
Robust Detection, Segmentation, and Metrology of High Bandwidth Memory 3D Scans Using an Improved Semi-Supervised Deep Learning Approach

Abstract
:1. Introduction
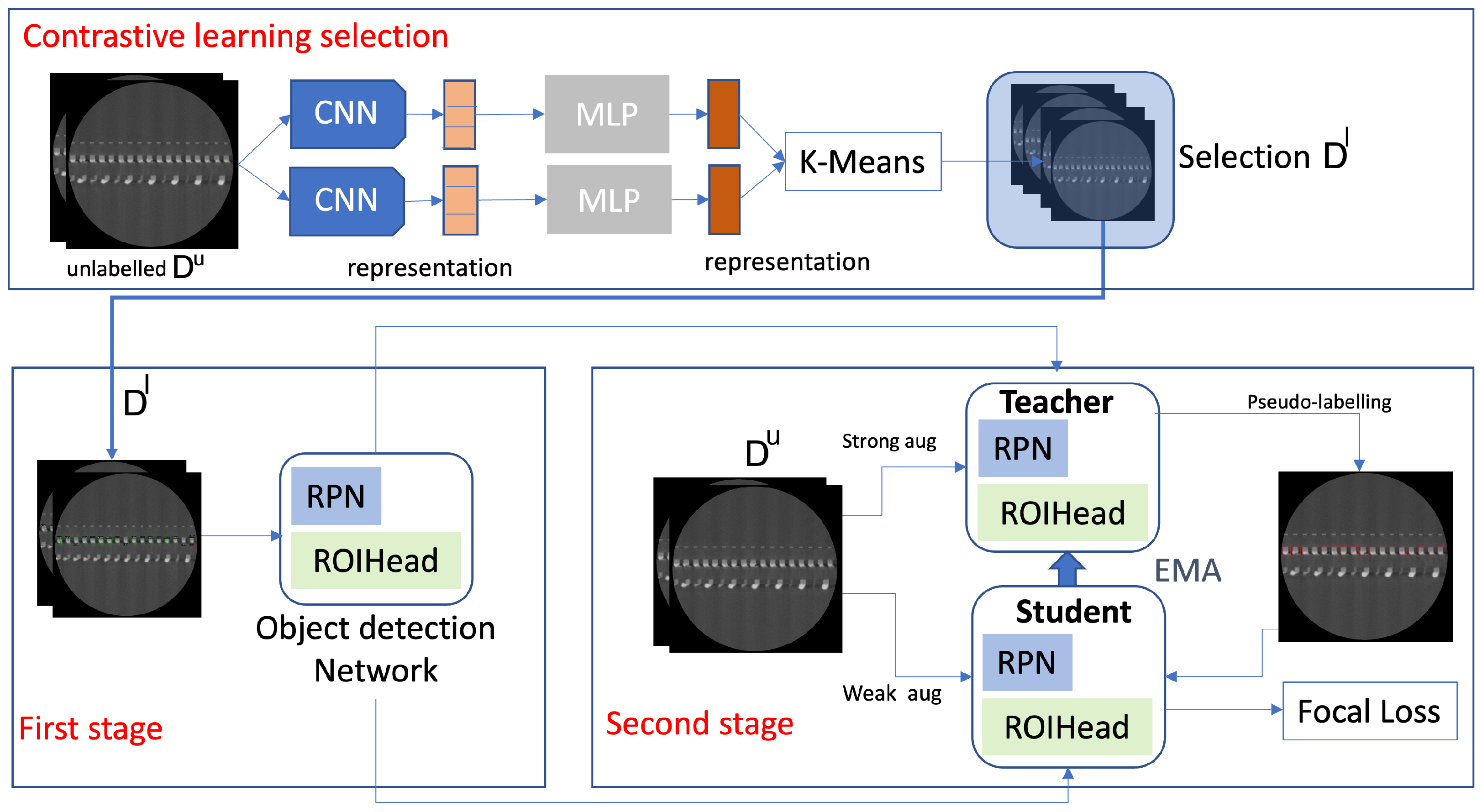
- A multi-view SSL 2.5D object detection approach to accurately identify each HBM bump using contrastive learning as data pre-selection.
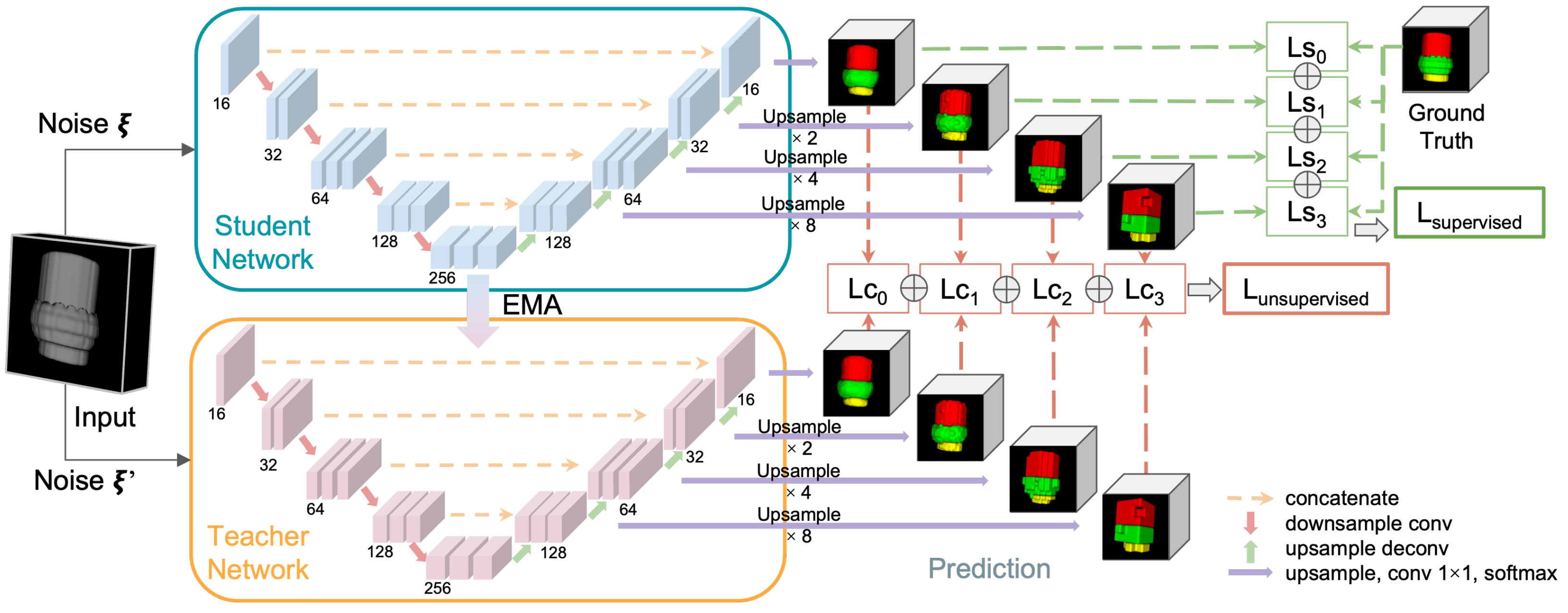
- An improved multi-scale 3D SSL semantic segmentation method for recognizing individual components of HBMs as well as void defects.
- A 3D Metrology package that performs data cleaning and measures critical features relevant for HBM failure analysis.
2. Related Work
2.1. Object Detection
2.2. Semantic Segmentation
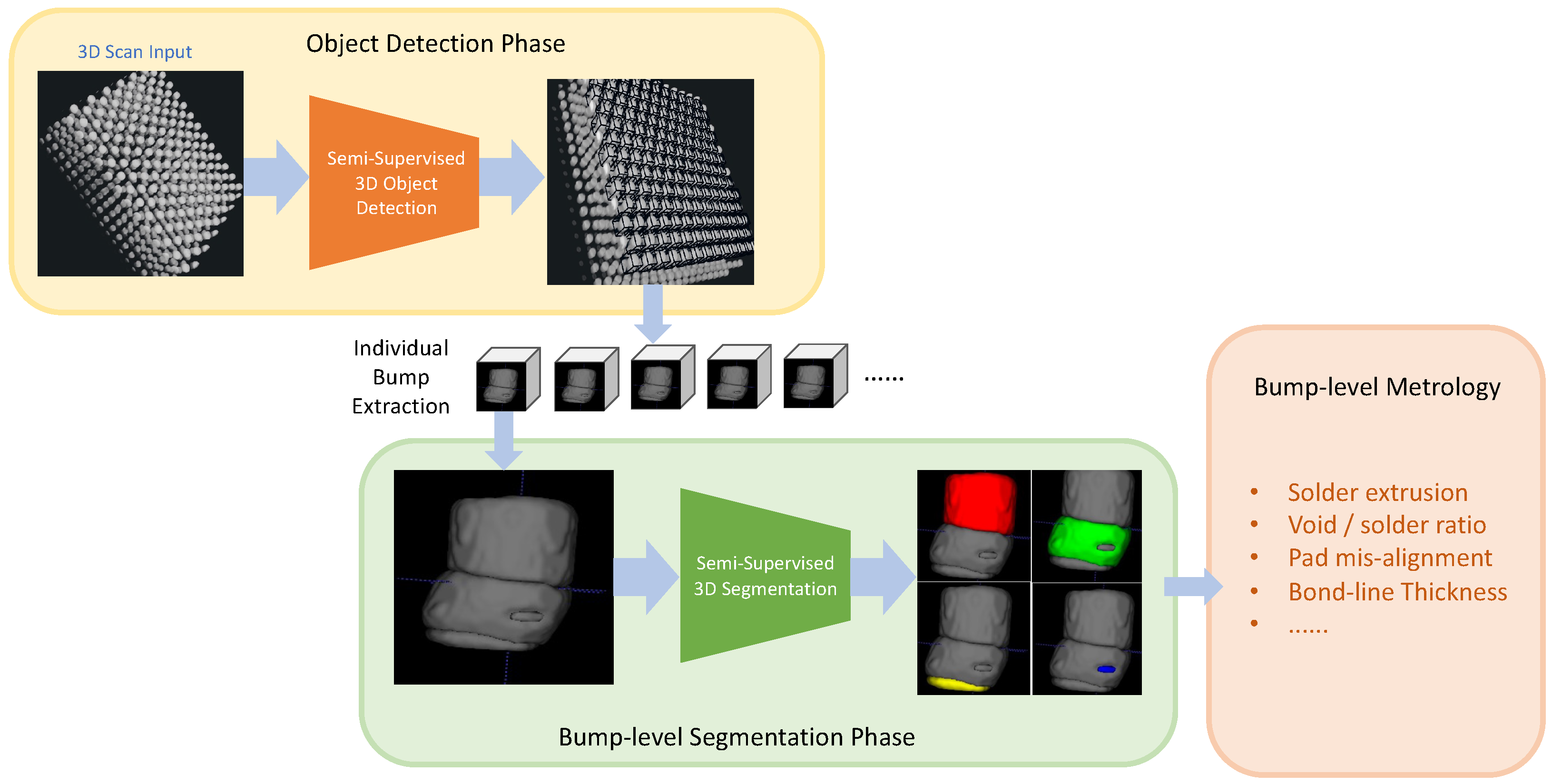
3. Our Approach
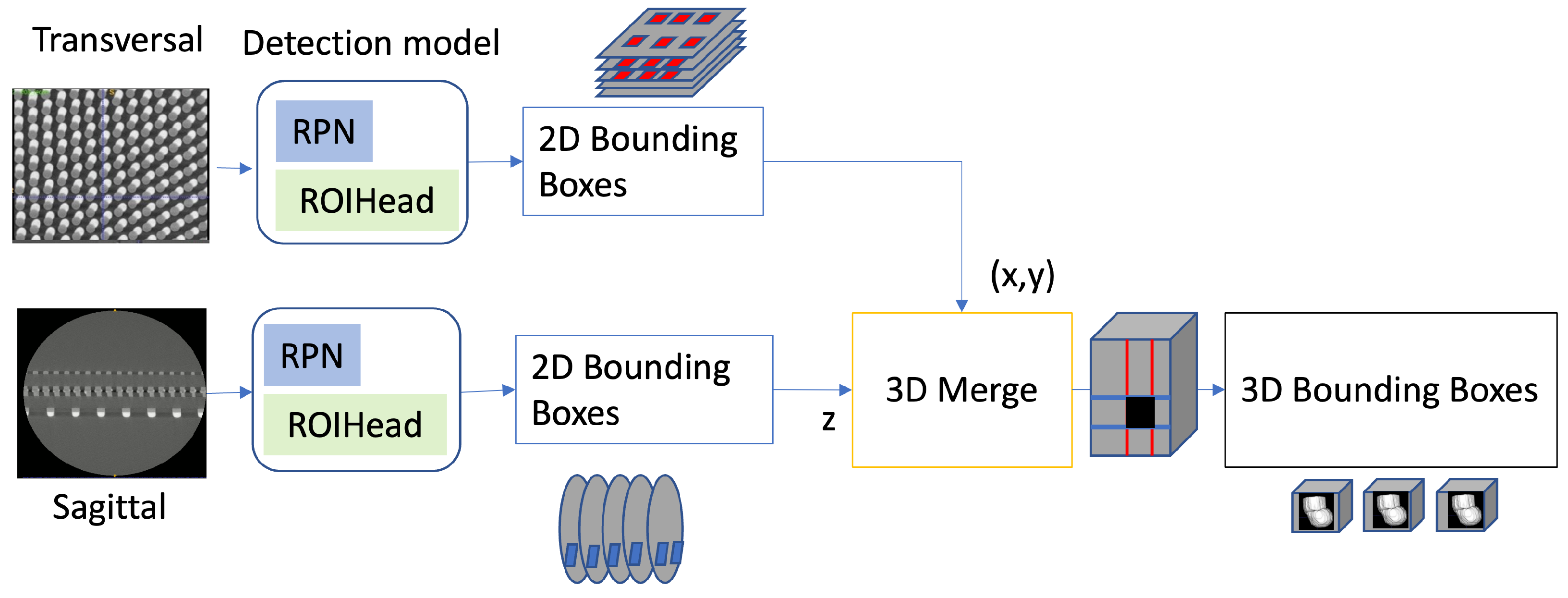
3.1. Object Detection
3.2. Semantic Segmentation
3.3. Three-Dimensional (3D) Metrology
4. Experiments
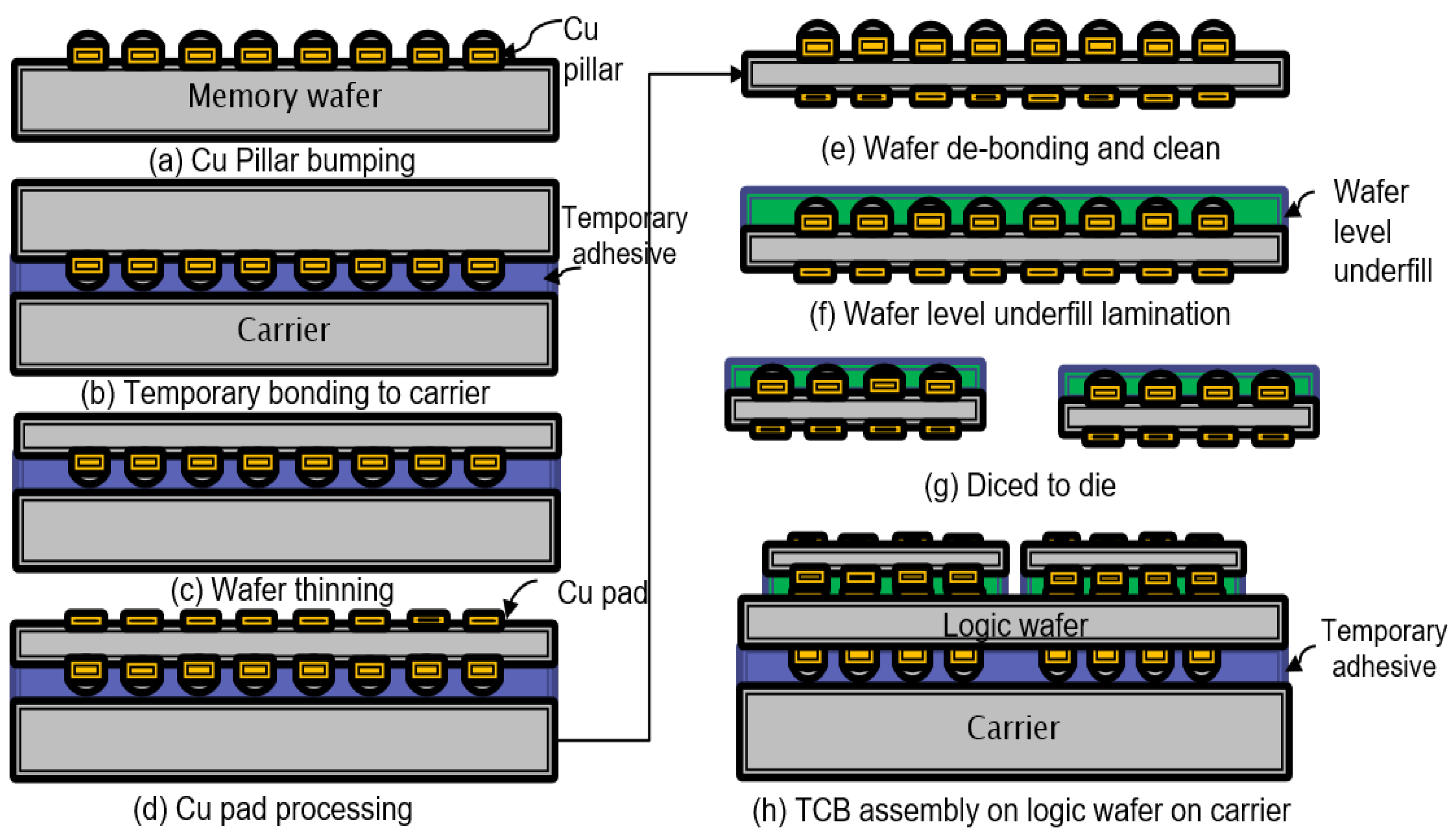
4.1. Data Fabrication
4.2. Object Detection
4.3. Semantic Segmentation
4.4. Three-Dimensional (3D) Metrology
5. Conclusions
Author Contributions
Funding
Institutional Review Board Statement
Informed Consent Statement
Data Availability Statement
Acknowledgments
Conflicts of Interest
References
- Pahwa, R.S.; Lay Nwe, M.T.; Chang, R.; Min, O.Z.; Jie, W.; Gopalakrishnan, S.; Soon Wee, D.H.; Qin, R.; Rao, V.S.; Dai, H.; et al. Automated Attribute Measurements of Buried Package Features in 3D X-ray Images using Deep Learning. In Proceedings of the IEEE 71st Electronic Components and Technology Conference (ECTC), Virtual, 1 June–4 July 2021; pp. 2196–2204. [Google Scholar] [CrossRef]
- Jie, W.; Chang, R.; Xun, X.; Lile, C.; Foo, C.S.; Pahwa, R.S. Improved Bump Detection and Defect Identification for HBMs using Refined Machine Learning Approach. In Proceedings of the IEEE 24th Electronics Packaging Technology Conference (EPTC), San Diego, CA, USA, 31 May–3 June 2022; pp. 848–853. [Google Scholar] [CrossRef]
- Balasubramaniam, A.; Pasricha, S. Object Detection in Autonomous Vehicles: Status and Open Challenges. arXiv 2022, arXiv:2201.07706. [Google Scholar]
- Rahman, H.; Bukht, T.F.N.; Imran, A.; Tariq, J.; Tu, S.; Alzahrani, A. A Deep Learning Approach for Liver and Tumor Segmentation in CT Images Using ResUNet. Bioengineering 2022, 9, 368. [Google Scholar] [CrossRef]
- Chang, R.; Pahwa, R.S.; Wang, J.; Chen, L.; Satini, S.; Wan, K.W.; Hsu, D. Creating Semi-supervised learning-based Adaptable Object Detection Models for Autonomous Service Robot. In Proceedings of the 12th Conference on Learning Factories (CLF), Singapore, 11–13 April 2022. [Google Scholar] [CrossRef]
- Redmon, J.; Farhadi, A. YOLOv3: An Incremental Improvement. arXiv 2018, arXiv:1804.02767. [Google Scholar]
- Wang, C.Y.; Bochkovskiy, A.; Liao, H.Y.M. YOLOv7: Trainable bag-of-freebies sets new state-of-the-art for real-time object detectors. arXiv 2022, arXiv:2207.02696. [Google Scholar]
- Liu, W.; Anguelov, D.; Erhan, D.; Szegedy, C.; Reed, S.E.; Fu, C.; Berg, A.C. SSD: Single Shot MultiBox Detector. arXiv 2015, arXiv:1512.02325. [Google Scholar]
- Ren, S.; He, K.; Girshick, R.; Sun, J. Faster R-CNN: Towards Real-Time Object Detection with Region Proposal Networks. In Proceedings of the Advances in Neural Information Processing Systems, Montreal, QC, Canada, 7–12 December 2015; Curran Associates, Inc.: Red Hook, NY, USA, 2015; Volume 28, pp. 91–99. [Google Scholar]
- Yang, A. 3D Object Detection from CT Scans Using a Slice-and-Fuse Approach. Ph.D. Thesis, Robotics Institute CMU, Pittsburgh, PA, USA, 2019. [Google Scholar]
- Pahwa, R.S.; Chang, R.; Jie, W.; Xun, X.; Zaw Min, O.; Sheng, F.C.; Ser Choong, C.; Rao, V.S. Automated Detection and Segmentation of HBMs in 3D X-ray Images using Semi-Supervised Deep Learning. In Proceedings of the IEEE 72nd Electronic Components and Technology Conference (ECTC), San Diego, CA, USA, 31 May–3 June 2022; pp. 1890–1897. [Google Scholar] [CrossRef]
- Lin, T.; Maire, M.; Belongie, S.; Bourdev, L.D.; Girshick, R.B.; Hays, J.; Perona, P.; Ramanan, D.; Dollár, P.; Zitnick, C.L. Microsoft COCO: Common Objects in Context. arXiv 2014, arXiv:1405.0312. [Google Scholar]
- Gao, J.; Wang, J.; Dai, S.; Li, L.; Nevatia, R. NOTE-RCNN: NOise Tolerant Ensemble RCNN for Semi-Supervised Object Detection. arXiv 2018, arXiv:1812.00124. [Google Scholar]
- Hoffman, J.; Guadarrama, S.; Tzeng, E.; Donahue, J.; Girshick, R.B.; Darrell, T.; Saenko, K. LSDA: Large Scale Detection Through Adaptation. arXiv 2014, arXiv:1407.5035. [Google Scholar]
- Sohn, K.; Zhang, Z.; Li, C.; Zhang, H.; Lee, C.; Pfister, T. A Simple Semi-Supervised Learning Framework for Object Detection. arXiv 2020, arXiv:2005.04757. [Google Scholar]
- Jeong, J.; Lee, S.; Kim, J.; Kwak, N. Consistency-based Semi-supervised Learning for Object detection. In Proceedings of the Advances in Neural Information Processing Systems, Montreal, QC, Canada, 8–14 December 2019; Curran Associates, Inc.: Red Hook, NY, USA, 2019; Volume 32. [Google Scholar]
- Tarvainen, A.; Valpola, H. Mean teachers are better role models: Weight-averaged consistency targets improve semi-supervised deep learning results. arXiv 2017, arXiv:1703.01780. [Google Scholar]
- Liu, Y.; Ma, C.; He, Z.; Kuo, C.; Chen, K.; Zhang, P.; Wu, B.; Kira, Z.; Vajda, P. Unbiased Teacher for Semi-Supervised Object Detection. arXiv 2021, arXiv:2102.09480. [Google Scholar]
- He, K.; Fan, H.; Wu, Y.; Xie, S.; Girshick, R. Momentum Contrast for Unsupervised Visual Representation Learning. arXiv 2020, arXiv:1911.05722. [Google Scholar]
- Chen, T.; Kornblith, S.; Norouzi, M.; Hinton, G. A Simple Framework for Contrastive Learning of Visual Representations. arXiv 2020, arXiv:2002.05709. [Google Scholar]
- Hadsell, R.; Chopra, S.; LeCun, Y. Dimensionality Reduction by Learning an Invariant Mapping. In Proceedings of the 2006 IEEE Computer Society Conference on Computer Vision and Pattern Recognition (CVPR’06), New York, NY, USA, 17–22 June 2006; Volume 2, pp. 1735–1742. [Google Scholar] [CrossRef]
- Goodfellow, I.; Pouget-Abadie, J.; Mirza, M.; Xu, B.; Warde-Farley, D.; Ozair, S.; Courville, A.; Bengio, Y. Generative Adversarial Nets. In Proceedings of the Advances in Neural Information Processing Systems, Montreal, QC, Canada, 8–14 December 2014; Ghahramani, Z., Welling, M., Cortes, C., Lawrence, N., Weinberger, K., Eds.; Curran Associates, Inc.: Red Hook, NY, USA, 2014; Volume 27. [Google Scholar]
- Donahue, J.; Simonyan, K. Large Scale Adversarial Representation Learning. arXiv 2019, arXiv:1907.02544. [Google Scholar]
- Bai, W.; Oktay, O.; Sinclair, M.; Suzuki, H.; Rajchl, M.; Tarroni, G.; Glocker, B.; King, A.; Matthews, P.M.; Rueckert, D. Semi-supervised Learning for Network-Based Cardiac MR Image Segmentation. In Proceedings of the Medical Image Computing and Computer-Assisted Intervention (MICCAI), Montreal, QC, Canada, 11–13 September 2017; Springer International Publishing: Berlin/Heidelberg, Germany, 2017; pp. 253–260. [Google Scholar]
- Long, J.; Shelhamer, E.; Darrell, T. Fully Convolutional Networks for Semantic Segmentation. arXiv 2015, arXiv:1411.4038. [Google Scholar]
- Ronneberger, O.; Fischer, P.; Brox, T. U-Net: Convolutional Networks for Biomedical Image Segmentation. arXiv 2015, arXiv:1505.04597. [Google Scholar]
- Milletari, F.; Navab, N.; Ahmadi, S. V-Net: Fully Convolutional Neural Networks for Volumetric Medical Image Segmentation. In Proceedings of the International Conference on 3D Vision (3DV), Stanford, CA, USA, 25–28 October 2016; pp. 565–571. [Google Scholar] [CrossRef] [Green Version]
- Li, Z.; Kamnitsas, K.; Glocker, B. Analyzing Overfitting Under Class Imbalance in Neural Networks for Image Segmentation. IEEE Trans. Med. Imaging 2021, 40, 1065–1077. [Google Scholar] [CrossRef]
- French, G.; Laine, S.; Aila, T.; Mackiewicz, M.; Finlayson, G. Semi-supervised semantic segmentation needs strong, varied perturbations. arXiv 2019, arXiv:1906.01916. [Google Scholar]
- Lin, T.Y.; Goyal, P.; Girshick, R.; He, K.; Dollár, P. Focal Loss for Dense Object Detection. arXiv 2017, arXiv:1708.02002. [Google Scholar]
- Liu, W.; Wen, Y.; Yu, Z.; Yang, M. Large-Margin Softmax Loss for Convolutional Neural Networks. arXiv 2016, arXiv:1612.02295. [Google Scholar]
- Hung, W.C.; Tsai, Y.H.; Liou, Y.T.; Lin, Y.Y.; Yang, M.H. Adversarial learning for semi-supervised semantic segmentation. In Proceedings of the British Machine Vision Conference, London, UK, 3–6 September 2018. [Google Scholar]
- Yang, L.; Zhuo, W.; Qi, L.; Shi, Y.; Gao, Y. ST++: Make Self-training Work Better for Semi-supervised Semantic Segmentation. arXiv 2022, arXiv:2106.05095. [Google Scholar]
- Li, S.; Zhang, C.; He, X. Shape-Aware Semi-supervised 3D Semantic Segmentation for Medical Images. In Medical Image Computing and Computer Assisted Intervention—MICCAI 2020; Springer International Publishing: Berlin/Heidelberg, Germany, 2020; pp. 552–561. [Google Scholar] [CrossRef]
- Yu, L.; Wang, S.; Li, X.; Fu, C.W.; Heng, P.A. Uncertainty-aware self-ensembling model for semi-supervised 3D left atrium segmentation. In Proceedings of the Medical Image Computing and Computer Assisted Intervention–MICCAI 2019: 22nd International Conference, Shenzhen, China, 13–17 October 2019; Proceedings, Part II 22. Springer: Berlin/Heidelberg, Germany, 2019; pp. 605–613. [Google Scholar]
- Li, X.; Yu, L.; Chen, H.; Fu, C.W.; Xing, L.; Heng, P.A. Transformation-consistent self-ensembling model for semisupervised medical image segmentation. IEEE Trans. Neural Netw. Learn. Syst. 2020, 32, 523–534. [Google Scholar] [CrossRef] [PubMed]
- Luo, X.; Chen, J.; Song, T.; Wang, G. Semi-supervised Medical Image Segmentation through Dual-task Consistency. arXiv 2020, arXiv:2009.04448. [Google Scholar] [CrossRef]
- Li, S.; Zhao, Z.; Xu, K.; Zeng, Z.; Guan, C. Hierarchical consistency regularized mean teacher for semi-supervised 3d left atrium segmentation. In Proceedings of the 2021 43rd Annual International Conference of the IEEE Engineering in Medicine & Biology Society (EMBC), Virtual Conference, 1–5 November 2021; IEEE: New Jersey, NJ, USA, 2021; pp. 3395–3398. [Google Scholar]
- Zhao, Z.; Xu, K.; Yeo, H.Z.; Yang, X.; Guan, C. MS-MT: Multi-Scale Mean Teacher with Contrastive Unpaired Translation for Cross-Modality Vestibular Schwannoma and Cochlea Segmentation. arXiv 2023, arXiv:2303.15826. [Google Scholar]
- Zhao, Z.; Zeng, Z.; Xu, K.; Chen, C.; Guan, C. Dsal: Deeply supervised active learning from strong and weak labelers for biomedical image segmentation. IEEE J. Biomed. Health Inform. 2021, 25, 3744–3751. [Google Scholar] [CrossRef]
- Wu, Y.; Kirillov, A.; Massa, F.; Lo, W.Y.; Girshick, R. Detectron2. 2019. Available online: https://github.com/facebookresearch/detectron2 (accessed on 22 May 2023).
- Lin, T.; Dollár, P.; Girshick, R.B.; He, K.; Hariharan, B.; Belongie, S. Feature Pyramid Networks for Object Detection. arXiv 2016, arXiv:1612.03144. [Google Scholar]
- He, K.; Zhang, X.; Ren, S.; Sun, J. Deep Residual Learning for Image Recognition. arXiv 2015, arXiv:1512.03385. [Google Scholar]
- Everingham, M.; Eslami, S.M.A.; Van Gool, L.; Williams, C.K.I.; Winn, J.; Zisserman, A. The Pascal Visual Object Classes Challenge: A Retrospective. Int. J. Comput. Vis. 2015, 111, 98–136. [Google Scholar] [CrossRef]
- Pahwa, R.S.; Ho, S.W.; Qin, R.; Chang, R.; Min, O.Z.; Jie, W.; Rao, V.S.; Nwe, T.L.; Yang, Y.; Neumann, J.T.; et al. Machine-Learning Based Methodologies for 3D X-Ray Measurement, Characterization and Optimization for Buried Structures in Advanced IC Packages. In Proceedings of the International Wafer Level Packaging Conference (IWLPC), Virtual, 13–30 October 2020; pp. 1–7. [Google Scholar] [CrossRef]
- Pahwa, R.S.; Nwe, T.L.; Chang, R.; Jie, W.; Min, O.Z.; Ho, S.W.; Qin, R.; Rao, V.S.; Yang, Y.; Neumann, J.T.; et al. Deep Learning Analysis of 3D X-ray Images for Automated Object Detection and Attribute Measurement of Buried Package Features. In Proceedings of the IEEE 22nd Electronics Packaging Technology Conference (EPTC), Singapore, 2–4 December 2020; pp. 221–227. [Google Scholar] [CrossRef]
- Lewis, D.D.; Gale, W.A. A Sequential Algorithm for Training Text Classifiers. 1994. Available online: https://link.springer.com/chapter/10.1007/978-1-4471-2099-5_1 (accessed on 22 May 2023).
- Scheffer, T.; Decomain, C.; Wrobel, S. Active Hidden Markov Models for Information Extraction. In Proceedings of the Advances in Intelligent Data Analysis, Cascais, Portugal, 13–15 September 2001; Springer: Berlin/Heidelberg, Germany, 2001. [Google Scholar]
- Settles, B. Active Learning Literature Survey; Computer Sciences Technical Report 1648; University of Wisconsin–Madison: Madison, WI, USA, 2009. [Google Scholar]







{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
| Accuracy on Data Selection Strategies (mAP) | |||
|---|---|---|---|
| Labeled dataset | |||
| LeastConfidence [47] | 61.87 | 78.9 | 84.34 |
| MarginSampling [48] | 62.67 | 79.12 | 84.53 |
| EntropySampling [49] | 61.34 | 79.32 | 84.92 |
| simCLR [20] | 63.07 | 79.54 | 86.56 |
| 1% | 2% | 5% | 10% | ||||||
|---|---|---|---|---|---|---|---|---|---|
| IOU = 0.5:0.95 | Prec. | Rec. | Prec. | Rec. | Prec. | Rec. | Prec. | Rec. | |
| Memory | |||||||||
| Sagittal | Det2 | 0.607 | 0.662 | 0.631 | 0.68 | 0.634 | 0.685 | 0.648 | 0.685 |
| UBT | 0.769 | 0.801 | 0.764 | 0.81 | 0.788 | 0.827 | 0.798 | 0.832 | |
| Ours | 0.786 | 0.81 | 0.791 | 0.826 | 0.824 | 0.831 | 0.821 | 0.845 | |
| Transver. | Det2 | 0.723 | 0.784 | 0.76 | 0.79 | 0.784 | 0.824 | 0.803 | 0.846 |
| UBT | 0.764 | 0.812 | 0.781 | 0.81 | 0.798 | 0.834 | 0.824 | 0.853 | |
| Ours | 0.843 | 0.873 | 0.854 | 0.879 | 0.874 | 0.892 | 0.886 | 0.916 | |
| Logic | |||||||||
| Sagittal | Det2 | 0.776 | 0.806 | 0.781 | 0.814 | 0.782 | 0.817 | 0.809 | 0.848 |
| UBT | 0.795 | 0.836 | 0.801 | 0.841 | 0.81 | 0.845 | 0.814 | 0.846 | |
| Ours | 0.848 | 0.873 | 0.889 | 0.917 | 0.906 | 0.927 | 0.917 | 0.943 | |
| Transver. | Det2 | 0.714 | 0.753 | 0.659 | 0.703 | 0.679 | 0.725 | 0.701 | 0.739 |
| UBT | 0.788 | 0.824 | 0.80 | 0.821 | 0.824 | 0.859 | 0.843 | 0.873 | |
| Ours | 0.824 | 0.859 | 0.862 | 0.893 | 0.894 | 0.923 | 0.903 | 0.931 | |
| 2.5% | 5% | 10% | 50% | 100% | ||||||
|---|---|---|---|---|---|---|---|---|---|---|
| Dice | IoU | Dice | IoU | Dice | IoU | Dice | IoU | Dice | IoU | |
| Memory | ||||||||||
| V-Net | 79.89 | 64.86 | 85.14 | 77.16 | 81.49 | 73.57 | 83.26 | 75.63 | 87.89 | 80.19 |
| MT | 80.63 | 72.38 | 85.50 | 70.25 | 86.69 | 71.75 | 86.10 | 82.03 | 88.67 | 82.81 |
| Ours (MMT) | 75.32 | 64.93 | 84.83 | 76.70 | 86.46 | 78.21 | 87.03 | 79.21 | 89.49 | 82.25 |
| Logic | ||||||||||
| V-Net | 81.82 | 75.07 | 84.51 | 78.74 | 84.51 | 78.85 | 85.26 | 79.85 | 84.34 | 78.55 |
| MT | 84.22 | 78.54 | 84.33 | 78.58 | 84.80 | 79.66 | 85.65 | 80.54 | 83.79 | 78.27 |
| Ours (MMT) | 57.27 | 48.18 | 91.13 | 84.86 | 92.29 | 86.86 | 92.58 | 87.41 | 91.59 | 86.06 |
| Metrology Error | MT | Ours | Post-Processed |
|---|---|---|---|
| Memory Die | |||
| Bond Line Thickness | 2.19 | 1.41 | 1.41 |
| Solder Extrusion | 3.30 | 3.27 | 2.53 |
| Pad Misalignment | 2.12 | 0.91 | 0.91 |
| Void-to-Solder Ratio | 0.046 | 0.046 | 0.045 |
| Logic Die | |||
| Bond Line Thickness | 3.57 | 1.63 | 1.45 |
| Solder Extrusion | 1.36 | 1.00 | 0.68 |
| Void-to-Solder Ratio | 1.20 | 0.0028 | 0.0029 |
Disclaimer/Publisher’s Note: The statements, opinions and data contained in all publications are solely those of the individual author(s) and contributor(s) and not of MDPI and/or the editor(s). MDPI and/or the editor(s) disclaim responsibility for any injury to people or property resulting from any ideas, methods, instructions or products referred to in the content. |
© 2023 by the authors. Licensee MDPI, Basel, Switzerland. This article is an open access article distributed under the terms and conditions of the Creative Commons Attribution (CC BY) license (https://creativecommons.org/licenses/by/4.0/).
Share and Cite
Wang, J.; Chang, R.; Zhao, Z.; Pahwa, R.S. Robust Detection, Segmentation, and Metrology of High Bandwidth Memory 3D Scans Using an Improved Semi-Supervised Deep Learning Approach. Sensors 2023, 23, 5470. https://doi.org/10.3390/s23125470
Wang J, Chang R, Zhao Z, Pahwa RS. Robust Detection, Segmentation, and Metrology of High Bandwidth Memory 3D Scans Using an Improved Semi-Supervised Deep Learning Approach. Sensors. 2023; 23(12):5470. https://doi.org/10.3390/s23125470
Chicago/Turabian StyleWang, Jie, Richard Chang, Ziyuan Zhao, and Ramanpreet Singh Pahwa. 2023. "Robust Detection, Segmentation, and Metrology of High Bandwidth Memory 3D Scans Using an Improved Semi-Supervised Deep Learning Approach" Sensors 23, no. 12: 5470. https://doi.org/10.3390/s23125470