1. Introduction
Activities of daily living (ADL) are a type of activity performed daily and repetitively. ADL relates to the personal tasks performed to sustain healthy living. The types of activity include eating, food preparation, reading, and dressing. In the medical literature, ADL is categorized according to its functional purpose. In the work by [
1], a hierarchical division of activities is used. At the highest level, ADL is divided into hygiene, food-related, and entertainment. It is of interest to monitor a person’s ADL if they are afflicted by disease or due to aging factors. Such factors cause ADL impairment that warrants close supervision by doctors and their caretakers.
In smart homes, vision-based activity recognition is used to observe the person’s image and predict their actions. This helps in several aspects, such as entertainment (playing favorite music, turning on TV channel, turning on the Aircon), daily assistance (turning on/off lighting, opening fridge, turning on the water heater, opening windows and doors, watering the plants, notifications to feed pets), health care (medicine time alarms, elderly fall detection), and security and surveillance (attacker recognition). In a smart city, vision-based activity recognition can also help to reduce the crime rate by detecting violent actions and sending alarms to police. Additionally, notifying fatigued drivers by detecting their actions can play a role in reducing car accidents. Furthermore, the detection of non-suicidal self-injury based on the spatiotemporal features of indoor activities was another application for human activity recognition [
2].
The assessment of ADL is commonly performed in hospitals using standardized methods such as SCIM measure [
3]. This procedure requires the caretaker to observe the patient for a long duration to assess if a person can perform the activities. The ADL performance is graded depending on the ability of the person to perform ADL independently, require partial assistance, or require total continuous assistance. Such an assessment takes a long time and is best performed at home so that the human behavior can be naturally observed. In this paper, an effective algorithm to classify videos into a set of pre-defined daily living activities is proposed. The system is capable of automatic video clip classification based on ADL events and thus supports various video analytics for healthcare monitoring. This contributes to more efficient patient monitoring and better diagnosis of a patient’s health status, thus facilitating timely intervention and rehabilitation.
Egocentric vision study images acquired from a first-person or camera-wearer perspective compares the conventional third-person perspective where the image is captured from an external observer. With the proliferation of small portable and wearable cameras, it is now easy to collect a large number of egocentric videos. The video can be used for the semantic understanding of the activities in a naturalistic setting. Egocentric video is useful for many applications related to daily living analysis. It is easy to set up and involves just wearing the camera. However, there are several inherent difficulties and challenges, including continuously moving cameras that lead to motion blur problems. Algorithms that rely on motion patterns are affected by unknown motion dynamics. In a realistic scenario, background clutter and large variations in how the activity is executed pose large intra-class variation. Additionally, an activity performed by numerous persons and in various locations exhibits high variations. Furthermore, different activity classes also share similar appearance patterns, and this leads to small inter-class variance. To address this issue, robust features are needed to discriminate between different activity classes, and these features should be invariant to intra-class variations.
Feature representation plays an important role in many classification tasks. Before a data sample can be classified, each sample must be encoded with suitable features in a fixed dimensional vector. This provides compact numerical representation of the data sample for discriminating between different activity classes. Moreover, a good feature vector allows a simpler classifier to predict accuracies with high generalization, whereas a weak feature vector requires a more complex classifier. This paper studies visual feature representations that are obtained from convolutional neural networks (CNNs). Such a network usually performs well when it is trained with a large image dataset such as ImageNet [
4]. To overcome the lack of training samples, many methods use pre-trained CNN for image and video classification. However, such studies in the egocentric video domain are still limited. Egocentric video has unique properties due to the importance of objects that help to predict activity being undertaken. Due to the difference in viewpoint, images in egocentric perspective appear different from the images in the ImageNet dataset. This paper aims to study the utility of features from pre-trained CNN for representing egocentric video frames. A novel CNN-based feature extraction technique that incorporates spatial and temporal pooling is proposed and evaluated. Features are extracted from individual video frames by taking the activation of the last convolution layer. The extracted deep convolutional feature vectors are aggregated with the use of average and max spatial pooling to obtain the proposed MMSP feature. Finally, the MMSP frame feature is integrated with both max and average temporal pooling as well. Experiment results highlight the strong performance of the proposed solution.
Even though there are recent CNNs, VGG network is still a popular deep learner and widely used in many applications. It has shown superior performance at image classification, and it is able to generalize well to the related tasks. VGG-16 is selected because it can balance good performance and fewer parameters.
The contributions of this work are summarized as follows:
We evaluated and compared two different sets of features that can be obtained from a pre-trained CNN, namely VGG16. The first feature set includes features from the fully connected layer (fc7), and the second feature set includes features from the last convolutional layer after pooling (fv-pool5).
We performed an ablation study to show the advantage of aggregating appearance and motion features for daily activity recognition.
We proposed a fusion of two methods, including mean and max spatial pooling (MMSP) and max mean temporal pyramid (TPMM) pooling to compose the final video descriptor.
2. Related Works
The use of an egocentric perspective for video-based activity recognition has become increasingly popular due to the widespread use of the wearable camera. The advancement of camera technology resulted in smaller compact devices and longer battery lifespan. This helps to facilitate the use of wearable cameras for activity recognition.
The typical activity recognition pipeline consists of a feature extraction phase followed by classification phase. For example, Internet of Healthcare Things systems have extensively emerged since the Industry 4.0 revolution [
5]. They used accelerometers and gyroscope sensors in smartphones to collect the data of handcrafted features obtained from the motion and acceleration signal. Random Forest is used as the classifier to recognize actions. This differs from vision-based activity recognition, where feature extraction is performed on the video frames and is mainly characterized by the types of features used. The important cues for egocentric video classification are the hand pose, objects used, visual features, motion patterns, and gaze points of the scene. This differs from the conventional activity classification from the third-person perspective. In this perspective, activity is observed by an external observer and uses RGB with depth images [
6] and skeleton information [
7,
8].
The activity recognition approaches can be categorized into techniques that use manual feature engineering (handcrafted features) and the more recent methods that use features learned from training data. To extract visual features, the manual feature extraction approach typically uses image-based heuristics that have been known to perform well in image recognition task [
9,
10]. The same feature extraction technique is applied to extract visual features from the video frames. Motion-based features are borrowed from the one used in action recognition from a third-person perspective (TPR) [
11,
12]. However, the major problem with the manual feature engineering approach is the need to customize the feature design for different tasks, and this involves a large amount of manual trials and human expertise. The feature-learning approach solves this problem by automatically learning from the training data related to the vision task. This results in a feature vector that is highly discriminative.
Early work on egocentric activity recognition uses handcrafted features adopted from the technique used in the image recognition domain. One of the important works in Daily Activity Recognition was conducted by Pirsiavash and Ramanan [
1]. They proposed a challenging dataset (ADL) that shows unscripted daily activities being performed by multiple persons in various locations. To capture the notion that daily living activities are object-based, the presence and absence of key objects are used as discriminative cues. The visual features extracted from each video frame are based on object detection scores for a few relevant objects. The objects are divided into active and passive categories: passive objects appear in the video frame as contextual information while active objects are objects that are manipulated when the activity is being performed by the camera wearer. The use of separate active and passive object detectors is motivated by the distinctive change in appearance when the object is manipulated, and thus change from a passive to active state and then back to a passive state. The object detection scores are aggregated in a two-level temporal pyramid to exploit the temporal ordering of the features. This pioneer work was further improved by [
13], which proposed to learn via a boosting method the spatiotemporal partitions of the pyramid that helped to discriminate the activities. This compares to the earlier work by Pirsiavash and Ramanan [
1] that assumed equally spaced partitions for the temporal pyramid and did not use spatial partition. However, only a small improvement was observed. This is due to the use of object detectors based on hand-crafted features, which perform poorly on the unconstrained dataset. Another researcher [
14] tried to use the salient region predicted from the video frame in the ADL dataset. This salient region attracted gaze points or human attention and thus might contain useful objects that could help in discriminating the activities. Active and passive objects were detected and further classified as salient or non-salient depending on the computed saliency score of the detected regions. This led to a slight improvement in activity recognition and accuracy.
In the work proposed by González Díaz et al. [
15], daily activity recognition was performed by relying on an image classification score for a selected set of relevant ADL objects. Object-centric representation was obtained based on the local SURF [
16] features aggregated using a Bag of Word method. This is different from the work proposed by Pirsiavash and Ramanan [
1], which used a parts-based object detection method that required exhaustive scanning of the whole video frame. Improved performance was observed when a predicted scene category was used and when the aggregated feature was weighted by a saliency map obtained from spatial, temporal, and geometric saliency measures.
Features from a deep convolutional neural network (CNN) pre-trained on a large image dataset such as ImageNet have been shown to be useful as discriminative visual features for many image classification problems [
17]. In [
18], the visual features were obtained from the first fully connected layer of the CNN network. The model was trained to perform object classification on the ILSVRC13 dataset. The recognition performance using the CNN feature outperformed many state-of-the-art handcrafted feature methods in many image classification problems. This shows that features from pre-trained CNN on a large image dataset can be used as a powerful visual feature for different image classification problems.
The CNN features have also been extended to be used for video classification tasks [
19,
20]. Jiang et al. [
21] used the outputs of the seventh fully connected layer of the AlexNet model [
22]. Karpathy et al. [
23] used a CNN model that fused features obtained from different video frames and predicted action categories in web-based videos. One interesting result shows that single-frame model performance is comparable to multi-frame model. Zha et al. [
24] employed image-trained CNN features from the VGG model [
25]. The output of the fully connected and class softmax layer is used as a frame descriptor. Since the number of frames in a video varies, uniform frame sampling was used. The video descriptor was obtained by performing spatial and temporal pooling of the frame-based features.
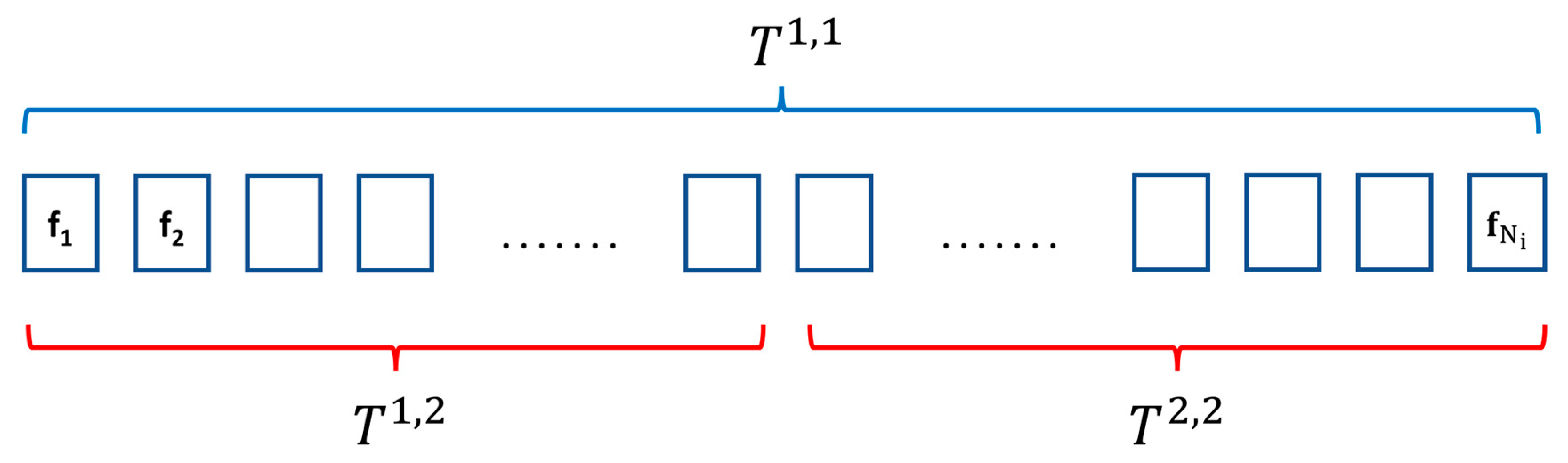
The CNN features are also used for egocentric video classification. The processing pipeline is similar to video classification for a third-person perspective. The major design issues lie in the selection of different CNN features and the pooling of the frame to form a video descriptor. To incorporate temporal dependencies within video frames, previous techniques applied time series temporal pooling [
26] and temporal pyramid of object detection scores [
1] to aggregate features to form a fixed-length representation of input to be applied to the classifier. Efficient temporal pooling methods are crucial to preserve salient temporal information from the video frames. Recent work by [
27,
28] showed that detecting the region where object manipulation takes place is important. This is known as the interactional image region where the activity is observed. The region frequently shows the hand manipulating selected objects related to the activity. Encoding objects and motion-based features from such a region has been shown to provide strong cues for predicting ongoing activity. In the work by Zhou et al. [
27], the foreground region related to the activity was detected by combining hand segmentation, salient region detection from CNN convolutional features, and motion maps from the estimated optical flow field. These three feature maps were stacked as a volumetric input sequence to the bounding box regression network based on VGG-16 in order to predict the interactional region. Another paper [
28] directly trained an object detector of the Faster-RCNN-ResNet 101 model. The object annotation from the ADL dataset was used. The detected object was tracked at 15 fps and motion features were extracted from the detected object regions in 2 to 3 seconds of video frames. The tracked motion is encoded as a boundary histogram feature (MBH) [
11] and a Histogram of Oriented Flow (HOF) [
29]. The local motion features obtained from the video were aggregated via Fisher vector encoding to form a final video descriptor for activity classification. Another study employed fine-tuned YOLO-v4 for activity detection and 3D-CNN for recognition using a UCF-Crime dataset [
30].
A sensor data contribution analysis method based on status frequency-inverse frequency was proposed for human activity. Spatial distance matrix for context-awareness of cross-activities was found. Novel wide time–domain CNN (WCNN, a powerful parallel feature extraction) was able to save time and produce good performance [
31].
Although multiple methods that use CNN for video classification have been proposed, there is still a lack of study on the use of convolutional features for content understanding in egocentric videos. Most existing works used the fully connected layer to obtain video frame features. This representation lacks spatial composition of the visual pattern. On the contrary, features from the convolutional layer give filter activations at relative spatial locations of the image. Additionally, these features are less biased to the concept used in ImageNet dataset. Thus, they can be a useful generic feature for frame-based representation.
In this paper, the use of a pre-trained image CNN for extracting features from egocentric video frame is studied. A new spatial pooling of the convolutional features extracted from a pre-trained CNN is proposed and evaluated. Additionally, a temporal pyramid method is proposed to aggregate the CNN features extracted from the sequence of adjacent video frames. This differs from the work in [
1] that requires a number of object detections to be performed for each video frame. Using a bank of object detectors is time-consuming and is sensitive to detection accuracy. Instead of running multiple object detectors, the proposed method uses a pre-trained CNN to extract visual features from each frame, and the features are pooled to form a fixed-length feature vector. The feature vector is used by SVM for multi-class classification in a one-vs.-all configuration.
The organization of this paper is as follows: The introduction to the problem and the data used is described in
Section 3. Furthermore, the approaches of CNN-based feature extraction, optical flow, and spatial and temporal pooling are also demonstrated in this section. The description of the three public datasets is described in
Section 4. Moreover,
Section 4 discusses the experiments conducted in this study and analyzes the results by comparing the proposed method with state-of-the-art methods. Finally, in
Section 5, the outcome of this work is summarized to give the readers a glimpse into potential improvements in the future.
5. Conclusions
In this paper, a novel fusion method was proposed to aggregate appearance and motion features and then combine mean and max spatial pooling (MMSP) with max mean temporal pyramid (TPMM) pooling to compose the final video descriptor. We targeted egocentric videos that involve activities of daily living. In such activities, the manipulation of objects is an important cue. The feature representation is designed to capture generic visual patterns that represent the fine-grained object parts and the spatial arrangement of these parts in the image. To extract motion, the technique of converting an optical flow field into an image representation is used. The pre-trained CNN (VGG16) is utilized to extract visual features for both video frames and optical flow images. The spatial and temporal redundancies of visual contents in the egocentric video are exploited by using mean and max spatial pooling (MMSP) for the frame features and max mean temporal pyramid (TPMM) pooling for the video clip. The proposed video descriptor MMSP–TPMM is evaluated in several experiments on three public benchmark datasets. Additionally, comparisons with alternative feature configurations and handcrafted feature methods are made. All the results show improvement in activity classification performance when the proposed solution is used. The fusion of frame appearance and motion features also shows classification performance enhancement, even though the egocentric video is unstable.
Although the proposed method for video features works well when compared to competing methods, there are several limitations. Firstly, the max pooling method will only take the maximum value of the feature over a fixed spatial region. If there are multiple features that are highly activated, only the feature with the maximum value will be taken. This will ignore contributions from other features. For the case of mean pooling, the average value of the feature is influenced by non-important background objects. This will reduce the discrimination strength of the feature. The pooling region is fixed at various spatial regions for the frame feature, and only three different fixed temporal regions are used. A more adaptive temporal pooling scheme may yield a higher discriminative video descriptor.
Given the efficiency of the proposed method, the current limitation is that the model should run on a powerful machine with a large RAM size to consider the model’s parameters and with GPU to obtain high-speed inference. In other words, the current method in its current status cannot run on an embedding system such as a Smartphone with limited RAM and a small processing unit. For future work, we propose replicating the same approach with more computationally efficient CNNs, such as MobileNet or EfficientNetB0, to balance accuracy and inference speed so that we can run the proposed method on an edge-computing IOT for real use of ADL system. Furthermore, we plan to improve the performance of the solution by training a recent pre-trained vision transformer to evaluate their abilities to focus more attention on the targeted objects.
Additionally, employing the proposed method in other real-life applications, such as medical image analysis, can contribute to improving the analysis performance by enhancing the detection of lung cancer tumors in CT scan imaging, considering the motion that needs to be estimated and corrected [
40].










{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}