
How Do Autonomous Vehicles Decide?



Abstract
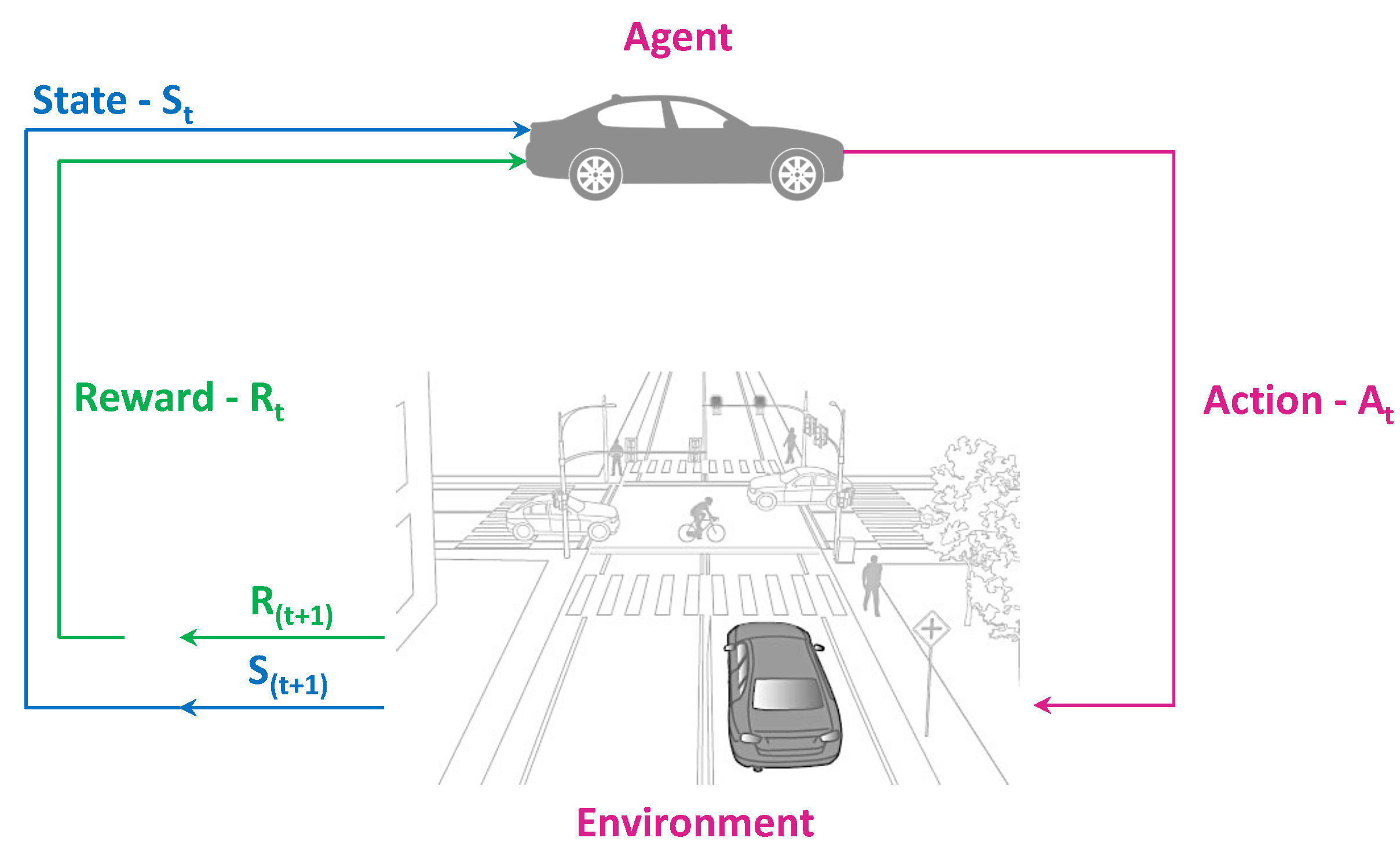
:1. Introduction
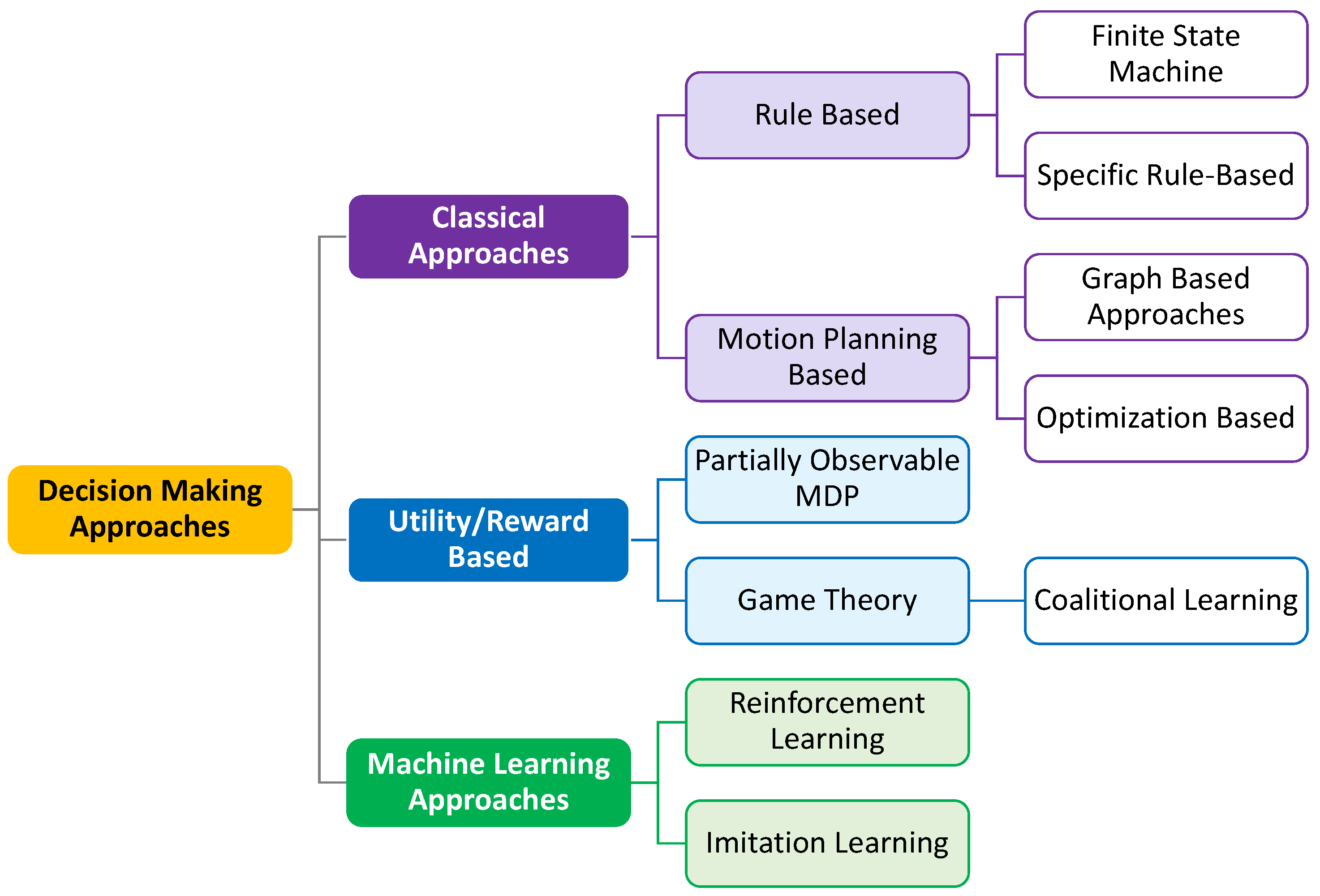
2. Decision Making in Autonomous Driving—An Overview
3. The Analyses of Decision-Making Relevant Solutions for Autonomous Driving
3.1. Classical Approaches
3.1.1. Rule-Based Approaches
3.1.2. Planning-Based Methods
Graph-Based Search
Optimization-Based Models
3.2. Reward/Utility Based Approaches
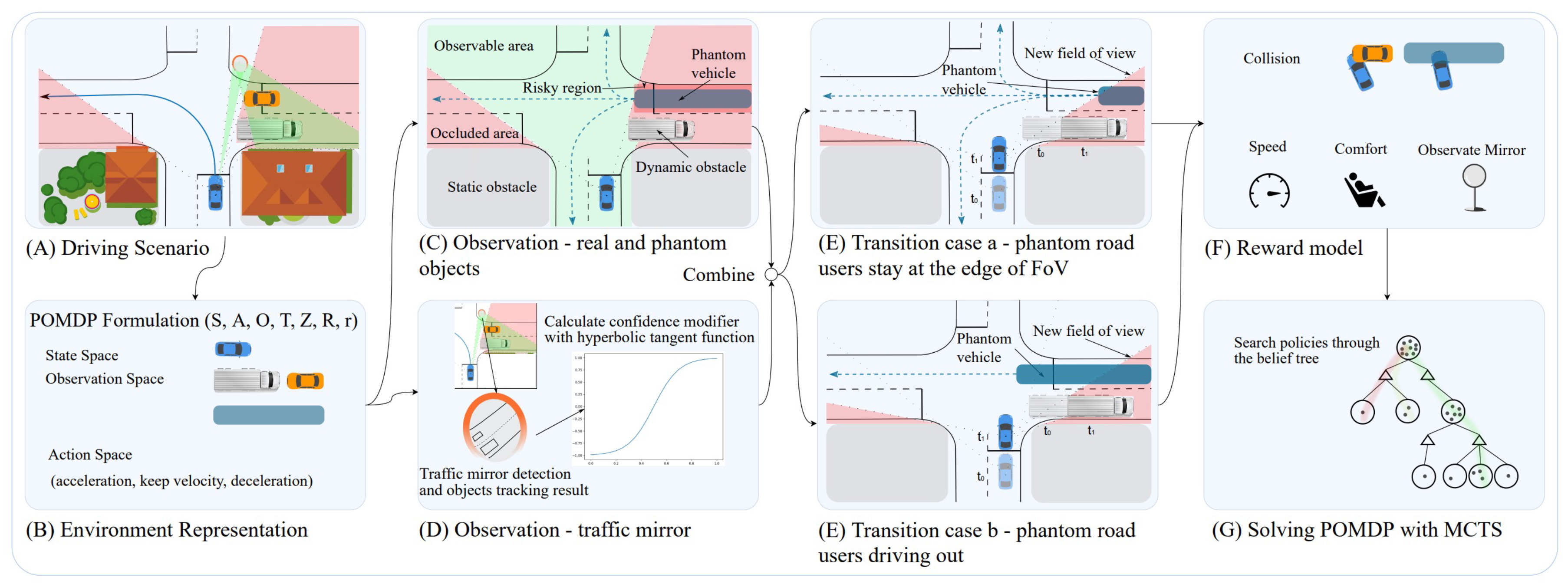
3.2.1. Partially Observable Markov Decision Process
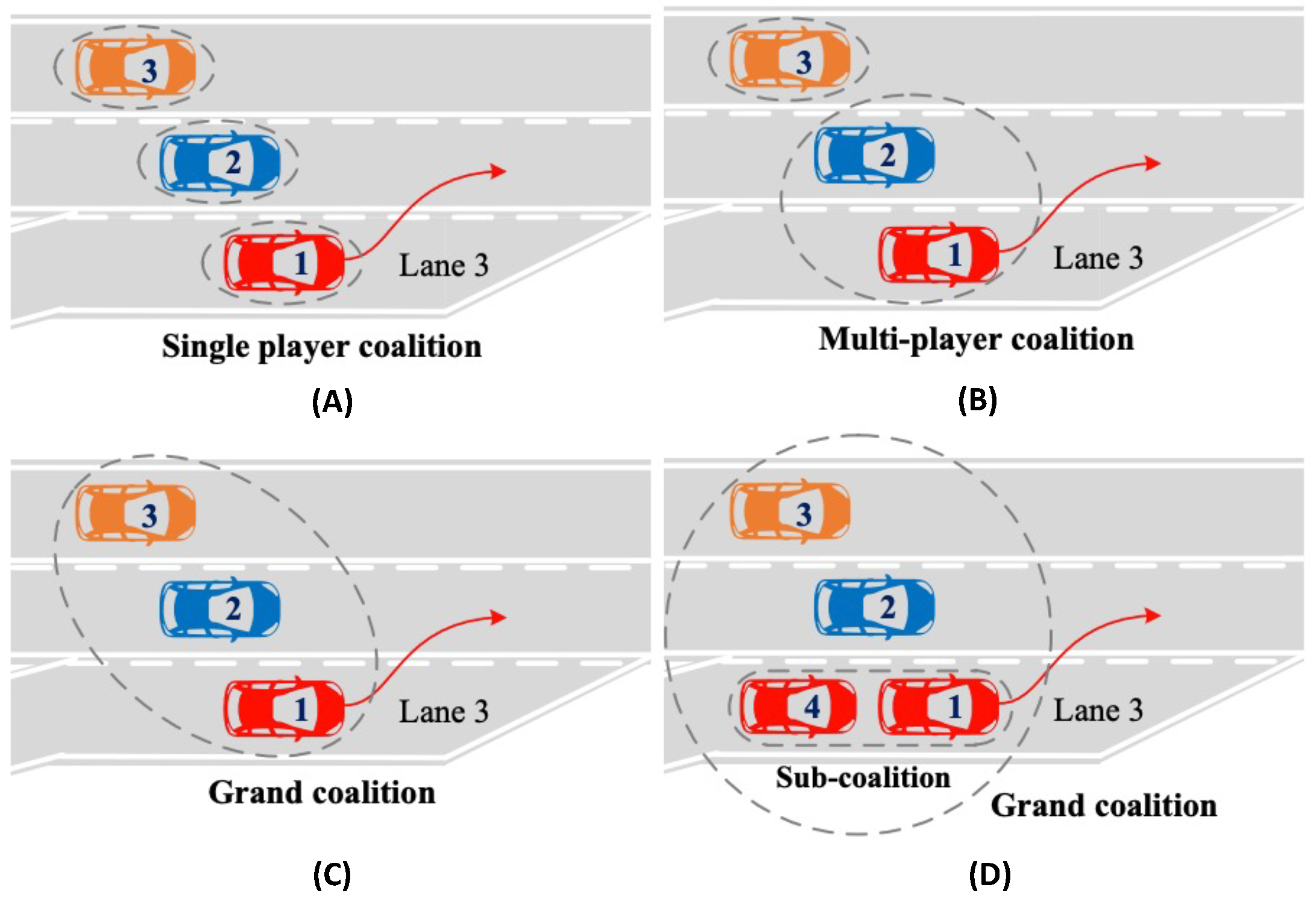
3.2.2. Coalitional Learning Approaches
- Coalitional GT for autonomous driving is a relatively newer and less explored area.
- It provides very fitting characteristics for realizing the solutions of complex and urban driving, specifically for short-term, highly dynamic, and L4/L5 platooning.
- In every theoretical framework, modeling a system necessarily entails some amount of abstraction. On the other hand, game theory has a particularly high level of abstraction since there are so many implicit assumptions that must be taken into consideration in game-theoretic models [78].
- Microscopic driving decisions based on the application of game theory modeling could result in computationally slow methods, making the chosen approach unsuitable for real-time simulation. This issue becomes even more obvious when working with more intricate driving scenarios [79].
- Increasing system complexity necessitates the use of greater computation resources and more potent decision-making execution capabilities [80].
3.3. Machine Learning Approaches
3.3.1. Reinforcement Learning
3.3.2. Imitation Learning
4. Challenges and Future Recommendations
4.1. Explainability in Decision Making
4.2. Robust Decision-Making for Higher Level Autonomous Vehicles
4.3. Vehicle → Pedestrian Interaction
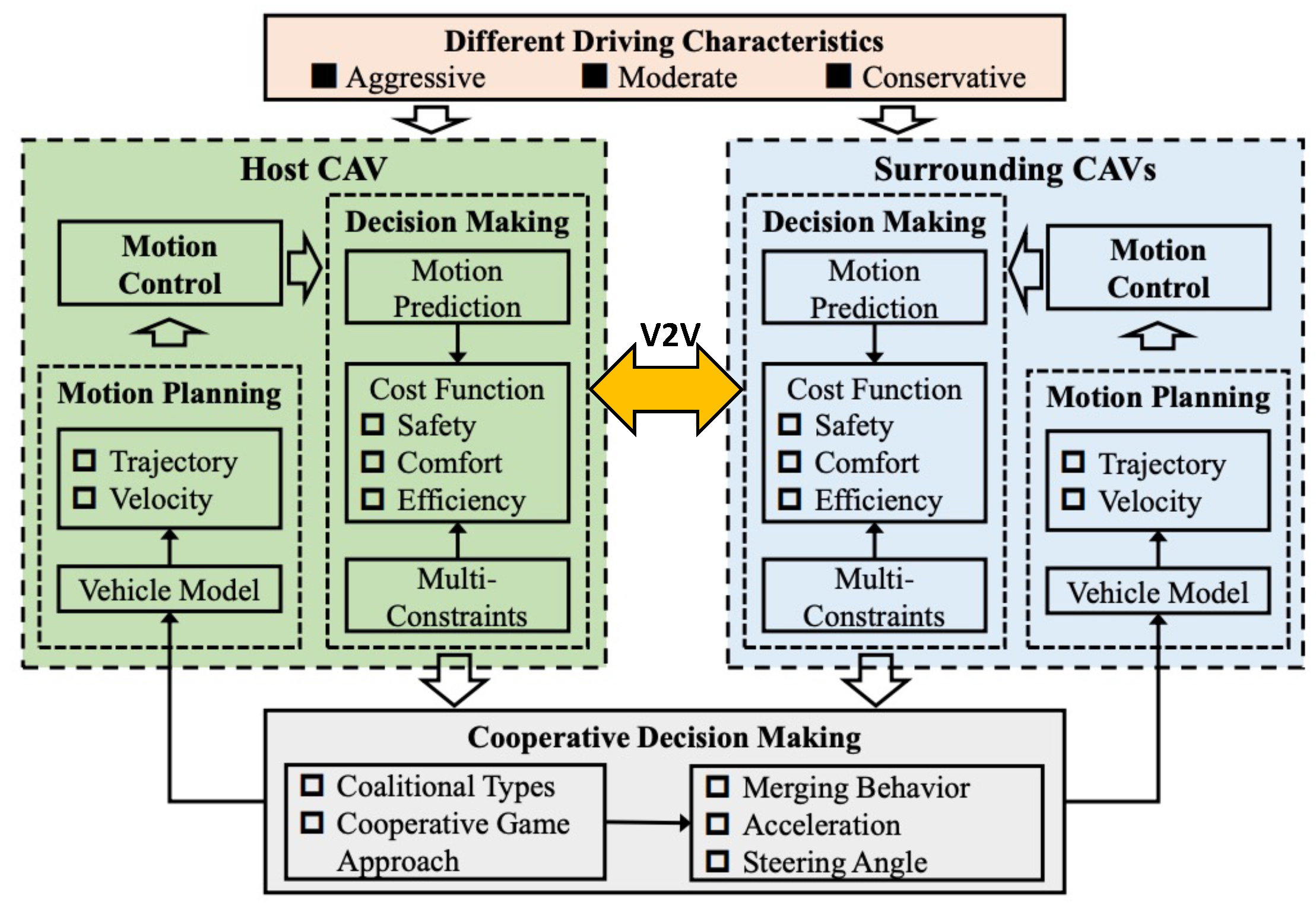
4.4. Collaborative Decision Making
4.5. Blended Approaches for Decision Making
5. Conclusions
Author Contributions
Funding
Institutional Review Board Statement
Informed Consent Statement
Data Availability Statement
Conflicts of Interest
Abbreviations
| ADAS | Advanced Driver Assistance System |
| AIRL | Adversarial Inverse Reinforcement Learning |
| AD | Autonomous Driving |
| AI | Artificial Intelligence |
| AV | Autonomous Vehicle |
| CNN | Convolutional Neural Network |
| CAV | Connected and Autonomous Vehicle |
| CDD | Convoy Driving Device |
| CGT | Cooperative Game Theory |
| DARPA | Defense Advanced Research Projects Agency |
| FSM | Finite State Machine |
| GT | Game Theory |
| HMM | Hidden Markov Model |
| IL | Imitation Learning |
| LiDAR | Light Detection and Ranging |
| ML | Machine Learning |
| MPC | Model Predictive Control |
| MPD | Markov Decision Process |
| NCGT | Non-Cooperative Game Theory |
| NHTSA | National Highway Traffic Safety Administration |
| NTU | Non-Transferable Utility |
| POMDP | Partially Observable Markov Decision Process |
| RADAR | Radio Detection And Ranging |
| RAIL | Randomized Adversarial Imitation Learning |
| RRTs | Rapidly Explored Random Trees |
| SAE | Society of Automotive Engineers |
| TU | Transferable Utility |
| V2P | Vehicle-to-Pedestrian |
| V2V | Vehicle-to-Vehicle |
| V2VX | Vehicle-to-Everything |
| VRU | Vulnerable Road User |
| XAI | Explainable AI |
References
- Batkovic, I. Enabling Safe Autonomous Driving in Uncertain Environments. Ph.D. Thesis, Chalmers Tekniska Hogskola, Gothenburg, Sweden, 2022. [Google Scholar]
- J3016_201806; Taxonomy and Definitions for Terms Related to Driving Automation Systems for on-Road Motor Vehicles. SAE International: Warrendale, PA, USA, 2016.
- Claussmann, L.; Revilloud, M.; Gruyer, D.; Glaser, S. A review of motion planning for highway autonomous driving. IEEE Trans. Intell. Transp. Syst. 2019, 21, 1826–1848. [Google Scholar] [CrossRef] [Green Version]
- Pendleton, S.D.; Andersen, H.; Du, X.; Shen, X.; Meghjani, M.; Eng, Y.H.; Rus, D.; Ang, M.H. Perception, planning, control, and coordination for autonomous vehicles. Machines 2017, 5, 6. [Google Scholar] [CrossRef]
- Katrakazas, C.; Quddus, M.; Chen, W.H.; Deka, L. Real-time motion planning methods for autonomous on-road driving: State-of-the-art and future research directions. Transp. Res. Part C Emerg. Technol. 2015, 60, 416–442. [Google Scholar] [CrossRef]
- Janai, J.; Güney, F.; Behl, A.; Geiger, A.; Geiger, A. Computer vision for autonomous vehicles: Problems, datasets and state of the art. Found. Trends Comput. Graph. Vis. 2020, 12, 1–308. [Google Scholar] [CrossRef]
- Paden, B.; Čáp, M.; Yong, S.Z.; Yershov, D.; Frazzoli, E. A survey of motion planning and control techniques for self-driving urban vehicles. IEEE Trans. Intell. Veh. 2016, 1, 33–55. [Google Scholar] [CrossRef] [Green Version]
- Hoel, C.J.E. Decision-Making in Autonomous Driving Using Reinforcement Learning. Ph.D. Thesis, Chalmers Tekniska Hogskola, Gothenburg, Sweden, 2021. [Google Scholar]
- Schwarting, W.; Alonso-Mora, J.; Rus, D. Planning and decision-making for autonomous vehicles. Annu. Rev. Control. Robot. Auton. Syst. 2018, 1, 187–210. [Google Scholar] [CrossRef]
- Li, S.; Shu, K.; Chen, C.; Cao, D. Planning and decision-making for connected autonomous vehicles at road intersections: A review. Chin. J. Mech. Eng. 2021, 34, 1–18. [Google Scholar] [CrossRef]
- Leon, F.; Gavrilescu, M. A Review of Tracking and Trajectory Prediction Methods for Autonomous Driving. Mathematics 2021, 9, 660. [Google Scholar] [CrossRef]
- Khan, M.A.; Sayed, H.E.; Malik, S.; Zia, T.; Khan, J.; Alkaabi, N.; Ignatious, H. Level-5 Autonomous Driving—Are We There Yet? A Review of Research Literature. ACM Comput. Surv. 2022, 55, 1–38. [Google Scholar] [CrossRef]
- Malik, S.; Khan, M.A.; El-Sayed, H. Collaborative autonomous driving—A survey of solution approaches and future challenges. Sensors 2021, 21, 3783. [Google Scholar] [CrossRef] [PubMed]
- Deshpande, N.; Vaufreydaz, D.; Spalanzani, A. Behavioral decision-making for urban autonomous driving in the presence of pedestrians using Deep Recurrent Q-Network. In Proceedings of the 2020 16th International Conference on Control, Automation, Robotics and Vision (ICARCV), Shenzhen, China, 13–15 December 2020; IEEE: Piscataway, NJ, USA, 2020; pp. 428–433. [Google Scholar]
- Bahram, M. Interactive Maneuver Prediction and Planning for Highly Automated Driving Functions. Ph.D. Thesis, Technische Universität München, Munich, Germany, 2017. [Google Scholar]
- Palatti, J.; Aksjonov, A.; Alcan, G.; Kyrki, V. Planning for Safe Abortable Overtaking Maneuvers in Autonomous Driving. In Proceedings of the 2021 IEEE International Intelligent Transportation Systems Conference (ITSC), Indianapolis, IN, USA, 19–22 September 2021; IEEE: Piscataway, NJ, USA, 2021; pp. 508–514. [Google Scholar]
- DARPA Urban Challenge. Available online: https://www.darpa.mil/about-us/timeline/darpa-urban-challenge (accessed on 25 February 2022).
- Urmson, C.; Bagnell, J.A.; Baker, C.; Hebert, M.; Kelly, A.; Rajkumar, R.; Rybski, P.E.; Scherer, S.; Simmons, R.; Singh, S.; et al. Tartan Racing: A Multi-Modal Approach to the Darpa Urban Challenge; Carnegie Mellon University: Pittsburgh, PA, USA, 2007. [Google Scholar]
- Montemerlo, M.; Becker, J.; Bhat, S.; Dahlkamp, H.; Dolgov, D.; Ettinger, S.; Haehnel, D.; Hilden, T.; Hoffmann, G.; Huhnke, B.; et al. Junior: The stanford entry in the urban challenge. J. Field Robot. 2008, 25, 569–597. [Google Scholar] [CrossRef] [Green Version]
- Wang, P.; Liu, D.; Chen, J.; Li, H.; Chan, C.Y. Decision making for autonomous driving via augmented adversarial inverse reinforcement learning. In Proceedings of the 2021 IEEE International Conference on Robotics and Automation (ICRA), Xi’an, China, 30 May–5 June 2021; IEEE: Piscataway, NJ, USA, 2021; pp. 1036–1042. [Google Scholar]
- Ardelt, M.; Waldmann, P.; Homm, F.; Kaempchen, N. Strategic decision-making process in advanced driver assistance systems. IFAC Proc. Vol. 2010, 43, 566–571. [Google Scholar] [CrossRef]
- Ziegler, J.; Bender, P.; Schreiber, M.; Lategahn, H.; Strauss, T.; Stiller, C.; Dang, T.; Franke, U.; Appenrodt, N.; Keller, C.G.; et al. Making bertha drive—An autonomous journey on a historic route. IEEE Intell. Transp. Syst. Mag. 2014, 6, 8–20. [Google Scholar] [CrossRef]
- Yu, L.; Kong, D.; Yan, X. A driving behavior planning and trajectory generation method for autonomous electric bus. Future Internet 2018, 10, 51. [Google Scholar] [CrossRef] [Green Version]
- Olsson, M. Behavior Trees for Decision-Making in Autonomous Driving. 2016. Available online: https://www.semanticscholar.org/paper/Behavior-Trees-for-decision-making-in-Autonomous-Olsson/2fe811fd9b8e466aa353d94ee7cf67ebae456e91 (accessed on 2 September 2022).
- Gu, T.; Dolan, J.M.; Lee, J.W. Automated tactical maneuver discovery, reasoning and trajectory planning for autonomous driving. In Proceedings of the 2016 IEEE/RSJ International Conference on Intelligent Robots and Systems (IROS), Daejeon, Korea, 9–14 October 2016; IEEE: Piscataway, NJ, USA, 2016; pp. 5474–5480. [Google Scholar]
- Artunedo, A.; Villagra, J.; Godoy, J. Real-time motion planning approach for automated driving in urban environments. IEEE Access 2019, 7, 180039–180053. [Google Scholar] [CrossRef]
- Artuñedo, A.; Godoy, J.; Villagra, J. A decision-making architecture for automated driving without detailed prior maps. In Proceedings of the 2019 IEEE Intelligent Vehicles Symposium (IV), Paris, France, 9–12 June 2019; IEEE: Piscataway, NJ, USA, 2019; pp. 1645–1652. [Google Scholar]
- Chang, C.W.; Lv, C.; Wang, H.; Wang, H.; Cao, D.; Velenis, E.; Wang, F.Y. Multi-point turn decision making framework for human-like automated driving. In Proceedings of the 2017 IEEE 20th International Conference on Intelligent Transportation Systems (ITSC), Yokohama, Japan, 16–19 October 2017; IEEE: Piscataway, NJ, USA, 2017; pp. 1–6. [Google Scholar]
- Orzechowski, P.F.; Burger, C.; Lauer, M. Decision-making for automated vehicles using a hierarchical behavior-based arbitration scheme. In Proceedings of the 2020 IEEE Intelligent Vehicles Symposium (IV), Las Vegas, NV, USA, 19 October–13 November 2020; IEEE: Piscataway, NJ, USA, 2020; pp. 767–774. [Google Scholar]
- Nilsson, J.; Silvlin, J.; Brannstrom, M.; Coelingh, E.; Fredriksson, J. If, when, and how to perform lane change maneuvers on highways. IEEE Intell. Transp. Syst. Mag. 2016, 8, 68–78. [Google Scholar] [CrossRef]
- Aksjonov, A.; Kyrki, V. Rule-Based Decision-Making System for Autonomous Vehicles at Intersections with Mixed Traffic Environment. In Proceedings of the 2021 IEEE International Intelligent Transportation Systems Conference (ITSC), Indianapolis, IN, USA, 19–22 September 2021; IEEE: Piscataway, NJ, USA, 2021; pp. 660–666. [Google Scholar]
- Thurachen, S. Decision Making in Autonomous Driving by Integrating Rules with Deep Reinforcement Learning. Master’s Thesis, Aalto University, Singapore, 2022. [Google Scholar]
- Hoel, C.J. Tactical Decision Making for Autonomous Driving: A Reinforcement Learning Approach. Ph.D. Thesis, Chalmers University of Technology, Gothenburg, Sweden, 2019. [Google Scholar]
- Qiao, Z. Reinforcement Learning for Behavior Planning of Autonomous Vehicles in Urban Scenarios. Ph.D. Thesis, Carnegie Mellon University, Pittsburgh, PA, USA, 2021. [Google Scholar]
- Hoel, C.J.; Driggs-Campbell, K.; Wolff, K.; Laine, L.; Kochenderfer, M.J. Combining planning and deep reinforcement learning in tactical decision making for autonomous driving. IEEE Trans. Intell. Veh. 2019, 5, 294–305. [Google Scholar] [CrossRef] [Green Version]
- Hubmann, C.; Aeberhard, M.; Stiller, C. A generic driving strategy for urban environments. In Proceedings of the 2016 IEEE 19th International Conference on Intelligent Transportation Systems (ITSC), Rio de Janeiro, Brazil, 1–4 November 2016; IEEE: Piscataway, NJ, USA, 2016; pp. 1010–1016. [Google Scholar]
- Liu, W.; Kim, S.W.; Chong, Z.J.; Shen, X.; Ang, M.H. Motion planning using cooperative perception on urban road. In Proceedings of the 2013 6th IEEE Conference on Robotics, Automation and Mechatronics (RAM), Manila, Philippines, 12–15 November 2013; IEEE: Piscataway, NJ, USA, 2013; pp. 130–137. [Google Scholar]
- Arab, A.; Yu, K.; Yi, J.; Song, D. Motion planning for aggressive autonomous vehicle maneuvers. In Proceedings of the 2016 IEEE International Conference on Automation Science and Engineering (CASE), Fort Worth, TX, USA, 21–25 August 2016; IEEE: Piscataway, NJ, USA, 2016; pp. 221–226. [Google Scholar]
- Li, H.; Yu, G.; Zhou, B.; Li, D.; Wang, Z. Trajectory Planning of Autonomous Driving Vehicles Based on Road-Vehicle Fusion. In Proceedings of the 20th COTA International Conference of Transportation Professionals, Xi’an, China, 14–16 August 2020; pp. 816–828. [Google Scholar]
- Hegedus, T.; Németh, B.; Gáspár, P. Design of a low-complexity graph-based motion-planning algorithm for autonomous vehicles. Appl. Sci. 2020, 10, 7716. [Google Scholar] [CrossRef]
- Speidel, O.; Ruof, J.; Dietmayer, K. Graph-Based Motion Planning For Automated Vehicles Using Multi-Model Branching And Admissible Heuristics. In Proceedings of the 2021 IEEE International Conference on Autonomous Systems (ICAS), Montreal, QC, Canada, 11–13 August 2021; IEEE: Piscataway, NJ, USA, 2021; pp. 1–5. [Google Scholar]
- Li, Z.; Jiang, J.; Chen, W.H. Automatic Lane Merge based on Model Predictive Control. In Proceedings of the 2021 26th International Conference on Automation and Computing (ICAC), Portsmouth, UK, 2–4 September 2021; IEEE: Piscataway, NJ, USA, 2021; pp. 1–6. [Google Scholar]
- Lin, Y.C.; Lin, C.L.; Huang, S.T.; Kuo, C.H. Implementation of an Autonomous Overtaking System Based on Time to Lane Crossing Estimation and Model Predictive Control. Electronics 2021, 10, 2293. [Google Scholar] [CrossRef]
- Viana, Í.B.; Kanchwala, H.; Aouf, N. Cooperative trajectory planning for autonomous driving using nonlinear model predictive control. In Proceedings of the 2019 IEEE International Conference on Connected Vehicles and Expo (ICCVE), Graz, Austria, 4–8 November 2019; IEEE: Piscataway, NJ, USA, 2019; pp. 1–6. [Google Scholar]
- Bey, H.; Dierkes, F.; Bayerl, S.; Lange, A.; Faßender, D.; Thielecke, J. Optimization-based tactical behavior planning for autonomous freeway driving in favor of the traffic flow. In Proceedings of the 2019 IEEE Intelligent Vehicles Symposium (IV), Paris, France, 9–12 June 2019; IEEE: Piscataway, NJ, USA, 2019; pp. 1033–1040. [Google Scholar]
- Yang, D.; Redmill, K.; Özgüner, Ü. A multi-state social force based framework for vehicle-pedestrian interaction in uncontrolled pedestrian crossing scenarios. In Proceedings of the 2020 IEEE Intelligent Vehicles Symposium (IV), Las Vegas, NV, USA, 19 October–13 November 2020; IEEE: Piscataway, NJ, USA, 2020; pp. 1807–1812. [Google Scholar]
- Sun, L.; Zhan, W.; Chan, C.Y.; Tomizuka, M. Behavior planning of autonomous cars with social perception. In Proceedings of the 2019 IEEE Intelligent Vehicles Symposium (IV), Paris, France, 9–12 June 2019; IEEE: Piscataway, NJ, USA, 2019; pp. 207–213. [Google Scholar]
- Werling, M.; Ziegler, J.; Kammel, S.; Thrun, S. Optimal trajectory generation for dynamic street scenarios in a frenet frame. In Proceedings of the 2010 IEEE International Conference on Robotics and Automation, Anchorage, Alaska, 3–8 May 2010; IEEE: Piscataway, NJ, USA, 2010; pp. 987–993. [Google Scholar]
- Chandiramani, J. Decision Making under Uncertainty for Automated Vehicles in Urban Situations. Master’s Thesis, Delft University of Technology, Delft, The Netherlands, 2017. [Google Scholar]
- Peng, B.; Yu, D.; Zhou, H.; Xiao, X.; Xie, C. A Motion Planning Method for Automated Vehicles in Dynamic Traffic Scenarios. Symmetry 2022, 14, 208. [Google Scholar] [CrossRef]
- Lima, P.F. Optimization-Based Motion Planning and Model Predictive Control for Autonomous Driving: With Experimental Evaluation on a Heavy-Duty Construction Truck. Ph.D. Thesis, KTH Royal Institute of Technology, Stockholm, Sweden, 2018. [Google Scholar]
- Liu, Q.; Li, X.; Yuan, S.; Li, Z. Decision-Making Technology for Autonomous Vehicles: Learning-Based Methods, Applications and Future Outlook. In Proceedings of the 2021 IEEE International Intelligent Transportation Systems Conference (ITSC), Indianapolis, IN, USA, 19–22 September 2021; IEEE: Piscataway, NJ, USA, 2021; pp. 30–37. [Google Scholar]
- Ma, J.; Xie, H.; Song, K.; Liu, H. Self-Optimizing Path Tracking Controller for Intelligent Vehicles Based on Reinforcement Learning. Symmetry 2022, 14, 31. [Google Scholar] [CrossRef]
- Liu, S.; Zheng, K.; Zhao, L.; Fan, P. A driving intention prediction method based on hidden Markov model for autonomous driving. Comput. Commun. 2020, 157, 143–149. [Google Scholar] [CrossRef] [Green Version]
- Hsu, T.M.; Chen, Y.R.; Wang, C.H. Decision Making Process of Autonomous Vehicle with Intention-Aware Prediction at Unsignalized Intersections. In Proceedings of the 2020 International Automatic Control Conference (CACS), Hsinchu, Taiwan, 4–7 November 2020; IEEE: Piscataway, NJ, USA, 2020; pp. 1–4. [Google Scholar]
- Song, W.; Xiong, G.; Chen, H. Intention-aware autonomous driving decision-making in an uncontrolled intersection. Math. Probl. Eng. 2016, 2016, 1025349. [Google Scholar] [CrossRef] [Green Version]
- Hubmann, C.; Schulz, J.; Becker, M.; Althoff, D.; Stiller, C. Automated driving in uncertain environments: Planning with interaction and uncertain maneuver prediction. IEEE Trans. Intell. Veh. 2018, 3, 5–17. [Google Scholar] [CrossRef]
- Huang, Y.; Zhao, W.; Xu, C.; Zou, S.; Zhang, H. An IMM-based POMDP decision algorithm using collision-risk function in mandatory lane change. Proc. Inst. Mech. Eng. Part D J. Automob. Eng. 2021, 236, 1500–1514. [Google Scholar] [CrossRef]
- Coskun, S.; Langari, R. Predictive fuzzy markov decision strategy for autonomous driving in highways. In Proceedings of the 2018 IEEE Conference on Control Technology and Applications (CCTA), Copenhagen, Denmark, 21–24 August 2018; IEEE: Piscataway, NJ, USA, 2018; pp. 1032–1039. [Google Scholar]
- Song, W.; Su, B.; Xiong, G.; Li, S. Intention-aware Decision Making in Urban Lane Change Scenario for Autonomous Driving. In Proceedings of the 2018 IEEE International Conference on Vehicular Electronics and Safety (ICVES), Madrid, Spain, 12–14 September 2018; IEEE: Piscataway, NJ, USA, 2018; pp. 1–8. [Google Scholar]
- Zhang, C.; Steinhauser, F.; Hinz, G.; Knoll, A. Traffic Mirror-Aware POMDP Behavior Planning for Autonomous Urban Driving. In Proceedings of the 2022 IEEE Intelligent Vehicles Symposium (IV), Aachen, Germany, 13 February 2022; IEEE: Piscataway, NJ, USA, 2022; pp. 323–330. [Google Scholar]
- Sierra Gonzalez, D. Towards Human-Like Prediction and Decision-Making for Automated Vehicles in Highway Scenarios. Ph.D. Thesis, Université Grenoble Alpes (ComUE), Saint-Martin-d’Hères, France, 2019. [Google Scholar]
- Saad, W. Coalitional Game Theory for Distributed Cooperation in Next Generation Wireless Networks. Ph.D. Thesis, University of Oslo, Oslo, Norway, 2010. [Google Scholar]
- Zhao, X.; Chen, Y.H.; Dong, F.; Zhang, B. A Leader–Follower Sequential Game Approach to Optimizing Parameters for Intelligent Vehicle Formation Control. Int. J. Fuzzy Syst. 2022, 24, 1390–1405. [Google Scholar] [CrossRef]
- Hang, P.; Lv, C.; Huang, C.; Xing, Y.; Hu, Z. Cooperative decision making of connected automated vehicles at multi-lane merging zone: A coalitional game approach. IEEE Trans. Intell. Transp. Syst. 2021, 23, 3829–3841. [Google Scholar] [CrossRef]
- Wang, H.; Meng, Q.; Chen, S.; Zhang, X. Competitive and cooperative behaviour analysis of connected and autonomous vehicles across unsignalised intersections: A game-theoretic approach. Transp. Res. Part B Methodol. 2021, 149, 322–346. [Google Scholar] [CrossRef]
- Hu, Z.; Huang, J.; Yang, Z.; Zhong, Z. Cooperative-game-theoretic optimal robust path tracking control for autonomous vehicles. J. Vib. Control 2022, 28, 520–535. [Google Scholar] [CrossRef]
- Liu, M.; Wan, Y.; Lewis, F.L.; Nageshrao, S.; Filev, D. A Three-Level Game-Theoretic Decision-Making Framework for Autonomous Vehicles. IEEE Trans. Intell. Transp. Syst. 2022. [Google Scholar] [CrossRef]
- Mabrouk, A.; Naja, A.; Oualhaj, O.A.; Kobbane, A.; Boulmalf, M. A cooperative game based mechanism for autonomous organization and ubiquitous connectivity in VANETs. Simul. Model. Pract. Theory 2021, 107, 102213. [Google Scholar] [CrossRef]
- Hang, P.; Lv, C.; Huang, C.; Hu, Z. Cooperative Decision Making of Lane-change for Automated Vehicles Considering Human-like Driving Characteristics. In Proceedings of the 2021 40th Chinese Control Conference (CCC), Shanghai, China, 26–28 July 2021; IEEE: Piscataway, NJ, USA, 2021; pp. 6106–6111. [Google Scholar]
- Hang, P.; Huang, C.; Hu, Z.; Lv, C. Decision Making for Connected Automated Vehicles at Urban Intersections Considering Social and Individual Benefits. arXiv 2022, arXiv:2201.01428. [Google Scholar] [CrossRef]
- Bui, K.H.N.; Jung, J.J. Cooperative game-theoretic approach to traffic flow optimization for multiple intersections. Comput. Electr. Eng. 2018, 71, 1012–1024. [Google Scholar]
- Wei, H.; Mashayekhy, L.; Papineau, J. Intersection management for connected autonomous vehicles: A game theoretic framework. In Proceedings of the 2018 21st International Conference on Intelligent Transportation Systems (ITSC), Maui, HI, USA, 4–7 November 2018; IEEE: Piscataway, NJ, USA, 2018; pp. 583–588. [Google Scholar]
- Calvo, J.A.L.; Mathar, R. Connected Vehicles Coordination: A Coalitional Game-Theory Approach. In Proceedings of the 2018 European Conference on Networks and Communications (EuCNC), Ljubljana, Slovenia, 18–21 June 2018; IEEE: Piscataway, NJ, USA, 2018; pp. 1–6. [Google Scholar]
- Khan, M.A.; Boloni, L. Convoy driving through ad-hoc coalition formation. In Proceedings of the 11th IEEE Real Time and Embedded Technology and Applications Symposium, San Francisco, CA, USA, 7–10 March 2005; IEEE: Piscataway, NJ, USA, 2005; pp. 98–105. [Google Scholar]
- Liu, Y.; Zong, C.; Han, X.; Zhang, D.; Zheng, H.; Shi, C. Spacing Allocation Method for Vehicular Platoon: A Cooperative Game Theory Approach. Appl. Sci. 2020, 10, 5589. [Google Scholar] [CrossRef]
- Hadded, M.; Minet, P.; Lasgouttes, J.M. A game theory-based route planning approach for automated vehicle collection. Concurr. Comput. Pract. Exp. 2021, 33, e6246. [Google Scholar] [CrossRef]
- Kiennert, C.; Ismail, Z.; Debar, H.; Leneutre, J. A survey on game-theoretic approaches for intrusion detection and response optimization. ACM Comput. Surv. 2018, 51, 1–31. [Google Scholar] [CrossRef]
- Talebpour, A.; Mahmassani, H.S.; Hamdar, S.H. Modeling lane-changing behavior in a connected environment: A game theory approach. Transp. Res. Procedia 2015, 7, 420–440. [Google Scholar] [CrossRef] [Green Version]
- Hang, P.; Lv, C.; Xing, Y.; Huang, C.; Hu, Z. Human-like decision making for autonomous driving: A noncooperative game theoretic approach. IEEE Trans. Intell. Transp. Syst. 2020, 22, 2076–2087. [Google Scholar] [CrossRef]
- Bachute, M.R.; Subhedar, J.M. Autonomous driving architectures: Insights of machine learning and deep learning algorithms. Mach. Learn. Appl. 2021, 6, 100164. [Google Scholar] [CrossRef]
- Yuan, T.; da Rocha Neto, W.; Rothenberg, C.E.; Obraczka, K.; Barakat, C.; Turletti, T. Machine learning for next-generation intelligent transportation systems: A survey. Trans. Emerg. Telecommun. Technol. 2022, 33, e4427. [Google Scholar] [CrossRef]
- Shetty, S.H.; Shetty, S.; Singh, C.; Rao, A. Supervised Machine Learning: Algorithms and Applications. In Fundamentals and Methods of Machine and Deep Learning: Algorithms, Tools and Applications; John Wiley & Sons, Inc.: Hoboken, NJ, USA, 2022; pp. 1–16. [Google Scholar]
- Lv, K.; Pei, X.; Chen, C.; Xu, J. A Safe and Efficient Lane Change Decision-Making Strategy of Autonomous Driving Based on Deep Reinforcement Learning. Mathematics 2022, 10, 1551. [Google Scholar] [CrossRef]
- Li, G.; Yang, Y.; Li, S.; Qu, X.; Lyu, N.; Li, S.E. Decision making of autonomous vehicles in lane change scenarios: Deep reinforcement learning approaches with risk awareness. Transp. Res. Part C Emerg. Technol. 2022, 134, 103452. [Google Scholar] [CrossRef]
- García Cuenca, L.; Puertas, E.; Fernandez Andrés, J.; Aliane, N. Autonomous driving in roundabout maneuvers using reinforcement learning with Q-learning. Electronics 2019, 8, 1536. [Google Scholar] [CrossRef] [Green Version]
- Zhang, Y.; Gao, B.; Guo, L.; Guo, H.; Chen, H. Adaptive decision-making for automated vehicles under roundabout scenarios using optimization embedded reinforcement learning. IEEE Trans. Neural Netw. Learn. Syst. 2020, 32, 5526–5538. [Google Scholar]
- Prathiba, S.B.; Raja, G.; Dev, K.; Kumar, N.; Guizani, M. A hybrid deep reinforcement learning for autonomous vehicles smart-platooning. IEEE Trans. Veh. Technol. 2021, 70, 13340–13350. [Google Scholar] [CrossRef]
- Chen, J.; Li, S.E.; Tomizuka, M. Interpretable end-to-end urban autonomous driving with latent deep reinforcement learning. IEEE Trans. Intell. Transp. Syst. 2021, 23, 5068–5078. [Google Scholar] [CrossRef]
- Wang, H.; Gao, H.; Yuan, S.; Zhao, H.; Wang, K.; Wang, X.; Li, K.; Li, D. Interpretable decision-making for autonomous vehicles at highway on-ramps with latent space reinforcement learning. IEEE Trans. Veh. Technol. 2021, 70, 8707–8719. [Google Scholar] [CrossRef]
- Chen, J.; Xu, Z.; Tomizuka, M. End-to-end autonomous driving perception with sequential latent representation learning. In Proceedings of the 2020 IEEE/RSJ International Conference on Intelligent Robots and Systems (IROS), Las Vegas, NV, USA, 25–29 October 2020; IEEE: Piscataway, NJ, USA, 2020; pp. 1999–2006. [Google Scholar]
- Mei, X.; Sun, Y.; Chen, Y.; Liu, C.; Liu, M. Autonomous Navigation through intersections with Graph ConvolutionalNetworks and Conditional Imitation Learning for Self-driving Cars. arXiv 2021, arXiv:2102.00675. [Google Scholar]
- Haydari, A.; Yilmaz, Y. Deep reinforcement learning for intelligent transportation systems: A survey. IEEE Trans. Intell. Transp. Syst. 2020, 23, 11–32. [Google Scholar] [CrossRef]
- Kiran, B.R.; Sobh, I.; Talpaert, V.; Mannion, P.; Al Sallab, A.A.; Yogamani, S.; Pérez, P. Deep reinforcement learning for autonomous driving: A survey. IEEE Trans. Intell. Transp. Syst. 2021, 23, 4909–4926. [Google Scholar] [CrossRef]
- Chen, J.; Yuan, B.; Tomizuka, M. Deep imitation learning for autonomous driving in generic urban scenarios with enhanced safety. In Proceedings of the 2019 IEEE/RSJ International Conference on Intelligent Robots and Systems (IROS), Macau, China, 3–8 November 2019; IEEE: Piscataway, NJ, USA, 2019; pp. 2884–2890. [Google Scholar]
- Wang, W.; Jiang, L.; Lin, S.; Fang, H.; Meng, Q. Imitation learning based decision-making for autonomous vehicle control at traffic roundabouts. Multimed. Tools Appl. 2022, 1–17. [Google Scholar] [CrossRef]
- Yun, W.J.; Shin, M.; Jung, S.; Kwon, S.; Kim, J. Parallelized and randomized adversarial imitation learning for safety-critical self-driving vehicles. J. Commun. Netw. 2022. [Google Scholar] [CrossRef]
- Bhattacharyya, R.P.; Phillips, D.J.; Liu, C.; Gupta, J.K.; Driggs-Campbell, K.; Kochenderfer, M.J. Simulating emergent properties of human driving behavior using multi-agent reward augmented imitation learning. In Proceedings of the 2019 International Conference on Robotics and Automation (ICRA), Montreal, QC, Canada, 20–24 May 2019; IEEE: Piscataway, NJ, USA, 2019; pp. 789–795. [Google Scholar]
- Hussein, A.; Gaber, M.M.; Elyan, E.; Jayne, C. Imitation learning: A survey of learning methods. ACM Comput. Surv. 2017, 50, 1–35. [Google Scholar] [CrossRef]
- Nozari, S.; Krayani, A.; Marin-Plaza, P.; Marcenaro, L.; Gómez, D.M.; Regazzoni, C. Active Inference Integrated With Imitation Learning for Autonomous Driving. IEEE Access 2022, 10, 49738–49756. [Google Scholar] [CrossRef]
- Le Mero, L.; Yi, D.; Dianati, M.; Mouzakitis, A. A survey on imitation learning techniques for end-to-end autonomous vehicles. IEEE Trans. Intell. Transp. Syst. 2022, 23, 14128–14147. [Google Scholar] [CrossRef]
- Zheng, B.; Verma, S.; Zhou, J.; Tsang, I.W.; Chen, F. Imitation Learning: Progress, Taxonomies and Opportunities. arXiv 2021, arXiv:2106.12177. [Google Scholar]
- Policy, F.A.V. Accelerating the next revolution in roadway safety. ITE J. 2016, 86, 11–13. [Google Scholar]
- Sado, F.; Loo, C.K.; Liew, W.S.; Kerzel, M.; Wermter, S. Explainable Goal-Driven Agents and Robots—A Comprehensive Review. arXiv 2020, arXiv:2004.09705. [Google Scholar] [CrossRef]
- Korpan, R.; Epstein, S.L. Toward natural explanations for a robot’s navigation plans. In Proceedings of the HRI WS on Explainable Robotic Systems, Chicago, IL, USA, 5–8 March 2018. [Google Scholar]
- Borgo, R.; Cashmore, M.; Magazzeni, D. Towards providing explanations for AI planner decisions. arXiv 2018, arXiv:1810.06338. [Google Scholar]
- Bidot, J.; Biundo, S.; Heinroth, T.; Minker, W.; Nothdurft, F.; Schattenberg, B. Verbal Plan Explanations for Hybrid Planning. In Proceedings of the MKWI, Goettingen, Germany, 23–25 February 2010; pp. 2309–2320. [Google Scholar]
- Global Status Report on Road Safety 2018. Available online: https://www.who.int/publications/i/item/9789241565684 (accessed on 28 August 2022).
- Montanaro, U.; Dixit, S.; Fallah, S.; Dianati, M.; Stevens, A.; Oxtoby, D.; Mouzakitis, A. Towards connected autonomous driving: Review of use-cases. Veh. Syst. Dyn. 2019, 57, 779–814. [Google Scholar] [CrossRef]




{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
| Route Planning | Prediction | Decision Making | Generation | Deformation | |
|---|---|---|---|---|---|
| Space | >100 m | >1 m <100 m | >10 m <100 m | >10 m <100 m | >0.5 m <10 ms |
| Time | >1 min <1 h | >1 s <1 min | >1 s <1 min | >1 s <1 min | >10 ms <1 s |
| Decision Making Approaches | Advantages | Disadvantages | ||
|---|---|---|---|---|
| Classical Approaches | Rule Based | Finite State Machine/ Hierarchical FSM | 1. Good decision-making breadth. 2. Easy to understand and debug [49]. 3. Easy to implement and efficient in deterministic decision-making [16]. | 1. Results in poor explainability, maintainability, and scalability 2. Fully reliant on knowledge certainty and can not be generalized to unknown situations. |
| Specific Rule Based | 1. Simple, reliable, and easy to interpret [10]. 2. Applicability is superior in simple use cases such as lane change [10]. | 1. Cyclic reasoning and the exhaustive enumeration of rules leading to infinite loop and impact the computation time [3]. 2. Cannot maintain safe and efficient driving [10]. 3. Deemed applicable to the L-2 to L-4 and task-driven autonomous driving modes. | ||
| Planning Based | Graph Based | 1. Strong path searching capability in complex spaces [50]. 2. Implementation and formulation is usually simpler, more scalable, and modular [51]. | Real-time performance is hard to achieve with graph-search algorithms [8]. | |
| Optimization Based | 1. Allows for a large action set to be used and optimized decisions can be generated [49,52]. 2. Interaction between different traffic participants can be modeled better [52]. | 1. Do not have the provision to consider uncertainty [49]. 2. Challenging to guarantee real-time performance and convergence [51]. 3. MPC requires a heavy computational load, due to its complex design and is unsuitable for high-speed autonomous driving and complex road trajectories [53]. | ||
| Coalitional Game Type | Ref. | Use Case/Application | Coalition of What? | Coalition Type | Cost Function Parameters/Metrics | Solution Concept | Simulator/Tool |
|---|---|---|---|---|---|---|---|
| Coalitional Formation | [65] | Multi-lane merging scenario | Connected AVs | Single Player, multi-player, grand & sub-coalition | Safety, Comfort, Efficiency | - | MATLAB/Simulink |
| Cooperative Coalitional | [70] | Cooperative lane change decision making. | Vehicles | - | Safety, Comfort, Efficiency | - | MATLAB/Simulink |
| Fuzzy Coalitional Game | [71] | Decision-making framework for CAVs at unsignalized intersection. | Connected AVs | Single Player & grand coalition | Driving safety, passing efficiency | Fuzzy Shapley value | MATLAB/Simulink |
| Coalitional Formation | [72] | Traffic optimization at multiple intersections. | Intersections | Dynamic | (1) Waiting time of vehicles; (2) number of vehicles passing in a certain time. | Nash equilibrium | NetLogo Simulator |
| Coalitional Graph | [73] | Platoon for intersection scenario. | Lanes | - | Throughput, the ratio of accidents | Nash equilibrium | - |
| Coalitional Formation | [74] | Platooning | Vehicles | Dynamic | Mean load per path, mean travel time | Shapley value | - |
| Coalitional Formation | [75] | Convoy driving on the highway. | Vehicles | Dynamic | - | - | Motes Devices, YAES simulator |
| Hedonic Coalition Formation | [77] | Platoon allocation and route planning for a shared transportation system in an urban environment. | Parked vehicles | - | Average number of the platoon, maximum tour duration, totally consumed energy | Nash stable | Java |
| Coalitional Formation | [76] | Spacing allocation method for platooning. | Vehicles | - | - | Shapley value, value & lexicographic value | - |
Disclaimer/Publisher’s Note: The statements, opinions and data contained in all publications are solely those of the individual author(s) and contributor(s) and not of MDPI and/or the editor(s). MDPI and/or the editor(s) disclaim responsibility for any injury to people or property resulting from any ideas, methods, instructions or products referred to in the content. |
© 2022 by the authors. Licensee MDPI, Basel, Switzerland. This article is an open access article distributed under the terms and conditions of the Creative Commons Attribution (CC BY) license (https://creativecommons.org/licenses/by/4.0/).
Share and Cite
Malik, S.; Khan, M.A.; El-Sayed, H.; Khan, J.; Ullah, O. How Do Autonomous Vehicles Decide? Sensors 2023, 23, 317. https://doi.org/10.3390/s23010317
Malik S, Khan MA, El-Sayed H, Khan J, Ullah O. How Do Autonomous Vehicles Decide? Sensors. 2023; 23(1):317. https://doi.org/10.3390/s23010317
Chicago/Turabian StyleMalik, Sumbal, Manzoor Ahmed Khan, Hesham El-Sayed, Jalal Khan, and Obaid Ullah. 2023. "How Do Autonomous Vehicles Decide?" Sensors 23, no. 1: 317. https://doi.org/10.3390/s23010317
APA StyleMalik, S., Khan, M. A., El-Sayed, H., Khan, J., & Ullah, O. (2023). How Do Autonomous Vehicles Decide? Sensors, 23(1), 317. https://doi.org/10.3390/s23010317