Abstract
The paper focuses on the importance of prompt and efficient process fault detection in contemporary manufacturing industries, where product quality and safety protocols are critical. The study compares the efficiencies of two techniques for process fault detection: Kernel Principal Component Analysis (KPCA) and the observer method. Both techniques are applied to observe water volume variation within a hydraulic system comprising three tanks. PCA is an unsupervised learning technique used for dimensionality reduction and pattern recognition. It is an extension of Principal Component Analysis (PCA) that utilizes kernel functions to transform data into higher-dimensional spaces, where it becomes easier to separate classes or identify patterns. In this paper, KPCA is applied to detect faults in the hydraulic system by analyzing the variation in water volume. The observer method originates from control theory and is utilized to estimate the internal states of a system based on its output measurements. It is commonly used in control systems to estimate the unmeasurable or hidden states of a system, which is crucial for ensuring proper control and fault detection. In this study, the observer method is applied to the hydraulic system to estimate the water volume variations within the three tanks. The paper presents a comparative study of these two techniques applied to the hydraulic system. The results show that both KPCA and the observer method perform similarly in detecting faults within the system. This similarity in performance highlights the efficacy of these techniques and their potential adaptability in various fault diagnosis scenarios within modern manufacturing processes.
1. Introduction
The contemporary manufacturing landscape necessitates heightened product quality and safety operational practices. To maintain optimal system functionality and reduce downtime in case of failure, the early detection of process faults is critical [1]. Consequently, several process monitoring-based Multivariate Statistical Process (MSP) methods were developed thanks to their efficiencies and simplicity [2,3].
The Kernel Principal Component Analysis (KPCA) method, a simple yet interesting technique developed by Ratch et al. [4], is designed to accurately model nonlinear relationships inherent in process data. Utilizing the principle of kernel tricks [5], KPCA can efficiently project the input data with linearly inseparable structures onto a higher dimensional feature space in which the data become linearly separable, facilitating the execution of conventional Principal Component Analysis (PCA) within the feature space. KPCA has shown good results in analysis, modeling, and fault detection accuracy across a range of applications such as face recognition [6], speech recognition, nonlinear process monitoring, and fault diagnosis [7,8].
The observer-based method is commonly employed in Fault Detection (FD). The fundamental concept behind the observer or filter-based technique involves approximating the system’s states using the collected measurement data. Consequently, the estimated states are compared to the measured states of the monitored system to produce the residual.
Different attempts have addressed the incorporation of the observer in control systems, specifically in the domains of electrical drives [9,10] and robotics [11]. The primary objective when designing the observer for control applications should focus on accurate state estimation.
The estimation of unmeasured states differs from the design of observers for fault detection, which focuses on estimating measured states [12]. Numerous studies have explored observer-based FD in various contexts [13,14,15].
For instance, Khalid et al. [16] detected sensor faults in small autonomous helicopters using Observer/Kalman filter identification. Yang and Liu [17] employed a Kalman filter for fault diagnosis and a hybrid genetic adaptive neuro-fuzzy inference system for fault classification.
Alkaya and Eker [18] introduced a state estimation approach using Kalman filtering to predict failures and prevent maintenance in a DC motor. Tarantino et al. [19] detected sensor faults in DC and BLDC motors using Luenberger observers.
Several issues are emerging, mainly related to fault diagnosis. The majority of them investigate single faults. However, a more intricate issue demands attention, namely the detection and localization of multiple faults-a situation where multiple breakdowns occur and overlap in time. We assess the system using a fault injection approach, where we deliberately introduce faults and observe system responses while adjusting the time parameter each time.
This problem occurs in many industrial systems. Nonetheless, the research dedicated to this domain remains limited due to the complexity of the task and the combinatorial explosion problem. In fact, the complexity of the current systems, with their multiple functionalities, makes them susceptible to multiple faults, which need to be considered simultaneously. The heterogeneity of the data that should be explored for diagnosis poses an additional challenge and requires adapted methods. The purpose of this paper is to propose a method for fault diagnosis in complex physical systems. Techniques derived from machine learning and control theory are used for this purpose, KPCA [20] and the observer method [21,22], respectively. We used KPCA and observer methods to simulate and detect faults in the three-tank system.
The rest of the article is structured as follows: Section 2 presents KPCA and its fault detection index. Section 3 introduces the observer approach and its underlying principles. In Section 4, a comparative study between the observer approach and the kernel method for fault detection in a hydraulic system with three tanks is presented. Conclusions are delivered at the conclusion of the paper.
2. Kernel Principal Component Analysis (KPCA)
Kernel Principal Component Analysis (KPCA) is a nonlinear extension of the traditional Principal Component Analysis (PCA) technique. PCA is a widely used method for dimensionality reduction and feature extraction in data analysis. However, PCA assumes linearity in the data, which limits its applicability to linearly separable or well-behaved datasets.
KPCA overcomes this limitation by employing a kernel function to map the input data into a higher-dimensional feature space, where it becomes easier to find nonlinear relationships and patterns. In this feature space, KPCA applies PCA to extract the principal components, which are the directions of maximum variance in the data.
The kernel function in KPCA allows for implicit computations in the high-dimensional space without explicitly transforming the data. Commonly used kernel functions include the Gaussian (or radial basis function), polynomial, and sigmoid kernels. These kernels measure the similarity or dissimilarity between data points, enabling the extraction of nonlinear features that would be challenging to capture using linear techniques.
The KPCA algorithm involves three main steps: (1) computation of the kernel matrix, which stores the pairwise similarities between data points based on the chosen kernel function, (2) agenda composition of the kernel matrix to obtain the principal components, and (3) projection of the data onto the principal components to obtain the transformed features.
KPCA finds applications in various fields, including computer vision, pattern recognition, bioinformatics, and signal processing. It enables the detection of nonlinear patterns, clustering of complex data, and nonlinear dimensionality reduction. By leveraging the power of nonlinear mapping, KPCA offers a valuable tool for analyzing and extracting meaningful information from high-dimensional and nonlinear datasets for education and analysis [23,24]. It consists of transforming the nonlinear aspects of input data space into linear ones within a newly high-dimensional feature space, denoted , and to perform PCA in that space. The feature space is nonlinearly transformed from the input space with a non-linear mapping function . The mapping of sample in the feature space can be written as:
Let us consider the training data matrix scaled to zero mean and unit variance. Where is a data vector, is the number of observation samples and is the number of process variables.
The monitoring phase based on the linear PCA approach requires the selection of principal components that maximize the variance in the data set. This is accomplished using the eigen decomposition of the covariance matrix. Similarly, this approach was generalized in the Kernel PCA approach by Ratsch [4]. The covariance matrix in the feature space is given by:
Let define the data matrix in the feature space , then can be expressed as:
The principal components of the mapped data are computed by solving the eigenvalue decomposition of , such that:
With being the th eigenvector and the associated th eigenvalue. For , there exist coefficients , such that all eigenvectors can be considered as a linear combination of and can be expressed by:
However, in practice, the mapping function is not defined and then the covariance matrix in the feature space cannot be calculated implicitly. Thus, instead of solving the eigenvalue problem directly on , we apply the kernel trick firstly used for Support Vector Machine (SVM) [25]. The inner product given in Equation (2) may be calculated by a kernel function that satisfies Mercer’s theorem [12] as follows:
Let us define a kernel matrix associated with a kernel function as:
Applying the kernel matrix may reduce the problem of the eigenvalue decomposition of [26]. Hence, eigendecomposition of the kernel matrix is equivalent to performing PCA in , so that:
where is the diagonal matrix of eigenvalues arranged in descending order
and is the matrix of their corresponding eigenvectors.
Since the principal components are orthonormal, it is required to guarantee the normality of in Equation (4), such that:
is the number of the first non-zero eigenvalues.
2.1. Number of Principal Components
Determining the number of retained principal components () is an important step of modeling based on KPCA. The Cumulative Percent Variance (CPV) has been proposed to compute the retained PC () [27,28]. The cumulative percent variance (CPV) is the sum of the first eigenvalues divided by their total variations. It can be expressed as:
The number of retained PCs is chosen if the CPV is higher than 95%.
2.2. Fault Detection
Like in the PCA approach, the squared prediction error (SPE) is usually used for fault detection using KPCA [29,30]. However, the conventional KPCA does not provide any approach to data reconstruction in the feature space. Thus, the computation SPE index is difficult in the KPCA method. Kim [31] and Lahdhiri [32] proposed a simple expression to calculate SPE in the feature space H, which is shown as follows:
where is the matrix of the first principal eigenvectors of , is the diagonal matrix of the first eigenvalues of [33], and .
The confidence limit for the SPE index can be calculated using the distribution and is given by:
where is the control limit expressed by:
with: and , where is the estimated mean and is the variance of the SPE [34,35].
3. The Observer Method
In fault diagnosis, an observer is a mathematical model or algorithm used to estimate the state variables and fault parameters of a system based on available measurements. The structure of an observer varies depending on the type of system being observed and the nature of the faults being diagnosed. However, the general structure of an observer typically involves the following components:
- System Model: The observer relies on a mathematical model that describes the dynamics of the system being observed. This model can be derived from first principles or obtained through system identification techniques.
- Measurement Equation: The observer uses a measurement equation that relates the system’s state variables to the available measurements. This equation can be derived from the system model and typically includes sensor equations and/or sensor noise models.
- State Estimation: The core of the observer is the state estimation algorithm, which updates and estimates the system’s state variables based on the available measurements. Various estimation techniques can be used, such as Kalman filters, extended Kalman filters, particle filters, or model-based observers like the sliding mode observer.
- Fault Detection: In fault diagnosis, the observer is also responsible for detecting the occurrence of faults. This can be done by comparing the estimated state variables with expected values or by analyzing the residuals between the measurements and the estimated values.
- Fault Parameter Estimation: If faults are detected, the observer may also estimate the fault parameters, such as fault magnitudes, locations, or characteristics. This is typically done by incorporating fault models into the observer and updating the estimated parameters based on the available measurements and fault detection results.
- Adaptation and Learning: Depending on the observer’s design, it may incorporate adaptation or learning mechanisms to improve its performance over time. These mechanisms allow the observer to adapt to changes in system dynamics or fault characteristics, or to learn from historical data to enhance its fault diagnosis capabilities.
It is important to note that the specific structure and algorithm used for fault diagnosis observers can vary greatly depending on the application, system complexity, and available information. Different domains, such as power systems, automotive, or aerospace, may have specialized observer designs tailored to their specific requirements. A system with p inputs denoted u(t) and m output measurements denoted x(t).
The dynamic behavior of this system is described by the following equations [36]:
where is the state vector, Ref. [37] is the output vector, and is the input vector.
Note that matrices A, B, and C represent the state-space description of a linear time-invariant system [38,39], and they have appropriate dimensions with those of the vectors , and .
Given that the state is not generally available [40], the objective is an observer in order to perform a feedback control condition and estimate this state by a variable which we denote as . This estimate is carried out by a dynamic system, the output will be precisely and the input will consist of all the information available [41], that is to say, u(t) and y(t). The structure of an observer can be written as:
where the correction term appears clearly in terms of the reconstruction error of the output , and the correct term can be written as an ion gain [42], L, or the determined observer gain [43]. This structure can be written as:
If we consider the estimation error: , we obtain: .
The observer described by Equation (15) is illustrated in Figure 1.
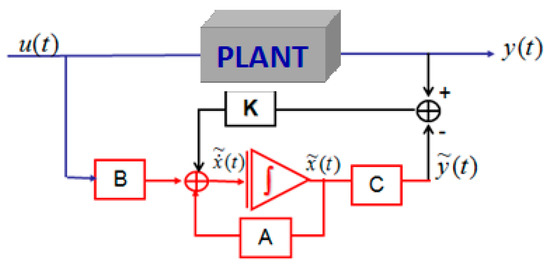
Figure 1.
Structure of the observer.
Fault Detection Observer
In this work, we assume that the actuators and sensors are affected by faults. Our goal is to detect and isolate the faults [43]. The state of the system model can be written as:
where is the actuator fault of the actuators and is a sensor fault.
where is an estimated state vector, is a matrix such that A − KC is stable and its proper values have a real part smaller than . This leads to:
If is such that is a Hurwitz matrix, the residue tends to 0 well in the absence of defects. Transfer between faults and residuals can be written:
where p is a temporal derivative operator.
Which leads to [44], taking into account the inversion lemma in:
which can be written as:
From this relationship and in the absence of actuator failure, the system for isolating fault sensors from residues can be written as:
This variable is estimated using the same system as before, that is to say:
And the estimation of sensor failure is given by the inversion of the initial model of the system:
where is the matrix filters as is bi-causal [45].
is not an estimate of faults but rather filtering defects; however, the character of diagonal allows the isolation [20].
4. Applications
4.1. Overview of Three-Tank System Applications
A three-tank water system, also referred to as a triple-tank or multi-tank system, exhibits a water storage and distribution network, using multiple tanks for various functions. Specific uses for three-tank water systems vary, but typically fall within environmental engineering, including Rainwater Harvesting and Reuse systems, greywater recycling, and off-grid water supply [46,47,48]. These applications have found their place in the heart of targeting sustainable practices, more specifically SDG6, by ensuring Clean Water and Sanitation [46]. A three-tank system can be employed for rainwater harvesting and reuse, with each tank serving its own specific function. One tank could collect rainwater from the roof, another could be dedicated to filtering and treating (primary, secondary, and tertiary water treatment processes), while a third could store treated rainwater for urban reuse in fields such as irrigation. This system helps decrease the reliance on freshwater sources while supporting sustainable water management practices [46].
Triple tank systems provide an effective method of greywater recycling via treating and reusing urban residual water, generated from domestic activities like bathing, handwashing, and laundry. One tank collects urban water for disinfection processes (mostly chlorine and combined chlorine sub-products) [49], while a second tank stores treated water for reuse, in activities such as toilet flushing or landscape irrigation. This approach helps release the stress on freshwater resources while alleviating strain on sewerage systems [47].
In remote or off-grid locations, the availability of reliable water resources is limited. Hence, a three-tank water system can serve as a reliable self-sufficient water supply source. One tank could hold water collected from natural sources like wells or springs, while another would treat and purify it before the third would store the treated water for domestic consumption [48].
On the other hand, several shortcomings and limitations may arise from the installation of three-tank systems. Following the sub-division of the system into three counterparts, the urge for complexity and space requirements are more demanding [46,47,48]. Additional space must also be implemented, as well as the multiple features required to connect the tanks (pumps, valves, etc.). In addition, this system exhibits low cost-effectiveness, as it involves high installation prices compared to the simple water storage system [50]. The maintenance and additional unit operations, required for water screening, treatment, and distribution, will incur additional expenses [51]. Following the complexity of the system, more design heuristics and trade-offs should be considered. This will make the maintenance operation more tedious and time-consuming [51]. On the human factor and engineering intuition level, a high level of skill and knowledge of handling are required, for the sake of preserving the integrity of the system [46,47,48].
Most of the aforementioned factors could be overcome by implementing a proper control system, based on the fact that multiple error sources could be generated. KPCA exhibits a highly convenient unsupervised machine learning approach for a three-tank system control, as it involves dealing with intercorrelated data input [52]. In other words, the error in one part of the system will definitely influence the other components.
4.2. Process Description of a Hydraulic System with Three Tanks
As illustrated in Figure 2, the considered process is a three-tank system with two inputs and three outputs. It consists of three tanks with identical sections, supplied with distilled water. They are serially interconnected by two cylindrical pipes with identical sections [53,54]. The pipes of communication between tanks T1 and T2 are equipped with manually adjustable valves; the flow rates of the connection pipes can be controlled using ball valves az1 and az2. The plant has one outlet pipe located at the bottom of tank T3. There are three other pipes each installed at the bottom of each tank, which are provided with a direct connection (outflow rate) to the reservoir with ball valves bz1, bz2, and bz3, respectively, The pipes can only be manipulated manually [12]. Pumps 1 and 2 are supplied by water from the reservoir with flow rates Q1(t) and Q2(t), respectively. The necessary level measurements h1(t), h2(t), and h3(t) are carried out by the piezo-resistive differential pressure sensors.
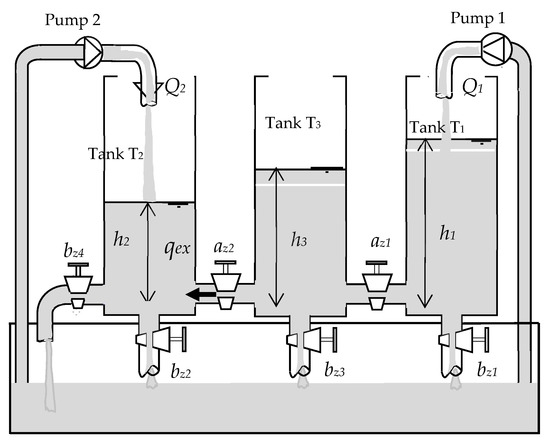
Figure 2.
Three-tank system.
The state equations are obtained by writing that the variation of the water volume in a tank is equal to the difference between the incoming flow and the outgoing flows which means the water of tanks 1 and 2 can flow toward tank 3.
Then, the system can be represented by the following equations:
where is the flow through pump i (i = 1; 2), and represents the flow rates of water between tanks i and j , and can be expressed using the law of Torricelli [29].
and represents the outflow rate, given by:
where hi(t), and are, respectively, the levels of water, the input flow rate, and the output flow rate.
The parameters of the three-tank system are defined as follows. The controlled signals are the water levels (h2, h3) of tank 2 and tank 3. These levels are controlled by two pumps. The system can be considered as a multi-input multi-output system (MIMO) [54], where the input is inflow rates Q1 and Q2 and the output is liquid levels h2 and h3. Then the three-tank system can be modeled by the following three differential equations:
where the parameters ci, i = 1, 3 and Bj, j = 1, 2, 3, 4 are defined by:
While taking B1 = B2 = B3 = 0, the three equations of the system become:
At equilibrium, for a constant water level set point, the level derivatives must be zero.
Therefore, using (31) in the steady state, the following algebraic relationship holds.
For the coupled-tank system, the fluid flow Q1 into tank 1 cannot be negative because the pump can only drive water into the tank, then:
From (36), we have:
and .
Then, (h1 − h3) ≥ 0 and (h3 − h2) ≥ 0. Therefore, if we assume
We have
Which can be written as:
where
4.3. Simulation Results
We are interested in the fault detection of the pressure sensors, which measure the water levels (h2, h3) of tank 2 and tank 3 using conventional KPCA and the observer method. A total of 5000 samples were generated from this process [55]. The 1000 first samples were used to construct the KPCA model; the last 3000 samples are used to test the fault detection methods. We have used the Radial Basis Function (RBF) [56,57]. Two types of faults are considered [58]: faults in the pressure sensor of tank 2 and faults in the pressure sensor of tank 3.
Case 1: faults in the pressure sensor of tank 2 (water level h2).
Fault 1: a step bias of h2 by adding 10% more than its range of variation [59]. The fault is introduced between samples 1500 and 3000.
The SPE index is a statistical measure commonly used in multivariate analysis or process monitoring. It quantifies the discrepancy between predicted and observed values in a model. In this context, Figure 3 represents the results of an analysis or experiment involving a fault (Fault 1) and the SPE (Squared Prediction Error) index, with the variable h2 being affected. The evolution indicates that the figure shows changes or trends over time or some other continuous parameter. It suggests that the data or analysis captured a dynamic process or progression.
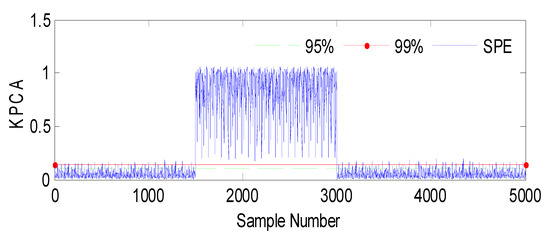
Figure 3.
Evolution of the SPE index with Fault 1 affecting h2 using KPCA.
Fault 2: a step bias of h2 by adding 20% more than its range of variation. The fault is introduced between samples 3500 and 4500.
Case 2: Faults in the pressure sensor of tank 3 (water level h3)
Fault 1: a step bias of h3 by adding 10% more than its range of variation. The fault is introduced between samples 2000 and 3000 [60].
Fault 2: a step bias of h3 by adding 20% more than its range of variation. The fault is introduced between samples 3000 and 4000.
Based on the observations from Figure 4, Figure 5, Figure 6, Figure 7, Figure 8, Figure 9 and Figure 10, it is evident that both the kernel method and the observer technique detect a fault occurrence, as indicated by the defective outputs h2 and h3. Both methods yield effective and comparable results in terms of sensor fault detection. In conclusion, the simulation results using the “observer-based model and a kernel technique called KPCA” show that these two techniques are comparable in the field of fault diagnosis. These methods have been evaluated and demonstrated similar performances in terms of fault identification and detection. This suggests that the use of an observer-based model and the KPCA technique can be effective in diagnosing faults in a system. However, it is important to note that the comparison of performance between these techniques may depend on the specific context of the application and the characteristics of the system being studied. Further studies and experimental tests may be necessary to confirm these results and assess their applicability in other domains.
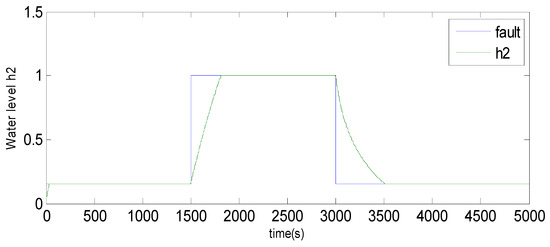
Figure 4.
Evolution of sensor h2 between 1500 and 3000 using the observer method.
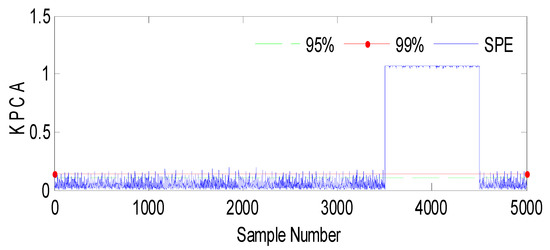
Figure 5.
Evolution of the SPE index with Fault 2 affecting h2 using KPCA.
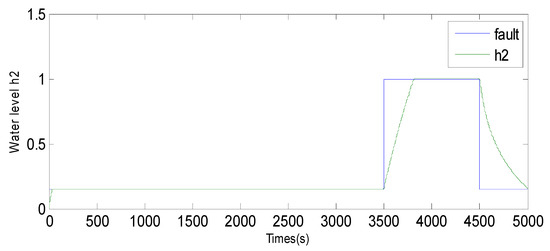
Figure 6.
Evolution of sensor h2 between 3500 and 4500 using the observer method.
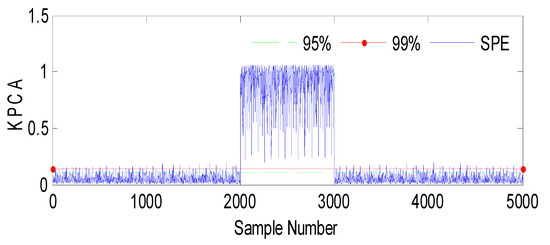
Figure 7.
Evolution of the SPE index with Fault1 affecting h3 using KPCA.
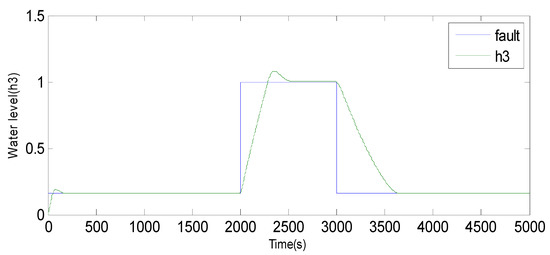
Figure 8.
Evolution of sensor h3 between 2000 and 3000 using the observer method.
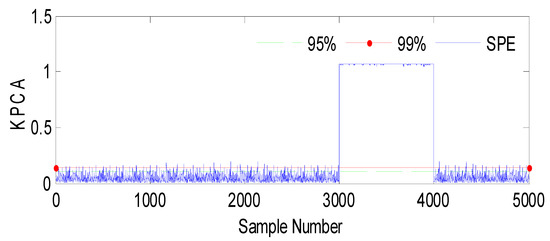
Figure 9.
Evolution of the SPE index with Fault 2 affecting h3 using KPCA.
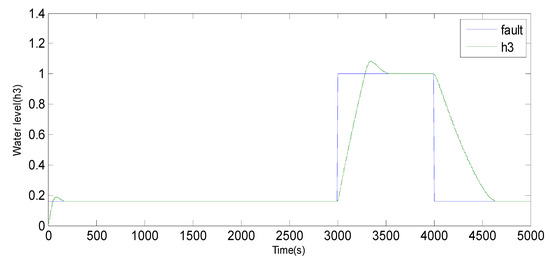
Figure 10.
Evolution of sensor h3 between 3000 and 4000 using the observer method.
5. Conclusions
This paper offers a comprehensive examination of an observer-based model and a kernel technique called KPCA, both employed for sensor fault detection [61]. The observer’s operational principle is thoroughly explained, providing a detailed understanding of its function. To assess the effectiveness of these two techniques, a comparative analysis is conducted using a three-tank process. The simulation results yield valuable insights, demonstrating that both the observer-based model and the KPCA method yield satisfactory results. However, it is important to note that these findings are based on a single case study and cannot be considered in isolation. To establish the broader applicability of these techniques across various systems and conditions, further investigation is necessary. The technique used to validate our system is the injection of faults and we observe the reaction of the system with modification of the time each time. The way of identifying faults is validated and can be used in industry, specifically in chemical systems.
The problem is the difficulty of detecting defects. Our method has approved the capability of detecting defects despite the change in the nature of defects and the integration time.
Consequently, additional research is planned to advance the understanding of fault detection techniques through a deeper exploration of these approaches.
“Kernel Principal Component Analysis (KPCA) and observer-based approaches are two distinct methods commonly used in fault detection within the realms of machine learning and control theory. KPCA is a nonlinear dimensionality reduction technique that maps data into a high-dimensional feature space using kernel functions, enabling the detection of faults in complex and nonlinear systems. Its advantages lie in its ability to handle nonlinearity, making it suitable for intricate processes. However, KPCA’s performance heavily relies on the appropriate choice of kernel and its associated parameters, which can be challenging to determine in practice. On the other hand, observer-based approaches leverage mathematical models to estimate the system’s behavior and compare it with the actual response for detecting faults. The advantage of observer-based methods is their inherent robustness to disturbances and noise, allowing them to perform well in noisy environments. Nevertheless, these approaches often require a comprehensive and accurate model of the system, and their performance may suffer if the model is not precise or if the system exhibits significant nonlinear behavior. Overall, choosing between KPCA and an observer-based approach depends on the specific characteristics of the system, the availability of accurate models, and the level of nonlinearity present, as each method offers distinct strengths and weaknesses in fault detection applications”.
Author Contributions
Methodology, F.L. and L.M.; Validation, W.A.; Formal analysis, H.D.; Writing—review & editing, K.Y. All authors have read and agreed to the published version of the manuscript.
Funding
This research received no external funding.
Institutional Review Board Statement
Not applicable.
Informed Consent Statement
Not applicable.
Data Availability Statement
Not applicable.
Conflicts of Interest
The authors declare no conflict of interest.
References
- Lima, A.; Zen, H.; Nankaku, Y.; Tokuda, K.; Kitamura, T.; Resende, F.G. Applying Sparse KPCA for Feature Extraction in Speech Recognition. IEICE Trans. Inf. Syst. 2005, 88, 401–409. [Google Scholar] [CrossRef][Green Version]
- Aronszajn, N. Theory of Reproducing Kernels. Trans. Am. Math. Soc. 1950, 68, 337–404. [Google Scholar] [CrossRef]
- Baklouti, R.; Mansouri, M.; Nounou, M.; Nounou, H.; Hamida, A.B. Iterated Robust Kernel Fuzzy Principal Component Analysis and Application to Fault Detection. J. Comput. Sci. 2016, 15, 34–49. [Google Scholar] [CrossRef]
- Ratsch, G. Input Space versus Feature Space in Kernel-Based Methods. IEEE Trans. Neural Netw. 1999, 10, 1000–1017. [Google Scholar]
- Botre, C.; Mansouri, M.; Nounou, M.; Nounou, H.; Karim, M.N. Kernel PLS-Based GLRT Method for Fault Detection of Chemical Processes. J. Loss Prev. Process Ind. 2016, 43, 212–224. [Google Scholar] [CrossRef]
- Chetouani, Y. A Neural Network Approach for the Real-Time Detection of Faults. Stoch. Environ. Res. Risk Assess. 2008, 22, 339–349. [Google Scholar] [CrossRef]
- Cho, J.-H.; Lee, J.-M.; Choi, S.W.; Lee, D.; Lee, I.-B. Fault Identification for Process Monitoring Using Kernel Principal Component Analysis. Chem. Eng. Sci. 2005, 60, 279–288. [Google Scholar] [CrossRef]
- Choi, S.W.; Lee, C.; Lee, J.-M.; Park, J.H.; Lee, I.-B. Fault Detection and Identification of Nonlinear Processes Based on Kernel PCA. Chemom. Intell. Lab. Syst. 2005, 75, 55–67. [Google Scholar] [CrossRef]
- Doan, P.T.; Bui, T.L.; Kim, H.K.; Kim, S.B. Sliding-Mode Observer Design for Sensorless Vector Control of AC Induction Motor. In Proceedings of the 2013 9th Asian Control Conference (ASCC), Istanbul, Turkey, 23–26 June 2013; pp. 1–5. [Google Scholar]
- Ruderman, M.; Iwasaki, M. Sensorless Control of Motor Velocity in Two-Mass Actuator Systems with Load Sensing Using Extended State Observer. In Proceedings of the 2014 IEEE/ASME International Conference on Advanced Intelligent Mechatronics, Besacon, France, 8–11 July 2014; pp. 360–365. [Google Scholar]
- Heredia, G.; Ollero, A. Sensor Fault Detection in Small Autonomous Helicopters Using Observer/Kalman Filter Identification. In Proceedings of the 2009 IEEE International Conference on Mechatronics, Malaga, Spain, 14–17 April 2009; pp. 1–6. [Google Scholar]
- Isermann, R. Fault-Diagnosis Systems. An Introduction from Fault Detection to Fault Tolerance; Springer: Berlin/Heidelberg, Germany, 2006. [Google Scholar] [CrossRef]
- Li, X.-J.; Yang, G.-H. Dynamic Observer-Based Robust Control and Fault Detection for Linear Systems. IET Control Theory Appl. 2012, 6, 2657–2666. [Google Scholar] [CrossRef]
- Kumar, V.E.; Jerome, J. Sensor Fault Detection in DC Servo System Using Unknown Input Observer with Structured Residual Generation. J. Electr. Eng. 2013, 13, 6. [Google Scholar]
- Yi, J.; Huang, Z.; Liu, W.; Yang, Y.; Zhang, X.; Liu, J. Actuator Fault Detection Based on Robust Adaptive Observer for CCBII Braking System. In Proceedings of the 26th Chinese Control and Decision Conference (2014 CCDC), Changsha, China, 31 May–2 June 2014; pp. 2841–2846. [Google Scholar]
- Khalid, H.M.; Khoukhi, A.; Al-Sunni, F.M. Fault Detection and Classification Using Kalman Filter and Genetic Neuro-Fuzzy Systems. In Proceedings of the 2011 Annual Meeting of the North American Fuzzy Information Processing Society, El Paso, TX, USA, 18–20 March 2011; pp. 1–6. [Google Scholar]
- Yang, S.K.; Liu, T.S. State Estimation for Predictive Maintenance Using Kalman Filter. Reliab. Eng. Syst. Saf. 1999, 66, 29–39. [Google Scholar] [CrossRef]
- Alkaya, A.; Eker, İ. Luenberger Observer-Based Sensor Fault Detection: Online Application to DC Motor. Turk. J. Electr. Eng. Comput. Sci. 2014, 22, 363–370. [Google Scholar] [CrossRef]
- Tarantino, R.; Szigeti, F.; Colina-Morles, E. Generalized Luenberger Observer-Based Fault-Detection Filter Design: An Industrial Application. Control Eng. Pract. 2000, 8, 665–671. [Google Scholar] [CrossRef]
- Schölkopf, B.; Smola, A.; Müller, K.-R. Nonlinear Component Analysis as a Kernel Eigenvalue Problem. Neural Comput. 1998, 10, 1299–1319. [Google Scholar] [CrossRef]
- Dong, D.; McAvoy, T.J. Nonlinear Principal Component Analysis—Based on Principal Curves and Neural Networks. Comput. Chem. Eng. 1996, 20, 65–78. [Google Scholar] [CrossRef]
- Fazai, R.; Taouali, O.; Harkat, M.F.; Bouguila, N. A New Fault Detection Method for Nonlinear Process Monitoring. Int. J. Adv. Manuf. Technol. 2016, 87, 3425–3436. [Google Scholar] [CrossRef]
- Harkat, M.-F.; Mourot, G.; Ragot, J. An Improved PCA Scheme for Sensor FDI: Application to an Air Quality Monitoring Network. J. Process Control 2006, 16, 625–634. [Google Scholar] [CrossRef]
- Ge, Z.; Yang, C.; Song, Z. Improved Kernel PCA-Based Monitoring Approach for Nonlinear Processes. Chem. Eng. Sci. 2009, 64, 2245–2255. [Google Scholar] [CrossRef]
- Vapnik, V. The Support Vector Method of Function Estimation. In Nonlinear Modeling: Advanced Black-Box Techniques; Springer: Berlin/Heidelberg, Germany, 1998; pp. 55–85. [Google Scholar]
- Harkat, M.-F.; Mourot, G.; Ragot, J. Multiple Sensor Fault Detection and Isolation of an Air Quality Monitoring Network Using RBF-NLPCA Model. IFAC Proc. Vol. 2009, 42, 828–833. [Google Scholar] [CrossRef]
- Jaffel, I.; Taouali, O.; Harkat, M.F.; Messaoud, H. Kernel Principal Component Analysis with Reduced Complexity for Nonlinear Dynamic Process Monitoring. Int. J. Adv. Manuf. Technol. 2017, 88, 3265–3279. [Google Scholar] [CrossRef]
- Jaffel, I.; Taouali, O.; Harkat, M.F.; Messaoud, H. Moving Window KPCA with Reduced Complexity for Nonlinear Dynamic Process Monitoring. ISA Trans. 2016, 64, 184–192. [Google Scholar] [CrossRef] [PubMed]
- Kallas, M.; Mourot, G.; Maquin, D.; Ragot, J. Diagnosis of Nonlinear Systems Using Kernel Principal Component Analysis. Proc. J. Phys. Conf. Ser. 2014, 570, 072004. [Google Scholar] [CrossRef]
- Kazor, K.; Holloway, R.W.; Cath, T.Y.; Hering, A.S. Comparison of Linear and Nonlinear Dimension Reduction Techniques for Automated Process Monitoring of a Decentralized Wastewater Treatment Facility. Stoch. Environ. Res. Risk Assess. 2016, 30, 1527–1544. [Google Scholar] [CrossRef]
- Kim, K.I.; Jung, K.; Kim, H.J. Face Recognition Using Kernel Principal Component Analysis. IEEE Signal Process. Lett. 2002, 9, 40–42. [Google Scholar]
- Lahdhiri, H.; Taouali, O.; Elaissi, I.; Jaffel, I.; Harakat, M.F.; Messaoud, H. A New Fault Detection Index Based on Mahalanobis Distance and Kernel Method. Int. J. Adv. Manuf. Technol. 2017, 91, 2799–2809. [Google Scholar] [CrossRef]
- Lefebvre, D.; Basile, F. An Approach Based on Timed Petri Nets and Tree Encoding to Implement Search Algorithms for a Class of Scheduling Problems. Inf. Sci. 2021, 559, 314–335. [Google Scholar] [CrossRef]
- Lajmi, F.; Talmoudi, A.J.; Dhouibi, H. Fault Diagnosis of Uncertain Systems Based on Interval Fuzzy PETRI Net. Stud. Inform. Control 2017, 26, 239–248. [Google Scholar] [CrossRef]
- Fatma, L.; Ghabi, J.; Dhouibi, H. Applying Interval Fuzzy Petri Net to Failure Analysis. Int. J. Serv. Sci. Manag. Eng. Technol. 2020, 11, 14–30. [Google Scholar]
- Lee, J.-M.; Yoo, C.; Lee, I.-B. Statistical Process Monitoring with Independent Component Analysis. J. Process Control 2004, 14, 467–485. [Google Scholar] [CrossRef]
- Lee, J.-M.; Yoo, C.; Choi, S.W.; Vanrolleghem, P.A.; Lee, I.-B. Nonlinear Process Monitoring Using Kernel Principal Component Analysis. Chem. Eng. Sci. 2004, 59, 223–234. [Google Scholar] [CrossRef]
- Li, G.; Qin, S.J.; Zhou, D. Geometric Properties of Partial Least Squares for Process Monitoring. Automatica 2010, 46, 204–210. [Google Scholar] [CrossRef]
- Li, H.; Zhang, D. Stochastic Representation and Dimension Reduction for Non-Gaussian Random Fields: Review and Reflection. Stoch. Environ. Res. Risk Assess. 2013, 27, 1621–1635. [Google Scholar] [CrossRef]
- Liu, X.; Kruger, U.; Littler, T.; Xie, L.; Wang, S. Moving Window Kernel PCA for Adaptive Monitoring of Nonlinear Processes. Chemom. Intell. Lab. Syst. 2009, 96, 132–143. [Google Scholar] [CrossRef]
- Aizerman, A. Theoretical Foundations of the Potential Function Method in Pattern Recognition Learning. Autom. Remote Control 1964, 25, 821–837. [Google Scholar]
- Mansouri, M.; Nounou, M.; Nounou, H.; Karim, N. Kernel PCA-Based GLRT for Nonlinear Fault Detection of Chemical Processes. J. Loss Prev. Process Ind. 2016, 40, 334–347. [Google Scholar] [CrossRef]
- Mercer, J. XVI. Functions of Positive and Negative Type, and Their Connection the Theory of Integral Equations. Philos. Trans. R. Soc. Lond. Ser. A Contain. Pap. A Math. Phys. Character 1909, 209, 415–446. [Google Scholar]
- Mika, S.; Schölkopf, B.; Smola, A.; Müller, K.-R.; Scholz, M.; Rätsch, G. Kernel PCA and De-Noising in Feature Spaces. In Proceedings of the Advances in Neural Information Processing Systems; MIT Press: Cambridge, MA, USA, 1998; Volume 11. [Google Scholar]
- Nomikos, P.; MacGregor, J.F. Multivariate SPC Charts for Monitoring Batch Processes. Technometrics 1995, 37, 41–59. [Google Scholar] [CrossRef]
- Teston, A.; Piccinini Scolaro, T.; Kuntz Maykot, J.; Ghisi, E. Comprehensive Environmental Assessment of Rainwater Harvesting Systems: A Literature Review. Water 2022, 14, 2716. [Google Scholar] [CrossRef]
- Al-Jayyousi, O.R. Greywater Reuse: Towards Sustainable Water Management. Desalination 2003, 156, 181–192. [Google Scholar] [CrossRef]
- Bahta, S.T. Design and Analyzing of an Off-Grid Hybrid Renewable Energy System to Supply Electricity for Rural Areas: Case Study: Atsbi District, North Ethiopia. Master’s Thesis, KTH School of Industrial Engineering and Management, Stockholm, Sweden, 2013. [Google Scholar]
- Cheremisinoff, P.N. Handbook of Water and Wastewater Treatment Technology; Routledge: London, UK, 2019. [Google Scholar]
- Bojan-Dragos, C.-A.; Szedlak-Stinean, A.-I.; Precup, R.-E.; Gurgui, L.; Hedrea, E.-L.; Mituletu, I.-C. Control Solutions for Vertical Three-Tank Systems. In Proceedings of the 2018 IEEE 12th International Symposium on Applied Computational Intelligence and Informatics (SACI), Timisoara, Romania, 17–19 May 2018; pp. 000593–000598. [Google Scholar]
- Peters, M.S.; Timmerhaus, K.D.; West, R.E. Plant Design and Economics for Chemical Engineers; McGraw-Hill: New York, NY, USA, 2003; Volume 4. [Google Scholar]
- Jolliffe, I. Principal Component Analysis. In Encyclopedia of Statistics in Behavioral Science; Wiley Online Library: New York, NY, USA, 2005. [Google Scholar]
- Sheriff, M.Z.; Mansouri, M.; Karim, M.N.; Nounou, H.; Nounou, M. Fault Detection Using Multiscale PCA-Based Moving Window GLRT. J. Process Control 2017, 54, 47–64. [Google Scholar] [CrossRef]
- Taouali, O.; Elaissi, I.; Messaoud, H. Dimensionality Reduction of RKHS Model Parameters. ISA Trans. 2015, 57, 205–210. [Google Scholar] [CrossRef] [PubMed]
- Tharrault, Y.; Mourot, G.; Ragot, J.; Maquin, D. Fault Detection and Isolation with Robust Principal Component Analysis. Int. J. Appl. Math. Comput. Sci. 2008, 18, 429–442. [Google Scholar] [CrossRef]
- Vapnik, V.N. An Overview of Statistical Learning Theory. IEEE Trans. Neural Netw. 1999, 10, 988–999. [Google Scholar] [CrossRef] [PubMed]
- Zhang, Y.; Li, S.; Teng, Y. Dynamic Processes Monitoring Using Recursive Kernel Principal Component Analysis. Chem. Eng. Sci. 2012, 72, 78–86. [Google Scholar] [CrossRef]
- Zhao, C.; Ma, J.; Wei, Y.; Long, Y.; Ou, H.; Bao, J.; Yin, J.; Liu, W.; Zhu, N.; Lu, X. Active Mass Transfer for Printable Electrochemical Sensors with Ultrasonic Stimuli. Mater. Today Commun. 2023, 34, 105382. [Google Scholar] [CrossRef]
- Magni, J.-F.; Mouyon, P. A Generalized Approach to Observers for Fault Diagnosis. In Proceedings of the 30th IEEE Conference on Decision and Control, Brighton, UK, 11–13 December 1991; pp. 2236–2241. [Google Scholar] [CrossRef]
- Zhong, M.; Yang, Y.; Sun, S.; Zhou, Y.; Postolache, O.; Ge, Y. Priority-Based Speed Control Strategy for Automated Guided Vehicle Path Planning in Automated Container Terminals. Trans. Inst. Meas. Control 2020, 42, 014233122094011. [Google Scholar] [CrossRef]
- Wu, P.; Xiao, F.; Sha, C.; Huang, H.; Sun, L. Trajectory Optimization for UAVs’ Efficient Charging in Wireless Rechargeable Sensor Networks. IEEE Trans. Veh. Technol. 2020, 69, 4207–4220. [Google Scholar] [CrossRef]










Disclaimer/Publisher’s Note: The statements, opinions and data contained in all publications are solely those of the individual author(s) and contributor(s) and not of MDPI and/or the editor(s). MDPI and/or the editor(s) disclaim responsibility for any injury to people or property resulting from any ideas, methods, instructions or products referred to in the content. |
© 2023 by the authors. Licensee MDPI, Basel, Switzerland. This article is an open access article distributed under the terms and conditions of the Creative Commons Attribution (CC BY) license (https://creativecommons.org/licenses/by/4.0/).