
An Implementation of Inverse Cosine Hardware for Sound Rendering Applications


Abstract
:1. Introduction
2. Background
2.1. Data Format
2.2. Linear Approximation for Trigonometric Functions
2.3. Look-Up Table
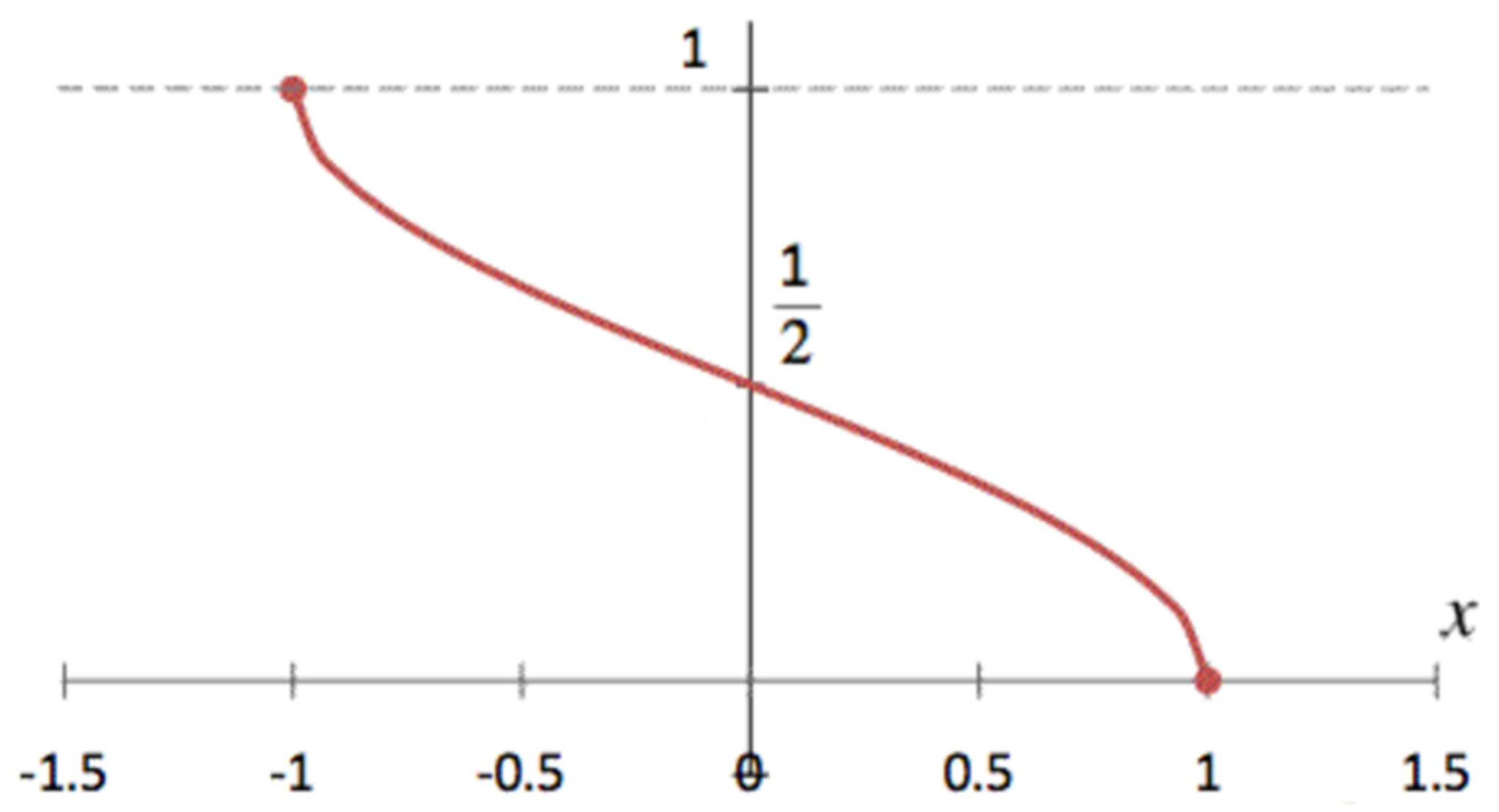
2.4. Applying Linear Interpolation and Lookup Table for the Inverse Cosine Function
3. Proposed Inverse Cosine Hardware
3.1. Design Decisions
3.2. Approximation Method for Inverse Cosine Function
3.3. Proposed Inverse Cosine Function Hardware
4. Experiment
4.1. Experiment Environment
4.2. Error Analysis
4.3. ASIC Evaluation
5. Conclusions
Author Contributions
Funding
Institutional Review Board Statement
Informed Consent Statement
Data Availability Statement
Conflicts of Interest
References
- Wang, D.; Muller, J.M.; Brisebarre, N.; Ercegovac, M.D. (M, p, k)-Friendly Points: A Table-Based Method to Evaluate Trigonometric Function. IEEE Trans. Circuits Syst. II Express Briefs 2014, 61, 711–715. [Google Scholar]
- Fowkes, R.E. Hardware efficient algorithms for trigonometric functions. IEEE Trans. Comput. 1993, 42, 235–239. [Google Scholar] [CrossRef] [Green Version]
- Kumar, P.A. FPGA implementation of the trigonometric functions using the CORDIC algorithm. In Proceedings of the 2019 5th International Conference on Advanced Computing & Communication Systems (ICACCS), Coimbatore, India, 15–16 March 2019; pp. 894–900. [Google Scholar]
- Detrey, J.; de Dinechin, F. Floating-point trigonometric functions for FPGAs. In Proceedings of the 2007 International Conference on Field Programmable Logic and Applications, Amsterdam, The Netherlands, 27–29 August 2007; pp. 29–34. [Google Scholar]
- De Dinechin, F.; Istoan, M.; Sergent, G. Fixed-point trigonometric functions on FPGAs. ACM SIGARCH Comput. Archit. News 2014, 41, 83–88. [Google Scholar] [CrossRef] [Green Version]
- Kim, E.; Choi, S.; Kim, C.G.; Park, W.C. Multi-Threaded Sound Propagation Algorithm to Improve Performance on Mobile Devices. Sensors 2023, 23, 973. [Google Scholar] [CrossRef] [PubMed]
- Taylor, M.T.; Chandak, A.; Antani, L.; Manocha, D. Resound: Interactive sound rendering for dynamic virtual environments. In Proceedings of the 17th ACM International Conference on Multimedia, Mountain View, CA, USA, 23 October 2009; pp. 271–280. [Google Scholar]
- Kim, M.; Jeon, C.; Kim, J. A study on immersion and presence of a portable hand haptic system for immersive virtual reality. Sensors 2017, 17, 1141. [Google Scholar] [CrossRef] [PubMed] [Green Version]
- Kim, K.; Kim, J.; Choi, J.; Kim, J.; Lee, S. Depth camera-based 3D hand gesture controls with immersive tactile feedback for natural mid-air gesture interactions. Sensors 2015, 15, 1022–1046. [Google Scholar] [CrossRef] [PubMed] [Green Version]
- Sim, D.; Baek, Y.; Cho, M.; Park, S.; Sagar, A.S.; Kim, H.S. Low-latency haptic open glove for immersive virtual reality interaction. Sensors 2021, 21, 3682. [Google Scholar] [CrossRef] [PubMed]
- Raghuvanshi, N.; Narain, R.; Lin, M.C. Efficient and accurate sound propagation using adaptive rectangular decomposition. IEEE Trans. Vis. Comput. Graph. 2009, 15, 789–801. [Google Scholar] [CrossRef] [PubMed]
- Aggarwal, S.; Khare, K. Hardware efficient architecture for generating sine/cosine waves. In Proceedings of the 2012 25th International Conference on VLSI Design, Massachusetts Ave, Washington, DC, USA, 7–11 January 2012; pp. 57–61. [Google Scholar]
- Volder, J.E. The CORDIC trigonometric computing technique. IRE Trans. Electron. Comput. 1959, EC-8, 330–334. [Google Scholar] [CrossRef]
- Walther, J.S. A unified algorithm for elementary functions. In Proceedings of the Spring Joint Computer Conference, Atlantic City, NJ, USA, 18–20 May 1971; pp. 379–385. [Google Scholar]
- Koren, I.; Zinaty, O. Evaluating elementary functions in a numerical coprocessor based on rational approximations. IEEE Trans. Comput. 1990, 39, 1030–1037. [Google Scholar] [CrossRef]
- Gal, S. Computing elementary functions: A new approach for achieving high accuracy and good performance. In Proceedings of the Accurate Scientific Computations: Symposium, Bad Neuenahr, FRG, Heidelberg, Berlin, Germany, 2–14 March 1985; pp. 1–16. [Google Scholar]
- Tang, P.T.P. Table-Lookup Algorithms for Elementary Functions and their Error Analysis. In Proceedings of the 10th IEEE Symposium on Computer Arithmetic, Grenoble, France, 26–28 June 1991. [Google Scholar]
- Gal, S. An accurate elementary mathematical library for the IEEE floating point standard. ACM Trans. Math. Softw. TOMS 1991, 17, 26–45. [Google Scholar] [CrossRef]
- Scalar, N. Vector Elementary Functions for the IBM System/370, by Ramesh C. Agarwal et al. IMB J. Res. Develop. 1986, 30, 126. [Google Scholar]
- Nguyen, M.X.; Dinh-Duc, A.V. Hardware-based algorithm for Sine and Cosine computations using fixed point processor. In Proceedings of the 2014 11th International Conference on Electrical Engineering/Electronics, Computer, Telecommunications and Information Technology (ECTI-CON), Nakhon Ratchasima, Thailand, 14–17 May 2014; pp. 1–6. [Google Scholar]
- Nah, J.H.; Kwon, H.J.; Kim, D.S.; Jeong, C.H.; Park, J.; Han, T.D.; Manocha, D.; Park, W.C. RayCore: A ray-tracing hardware architecture for mobile devices. ACM Trans. Graph. TOG 2014, 33, 162. [Google Scholar] [CrossRef]
- Hong, D.; Lee, T.H.; Joo, Y.; Park, W.C. Real-time sound propagation hardware accelerator for immersive virtual reality 3D audio. In Proceedings of the 21st ACM SIGGRAPH Symposium on Interactive 3D Graphics and Games, Association for Computing Machinery, New York, NY, USA, 25–27 February 2017; pp. 1–2. [Google Scholar]
- Hastings, C., Jr.; Wayward, J.T.; Wong, J.P., Jr. Approximations for Digital Computers; Princeton University Press: Princeton, NJ, USA, 2015; p. 2040. [Google Scholar]
- Paul, S.; Jayakumar, N.; Khatri, S.P. A fast hardware approach for approximate, efficient logarithm and antilogarithm computations. IEEE Trans. Very Large Scale Integr. VLSI Syst. 2008, 17, 269–277. [Google Scholar] [CrossRef] [Green Version]
- Yousif, R.K.; Hashim, I.A.; Abd, B.H. FPGA Implementation of Polynomial Curve Fitting Approximation for Sine and Cosine Generator. In Proceedings of the 2022 5th International Conference on Engineering Technology and Its Applications (IICETA), AI-Najaf, Iraq, 31 May–1 June 2022; pp. 361–366. [Google Scholar]
- Kouyoumjian, R.G.; Pathak, P.H. A uniform geometrical theory of diffraction for an edge in a perfectly conducting surface. Proc. IEEE 1974, 62, 1448–1461. [Google Scholar] [CrossRef] [Green Version]








{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
| Divided Sections | ||||||
|---|---|---|---|---|---|---|
| k | 1 | 2 | 3 | - | Second to Last Section | Last Section |
| Gradient | ||||||
| 64 | −0.31 | −0.31 | −0.31 | - | −1.50 | −3.60 |
| 128 | −0.31 | −0.31 | −0.31 | - | −2.11 | −5.09 |
| 256 | −0.31 | −0.31 | −0.31 | - | −2.98 | −7.20 |
| 512 | −0.31 | −0.31 | −0.31 | - | −4.22 | −10.18 |
| ka for Domain [0, 1] (Main Domain) | kb for Section with Sharp Slope (Sub-Domain) | Total Entries | |
|---|---|---|---|
| (a) | 24 | 29 | 527 |
| (b) | 25 | 28 | 287 |
| (c) | 27 (26) | 26 (27) | 191 |
| k | 64 | 128 | 256 | 512 |
|---|---|---|---|---|
| F_input | 0.9850 | 0.9926 | 0.9964 | 0.9983 |
| Maximum Error Value | 0.01405 | 0.0099 | 0.0070 | 0.0049 |
| Reduction Rate of MEV | Standard | 70.764 | 70.747 | 70.659 |
| LUT | REGISTER | BLOCK MEMORY | URAM | |
|---|---|---|---|---|
| Used | 224 | 58 | 0.5 | 0 |
| Available | 1,728,000 | 3,456,000 | 2688 | 1280 |
| Utilization (%) | 0.01 | <0.01 | 0.02 | 0 |
| Total Area (μm2) | Gate Counts | Operation Frequency | |
|---|---|---|---|
| Inverse Cosine Hardware | 2672.7 | 7342 | 769 Mhz |
Disclaimer/Publisher’s Note: The statements, opinions and data contained in all publications are solely those of the individual author(s) and contributor(s) and not of MDPI and/or the editor(s). MDPI and/or the editor(s) disclaim responsibility for any injury to people or property resulting from any ideas, methods, instructions or products referred to in the content. |
© 2023 by the authors. Licensee MDPI, Basel, Switzerland. This article is an open access article distributed under the terms and conditions of the Creative Commons Attribution (CC BY) license (https://creativecommons.org/licenses/by/4.0/).
Share and Cite
Lee, J.; Kim, C.-G.; Moon, Y.-K.; Park, W.-C. An Implementation of Inverse Cosine Hardware for Sound Rendering Applications. Sensors 2023, 23, 6731. https://doi.org/10.3390/s23156731
Lee J, Kim C-G, Moon Y-K, Park W-C. An Implementation of Inverse Cosine Hardware for Sound Rendering Applications. Sensors. 2023; 23(15):6731. https://doi.org/10.3390/s23156731
Chicago/Turabian StyleLee, Jinyoung, Cheong-Ghil Kim, Yeon-Kug Moon, and Woo-Chan Park. 2023. "An Implementation of Inverse Cosine Hardware for Sound Rendering Applications" Sensors 23, no. 15: 6731. https://doi.org/10.3390/s23156731