
A Study on the Influence of Sensors in Frequency and Time Domains on Context Recognition

 ,
,  , , ,
, , ,
Abstract
:1. Introduction
- 1
- Generation of a set of features using the frequency domain and the analysis of the most relevant features for the CHAR task;
- 2
- Quantitative comparison of the results using time-domain and frequency-domain features for context recognition;
- 3
- Study on the contribution of every sensor and combination of sensors to recognizing specific activities and contexts.
2. Related Works
3. Materials and Methods
3.1. The Datasets
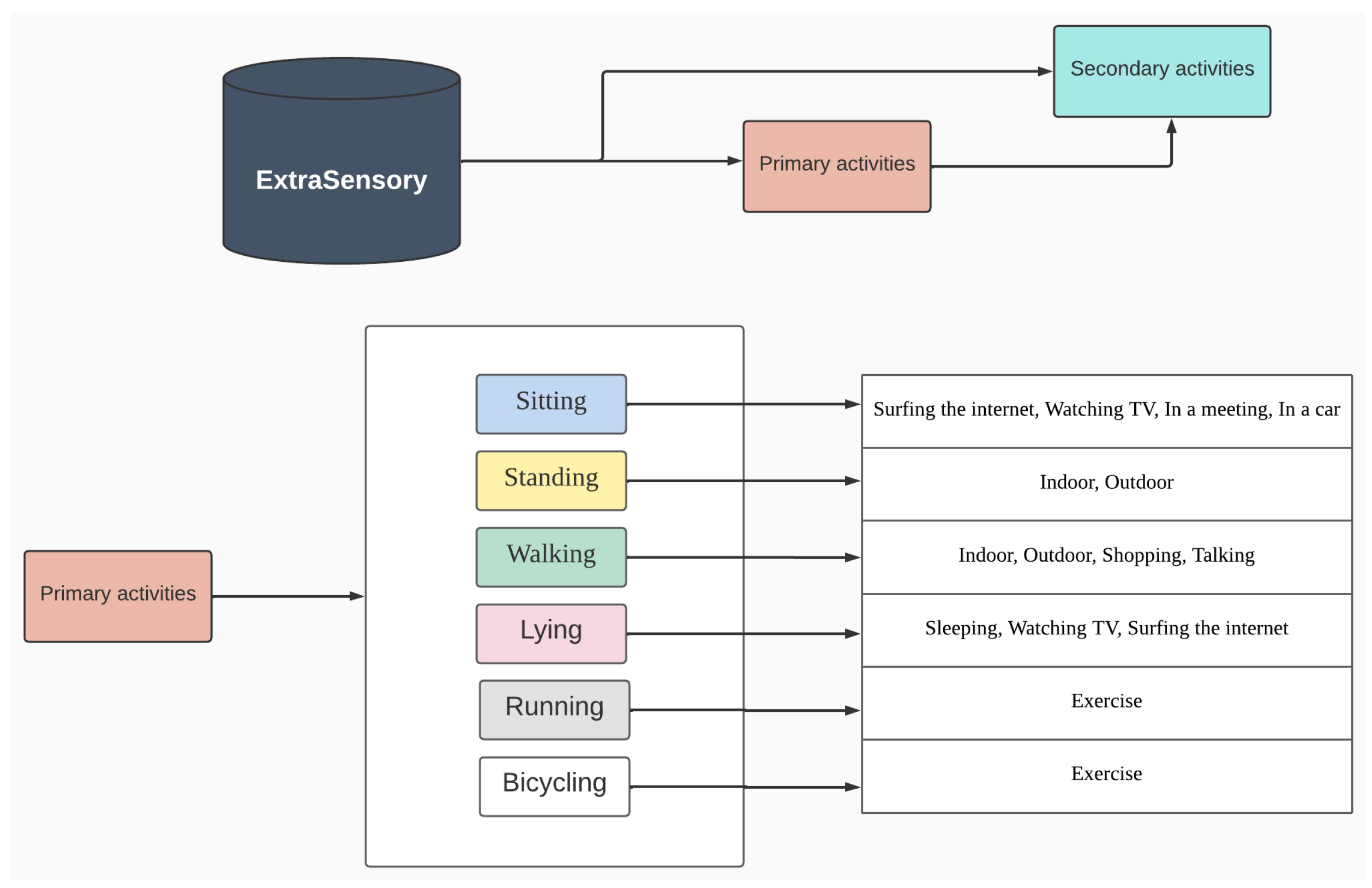
3.1.1. ExtraSensory Dataset
3.1.2. WISDM
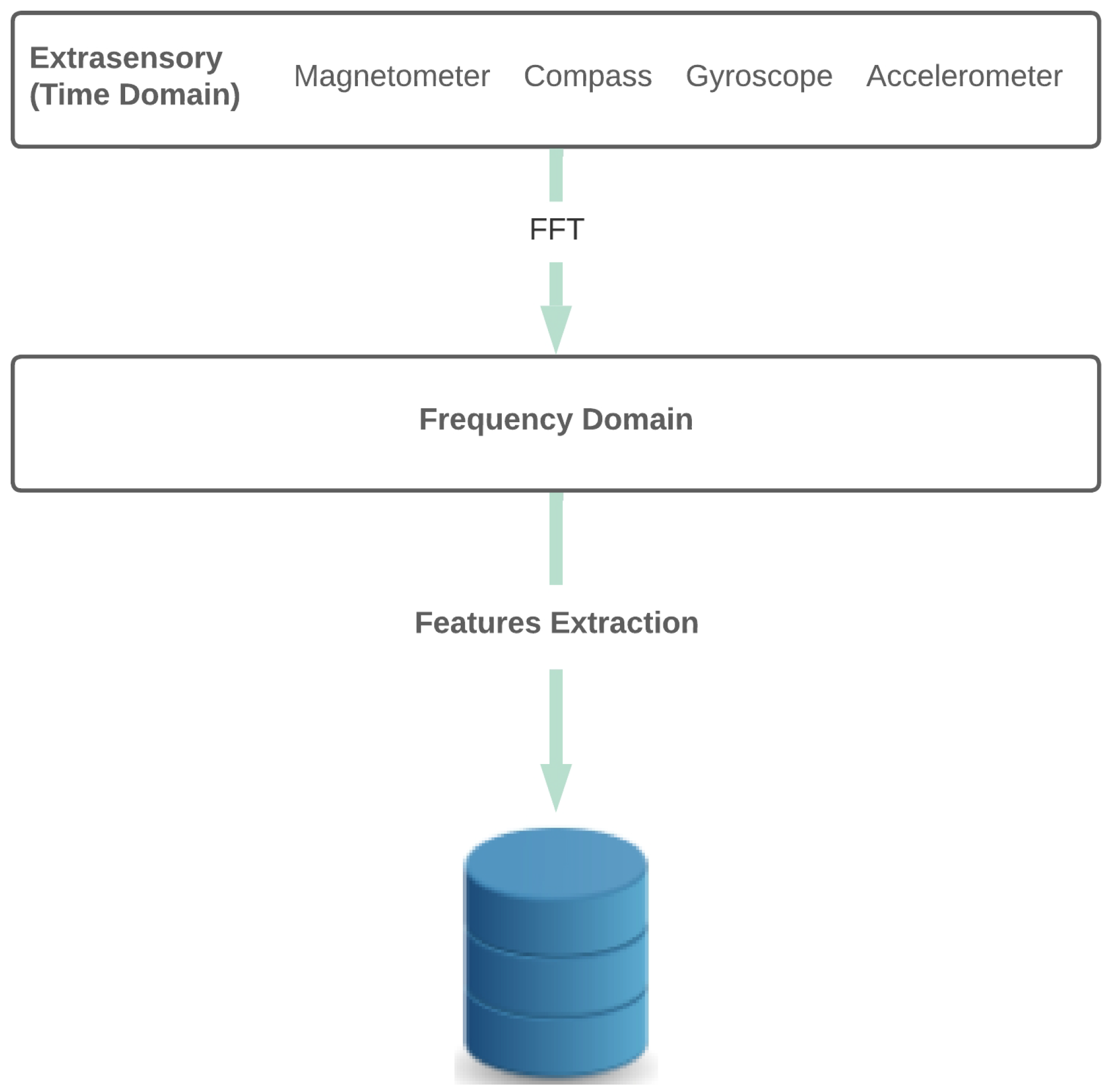
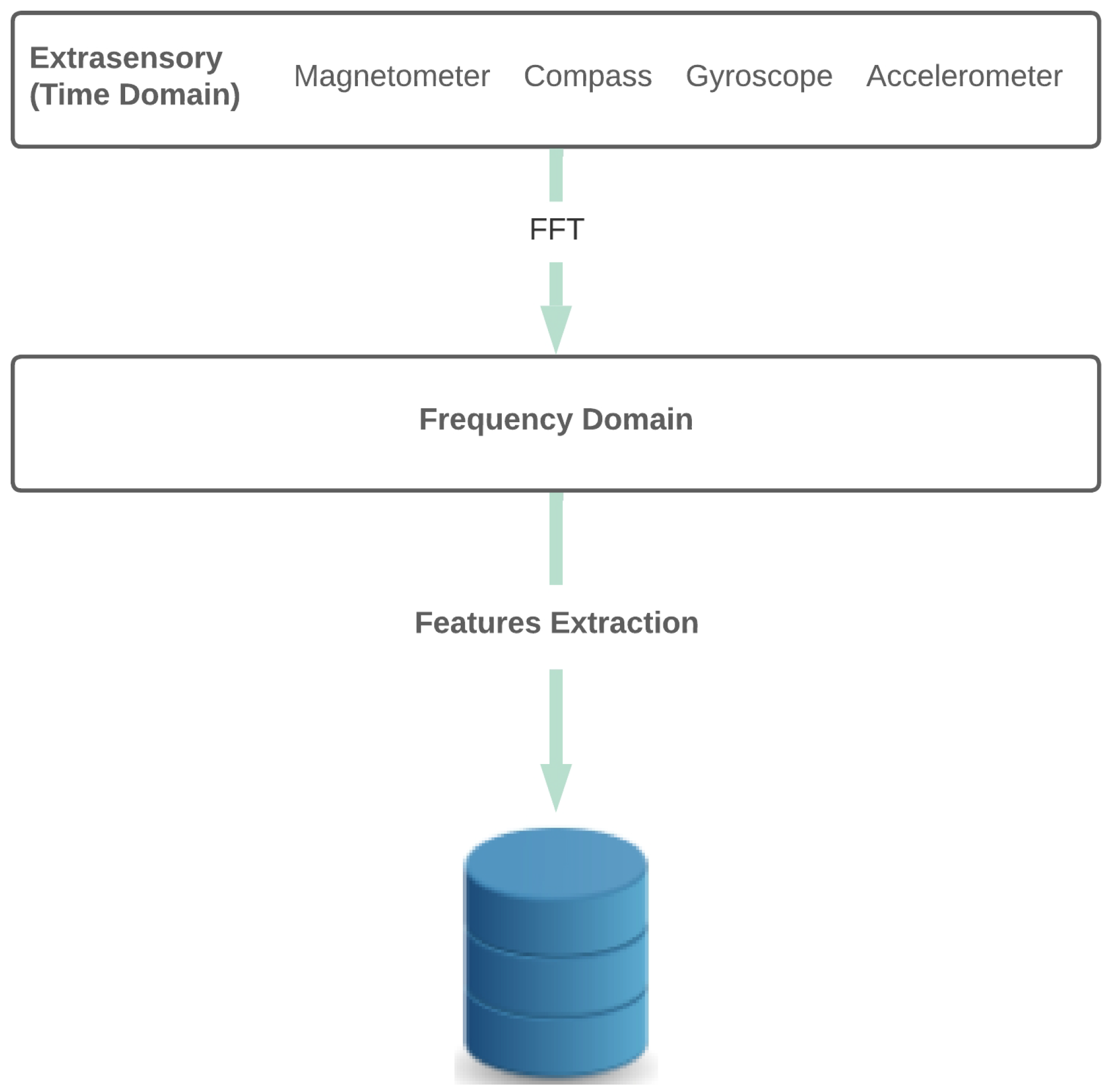
3.2. Feature Extraction
Discrete Fourier Transform
3.3. Model Description and Training
3.4. Experiments
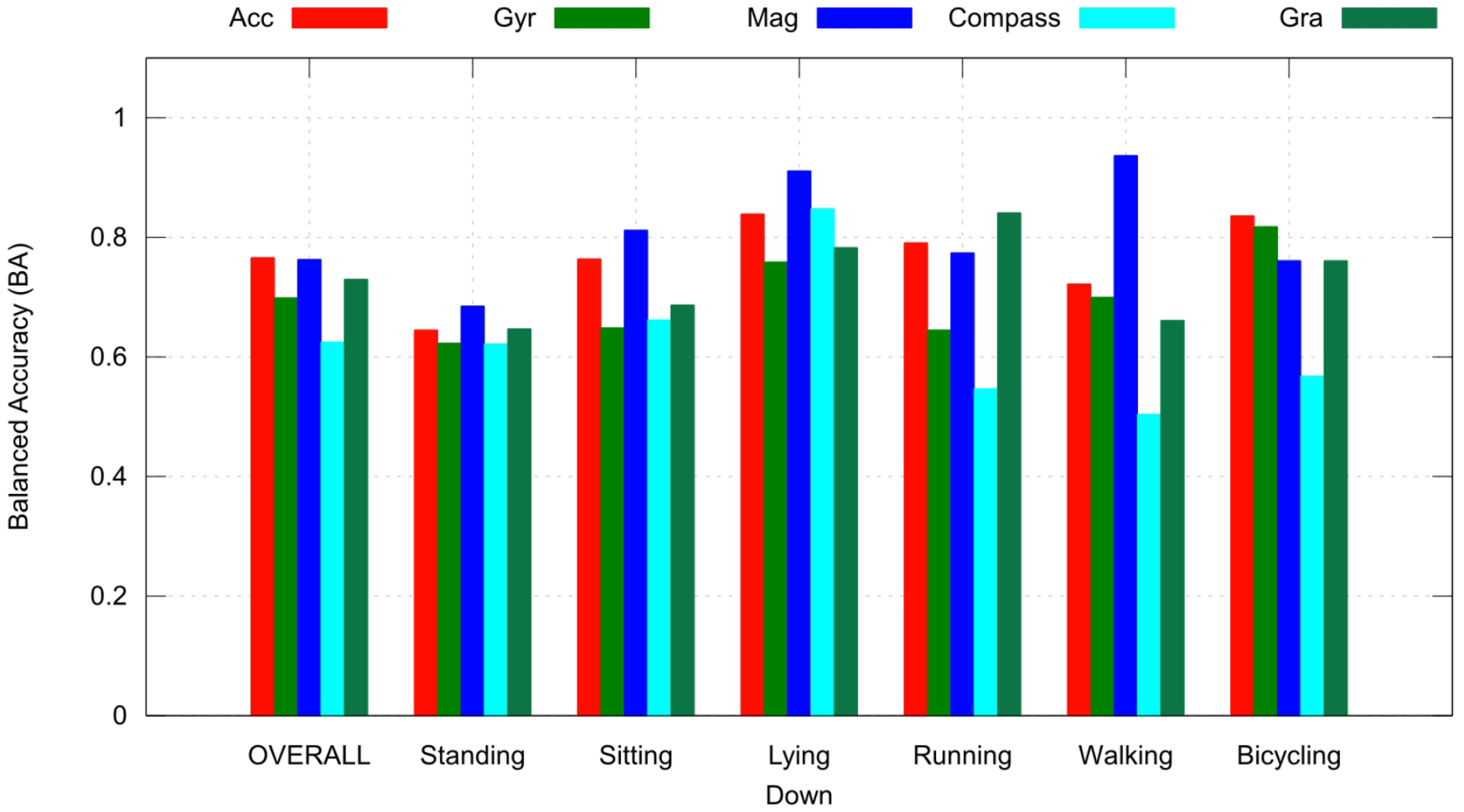
3.4.1. Influence of Sensors
3.4.2. Time-Domain Features vs. Frequency-Domain Features
4. Results
4.1. Metrics
- TP: number of true-positive cases;
- TN: number of true-negative cases;
- FP: number of false-positive cases;
- FN: number of false-negative cases.
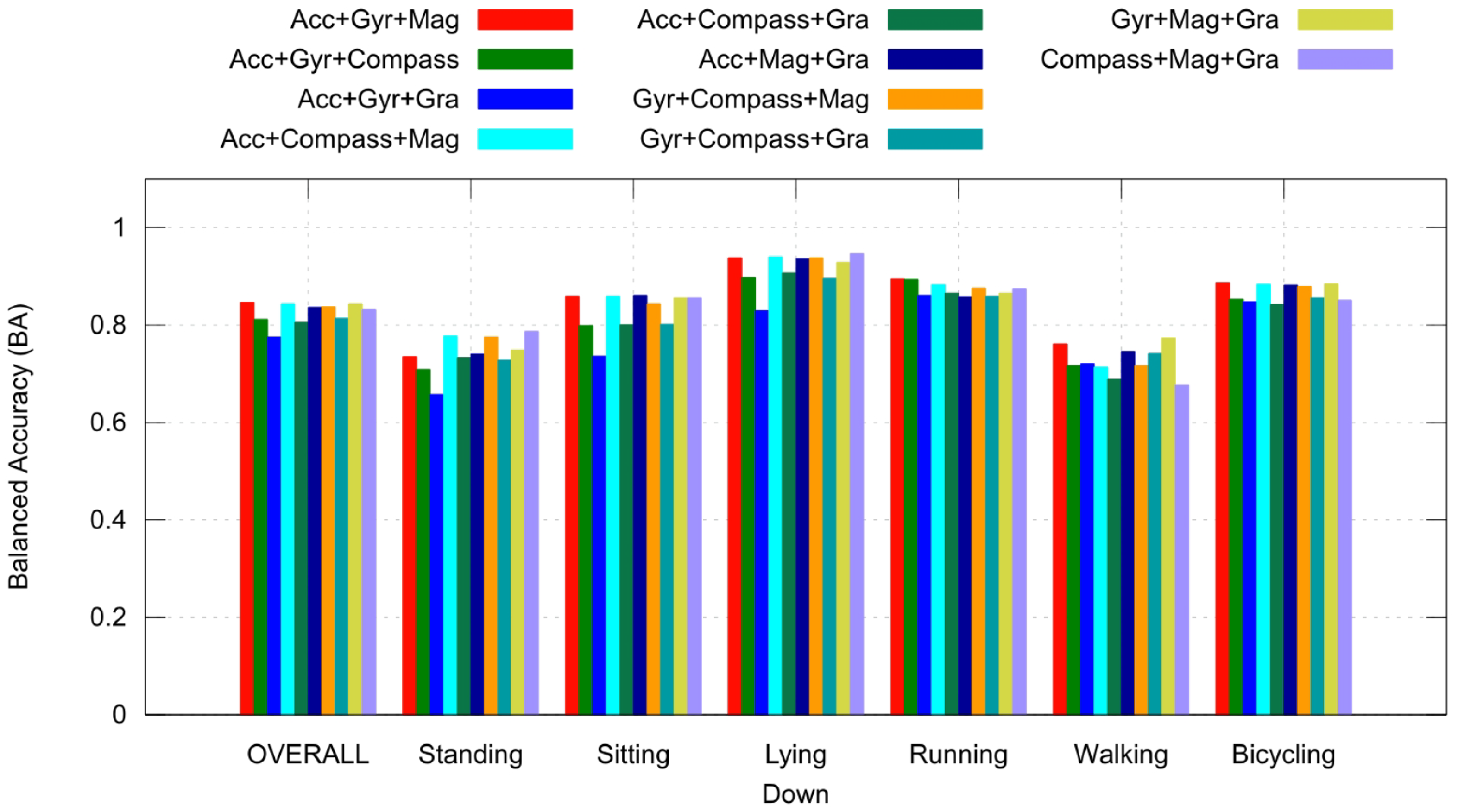
4.2. Sensor Contribution Evaluation
Context Recognition
4.3. Comparison between Time Features and DFT-Transformed Features
5. Discussion
- 1
- How can the number of sensors influence model performance in CHAR tasks?
- 2
- Does a sensor contribute differently to different activities?
- 3
- Are DFT-extracted features more suitable than trivial statistic features?
6. Conclusions
Author Contributions
Funding
Informed Consent Statement
Data Availability Statement
Conflicts of Interest
References
- Khurshid, S.; Weng, L.C.; Nauffal, V.; Pirruccello, J.P.; Venn, R.A.; Al-Alusi, M.A.; Benjamin, E.J.; Ellinor, P.T.; Lubitz, S.A. Wearable accelerometer-derived physical activity and incident disease. NPJ Digit. Med. 2022, 5, 131. [Google Scholar] [CrossRef] [PubMed]
- Sylvia, L.G.; Bernstein, E.E.; Hubbard, J.L.; Keating, L.; Anderson, E.J. A practical guide to measuring physical activity. J. Acad. Nutr. Diet. 2014, 114, 199. [Google Scholar] [CrossRef] [PubMed] [Green Version]
- Trost, S.G.; O’Neil, M. Clinical use of objective measures of physical activity. Br. J. Sport. Med. 2014, 48, 178–181. [Google Scholar] [CrossRef]
- Dehghani, M. Exploring the motivational factors on continuous usage intention of smartwatches among actual users. Behav. Inf. Technol. 2018, 37, 145–158. [Google Scholar] [CrossRef]
- Chandel, R.S.; Sharma, S.; Kaur, S.; Singh, S.; Kumar, R. Smart watches: A review of evolution in bio-medical sector. Mater. Today Proc. 2022, 50, 1053–1066. [Google Scholar] [CrossRef]
- Song, Z.; Cao, Z.; Li, Z.; Wang, J.; Liu, Y. Inertial motion tracking on mobile and wearable devices: Recent advancements and challenges. Tsinghua Sci. Technol. 2021, 26, 692–705. [Google Scholar] [CrossRef]
- Ehatisham-ul Haq, M.; Murtaza, F.; Azam, M.A.; Amin, Y. Daily Living Activity Recognition In-The-Wild: Modeling and Inferring Activity-Aware Human Contexts. Electronics 2022, 11, 226. [Google Scholar] [CrossRef]
- Mekruksavanich, S.; Jantawong, P.; Jitpattanakul, A. Recognition of Complex Human Activities for Wellness Management from Smartwatch using Deep Residual Neural Network. In Proceedings of the 2022 Joint International Conference on Digital Arts, Media and Technology with ECTI Northern Section Conference on Electrical, Electronics, Computer and Telecommunications Engineering (ECTI DAMT & NCON), Chiang Rai, Thailand, 26–28 January 2022; pp. 350–353. [Google Scholar] [CrossRef]
- Vaizman, Y.; Ellis, K.; Lanckriet, G. Recognizing Detailed Human Context in the Wild from Smartphones and Smartwatches. IEEE Pervasive Comput. 2017, 16, 62–74. [Google Scholar] [CrossRef] [Green Version]
- Zhu, Z.; Li, H.; Xiao, J.; Xu, W.; Huang, M.C. A fitness training optimization system based on heart rate prediction under different activities. Methods 2022, 205, 89–96. [Google Scholar] [CrossRef]
- Asim, Y.; Azam, M.A.; Ehatisham-ul Haq, M.; Naeem, U.; Khalid, A. Context-Aware Human Activity Recognition (CAHAR) in-the-Wild Using Smartphone Accelerometer. IEEE Sens. J. 2020, 20, 4361–4371. [Google Scholar] [CrossRef]
- Chen, Y.; Xue, Y. A Deep Learning Approach to Human Activity Recognition Based on Single Accelerometer. In Proceedings of the 2015 IEEE International Conference on Systems, Man, and Cybernetics, Hong Kong, China, 9–12 October 2015; pp. 1488–1492. [Google Scholar] [CrossRef]
- Ronao, C.A.; Cho, S.B. Human activity recognition with smartphone sensors using deep learning neural networks. Expert Syst. Appl. 2016, 59, 235–244. [Google Scholar] [CrossRef]
- Fazli, M.; Kowsari, K.; Gharavi, E.; Barnes, L.; Doryab, A. HHAR-net: Hierarchical Human Activity Recognition using Neural Networks. In Proceedings of the Intelligent Human Computer Interaction, Daegu, Republic of Korea, 24–26 November 2020; Singh, M., Kang, D.K., Lee, J.H., Tiwary, U.S., Singh, D., Chung, W.Y., Eds.; Springer International Publishing: Cham, Switzerland, 2021; pp. 48–58. [Google Scholar]
- Zhang, T.; Lin, Y.; He, W.; Yuan, F.; Zeng, Y.; Zhang, S. GCN-GENE: A novel method for prediction of coronary heart disease-related genes. Comput. Biol. Med. 2022, 150, 105918. [Google Scholar] [CrossRef] [PubMed]
- Sophocleous, F.; Bône, A.; Shearn, A.I.; Forte, M.N.V.; Bruse, J.L.; Caputo, M.; Biglino, G. Feasibility of a longitudinal statistical atlas model to study aortic growth in congenital heart disease. Comput. Biol. Med. 2022, 144, 105326. [Google Scholar] [CrossRef] [PubMed]
- Huang, Y.; Ren, Y.; Yang, H.; Ding, Y.; Liu, Y.; Yang, Y.; Mao, A.; Yang, T.; Wang, Y.; Xiao, F.; et al. Using a machine learning-based risk prediction model to analyze the coronary artery calcification score and predict coronary heart disease and risk assessment. Comput. Biol. Med. 2022, 151, 106297. [Google Scholar] [CrossRef]
- Garcia-Ceja, E.; Brena, R. Activity Recognition Using Community Data to Complement Small Amounts of Labeled Instances. Sensors 2016, 16, 877. [Google Scholar] [CrossRef] [Green Version]
- Vaizman, Y.; Weibel, N.; Lanckriet, G. Context Recognition In-the-Wild: Unified Model for Multi-Modal Sensors and Multi-Label Classification. Proc. Acm Interact. Mob. Wearable Ubiquitous Technol. 2018, 1, 1–22. [Google Scholar] [CrossRef]
- Ge, W.; Agu, E.O. QCRUFT: Quaternion Context Recognition under Uncertainty using Fusion and Temporal Learning. In Proceedings of the 2022 IEEE 16th International Conference on Semantic Computing (ICSC), Laguna Hills, CA, US, 26–28 January 2022; pp. 41–50. [Google Scholar] [CrossRef]
- Ehatisham-ul Haq, M.; Azam, M.A. Opportunistic sensing for inferring in-the-wild human contexts based on activity pattern recognition using smart computing. Future Gener. Comput. Syst. 2020, 106, 374–392. [Google Scholar] [CrossRef]
- Ehatisham-ul Haq, M.; Awais Azam, M.; Asim, Y.; Amin, Y.; Naeem, U.; Khalid, A. Using Smartphone Accelerometer for Human Physical Activity and Context Recognition in-the-Wild. Procedia Comput. Sci. 2020, 177, 24–31. [Google Scholar] [CrossRef]
- Zhu, C.; Sheng, W. Human daily activity recognition in robot-assisted living using multi-sensor fusion. In Proceedings of the 2009 IEEE International Conference on Robotics and Automation, Kobe, Japan, 12–17 May 2009; pp. 2154–2159. [Google Scholar] [CrossRef] [Green Version]
- Webber, M.; Rojas, R.F. Human Activity Recognition With Accelerometer and Gyroscope: A Data Fusion Approach. IEEE Sens. J. 2021, 21, 16979–16989. [Google Scholar] [CrossRef]
- Chung, S.; Lim, J.; Noh, K.J.; Kim, G.; Jeong, H. Sensor Data Acquisition and Multimodal Sensor Fusion for Human Activity Recognition Using Deep Learning. Sensors 2019, 19, 1716. [Google Scholar] [CrossRef] [Green Version]
- Nweke, H.F.; Teh, Y.W.; Alo, U.R.; Mujtaba, G. Analysis of Multi-Sensor Fusion for Mobile and Wearable Sensor Based Human Activity Recognition. In Proceedings of the International Conference on Data Processing and Applications–ICDPA 2018, Guangzhou, China, 12–14 May 2018; ACM Press: Guangdong, China, 2018; pp. 22–26. [Google Scholar] [CrossRef]
- Münzner, S.; Schmidt, P.; Reiss, A.; Hanselmann, M.; Stiefelhagen, R.; Dürichen, R. CNN-based sensor fusion techniques for multimodal human activity recognition. In Proceedings of the 2017 ACM International Symposium on Wearable Computers, Maui, HI, USA, 11–15 September 2017; ACM: Maui, HI, USA, 2017; pp. 158–165. [Google Scholar] [CrossRef]
- Arnon, P. Classification model for multi-sensor data fusion apply for Human Activity Recognition. In Proceedings of the 2014 International Conference on Computer, Communications, and Control Technology (I4CT), Langkawi, Malaysia, 2–4 September 2014; IEEE: Langkawi, Malaysia, 2014; pp. 415–419. [Google Scholar] [CrossRef]
- Chen, J.; Sun, Y.; Sun, S. Improving Human Activity Recognition Performance by Data Fusion and Feature Engineering. Sensors 2021, 21, 692. [Google Scholar] [CrossRef] [PubMed]
- ST-Microelectronics. LIS331DLH, MEMS Digital Output Motion Sensorultra Low-Power High Performance 3-Axes “Nano” Accelerometer. Rev. 3. July 2009. Available online: https://www.st.com/en/mems-and-sensors/lis331dlh.html (accessed on 1 June 2023).
- ST-Microelectronics. L3G4200DMEMS, Motion Sensor:Ultra-Stable Three-Axis Digital Output Gyroscope. December 2009. Available online: https://pdf1.alldatasheet.com/datasheet-pdf/view/332531/STMICROELECTRONICS/L3G4200D.html (accessed on 20 May 2023).
- AsahiKasei. AK8975/AK8975C 3-Axis Electronic Compass. May 2010. Available online: https://pdf1.alldatasheet.com/datasheet-pdf/view/535562/AKM/AK8975.html (accessed on 15 May 2023).
- AsahiKasei. AK8963 3-Axis Electronic Compass. February 2012. Available online: https://www.datasheet-pdf.info/attach/1/2275303065.pdf (accessed on 30 May 2023).
- Bosh. BMA220 Digital, Triaxial Acceleration Sensor. August 2011. Available online: https://pdf1.alldatasheet.com/datasheet-pdf/view/608862/ETC2/BMA220.html (accessed on 3 June 2023).
- InvenSense. MPU-3000/MPU-3050, Motion Processing UnitProduct Specification. Rev. 2.7. November 2011. San Jose, CA, USA. Available online: https://invensense.tdk.com/wp-content/uploads/2015/02/PS-MPU-3050A-00-v2-7.pdf (accessed on 3 June 2023).
- Yamaha. YAS530, MS-3E - Magnetic Field Sensor Type 3E. Yamaha. 2010. Japan. Available online: https://www.datasheets360.com/pdf/6160238513738637956 (accessed on 3 June 2023).
- Mourcou, Q.; Fleury, A.; Franco, C.; Klopcic, F.; Vuillerme, N. Performance evaluation of smartphone inertial sensors measurement for range of motion. Sensors 2015, 15, 23168–23187. [Google Scholar] [CrossRef] [PubMed] [Green Version]
- IEEE. 2700-2014-IEEE Standard for Sensor Performance Parameter Definitions; IEEE: Piscataway, NJ, USA, 2014; pp. 1–64. ISBN 78-0-7381-9252-9. Available online: https://ieeexplore.ieee.org/servlet/opac?punumber=8277145 (accessed on 3 June 2023).
- Weiss, G.M.; Yoneda, K.; Hayajneh, T. Smartphone and smartwatch-based biometrics using activities of daily living. IEEE Access 2019, 7, 133190–133202. [Google Scholar] [CrossRef]
- Chollet, F. Deep Learning with Python; Tony Arritola: New York, NY, USA, 2018. [Google Scholar]
- Vaizman, Y.; Ellis, K.; Lanckriet, G.; Weibel, N. Extrasensory app: Data collection in-the-wild with rich user interface to self-report behavior. In Proceedings of the 2018 CHI Conference on Human Factors in Computing Systems, Montreal, QC, Canada, 21–26 April 2018; pp. 1–12. [Google Scholar]
- Shen, S.; Wu, X.; Sun, P.; Zhou, H.; Wu, Z.; Yu, S. Optimal privacy preservation strategies with signaling Q-learning for edge-computing-based IoT resource grant systems. Expert Syst. Appl. 2023, 225, 120192. [Google Scholar] [CrossRef]
- Ge, W.; Mou, G.; Agu, E.O.; Lee, K. Heterogeneous Hyper-Graph Neural Networks for Context-aware Human Activity Recognition. In Proceedings of the 21st International Conference on Pervasive Computing and Communications (PerCom 2023), Atlanta, GA, USA, 13–17 March 2023. [Google Scholar]




{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
| Sensor | Description |
|---|---|
| Accelerometer | Tri-axial direction and magnitude of acceleration. |
| Gyroscope | Rate of rotation around phone’s three axes. |
| Magnetometer | Tri-axial direction and magnitude of the magnetic field. |
| Smartwatch compass | Watch heading (degrees). |
| Gravity | Estimated gravity. |
| Loc | Latitude, longitude, altitude, speed, accuracies, and quick location variability. |
| PS | App state, battery state, WiFi availability, on the phone, time of day. |
| Feature | Description | Equation |
|---|---|---|
| AV | Coefficient average | |
| F[0] | Signal DC value | |
| SD | Standard deviation | |
| MIN | Minimum value | |
| MAX | Maximum value | |
| RG | Range | |
| FQ | First quartile | term |
| SQ | Second quartile | |
| RMS | RMS value | RMS = |
| MED | Median | for N even for N odd |
| Parameter | Value | Activation Function |
|---|---|---|
| Max Input Layer | 130 (frequency) 92 (time) | ReLU |
| Hidden layer 1 | 64 neurons | ReLU |
| Dropout layer | 0.3 | |
| Hidden layer 2 | 128 neurons | ReLU |
| Output layer | No. of labels | Softmax |
| Optimizer | Adam | |
| Learning rate | 0.001 | |
| Loss function | Sparce Categorical Cross-Entropy | |
| Batch size | 10 |
| Number of Sensors | Number of Experiments |
|---|---|
| 1 | 5 |
| 2 | 10 |
| 3 | 10 |
| 4 | 5 |
| 5 | 1 |
| Total | 31 |
| Sensor | Samples | Lying Down | Sitting | Walking | Running | Bicycling | Standing |
|---|---|---|---|---|---|---|---|
| Acc | 51,159 | 18,174 | 19,353 | 3173 | 723 | 2421 | 7315 |
| Gyr | 48,936 | 17,597 | 18,407 | 2986 | 711 | 2374 | 6861 |
| Mag | 46,152 | 17,044 | 17,467 | 2592 | 635 | 2082 | 6332 |
| Compass | 24,104 | 4477 | 11,038 | 1448 | 405 | 1606 | 5130 |
| Gra | 48,936 | 17,597 | 18,407 | 2986 | 711 | 2374 | 6861 |
| Sensors | Samples | Lying Down | Sitting | Walking | Running | Bicycling | Standing |
|---|---|---|---|---|---|---|---|
| Acc + Gyr | 48,936 | 17,597 | 18,407 | 2986 | 711 | 2374 | 6861 |
| Acc + Mag | 46,152 | 17,044 | 17,467 | 2592 | 635 | 2082 | 6332 |
| Acc + Compass | 24,104 | 4477 | 11,038 | 1448 | 405 | 1606 | 5130 |
| Acc + Gra | 48,936 | 17,597 | 18,407 | 2986 | 711 | 2374 | 6861 |
| Mag + Gyr | 46,152 | 17,044 | 17,467 | 2592 | 635 | 2082 | 6332 |
| Mag + Gra | 46,152 | 17,044 | 17,467 | 2592 | 635 | 2082 | 6332 |
| Mag + Compass | 21,724 | 4231 | 10,089 | 1190 | 370 | 1372 | 4472 |
| Gyr + Gra | 48,936 | 17,597 | 18,407 | 2986 | 711 | 2374 | 6861 |
| Gyr + Compass | 23,372 | 4413 | 10,661 | 1417 | 404 | 1601 | 4876 |
| Gra + Compass | 23,372 | 4413 | 10,661 | 1417 | 404 | 1601 | 4876 |
| Sensors | Samples | Lying Down | Sitting | Walking | Running | Bicycling | Standing |
|---|---|---|---|---|---|---|---|
| Acc + Gyr + Mag | 46,152 | 17,044 | 17,467 | 2592 | 635 | 2082 | 6332 |
| Acc + Gyr + Compass | 23,372 | 4413 | 10,661 | 1417 | 404 | 1601 | 4876 |
| Acc + Gyr + Gra | 48,936 | 17,597 | 18,407 | 2986 | 711 | 2374 | 6861 |
| Acc + Mag + Compass | 21,724 | 4231 | 10,089 | 1190 | 370 | 1372 | 4472 |
| Acc + Gra + Compass | 23,372 | 4413 | 10,661 | 1417 | 404 | 1601 | 4876 |
| Acc + Mag + Gra | 46,152 | 17,044 | 17,467 | 2592 | 635 | 2082 | 6332 |
| Gyr + Mag + Compass | 21,724 | 4231 | 10,089 | 1190 | 370 | 1372 | 4472 |
| Gyr + Gra + Compass | 23,372 | 4413 | 10,661 | 1417 | 404 | 1601 | 4876 |
| Gyr + Mag + Gra | 46,152 | 17,044 | 17,467 | 2592 | 635 | 2082 | 6332 |
| Mag + Gra + Compass | 21,724 | 4231 | 10,089 | 1190 | 370 | 1372 | 4472 |
| Acc + Gyr + Mag + Compass | 21,724 | 4231 | 10,089 | 1190 | 370 | 1372 | 4472 |
| Acc + Gyr + Mag + Gra | 46,152 | 17,044 | 17,467 | 2592 | 635 | 2082 | 6332 |
| Acc + Gyr + Gra + Compass | 23,372 | 4413 | 10,661 | 1417 | 404 | 1601 | 4876 |
| Acc + Mag + Gra + Compass | 21,724 | 4231 | 10,089 | 1190 | 370 | 1372 | 4472 |
| Gyr + Mag + Gra + Compass | 21,724 | 4231 | 10,089 | 1190 | 370 | 1372 | 4472 |
| Acc + Gyr + Mag + Gra + Compass | 21,724 | 4231 | 10089 | 1190 | 370 | 1372 | 4472 |
| No. of Sensors | Primary Network | Secondary (Sitting) | Secondary (Standing) | Secondary (Walking) | Secondary (Lying) |
|---|---|---|---|---|---|
| 1 sensor | 73.0% | 66.6% | 51.2% | 50.9% | 50.0% |
| 2 sensors | 77.8% | 73.2% | 54.0% | 51.9% | 50.4% |
| 3 sensors | 83.4% | 78.5% | 54.0% | 52.1% | 51.9% |
| 4 sensors | 84.2% | 78.9% | 56.3% | 51.8% | 51.3% |
| 5 sensors | 84.6% | 77.7% | 57.9% | 54.6% | 58.2% |
| 5 sensors + Loc and PS | 96.4% | 83.6% | 64.2% | 54.1% | 57.3% |
| Label | BA (Mean ± SD) | Sensitivity (Mean ± SD) |
|---|---|---|
| Standing | 72.8 ± 5% | 51.3 ± 13% |
| Sitting | 81.2 ± 6% | 85.4 ± 12% |
| Lying Down | 91.1 ± 5% | 89.0 ± 4% |
| Running | 86.1 ± 7% | 72.3 ± 16% |
| Walking | 71.7 ± 7% | 45.7 ± 11% |
| Bicycling | 85.1 ± 6% | 71.3 ± 12% |
| Label | BA |
|---|---|
| Talking | 97.0% |
| Sleeping | 95.1% |
| Eating | 79.8% |
| Watching TV | 91.8% |
| Surfing the Internet | 92.6% |
| With Friends | 73.4% |
| Computer Work | 96.6% |
| With Co-Workers | 84.7% |
| OVERALL | 88.9% |
| Technique | Primary Network | Secondary (Standing) | Secondary (Sitting) | Secondary (Lying Down) | Secondary (Walking) |
|---|---|---|---|---|---|
| ExtraSensory App | 76.0% | 74.5% | 87.0% | 78.3% | 81.6% |
| HHAR (time) | 87.1% | 57.3% | 80.6% | 52.7% | 55.5% |
| HHAR (frequency) | 85.1% | 58.4% | 72.8% | 50.1% | 50.8% |
| Technique | Secondary (Standing) | Secondary (Sitting) | Secondary (Lying Down) | Secondary (Walking) |
|---|---|---|---|---|
| ExtraSensory App | 74.5% | 87.0% | 78.3% | 81.6% |
| HHAR (time) | 70.6% | 91.4% | 50.5% | 82.5% |
| HHAR (frequency) | 79.5% | 91.6% | 90.0% | 82.9% |
| Technique | BA |
|---|---|
| HHAR (time) | 86.7% |
| HHAR (frequency) | 88.4% |
Disclaimer/Publisher’s Note: The statements, opinions and data contained in all publications are solely those of the individual author(s) and contributor(s) and not of MDPI and/or the editor(s). MDPI and/or the editor(s) disclaim responsibility for any injury to people or property resulting from any ideas, methods, instructions or products referred to in the content. |
© 2023 by the authors. Licensee MDPI, Basel, Switzerland. This article is an open access article distributed under the terms and conditions of the Creative Commons Attribution (CC BY) license (https://creativecommons.org/licenses/by/4.0/).
Share and Cite
de Souza, P.; Silva, D.; de Andrade, I.; Dias, J.; Lima, J.P.; Teichrieb, V.; Quintino, J.P.; da Silva, F.Q.B.; Santos, A.L.M. A Study on the Influence of Sensors in Frequency and Time Domains on Context Recognition. Sensors 2023, 23, 5756. https://doi.org/10.3390/s23125756
de Souza P, Silva D, de Andrade I, Dias J, Lima JP, Teichrieb V, Quintino JP, da Silva FQB, Santos ALM. A Study on the Influence of Sensors in Frequency and Time Domains on Context Recognition. Sensors. 2023; 23(12):5756. https://doi.org/10.3390/s23125756
Chicago/Turabian Stylede Souza, Pedro, Diógenes Silva, Isabella de Andrade, Júlia Dias, João Paulo Lima, Veronica Teichrieb, Jonysberg P. Quintino, Fabio Q. B. da Silva, and Andre L. M. Santos. 2023. "A Study on the Influence of Sensors in Frequency and Time Domains on Context Recognition" Sensors 23, no. 12: 5756. https://doi.org/10.3390/s23125756
APA Stylede Souza, P., Silva, D., de Andrade, I., Dias, J., Lima, J. P., Teichrieb, V., Quintino, J. P., da Silva, F. Q. B., & Santos, A. L. M. (2023). A Study on the Influence of Sensors in Frequency and Time Domains on Context Recognition. Sensors, 23(12), 5756. https://doi.org/10.3390/s23125756