

Site Agnostic Approach to Early Detection of Cyberbullying on Social Media Networks


Abstract
1. Introduction
- RQ1: Can Doc2Vec features significantly improve performance for the early detection models?
- RQ2: Can multiple instance learning improve results for the early detection models?
2. Related Work
3. Methods
3.1. Problem Definition
3.2. Features
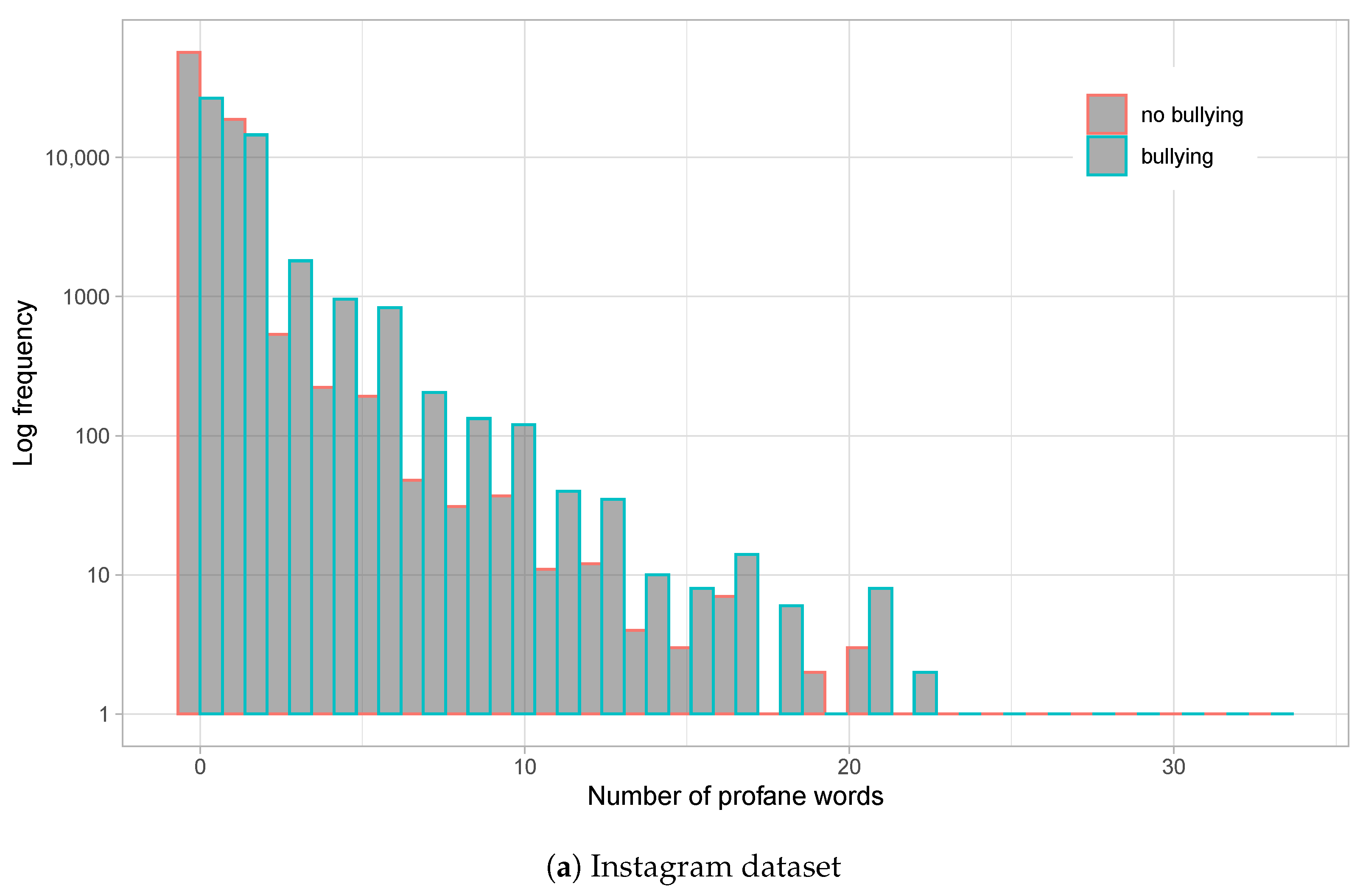
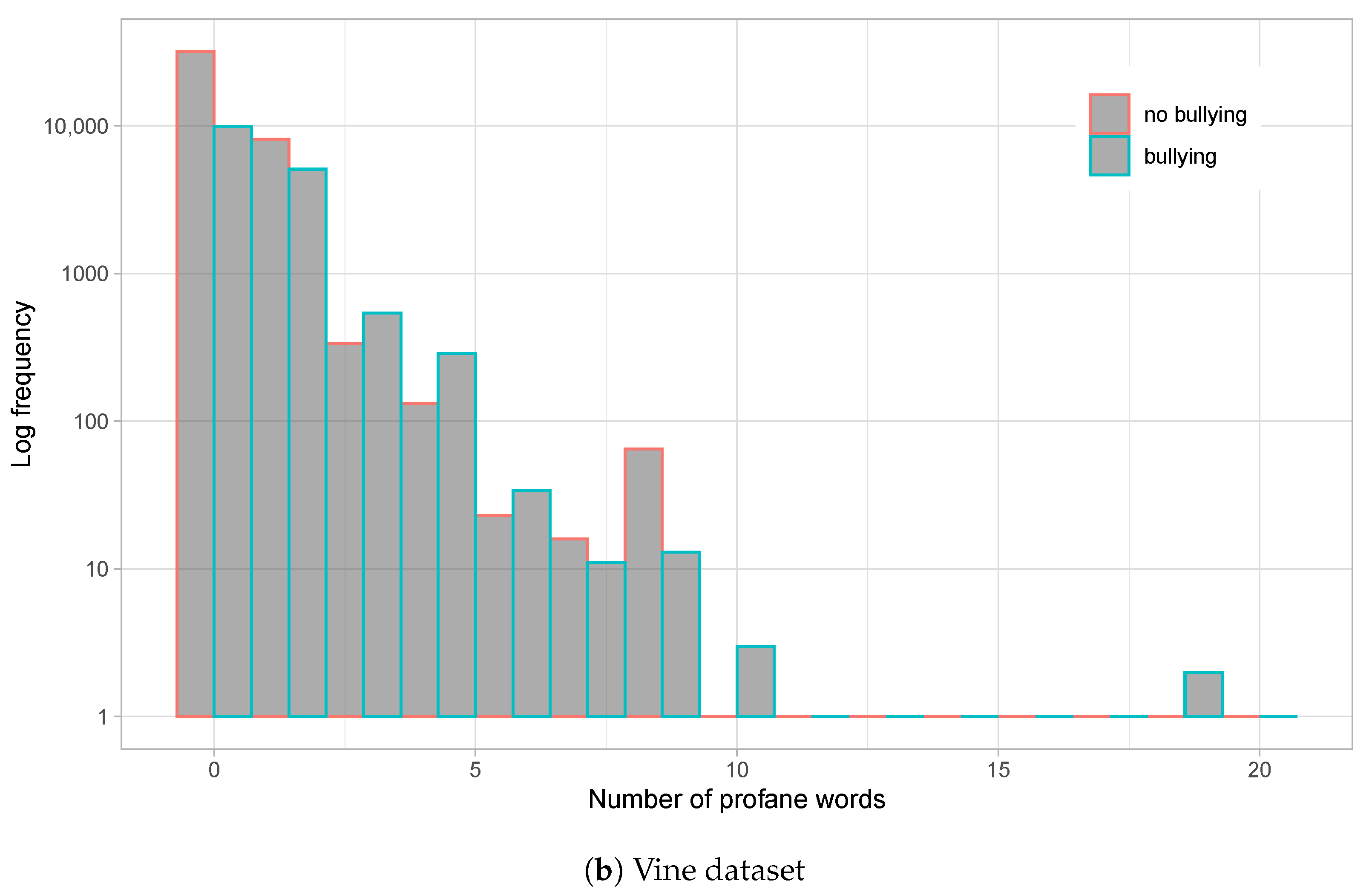
- Impolite comments: Following [14,39], we identified profane words for each post, where profane words are obtained from a dictionary. For each comment, we calculated its percentage of profane words, and we defined a comment as rude if it contained at least one profane word. For each session, we computed the percentage of rude comments.
- Sentiment analysis: Following [13], we measured polarity (positive and negative) and subjectivity for each comment. For each session, we calculated average values and the percentage of negative and subjective comments.
- Tf-idf: For each comment, we built a Tf-idf (term frequency–inverse document frequency) representation, following [6]. We performed a grid search for optimal hyperparameters using of the Instagram dataset. Stopwords were removed and unigrams, bigrams, and trigrams were considered. The 100 most frequent n-grams were extracted as features, a minimum document frequency of 2 was required, and terms that appear in more than of the documents were ignored. Features were computed for each individual post and partial session.
4. Experiments
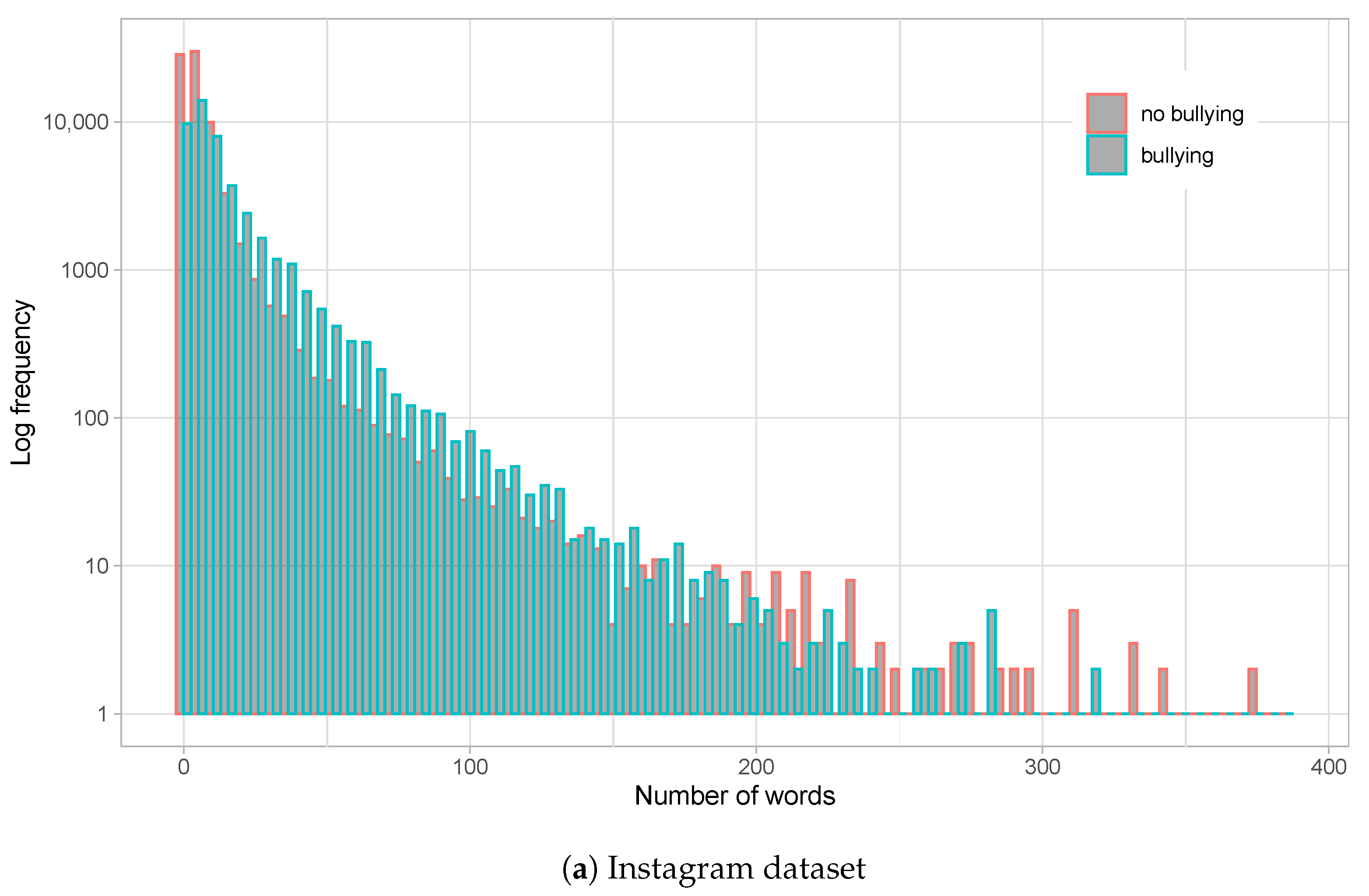
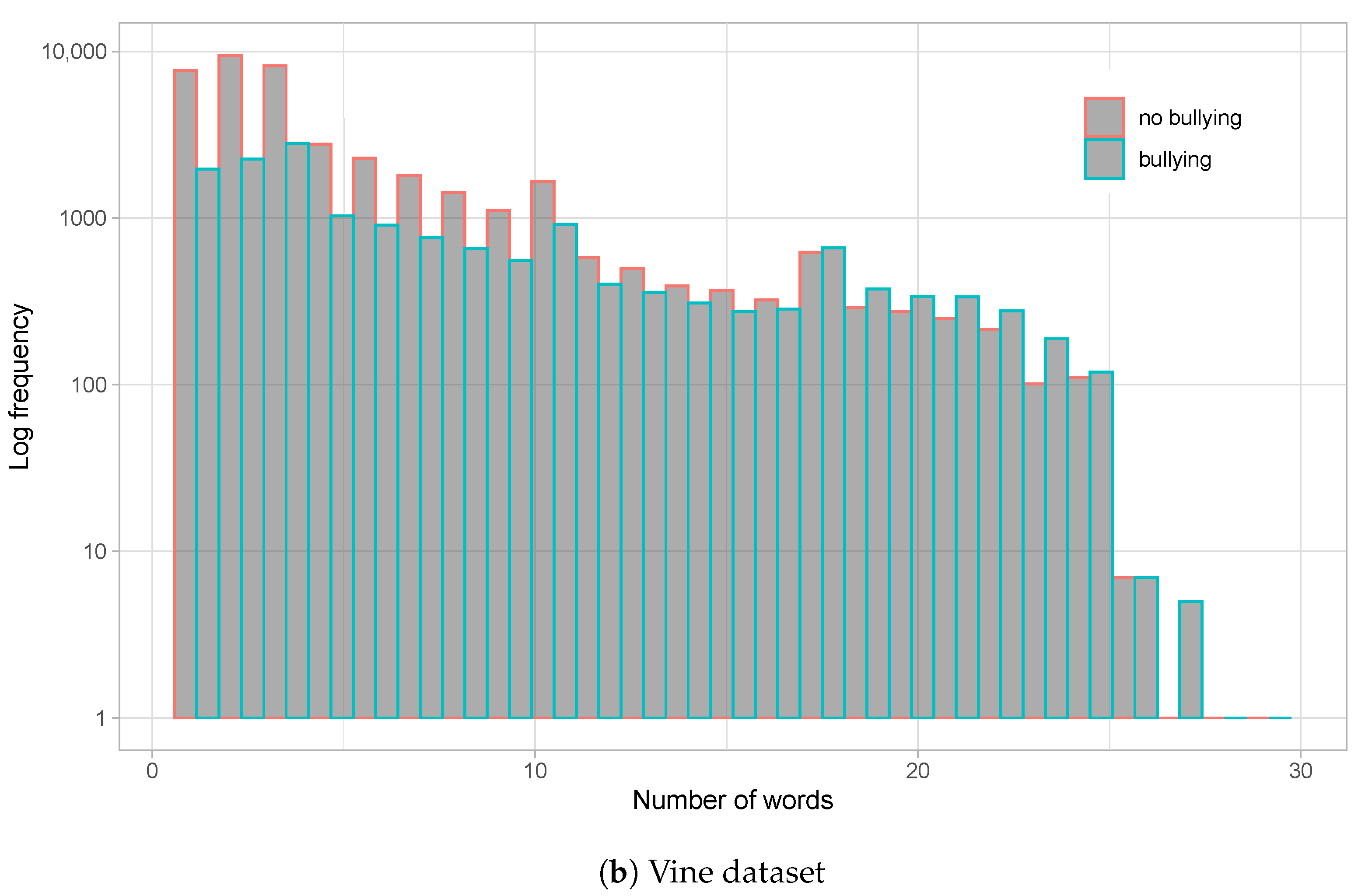
4.1. Datasets
4.2. Early Detection Metrics
4.3. Baseline
- A fixed early detection model consists of a simple adaptation of a standard machine learning model by considering a fixed number of input comments. Meanwhile, a delay is produced until this number is reached; hence, a final prediction will be generated by the model [6]. In our experiments, we consider different values for the number of input comments: 1, 5, 10, 15, and 25. A different performance result is obtained for each fixed point and for each machine learning model. For simplicity, we will denote each model with a subscript at a decision point (e.g., or ).
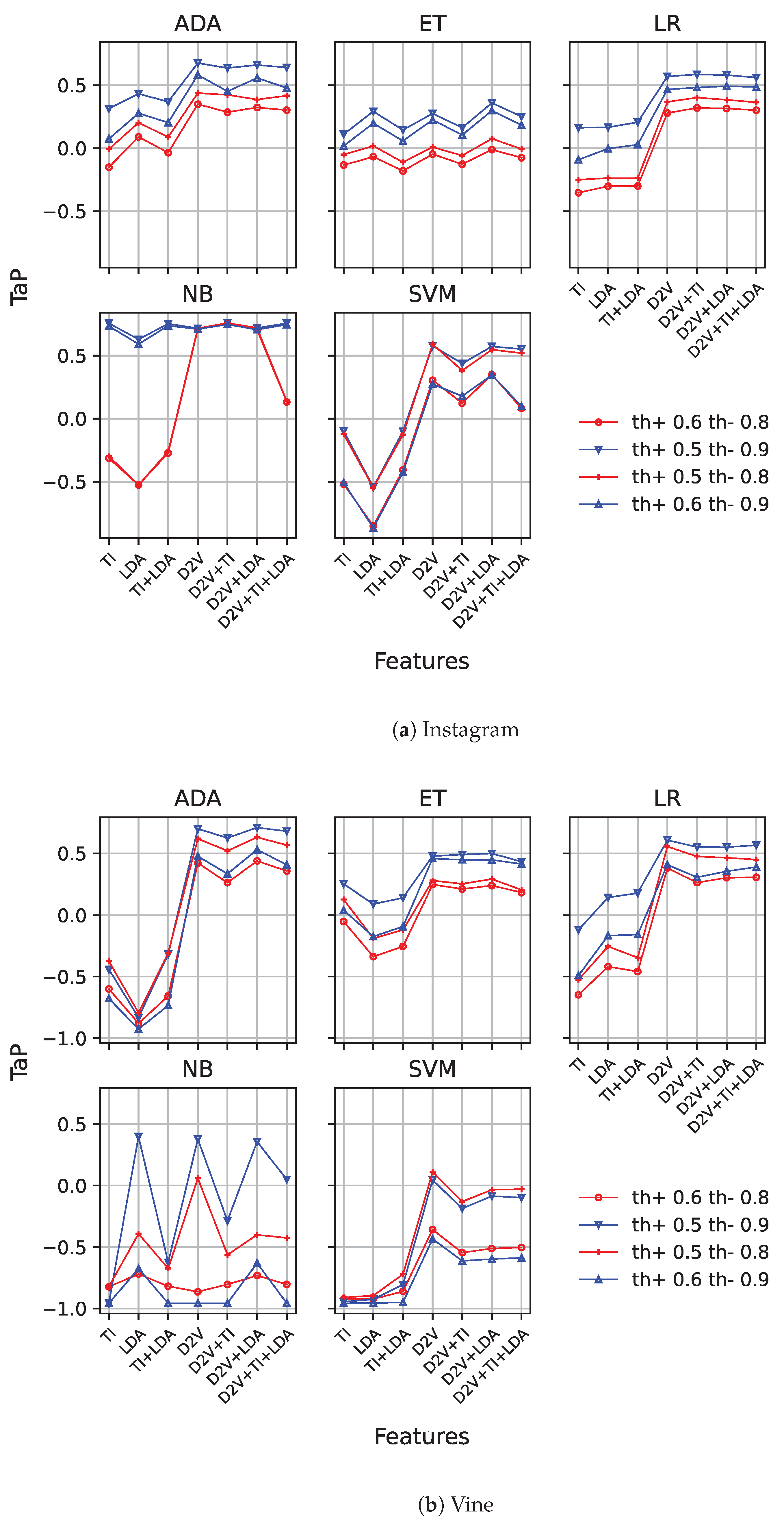
- A threshold early detection model uses a machine learning model, and sets a positive threshold () and a negative threshold () based on the class probability returned by the model to decide when to make a final decision (i.e., cyberbullying or non-cyberbullying) [6]. That is, for a specific media session s, after processing post i of s, , the model tests whether the class probability is higher or equal to to emit a cyberbullying prediction, and if not, tests whether it is higher or equal to to produce a non-cyberbullying prediction. Otherwise, a delay output is generated, and further posts must be processed.
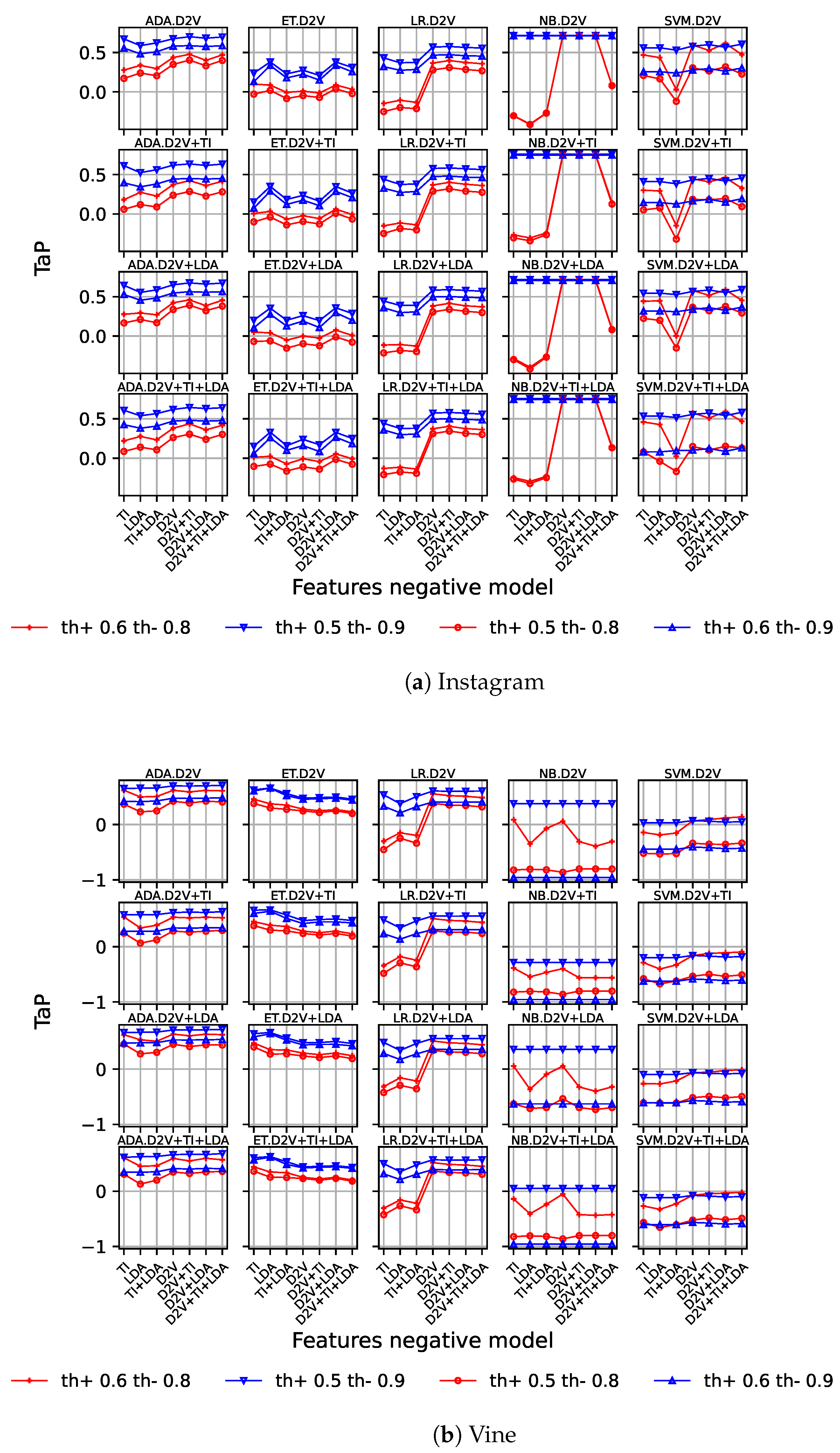
- A dual early detection model relies on two independent machine learning models, with one model () trained to detect cyberbullying cases and another model () trained to detect non-cyberbullying cases. Positive and negative thresholds are also required, but in this case are associated to its own model. Therefore, after processing by , the class probability must be higher or equal to to be considered cyberbullying, and likewise, when processed by , it must be above or equal to to be considered non-cyberbullying. In any other case, a delay output is produced.
4.4. Performance Evaluation
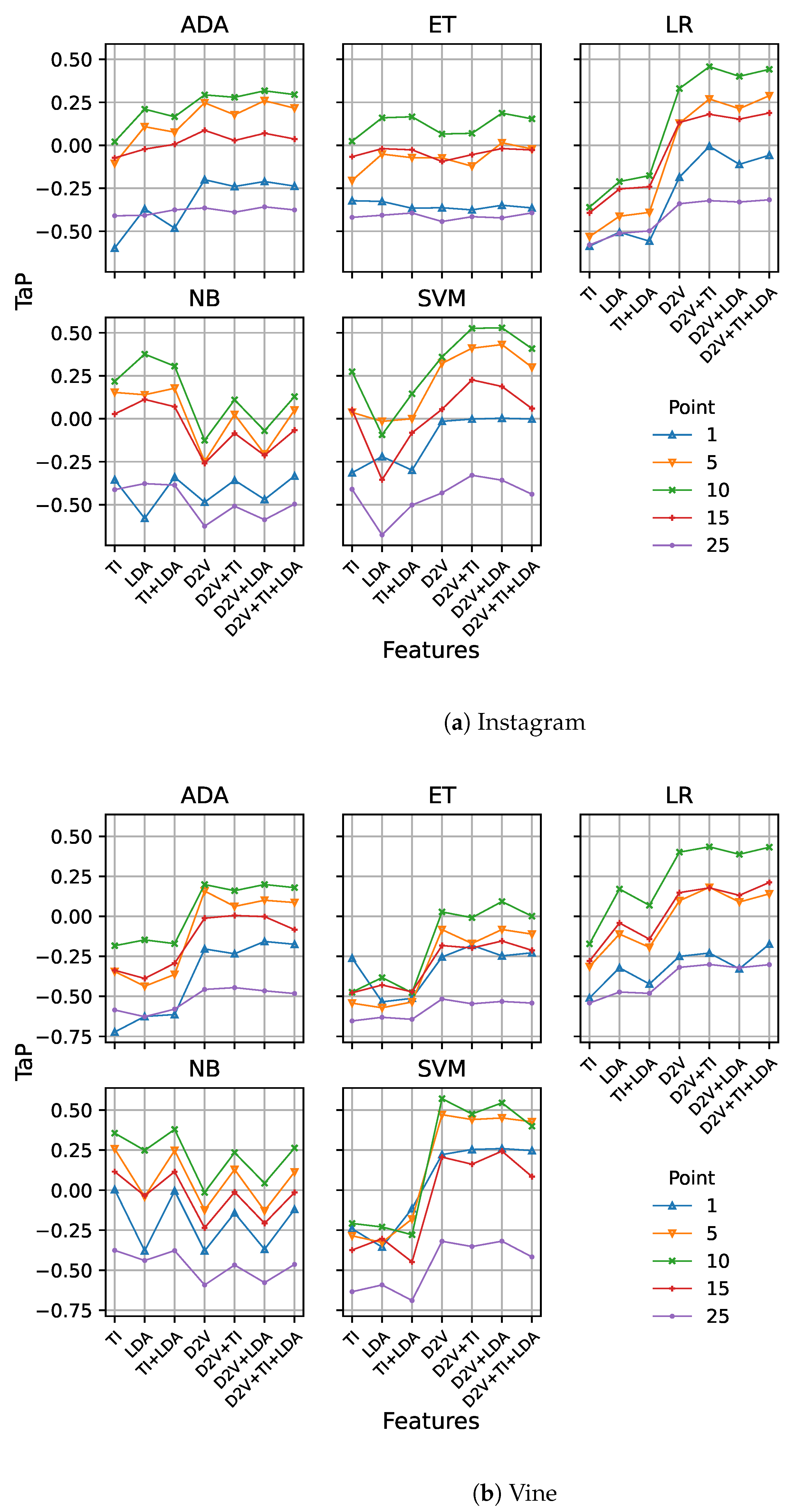
4.4.1. Baseline
4.4.2. Doc2Vec Features
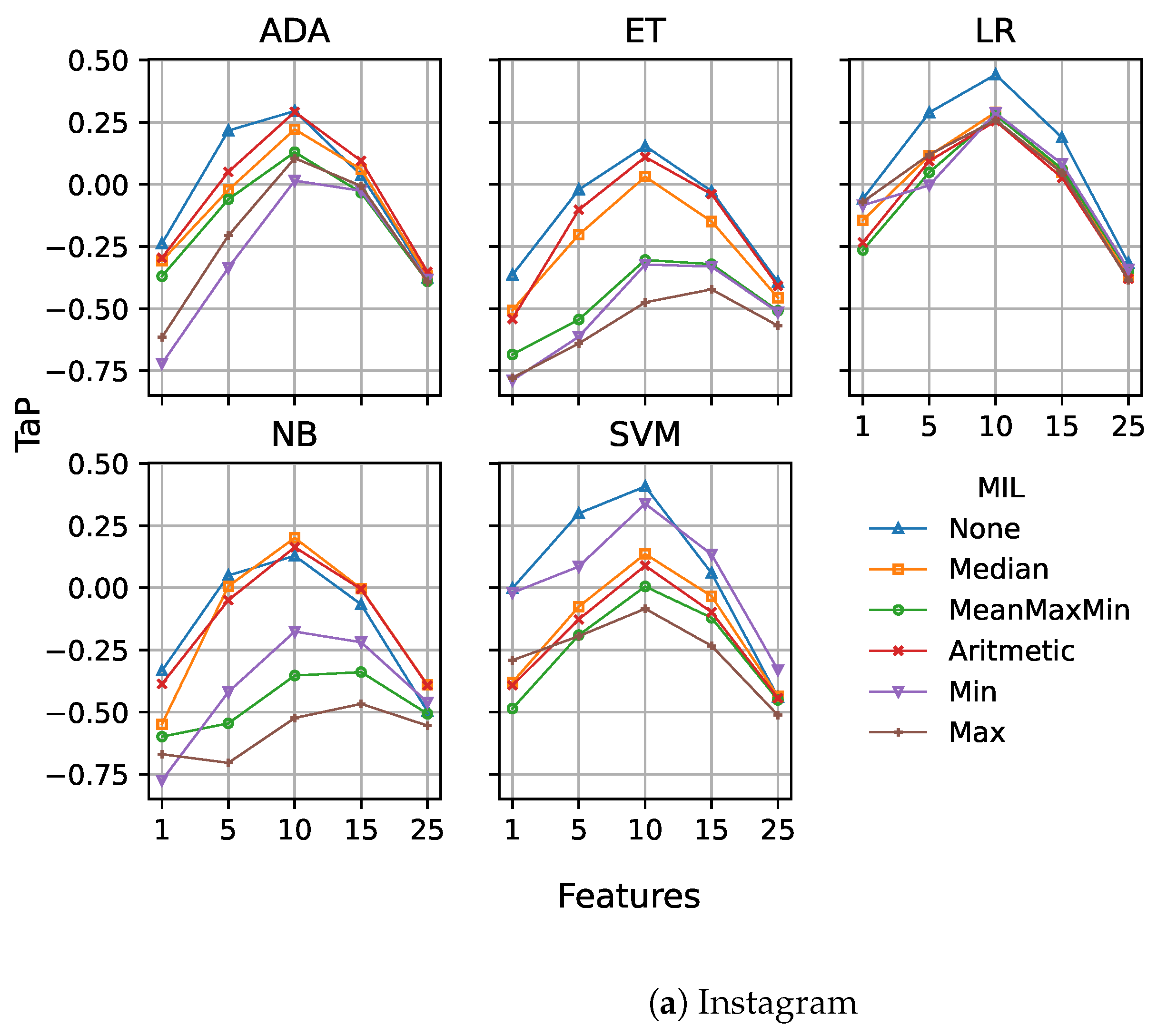
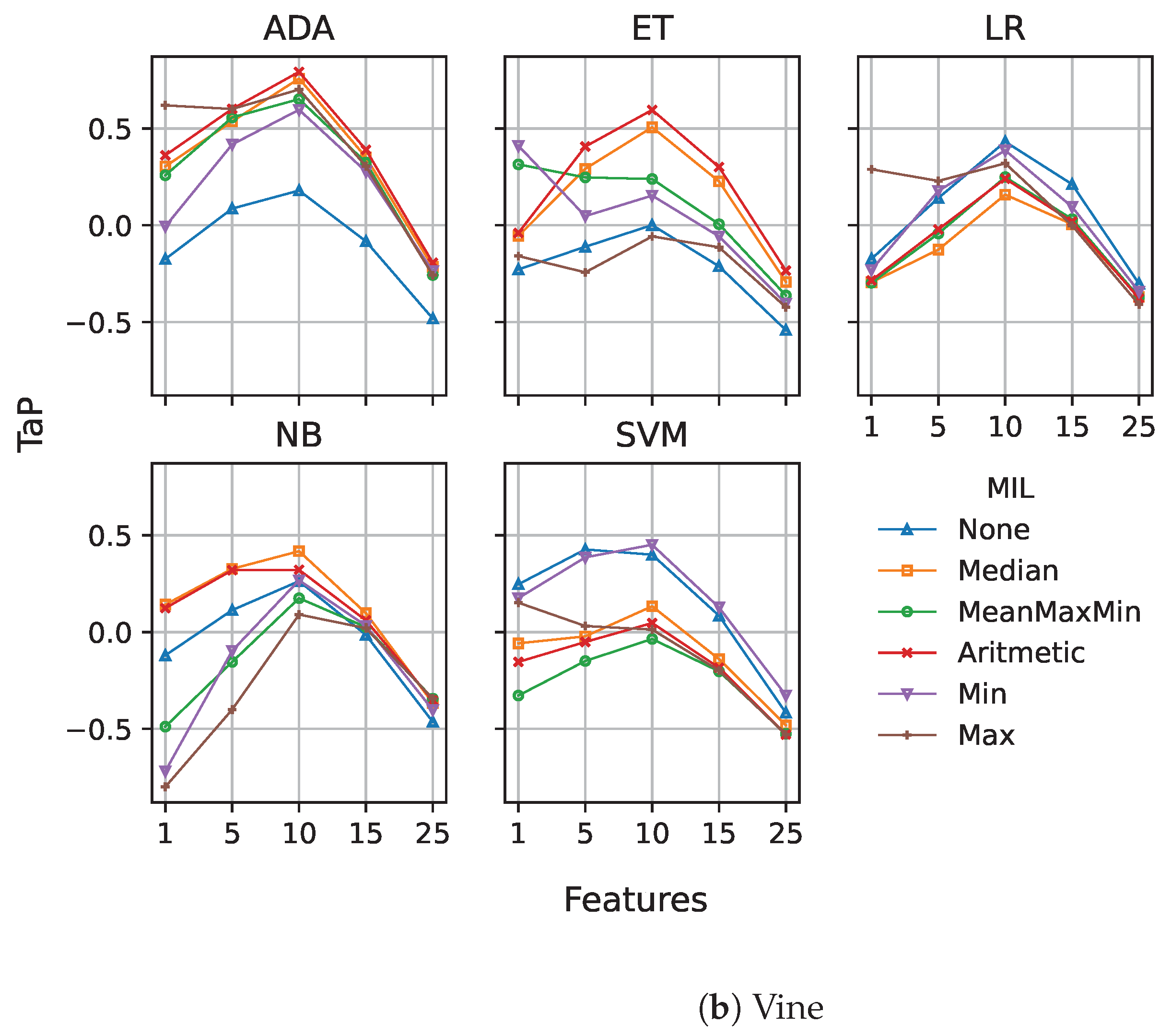
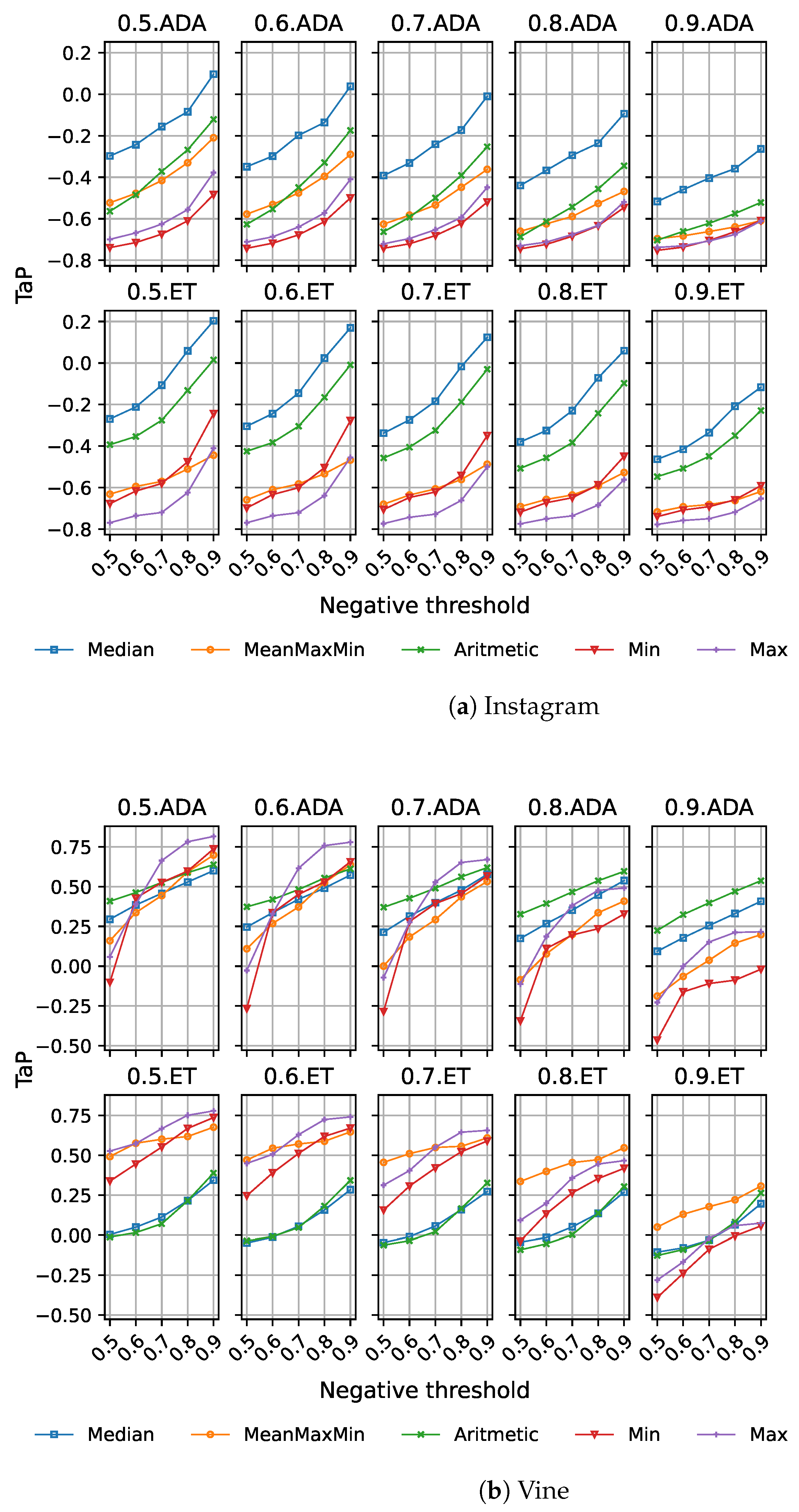
4.4.3. Multiple Instance Learning
5. Results and Discussion
6. Conclusions and Future Work
Author Contributions
Funding
Institutional Review Board Statement
Informed Consent Statement
Conflicts of Interest
Abbreviations
| MDPI | Multidisciplinary Digital Publishing Institute |
| LDA | Latent Dirichlet Allocation |
| MIL | Multiple Instance Learning |
| SVM | Support Vector Machines |
| Tf-idf | Term Frequency–Inverse Document Frequency |
| ET | Extra Trees |
| LR | Logistic Regression |
| NB | Naïve Bayes |
| D2V | Doc to Vec |
| EMDD | Expectation–Maximisation Diverse Density |
| NST-SVM | Normalized Set Kernel Support Vector Machines |
| MILES | Multiple Instance Learning via Embedded Instance Selection |
References
- Smith, P.K.; Mahdavi, J.; Carvalho, M.; Fisher, S.; Russell, S.; Tippett, N. Cyberbullying: Its nature and impact in secondary school pupils. J. Child Psychol. Psychiatry 2008, 49, 376–385. [Google Scholar] [CrossRef] [PubMed]
- Rybnicek, M.; Poisel, R.; Tjoa, S. Facebook watchdog: A research agenda for detecting online grooming and bullying activities. In Proceedings of the 2013 IEEE International Conference on Systems, Man, and Cybernetics, SMC 2013, Manchester, UK, 13–16 October 2013; pp. 2854–2859. [Google Scholar] [CrossRef]
- Koehler, C.; Weber, M. “Do I really need to help?!” Perceived severity of cyberbullying, victim blaming, and bystanders’ willingness to help the victim. Cyberpsychology J. Psychosoc. Res. Cyberspace 2018, 12, 4. [Google Scholar] [CrossRef]
- Kowalski, R.M.; Giumetti, G.W.; Schroeder, A.N.; Lattanner, M.R. Bullying in the digital age: A critical review and meta-analysis of cyberbullying research among youth. Psychol. Bull. 2014, 140, 1073–1137. [Google Scholar] [CrossRef] [PubMed]
- Royen, K.V.; Poels, K.; Daelemans, W.; Vandebosch, H. Automatic monitoring of cyberbullying on social networking sites: From technological feasibility to desirability. Telemat. Inform. 2015, 32, 89–97. [Google Scholar] [CrossRef]
- López-Vizcaíno, M.F.; Nóvoa, F.J.; Carneiro, V.; Cacheda, F. Early detection of cyberbullying on social media networks. Future Gener. Comput. Syst. 2021, 118, 219–229. [Google Scholar] [CrossRef]
- Soni, D.; Singh, V. See no evil, hear no evil: Audio-visual-textual cyberbullying detection. Proc. ACM Hum.-Comput. Interact. 2018, 2, 1–26. [Google Scholar] [CrossRef]
- Dinakar, K.; Reichart, R.; Lieberman, H. Modeling the Detection of Textual Cyberbullying; Technical report; AAAI Press: Washington, DC, USA, 2011. [Google Scholar]
- Zhong, H.; Li, H.; Squicciarini, A.C.; Rajtmajer, S.M.; Griffin, C.; Miller, D.J.; Caragea, C. Content-Driven Detection of Cyberbullying on the Instagram Social Network. In Proceedings of the Twenty-Fifth International Joint Conference on Artificial Intelligence (IJCAI-16), New York, NY, USA, 9–15 July 2016; Volume 16, pp. 3952–3958. [Google Scholar]
- Chen, Y.; Zhou, Y.; Zhu, S.; Xu, H. Detecting offensive language in social media to protect adolescent online safety. In Proceedings of the 2012 ASE/IEEE International Conference on Privacy, Security, Risk and Trust and 2012 ASE/IEEE International Conference on Social Computing, Amsterdam, The Netherlands, 3–6 September 2012; pp. 71–80. [Google Scholar] [CrossRef]
- Blackburn, J.; Binghamton, S.; Vakali, A.; Chatzakou, D.; Leontiadis, I.; Cristofaro, E.D.; Stringhini, G.; Kourtellis, N. Detecting Cyberbullying and Cyberaggression in Social Media. ACM Trans. Web 2019, 13, 51. [Google Scholar] [CrossRef]
- Rafiq, R.I.; Hosseinmardi, H.; Han, R.; Lv, Q.; Mishra, S.; Mattson, S.A. Careful what you share in six seconds: Detecting cyberbullying instances in Vine. In Proceedings of the 2015 IEEE/ACM International Conference on Advances in Social Networks Analysis and Mining, ASONAM 2015, Paris, France, 25–28 August 2015; pp. 617–622. [Google Scholar] [CrossRef]
- Rafiq, R.I.; Hosseinmardi, H.; Mattson, S.A.; Han, R.; Lv, Q.; Mishra, S. Analysis and detection of labeled cyberbullying instances in Vine, a video-based social network. Soc. Netw. Anal. Min. 2016, 6, 1–16. [Google Scholar] [CrossRef]
- Hosseinmardi, H.; Mattson, S.A.; Rafiq, R.I.; Han, R.; Lv, Q.; Mishra, S. Detection of Cyberbullying Incidents on the Instagram Social Network. arXiv 2015, arXiv:1503.03909. [Google Scholar] [CrossRef]
- Alsafari, S.; Sadaoui, S.; Mouhoub, M. Hate and offensive speech detection on Arabic social media. Online Soc. Netw. Media 2020, 19, 100096. [Google Scholar] [CrossRef]
- Al-Garadi, M.A.; Varathan, K.D.; Ravana, S.D. Cybercrime detection in online communications: The experimental case of cyberbullying detection in the Twitter network. Comput. Hum. Behav. 2016, 63, 433–443. [Google Scholar] [CrossRef]
- Reynolds, K.; Kontostathis, A.; Edwards, L. Using machine learning to detect cyberbullying. In Proceedings of the 10th International Conference on Machine Learning and Applications, ICMLA 2011, Honolulu, HI, USA, 18–21 December 2011; Volume 2, pp. 241–244. [Google Scholar] [CrossRef]
- Nahar, V.; Li, X.; Pang, C. An effective approach for cyberbullying detection. Commun. Inf. Sci. Manag. Eng. 2013, 3, 238. [Google Scholar]
- Hee, C.V.; Lefever, E.; Verhoeven, B.; Mennes, J.; Desmet, B.; Pauw, G.D.; Daelemans, W.; Hoste, V. Detection and fine-grained classification of cyberbullying events. In Proceedings of the International Conference Recent Advances in Natural Language Processing, Online, 1–3 September 2015; pp. 672–680. [Google Scholar]
- Dani, H.; Li, J.; Liu, H. Sentiment Informed Cyberbullying Detection in Social Media. In Lecture Notes in Computer Science (Including Subseries Lecture Notes in Artificial Intelligence and Lecture Notes in Bioinformatics); Springer: Berlin/Heidelberg, Germany, 2017; Volume 10534 LNAI, pp. 52–67. [Google Scholar] [CrossRef]
- Zhang, J.; Otomo, T.; Li, L.; Nakajima, S. Cyberbullying Detection on Twitter using Multiple Textual Features. In Proceedings of the 2019 IEEE 10th International Conference on Awareness Science and Technology, iCAST 2019, Morioka, Japan, 23–25 October 2019. [Google Scholar] [CrossRef]
- Balakrishnan, V.; Khan, S.; Arabnia, H.R. Improving cyberbullying detection using Twitter users’ psychological features and machine learning. Comput. Secur. 2020, 90, 101710. [Google Scholar] [CrossRef]
- Yuvaraj, N.; Srihari, K.; Dhiman, G.; Somasundaram, K.; Sharma, A.; Rajeskannan, S.; Soni, M.; Gaba, G.S.; Alzain, M.A.; Masud, M. Nature-Inspired-Based Approach for Automated Cyberbullying Classification on Multimedia Social Networking. Math. Probl. Eng. 2021, 2021, 1–12. [Google Scholar] [CrossRef]
- Talpur, B.A.; O’Sullivan, D. Cyberbullying severity detection: A machine learning approach. PLoS ONE 2020, 15, e0240924. [Google Scholar] [CrossRef]
- Arif, M. A Systematic Review of Machine Learning Algorithms in Cyberbullying Detection: Future Directions and Challenges. J. Inf. Secur. Cybercrimes Res. 2021, 4, 1–26. [Google Scholar] [CrossRef]
- Singh, N.; Sharma, S.K. Review of Machine Learning methods for Identification of Cyberbullying in Social Media. In Proceedings of the International Conference on Artificial Intelligence and Smart Systems, ICAIS 2021, Coimbatore, India, 25–27 March 2021; pp. 284–288. [Google Scholar] [CrossRef]
- Cheng, L.; Shu, K.; Wu, S.; Silva, Y.N.; Hall, D.L.; Liu, H. Unsupervised Cyberbullying Detection via Time-Informed Gaussian Mixture Model. arXiv 2020, arXiv:2008.02642. [Google Scholar]
- Gupta, A.; Yang, W.; Sivakumar, D.; Silva, Y.; Hall, D.; Barioni, M.N. Temporal Properties of Cyberbullying on Instagram. In Proceedings of the Web Conference 2020—Companion of the World Wide Web Conference, WWW 2020, Taipei, Taiwan, 20–24 April 2020; pp. 576–583. [Google Scholar] [CrossRef]
- Cheng, L.; Guo, R.; Silva, Y.; Hall, D.; Liu, H. Hierarchical attention networks for cyberbullying detection on the instagram social network. In Proceedings of the 2019 SIAM international conference on data mining. Society for Industrial and Applied Mathematics, Calgary, AB, Canada, 2–4 May 2019; pp. 235–243. [Google Scholar] [CrossRef]
- Soni, D.; Singh, V. Time Reveals All Wounds: Modeling Temporal Characteristics of Cyberbullying. In Proceedings of the International AAAI Conference on Web and Social Media, Palo Alto, CA, USA, 25–28 June 2018; Volume 12. [Google Scholar]
- Al-Garadi, M.A.; Hussain, M.R.; Khan, N.; Murtaza, G.; Nweke, H.F.; Ali, I.; Mujtaba, G.; Chiroma, H.; Khattak, H.A.; Gani, A. Predicting Cyberbullying on Social Media in the Big Data Era Using Machine Learning Algorithms: Review of Literature and Open Challenges. IEEE Access 2019, 7, 70701–70718. [Google Scholar] [CrossRef]
- Salawu, S.; He, Y.; Lumsden, J. Approaches to Automated Detection of Cyberbullying: A Survey. IEEE Trans. Affect. Comput. 2020, 11, 3–24. [Google Scholar] [CrossRef]
- Rosa, H.; Pereira, N.; Ribeiro, R.; Ferreira, P.C.; Carvalho, J.P.; Oliveira, S.; Coheur, L.; Paulino, P.; Simão, A.M.V.; Trancoso, I. Automatic cyberbullying detection: A systematic review. Comput. Hum. Behav. 2019, 93, 333–345. [Google Scholar] [CrossRef]
- Samghabadi, N.S.; Monroy, A.P.L.; Solorio, T. Detecting Early Signs of Cyberbullying in Social Media. In Proceedings of the Second Workshop on Trolling, Aggression and Cyberbullying, Marseille, France, 11–16 May 2020; pp. 144–149. [Google Scholar]
- Chen, H.Y.; Li, C.T. HENIN: Learning Heterogeneous Neural Interaction Networks for Explainable Cyberbullying Detection on Social Media. arXiv 2020, arXiv:2010.04576. [Google Scholar]
- Zaib, M.H.; Bashir, F.; Qureshi, K.N.; Kausar, S.; Rizwan, M.; Jeon, G. Deep learning based cyber bullying early detection using distributed denial of service flow. Multimed. Syst. 2021, 1, 1–20. [Google Scholar] [CrossRef]
- Yang, K.; Zhang, T.; Ananiadou, S. A mental state Knowledge–aware and Contrastive Network for early stress and depression detection on social media. Inf. Process. Manag. 2022, 59, 102961. [Google Scholar] [CrossRef]
- Lopez-Vizcaino, M.; Novoa, F.J.; Fernandez, D.; Carneiro, V.; Cacheda, F. Early Intrusion Detection for OS Scan Attacks. In Proceedings of the 2019 IEEE 18th International Symposium on Network Computing and Applications, NCA 2019, Cambridge, MA, USA, 26–28 September 2019. [Google Scholar] [CrossRef]
- Hosseinmardi, H.; Mattson, S.A.; Rafiq, R.I.; Han, R.; Lv, Q.; Mishra, S. Analyzing labeled cyberbullying incidents on the instagram social network. In Proceedings of the Social Informatics: 7th International Conference, SocInfo 2015, Beijing, China, 9–12 December 2015; Volume 9471, pp. 49–66. [Google Scholar] [CrossRef]
- Le, Q.; Mikolov, T. Distributed Representations of Sentences and Documents. In Proceedings of the International Conference on Machine Learning, Beijing, China, 22–24 June 2014; Volume 32, pp. 1188–1196. [Google Scholar]
- Karvelis, P.; Gavrilis, D.; Georgoulas, G.; Stylios, C. Topic recommendation using Doc2Vec. In Proceedings of the International Joint Conference on Neural Networks, Rio de Janeiro, Brazil, 8–13 July 2018. [Google Scholar] [CrossRef]
- Budiarto, A.; Rahutomo, R.; Putra, H.N.; Cenggoro, T.W.; Kacamarga, M.F.; Pardamean, B. Unsupervised News Topic Modelling with Doc2Vec and Spherical Clustering. Procedia Comput. Sci. 2021, 179, 40–46. [Google Scholar] [CrossRef]
- Lopez-Vizcaino, M.F.; Novoa, F.J.; Fernandez, D.; Cacheda, F. Measuring Early Detection of Anomalies. IEEE Access 2022, 10, 127695–127707. [Google Scholar] [CrossRef]
- Cacheda, F.; Fernandez, D.; Novoa, F.J.; Carneiro, V. Early Detection of Depression: Social Network Analysis and Random Forest Techniques. J. Med. Internet Res. 2019, 21, e12554. [Google Scholar] [CrossRef]
- Cacheda, F.; Fernández, D.; Novoa, F.J.; Carneiro, V. Analysis and Experiments on Early Detection of Depression. CLEF (Work. Notes) 2018, 2125, 43. [Google Scholar]
- Dietterich, T.G.; Lathrop, R.H.; Lozano-Pérez, T. Solving the multiple instance problem with axis-parallel rectangles. Artif. Intell. 1997, 89, 31–71. [Google Scholar] [CrossRef]
- Amores, J. Multiple instance classification: Review, taxonomy and comparative study. Artif. Intell. 2013, 201, 81–105. [Google Scholar] [CrossRef]











{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
| Vine | ||||||
|---|---|---|---|---|---|---|
| Cyberbullying | Normal | Total | Cyberbullying | Normal | Total | |
| Media sessions | 585 | 1369 | 1954 | 190 | 557 | 747 |
| 29.94% | 70.06% | 100% | 25.44% | 74.56% | 100% | |
| Comments | 45,372 | 76,862 | 122,234 | 15,810 | 40,389 | 56,199 |
| 37.12% | 62.88% | 100% | 28.13% | 71.87% | 100% | |
| Comments/session | 77.56 | 56.14 | 62.56 | 83.21 | 72.51 | 75.23 |
| Words/comment | 14.00 | 7.13 | 9.68 | 7.64 | 4.96 | 5.72 |
| English | 74.16% | 73.22% | 73.74% | 47.62% | 34.43% | 38.69% |
| Features | Vine | ||||||||||
|---|---|---|---|---|---|---|---|---|---|---|---|
| Features | Points | ADA | ET | LR | NB | SVM | ADA | ET | LR | NB | SVM |
| TI | 1 | −0.5975 | −0.3222 | −0.5864 | −0.3545 | −0.3138 | −0.7228 | −0.2609 | −0.5100 | 0.0036 | −0.2414 |
| 5 | −0.1060 | −0.2044 | −0.5313 | 0.1531 | 0.0370 | −0.3444 | −0.5424 | −0.3139 | 0.2577 | −0.2854 | |
| 10 | 0.0204 | 0.0236 | −0.3601 | 0.2172 | 0.2734 | −0.1836 | −0.4737 | −0.1720 | 0.3561 | −0.2080 | |
| 15 | −0.0732 | −0.0664 | −0.3933 | 0.0276 | 0.0520 | −0.3373 | −0.4774 | −0.2795 | 0.1156 | −0.3744 | |
| 25 | −0.4097 | −0.4191 | −0.5794 | −0.4122 | −0.4101 | −0.5851 | −0.6533 | −0.5414 | −0.3761 | −0.6345 | |
| LDA | 1 | −0.3700 | −0.3265 | −0.5055 | −0.5793 | −0.2195 | −0.6255 | −0.5342 | −0.3215 | −0.3793 | −0.3555 |
| 5 | 0.1080 | −0.0512 | −0.4127 | 0.1395 | −0.0151 | −0.4367 | −0.5712 | −0.1107 | −0.0412 | −0.3269 | |
| 10 | 0.2097 | 0.1597 | −0.2108 | 0.3755 | −0.0932 | −0.1472 | −0.3829 | 0.1708 | 0.2485 | −0.2300 | |
| 15 | −0.0223 | −0.0195 | −0.2541 | 0.1123 | −0.3550 | −0.3880 | −0.4290 | −0.0415 | −0.0352 | −0.3031 | |
| 25 | −0.4077 | −0.4067 | −0.5121 | −0.3771 | −0.6757 | −0.6270 | −0.6308 | −0.4729 | −0.4396 | −0.5923 | |
| TI+LDA | 1 | −0.4815 | −0.3662 | −0.5575 | −0.3397 | −0.2993 | −0.6135 | −0.5122 | −0.4226 | −0.0046 | −0.1147 |
| 5 | 0.0761 | −0.0723 | −0.3900 | 0.1774 | 0.0000 | −0.3632 | −0.5350 | −0.1935 | 0.2480 | −0.1803 | |
| 10 | 0.1659 | 0.1658 | −0.1764 | 0.3060 | 0.1453 | −0.1705 | −0.4771 | 0.0688 | 0.3794 | −0.2787 | |
| 15 | 0.0056 | −0.0265 | −0.2412 | 0.0701 | −0.0817 | −0.2931 | −0.4716 | −0.1426 | 0.1153 | −0.4486 | |
| 25 | −0.3754 | −0.3938 | −0.4976 | −0.3861 | −0.5017 | −0.5796 | −0.6435 | −0.4811 | −0.3780 | −0.6897 | |
| Vine | ||||||||||||
|---|---|---|---|---|---|---|---|---|---|---|---|---|
| Features | Th+ | Th− | ADA | ET | LR | NB | SVM | ADA | ET | LR | NB | SVM |
| TI | 0.5 | 0.8 | −0.0077 | −0.0509 | −0.2500 | −0.2986 | −0.1241 | −0.3751 | 0.1267 | −0.5252 | −0.8225 | −0.9098 |
| 0.5 | 0.9 | 0.3136 | 0.1106 | 0.1623 | 0.7561 | −0.0970 | −0.4404 | 0.2510 | −0.1199 | −0.9563 | −0.9449 | |
| 0.6 | 0.8 | −0.1509 | −0.1339 | −0.3540 | −0.3142 | −0.5194 | −0.6003 | −0.0520 | −0.6480 | −0.8225 | −0.9213 | |
| 0.6 | 0.9 | 0.0743 | 0.0176 | −0.0918 | 0.7346 | −0.5075 | −0.6779 | 0.0399 | −0.4913 | −0.9563 | −0.9563 | |
| LDA | 0.5 | 0.8 | 0.2022 | 0.0182 | −0.2374 | −0.5271 | −0.5481 | −0.7947 | −0.1892 | −0.2547 | −0.3915 | −0.8941 |
| 0.5 | 0.9 | 0.4318 | 0.2915 | 0.1651 | 0.6294 | −0.5435 | −0.8331 | 0.0901 | 0.1440 | 0.3990 | −0.9247 | |
| 0.6 | 0.8 | 0.0896 | −0.0678 | −0.3015 | −0.5257 | −0.8515 | −0.8793 | −0.3377 | −0.4189 | −0.7190 | −0.9224 | |
| 0.6 | 0.9 | 0.2770 | 0.1976 | −0.0034 | 0.5910 | −0.8672 | −0.9274 | −0.1740 | −0.1664 | −0.6755 | −0.9550 | |
| TI+LDA | 0.5 | 0.8 | 0.0884 | −0.1117 | −0.2385 | −0.2605 | −0.1272 | −0.3082 | −0.1204 | −0.3457 | −0.6740 | −0.7219 |
| 0.5 | 0.9 | 0.3686 | 0.1445 | 0.2062 | 0.7529 | −0.0996 | −0.3170 | 0.1402 | 0.1786 | −0.6250 | −0.8050 | |
| 0.6 | 0.8 | −0.0354 | −0.1807 | −0.2996 | −0.2721 | −0.4075 | −0.6584 | −0.2547 | −0.4584 | −0.8186 | −0.8607 | |
| 0.6 | 0.9 | 0.2031 | 0.0575 | 0.0280 | 0.7368 | −0.4260 | −0.7341 | −0.0931 | −0.1586 | −0.9563 | −0.9498 | |
| Features | Vine | ||||||||||
|---|---|---|---|---|---|---|---|---|---|---|---|
| Positive | Negative | ADA | ET | LR | NB | SVM | ADA | ET | LR | NB | SVM |
| TI | TI | 0.3136 | 0.1106 | 0.1623 | 0.7561 | −0.0970 | −0.4404 | 0.2510 | −0.1199 | −0.9563 | −0.9449 |
| LDA | 0.2609 | 0.3230 | 0.1524 | 0.7561 | −0.1006 | −0.4449 | 0.3004 | −0.1630 | −0.9563 | −0.9438 | |
| TI+LDA | 0.2936 | 0.1735 | 0.1716 | 0.7561 | −0.0984 | −0.4410 | 0.2526 | −0.1097 | −0.9563 | −0.9449 | |
| LDA | TI | 0.4710 | 0.1283 | 0.1791 | 0.6294 | −0.5398 | −0.8287 | 0.0298 | 0.1981 | 0.3990 | −0.9258 |
| LDA | 0.4318 | 0.2915 | 0.1651 | 0.6294 | −0.5435 | −0.8331 | 0.0901 | 0.1440 | 0.3990 | −0.9247 | |
| TI+LDA | 0.4464 | 0.1797 | 0.1759 | 0.6294 | −0.5413 | −0.8293 | −0.0004 | 0.2046 | 0.3990 | −0.9258 | |
| TI+LDA | TI | 0.3858 | 0.0882 | 0.2216 | 0.7529 | −0.0981 | −0.3165 | 0.1549 | 0.1741 | −0.6250 | −0.8050 |
| LDA | 0.3472 | 0.2646 | 0.1976 | 0.7529 | −0.1018 | −0.3209 | 0.2302 | 0.1034 | −0.6250 | −0.8039 | |
| TI+LDA | 0.3472 | 0.2646 | 0.1976 | 0.7529 | −0.1018 | −0.3209 | 0.2302 | 0.1034 | −0.6250 | −0.8039 | |
| Vine | ||||||
|---|---|---|---|---|---|---|
| Model | Baseline | Doc2Vec | % | Baseline | Doc2Vec | % |
| Fixed | (NB) | (SVM) | (NB) | (SMV) | ||
| Threshold | (NB) | (NB) | (NB) | (ADA) | ||
| Dual | (NB) | (NB) | (NB) | (ADA) | ||
Disclaimer/Publisher’s Note: The statements, opinions and data contained in all publications are solely those of the individual author(s) and contributor(s) and not of MDPI and/or the editor(s). MDPI and/or the editor(s) disclaim responsibility for any injury to people or property resulting from any ideas, methods, instructions or products referred to in the content. |
© 2023 by the authors. Licensee MDPI, Basel, Switzerland. This article is an open access article distributed under the terms and conditions of the Creative Commons Attribution (CC BY) license (https://creativecommons.org/licenses/by/4.0/).
Share and Cite
López-Vizcaíno, M.; Nóvoa, F.J.; Artieres, T.; Cacheda, F. Site Agnostic Approach to Early Detection of Cyberbullying on Social Media Networks. Sensors 2023, 23, 4788. https://doi.org/10.3390/s23104788
López-Vizcaíno M, Nóvoa FJ, Artieres T, Cacheda F. Site Agnostic Approach to Early Detection of Cyberbullying on Social Media Networks. Sensors. 2023; 23(10):4788. https://doi.org/10.3390/s23104788
Chicago/Turabian StyleLópez-Vizcaíno, Manuel, Francisco J. Nóvoa, Thierry Artieres, and Fidel Cacheda. 2023. "Site Agnostic Approach to Early Detection of Cyberbullying on Social Media Networks" Sensors 23, no. 10: 4788. https://doi.org/10.3390/s23104788
APA StyleLópez-Vizcaíno, M., Nóvoa, F. J., Artieres, T., & Cacheda, F. (2023). Site Agnostic Approach to Early Detection of Cyberbullying on Social Media Networks. Sensors, 23(10), 4788. https://doi.org/10.3390/s23104788