

SPT: Single Pedestrian Tracking Framework with Re-Identification-Based Learning Using the Siamese Model

 , , , and
, , , and 
Abstract
:1. Introduction
- We present an offline single object tracking framework for pedestrian tracking, which contains three main modules:
- (a)
- Pedestrian detection module.
- (b)
- Pedestrian re-identification module.
- (c)
- Tracking module that combines both detection and re-identification modules.
- We propose two models for the pedestrian re-identification module:
- (a)
- MNet-Siam using transfer learning.
- (b)
- DCNet-Siam from scratch.
- We evaluated both re-identification models on two datasets:
- (a)
- Large dataset: CUHK03.
- (b)
- Small dataset (our own collected dataset).
- We performed a comparison of re-identification models with existing models.
- (a)
- We obtained improved accuracy.
- We enhanced the architecture of the Siamese network by introducing the custom lambda block (CLB) in DCNet-Siam, which encourages the network to remove the tight dependency on the feature and custom head block (CHB) in MNet-Siam to improve its accuracy.
- We combined the advantages of the deep learning-based one-stage detector and the metric learning-based Siamese re-identification model for data association in tracking module.
- We performed qualitative and quantitative analyses with SOTA trackers for performance evaluation.
- We performed practical experiments on both indoor and outdoor video datasets for single pedestrian tracking.
- (a)
- We obtained a higher success rate and tracking frames per second.
2. Literature Review
2.1. Pedestrian Detection
2.2. Pedestrian Re-Identification
2.3. Single Object Trackers
3. Proposed Framework
- Detection module;
- Pedestrian re-identification module;
- Tracking module.
3.1. Detection Module
3.2. Pedestrian Re-Identification Module
3.2.1. Model 1: From Scratch
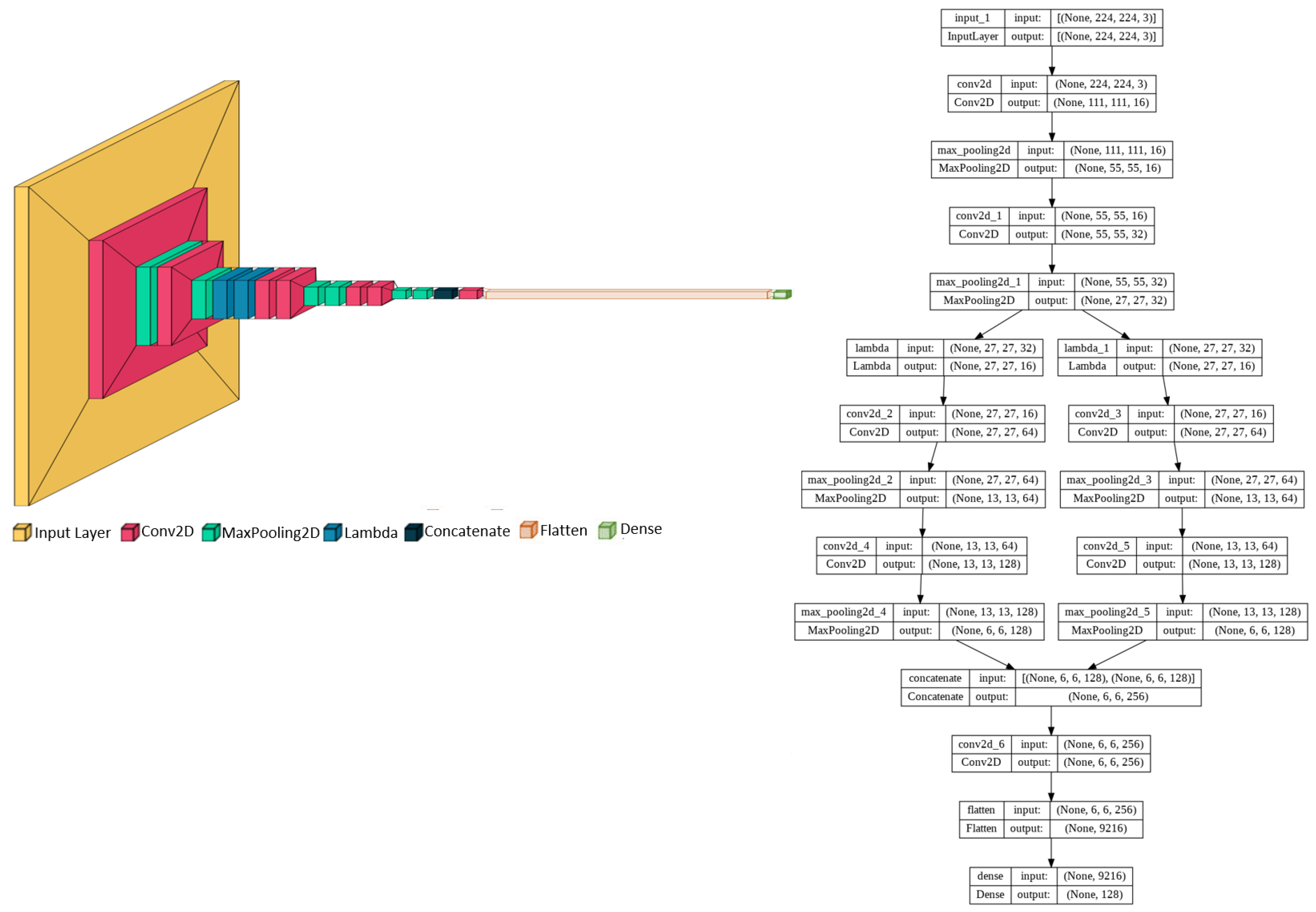
DCNet: Backbone Architecture
DCNet-Saim: Pedestrian Re-Identification Architecture
3.2.2. Model 2: Using Transfer Learning
MNet: Backbone Architecture
MNet-Saim: Pedestrian Re-Identification Architecture
3.3. Tracking Module
3.4. Loss Function
- When the image pairs are similar, the label becomes zero (y = 0) and only the first part of the loss function is executed, while the right-hand side additive part is omitted. In this case, the loss becomes the distance of two encodings extracted from two similar images, and E is minimized using squared distance to ensure that the model is penalized if it gives a high distance for similar encodings.
- When the image pairs are dissimilar, the label of Y becomes Y = 1, and only the second part of the loss function executes while the first left-hand side part is excluded. The loss function is based on the distance between dissimilar encodings, and E is maximized to the margin. The margin m ensures that the embeddings produced for a negative pair are distant enough. If the image pairs are well separated with the defined margin, then the error contribution will be zero. For example, suppose we choose 10 for the margin, and 17 and 1 as the predicted Euclidean distances between two encoding pairs (,) and (,).For encoding_pair_1 = , with no contribution to the error. For encoding_pair_2 = , with high contribution to the error.
4. Ablation Study
5. Results
5.1. Module 2: Pedestrian Re-Identification
- Computational cost: Models with higher performance require more computing power and time. The total number of parameters of the model is a good indicator of the computational cost. A large number of parameters shows that the model requires more calculation time to train the network.
- Accuracy: The top-1 accuracy is a good estimator of performance in the model selection. It measures the performance in terms of the time taken by a transfer learning-based model to make a correct top-class prediction.
5.1.1. Results on Large Dataset

{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
| # | Siamese Models | Base Models | Parameters | R1 Accuracy on CUHK03 | |
|---|---|---|---|---|---|
| 1 | SVDNet [91] | ResNet | >23.5 | 41.5% | |
| 2 | DPFL [87] | InceptionNet | >6.8 | 40.7% | |
| 3 | MLFN [89] | ResNetXt | 32.5 | 52.8% | |
| 4 | PCB [83] | ResNet | 27.2 | 63.7% | |
| 5 | Mancs [84] | ResNet | >25.1 | 65.5% | |
| 6 | CAMA [85] | ResNet | >23.5 | 66.6% | |
| 7 | DGNet [86] | ResNet | >23.5 | 65.6% | |
| 8 | Auto-ReID [90] | Auto | 13.1 | 73.3% | |
| 9 | OSNet [88] | OSNet | 2.2 | 72.3% | |
| Our Models | 10 | MNet-Siam | MobileNet-v2 | 2.3 | 79.2% |
| 11 | DCNet-Siam | DCNet | 1.9 | 83.9% |
5.1.2. Results on Our Small Dataset
5.2. Module 3: Pedestrian Tracking
5.2.1. Qualitative Analysis
5.2.2. Quantitative Analysis
- Success Rate Evaluation:For this, we used the success rate for each frame by following the formula , where f shows the frame, represents the function for the success criterion, illustrates the bounding box prediction returned by the tracker, while is the ground truth bounding box; finally, we divide the intersection area by the area of the union. To objectively perform the quantitative analysis in each video frame, we count the number of correct tracking frames and divide them by the total number of frames to calculate the success rate.
- Time Demand Evaluation:For this criterion, we used frame rate in terms of FPS or frame per second to measure the time taken by the tracking models for processing the single frame in each video sequence. To equitably measure the time for each frame, we propose , where is the model’s processing time for the existing frame and t is the time it takes for the current frame processing.
5.2.3. Experimental Setup
5.2.4. Indoor Environment
5.2.5. Outdoor Environment
- The qualitative analysis, based on the six environmental factors discussed in Table 3, demonstrates that our tracker can handle appearance variation due to pose change, partial occlusion, illumination variation, and change in position. However, its performance is inadequate in the case of fast motion. The qualitative investigation also shows that the overall performance of DiamSiamRPN is better than the other trackers considering all six environmental factors. The performance of the GOTURN tracker is satisfactory in case of appearance variation due to pose change while the performance of KCF is better in case of position change. However, the overall performance of GOTURN and KCF trackers is not satisfactory compared to all others. CSRT’s performance is better than in cases of appearance variant, illumination change, and fast motion. Although SiamMask’s performance is better than SiamFC for a partially occluded target, both trackers fail to track the fully occluded target. The corresponding results based on qualitative comparison are summarized in Table 10.
- The quantitative analysis is conducted by counting the number of correct tracking frames and dividing them by the total number of frames for the success rate evaluation.The experimental results in Figure 33 demonstrate that our tracker achieves the highest success rate among other trackers in video_1 (indoor) and video_4 (outdoor) datasets for partial occlusion, illumination variation, pose, and position change factors with success rates of 100% and 83.1%, respectively. In video_2 (indoor), our tracker outperformed KCF, CSRT, GOTURN, and SiamMask trackers with a success rate of 73.0% for appearance variation due to pose change and illumination change. For video_3 (indoor), our tracker achieved a success rate of 100%, which is higher than GOTURN, SiamFC, and CSRT trackers for pose, illumination, and position changes of the target person. However, in video_5 (outdoor), our tracker’s success rate of 81.0% was better than all trackers except DiaSiamRPN. Similarly, in the video_6 dataset, although our tracker’s success rate of 41.3% was higher than GOTURN and KCF trackers, it was still not high enough to effectively track a fast-moving target.

6. Conclusions
Author Contributions
Funding
Institutional Review Board Statement
Informed Consent Statement
Data Availability Statement
Conflicts of Interest
Abbreviations
| SPT | Single Pedestrian Tracker |
| DL | Deep Learning |
| TL | Transfer Learning |
| BBox | Bounding box |
| VOT | Visual Object Tracking |
| CNN | Convolutional Neural Network |
| DCNet-Siam | Convolutional Neural Network Siamese |
| MNet-Siam | Mobile Net Siamese |
| CUHK | Chinese University of Hong Kong |
| SOTA | State of the art |
| LSTM | Long Short-Term Memory |
| CML | Classical Metric Learning |
| DML | Deep Metric Learning |
| SOT | Single Object Tracking |
References
- Shehzed, A.; Jalal, A.; Kim, K. Multi-person tracking in smart surveillance system for crowd counting and normal/abnormal events detection. In Proceedings of the 2019 International Conference on Applied and Engineering Mathematics (ICAEM), London, UK, 3–5 July 2019; pp. 163–168. [Google Scholar]
- Jain, N.K.; Saini, R.; Mittal, P. A review on traffic monitoring system techniques. Soft Comput. Theor. Appl. 2019, 742, 569–577. [Google Scholar]
- Gupta, M.; Kumar, S.; Behera, L.; Subramanian, V.K. A novel vision-based tracking algorithm for a human-following mobile robot. IEEE Trans. Syst. Man Cybern. Syst. 2016, 47, 1415–1427. [Google Scholar] [CrossRef]
- Dang, L.M.; Min, K.; Wang, H.; Piran, M.J.; Lee, C.H.; Moon, H. Sensor-based and vision-based human activity recognition: A comprehensive survey. Pattern Recognit. 2020, 108, 107561. [Google Scholar] [CrossRef]
- Lu, W.L.; Ting, J.A.; Little, J.J.; Murphy, K.P. Learning to track and identify players from broadcast sports videos. IEEE Trans. Pattern Anal. Mach. Intell. 2013, 35, 1704–1716. [Google Scholar]
- Lévêque, L.; Bosmans, H.; Cockmartin, L.; Liu, H. State of the art: Eye-tracking studies in medical imaging. IEEE Access 2018, 6, 37023–37034. [Google Scholar] [CrossRef]
- Kaya, M.; Denasi, A.; Scheggi, S.; Agbahca, E.; Yoon, C.; Gracias, D.H.; Misra, S. A multi-rate state observer for visual tracking of magnetic micro-agents using 2d slow medical imaging modalities. In Proceedings of the 2018 IEEE/RSJ International Conference on Intelligent Robots and Systems (IROS), Madrid, Spain, 1–5 October 2018; pp. 1–8. [Google Scholar]
- Rangesh, A.; Trivedi, M.M. No blind spots: Full-surround multi-object tracking for autonomous vehicles using cameras and lidars. IEEE Trans. Intell. Veh. 2019, 4, 588–599. [Google Scholar] [CrossRef]
- Ondrašovič, M.; Tarábek, P. Siamese visual object tracking: A survey. IEEE Access 2021, 9, 110149–110172. [Google Scholar] [CrossRef]
- Mazzeo, P.L.; Ramakrishnan, S.; Spagnolo, P. Visual Object Tracking with Deep Neural Networks; BoD–Books on Demand: Guadalajara, Mexico, 2015; pp. 1–6. [Google Scholar] [CrossRef]
- Zuo, M.; Zhu, X.; Chen, Y.; Yu, J. Survey of Object Tracking Algorithm Based on Siamese Network. J. Phys. Conf. Ser. 2022, 2203, 012035. [Google Scholar] [CrossRef]
- Zhou, H.; Hu, H. Human motion tracking for rehabilitation—A survey. Biomed. Signal Process. Control 2008, 3, 1–18. [Google Scholar] [CrossRef]
- Yilmaz, A.; Javed, O.; Shah, M. Object tracking: A survey. ACM Comput. Surv. (CSUR) 2006, 38, 13-es. [Google Scholar] [CrossRef]
- Chen, Z.; Hong, Z.; Tao, D. An experimental survey on correlation filter-based tracking. arXiv 2015, arXiv:1509.05520. [Google Scholar]
- Bolme, D.S.; Beveridge, J.R.; Draper, B.A.; Lui, Y.M. Visual object tracking using adaptive correlation filters. In Proceedings of the 2010 IEEE computer society conference on computer vision and pattern recognition, Seattle, WA, USA, 14–19 June 2010; pp. 2544–2550. [Google Scholar]
- Fiaz, M.; Mahmood, A.; Jung, S.K. Deep siamese networks toward robust visual tracking. In Visual Object Tracking with Deep Neural Networks; IntechOpen: London, UK, 2019. [Google Scholar]
- Chicco, D. Siamese neural networks: An overview. Artif. Neural Netw. 2021, 2190, 73–94. [Google Scholar]
- He, A.; Luo, C.; Tian, X.; Zeng, W. A twofold siamese network for real-time object tracking. In Proceedings of the 2018 IEEE Conference on Computer Vision and Pattern Recognition, Salt Lake City, UT, USA, 18–23 June 2018; pp. 4834–4843. [Google Scholar]
- Ntwari, T.; Park, H.; Shin, J.; Paik, J. SNS-CF: Siamese Network with Spatially Semantic Correlation Features for Object Tracking. Sensors 2020, 20, 4881. [Google Scholar] [CrossRef] [PubMed]
- Gleize, M.; Shnarch, E.; Choshen, L.; Dankin, L.; Moshkowich, G.; Aharonov, R.; Slonim, N. Are you convinced? Choosing the more convincing evidence with a Siamese network. arXiv 2019, arXiv:1907.08971. [Google Scholar]
- Bertinetto, L.; Valmadre, J.; Henriques, J.F.; Vedaldi, A.; Torr, P.H. Fully-convolutional siamese networks for object tracking. In Computer Vision–ECCV 2016 Workshops: Amsterdam, The Netherlands, October 8–10 and 15–16, 2016, Proceedings, Part II 14; Springer: Berlin/Heidelberg, Germany, 2016; pp. 850–865. [Google Scholar]
- Tao, R.; Gavves, E.; Smeulders, A.W. Siamese instance search for tracking. In Proceedings of the IEEE Conference on Computer Vision and Pattern Recognition, Las Vegas, NV, USA, 27–30 June 2016; pp. 1420–1429. [Google Scholar]
- Han, R.; Feng, W.; Guo, Q.; Hu, Q. Single Object Tracking Research: A Survey. arXiv 2022, arXiv:2204.11410. [Google Scholar]
- Zhou, J.; Yao, Y.; Yang, R. Deep Learning for Single-object Tracking: A Survey. In Proceedings of the 2022 IEEE 2nd International Conference on Software Engineering and Artificial Intelligence (SEAI), Xiamen, China, 10–12 June 2022; pp. 12–19. [Google Scholar]
- Luo, W.; Xing, J.; Milan, A.; Zhang, X.; Liu, W.; Kim, T.K. Multiple object tracking: A literature review. Artif. Intell. 2021, 293, 103448. [Google Scholar] [CrossRef]
- Ciaparrone, G.; Sánchez, F.L.; Tabik, S.; Troiano, L.; Tagliaferri, R.; Herrera, F. Deep learning in video multi-object tracking: A survey. Neurocomputing 2020, 381, 61–88. [Google Scholar] [CrossRef]
- Qin, X.; Fan, Z. Initial matting-guided visual tracking with siamese network. IEEE Access 2019, 7, 41669–41677. [Google Scholar] [CrossRef]
- Dalal, N.; Triggs, B. Histograms of oriented gradients for human detection. In Proceedings of the 2005 IEEE Computer Society Conference on Computer Vision and Pattern Recognition (CVPR’05), San Diego, CA, USA, 20–26 June 2005; Volume 1, pp. 886–893. [Google Scholar]
- Zhang, S.; Bauckhage, C.; Cremers, A.B. Informed haar-like features improve pedestrian detection. In Proceedings of the IEEE Conference on Computer Vision and Pattern Recognition, Columbus, OH, USA, 23–28 June 2014; pp. 947–954. [Google Scholar]
- Dollár, P.; Belongie, S.; Perona, P. The fastest pedestrian detector in the west. In Proceedings of the British Machine Vision Conference BMVC 2010, Aberystwyth, Wales, 31 August–3 September 2010. [Google Scholar]
- Nam, W.; Dollár, P.; Han, J.H. Local decorrelation for improved pedestrian detection. Adv. Neural Inf. Process. Syst. 2014, 27. [Google Scholar]
- Hariharan, B.; Malik, J.; Ramanan, D. Discriminative decorrelation for clustering and classification. In Proceedings of the European Conference on Computer Vision, Florence, Italy, 7–13 October 2012; Springer: Berlin/Heidelberg, Germany, 2012; pp. 459–472. [Google Scholar]
- Cai, Z.; Fan, Q.; Feris, R.S.; Vasconcelos, N. A unified multi-scale deep convolutional neural network for fast object detection. In Proceedings of the European Conference on Computer Vision, Amsterdam, The Netherlands, 11–14 October 2016; Springer: Berlin/Heidelberg, Germany, 2016; pp. 354–370. [Google Scholar]
- Lin, C.Y.; Xie, H.X.; Zheng, H. PedJointNet: Joint head-shoulder and full body deep network for pedestrian detection. IEEE Access 2019, 7, 47687–47697. [Google Scholar] [CrossRef]
- Wang, S.; Cheng, J.; Liu, H.; Wang, F.; Zhou, H. Pedestrian detection via body part semantic and contextual information with DNN. IEEE Trans. Multimed. 2018, 20, 3148–3159. [Google Scholar] [CrossRef]
- Hsu, W.Y.; Lin, W.Y. Ratio-and-scale-aware YOLO for pedestrian detection. IEEE Trans. Image Process. 2020, 30, 934–947. [Google Scholar] [CrossRef] [PubMed]
- Cao, J.; Pang, Y.; Li, X. Learning multilayer channel features for pedestrian detection. IEEE Trans. Image Process. 2017, 26, 3210–3220. [Google Scholar] [CrossRef] [PubMed]
- Tian, Y.; Luo, P.; Wang, X.; Tang, X. Deep learning strong parts for pedestrian detection. In Proceedings of the IEEE International Conference on Computer Vision, Santiago, Chile, 7–13 December 2015; pp. 1904–1912. [Google Scholar]
- Tesema, F.B.; Wu, H.; Chen, M.; Lin, J.; Zhu, W.; Huang, K. Hybrid channel based pedestrian detection. Neurocomputing 2020, 389, 1–8. [Google Scholar] [CrossRef]
- Hu, Q.; Wang, P.; Shen, C.; van den Hengel, A.; Porikli, F. Pushing the limits of deep cnns for pedestrian detection. IEEE Trans. Circuits Syst. Video Technol. 2017, 28, 1358–1368. [Google Scholar] [CrossRef]
- Zhang, S.; Bauckhage, C.; Klein, D.A.; Cremers, A.B. Exploring human vision driven features for pedestrian detection. IEEE Trans. Circuits Syst. Video Technol. 2015, 25, 1709–1720. [Google Scholar] [CrossRef]
- Dollár, P.; Appel, R.; Kienzle, W. Crosstalk cascades for frame-rate pedestrian detection. In Proceedings of the European Conference on Computer Vision, Florence, Italy, 7–13 October 2012; Springer: Berlin/Heidelberg, Germany, 2012; pp. 645–659. [Google Scholar]
- Zhu, Y.; Wang, J.; Zhao, C.; Guo, H.; Lu, H. Scale-adaptive deconvolutional regression network for pedestrian detection. In Proceedings of the Asian Conference on Computer Vision, Seoul, Republic of Korea, 15–17 November 2017; Springer: Berlin/Heidelberg, Germany, 2017; pp. 416–430. [Google Scholar]
- Liu, T.; Elmikaty, M.; Stathaki, T. SAM-RCNN: Scale-aware multi-resolution multi-channel pedestrian detection. arXiv 2018, arXiv:1808.02246. [Google Scholar]
- Yun, I.; Jung, C.; Wang, X.; Hero, A.O.; Kim, J.K. Part-level convolutional neural networks for pedestrian detection using saliency and boundary box alignment. IEEE Access 2019, 7, 23027–23037. [Google Scholar] [CrossRef]
- Yang, B.; Yan, J.; Lei, Z.; Li, S.Z. Convolutional channel features. In Proceedings of the IEEE International Conference on Computer Vision, Santiago, Chile, 7–13 December 2015; pp. 82–90. [Google Scholar]
- Weinberger, K.Q.; Saul, L.K. Fast solvers and efficient implementations for distance metric learning. In Proceedings of the 25th International Conference on Machine Learning, Helsinki, Finland, 5–9 July 2008; pp. 1160–1167. [Google Scholar]
- Dikmen, M.; Akbas, E.; Huang, T.S.; Ahuja, N. Pedestrian recognition with a learned metric. In Proceedings of the Asian Conference on Computer Vision, Kyoto, Japan, 30 November–4 December 2010; Springer: Berlin/Heidelberg, Germany, 2010; pp. 501–512. [Google Scholar]
- Koestinger, M.; Hirzer, M.; Wohlhart, P.; Roth, P.M.; Bischof, H. Large scale metric learning from equivalence constraints. In Proceedings of the 2012 IEEE Conference on Computer Vision and Pattern Recognition, Providence, RI, USA, 16–21 June 2012; pp. 2288–2295. [Google Scholar]
- Zheng, W.S.; Gong, S.; Xiang, T. Person re-identification by probabilistic relative distance comparison. In Proceedings of the CVPR 2011, Providence, RI, USA, 20–25 June 2011; pp. 649–656. [Google Scholar]
- Zheng, W.S.; Gong, S.; Xiang, T. Reidentification by relative distance comparison. IEEE Trans. Pattern Anal. Mach. Intell. 2012, 35, 653–668. [Google Scholar] [CrossRef]
- Pedagadi, S.; Orwell, J.; Velastin, S.; Boghossian, B. Local fisher discriminant analysis for pedestrian re-identification. In Proceedings of the IEEE Conference on Computer Vision and Pattern Recognition, Portland, OR, USA, 23–28 June 2013; pp. 3318–3325. [Google Scholar]
- Zhou, Q.; Zheng, S.; Yang, H.; Wang, Y.; Su, H. Joint instance and feature importance re-weighting for person reidentification. In Proceedings of the 2016 IEEE International Conference on Acoustics, Speech and Signal Processing (ICASSP), Shanghai, China, 20–25 March 2016; pp. 1546–1550. [Google Scholar]
- Wang, J.; Wang, Z.; Liang, C.; Gao, C.; Sang, N. Equidistance constrained metric learning for person re-identification. Pattern Recognit. 2018, 74, 38–51. [Google Scholar] [CrossRef]
- Syed, M.A.; Jiao, J. Multi-kernel metric learning for person re-identification. In Proceedings of the 2016 IEEE International Conference on Image Processing (ICIP), Phoenix, AZ, USA, 25–28 September 2016; pp. 784–788. [Google Scholar]
- Mei-Bin, Q.; Sheng-Shun, T.; Yun-Xia, W.; Hao, L.; Jian-Guo, J. Multi-feature subspace and kernel learning for person re-identification. Acta Autom. Sin. 2016, 42, 299–308. [Google Scholar]
- Feng, Z.; Lai, J.; Xie, X. Learning view-specific deep networks for person re-identification. IEEE Trans. Image Process. 2018, 27, 3472–3483. [Google Scholar] [CrossRef] [PubMed]
- Varior, R.R.; Haloi, M.; Wang, G. Gated siamese convolutional neural network architecture for human re-identification. In Proceedings of the European Conference on Computer Vision, Amsterdam, The Netherlands, 11–14 October 2016; Springer: Berlin/Heidelberg, Germany, 2016; pp. 791–808. [Google Scholar]
- Song, C.; Huang, Y.; Ouyang, W.; Wang, L. Mask-guided contrastive attention model for person re-identification. In Proceedings of the IEEE Conference on Computer Vision and Pattern Recognition, Salt Lake City, UT, USA, 18–22 June 2018; pp. 1179–1188. [Google Scholar]
- Chen, H.; Lagadec, B.; Bremond, F. Ice: Inter-instance contrastive encoding for unsupervised person re-identification. In Proceedings of the IEEE/CVF International Conference on Computer Vision, Montreal, QC, Canada, 10–17 October 2021; pp. 14960–14969. [Google Scholar]
- Henriques, J.F.; Caseiro, R.; Martins, P.; Batista, J. High-speed tracking with kernelized correlation filters. IEEE Trans. Pattern Anal. Mach. Intell. 2014, 37, 583–596. [Google Scholar] [CrossRef] [PubMed]
- Li, Y.; Zhu, J. A scale adaptive kernel correlation filter tracker with feature integration. In Proceedings of the 13th European Conference on Computer Vision (ECCV), Zurich, Switzerland, 6–12 September 2014; Springer: Berlin/Heidelberg, Germany, 2014; pp. 254–265. [Google Scholar]
- Bertinetto, L.; Valmadre, J.; Golodetz, S.; Miksik, O.; Torr, P.H. Staple: Complementary learners for real-time tracking. In Proceedings of the 2016 IEEE Conference on Computer Vision and Pattern Recognition, Las Vegas, NV, USA, 27–30 June 2016; pp. 1401–1409. [Google Scholar]
- Kiani Galoogahi, H.; Sim, T.; Lucey, S. Correlation filters with limited boundaries. In Proceedings of the 2015 IEEE Conference on Computer Vision and Pattern Recognition, Boston, MA, USA, 7–12 June 2015; pp. 4630–4638. [Google Scholar]
- Danelljan, M.; Hager, G.; Shahbaz Khan, F.; Felsberg, M. Learning spatially regularized correlation filters for visual tracking. In Proceedings of the 2015 IEEE International Conference on Computer Vision, Santiago, Chile, 7–13 December 2015; pp. 4310–4318. [Google Scholar]
- LuNežič, A.; Vojíř, T.; Čehovin Zajc, L.; Matas, J.; Kristan, M. Discriminative correlation filter TracNer with channel and spatial reliability. Int. J. Comput. Vis. 2018, 126, 671–688. [Google Scholar] [CrossRef]
- Nam, H.; Han, B. Learning multi-domain convolutional neural networks for visual tracking. In Proceedings of the 2016 IEEE Conference on Computer Vision and Pattern Recognition, Las Vegas, NV, USA, 27–30 June 2016; pp. 4293–4302. [Google Scholar]
- Held, D.; Thrun, S.; Savarese, S. Learning to track at 100 fps with deep regression networks. In Proceedings of the 2016 European Conference on Computer Vision, Amsterdam, The Netherlands, 8–16 October 2016; Springer: Berlin/Heidelberg, Germany, 2016; pp. 749–765. [Google Scholar]
- Wang, Q.; Zhang, L.; Bertinetto, L.; Hu, W.; Torr, P.H. Fast online object tracking and segmentation: A unifying approach. In Proceedings of the 2019 IEEE/CVF Conference on Computer Vision and Pattern Recognition, Long Beach, CA, USA, 15–20 June 2019; pp. 1328–1338. [Google Scholar]
- He, K.; Zhang, X.; Ren, S.; Sun, J. Deep residual learning for image recognition. In Proceedings of the 2016 IEEE Conference on Computer Vision and Pattern Recognition, Las Vegas, NV, USA, 27–30 June 2016; pp. 770–778. [Google Scholar]
- Bertinetto, L.; Henriques, J.F.; Valmadre, J.; Torr, P.; Vedaldi, A. Learning feed-forward one-shot learners. Adv. Neural Inf. Process. Syst. 2016, 29. [Google Scholar]
- Zhu, Z.; Wang, Q.; Li, B.; Wu, W.; Yan, J.; Hu, W. Distractor-aware siamese networks for visual object tracking. In Proceedings of the 15th European Conference on Computer Vision, Munich, Germany, 8–14 September 2018; pp. 101–117. [Google Scholar]
- Ultralytics. YOLOv8. Available online: https://github.com/ultralytics/ultralytics (accessed on 18 March 2023).
- Ultralytics. YOLOv8 Module. Available online: https://github.com/ultralytics/ultralytics/blob/dba3f178849692a13f3c43e81572255b1ece7da9/ultralytics/nn/modules.py?ref=blog.roboflow.com#L196 (accessed on 18 March 2023).
- Ultralytics. YOLOv8 Common. Available online: https://github.com/ultralytics/yolov5/blob/cdd804d39ff84b413bde36a84006f51769b6043b/models/common.py?ref=blog.roboflow.com#L157 (accessed on 18 March 2023).
- Ultralytics. YOLOv5. Available online: https://github.com/ultralytics/yolov5/releases (accessed on 20 March 2023).
- Ultralytics. YOLOv8 Objectness. Available online: https://github.com/ultralytics/ultralytics/issues/189 (accessed on 18 March 2023).
- Sandler, M.; Howard, A.; Zhu, M.; Zhmoginov, A.; Chen, L.C. Mobilenetv2: Inverted residuals and linear bottlenecks. In Proceedings of the 2018 IEEE Conference on Computer Vision and Pattern Recognition, Salt Lake City, UT, USA, 18–23 June 2018; pp. 4510–4520. [Google Scholar]
- Weiss, K.; Khoshgoftaar, T.M.; Wang, D. A survey of transfer learning. J. Big Data 2016, 3, 9. [Google Scholar] [CrossRef]
- Chollet, F. Xception: Deep learning with depthwise separable convolutions. In Proceedings of the 2017 IEEE Conference on Computer Vision and Pattern Recognition, Honolulu, HI, USA, 21–26 July 2017; pp. 1251–1258. [Google Scholar]
- Szegedy, C.; Vanhoucke, V.; Ioffe, S.; Shlens, J.; Wojna, Z. Rethinking the inception architecture for computer vision. In Proceedings of the 2016 IEEE Conference on Computer Vision and Pattern Recognition, Las Vegas, NV, USA, 27–30 June 2016; pp. 2818–2826. [Google Scholar]
- Li, W.; Zhao, R.; Xiao, T.; Wang, X. Deepreid: Deep filter pairing neural network for person re-identification. In Proceedings of the 2014 IEEE Conference on Computer Vision and Pattern Recognition, Columbus, OH, USA, 23–28 June 2014; pp. 152–159. [Google Scholar]
- Sun, Y.; Zheng, L.; Yang, Y.; Tian, Q.; Wang, S. Beyond part models: Person retrieval with refined part pooling (and a strong convolutional baseline). In Proceedings of the European Conference on Computer Vision (ECCV), Munich, Germany, 8–14 September 2018; pp. 480–496. [Google Scholar]
- Wang, C.; Zhang, Q.; Huang, C.; Liu, W.; Wang, X. Mancs: A multi-task attentional network with curriculum sampling for person re-identification. In Proceedings of the European Conference on Computer Vision (ECCV), Munich, Germany, 8–14 September 2018; pp. 365–381. [Google Scholar]
- Yang, W.; Huang, H.; Zhang, Z.; Chen, X.; Huang, K.; Zhang, S. Towards rich feature discovery with class activation maps augmentation for person re-identification. In Proceedings of the 2019 IEEE/CVF Conference on Computer Vision and Pattern Recognition, Long Beach, CA, USA, 15–20 June 2019; pp. 1389–1398. [Google Scholar]
- Zheng, Z.; Yang, X.; Yu, Z.; Zheng, L.; Yang, Y.; Kautz, J. Joint discriminative and generative learning for person re-identification. In Proceedings of the 2019 IEEE/CVF Conference on Computer Vision and Pattern Recognition, Long Beach, CA, USA, 15–20 June 2019; pp. 2138–2147. [Google Scholar]
- Chen, Y.; Zhu, X.; Gong, S. Person re-identification by deep learning multi-scale representations. In Proceedings of the 2017 IEEE International Conference on Computer Vision Workshops, Venice, Italy, 22–29 October 2017; pp. 2590–2600. [Google Scholar]
- Zhou, K.; Yang, Y.; Cavallaro, A.; Xiang, T. Learning generalisable omni-scale representations for person re-identification. IEEE Trans. Pattern Anal. Mach. Intell. 2021, 44, 5056–5069. [Google Scholar] [CrossRef]
- Chang, X.; Hospedales, T.M.; Xiang, T. Multi-level factorisation net for person re-identification. In Proceedings of the 2018 IEEE Conference on Computer Vision and Pattern Recognition, Salt Lake City, UT, USA, 18–23 June 2018; pp. 2109–2118. [Google Scholar]
- Quan, R.; Dong, X.; Wu, Y.; Zhu, L.; Yang, Y. Auto-reid: Searching for a part-aware convnet for person re-identification. In Proceedings of the 2019 IEEE/CVF International Conference on Computer Vision, Long Beach, CA, USA, 15–20 June 2019; pp. 3750–3759. [Google Scholar]
- Sun, Y.; Zheng, L.; Deng, W.; Wang, S. Svdnet for pedestrian retrieval. In Proceedings of the 2017 IEEE International Conference on Computer Vision, Venice, Italy, 22–29 October 2017; pp. 3800–3808. [Google Scholar]
- Manzoor, S.; Kim, E.J.; Joo, S.H.; Bae, S.H.; In, G.G.; Joo, K.J.; Choi, J.H.; Kuc, T.Y. Edge Deployment Framework of GuardBot for Optimized Face Mask Recognition with Real-Time Inference using Deep Learning. IEEE Access 2022, 10, 77898–77921. [Google Scholar] [CrossRef]


































| Backbone | # | Component | Rank-1 |
|---|---|---|---|
| DCNet | a | Without CLB | 0.764 |
| b | CLB without FMS | 0.811 | |
| c | CLB with FMS | 0.839 | |
| MNet | d | Without CHB | 0.756 |
| e | With CHB | 0.792 |
| Video Sequence Name | Environment | Appearance Variation Due to Pose Change | Partial Occlusion | Full Occlusion | Illumination Change | Change in Position | Fast Motion |
|---|---|---|---|---|---|---|---|
| video_1 | Indoor | - | Yes | - | Yes | - | - |
| video_2 | Yes | - | - | Yes | - | - | |
| video_3 | Yes | - | - | Yes | Yes | - | |
| video_4 | Outdoor | - | Yes | - | Yes | - | - |
| video_5 | - | Yes | Yes | Yes | - | - | |
| video_6 | - | - | - | - | - | Yes |
| Trackers | Environment | Total Frames | Frames with Successful Tracking | Frames with Unsuccessful Tracking | Success Rate |
|---|---|---|---|---|---|
| SiamFC | Indoor | 444 | 222 | 222 | 50.0% |
| CSRT | 444 | 241 | 199 | 54.3% | |
| DiamSiamRPN | 444 | 350 | 94 | 78.8% | |
| GOTURN | 444 | 44 | 400 | 9.9% | |
| KCF | 444 | 76 | 368 | 17.1% | |
| SiamMask | 444 | 413 | 31 | 93.0% | |
| SPT (our) | 444 | 444 | 0 | 100.0% |
| Trackers | Environment | Total Frames | Frames with Successful Tracking | Frames with Unsuccessful Tracking | Success Rate |
|---|---|---|---|---|---|
| SiamFC | Indoor | 200 | 138 | 62 | 69.0% |
| CSRT | 200 | 168 | 32 | 84.0% | |
| DiamSiamRPN | 200 | 140 | 60 | 70.0% | |
| GOTURN | 200 | 116 | 84 | 58.0% | |
| KCF | 200 | 148 | 52 | 74.0% | |
| SiamMask | 200 | 142 | 58 | 71.0% | |
| SPT (our) | 200 | 146 | 54 | 73.0% |
| Trackers | Environment | Total Frames | Frames with Successful Tracking | Frames with Unsuccessful Tracking | Success Rate |
|---|---|---|---|---|---|
| SiamFC | Indoor | 1495 | 1420 | 75 | 95.0% |
| CSRT | 1495 | 897 | 598 | 60.0% | |
| DiamSiamRPN | 1495 | 1495 | 0 | 100.0% | |
| GOTURN | 1495 | 623 | 882 | 41.0% | |
| KCF | 1495 | 1495 | 0 | 100.0% | |
| SiamMask | 1495 | 1495 | 0 | 100.0% | |
| SPT (our) | 1495 | 1495 | 0 | 100.0% |
| Trackers | Environment | Total Frames | Frames with Successful Tracking | Frames with Unsuccessful Tracking | Success Rate |
|---|---|---|---|---|---|
| SiamFC | Outdoor | 960 | 96 | 864 | 10.0% |
| CSRT | 960 | 788 | 172 | 82.1% | |
| DiamSiamRPN | 960 | 662 | 298 | 69.0% | |
| GOTURN | 960 | 106 | 854 | 11.0% | |
| KCF | 960 | 173 | 787 | 18.0% | |
| SiamMask | 960 | 438 | 522 | 45.6% | |
| SPT (our) | 768 | 162 | 95 | 83.1% |
| Trackers | Environment | Total Frames | Frames with Successful Tracking | Frames with Unsuccessful Tracking | Success Rate |
|---|---|---|---|---|---|
| SiamFC | Outdoor | 1276 | 383 | 893 | 30.0% |
| CSRT | 1276 | 318 | 958 | 24.9% | |
| DiamSiamRPN | 1276 | 1189 | 87 | 93.2% | |
| GOTURN | 1276 | 12 | 1264 | 0.9% | |
| KCF | 1276 | 166 | 1110 | 13.0% | |
| SiamMask | 1276 | 970 | 306 | 76.0% | |
| SPT (our) | 1276 | 1033 | 243 | 81.0% |
| Trackers | Environment | Total Frames | Frames with Successful Tracking | Frames with Unsuccessful Tracking | Success Rate |
|---|---|---|---|---|---|
| SiamFC | Outdoor | 955 | 955 | 0 | 100.0% |
| CSRT | 955 | 926 | 29 | 97.0% | |
| DiamSiamRPN | 955 | 955 | 0 | 100.0% | |
| GOTURN | 955 | 19 | 936 | 2.0% | |
| KCF | 955 | 392 | 563 | 41.0% | |
| SiamMask | 955 | 955 | 0 | 100.0% | |
| SPT (our) | 955 | 394 | 561 | 41.3% |
| Appearance Variation Due to Pose Change | Partial Occlusion | Full Occlusion | Illumination Change | Change in Position | Fast Motion | |
|---|---|---|---|---|---|---|
| SiamFC | Yes | Poor | Poor | Yes | Yes | Yes |
| CSRT | Yes | Poor | Poor | Yes | Poor | Yes |
| DiamSiamRPN | Yes | Yes | Yes | Yes | Yes | Yes |
| GOTURN | Yes | Poor | Poor | Poor | Poor | Poor |
| KCF | Poor | Poor | Poor | Poor | Yes | Poor |
| SiamMask | Yes | Yes | Poor | Yes | Yes | Yes |
| SPT (our) | Yes | Yes | Yes | Yes | Yes | Poor |
Disclaimer/Publisher’s Note: The statements, opinions and data contained in all publications are solely those of the individual author(s) and contributor(s) and not of MDPI and/or the editor(s). MDPI and/or the editor(s) disclaim responsibility for any injury to people or property resulting from any ideas, methods, instructions or products referred to in the content. |
© 2023 by the authors. Licensee MDPI, Basel, Switzerland. This article is an open access article distributed under the terms and conditions of the Creative Commons Attribution (CC BY) license (https://creativecommons.org/licenses/by/4.0/).
Share and Cite
Manzoor, S.; An, Y.-C.; In, G.-G.; Zhang, Y.; Kim, S.; Kuc, T.-Y. SPT: Single Pedestrian Tracking Framework with Re-Identification-Based Learning Using the Siamese Model. Sensors 2023, 23, 4906. https://doi.org/10.3390/s23104906
Manzoor S, An Y-C, In G-G, Zhang Y, Kim S, Kuc T-Y. SPT: Single Pedestrian Tracking Framework with Re-Identification-Based Learning Using the Siamese Model. Sensors. 2023; 23(10):4906. https://doi.org/10.3390/s23104906
Chicago/Turabian StyleManzoor, Sumaira, Ye-Chan An, Gun-Gyo In, Yueyuan Zhang, Sangmin Kim, and Tae-Yong Kuc. 2023. "SPT: Single Pedestrian Tracking Framework with Re-Identification-Based Learning Using the Siamese Model" Sensors 23, no. 10: 4906. https://doi.org/10.3390/s23104906
APA StyleManzoor, S., An, Y.-C., In, G.-G., Zhang, Y., Kim, S., & Kuc, T.-Y. (2023). SPT: Single Pedestrian Tracking Framework with Re-Identification-Based Learning Using the Siamese Model. Sensors, 23(10), 4906. https://doi.org/10.3390/s23104906