
Frequent and Automatic Update of Lane-Level HD Maps with a Large Amount of Crowdsourced Data Acquired from Buses and Taxis in Seoul


Abstract
:1. Introduction
2. Crowdsourced Data
3. Frequent and Automatic Update of HD Maps
3.1. Overview of Map Update
3.2. Loading ROD and HD Map
3.3. Observation Correction
3.3.1. Pose Correction
3.3.2. Validation Check
3.4. Observation Learner
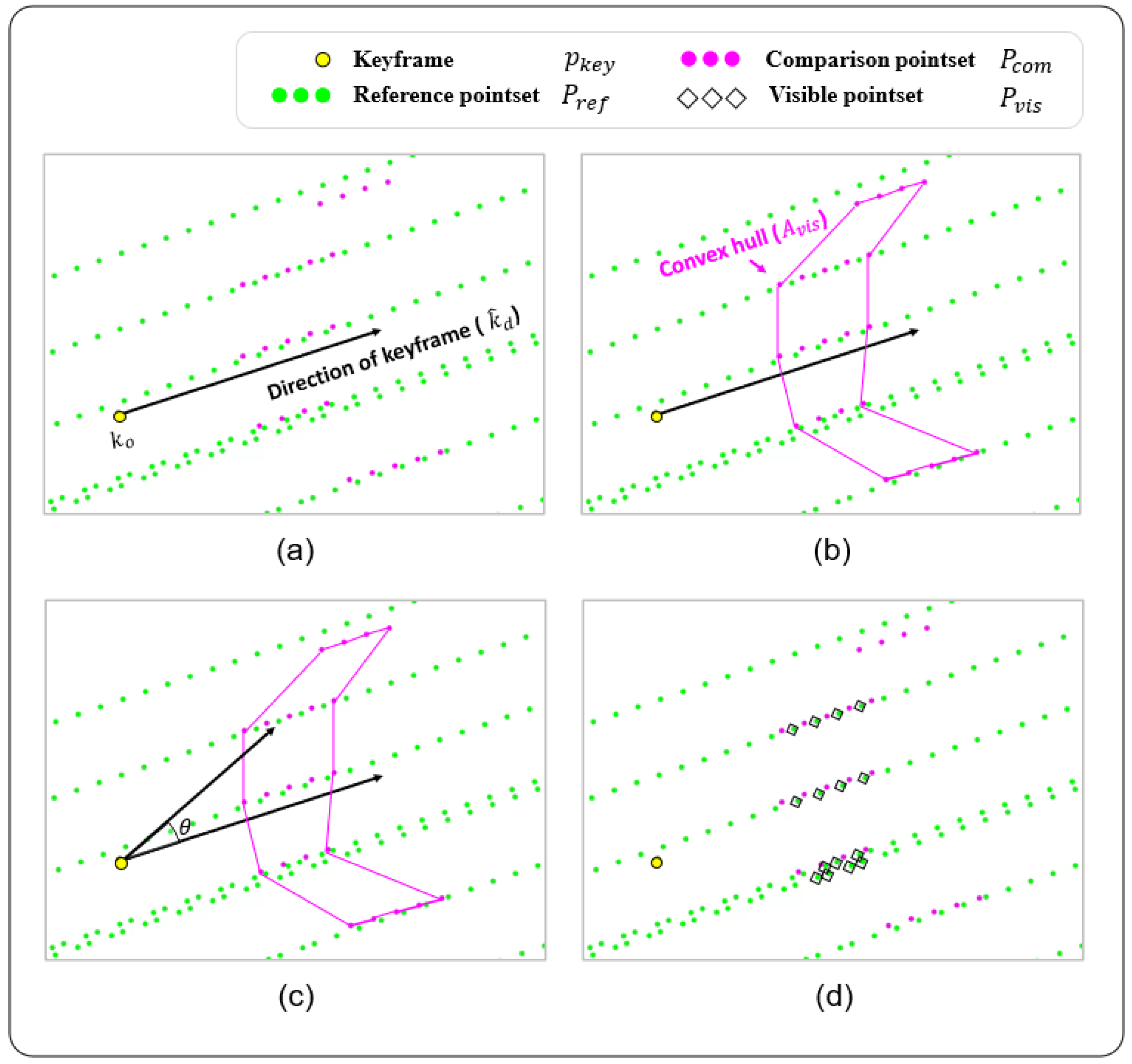
3.4.1. Observation Assignment
| Algorithm 1: Searching procedure for visible landmarks. |
 |
3.4.2. Observation Clustering
3.5. Landmark Update
3.5.1. Landmark Class Classification
| Algorithm 2: State estimation procedure for an existent landmark on the HD map. |
 |
3.5.2. Landmark State Update
4. Experimental Result
4.1. Validation Check Results
4.2. Qualitative Evaluation
4.3. Quantitative Evaluation
4.4. Updated HD Maps
5. Conclusions
Author Contributions
Funding
Institutional Review Board Statement
Informed Consent Statement
Data Availability Statement
Conflicts of Interest
References
- Aerometrex. Available online: https://aerometrex.com.au/ (accessed on 4 November 2022).
- Nearmap. Available online: https://www.nearmap.com/us/en/products/3d-mapping-dsm-textured-mesh-point-cloud (accessed on 4 November 2022).
- WRLD3D Augmented Reality Maps. Available online: https://www.wrld3d.com/3d-maps/augmented-reality-3d-maps (accessed on 4 November 2022).
- Tomtom HD Map. Available online: https://www.tomtom.com/products/hd-map/ (accessed on 4 November 2022).
- HERE HD Live Map. Available online: https://www.here.com/platform/HD-live-map (accessed on 4 November 2022).
- Ma, W.C.; Tartavull, I.; Bârsan, I.A.; Wang, S.; Bai, M.; Mattyus, G.; Homayounfar, N.; Lakshmikanth, S.K.; Pokrovsky, A.; Urtasun, R. Exploiting sparse semantic HD maps for self-driving vehicle localization. In Proceedings of the 2019 IEEE/RSJ International Conference on Intelligent Robots and Systems (IROS), Macau, China, 3–8 November 2019; pp. 5304–5311. [Google Scholar]
- Ghallabi, F.; Nashashibi, F.; El-Haj-Shhade, G.; Mittet, M.A. Lidar-based lane marking detection for vehicle positioning in an hd map. In Proceedings of the 2018 21st International Conference on Intelligent Transportation Systems (ITSC), Maui, HI, USA, 4–7 November 2018; pp. 2209–2214. [Google Scholar]
- Yang, B.; Liang, M.; Urtasun, R. Hdnet: Exploiting hd maps for 3d object detection. In Proceedings of the Conference on Robot Learning, Zurich, Switzerland, 29–31 October 2018; pp. 146–155. [Google Scholar]
- Jian, Z.; Zhang, S.; Chen, S.; Lv, X.; Zheng, N. High-definition map combined local motion planning and obstacle avoidance for autonomous driving. In Proceedings of the 2019 IEEE Intelligent Vehicles Symposium (IV), Paris, France, 9–12 June 2019; pp. 2180–2186. [Google Scholar]
- Diaz-Diaz, A.; Ocaña, M.; Llamazares, Á.; Gómez-Huélamo, C.; Revenga, P.; Bergasa, L.M. HD maps: Exploiting OpenDRIVE potential for Path Planning and Map Monitoring. In Proceedings of the 2022 IEEE Intelligent Vehicles Symposium (IV), Aachen, Germany, 5–9 June 2022; pp. 1211–1217. [Google Scholar]
- Petrie, G. An Introduction to the Technology: Mobile Mapping Systems. GeoInformatics 2010, 13, 32–33,35–43. [Google Scholar]
- Ziegler, J.; Bender, P.; Schreiber, M.; Lategahn, H.; Strauss, T.; Stiller, C.; Dang, T.; Franke, U.; Appenrodt, N.; Keller, C.G.; et al. Making bertha drive—An autonomous journey on a historic route. IEEE Intell. Transp. Syst. Mag. 2014, 6, 8–20. [Google Scholar] [CrossRef]
- Yang, B.; Fang, L.; Li, J. Semi-automated extraction and delineation of 3D roads of street scene from mobile laser scanning point clouds. ISPRS J. Photogramm. Remote Sens. 2013, 79, 80–93. [Google Scholar] [CrossRef]
- Fukano, K.; Masuda, H. Detection and Classification of Pole-like Objects from Mobile Mapping Data. ISPRS Ann. Photogramm. Remote Sens. Spat. Inf. Sci. 2015, 2, 57–64. [Google Scholar] [CrossRef] [Green Version]
- Yu, Y.; Li, J.; Guan, H.; Jia, F.; Wang, C. Learning hierarchical features for automated extraction of road markings from 3 to D mobile LiDAR point clouds. IEEE J. Sel. Top. Appl. Earth Obs. Remote Sens. 2014, 8, 709–726. [Google Scholar] [CrossRef]
- He, B.; Ai, R.; Yan, Y.; Lang, X. Lane marking detection based on convolution neural network from point clouds. In Proceedings of the 2016 IEEE 19th International Conference on Intelligent Transportation Systems (ITSC), Rio de Janeiro, Brazil, 1–4 November 2016; pp. 2475–2480. [Google Scholar]
- Rachmadi, R.F.; Uchimura, K.; Koutaki, G.; Ogata, K. Road edge detection on 3D point cloud data using Encoder-Decoder Convolutional Network. In Proceedings of the 2017 International Electronics Symposium on Knowledge Creation and Intelligent Computing (IES-KCIC), Surabaya, Indonesia, 26–27 September 2017; pp. 95–100. [Google Scholar]
- Zheng, H.; Wang, R.; Xu, S. Recognizing street lighting poles from mobile LiDAR data. IEEE Trans. Geosci. Remote Sens. 2016, 55, 407–420. [Google Scholar] [CrossRef]
- Crowd Sourcing for Automated Driving: BMW Group and Mobileye Agree to Generate New Kind of Sensor Data. Available online: https://www.press.bmwgroup.com/global/article/detail/T0268039EN/crowd-sourcing-for-automated-driving:-bmw-group-and-mobileye-agree-to-generate-new-kind-of-sensor-data (accessed on 4 November 2022).
- Collaboration with TomTom for Real-Time HD Map Updating. Available online: https://hella-aglaia.com/2019/09/05/tomtom-collaborates-with-hella-aglaia-for-real-time-hd-map-updating/ (accessed on 4 November 2022).
- Mobileye REMTM-Road Experience Management. Available online: https://www.mobileye.com/technology/rem/ (accessed on 4 November 2022).
- Seoul and SKT to Jointly Develop the Real Time Super Precision Road Map Indispensable for AV with 5G and AI. Available online: http://english.seoul.go.kr/seoul-and-skt-to-jointly-develop-the-real-time-super-precision-road-map-indispensable/ (accessed on 4 November 2022).
- Shu, J.; Wang, S.; Jia, X.; Zhang, W.; Xie, R.; Huang, H. Efficient lane-level map building via vehicle-based crowdsourcing. IEEE Trans. Intell. Transp. Syst. 2020, 23, 4049–4062. [Google Scholar] [CrossRef]
- Yang, X.; Tang, L.; Niu, L.; Zhang, X.; Li, Q. Generating lane-based intersection maps from crowdsourcing big trace data. Transp. Res. Part Emerg. Technol. 2018, 89, 168–187. [Google Scholar] [CrossRef]
- Guo, C.; Kidono, K.; Meguro, J.; Kojima, Y.; Ogawa, M.; Naito, T. A low-cost solution for automatic lane-level map generation using conventional in-car sensors. IEEE Trans. Intell. Transp. Syst. 2016, 17, 2355–2366. [Google Scholar] [CrossRef]
- Zhou, Y.; Takeda, Y.; Tomizuka, M.; Zhan, W. Automatic construction of lane-level hd maps for urban scenes. In Proceedings of the 2021 IEEE/RSJ International Conference on Intelligent Robots and Systems (IROS), Prague, Czech Republic, 27 September–1 October 2021; pp. 6649–6656. [Google Scholar]
- Dabeer, O.; Ding, W.; Gowaiker, R.; Grzechnik, S.K.; Lakshman, M.J.; Lee, S.; Reitmayr, G.; Sharma, A.; Somasundaram, K.; Sukhavasi, R.T.; et al. An end-to-end system for crowdsourced 3D maps for autonomous vehicles: The mapping component. In Proceedings of the 2017 IEEE/RSJ International Conference on Intelligent Robots and Systems (IROS), Vancouver, BC, Canada, 24–28 September 2017; pp. 634–641. [Google Scholar]
- Liang, D.; Guo, Y.; Zhang, S.; Zhang, S.H.; Hall, P.; Zhang, M.; Hu, S. LineNet: A zoomable CNN for crowdsourced high definition maps modeling in urban environments. arXiv 2018, arXiv:1807.05696. [Google Scholar]
- Wijaya, B.; Jiang, K.; Yang, M.; Wen, T.; Tang, X.; Yang, D. Crowdsourced Road Semantics Mapping Based on Pixel-Wise Confidence Level. Automot. Innov. 2022, 5, 43–56. [Google Scholar] [CrossRef]
- Zhou, J.; Guo, Y.; Bian, Y.; Huang, Y.; Li, B. Lane Information Extraction for High Definition Maps Using Crowdsourced Data. IEEE Trans. Intell. Transp. Syst. 2022. [Google Scholar] [CrossRef]
- Schreiber, M.; Hellmund, A.M.; Stiller, C. Multi-drive feature association for automated map generation using low-cost sensor data. In Proceedings of the 2015 IEEE Intelligent Vehicles Symposium (IV), Seoul, Republic of Korea, 28 June–1 July 2015; pp. 1140–1147. [Google Scholar]
- Tang, L.; Yang, X.; Dong, Z.; Li, Q. CLRIC: Collecting lane-based road information via crowdsourcing. IEEE Trans. Intell. Transp. Syst. 2016, 7, 2552–2562. [Google Scholar] [CrossRef]
- Jo, K.; Kim, C.; Sunwoo, M. Simultaneous localization and map change update for the high definition map-based autonomous driving car. Sensors 2018, 18, 3145. [Google Scholar] [CrossRef] [PubMed] [Green Version]
- Kim, C.; Cho, S.; Sunwoo, M.; Jo, K. Crowd-sourced mapping of new feature layer for high-definition map. Sensors 2018, 18, 4172. [Google Scholar] [CrossRef] [PubMed] [Green Version]
- Kim, C.; Cho, S.; Sunwoo, M.; Resende, P.; Bradaï, B.; Jo, K. Updating point cloud layer of high definition (hd) map based on crowd-sourcing of multiple vehicles installed lidar. IEEE Access 2021, 9, 8028–8046. [Google Scholar] [CrossRef]
- Welte, A.; Xu, P.; Bonnifait, P.; Zinoune, C. HD Map Errors Detection using Smoothing and Multiple Drives. In Proceedings of the 2021 IEEE Intelligent Vehicles Symposium Workshops (IV Workshops), Nagoya, Japan, 11–17 July 2021; pp. 37–42. [Google Scholar]
- Sun, P.; Wang, Y.; He, P.; Pei, X.; Yang, M.; Jiang, K.; Yang, D. GCD-L: A Novel Method for Geometric Change Detection in HD Maps Using Low-Cost Sensors. Automot. Innov. 2022, 5, 324–332. [Google Scholar] [CrossRef]
- Pannen, D.; Liebner, M.; Burgard, W. Hd map change detection with a boosted particle filter. In Proceedings of the 2019 International Conference on Robotics and Automation (ICRA), Montreal, QC, Canada, 20–24 May 2019; pp. 2561–2567. [Google Scholar]
- Pannen, D.; Liebner, M.; Hempel, W.; Burgard, W. How to keep HD maps for automated driving up to date. In Proceedings of the 2020 IEEE International Conference on Robotics and Automation (ICRA), Paris, France, 31 May–31 August 2020; pp. 2288–2294. [Google Scholar]
- Massow, K.; Kwella, B.; Pfeifer, N.; Häusler, F.; Pontow, J.; Radusch, I.; Hipp, J.; Dölitzscher, F.; Haueis, M. Deriving HD maps for highly automated driving from vehicular probe data. In Proceedings of the 2016 IEEE 19th International Conference on Intelligent Transportation Systems (ITSC), Rio de Janeiro, Brazil, 1–4 November 2016; pp. 1745–1752. [Google Scholar]
- Kim, C.; Jo, K.; Bradai, B.; Sunwoo, M. Multiple vehicles based new landmark feature mapping for highly autonomous driving map. In Proceedings of the 2017 14th Workshop on Positioning, Navigation and Communications (WPNC), Bremen, Germany, 25–26 October 2017; pp. 1–6. [Google Scholar]
- Stoven-Dubois, A.; Miguel, K.K.; Dziri, A.; Leroy, B.; Chapuis, R. A collaborative framework for high-definition mapping. In Proceedings of the 2019 IEEE Intelligent Transportation Systems Conference (ITSC), Auckland, New Zealand, 27–30 October 2019; pp. 1845–1850. [Google Scholar]
- Jiao, J. Machine learning assisted high-definition map creation. In Proceedings of the 2018 IEEE 42nd Annual Computer Software and Applications Conference (COMPSAC), Tokyo, Japan, 23–27 July 2018; Volume 1, pp. 367–373. [Google Scholar]
- Kim, K.; Cho, S.; Chung, W. HD map update for autonomous driving with crowdsourced data. IEEE Robot. Autom. Lett. 2021, 6, 1895–1901. [Google Scholar] [CrossRef]
- Grisetti, G.; Kümmerle, R.; Strasdat, H.; Konolige, K. g2o: A general framework for (hyper) graph optimization. In Proceedings of the IEEE International Conference on Robotics and Automation (ICRA), Shanghai, China, 9–13 May 2011; pp. 9–13. [Google Scholar]
- Green, P.; Silverman, B.W. Constructing the convex hull of a set of points in the plane. Comput. J. 1979, 22, 262–266. [Google Scholar] [CrossRef]
- Pannen, D.; Liebner, M.; Burgard, W. Lane marking learning based on crowdsourced data. In Proceedings of the 2019 IEEE/RSJ International Conference on Intelligent Robots and Systems (IROS), Macau, China, 3–8 November 2019; pp. 7040–7046. [Google Scholar]
- Ester, M.; Kriegel, H.P.; Sander, J.; Xu, X. A density-based algorithm for discovering clusters in large spatial databases with noise. In Proceedings of the Kdd, Portland, OR, USA, 2–4 August 1996; Volume 96, pp. 226–231. [Google Scholar]
- Gonzalez, T.; Diaz-Herrera, J.; Tucker, A. Computing Handbook: Computer Science and Software Engineering; CRC Press: Boca Raton, FL, USA, 2014; Volume 1, pp. 14–32. [Google Scholar]
- Kakao Map. Available online: https://map.kakao.com (accessed on 4 November 2022).
- Naver Map. Available online: https://m.map.naver.com/ (accessed on 4 November 2022).







{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
| Landmark Existence | ||
|---|---|---|
| Class | Before Update | After Update |
| Normal | existent | existent |
| Deleted | existent | non-existent |
| New | non-existent | existent |
| Outlier | non-existent | non-existent |
| Keyframe | Lane Observation | |||
|---|---|---|---|---|
| Without Pose Corrention | With Pose Correction | Without Pose Correction | With Pose Correction | |
| Test area 1 | 50.38% | 55.30% | 63.83% | 70.86% |
| Test area 2 | 43.18% | 50.42% | 51.91% | 61.60% |
| Test area 3 | 40.22% | 47.59% | 45.63% | 55.50% |
| Test area 4 | 50.55% | 58.69% | 64.84% | 75.89% |
| Test area 5 | 32.46% | 37.02% | 38.74% | 44.79% |
| Normal-Deleted Classification | ||||||||
|---|---|---|---|---|---|---|---|---|
| Precision | Recall | F1-Score | Specificity | |||||
| Previous method | Proposed Method | Previous Method | Proposed Method | Previous Method | Proposed Method | Previous Method | Proposed Method | |
| Test area 1 | 0.99 | 0.99 | 0.72 | 0.89 | 0.83 | 0.94 | 0.82 | 0.75 |
| Test area 2 | 0.95 | 0.95 | 0.72 | 0.84 | 0.82 | 0.89 | 0.60 | 0.54 |
| Test area 3 | 1.00 | 1.00 | 0.68 | 0.88 | 0.81 | 0.94 | - | - |
| Test area 4 | 0.98 | 0.99 | 0.69 | 0.85 | 0.81 | 0.91 | 0.63 | 0.67 |
| Test area 5 | 0.99 | 0.99 | 0.70 | 0.88 | 0.82 | 0.94 | 0.5 | 0.5 |
| New-Outlier Classification | ||||||||
|---|---|---|---|---|---|---|---|---|
| Precision | Recall | F1-Score | Specificity | |||||
| Previous Method | Proposed Method | Previous Method | Proposed Method | Previous Method | Proposed Method | Previous Method | Proposed Method | |
| Test area 1 | 0.29 | 0.86 | 0.44 | 0.60 | 0.35 | 0.71 | 0.91 | 0.95 |
| Test area 2 | 0.33 | 0.63 | 0.38 | 0.63 | 0.35 | 0.63 | 0.93 | 0.94 |
| Test area 3 | 0.38 | 0.75 | 0.55 | 0.67 | 0.44 | 0.71 | 0.92 | 0.97 |
| Test area 4 | 0.26 | 0.63 | 0.38 | 0.50 | 0.31 | 0.56 | 0.84 | 0.94 |
| Test area 5 | 0.26 | 0.75 | 0.56 | 0.60 | 0.36 | 0.67 | 0.84 | 0.98 |
Disclaimer/Publisher’s Note: The statements, opinions and data contained in all publications are solely those of the individual author(s) and contributor(s) and not of MDPI and/or the editor(s). MDPI and/or the editor(s) disclaim responsibility for any injury to people or property resulting from any ideas, methods, instructions or products referred to in the content. |
© 2022 by the authors. Licensee MDPI, Basel, Switzerland. This article is an open access article distributed under the terms and conditions of the Creative Commons Attribution (CC BY) license (https://creativecommons.org/licenses/by/4.0/).
Share and Cite
Cho, M.; Kim, K.; Cho, S.; Cho, S.-M.; Chung, W. Frequent and Automatic Update of Lane-Level HD Maps with a Large Amount of Crowdsourced Data Acquired from Buses and Taxis in Seoul. Sensors 2023, 23, 438. https://doi.org/10.3390/s23010438
Cho M, Kim K, Cho S, Cho S-M, Chung W. Frequent and Automatic Update of Lane-Level HD Maps with a Large Amount of Crowdsourced Data Acquired from Buses and Taxis in Seoul. Sensors. 2023; 23(1):438. https://doi.org/10.3390/s23010438
Chicago/Turabian StyleCho, Minwoo, Kitae Kim, Soohyun Cho, Seung-Mo Cho, and Woojin Chung. 2023. "Frequent and Automatic Update of Lane-Level HD Maps with a Large Amount of Crowdsourced Data Acquired from Buses and Taxis in Seoul" Sensors 23, no. 1: 438. https://doi.org/10.3390/s23010438
APA StyleCho, M., Kim, K., Cho, S., Cho, S.-M., & Chung, W. (2023). Frequent and Automatic Update of Lane-Level HD Maps with a Large Amount of Crowdsourced Data Acquired from Buses and Taxis in Seoul. Sensors, 23(1), 438. https://doi.org/10.3390/s23010438