Abstract
In cognitive radio systems, cooperative spectrum sensing (CSS) can effectively improve the sensing performance of the system. At the same time, it also provides opportunities for malicious users (MUs) to launch spectrum-sensing data falsification (SSDF) attacks. This paper proposes an adaptive trust threshold model based on a reinforcement learning (ATTR) algorithm for ordinary SSDF attacks and intelligent SSDF attacks. By learning the attack strategies of different malicious users, different trust thresholds are set for honest and malicious users collaborating within a network. The simulation results show that our ATTR algorithm can filter out a set of trusted users, eliminate the influence of malicious users, and improve the detection performance of the system.
1. Introduction
With the rapid development of wireless communication technology, the demand for wireless communication equipment and Internet of Things equipment has expanded rapidly, and the available spectrum resources are becoming increasingly scarce. However, due to the existing static spectrum allocation scheme, most of the licensed radio spectrum is not efficiently utilized. According to a research report by the Federal Communications Commission (FCC) of the United States, licensed spectrum utilization ranges from 15% to 85% [1]. In order to solve the contradiction between the shortage of spectrum resources and the low utilization of the spectrum, Dr. J. Mitola et al. have proposed the concept of the cognitive radio network (CRN) [2], which allows a secondary user (SU) with sensing ability to sense and use the spectrum of a nearby primary user (PU) without interfering with the communication of the primary user [3]. Spectrum sensing is a necessary prerequisite in cognitive radio systems. Cooperative spectrum sensing (CSS) can avoid the impact of shadowing and multipath fading, make full use of spatial differences, and overcome the shortcomings of single-user spectrum sensing [4,5]. However, malicious users (MUs) in the network may send incorrect data when uploading data to the fusion center (FC) to achieve their own purposes. This phenomenon is called a spectrum-sensing data falsification (SSDF) attack [6,7].
An ordinary SSDF attack is also known as a “Byzantine attack” [8], and its attack methods mainly include the following: “always yes”, “always no”, “always false”, and “Ffixed probability”. In order to defend against ordinary SSDF attacks, some scholars have conducted corresponding research [9,10,11,12,13,14,15,16,17,18,19,20,21]. In [12], a method based on Bayesian detection was used to defend against SSDF attacks, but it needs to detect a fixed number of nodes, which consumes a large amount of energy on the system. Lu et al. explained that when a system is attacked by SSDF independently or jointly launched by MUs [13], it can defend against malicious users (MUs) with the help of trusted SUs, that is, by only relying on the data of trusted SUs during data fusion, it can find MUs. This algorithm can improve the robustness of system perception, but when there is no prior information from trusted SUs in the network, this algorithm will not be applicable. In [14], the authors proposed an adaptive clustering defense method for cooperative attack users. It clusters secondary users (SUs) based on the historical sensing information and reputation value of the SUs in the network, reducing the impact of MUs on the global decision results. In [16], the authors considered using the method of double reputation value to maximize the throughput of a CRN network under a small number of SSDF attacks. For SSDF attacks, the optimal trust threshold is derived, but this requires prior information, such as the MU attack probability.
Among the algorithms for defending against SSDF attacks, trust mechanism-based defense algorithms are widely used [14,15,16]. The core idea of the trust mechanism is to construct a trust value for SUs based on their historical sensing information. The trust value of each SU is compared with a pre-set fixed trust threshold. The SUs below the trust threshold will be excluded, or the trust value can be used to assign corresponding weights and penalty values to the sensing results of the SUs. In the trust mechanism, if the fixed trust threshold or weight factor calculation is not accurate enough, MUs cannot be detected, and honest secondary users (HSUs) may be misjudged and assumed to be MUs.
When there are intelligent malicious users (IMUs) in the network, a trust mechanism based on a fixed threshold cannot calculate an appropriate trust threshold due to the lack of prior information, such as the attack probability and proportion of IMUs. This is because, unlike an ordinary SSDF attack, an intelligent malicious user (IMU) who launches an intelligent SSDF attack can dynamically adjust its attack strategies by evaluating its own behavior. During the incubation period, IMUs can upload real results, disguise themselves as honest secondary users (HSUs), and bypass the system’s defense and detection mechanism. For such intelligent SSDF attacks, Feng et al. proposed an additive penalty factor and a multiplicative attenuation factor after analyzing the historical sensing data of malicious users to achieve the dynamic attenuation of their trust values, thereby inhibiting such SSDF attacks [22]. However, such defense methods can easily form false judgments. Once HSUs are marked as MUs, their subsequent sensing results cannot be uploaded to the FC. Zhao et al. introduced a k-means algorithm combined with trust value defense [23] and classified MUs and HSUs through analysis of historical data so as to detect MUs. However, this method only targets a few malicious user scenarios and can only defend against an intelligent SSDF attack with a fixed attack threshold. When the number of IMUs increases and their attack strategies are complex and variable, the detection accuracy of this method is greatly reduced. In [24], Fu et al. proposed the principle of reputation updating based on a cumulative weight sliding window, which assigns less weight to historical sensing observation data, to suppress dynamic attacks. However, when the attack intensity of MUs changes greatly, this method is not applicable.
In order to better defend against the intelligent SSDF attacks described above, this paper introduces the combination of reinforcement learning and a trust value mechanism. Through learning the attack strategies of different MUs, we set corresponding adaptive trust thresholds for different secondary users to ensure the credibility of honest secondary users while identifying malicious users, enabling us to defend against each dynamic attack user and improve the detection performance of the system. The main contributions of this paper are as follows:
- We consider the presence of both ordinary SSDF attacks and more complex intelligent SSDF attacks since IMUs have different attack thresholds and more diverse attack strategies when conducting intelligent SSDF attacks.
- We analyze and summarize the sensing results uploaded by all the secondary users participating in the collaboration and use the trust values established by the beta distribution for each SU to analyze their honesty attributes. We compare the attack intensity of MUs at different periods.
- We introduce reinforcement learning to establish an adaptive trust threshold defense algorithm (ATTR). By analyzing the sensing results of different SUs, we set corresponding trust thresholds for each participating SU to detect malicious users, filter out a set of trusted SUs, and thereby improve the detection probability of the system.
The rest of this article is organized as follows. Section 2 gives the system model and attack model, and Section 3 gives the proposed cooperative spectrum-sensing scheme based on reinforcement learning. Section 4 shows the simulation evaluation of the proposed algorithm and discusses the simulation results. Finally, we give a conclusion in Section 5.
2. Preliminaries
2.1. System Model
As is shown in Figure 1, in this paper, we consider a centralized cooperative spectrum sensing network with a central base station as the FC, and there is one PU and N SUs in the network. The PU communicates on its authorized channel, with PU-Tx as the PU’s signal transmitter and PU-Rx as the PU’s signal receiver. There are two types of secondary users with different honesty attributes among the N SUs, namely HSUs and MUs. The HSUs always upload true sensing results in spectrum sensing, while the MUs upload false sensing information based on their attack strategy. The MUs include ordinary MUs and IMUs. The number of HSUs is , the number of ordinary MUs is , and the number of IMUs is . Due to the different locations of the SUs, they are affected by shadow fading and noise, and this results in different detection capabilities.
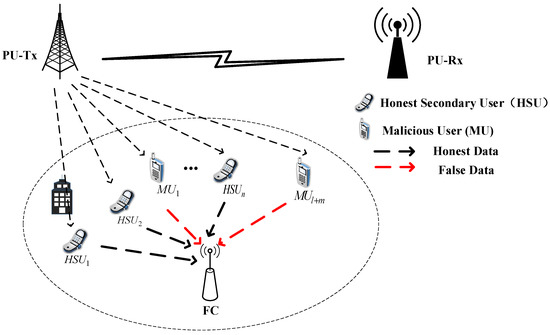
Figure 1.
System model frame diagram.
In the local sensing stage, the spectrum is detected using the energy detection method. Each SU obtains the local sensing result through energy detection and uploads it to the data fusion center (FC). The MU selects an upload result according to its own attack strategy. The energy detection method can describe a binary hypothesis problem:
where is the signal sensed by each SU, is the transferred PU signal, is the channel gain on the sensed frequency band, and is the additive white Gaussian noise on the sensed frequency band. and represent the hypotheses of the inexistence and the existence of the PU signal.
Firstly, the signal about the PU received by the SU is sent to the band-pass filter with bandwidth to filter out the noise signal and obtain the instantaneous energy value of the received signal. Secondly, is passed through the digital-to-analog converter to obtain the sampling signal of the N-point FFT, and then the modulus squared is calculated using the squarer. The calculation result is then integrated within a certain period of time T to obtain the test statistic Y. Finally, Y is compared with the preset threshold . If Y is greater than , the PU is determined to exist in the authorized frequency band; otherwise, the PU does not exist. The detection probability and false alarm probability of local spectrum sensing can be expressed as:
where is the signal-to-noise ratio, is the energy decision threshold, and is the noise variance. After a single sensing, the local sensing result of is obtained, and this is generally represented by binary variables:
Each SU uploads its local sensing result, and the FC obtains the final global sensing result , according to the different data fusion rule. Common data fusion methods include the “OR”, “AND”, and “Majority” rules:
- In the “OR” rule, the main idea is that once an SU determines that the channel is occupied, the FC assumes that the PU is using the authorized channel for communication and does not engage in spectrum access. This can protect the normal communication of the PU but reduce the chance of discovering an idle spectrum.
- In the “AND” rule, the FC only considers the PU to be communicating when all the SUs determine that the channel is occupied. This can increase the probability of discovering spectrum voids, but once judged incorrectly it can easily cause interference for the PU.
- In the “Majority” rule, when K () or more of the N SUs participating in the collaboration determine that the channel is occupied, the FC will determine that the PU is communicating.
2.2. SSDF Attack Model
In [25], the authors define four types of ordinary SSDF attacks to test the resiliency of the proposed data aggregation scheme:
- “Always yes” attack: regardless of whether the PU exists or not, the MU always uploads to determine the existence of the PU.
- “Always no” attack: regardless of whether the PU exists or not, the MU always uploads and determines that the PU does not exist.
- “Always false” attack: the MU always uploads information that is different from the real sensing result.
- “Fixed probability” attack: the MU uploads false error-sensing information with a fixed probability.
For the above four ordinary SSDF attack models, a large number of trust mechanism-based defense methods have been proposed, but there are few studies on intelligent SSDF attacks. In [23,26], the authors analyze such intelligent SSDF attacks. IMUs will estimate their own trust value , upload the correct sensing results in the early stage, accumulate their own trust value, and attack when their own trust value reaches , where is the basic trust threshold and is the attack threshold of the . At this point, the IMUs have a high trust value and can therefore bypass the traditional trust mechanism.
In Figure 2, we set two IMUs (). According to the changes in the IMUs’ trust values, they can be divided into an “incubation period” and an “attack period”:
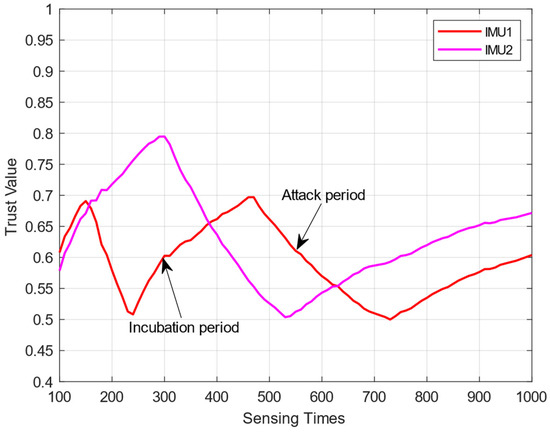
Figure 2.
Fluctuation analysis of trust values for IMUs.
- “Incubation period”: At this time, the trust value of the meets . During this period, the will upload correct sensing results and masquerade as an HSU, thus improving its own trust value so as to hide in the network. The trust value shows an upward trend.
- “Attack period”: At this time, the trust value of the meets . During this period, the will launch attacks and upload the wrong sensing results. Because the trust value of the is high at this time, the traditional trust mechanism will consider it an HSU, which affects the detection performance of the system. Due to its upload error-sensing results, its trust value will show a downward trend, and when , it will enter the “incubation period” again.
In [23], the authors use a k-means algorithm to cluster MUs according to the their simultaneously decreasing trust values. However, it assumes that all the IMUs have the same attack threshold. When the attack threshold is different, this method cannot distinguish HSUs from IMUs, and new methods are needed to prevent such attacks.
2.3. Reinforcement Learning in CRN
The core idea of reinforcement learning is to treat agent learning as a Markov decision test process, represented by tuples . S is the set of environmental states, which indicates that there are a finite number of state sets in the environment. A is the set of agent actions, which indicates the finite actions that an agent may send out. P is the state transition probability function, which indicates the probability of transitioning from one state to another. R (s, a) is a return function reflecting the learning goal, and it indicates the reward or punishment that can be obtained after an action is issued.
In [27], the authors study the scheduling strategy for different buffers on multiple channels by using Q-learning and deep learning to maximize the system throughput. In [28], the authors formulate the online sequential channel-sensing and -accessing problem as a sequencing multi-armed bandit problem to improve the throughput. For the intelligent malicious attack users proposed above, this paper introduces reinforcement learning to learn their attack strategies.
3. Adaptive Trust Threshold Algorithm Based on Reinforcement Learning
By judging the sensing results uploaded by SUs and the global sensing results, we calculate the real-time trust value of . At the same time, we use the reinforcement learning strategy to iterate the trust threshold of each SU. Finally, we calculate the optimal trust threshold of so as to obtain the set of HSUs in the cognitive radio network and eliminate the influence of MUs during data fusion.
3.1. Trust Value Establishment
By observing the previous perceptual behaviors of cooperative SUs, we found that the two types of perceptual data they send to the FC have binary characteristics: false sensing data and real sensing data. Therefore, the FC can initialize its sensing trust value by using the true sensing times (TRU) and false sensing times (FAL) of the SUs. The trust values of the SUs that provide real sensing information will be larger, while the trust values of the SUs that continuously provide false sensing information will be smaller. For such binary events, predicting the probability that they will produce favorable events next time is a posterior probability of predicting subsequent behaviors based on historical behaviors [23]:
The probability of binary events can be described using the beta distribution. The known beta probability density function is:
where represents the probability of the occurrence of perceptual behavior, , , and , and when , . Taking the as an example, and represent, respectively, the number of honest and false perceptions, and thus the formula for calculating the trust value can be obtained:
3.2. Adaptive Trust Threshold Calculation
Q-learning evolves from value iterations in the Markov decision process, but it removes the dependence on transition models, so it is a model-free method. In Q-learning, the agent first selects and performs an action according to the action-selection strategy based on the current state and then calculates the reward according to the reward function. Finally, the agent updates the Q-matrix and jumps to the next state. In the proposed Q-learning framework, the definitions of the state, the action, the reward, the trust threshold, and the trust factor are as follows.
(1) The definition of the state set represents the trust value set of the SUs and the real-time trust value represented by the state , which is calculated by comparing the sensing results uploaded by SUs with the global decision results using the aforementioned method of establishing trust values, representing the recognition of each SU by the FC.
(2) The action set is defined as to indicate trust in the SUs. During the update process, the action should be selected. If , this indicates that the SU is not trusted, and if , this indicates that the SU is trusted.
(3) To define the reward we compared the upload results of the SUs with the actual channel status and provided feedback on action rewards. When the proportion of MUs is less than 50% of the total number of SUs, the global results of collaborative perception have higher credibility. At the same time, when the FC determines that the channel is idle and allows the SUs to access the channel, action rewards can be evaluated based on whether the access is successful and on the interference feedback when the PU is disturbed.
(4) represents the real-time trust threshold for and can be compared with the real-time trust value of the SU to determine whether to trust the sensing result of the SU.
(5) is the trust factor, which represents the severity of the FC’s decision concerning the maximum trust value of an SU. If its value is too small, it will cause the trust threshold to be set too high, leading to the possible misjudgment of an HSU. Conversely, if its value is too high, it will cause the trust threshold to be set too low, making it impossible to filter MUs.
Policy : can be defined as follows: In the reinforcement learning process, after each round of spectrum sensing, the data fusion center (FC) calculates the real-time trust value of each SU according to the sensing results uploaded by each SU, senses the current state , and selects the action according to the policy . If it is determined that the SU is trusted, the trust value threshold of the SU at will be increased. If it is determined that the SU is not trusted, the trust value threshold of the SU will be reduced. According to the trust threshold, the upload results of HSUs are fused according to the K-out-of-N criterion to obtain a new global sensing result D and the reward of action . This process is repeated until the optimal strategy is obtained. The status value under policy is:
where represents the discount factor and represents the expected discount reward. After repeated learning, the optimal action is obtained from the maximum cumulative return value over a period of time.
The state action value function is used as the estimation function. After the optimal strategy is obtained by optimizing the Q-function, the is updated according to the following formula:
where is the discount rate and is the learning rate. The Q-value formula is updated iteratively, and the maximum state action value is selected.
By repeating the above process and updating , the optimal trust threshold of each SU is finally obtained. After the adaptive trust threshold of is obtained, the honest user set is obtained by comparing the trust value of each SU with its trust threshold. The number of trusted secondary users in set is defined as :
In data fusion, only the sensing result of the trusted secondary user set is used to eliminate the impact of MUs. The K-out-of-N criterion is used to fuse the data, and the global detection result is calculated as follows:
where is the upload local sensing result of , . The global detection probability and the global false alarm probability of the system are calculated as follows:
Algorithm 1 shows our proposed ATTR algorithm in detail.
| Algorithm 1: ATTR Algorithm |
| Initialization parameters: Sensing times: K; Iteration times of Q-learning: T; Learning rate:; Discount rate:. Input: Total SUs: N. Output: The trust threshold of the : ; The global detection probability of the algorithm: ; The trusted SUs set: . 1: for k = 1 to K do 2: for i = 1 to N do 3: perform local spectrum sensing and report the result to the FC, MUs upload according to their own attack strategy; 4: FC calculates the trust value of the ,; 5: Initialize Q-learning table entry: ; 6: for t = 1 to T do 7: Choose action using a policy derived from ; (e.g., ε-greedy rules) 8: Update , ; 9: Use the trust threshold at this time to obtain reward ; 10: Update ; 11: end for 12: Obtain the trust threshold ; 13: if do 14: ; 15: end if 16: end for 17: Calculate the new global result via K-out-of-N principle using ; 18: end for 19: Calculate the global detection probability . |
4. Simulation Result
In this section, the simulation results of the proposed algorithm in MATLAB are presented. The general simulation setup is shown in Table 1.

Table 1.
Simulation parameters.
Constant false alarm rate (CFAR) detection is adopted for performance detection, and the global false alarm rate detection probability is set to 0.1. In order to verify that our proposed algorithm can effectively detect HSUs and eliminate the influence of MUs during data fusion, we define as the proportion of HSUs correctly identified, which can be calculated as follows:
We also use the final global detection probability to evaluate the performance of the proposed algorithm. To analyze the simulation result of our ATTR algorithm more effectively, we compare it with the TFCA (trust fluctuation clustering analysis) algorithm [23] and SWTM (sliding window trust model) algorithm [24]. The TFCA algorithm is mainly based on the k-means clustering method, which clusters based on decreased trust values when MUs attack simultaneously in order to distinguish between MUs and HSUs. The SWTM algorithm establishes a weighted trust calculation scheme based on multiple small sliding windows using a sigmoid log function to generate the final trust value for each SU, eliminating the need to set the optimal detection threshold. The comparison details are shown in Table 2.
Table 2.
Comparison of different schemes.
In Figure 3, we compare the changes in value under different circumstances. We set up two ordinary MUs (“always false” attack and “fixed probability” attack) and different numbers of IMUs (m = 4, 6, and 8 respectively) with the same attack threshold () who only launch their attacks after their own trust values reach the attack threshold. As can be seen from Figure 3, our proposed algorithm can maintain a high recognition rate for honest users (above 90%). When the number of MUs is small, their impact on the global perception of the system is small, so the HSU recognition rate is higher. When the total number of SUs participating in cooperation increases, the number of MUs remains unchanged, which means that their proportion is reduced, the system is able to detect HSUs more easily, and the HSU recognition rate is improved.
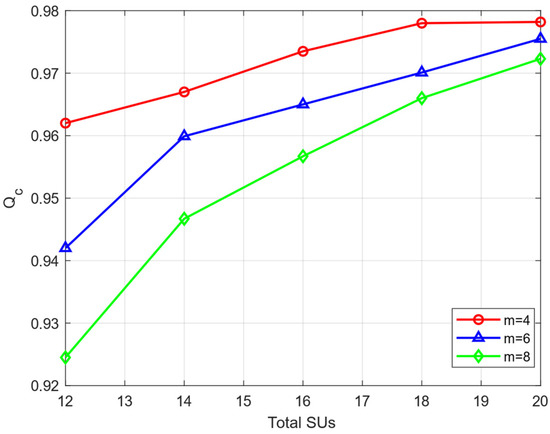
Figure 3.
The under different numbers of SUs.
In the actual cognitive radio network, due to the different environment of each SU, it is affected differently by shadow fading and environmental noise. Therefore, in Figure 4, we compare the advantages and disadvantages of different algorithms in spectrum sensing under different SNR and SU numbers, where IMU accounts for 20% (λi = 0.2 and 0.3, respectively). As is shown in Figure 4, with the improvement in the SNR, the SUs’ local detection ability has been improved, and the final global detection performance has also been improved. When the SNR is low, the detection probability of each SU is limited, and the detection probability of each algorithm is low. As the SNR increases, the attack ability of MUs will also increase. Our ATTR algorithm can set a specific trust threshold for each SU according to different situations. At an SNR of −14.6dB, the detection probability of our proposed algorithm can reach over 90%.
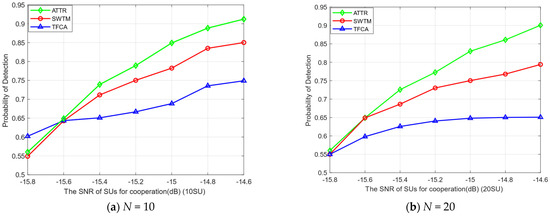
Figure 4.
The probability of detection of SNR of SUs.
In Figure 5, we compare the detection performance of each algorithm with the attack intensity of the MUs in the network. In Figure 5, there are 15 HSUs and 5 IMUs. The attack strength, that is, the attack threshold of each IMU, is increased from 0.2 to 0.3. As can be seen from Figure 5, with the increase in the attack threshold of the IMUs, their attack frequency decreases in general, and the overall detection performance improves. The algorithm proposed in this paper has high detection probability and good robustness under different attack thresholds, and the global detection probability can always be maintained at about 92%.
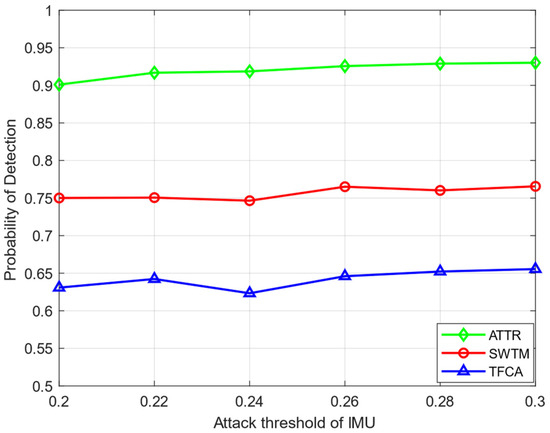
Figure 5.
The probability of detection of different attack thresholds.
In Figure 6, we compare the overall ROC curves, set the false alarm detection probability to between 10% and 30%, set the number of collaborative SUs to 10 in (a) and 20 in (b) (IMU attack threshold ), and observe the detection probability of each algorithm. It can be seen from the ROC curves that our proposed algorithm has advantages in overall detection performance. With the improvement of the false alarm detection probability, the detection probability can reach more than 90%.
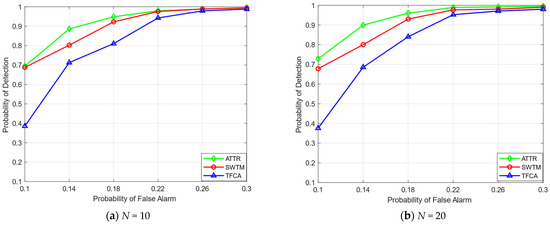
Figure 6.
The ROC curves.
5. Conclusions
This paper introduces the combination of reinforcement learning and a trust mechanism defense. For ordinary SSDF attacks and intelligent SSDF attacks in cooperative spectrum sensing, intelligent SSDF attacks with different attack thresholds are considered, and an adaptive trust threshold defense algorithm based on Q-learning is proposed. By using the trust values established for each SU, using the beta distribution to analyze their honesty attributes, comparing the attack intensity of MUs in different periods, analyzing the sensing results of different SUs, setting corresponding trust thresholds for each participating SU to detect MUs, and filtering out a set of trusted SUs, we improved the detection probability of the system. From the simulation results, it can be seen that the algorithm proposed in this paper can effectively defend against ordinary SSDF attacks and intelligent SSDF attacks in perception networks. In addition, when the proportion of MUs increases and the attack strategy changes, it can also respond well and adjust in time.
Author Contributions
System model, G.X. and X.Z.; model with MATLAB, X.Z.; simulation data and system model, G.X. and X.Z.; writing—original draft preparation, G.X. and X.Z.; modifications and suggestions, J.G. All authors have read and agreed to the published version of the manuscript.
Funding
This work was supported by the Laboratory Open Fund of Beijing Smart-chip Microelectronics Technology Co., Ltd.
Institutional Review Board Statement
Not applicable.
Informed Consent Statement
Not applicable.
Data Availability Statement
The data could be obtained from the authors upon reasonable request.
Conflicts of Interest
The authors declare no conflict of interest.
References
- Marcus, M.; Burtle, J.; Franca, B.; Lahjouji, A.; McNeil, N. FCC Spectrum Policy Task Force, Report of the Spectrum Efficiency Working Group; Technical Report; Federal Communications Commission: Washington, DC, USA, 2002. [Google Scholar]
- Mitola, J.I. Cognitive Radio an Integrated Agent Architecture for Software Defined Radio. Ph.D. Thesis, Royal Institute of Technology (KTH), Kista, Sweden, 2000. [Google Scholar]
- Zheng, K.; Jia, X.; Chi, K.; Liu, X. DDPG-based joint time and energy management in ambient backscatter-assisted hybrid underlay CRNs. IEEE Trans. Commun. 2022, 71, 441–456. [Google Scholar] [CrossRef]
- Aref, M.A.; Jayaweera, S.K. Spectrum-agile cognitive radios using multi-task transfer deep reinforcement learning. IEEE Trans. Wireless Commun. 2021, 20, 6729–6742. [Google Scholar] [CrossRef]
- Liu, X.; Xu, B.; Wang, X.; Zheng, K.; Chi, K.; Tian, X. Impacts of sensing energy and data availability on throughput of energy harvesting cognitive radio networks. IEEE Trans. Veh. Technol. 2023, 72, 747–759. [Google Scholar] [CrossRef]
- Fragkiadakis, A.G.; Tragos, E.Z.; Askoxylakis, I.G. A survey on security threats and detection techniques in cognitive radio networks. IEEE Commun. Surv. Tutor. 2012, 15, 428–445. [Google Scholar] [CrossRef]
- Attar, A.; Tang, H.; Vasilakos, A.V.; Yu, F.R.; Leung, V.C. A survey of security challenges in cognitive radio networks: Solutions and future research directions. Proc. IEEE 2012, 100, 3172–3186. [Google Scholar] [CrossRef]
- Rawat, A.S.; Anand, P.; Chen, H.; Varshney, P.K. Collaborative spectrum sensing in the presence of byzantine attacks in cognitive radio networks. IEEE Trans. Signal Process. 2010, 59, 774–786. [Google Scholar] [CrossRef]
- Qin, T.; Yu, H.; Leung, C.; Miao, C. Towards a trust aware cognitive radio architecture. SIGMOBILE Mob. Comput. Commun. Rev. 2009, 13, 86–95. [Google Scholar] [CrossRef]
- Lin, Z.; Lin, M.; Champagne, B.; Zhu, W.P.; Al-Dhahir, N. Secrecy-energy efficient hybrid beamforming for satellite-terrestrial integrated networks. IEEE Trans. Commun. 2021, 69, 6345–6360. [Google Scholar] [CrossRef]
- An, K.; Liang, T.; Zheng, G.; Yan, X.; Li, Y.; Chatzinotas, S. Performance limits of cognitive-uplink FSS and terrestrial FS for Ka-band. IEEE Trans. Aerosp. Electron. Syst. 2018, 55, 2604–2611. [Google Scholar] [CrossRef]
- Zhou, M.; Shen, J.; Chen, H.; Xie, L. A cooperative spectrum sensing scheme based on the Bayesian reputation model in cognitive radio networks. In Proceedings of the 2013 IEEE wireless communications and networking conference (WCNC 2013), Shanghai, China, 7–10 April 2013; pp. 614–619. [Google Scholar]
- Lu, J.; Wei, P.; Chen, Z. A scheme to counter SSDF attacks based on hard decision in cognitive radio networks. Ratio (SNR) 2014, 2, 2. [Google Scholar]
- Hyder, C.S.; Grebur, B.; Xiao, L. ARC: Adaptive reputation based clustering against spectrum sensing data falsification attacks. IEEE Trans. Mob. Comput. 2014, 13, 1707–1719. [Google Scholar] [CrossRef]
- Ma, L.; Xiang, Y.; Pei, Q.; Xiang, Y.; Zhu, H. Robust reputation-based cooperative spectrum sensing via imperfect common control channel. IEEE Trans. Veh. Technol. 2017, 67, 3950–3963. [Google Scholar] [CrossRef]
- Xu, Z.; Sun, Z.; Guo, L. Throughput Maximization of Collaborative Spectrum Sensing Under SSDF Attacks. IEEE Trans. Vehr. Technol. 2021, 70, 8378–8383. [Google Scholar] [CrossRef]
- Yucek, T.; Arslan, H. A survey of spectrum sensing algorithms for cognitive radio applications. IEEE Commun. Surv. Tutor. 2009, 11, 116–130. [Google Scholar] [CrossRef]
- Althunibat, S.; Denise, B.J.; Granelli, F. Identification and punishment policies for spectrum sensing data falsification attackers using delivery-based assessment. IEEE Trans. Veh. Technol. 2015, 65, 7308–7321. [Google Scholar] [CrossRef]
- Zhao, H.; Zhang, W.; Wu, X.; Li, H.; He, L. Outlier Detection and Trust based Distributed Cooperative Spectrum Sensing in Internet of Vehicles. In Proceedings of the 2022 International Conference on Computing, Communication, Perception and Quantum Technology (CCPQT 2022), Xiamen, China, 5–7 August 2022; pp. 117–122. [Google Scholar]
- Ling, M.H.; Yau, K.L.A. Reinforcement learning-based trust and reputation model for cluster head selection in cognitive radio networks. In Proceedings of the 9th International Conference for Internet Technology and Secured Transactions (ICITST 2014), London, UK, 8–10 December 2014; pp. 256–261. [Google Scholar]
- Ling, M.H.; Yau, K.L.A.; Qadir, J.; Poh, G.S.; Ni, Q. Application of reinforcement learning for security enhancement in cognitive radio networks. Appl. Soft Comput. 2015, 37, 809–829. [Google Scholar] [CrossRef]
- Feng, J.; Lu, G.; Zhang, Y.; Wang, H. Avoiding monopolization: Mutual-aid collusive attack detection in cooperative spectrum sensing. Sci. China Inf. Sci. 2017, 60, 1–3. [Google Scholar] [CrossRef]
- Zhao, F.; Li, S.; Feng, J. Securing cooperative spectrum sensing against DC-SSDF attack using trust fluctuation clustering analysis in cognitive radio networks. Wirel. Commun. Mob. Comput. 2019, 2019, 11. [Google Scholar] [CrossRef]
- Fu, Y.; He, Z. Bayesian-inference-based sliding window trust model against probabilistic SSDF attack in cognitive radio networks. IEEE Syst. J. 2019, 14, 1764–1775. [Google Scholar] [CrossRef]
- Wang, J.; Chen, R.; Tsai, J.J.; Wang, D.C. Trust-based cooperative spectrum sensing against SSDF attacks in distributed cognitive radio networks. In Proceedings of the 2016 IEEE International Workshop Technical Committee on Communications Quality and Reliability (CQR 2016), Stevenson, WA, USA, 10–12 May 2016; pp. 1–6. [Google Scholar]
- Feng, J.; Zhang, Y.; Lu, G.; Zheng, W. Securing cooperative spectrum sensing against ISSDF attack using dynamic trust evaluation in cognitive radio networks. Secur. Comm Netw. 2015, 8, 3157–3166. [Google Scholar] [CrossRef]
- Zhu, J.; Song, Y.; Jiang, D.; Song, H. A new deep-Q-learning-based transmission scheduling mechanism for the cognitive Internet of Things. IEEE Internet Things J. 2017, 5, 2375–2385. [Google Scholar] [CrossRef]
- Li, B.; Yang, P.; Wang, J.; Wu, Q.; Tang, S.; Li, X.Y.; Liu, Y. Almost optimal dynamically-ordered channel sensing and accessing for cognitive networks. IEEE Trans. Mob. Comput. 2013, 13, 2215–2228. [Google Scholar] [CrossRef]






Disclaimer/Publisher’s Note: The statements, opinions and data contained in all publications are solely those of the individual author(s) and contributor(s) and not of MDPI and/or the editor(s). MDPI and/or the editor(s) disclaim responsibility for any injury to people or property resulting from any ideas, methods, instructions or products referred to in the content. |
© 2023 by the authors. Licensee MDPI, Basel, Switzerland. This article is an open access article distributed under the terms and conditions of the Creative Commons Attribution (CC BY) license (https://creativecommons.org/licenses/by/4.0/).