Abstract
This paper presents a novel object transportation method using deep reinforcement learning (DRL) and the task space decomposition (TSD) method. Most previous studies on DRL-based object transportation worked well only in the specific environment where a robot learned how to transport an object. Another drawback was that DRL only converged in relatively small environments. This is because the existing DRL-based object transportation methods are highly dependent on learning conditions and training environments; they cannot be applied to large and complicated environments. Therefore, we propose a new DRL-based object transportation that decomposes a difficult task space to be transported into simple multiple sub-task spaces using the TSD method. First, a robot sufficiently learned how to transport an object in a standard learning environment (SLE) that has small and symmetric structures. Then, a whole-task space was decomposed into several sub-task spaces by considering the size of the SLE, and we created sub-goals for each sub-task space. Finally, the robot transported an object by sequentially occupying the sub-goals. The proposed method can be extended to a large and complicated new environment as well as the training environment without additional learning or re-learning. Simulations in different environments are presented to verify the proposed method, such as a long corridor, polygons, and a maze.
1. Introduction
Object transportation is where a robot manipulates an object to a goal, and it is applied to various fields, such as logistics [1,2], exploration [3,4], retrieval tasks [5], and foraging [6].
Representative methods of transporting an object are prehensile and non-prehensile manipulation [7]. In prehensile manipulation, a robot first firmly grasps or captures an object using an equipped tool such as a gripper [8] or a dexterous robotic hand [9]. The robot and the object then move toward a goal as one body. The advantage of prehensile manipulation is that the object remains stationary during the transportation process, which allows the robot to precisely control the object. However, the disadvantage is that a pre-gripping or capturing motion is required before the object is transported. In addition, a robot should carefully determine how to grasp or where to apply force depending on the shape and material of the object. In contrast to prehensile manipulation, in non-prehensile manipulation, a robot does not use any tools and only pushes an object with its body [10,11,12]; preliminary grasping actions for object transportation are not required. In addition, the control of the robot is easier than that of prehensile manipulation because the robot is not tied to an object. However, it is difficult to predict the motion of the object, and thus a robot should reposition its pushing point every second to transport an object to a goal. Because of these characteristics, prehensile manipulation is an appropriate method for structured objects (i.e., known objects) [13] and non-prehensile manipulation is applicable to unstructured objects (i.e., unknown objects) [14,15].
Recently, reinforcement learning (RL)-based non-prehensile manipulation methods have been studied by many researchers [16,17,18,19]. These methods have performed well by learning how to transport an object without external intervention, but they only worked in limited environments (i.e., trained environments). In other words, their methods did not work well when the test and learning environments were different. In order to operate in a new environment, a robot would have to be retrained; this is an inefficient method due to time and space constraints.
Therefore, we propose a novel object transportation using deep reinforcement learning (DRL) and task space decomposition (TSD). First, a robot learns how to transport an object in a standard learning environment (SLE). The SLE is a learning space with a symmetric structure, which is usually smaller than a test environment, that allows a robot to learn a basic policy required for object transportation. In this phase, the robot becomes proficient in transporting an object using DRL. Second, a test environment (i.e., a whole task space) is divided into multiple sub-task spaces by considering the maximum traveled distance of a robot, which is called the TSD method. The TSD method divides a large and complex environment into many small and simple environments, making it easier to transport objects step-by-step. Finally, the object is transported to the goal by following the policy learned from the SLE in sub-task spaces. Each sub-task space computed from the TSD is smaller than the SLE, and thus the robot can apply the policy learned in the SLE. In other words, we simplified the problem by extending the learning results in the sub-task space to the whole-task space, as opposed to the existing DRL-based object transportation in the whole environment at once (i.e., end-to-end learning); this is the main contribution of this paper.
The proposed method has retained the advantage of prehensile manipulation, where a robot can learn how to transport without the complexity of control. At the same time, it trains only in a small environment (i.e., SLE), where it is easy to learn by DRL, and solves problems in large environments using the results in the SLE. This is similar to the divide and conquer strategy in computer science [20], and it has the advantage of being applicable to a wide variety of environments.
The contributions of this paper are summarized as follows:
- We present a novel object transportation method using DRL and TSD.
- We propose a DRL-based object transportation training method within an SLE.
- A TSD approach is introduced that can be applied to arbitrary object transportation environments.
- We verify the proposed method by performing simulations in a variety of environments, such as a long corridor, a polygon, and a maze.
This paper is organized as follows. Section 2 describes DRL-based non-prehensile object transportation methods and task decomposition methods. The object transportation problem is defined in Section 3, and the system overview is presented in Section 4. Section 5 and Section 6 explain the proposed object transportation method by separating the training and TSD steps. Simulations are shown in Section 7, and the conclusion is presented in Section 9.
2. Related Work
Traditionally, RL has been used as a tool to solve the object transportation problem and has been studied by many researchers. Manko et al. [21] presented a Q-learning-based large-object transportation method in a complex environment. Wang and De Silva [22] compared a single-agent Q-learning with a team Q-learning. They showed that single-agent Q-learning is better than the team Q-learning in a complicated environment because of the local-minima. Similarly, Rahimi et al. [23] compared different Q-learning-based box-pushing algorithms, and Wang and de Silva [24] proposed sequential Q-learning with the Kalman filtering method.
The above-mentioned RL-based object transportation methods showed limited performance under certain conditions because traditional Q-learning algorithms (e.g., the tabular method) have finite possible states. In the real-world, the possible states are very large, and thus a robot cannot sufficiently learn how to transport due to the limited size of the Q-table. Therefore, Mnih et al. [25] and Silver et al. [26] presented a deep Q-network (DQN) algorithm that shows a good performance by approximating the Q-table with a deep neural network.
Based on the improved performance of DQN, many DRL-based object transportation studies have been proposed. Zhang et al. [27] proposed multi-robot object transportation based on DRL. A large rod is carried to an exit by two robots using DQN. Xiao et al. [28] presented a decentralized macro-action-based policy via a centralized Q-net. Each decentralized Q-net is trained with the help of a centralized Q-net. Eoh and Park [29] proposed a curriculum-learning-based object transportation method using difficulty map generation and an adaptive determination of the episode size. Shibata et al. [30] presented a DRL-based multi-robot transportation method using an event-triggered communication and consensus-based control. The proposed multi-robot team can balance the control performance and communication savings even when the number of agents is different from that in the learning environment. In addition, various manipulation skills (e.g., pushing, pulling, and moving objects) based on RL have been studied in the fields of animation and virtual reality [31,32]. Their proposed methods allow a producer to create transport animations without complicated and tricky editing.
Meanwhile, various task decomposition methods have been proposed by many researchers to simplify complex navigation tasks. Kawano [33] proposed an automatic hierarchical sub-task decomposition method for a multi-robot delivery mission. They decomposed a task into multiple sub-tasks and learned in a stepwise manner by expanding the activity radius of the robot. This is a similar method to our proposed method, but their method only works in a grid world; robots have limited movements and action policies, such as pushing, non-pushing, and waiting. Mesesan et al. [34] proposed a hierarchical path planner that consists of two stages: a global planner and several local planners. It solves a complicated global path-planning problem by decomposing it into simpler local path-planning problems. Zhang et al. [35] proposed task-space-decomposed motion planning. The constrained manifold can be easily solved by a dual-resolution motion planning framework consisting of a global planner and a local planner. Fosong et al. [36] presented a multi-agent teamwork-learning method using a sub-task curriculum. A multi-agent learns simple specific sub-tasks, and then the policy of the team is merged and transferred to the target task. The above-mentioned task decomposition methods have different methodologies, but they all have one thing in common: they solve problems by breaking down a difficult problem into multiple easy problems. Following this principle, we propose a new object transportation approach that applies the learning results in a small and simple SLE to large and complex environments.
3. Problem Description
The problem of object transportation is manipulating an object to a goal within the goal boundary using a robot as follows:
where is the position of the object at time t and is the position of the goal. If an object is within , the object transport is considered complete. The robot is able to manipulate an object by pushing under its own power. We assumed that the object follows the quasi-static model, which is a reasonable assumption except for when the object is spherical. The environment was assumed to be polygonal in shape and, if it is not, it can be approximated as a polygon. We also assumed that there are no obstacles in the environment in order to focus on how an object is transported.
4. System Overview
The proposed object transportation method is based on DRL and TSD. This process is performed in three steps: (1) training to transport an object in an SLE, (2) TSD and sub-goal generation, and (3) transporting an object via sub-goals in the whole-task space.
First, we created the SLE in a small and square shape to facilitate learning, as shown in Figure 1a. In the training phase, we initialized the robot’s position randomly but ensured that the goal position is always in the center of the environment for symmetry. The size of the SLE can vary, but there are tradeoffs, such as the following. If the SLE is small, it is easy to converge and fast to learn, but the whole-task space should be divided into many small pieces in the transportation phase. On the other hand, if the SLE is large, then the number of sub-goals will decrease because the space of the sub-tasks will also be large. However, it is prone to divergence and the learning speed is slow.
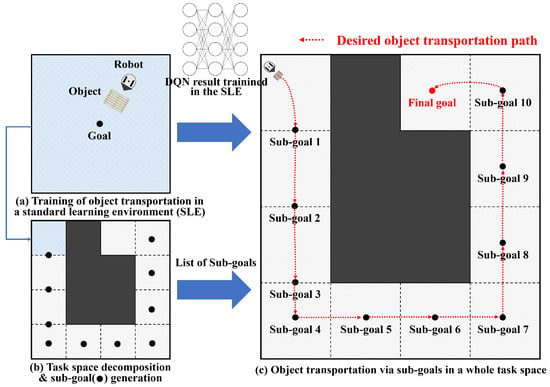
Figure 1.
Overview of DRL-based object transport using the TSD method. (a) A robot learns how to transport an object to a goal in an SLE. A deep Q-network (DQN) is used for training. (b) A whole-task space is decomposed into sub-task spaces by considering the size of the SLE. The size of the sub-task spaces cannot exceed the size of the SLE. For each sub-task space, sub-goals are generated by considering the maximum traveled distance of a robot. (c) The object is transported via the sub-goals by the pushing motion of a robot.
Second, a whole-task space was decomposed into the spaces of sub-tasks, taking into account the size of the SLE in the first phase, as shown in Figure 1b. The size of the sub-tasks cannot exceed that of the SLE because a robot cannot learn how to transport an object beyond the size of the SLE. Several sub-goals were then computed, taking into account the shape of the environment and the size of the sub-task spaces.
Finally, a robot transported an object to a goal via sub-goals that were generated in the previous phase, as shown in Figure 1c. For each space of sub-tasks, the robot takes an action by applying the inference result of the DQN, which was pre-trained in the SLE. The robot can iteratively use the pre-trained results by sequentially changing a goal from the initial to the final sub-goal. For example, in Figure 1c, the robot selects a goal as sub-goal 1 at the beginning. When the robot has successfully transported an object to sub-goal 1, a goal is changed to sub-goal 2. The robot then transports an object to sub-goal 2. This continues until the object is successfully transported to the final goal.
5. Training in a Standard Learning Environment
In this section, we describe the training process for object transportation in an SLE. First, a Markov decision process (MDP) was introduced to solve the RL problem. Next, the DRL framework for object transportation is presented and each component of the framework is described. Finally, an object transportation training method based on DQN is proposed for efficient learning.
5.1. Markov Decision Process
The RL problem can be solved by finding sequential decisions under uncertainty, which was formulated by the MDP. The MDP consists of four tuples: state space (), action space (), state transition probability (), and reward function (). A robot observes the state at time t and takes an action according to a policy function . The policy maps states to actions and determines how the robot interacts with the environment. The state transition probability is the probability when a robot takes the action a at the state s. A robot receives a reward if a robot performs an action in a given state . The goal of RL is to find a policy function that maximizes the sum of all expected rewards over time.
5.2. Reinforcement Learning Framework for Object Transportation
An RL framework for object transportation is presented in Figure 2. A square environment () was created for standardized learning. The initial positions of a robot and an object were chosen randomly. However, the goal position should be fixed in the center (i.e., origin) of the SLE to preserve symmetry: and .
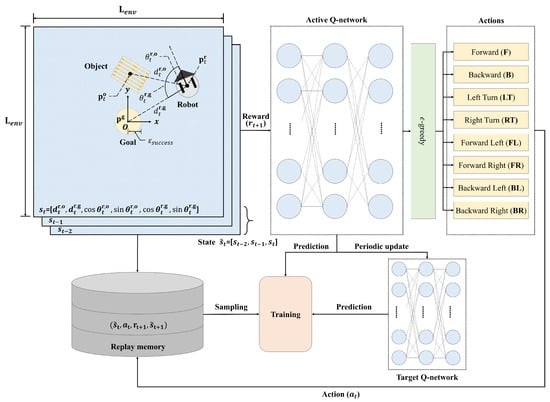
Figure 2.
Object transport training process in a square SLE.
A state consists of a six-dimensional array as follows:
where and are the distance and the angle between i and j, respectively. The indices i and j can represent a robot, an object, and a goal: . In order to represent the robot’s pushing motion, we defined a new state by concatenating the last three consecutive frames similar to [25]:
The actions of the robot are represented by eight motions using translational and rotational velocities () as follows:
A robot receives a reward according to action given the state as follows:
where and are rewards according to the success of object transportation and the collision with respect to the wall, respectively. The margin parameter is determined by considering the size of the SLE, a robot, and an object. The indicator function is how close an agent i is getting to an agent j (). Since it is most important that the object reaches its goal, we set and to satisfy the following conditions: .
5.3. Object Transportation Learning Using Deep Q-Network
Q-learning is a model-free RL that uses the Bellman equation to iteratively update estimates of the expected rewards of each action, allowing an agent to learn an optimal policy that maximizes the long-term expected return [37]. This process is formulated as a Q-learning algorithm:
where is a learning rate that determines how fast a robot will learn. If , a robot will not learn anything. On the contrary, a robot will ignore previous information if . Parameter is the discount factor that determines how much future rewards will be considered. If , a robot will consider a long-term reward. Conversely, a robot will only consider a short-term (i.e., immediate) reward if .
The Q-table generated by the Q-learning algorithm can be parameterized by a neural network denoted as . We can rewrite Equation (6) as follows:
where and are the weights and biases in the active and target Q-networks, respectively. The active and target Q-networks are illustrated in Figure 2.
The loss function is defined as follows:
and the weights and biases are updated to minimize a differentiable loss function:
A robot explores a new environment or exploits the existing information in the learning phase. This is called the exploration–exploitation tradeoff [38]. The -greedy strategy strikes a balance between exploration and exploitation by gradually decreasing the value from 1.0 to 0.1. The action of a robot is chosen by the -greedy algorithm using the active Q-network, as shown in the upper part of Figure 2.
Meanwhile, if only a single Q-network is used for learning, there may be oscillation or divergence problems during updating. Therefore, we separated the active (top) and target (bottom) Q-networks, as shown in Figure 2. The learning system is stable by periodically copying the parameters of the active Q-network to the target Q-network during the learning phase [25].
Finally, an experience replay memory is introduced to uncorrelate between information [39]; this records experiences in a replay memory , and randomly extracts samples for each learning phase.
The pseudo-code for training in an SLE is given in Algorithm 1. First, we initialized the replay memory , the weights and biases of two neural networks and with identical values, and the episode size (line 9–11). Second, we initialized the positions of a robot and an object in space for each episode (line 14). A concatenated new state was also initialized with the identical states (line 15). The decreases linearly with the -greedy algorithm (line 16). During the episode, a robot takes a random action using the -greedy algorithm, observes a new state , and then receives a reward (line 18–19). A new concatenated state at time is generated from three consecutive frames, and an experience is recorded in the experience replay memory (line 20–21). This process is repeated times until the end of the episode (line 17). In the training phase, we extracted random mini-batch samples from and it trains times to minimize the loss function (line 23–25). The weights of the target Q-network are substituted with those of the active Q-network every episodes (line 26). Then, we measured the success rate of object transportation to check the current performance (line 27–29). If a robot succeeds in transporting an object to a goal with the success rate , it stops training at the current level. On the contrary, if the success rate is less than , it trains more by increasing the unit size of episodes () (line 30–33). When using DRL, there are cases where overtraining can actually hinder learning, and this can be prevented by stopping training after .
| Algorithm 1: Training in a standard learning environment |
  |
6. Object Transportation Using a Task Space Decomposition Method
In the previous section, we presented how a robot could learn how to transport an object in the SLE. While this worked well in the SLE, it was difficult to generalize to larger or more complex environments. In this section, we present a method for transporting objects in complex and large environments using the training results of the SLE. To achieve this, we first generated midpoints, taking into account the inner and outer vertices of the polygonal environment (Section 6.1). Then, we divided a whole task space into several sub-task spaces considering the midpoints and the size of the SLE (Section 6.2). Finally, we computed sub-goals of object transportation for each sub-task space, and the robot can transport the object via the sub-goals (Section 6.3).
6.1. Midpoint Generation
In order to divide a whole-task space into sub-task spaces, we should first compute the midpoints of the transportation path using sets of the inner and outer vertices in the test environment. Algorithm 2 shows the process of generating midpoints. First, we declared two arrays to hold the distances () and the indices () between the inner and outer vertices (line 1–2). Second, we computed the Euclidean distances between all inner and outer vertices, and inserted the results into the (line 3–5). Third, we computed the outer vertex indices of the minimum distances for each inner vertex and appended them to the (line 6–8). Finally, we computed the midpoints of the inner and outer vertices using the minimum distance pair as (line 9–11). A list of all midpoints, , is returned as the final result (line 12). Figure 3 shows two examples of midpoint generation. A list of midpoints displayed in red dots () is created by calculating the midpoints of the shortest line segment between the inner and outer vertices.
| Algorithm 2: Midpoint generation |
 |
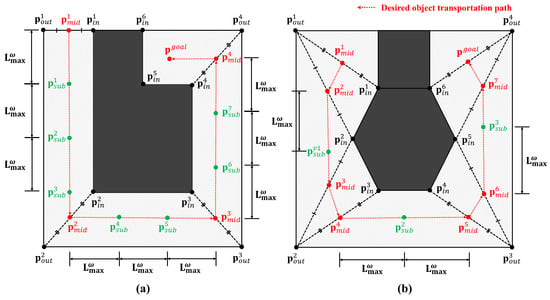
Figure 3.
(a,b) Two examples of midpoints and sub-goal generation using the task space decomposition method.
6.2. Task Space Decomposition
In general, a whole-task space is larger than the SLE, as already mentioned in Section 5. If the robot is located beyond the size of its SLE, the robot will not know how to transport an object because its state (e.g., the distance from the robot to the object) has not been used for training. Therefore, the whole-task space (i.e., the test environment) should be divided into several sub-task spaces with sizes that are smaller than that of the SLE. This allows a robot to transport an object by following connected lines through midpoints for each sub-task space. However, if a connected line is longer than the size of the SLE, the line should be split into multiple shorter lines. This TSD method is described in detail in Algorithm 3.
| Algorithm 3: Task space decomposition |
 |
First, the recursive flag is initialized to and the Euclidean distance between the start and the end points, , is calculated (line 2–3). The maximum distance traveled between sub-goals is equal to in the SLE because a robot has learned to transport only by the length of . If the distance is greater than , an intermediate point is calculated by dividing and by (line 5). In this case, the recursive flag is set to for recursive calculations with respect to the remaining line (line 6). On the other hand, if the distance is less than , the intermediate point () and the recursive flag are returned unchanged (line 8–9).
6.3. Sub-Goal Generation and Object Transportation
In the proposed method, a robot can transport an object by sequentially traversing multiple sub-goals. Algorithm 4 shows how to generate a list of sub-goals using the results of Algorithms 2 and 3. Using the function in Algorithm 3, we divided a sub-task space for successive midpoints by considering the size of the SLE, (line 2–3). The starting midpoint is inserted unconditionally into the list (line 4). If the distance between and is greater than , the TSD method is performed recursively until the remaining line is shorter than (line 5–8). The final output is a list of sub-goals, (line 9).
Now, a robot can transport an object using the Q-network inference result from Algorithm 1 and a list of sub-goals from Algorithm 4. Algorithm 5 shows the object transportation process via sub-goals. First, the index of the sub-goals and the flag are initialized as initial values (line 1–2). A robot observes the state, takes an action to maximize the Q-value from the deep Q-network inference (line 4–6). When an object reaches the sub-goal by robot pushing, the sub-goal index increases by one (line 7–8). When a robot reaches all sub-goals, we consider the object transportation to have succeeded and set the flag to true (line 9–10). Finally, the success flag is returned.
| Algorithm 4: Sub-goal generation for object transportation |
 |
| Algorithm 5: Object transportation via sub-goals |
 |
7. Simulations
7.1. Simulation Environment
We verified the proposed method using a Gazebo simulator based on the ROS [40]. The Gazebo simulator ran 60–80 times faster, and we trained the object transportation model on the Nvidia Geforce GTX-3090 with AMD Ryzen-5950X. In the simulation, the robot was TurtleBot3-waffle [41], and a pallet (1.2 m (W) × 0.8 m (H)) was used as an object. The margins of the goal () and the collision () in Equation (5) are 0.3 m and 0.1 m, respectively.
The state and action parameters are presented in Table 1. The transitional velocity of 0.3 m/s is the speed at which the robot moves steadily but not too slowly, and the rotational velocity of 1.0 rad/s is the speed at which the robot can adjust its heading in the target direction without turning too sharply when turning from one side to the other, thus compromising the stability of the robot’s motion. The values of the rotational and translational velocities were chosen for the free movement of the robot. The reward of is 20 times larger than in absolute value. We also gave more weight to the distance difference between the goal–object than the robot–object. This is because completing the object transportation is the most important mission; it does not matter if the robot arrives at the goal or not.

Table 1.
State and action parameters of the proposed object transportation.
The hyperparameters of the training phase are shown in Table 2. These hyperparameters were chosen to quickly and efficiently learn the object transportation method in the SLE. In particular, we varied the length of one side of the SLE to 6, 8, and 12 m. In order to compare the performance of different training space sizes, we ran the training in different SLE. In addition, the threshold of the success rate was set to 0.98 to guarantee the minimum performance of object transportation. The learning capacity of the Q-network is related to the depth and width of the layers, and thus we chose a depth and width of 4 and 256, respectively.
Table 2.
Hyperparameters of the training phase.
7.2. Training Results in Standard Learning Environments
We trained the object transportation method based on DRL in SLEs of different sizes: m, m, and m. The goal position was fixed to the origin, and the position of the robot was randomly initialized for each episode. If the current success rate is lower than the success threshold (), we increased the episode by one unit step () until the current success rate reached the threshold, as already mentioned in Algorithm 1. The final training results are described in Table 3. The success rates were higher than the success rate threshold for all environments. In addition, the number of episodes needed to reach the success rate threshold increased as the size of the environment increased. This is because a robot should learn more in the large environment.
Table 3.
Results in the standard learning environment.
Figure 4 shows 100 trajectories of an object in different SLEs. The robot successfully learned how to transport an object in SLEs regardless of the initial positions of the robot and an object. This result will be used for transporting an object in different test environments, which will be discussed in the next section.
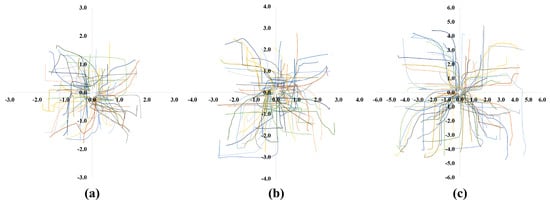
Figure 4.
One hundred transportation trajectories of an object in different sizes of SLEs: (a) m environment; (b) m environment; (c) m environment.
7.3. Test Results in Various-Shaped Environments
In the training phase, the SLEs are square environments of different sizes. These environments are designed to facilitate optimization and to improve convergence in the training phase. However, in the real world, there are many different sizes and shapes of environments. Therefore, we built our test environment with the following two aspects in mind: (1) sub-goal changes and (2) path length. For example, if a robot transports along a straight line, the path length is long, but the sub-goal changes are infrequent. Conversely, in a maze, the length of the segmented path is typically short, but the sub-goals change frequently and sequentially as the object is transported. In the real world, sub-goal changes and path length changes occur frequently, and thus the following environments are constructed to reflect this, as shown in Figure 5: (a) a long corridor; (b) a simple polygon; (c) a complex polygon; (d) a maze-shaped environment.
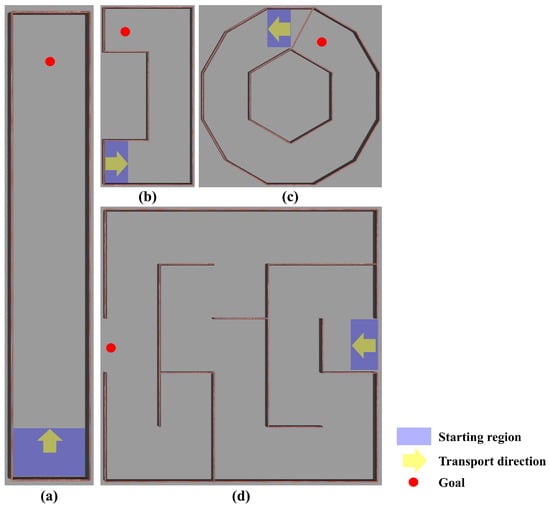
Figure 5.
Various simulation environments for the testing of the proposed method: (a) long corridor; (b) simple polygon; (c) complex polygon; (d) maze.
Table 4 shows the end-to-end DRL (i.e., the existing method) results in the differently shaped environments. The robot can be trained without any pre-processing, such as task decomposition, which is called end-to-end DRL. While the end-to-end DRL-based object transportation methods are easy to adapt to a wide variety of environments, they perform poorly in complex environments, as shown in Table 4; there are some successes with relatively simple environments, such as long corridors, but the robot cannot transport objects in complex shapes, such as polygons and mazes. However, in the case of end-to-end learning, we found that the transport distance is relatively short because we did not specify any waypoints.
Table 4.
Results in the end-to-end deep reinforcement learning method (the existing method).
Meanwhile, Figure 6, Figure 7, Figure 8 and Figure 9 show representative trajectories of an object and a robot using the proposed method for each test environment; only 10 trajectories out of a total of 200 trials are shown for easy comparison between trajectories. The left and right sides of each figure show the trajectories of an object and a robot, respectively. By comparing (a), (b), (d) or (c), (e) for each figure, we can see that the larger the size of the SLE, the less volatile the desired trajectory of the robot and the object. This means that if a robot learns how to transport in a large learning environment, the motion variations in the test environment are small. Meanwhile, for the same SLE size, the smaller the maximum distance traveled between sub-goals, the more likely the robot is to travel directly to the goal without motion variation. This is because the larger the maximum distance between sub-goals, the longer the object will stay in its current pushing direction once it starts pushing, making it harder to change the pushing direction; we can derive these conclusions by comparing (b), (c) or (d), (e), (f) for each figure. In general, it is a good result if the trajectory is plotted consistently and without deviation over several trials. For example, we can see that the case of Figure 6d has less path variability than that of (f). This indicates that Figure 6d performs better than (f) in that it is able to transport the object reliably every time.

Figure 6.
Ten trajectories of object transportation in a long corridor environment (Figure 5a). The left and right sides of each figure represent the trajectory of an object and a robot, respectively. (a) m and m; (b) m and m; (c) m and m; (d) m and m; (e) m and m; (f) m and m.
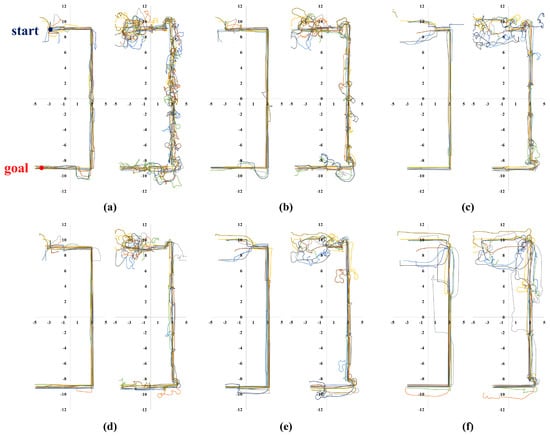
Figure 7.
Ten trajectories of object transportation in a simple polygon environment (Figure 5b). The left and right sides of each figure represent the trajectory of an object and a robot, respectively. (a) m and m; (b) m and m; (c) m and m; (d) m and m; (e) m and m; (f) m and m.
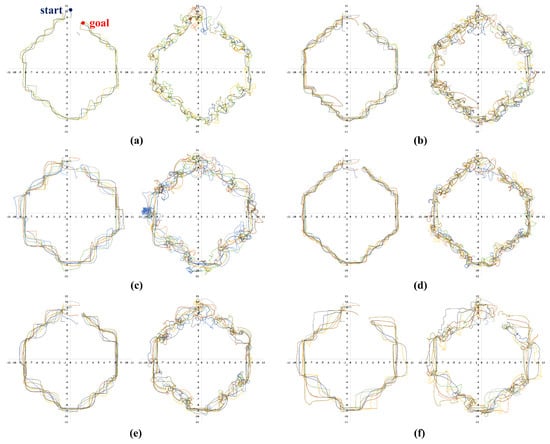
Figure 8.
Ten trajectories of object transportation in a complex polygon environment (Figure 5c). The left and right sides of each figure represent the trajectory of an object and a robot, respectively. (a) m and m; (b) m and m; (c) m and m; (d) m and m; (e) m and m; (f) m and m.
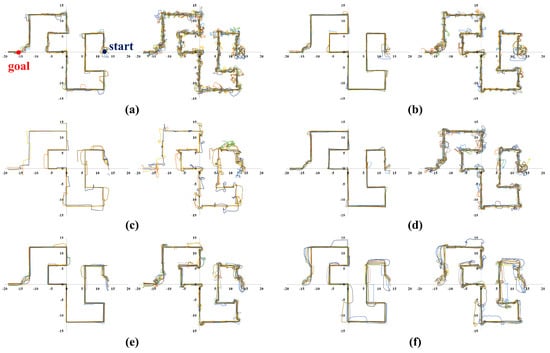
Figure 9.
Ten trajectories of object transportation in a maze environment (Figure 5d). The left and right sides of each figure represent the trajectory of an object and a robot, respectively. (a) m and m; (b) m and m; (c) m and m; (d) m and m; (e) m and m; (f) m and m.
Table 5 shows the test results in differently shaped environments using the proposed method. We tested 200 trials in four test environments using the deep Q-network learned from the differently sized SLEs. The average distance traveled by the robot and the object was recorded only if the object transportation was succeeded.
Table 5.
Test results in differently shaped environments.
From the table, we can see the following results. First, we can see that the success rate is generally higher for m. This is because the robot can also transport an object in a small environment if it has learned on a large environment. However, as shown in Table 3, the larger the training environment, the more episodes needed for training, which could lead to long training times or show poor convergence. Therefore, we should design the size of the SLE appropriately by considering the trade-off between the performance and training time. Second, the success rate increases as the maximum distance traveled between sub-goals increases. Conversely, the smaller the distance between sub-goals, the greater the risk that the object transportation will fail. This is because the greater the number of sub-goals, the more motion changes that are required to reach the sub-goals; frequent motion changes make it difficult for a robot to control precisely.
8. Discussion
In general, DRL-based object transportation has the advantage of it being easy to learn pushing motions, but it has the disadvantage of it being difficult to apply in various environments; this is because the DRL algorithm only works well within the specific conditions and environment in which it has been trained. Therefore, we solved this problem by using the task space decomposition method while maintaining the advantages of the DRL algorithm’s ease of learning how to transport an object.
Furthermore, the proposed method has shown that a robot can transport an object not only in simple environments but also in complex environments. A robot learns how to transport an object on short paths in simple environments (e.g., a square environment) and extends these results to set up multiple sub-goals to apply to larger, more complex environments, such as a long corridor, polygon, and maze. Finally, the robot transports the object by passing through the set sub-goals in sequence. In this way, it is possible to transport objects in unknown and arbitrary environments, not just the environment in which they were trained; the proposed method will be useful in the real world, where complex structures and environments exist.
On the other hand, the proposed method has some limitations. First, objects have to be transported via sub-goals, which may lead to inefficient routes. Inefficient energy consumption may occur because the minimum distance is not considered in the process of setting sub-goals. Therefore, it is necessary to consider the efficiency of the route at the sub-goal selection stage for optimal object transport. Second, depending on the environmental conditions, it may not be possible to transport with a single robot. Due to the shape of the object and the surrounding environment, there is a possibility of falling into a local minimum, so a transport solution may not exist with a single robot. In this case, a multi-robot object transport method should be considered.
9. Conclusions
This paper proposed a novel DRL-based object transportation using a task space decomposition method. First, a robot learned how to transport an object in the SLE based on DRL. Second, a whole-task space was divided into several sub-task spaces using the task space decomposition method. The learning results from the SLE can be applied to each sub-task space without modification. Finally, the robot can transport an object in arbitrary environments as well as in the SLE; the performance of the existing DRL-based object transportation method dropped dramatically when the test environment was different from the training environment or in large and complex environments. On the other hand, since our proposed method decomposes the whole environment into simple and easy environment units to transport objects, we found that it works well in arbitrary environments such as a long corridor, polygon, and maze. In the future work, we will consider various environments with static and dynamic obstacles, such as a logistics and airport environment. We will also verify the performance of the proposed algorithm on a real robot.
Funding
This research was funded by Basic Science Research Program through the National Research Foundation of Korea (NRF) funded by the Ministry of Education (No. NRF-2022R1F1A1069515).
Institutional Review Board Statement
Not applicable.
Informed Consent Statement
Not applicable.
Data Availability Statement
Not applicable.
Acknowledgments
This work was supported by the National Research Foundation of Korea (NRF) grant funded by the Korea government (No. NRF-2022R1F1A1069515) and the Academic Promotion System of Tech University of Korea (2022).
Conflicts of Interest
The author declares no conflict of interest.
Abbreviations
The following abbreviations are used in this manuscript:
| RL | Reinforcement learning |
| DRL | Deep reinforcement learning |
| SLE | Standard learning environment |
| TSD | Task space decomposition |
| DQN | Deep Q-network |
References
- Matsuo, I.; Shimizu, T.; Nakai, Y.; Kakimoto, M.; Sawasaki, Y.; Mori, Y.; Sugano, T.; Ikemoto, S.; Miyamoto, T. Q-bot: Heavy object carriage robot for in-house logistics based on universal vacuum gripper. Adv. Robot. 2020, 34, 173–188. [Google Scholar] [CrossRef]
- Koung, D.; Kermorgant, O.; Fantoni, I.; Belouaer, L. Cooperative multi-robot object transportation system based on hierarchical quadratic programming. IEEE Robot. Autom. Lett. 2021, 6, 6466–6472. [Google Scholar] [CrossRef]
- Hu, J.; Niu, H.; Carrasco, J.; Lennox, B.; Arvin, F. Voronoi-based multi-robot autonomous exploration in unknown environments via deep reinforcement learning. IEEE Trans. Veh. Technol. 2020, 69, 14413–14423. [Google Scholar] [CrossRef]
- Choi, D.; Kim, D. Intelligent multi-robot system for collaborative object transportation tasks in rough terrains. Electronics 2021, 10, 1499. [Google Scholar] [CrossRef]
- Eoh, G.; Choi, J.S.; Lee, B.H. Faulty robot rescue by multi-robot cooperation. Robotica 2013, 31, 1239. [Google Scholar] [CrossRef]
- Ordaz-Rivas, E.; Rodriguez-Liñan, A.; Torres-Treviño, L. Autonomous foraging with a pack of robots based on repulsion, attraction and influence. Auton. Robot. 2021, 45, 919–935. [Google Scholar] [CrossRef]
- Imtiaz, M.B.; Qiao, Y.; Lee, B. Prehensile and Non-Prehensile Robotic Pick-and-Place of Objects in Clutter Using Deep Reinforcement Learning. Sensors 2023, 23, 1513. [Google Scholar] [CrossRef]
- Appius, A.X.; Bauer, E.; Blöchlinger, M.; Kalra, A.; Oberson, R.; Raayatsanati, A.; Strauch, P.; Suresh, S.; von Salis, M.; Katzschmann, R.K. Raptor: Rapid aerial pickup and transport of objects by robots. In Proceedings of the 2022 IEEE/RSJ International Conference on Intelligent Robots and Systems (IROS), Kyoto, Japan, 23–27 October 2022; IEEE: Piscataway, NJ, USA, 2022; pp. 349–355. [Google Scholar]
- Gupta, A.; Eppner, C.; Levine, S.; Abbeel, P. Learning dexterous manipulation for a soft robotic hand from human demonstrations. In Proceedings of the 2016 IEEE/RSJ International Conference on Intelligent Robots and Systems (IROS), Daejeon, Republic of Korea, 9–14 October 2016; IEEE: Piscataway, NJ, USA, 2016; pp. 3786–3793. [Google Scholar]
- Ebel, H.; Eberhard, P. Non-prehensile cooperative object transportation with omnidirectional mobile robots: Organization, control, simulation, and experimentation. In Proceedings of the 2021 International Symposium on Multi-Robot and Multi-Agent Systems (MRS), Cambridge, UK, 4–5 November 2021; IEEE: Piscataway, NJ, USA, 2021; pp. 1–10. [Google Scholar]
- Stüber, J.; Zito, C.; Stolkin, R. Let’s Push Things Forward: A Survey on Robot Pushing. Front. Robot. AI 2020, 7, 8. [Google Scholar] [CrossRef]
- De Berg, M.; Gerrits, D.H. Computing push plans for disk-shaped robots. Int. J. Comput. Geom. Appl. 2013, 23, 29–48. [Google Scholar] [CrossRef]
- Lamiraux, F.; Mirabel, J. Prehensile manipulation planning: Modeling, algorithms and implementation. IEEE Trans. Robot. 2021, 38, 2370–2388. [Google Scholar] [CrossRef]
- Pasricha, A.; Tung, Y.S.; Hayes, B.; Roncone, A. PokeRRT: Poking as a Skill and Failure Recovery Tactic for Planar Non-Prehensile Manipulation. IEEE Robot. Autom. Lett. 2022, 7, 4480–4487. [Google Scholar] [CrossRef]
- Lee, J.; Nam, C.; Park, J.; Kim, C. Tree search-based task and motion planning with prehensile and non-prehensile manipulation for obstacle rearrangement in clutter. In Proceedings of the 2021 IEEE International Conference on Robotics and Automation (ICRA), Xi’an, China, 30 May–5 June 2021; IEEE: Piscataway, NJ, USA, 2021; pp. 8516–8522. [Google Scholar]
- Wu, J.; Sun, X.; Zeng, A.; Song, S.; Rusinkiewicz, S.; Funkhouser, T. Learning pneumatic non-prehensile manipulation with a mobile blower. IEEE Robot. Autom. Lett. 2022, 7, 8471–8478. [Google Scholar] [CrossRef]
- Eoh, G.; Park, T.H. Cooperative Object Transportation Using Curriculum-Based Deep Reinforcement Learning. Sensors 2021, 21, 4780. [Google Scholar] [CrossRef]
- Kalashnikov, D.; Irpan, A.; Pastor, P.; Ibarz, J.; Herzog, A.; Jang, E.; Quillen, D.; Holly, E.; Kalakrishnan, M.; Vanhoucke, V.; et al. Scalable deep reinforcement learning for vision-based robotic manipulation. In Proceedings of the Conference on Robot Learning, Zurich, Switzerland, 29–31 October 2018; pp. 651–673. [Google Scholar]
- Lowrey, K.; Kolev, S.; Dao, J.; Rajeswaran, A.; Todorov, E. Reinforcement learning for non-prehensile manipulation: Transfer from simulation to physical system. In Proceedings of the 2018 IEEE International Conference on Simulation, Modeling, and Programming for Autonomous Robots (SIMPAR), Brisbane, Australia, 16–19 May 2018; IEEE: Piscataway, NJ, USA, 2018; pp. 35–42. [Google Scholar]
- Smith, D.R. The design of divide and conquer algorithms. Sci. Comput. Program. 1985, 5, 37–58. [Google Scholar] [CrossRef]
- Manko, S.V.; Diane, S.A.; Krivoshatskiy, A.E.; Margolin, I.D.; Slepynina, E.A. Adaptive control of a multi-robot system for transportation of large-sized objects based on reinforcement learning. In Proceedings of the 2018 IEEE Conference of Russian Young Researchers in Electrical and Electronic Engineering (EIConRus), Moscow and St. Petersburg, Russia, 29 January–1 February 2018; IEEE: Piscataway, NJ, USA, 2018; pp. 923–927. [Google Scholar]
- Wang, Y.; De Silva, C.W. Multi-robot box-pushing: Single-agent q-learning vs. team q-learning. In Proceedings of the 2006 IEEE/RSJ International Conference on Intelligent Robots and Systems, Beijing, China, 9–13 October 2006; IEEE: Piscataway, NJ, USA, 2006; pp. 3694–3699. [Google Scholar]
- Rahimi, M.; Gibb, S.; Shen, Y.; La, H.M. A comparison of various approaches to reinforcement learning algorithms for multi-robot box pushing. In Proceedings of the International Conference on Engineering Research and Applications, Tokyo, Japan, 22–24 August 2018; Springer: Berlin/Heidelberg, Germany, 2018; pp. 16–30. [Google Scholar]
- Wang, Y.; de Silva, C.W. Sequential Q-Learning with Kalman Filtering for Multirobot Cooperative Transportation. IEEE/ASME Trans. Mechatron. 2009, 15, 261–268. [Google Scholar] [CrossRef]
- Mnih, V.; Kavukcuoglu, K.; Silver, D.; Rusu, A.A.; Veness, J.; Bellemare, M.G.; Graves, A.; Riedmiller, M.; Fidjeland, A.K.; Ostrovski, G.; et al. Human-level control through deep reinforcement learning. Nature 2015, 518, 529–533. [Google Scholar] [CrossRef]
- Silver, D.; Huang, A.; Maddison, C.J.; Guez, A.; Sifre, L.; Van Den Driessche, G.; Schrittwieser, J.; Antonoglou, I.; Panneershelvam, V.; Lanctot, M.; et al. Mastering the game of Go with deep neural networks and tree search. Nature 2016, 529, 484–489. [Google Scholar] [CrossRef]
- Zhang, L.; Sun, Y.; Barth, A.; Ma, O. Decentralized Control of Multi-Robot System in Cooperative Object Transportation Using Deep Reinforcement Learning. IEEE Access 2020, 8, 184109–184119. [Google Scholar] [CrossRef]
- Xiao, Y.; Hoffman, J.; Xia, T.; Amato, C. Learning Multi-Robot Decentralized Macro-Action-Based Policies via a Centralized Q-Net. In Proceedings of the 2020 IEEE International Conference on Robotics and Automation (ICRA), Paris, France, 31 May–31 August 2020; IEEE: Piscataway, NJ, USA, 2020; pp. 10695–10701. [Google Scholar]
- Eoh, G.; Park, T.H. Automatic Curriculum Design for Object Transportation Based on Deep Reinforcement Learning. IEEE Access 2021, 9, 137281–137294. [Google Scholar] [CrossRef]
- Shibata, K.; Jimbo, T.; Matsubara, T. Deep reinforcement learning of event-triggered communication and consensus-based control for distributed cooperative transport. Robot. Auton. Syst. 2023, 159, 104307. [Google Scholar] [CrossRef]
- Yang, H.Y.; Wong, S.K. Agent-based cooperative animation for box-manipulation using reinforcement learning. Proc. ACM Comput. Graph. Interact. Tech. 2019, 2, 1–18. [Google Scholar] [CrossRef]
- Rybak, L.; Behera, L.; Averbukh, M.; Sapryka, A. Development of an algorithm for managing a multi-robot system for cargo transportation based on reinforcement learning in a virtual environment. In Proceedings of the IOP Conference Series: Materials Science and Engineering, Chennai, India, 16–17 September 2020; IOP Publishing: Bristol, UK, 2020; Volume 945, p. 012083. [Google Scholar]
- Kawano, H. Hierarchical sub-task decomposition for reinforcement learning of multi-robot delivery mission. In Proceedings of the 2013 IEEE International Conference on Robotics and Automation, Karlsruhe, Germany, 6–10 May 2013; IEEE: Piscataway, NJ, USA, 2013; pp. 828–835. [Google Scholar]
- Mesesan, G.; Roa, M.A.; Icer, E.; Althoff, M. Hierarchical path planner using workspace decomposition and parallel task-space rrts. In Proceedings of the 2018 IEEE/RSJ International Conference on Intelligent Robots and Systems (IROS), Madrid, Spain, 1–5 October 2018; IEEE: Piscataway, NJ, USA, 2018; pp. 1–9. [Google Scholar]
- Zhang, X.; Yan, L.; Lam, T.L.; Vijayakumar, S. Task-space decomposed motion planning framework for multi-robot loco-manipulation. In Proceedings of the 2021 IEEE International Conference on Robotics and Automation (ICRA), Xi’an, China, 30 May–5 June 2021; IEEE: Piscataway, NJ, USA, 2021; pp. 8158–8164. [Google Scholar]
- Fosong, E.; Rahman, A.; Carlucho, I.; Albrecht, S.V. Learning Complex Teamwork Tasks using a Sub-task Curriculum. arXiv 2023, arXiv:2302.04944. [Google Scholar]
- Watkins, C.J.; Dayan, P. Q-learning. Mach. Learn. 1992, 8, 279–292. [Google Scholar] [CrossRef]
- Yogeswaran, M.; Ponnambalam, S. Reinforcement learning: Exploration–exploitation dilemma in multi-agent foraging task. Opsearch 2012, 49, 223–236. [Google Scholar] [CrossRef]
- Lin, L.J. Self-improving reactive agents based on reinforcement learning, planning and teaching. Mach. Learn. 1992, 8, 293–321. [Google Scholar] [CrossRef]
- Takaya, K.; Asai, T.; Kroumov, V.; Smarandache, F. Simulation environment for mobile robots testing using ROS and Gazebo. In Proceedings of the 2016 20th International Conference on System Theory, Control and Computing (ICSTCC), Sinaia, Romania, 13–15 October 2016; IEEE: Piscataway, NJ, USA, 2016; pp. 96–101. [Google Scholar]
- Amsters, R.; Slaets, P. Turtlebot 3 as a robotics education platform. In Proceedings of the Robotics in Education: Current Research and Innovations 10, Vienna, Austria, 10–12 April 2019; Springer: Berlin/Heidelberg, Germany, 2020; pp. 170–181. [Google Scholar]









Disclaimer/Publisher’s Note: The statements, opinions and data contained in all publications are solely those of the individual author(s) and contributor(s) and not of MDPI and/or the editor(s). MDPI and/or the editor(s) disclaim responsibility for any injury to people or property resulting from any ideas, methods, instructions or products referred to in the content. |
© 2023 by the author. Licensee MDPI, Basel, Switzerland. This article is an open access article distributed under the terms and conditions of the Creative Commons Attribution (CC BY) license (https://creativecommons.org/licenses/by/4.0/).