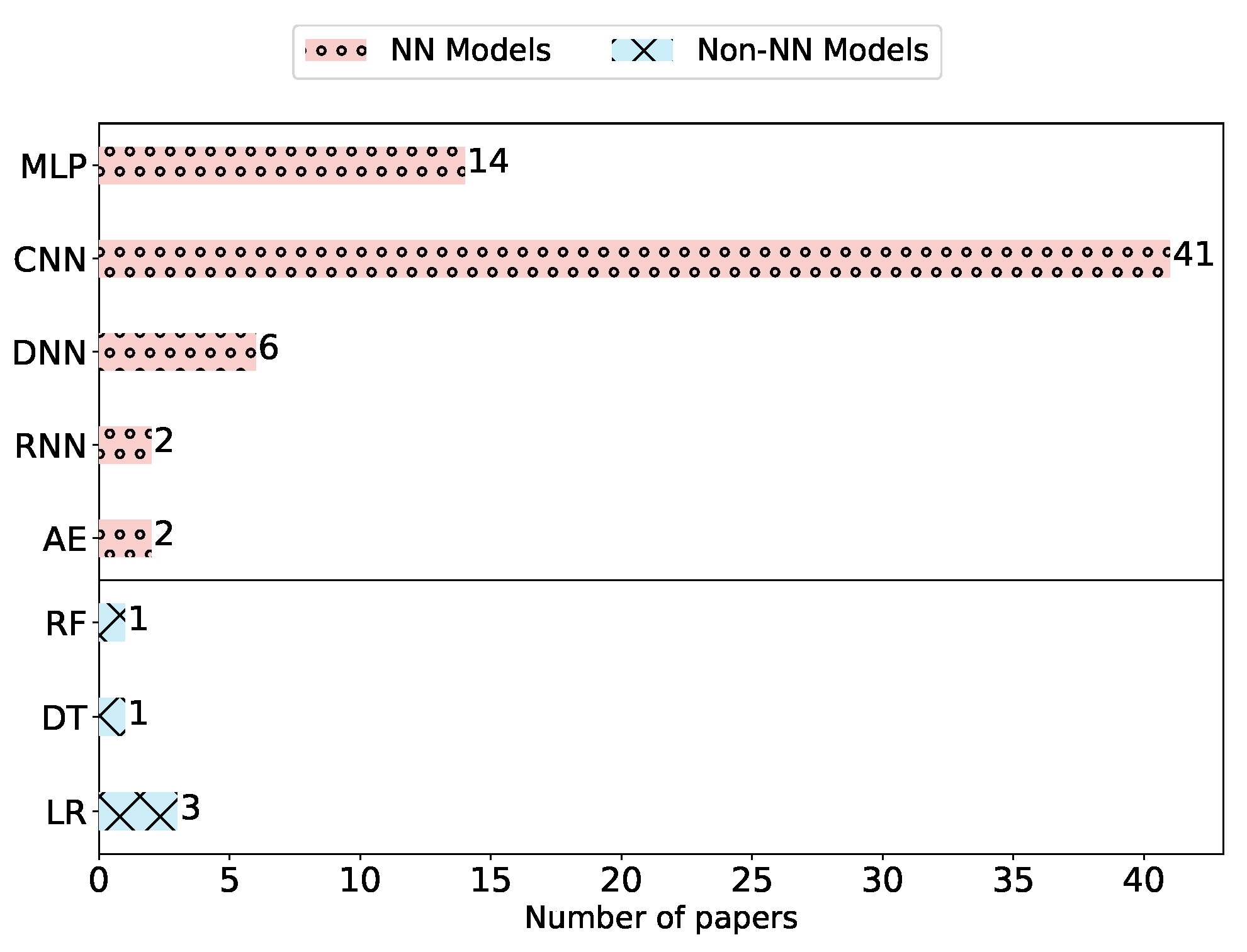
| ID | Paper | Target Model | Num. of Datasets | Countermeasures | Public Code | Python | Libraries |
|---|---|---|---|---|---|---|---|
| 1 | Hitaj et al. [18] | CNN | 2 | NU | ✗ | ✗ | t7 |
| 3 | Bagdasaryan et al. [16] | CNN,RNN | 2 | AD,NU,RA | ✗ | ✓ | pt |
| 3 | Bhagoji et al. [17] | CNN | 1 | ✗ | ✗ | ? | ✗ |
| 4 | Bhagoji et al. [67] | CNN,MLP | 2 | RA | ✗ | ? | ✗ |
| 5 | Wang et al. [25] | CNN | 2 | ✗ | ✗ | ? | ✗ |
| 6 | Nasr et al. [27] | CNN,MLP | 3 | ✗ | ✗ | ✓ | pt |
| 7 | Zhu et al. [19] | CNN,AE | 4 | NU,RU,SS,HE | ✓ | ✓ | pt |
| 8 | Wang et al. [68] | CNN,MLP | 4 | RU,Reg | ✗ | ✓ | pt,sk |
| 9 | Melis et al. [69] | CNN | 7 | RU,Reg,NU | ✗ | ? | ✗ |
| 10 | Mao et al. [70] | CNN,DNN | 2 | ✗ | ✗ | ? | ✗ |
| 11 | Liu et al. [71] | CNN,AE | 3 | ✗ | ✗ | ? | ✗ |
| 12 | Sun et al. [72] | CNN | 1 | NU,Reg | ✓ | ✓ | tf,tff |
| 13 | Fang et al. [51] | LR,CNN,DNN | 4 | AD | ✗ | ? | ✗ |
| 14 | Zhang et al. [73] | CNN | 2 | ✗ | ✗ | ✓ | pt |
| 15 | Mahloujifar et al. [54] | ✗ | ✗ | ✗ | ✗ | ? | ✗ |
| 16 | Tomsett et al. [74] | CNN | 1 | ✗ | ✗ | ✓ | pt |
| 17 | Cao et al. [75] | CNN | 1 | RA | ✗ | ? | ✗ |
| 18 | Baruch et al. [76] | CNN,MLP | 2 | AD,RA | ✓ | ✓ | pt |
| 19 | Fung et al. [77] | CNN | 4 | AD,RA | ✗ | ✓ | sk |
| 20 | Zhao et al. [20] | CNN | 3 | ✗ | ✓ | ✓ | pt |
| 21 | Wei et al. [78] | CNN,MLP | 5 | NU,Reg | ✗ | ? | ✗ |
| 22 | Pustozerova and Mayer [56] | MLP | 1 | NU | ✗ | ? | ✗ |
| 23 | Geiping et al. [79] | CNN | 3 | ✗ | ✗ | ? | ✗ |
| 24 | Sun et al. [80] | CNN | 4 | ✗ | ✗ | ? | ✗ |
| 25 | Nguyen et al. [81] | RNN | 3 | NU,AD,Reg | ✗ | ✓ | pt |
| 26 | Chen et al. [63] | CNN | 2 | AD | ✗ | ? | ✗ |
| 27 | Song et al. [82] | CNN | 2 | HE,RA,RU,TEE | ✗ | ✓ | kr |
| 28 | Zhang et al. [21] | ✗ | 1 | ✗ | ✗ | ✓ | pt,kr,tf,sk |
| 29 | Zhang et al. [83] | CNN | 3 | AD | ✗ | ✓ | pt |
| 30 | Tolpegin et al. [50] | CNN,DNN | 2 | AD | ✓ | ✓ | pt |
| 31 | Luo et al. [52] | LR,DT,RF,MLP | 4 | NU,Reg | ✗ | ✓ | pt,sk |
| 32 | Zhu et al. [84] | CNN,DNN | 2 | TEE | ✓ | ✓ | pt |
| 33 | Mo et al. [85] | CNN,DNN | 3 | ✗ | ✓ | ✓ | pt,th |
| 34 | Wu et al. [86] | CNN | 3 | NU,RU | ✗ | ✓ | tf |
| 35 | Wang et al. [87] | CNN,DNN | 4 | ✗ | ✗ | ✓ | pt |
| 36 | Xu et al. [88] | CNN | 2 | ✗ | ✗ | ? | ✗ |
| 37 | Chen et al. [89] | CNN | 2 | ✗ | ✗ | ✓ | pt,kr,tf |
| 38 | Lu et al. [90] | MLP | 2 | ✗ | ✗ | ? | ✗ |
| 39 | Xu et al. [91] | LR,MLP | 2 | ✗ | ✗ | ✓ | kr,tf,tff,f |
| 40 | Qian et al. [92] | CNN,MLP | 6 | NU | ✗ | ? | ✗ |
| 41 | Xie et al. [93] | CNN | 1 | RA | ✗ | ? | ✗ |
| 42 | Wainakh et al. [94] | CNN | 2 | ✗ | ✗ | ✓ | pt |
| 43 | Shen et al. [95] | CNN,MLP | 4 | ✗ | ✗ | ? | ✗ |
| 44 | Enthoven et al. [22] | CNN,MLP | 2 | ✗ | ✗ | ? | ✗ |
| 45 | Fu et al. [96] | CNN,MLP | 6 | NU,RU | ✗ | ? | ✗ |
| 46 | Shejwalkar et al. [23] | CNN,MLP | 3 | RU,RA | ✗ | ? | ✗ |
| 47 | Wainakh et al. [97] | CNN | 4 | NU,RU | ✗ | ? | ✗ |
| 48 | Shejwalkar et al. [98] | CNN,MLP | 4 | RA | ✗ | ? | ✗ |
5. Discussion
5.1. Main Research Gaps
5.2. Assumption Issues
5.3. Fallacies in Evaluation Setups
6. Conclusions
Author Contributions
Funding
Institutional Review Board Statement
Informed Consent Statement
Data Availability Statement
Conflicts of Interest
Abbreviations
| AE | Autoencoder |
| CIFG | Coupled Input and Forget Gate |
| CL | Collaborative learning |
| CNN | Convolutional Neural Network |
| DNN | Deconvolutional Neural Network |
| DOSN | Decentralized Online Social Network |
| DP | Differential Privacy |
| DT | decision tree |
| FL | Federated learning |
| HFL | Hierarchical federated learning |
| IID | Independent and Identically Distributed |
| IoT | Internet of Things |
| LR | logistic regression |
| LSTM | Long Short-Term Memory |
| ML | Machine learning |
| MLP | Multilayer Perceptron |
| NN | Neural Network |
| OSN | Online Social Network |
| RF | random forest |
| RNN | Recurrent Neural Network |
| SLR | systematic literature review |
| SMS | systematic mapping study |
| TEE | Trusted execution environment |
References
- Arp, D.; Quiring, E.; Pendlebury, F.; Warnecke, A.; Pierazzi, F.; Wressnegger, C.; Cavallaro, L.; Rieck, K. Dos and Do nots of Machine Learning in Computer Security. arXiv 2020, arXiv:2010.09470. [Google Scholar]
- Wani, A.; Khaliq, R. SDN-based intrusion detection system for IoT using deep learning classifier (IDSIoT-SDL). CAAI Trans. Intell. Technol. 2021, 6, 281–290. [Google Scholar] [CrossRef]
- Chen, Z. Research on Internet Security Situation Awareness Prediction Technology based on Improved RBF Neural Network Algorithm. J. Comput. Cogn. Eng. 2022, 1. [Google Scholar] [CrossRef]
- Yao, Y.; Peng, Z.; Xiao, B.; Guan, J. An efficient learning-based approach to multi-objective route planning in a smart city. In Proceedings of the 2017 IEEE International Conference on Communications (ICC), Paris, France, 21–25 May 2017; IEEE: Piscataway, NJ, USA, 2017; pp. 1–6. [Google Scholar]
- Peng, Z.; Yao, Y.; Xiao, B.; Guo, S.; Yang, Y. When urban safety index inference meets location-based data. IEEE Trans. Mob. Comput. 2018, 18, 2701–2713. [Google Scholar] [CrossRef]
- Yao, Y.; Xiao, B.; Wang, W.; Yang, G.; Zhou, X.; Peng, Z. Real-time cache-aided route planning based on mobile edge computing. IEEE Wirel. Commun. 2020, 27, 155–161. [Google Scholar] [CrossRef]
- Lin, J.; Chen, W.M.; Cai, H.; Gan, C.; Han, S. MCUNetV2: Memory-Efficient Patch-based Inference for Tiny Deep Learning. In Proceedings of the Annual Conference on Neural Information Processing Systems (NeurIPS), Virtual, 6–14 December 2021. [Google Scholar]
- Mirshghallah, F.; Taram, M.; Vepakomma, P.; Singh, A.; Raskar, R.; Esmaeilzadeh, H. Privacy in deep learning: A survey. arXiv 2020, arXiv:2004.12254. [Google Scholar]
- McMahan, H.B.; Moore, E.; Ramage, D.; Hampson, S.; Arcas, B.A. Communication-efficient learning of deep networks from decentralized data. arXiv 2016, arXiv:1602.05629. [Google Scholar]
- Namasudra, S. A secure cryptosystem using DNA cryptography and DNA steganography for the cloud-based IoT infrastructure. Comput. Electr. Eng. 2022, 104, 108426. [Google Scholar] [CrossRef]
- Namasudra, S.; Roy, P. A new table based protocol for data accessing in cloud computing. J. Inf. Sci. Eng. 2017, 33, 585–609. [Google Scholar]
- Namasudra, S.; Sharma, S.; Deka, G.C.; Lorenz, P. DNA computing and table based data accessing in the cloud environment. J. Netw. Comput. Appl. 2020, 172, 102835. [Google Scholar] [CrossRef]
- Sarkar, S.; Saha, K.; Namasudra, S.; Roy, P. An efficient and time saving web service based android application. SSRG Int. J. Comput. Sci. Eng. (SSRG-IJCSE) 2015, 2, 18–21. [Google Scholar]
- Gutub, A. Boosting image watermarking authenticity spreading secrecy from counting-based secret-sharing. CAAI Trans. Intell. Technol. 2022. [Google Scholar] [CrossRef]
- Verma, R.; Kumari, A.; Anand, A.; Yadavalli, V. Revisiting Shift Cipher Technique for Amplified Data Security. J. Comput. Cogn. Eng. 2022. [Google Scholar] [CrossRef]
- Bagdasaryan, E.; Veit, A.; Hua, Y.; Estrin, D.; Shmatikov, V. How to backdoor federated learning. In Proceedings of the International Conference on Artificial Intelligence and Statistics, Virtual, 26–28 August 2020; pp. 2938–2948. [Google Scholar]
- Bhagoji, A.N.; Chakraborty, S.; Mittal, P.; Calo, S. Model poisoning attacks in federated learning. In Proceedings of the 32nd Conference on Neural Information Processing Systems, Montréal, QC, Canada, 3–8 December 2018. [Google Scholar]
- Hitaj, B.; Ateniese, G.; Perez-Cruz, F. Deep Models under the GAN: Information leakage from collaborative deep learning. In Proceedings of the ACM Conference on Computer and Communications Security, Dallas, TX, USA, 30 October–3 November 2017. [Google Scholar] [CrossRef]
- Zhu, L.; Liu, Z.; Han, S. Deep leakage from gradients. In Proceedings of the Advances in Neural Information Processing Systems, Vancouver, BC, Canada, 8–14 December 2019; pp. 14747–14756. [Google Scholar]
- Zhao, B.; Mopuri, K.R.; Bilen, H. iDLG: Improved Deep Leakage from Gradients. arXiv 2020, arXiv:2001.02610. [Google Scholar]
- Zhang, J.; Zhang, J.; Chen, J.; Yu, S. GAN Enhanced Membership Inference: A Passive Local Attack in Federated Learning. In Proceedings of the ICC 2020-2020 IEEE International Conference on Communications (ICC), Dublin, Ireland, 7–11 June 2020; IEEE: Piscataway, NJ, USA, 2020; pp. 1–6. [Google Scholar]
- Enthoven, D.; Al-Ars, Z. Fidel: Reconstructing private training samples from weight updates in federated learning. arXiv 2021, arXiv:2101.00159. [Google Scholar]
- Shejwalkar, V.; Houmansadr, A.; Kairouz, P.; Ramage, D. Back to the drawing board: A critical evaluation of poisoning attacks on federated learning. arXiv 2021, arXiv:2108.10241. [Google Scholar]
- Kairouz, P.; McMahan, H.B.; Avent, B.; Bellet, A.; Bennis, M.; Bhagoji, A.N.; Bonawitz, K.; Charles, Z.; Cormode, G.; Cummings, R.; et al. Advances and open problems in federated learning. arXiv 2019, arXiv:1912.04977. [Google Scholar]
- Wang, Z.; Song, M.; Zhang, Z.; Song, Y.; Wang, Q.; Qi, H. Beyond Inferring Class Representatives: Client-Level Privacy Leakage from Federated Learning. In Proceedings of the 38th Annual IEEE International Conference on Computer Communications (INFOCOM 2019), Paris, France, 29 April–2 May 2019. [Google Scholar] [CrossRef]
- Wainakh, A.; Guinea, A.S.; Grube, T.; Mühlhäuser, M. Enhancing privacy via hierarchical federated learning. In Proceedings of the 2020 IEEE European Symposium on Security and Privacy Workshops (EuroS&PW), Genoa, Italy, 7–11 September 2020; IEEE: Piscataway, NJ, USA, 2020; pp. 344–347. [Google Scholar]
- Nasr, M.; Shokri, R.; Houmansadr, A. Comprehensive privacy analysis of deep learning. In Proceedings of the 2019 IEEE Symposium on Security and Privacy, San Francisco, CA, USA, 19–23 May 2019. [Google Scholar]
- Papernot, N.; McDaniel, P.; Sinha, A.; Wellman, M.P. Sok: Security and privacy in machine learning. In Proceedings of the 2018 IEEE European Symposium on Security and Privacy (EuroS&P), London, UK, 24–26 April 2018; IEEE: Piscataway, NJ, USA, 2018; pp. 399–414. [Google Scholar]
- Al-Rubaie, M.; Chang, J.M. Privacy-Preserving Machine Learning: Threats and Solutions. IEEE Secur. Priv. 2019, 17, 49–58. [Google Scholar] [CrossRef]
- De Cristofaro, E. An Overview of Privacy in Machine Learning. arXiv 2020, arXiv:2005.08679. [Google Scholar]
- Rigaki, M.; Garcia, S. A Survey of Privacy Attacks in Machine Learning. arXiv 2020, arXiv:2007.07646. [Google Scholar]
- Zhang, J.; Li, C.; Ye, J.; Qu, G. Privacy Threats and Protection in Machine Learning. In Proceedings of the 2020 on Great Lakes Symposium on VLSI, Knoxville, TN, USA, 7–9 September 2020; pp. 531–536. [Google Scholar]
- Liu, X.; Xie, L.; Wang, Y.; Zou, J.; Xiong, J.; Ying, Z.; Vasilakos, A.V. Privacy and Security Issues in Deep Learning: A Survey. IEEE Access 2020, 9, 4566–4593. [Google Scholar] [CrossRef]
- Enthoven, D.; Al-Ars, Z. An Overview of Federated Deep Learning Privacy Attacks and Defensive Strategies. arXiv 2020, arXiv:2004.04676. [Google Scholar]
- Lyu, L.; Yu, H.; Yang, Q. Threats to Federated Learning: A Survey. arXiv 2020, arXiv:2003.02133. [Google Scholar]
- Jere, M.S.; Farnan, T.; Koushanfar, F. A Taxonomy of Attacks on Federated Learning. IEEE Security Privacy 2020, 19, 20–28. [Google Scholar] [CrossRef]
- Li, Q.; Wen, Z.; Wu, Z.; Hu, S.; Wang, N.; He, B. A survey on federated learning systems: Vision, hype and reality for data privacy and protection. arXiv 2019, arXiv:1907.09693. [Google Scholar] [CrossRef]
- Aledhari, M.; Razzak, R.; Parizi, R.M.; Saeed, F. Federated learning: A survey on enabling technologies, protocols, and applications. IEEE Access 2020, 8, 140699–140725. [Google Scholar] [CrossRef]
- Petersen, K.; Feldt, R.; Mujtaba, S.; Mattsson, M. Systematic mapping studies in software engineering. In Proceedings of the 12th International Conference on Evaluation and Assessment in Software Engineering (EASE), Bari, Italy, 26–27 June 2008; pp. 1–10. [Google Scholar]
- Petersen, K.; Vakkalanka, S.; Kuzniarz, L. Guidelines for conducting systematic mapping studies in software engineering: An update. Inf. Softw. Technol. 2015, 64, 1–18. [Google Scholar] [CrossRef]
- Kitchenham, B.; Charters, S. Guidelines for Performing Systematic Literature Reviews in Software Engineering; EBSE Technical Report; Keele University: Staffordshire, UK; University of Durham: Durham, UK, 2007. [Google Scholar]
- Cummaudo, A.; Vasa, R.; Grundy, J. What should I document? A preliminary systematic mapping study into API documentation knowledge. In Proceedings of the 2019 ACM/IEEE International Symposium on Empirical Software Engineering and Measurement (ESEM), Recife, Brazil, 19–20 September 2019; IEEE: Piscataway, NJ, USA, 2019; pp. 1–6. [Google Scholar]
- Gonçales, L.J.; Farias, K.; Oliveira, T.C.D.; Scholl, M. Comparison of Software Design Models: An Extended Systematic Mapping Study. ACM Comput. Surv. (CSUR) 2019, 52, 1–41. [Google Scholar] [CrossRef]
- Wieringa, R.; Maiden, N.; Mead, N.; Rolland, C. Requirements engineering paper classification and evaluation criteria: A proposal and a discussion. Requir. Eng. 2006, 11, 102–107. [Google Scholar] [CrossRef]
- Bonawitz, K.; Ivanov, V.; Kreuter, B.; Marcedone, A.; McMahan, H.B.; Patel, S.; Ramage, D.; Segal, A.; Seth, K. Practical secure aggregation for privacy-preserving machine learning. In Proceedings of the 2017 ACM SIGSAC Conference on Computer and Communications Security, Dallas, TX, USA, 30 October–3 November 2017; pp. 1175–1191. [Google Scholar]
- McMahan, H.B.; Ramage, D.; Talwar, K.; Zhang, L. Learning differentially private language models without losing accuracy. arXiv 2017, arXiv:1710.06963. [Google Scholar]
- Balle, B.; Kairouz, P.; McMahan, H.B.; Thakkar, O.; Thakurta, A. Privacy Amplification via Random Check-Ins. arXiv 2020, arXiv:2007.06605. [Google Scholar]
- Shokri, R.; Stronati, M.; Song, C.; Shmatikov, V. Membership inference attacks against machine learning models. In Proceedings of the 2017 IEEE Symposium on Security and Privacy (SP), San Jose, CA, USA, 22–24 May 2017; IEEE: Piscataway, NJ, USA, 2017; pp. 3–18. [Google Scholar]
- Ganju, K.; Wang, Q.; Yang, W.; Gunter, C.A.; Borisov, N. Property inference attacks on fully connected neural networks using permutation invariant representations. In Proceedings of the 2018 ACM SIGSAC Conference on Computer and Communications Security, Toronto, ON, Canada, 15–19 October 2018; pp. 619–633. [Google Scholar]
- Tolpegin, V.; Truex, S.; Gursoy, M.E.; Liu, L. Data Poisoning Attacks Against Federated Learning Systems. In Proceedings of the European Symposium on Research in Computer Security, Guildford, UK, 14–18 September 2020; Springer: New York, NY, USA, 2020; pp. 480–501. [Google Scholar]
- Fang, M.; Cao, X.; Jia, J.; Gong, N.Z. Local model poisoning attacks to Byzantine-robust federated learning. arXiv 2019, arXiv:1911.11815. [Google Scholar]
- Luo, X.; Wu, Y.; Xiao, X.; Ooi, B.C. Feature Inference Attack on Model Predictions in Vertical Federated Learning. arXiv 2020, arXiv:2010.10152. [Google Scholar]
- Hayes, J.; Melis, L.; Danezis, G.; De Cristofaro, E. LOGAN: Membership Inference Attacks Against Generative Models. Proc. Priv. Enhancing Technol. 2019, 2019, 135–152. [Google Scholar] [CrossRef]
- Mahloujifar, S.; Mahmoody, M.; Mohammed, A. Universal multi-party poisoning attacks. In Proceedings of the 36th International Conference on Machine Learning ICML, Long Beach, CA, USA, 10–15 June 2019. [Google Scholar]
- Xiao, H.; Rasul, K.; Vollgraf, R. Fashion-mnist: A novel image dataset for benchmarking machine learning algorithms. arXiv 2017, arXiv:1708.07747. [Google Scholar]
- Pustozerova, A.; Mayer, R. Information Leaks in Federated Learning. In Proceedings of the Network and Distributed System Security Symposium, San Diego, CA, USA, 23–26 February 2020; Volume 10. [Google Scholar] [CrossRef]
- Shokri, R.; Shmatikov, V. Privacy-preserving deep learning. In Proceedings of the 22nd ACM SIGSAC conference on Computer and Communications Security, Denver, CO, USA, 12–16 October 2015; pp. 1310–1321. [Google Scholar]
- Konečnỳ, J.; McMahan, H.B.; Yu, F.X.; Richtárik, P.; Suresh, A.T.; Bacon, D. Federated learning: Strategies for improving communication efficiency. arXiv 2016, arXiv:1610.05492. [Google Scholar]
- Truex, S.; Liu, L.; Gursoy, M.E.; Yu, L.; Wei, W. Demystifying Membership Inference Attacks in Machine Learning as a Service. IEEE Trans. Serv. Comput. 2019, 14, 2073–2089. [Google Scholar] [CrossRef]
- Aono, Y.; Hayashi, T.; Wang, L.; Moriai, S. Privacy-preserving deep learning via additively homomorphic encryption. IEEE Trans. Inf. Forensics Secur. 2017, 13, 1333–1345. [Google Scholar]
- Yin, D.; Chen, Y.; Ramchandran, K.; Bartlett, P. Byzantine-robust distributed learning: Towards optimal statistical rates. arXiv 2018, arXiv:1803.01498. [Google Scholar]
- Shen, S.; Tople, S.; Saxena, P. Auror: Defending against poisoning attacks in collaborative deep learning systems. In Proceedings of the 32nd Annual Conference on Computer Security Applications, Los Angeles, CA, USA, 5–8 December 2016; pp. 508–519. [Google Scholar]
- Chen, C.L.; Golubchik, L.; Paolieri, M. Backdoor attacks on federated meta-learning. arXiv 2020, arXiv:2006.07026. [Google Scholar]
- Peng, Z.; Xu, J.; Hu, H.; Chen, L.; Kong, H. BlockShare: A Blockchain empowered system for privacy-preserving verifiable data sharing. Bull. IEEE Comput. Soc. Tech. Commum. Data Eng. 2022, 1, 14–24. [Google Scholar]
- Peng, Z.; Xu, J.; Chu, X.; Gao, S.; Yao, Y.; Gu, R.; Tang, Y. Vfchain: Enabling verifiable and auditable federated learning via blockchain systems. IEEE Trans. Netw. Sci. Eng. 2021, 9, 173–186. [Google Scholar] [CrossRef]
- Dacrema, M.F.; Cremonesi, P.; Jannach, D. Are We Really Making Much Progress? A Worrying Analysis of Recent Neural Recommendation Approaches. In Proceedings of the 13th ACM Conference on Recommender Systems, Association for Computing Machinery, RecSys ’19, Copenhagen, Denmark, 16–20 September 2019; pp. 101–109. [Google Scholar] [CrossRef]
- Bhagoji, A.N.; Chakraborty, S.; Mittal, P.; Calo, S. Analyzing federated learning through an adversarial lens. In Proceedings of the 36th International Conference on Machine Learning, ICML, Long Beach, CA, USA, 10–15 June 2019. [Google Scholar]
- Wang, L.; Xu, S.; Wang, X.; Zhu, Q. Eavesdrop the Composition Proportion of Training Labels in Federated Learning. arXiv 2019, arXiv:1910.06044. [Google Scholar]
- Melis, L.; Song, C.; De Cristofaro, E.; Shmatikov, V. Exploiting unintended feature leakage in collaborative learning. In Proceedings of the IEEE Symposium on Security and Privacy, San Francisco, CA, USA, 20–22 May 2019. [Google Scholar] [CrossRef]
- Mao, Y.; Zhu, X.; Zheng, W.; Yuan, D.; Ma, J. A Novel client Membership Leakage Attack in Collaborative Deep Learning. In Proceedings of the 2019 11th International Conference on Wireless Communications and Signal Processing (WCSP), Xi’an, China, 23–25 October 2019; IEEE: Piscataway, NJ, USA, 2019; pp. 1–6. [Google Scholar]
- Liu, K.S.; Xiao, C.; Li, B.; Gao, J. Performing co-membership attacks against deep generative models. In Proceedings of the IEEE International Conference on Data Mining, ICDM, Beijing, China, 8–11 November 2019. [Google Scholar] [CrossRef]
- Sun, Z.; Kairouz, P.; Suresh, A.T.; McMahan, H.B. Can You Really Backdoor Federated Learning? arXiv 2019, arXiv:1911.07963. [Google Scholar]
- Zhang, J.; Chen, J.; Wu, D.; Chen, B.; Yu, S. Poisoning attack in federated learning using generative adversarial nets. In Proceedings of the 2019 18th IEEE International Conference on Trust, Security and Privacy in Computing and Communications/13th IEEE International Conference on Big Data Science and Engineering, TrustCom/BigDataSE, Rotorua, New Zealand, 5–8 August 2019. [Google Scholar] [CrossRef]
- Tomsett, R.; Chan, K.; Chakraborty, S. Model poisoning attacks against distributed machine learning systems. In Proceedings of the Artificial Intelligence and Machine Learning for Multi-Domain Operations Applications, Baltimore, MD, USA, 15–17 April 2019; International Society for Optics and Photonics: San Diego, CA, USA, 2019; Volume 11006, p. 110061D. [Google Scholar]
- Cao, D.; Chang, S.; Lin, Z.; Liu, G.; Sun, D. Understanding distributed poisoning attack in federated learning. In Proceedings of the 2019 IEEE 25th International Conference on Parallel and Distributed Systems (ICPADS), Tianjin, China, 4–6 December 2019; IEEE: Piscataway, NJ, USA, 2019; pp. 233–239. [Google Scholar]
- Baruch, G.; Baruch, M.; Goldberg, Y. A Little Is Enough: Circumventing Defenses For Distributed Learning. Adv. Neural Inf. Process. Syst. 2019, 32, 8635–8645. [Google Scholar]
- Fung, C.; Yoon, C.J.; Beschastnikh, I. Mitigating sybils in federated learning poisoning. arXiv 2018, arXiv:1808.04866. [Google Scholar]
- Wei, W.; Liu, L.; Loper, M.; Chow, K.H.; Gursoy, M.E.; Truex, S.; Wu, Y. A Framework for Evaluating Gradient Leakage Attacks in Federated Learning. arXiv 2020, arXiv:2004.10397. [Google Scholar]
- Geiping, J.; Bauermeister, H.; Dröge, H.; Moeller, M. Inverting Gradients—How easy is it to break privacy in federated learning? arXiv 2020, arXiv:2003.14053. [Google Scholar]
- Sun, G.; Cong, Y.; Dong, J.; Wang, Q.; Liu, J. Data Poisoning Attacks on Federated Machine Learning. arXiv 2020, arXiv:2004.10020. [Google Scholar] [CrossRef]
- Nguyen, T.D.; Rieger, P.; Miettinen, M.; Sadeghi, A.R. Poisoning Attacks on Federated Learning-based IoT Intrusion Detection System. In Proceedings of the Decentralized IoT Systems and Security (DISS), San Diego, CA, USA, 23–26 February 2020. [Google Scholar]
- Song, M.; Wang, Z.; Zhang, Z.; Song, Y.; Wang, Q.; Ren, J.; Qi, H. Analyzing user-level privacy attack against federated learning. IEEE J. Sel. Areas Commun. 2020, 38, 2430–2444. [Google Scholar] [CrossRef]
- Zhang, J.; Chen, B.; Cheng, X.; Binh, H.T.T.; Yu, S. PoisonGAN: Generative Poisoning Attacks against Federated Learning in Edge Computing Systems. IEEE Internet Things J. 2020, 8, 3310–3322. [Google Scholar] [CrossRef]
- Zhu, J.; Blaschko, M. R-GAP: Recursive Gradient Attack on Privacy. arXiv 2020, arXiv:2010.07733. [Google Scholar]
- Mo, F.; Borovykh, A.; Malekzadeh, M.; Haddadi, H.; Demetriou, S. Layer-wise Characterization of Latent Information Leakage in Federated Learning. arXiv 2020, arXiv:2010.08762. [Google Scholar]
- Wu, F. PLFG: A Privacy Attack Method Based on Gradients for Federated Learning. In Proceedings of the International Conference on Security and Privacy in Digital Economy, Quzhou, China, 30 October–1 November 2020; Springer: New York, NY, USA, 2020; pp. 191–204. [Google Scholar]
- Wang, Y.; Deng, J.; Guo, D.; Wang, C.; Meng, X.; Liu, H.; Ding, C.; Rajasekaran, S. SAPAG: A Self-Adaptive Privacy Attack From Gradients. arXiv 2020, arXiv:2009.06228. [Google Scholar]
- Xu, M.; Li, X. Subject Property Inference Attack in Collaborative Learning. In Proceedings of the 2020 12th International Conference on Intelligent Human–Machine Systems and Cybernetics (IHMSC), Hangzhou, China, 22–23 August 2020; IEEE: Piscataway, NJ, USA, 2020; Volume 1, pp. 227–231. [Google Scholar]
- Chen, J.; Zhang, J.; Zhao, Y.; Han, H.; Zhu, K.; Chen, B. Beyond Model-Level Membership Privacy Leakage: An Adversarial Approach in Federated Learning. In Proceedings of the 2020 29th International Conference on Computer Communications and Networks (ICCCN), Honolulu, HI, USA, 3–6 August 2020; IEEE: Piscataway, NJ, USA, 2020; pp. 1–9. [Google Scholar]
- Lu, H.; Liu, C.; He, T.; Wang, S.; Chan, K.S. Sharing Models or Coresets: A Study based on Membership Inference Attack. arXiv 2020, arXiv:2007.02977. [Google Scholar]
- Xu, X.; Wu, J.; Yang, M.; Luo, T.; Duan, X.; Li, W.; Wu, Y.; Wu, B. Information Leakage by Model Weights on Federated Learning. In Proceedings of the 2020 Workshop on Privacy-Preserving Machine Learning in Practice, Virtual, 9–13 November 2020; pp. 31–36. [Google Scholar]
- Qian, J.; Nassar, H.; Hansen, L.K. Minimal conditions analysis of gradient-based reconstruction in Federated Learning. arXiv 2020, arXiv:2010.15718. [Google Scholar]
- Xie, C.; Koyejo, O.; Gupta, I. Fall of empires: Breaking Byzantine-tolerant SGD by inner product manipulation. In Proceedings of the Uncertainty in Artificial Intelligence, Toronto, ON, Canada, 3–6 August 2020; pp. 261–270. [Google Scholar]
- Wainakh, A.; Müßig, T.; Grube, T.; Mühlhäuser, M. Label leakage from gradients in distributed machine learning. In Proceedings of the 2021 IEEE 18th Annual Consumer Communications & Networking Conference (CCNC), Las Vegas, NV, USA, 9–12 January 2021; IEEE: Piscataway, NJ, USA, 2021; pp. 1–4. [Google Scholar]
- Shen, M.; Wang, H.; Zhang, B.; Zhu, L.; Xu, K.; Li, Q.; Du, X. Exploiting Unintended Property Leakage in Blockchain-Assisted Federated Learning for Intelligent Edge Computing. IEEE Internet Things J. 2020, 8, 2265–2275. [Google Scholar] [CrossRef]
- Fu, C.; Zhang, X.; Ji, S.; Chen, J.; Wu, J.; Guo, S.; Zhou, J.; Liu, A.X.; Wang, T. Label Inference Attacks Against Vertical Federated Learning. In Proceedings of the 31st USENIX Security Symposium (USENIX Security 22), Boston, MA, USA, 10–12 August 2022. [Google Scholar]
- Wainakh, A.; Ventola, F.; Müßig, T.; Keim, J.; Cordero, C.G.; Zimmer, E.; Grube, T.; Kersting, K.; Mühlhäuser, M. User Label Leakage from Gradients in Federated Learning. arXiv 2021, arXiv:2105.09369. [Google Scholar] [CrossRef]
- Shejwalkar, V.; Houmansadr, A. Manipulating the Byzantine: Optimizing Model Poisoning Attacks and Defenses for Federated Learning. In Proceedings of the Network and Distributed Systems Security (NDSS) Symposium 2021, Virtual, 21–25 February 2021; p. 18. [Google Scholar] [CrossRef]
- So, J.; Güler, B.; Avestimehr, A.S. Turbo-Aggregate: Breaking the Quadratic Aggregation Barrier in Secure Federated Learning. IEEE J. Sel. Areas Inf. Theory 2021, 2, 479–489. [Google Scholar] [CrossRef]
- Hosseinalipour, S.; Azam, S.S.; Brinton, C.G.; Michelusi, N.; Aggarwal, V.; Love, D.J.; Dai, H. Multi-stage hybrid federated learning over large-scale wireless fog networks. arXiv 2020, arXiv:2007.09511. [Google Scholar]
- Liu, L.; Zhang, J.; Song, S.; Letaief, K. Client-edge-cloud hierarchical federated learning. In Proceedings of the 2020 IEEE International Conference on Communications (ICC), Dublin, Ireland, 7–11 June 2020. [Google Scholar]
- Yates, A.; Nogueira, R.; Lin, J. Pretrained Transformers for Text Ranking: BERT and Beyond. In Proceedings of the 14th ACM International Conference on Web Search and Data Mining, Virtual, 8–12 March 2021; pp. 1154–1156. [Google Scholar]
- Pan, Y.; Huo, Y.; Tang, J.; Zeng, Y.; Chen, B. Exploiting relational tag expansion for dynamic user profile in a tag-aware ranking recommender system. Inf. Sci. 2021, 545, 448–464. [Google Scholar] [CrossRef]
- Balaban, S. Deep learning and face recognition: The state of the art. arXiv 2015, arXiv:1902.03524v1. [Google Scholar]
- De Cock, M.; Dowsley, R.; Nascimento, A.C.; Railsback, D.; Shen, J.; Todoki, A. High performance logistic regression for privacy-preserving genome analysis. BMC Med. Genom. 2021, 14, 1–18. [Google Scholar] [CrossRef] [PubMed]
- Gao, C.; Elzarka, H. The use of decision tree based predictive models for improving the culvert inspection process. Adv. Eng. Inform. 2021, 47, 101203. [Google Scholar] [CrossRef]
- Yang, T.; Andrew, G.; Eichner, H.; Sun, H.; Li, W.; Kong, N.; Ramage, D.; Beaufays, F. Applied federated learning: Improving google keyboard query suggestions. arXiv 2018, arXiv:1812.02903. [Google Scholar]
- Hard, A.; Rao, K.; Mathews, R.; Ramaswamy, S.; Beaufays, F.; Augenstein, S.; Eichner, H.; Kiddon, C.; Ramage, D. Federated learning for mobile keyboard prediction. arXiv 2018, arXiv:1811.03604. [Google Scholar]
- Abadi, M.; McMahan, H.B.; Chu, A.; Mironov, I.; Zhang, L.; Goodfellow, I.; Talwar, K. Deep learning with differential privacy. In Proceedings of the ACM Conference on Computer and Communications Security, Vienna, Austria, 24–28 October 2016. [Google Scholar]
- Davenport, C. Gboard Passes One Billion Installs on the Play Store. 2018. Available online: https://www.androidpolice.com/2018/08/22/gboard-passes-one-billion-installs-play-store/ (accessed on 23 June 2021).
- Jayaraman, B.; Wang, L.; Evans, D.; Gu, Q. Revisiting membership inference under realistic assumptions. arXiv 2020, arXiv:2005.10881. [Google Scholar] [CrossRef]
- Long, Y.; Bindschaedler, V.; Gunter, C.A. Towards measuring membership privacy. arXiv 2017, arXiv:1712.09136. [Google Scholar]
- Salem, A.; Zhang, Y.; Humbert, M.; Berrang, P.; Fritz, M.; Backes, M. ML-Leaks: Model and Data Independent Membership Inference Attacks and Defenses on Machine Learning Models. In Proceedings of the Network and Distributed Systems Security (NDSS) Symposium, San Diego, CA, USA, 24–27 February 2019. [Google Scholar] [CrossRef]
- Hamner, B. Popular Datasets Over Time. 2017. Available online: https://www.kaggle.com/benhamner/popular-datasets-over-time/code (accessed on 31 May 2021).
- LeCun, Y.; Bottou, L.; Bengio, Y.; Haffner, P. Gradient-based learning applied to document recognition. Proc. IEEE 1998, 86, 2278–2324. [Google Scholar] [CrossRef]
- Hargreaves, T. Is It Time to Ditch the MNIST Dataset? 2020. Available online: https://www.ttested.com/ditch-mnist/ (accessed on 1 June 2021).
- Deng, J.; Dong, W.; Socher, R.; Li, L.J.; Li, K.; Fei-Fei, L. Imagenet: A large-scale hierarchical image database. In Proceedings of the 2009 IEEE Conference on Computer Vision and Pattern Recognition, Miami, FL, USA, 20–25 June 2009; IEEE: Piscataway, NJ, USA, 2009; pp. 248–255. [Google Scholar]
- Goodfellow, I.J.; Erhan, D.; Carrier, P.L.; Courville, A.; Mirza, M.; Hamner, B.; Cukierski, W.; Tang, Y.; Thaler, D.; Lee, D.H.; et al. Challenges in representation learning: A report on three machine learning contests. In Proceedings of the International Conference on Neural Information Processing, Daegu, Republic of Korea, 3–7 November 2013; Springer: New York, NY, USA, 2013; pp. 117–124. [Google Scholar]
- Codella, N.; Rotemberg, V.; Tschandl, P.; Celebi, M.E.; Dusza, S.; Gutman, D.; Helba, B.; Kalloo, A.; Liopyris, K.; Marchetti, M.; et al. Skin lesion analysis toward melanoma detection 2018: A challenge hosted by the international skin imaging collaboration (isic). arXiv 2019, arXiv:1902.03368. [Google Scholar]
- Cohen, G.; Afshar, S.; Tapson, J.; Van Schaik, A. EMNIST: Extending MNIST to handwritten letters. In Proceedings of the 2017 International Joint Conference on Neural Networks (IJCNN), Anchorage, AK, USA, 14–19 May 2017; IEEE: Piscataway, NJ, USA, 2017; pp. 2921–2926. [Google Scholar]
- Luo, J.; Wu, X.; Luo, Y.; Huang, A.; Huang, Y.; Liu, Y.; Yang, Q. Real-world image datasets for federated learning. arXiv 2019, arXiv:1910.11089. [Google Scholar]
- Caldas, S.; Wu, P.; Li, T.; Konecný, J.; McMahan, H.B.; Smith, V.; Talwalkar, A. LEAF: A Benchmark for Federated Settings. arXiv 2018, arXiv:1812.01097. [Google Scholar]
- Simonyan, K.; Zisserman, A. Very deep convolutional networks for large-scale image recognition. arXiv 2014, arXiv:1409.1556. [Google Scholar]
- He, K.; Zhang, X.; Ren, S.; Sun, J. Deep residual learning for image recognition. In Proceedings of the IEEE Conference on Computer Vision and Pattern Recognition, Las Vegas, NV, USA, 27–30 June 2016; pp. 770–778. [Google Scholar]
- Huang, G.; Liu, Z.; Van Der Maaten, L.; Weinberger, K.Q. Densely connected convolutional networks. In Proceedings of the IEEE Conference on Computer Vision and Pattern Recognition, Honolulu, HI, USA, 21–26 July 2017; pp. 4700–4708. [Google Scholar]
- Russakovsky, O.; Deng, J.; Su, H.; Krause, J.; Satheesh, S.; Ma, S.; Huang, Z.; Karpathy, A.; Khosla, A.; Bernstein, M.; et al. ImageNet Large Scale Visual Recognition Challenge. Int. J. Comput. Vis. (IJCV) 2015, 115, 211–252. [Google Scholar] [CrossRef]
- Kim, Y.; Park, W.; Roh, M.C.; Shin, J. Groupface: Learning latent groups and constructing group-based representations for face recognition. In Proceedings of the IEEE/CVF Conference on Computer Vision and Pattern Recognition, Seattle, WA, USA, 13–19 June 2020; pp. 5621–5630. [Google Scholar]
- Evtimov, I.; Cui, W.; Kamar, E.; Kiciman, E.; Kohno, T.; Li, J. Security and Machine Learning in the Real World. arXiv 2020, arXiv:2007.07205. [Google Scholar]
- Liu, K.; Dolan-Gavitt, B.; Garg, S. Fine-pruning: Defending against backdooring attacks on deep neural networks. In Proceedings of the International Symposium on Research in Attacks, Intrusions, and Defenses, Heraklion, Greece, 10–12 September 2018; Springer: New York, NY, USA, 2018; pp. 273–294. [Google Scholar]
- Tan, M.; Le, Q. Efficientnet: Rethinking model scaling for convolutional neural networks. In Proceedings of the International Conference on Machine Learning, Long Beach, CA, USA, 9–15 June 2019; pp. 6105–6114. [Google Scholar]
- Greff, K.; Srivastava, R.K.; Koutník, J.; Steunebrink, B.R.; Schmidhuber, J. LSTM: A search space odyssey. IEEE Trans. Neural Networks Learn. Syst. 2016, 28, 2222–2232. [Google Scholar] [CrossRef]
- Ryffel, T.; Trask, A.; Dahl, M.; Wagner, B.; Mancuso, J.; Rueckert, D.; Passerat-Palmbach, J. A generic framework for privacy preserving deep learning. arXiv 2018, arXiv:1811.04017. [Google Scholar]
- Yang, Q.; Liu, Y.; Cheng, Y.; Kang, Y.; Chen, T.; Yu, H. Federated learning. Synth. Lect. Artif. Intell. Mach. Learn. 2019, 13, 1–207. [Google Scholar]
- He, C.; Li, S.; Thus, J.; Zhang, M.; Wang, H.; Wang, X.; Vepakomma, P.; Singh, A.; Qiu, H.; Shen, L.; et al. Fedml: A research library and benchmark for federated machine learning. arXiv 2020, arXiv:2007.13518. [Google Scholar]











| Journal | Name | Publisher * |
|---|---|---|
| TOPS | Transactions on Privacy and Security | ACM |
| TIFS | Transactions on Information Forensics and Security | IEEE |
| Conference | Name | Publisher * |
| S&P | Symposium on Security and Privacy | IEEE |
| CCS | Conference on Computer and Communications Security | ACM |
| USENIX Security | USENIX Security Symposium | USENIX |
| PETS | Privacy Enhancing Technologies Symposium | Sciendo |
| EuroS&P | European Symposium on Security and Privacy | IEEE |
| NDSS | Network and Distributed System Security Symposium | Internet Society |
| CSF | Computer Security Foundations Symposium | IEEE |
| ACSAC | Annual Computer Security Applications Conference | ACM |
| ESORICS | European Symposium on Research in Computer Security | Springer |
| NeurIPS | Neural Information Processing Systems | Curran Associates |
| ICML | International Conference on Machine Learning | PMLR |
| ICLR | International Conference on Learning Representations | OpenReview.net |
| InfoCom | International Conference on Computer Communications | IEEE |
| AISTATS | Artificial Intelligence and Statistics | - |
Disclaimer/Publisher’s Note: The statements, opinions and data contained in all publications are solely those of the individual author(s) and contributor(s) and not of MDPI and/or the editor(s). MDPI and/or the editor(s) disclaim responsibility for any injury to people or property resulting from any ideas, methods, instructions or products referred to in the content. |
© 2022 by the authors. Licensee MDPI, Basel, Switzerland. This article is an open access article distributed under the terms and conditions of the Creative Commons Attribution (CC BY) license (https://creativecommons.org/licenses/by/4.0/).
Share and Cite
Wainakh, A.; Zimmer, E.; Subedi, S.; Keim, J.; Grube, T.; Karuppayah, S.; Sanchez Guinea, A.; Mühlhäuser, M. Federated Learning Attacks Revisited: A Critical Discussion of Gaps, Assumptions, and Evaluation Setups. Sensors 2023, 23, 31. https://doi.org/10.3390/s23010031
Wainakh A, Zimmer E, Subedi S, Keim J, Grube T, Karuppayah S, Sanchez Guinea A, Mühlhäuser M. Federated Learning Attacks Revisited: A Critical Discussion of Gaps, Assumptions, and Evaluation Setups. Sensors. 2023; 23(1):31. https://doi.org/10.3390/s23010031
Chicago/Turabian StyleWainakh, Aidmar, Ephraim Zimmer, Sandeep Subedi, Jens Keim, Tim Grube, Shankar Karuppayah, Alejandro Sanchez Guinea, and Max Mühlhäuser. 2023. "Federated Learning Attacks Revisited: A Critical Discussion of Gaps, Assumptions, and Evaluation Setups" Sensors 23, no. 1: 31. https://doi.org/10.3390/s23010031
APA StyleWainakh, A., Zimmer, E., Subedi, S., Keim, J., Grube, T., Karuppayah, S., Sanchez Guinea, A., & Mühlhäuser, M. (2023). Federated Learning Attacks Revisited: A Critical Discussion of Gaps, Assumptions, and Evaluation Setups. Sensors, 23(1), 31. https://doi.org/10.3390/s23010031