
Diffusion Weighted Imaging Super-Resolution Algorithm for Highly Sparse Raw Data Sequences

Institute of Information Technology, Warsaw University of Life Sciences, 159 Nowoursynowska, 02776 Warsaw, Poland
Sensors 2023, 23(12), 5698; https://doi.org/10.3390/s23125698
Submission received: 29 April 2023
/
Revised: 22 May 2023
/
Accepted: 31 May 2023
/
Published: 19 June 2023
(This article belongs to the Section Sensing and Imaging)
Abstract
:The utilization of quick compression-sensed magnetic resonance imaging results in an enhancement of diffusion imaging. Wasserstein Generative Adversarial Networks (WGANs) leverage image-based information. The article presents a novel G-guided generative multilevel network, which leverages diffusion weighted imaging (DWI) input data with constrained sampling. The present study aims to investigate two primary concerns pertaining to MRI image reconstruction, namely, image resolution and reconstruction duration. The implementation of simultaneous k-q space sampling has been found to enhance the performance of Rotating Single-Shot Acquisition (RoSA) without necessitating any hardware modifications. Diffusion weighted imaging (DWI) is capable of decreasing the duration of testing by minimizing the amount of input data required. The synchronization of diffusion directions within PROPELLER blades is achieved through the utilization of compressed k-space synchronization. The grids utilized in DW-MRI are represented by minimal-spanning trees. The utilization of conjugate symmetry in sensing and the Partial Fourier approach has been observed to enhance the efficacy of data acquisition as compared to unaltered k-space sampling systems. The image’s sharpness, edge readings, and contrast have been enhanced. These achievements have been certified by numerous metrics including PSNR and TRE. It is desirable to enhance image quality without necessitating any modifications to the hardware.
1. Introduction
Diffusion magnetic resonance imaging enables the analysis of brain tissue structure at a significantly smaller scale than what can be achieved through empirical voxel resolution when collecting data on water molecule activity in the brain. The effectiveness of this instrument is restricted by various hindrances such as spatial resolution, acquisition time, and potential distortions caused by motion. Super-Resolution Reconstruction has undergone significant development and rigorous testing over the course of the last twenty years. Notwithstanding the advancements made, there remain numerous unresolved issues. Certain entities are subject to regular simplification. Scientists commonly aim to optimize the inter-frame motion scheme. The commonly employed global motion estimation algorithm, which is defined manually, fails to consider the potential motion trajectories that may arise within sets of frames. The algorithm presented in this study integrates discrete dense displacement sampling into its framework, thereby facilitating the deformable registration of high-resolution images. The efficacy of Super-Resolution Reconstruction (SRR) has been evidenced in various medical imaging modalities, including Functional MRI (fMRI) as cited in references [1,2], as well as Computerized Tomography (CT) and Positron-Emission Tomography (PET), as cited in reference [3].
The persuasive argument put forth by the authors suggests that residual learning techniques have the potential to improve the effectiveness of said algorithms. By employing a modified optimization technique that involves eliminating unnecessary modules from conventional residual networks, additional improvements have been attained [4]. Furthermore, the authors have proposed to augment the magnitude of the model. The aforementioned alteration resulted in a stabilization of the training procedure. The utilization of these algorithms in medical image processing poses a challenge due to the necessity of training sets.
Zhang in [5] provided a technique that may significantly enhance the performance of saliency identification, keypoint recognition, and underwater picture segmentation. The authors of reference [6] employed 2D convolution as a means of extracting both spatial and texture features. Subsequently, an attention mechanism is incorporated into the 2D convolution module to enhance the precision of the spatial and texture characteristics. The utilization of both 3D and 2D convolutions is advantageous due to their complementary properties, which enable the comprehensive exploitation of spatial and textural features in hyperspectral images. In addition, a hyperspectral image dataset comprising 1200 samples of ten distinct corn varieties was developed by them [6]. Empirical investigations conducted on the proposed dataset revealed that SSTNet exhibited superior performance in comparison to the existing cutting-edge techniques for the purpose of identifying corn varieties. Wu et al. (2023) introduced a novel methodology for detecting and quantifying the quantity of banana clusters in intricate orchard settings, during both the SBR and harvesting phases [7]. The authors Zhang et al. conducted an investigation into techniques aimed at enhancing the detection of fruits in intricate surroundings. The authors delineated the prevalent categories of intricate backgrounds observed in open-air orchard settings [8]. The authors Wang et al. (2019) presented a new technique, referred to as HR optical flow estimation (SOF-VSR), which aims to improve the quality of videos. The objective of the shown methodology was to improve the precision of motion compensation through the reconstruction of high-resolution optical flow [9]. The aforementioned result was achieved by approximating optical flow between frames with decreased resolution. Chu et al. [10] introduced the topology of Temporally Coherent Generative Adversarial Networks (GANs). The research utilized optical flow networks and novel loss functions to improve temporal coherence. Furthermore, it has been noted that the proposed methodology enhances the perceptual quality of magnetic resonance (MR) images by reducing feature space losses. The utilization of the deformable motion registration network has been observed to enhance the pragmatic outcomes, albeit at the expense of augmented computational and memory expenditures. The presence of artifacts stemming from inaccurate computation of motion vectors would persist in the restored high-definition frame. The successful attainment of super-resolution reconstruction can be credited to the utilization of deformable registration of low-resolution images. The methodology in question involves the analysis of a series of photographic captures, as opposed to being dependent on a solitary image frame. The diagram depicted in Figure 1 portrays the model framework currently being examined. The framework comprises two discrete elements, specifically the deformable registration module and the reconstruction neural network. The second component is composed of two elements, namely, a generator referred to as and a discriminator designated as .
The efficacy of employing a Generative Adversarial Network (GAN) architecture for motion correction is predicated on its established capacity to tackle concerns associated with image restoration and facilitate Magnetic Resonance Imaging (MRI) reconstruction. The above-mentioned capability is attributed to its proficiency in generating high-quality images, as evidenced by the reference [11]. The GAN framework consists of two fundamental components, namely, a generator represented by the symbol , and a discriminator represented by the symbol . The two aforementioned entities are engaged in a competitive rivalry with the aim of surpassing one another. The principal objective of the generator is to generate samples that exhibit a high degree of similarity to authentic data, whereas the discriminator’s primary aim is to effectively distinguish between genuine and synthetic samples.
The primary cause of image deformations in Magnetic Resonance Imaging (MRI) is the in-plane motion of the patient. However, this motion can also be utilized as a significant advantage for super-resolution. The tasks of image registration and motion artifact removal are complex and are elaborated upon in Section 4.1. Nevertheless, a significant drawback of Magnetic Resonance Imaging (MRI) is its protracted examination duration. In addition to these variables, the hastening of Magnetic Resonance Imaging (MRI) data acquisition has been examined by numerous scholars. One prospective avenue for future development involves modifications to the phase encoding intervals utilized during k-space filling. Regrettably, this attribute commonly leads to a decline in the quality of the image. Thankfully, the suggested k-space sampling pattern presents a viable solution to circumvent this issue. The utilization of single-shot echo planar imaging (SS-EPI) has gained significant popularity as an acquisition technique in the realm of Diffusion Weighted Imaging (DWI). However, despite its unquestionable importance, specific attributes have persisted as a cause for perplexity and logical discourse. The primary constraint of the imaging technique under consideration is its spatial resolution, which poses challenges in the visualization of small anatomical features. Furthermore, despite the latest advancements in parallelizing input data capture, this obstacle persists as a significant challenge. Cheryauka and colleagues have referenced six suggested techniques for shortening the examination time in multishot diffusion weighted imaging (DWI) [12]. These techniques include capturing only a subset of fast spin echo (FSE) blades in each scan and utilizing a tensor model-based reconstruction. In the late 1990s, the PROPELLER (Periodically Rotated Overlapping ParallEL Lines with Enhanced Reconstruction) procedure was developed by Pipe with the aim of mitigating motion artifacts. The fundamental principle of this approach involves the utilization of a series of radially oriented segments or “blades” to sample k-space. The blade is comprised of multiple parallel phase-encoded lines that can be acquired through the utilization of fast spin echo or gradient echo techniques. The identification of a time-efficient acquisition algorithm involves the selection of a subset of PROPELLER FSE blades per DW image and the utilization of a tensor model-based reconstruction. A modified reconstruction component was proposed as a means of accelerating PROPELLER EPI (echo planar imaging) through a comparable approach. This involved capturing only 10 distinct diffusion directions using a single blade from a given sampling pattern for each direction, and subsequently obtaining a diffusion weighted scan at full resolution by utilizing all of the blades. Despite the promising outcomes of reduced data acquisition in various studies [12,13], the feasibility of extending these approaches to accommodate arbitrary diffusion direction schemes comprising more than ten directions is low. Furthermore, the algorithms utilized are capable of processing data from various diffusion directions to produce a single DW scan. Hence, the strong correlation coefficient observed between neighboring DW images is either disregarded or only partially considered in the literature. DW scans demonstrate comparable diffusion contrast when their diffusion directions are proximate within a q-space sphere. To date, the potential of this similarity to expedite the examination process has not been harnessed.
The authors proposed a method for accelerating data acquisition through the use of a rotating single-shot acquisition (RoSA) procedure with model-free reconstruction, based on the observed correlation. The crux of this algorithm involves acquiring a solitary blade for each diffusion direction in a single shot. The RoSA technique utilizes similarities that are apparent in diffusion weighted contrast for the purpose of image reconstruction. Therefore, it is necessary to utilize a subset of diffusion weighted (DW) data that has diffusion directions in proximity to the DW image under examination. It is assumed that DW scans that are adjacent exhibit a significant correlation coefficient. The modification of the highly constrained back-projection (HYPR) reconstruction procedure was undertaken for the purpose of reconstructing the RoSA images. The HYPR method is a standard non-iterative reconstruction technique utilized in subsampled radial acquisition for time-resolved MRI. According to reference [14], this technique addresses one-dimensional temporal domain correlations. RoSA measures correlations in three-dimensional q-space. Parallel imaging via RoSA reduces data collection time. This study uses the PROPELLER sampling strategy with Compressed Sensing and Partial Fourier methods. According to Partial Fourier, the scanned object’s phase changes gradually. SMASH (simultaneous acquisition of spatial harmonics) and SENSE (sensitivity encoding method) use receiver-coil sensitivity previous information to reduce acquisition time. According to reference [15], conjugate symmetry may rebuild the missing k-space section [16]. Acceleration has been problematic in previous research. Thus, different sample trajectories - rosette, spiral, radial, PROPELLER, and others—have been verified [17,18]. Formally, acceleration efficiency is proportional to receiver coil count. Upon taking into account all hardware constraints, such as noise, the realized level of acceleration is generally reduced. The acceleration rates are generally moderate. The utilization of Compressed Sensing (CS) techniques, as referenced in sources [19,20,21], has the potential to enhance the speed of data acquisition in Magnetic Resonance (MR) imaging. The suitability of MRI as an application of computer science is attributable to its inherent characteristics.The relative ICI (RICI) method is used to create an adaptive data-driven picture denoising technique by [22]. An adaptive image technique for noise reduction enhances X-ray pictures in [23]. The authors of [22,23], in contrast to the presented algorithm, focus on denoising methods while ignoring the proposed algorithm’s features, such as resolution enhancement, compressed sensing, and motion correction. In addition, the proposed method is intended for DW-MRI.
In the meantime, RoSA has demonstrated its effectiveness by permitting high acceleration rates, namely [17]. In this paper, the presented algorithm makes use of its assets, but unlike other algorithms, the input sequences are additionally compressed. The method uses compressed sensing, partial Fourier, super-resolution, GRAPPA, and RoSA. Unlike PI (Parallel Imaging) methods, they may speed up the procedure. Multiple compression-sensing methods have been tested. Due to the differences across k-space sampling methods, several attempts have been made to combine unique, redundant information from different schemes. The CS framework lowers picture noise better than parallel imaging approaches alone.
DW image similarities are ignored by several approaches, including [24,25,26,27]. Despite comparable diffusion disparities, the writers of ref. [28] do not disregard them; q-space has near diffusion directions. The authors claimed their strategy would speed up testing. This work presents a super-resolution, motion correction, and robust sampling trajectory pattern MRI area-associated approach. Experimental findings are promising and demonstrate the method’s utility. The goal was to increase picture resolution and edge delineation while reducing collection time. Thus, the compressed sensing approach may apply irregular sampling processes to well-known PROPELLER blades, benefiting the novel sampling pattern [29]. Like the PROPELLER blades, this k-space filling procedure acquires k-space subsets in one phase encoding direction, but it has been “halved” in Hermitian symmetry of the complex space [30,31]. This advantage makes recovering the missing k-space component easy. This approach improves high-frequency component interpretation.
The main contributions of this work are:
- The framework algorithm exhibits comprehensiveness with respect to the reconstruction procedure of DW images, sampling schemes of raw data, synchronization of k-q spaces, deblurring, denoising, motion estimation, and ultimately, the reconstruction of super-resolution images.
- A new GAN-based super-resolution image reconstruction model for DW-MR images is presented.
- The algorithm extracts image features at different scales. Other authors usually simplify this issue.
- At various scales, the algorithm extracts visual characteristics. This topic is often simplified by other authors.
- The technique uses different preprocessing phases for deblurring and denoising layers.
- The method uses a DW image reconstruction approach based on convolutional neural networks to rebuild low quality images from very sparse k-q spaces.
- The scheme uses the compressed sensing architecture to focus on reducing acquisition times.
- The procedure nests the author’s deformable motion estimation procedure as its reconstruction layer.
2. The Efficiency of MRI k-Space in Relation to Sparse Sampling Techniques
The utilization of algorithms in compressed sensing requires the acquisition of samples that are entirely random. Subsampling at a rate lower than the Nyquist frequency can lead to the occurrence of aliasing artifacts, thereby necessitating the need to prevent such an occurrence. The model mentioned previously, as referenced in [21], facilitates conduct that is similar to that of additive white Gaussian noise (AWGN). The effectiveness of utilizing a subsampling pattern that is founded on a Gaussian probability density function to acquire samples that are both completely random and incoherent with aliasing was demonstrated through an illustrative example. The acquisition of a truly random subsample can pose difficulties owing to apparent constraints in hardware. The present matter can be partially alleviated by employing matched k-space sampling patterns, which ensure the incoherence of interference and pseudorandomness of the samples (refer to source [23]). According to the paper [27] the implementation of a non-uniform sampling pattern with a linear distribution of power across high-frequency components can lead to advantageous results and mitigate the incidence of aliasing artifacts.
The Poisson-disc sampling methodology generates a dense arrangement of points that are spaced apart by a predetermined minimum distance, resulting in a more naturalistic configuration. This methodology satisfies all necessary requirements, including the absence of coherence and the specified spacing among specimens. Moreover, it ensures the requisite noise characteristics. The concept of sampling low-frequency components at a higher sampling frequency is proposed by the author, as these components are considered to possess significant information.
According to Otazo et al. [19], it is recommended to use a higher sampling frequency for low frequencies as they offer valuable contrast. Their objective is to accelerate the phase contrast cine MRI procedure by combining compressed sensing and parallel imaging techniques. The phrase “k-t SPARSE-SENSE” is being alluded to. The author’s utilization of an altered sampling methodology elicits reflection on the possibility of nonconformity. The k-space sampling algorithm that has been proposed involves the subsampling of PROPELLER blades along the phase-encoding directions, in accordance with a Poisson point process.
Theoretical enhancement of temporal efficiency is the aim of the integration of the Partial Fourier concept with compressively-sensed data, as proposed in [32]. The optimization of raw data redundancy, as elaborated in [13], results in a reduction of scanning times. Considerable resources are dedicated to retrospectively acquiring all samples, which prevents the application of Partial Fourier and Compressed Sensing methodologies. This approach is frequently utilized to specifically capture the high-frequency components. The potential result may entail a reduction in the accuracy of edge demarcation [33]. The aforementioned characteristics of images may have a significant impact on enabling an accurate medical diagnosis. Accurate identification of organ boundaries is of utmost importance in medical contexts, as it facilitates precise diagnoses through the alignment of motion parameters or internal organ characteristics. The presented sampling technique involves an augmented sampling density for high-frequency components, which utilizes Partial Fourier [18] and Compressed Sensing [34]. The utilization of technology enables the achievement of efficient scanning durations while maintaining optimal levels of all essential image attributes. The current investigation presents a sampling methodology that endeavors to minimize redundancy to the maximum degree feasible. The utilization of compressed sensing techniques is a prevalent practice in practical scenarios, wherein it is employed to diminish the dimensionality of subspace sampling trajectories, thereby leading to sparsity. In the acquisition phase, subsets are gathered, which bears resemblance to the PROPELLER concept as cited in reference [29].
On the premise that the subject transitions among obtained k-q-space structural components, the subsequent subgroup is linked to patient motion that may be rectified and integrated into a super-resolution algorithm as its fundamental feature, as illustrated in Figure 1.
The low-resolution DW image reconstruction algorithm commences by utilizing k-q-spaces that are highly compressed. The non-uniform fast Fourier transform (NUFFT) is utilized due to the presence of irregular sampling schemes. The subsequent phase utilizes the zero-filling (ZF) methodology.
The technique of zero-filling is commonly employed for the purpose of increasing the dimensions of the image matrix along the phase-encoded direction. In the context of 2D imaging, the observed rise in matrix size pertains to the “within-plane” dimension, wherein the pixel count escalates from 256 to 512. The utilization of ZIP in 3D imaging can enhance the perceived resolution in the slab-select direction by employing the “through-plane” approach, resulting in an increase from 64 to 128 slices. The benefits are observed only during the initial doubling of the matrix size, beyond which no further advantage is obtained. While the process of zero-filling does not introduce any additional information to the original raw data, it can enhance the perceived spatial resolution of the resulting image by mitigating the effects of partial volume artifacts. The process of zero filling serves as a means of signal interpolation between adjacent voxels, resulting in a more uniform and less granular visual representation of the image.
The convolutional recurrent neural network architecture is utilized in the proposed algorithm for MR image reconstruction. This approach enables the reconstruction of high quality images from highly undersampled k-space data by jointly exploiting the dependencies of the utilized sequences.
The architecture under consideration incorporates the framework of conventional iterative algorithms, adeptly representing the repetition of the iterative reconstruction phases through the utilization of recurrent hidden connections across said iterations. Furthermore, the acquisition of spatio-temporal dependencies is achieved through the utilization of bidirectional recurrent hidden connections across temporal sequences.
Subsequently, a correction in k space is required. The utilization of the inverse non-fast Fourier transform is aimed at generating a sequence of rectified k spaces. Ultimately, a collection of low-resolution diffusion weighted images is obtained through the utilization of an image reconstruction technique that employs the non-uniform fast Fourier transform (NUFFT) as its fundamental component. This study examines the alterations made to the motion effects in order to facilitate the reconstruction of super-resolution magnetic resonance images. Moreover, the registration algorithm exhibits a high degree of precision and effectively mitigates problems related to in-plane and out-of-plane motion.
3. The Algorithms for SR Image Reconstruction
The implementation of multiple frames of images demonstrates temporal correlation between frames, thereby augmenting the information contained within each individual frame. Therefore, it is essential to consider both precision and uniformity simultaneously. Achieving this objective typically involves two primary approaches: motion compensation and super-resolution restoration [35]. The notion of video super-resolution (SR) was initially fragmented into separate subtasks of multi-frame SR, as evidenced by the reference [36]. The main aim was to achieve superior results in image reconstruction for every individual image. However, the high-resolution frames produced independently exhibit a temporal inconsistency issue, leading to the presence of disruptive flickering irregularities. The aforementioned methodologies were insufficient in effectively utilizing the data available in the temporal domain. The integration of optical flow networks in Video Super-Resolution (VSR) with the aim of motion estimation has garnered significant attention in current academic research. Caballero et al. (2017) proposed the utilization of the sub-pixel convolution network model for the purpose of video processing in their research [37]. The approach adopted by the authors was designed to optimize the efficacy of the model under consideration. The current research employed spatio-temporal sub pixel convolution networks and optical flow networks to improve the efficacy of the previously established sub pixel convolutional neural network model [38,39]. Caballero’s model attained expertise in motion compensation through the former and improved its real-time accuracy through the latter. Sajjadi et al. introduced a new methodology termed frame recurrent video super-resolution in their published work [40]. The approach mentioned above utilizes pre-existing SR frames to reconstruct subsequent frames. The methodology being examined in the study has been labeled as “frame and feature-context video super-resolution” by the authors [40]. The methodology involves employing pre-constructed frames with a high level of resolution and reusing features from previous frames in a recurring manner. The authors Wang et al. (2019) proposed a new method, referred to as HR optical flow estimation (SOF-VSR), aimed at enhancing the quality of videos [9]. The objective of the proposed methodology was to improve the precision of motion compensation through the reconstruction of high-resolution optical flow. The aforementioned result was achieved by approximating optical flow between frames with reduced resolution. Chu et al. [10] introduced the topology of Temporally Coherent Generative Adversarial Networks (GANs). The research utilized optical flow networks and novel loss functions to improve the temporal coherence. Furthermore, it has been observed that the proposed methodology has the capability to improve the perceptual quality of Magnetic Resonance (MR) images by reducing feature space losses. The utilization of the deformable motion registration network has been observed to enhance the pragmatic outcomes, albeit at the expense of augmented computational and memory expenditures. The high-definition frame that has been restored may still contain artifacts resulting from inaccurate computation of motion vectors. The successful attainment of super-resolution reconstruction can be credited to the utilization of deformable registration of low-resolution images. The methodology in question involves the analysis of consecutive photographic captures, as opposed to being dependent on a solitary image frame. The diagram depicted in Figure 2 represents the model framework currently being examined. The framework comprises two discrete components, specifically, the deformable registration block and the reconstruction network. The second component is composed of a generator, referred to as , and a discriminator, designated as .
The efficacy of employing a Generative Adversarial Network (GAN) architecture for motion correction is predicated on its demonstrated capacity to mitigate challenges associated with image restoration and facilitate Magnetic Resonance Imaging (MRI) reconstruction. The aforementioned capability is attributed to its proficiency in generating high-quality images, as evidenced by the reference [11]. The GAN framework consists of two fundamental components, namely, a generator represented by the symbol , and a discriminator represented by the symbol . The two aforementioned entities are engaged in a competitive rivalry with the aim of surpassing each other. The main objective of the generator is to generate samples that exhibit a high degree of similarity to authentic data, whereas the discriminator’s primary goal is to effectively distinguish between genuine and synthetic samples.
The symbols y and x represent the graphical representations that have undergone motion distortion and those that have been rectified for it, respectively. The encoder block, excluding the central layer, is composed of five convolutional layers and includes feature maps, with each map containing n features. The structural design of the decoder blocks displays resemblances to that of the encoder blocks, with the exception being the utilization of transposed convolutions instead of convolutional layers. The implementation of image registration technology involves the calculation of spatial transformation parameters through an image registration methodology, as described in reference [41]. Following this, the rectification of the incongruity in displacement among consecutive frames is executed. The implementation of displacement parameters facilitates the performance of a spatial transformation on neighboring frames of images, which were obtained at different times and locations, yet depict the identical object.
The module responsible for registration produces several sets of results, which are subsequently combined with the objective frames denoted by through the utilization of a convolutional layer. The output that is obtained is then fed into the generator network, which is represented as . The current investigation utilized a generator -network framework that was based on the SRGAN -network architecture, as illustrated in Figure 2. The -network has been developed to integrate a unique residual block with the objective of reducing the parameter count, while preserving the network’s capacity to generalize. The utilization of residual network has been documented in reference [42] to implement two sub-pixel convolutional layers on the image. This approach is adopted to facilitate the achievement of the intended resolution. The discriminator’s architecture, labeled as in Figure 3, comprises eight convolutional layers in total.
Increasing the number of network layers leads to a corresponding rise in the number of features. The decrease in the number of feature dimensions can be ascribed to the declining magnitude of the convolutional kernel. Two modifications were implemented to address the suboptimal reconstruction outcomes of the SRGAN and to surmount the challenges encountered during the network’s training and convergence. The omission of the activation function from the output layer of the discriminator was observed in the initial implementation. Additionally, it is noteworthy to mention that the adjustments performed on the parameters were limited to a consistent numerical value denoted as c (precisely, 0.01) in terms of absolute magnitude. The study of Generative Adversarial Network (GAN) has gained significant prominence in recent times, owing to its complex and challenging nature [43].The focus of this study is primarily on the insufficiency of security protocols during the training phase and the complex convergence of the model. This is supported by the reference cited as [44]. The observed phenomenon can be explained by the restricted intersection between the authentic and artificially generated distributions. Insufficient attention to the JS divergence, a metric employed for assessing the relative divergence between two probability distributions, may hinder the convergence of the neural network. The study conducted by Arjovsky et al. showcases the effectiveness of the Wasserstein distance in measuring the degree of dissimilarity between two distributions, even when their intersection is minimal.
4. The Algorithm for Reconstructing DWI Images with Super Resolution
The algorithm commences by reconstructing a set of low-resolution DWI images from a cluster of highly sparse k-q spaces, as cited in the Figure 1. The algorithm employs deblurring and registration layers, and its primary reconstruction process is structured as depicted in Figure 2, Figure 3, Figure 4 and Figure 5.
The effectiveness of creating a confrontation network through the utilization of the Wasserstein distance is augmented by a particular attribute, as evidenced by the WGAN [45]. The definition of the Wasserstein distance is as follows:
The equation mentioned above employs the mathematical notation to represent the set of all possible joint distributions between and . The equation provided specifies that the symbol represents the discrimination function of the adversarial network that was generated. Consequently, the range of the derivative of the input sample for the discriminator is restricted. The discriminator’s parameter w is subject to an update process that is restricted to a range of values between and c. The technique mentioned above is utilized to emphasize the significance of the gradient update generator and mitigate the possibility of the vanishing gradient phenomenon. The function represented by the symbol fulfills the following equation:
With each increment of the variable , an estimation of the Wasserstein distance between the probability distributions and can be obtained. The initial distribution pertains to authentic data, while the subsequent distribution pertains to artificially generated data. The loss functions for the discriminator and generator can be precisely defined as follows:
The function that measures the loss of the discriminator during training, denoted as , is a crucial component of the training process. The evaluation of Generative Adversarial Network (GAN) training can be deduced through a decrease in the Wasserstein distance between the authentic and synthesized distributions. This metric exhibits a negative correlation with the magnitude of the distance.
The principal aim of this methodology is to enhance the training process of the generator, denoted as . The aim of this task is to evaluate the correlation between the input sequence and its corresponding counterpart . The task was accomplished by utilizing a feedforward convolutional nn.
The neural network underwent a training procedure utilizing the parameter identified as . The literature [36] states that the parameters of a neural network with layers, denoted as , are acquired through the minimization of the loss function for the super-resolution generation network.
The present study employs a loss function denoted as , which is grounded in previous academic literature and has been duly referenced in [36].
where denotes adversarial loss. The SRGAN model integrates the loss functions of the generator and discriminator, denoted as and , respectively, into a comprehensive net loss function. We define by a real-valued tensor of size W by H by C for an image with C color channels, and , by , and C, respectively.
The provided equation concerns the reconstruction of the generator of the discriminator, which is symbolized as , and the initial image , which is denoted by and , correspondingly. The symbol N denotes the quantity of target images. The symbols , , and denote variables that have been explicitly defined in the following manner:
The reduction in PSNR and SSIM metrics has been attributed to the smoothing effect of the reconstructed image through the utilization of the GAN architecture, as reported in the reference [46]. The authors of the study have augmented the all-inclusive loss function of the model by integrating an extra registration loss component, with the objective of enhancing the restoration of high-frequencies [46]. The concept of “Residual Localisation Error” (RLT) is utilized to refer to the anticipated discrepancy between the calculated and actual results of the spatial transformation. The main aim is to reduce the loss of complex details that may occur during the geometric transformation of consecutive frames. The action referred to above is executed with the intention of aiding in the recovery of the original image with an increased level of precision. The diagram provided below illustrates the RLT loss function.
The aforementioned equation illustrates the outcome of the application of the registration network on the image denoted as . The aforementioned process results in the emergence of a novel visual representation denoted as . The subsequent equation denotes the magnitude of the center of gravity’s length, represented by the variable :
Based on the outcomes of the experiment, the weight coefficient for RLT, denoted by the variable , has been determined to be 0.001. Regarding the notion of Wasserstein Generative Adversarial Networks (WGAN), it is possible to exclude the variables and , resulting in a modification of the objective function .
4.1. Registration of DWI Scans
The efficacy of the motion estimation in the network, which utilizes a multi-scale methodology, has been established in conventional techniques, as indicated by prior research [29]. The process receives input consisting of the target frame, which is identified as , and the adjacent frame, which is denoted as . The image undergoes motion correction via pyramidal registration techniques, which involve the training and utilization of spatial transformation parameters. The registration of a three-image input entails the distinct alignment of a pair of images via the registration layer. The process of optimizing the parameters of the spatial transform network can be accomplished by minimizing the mean-squared error between the compensated scan and the reference one, which is represented by the symbol . The utilization of this specific training methodology amplifies the neural net’s capability to conduct motion compensation on the given image set.
The notation represents the outcome of the registration layer denoted as that follows the registration procedure.
The sequential arrangement of the images is under observation. The diagram illustrated in Figure 1 represents the configuration of the network layer accountable for executing the registration procedure. The effectiveness of deformable registration representation in classical methods has been demonstrated by various sources, including references [47,48]. These sources implemented a multi-scale design to achieve their results.
The current investigation utilizes an algorithm to derive a spanning tree that exhibits the lowest collective edge costs. The nodes denoted by the symbol denote discrete entities that could potentially exist as singular pixels or as agglomerations of pixels. Each node is associated with a set of hidden labels that correspond to motion fields, expressed as . The energy function utilized for optimization comprises of two distinct components, namely, the data cost denoted by the symbol S, and the pair-wise regularization cost denoted by for all nodes that are interconnected with nodes m.
The aforementioned cost function provides an estimation of the similarity of pixels between two compared images. This term remains unaffected by the displacements exhibited by its adjacent entities. The utilization of the parameter serves the purpose of assigning weight and determining the impact of the regularization factor. The first component of the equation denoted as (15) (expressed as ) pertains to the data term, whereas the subsequent component (expressed as ) pertains to the regularization term.
4.2. The DWI Images Deblurring Network
The aim of this study is to achieve the retrieval of a well-defined and specific visual depiction, referred to as , through the utilization of a blurred visual representation, , as the exclusive input, without any supplementary knowledge regarding the blur kernel. The deblurring procedure involves the utilization of a convolutional neural network that has undergone training, referred to as and commonly recognized as the Generator. An estimation is computed for the corresponding image of the saturation current () for every value of the base current (). Moreover, during the learning process, the critic network denoted as is incorporated, and both networks undergo adversarial training. The composite loss function is derived by combining content and adversarial losses:
where and denote adversarial loss and content loss, respectively. The experimental trials maintained a constant value of 100 for the parameter . The present study’s methodology differs from that of Isola et al. [49] as it does not entail the conditioning of the discriminator. The lack of requirement to enforce sanctions for discrepancies between the input and output is the rationale behind this. The notion of adversarial loss constitutes a fundamental element within the domain of machine learning. The aforementioned expression pertains to the utilization of a loss function that is specifically crafted to incentivize the generation of outputs that bear a striking resemblance to those generated by a human or a reference model. The effectiveness of this approach has been proven in various fields, including but not limited to image and speech identification, processing of natural language, and other related domains. Scholars and professionals have discovered that incorporating adversarial loss into machine learning models can improve their accuracy and robustness. This phenomenon leads to improved performance and greater reliability of results (Figure 6).
The formulation for calculating the loss can be defined as follows:
The research results outlined in reference [50] indicate that the DeblurGAN model exhibits convergence in the absence of the Generative Adversarial Network (GAN) component during its training phase. Nevertheless, the images produced by the model exhibit features that encompass both fluidity and indistinctness, as well as the concept of content loss. When exclusively optimizing the aforementioned functions, the resulting images may contain ambiguous anomalies. The observed deviations can be attributed to the average potential solution values at the pixel level within the pixel space, as referenced in [24]. The implementation of the -loss approach within the perceptual loss function facilitates the computation of the dissimilarity between the convolutional neural network (CNN) feature maps of the produced image and the desired image using a mathematical expression. The aforementioned terminology is articulated as follows:
where is a blurred image defined in the way following way:
The symbol is unknown blur kernel determined by motion field M.
As per the reference [13], the symbol denotes the feature map obtained from the n-th convolution operation, located after activation and before the k-th maxpooling layer, in a pre-existing MRI set network. The feature map dimensions are denoted by the variables and .
4.3. DWI Images Denoising Net
One of the challenges encountered during the denoising procedure for DWI involves the predominance of magnitude images as the principal representation, which are obtained from the real and imaginary components [51]. The Rician distribution is a statistical model that accounts for the manifestation of noise in magnitude images. It is distinguished by a greater degree of intricacy in contrast to conventional forms of additive noise. Several statistical methods have been suggested to model the process of degradation. The level of precision exhibited by the model mentioned above plays a crucial role in determining the final results of the noise reduction process. The utilization of deep learning (DL) presents a potentially efficacious approach to tackle the aforementioned challenge. This phenomenon can be explained by its ability to disregard the underlying physical processes and instead adapt to changes in these processes through the mechanism of sample-based learning.
The objective of mitigating Diffusion Weighted Imaging (DWI) noise is to enhance the quality of the diagnostic image that has been negatively impacted by noise, leading to an improved image. The variable x is utilized to represent a DWI image that has been subjected to noise corruption, whereas the variable y denotes the DWI image that is devoid of any noise. The matrices represented by the symbols x and y possess the same dimensions, which are specifically . Additionally, both matrices are composed of elements that are real-valued. The depiction of the relationship between entities can be illustrated as follows:
The mapping function is utilized to denote the function that represents the presence of noise contamination. The deep learning approach is widely recognized as a technique that operates as a black box, functioning independently of the statistical properties of the noise. Consequently, the optimization of the search for the most suitable approximation of the function has the potential to streamline the procedure of denoising DWI images. The formulation of the denoising process can be expressed as follows:
The function is used to estimate the dependent variable y, while the variable represents the expected outcome. The appropriateness of estimating the inverse of is commonly attributed to the function .
From a statistical perspective, it is possible to consider x and y as two separate samples originating from two distinct data distributions. The distributions in question refer to the probability distribution of the noisy image, which is represented as , and the probability distribution of the noise-free image, which is represented as . The denoising procedure involves the utilization of a mapping algorithm to transform a designated distribution into a different distribution. The mapping of samples from the set to a distribution , which exhibits a significant resemblance to , is accomplished by the function f.
The utilization of Generative Adversarial Networks (GANs) has been widespread across multiple domains, such as image super-resolution, image modality transformation, and image synthesis. The domains mentioned above have been thoroughly investigated, as evidenced by the extant literature [49,52,53]. The discriminative model was created to differentiate between the origin of a particular sample, determining whether it is derived from the generative model’s distribution or the authentic data’s distribution. The primary aim of the generative model is to generate a new instance that closely resembles the authentic data distribution, with the input instance acting as a reference point.
The expression presented denotes the loss function employed for the denoising layer:
The ultimate element of the equation denotes a gradient penalty term, where the penalty parameter is denoted by the symbol . The probability distribution denoted as is derived through the uniform sampling on straight lines that link two of points sampled from the actual data distribution, , and the generator distribution, . The following is the presentation of the loss function formulation for the generator .
The Mean Squared Error (MSE) loss function is a frequently utilized approach in tasks that involve modifications at the pixel level. The primary objective is to minimize the disparities between the genuine depiction and the generated representation on a pixel-by-pixel basis. The aforementioned computation can be derived utilizing the subsequent methodology:
The dimensions of the image are represented by the variables o, p, and r. Recent research has indicated that the Mean Squared Error (MSE) loss function can lead to a noteworthy improvement in the peak signal-to-noise ratio. The envisaged result of this methodology is a decrease in precision, specifically in relation to frequently recurring particulars, which could significantly affect clinical diagnosis [52].
The proposed loss function can effectively tackle the issue by integrating a perceptual loss, as mentioned in references [35,51,54]. Utilizing a pre-existing neural network constitutes a feasible strategy for distinguishing distinctive characteristics between genuine and synthetically produced images. Perceptual similarity refers to the extent of dissimilarity between the characteristics of a genuine image and a generated image. The subsequent explanation pertains to the perceptual loss function.
The variable is employed as a tool for extracting features, while the dimensions of the feature map are denoted by g, h, and i. The present study employs the pre-existing VGG-19 neural network [55] to extract image features. The VGG-19 convolutional neural network is composed of nineteen layers, with the initial sixteen layers being convolutional and the final three layers being fully connected. The process of extracting features is limited solely to the first sixteen layers. The execution of the perceptual loss based on the VGG network is carried out in a sequential manner as follows:
The generator denoted by is associated with a composite loss function that is weighted and encompasses the Mean Squared Error (MSE) loss, VGG loss, and discriminator loss. Figure 7 illustrates the schematic representation of the discriminator network, which is referred to as . The model proposed in this study comprises three convolutional layers, with each layer utilizing filters of different magnitudes, specifically 32, 64, and 128. The configuration of the convolution layers has utilized a uniform kernel size of 3 × 3 × 3. The highest tier is composed of a completely interconnected layer that exclusively generates a singular result. The VGG-19 network, which has been pre-trained, is utilized for the purpose of feature extraction. For further elucidation, those who express interest may refer to the primary source material as recorded in reference [55]. Pan and Yang (2019) have shown that the utilization of transfer learning eliminates the need for retraining the neural network for the targeted MRI images [56]. The aforementioned discovery implies that transfer learning may constitute a viable strategy for enhancing the efficacy of neural networks in the context of medical imaging implementations.
The diagram illustrating the structure of the RED-WGAN model proposed can be found in Figure 7. The system is composed of three discrete components, namely, a generator network labeled as , a discriminator network labeled as , and a VGG network employed as a feature extractor. The convolutional and deconvolutional layer pairs are connected through short connections in a corresponding manner. With the exception of the last layer, each layer performs a series of operations that include three-dimensional convolution, activation through Leaky-ReLU, and normalization through batch processing. The ultimate layer exclusively executes a 3D convolution operation and applies a Leaky Rectified Linear Unit activation function. The current investigation utilizes a 3 × 3 × 3 kernel setup for all kernels and implements a filter sequence comprising of 32-64-128-256-128-64-32, and 1.
5. Results
The effectiveness of the algorithm was assessed through the analysis of in vivo patient cases and phantom data. The MATLAB software was utilized for conducting all trials and investigations. The objective of the assessments was to assess the effectiveness of super-resolution image reconstruction through the utilization of compressed input. An additional aim was to assess the efficacy of the MR sampling technique. This study involved the analysis of both in vivo and phantom data. The simulation results are illustrated in Figure 8 and Figure 9. It is noteworthy that the utilization of Compressed Sensing in conjunction with its conjugate symmetry and partial Fourier technique expedites the process of data acquisition in comparison to alternative unaltered k-space sampling patterns. The analysis of human data involved the processing of Siemens Prisma scanner files, which had a measurement of 3.0 terabytes. In order to replicate the performance of a multi-channel head coil across a range of in-plane resolutions, diffusion directions, and slice thicknesses, fully sampled k-q spaces have undergone decimation. The denoising problem is defined within the framework of Maximum A Posteriori (MAP) estimation by the proposed method. The algorithm for noise reduction under consideration yields an average value of approximately 2.1 dB, as determined by the tests conducted. Phantom-based experiments were conducted on high-quality DW multi-shot EPI sequences. The simulation of off-resonance effects was conducted utilizing fugue. The study employed D-BRAIN phantom models, which are diffusion MRI brain data models that are anatomically precise. The training of the model was conducted on an NVIDIA DGX machine equipped with GPU A100, utilizing the resources of Google Colab Pro. The generator undergoes training using a pair of LR images, which are stacked and have dimensions of 60 × 60 × 2. The objective is to generate a single HR image with dimensions of 240 × 240. The generator employs a tripartite loss function comprising of content loss, perceptual loss, and adversarial loss. The discriminator is subjected to both the SR and HR images obtained from MRI. The binary classifier known as the discriminator employs binary cross-entropy as its optimization technique. The utilized optimizer is Adam, which is applied to both the generator and discriminator. The learning rate is (Table 1, Table 2, Table 3, Table 4 and Table 5).
The present study incorporates the technique of compressed-sensing with super-resolution image reconstruction for application in Magnetic Resonance Imaging scanners. The utilization of phantom data has been employed to expose the inverse challenges associated with compressed sensing in the context of magnetic resonance imaging (MRI). The utilization of sparse projections has been observed in the retrieval of Shepp–Logan phantom data, as depicted in Figure 8. Twenty-five and twelve radial lines in the frequency domain are capable of reconstruction. The data reconstruction process employed by the author involves utilizing a subset of sixty projections within a ninety-degree aperture to reconstruct data from limited-angle projections. The method employed for the creation of all Shepp–Logan phantom images was this. The input frame was degraded by a nonrigid transformation. The application of rotation and subpixel shift factors was carried out in the following manner. Local affine simulations were utilized to model motion artifacts of internal organ tissue in order to demonstrate blurring. The low-resolution photos were subjected to a Gaussian blur kernel resulting in blurring. Subsampling using a predetermined ratio will ensue. The addition of white Gaussian noise occurred subsequently. The noise level of the test photos was measured to be twenty-five standard deviations. The recording of deformable medical images presents a challenge. The utilization of Markov random field (MRF) optimization in a registration method based on structural representation reduces the dimensionality of transformation parameters and imposes constraints on energy function values in the image region associated with non-rigid deformation.
This study employs various descriptors, namely, the hybrid L-BFGS-B and cat swarm optimisation (HLCSO), sum of squared differences on entropy images, MIND (Modality independent neighbourhood descriptor), and self-similarity context (SSC).
The assessment of motion estimating algorithms has employed Target Registration Error (TRE) as a metric.
The variable denotes the forced deformation, which is obtained through a linear combination of radial basis functions and serves as the reference ground truth. On the other hand, the variable represents the estimated deformation parameters that are obtained through the motion estimation techniques presented in Table 6. Furthermore, the variable N denotes the quantity of landmarks that have been manually marked according to the recommendations of medical professionals. The study aimed to evaluate the effectiveness of the the WGAN-based deformable motion registration algorithm by comparing it to several image registration techniques in order to identify the most successful approach. The statistical analysis was performed on each of the registration algorithms listed by utilizing the mean and standard deviation. (std). Table 6 presents the computed values of Type I error rate (TRE) and probability (P) for the t-test conducted at a significance level of 0.05. The statistical analysis reveals that the the author’s method exhibits a significant superiority over its competitors, as evidenced by all p values being less than 0.002. The registration of input images using the “deeds” method resulted in mean and standard deviation values of 1.4 voxels and 0.2 voxels, respectively, for the TRE values. These values are demonstrated to be more favorable compared to other algorithms, as presented in Table 6.
6. Discussion
The limitations of medical imaging modalities, such as low spatial resolution, weak contrast, visual noise scattering, and blurring caused by the complexity of internal body tissues, can have a substantial impact on the accuracy of medical diagnosis. The text outlines a number of improvements that are purported to be advantageous in augmenting the quality of images while simultaneously minimizing scanning durations. Despite the presence of motion distortions, the algorithm that has been suggested effectively mitigates artifacts that are caused by data that has been highly undersampled. The algorithm presented in this study integrates an effective highly sparse acquisition strategy, namely, partial Fourier and Poisson Disc sampling, with super-resolution reconstruction to yield superior outcomes. The outcome is an improvement in the quality of dMR images and a decrease in time complexity. Furthermore, the augmentation of sampling for high-frequency components results in an improvement of edge depiction. The aforementioned methodology has the potential to be executed on dMR scanners without necessitating any alterations to the hardware. Therefore, it is apparent that the algorithm that has been implemented has the capability to generate images that are improved and more accurate. This study investigates the viability of a newly proposed DW-MRI algorithm, which aims to enable rapid and effective high-resolution diffusion imaging. The algorithm in question, known as RoSA, operates by selecting a single compressively sensed rotating blade of a PROPELLER in each diffusion direction. Moreover, the utilization of the resemblances among contiguous DW images constitutes a pivotal facet of the method’s execution. The short-axis EPI readout model has retained the advantages of short-axis EPI with regards to distortion reduction and significant improvement in resolution along the phase-encoding direction as a result of T2 decay.
Improving spatial resolution yields clear advantages for both clinical diagnosis and fundamental research. Early detection of soft tissue abnormalities is possible. Furthermore, as a result of the reduction in movement aberrations, the algorithm has the capacity to augment the perceptibility of white matter tractography, as well as the trajectory of nerve fibers in close proximity to neoplasms. In comparison to T1/T2-weighted imaging, which generally offers isotropic resolutions of 1.0 mm or more for complete brain coverage, diffusion MRI is constrained by either excessively large voxel sizes or insufficient coverage. The proposed algorithm offers a major advantage in terms of enhancing image resolution and reducing examination time, in comparison to existing solutions. The aforementioned outcome is attained by means of amalgamating super-resolution image reconstruction, accurate motion estimation, and capitalizing on the similarity in the sequence of diffusion weighted (DW) images of neighboring diffusion directions. The efficacy of the algorithm was evaluated through a range of studies carried out under varied circumstances, wherein the quantity of PROPELLER blades, overall diffusion directions, and window dimensions were altered within the range of 5 to 40. In addition, the existence of off-resonance artifact is commonly acknowledged as a significant obstacle to EPI-based acquisition protocols. The implementation of improved sampling techniques has led to the reduction of aberrations and the mitigation of motion-induced distortions.
The enhanced precision of tissue demarcation heightens the probability of arriving at a precise clinical diagnosis, for reasons that are self-evident. This mode entails certain financial considerations that necessitate attention. Hence, it is yet to be ascertained whether the increased procurement expenses associated with DW-MRI would be rationalized in the foreseeable future. The objective of this study was to showcase the capabilities of integrating various methodologies to enhance DW-MRI images, while simultaneously preserving a swift acquisition rate. As per anticipated outcomes, the algorithm put forth has the potential to enhance image resolution without necessitating any alterations to the hardware. Moreover, this approach has the potential to mitigate motion distortions while compromising on resolution. Preliminary trial data can serve as a valuable source of background information that may aid in the reduction of examination duration. The utilization of motion estimation algorithm can significantly reduce the presence of image artifacts in diagnostic imaging, thus enhancing the probability of an accurate diagnosis.
Please refer to Figure 7 and Figure 8 for empirical support of the enhancement in both image resolution and quality. The improved resolution and legibility of the procedures utilized for potentially malignant or premalignant lesions have resulted in an increased capacity to detect them. The method’s anticipated efficacy is largely attributed to its potential advantages, such as achieving a heightened contrast while preserving a superior level of resolution. The present study investigates the integration of magnetic resonance (MR) with super-resolution and compressed-sensing techniques. The enhancements that were obtained have led to notable improvements in sharpness, edge interpretation, and contrast. The achievements have been verified by PSNR as well. The impact of CS quality ratios on PSNR values is significant, as demonstrated by the Table 1, Table 2, Table 3, Table 4 and Table 5.
The average peak signal-to-noise ratio (PSNR) is computed by utilizing various method outputs and ground truth images. The simulation was conducted on one hundred occasions. To ensure the statistical reliability of quality measurements, the PSNR calculation procedure was replicated for every simulation case and subsequently averaged. It is noteworthy that the most favorable outcomes were achieved utilizing a compression ratio of 50%. This implies that a further reduction in the overall quantity of input samples leads to a slight improvement in the peak signal-to-noise ratio (PSNR), as evidenced by the data presented in Table 1, Table 2, Table 3, Table 4 and Table 5. The reduction in exam duration is directly proportional to this particular value. Furthermore, this approach has the potential to mitigate motion distortions in addition to compromising on resolution. The approach centers on expediting the convergence of algorithms, incorporating image prior, and recognizing blur kernels. Preliminary trial data can serve as valuable background information to expedite the duration of examinations. Notwithstanding the capability of the motion estimation algorithm to significantly mitigate diagnostic image artifacts, thereby enhancing the probability of an accurate diagnosis; it is incapable of completely eliminating all artifacts. Figure 8 and Figure 9 demonstrate an enhancement in the resolution and caliber of the outcomes acquired. The results mentioned above are provisional and susceptible to modification. The algorithm’s advantages were demonstrated through a qualitative evaluation of the neuroimages of twenty patients. The study involved the collection of DW-MRI data from twenty patients with oncological conditions, using a single scanner. The calculation of the mean square error (MSE) was performed for each instance of reconstruction in order to obtain statistically significant measurements. The study employed the signed rank test to examine the null hypothesis that the central tendency of the difference across different sparsity rates was equivalent to zero. The statistical analyses were conducted using the R Project for Statistical Computing. A statistical analysis was performed utilizing a t-test for independent groups to compare the mean values of peak signal-to-noise ratio (PSNR) between two distinct groups. Additionally, a paired t-test was conducted to analyze paired data. The algorithm’s robustness has been confirmed by the probability, which was determined through a significance test and Student’s t-test conducted on the PSNR. The outcomes are exhibited in Table 3, Table 4 and Table 5. The statistical significance of the results was high, as indicated by the obtained p-values.
The study conducted a comparison between the proposed algorithm’s robustness and other existing image resolution enhancement algorithms, namely, bicubic spline interpolation, Yang’s N-R-M-3D [57] (3DKR) as cited in reference [4], and IBP that utilizes optical flow-based motion estimation as its fundamental technique. The results of the comparison are presented inTable 1, Table 2, Table 3, Table 4 and Table 5. The results are visually represented through the use of graphical illustrations, as evidenced by Figure 8. The obtained outcomes have been contrasted with four advanced super-resolution image reconstruction techniques, namely, sightly modified the MRI super-resolution using GAN and DWT [43] and the brain MRI super-resolution using 3D GANs [44] Yang’s N-R-M-3D [57], Lim’s E-D-R-N-S-I-S-R [58], RCAN SRR [60], and Zhang’s R-D-N-I-S-R [59]. The Lim’s E-D-R-N-S-I-S-R [58], RCAN SRR [60], z z Zhang’s R-D-N-I-S-R [59] methods employ the -loss function for network training purposes.
Compressed sensing (CS) theory provides a feasible approach to reconstructing signals with sparsity by projecting them onto a linear subspace of low dimensionality. This methodology exhibits significant potential owing to the theoretical assurances it offers. The methodology employed in this study involves the integration of Generative Adversarial Networks (GANs) in the image domain, along with k-space corrections. Generative Adversarial Networks (GANs) are accountable for encoding prior knowledge that is specific to images. Hence, it is imperative to establish a spurious linkage between the input and output strata of Generative Adversarial Networks (GANs). Possible areas for future research include enhancing reconstruction algorithms and refining raw data sampling schemes.
Funding
This research received no external funding.
Institutional Review Board Statement
Not applicable.
Informed Consent Statement
Not applicable.
Data Availability Statement
Data is unavailable due to privacy or ethical restrictions.
Conflicts of Interest
The author declares no conflict of interest.
References
- Malczewski, K. Breaking The Resolution Limit In Medical Imaging Modalities. In Proceedings of the 2012 International Conference on Image Processing, Computer Vision, and Pattern Recognition (IPCV’12), Las Vegas, NV, USA, 16–19 July 2012. [Google Scholar]
- Malczewski, K.; Stasinski, R. Super Resolution for Multimedia, Image, and Video Processing Applications. In Recent Advances in Multimedia Signal Processing and Communications; Studies in Computational Intelligence; Springer: Berlin/Heidelberg, Germany, 2009; Volume 231. [Google Scholar]
- Kennedy, A.; Israel, O.; Frenkel, A.; Bar-Shalom, R.; Azhari, H. Super-resolution in PET imaging. IEEE Trans. Med. Imaging 2006, 25, 137–147. [Google Scholar]
- Yang, F.; Ding, M.; Zhang, X. Non-Rigid Multi-Modal 3D Medical Image Registration Based on Foveated Modality Independent Neighborhood Descriptor. Sensors 2019, 19, 4675. [Google Scholar] [CrossRef] [Green Version]
- Zhang, W.; Zhuang, P.; Sun, H.H.; Li, G.; Kwong, S.; Li, C. Underwater Image Enhancement via Minimal Color Loss and Locally Adaptive Contrast Enhancement. IEEE Trans. Image Process. 2022, 31, 3997–4010. [Google Scholar] [CrossRef]
- Zhang, W.; Li, Z.; Sun, H.H.; Zhang, Q.; Zhuang, P.; Li, C. SSTNet: Spatial, Spectral, and Texture Aware Attention Network Using Hyperspectral Image for Corn Variety Identification. IEEE Geosci. Remote Sens. Lett. 2022, 19, 5514205. [Google Scholar] [CrossRef]
- Wu, F.; Yang, Z.; Mo, X.; Wu, Z.; Tang, W.; Duan, J.; Zou, X. Detection and counting of banana bunches by integrating deep learning and classic image-processing algorithms. Comput. Electron. Agric. 2023, 209, 107827. [Google Scholar] [CrossRef]
- Tang, Y.; Qiu, J.; Zhang, Y.; Wu, D.; Cao, Y.; Zhao, K.; Zhu, L. Optimization strategies of fruit detection to overcome the challenge of unstructured background in field orchard environment: A review. Precis. Agric. 2023, 24, 1–37. [Google Scholar] [CrossRef]
- Wang, Y.; Bai, H.; Zhao, L.; Zhao, Y. Cascaded reconstruction network for compressive image sensing. EURASIP J. Image Video Process. 2018, 2018, 77. [Google Scholar] [CrossRef]
- Chu, M.; Xie, Y.; Mayer, J.; Leal-Taixé, L.; Thuerey, N. Learning temporal coherence via self-supervision for GAN-based video generation. ACM Trans. Graph. 2020, 39, 75–76. [Google Scholar] [CrossRef]
- Lidke, K.A.; Rieger, B.; Jovin, T.M.; Heintzmann, R. Superresolution by localization of quantum dots using blinking statistics. Opt. Express 2005, 13, 7052–7062. [Google Scholar] [CrossRef]
- Cheryauka, A.B.; Lee, J.N.; Samsonov, A.A.; Defrise, M.; Gullberg, G.T. MRI diffusion tensor reconstruction with PROPELLER data acquisition. Magn. Reson. Imaging 2004, 22, 139–148. [Google Scholar] [CrossRef]
- Engstrom, M.; Nordell, A.; Nordell, B.; Skare, S. Fast Diffusion Imaging Using Undersampled PROPELLER EPI. In Proceedings of the 16th Annual Meeting of ISMRM, Toronto, ON, Canada, 3–5 May 2008; p. 415. [Google Scholar]
- Mistretta, C.A.; Wieben, O.; Velikina, J.; Block, W.; Perry, J.; Wu, Y.; Johnson, K.; Wu, Y. Highly constrained backprojection for time-resolved MRI. Magn. Reson. Med. 2006, 5, 30–40. [Google Scholar] [CrossRef] [Green Version]
- Kuestner, T.; Wurslin, C.; Gatidis, S.; Martirosian, P.; Niolaou, K.; Schwenzer, N.F.; Schick, F.; Yang, B.; Schmidt, H. MR image reconstruction using a combination of Compressed Sensing and partial Fourier acquisition: ESPReSSo. IEEE Trans. Med. Imaging 2016, 35, 2447–2458. [Google Scholar] [CrossRef]
- Jung, H.; Ye, J.C.; Kim, E.Y. Improved k-t BLAST and k-t SENSE using FOCUSS. Phys. Med. Biol. 2007, 52, 3201–3226. [Google Scholar] [CrossRef]
- Ding, Y.; Chung, Y.C.; Jekic, M.; Simonetti, O.P. A new approach to auto-calibrated dynamic parallel imaging based on the Karhunen-Loeve transform: KL-TSENSE and KL-TGRAPPA. Magn. Reson. Imaging 2011, 65, 1786–1792. [Google Scholar]
- Kim, D.; Dyvorne, H.A.; Otazo, R.; Feng, L.; Sodickson, D.K.; Lee, V.S. Accelerated phase-contrast cine MRI using k-t SPARSE-SENSE. Magn. Reson. Med. 2012, 67, 1054–1064. [Google Scholar] [CrossRef] [Green Version]
- Otazo, R.; Kim, D.; Axel, L.; Sodickson, D. Combination of compressed sensing and parallel imaging for highly accelerated first-pass cardiac perfusion MRI. Magn. Reson. Med. 2010, 64, 767–776. [Google Scholar] [CrossRef] [Green Version]
- Lustig, M.; Donoho, D.; Pauly, J.M. Sparse MRI: The application of compressed sensing for rapid MR imaging. Magn. Reson. Med. 2007, 58, 1182–1195. [Google Scholar] [CrossRef]
- Pedersen, H.; Kozerke, S.; Ringgaard, S.; Nehrke, K.; Kim, W. k-t PCA: Temporally constrained k-t BLAST reconstruction using principal component analysis. Magn. Reson. Imaging 2009, 63, 706–716. [Google Scholar] [CrossRef]
- Lerga, J.; Mandić, I.; Peić, H.; Brščić, D. An adaptive method based on the improved LPA-ICI algorithm for MRI enhancement. Imaging Sci. J. 2018, 66, 372–381. [Google Scholar] [CrossRef]
- Mandic, I.; Peic, H.; Lerga, J.; Stajduhar, I. Denoising of X-ray images using the adaptive algorithm based on the LPA-RICI algorithm. J. Imaging 2018, 4, 34. [Google Scholar] [CrossRef] [Green Version]
- Griswold, M.A.; Jakob, P.M.; Heidemann, R.M.; Nittka, M.; Jellus, V.; Wang, J.; Kiefer, B.; Haase, A. Generalized autocalibrating partially parallel acquisitions (GRAPPA). Magn. Reson. Med. 2002, 47, 1202–1210. [Google Scholar] [CrossRef] [Green Version]
- Davenport, M. The Fundamentals of Compressive Sensing. IEEE Signal Process. Soc. Online Tutor. Libr. 2013, 12. [Google Scholar]
- Thüring, T.E.; Doneva, H.; Kozerke, S. A fast reconstruction algorithm using Compressive Sensing and an additional phase constraint. In Proceedings of the 26th European Society for Magnetic Resonance in Medicine and Biology (ESMRMB), Antalya, Turkey, 1–3 October 2009; p. 31. [Google Scholar]
- Cook, R.L. Stochastic sampling in computer graphics. Acm Trans. Graph. (TOG) 1986, 5, 51–72. [Google Scholar] [CrossRef]
- Atkinson, D.; Porter, D.A.; Hill, D.L.; Calamante, F.; Connelly, A. Sampling and reconstruction effects due to motion in diffusion-weighted interleaved echo planar imaging. Magn. Reson. Med. 2000, 44, 101–109. [Google Scholar] [CrossRef]
- Malczewski, K. Super-Resolution with compressively sensed MR/PET signals at its input. Inform. Med. Unlocked 2020, 18, 100302. [Google Scholar] [CrossRef]
- Cuppen, A. Reducing MR imaging time by one-sided reconstruction. Magn. Reson. Med. 1987, 5, 526–527. [Google Scholar] [CrossRef]
- McGibney, G.; Smith, M.R.; Nichols, S.T.; Crawley, A. Quantitative evaluation of several partial Fourier reconstruction algorithms used in MRI. Magn. Reson. Med. 1993, 30, 51–59. [Google Scholar] [CrossRef]
- Pipe, J.G.; Farthing, V.G.; Forbes, K.P. Multi-shot diffusion-weighted FSE using PROPELLER MRI. Magn. Reson. Med. 2002, 47, 42–52. [Google Scholar] [CrossRef]
- Raj, A.; Singh, G.; Zabih, R.; Kressler, B.; Wang, Y.; Schuff, N.; Weiner, M. Bayesian parallel imaging with edge-preserving priors. Magn. Reson. Med. 2007, 57, 8–21. [Google Scholar] [CrossRef] [Green Version]
- Feng, L.; Xu, J.; Dan, K.; Leon, A.; Deniel, S.K.; Otazo, R. Combination of compressed sensing, parallel imaging and partial Fourier for highly-accelerated 3D first-pass cardiac perfusion MRI. In Proceedings of the 19th International Society for Magnetic Resonance in Medicine (ISMRM), Montreal, QC, Canada, 7–13 May 2011; p. 4368. [Google Scholar]
- Bruna, J.; Sprechmann, P.; Lecun, Y. Super-resolution with deep convolutional sufficient statistics. arXiv 2015, arXiv:1511.05666. [Google Scholar]
- Liu, D.; Wang, Z.; Fan, Y.; Liu, X.; Wang, Z.; Chang, S.; Huang, T. Robust video super-resolution with learned temporal dynamics. In Proceedings of the IEEE International Conference on Computer Vision, Venice, Italy, 22–29 October 2017. [Google Scholar]
- Caballero, J.; Ledig, C.; Aitken, A.; Acosta, A.; Totz, J.; Wang, Z.; Shi, W. Real-Time Video Super-Resolution with Spatio-Temporal Networks and Motion Compensation. In Proceedings of the IEEE Conference on Computer Vision and Pattern Recognition (CVPR), Honolulu, HI, USA, 21–26 July 2017. [Google Scholar]
- Shi, W.; Jiang, F.; Zhang, S.; Zhao, D. Deep networks for compressed image sensing. In Proceedings of the 2017 IEEE International Conference on Multimedia and Expo (ICME), Hong Kong, China, 10–14 July 2017; pp. 877–882. [Google Scholar]
- Huang, G.; Liu, Z.; van der Maaten, L.; Weinberger, K.Q. Densely Connected Convolutional Networks. In Proceedings of the 2017 IEEE Conference on Computer Vision and Pattern Recognition, Honolulu, HI, USA, 21–26 July 2017; pp. 4700–4708. [Google Scholar]
- Sajjadi, M.S.M.; Vemulapalli, R.; Brown, M. Frame-Recurrent Video Super-Resolution. In Proceedings of the 2018 IEEE/CVF Conference on Computer Vision and Pattern Recognition, Salt Lake City, UT, USA, 18–23 June 2018; pp. 6626–6634. [Google Scholar]
- Gu, J.; Lu, H.; Zuo, W.; Dong, C. Blind Super-Resolution with Iterative Kernel Correction. In Proceedings of the 2019 IEEE/CVF Conference on Computer Vision and Pattern Recognition (CVPR), Long Beach, CA, USA, 16–20 June 2019; pp. 1604–1613. [Google Scholar]
- Maeda, S. Unpaired Image Super-Resolution Using Pseudo-Supervision. In Proceedings of the 2020 IEEE/CVF Conference on Computer Vision and Pattern Recognition (CVPR), Seattle, WA, USA, 14–19 June 2020; pp. 288–297. [Google Scholar]
- Balasubramanian, A.; Dhanasekaran, H.; Raghu, B.; Kumarasamy, K. MRI Super-Resolution using Generative Adversarial Network and Discrete Wavelet Transform. In Proceedings of the 2022 International Conference on Augmented Intelligence and Sustainable Systems (ICAISS), Trichy, India, 24–26 November 2022; pp. 1314–1318. [Google Scholar] [CrossRef]
- Sanchez, I.; Vilaplana, V. Brain MRI super-resolution using 3D generative adversarial networks. arXiv 2018, arXiv:1812.11440. [Google Scholar]
- Hu, X.; Mu, H.; Zhang, X.; Wang, Z.; Tan, T.; Sun, J. Meta-SR: A Magnification-Arbitrary Network for Super-Resolution. In Proceedings of the 2019 IEEE/CVF Conference on Computer Vision and Pattern Recognition (CVPR), Long Beach, CA, USA, 16–20 June 2019; pp. 1575–1584. [Google Scholar]
- Ning, K.; Zhihao, Z.; Kai, H.; Siyu, H.; Xiqing, Z. Multi-Frame Super-Resolution Algorithm Based on a WGAN. IEEE Access 2021, 9, 85839–85851. [Google Scholar] [CrossRef]
- Dong, C.; Loy, C.C.; Tang, X. Accelerating the Super-Resolution Convolutional Neural Network. In Proceedings of the Lecture Notes in Computer Science; Springer: Berlin/Heidelberg, Germany, 2016; pp. 391–407. [Google Scholar]
- Shi, W.; Caballero, J.; Huszar, F.; Totz, J.; Aitken, A.P.; Bishop, R.; Rueckert, D.; Wang, Z. Real-Time Single Image and Video Super-Resolution Using an Efficient Sub-Pixel Convolutional Neural Network. In Proceedings of the 2016 IEEE Conference on Computer Vision and Pattern Recognition (CVPR), Las Vegas, NV, USA, 27–30 June 2016; pp. 1874–1883. [Google Scholar]
- Isola, P.; Zhu, J.Y.; Zhou, T.; Efros, A.A. Image-to-image translation with conditional adversarial networks. In Proceedings of the IEEE Conference on Computer Vision and Pattern Recognition, Honolulu, HI, USA, 21–26 July 2017. [Google Scholar]
- Kupyn, O.; Budzan, V.; Mykhailych, M.; Mishkin, D.; Matas, J. DeblurGAN: Blind Motion Deblurring Using Conditional Adversarial Networks. In Proceedings of the 2018 IEEE/CVF Conference on Computer Vision and Pattern Recognition, Salt Lake City, UT, USA, 18–22 June 2018. [Google Scholar]
- Gatys, L.A.; Ecker, A.S.; Bethge, M. Texture synthesis using convolutional neural networks. In Proceedings of the Advances in Neural Information Processing Systems 28 (NIPS 2015), Montreal, QC, Canada, 7–12 December 2015; pp. 262–270. [Google Scholar]
- Ledig, C.; Theis, L.; Huszár, F.; Caballero, J.; Cunningham, A.; Acosta, A.; Aitken, A.; Tejani, A.; Totz, J.; Wang, Z.; et al. Photo-realistic single image super-resolution using a generative adversarial network. In Proceedings of the IEEE Conference on Computer Vision and Pattern Recognition, Honolulu, HI, USA, 21–26 July 2017. [Google Scholar]
- Kataoka, K.; Shiraishi, Y.; Takeda, Y.; Sakata, S.; Matsumoto, M.; Nagano, S.; Maeda, T.; Nagata, Y.; Kitanaka, A.; Mizuno, S.; et al. Aberrant PD-L1 expression through 3’-UTR disruption in multiple cancers. Nature 2016, 534, 402–406. [Google Scholar] [CrossRef]
- Johnson, J.; Alahi, A.; Li, F.F. Perceptual losses for real-time style transfer and super-resolution. In Proceedings of the Computer Vision–ECCV 2016: 14th European Conference, Amsterdam, The Netherlands, 11–14 October 2016; pp. 694–711. [Google Scholar]
- Simonyan, K.; Zisserman, A. Very deep convolutional networks for large-scale image recognition. arXiv 2014, arXiv:1409.1556. [Google Scholar]
- Pan, S.J.; Yang, Q. A survey on transfer learning. IEEE Trans. Knowl. Data Eng. 2010, 22, 1345–1359. [Google Scholar] [CrossRef]
- Yang, F.; Ding, M.; Zhang, X.; Hou, W.; Zhong, C. Non-rigid multi-modal medical image registration by combining L-BFGS-B with cat swarm optimization. Inf. Sci. 2015, 316, 440–456. [Google Scholar] [CrossRef]
- Lim, B.; Son, S.; Kim, H.; Nah, S.; Lee, K.M. Enhanced Deep Residual Networks for Single Image Super-Resolution. In Proceedings of the 2017 IEEE Conference on Computer Vision and Pattern Recognition Workshops (CVPRW), Honolulu, HI, USA, 21–26 July 2017; pp. 1132–1140. [Google Scholar]
- Zhang, Y.; Tian, Y.; Kong, Y.; Zhong, B.; Fu, Y. Residual dense network for image super-resolution. In Proceedings of the IEEE Conference on Computer Vision and Pattern Recognition, Salt Lake City, UT, USA, 18–22 June 2018. [Google Scholar]
- Zhang, Y.; Li, K.; Li, K.; Wang, L.; Zhong, B.; Fu, Y. Image Super-Resolution Using Very Deep Residual Channel Attention Networks. In Proceedings of the 15th European Conference on Computer Vision, Munich, Germany, 8–14 September 2018. [Google Scholar]
- Takeda, H.; Milanfar, P.; Protter, M.; Elad, M. Super-resolution without explicit subpixel motion estimation. IEEE Trans. Image Process. 2009, 18, 1958–1975. [Google Scholar] [CrossRef] [Green Version]
- Wachinger, C.; Navab, N. Entropy and Laplacian images: Structural representations for multi-modal registration. Med. Image Anal. 2012, 16, 1–17. [Google Scholar] [CrossRef]
- Heinrich, M.P.; Jenkinson, M.; Bhushan, M.; Matin, T.; Gleeson, F.V.; Brady, M.; Schnabel, J.A. MIND: Modality independent neighbourhood descriptor for multi-modal deformable registration. Med. Image Anal. 2012, 16, 1423–1435. [Google Scholar] [CrossRef]
Figure 1.
Thesimplified flowchart of the presented low resolution DW image reconstruction from a compressed sensing k-q spaces. Signals are transferred from layer to layer through the input-output manner.
Figure 1.
Thesimplified flowchart of the presented low resolution DW image reconstruction from a compressed sensing k-q spaces. Signals are transferred from layer to layer through the input-output manner.
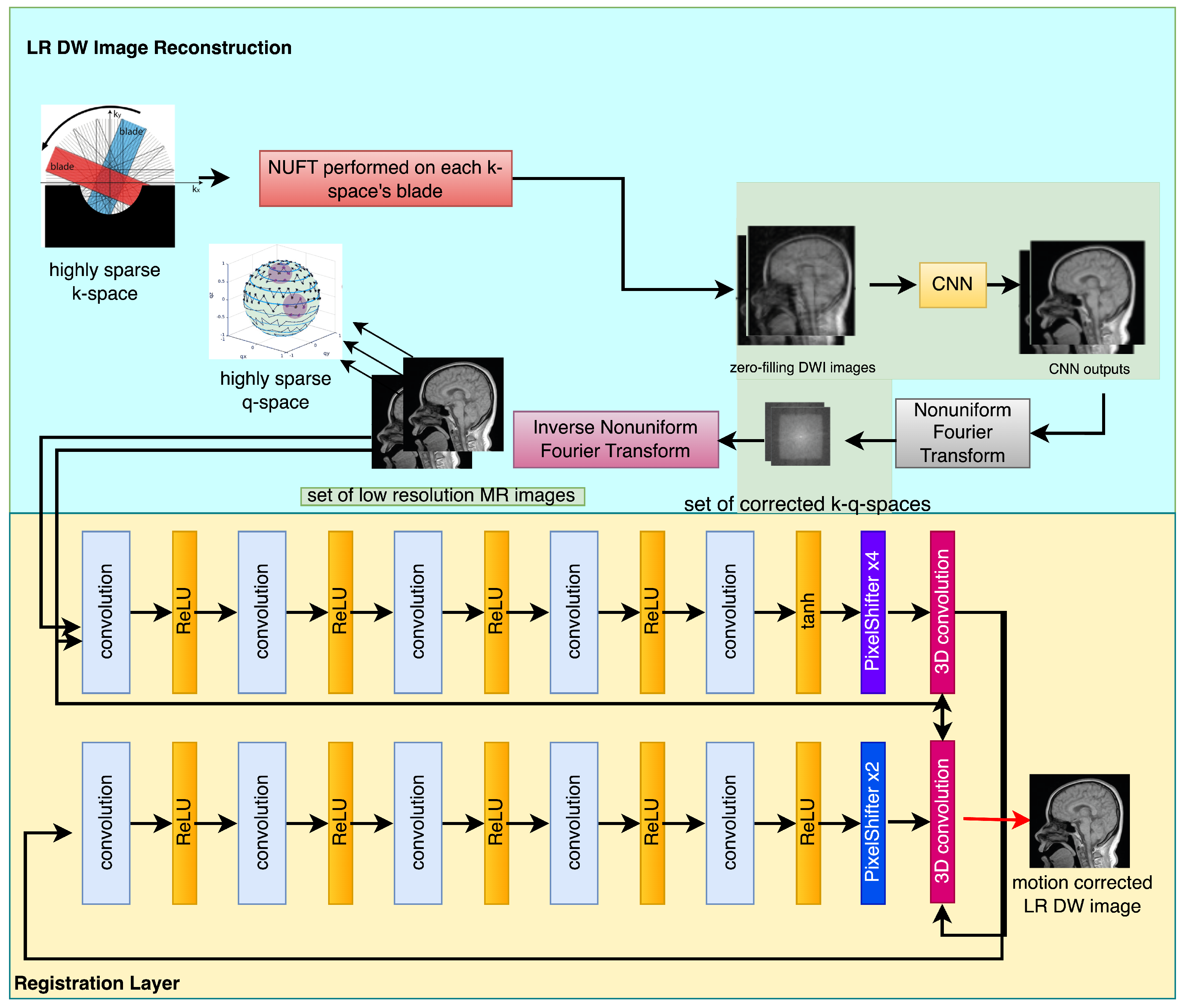
Figure 2.
The flowchart of the generator network.
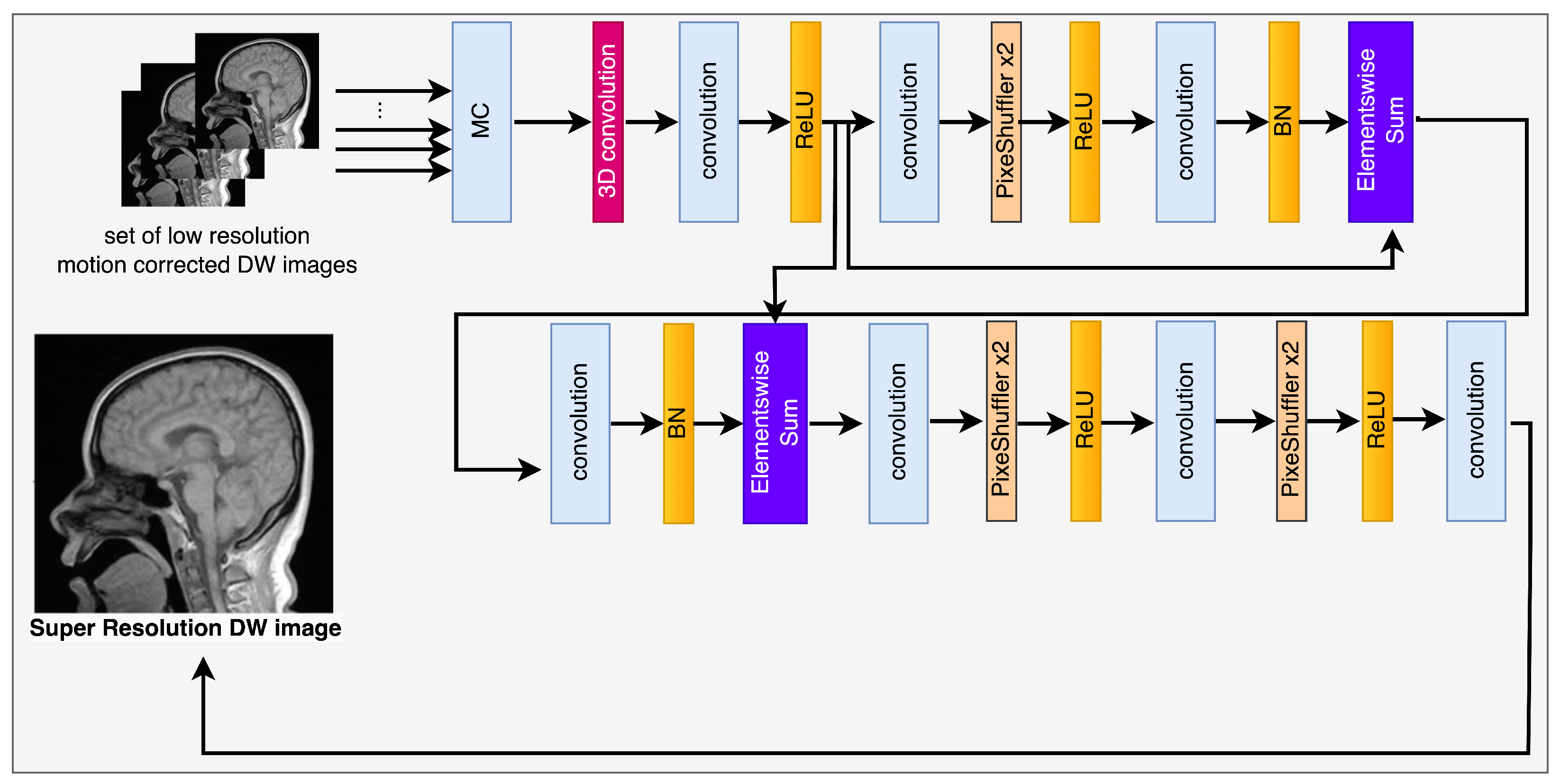
Figure 3.
Flowchart of the discriminator network.

Figure 4.
Theproposed DW super-resolution image reconstruction algorithm.

Figure 5.
The algorithm utilizes test and train images in order to reconstruct super-resolution DW images.
Figure 5.
The algorithm utilizes test and train images in order to reconstruct super-resolution DW images.
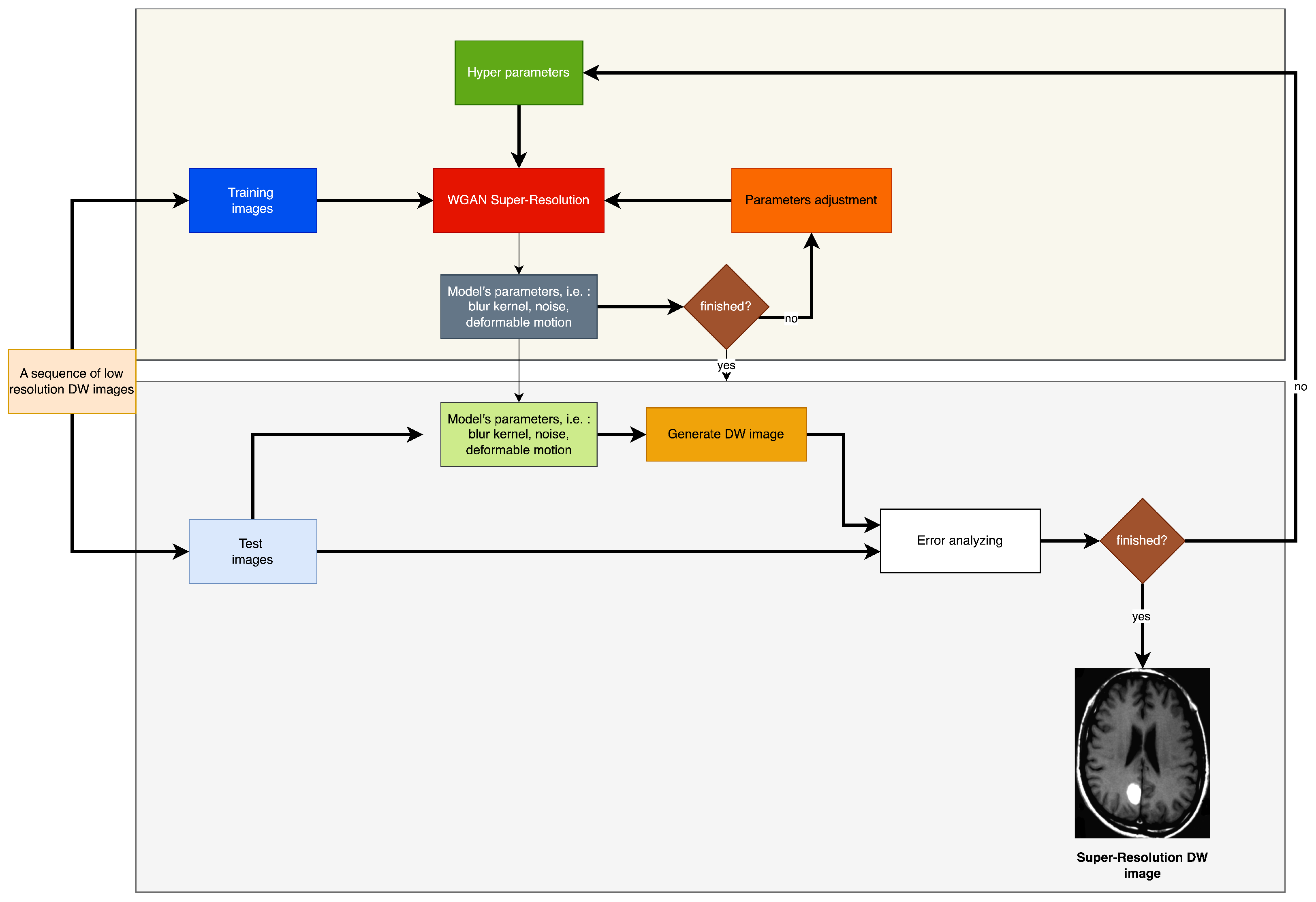
Figure 6.
Deblurring net.

Figure 7.
Denoising net.

Figure 8.
This study assessed the efficacy of diverse super-resolution image reconstruction techniques for Magnetic Resonance Imaging (MRI) T1, T2, and Diffusion Weighted Imaging (DWI) images, using clinical illustrations. The findings of this assessment indicated the existence of a hyperintense hematoma located in the right parietal lobe. The methodology utilized in the investigation comprises of LR input, B-spline Cubic interpolation, Non-rigid multi-modal medical image registration by combining L-BFGS-B with cat swarm optimization (Yang’s N-R-M-3D) [57], Enhanced Deep Residual Networks for Single Image Super-Resolution (Lim’s E-D-R-N-S-I-S-R [58]), image super-resolution using very deep residual channel attention networks (Zhang’s R-D-N-I-S-R [59]), Residual dense network for image super-resolution (RCAN SRR [60]), MRI Super-Resolution using GAN and DWT [43], Brain MRI SRR using 3DGAN [44] and the algorithm suggested by the author. The techniques were organized in a horizontal sequence from the leftmost to the rightmost position. The aforementioned techniques are supported by references [4,61], and [58], as cited in the study. Zoomed-in views are shown in the last three rows.
Figure 8.
This study assessed the efficacy of diverse super-resolution image reconstruction techniques for Magnetic Resonance Imaging (MRI) T1, T2, and Diffusion Weighted Imaging (DWI) images, using clinical illustrations. The findings of this assessment indicated the existence of a hyperintense hematoma located in the right parietal lobe. The methodology utilized in the investigation comprises of LR input, B-spline Cubic interpolation, Non-rigid multi-modal medical image registration by combining L-BFGS-B with cat swarm optimization (Yang’s N-R-M-3D) [57], Enhanced Deep Residual Networks for Single Image Super-Resolution (Lim’s E-D-R-N-S-I-S-R [58]), image super-resolution using very deep residual channel attention networks (Zhang’s R-D-N-I-S-R [59]), Residual dense network for image super-resolution (RCAN SRR [60]), MRI Super-Resolution using GAN and DWT [43], Brain MRI SRR using 3DGAN [44] and the algorithm suggested by the author. The techniques were organized in a horizontal sequence from the leftmost to the rightmost position. The aforementioned techniques are supported by references [4,61], and [58], as cited in the study. Zoomed-in views are shown in the last three rows.

Figure 9.
A comparison of results obtained from the Shepp–Logan phantom. The reconstructed output of the PROPELLER sampling pattern is presented on the left, while the outcome of the proposed algorithm with improved resolution is displayed on the right. The bottom row reveals intricate visuals.
Figure 9.
A comparison of results obtained from the Shepp–Logan phantom. The reconstructed output of the PROPELLER sampling pattern is presented on the left, while the outcome of the proposed algorithm with improved resolution is displayed on the right. The bottom row reveals intricate visuals.


{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
Table 1.
The performance of the SRR algorithm under consideration.
| Sparsity Rate * [%] | N | PSNR | SD | t | p |
|---|---|---|---|---|---|
| 20 | 100 | 19.22 | 0.02 | 0.021 | 1.231 |
| 40 | 100 | 24.43 | 0.02 | 0.995 | 0.098 |
| 60 | 100 | 31.21 | 0.03 | −0.631 | 0.431 |
| 80 | 100 | 33.77 | 0.04 | 0.001 | 0.923 |
| 100 | 100 | 36.19 | 0.03 | −1.232 | 0.069 |
* The term “sparsity rate” pertains to the proportion of input samples that remain after a comparison with fully sampled scans. For instance, a sparsity rate of 60 indicates that 40% of the samples from a fully sampled scan have been eliminated.
Table 2.
The statistical parameters of the model’s PSNR metrics were analyzed on the aforementioned Figure 8.
Table 2.
The statistical parameters of the model’s PSNR metrics were analyzed on the aforementioned Figure 8.
| Reconstruction Algorithm | N | PSNR | SD | t | p |
|---|---|---|---|---|---|
| No SRR. MC-not-applied | 100 | 26.09 | 0.01 | −1.291 | 0.131 |
| B spline. MC-not-applied | 100 | 28.01 | 0.01 | −0.192 | 0.621 |
| Yang’s N-R-M-3D [57] | 100 | 31.20 | 0.01 | −0.592 | 0.382 |
| Lim’s E-D-R-N-S-I-S-R [58] | 100 | 30.21 | 0.01 | −0.292 | 0.312 |
| Zhang’s R-D-N-I-S-R [59] | 100 | 29.91 | 0.01 | −0.391 | 0.391 |
| RCAN SRR [60] | 100 | 31.23 | 0.01 | −0.311 | 0.231 |
| MRI Super-Resolution using GAN and DWT [43] | 100 | 31.78 | 0.01 | −0.232 | 0.159 |
| Brain MRI SRR using 3DGAN [44] | 100 | 32.66 | 0.01 | −0.114 | 0.162 |
| The author’s method | 100 | 34.23 | 0.00 | −1.001 | 0.012 |
Table 3.
This study evaluates the efficacy of various reconstruction algorithms for in vivo brain imaging, specifically in the context of MC-motion correction. Please refer to Figure 8 for the relevant image.
Table 3.
This study evaluates the efficacy of various reconstruction algorithms for in vivo brain imaging, specifically in the context of MC-motion correction. Please refer to Figure 8 for the relevant image.
| HR Image Reconstruction Method | N | PSNR | SD | t | p |
|---|---|---|---|---|---|
| no SRR/MC-not-applied | 100 | 27.21 | 0.01 | −1.144 | 0.254 |
| no SRR/MC-applied | 100 | 29.99 | 0.01 | 0.323 | 0.665 |
| B-spline/MC-not-applied | 100 | 30.77 | 0.01 | −0.312 | 0.555 |
| the author’s method/MC-applied | 100 | 35.22 | 0.01 | 0.031 | 1.102 |
Table 4.
The statistical parameters pertaining to the PSNR metrics of the model are presented in relation to Figure 9.
Table 4.
The statistical parameters pertaining to the PSNR metrics of the model are presented in relation to Figure 9.
| Sparsity Rate [%] | N | PSNR | SD | t(99) | p |
|---|---|---|---|---|---|
| 20 | 100 | 29.77 | 0.01 | −1.001 | 0.192 |
| 40 | 100 | 32.22 | 0.03 | −1.032 | 0.111 |
| 60 | 100 | 35.66 | 0.01 | −1.041 | 0.132 |
| 80 | 100 | 37.02 | 0.01 | −1.046 | 0.211 |
| 100 | 100 | 37.11 | 0.01 | −1.022 | 0.100 |
Table 5.
The present research assesses the effectiveness of diverse reconstruction algorithms for in-vivo brain imaging, encompassing MC-motion correction and HR-upscaling through the utilization of the presented algorithm. Kindly consult Figure 4 for the corresponding cerebral image.
Table 5.
The present research assesses the effectiveness of diverse reconstruction algorithms for in-vivo brain imaging, encompassing MC-motion correction and HR-upscaling through the utilization of the presented algorithm. Kindly consult Figure 4 for the corresponding cerebral image.
| The Algorithm for Sampling and Reconstructing k-Space | N | PSNR | SD | t(99) | p |
|---|---|---|---|---|---|
| P-R-O-P-E-L-L-E-R | 100 | 21.96 | 0.03 | −1.357 | 0.178 |
| The author’s sampling scheme | 100 | 34.49 | 0.04 | 1.286 | 0.202 |
Table 6.
The statistical performance of numerous registration algorithms vs. the applied procedure.
| Motion Compensation Procedure | TRE [Voxels] | ||
|---|---|---|---|
| Mean | Std | p-Value | |
| not-applied | 4.7 | 2.2 | |
| Wachinger’s [62] | 2.2 | 0.9 | <0.002 |
| Yang’s et al. [57] | 2.2 | 0.3 | <0.002 |
| MIND [63] | 1.8 | 0.1 | <0.002 |
| WGAN deformable MC-the author’s method | 1.4 | 0.2 | <0.001 |
Disclaimer/Publisher’s Note: The statements, opinions and data contained in all publications are solely those of the individual author(s) and contributor(s) and not of MDPI and/or the editor(s). MDPI and/or the editor(s) disclaim responsibility for any injury to people or property resulting from any ideas, methods, instructions or products referred to in the content. |
© 2023 by the author. Licensee MDPI, Basel, Switzerland. This article is an open access article distributed under the terms and conditions of the Creative Commons Attribution (CC BY) license (https://creativecommons.org/licenses/by/4.0/).
Share and Cite
MDPI and ACS Style
Malczewski, K. Diffusion Weighted Imaging Super-Resolution Algorithm for Highly Sparse Raw Data Sequences. Sensors 2023, 23, 5698. https://doi.org/10.3390/s23125698
AMA Style
Malczewski K. Diffusion Weighted Imaging Super-Resolution Algorithm for Highly Sparse Raw Data Sequences. Sensors. 2023; 23(12):5698. https://doi.org/10.3390/s23125698
Chicago/Turabian StyleMalczewski, Krzysztof. 2023. "Diffusion Weighted Imaging Super-Resolution Algorithm for Highly Sparse Raw Data Sequences" Sensors 23, no. 12: 5698. https://doi.org/10.3390/s23125698
Note that from the first issue of 2016, this journal uses article numbers instead of page numbers. See further details here.