1. Introduction
In the field of information security and the prevention of social crimes, covertly acquiring clear remote speech signals has become an important research topic [
1,
2]. For years, researchers have proposed a variety of methods for measuring vibration signals [
3,
4,
5,
6,
7,
8,
9,
10,
11], many of which are used in speech signal reconstruction and are based on laser. There are two main methods based on remote vibration signals detection: one is based on laser Doppler vibrometer (LDV) [
3,
4,
5,
6,
7,
8] and the other is optical sensing and image processing technologies [
9,
10,
11]. LDV has the advantages of non-contact, high spatial and temporal resolution, real-time processing. But LDV cannot fulfill the full field detection. The optical sensing and image processing technology is mainly divided into two types: natural light image processing [
12] and coherent light image processing [
13,
14,
15,
16]. The former has simple system structure and easy to implement. However, it requires high computational cost, and its processing speed is slow. In the 1980s, researchers of [
13,
14] proposed the method to extract subtle motion from speckle images. Additionally, in recent years, researchers have also reconstructed speech based on speckle images [
15,
16]. The principle of this method is to irradiate the rough surface object near the sound source with laser, and the reflected light interferes to form secondary speckle [
17]. Then the sound makes the surrounding objects vibrate slightly, which makes the speckle pattern shift slightly. The remote speech signal is reconstructed by extracting the small movement between speckle images. The system of remote speech reconstruction based on laser speckle pattern is mainly divided into two parts: the first is the construction of an optical system, which is used to collect continuous speckle image sequences; the second is the design of a reconstruction algorithm, which is used to detect movement from speckle images and reconstruct remote speech signal.
As regards optical system construction, ref. [
18] proposed a set of simplified optical equipment, it reduces the cost and realizes full-field non-contact detection. This optical device makes the technology more suitable for remote monitoring. The current laser technology and imaging technology can collect high-quality speckle images at a low price.
Regarding speech reconstruction algorithm, researchers have proposed a variety of methods, including digital image correlation (DIC) [
19,
20,
21,
22,
23,
24], optical flow method [
16,
25,
26], and intensity method [
27,
28]. Ref. [
29] proposed a geometric method to explain the motion of speckle. Ncorr [
20] is a digital correlation algorithm specially designed by researchers for two-dimensional images. In recent years, with the rapid development of machine learning and artificial intelligence technology, many neural-network-based methods have been proposed, such as convolutional neural network (CNN) [
30,
31,
32] and convolutional long short-term memory (LSTM) [
33].
At present, the detection method based on laser speckle images is the most suitable for this task, but the problem of frequency response has been found in the actual experiments and applications. We found that the speech signal reconstructed by this optical device [
18] has inhomogeneous enhancement or attenuation of speech components at different frequencies, and the frequency response of different vibration objects is different. Any object has a natural frequency, when the vibration sound wave of this natural frequency is transmitted to the object, the vibration amplitude of the object will have the maximum growth. Different objects have different natural frequencies, so the performance of frequency response is also different. This phenomenon greatly affects the accuracy of the reconstructed sound signal.
At present, many reconstruction algorithms ignore the frequency response, fewer algorithm is proposed to solve this problem. In this paper, a speech enhancement algorithm for different vibration objects is proposed to weaken the frequency response and improve the accuracy of speech reconstruction.
This paper has two main contributions.
The frequency response of long-distance speech reconstruction based on laser speckle image is proposed.
Our algorithm is a speech enhancement algorithm designed to reduce the influence of frequency response, which greatly improves the accuracy of reconstructed speech signals.
The rest of this paper is organized as follows:
Section 2 introduces the methodology of this paper, including DIC method and speech enhancement algorithm.
Section 3 present the experimental setup.
Section 4 introduces the experimental datasets and evaluation metrics.
Section 5 is the result.
Section 6 is the conclusion.
3. Experimental Setup
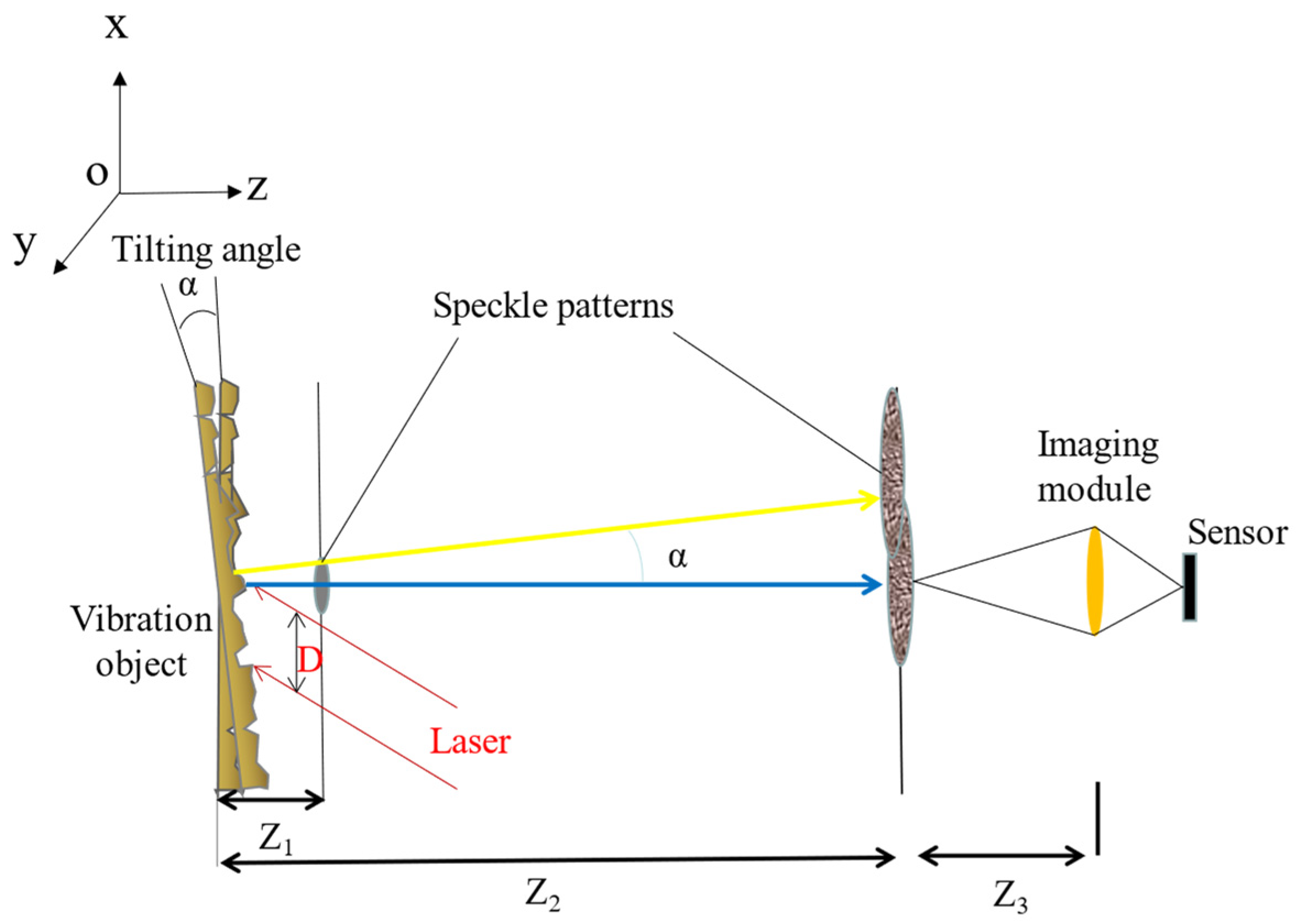
According to previous research results, the formation and acquisition process of laser speckle image can be set (as
Figure 8). Speckle is a three-dimensional ellipsoidal shape with its long axes facing the light propagation direction.
Figure 9 shows the experimental platform.
Figure 10 and
Figure 11 are the equipment simulation diagrams of two kinds of lasers, and
Figure 12 is the equipment physical map. The equipment used mainly includes:
The high-speed camera MVCAM AI-030U815M, with a maximum frame rate of 3200 frames per second (fps);
He-Ne laser (detailed parameters are shown in
Table 2);
Fiber laser (detailed parameters are shown in
Table 3);
Machine vision experiment frame, with fine-tuning camera clip and universal clip;
One personal computer (PC) with universal serial bus 3.0 (USB3.0) interface.
In this experiment, the high-speed camera is used to collect speckle images. The frame rate of the camera is closely related to the exposure interval. The process of speckle image acquisition by high-speed charge coupled device (CCD) camera can be regarded as uniform sampling of continuous speckle video. The sampling frequency
of the high-speed camera and the highest frequency of speech
need to satisfy the Nyquist theorem (Equation (11)).
Equation (11) shows that the frame rate of the high-speed camera should be greater than or equal to two times of the highest frequency of speech. The data in
Table 1 show the speech frequency range of male and female, and
= 1200 Hz. This paper considers that all the frequency ranges in the speech can be restored to meet the actual use requirements, so the frame rate of the high-speed camera is greater than or equal to 2400 fps. The frame rate of the high-speed camera used in this experiment is 3200 fps, which meets the basic requirements of speech reconstruction.
In conjunction with
Figure 1, we describe various physical parameters of speckle images. The first is the resolution of the speckle patterns in the
plane:
where
is the diameter of the laser beam,
are different distances in
Figure 1.
is the focal length of the lens.
is the optical wavelength.
The optical system has requirements for the focal length
. The size of the pixel in the detector is
. It is assumed that every speckle in this plane will be observed at least by
pixels. The requirements for
are as follows:
The distance
needs to be satisfied:
Finally, the number of speckles in every dimension of the spot is
:
where
is the is the diameter of the aperture of the lens,
is the
number of the lens,
represents the speckle size obtained on the
-plane.
6. Conclusions
The main innovation of this paper is to propose a speech enhancement algorithm to solve the frequency response problem of speech signal reconstruction from laser speckle images. The experimental results in this paper show that our speech enhancement algorithm can effectively improve the accuracy of reconstructed speech, and the comparison of the reconstruction accuracy of different vibration object datasets verifies the practicability of the algorithm. In the experimental results, we found that when the ambient noise is small and the vibration interference of the experimental platform is small, the reconstructed speech accuracy is high. Our algorithm achieves a major advance of reconstructing speech from laser speckle images.
Although our speech enhancement algorithm has an obvious effect on reducing the frequency response problem, it also introduces some noise signals while increasing the accuracy of the reconstructed speech. In order to obtain higher-definition speech signals, we also need to make further improvements to the speech enhancement algorithm. In the future, we will focus on reconstructing speech with a small frequency response and high definition.

















{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}