
HGR-ViT: Hand Gesture Recognition with Vision Transformer


Abstract
1. Introduction
- The Vision Transformer model leverages the self-attention mechanism to capture complex relationships between the image patches which enables it to better handle the similarity problem between hand gestures as well as variations in pose, lighting, background and occlusions.
- Early stopping and adaptive learning rate are introduced to prevent overfitting and reduce generalisation error.
- Evaluating the proposed HGR-ViT method on three benchmark hand gesture datasets, including American Sign Language (ASL), ASL with Digits, and National University of Singapore (NUS) hand gesture datasets, and achieving promising performance on all three datasets.
2. Related Works
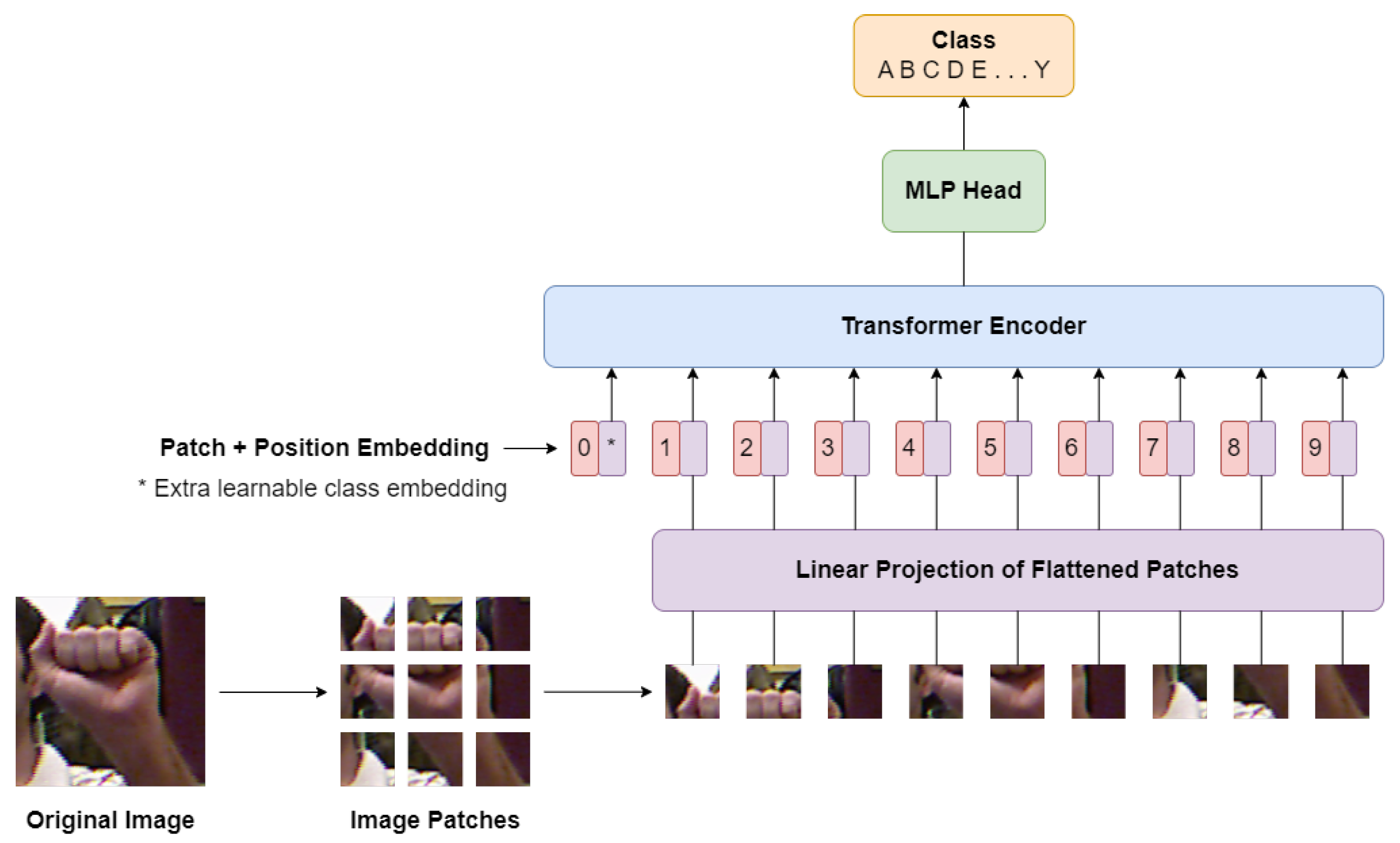
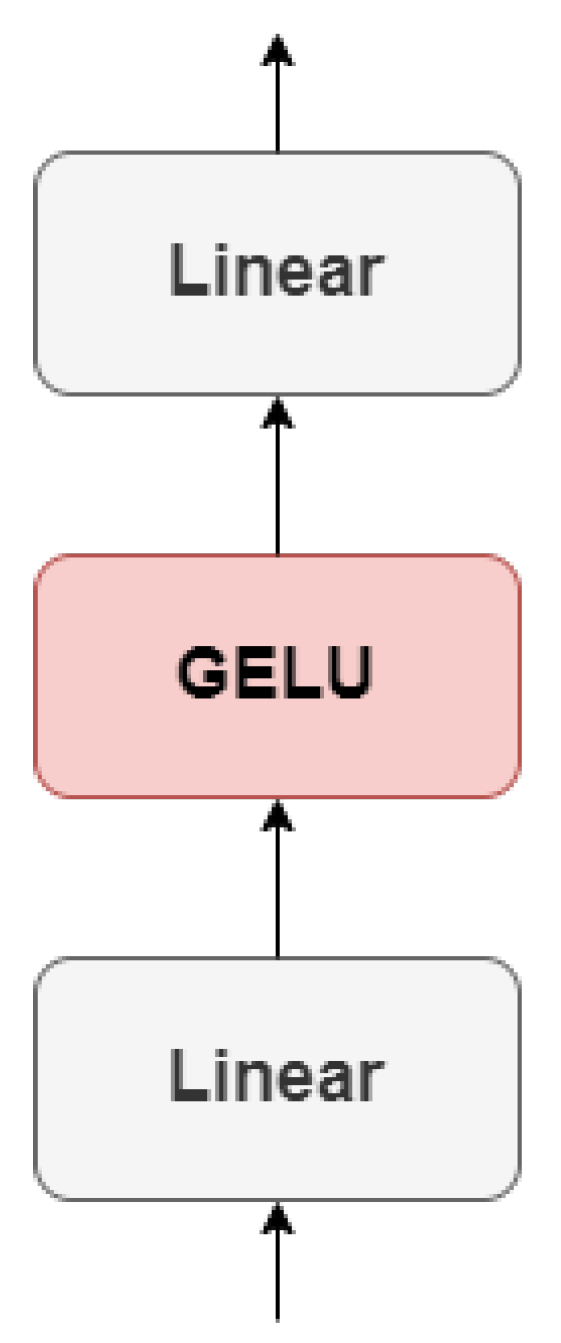
3. Hand Gesture Recognition with Vision Transformer (HGR-ViT)
| Algorithm 1 Algorithm of the training procedure of the proposed HGR-ViT |
| Require: Hand gesture training data Dtrain |
| 1: for e epochs do |
| 2: for b batch_size do |
| 3: x, y←Dtrain |
| 4: vit_model(x,y) |
| 5: end for |
| 6: Get es_monitor, es_patience, lr_monitor, lr_patience |
| 7: if es_monitor < self.best and es_patience ⩾ self.wait then |
| 8: break |
| 9: end if |
| 10: if lr_monitor < self.best and lr_patience ⩾ self.wait and lr > min_delta then |
| 11: Update learning rate |
| 12: end if |
| 13: end for |
| 14: return vit_model |
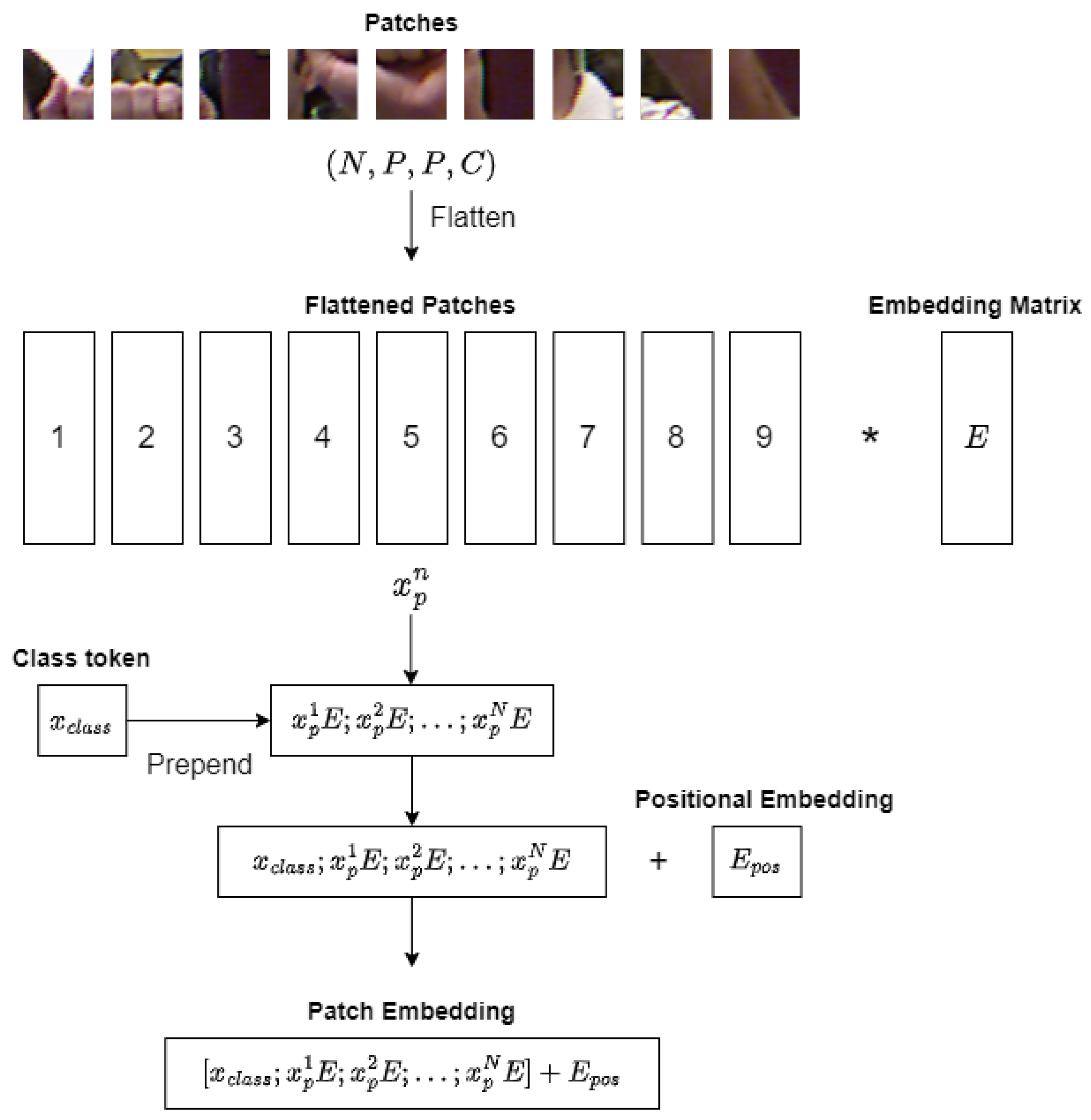
3.1. Linear Projection of Flattened Patches
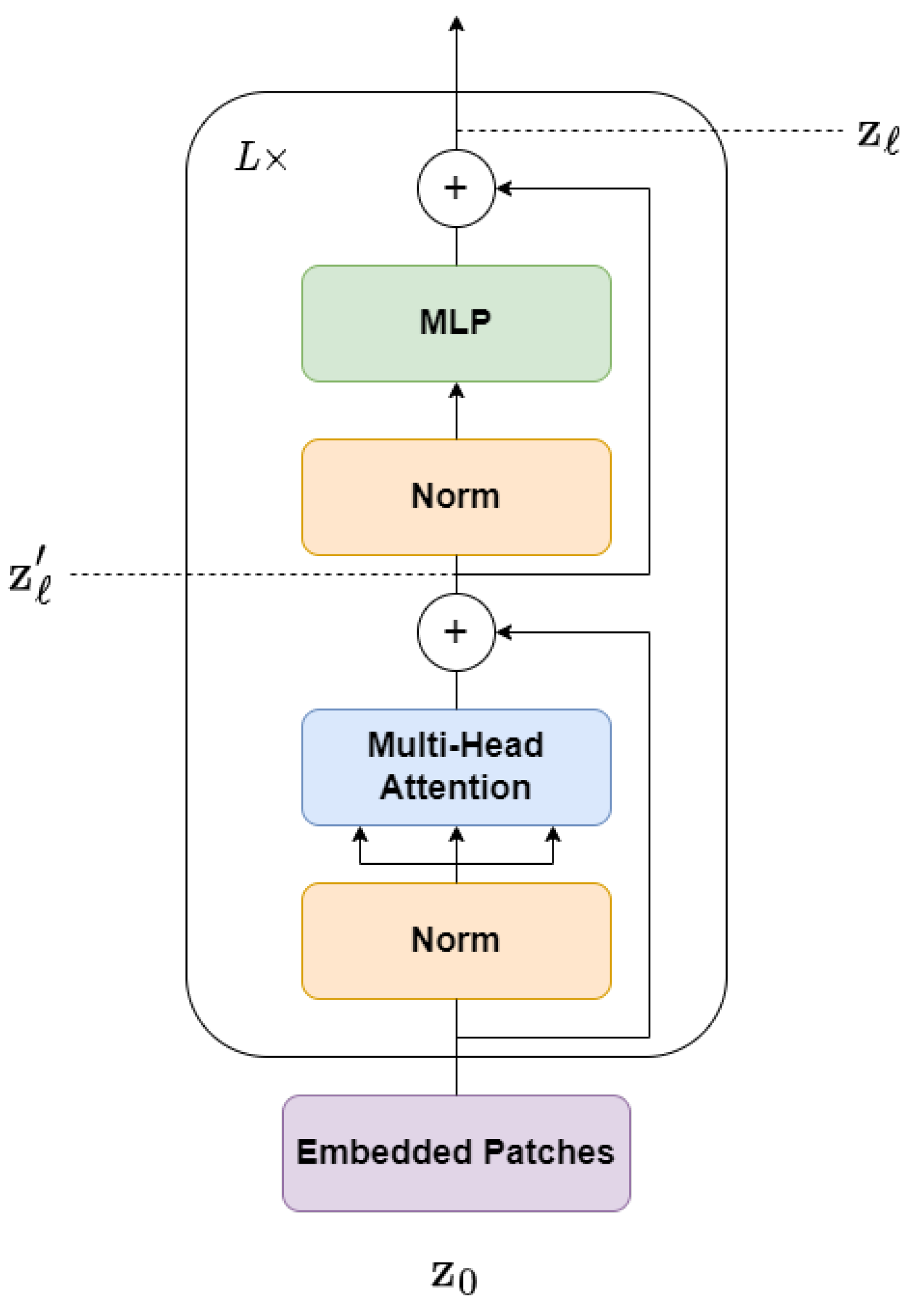
3.2. Transformer Encoder
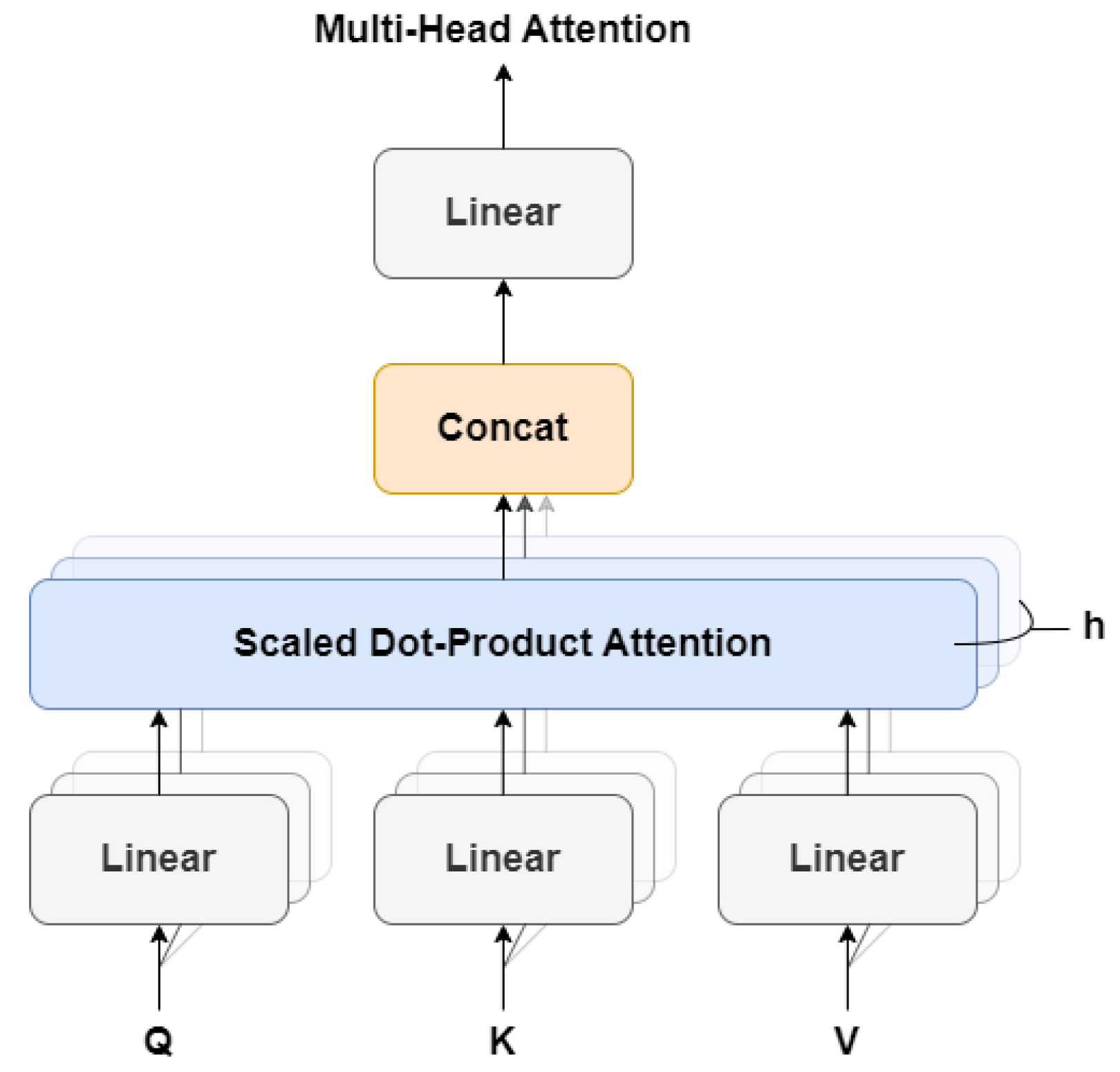
- Multi-head Self-Attention (MSA)
- Multi-Layer Perceptron (MLP)
3.3. Early Stopping
3.4. Adaptive Learning Rate
4. Experiment and Analysis
4.1. Datasets
4.2. Experimental Setup
4.3. Experimental Analysis
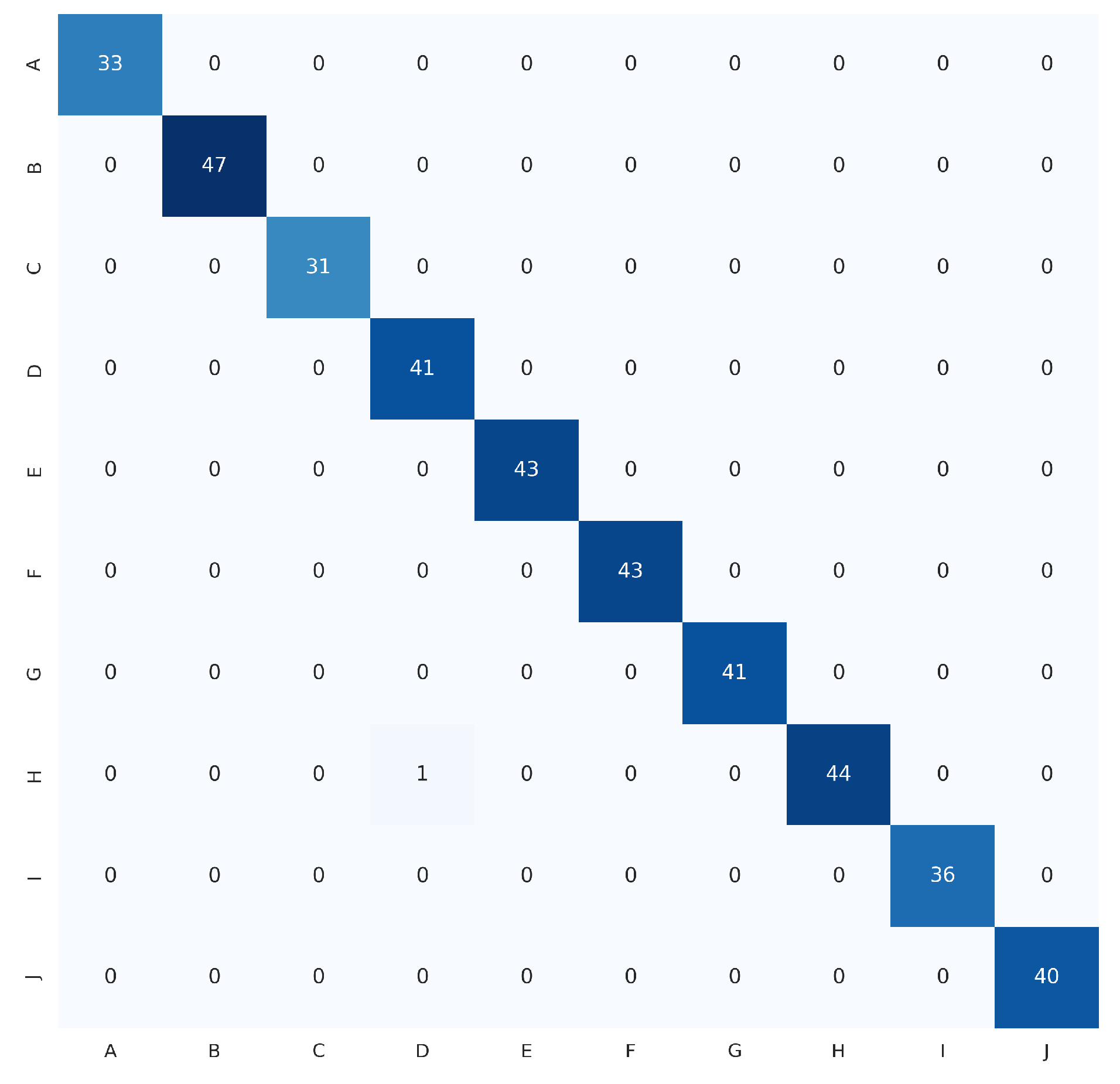
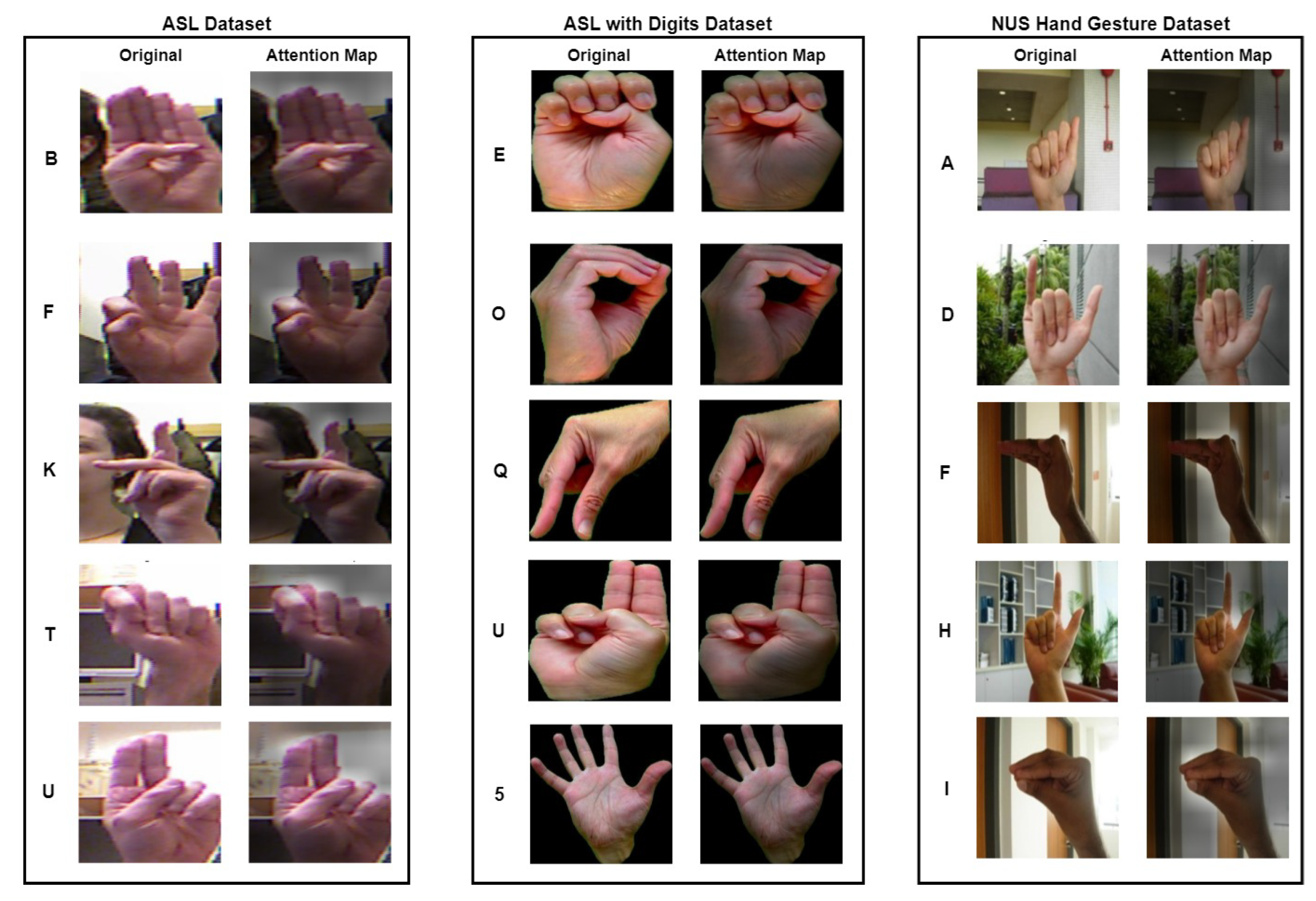
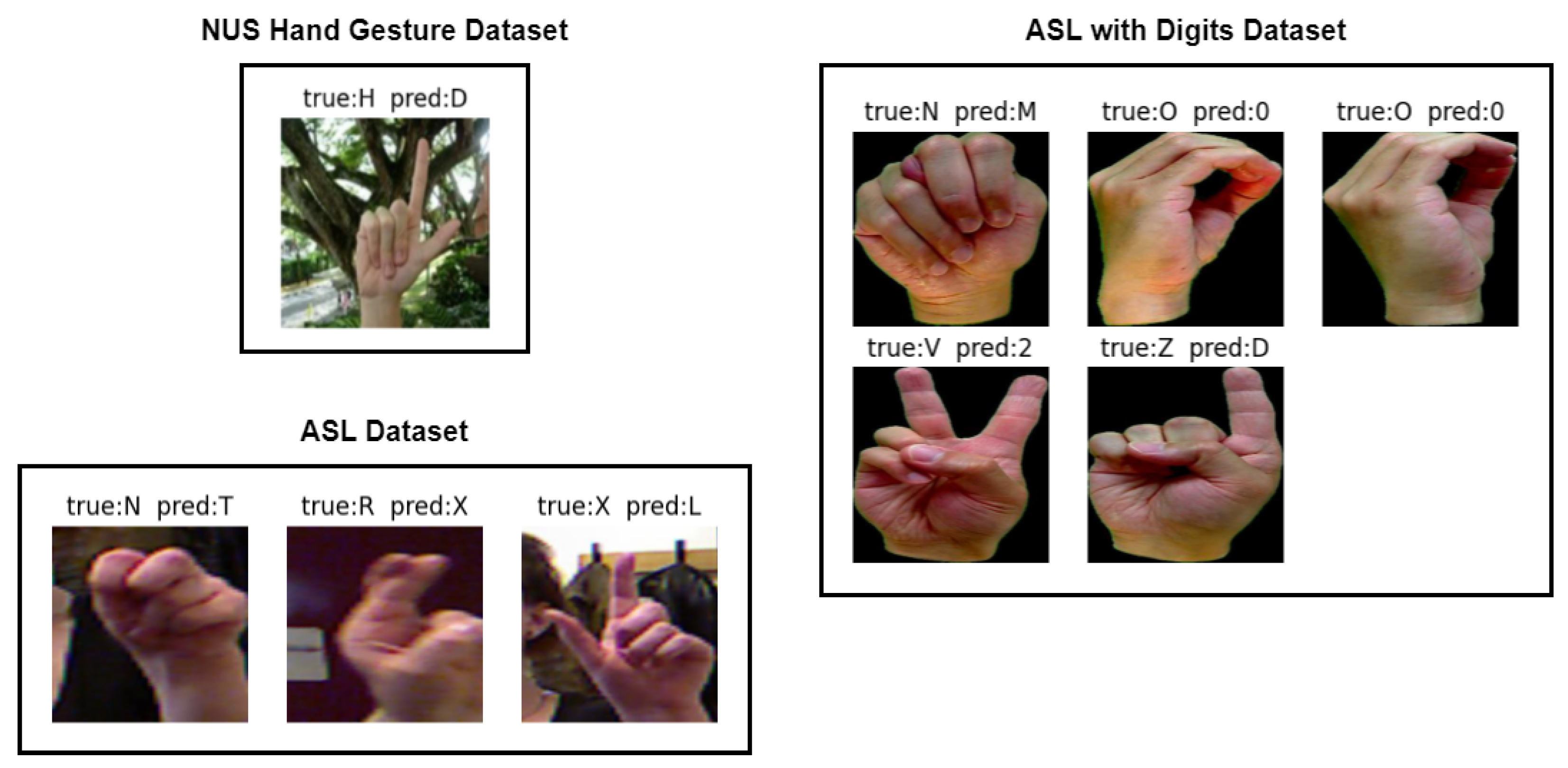
4.4. Experimental Results and Discussions
5. Conclusions
Author Contributions
Funding
Institutional Review Board Statement
Informed Consent Statement
Data Availability Statement
Conflicts of Interest
References
- Khari, M.; Garg, A.K.; Crespo, R.G.; Verdú, E. Gesture Recognition of RGB and RGB-D Static Images Using Convolutional Neural Networks. Int. J. Interact. Multim. Artif. Intell. 2019, 5, 22–27. [Google Scholar] [CrossRef]
- Ozcan, T.; Basturk, A. Transfer learning-based convolutional neural networks with heuristic optimization for hand gesture recognition. Neural Comput. Appl. 2019, 31, 8955–8970. [Google Scholar] [CrossRef]
- Tan, Y.S.; Lim, K.M.; Tee, C.; Lee, C.P.; Low, C.Y. Convolutional neural network with spatial pyramid pooling for hand gesture recognition. Neural Comput. Appl. 2021, 33, 5339–5351. [Google Scholar] [CrossRef]
- Mujahid, A.; Awan, M.J.; Yasin, A.; Mohammed, M.A.; Damaševičius, R.; Maskeliūnas, R.; Abdulkareem, K.H. Real-time hand gesture recognition based on deep learning YOLOv3 model. Appl. Sci. 2021, 11, 4164. [Google Scholar] [CrossRef]
- Ewe, E.L.R.; Lee, C.P.; Kwek, L.C.; Lim, K.M. Hand Gesture Recognition via Lightweight VGG16 and Ensemble Classifier. Appl. Sci. 2022, 12, 7643. [Google Scholar] [CrossRef]
- Tan, Y.S.; Lim, K.M.; Lee, C.P. Hand gesture recognition via enhanced densely connected convolutional neural network. Expert Syst. Appl. 2021, 175, 114797. [Google Scholar] [CrossRef]
- Tan, Y.S.; Lim, K.M.; Lee, C.P. Wide Residual Network for Vision-based Static Hand Gesture Recognition. IAENG Int. J. Comput. Sci. 2021, 48, 906–914. [Google Scholar]
- Lim, K.M.; Tan, A.W.; Tan, S.C. A four dukkha state-space model for hand tracking. Neurocomputing 2017, 267, 311–319. [Google Scholar] [CrossRef]
- Chen, X.; Wang, G.; Guo, H.; Zhang, C.; Wang, H.; Zhang, L. Mfa-net: Motion feature augmented network for dynamic hand gesture recognition from skeletal data. Sensors 2019, 19, 239. [Google Scholar] [CrossRef]
- Rahim, M.A.; Islam, M.R.; Shin, J. Non-touch sign word recognition based on dynamic hand gesture using hybrid segmentation and CNN feature fusion. Appl. Sci. 2019, 9, 3790. [Google Scholar] [CrossRef]
- Vaitkevičius, A.; Taroza, M.; Blažauskas, T.; Damaševičius, R.; Maskeliūnas, R.; Woźniak, M. Recognition of American sign language gestures in a virtual reality using leap motion. Appl. Sci. 2019, 9, 445. [Google Scholar] [CrossRef]
- Dong, Y.; Liu, J.; Yan, W. Dynamic hand gesture recognition based on signals from specialized data glove and deep learning algorithms. IEEE Trans. Instrum. Meas. 2021, 70, 1–14. [Google Scholar] [CrossRef]
- Athira, P.; Sruthi, C.; Lijiya, A. A signer independent sign language recognition with co-articulation elimination from live videos: An Indian scenario. J. King Saud Univ.-Comput. Inf. Sci. 2022, 34, 771–781. [Google Scholar] [CrossRef]
- Ma, L.; Huang, W. A static hand gesture recognition method based on the depth information. In Proceedings of the 2016 8th International Conference on Intelligent Human-Machine Systems and Cybernetics (IHMSC), Hangzhou, China, 27–28 August 2016; Volume 2, pp. 136–139. [Google Scholar]
- Bamwenda, J.; Özerdem, M.S. Recognition of static hand gesture with using ANN and SVM. Dicle Univ. J. Eng. 2019, 10, 561–568. [Google Scholar]
- Candrasari, E.B.; Novamizanti, L.; Aulia, S. Discrete Wavelet Transform on static hand gesture recognition. J. Phys. Conf. Ser. 2019, 1367, 012022. [Google Scholar] [CrossRef]
- Gao, Q.; Liu, J.; Ju, Z.; Li, Y.; Zhang, T.; Zhang, L. Static hand gesture recognition with parallel CNNs for space human-robot interaction. In Proceedings of the International Conference on Intelligent Robotics and Applications, Wuhan, China, 16–18 August 2017; pp. 462–473. [Google Scholar]
- Xie, B.; He, X.; Li, Y. RGB-D static gesture recognition based on convolutional neural network. J. Eng. 2018, 2018, 1515–1520. [Google Scholar] [CrossRef]
- Adithya, V.; Rajesh, R. A deep convolutional neural network approach for static hand gesture recognition. Procedia Comput. Sci. 2020, 171, 2353–2361. [Google Scholar]
- Li, Y.; Deng, J.; Wu, Q.; Wang, Y. Eye-Tracking Signals Based Affective Classification Employing Deep Gradient Convolutional Neural Networks. Int. J. Interact. Multimed. Artif. Intell. 2021, 7, 34–43. [Google Scholar] [CrossRef]
- Adimoolam, M.; Mohan, S.; A., J.; Srivastava, G. A Novel Technique to Detect and Track Multiple Objects in Dynamic Video Surveillance Systems. Int. J. Interact. Multimed. Artif. Intell. 2022, 7, 112–120. [Google Scholar] [CrossRef]
- Kaur, G.; Bathla, G. Hand Gesture Recognition based on Invariant Features and Artifical Neural Network. Indian J. Sci. Technol. 2016, 9, 1–6. [Google Scholar] [CrossRef]
- Gupta, B.; Shukla, P.; Mittal, A. K-nearest correlated neighbor classification for Indian sign language gesture recognition using feature fusion. In Proceedings of the 2016 International Conference on Computer Communication and Informatics (ICCCI), Coimbatore, India, 7–9 January 2016; pp. 1–5. [Google Scholar]
- Lahiani, H.; Neji, M. Hand gesture recognition method based on HOG-LBP features for mobile device. Procedia Comput. Sci. 2018, 126, 254–263. [Google Scholar] [CrossRef]
- Sahoo, J.P.; Ari, S.; Ghosh, D.K. Hand gesture recognition using DWT and Fratio based feature descriptor. IET Image Process. 2018, 12, 1780–1787. [Google Scholar] [CrossRef]
- Parvathy, P.; Subramaniam, K.; Venkatesan, G.K.P.; Karthikaikumar, P.; Varghese, J.; Jayasankar, T. Development of hand gesture recognition system using machine learning. J. Ambient Intell. Humaniz. Comput. 2021, 12, 6793–6800. [Google Scholar] [CrossRef]
- Flores, C.J.L.; Cutipa, A.G.; Enciso, R.L. Application of convolutional neural networks for static hand gestures recognition under different invariant features. In Proceedings of the 2017 IEEE XXIV International Conference on Electronics, Electrical Engineering and Computing (INTERCON), Cusco, Peru, 15–18 August 2017; pp. 1–4. [Google Scholar]
- Alani, A.A.; Cosma, G.; Taherkhani, A.; McGinnity, T.M. Hand gesture recognition using an adapted convolutional neural network with data augmentation. In Proceedings of the 2018 4th International Conference on Information Management (ICIM), Oxford, UK, 25–27 May 2018. [Google Scholar] [CrossRef]
- Arenas, J.O.P.; Moreno, R.J.; Bele no, R.D.H. Convolutional neural network with a dag architecture for control of a robotic arm by means of hand gestures. Contemp. Eng. Sci. 2018, 11, 547–557. [Google Scholar] [CrossRef]
- Dadashzadeh, A.; Targhi, A.T.; Tahmasbi, M.; Mirmehdi, M. HGR-Net: A fusion network for hand gesture segmentation and recognition. IET Comput. Vis. 2019, 13, 700–707. [Google Scholar] [CrossRef]
- Ahuja, R.; Jain, D.; Sachdeva, D.; Garg, A.; Rajput, C. Convolutional neural network based american sign language static hand gesture recognition. Int. J. Ambient Comput. Intell. (IJACI) 2019, 10, 60–73. [Google Scholar] [CrossRef]
- Osimani, C.; Ojeda-Castelo, J.J.; Piedra-Fernandez, J.A. Point Cloud Deep Learning Solution for Hand Gesture Recognition. Int. J. Interact. Multimed. Artif. Intell. 2023, 1–10, in press. [Google Scholar] [CrossRef]
- Badi, H. Recent methods in vision-based hand gesture recognition. Int. J. Data Sci. Anal. 2016, 1, 77–87. [Google Scholar] [CrossRef]
- Dosovitskiy, A.; Beyer, L.; Kolesnikov, A.; Weissenborn, D.; Zhai, X.; Unterthiner, T.; Dehghani, M.; Minderer, M.; Heigold, G.; Gelly, S.; et al. An image is worth 16 × 16 words: Transformers for image recognition at scale. arXiv 2020, arXiv:2010.11929. [Google Scholar]
- Pugeault, N.; Bowden, R. Spelling it out: Real-time ASL fingerspelling recognition. In Proceedings of the 2011 IEEE International Conference on Computer Vision Workshops (ICCV Workshops), Barcelona, Spain, 6–13 November 2011; pp. 1114–1119. [Google Scholar] [CrossRef]
- Barczak, A.L.C.; Reyes, N.H.; Abastillas, M.; Piccio, A.; Susnjak, T. A New 2D Static Hand Gesture Colour Image Dataset for ASL Gestures. Res. Lett. Inf. Math. Sci 2011, 15, 12–20. [Google Scholar]
- Pisharady, P.K.; Vadakkepat, P.; Loh, A.P. Attention based detection and recognition of hand postures against complex backgrounds. Int. J. Comput. Vis. 2013, 101, 403–419. [Google Scholar] [CrossRef]














{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
| Category | Method | Reference |
|---|---|---|
| Hand-Crafted | SIFT feature extraction with Sparse Autoencoder neural network classification | [14] |
| SIFT feature extraction with feedforward neural network classification | [22] | |
| HOG and SIFT feature extraction with K-Nearest Neighbour classification | [23] | |
| LBP and HOG feature extraction with AdaBoost classification | [24] | |
| HOG feature extraction with SVM and ANN classification | [15] | |
| DWT with F-ratio coefficient selection feature extraction with SVM classification | [25] | |
| DWT feature extraction with HMM classification | [16] | |
| Two-dimensional DWT feature extraction, SURF key point extraction and BOF feature space conversion with SVM classification | [26] | |
| Deep Learning | RGB and Depth parallel CNN | [17] |
| Smoothing and contrast enhancement, segmentation and delimitation and extraction of object of interest before classification using CNN | [27] | |
| Smoothing and disturbance removal, feature extraction with dilation and erosion before classification using CNN | [31] | |
| CNN with network initialisation and L2 regularisation | [28] | |
| Application of CNN with DAG network structure | [29] | |
| RGB and Depth parallel transfer learning VGG19 | [1] | |
| Pre-trained AlexNet with optimisation using ABC algorithm | [2] | |
| Two-stage HGR: 1 CNN model trained for hand gesture recognition in first stage; 2 CNN model, 1 trained on segmented image, 1 trained on original image in second stage | [30] | |
| YOLOv3 with DarkNet-53 CNN | [4] | |
| CNN with spatial pyramid pooling (CNN-SPP) | [3] | |
| DenseNet with modified transition layer (EDenseNet) | [6] | |
| Network based on PointNet architecture | [32] |
| Dataset | Folds | Training Set (80%) | Testing Set (20%) | Total (100%) |
|---|---|---|---|---|
| ASL | 5 | 52,619 | 13,155 | 65,774 |
| ASL with Digits | 5 | 2012 | 503 | 2515 |
| NUS Hand Gesture | 5 | 1600 | 400 | 2000 |
| Dataset | Cross Validation Set | Train Accuracy (%) | Test Accuracy (%) |
|---|---|---|---|
| ASL | 1 | 100.00 | 99.98 |
| 2 | 100.00 | 99.98 | |
| 3 | 100.00 | 99.98 | |
| 4 | 100.00 | 99.98 | |
| 5 | 100.00 | 99.99 | |
| Average | 100.00 | 99.98 | |
| ASL with digits | 1 | 100.00 | 99.20 |
| 2 | 100.00 | 99.60 | |
| 3 | 100.00 | 99.80 | |
| 4 | 100.00 | 99.20 | |
| 5 | 100.00 | 99.01 | |
| Average | 100.00 | 99.36 | |
| NUS hand gesture | 1 | 100.00 | 99.50 |
| 2 | 100.00 | 99.75 | |
| 3 | 100.00 | 100.00 | |
| 4 | 100.00 | 100.00 | |
| 5 | 100.00 | 100.00 | |
| Average | 100.00 | 99.85 |
| Method | ASL Dataset | ASL with Digits Dataset | NUS Hand Gesture Dataset | Average Accuracy |
|---|---|---|---|---|
| CNN Baseline A [27] | 99.85 | 98.69 | 89.15 | 95.90 |
| CNN Baseline B [31] | 99.78 | 98.65 | 89.30 | 95.91 |
| ADCNN [28] | 98.50 | 98.49 | 83.10 | 93.36 |
| DAG-CNN [29] | 99.89 | 98.13 | 91.05 | 96.36 |
| EdenseNet [6] | 99.89 | 98.85 | 96.75 | 98.50 |
| CNN-SPP [3] | 99.94 | 99.17 | 95.95 | 98.35 |
| HGR-ViT (Ours) | 99.98 | 99.36 | 99.85 | 99.73 |
Disclaimer/Publisher’s Note: The statements, opinions and data contained in all publications are solely those of the individual author(s) and contributor(s) and not of MDPI and/or the editor(s). MDPI and/or the editor(s) disclaim responsibility for any injury to people or property resulting from any ideas, methods, instructions or products referred to in the content. |
© 2023 by the authors. Licensee MDPI, Basel, Switzerland. This article is an open access article distributed under the terms and conditions of the Creative Commons Attribution (CC BY) license (https://creativecommons.org/licenses/by/4.0/).
Share and Cite
Tan, C.K.; Lim, K.M.; Chang, R.K.Y.; Lee, C.P.; Alqahtani, A. HGR-ViT: Hand Gesture Recognition with Vision Transformer. Sensors 2023, 23, 5555. https://doi.org/10.3390/s23125555
Tan CK, Lim KM, Chang RKY, Lee CP, Alqahtani A. HGR-ViT: Hand Gesture Recognition with Vision Transformer. Sensors. 2023; 23(12):5555. https://doi.org/10.3390/s23125555
Chicago/Turabian StyleTan, Chun Keat, Kian Ming Lim, Roy Kwang Yang Chang, Chin Poo Lee, and Ali Alqahtani. 2023. "HGR-ViT: Hand Gesture Recognition with Vision Transformer" Sensors 23, no. 12: 5555. https://doi.org/10.3390/s23125555
APA StyleTan, C. K., Lim, K. M., Chang, R. K. Y., Lee, C. P., & Alqahtani, A. (2023). HGR-ViT: Hand Gesture Recognition with Vision Transformer. Sensors, 23(12), 5555. https://doi.org/10.3390/s23125555