
Zero-Shot Neural Decoding with Semi-Supervised Multi-View Embedding

Abstract
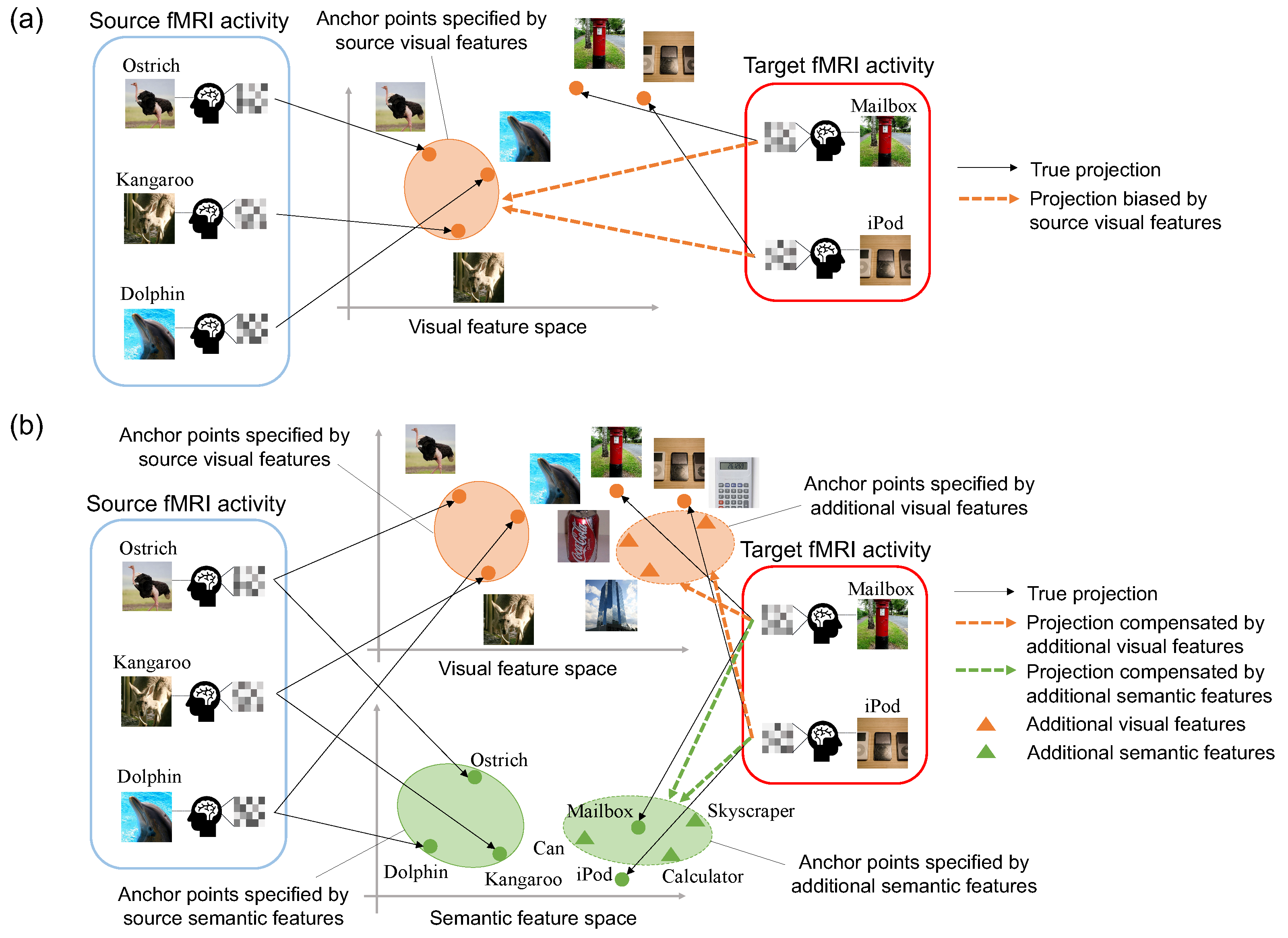
:1. Introduction
- To the best of our knowledge, this is the first study to address the projection domain shift problem in zero-shot neural decoding. For this problem, we introduce the semi-supervised framework that employs images related to the target categories without fMRI activity patterns.
- We propose multi-view embeddings that associate fMRI activity patterns with visual features from images and semantic features from image categories.
- We address the difficulty in collecting fMRI data and estimate unobserved fMRI activity patterns in a fully probabilistic manner [22]. Furthermore, the Bayesian framework of our model automatically selects a small set of appropriate components from high dimensional fMRI voxels.
2. Related Work
2.1. Multi-View Learning
2.2. Zero-Shot Learning
2.3. Neural Decoding
3. Proposed Method
3.1. Semi-Supervised Multi-View Generative Model
3.2. Optimization of Model Parameters via Variational Inference
| Algorithm 1 Update procedures of model parameters |
| Input: Observed variables Initialize , , , , and by prior distributions in Equations (1), (2), (4), (5) for number of training iterations do Update the projection matrix in Equation (7) Update the shared latent variables in Equation (10) Update the missing values in Equation (14) Update the inverse variances in Equation (15) Update the inverse variance in Equation (18) end for Output: Updated distributions of , , , , and |
3.3. Decoding of Viewed Image Categories from fMRI Activity
4. Experimental Results
4.1. Dataset
4.2. Conditions
4.3. Results and Discussion
5. Conclusions
Author Contributions
Funding
Institutional Review Board Statement
Informed Consent Statement
Data Availability Statement
Conflicts of Interest
References
- Wolpaw, J.R.; Birbaumer, N.; McFarland, D.J.; Pfurtscheller, G.; Vaughan, T.M. Brain–computer interfaces for communication and control. Clin. Neurophysiol. 2002, 113, 767–791. [Google Scholar] [CrossRef] [PubMed]
- Haxby, J.V.; Gobbini, M.I.; Furey, M.L.; Ishai, A.; Schouten, J.L.; Pietrini, P. Distributed and overlapping representations of faces and objects in ventral temporal cortex. Science 2001, 293, 2425–2430. [Google Scholar] [CrossRef] [Green Version]
- Cox, D.D.; Savoy, R.L. Functional magnetic resonance imaging (fMRI) “brain reading”: Detecting and classifying distributed patterns of fMRI activity in human visual cortex. NeuroImage 2003, 19, 261–270. [Google Scholar] [CrossRef] [PubMed]
- Reddy, L.; Tsuchiya, N.; Serre, T. Reading the mind’s eye: Decoding category information during mental imagery. NeuroImage 2010, 50, 818–825. [Google Scholar] [CrossRef] [PubMed] [Green Version]
- Kay, K.N.; Naselaris, T.; Prenger, R.J.; Gallant, J.L. Identifying natural images from human brain activity. Nature 2008, 452, 352–355. [Google Scholar] [CrossRef] [Green Version]
- Horikawa, T.; Kamitani, Y. Generic decoding of seen and imagined objects using hierarchical visual features. Nat. Commun. 2017, 8, 15037. [Google Scholar] [CrossRef]
- Akamatsu, Y.; Harakawa, R.; Ogawa, T.; Haseyama, M. Estimating viewed image categories from human brain activity via semi-supervised fuzzy discriminative canonical correlation analysis. In Proceedings of the ICASSP 2019—2019 IEEE International Conference on Acoustics, Speech and Signal Processing (ICASSP), Brighton, UK, 12–17 May 2019; pp. 1105–1109. [Google Scholar]
- Papadimitriou, A.; Passalis, N.; Tefas, A. Visual representation decoding from human brain activity using machine learning: A baseline study. Pattern Recognit. Lett. 2019, 128, 38–44. [Google Scholar] [CrossRef]
- O’Connell, T.P.; Chun, M.M.; Kreiman, G. Zero-shot neural decoding of visual categories without prior exemplars. bioRxiv 2019, 700344. [Google Scholar]
- McCartney, B.; Martinez-del Rincon, J.; Devereux, B.; Murphy, B. A zero-shot learning approach to the development of brain-computer interfaces for image retrieval. PLoS ONE 2019, 14, e0214342. [Google Scholar] [CrossRef] [Green Version]
- Mitchell, T.M.; Shinkareva, S.V.; Carlson, A.; Chang, K.; Malave, V.L.; Mason, R.A.; Just, M.A. Predicting human brain activity associated with the meanings of nouns. Science 2008, 320, 1191–1195. [Google Scholar] [CrossRef] [Green Version]
- Palatucci, M.; Pomerleau, D.; Hinton, G.E.; Mitchell, T.M. Zero-shot learning with semantic output codes. In Proceedings of the Advances in Neural Information Processing Systems 22 (NIPS 2009), Vancouver, BC, Canada, 7–10 December 2009; pp. 1410–1418. [Google Scholar]
- Pereira, F.; Lou, B.; Pritchett, B.; Ritter, S.; Gershman, S.J.; Kanwisher, N.; Botvinick, M.; Fedorenko, E. Toward a universal decoder of linguistic meaning from brain activation. Nat. Commun. 2018, 9, 963. [Google Scholar] [CrossRef] [PubMed] [Green Version]
- Akamatsu, Y.; Harakawa, R.; Ogawa, T.; Haseyama, M. Estimation of viewed image categories via CCA using human brain activity. In Proceedings of the 2018 IEEE 7th Global Conference on Consumer Electronics (GCCE), Nara, Japan, 9–12 October 2018; pp. 171–172. [Google Scholar]
- Krizhevsky, A.; Sutskever, I.; Hinton, G.E. ImageNet classification with deep convolutional neural networks. In Proceedings of the Advances in Neural Information Processing Systems 25 (NIPS 2012), Lake Tahoe, NV, USA, 3–6 December 2012; pp. 1097–1105. [Google Scholar]
- Fu, Y.; Hospedales, T.M.; Xiang, T.; Gong, S. Transductive multi-view zero-shot learning. IEEE Trans. Pattern Anal. Mach. Intell. 2015, 37, 2332–2345. [Google Scholar] [CrossRef] [PubMed]
- Kodirov, E.; Xiang, T.; Fu, Z.; Gong, S. Unsupervised domain adaptation for zero-shot learning. In Proceedings of the 2015 IEEE International Conference on Computer Vision (ICCV), Santiago, Chile, 7–13 December 2015; pp. 2452–2460. [Google Scholar]
- Kodirov, E.; Xiang, T.; Gong, S. Semantic autoencoder for zero-shot learning. In Proceedings of the 2017 IEEE Conference on Computer Vision and Pattern Recognition (CVPR), Honolulu, HI, USA, 21–26 July 2017; pp. 3174–3183. [Google Scholar]
- Fujiwara, Y.; Miyawaki, Y.; Kamitani, Y. Modular encoding and decoding models derived from Bayesian canonical correlation analysis. Neural Comput. 2013, 25, 979–1005. [Google Scholar] [CrossRef]
- Klami, A.; Virtanen, S.; Leppäaho, E.; Kaski, S. Group factor analysis. IEEE Trans. Neural Netw. Learn. Syst. 2015, 26, 2136–2147. [Google Scholar] [CrossRef] [PubMed] [Green Version]
- Maaten, L.v.d.; Hinton, G. Visualizing data using t-SNE. J. Mach. Learn. Res. 2008, 9, 2579–2605. [Google Scholar]
- Oba, S.; Sato, M.; Takemasa, I.; Monden, M.; Matsubara, K.I.; Ishii, S. A Bayesian missing value estimation method for gene expression profile data. Bioinformatics 2003, 19, 2088–2096. [Google Scholar] [CrossRef] [Green Version]
- Xu, C.; Tao, D.; Xu, C. A survey on multi-view learning. arXiv 2013, arXiv:1304.5634. [Google Scholar]
- Zhao, J.; Xie, X.; Xu, X.; Sun, S. Multi-view learning overview: Recent progress and new challenges. Inf. Fusion 2017, 38, 43–54. [Google Scholar] [CrossRef]
- Hotelling, H. Relations between two sets of variates. Biometrika 1936, 28, 321–377. [Google Scholar] [CrossRef]
- Kimura, A.; Sugiyama, M.; Nakano, T.; Kameoka, H.; Sakano, H.; Maeda, E.; Ishiguro, K. SemiCCA: Efficient semi-supervised learning of canonical correlations. Inf. Media Technol. 2013, 8, 311–318. [Google Scholar] [CrossRef] [Green Version]
- Wang, C. Variational Bayesian approach to canonical correlation analysis. IEEE Trans. Neural Netw. 2007, 18, 905–910. [Google Scholar] [CrossRef] [PubMed]
- Neal, R.M. Bayesian Learning for Neural Networks; Springer Science & Business Media: Berlin/Heidelberg, Germany, 2012; Volume 118. [Google Scholar]
- Akamatsu, Y.; Harakawa, R.; Ogawa, T.; Haseyama, M. Estimating viewed image categories from fMRI activity via multi-view Bayesian generative model. In Proceedings of the 2019 IEEE 8th Global Conference on Consumer Electronics (GCCE), Osaka, Japan, 15–18 October 2019; pp. 127–128. [Google Scholar]
- Beliy, R.; Gaziv, G.; Hoogi, A.; Strappini, F.; Golan, T.; Irani, M. From voxels to pixels and back: Self-supervision in natural-image reconstruction from fMRI. In Proceedings of the Advances in Neural Information Processing Systems 32 (NeurIPS 2019), Vancouver, BC, Canada, 8–14 December 2019; pp. 6517–6527. [Google Scholar]
- Akamatsu, Y.; Harakawa, R.; Ogawa, T.; Haseyama, M. Brain decoding of viewed image categories via semi-supervised multi-view Bayesian generative model. IEEE Trans. Signal Process. 2020, 68, 5769–5781. [Google Scholar] [CrossRef]
- Du, C.; Fu, K.; Li, J.; He, H. Decoding Visual Neural Representations by Multimodal Learning of Brain-Visual-Linguistic Features. IEEE Trans. Pattern Anal. Mach. Intell. 2023; early access. [Google Scholar]
- Liu, Y.; Ma, Y.; Zhou, W.; Zhu, G.; Zheng, N. BrainCLIP: Bridging Brain and Visual-Linguistic Representation via CLIP for Generic Natural Visual Stimulus Decoding from fMRI. arXiv 2023, arXiv:2302.12971. [Google Scholar]
- Radford, A.; Kim, J.W.; Hallacy, C.; Ramesh, A.; Goh, G.; Agarwal, S.; Sastry, G.; Askell, A.; Mishkin, P.; Clark, J.; et al. Learning transferable visual models from natural language supervision. In Proceedings of the International Conference on Machine Learning, PMLR, Virtual, 18–24 July 2021; pp. 8748–8763. [Google Scholar]
- Simonyan, K.; Zisserman, A. Very deep convolutional networks for large-scale image recognition. arXiv 2014, arXiv:1409.1556. [Google Scholar]
- Horikawa, T.; Aoki, S.C.; Tsukamoto, M.; Kamitani, Y. Characterization of deep neural network features by decodability from human brain activity. Sci. Data 2019, 6, 190012. [Google Scholar] [CrossRef] [PubMed] [Green Version]
- Mikolov, T.; Sutskever, I.; Chen, K.; Corrado, G.; Dean, J. Distributed representations of words and phrases and their compositionality. In Proceedings of the Advances in Neural Information Processing Systems 26 (NIPS 2013), Lake Tahoe, NV, USA, 5–10 December 2013; pp. 3111–3119. [Google Scholar]
- Yamashita, O.; Sato, M.; Yoshioka, T.; Tong, F.; Kamitani, Y. Sparse estimation automatically selects voxels relevant for the decoding of fMRI activity patterns. NeuroImage 2008, 42, 1414–1429. [Google Scholar] [CrossRef] [Green Version]
- Attias, H. Inferring parameters and structure of latent variable models by variational Bayes. In Proceedings of the Fifteenth Conference on Uncertainty in Artificial Intelligence (UAI1999), Stockholm, Sweden, 30 July–1 August 1999; pp. 21–30. [Google Scholar]
- Deng, J.; Dong, W.; Socher, R.; Li, L.; Li, L.J.; Li, K.; Li, F. ImageNet: A large-scale hierarchical image database. In Proceedings of the 2009 IEEE Conference on Computer Vision and Pattern Recognition, Miami, FL, USA, 20–25 June 2009; pp. 248–255. [Google Scholar]
- Haykin, S.S. Neural Networks and Learning Machines; Prentice Hall: New York, NY, USA, 2009. [Google Scholar]






{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
| Symbol | Meaning | Role |
|---|---|---|
| Observed variables (): | ||
| fMRI activity | Input for neural decoding | |
| Visual features | Visual information of viewed image | |
| Semantic features | Semantic information of viewed image | |
| Additional visual features | Alleviate the projection domain shift problem | |
| Additional semantic features | Alleviate the projection domain shift problem | |
| Concatenated observed variables | Concatenate original and additional features | |
| Model parameters (): | ||
| Shared latent variables | Link with and | |
| Unobserved fMRI activity | fMRI activity corresponding to additional features | |
| Projection matrix | Project into , , and | |
| Hyperprior distribution for | Control the variance of | |
| Inverse variance for | Control the noise of | |
| Mammal | Bird | Invertebrate | Device | Container | Equipment | Structure | Commodity | |
|---|---|---|---|---|---|---|---|---|
| # Training | 134 | 144 | 138 | 106 | 135 | 135 | 145 | 144 |
| # Test | 6 | 3 | 4 | 8 | 7 | 3 | 4 | 6 |
| # Additional | 1077 | 814 | 626 | 1038 | 639 | 417 | 1100 | 551 |
| Method | Target Group | |||||||
|---|---|---|---|---|---|---|---|---|
| Mammal | Bird | Invertebrate | Device | Container | Equipment | Structure | Commodity | |
| SLR [6] | 49.29 ± 4.17 | 83.90 ± 2.27 | 85.50 ± 2.26 | 87.11 ± 1.83 | 96.67 ± 0.33 | 94.25 ± 1.31 | 90.72 ± 1.08 | 87.39 ± 3.02 |
| CCA [14] | 76.90 ± 4.38 | 73.12 ± 2.43 | 74.85 ± 6.98 | 78.23 ± 2.11 | 87.20 ± 1.01 | 77.73 ± 1.89 | 72.44 ± 7.23 | 73.61 ± 5.86 |
| Semi-FDCCA [7] | 85.38 ± 0.91 | 86.60 ± 2.42 | 89.73 ± 0.98 | 83.76 ± 1.94 | 89.43 ± 2.42 | 91.95 ± 3.86 | 77.67 ± 6.45 | 80.10 ± 3.57 |
| MLP [8] | 75.14 ± 2.31 | 95.73 ± 0.98 | 91.25 ± 1.91 | 89.98 ± 1.65 | 97.63 ± 0.32 | 92.74 ± 1.34 | 90.90 ± 0.94 | 88.44 ± 1.98 |
| BCCA-V [19] | 45.65 ± 3.60 | 84.41 ± 3.68 | 82.90 ± 3.46 | 88.34 ± 1.78 | 96.56 ± 0.51 | 93.81 ± 0.79 | 89.13 ± 1.04 | 85.99 ± 2.49 |
| BCCA-S [19] | 83.51 ± 0.38 | 94.22 ± 0.48 | 84.64 ± 0.41 | 73.54 ± 1.71 | 65.39 ± 1.54 | 82.48 ± 1.32 | 77.14 ± 0.95 | 81.03 ± 0.46 |
| MGM | 83.97 ± 0.28 | 95.15 ± 0.59 | 90.46 ± 1.09 | 89.18 ± 1.50 | 97.19 ± 0.38 | 95.30 ± 0.61 | 91.47 ± 0.37 | 89.14 ± 1.62 |
| Ours | 86.91± 0.33 | 97.69± 0.49 | 93.10± 1.20 | 91.61± 1.49 | 98.19± 0.23 | 95.36± 0.63 | 93.11± 0.22 | 91.63± 1.55 |
| Metric (Chance Level) | SLR | CCA | Semi-FDCCA | MLP | BCCA-V | BCCA-S | MGM | Ours |
|---|---|---|---|---|---|---|---|---|
| Rank-100 accuracy (1.0%) | 16.03 | 9.092 | 11.58 | 20.76 | 14.32 | 0.4167 | 21.32 | 30.22 |
| Rank-1000 accuracy (10%) | 58.35 | 41.41 | 56.67 | 71.10 | 57.11 | 31.24 | 70.16 | 77.66 |
| Rank-5000 accuracy (50%) | 91.77 | 82.72 | 94.64 | 97.81 | 90.63 | 94.06 | 98.75 | 99.06 |
| Method | Target Group | |||||||
|---|---|---|---|---|---|---|---|---|
| Mammal | Bird | Invertebrate | Device | Container | Equipment | Structure | Commodity | |
| SLR [6] | 65.18 ± 3.03 | 86.42 ± 4.86 | 75.17 ± 5.81 | 81.31 ± 3.00 | 92.75 ± 2.07 | 76.96 ± 9.11 | 79.96 ± 3.35 | 92.85 ± 2.86 |
| CCA [14] | 60.29 ± 1.77 | 73.62 ± 16.38 | 65.88 ± 17.45 | 75.17 ± 6.50 | 82.93 ± 3.29 | 71.35 ± 4.48 | 59.99 ± 16.58 | 69.38 ± 13.15 |
| Semi-FDCCA [7] | 73.34 ± 3.30 | 80.50 ± 9.93 | 79.18 ± 5.45 | 79.44 ± 6.65 | 82.87 ± 7.17 | 80.90 ± 12.12 | 60.40 ± 11.25 | 83.01 ± 7.30 |
| MLP [8] | 73.98 ± 3.62 | 91.26 ± 2.34 | 80.42 ± 6.76 | 86.57 ± 3.28 | 94.23 ± 1.93 | 75.40 ± 7.28 | 76.61 ± 4.44 | 92.59 ± 2.30 |
| BCCA-V [19] | 65.38 ± 1.61 | 83.90 ± 2.77 | 74.06 ± 6.06 | 84.41 ± 5.20 | 92.80 ± 2.53 | 73.99 ± 5.89 | 77.80 ± 2.41 | 93.42 ± 1.49 |
| BCCA-S [19] | 61.83 ± 1.51 | 78.79 ± 2.70 | 58.96 ± 2.90 | 74.80 ± 1.94 | 50.63 ± 4.11 | 86.23 ± 0.96 | 87.14 ± 1.00 | 87.04 ± 0.27 |
| MGM | 74.68 ± 2.10 | 92.62 ± 2.80 | 78.71 ± 5.08 | 87.11 ± 3.31 | 93.48 ± 1.94 | 90.14 ± 1.56 | 88.59 ± 1.13 | 95.87 ± 0.68 |
| Ours | 77.38± 2.72 | 94.45± 1.86 | 82.54± 6.14 | 90.46± 2.59 | 95.07± 1.33 | 90.37± 1.58 | 88.62± 1.98 | 96.03± 0.77 |
| Mammal | Bird | Invertebrate | Device | Container | Equipment | Structure | Commodity | |
|---|---|---|---|---|---|---|---|---|
| Normal | 96.49 | 98.84 | 97.28 | 95.33 | 98.88 | 97.58 | 97.04 | 94.21 |
| Zero-shot | 86.91 | 97.69 | 93.10 | 91.61 | 98.19 | 95.36 | 93.11 | 91.63 |
| Mammal | Bird | Invertebrate | Device | Container | Equipment | Structure | Commodity | |
|---|---|---|---|---|---|---|---|---|
| Subject 1 | 0.3 | 0.5 | 0.4 | 0.7 | 0.8 | 0.4 | 0.5 | 0.3 |
| Subject 2 | 0.7 | 0.8 | 0.7 | 0.6 | 0.7 | 0.5 | 0.5 | 0.5 |
| Subject 3 | 0.7 | 0.7 | 0.8 | 0.6 | 0.8 | 0.4 | 0.5 | 0.6 |
| Subject 4 | 0.5 | 0.7 | 0.7 | 0.5 | 0.8 | 0.5 | 0.6 | 0.7 |
| Subject 5 | 0.6 | 0.7 | 0.7 | 0.6 | 0.8 | 0.5 | 0.6 | 0.5 |
| Mean | 0.56 | 0.68 | 0.66 | 0.60 | 0.78 | 0.46 | 0.54 | 0.52 |
| Mammal | Bird | Invertebrate | Device | Container | Equipment | Structure | Commodity | |
|---|---|---|---|---|---|---|---|---|
| Subject 1 | 0 | 0.4 | 0.3 | 0.7 | 0.8 | 0.4 | 0.5 | 0.3 |
| Subject 2 | 0 | 0.7 | 0.6 | 1.0 | 0.7 | 0.7 | 0.6 | 0.5 |
| Subject 3 | 0.3 | 0.8 | 0.6 | 0.7 | 0.7 | 0.4 | 0.5 | 0.7 |
| Subject 4 | 0.2 | 0.7 | 0.5 | 0.6 | 0.9 | 0.5 | 0.7 | 0.7 |
| Subject 5 | 0 | 0.3 | 0.4 | 0.7 | 0.8 | 0.5 | 0.6 | 0.6 |
| Mean | 0.10 | 0.58 | 0.48 | 0.74 | 0.78 | 0.5 | 0.58 | 0.56 |
Disclaimer/Publisher’s Note: The statements, opinions and data contained in all publications are solely those of the individual author(s) and contributor(s) and not of MDPI and/or the editor(s). MDPI and/or the editor(s) disclaim responsibility for any injury to people or property resulting from any ideas, methods, instructions or products referred to in the content. |
© 2023 by the authors. Licensee MDPI, Basel, Switzerland. This article is an open access article distributed under the terms and conditions of the Creative Commons Attribution (CC BY) license (https://creativecommons.org/licenses/by/4.0/).
Share and Cite
Akamatsu, Y.; Maeda, K.; Ogawa, T.; Haseyama, M. Zero-Shot Neural Decoding with Semi-Supervised Multi-View Embedding. Sensors 2023, 23, 6903. https://doi.org/10.3390/s23156903
Akamatsu Y, Maeda K, Ogawa T, Haseyama M. Zero-Shot Neural Decoding with Semi-Supervised Multi-View Embedding. Sensors. 2023; 23(15):6903. https://doi.org/10.3390/s23156903
Chicago/Turabian StyleAkamatsu, Yusuke, Keisuke Maeda, Takahiro Ogawa, and Miki Haseyama. 2023. "Zero-Shot Neural Decoding with Semi-Supervised Multi-View Embedding" Sensors 23, no. 15: 6903. https://doi.org/10.3390/s23156903